
Optimal Feature Selection-Based Dental Caries Prediction Model Using Machine Learning for Decision Support System




Abstract
:1. Introduction
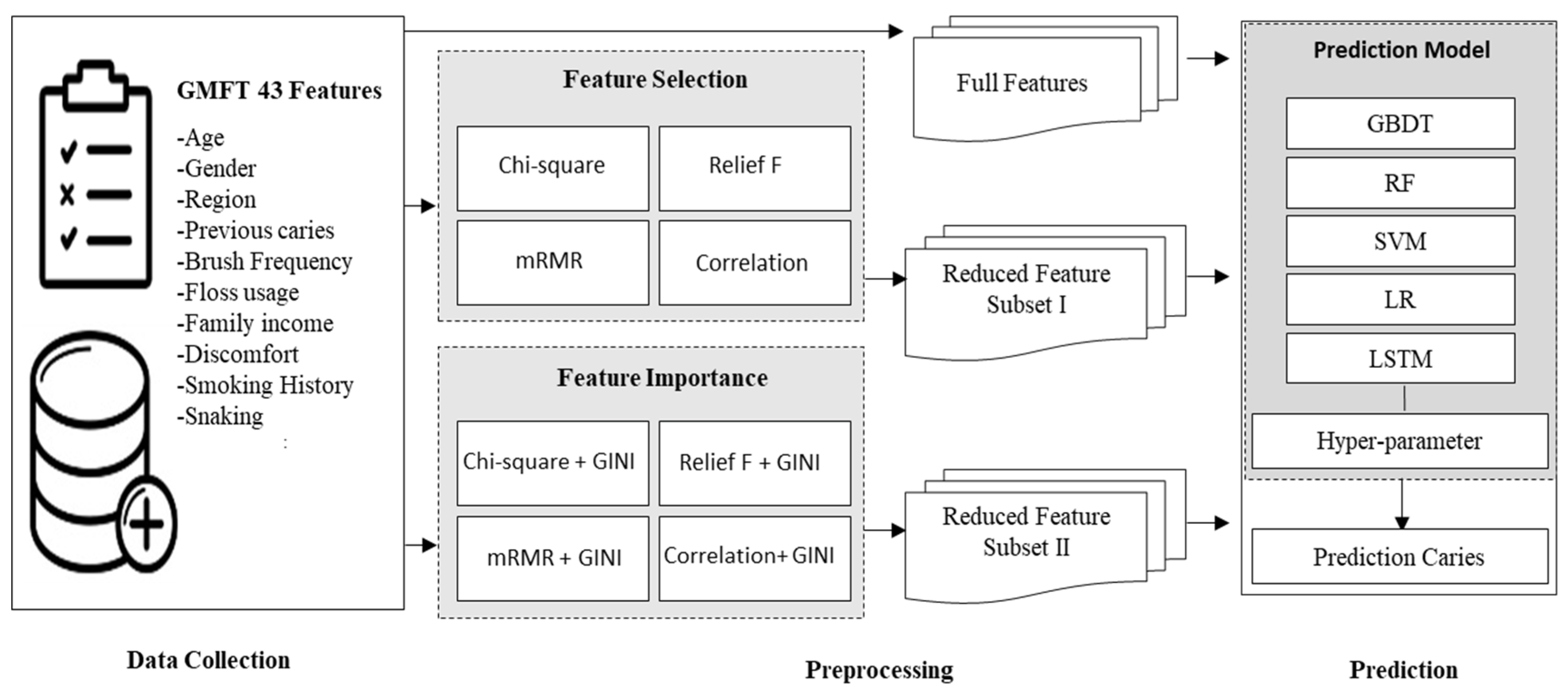
2. Materials and Methods
2.1. Data Collection
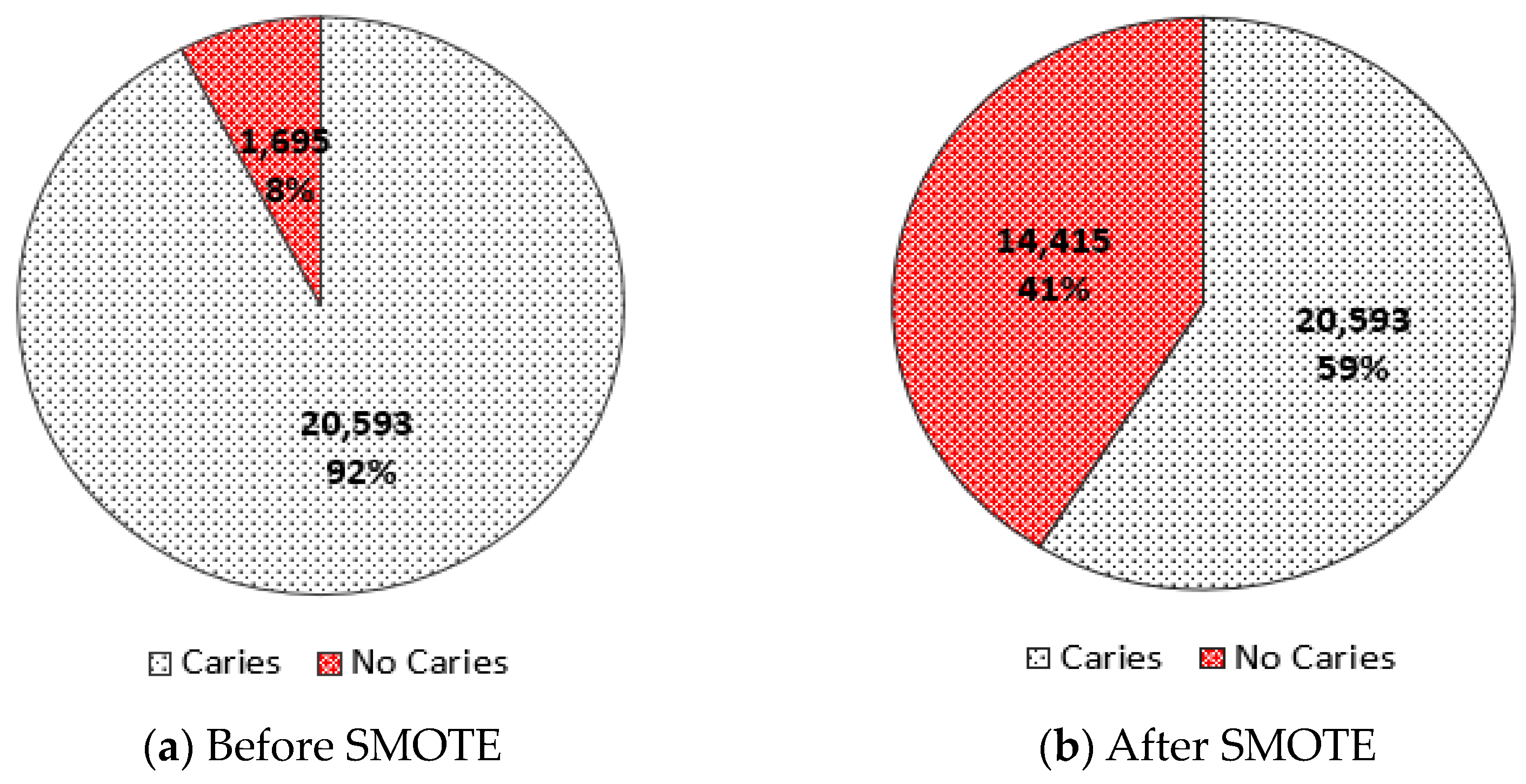
2.2. Data Preprocessing
2.3. Methods Used in the Proposed Prediction Model
2.3.1. Minimum Redundancy–Maximum Relevance (mRMR)
2.3.2. GINI
2.3.3. Gradient Boosting Decision Tree (GBDT)
2.4. Dental Caries Prediction Model
| Algorithm 1: Proposed model for Dental Caries Prediction. |
| Input: Training dataset (,), (, ), …, (,); Number of features to be selected, and threshold of feature importance. Output: highest performing classification approach C.
redundancy = initialize to 0 in , += (fi, fj) end for relevance ;
Machine Learning model include: : GBDT, RF, SVM, LR, LSTM for in : ) ) end for
11. END algorithm |
3. Experimentation
3.1. Dataset
3.2. Hyperparameters of Different Machine Learning Models
3.3. Results
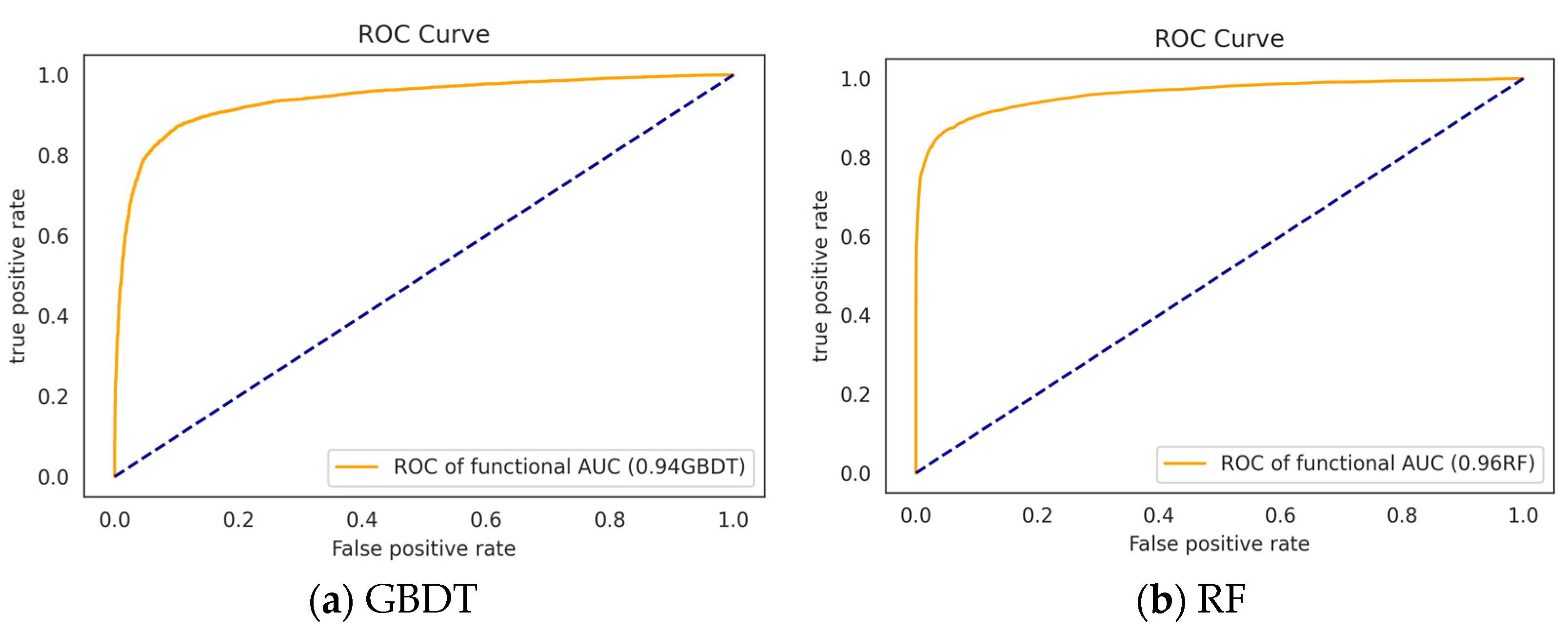
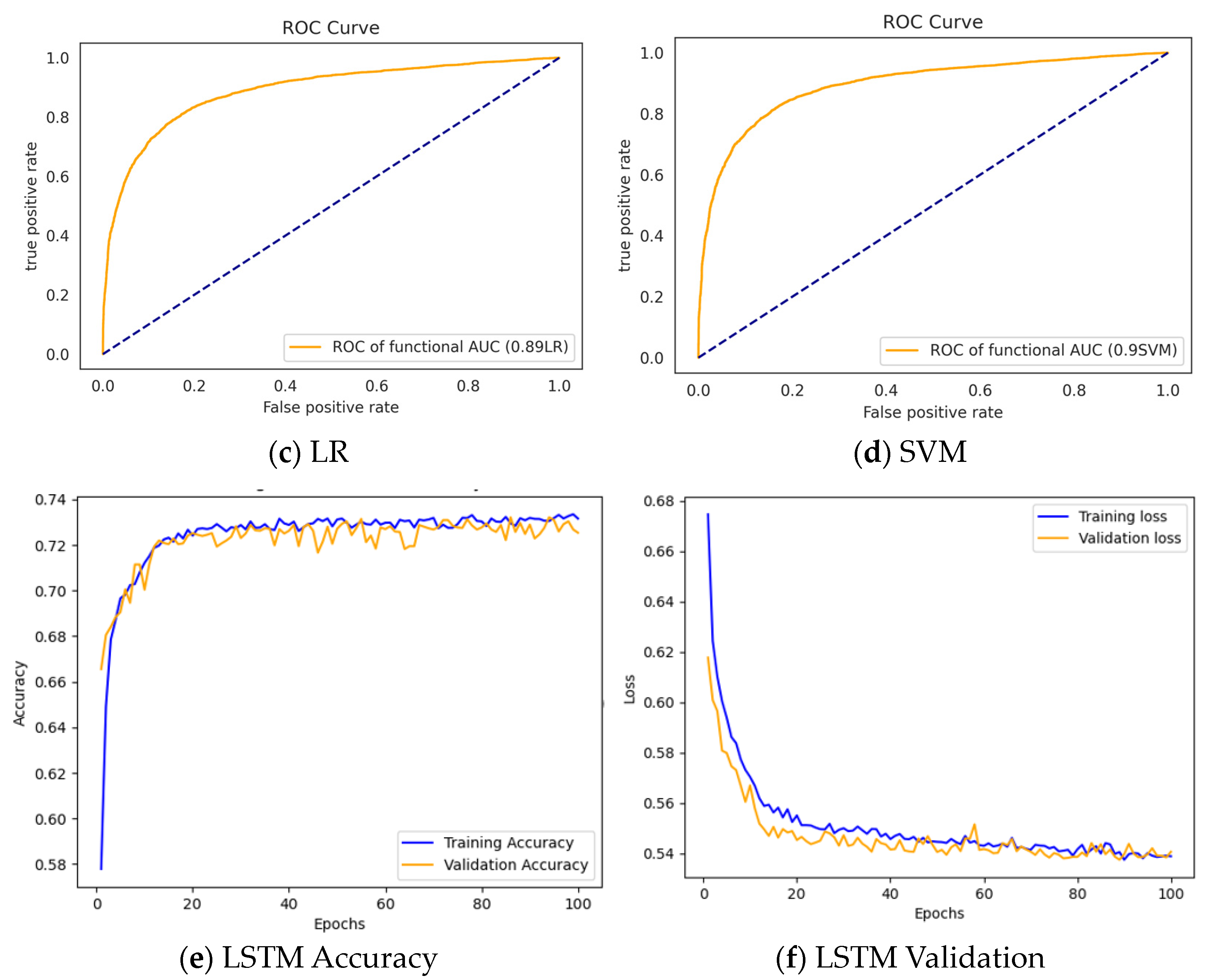
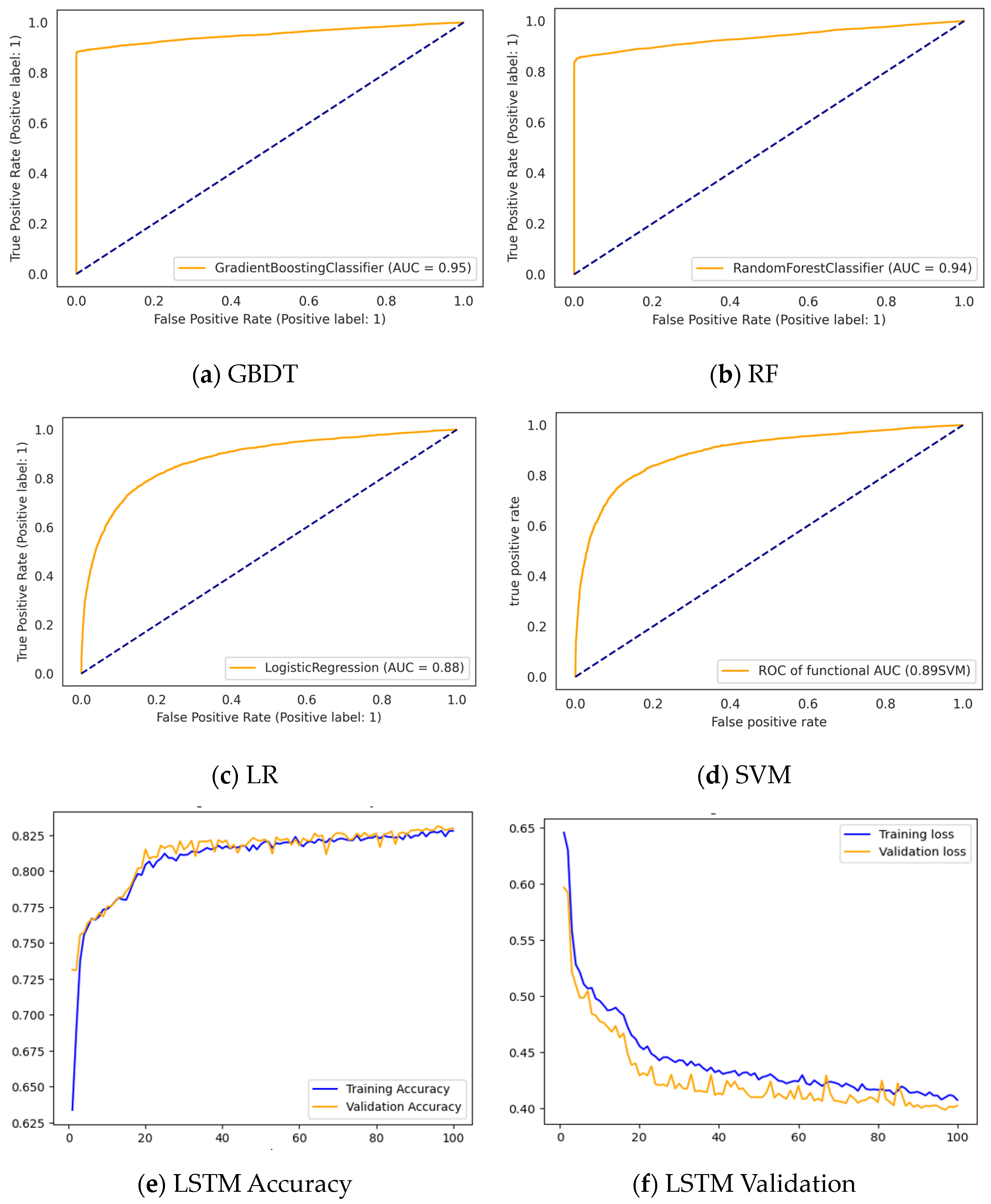
3.3.1. Performance of the Classifiers without Feature Selection
3.3.2. Performance of the Classifiers after Feature Selection
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Institute for Health Metrics and Evaluation (IHME). Explore Results from the 2019 Global Burden of Disease (GBD) Study. Available online: https://vizhub.healthdata.org/gbd-results/ (accessed on 14 December 2022).
- Health Insurance Review and Assessment Service HIRA. 2021. Available online: https://www.hira.or.kr/bbsDummy.do?pgmid=HIRAA020041000100&brdScnBltNo=4&brdBltNo=10368&pageIndex=1 (accessed on 14 December 2022).
- Rimi, I.F.; Arif, M.A.I.; Akter, S.; Rahman, M.R.; Islam, A.H.M.S.; Habib, M.T. Machine Learning Techniques for Dental Disease Prediction. Iran J. Comput. Sci. 2022, 5, 187–195. [Google Scholar] [CrossRef]
- Zhang, X.; Liang, Y.; Li, W.; Liu, C.; Gu, D.; Sun, W.; Miao, L. Development and Evaluation of Deep Learning for Screening Dental Caries from Oral Photographs. Oral Dis. 2022, 28, 173–181. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Oh, S.; Jo, J.; Kang, S.; Shin, Y.; Park, J. Deep Learning for Early Dental Caries Detection in Bitewing Radiographs. Sci. Rep. 2021, 11, 16807. [Google Scholar] [CrossRef]
- Estai, M.; Tennant, M.; Gebauer, D.; Brostek, A.; Vignarajan, J.; Mehdizadeh, M.; Saha, S. Evaluation of a Deep Learning System for Automatic Detection of Proximal Surface Dental Caries on Bitewing Radiographs. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 2022, 134, 262–270. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.-H.; Kim, D.-H.; Jeong, S.-N.; Choi, S.-H. Detection and Diagnosis of Dental Caries Using a Deep Learning-Based Convolutional Neural Network Algorithm. J. Dent. 2018, 77, 106–111. [Google Scholar] [CrossRef]
- Megalan Leo, L.; Kalpalatha Reddy, T. Dental Caries Classification System Using Deep Learning Based Convolutional Neural Network. J. Comput. Theor. Nanosci. 2020, 17, 4660–4665. [Google Scholar] [CrossRef]
- Karhade, D.S.; Roach, J.; Shrestha, P.; Simancas-Pallares, M.A.; Ginnis, J.; Burk, Z.J.; Ribeiro, A.A.; Cho, H.; Wu, D.; Divaris, K. An Automated Machine Learning Classifier for Early Childhood Caries. Pediatr. Dent. 2021, 43, 191–197. [Google Scholar]
- Ramos-Gomez, F.; Marcus, M.; Maida, C.A.; Wang, Y.; Kinsler, J.J.; Xiong, D.; Lee, S.Y.; Hays, R.D.; Shen, J.; Crall, J.J.; et al. Using a Machine Learning Algorithm to Predict the Likelihood of Presence of Dental Caries among Children Aged 2 to 7. Dent. J. 2021, 9, 141. [Google Scholar] [CrossRef]
- Park, Y.-H.; Kim, S.-H.; Choi, Y.-Y. Prediction Models of Early Childhood Caries Based on Machine Learning Algorithms. Int. J. Environ. Res. Public Health 2021, 18, 8613. [Google Scholar] [CrossRef]
- Remeseiro, B.; Bolon-Canedo, V. A review of feature selection methods in medical applications. Comput. Biol. Med. 2019, 112, 103375. [Google Scholar] [CrossRef]
- Memiş, S.; Enginoğlu, S.; Erkan, U. Fuzzy parameterized fuzzy soft k-nearest neighbor classifier. Neurocomputing 2022, 500, 351–378. [Google Scholar] [CrossRef]
- Saberi-Movahed, F.; Rostami, M.; Berahmand, K.; Karami, S.; Tiwari, P.; Oussalah, M.; Band, S.S. Dual regularized unsupervised feature selection based on matrix factorization and minimum redundancy with application in gene selection. Knowl.-Based Syst. 2022, 256, 109884. [Google Scholar] [CrossRef]
- Azadifar, S.; Rostami, M.; Berahmand, K.; Moradi, P.; Oussalah, M. Graph-based relevancy-redundancy gene selection method for cancer diagnosis. Comput. Biol. Med. 2022, 147, 105766. [Google Scholar] [CrossRef] [PubMed]
- Singh, D.; Singh, B. Investigating the Impact of Data Normalization on Classification Performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Memiş, S.; Enginoğlu, S.; Erkan, U. A classification method in machine learning based on soft decision-making via fuzzy parameterized fuzzy soft matrices. Soft Comput. 2022, 26, 1165–1180. [Google Scholar] [CrossRef]
- Hu, Q.; Si, X.-S.; Qin, A.-S.; Lv, Y.-R.; Zhang, Q.-H. Machinery Fault Diagnosis Scheme Using Redefined Dimensionless Indicators and MRMR Feature Selection. IEEE Access 2020, 8, 40313–40326. [Google Scholar] [CrossRef]
- Bugata, P.; Drotar, P. On Some Aspects of Minimum Redundancy Maximum Relevance Feature Selection. Sci. China Inf. Sci. 2020, 63, 112103. [Google Scholar] [CrossRef]
- Wang, Y.; Li, X.; Ruiz, R. Feature Selection with Maximal Relevance and Minimal Supervised Redundancy. IEEE Trans. Cybern. 2022, 53, 707–717. [Google Scholar] [CrossRef]
- Ghasemi, F.; Neysiani, B.S.; Nematbakhsh, N. Feature Selection in Pre-Diagnosis Heart Coronary Artery Disease Detection: A Heuristic Approach for Feature Selection Based on Information Gain Ratio and Gini Index. In Proceedings of the 2020 6th International Conference on Web Research (ICWR), Tehran, Iran, 22–23 April 2020; pp. 27–32. [Google Scholar]
- Sung, S.-H.; Kim, S.; Park, B.-K.; Kang, D.-Y.; Sul, S.; Jeong, J.; Kim, S.-P. A Study on Facial Expression Change Detection Using Machine Learning Methods with Feature Selection Technique. Mathematics 2021, 9, 2062. [Google Scholar] [CrossRef]
- Zhang, W.; Yu, J.; Zhao, A.; Zhou, X. Predictive Model of Cooling Load for Ice Storage Air-Conditioning System by Using GBDT. Energy Rep. 2021, 7, 1588–1597. [Google Scholar] [CrossRef]
- Liang, W.; Luo, S.; Zhao, G.; Wu, H. Predicting Hard Rock Pillar Stability Using GBDT, XGBoost, and LightGBM Algorithms. Mathematics 2020, 8, 765. [Google Scholar] [CrossRef]
- Li, S.; Lin, Y.; Zhu, T.; Fan, M.; Xu, S.; Qiu, W.; Chen, C.; Li, L.; Wang, Y.; Yan, J.; et al. Development and external evaluation of predictions models for mortality of COVID-19 patients using machine learning method. Neural Comput. Appl. 2021, 1–10. [Google Scholar] [CrossRef] [PubMed]
- SVC’ Object Has No Attribute “Feature_importances_”. Available online: https://stackoverflow.com/questions/59681421/svc-object-has-no-attribute-feature-importances (accessed on 1 January 2023).
- Spencer, R.; Thabtah, F.; Abdelhamid, N.; Thompson, M. Exploring Feature Selection and Classification Methods for Predicting Heart Disease. Digit. Health 2020, 6, 205520762091477. [Google Scholar] [CrossRef]
- Scikit-Learn Developers Sklearn Feature Selection Chi. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.chi2.html#sklearn.feature_selection.chi2 (accessed on 1 December 2022).
- Thaseen, I.S.; Kumar, C.A.; Ahmad, A. Integrated intrusion detection model using chi-square feature selection and ensemble of classifiers. Arab. J. Sci. Eng. 2019, 44, 3357–3368. [Google Scholar] [CrossRef]
- Zhang, B.; Li, Y.; Chai, Z. A Novel Random Multi-Subspace Based ReliefF for Feature Selection. Knowl.-Based Syst. 2022, 252, 109400. [Google Scholar] [CrossRef]
- Ghosh, P.; Azam, S.; Jonkman, M.; Karim, A.; Shamrat, F.M.J.M.; Ignatious, E.; Shultana, S.; Beeravolu, A.R.; De Boer, F. Efficient Prediction of Cardiovascular Disease Using Machine Learning Algorithms with Relief and LASSO Feature Selection Techniques. IEEE Access 2021, 9, 19304–19326. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, J.; Zhou, Y.; Guo, X.; Ma, Y. A Feature Selection Algorithm of Decision Tree Based on Feature Weight. Expert Syst. Appl. 2021, 164, 113842. [Google Scholar] [CrossRef]
- Saidi, R.; Bouaguel, W.; Essoussi, N. Hybrid Feature Selection Method Based on the Genetic Algorithm and Pearson Correlation Coefficient. In Machine Learning Paradigms: Theory and Application; Hassanien, A.E., Ed.; Studies in Computational Intelligence; Springer International Publishing: Cham, Switzerland, 2019; Volume 801, pp. 3–24. ISBN 978-3-030-02356-0. [Google Scholar]
- Kumar, M.S.; Soundarya, V.; Kavitha, S.; Keerthika, E.S.; Aswini, E. Credit Card Fraud Detection Using Random Forest Algorithm. In Proceedings of the 3rd International Conference on Computing and Communications Technologies (ICCCT), Chennai, India, 21–22 February 2019. [Google Scholar]
- Xing, J.; Wang, H.; Luo, K. Predictive single-step kinetic model of biomass devolatilization for CFD applications: A comparison study of empirical correlations (EC), artificial neural networks (ANN) and random forest (RF). Renew. Energy 2019, 136, 104–114. [Google Scholar] [CrossRef]
- Otchere, D.A.; Arbi Ganat, T.O.; Gholami, R.; Ridha, S. Application of Supervised Machine Learning Paradigms in the Prediction of Petroleum Reservoir Properties: Comparative Analysis of ANN and SVM Models. J. Pet. Sci. Eng. 2021, 200, 108182. [Google Scholar] [CrossRef]
- Iwendi, C.; Mahboob, K.; Khalid, Z.; Javed, A.R.; Rizwan, M.; Ghosh, U. Classification of COVID-19 Individuals Using Adaptive Neuro-Fuzzy Inference System. Multimed. Syst. 2022, 28, 1223–1237. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Zhang, C.; Jia, N.; Duncan, I.; Yang, S.; Yang, Y. A machine learning model for predicting the minimum miscibility pressure of CO2 and crude oil system based on a support vector machine algorithm approach. Fuel 2021, 290, 120048. [Google Scholar] [CrossRef]
- Kurt, I.; Ture, M.; Kurum, A.T. Comparing performances of logistic regression, classification and regression tree, and neural networks for predicting coronary artery disease. Expert Syst. Appl. 2008, 34, 366–374. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Hamayel, M.J.; Owda, A.Y. A Novel Cryptocurrency Price Prediction Model Using GRU, LSTM and Bi-LSTM Machine Learning Algorithms. AI 2021, 2, 477–496. [Google Scholar] [CrossRef]
- Absar, N.; Uddin, M.N.; Khandaker, M.U.; Ullah, M.H. The efficacy of deep learning based LSTM model in forecasting the outbreak of contagious diseases. Infect. Dis. Model. 2022, 7, 170–183. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Feature Selection/ Feature Importance | Parameters | Optimal Values |
|---|---|---|---|
| GBDT | mRMR + GINI | subsample | 0.80 |
| n_estimators | 200 | ||
| min_samples_leaf | 8 | ||
| max_features | 5 | ||
| max_depth | 320 | ||
| learning_rate | 0.02 | ||
| RF | Relief F + GINI | n_estimators | 320 |
| min_samples_leaf | 1 | ||
| max_features | 5 | ||
| max_depth | None | ||
| LR | Chi-Square + GINI | solver | sag |
| penalty | l2 | ||
| C | 5 | ||
| SVM | Relief F | probability | True |
| kernel | rbf | ||
| gamma | 0.01 | ||
| C | 10 | ||
| LSTM | Chi-Square | learning rate | 0.001 |
| beta_1 | 0.09 | ||
| beta_2 | 0.999 | ||
| epsilon | 1 × 10−2 | ||
| epochs | 100 |
| Models | #of Features | F1-Score | Precision | Recall | Accuracy |
|---|---|---|---|---|---|
| GBDT | 43 | 0.8635 | 0.9490 | 0.7921 | 0.8966 |
| RF | 0.8868 | 0.9186 | 0.8572 | 0.9105 | |
| LR | 0.7773 | 0.7959 | 0.7598 | 0.8203 | |
| SVM | 0.7862 | 0.7434 | 0.8345 | 0.8128 | |
| LSTM | 0.7575 | 0.7428 | 0.7436 | 0.7467 |
| Models | Feature Selection | # of Features | F1-Score | Precision | Recall | Accuracy |
|---|---|---|---|---|---|---|
| GBDT | mRMR + GINI | 18 | 0.9379 | 0.9984 | 0.8844 | 0.9519 |
| RF | Relief F + GINI | 20 | 0.9372 | 0.9978 | 0.8835 | 0.9513 |
| LR | Chi-Square + GINI | 40 | 0.7814 | 0.8012 | 0.7625 | 0.8256 |
| SVM | Relief F | 43 | 0.8806 | 0.9028 | 0.8596 | 0.9039 |
| LSTM | Chi-Square | 15 | 0.8300 | 0.8400 | 0.8300 | 0.8400 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, I.-A.; Njimbouom, S.N.; Kim, J.-D. Optimal Feature Selection-Based Dental Caries Prediction Model Using Machine Learning for Decision Support System. Bioengineering 2023, 10, 245. https://doi.org/10.3390/bioengineering10020245
Kang I-A, Njimbouom SN, Kim J-D. Optimal Feature Selection-Based Dental Caries Prediction Model Using Machine Learning for Decision Support System. Bioengineering. 2023; 10(2):245. https://doi.org/10.3390/bioengineering10020245
Chicago/Turabian StyleKang, In-Ae, Soualihou Ngnamsie Njimbouom, and Jeong-Dong Kim. 2023. "Optimal Feature Selection-Based Dental Caries Prediction Model Using Machine Learning for Decision Support System" Bioengineering 10, no. 2: 245. https://doi.org/10.3390/bioengineering10020245
APA StyleKang, I. -A., Njimbouom, S. N., & Kim, J. -D. (2023). Optimal Feature Selection-Based Dental Caries Prediction Model Using Machine Learning for Decision Support System. Bioengineering, 10(2), 245. https://doi.org/10.3390/bioengineering10020245