
Point-of-Interest Preference Model Using an Attention Mechanism in a Convolutional Neural Network

 ,
,  ,
,
Abstract
:1. Introduction
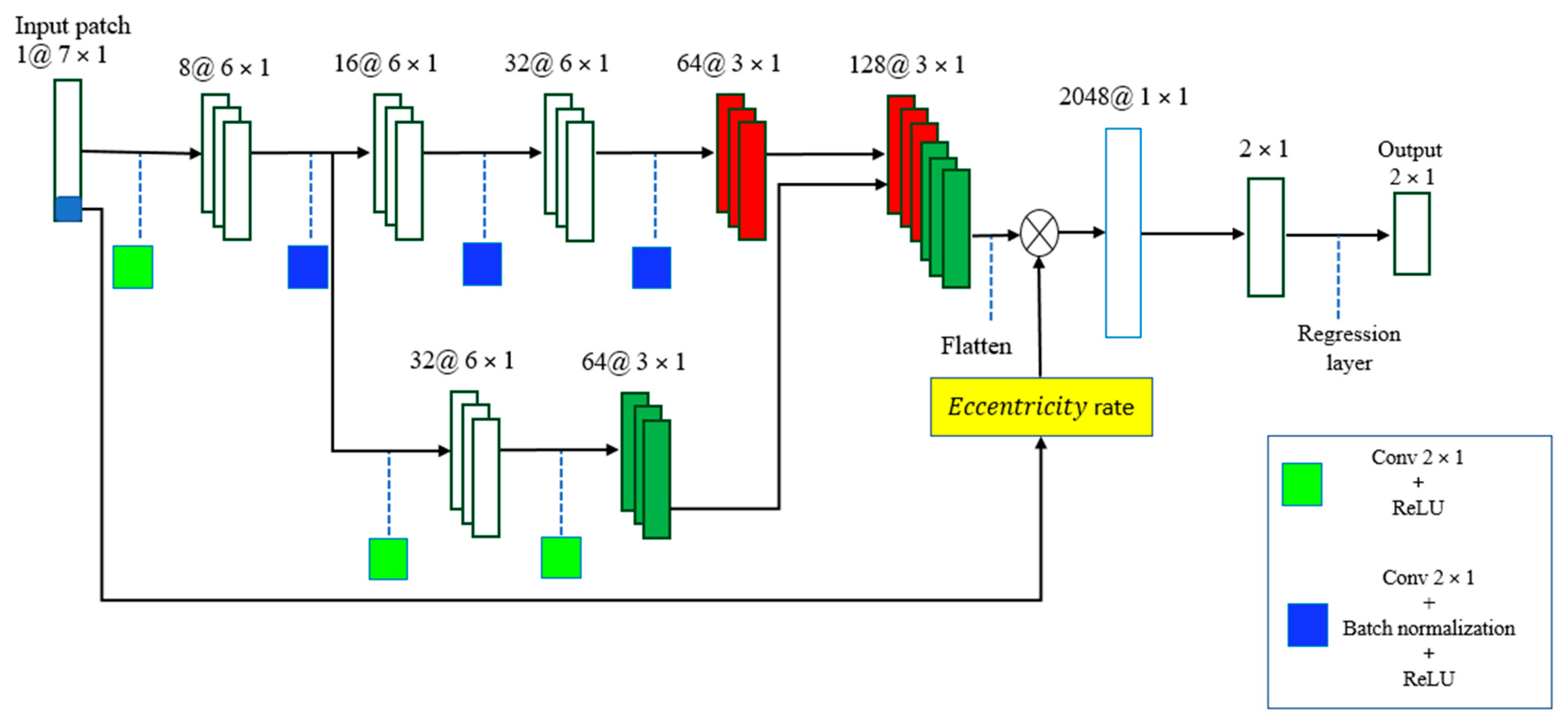
- We suggest a two-route CNN model to extract key features more effectively.
- This study attempts to address the issue in current POI recommendation techniques of unsatisfactorily merging a user’s relevant context, leading to unsatisfactory suggestions. Consequently, a well-organized POI recommendation model based on the user’s geographical position, check-in time, and preference is suggested.
- An attention mechanism is used to investigate the effect of geographical position more accurately.
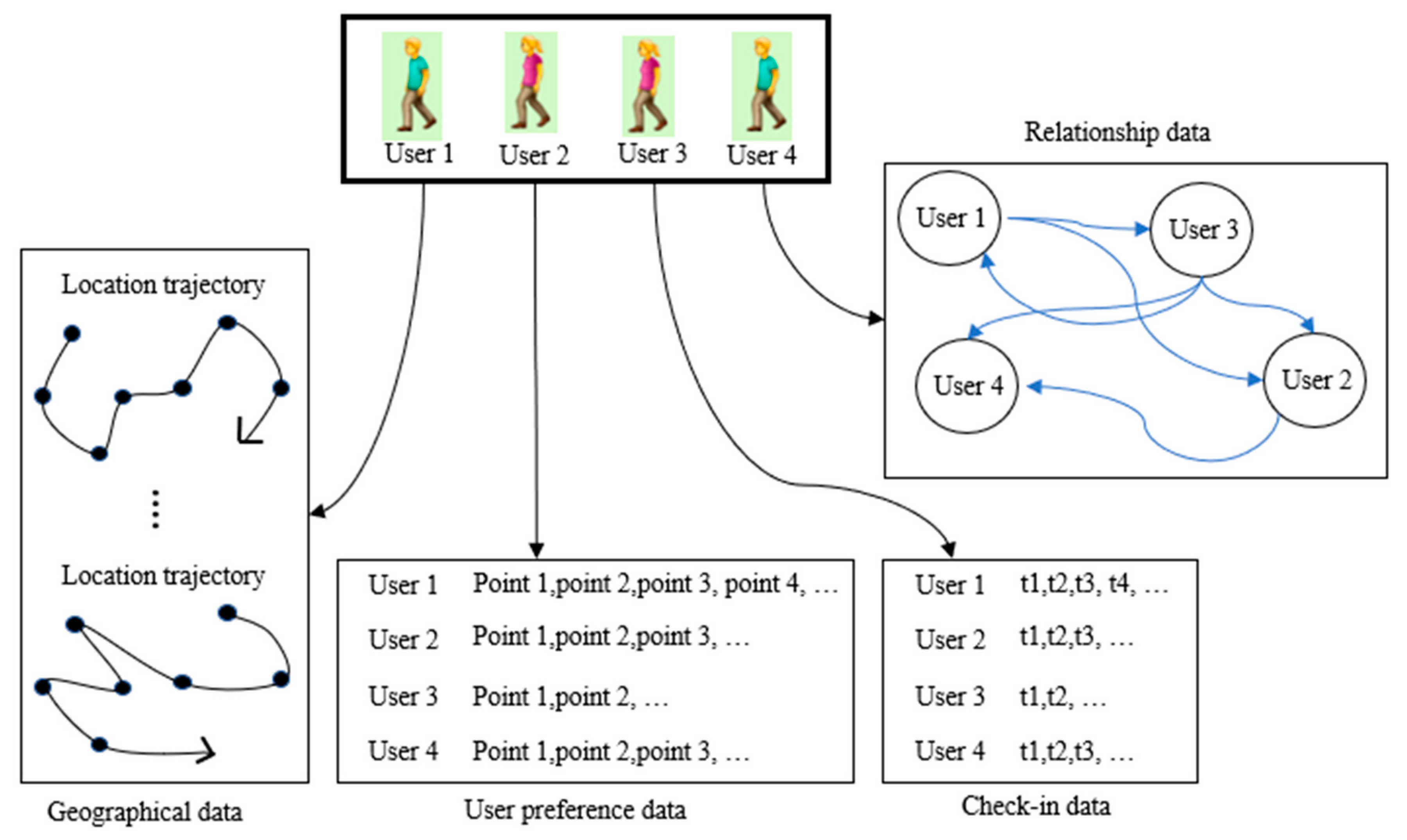
2. Material and Methods
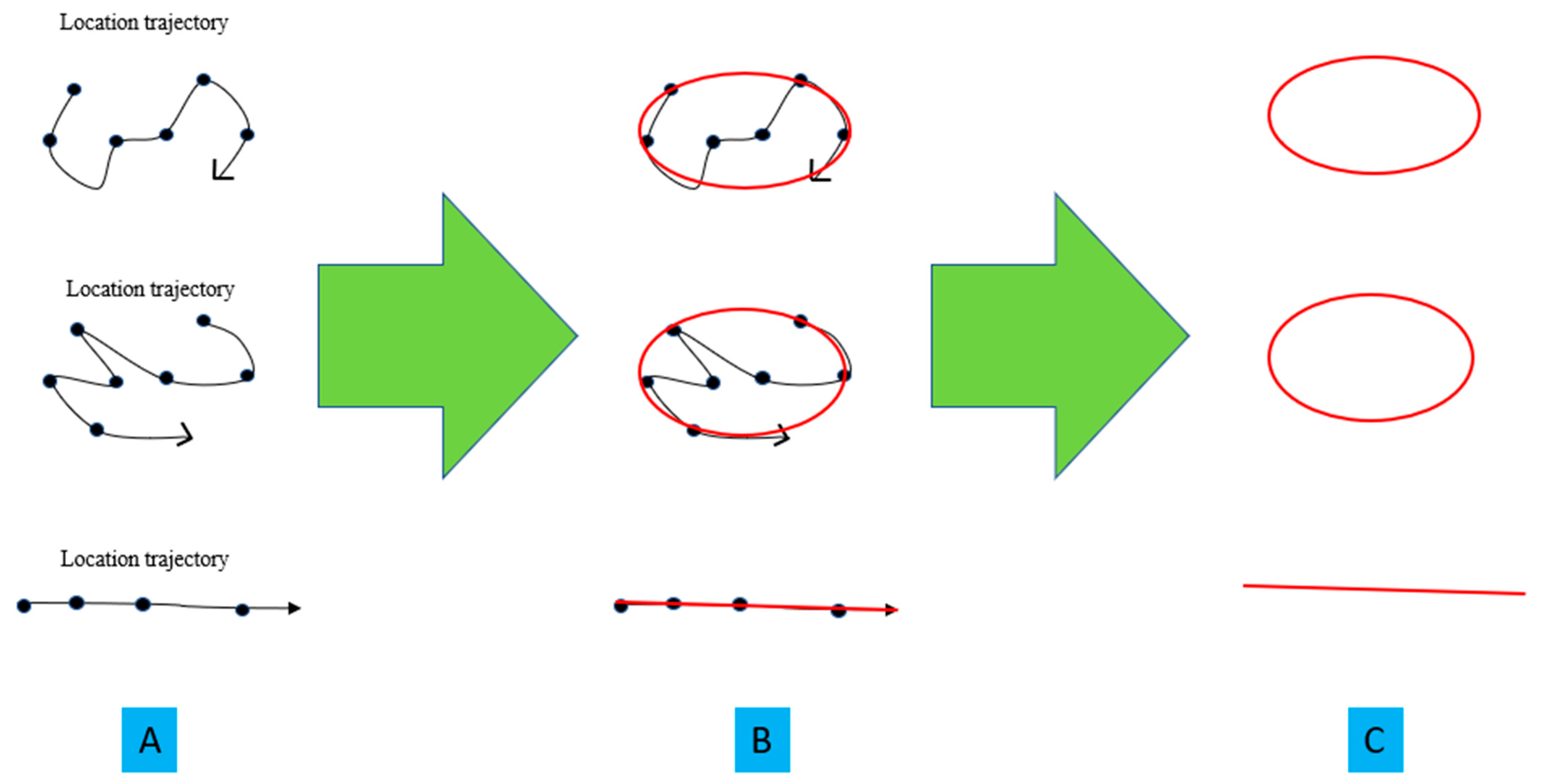
2.1. Attention Mechanism
2.2. Proposed CNN Model
3. Experiments
3.1. Datasets
3.2. Evaluation Measures
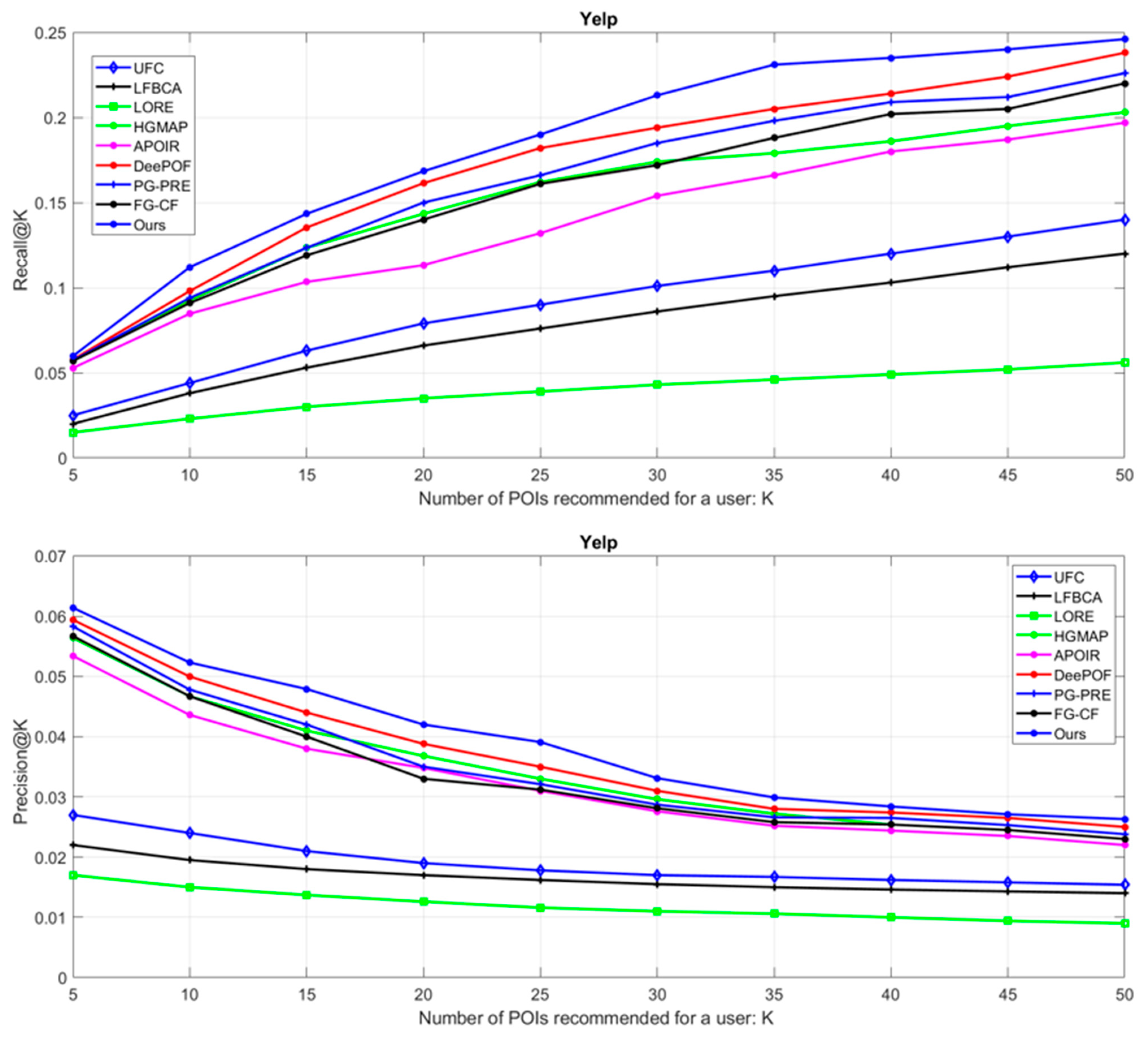
3.3. Experimental Results
- UFC [63]: This model attempts to incorporate check-in correlation, friend importance, and user preference for addressing problems of the sparsity of the user-POI matrix. Using collaboration filtering, the user favorite is individualized. As distant and close friends share a familiar influence, this model focuses on merging these two diverse factors to formulize friend importance.
- DeePOF [64]: This pipeline investigated the impact of the most analogous pattern of fellowship rather than using the pattern of the fellowship of all users. In order to detect the similarity, the mean-shift clustering strategy was employed. In addition, the most common friends’ spatial and temporal features were used to apply to a suggested CNN model. The output of some suggested convolutional layers can predict the longitude, latitude, and ID of subsequent right spots.
- HGMAP [3]: A multi-head attention mechanism inside a hybrid graph convolutional network with (HGMAP) was suggested to construct a spatial graph on the basis of the geographical gap between leverage graph convolutional networks (GCNs) and pairs of POIs for expressing the high-order connectivity among POIs. The HGMAP model was also used to address the difficulties in traditional recommender systems, such as data sparsity and cold start.
- LORE [65]: This model investigated the sequential influence on users’ check-in activities in LBSNs. The LORE strategy tries to explore sequential forms from a check-in position stream of all users. In addition, a tenth-order additive Markov chain (AMC) was used for computing the probability of a new location using user visiting information. The LORE model not only used the most recently visited locations for predicting a new visiting location but also employed the sequential influence more comprehensively.
- LFBCA [66]: In the LFBCA pipeline, the impact of social relations for each user was explored to suggest POIs. In addition, for characterizing the check-in behaviour, positions and users are added to the diagram. This model can handle the sparsity problem by incorporating the attributes of POIs into the recommendation process. However, it can still suffer from the cold-start problem, where there is not enough information available about a new user.
- APOIR [1]: This strategy is one of the primary POI recommendation systems based on an adversarial learning technique. The APOIR model has two main modules, including a discriminator and a recommender. These modules are able to be trained in a mutual manner for learning user inclination by considering both social relations and geographical. This model can handle the sparsity problem by incorporating the aspects of POIs into the recommendation process. However, it may require a large amount of data to learn the different aspects of POIs accurately.
- PG-PRE [67]: This technique proposes a new ensemble learning framework for point-of-interest (POI) recommendation in location-based social networks (LBSNs), named preference–geographical point-of-interest recommendation ensemble (PG-PRE). Traditional POI recommendation pipelines rely on discovering similar users and exploring their check-in histories to generate suggestions. However, such suggestions may be biased and lack variety. To overcome this limitation, PG-PRE constructs multiple similar user groups for a target user employing a roulette selection-based sampling technique to enhance the diversity of these groups. Each group generates a POI recommendation suggestion, and a Gaussian mixture-based technique is used to estimate the voting weight of each group. Lastly, a recommendation list for the target user is obtained by comprehensively considering the proposals of each group according to their corresponding voting weight.
- FG-CF [68]: This model suggests a novel approach for point-of-interest (POI) recommendation in location-based social networks (LBSNs) called friends-aware graph collaborative filtering (FG-CF). Traditional POI recommendation techniques suffer from the sparsity of check-in data, which GCN can overcome by capturing the high-order connectivity of POIs and users. However, social ties are ignored in most current graph-based approaches, which are crucial for POI recommendation in real-world scenarios. FG-CF incorporates social information into a user-POI graph, updating user embedding according to a user-POI correlation matrix. Interaction messages are constructed by integrating nodes’ ego embeddings, neighbor embeddings, and social embeddings.
4. Discussion
5. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, F.; Yin, R.; Zhang, K.; Trajcevski, G.; Zhong, T.; Wu, J. Adversarial Point-of-Interest Recommendation. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 3462–3468. [Google Scholar] [CrossRef]
- Ali, E.; Caputo, A.; Lawless, S.; Conlan, O. Where Should I Go? A Deep Learning Approach to Personalize Type-Based Facet Ranking for POI Suggestion. In Proceedings of the Web Information Systems Engineering–WISE 2021: 22nd International Conference on Web Information Systems Engineering, WISE 2021, Melbourne, VIC, Australia, 26–29 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 207–215. [Google Scholar] [CrossRef]
- Zhong, T.; Zhang, S.; Zhou, F.; Zhang, K.; Trajcevski, G.; Wu, J. Hybrid graph convolutional networks with multi-head attention for location recommendation. World Wide Web 2020, 23, 3125–3151. [Google Scholar] [CrossRef]
- Wang, H.; Li, P.; Liu, Y.; Shao, J. Towards real-time demand-aware sequential POI recommendation. Inf. Sci. 2021, 547, 482–497. [Google Scholar] [CrossRef]
- Chakraborty, A.; Ganguly, D.; Caputo, A.; Jones, G.J.F. Kernel density estimation based factored relevance model for multi-contextual point-of-interest recommendation. Inf. Retr. 2022, 25, 44–90. [Google Scholar] [CrossRef]
- Wang, K.; Wang, X.; Lu, X. POI recommendation method using LSTM-attention in LBSN considering privacy protection. Complex Intell. Syst. 2021, 1–12. [Google Scholar] [CrossRef]
- Huang, J.; Tong, Z.; Feng, Z. Geographical POI recommendation for Internet of Things: A federated learning approach using matrix factorization. Int. J. Commun. Syst. 2022, e5161. [Google Scholar] [CrossRef]
- Davtalab, M.; Alesheikh, A.A. A POI recommendation approach integrating social spatio-temporal information into probabilistic matrix factorization. Knowl. Inf. Syst. 2021, 63, 65–85. [Google Scholar] [CrossRef]
- Jeon, J.; Kang, S.; Jo, M.; Cho, S.; Park, N.; Kim, S.; Song, C. LightMove: A Lightweight Next-POI Recommendation forTaxicab Rooftop Advertising. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Gold Coast, QC, Australia, 1–5 November 2021; pp. 3857–3866. [Google Scholar] [CrossRef]
- Zhang, M.; Yang, Y.; Abbas, R.; Deng, K.; Li, J.; Zhang, B. SNPR: A Serendipity-Oriented Next POI Recommendation Model. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Gold Coast, QC, Australia, 1–5 November 2021. [Google Scholar] [CrossRef]
- Islam, A.; Mohammad, M.M.; Sarathi Das, S.S.; Ali, M.E. A survey on deep learning based Point-of-Interest (POI) recommendations. Neurocomputing 2021, 472, 306–325. [Google Scholar] [CrossRef]
- Qian, T.; Liu, B.; Nguyen, Q.V.H.; Yin, H. Spatiotemporal Representation Learning for Translation-Based POI Recommendation. ACM Trans. Inf. Syst. 2019, 37, 1–24. [Google Scholar] [CrossRef]
- Li, M.; Zheng, W.; Xiao, Y.; Zhu, K.; Huang, W. Exploring Temporal and Spatial Features for Next POI Recommendation in LBSNs. IEEE Access 2021, 9, 35997–36007. [Google Scholar] [CrossRef]
- Shi, M.; Shen, D.; Kou, Y.; Nie, T.; Yu, G. Attentional Memory Network with Correlation-based Embedding for time-aware POI recommendation. Knowl. Based Syst. 2021, 214, 106747. [Google Scholar] [CrossRef]
- Li, K.; Wei, H.; He, X.; Tian, Z. Relational POI recommendation model combined with geographic information. PLoS ONE 2022, 17, e0266340. [Google Scholar] [CrossRef]
- Halder, S.; Lim, K.H.; Chan, J.; Zhang, X. Transformer-Based Multi-task Learning for Queuing Time Aware Next POI Recommendation. In Proceedings of the Advances in Knowledge Discovery and Data Mining: 25th Pacific-Asia Conference, PAKDD 2021, Virtual Event, 11–14 May 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 510–523. [Google Scholar]
- Chen, L.; Ying, Y.; Lyu, D.; Yu, S.; Chen, G. A multi-task embedding based personalized POI recommendation method. CCF Trans. Pervasive Comput. Interact. 2021, 3, 253–269. [Google Scholar] [CrossRef]
- Taylan, P.; Yerlikaya-Özkurt, F.; Uçak, B.B.; Weber, G.-W. A new outlier detection method based on convex optimization: Application to diagnosis of Parkinson’s disease. J. Appl. Stat. 2020, 48, 2421–2440. [Google Scholar] [CrossRef] [PubMed]
- Onak, Ö.N.; Erenler, T.; Dogrusoz, Y.S. A Novel Data-Adaptive Regression Framework Based on Multivariate Adaptive Regression Splines for Electrocardiographic Imaging. IEEE Trans. Biomed. Eng. 2021, 69, 963–974. [Google Scholar] [CrossRef] [PubMed]
- Onak, Ö.N.; Dogrusoz, Y.S.; Weber, G.W. Evaluation of multivariate adaptive non-parametric reduced-order model for solving the inverse electrocardiography problem: A simulation study. Med. Biol. Eng. Comput. 2019, 57, 967–993. [Google Scholar] [CrossRef]
- Temocin, B.Z.; Korn, R.; Selcuk-Kestel, A.S. Constant proportion portfolio insurance in defined contribution pension plan management under discrete-time trading. Ann. Oper. Res. 2018, 260, 515–544. [Google Scholar] [CrossRef]
- Kuter, S.; Bolat, K.; Akyurek, Z. A machine learning-based accuracy enhancement on EUMETSAT H-SAF H35 effective snow-covered area product. Remote Sens. Environ. 2022, 272, 112947. [Google Scholar] [CrossRef]
- Chandio, A.; Gui, G.; Kumar, T.; Ullah, I.; Ranjbarzadeh, R.; Roy, A.M.; Hussain, A.; Shen, Y. Precise Single-stage Detector. arXiv 2022, arXiv:2210.04252. [Google Scholar]
- Sojahrood, Z.B.; Taleai, M. Behavior-based POI recommendation for small groups in location-based social networks. Trans. GIS 2021, 26, 259–277. [Google Scholar] [CrossRef]
- Wang, D.; Wang, X.; Xiang, Z.; Yu, D.; Deng, S.; Xu, G. Attentive sequential model based on graph neural network for next poi recommendation. World Wide Web 2021, 24, 2161–2184. [Google Scholar] [CrossRef]
- Singh, A.; Ranjbarzadeh, R.; Raj, K.; Kumar, T.; Roy, A.M. Understanding EEG signals for subject-wise Definition of Armoni Activities. arXiv 2023, arXiv:2301.00948. [Google Scholar]
- Ranjbarzadeh, R.; Zarbakhsh, P.; Caputo, A.; Tirkolaee, E.B.; Bendechache, M. Brain Tumor Segmentation based on an Optimized Convolutional Neural Network and an Improved Chimp Optimization Algorithm. SSRN 2022. [Google Scholar] [CrossRef]
- Haseli, G.; Ranjbarzadeh, R.; Hajiaghaei-Keshteli, M.; Ghoushchi, S.J.; Hasani, A.; Deveci, M.; Ding, W. HECON: Weight assessment of the product loyalty criteria considering the customer decision’s halo effect using the convolutional neural networks. Inf. Sci. 2023, 623, 184–205. [Google Scholar] [CrossRef]
- Yin, H.; Wang, W.; Wang, H.; Chen, L.; Zhou, X. Spatial-Aware Hierarchical Collaborative Deep Learning for POI Recommendation. IEEE Trans. Knowl. Data Eng. 2017, 29, 2537–2551. [Google Scholar] [CrossRef]
- Hao, P.Y.; Cheang, W.H.; Chiang, J.H. Real-time event embedding for POI recommendation. Neurocomputing 2019, 349, 1–11. [Google Scholar] [CrossRef]
- Doan, K.D.; Yang, G.; Reddy, C.K. An attentive spatio-temporal neural model for successive point of interest recom-mendation. In Proceedings of the Advances in Knowledge Discovery and Data Mining: 23rd Pacific-Asia Conference, PAKDD 2019, Macau, China, 14–17 April 2019; Springer: Berlin/Heidelberg, Germany, 2016; pp. 346–358. [Google Scholar] [CrossRef]
- He, F.; Wei, P. Research on comprehensive point of interest (POI) recommendation based on spark. Clust. Comput. 2018, 22, 9049–9057. [Google Scholar] [CrossRef]
- Ding, R.; Chen, Z. RecNet: A deep neural network for personalized POI recommendation in location-based social net-works. Int. J. Geogr. Inf. Sci. 2018, 32, 1631–1648. [Google Scholar] [CrossRef]
- Rahmani, H.A.; Deldjoo, Y.; di Noia, T. The role of context fusion on accuracy, beyond-accuracy, and fairness of point-of-interest recommendation systems. Expert Syst. Appl. 2022, 205, 117700. [Google Scholar] [CrossRef]
- Wu, J.; Hu, R.; Li, D.; Xiao, Y.; Ren, L.; Hu, W. Where Have You Gone: Category-aware Multigraph Embedding for Missing Point-of-Interest Identification. Neural Process. Lett. 2022, 1–20. [Google Scholar] [CrossRef]
- Liu, K.; Zheng, W.; Xiao, Y.; Zhai, X. POI Recommendation Algorithm based on Region Transfer Collaborative Filtering. In Proceedings of the 25th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Hangzhou, China, 4–6 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 903–907. [Google Scholar] [CrossRef]
- Yu, D.; Yu, T.; Wang, D.; Shen, Y. NGPR: A comprehensive personalized point-of-interest recommendation method based on heterogeneous graphs. Multimed. Tools Appl. 2022, 81, 39207–39228. [Google Scholar] [CrossRef]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3061–3070. [Google Scholar]
- Corbetta, M.; Shulman, G.L. Control of goal-directed and stimulus-driven attention in the brain. Nat. Rev. Neurosci. 2002, 3, 201–215. [Google Scholar] [CrossRef] [PubMed]
- Tsotsos, J.K.; Culhane, S.M.; Wai, W.Y.K.; Lai, Y.; Davis, N.; Nuflo, F. Modeling visual attention via selective tuning. Artif. Intell. 1995, 78, 507–545. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Ranjbarzadeh, R.; Dorosti, S.; Ghoushchi, S.J.; Caputo, A.; Tirkolaee, E.B.; Ali, S.S.; Arshadi, Z.; Bendechache, M. Breast tumor localization and segmentation using machine learning techniques: Overview of datasets, findings, and methods. Comput. Biol. Med. 2023, 152, 106443. [Google Scholar] [CrossRef] [PubMed]
- Ranjbarzadeh, R.; Kasgari, A.B.; Ghoushchi, S.J.; Anari, S.; Naseri, M.; Bendechache, M. Brain tumor segmentation based on deep learning and an attention mechanism using MRI multi-modalities brain images. Sci. Rep. 2021, 11, 10930. [Google Scholar] [CrossRef] [PubMed]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Susanto, A.; Mulyono, I.U.W.; Sari, C.A.; Rachmawanto, E.H.; Setiadi, D.R.I.M. Javanese Script Recognition based on Metric, Eccentricity and Local Binary Pattern. In Proceedings of the 2021 International Seminar on Application for Technology of Information and Communication (iSemantic), Kota Semarang, Indonesia, 18–19 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 118–121. [Google Scholar] [CrossRef]
- Sindel, T.; Naraharisetti, P.R.; Saliba, M.A.; Fabri, S.G. Bounding Box Matching: A Sparse Object-centric Correspondence Method for Stereo Vision. In Proceedings of the 2022 8th International Conference on Automation, Robotics and Applications (ICARA), Prague, Czech Republic, 18–20 February 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 223–227. [Google Scholar] [CrossRef]
- Arneson-Wissink, P.C.; Doles, J.D. Quantification of Muscle Stem Cell Differentiation Using Live-Cell Imaging and Ec-centricity Measures. Methods Mol. Biol. 2022, 2429, 455–471. [Google Scholar] [CrossRef]
- Saadi, S.B.; Sarshar, N.T.; Sadeghi, S.; Ranjbarzadeh, R.; Forooshani, M.K.; Bendechache, M. Investigation of Effectiveness of Shuffled Frog-Leaping Optimizer in Training a Convolution Neural Network. J. Health Eng. 2022, 2022, 1–11. [Google Scholar] [CrossRef]
- Ranjbarzadeh, R.; Sarshar, N.T.; Ghoushchi, S.J.; Esfahani, M.S.; Parhizkar, M.; Pourasad, Y.; Anari, S.; Bendechache, M. MRFE-CNN: Multi-route feature extraction model for breast tumor segmentation in Mammograms using a convolutional neural network. Ann. Oper. Res. 2022, 1–22. [Google Scholar] [CrossRef]
- Ambrosanio, M.; Franceschini, S.; Pascazio, V.; Baselice, F. An End-to-End Deep Learning Approach for Quantitative Microwave Breast Imaging in Real-Time Applications. Bioengineering 2022, 9, 651. [Google Scholar] [CrossRef]
- Lu, Q.; Wang, C.; Lian, Z.; Zhang, X.; Yang, W.; Feng, Q.; Feng, Y. Cascade of Denoising and Mapping Neural Networks for MRI R2* Relaxometry of Iron-Loaded Liver. Bioengineering 2023, 10, 209. [Google Scholar] [CrossRef] [PubMed]
- Ranjbarzadeh, R.; Dorosti, S.; Ghoushchi, S.J.; Safavi, S.; Razmjooy, N.; Sarshar, N.T.; Anari, S.; Bendechache, M. Nerve optic segmentation in CT images using a deep learning model and a texture descriptor. Complex Intell. Syst. 2022, 8, 3543–3557. [Google Scholar] [CrossRef]
- Saha, S.; Chakraborty, N.; Kundu, S.; Paul, S.; Mollah, A.F.; Basu, S.; Sarkar, R. Multi-lingual scene text detection and language identification. Pattern Recognit. Lett. 2020, 138, 16–22. [Google Scholar] [CrossRef]
- Altini, N.; Brunetti, A.; Puro, E.; Taccogna, M.G.; Saponaro, C.; Zito, F.A.; De Summa, S.; Bevilacqua, V. NDG-CAM: Nuclei Detection in Histopathology Images with Semantic Segmentation Networks and Grad-CAM. Bioengineering 2022, 9, 475. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Jin, L.; Zhang, S.; Luo, C.; Zhang, S. Curved scene text detection via transverse and longitudinal sequence connection. Pattern Recognit. 2019, 90, 337–345. [Google Scholar] [CrossRef]
- Ranjbarzadeh, R.; Jafarzadeh Ghoushchi, S.; Anari, S.; Safavi, S.; Tataei Sarshar, N.; Babaee Tirkolaee, E.; Bendechache, M. A Deep Learning Approach for Robust, Multi-oriented, and Curved Text Detection. Cognit. Comput. 2022, 1, 1–13. [Google Scholar] [CrossRef]
- Saadi, S.B.; Ranjbarzadeh, R.; Kazemi, O.; Amirabadi, A.; Ghoushchi, S.J.; Kazemi, O.; Azadikhah, S.; Bendechache, M. Osteolysis: A Literature Review of Basic Science and Potential Computer-Based Image Processing Detection Methods. Comput. Intell. Neurosci. 2021, 2021, 1–21. [Google Scholar] [CrossRef]
- Valizadeh, A.; Ghoushchi, S.J.; Ranjbarzadeh, R.; Pourasad, Y. Presentation of a Segmentation Method for a Diabetic Retinopathy Patient’s Fundus Region Detection Using a Convolutional Neural Network. Comput. Intell. Neurosci. 2021, 2021, 1–14. [Google Scholar] [CrossRef]
- Kim, T.Y.; Cho, S.B. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]
- Sarshar, N.T.; Ranjbarzadeh, R.; Ghoushchi, S.J.; de Oliveira, G.G.; Anari, S.; Parhizkar, M.; Bendechache, M. Glioma Brain Tumor Segmentation in Four MRI Modalities Using a Convolutional Neural Network and Based on a Transfer Learning Method. In Proceedings of the 7th Brazilian Technology Symposium (BTSym’21) 24–26 October: Emerging Trends in Human Smart and Sustainable Future of Cities; Springer: Berlin/Heidelberg, Germany, 2022; Volume 1, pp. 386–402. [Google Scholar] [CrossRef]
- Liu, H.; Zheng, C.; Li, D.; Zhang, Z.; Lin, K.; Shen, X.; Xiong, N.N.; Wang, J. Multi-perspective social recommendation method with graph representation learning. Neurocomputing 2021, 468, 469–481. [Google Scholar] [CrossRef]
- Dhelim, S.; Aung, N.; Bouras, M.A.; Ning, H.; Cambria, E. A survey on personality-aware recommendation systems. Artif. Intell. Rev. 2021, 55, 2409–2454. [Google Scholar] [CrossRef]
- Zhou, J.; Liu, B.; Chen, Y.; Lin, F. UFC: A Unified POI Recommendation Framework. Arab. J. Sci. Eng. 2019, 44, 9321–9332. [Google Scholar] [CrossRef]
- Safavi, S.; Jalali, M. DeePOF: A hybrid approach of deep convolutional neural network and friendship to Point-of-Interest (POI) recommendation system in location-based social networks. Concurr. Comput. Pr. Exp. 2022, 34, e6981. [Google Scholar] [CrossRef]
- Zhang, J.-D.; Chow, C.-Y.; Li, Y. LORE: Exploiting Sequential Influence for Location Recommendations. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, New York, NY, USA, 4–7 November 2014; pp. 109–112. [Google Scholar] [CrossRef]
- Wang, H.; Terrovitis, M.; Mamoulis, N. Location recommendation in location-based social networks using user check-in data. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013. [Google Scholar]
- Liu, S.; Yang, L.; Zheng, W.; Xiao, Y.; Liu, L. An ensemble learning model for preference-geographical aware point-of interest recommendation. Appl. Intell. 2022, 52, 13763–13780. [Google Scholar] [CrossRef]
- Cai, Z.; Yuan, G.; Qiao, S.; Qu, S.; Zhang, Y.; Bing, R. FG-CF: Friends-aware graph collaborative filtering for POI recommendation. Neurocomputing 2022, 488, 107–119. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| POIs | Sparsity (%) | Records | Social Relations | Users | |
|---|---|---|---|---|---|
| Yelp | 18,995 | 99.860 | 265,533 | 860,888 | 30,887 |
| Gowalla | 32,510 | 99.865 | 86,985 | 1,278,274 | 18,737 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kasgari, A.B.; Safavi, S.; Nouri, M.; Hou, J.; Sarshar, N.T.; Ranjbarzadeh, R. Point-of-Interest Preference Model Using an Attention Mechanism in a Convolutional Neural Network. Bioengineering 2023, 10, 495. https://doi.org/10.3390/bioengineering10040495
Kasgari AB, Safavi S, Nouri M, Hou J, Sarshar NT, Ranjbarzadeh R. Point-of-Interest Preference Model Using an Attention Mechanism in a Convolutional Neural Network. Bioengineering. 2023; 10(4):495. https://doi.org/10.3390/bioengineering10040495
Chicago/Turabian StyleKasgari, Abbas Bagherian, Sadaf Safavi, Mohammadjavad Nouri, Jun Hou, Nazanin Tataei Sarshar, and Ramin Ranjbarzadeh. 2023. "Point-of-Interest Preference Model Using an Attention Mechanism in a Convolutional Neural Network" Bioengineering 10, no. 4: 495. https://doi.org/10.3390/bioengineering10040495
APA StyleKasgari, A. B., Safavi, S., Nouri, M., Hou, J., Sarshar, N. T., & Ranjbarzadeh, R. (2023). Point-of-Interest Preference Model Using an Attention Mechanism in a Convolutional Neural Network. Bioengineering, 10(4), 495. https://doi.org/10.3390/bioengineering10040495