1. Introduction
In recent years, in particular since the turn of the 20th and 21st centuries, a significant development of the global economy has been noticed. In spite of numerous regional problems that involved diverse international sanctions in different sectors and the global financial crisis, many industrial branches have been created as well as other ones have made a noticeable progress [
1,
2]. One of these branches is logistics, which incorporates complex processes combining various activities related to production, transport, and trade [
3].
One of the reasons for the global economic growth is a technological development of the personal computers that allow one to perform sophisticated computations in a relatively short time. Commonly available computers enable to analyze various data using soft computing methods based on artificial intelligence ideas [
4,
5,
6]. Nowadays, both global enterprises and regional companies are collecting as much data as possible from their clients and users. They are aware of countless opportunities to utilize any information in the future. Numerous modern fields of computer science, e.g., Internet of Things, are based on the data analysis and are evolving constantly [
7]. Many datasets obtained from real-life operations may be processed in various ways in order to extract additional information that is not seemingly noticeable. From the logistics sector point of view, data processing frequently leads to providing a high service level. This is an important factor in optimization issues related to distribution networks, supply chains, delivery scheduling, etc. For instance, the historical demand data of a given supply system may be used to make predictions of customer behaviors in the future. Moreover, data processing is a key direction in current transport studies in worldwide companies, like Google or TomTom. They are discovering their mobile mapping technologies based on geometrical data collected by mobile systems of LIDARs and cameras placed on the metering cars. Then, these data enable one to create highly accurate 3D models of roads for autonomous driving purposes, which are groundbreaking for the prospective logistic solutions [
8].
Nonetheless, the research of modern logistic systems is a complicated issue by virtue of sophisticated analytical models of entity interactions and, consequently, high computational complexity. Until now, the scientific literature is mostly focused on single-stage systems [
9,
10], serial interconnections [
11,
12,
13], and tree-like organizations [
14,
15,
16]. This paper explores the goods distribution process that takes place in the networks with a non-trivial architecture.
Due to the globalization and consequently a rapid extension of existing supply chains, the optimization issues are more and more crucial for worldwide enterprises. Configurations of the distribution systems are getting increasingly complex and sophisticated structurally. In order to face this challenge a variety of resource management policies [
17,
18] and heuristics [
19,
20] are being developed. The main difficulty of their implementation is related to the issue of computational complexity and, thus, hardware requirements. In this paper, an optimization of resource distribution taken place in mesh-type logistic networks have been supported using continuous-domain genetic algorithms (GAs). The goods reflow is managed by an order-up-to inventory policy implemented in a centralized way.
At first, the network model and the inventory management strategy are proposed analytically. Afterwards, a continuous-domain GA is adapted to a given class of logistic systems. The optimization problem under consideration is multidimensional, but its objectives are taken into account to formulate a multi-criteria dependent function. This function aims to provide a desirable balance between the reduction of goods storing cost while maintaining the high service level that results in customer satisfaction. The optimization objectives are determined numerically as input parameters. The network costs are based on a quantity of goods stored by controlled nodes in each period of time, i.e., one piece of goods equals one unit of holding costs. The customer satisfaction is measured as a percentage of fulfilled external demands against all the demands imposed on the network, i.e., fulfillment of all demands means the full customer satisfaction. The proposed GA with a continuous domain enables an adjustment of the inventory management policy to the specified priorities of the optimization objectives. Various numerical examinations have been performed in order to prove efficiency of GAs in discussed optimization process in non-trivial logistic system configurations.
2. Network Model
2.1. Logistic Structure and Operations
The structure of the considered class of logistic networks is composed of two types of entities—controlled nodes and external sources—with finite storage capacity. Let us denote N and M as a quantity of controlled nodes and external sources, respectively. The interconnection system is established using one-way links between nodes that form a mesh-type structure with neither simplifications nor restrictions. The network assumptions exclude a presence of separate nodes besides no node can supply itself. The interconnection of two particular nodes i and j is parameterized by a pair of attributes (SCij, TDij), where SCij denotes a supplier contribution (SC) and TDij is a lead-time delay (LT) of replenishment orders. SC determines the part of goods that a controlled node orders from a given supplier. The distribution environment involves uncertain customer demands imposed on the network during the whole resource reflow process.
The model of network interactions assumes the fixed order of operations performed by controlled nodes in each period of time.
Figure 1 illustrates the node operational sequence emphasizing incoming and outgoing activities. At first, goods from incoming replenishment orders are registered to the on-hand stocks. Subsequently, the node strives to guarantee a high service level by meeting the customer demands. At the end, the node will satisfy replenishment signals from neighbors, if there are available goods at its stock.
2.2. Model of Network Dynamics
The node operational sequence described in the previous section enables to formulate the equation of the stock level dynamics at node
i as:
where:
—the amount of goods in incoming replenishment orders received by node i,
—the amount of goods in outgoing replenishment orders sent to the neighbours, and
—the amount of satisfied customer demands.
Let us denote
P as a quantity of all the nodes existing in the network, i.e.,
P =
N +
M. The amount of incoming goods in replenishment orders received from all the suppliers assigned to node
i can be calculated by:
Analogously, the amount of resources sent to the neighboring nodes is expressed by:
The notations applied in Equations (2) and (3) denote:
—SC with respect to supplier j, where and for denoting the indices set of node i suppliers,
—the amount of all the resources requested from node i, and
—the LT of the replenishment order coming from supplier j to node i, , with Γ denoting the highest values of LT occurring in the network structure. Moreover, , where is the time of order preparation at supplier j and lists the shipment delivery between nodes j and i. All the delays are positive integer values.
2.3. State-Space Model
In order to enable an implementation of the analyzed network model in a programming way, it ought to be transformed into matrix-vector form. Let us group all the node dependencies occurring in the logistic system. The proposed state-space equation is equal to:
where:
—the vector storing information about on-hand stock levels in period t,
—the vector storing information about replenishment orders processed in period t,
—the vector storing external demand requests processed in period t, and
—the matrix containing information about network interconnections:
for k ∈ {1, …, N}.
2.4. Networked Inventory Policy
The resource distribution considered in this paper is governed using an order-up-to policy implemented in a networked manner. This policy requires, as an input, a vector containing target inventory levels (TILs) of all the controlled nodes. TIL is a reference stock level, which a particular node strives to obtain in each distribution period generating replenishment signals for its suppliers. The amount of resources that should be ordered by node
i from the suppliers in period
t is equal to:
where:
—the vector storing TILs of all the controlled nodes, and
—the matrix containing the combined information about the network structure:
In order to adjust this networked policy to a given logistic topology, it is necessary to define the initial TIL vector as a baseline. According to analytical description in reference [
20], it is convenient to consider a constant demands equal to the highest values from the whole distribution process. The TIL vector based on such a demand assumption will provide full customer satisfaction and allow one to establish the search space boundaries for each controlled node. Owing to the assumption of constant demand, higher values of the elements of TIL vector do not have to be taken into account in the simulations. Let us indicate the vector of the highest values of demands imposed on each controlled node in the entire goods distribution by
and
as an identity matrix of size
N ×
N. The TIL vector for a constant demands imposed on each controlled node is equal to:
The elements of specify the upper boundaries of TILs search space for optimization processes discussed further in the numerical section.
More details regarding the policy analytical treatment have been given in [
21].
3. Continuous-Domain GA Optimization
The purpose of this paper is to investigate an idea of GA-based assistance in adjusting the analyzed resource management strategy to mesh-type logistic topologies. This operation is computationally sophisticated due to the complex network structure and the external demands not known a priori. In order to find the optimal TIL vector for a given case, it is necessary to search the multidimensional solutions space, where the initial TIL vector calculated from Equation (9) determines the boundaries. Due to the number of candidate solutions, an intelligent support for simulation-based optimization should be applied, because full-search algorithms would not be efficient. This optimization process aims a proper selection of the optimal TIL vector, which will satisfy predefined distribution priorities, i.e., a balance between the holding costs and the service level. By virtue of the continuous search space in the inventory management issue under consideration (TILs belong to the ranges from 0 to the given upper limits), it is convenient to apply the continuous-domain GAs [
22] (Chapter 3). This variant of GA allows one to avoid transforming a candidate solution into a binary form, typical for GA applications. Thus, this improvement leads to expedite computations by directly relation between the problem variables and the obtained results.
3.1. Fitness Function
The proper definition of the fitness function (FF) is a key aspect of the GA operation. It does not allow finding the optimal solution, but it enables the comparison of multiple individuals, e.g., the entire population, through calculating how good they are and deciding which of them is a better solution from the others. The FF gets a particular TIL vector as an input parameter and calculates the FF value that indicates the importance of this candidate solution in the population. After the optimization the best TIL vector, i.e., the candidate solution with the greatest FF value, is selected.
In the distribution issue under consideration, the optimization process aims to reduce the costs related to storing resources in the network while providing high customer satisfaction. Analytical research and experimental simulations led to formulate the FF that quantifies these partly contradictory goals as:
where:
SL—the service level related to the percentage of satisfied external demands, SL ∈ [0, 1],
—the initial holding cost established according to (9),
—the holding cost obtained for a given TIL vector,
ω—the coefficient determining the importance of the service level, and
μ—the coefficient determining the importance of the cost reduction.
3.2. Selection
Selection probability, based on the FF value, is calculated for each individual in a given population. One of the classical GAs selection methods—stochastic universal sampling (SUS)—has been applied in the considered algorithm. As opposed to the majority of selection methods, e.g., roulette wheel selection, the implemented SUS makes use of two random points in order to divide a given population into pairs. Consequently, a pair of individuals will be formed in each iteration as opposed to single-point methods, which relieves the computational time—crucial in the analyzed class of evolutionary applications. In fact, it allows one to reduce the number of selections twice because the pair of parents is an output from a single selection operation.
3.3. Crossover
The operation of recombination takes a pair of individuals from the original population (parents) and combines them into two new individuals (children). As in a biological evolution, the children inherit features of their parents in a nondeterministic way. In the network optimization issue under consideration, two source TIL vectors forms by crossing a pair of new vectors. In the implemented GA, a multi-point method draws two random split points A and B from the range [0, N]. These points cannot be the same (A ≠ B) and are sorted in ascending order. The split points selection is established for each pair of candidate solutions from the original population. In contrast to basic crossover methods, e.g., single-point one, multi-point crossover enables the creation of more diverse children in relation to parents.
3.4. Mutation
The mutation is a real evolution process, which consists in an unpredictable alteration of one or multiple genes in a particular genotype. In the considered case this phenomenon involves a random modification of a one or more TIL values in a given
vector. According to the continuous-domain of a considered problem, the mutated TIL value for node
i may be set only within the boundaries of the search space, i.e.,
where
denotes the TIL of node
i from the initial vector calculated using Equation (9).
4. Numerical Tests
The performance of the proposed GA in the optimization of logistic systems under consideration has been evaluated numerically. In order to perform computational experiments a computing engine for goods distribution simulations has been created and the algorithm described in
Section 3 has been implemented. This program enables one to create network topologies, establish interconnection schema, and perform simulation-based optimization. The numerical studies presented in this section take into account three different topologies:
Small network (N–1)—the structure consists of five nodes—two external sources and three controlled nodes,
Medium network (N–2)—the structure consists of nine nodes—five external sources and fifteen controlled nodes, and
Large network (N–3)—the structure consists of twenty nodes—five external sources and fifteen controlled nodes.
In each case, the goods distribution process is analyzed with two different types of external demand imposed on the network. The first one is generated using the Poisson distribution parameterized by a rate parameter set as 10. The second one is obtained from the gamma distribution with shape and scale coefficients equal to 5 and 10, respectively. The external demands from the Poisson-based process have a lower average as well as the standard deviation, while the second case is characterized by significantly intensified fluctuations. Analyzing the topologies discussed in this section, these values may be averaged as:
external demands generated using Poisson distribution—the mean and the standard deviation equal to 10 and 3, respectively. And
external demands generated using gamma distribution—the mean and the standard deviation equal to 50 and 23, respectively.
Contrary to [
23], the numerical studies presented in this work involve more advanced GA optimization in terms of the computational complexity. The population comprises 50 candidate solutions. In order to prevent the evolutionary process from including repeated individuals into the populations, the mutation probability has been set as 40%.
The priority coefficients are chosen so that a significant holding cost reduction is obtained while maintaining near full customer satisfaction. For this reason, numerous cases considered lead to determine the priority coefficients of fitness function equal to ω = 40 and μ = 10, respectively. The single simulation run lasts 30 periods and the initial inventory levels are set equal to the target ones, i.e.,. Two stop criteria: the generation limit of 104 and the number of generations without fitness values improvements of 2 × 103 are enforced.
4.1. Small Network N–1
For the illustrative purposes, the first environment assumes a non-sophisticated network topology. Let us consider the structure depicted in
Figure 2. There are three controlled nodes (1–3) and two external sources (4–5). The pair of attributes above the connection arrows denote the SC and LT, respectively. In the considered example, node 3 orders 70% of the required goods from node 1 and their delivery takes three periods. The rest of required goods is ordered from external source 4 and its delivery lasts one period.
4.1.1. Results for Poisson Demand
Poisson distribution is convenient to generate external demands because it generates integer values, hence, there is no need for rounding to get legitimate order quantities.
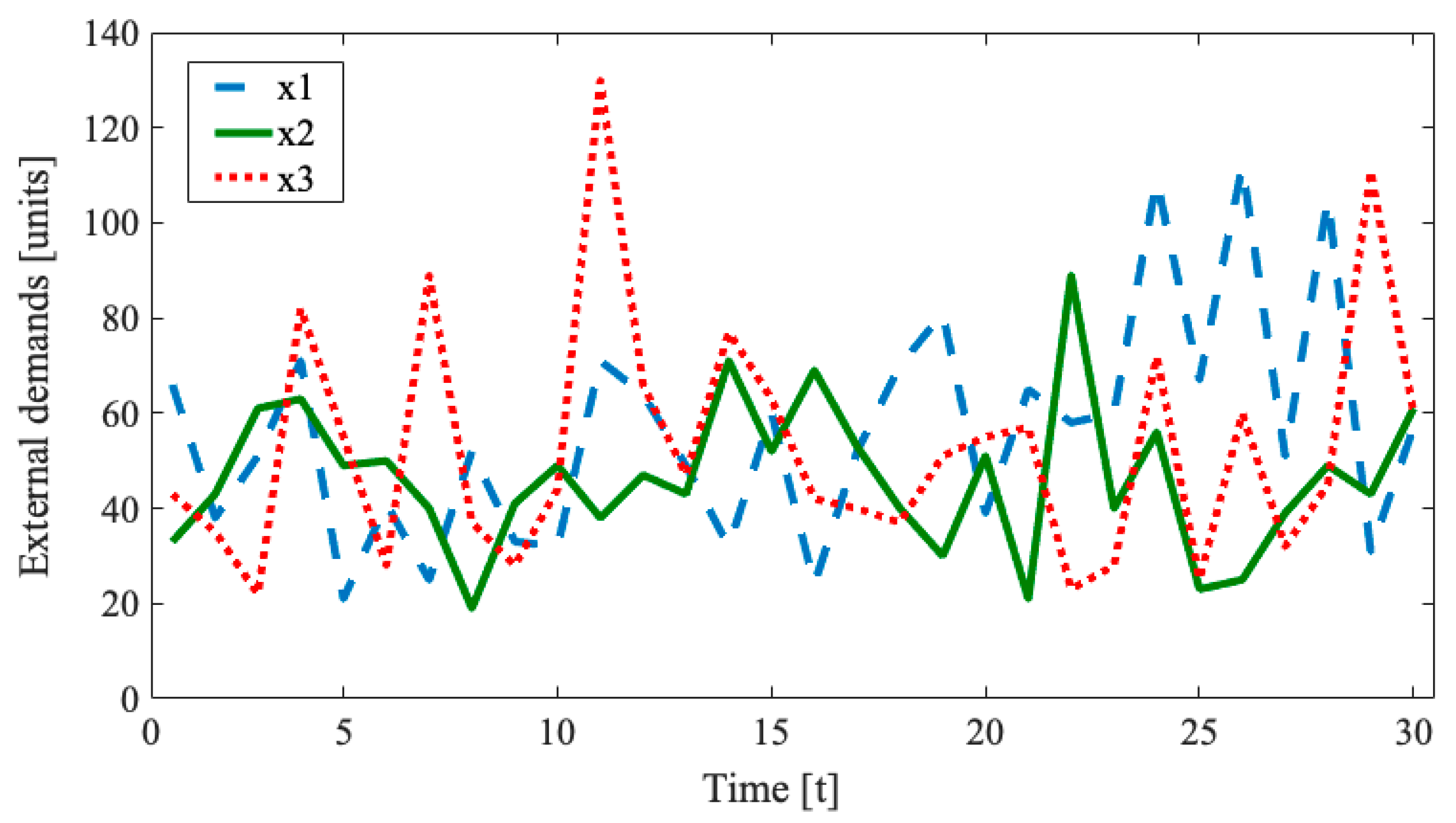
Figure 3 illustrates the external demands imposed on all the controlled nodes (1–3) during the simulation interval.
The initial TIL vector assuming the highest values of demands calculated according to Equation (9) equals [176, 180, 66] units. The GA-based optimization lasts only 57 generations and results in the selection of
= [86, 86, 45] units and the holding cost reduction from the initial 6.8 × 10
3 to 8.5 × 10
2, while maintaining full customer satisfaction.
Figure 4 proves the lack of excess inventory in the on-hand stock of the controlled nodes.
4.1.2. Results for Gamma Demand
In this case, the external demand is generated using gamma distribution with the values rounded to the nearest integer.
Figure 5 shows the demand requests that the controlled nodes aim to fulfill.
The baseline TIL vector [1156, 920, 496] units results in the holding cost equals to 4.7 × 10
4. The optimization process in the 728th generation allows one to find the optimal TIL vector [474, 409, 256] units, which satisfies the external demands in full. The network costs are reduced to 5.5 × 10
3. The resource flow is illustrated in
Figure 6. It indicates that for both slowly and rapidly varying demand, the optimization process allows one to reduce the excess resources stored in the node warehouses.
4.2. Medium Network N–2
Figure 7 presents the topology of network N–2 and
Table A1 lists the interconnection details. Due to increased structural complexity of this network and the next one, the visualization of the external demand and on-hand stocks using charts is not readable. Instead, the numerical data will be presented.
4.2.1. Results for Poisson Demand
The generated demand is in the range [2, 20] units. Using its highest value for each controlled node, the initial TIL vector is established as [231, 127, 57, 216, 123, 232] units and yields the storage costs of 1.6 × 104. In this case, the full-search algorithm needs to check over 1013 candidate solutions. GA-based optimization reduces the costs to less than 103 by finding the optimal solution— = [101, 37, 35, 98, 59, 99]—in the 13254th generation, i.e., after calculating 6.6 × 105 potential solutions.
4.2.2. Results for Gamma Demand
The gamma distribution-based external demands belong to the range [20, 123] units. The initial TIL vector determined for this demand is equal to [1491, 743, 360, 1347, 784, 1337] units and results in 1.13 × 105 holding costs. The optimal TIL vector obtained in 33 generations equals [477, 233, 222, 500, 304, 537] units and decreases the costs to 8 × 103. The full-search method with the granularity of one unit requires to perform about 5.5 × 1017 simulations to find the best solution.
4.3. Large Network N–3
Figure 8 presents the interconnection structure of network N–3, which is yet more complex than the previously discussed ones.
Table A2 groups the attributes of links between the nodes. The external demands are imposed on all the controlled nodes.
4.3.1. Results for Poisson Demand
The baseline setting for the optimization process leads to the holding costs equal to 5.9 × 10
4 with TIL vector calculated from (9) as:
The GA-based optimization needs 5403 generations to approach the optimal solution that reduces costs related to the inventory storage to 3 × 10
3. It is not feasible to find the best solution using the full-search algorithm, as it would involve running 6.2 × 10
33 simulations. The optimal TIL vector is obtained as:
4.3.2. Results for Gamma Demand
Similarly as in the previous cases, the external demands generated using gamma distribution are characterized by greater uncertainty than the Poisson-based ones. The initial holding cost for the vector
equals 4.2 × 10
5. In the analyzed case, there are 4.45 × 10
45 candidate solutions for the TIL vector to consider. The GA-based optimization selected the TIL vector that leads to reducing the holding costs to 1.9 × 10
4 (less than 5% of the initial state) in just 1394th generation, i.e., it needs to perform less than 7 × 10
4 simulations. The best TIL vector is
Figure 9 presents the course of the fitness function changes as the optimization process evolves for network N–3. The dashed red line highlights the best solution evaluated using the parallel full-search algorithm.
To sum up, the presented numerical studies demonstrate the efficiency of the simulation-based optimization of logistic networks assisted by a continuous-domain GA algorithm. The external demands, which in practical settings considered here are not known a prori, lead to large search space of candidate solutions for any realistic logistic structure. Even with the hardware capabilities of today’s computers, it is not possible to perform the full-search operation for sophisticated architectures. The AI method applied in this work permits obtaining a solution close to the best one in a significantly shorter time.
5. Conclusions
The paper investigates the application of simulation-based optimization in order to improve the effectiveness of goods reflow in distribution networks with mesh-type architectures. The class of networks under consideration are influenced by uncertain exogenous demand. The resource redistribution is governed using an order-up-to inventory management strategy implemented in a networked manner. The optimization process based on continuous GA adjusts the policy parameters to the logistic system under consideration. The GA-based optimization provides a target inventory level so that a balance between two partially conflicting objectives—holding cost reduction and maintaining high customer satisfaction—is obtained. The numerical studies, assuming various system scales and external demands generated using different stochastic distributions, demonstrate the effectiveness of both the considered policy and GA as tools for AI-assisted optimization of modern logistic systems. Moreover, the analyzed cases indicate that the bigger the connection complexity, the greater the benefit of application of GA-based optimization in comparison to the full-search methods.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








