
Application of Machine Learning Models in Coaxial Bioreactors: Classification and Torque Prediction



Abstract
:1. Introduction
2. Methods
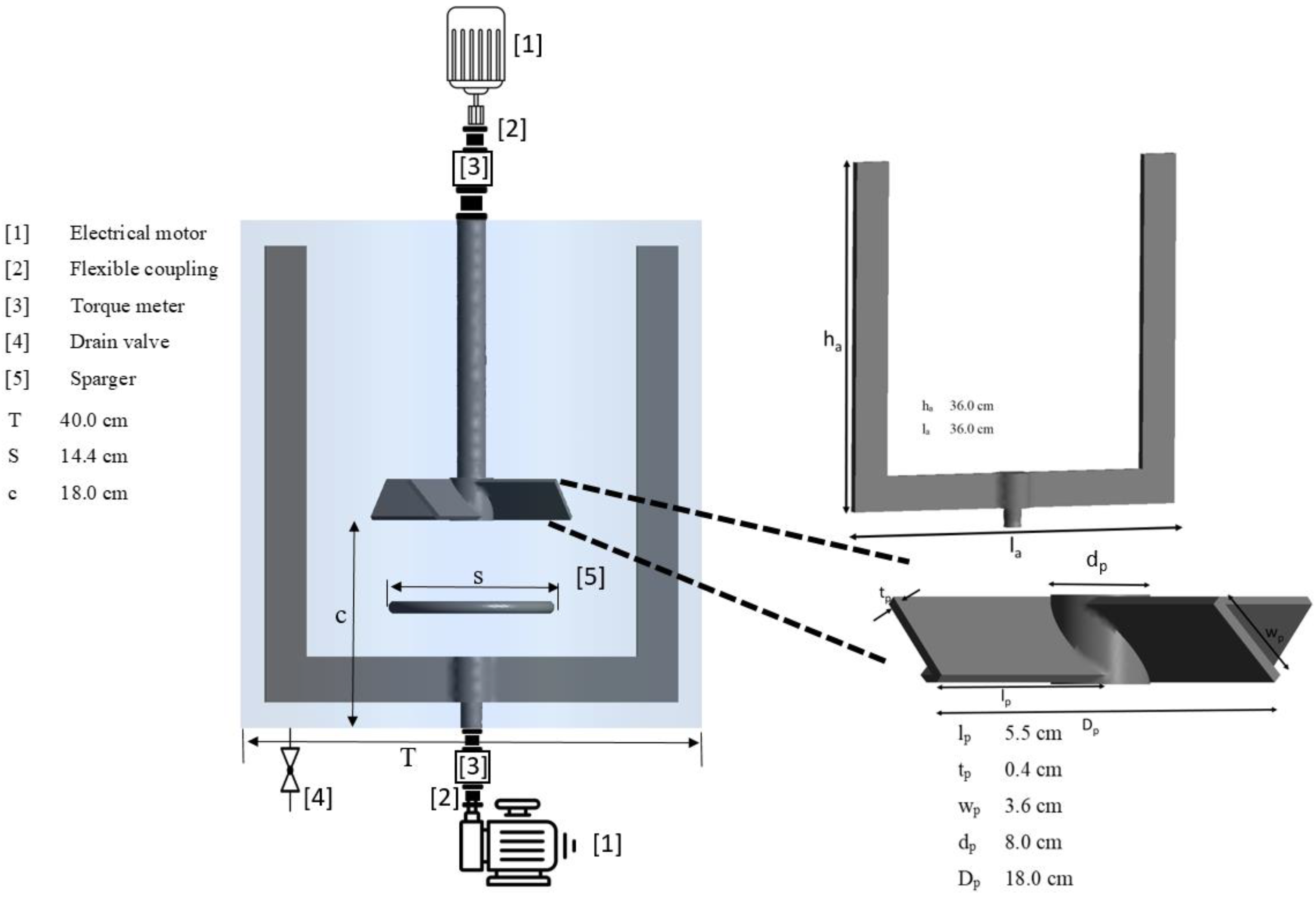
2.1. Experiments
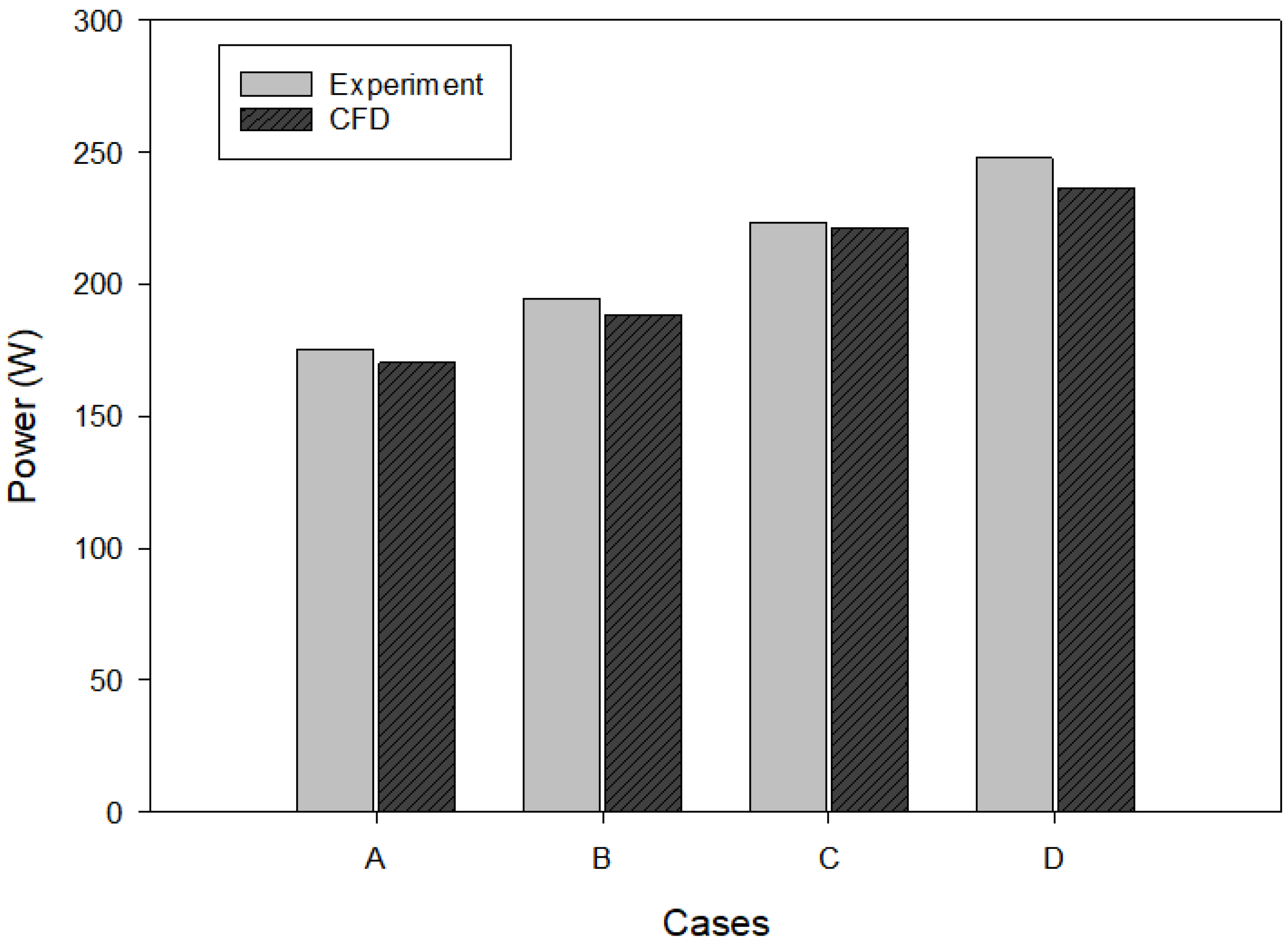
2.2. Computational Fluid Dynamics
2.3. Machine Learning Model
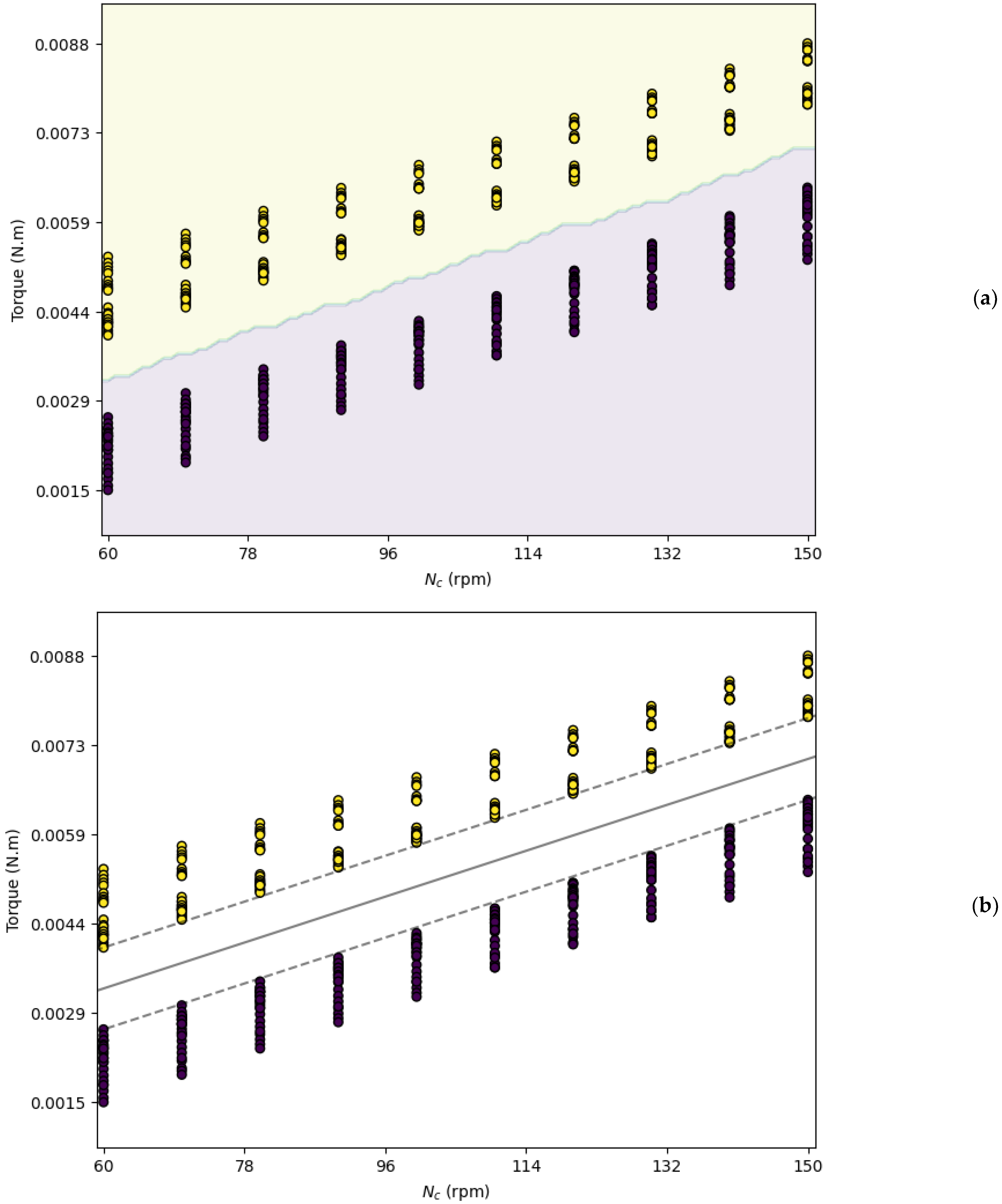
2.3.1. Classification Models
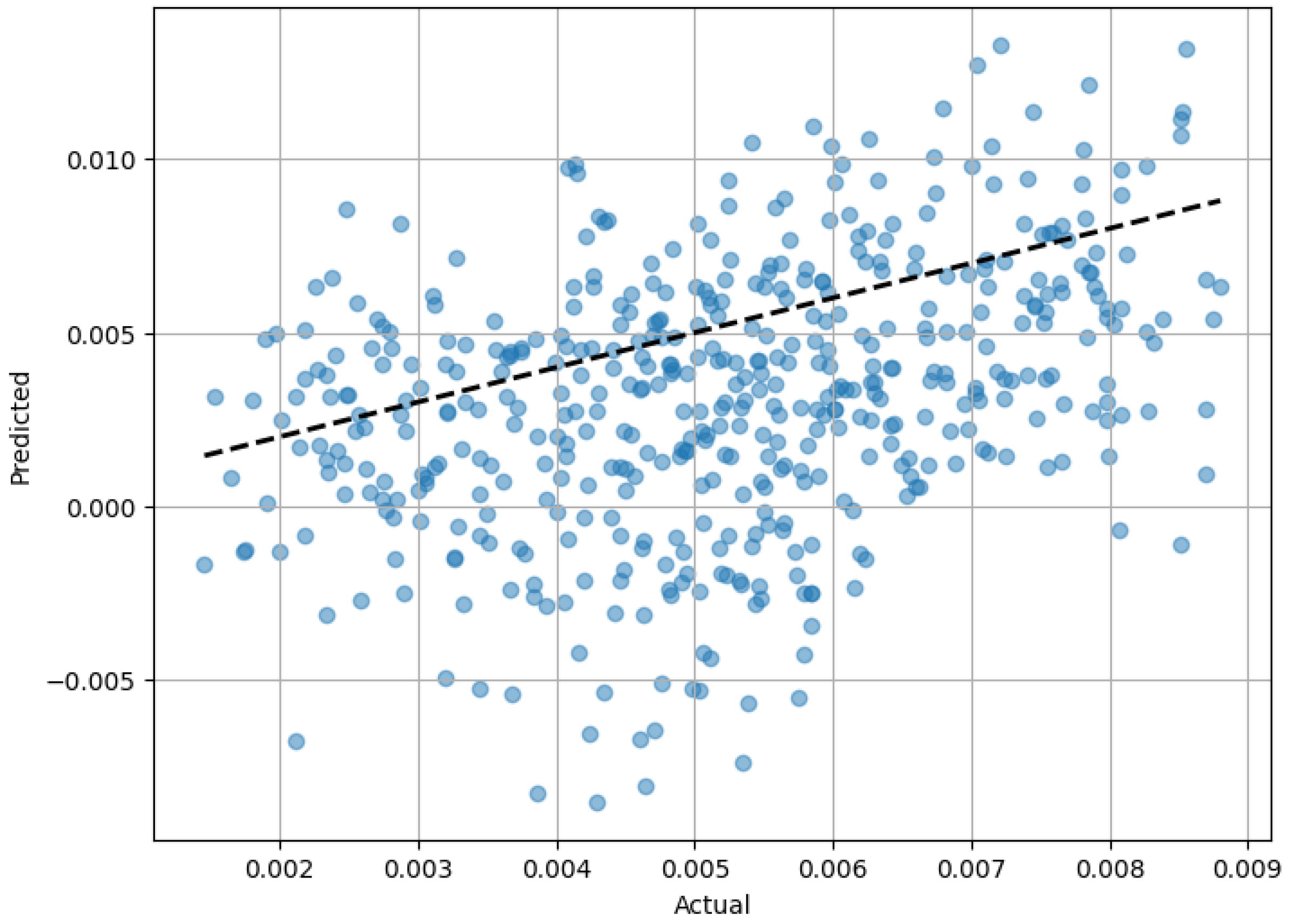
2.3.2. Regression Models
3. Results and Discussion
3.1. Classification
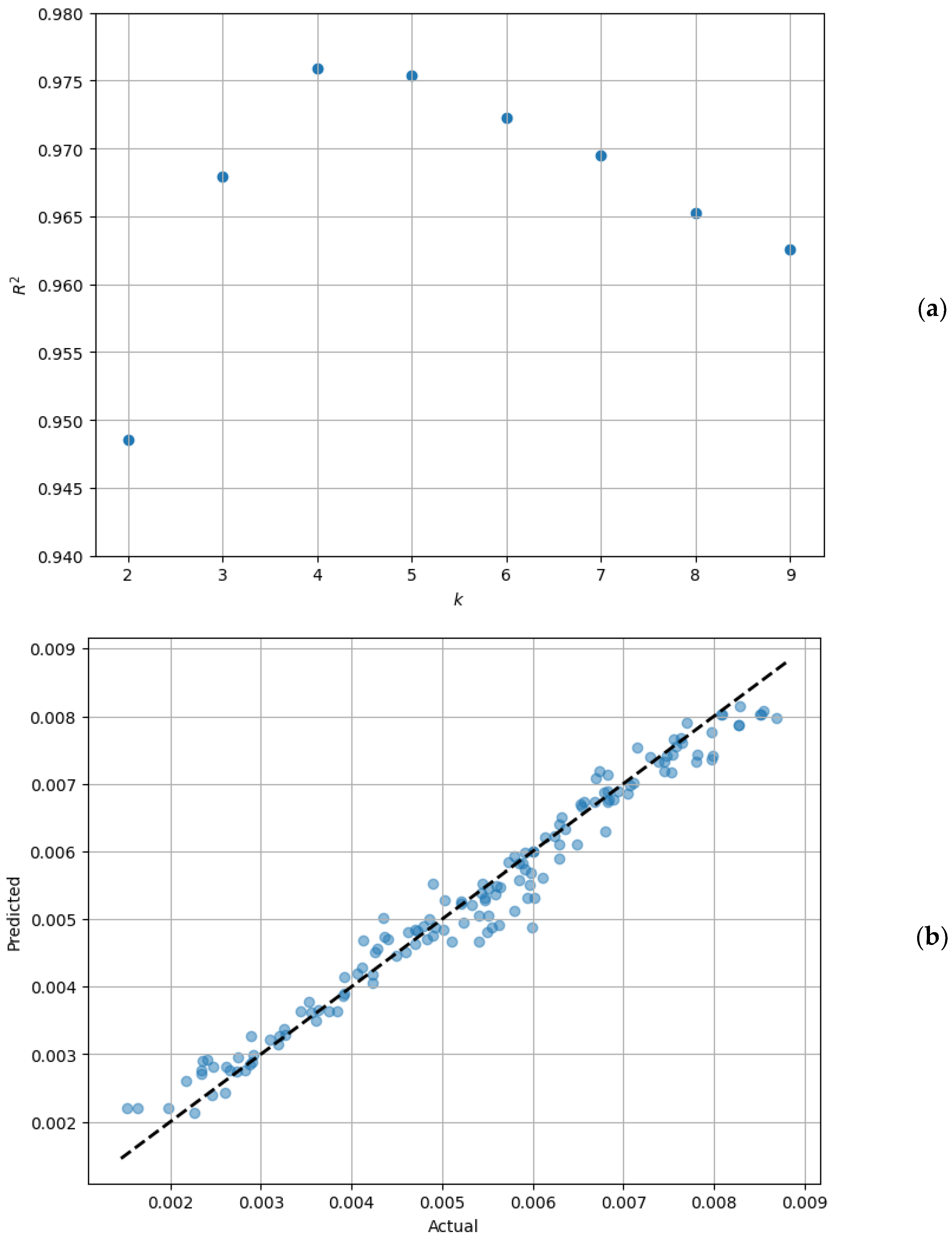
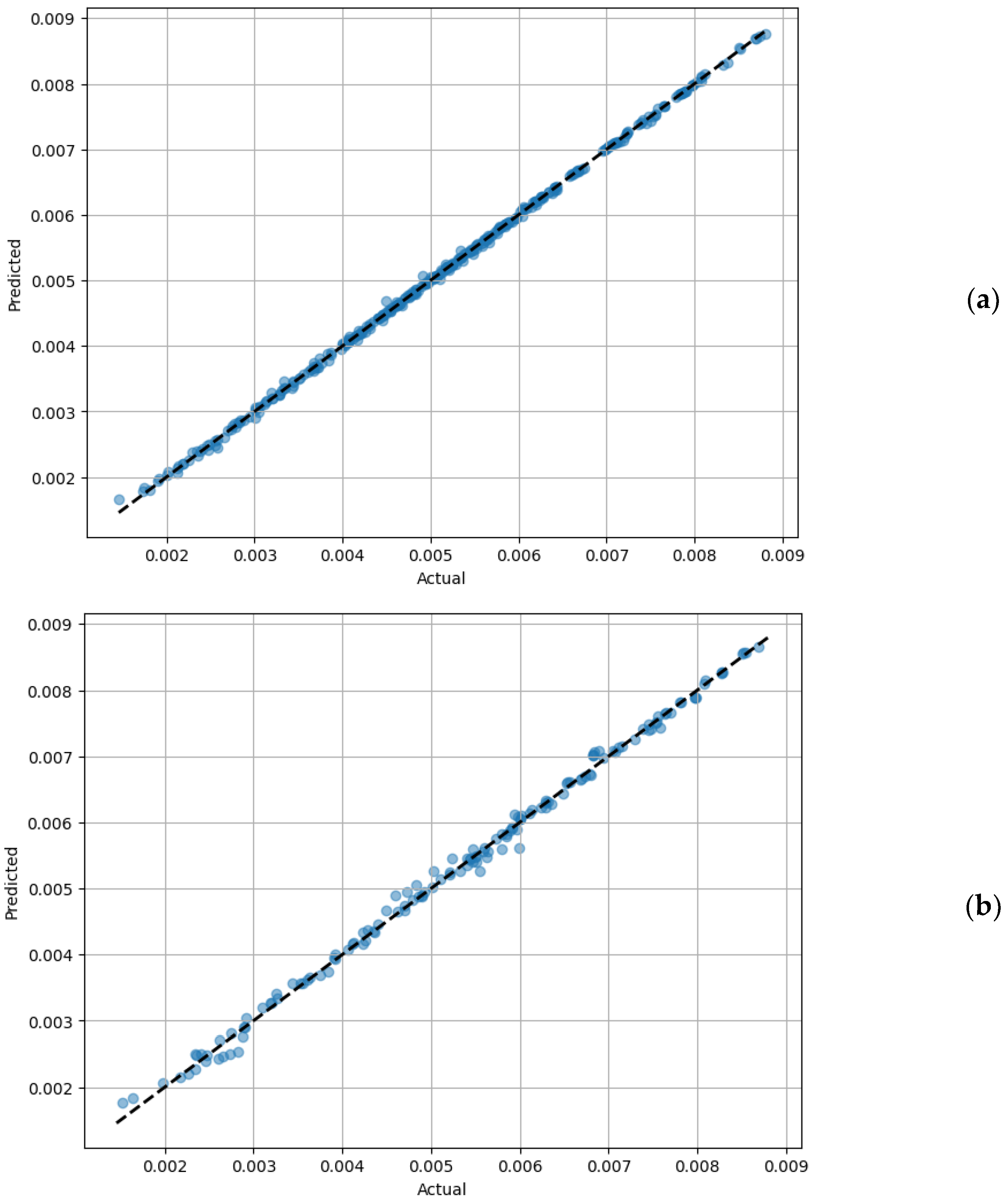
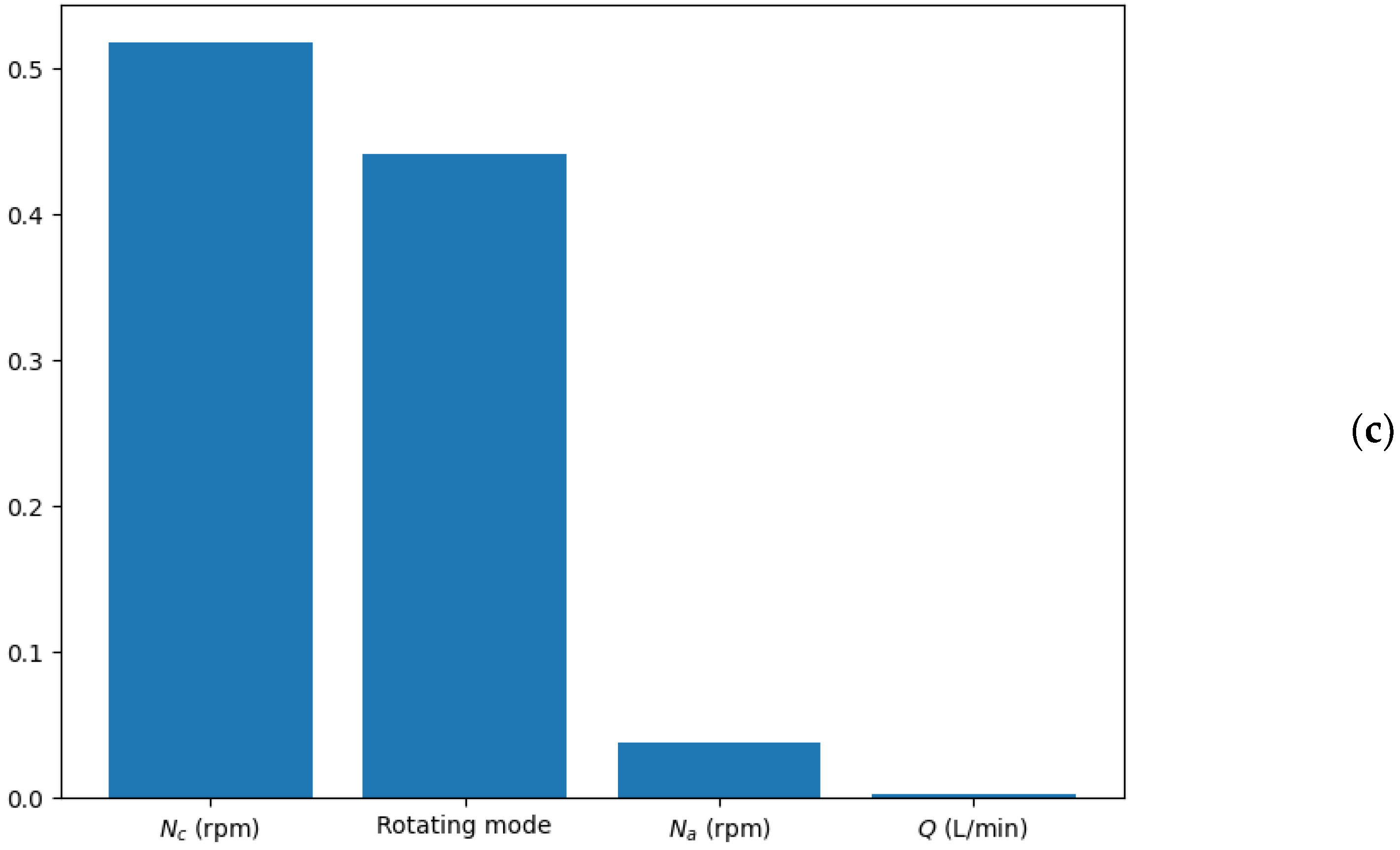
3.2. Regression
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Petříček, R.; Moucha, T.; Rejl, F.J.; Valenz, L.; Haidl, J.; Čmelíková, T. Volumetric mass transfer coefficient, power input and gas hold-up in viscous liquid in mechanically agitated fermenters. Measurements and scale-up. Int. J. Heat Mass Transf. 2018, 124, 1117–1135. [Google Scholar] [CrossRef]
- Roque, T.; Augier, F.; Hardy, N.; Chaabane, F.B.; Béal, C.; Roque, T.; Augier, F.; Hardy, N.; Chaabane, F.B.; Nienow, A. Mitigation of hydrodynamics related stress in bioreactors: A key for the scale-up of enzyme production by filamentous fungi. In Proceedings of the 16th European Conference on Mixing–Mixing, Birmingham, UK, 9–12 September 2018. [Google Scholar]
- Garcia-Ochoa, F.; Gomez, E. Bioreactor scale-up and oxygen transfer rate in microbial processes: An overview. Biotechnol. Adv. 2009, 27, 153–176. [Google Scholar] [CrossRef] [PubMed]
- Amiraftabi, M.; Khiadani, M.; Mohammed, H.A. Performance of a dual helical ribbon impeller in a two-phase (gas-liquid) stirred tank reactor. Chem. Eng. Process. Process Intensif. 2020, 148, 107811. [Google Scholar] [CrossRef]
- Nienow, A.W.; Bujalski, W. The Versatility of Up-Pumping Hydrofoil Agitators. Chem. Eng. Res. Des. 2004, 82, 1073–1081. [Google Scholar] [CrossRef]
- Paglianti, A.; Takenaka, K.; Bujalski, W. Simple model for power consumption in aerated vessels stirred by Rushton disc turbines. AIChE J. 2001, 47, 2673–2683. [Google Scholar] [CrossRef]
- McFarlane, C.M.; Zhao, X.-M.; Nienow, A.W. Studies of high solidity ratio hydrofoil impellers for aerated bioreactors. 2. Air-water studies. Biotechnol. Prog. 1995, 11, 608–618. [Google Scholar] [CrossRef]
- Nienow, A.W. Hydrodynamics of Stirred Bioreactors. Appl. Mech. Rev. 1998, 51, 3–32. [Google Scholar] [CrossRef]
- Aubin, J.; Mavros, P.; Fletcher, D.F.; Bertrand, J.; Xuereb, C. Effect of Axial Agitator Configuration (Up-Pumping, Down-Pumping, Reverse Rotation) on Flow Patterns Generated in Stirred Vessels. Chem. Eng. Res. Des. 2001, 79, 845–856. [Google Scholar] [CrossRef]
- Vrábel, P.; van der Lans, R.G.J.M.J.M.; Luyben, K.C.A.A.M.; Boon, L.; Nienow, A.W. Mixing in large-scale vessels stirred with multiple radial or radial and axial up-pumping impellers: Modelling and measurements. Chem. Eng. Sci. 2000, 55, 5881–5896. [Google Scholar] [CrossRef]
- Vilaça, P.R.; Badino, A.C.; Facciotti, M.C.R.; Schmidell, W. Determination of power consumption and volumetric oxygen transfer coefficient in bioreactors. Bioprocess Eng. 2000, 22, 261–265. [Google Scholar] [CrossRef]
- Bouaifi, M.; Roustan, M. Power consumption, mixing time and homogenisation energy in dual-impeller agitated gas–liquid reactors. Chem. Eng. Process. Process Intensif. 2001, 40, 87–95. [Google Scholar] [CrossRef]
- Doran, P. Bioprocess Engineering Principles, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar] [CrossRef]
- Taghavi, M.; Zadghaffari, R.; Moghaddas, J.; Moghaddas, Y. Experimental and CFD investigation of power consumption in a dual Rushton turbine stirred tank. Chem. Eng. Res. Des. 2011, 89, 280–290. [Google Scholar] [CrossRef]
- Rahimzadeh, A.; Ein-mozaffari, F.; Lohi, A. A Methodical Approach to Scaling Up an Aerated Coaxial Mixer Containing a Shear-Thinning Fluid: Effect of the Fluid Rheology. Ind. Eng. Chem. Res. 2023, 62, 8454–8476. [Google Scholar] [CrossRef]
- Rahimzadeh, A.; Ein-mozaffari, F.; Lohi, A. Development of a scale-up strategy for an aerated coaxial mixer containing a non-Newtonian fluid: A mass transfer approach. Phys. Fluids 2023, 35, 073103. [Google Scholar] [CrossRef]
- Rahimzadeh, A.; Ein-mozaffari, F.; Lohi, A. Investigation of power consumption, torque fluctuation, and local gas hold-up in coaxial mixers containing a shear-thinning fluid: Experimental and numerical approaches. Chem. Eng. Process. Process Intensif. 2022, 177, 108983. [Google Scholar] [CrossRef]
- Liu, B.; Huang, B.; Zhang, Y.; Liu, J.; Jin, Z. Numerical study on gas dispersion characteristics of a coaxial mixer with viscous fluids. J. Taiwan Inst. Chem. Eng. 2016, 66, 54–61. [Google Scholar] [CrossRef]
- Barros, P.L.; Ein-Mozaffari, F.; Lohi, A. Power Consumption Characterization of Energy-Efficient Aerated Coaxial Mixers Containing Yield-Stress Biopolymer Solutions. Ind. Eng. Chem. Res. 2022, 61, 12813–12824. [Google Scholar] [CrossRef]
- Sharifi, F.; Behzadfar, E.; Ein-Mozaffari, F. Investigating the power consumption for the intensification of gas dispersion in a dual coaxial mixer containing yield-pseudoplastic fluids. Chem. Eng. Process. Process Intensif. 2023, 191, 109461. [Google Scholar] [CrossRef]
- Bowler, A.L.; Bakalis, S.; Watson, N.J. Monitoring Mixing Processes Using Ultrasonic Sensors and Machine Learning Alexander. Sensor 2020, 20, 1813. [Google Scholar] [CrossRef]
- Kumar, P.; Sinha, K.; Nere, N.K.; Shin, Y.; Ho, R.; Mlinar, L.B.; Sheikh, A.Y. A machine learning framework for computationally expensive transient models. Sci. Rep. 2020, 10, 11492. [Google Scholar] [CrossRef]
- Barros, P.L.; Ein-Mozaffari, F.; Lohi, A.; Upreti, S. Exploiting the prediction of mass transfer performance in aerated coaxial mixers containing biopolymer solutions using empirical correlations and neural networks. Can. J. Chem. Eng. 2023, 1–18. [Google Scholar] [CrossRef]
- Yang, C.; Yao, J.; Chen, X.; Xie, M.; Zhou, G.; Xu, Z.; Liu, B. Chemical Engineering Research and Design Experimental study on gas-liquid flow regimes of coaxial mixers equipped with a Rushton/pitched blade turbine and anchor. Chem. Eng. Res. Des. 2024, 202, 377–389. [Google Scholar] [CrossRef]
- Bibeau, V.; Barbeau, L.; Boffito, D.C.; Blais, B. Artificial neural network to predict the power number of agitated tanks fed by CFD simulations. Can. J. Chem. Eng. 2023, 101, 5992–6002. [Google Scholar] [CrossRef]
- Chen, M.; Wang, J.; Zhao, S.; Xu, C.; Feng, L. Optimization of Dual-Impeller Configurations in a Gas-Liquid Stirred Tank Based on Computational Fluid Dynamics and Multiobjective Evolutionary Algorithm. Ind. Eng. Chem. Res. 2016, 55, 9054–9063. [Google Scholar] [CrossRef]
- Kang, Z.; Feng, L.; Wang, J. Optimization of a Gas–Liquid Dual-Impeller Stirred Tank Based on Deep Learning with a Small Data Set from CFD Simulation. Ind. Eng. Chem. Res. 2023, 63, 843–855. [Google Scholar] [CrossRef]
- Laubscher, R.; Rousseau, P. Application of generative deep learning to predict temperature, flow and species distributions using simulation data of a methane combustor. Int. J. Heat Mass Transf. 2020, 163, 120417. [Google Scholar] [CrossRef]
- Taira, K.; McInnes, D.; Zhang, L. How many data points and how large an R-squared value is essential for Arrhenius plots? J. Catal. 2023, 419, 26–36. [Google Scholar] [CrossRef]
- Liu, Y.; Li, C.; Bao, J.; Wang, X.; Yu, W.; Shao, L. Degradation of Azo Dyes with Different Functional Groups in Simulated Wastewater by Electrocoagulation. Water 2022, 14, 123. [Google Scholar] [CrossRef]
- Kathamuthu, N.D.; Subramaniam, S.; Le, Q.H.; Muthusamy, S.; Panchal, H.; Sundararajan, S.C.M.; Alrubaie, A.J.; Zahra, M.M.A. A deep transfer learning-based convolution neural network model for COVID-19 detection using computed tomography scan images for medical applications. Adv. Eng. Softw. 2023, 175, 103317. [Google Scholar] [CrossRef]
- Mu’azu, N.D.; Olatunji, S.O. K-nearest neighbor based computational intelligence and RSM predictive models for extraction of Cadmium from contaminated soil. Ain Shams Eng. J. 2023, 14, 101944. [Google Scholar] [CrossRef]
- Briceno-Mena, L.A.; Arges, C.G.; Romagnoli, J.A. Machine learning-based surrogate models and transfer learning for derivative free optimization of HT-PEM fuel cells. Comput. Chem. Eng. 2023, 171, 108159. [Google Scholar] [CrossRef]
- Houssein, E.H.; Hosney, M.E.; Oliva, D.; Mohamed, W.M.; Hassaballah, M. A novel hybrid Harris hawks optimization and support vector machines for drug design and discovery. Comput. Chem. Eng. 2020, 133, 106656. [Google Scholar] [CrossRef]
- Mir, A.; Nasiri, J.A. KNN-based least squares twin support vector machine for pattern classification. Appl. Intell. 2018, 48, 4551–4564. [Google Scholar] [CrossRef]
- Tang, L.; Tian, Y.; Yang, C. Nonparallel support vector regression model and its SMO-type solver. Neural Netw. 2018, 105, 431–446. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Zhang, Z.; Li, X.; Zong, M.; Wang, Y.; Wang, S.; Chen, P.; Wan, Z.; Liu, L.; Liang, Y.; et al. Machine learning assisted phase and size-controlled synthesis of iron oxide particles. Chem. Eng. J. 2023, 473, 145216. [Google Scholar] [CrossRef]
- Zhao, S.; Guo, J.; Dang, X.; Ai, B.; Zhang, M.; Li, W.; Zhang, J. Energy consumption, flow characteristics and energy-efficient design of cup-shape blade stirred tank reactors: Computational fluid dynamics and artificial neural network investigation. Energy 2022, 240, 122474. [Google Scholar] [CrossRef]
- Frontistis, Z.; Lykogiannis, G.; Sarmpanis, A. Machine Learning Implementation in Membrane Bioreactor Systems: Progress, Challenges, and Future Perspectives: A Review. Environments 2023, 10, 127. [Google Scholar] [CrossRef]
- Wang, T.; Li, Y.Y. Predictive modeling based on artificial neural networks for membrane fouling in a large pilot-scale anaerobic membrane bioreactor for treating real municipal wastewater. Sci. Total Environ. 2024, 912, 169164. [Google Scholar] [CrossRef] [PubMed]
- Zaghloul, M.S.; Iorhemen, O.T.; Hamza, R.A.; Tay, J.H.; Achari, G. Development of an ensemble of machine learning algorithms to model aerobic granular sludge reactors. Water Res. 2021, 189, 116657. [Google Scholar] [CrossRef]
- Rajković, D.; Jeromela, A.M.; Pezo, L.; Lončar, B.; Grahovac, N.; Špika, A.K. Artificial neural network and random forest regression models for modelling fatty acid and tocopherol content in oil of winter rapeseed. J. Food Compos. Anal. 2023, 115, 105020. [Google Scholar] [CrossRef]
- Yan, B.; Jiang, L.; Zhou, H.; Atakpa, E.O.; Bo, K.; Li, P.; Xie, Q.; Li, Y.; Zhang, C. Performance and microbial community analysis of combined bioreactors in treating high–salinity hydraulic fracturing flowback and produced water. Bioresour. Technol. 2023, 386, 129469. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Range |
|---|---|
| Central impeller speed (Nc) | 60–150 rpm |
| Anchor impeller speed (Na) | 3.5–9.5 rpm |
| Aeration rate (Q) | 2–6 L/min |
| Rotating mode | Co-rotating and counter-rotating |
| Number of Cross Validation Fold | k | Accuracy |
|---|---|---|
| cv = 3 | 7 | 0.6552 |
| cv = 4 | 7 | 0.7795 |
| cv = 5 | 8 | 0.9510 |
| cv = 6 | 7 | 0.8732 |
| cv = 7 | 7 | 0.9183 |
| cv = 8 | 7 | 0.9392 |
| cv = 9 | 7 | 0.9532 |
| cv = 10 | 8 | 0.9632 |
| cv = 11 | 7 | 0.9652 |
| cv = 12 | 7 | 0.9629 |
| cv = 13 | 7 | 0.9775 |
| cv = 14 | 7 | 0.9836 |
| cv = 15 | 7 | 0.9837 |
| cv = 16 | 7 | 0.9837 |
| cv = 17 | 7 | 0.9857 |
| cv = 18 | 7 | 0.9920 |
| cv = 19 | 7 | 0.9939 |
| cv = 20 | 7 | 0.9940 |
| Number of Hidden Layers | Number of Neurons | Activation Function | Solver | Regularization Term | Learning Rate | Initial Learning Rate |
|---|---|---|---|---|---|---|
| 2 | 100,100 | Relu | ADAM | L2 | 0.001 | 0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahimzadeh, A.; Ranjbarrad, S.; Ein-Mozaffari, F.; Lohi, A. Application of Machine Learning Models in Coaxial Bioreactors: Classification and Torque Prediction. ChemEngineering 2024, 8, 42. https://doi.org/10.3390/chemengineering8020042
Rahimzadeh A, Ranjbarrad S, Ein-Mozaffari F, Lohi A. Application of Machine Learning Models in Coaxial Bioreactors: Classification and Torque Prediction. ChemEngineering. 2024; 8(2):42. https://doi.org/10.3390/chemengineering8020042
Chicago/Turabian StyleRahimzadeh, Ali, Samira Ranjbarrad, Farhad Ein-Mozaffari, and Ali Lohi. 2024. "Application of Machine Learning Models in Coaxial Bioreactors: Classification and Torque Prediction" ChemEngineering 8, no. 2: 42. https://doi.org/10.3390/chemengineering8020042
APA StyleRahimzadeh, A., Ranjbarrad, S., Ein-Mozaffari, F., & Lohi, A. (2024). Application of Machine Learning Models in Coaxial Bioreactors: Classification and Torque Prediction. ChemEngineering, 8(2), 42. https://doi.org/10.3390/chemengineering8020042