

CTS-Net: A Segmentation Network for Glaucoma Optical Coherence Tomography Retinal Layer Images

 , , , , , , and
, , , , , , and 
Abstract
:1. Introduction
- We design a CSWin-Transformer-based OCT image segmentation network for glaucoma retinal layers. After carefully analyzing the cross-attention mechanism of the CSWin Transformer, it is found that its self-attention in the horizontal and vertical directions matches the features of the retinal layer. Therefore, we developed the neural network and applied it to the segmentation task of glaucomatous retinal layers, which provides a new reference direction for using an attention mechanism for retinal layer segmentation.
- We present a Dice loss function based on edge regions. In retinal layer segmentation tasks, features are often condensed in edge regions. Based on the Dice loss function, we developed a loss function that only calculates the overlapping loss of the edge region, which can guide the depth learning model to learn more edge features to improve the accuracy of edge segmentation.
2. Related Works
2.1. Retinal Layer Segmentation
2.2. Transformer
2.3. Loss Function
3. Method
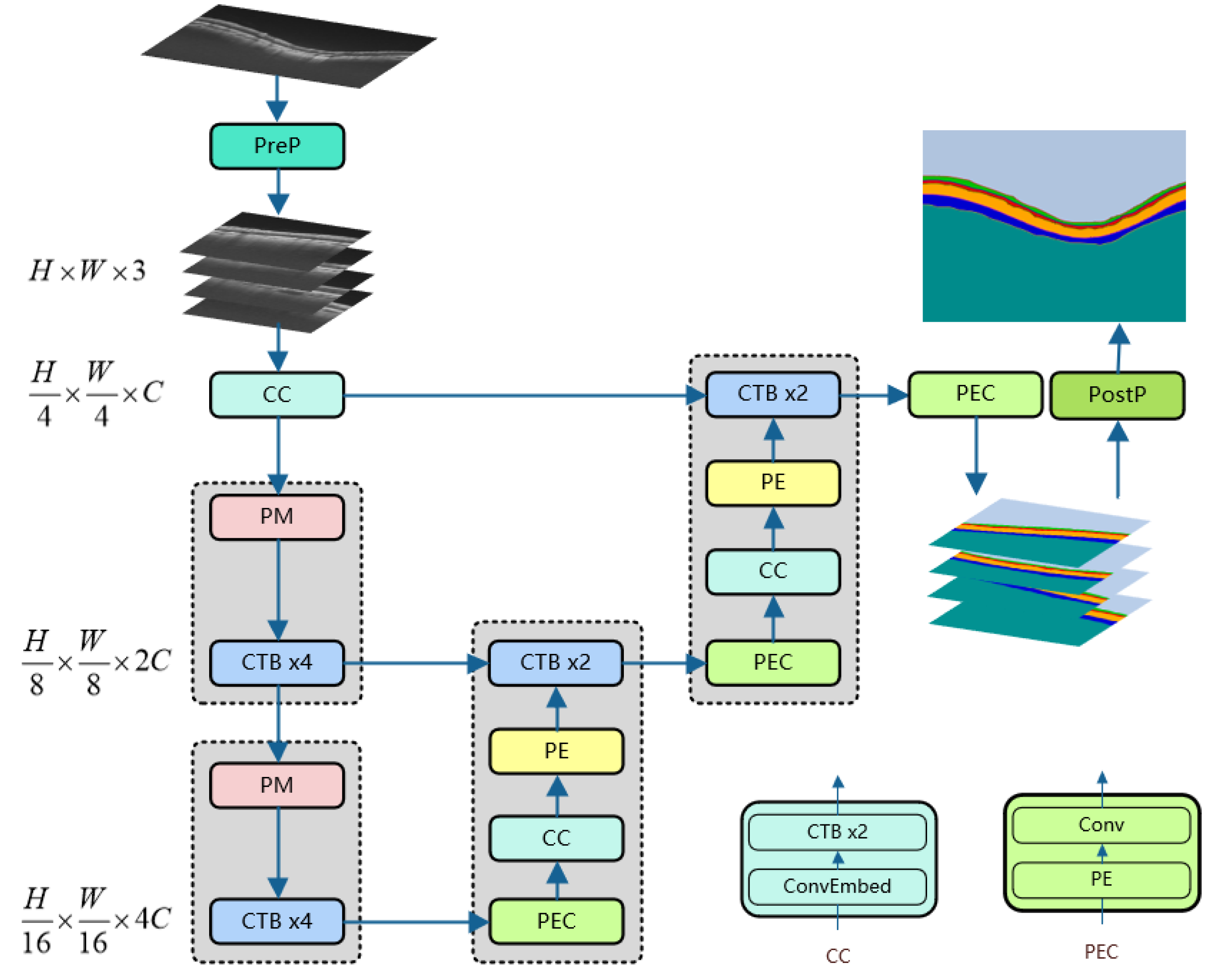
3.1. Network Architecture
3.2. CSwin Transformer Block
3.3. Encoder
3.4. Decoder
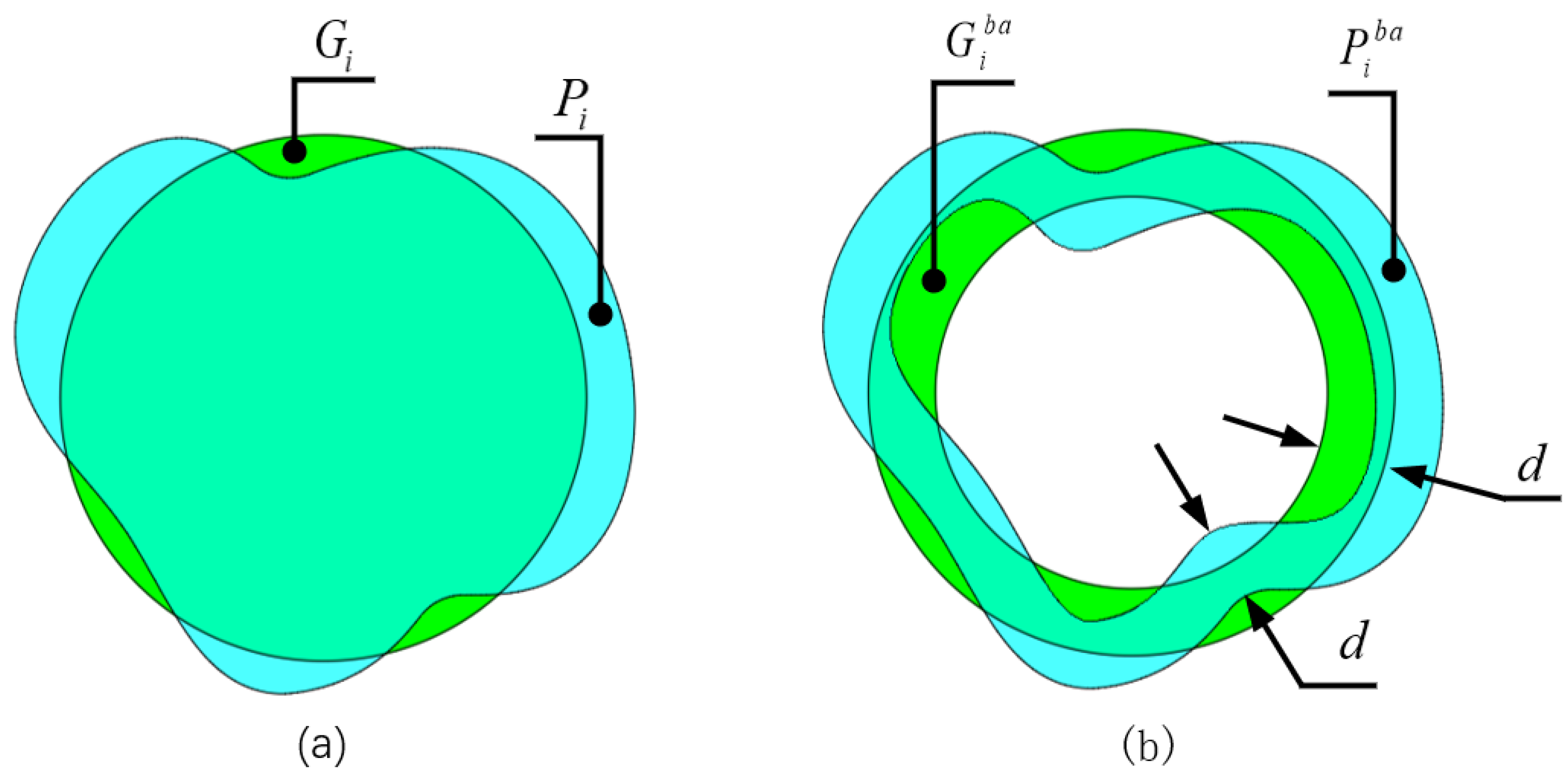
3.5. Loss Function
4. Experiments
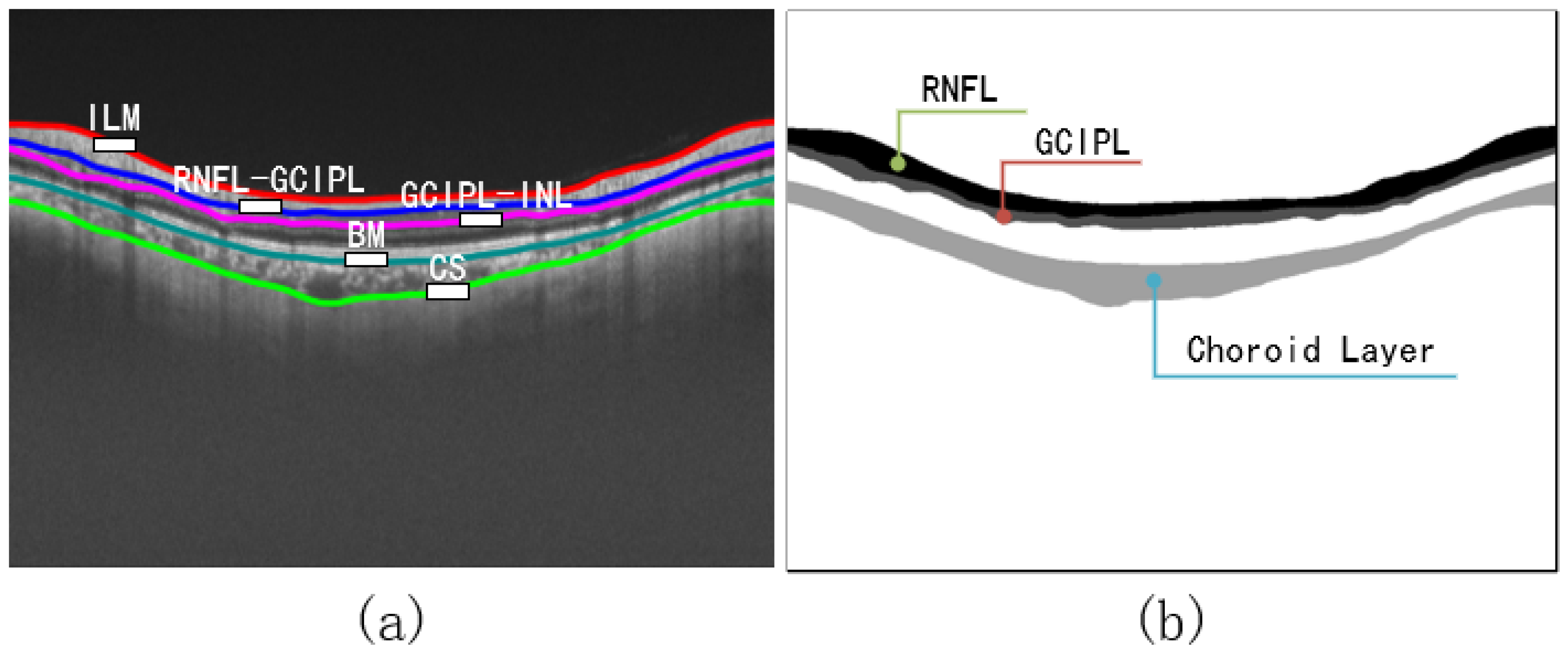
4.1. Dataset
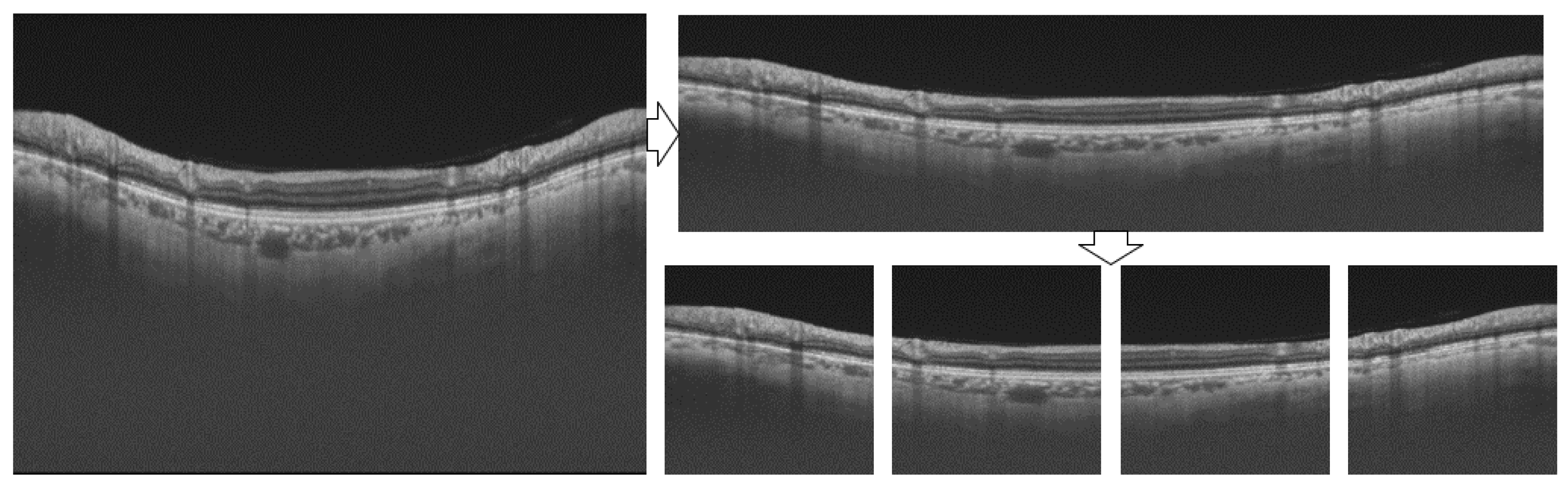
4.2. Image Processing
4.2.1. Pre-Processing
4.2.2. Post-Processing
4.3. Implementation Details
4.4. Evaluation Metrics
4.5. Experimental Results
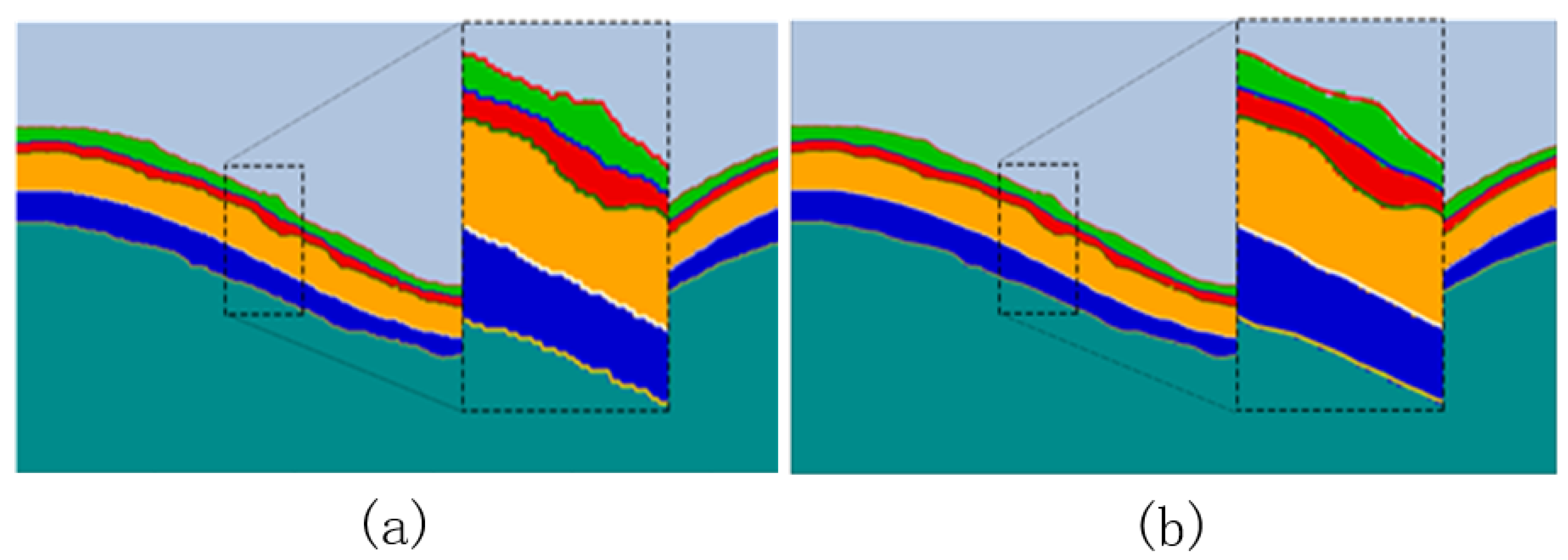
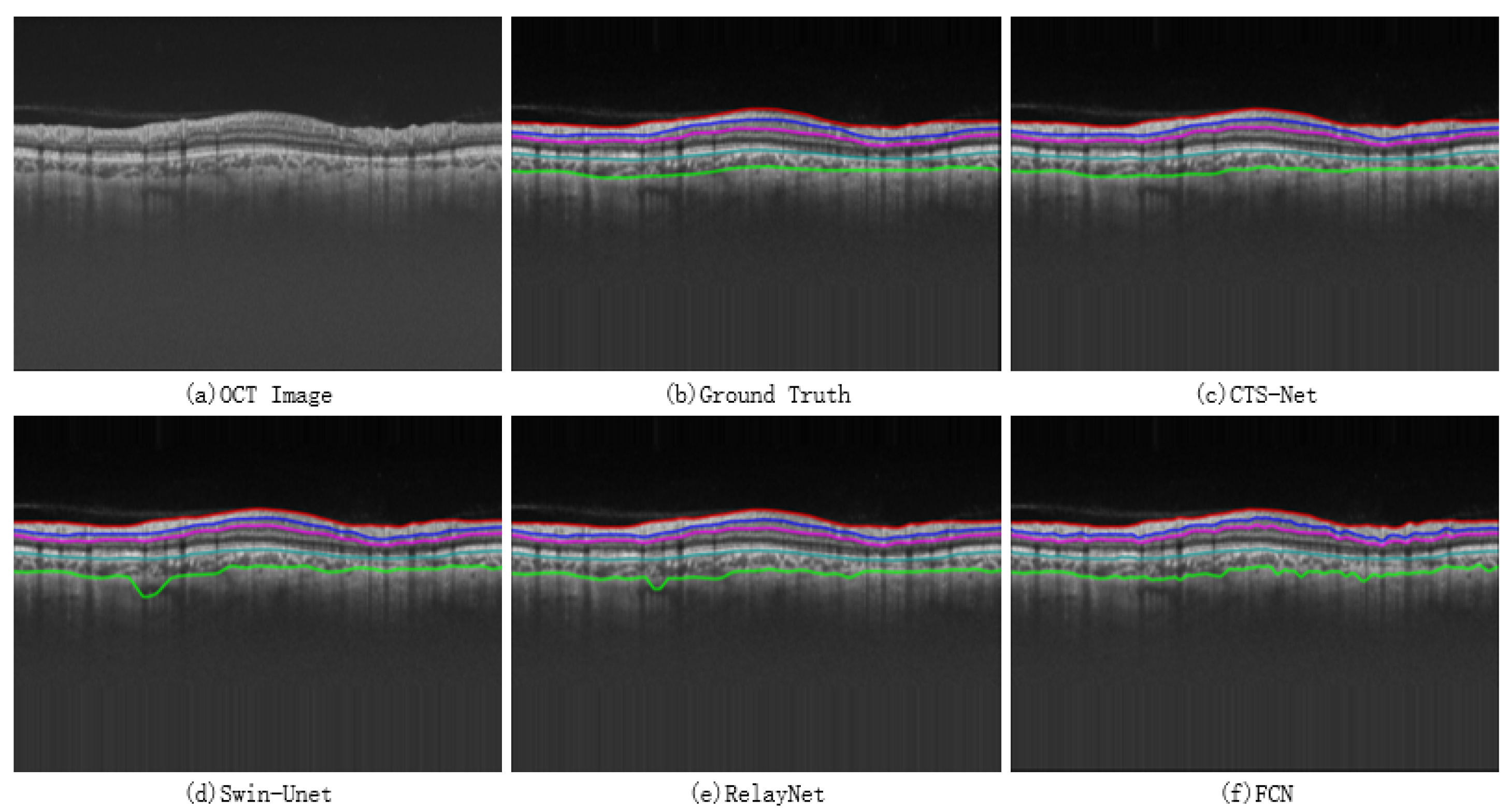
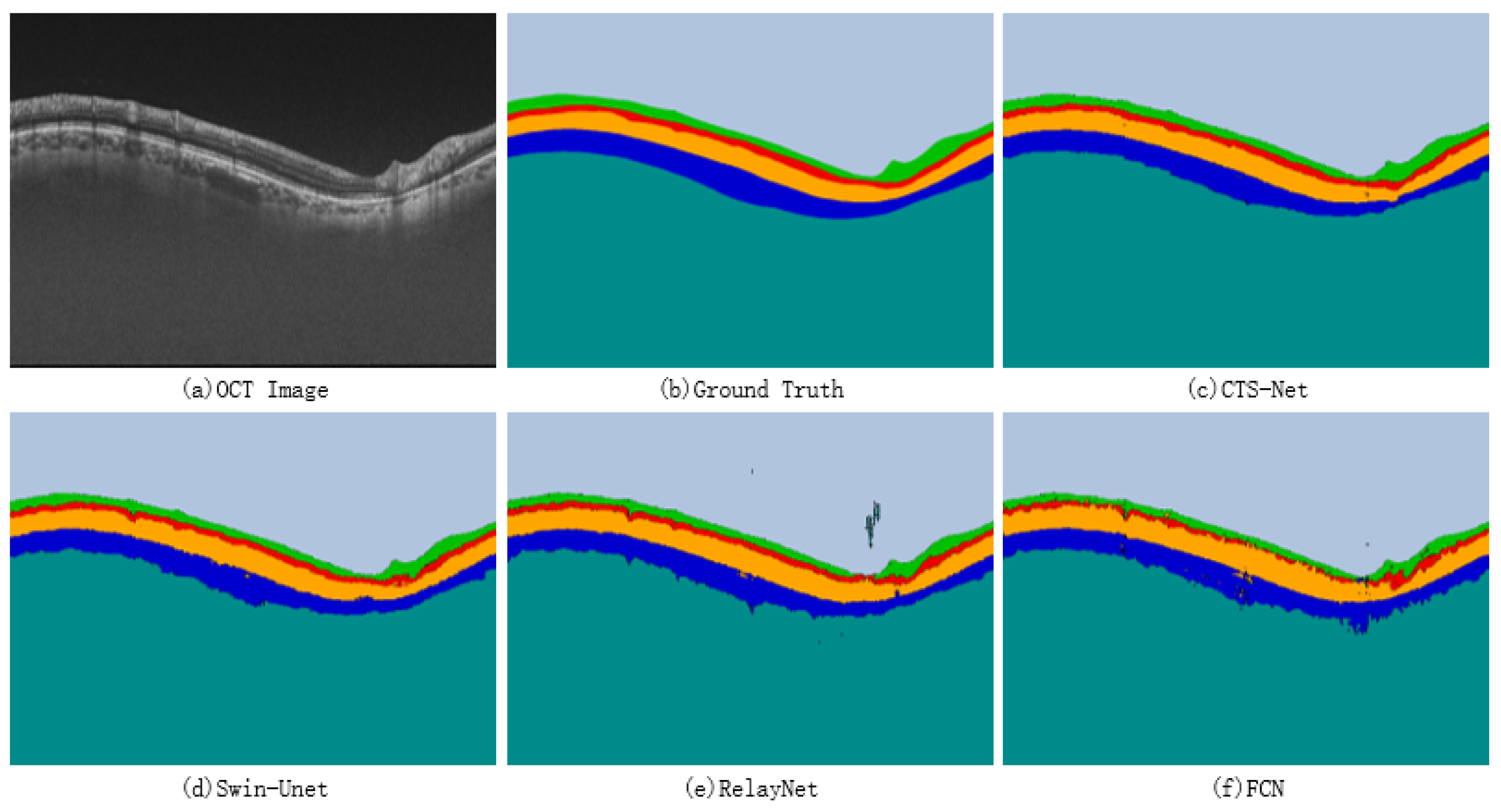
4.5.1. Analysis of Retinal Image Segmentation Results
4.5.2. Loss Function Experimental Results
4.5.3. Cross Validation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bechar, M.E.A.; Settouti, N.; Barra, V.; Chikh, M.A. Semi-supervised superpixel classification for medical images segmentation: Application to detection of glaucoma disease. Multidimens. Syst. Signal Process. 2018, 29, 979–998. [Google Scholar] [CrossRef]
- Baudouin, C.; Kolko, M.; Melik-Parsadaniantz, S.; Messmer, E.M. Inflammation in Glaucoma: From the back to the front of the eye, and beyond. Prog. Retin. Eye Res. 2021, 83, 100916. [Google Scholar] [CrossRef] [PubMed]
- Weinreb, R.N.; Aung, T.; Medeiros, F.A. The pathophysiology and treatment of glaucoma: A review. JAMA 2014, 311, 1901–1911. [Google Scholar] [CrossRef] [PubMed]
- Usman, M.; Fraz, M.M.; Barman, S.A. Computer vision techniques applied for diagnostic analysis of retinal OCT images: A review. Arch. Comput. Methods Eng. 2017, 24, 449–465. [Google Scholar] [CrossRef]
- Huang, D.; Swanson, E.A.; Lin, C.P.; Schuman, J.S.; Stinson, W.G.; Chang, W.; Hee, M.R.; Flotte, T.; Gregory, K.; Puliafito, C.A.; et al. Optical coherence tomography. Science 1991, 254, 1178–1181. [Google Scholar] [CrossRef]
- Drexler, W.; Fujimoto, J.G. State-of-the-art retinal optical coherence tomography. Prog. Retin. Eye Res. 2008, 27, 45–88. [Google Scholar] [CrossRef]
- Saidha, S.; Sotirchos, E.S.; Ibrahim, M.A.; Crainiceanu, C.M.; Gelfand, J.M.; Sepah, Y.J.; Ratchford, J.N.; Oh, J.; Seigo, M.A.; Newsome, S.D.; et al. Microcystic macular oedema, thickness of the inner nuclear layer of the retina, and disease characteristics in multiple sclerosis: A retrospective study. Lancet Neurol. 2012, 11, 963–972. [Google Scholar] [CrossRef]
- Kirbas, S.; Turkyilmaz, K.; Anlar, O.; Tufekci, A.; Durmus, M. Retinal nerve fiber layer thickness in patients with Alzheimer disease. J. Neuro-Ophthalmol. 2013, 33, 58–61. [Google Scholar] [CrossRef]
- Antony, B.J.; Chen, M.; Carass, A.; Jedynak, B.M.; Al-Louzi, O.; Solomon, S.D.; Saidha, S.; Calabresi, P.A.; Prince, J.L. Voxel based morphometry in optical coherence tomography: Validation and core findings. In Proceedings of the Medical Imaging 2016: Biomedical Applications in Molecular, Structural, and Functional Imaging, San Diego, CA, USA, 27 February 2016; Volume 9788, pp. 180–187. [Google Scholar]
- Lee, S.; Charon, N.; Charlier, B.; Popuri, K.; Lebed, E.; Sarunic, M.V.; Trouvé, A.; Beg, M.F. Atlas-based shape analysis and classification of retinal optical coherence tomography images using the functional shape (fshape) framework. Med. Image Anal. 2017, 35, 570–581. [Google Scholar] [CrossRef]
- Dufour, P.A.; Ceklic, L.; Abdillahi, H.; Schroder, S.; De Dzanet, S.; Wolf-Schnurrbusch, U.; Kowal, J. Graph-based multi-surface segmentation of OCT data using trained hard and soft constraints. IEEE Trans. Med. Imaging 2012, 32, 531–543. [Google Scholar] [CrossRef]
- Chiu, S.J.; Li, X.T.; Nicholas, P.; Toth, C.A.; Izatt, J.A.; Farsiu, S. Automatic segmentation of seven retinal layers in SDOCT images congruent with expert manual segmentation. Opt. Express 2010, 18, 19413–19428. [Google Scholar] [CrossRef]
- Karri, S.; Chakraborthi, D.; Chatterjee, J. Learning layer-specific edges for segmenting retinal layers with large deformations. Biomed. Opt. Express 2016, 7, 2888–2901. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Viedma, I.A.; Alonso-Caneiro, D.; Read, S.A.; Collins, M.J. Deep learning in retinal optical coherence tomography (OCT): A comprehensive survey. Neurocomputing 2022, 507, 247–264. [Google Scholar] [CrossRef]
- He, Y.; Carass, A.; Yun, Y.; Zhao, C.; Jedynak, B.M.; Solomon, S.D.; Saidha, S.; Calabresi, P.A.; Prince, J.L. Towards topological correct segmentation of macular OCT from cascaded FCNs. In Fetal, Infant and Ophthalmic Medical Image Analysis; Springer: Cham, Switzerland, 2017; pp. 202–209. [Google Scholar]
- Liu, X.; Fu, T.; Pan, Z.; Liu, D.; Hu, W.; Liu, J.; Zhang, K. Automated layer segmentation of retinal optical coherence tomography images using a deep feature enhanced structured random forests classifier. IEEE J. Biomed. Health Inform. 2018, 23, 1404–1416. [Google Scholar] [CrossRef]
- He, Y.; Carass, A.; Liu, Y.; Jedynak, B.M.; Solomon, S.D.; Saidha, S.; Calabresi, P.A.; Prince, J.L. Structured layer surface segmentation for retina OCT using fully convolutional regression networks. Med. Image Anal. 2021, 68, 101856. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 12124–12134. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Sonka, M.; Abràmoff, M.D. Quantitative analysis of retinal OCT. Med. Image Anal. 2016, 33, 165–169. [Google Scholar] [CrossRef]
- Dong, S.; Wang, P.; Abbas, K. A survey on deep learning and its applications. Comput. Sci. Rev. 2021, 40, 100379. [Google Scholar] [CrossRef]
- Badar, M.; Haris, M.; Fatima, A. Application of deep learning for retinal image analysis: A review. Comput. Sci. Rev. 2020, 35, 100203. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Available online: https://aistudio.baidu.com/aistudio/competition/detail/532/0/introduction (accessed on 18 October 2022).
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. Int. Conf. Mach. Learn. 2015, 37, 448–456. [Google Scholar]
- Smith, S.L.; Kindermans, P.J.; Ying, C.; Le, Q.V. Don’t decay the learning rate, increase the batch size. arXiv 2017, arXiv:1711.00489. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 6, 679–698. [Google Scholar] [CrossRef]
- Savitzky, A.; Golay, M.J. Smoothing and differentiation of data by simplified least squares procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Ben-Cohen, A.; Mark, D.; Kovler, I.; Zur, D.; Barak, A.; Iglicki, M.; Soferman, R. Retinal layers segmentation using fully convolutional network in OCT images. RSIP Vis. 2017, 6, 1–8. [Google Scholar]
- Roy, A.G.; Conjeti, S.; Karri, S.P.K.; Sheet, D.; Katouzian, A.; Wachinger, C.; Navab, N. ReLayNet: Retinal layer and fluid segmentation of macular optical coherence tomography using fully convolutional networks. Biomed. Opt. Express 2017, 8, 3627–3642. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Boundary | MAD(Std) | RMSE(Std) | ||||||
|---|---|---|---|---|---|---|---|---|
| FCN | RelayNet | Swin-Unet | CTS-Net | FCN | RelayNet | Swin-Unet | CTS-Net | |
| ILM | 1.44(0.45) | 1.23(0.35) | 1.44(0.36) | 1.40(0.41) | 1.85(1.07) | 1.62(0.84) | 1.70(0.38) | 1.63(0.41) |
| RNFL-GCIPL | 2.24(0.69) | 2.05(0.64) | 1.97(0.59) | 1.47(0.36) | 3.05(0.98) | 2.70(0.83) | 2.53(0.76) | 1.86(0.45) |
| GCIPL-INL | 2.64(1.71) | 1.84(0.72) | 2.05(0.63) | 1.58(0.53) | 3.40(2.13) | 2.29(0.83) | 2.51(0.76) | 1.89(0.57) |
| BM | 1.76(0.52) | 1.89(0.70) | 1.97(0.60) | 1.73(0.65) | 2.38(0.95) | 2.29(0.74) | 2.41(0.68) | 2.06(0.71) |
| CS | 5.57(3.01) | 3.51(1.27) | 3.82(1.17) | 2.77(0.92) | 7.76(5.2) | 4.25(1.46) | 4.93(1.95) | 3.30(0.94) |
| Overall | 2.73(1.28) | 2.10(0.74) | 2.25(0.67) | 1.79(0.57) | 3.69(2.07) | 2.63(0.94) | 2.82(0.91) | 2.15(0.62) |
| Layer | FCN | RelayNet | Swin-Unet | CTS-Net |
|---|---|---|---|---|
| RNFL | 91.93% | 93.06% | 93.14% | 94.62% |
| GCIPL | 78.96% | 84.88% | 85.36% | 89.60% |
| CL | 89.98% | 92.44% | 91.98% | 94.14% |
| Overall | 86.96% | 90.12% | 90.16% | 92.79% |
| d | MAD(Std) | RMSE(Std) | DSC | |||
|---|---|---|---|---|---|---|
| RNFL | GCIPL | CL | Overall | |||
| 6 | 1.91(0.65) | 2.28(0.71) | 94.60% | 88.81% | 93.79% | 92.40% |
| 8 | 1.97(0.65) | 2.35(0.69) | 94.68% | 88.71% | 93.57% | 92.32% |
| 10 | 1.83(0.61) | 2.22(0.68) | 94.50% | 89.01% | 93.81% | 92.44% |
| 12 | 2.02(0.70) | 2.44(0.79) | 94.63% | 88.90% | 93.39% | 92.31% |
| 14 | 1.98(0.63) | 2.37(0.68) | 94.56% | 88.86% | 93.61% | 92.34% |
| Model | Loss Function | MAD(Std) | RMSE(Std) | DSC | |||
|---|---|---|---|---|---|---|---|
| RNFL | GCIPL | CL | Overall | ||||
| RelayNet | CEL | 2.10(0.69) | 2.58(0.79) | 93.09% | 84.51% | 92.44% | 90.01% |
| CEL+BADL | 2.04(0.66) | 2.69(1.31) | 93.39% | 86.37% | 92.54% | 90.77% | |
| DL | 1.98(0.74) | 2.56(1.40) | 93.85% | 87.26% | 93.08% | 91.40% | |
| DL+BADL | 1.98(0.66) | 2.47(1.06) | 94.08% | 87.81% | 92.83% | 91.58% | |
| Swin-Unet | CEL | 2.64(0.75) | 3.44(1.21) | 90.92% | 79.35% | 88.69% | 86.32% |
| CEL+BADL | 2.16(0.64) | 2.71(0.85) | 93.19% | 85.25% | 91.84% | 90.09% | |
| DL | 2.17(0.64) | 2.68(0.80) | 93.56% | 86.21% | 92.39% | 90.72% | |
| DL+BADL | 2.13(0.61) | 2.65(0.88) | 93.65% | 86.73% | 92.34% | 90.91% | |
| CTS-Net | CEL | 2.03(0.64) | 2.45(0.69) | 94.12% | 87.48% | 93.40% | 91.67% |
| CEL+BADL | 1.78(0.55) | 2.14(0.60) | 94.62% | 89.35% | 93.80% | 92.59% | |
| DL | 1.82(0.58) | 2.19(0.61) | 94.80% | 89.43% | 93.97% | 92.73% | |
| DL+BADL | 1.79(0.57) | 2.15(0.62) | 94.62% | 89.60% | 94.14% | 92.79% | |
| Boundary | MAD(Std) | |||||
|---|---|---|---|---|---|---|
| K = 1 | K = 2 | K = 3 | K = 4 | K = 5 | Mean | |
| ILM | 1.30(0.36) | 1.23(0.36) | 1.41(0.40) | 1.31(0.37) | 1.36(0.38) | 1.32(0.37) |
| RNFL-GCIPL | 1.67(0.39) | 1.71(0.48) | 1.69(0.44) | 1.79(0.48) | 1.73(0.45) | 1.72(0.45) |
| GCIPL-INL | 1.73(0.54) | 1.90(0.61) | 1.53(0.53) | 1.75(0.58) | 1.58(0.53) | 1.70(0.56) |
| BM | 1.65(0.49) | 1.67(0.52) | 1.69(0.53) | 1.67(0.54) | 1.74(0.64) | 1.68(0.54) |
| CS | 3.12(1.07) | 3.05(0.99) | 3.03(1.14) | 2.96(1.04) | 2.90(0.86) | 3.01(1.02) |
| Overall | 1.89(0.57) | 1.91(0.59) | 1.87(0.61) | 1.90(0.60) | 1.86(0.57) | 1.89(0.59) |
| RMSE(Std) | ||||||
| K = 1 | K = 2 | K = 3 | K = 4 | K = 5 | Mean | |
| ILM | 1.52(0.37) | 1.47(0.38) | 1.64(0.39) | 1.53(0.37) | 1.60(0.38) | 1.55(0.38) |
| RNFL-GCIPL | 2.08(0.53) | 2.12(0.64) | 2.09(0.58) | 2.19(0.61) | 2.15(0.61) | 2.13(0.59) |
| GCIPL-INL | 2.05(0.57) | 2.23(0.64) | 1.86(0.59) | 2.08(0.61) | 1.92(0.55) | 2.03(0.59) |
| BM | 1.99(0.55) | 2.01(0.59) | 2.04(0.57) | 2.00(0.60) | 2.06(0.69) | 2.02(0.60) |
| CS | 3.75(1.20) | 3.59(0.97) | 3.61(1.18) | 3.56(1.11) | 3.55(0.99) | 3.61(1.09) |
| Overall | 2.28(0.64) | 2.28(0.64) | 2.25(0.66) | 2.27(0.66) | 2.26(0.64) | 2.27(0.65) |
| Layer | K = 1 | K = 2 | K = 3 | K = 4 | K = 5 | Mean |
|---|---|---|---|---|---|---|
| RNFL | 94.72% | 94.75% | 94.68% | 94.71% | 94.55% | 94.68% |
| GCIPL | 89.42% | 89.12% | 89.22% | 89.04% | 88.65% | 89.09% |
| CL | 93.85% | 93.68% | 93.78% | 93.87% | 93.78% | 93.79% |
| Overall | 92.66% | 92.52% | 92.56% | 92.54% | 92.33% | 92.52% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, S.; Wang, H.; Guo, X.; Sun, M.; Song, K.; Shao, Y.; Zhang, H.; Zhang, T. CTS-Net: A Segmentation Network for Glaucoma Optical Coherence Tomography Retinal Layer Images. Bioengineering 2023, 10, 230. https://doi.org/10.3390/bioengineering10020230
Xue S, Wang H, Guo X, Sun M, Song K, Shao Y, Zhang H, Zhang T. CTS-Net: A Segmentation Network for Glaucoma Optical Coherence Tomography Retinal Layer Images. Bioengineering. 2023; 10(2):230. https://doi.org/10.3390/bioengineering10020230
Chicago/Turabian StyleXue, Songfeng, Haoran Wang, Xinyu Guo, Mingyang Sun, Kaiwen Song, Yanbin Shao, Hongwei Zhang, and Tianyu Zhang. 2023. "CTS-Net: A Segmentation Network for Glaucoma Optical Coherence Tomography Retinal Layer Images" Bioengineering 10, no. 2: 230. https://doi.org/10.3390/bioengineering10020230
APA StyleXue, S., Wang, H., Guo, X., Sun, M., Song, K., Shao, Y., Zhang, H., & Zhang, T. (2023). CTS-Net: A Segmentation Network for Glaucoma Optical Coherence Tomography Retinal Layer Images. Bioengineering, 10(2), 230. https://doi.org/10.3390/bioengineering10020230