Predicting Runoff Chloride Concentrations in Suburban Watersheds Using an Artificial Neural Network (ANN)



Abstract
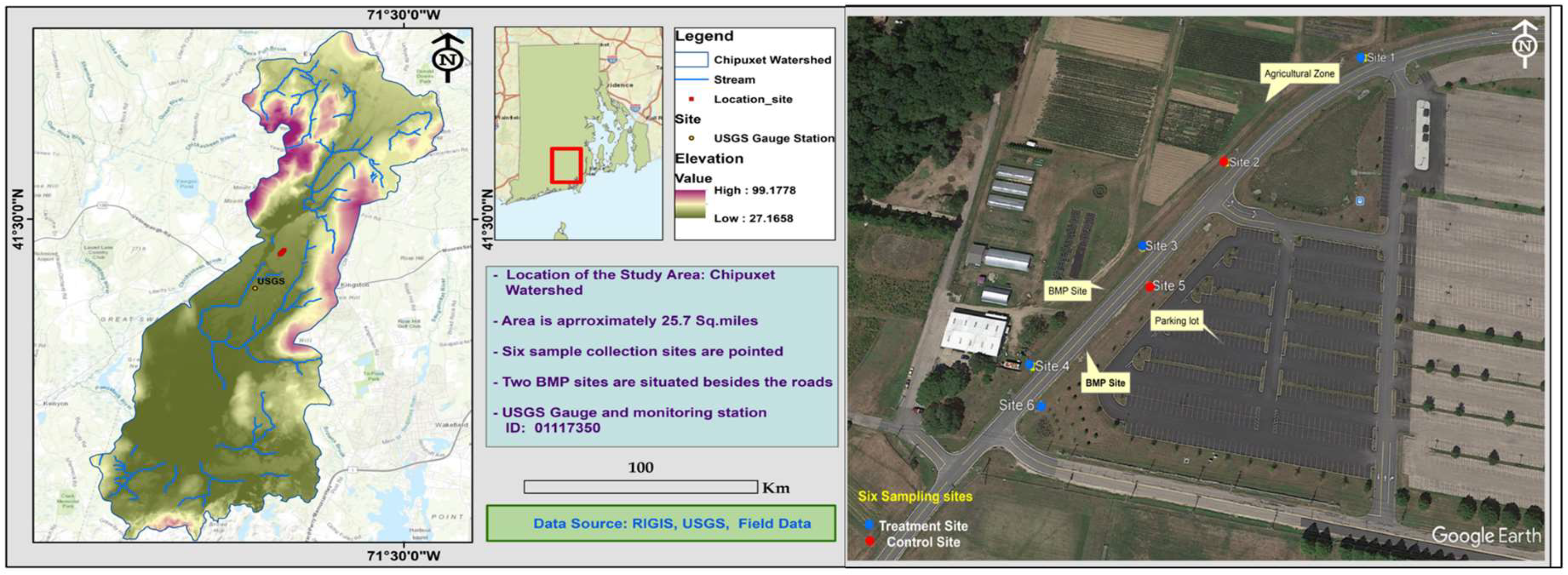
:1. Introduction
2. Materials and Methods
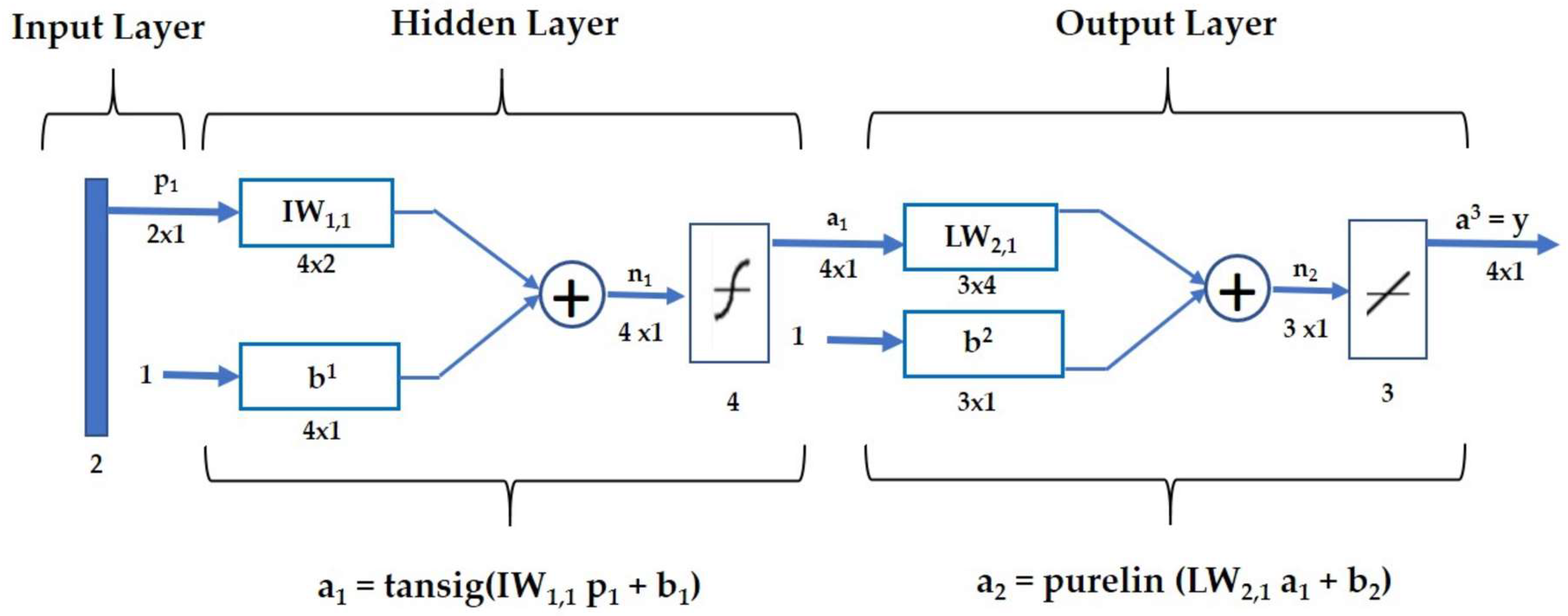
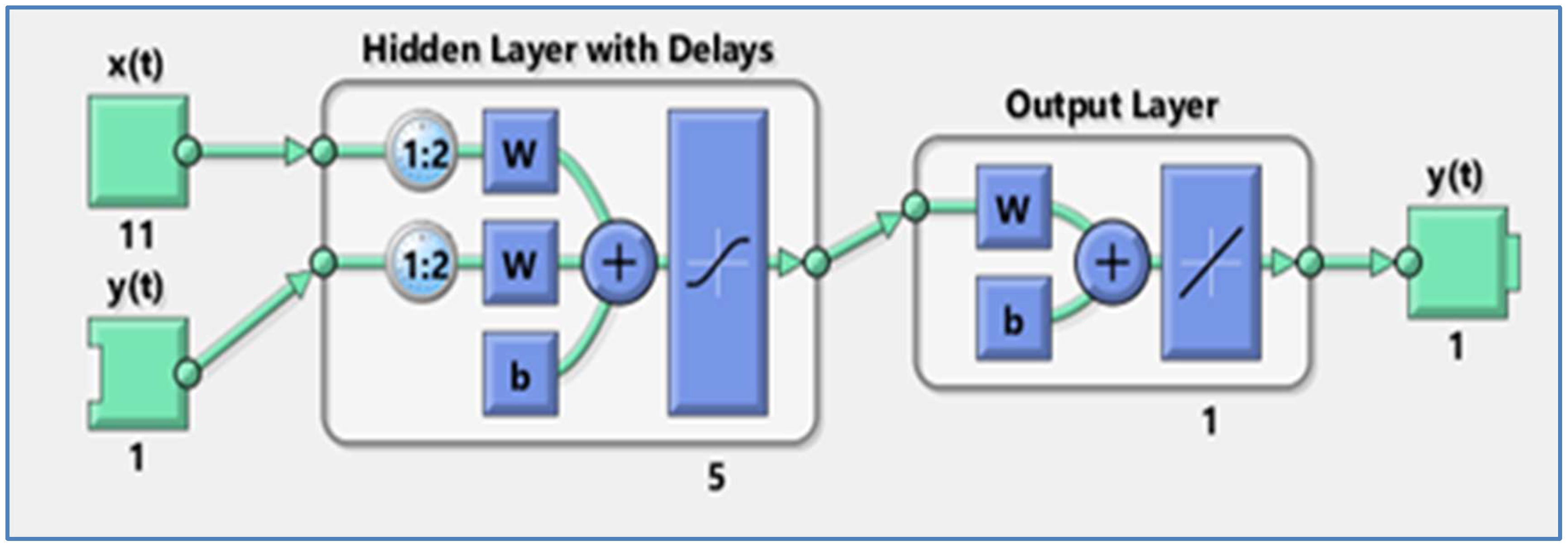
2.1. Artificial Neural Network (ANN)
2.2. Back Propagation (BP) Algorithm
2.3. Curve Fitting Algorithm
2.4. Density Distribution Algorithm
2.5. Model Structure
2.5.1. ANN Parameter Selection: Hidden Layers and Nodes
2.5.2. ANN Parameter Selection: Learning Rate and Momentum
2.5.3. ANN Parameter Selection: Initial Weights
2.5.4. ANN Parameter Selection: Selection of Input Variables
2.5.5. ANN Parameter Selection: Data Partition
2.5.6. ANN Parameter Selection: Model Performance Evaluation
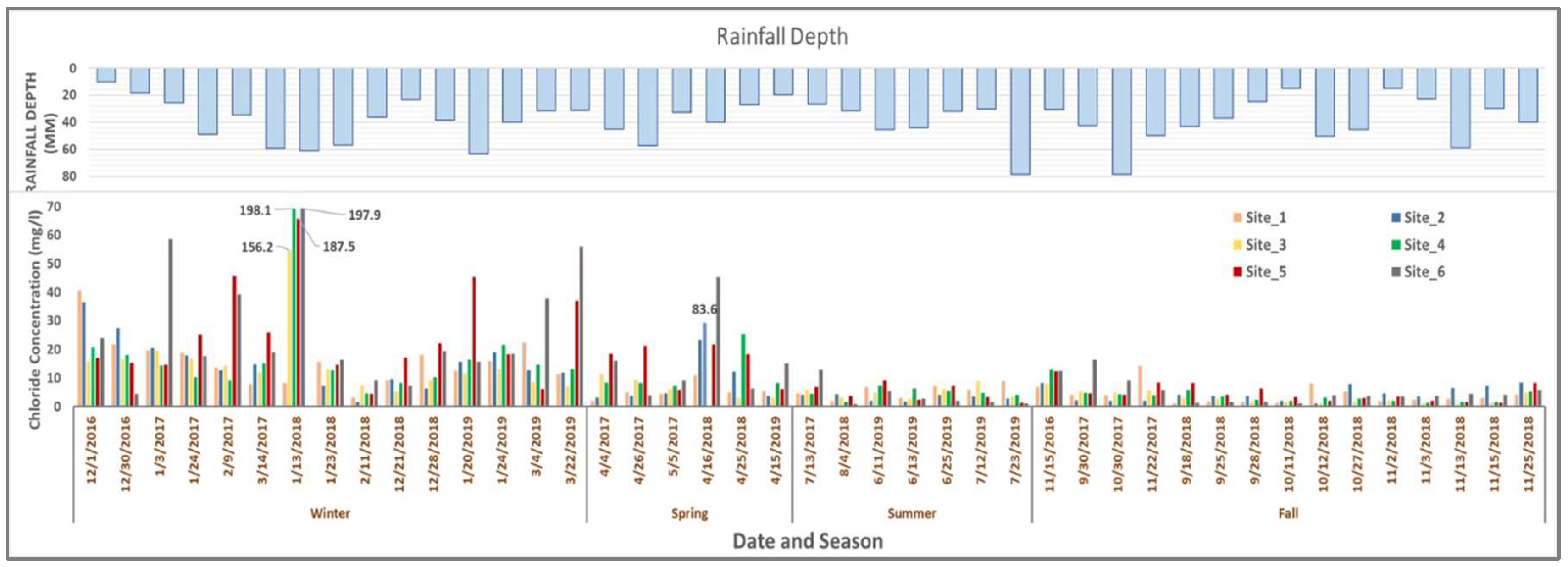
3. Results and Discussion
3.1. Model Output
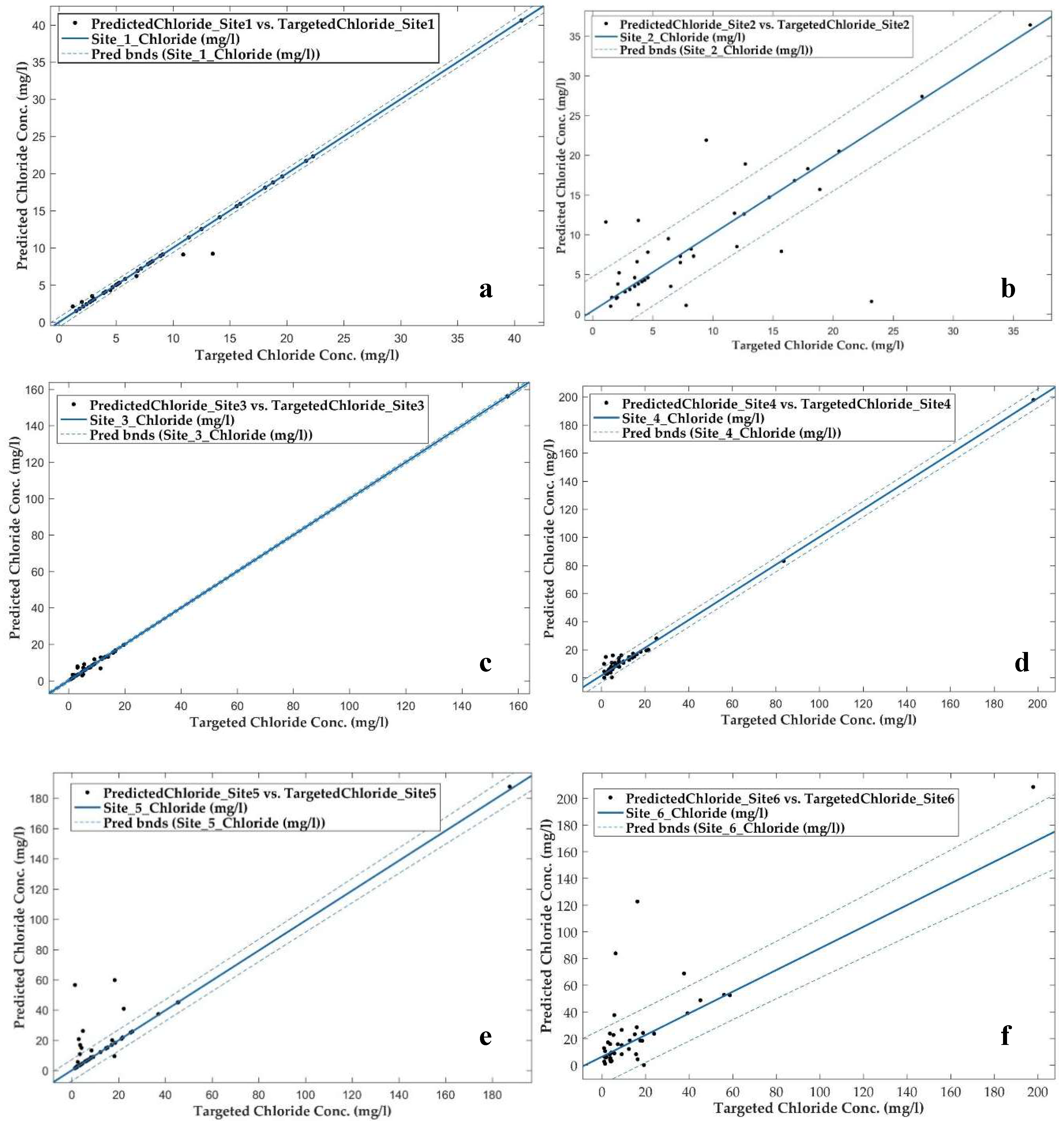
3.2. Curve Fitting Analysis
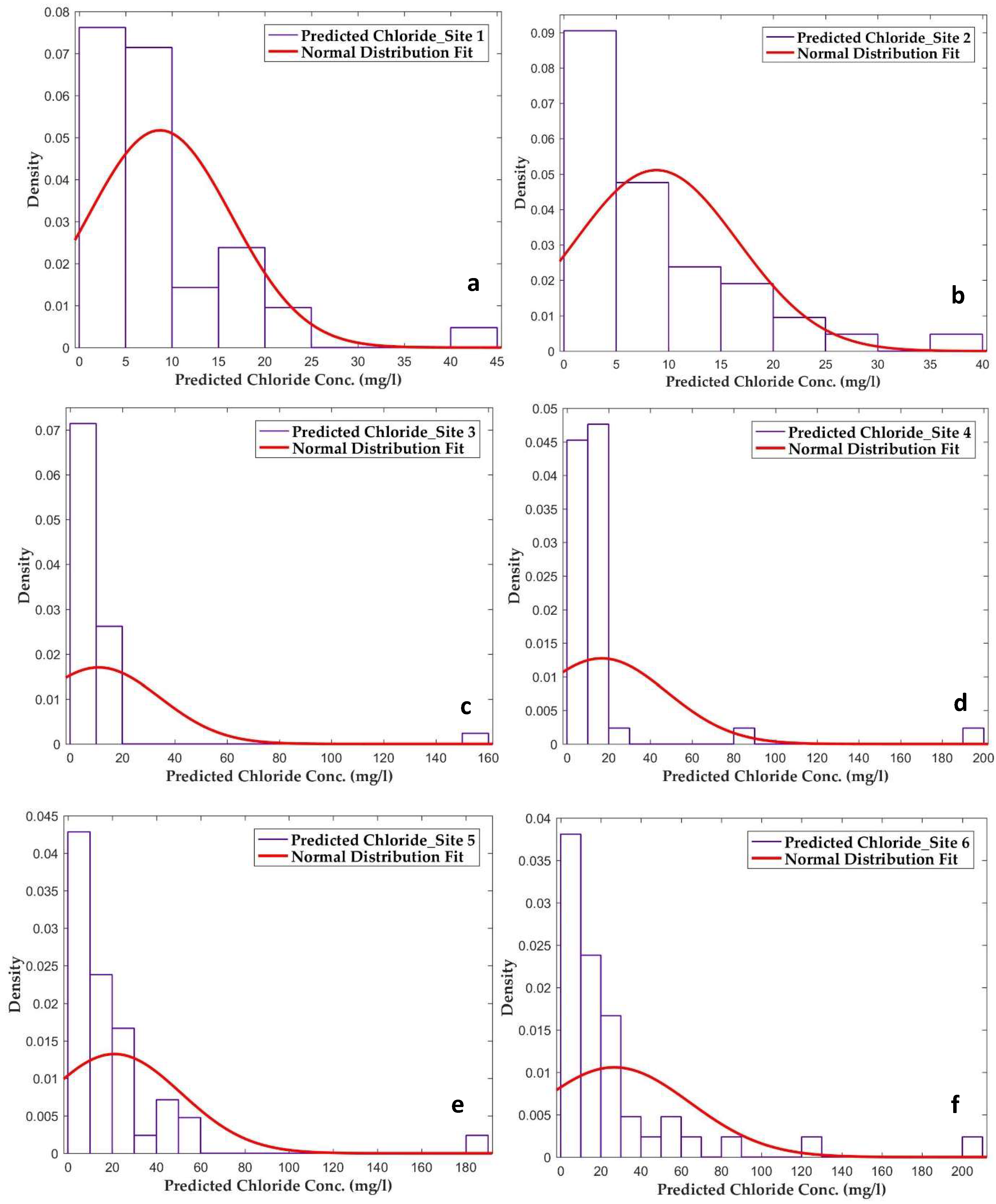
3.3. Density Distribution of the Predicted Chloride Concentration
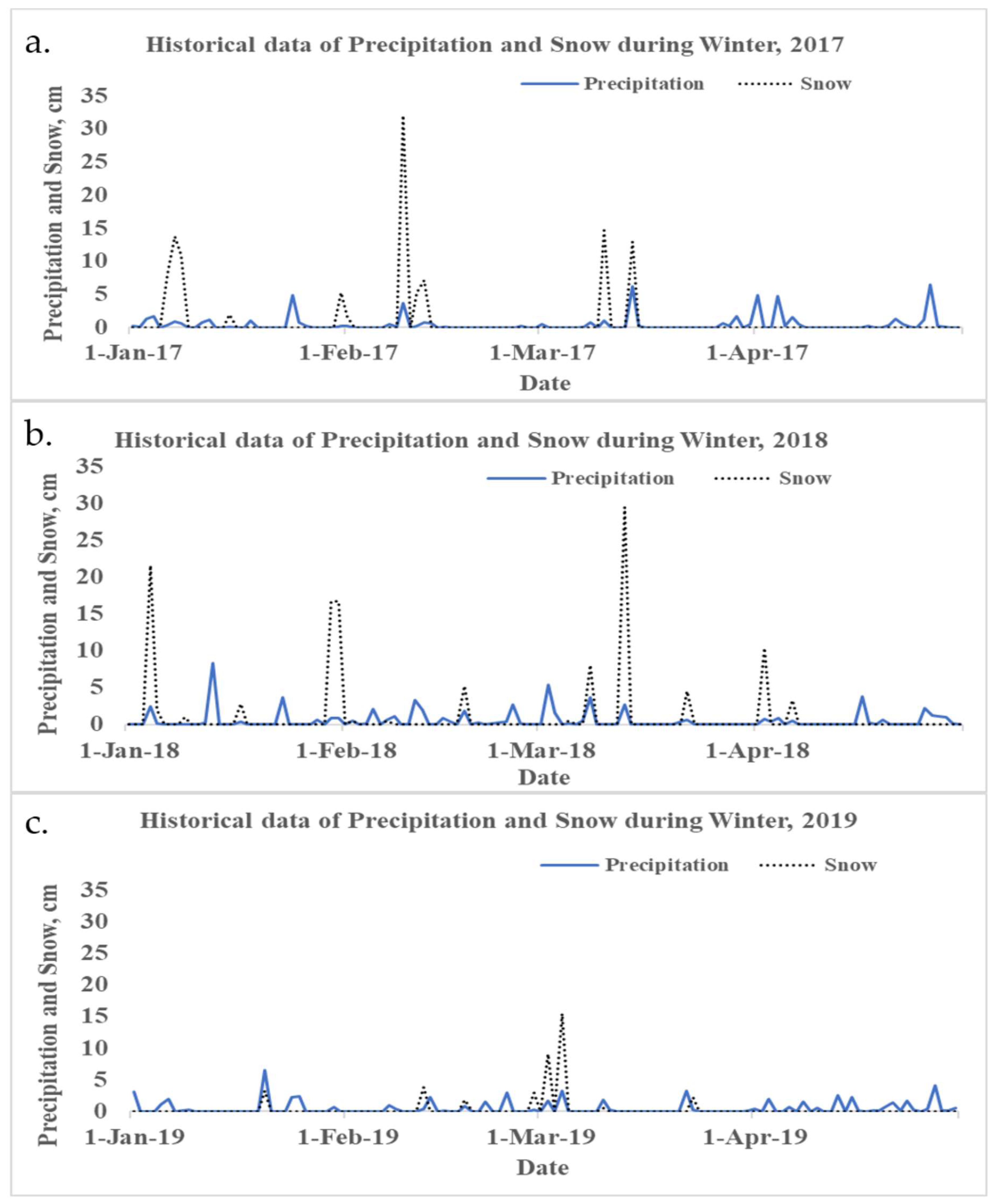
3.4. Cross Validation Based on Snow and Precipitation Events
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, D.; Wan, J.; Ma, Y.; Wang, Y.; Huang, M.; Chen, Y. Stormwater Runoff Pollutant Loading Distributions and Their Correlation with Rainfall and Catchment Characteristics in a Rapidly Industrialized City. PLoS ONE 2015, 10, e0118776. [Google Scholar] [CrossRef] [PubMed]
- Koleskar, R.K.; Mattson, N.C.; Peterson, K.P.; May, W.N.; Prendergast, K.R.; Pratt, A.K. Increase in wintertime PM2.5 sodium and chloride linked to snowfall and road salt application. Atmos. Environ. 2018, 177, 195–202. [Google Scholar] [CrossRef]
- Dugan, H.A.; Bartlett, S.L.; Burke, S.M.; Doubek, J.P.; Krivak-Tetley, F.E.; Skaff, N.K.; Summers, J.C.; Farrell, K.J.; McCullough, I.M.; Morales-Williams, A.M.; et al. Salting our freshwater lakes. Proc. Natl. Acad. Sci. USA 2017, 114, 4453–4458. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jackson, R.B.; Jobbagy, E.G. From icy roads to salty streams. Proc. Natl. Acad. Sci. USA 2005, 102, 14487–14488. [Google Scholar] [CrossRef] [Green Version]
- Kelting, D.L.; Laxson, C.L.; Yerger, E.C. Regional analysis of the effect of paved roads on sodium and chloride in lakes. Water Res. 2012, 46, 2749–2758. [Google Scholar] [CrossRef]
- Findlay, S.E.G.; Kelly, V.R. Emerging indirect and long-term road salt effects on ecosystems. Year Ecol. Conserv. Biol. 2011, 1223, 58–68. [Google Scholar] [CrossRef]
- Levelton Consultants Limited. Guidelines for the Selection of Snow and Ice Control Materials to Mitigate Environmental Impacts; National Cooperative Highway Research Program, American Association of State Highway, and Transportation Officials; Transportation Research Board: Washington, DC, USA, 2008; Volume 577. [Google Scholar]
- USGS. Evaluating Chloride Trends Due to Road-Salt Use and Its Impacts on Water Quality and Aquatic Organisms; USGS: Reston, VA, USA, 2014.
- Salinity Network. FWRMC Salinity Network Workgroup, Watershed Monitoring Section Quick Links. 2019. Available online: https://floridadep.gov/dear/watershed-monitoring-section/content/salinity-network#:~:text=Over%20the%20past%20several%20decades,of%20groundwater%20from%20our%20aquifers (accessed on 10 May 2019).
- Florida Salinity Network Workgroup. Groundwater Level Conditions for the Upper Floridan Aquifer Based on Percentile Ranks Pilot Study for May, 2010. 2015. Available online: http://publicfiles.dep.state.fl.us/DEAR/DEARweb/FWRMC/FWRMC%20Salnet_document_SNWGWLPRIPilotFinal_cv%20ada%203-27-15.pdf (accessed on 30 September 2015).
- Status and Trends Report, SFNRC Technical Series 2012:1, Salinity and Hydrology of Florida Bay, Status and Trends 1990–2009. South Florida Natural Resources Center, Everglades National Park: Homestead, FL, USA. Available online: https://www.nps.gov/ever/learn/nature/upload/SecureSFNRC2012-1LoRes.pdf (accessed on 10 January 2012).
- Kumar, A.; Sharma, M.P. Assessment of water quality of Ganga river stretch near Koteshwar hydropower station, Uttarakhand, India. Int. J. Mech. Prod. Eng. 2015, 3, 82–85. [Google Scholar]
- Juair, H.; Sharifuddin, M.Z. Sensitivity analysis for water quality index (WQI) prediction for Kinta River. World Appl. Sci. J. 2011, 14, 60–65. [Google Scholar]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall: Upper Saddle River, NJ, USA, 1999. [Google Scholar]
- Vasanthi, S.; Kumar, A. Application of artificial neural network techniques for predicting the water quality index in the parakai lake, Tamil Nadu, India. Appl. Ecol. Environ. Res. 2018, 17, 1947–1958. [Google Scholar] [CrossRef]
- Najah, A.; El-Shafie, A.; Karim Amr, O.A. Application of artificial neural networks for water quality prediction. Neural Comput. Appl. 2013, 22, 187–201. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning internal representations by error propagation. In Parallel Distributed Processing; Rumelhart, D.E., McClelland, J.L., Eds.; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Palani, S.; Liong, S.; Tkalich, P. An ANN application for water quality forecasting. Mar. Pollut. Bull. 2008, 56, 1586–1597. [Google Scholar] [CrossRef] [PubMed]
- Deep Artificial Intelligence, Hidden Layer. Available online: https://deepai.org/machine-learning-glossary-and-terms/hidden-layer-machine-learning (accessed on 20 December 2012).
- Obuchowski, A. Understanding Neural Networks 1: The Concept of Neurons. 2019. Available online: https://becominghuman.ai/understanding-neural-networks-1-the-concept-of-neurons-287be36d40f (accessed on 23 March 2019).
- Sing, K.; Basant, A.; Malik, A.; Jain, G. Artificial neural network modeling of the river water quality—A case study. Ecol. Model. 2008, 220, 888–895. [Google Scholar] [CrossRef]
- Gavindaraju, R.S. Artificial neural network in hydrology, II: Hydrologic application. ASCE task committee application of artificial neural networks in hydrology. J. Hydrol. Eng. 2000, 5, 124–137. [Google Scholar]
- Wang, Q.H. Improvement on BP algorithm in artificial neural network. J. Qinghai Univ. 2004, 22, 82–84. [Google Scholar]
- Kuo, J.T.; Hseih, M.H.; Lung, W.S.; She, N. Using artificial neural network for reservoir eutrophication prediction. Ecol. Model. 2006, 200, 171–177. [Google Scholar] [CrossRef]
- Mathworks. Matlab User’s Guide (for Use with MATLAB); MathWorks, Inc.: Natick, MA, USA, 2001. [Google Scholar]
- Lee, T.L.; Jeng, D.S. Application of artificial neural network for long-term tidal predictions. Ocean Eng. 2002, 29, 1003–1022. [Google Scholar] [CrossRef]
- Moon, S.K.; Woo, N.C.; Lee, K.S. Statistical analysis of hydrographs and water table fluctuation to estimate groundwater recharge. J. Hydrol. 2004, 292, 198–204. [Google Scholar] [CrossRef]
- Wu, Z.S.; Xu, B.; Yokoyama, K. Decentralized parametric damage detection based on neural networks. Comput. Aided Civ. Infrastruct. Eng. 2002, 17, 175–184. [Google Scholar] [CrossRef]
- Kumar, N. Sigmoid Neuron—Building Block of Deep Neural Networks, Towards Data Science. 2019. Available online: https://towardsdatascience.com/sigmoid-neuron-deep-neural-networks-a4cd35b629d7 (accessed on 7 March 2019).
- Xu, B.; Wu, Z.S.; Yokoyama, K. Response time series-based structural parametric assessment approach with neural networks. In Proceedings of the 1st International Conference on Structural Health Monitoring and Intelligent Infrastructure (SHMII-1 2003), Tokyo, Japan, 13–15 November 2003; Swets & Zeitlinger: Lisse, The Netherlands, 2003; pp. 601–609. [Google Scholar]
- Tarassenko, L. A Guide to Neural Computing Applications; Arnold Publishers: London, UK, 1998. [Google Scholar]
- Hechit-Neilsen, R. Kolmogorov’s mapping neural network existence theorem. In Proceedings of the 1st IEEE International joint Conference of Neural Network, San Diego, CA, USA, 23–28 August 1987; Institute of Electrical and Electronics Engineers: New York, NY, USA, 1987. [Google Scholar]
- Tsoukalas, L.H.; Uhrig, R.E. Fuzzy and Neural Approaches in Engineering; Wiley Interscience: New York, NY, USA, 1997; 587p. [Google Scholar]
- Maier, H.R.; Dandy, G.C. The use of artificial neural networks for the prediction of water quality parameters. Water Resour. Res. 1996, 32, 1013–1022. [Google Scholar] [CrossRef]
- Anand, S. Why Domain Knowledge Is Important in Data Science, medium.com. 2019. Available online: https://medium.com/@anand0427/why-domain-knowledge-is-important-in-data-science-anand0427-3002c659c0a5 (accessed on 18 March 2019).
- Yang, X.; Gandomi, A.; Talatahri, S.; Alavi, A.H. Metaheuristics in Water, Geotechnical and Transport Engineering; Zali, M.A., Retnam, A., Eds.; Elevier Inc.: Amsterdam, The Netherlands, 2013; ISBN 978-0-12-398296-4. [Google Scholar]
- Masters, T. Advanced Algorithms for Neural Networks. A C++ Sourcebook; John Wiley and Sons, Inc.: New York, NY, USA, 1993. [Google Scholar]
- Neuroshell 2TM. Neuroshell Tutorial; Ward Systems Group, Inc.: Frederick, MD, USA, 2000. [Google Scholar]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models; part 1—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Wilcox, B.P.; Rawls, W.J.; Brakensiek, D.I.; Wight, J.R. Predicting runoff from rangeland catchment: A comparison of two models. Water Resour. Res. 1990, 26, 2401–2410. [Google Scholar] [CrossRef]
- Rhode Island Division of Planning. Road Salt/Sand Application in Rhode Island, Statewide Planning; Technical Paper Number: # 163; Rhode Island Division of Planning: Providence, RI, USA, 2014. Available online: http://www.planning.ri.gov/documents/LU/RoadSaltTechPaper2013_12114rev.pdf (accessed on 31 March 2014).
- Hinsdale, J. How Road Salt Harms the Environment, State of the Planet. 2018. Available online: https://blogs.ei.columbia.edu/2018/12/11/road-salt-harms-environment/ (accessed on 11 December 2018).
- Elgin, E.; Salt Runoff Can Impair Lakes. Salting Roads, Parking Lots, and Sidewalks Can Turn Our “Fresh” Water Salty. 2018. Available online: https://www.canr.msu.edu/news/salt_runoff_can_impair_lakes (accessed on 22 February 2018).
- Kelting, D.; Laxson, C. Review of Effects and Costs of Roads De-Icing with Recommendations for Winter Road Management in the Adirondack Park. Adirondack Watershed Institute Report # AWI2010-01. 2010. Available online: http://www.protectadks.org/wp-content/uploads/2010/12/Road_Deicing-1.pdf (accessed on 22 February 2010).
- Rastogi, N. Salting the Earth: Does Road Salt Harm the Environment? The Green Lantern. 2010. Available online: https://slate.com/technology/2010/02/does-road-salt-harm-the-environment.html (accessed on 16 February 2010).
- Nagpal, N.K.; Levy, D.A.; MacDonald, D.D. Ambient Water Quality Guidelines for Chloride 2. National Library of Canada Cataloguing in Publication. Environmental Management Act, 1981. (3 of 22). 2004. Available online: http://wlapwww.gov.bc.ca/wat/wq/BCguidelines/chloride.html (accessed on 15 January 2004).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Location | Performance (Epoch) | Training (%) | Validation (%) | Testing (%) |
|---|---|---|---|---|
| Site_1 | 9 | 95 | 87 | 88 |
| Site_2 | 5 | 100 | 72 | 95 |
| Site_3 | 5 | 100 | 52 | 93 |
| Site_4 | 3 | 99 | 97 | 93 |
| Site_5 | 3 | 99 | 78 | 91 |
| Site_6 | 2 | 97 | 83 | 88 |
| File Name | SSE | R-Square | Adj R-sq | RMSE |
|---|---|---|---|---|
| Site_1 | 1.96 | 0.99 | 0.99 | 0.22 |
| Site_2 | 171.58 | 0.93 | 0.93 | 2.07 |
| Site_3 | 7.9 | 0.99 | 0.99 | 0.44 |
| Site_4 | 231.3 | 0.99 | 0.99 | 2.4 |
| Site_5 | 473.6 | 0.98 | 0.98 | 3.4 |
| Site_6 | 4051 | 0.93 | 0.92 | 10.06 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jahan, K.; Pradhanang, S.M. Predicting Runoff Chloride Concentrations in Suburban Watersheds Using an Artificial Neural Network (ANN). Hydrology 2020, 7, 80. https://doi.org/10.3390/hydrology7040080
Jahan K, Pradhanang SM. Predicting Runoff Chloride Concentrations in Suburban Watersheds Using an Artificial Neural Network (ANN). Hydrology. 2020; 7(4):80. https://doi.org/10.3390/hydrology7040080
Chicago/Turabian StyleJahan, Khurshid, and Soni M. Pradhanang. 2020. "Predicting Runoff Chloride Concentrations in Suburban Watersheds Using an Artificial Neural Network (ANN)" Hydrology 7, no. 4: 80. https://doi.org/10.3390/hydrology7040080
APA StyleJahan, K., & Pradhanang, S. M. (2020). Predicting Runoff Chloride Concentrations in Suburban Watersheds Using an Artificial Neural Network (ANN). Hydrology, 7(4), 80. https://doi.org/10.3390/hydrology7040080