
Using AI Segmentation Models to Improve Foreign Body Detection and Triage from Ultrasound Images


Abstract
:1. Introduction
Overview of Ultrasound Imaging Artificial Intelligent Segmentation Models
2. Materials and Methods
2.1. Phantom Preparation and Imaging
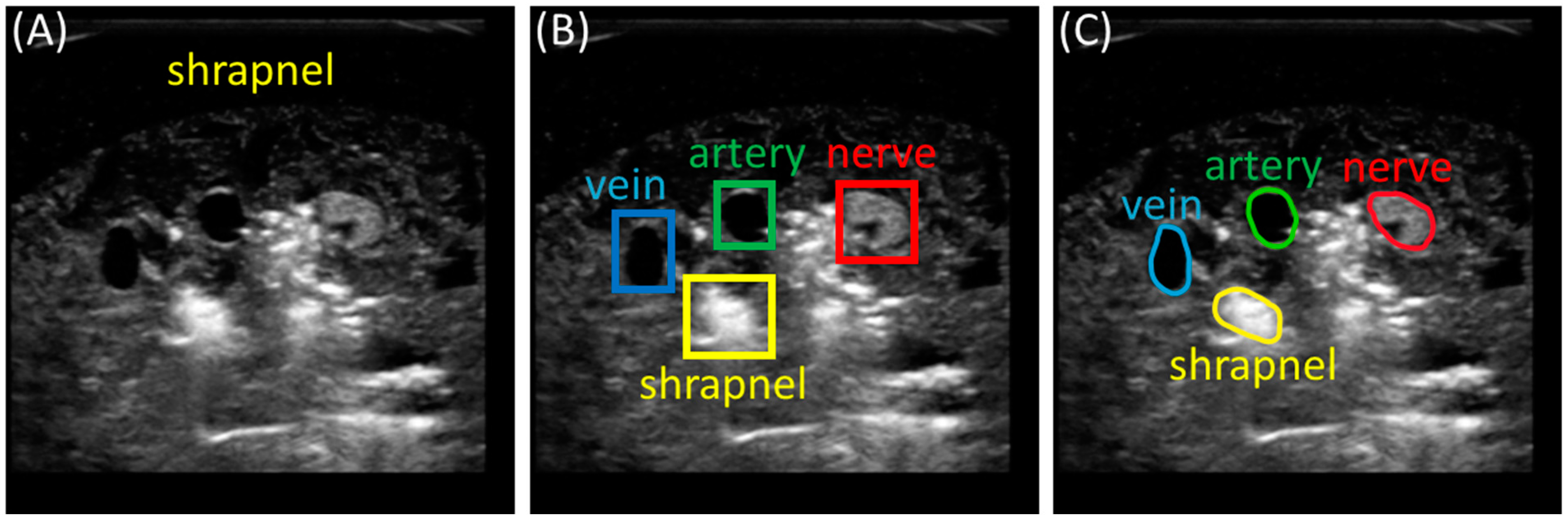
2.2. Preprocessing and Labeling Images
2.3. Training Segmentation Algorithms
2.4. Performance Metrics for Evaluating Trained Models
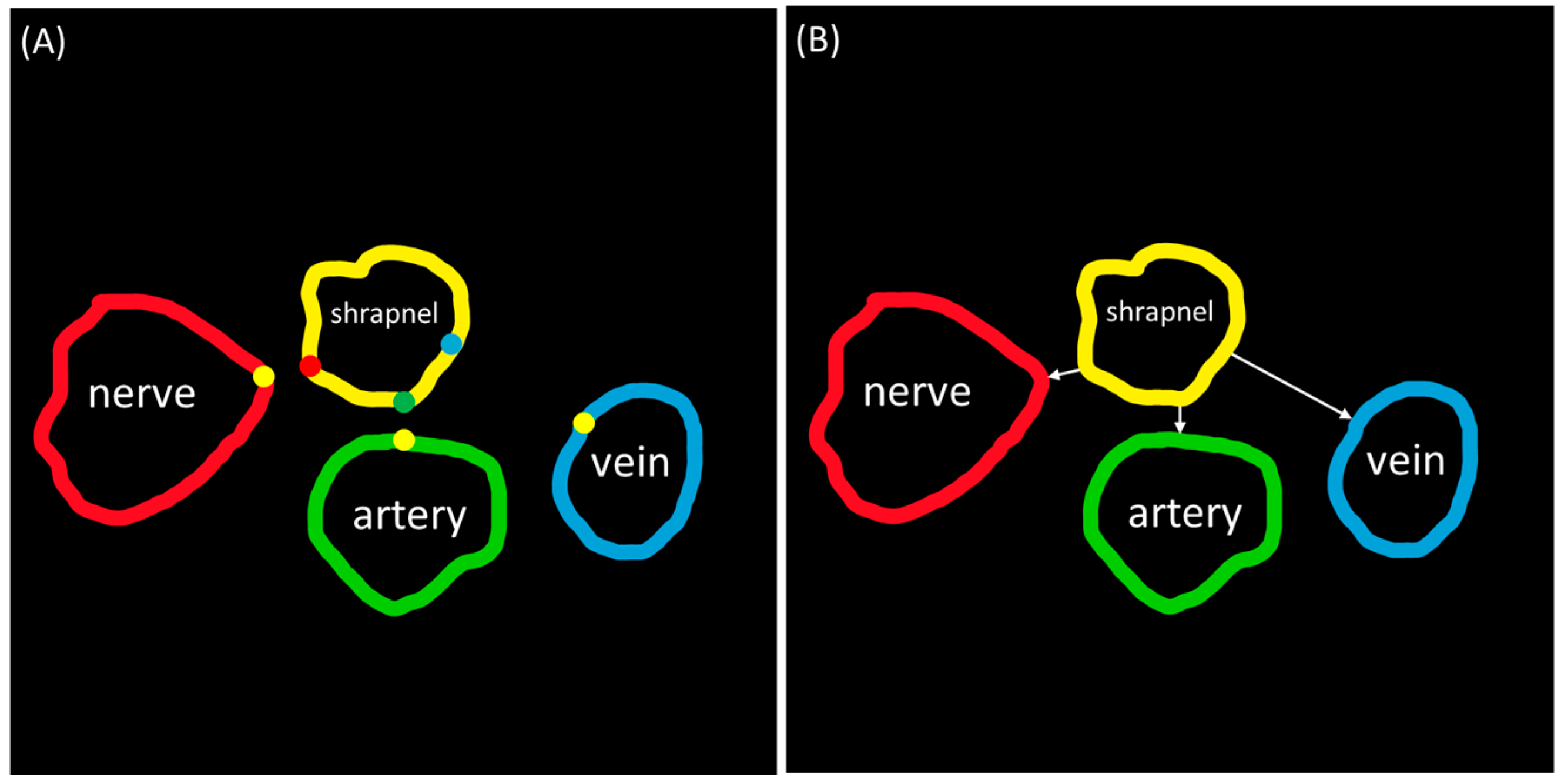
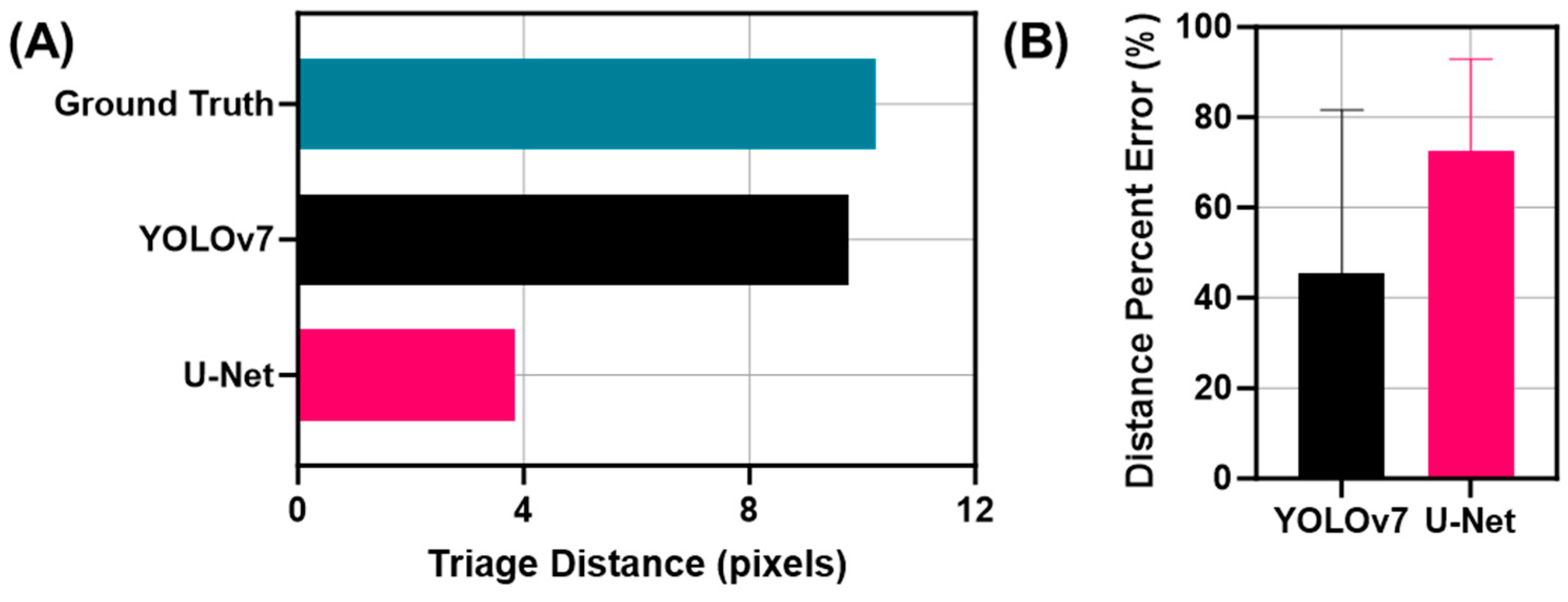
2.5. Distance Triage
3. Results
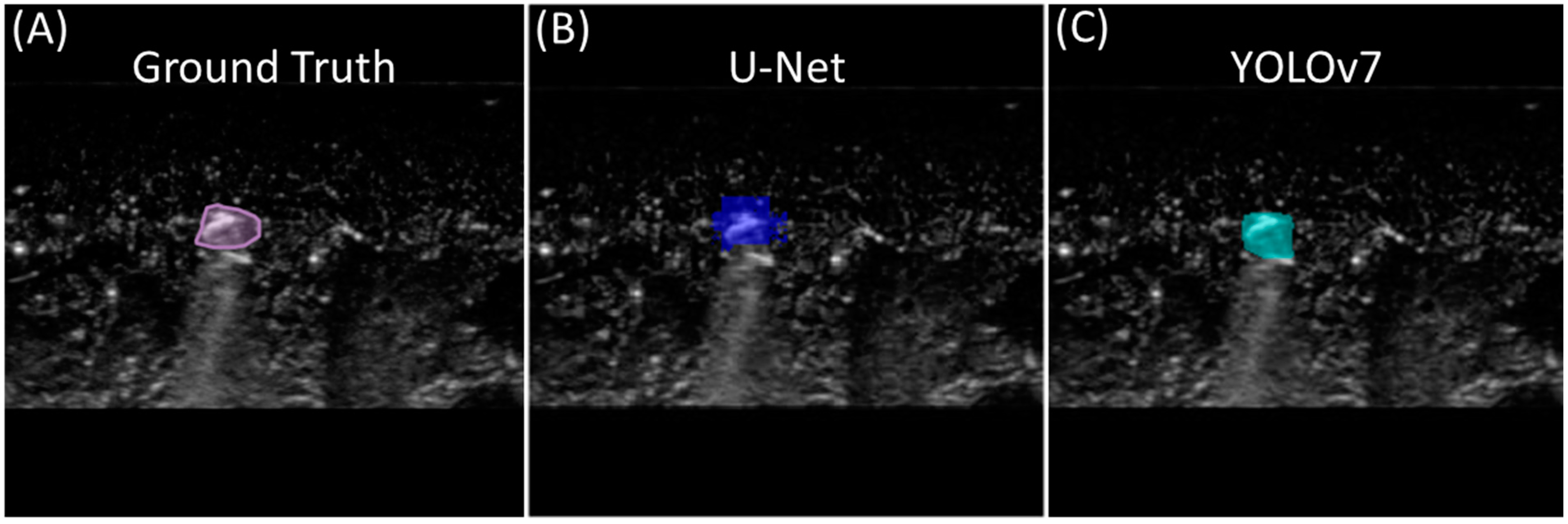
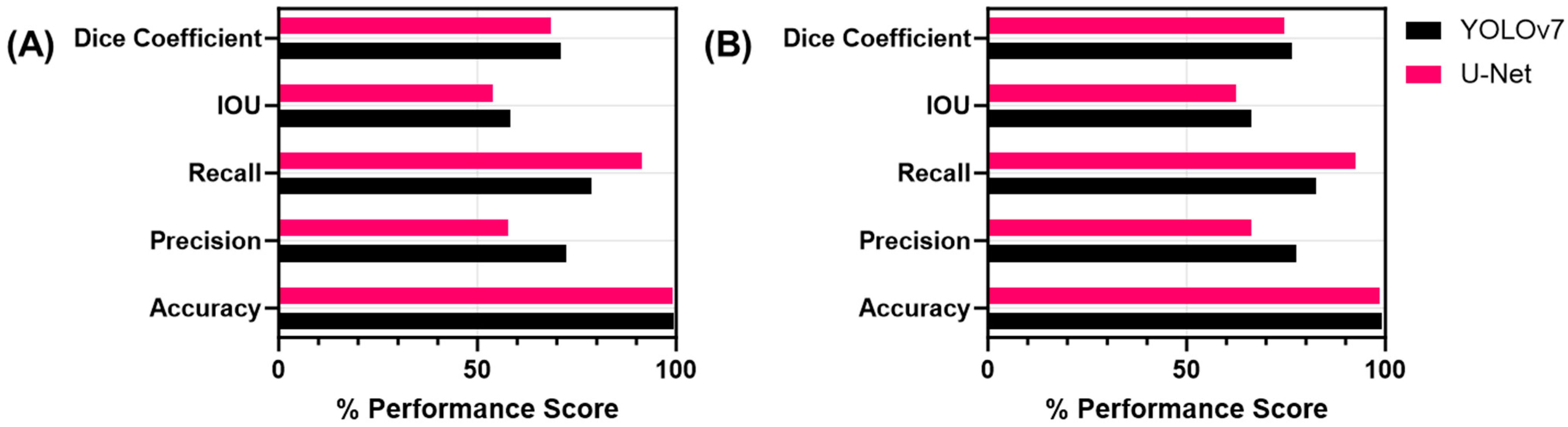
3.1. Single-Class Segmentation Models for Shrapnel
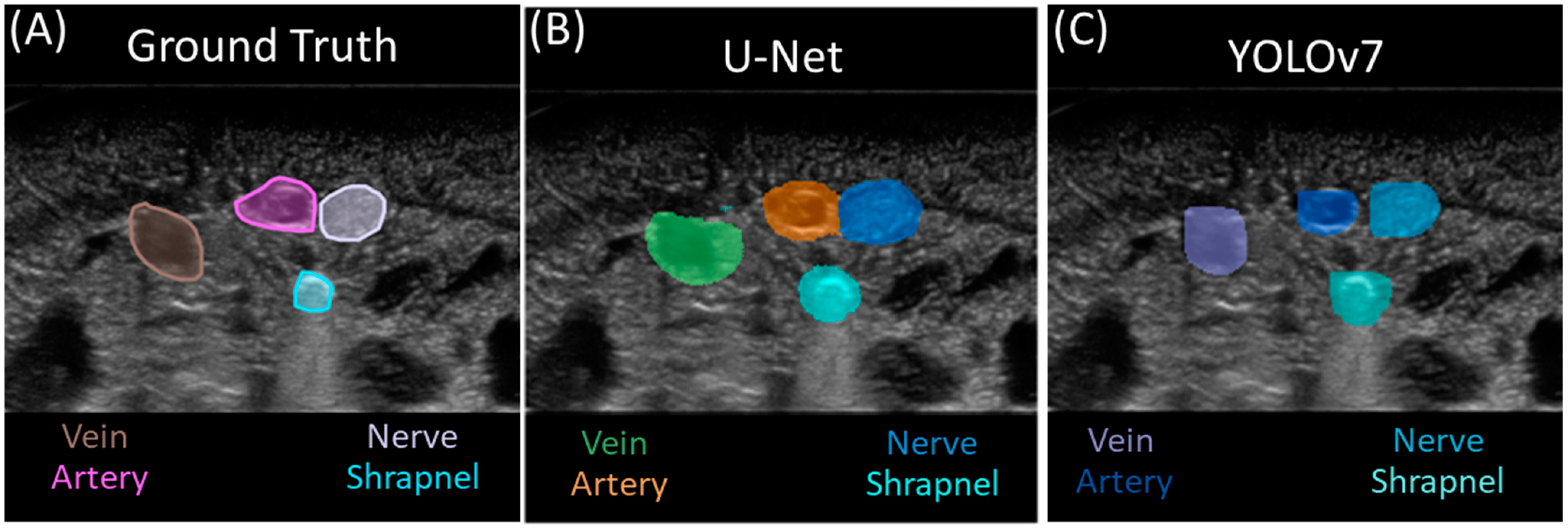
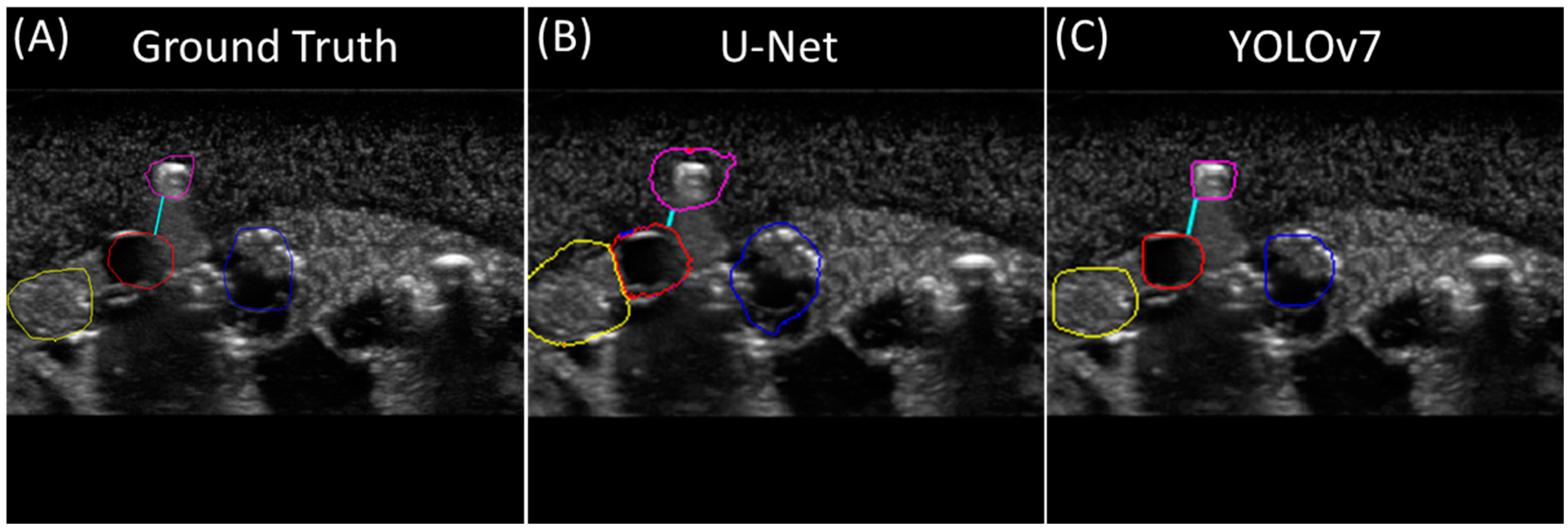
3.2. Multi-Class Segmentation Models
3.3. Triage Metric for Segmentation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
DoD Disclaimer
References
- Townsend, S.; Lasher, W. The U.S. Army in Multi-Domain Operations 2028; U.S. Army: Arlington County, VA, USA, 2018. [Google Scholar]
- Epstein, A.; Lim, R.; Johannigman, J.; Fox, C.J.; Inaba, K.; Vercruysse, G.A.; Thomas, R.W.; Martin, M.J.; Konstantyn, G.; Schwaitzberg, S.D.; et al. Putting Medical Boots on the Ground: Lessons from the War in Ukraine and Applications for Future Conflict with Near-Peer Adversaries. J. Am. Coll. Surg. 2023, 237, 364–373. [Google Scholar] [CrossRef]
- Harper, H.; Myers, M. Military and Tactical Ultrasound. In Emergency Ultrasound; ACEP: Irving, TX, USA, 2008. [Google Scholar]
- Snider, E.J.; Hernandez-Torres, S.I.; Boice, E.N. An Image Classification Deep-Learning Algorithm for Shrapnel Detection from Ultrasound Images. Sci. Rep. 2022, 12, 8427. [Google Scholar] [CrossRef]
- Diaz-Escobar, J.; Ordóñez-Guillén, N.E.; Villarreal-Reyes, S.; Galaviz-Mosqueda, A.; Kober, V.; Rivera-Rodriguez, R.; Rizk, J.E.L. Deep-Learning Based Detection of COVID-19 Using Lung Ultrasound Imagery. PLoS ONE 2021, 16, e0255886. [Google Scholar] [CrossRef] [PubMed]
- Canelli, R.; Leo, M.; Mizelle, J.; Shrestha, G.S.; Patel, N.; Ortega, R. Use of eFAST in Patients with Injury to the Thorax or Abdomen. N. Engl. J. Med. 2022, 386, e23. [Google Scholar] [CrossRef]
- Farshad-Amacker, N.A.; Bay, T.; Rosskopf, A.B.; Spirig, J.M.; Wanivenhaus, F.; Pfirrmann, C.W.A.; Farshad, M. Ultrasound-Guided Interventions with Augmented Reality in Situ Visualisation: A Proof-of-Mechanism Phantom Study. Eur. Radiol. Exp. 2020, 4, 7. [Google Scholar] [CrossRef] [PubMed]
- Abolmaesumi, P.; Salcudean, S.E.; Zhu, W.H.; DiMaio, S.P.; Sirouspour, M.R. A User Interface for Robot-Assisted Diagnostic Ultrasound. In Proceedings of the Proceedings 2001 ICRA, IEEE International Conference on Robotics and Automation (Cat. No.01CH37164), Seoul, Republic of Korea, 21–26 May 2001; Volume 2, pp. 1549–1554. [Google Scholar]
- Snider, E.J.; Hernandez-Torres, S.I.; Avital, G.; Boice, E.N. Evaluation of an Object Detection Algorithm for Shrapnel and Development of a Triage Tool to Determine Injury Severity. J. Imaging 2022, 8, 252. [Google Scholar] [CrossRef]
- Hernandez-Torres, S.I.; Hennessey, R.P.; Snider, E.J. Performance Comparison of Object Detection Networks for Shrapnel Identification in Ultrasound Images. Bioengineering 2023, 10, 807. [Google Scholar] [CrossRef] [PubMed]
- Bowyer, G.W. Management of Small Fragment Wounds: Experience from the Afghan Border. J. Trauma 1996, 40, S170–S172. [Google Scholar] [CrossRef]
- Patil, D.D.; Deore, S.G. Medical Image Segmentation: A Review. Int. J. Comput. Sci. Mob. Comput. 2013, 2, 22–27. [Google Scholar]
- Wang, Z. Deep Learning in Medical Ultrasound Image Segmentation: A Review. arXiv 2020, arXiv:2002.07703. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Ho, T.-W.; Qi, H.; Lai, F.; Xiao, F.-R.; Wu, J.-M. Brain Tumor Segmentation Using U-Net and Edge Contour Enhancement. In Proceedings of the 2019 3rd International Conference on Digital Signal Processing, Jeju Island, Republic of Korea, 24–26 February 2019; pp. 75–79. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. Available online: https://arxiv.org/abs/1506.02640v5 (accessed on 20 March 2023).
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. Available online: https://arxiv.org/abs/2207.02696v1 (accessed on 20 March 2023).
- Yildirim, E.; Sefercik, U.G.; Kavzoglu, T. Automated Vehicle Detection and Instance Segmentation from High-Resolution UAV Imagery Using YOLOv7 Model. Intercont. Geoinf. Days 2022, 5, 116–119. [Google Scholar]
- Ahmad, S.; Kim, J.-S.; Park, D.K.; Whangbo, T. Automated Detection of Gastric Lesions in Endoscopic Images by Leveraging Attention-Based YOLOv7. IEEE Access 2023, 11, 87166–87177. [Google Scholar] [CrossRef]
- Liu, Z.; Zheng, L.; Gu, L.; Yang, S.; Zhong, Z.; Zhang, G. InstrumentNet: An Integrated Model for Real-Time Segmentation of Intracranial Surgical Instruments. Comput. Biol. Med. 2023, 166, 107565. [Google Scholar] [CrossRef]
- Azad, R.; Aghdam, E.K.; Rauland, A.; Jia, Y.; Avval, A.H.; Bozorgpour, A.; Karimijafarbigloo, S.; Cohen, J.P.; Adeli, E.; Merhof, D. Medical Image Segmentation Review: The Success of U-Net. arXiv 2022, arXiv:2211.14830. [Google Scholar]
- Siddique, N.; Paheding, S.; Elkin, C.P.; Devabhaktuni, V. U-Net and Its Variants for Medical Image Segmentation: A Review of Theory and Applications. IEEE Access 2021, 9, 82031–82057. [Google Scholar] [CrossRef]
- Huang, L.; Lin, Y.; Cao, P.; Zou, X.; Qin, Q.; Lin, Z.; Liang, F.; Li, Z. Automated Detection and Segmentation of Pleural Effusion on Ultrasound Images Using an Attention U-Net. J. Appl. Clin. Med. Phys. 2024, 25, e14231. [Google Scholar] [CrossRef] [PubMed]
- Pang, M.; Liu, S.; Lin, F.; Liu, S.; Tian, B.; Yang, W.; Chen, X. Measurement of Optic Nerve Sheath on Ocular Ultrasound Image Based on Segmentation by CNN. In Proceedings of the 2019 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Chongqing, China, 11–13 December 2019; pp. 1–5. [Google Scholar]
- Lin, Z.; Li, Z.; Cao, P.; Lin, Y.; Liang, F.; He, J.; Huang, L. Deep Learning for Emergency Ascites Diagnosis Using Ultrasonography Images. J. Appl. Clin. Med. Phys. 2022, 23, e13695. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Fang, J.; Liu, S.; Liang, X.; Yang, X.; Mai, Z.; Van, M.T.; Wang, T.; Chen, Z.; Ni, D. CR-Unet: A Composite Network for Ovary and Follicle Segmentation in Ultrasound Images. IEEE J. Biomed. Health Inform. 2020, 24, 974–983. [Google Scholar] [CrossRef]
- NAS-Unet: Neural Architecture Search for Medical Image Segmentation|IEEE Journals & Magazine|IEEE Xplore. Available online: https://ieeexplore.ieee.org/abstract/document/8681706 (accessed on 19 January 2024).
- Iriani Sapitri, A.; Nurmaini, S.; Naufal Rachmatullah, M.; Tutuko, B.; Darmawahyuni, A.; Firdaus, F.; Rini, D.P.; Islami, A. Deep Learning-Based Real Time Detection for Cardiac Objects with Fetal Ultrasound Video. Inform. Med. Unlocked 2023, 36, 101150. [Google Scholar] [CrossRef]
- Effective Kidney Stone Prediction Based on Optimized Yolov7 Segmentation and Deep Learning Classification|International Journal of Intelligent Systems and Applications in Engineering. Available online: https://ijisae.org/index.php/IJISAE/article/view/3776 (accessed on 19 January 2024).
- Ariji, Y.; Kise, Y.; Fukuda, M.; Kuwada, C.; Ariji, E. Segmentation of Metastatic Cervical Lymph Nodes from CT Images of Oral Cancers Using Deep-Learning Technology. Dentomaxillofac. Radiol. 2022, 51, 20210515. [Google Scholar] [CrossRef]
- Hernandez-Torres, S.I.; Boice, E.N.; Snider, E.J. Using an Ultrasound Tissue Phantom Model for Hybrid Training of Deep Learning Models for Shrapnel Detection. J. Imaging 2022, 8, 270. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Formula |
|---|---|
| Accuracy | (TP + TN)/(TP + FN + TN + FP) |
| Precision | TP/(FP + TP) |
| Recall | TP/(FN + TP) |
| IOU | TP/(TP + FP + FN) |
| Dice Coefficient | 2 × TP/(2 × TP + FP + FN) |
| Accuracy | Precision | Recall | IOU | Dice Coefficient | |
|---|---|---|---|---|---|
| YOLOv7 | 99.1% | 76.0% | 74.3% | 55.1% | 69.7% |
| U-Net | 99.1% | 63.8% | 67.7% | 51.5% | 64.7% |
| YOLOv7 | |||||
| Accuracy | Precision | Recall | IOU | Dice Coefficient | |
| Vein | 99.4% | 75.9% | 76.2% | 61.6% | 74.0% |
| Artery | 99.5% | 79.2% | 78.3% | 64.0% | 76.8% |
| Nerve | 99.4% | 76.9% | 81.4% | 61.9% | 74.9% |
| Shrapnel | 99.2% | 57.5% | 78.8% | 45.7% | 58.6% |
| Background | 97.8% | 99.0% | 98.7% | 97.7% | 98.8% |
| U-Net | |||||
| Accuracy | Precision | Recall | IOU | Dice Coefficient | |
| Vein | 99.2% | 60.5% | 85.2% | 54.7% | 69.9% |
| Artery | 99.4% | 72.1% | 84.1% | 63.7% | 77.1% |
| Nerve | 98.9% | 55.2% | 97.4% | 54.3% | 69.5% |
| Shrapnel | 98.9% | 43.7% | 84.1% | 43.5% | 58.2% |
| Background | 97.1% | 99.8% | 97.1% | 96.9% | 98.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Holland, L.; Hernandez Torres, S.I.; Snider, E.J. Using AI Segmentation Models to Improve Foreign Body Detection and Triage from Ultrasound Images. Bioengineering 2024, 11, 128. https://doi.org/10.3390/bioengineering11020128
Holland L, Hernandez Torres SI, Snider EJ. Using AI Segmentation Models to Improve Foreign Body Detection and Triage from Ultrasound Images. Bioengineering. 2024; 11(2):128. https://doi.org/10.3390/bioengineering11020128
Chicago/Turabian StyleHolland, Lawrence, Sofia I. Hernandez Torres, and Eric J. Snider. 2024. "Using AI Segmentation Models to Improve Foreign Body Detection and Triage from Ultrasound Images" Bioengineering 11, no. 2: 128. https://doi.org/10.3390/bioengineering11020128
APA StyleHolland, L., Hernandez Torres, S. I., & Snider, E. J. (2024). Using AI Segmentation Models to Improve Foreign Body Detection and Triage from Ultrasound Images. Bioengineering, 11(2), 128. https://doi.org/10.3390/bioengineering11020128