Machine-Learning Models for Sales Time Series Forecasting †

Abstract
:1. Introduction
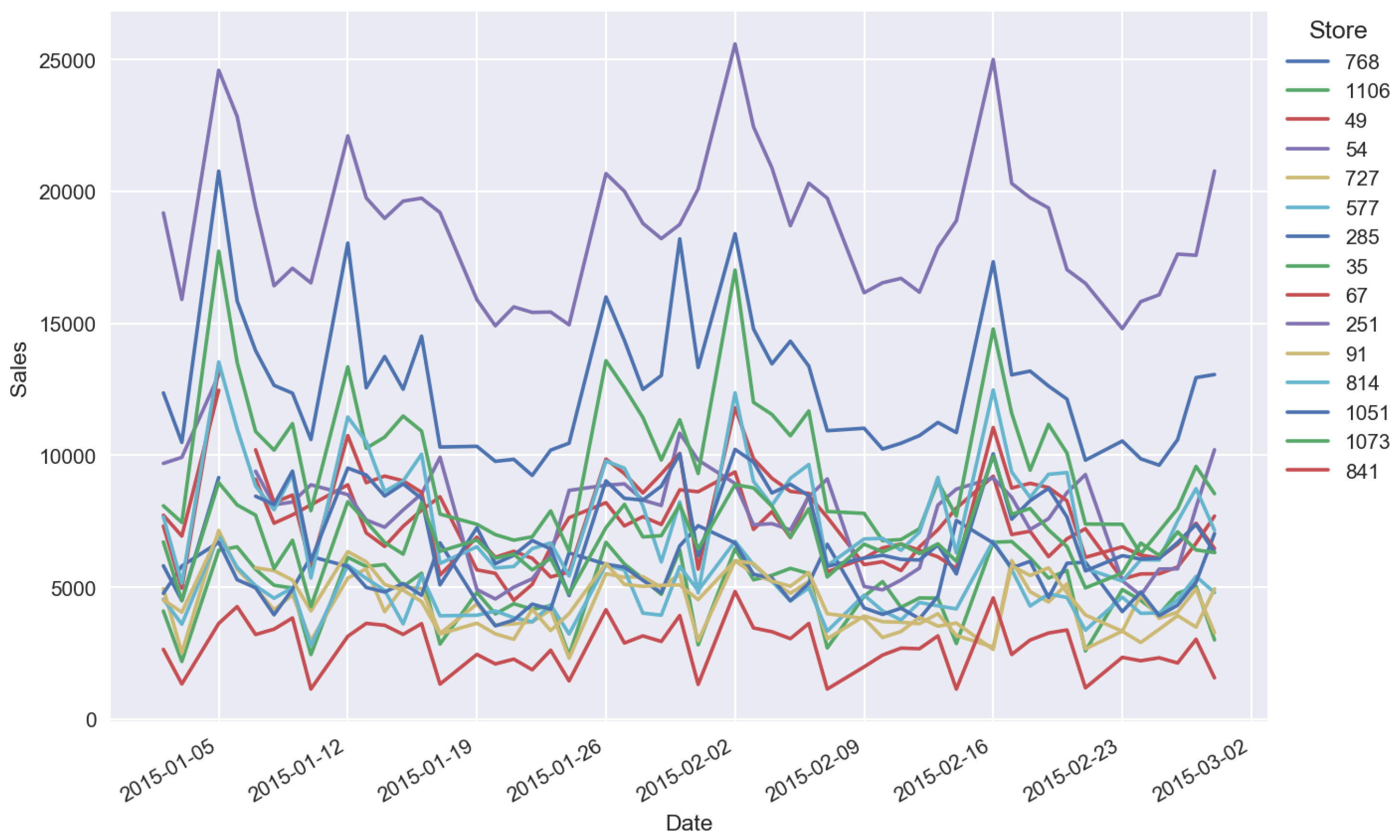
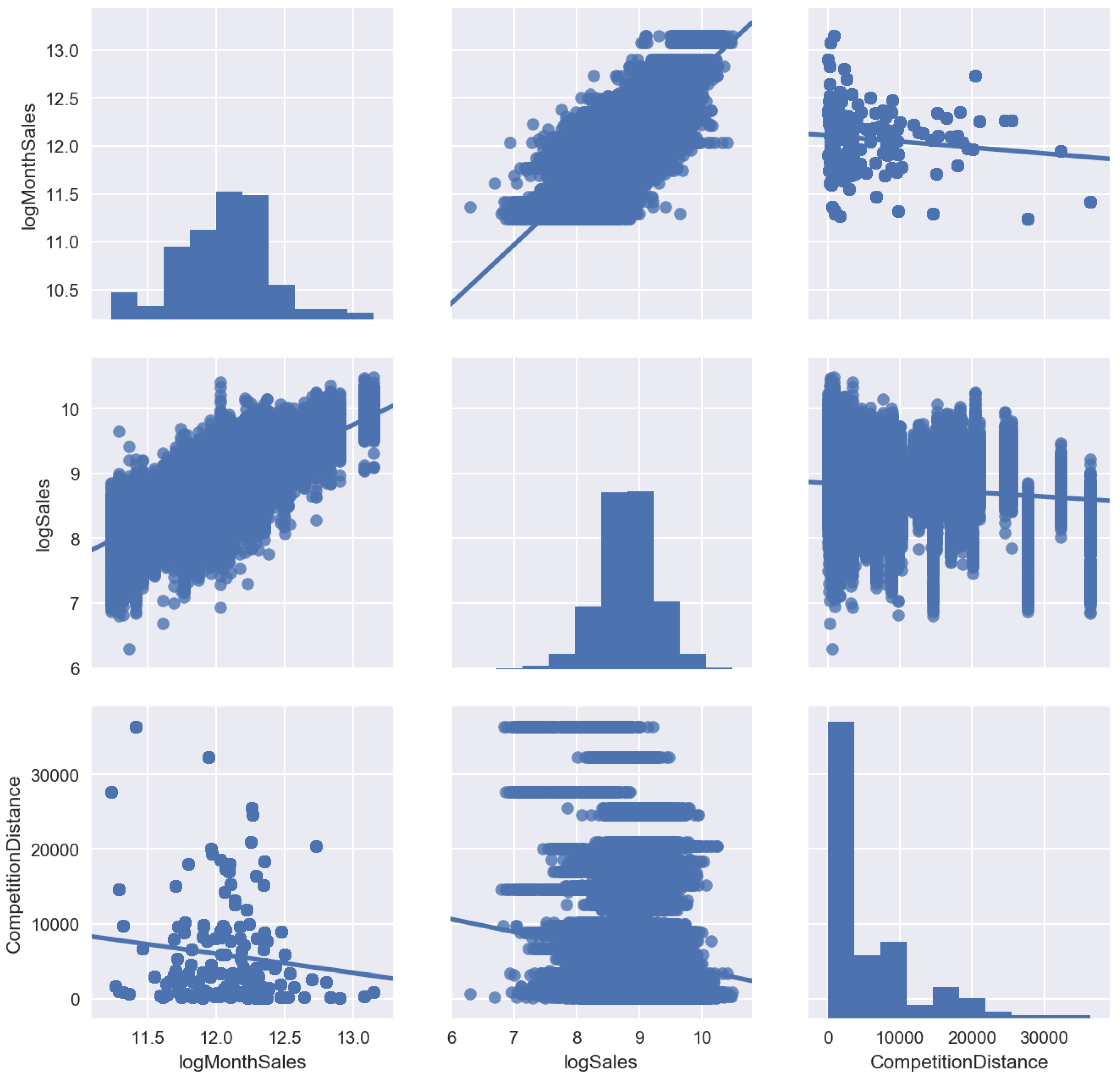
- We need to have historical data for a long time period to capture seasonality. However, often we do not have historical data for a target variable, for example in case when a new product is launched. At the same time we have sales time series for a similar product and we can expect that our new product will have a similar sales pattern.
- Sales data can have a lot of outliers and missing data. We must clean outliers and interpolate data before using a time series approach.
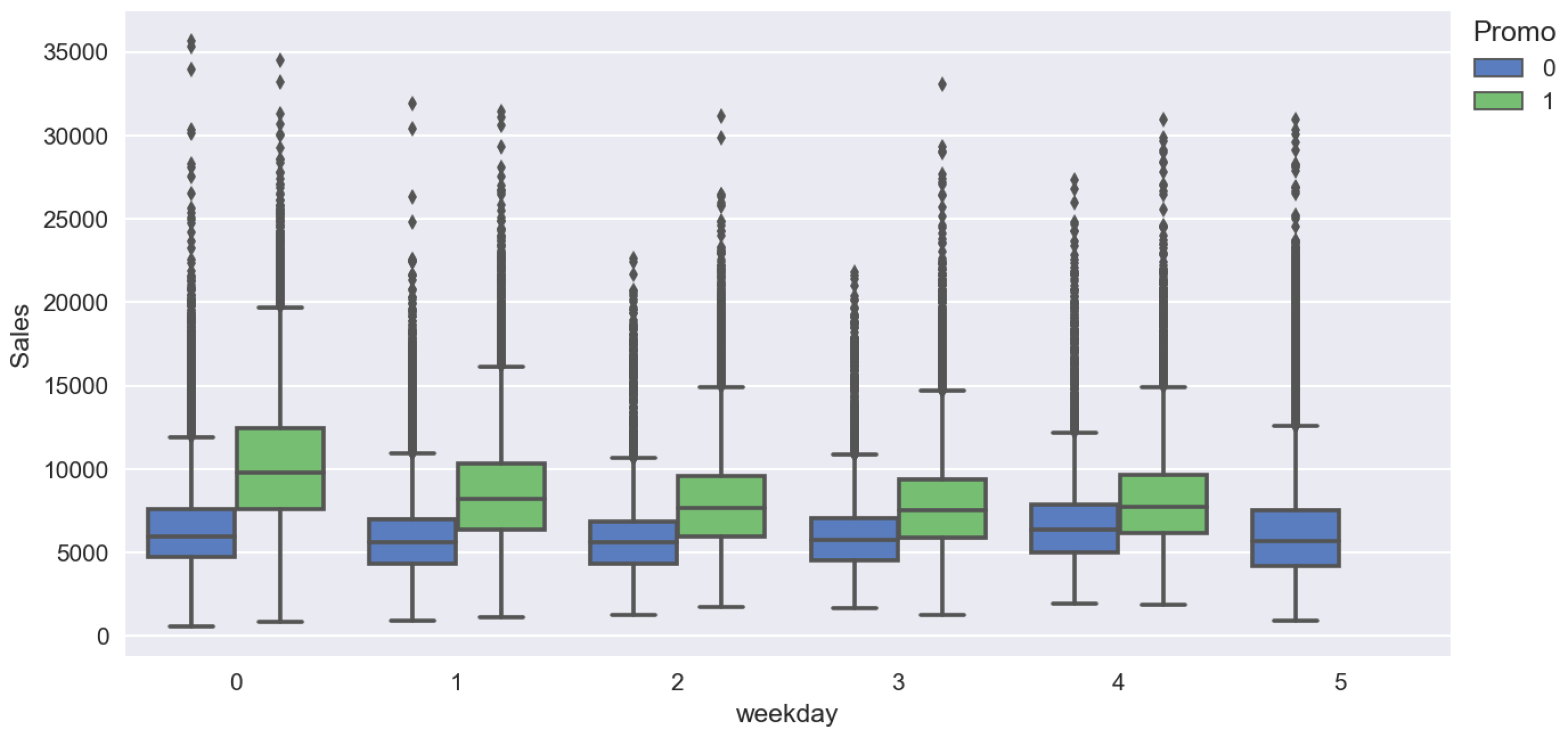
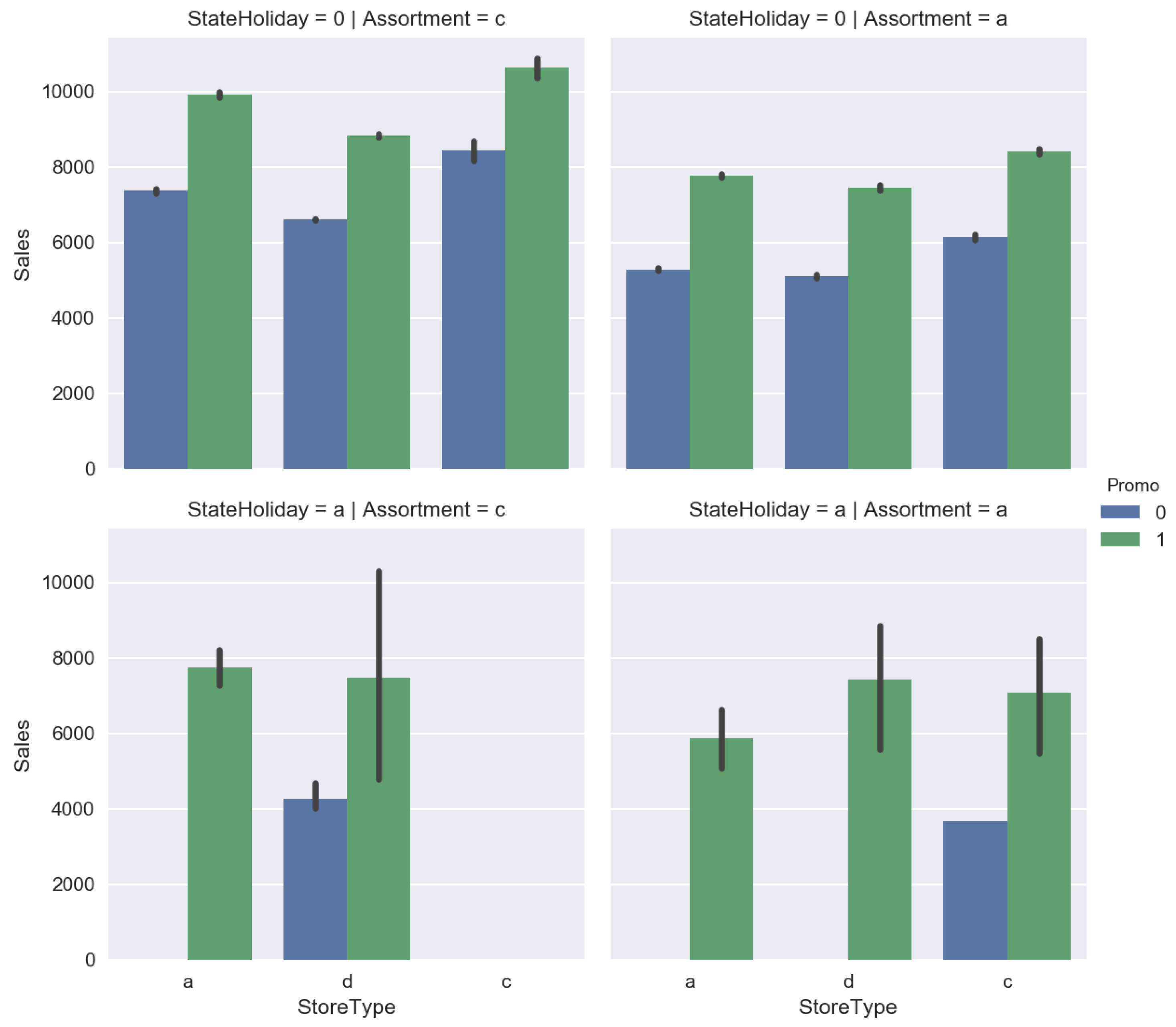
- We need to take into account a lot of exogenous factors which have impact on sales.
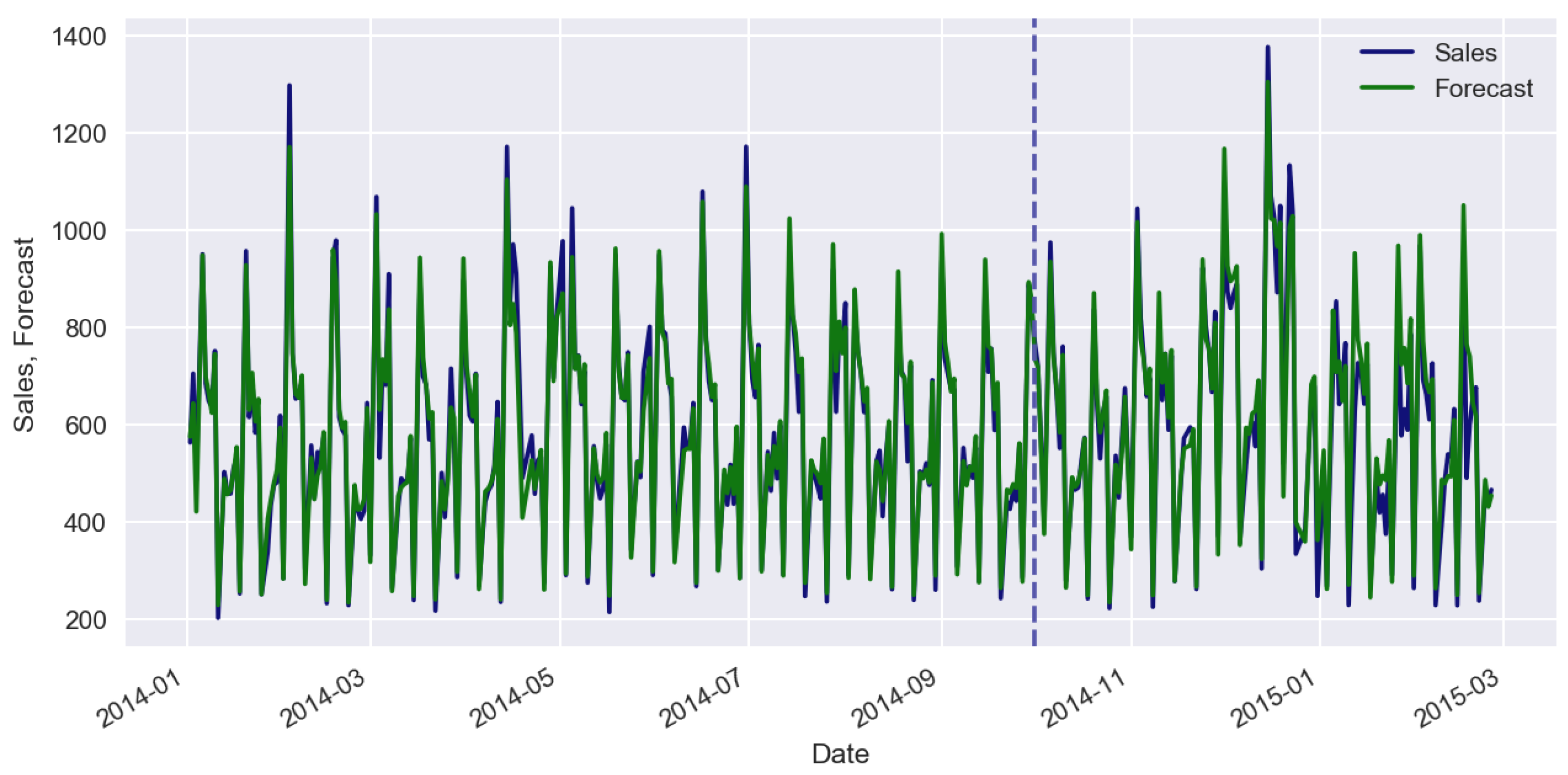
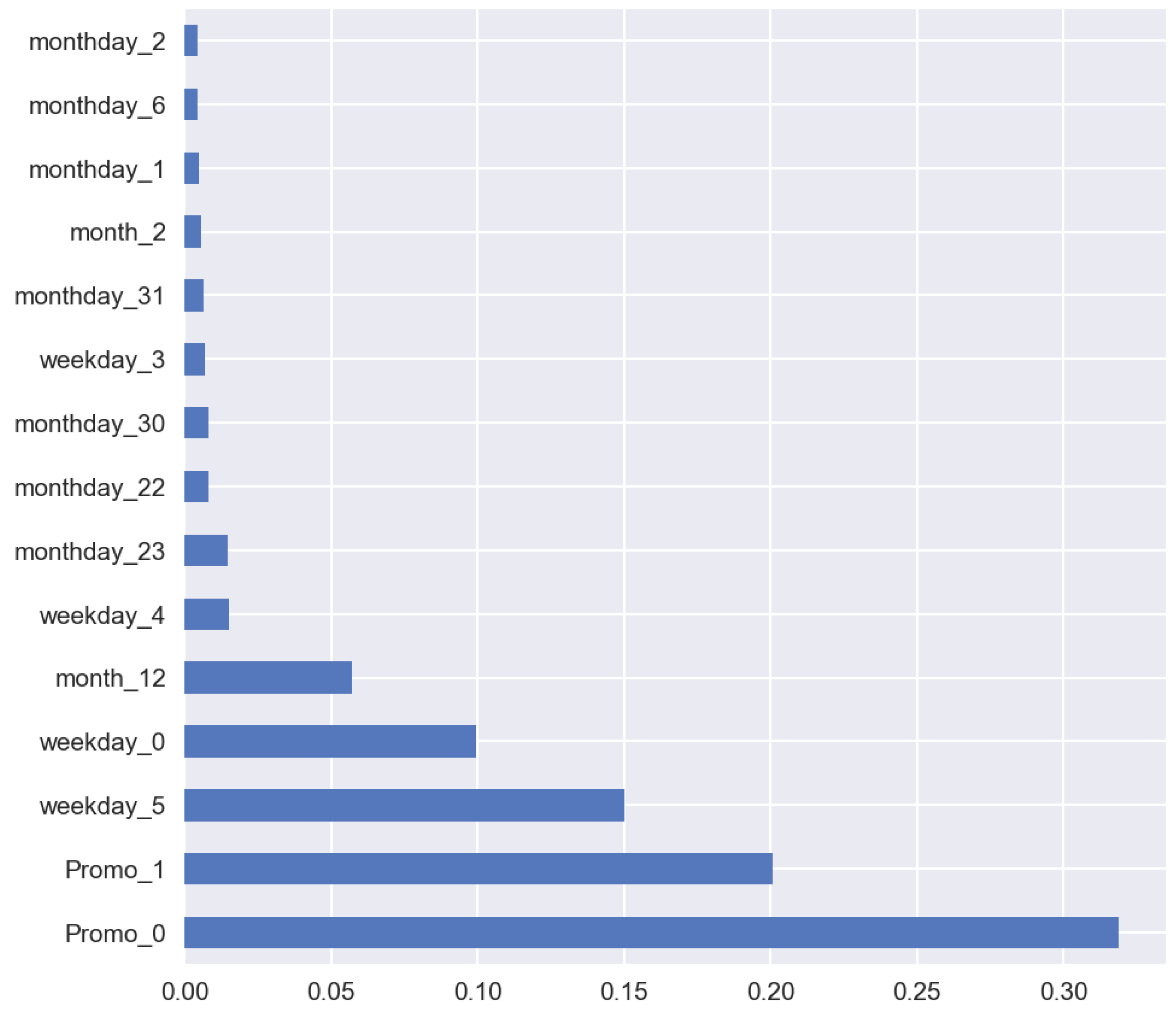
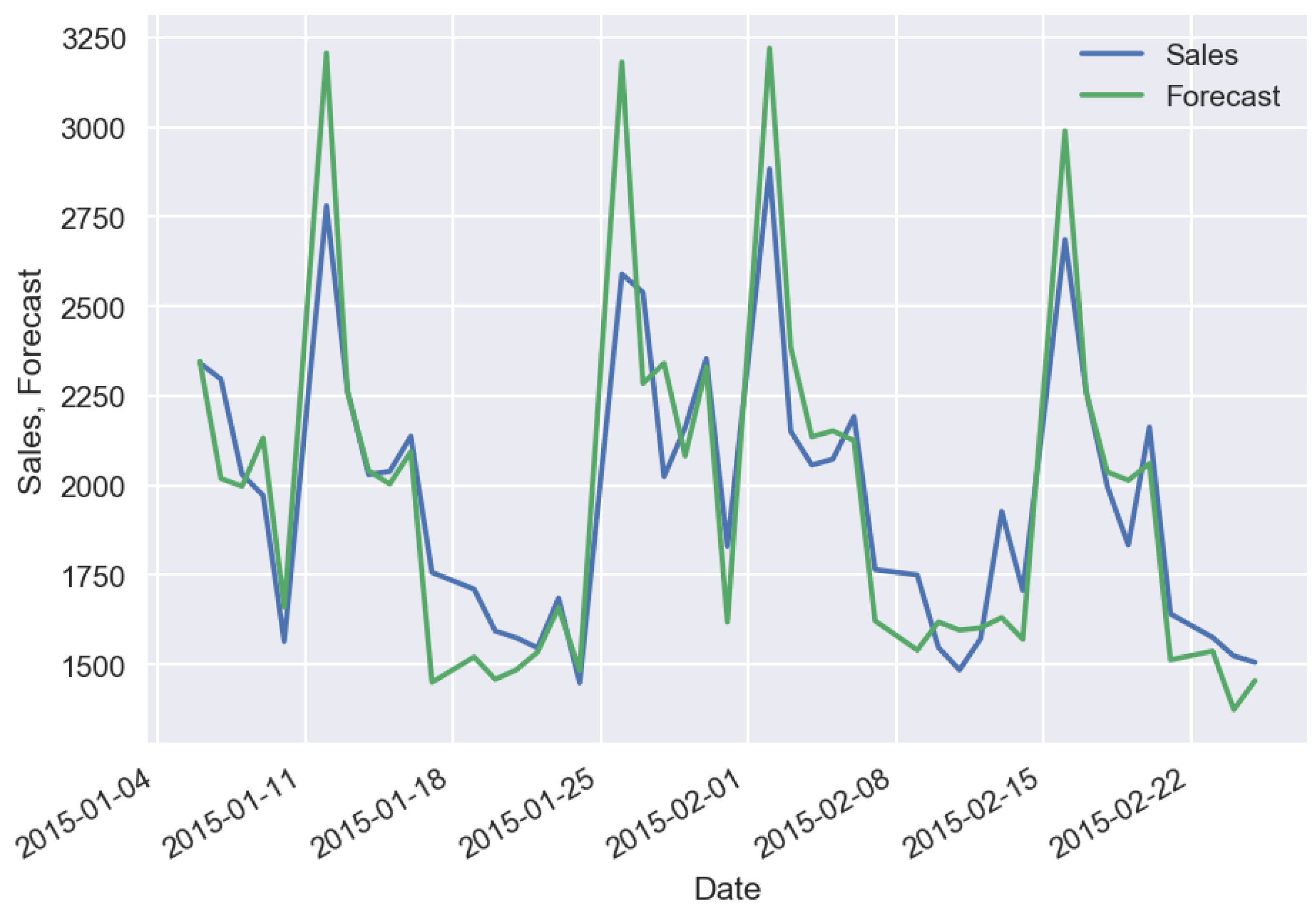
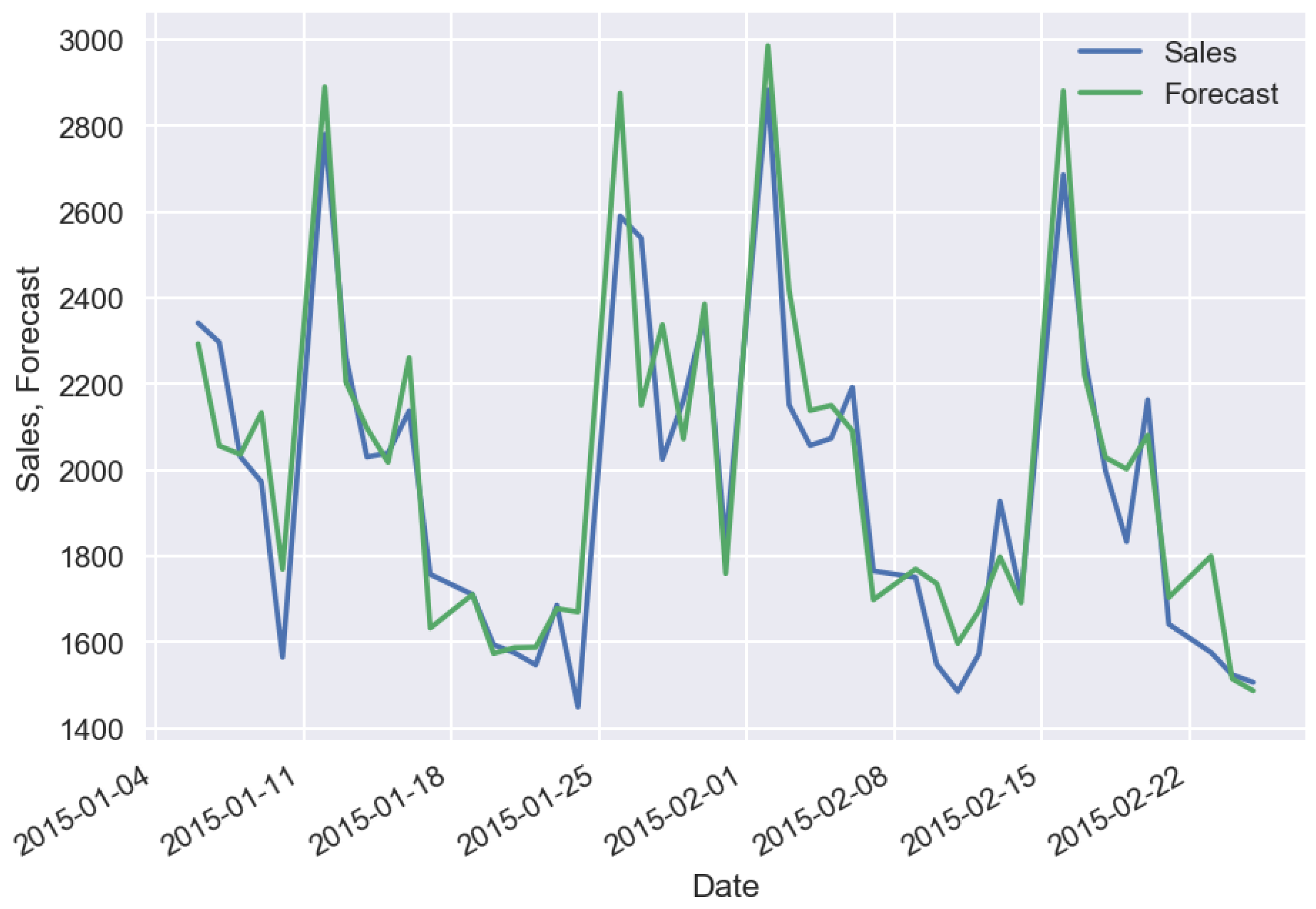
2. Machine-Learning Predictive Models
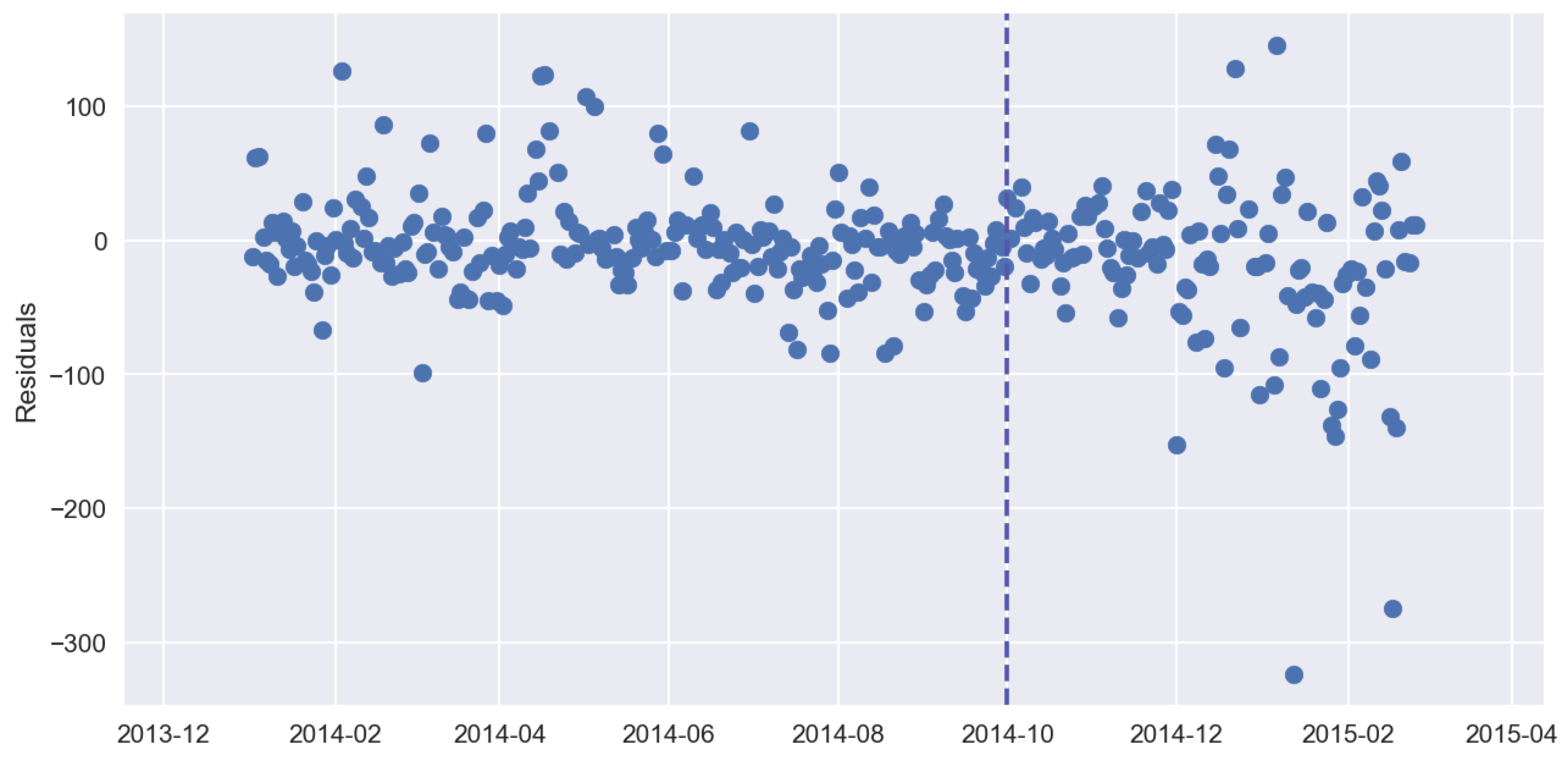
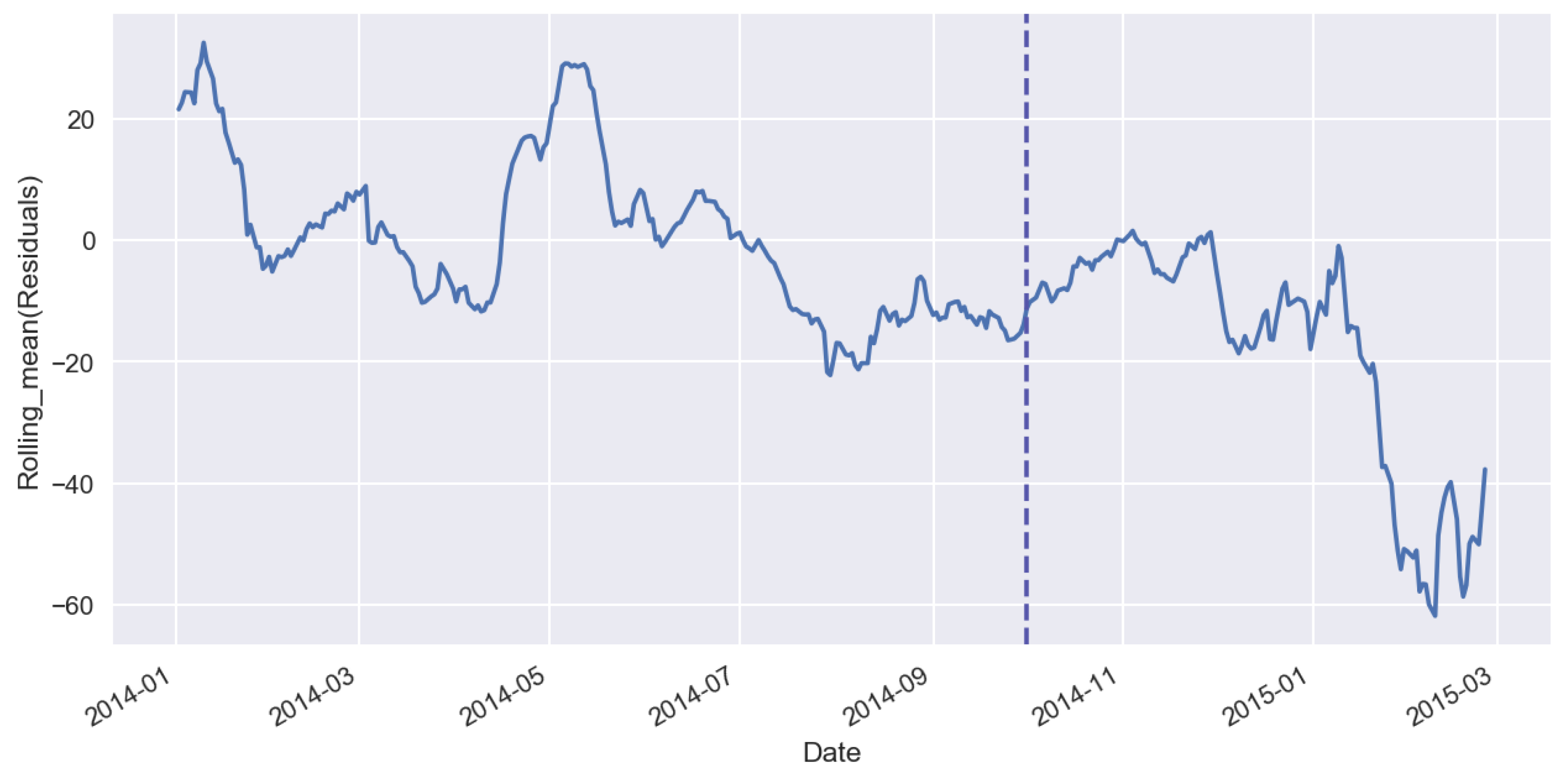
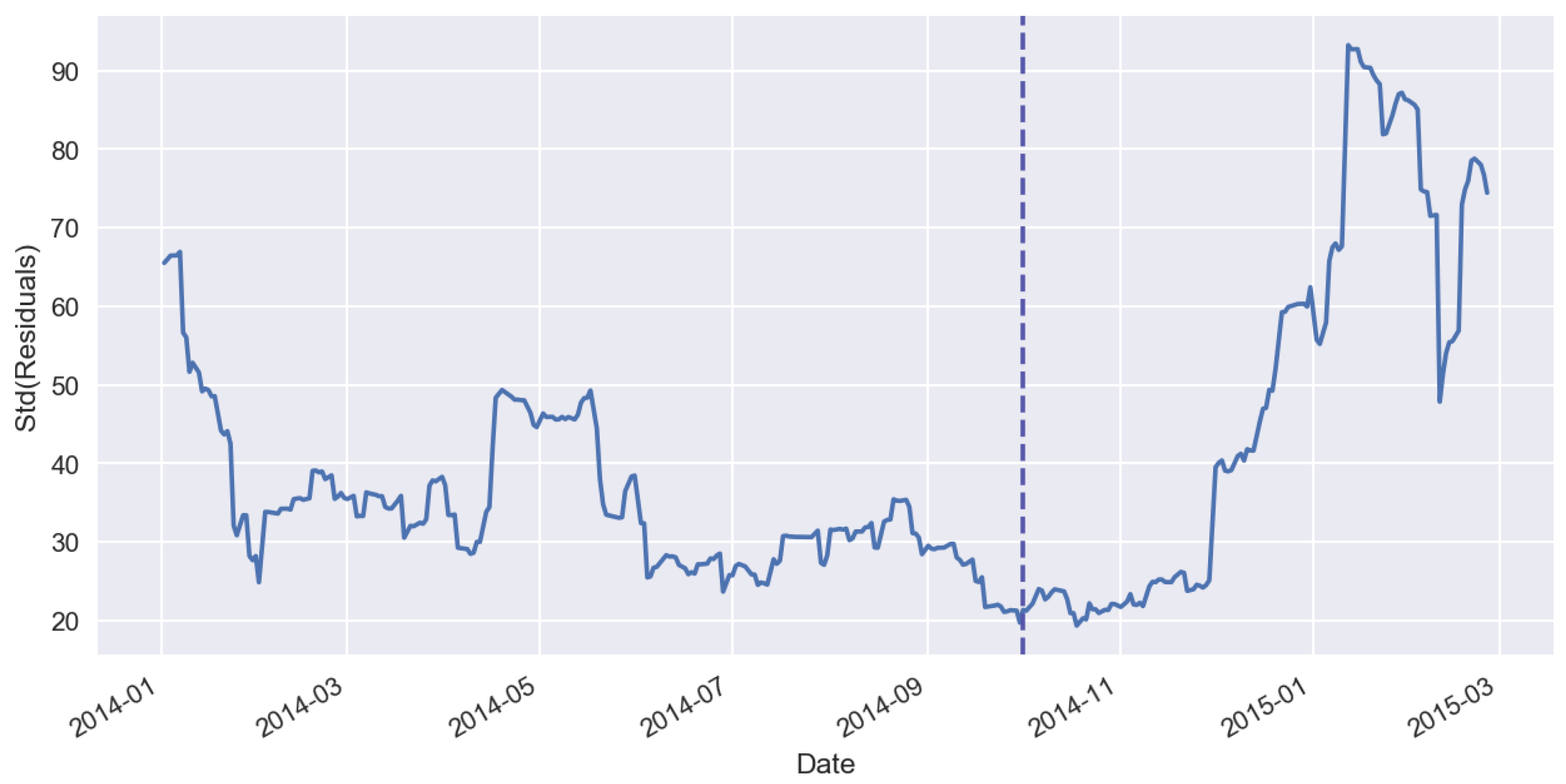
3. Effect of Machine-Learning Generalization
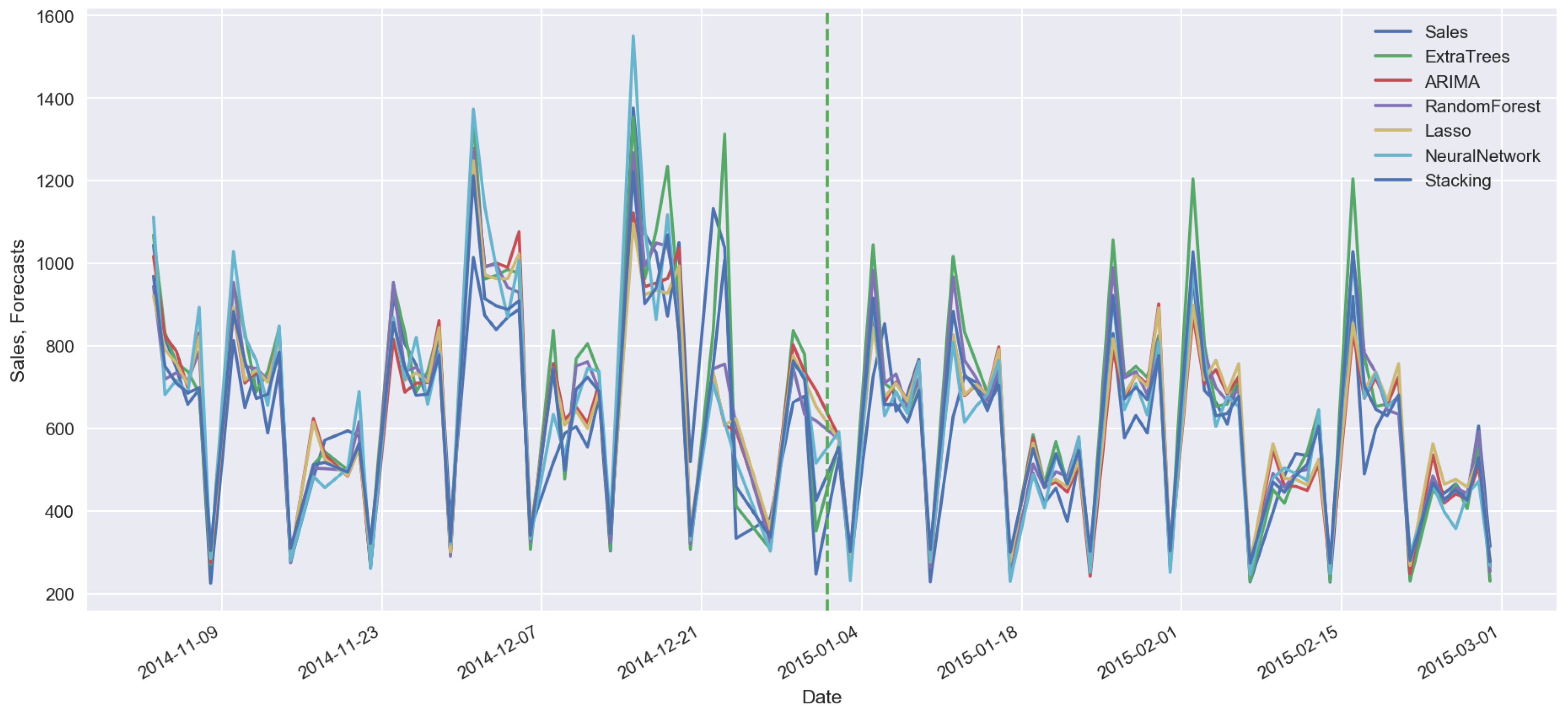
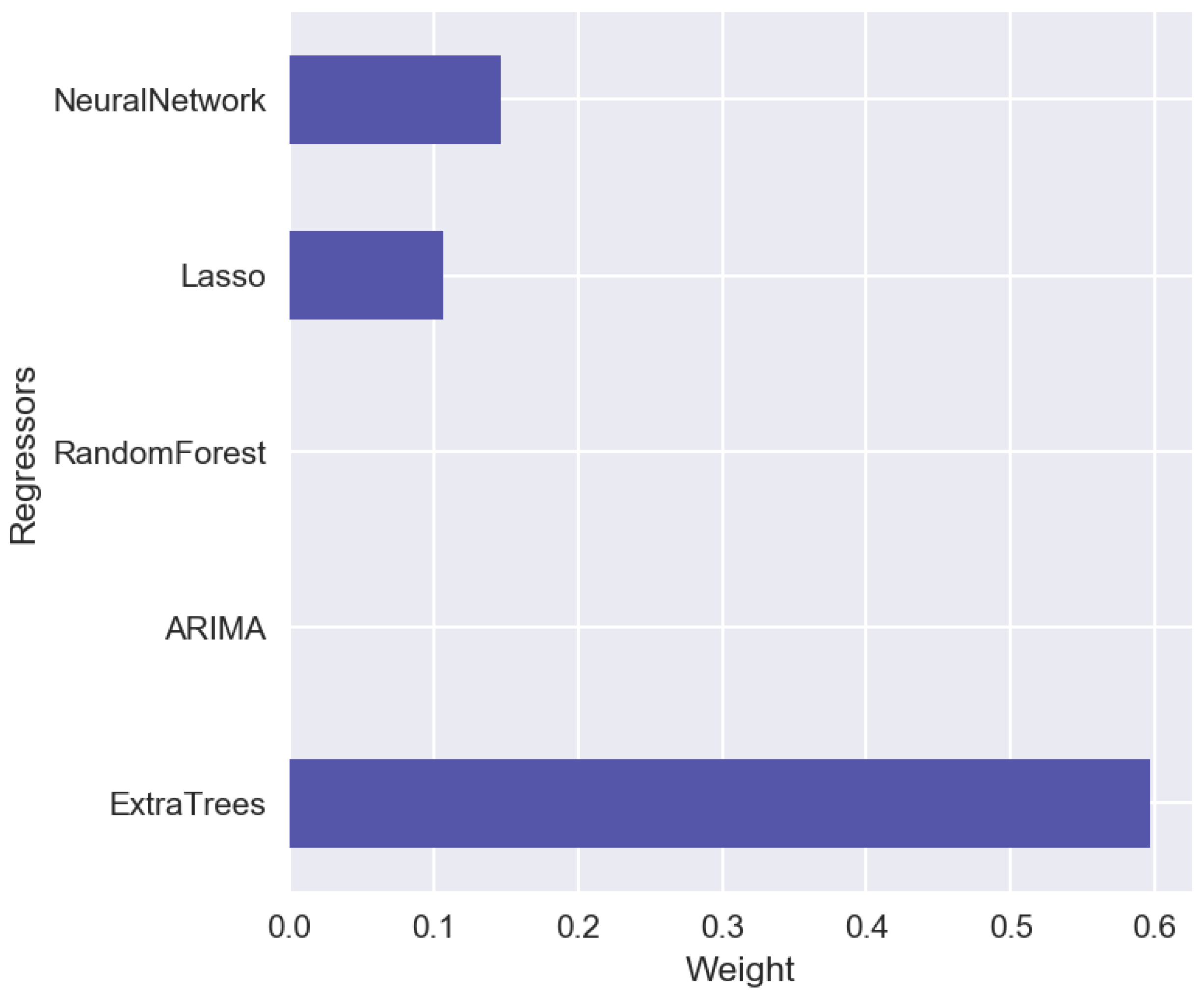
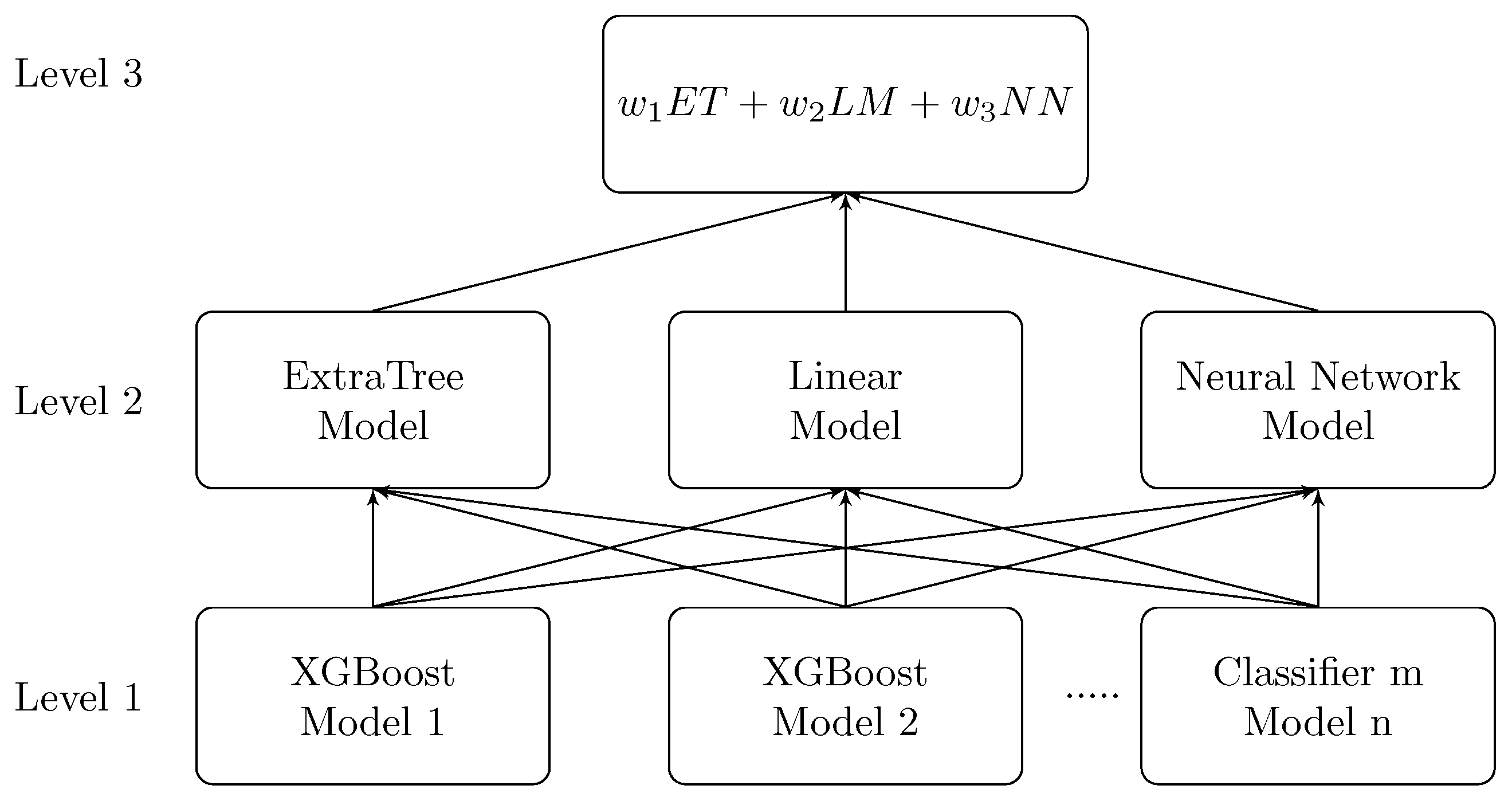
4. Stacking of Machine-Learning Models
5. Conclusions
Funding
Conflicts of Interest
References
- Mentzer, J.T.; Moon, M.A. Sales Forecasting Management: A Demand Management Approach; Sage: Thousand Oaks, CA, USA, 2004. [Google Scholar]
- Efendigil, T.; Önüt, S.; Kahraman, C. A decision support system for demand forecasting with artificial neural networks and neuro-fuzzy models: A comparative analysis. Expert Syst. Appl. 2009, 36, 6697–6707. [Google Scholar] [CrossRef]
- Zhang, G.P. Neural Networks in Business Forecasting; IGI Global: Hershey, PA, USA, 2004. [Google Scholar]
- Chatfield, C. Time-Series Forecasting; Chapman and Hall/CRC: Boca Raton, FL, USA, 2000. [Google Scholar]
- Brockwell, P.J.; Davis, R.A.; Calder, M.V. Introduction to Time Series and Forecasting; Springer: Cham, Switzerland, 2002; Volume 2. [Google Scholar]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Doganis, P.; Alexandridis, A.; Patrinos, P.; Sarimveis, H. Time series sales forecasting for short shelf-life food products based on artificial neural networks and evolutionary computing. J. Food Eng. 2006, 75, 196–204. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice; OTexts: Melbourne, Australia, 2018. [Google Scholar]
- Tsay, R.S. Analysis of Financial Time Series; John Wiley & Sons: Hoboken, NJ, USA, 2005; Volume 543. [Google Scholar]
- Wei, W.W. Time series analysis. The Oxford Handbook of Quantitative Methods in Psychology: Volume 2; Oxford University Press: Oxford, UK, 2006. [Google Scholar]
- Cerqueira, V.; Torgo, L.; Pinto, F.; Soares, C. Arbitrage of forecasting experts. Mach. Learn. 2018, 1, 1–32. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Khandakar, Y. Automatic Time Series for Forecasting: The Forecast Package for R; Number 6/07; Monash University, Department of Econometrics and Business Statistics: Melbourne, Australia, 2007. [Google Scholar]
- Papacharalampous, G.A.; Tyralis, H.; Koutsoyiannis, D. Comparison of stochastic and machine learning methods for multi-step ahead forecasting of hydrological processes. J. Hydrol. 2017, 10. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G. Variable selection in time series forecasting using random forests. Algorithms 2017, 10, 114. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.A. Large-scale assessment of Prophet for multi-step ahead forecasting of monthly streamflow. Adv. Geosci. 2018, 45, 147–153. [Google Scholar] [CrossRef]
- Papacharalampous, G.; Tyralis, H.; Koutsoyiannis, D. Predictability of monthly temperature and precipitation using automatic time series forecasting methods. Acta Geophys. 2018, 66, 807–831. [Google Scholar] [CrossRef]
- Taieb, S.B.; Bontempi, G.; Atiya, A.F.; Sorjamaa, A. A review and comparison of strategies for multi-step ahead time series forecasting based on the NN5 forecasting competition. Expert Syst. Appl. 2012, 39, 7067–7083. [Google Scholar] [CrossRef] [Green Version]
- Graefe, A.; Armstrong, J.S.; Jones, R.J., Jr.; Cuzán, A.G. Combining forecasts: An application to elections. Int. J. Forecast. 2014, 30, 43–54. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef] [Green Version]
- Rokach, L. Ensemble-based classifiers. Artif. Intell. Rev. 2010, 33, 1–39. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Gomes, H.M.; Barddal, J.P.; Enembreck, F.; Bifet, A. A survey on ensemble learning for data stream classification. ACM Comput. Surv. (CSUR) 2017, 50, 23. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble methods in machine learning. In Proceedings of the International Workshop on Multiple Classifier Systems, Cagliari, Italy, 21–23 June 2000; Springer: Cham, Switzerland, 2000; pp. 1–15. [Google Scholar]
- Rokach, L. Ensemble methods for classifiers. Data Mining and Knowledge Discovery Handbook; Springer: Cham, Switzerland, 2005; pp. 957–980. [Google Scholar]
- Armstrong, J.S. Combining forecasts: The end of the beginning or the beginning of the end? Int. J. Forecast. 1989, 5, 585–588. [Google Scholar] [CrossRef] [Green Version]
- Papacharalampous, G.; Tyralis, H.; Koutsoyiannis, D. Univariate time series forecasting of temperature and precipitation with a focus on machine learning algorithms: A multiple-case study from Greece. Water Resour. Manag. 2018, 32, 5207–5239. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Cham, Switzerland, 2013; Volume 112. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef] [Green Version]
- Pavlyshenko, B.M. Linear, machine learning and probabilistic approaches for time series analysis. In Proceedings of the IEEE First International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 23–27 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 377–381. [Google Scholar] [Green Version]
- Pavlyshenko, B. Machine learning, linear and Bayesian models for logistic regression in failure detection problems. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2046–2050. [Google Scholar] [Green Version]
- Pavlyshenko, B. Using Stacking Approaches for Machine Learning Models. In Proceedings of the 2018 IEEE Second International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 255–258. [Google Scholar]
- ’Rossmann Store Sales’, Kaggle.Com. Available online: http://www.kaggle.com/c/rossmann-store-sales (accessed on 3 November 2018).
- Kaggle: Your Home for Data Science. Available online: http://kaggle.com (accessed on 3 November 2018).
- Kaggle Competition ’Grupo Bimbo Inventory Demand’. Available online: https://www.kaggle.com/c/grupo-bimbo-inventory-demand (accessed on 3 November 2018).
- Kaggle Competition ’Grupo Bimbo Inventory Demand’ #1 Place Solution of The Slippery Appraisals Team. Available online: https://www.kaggle.com/c/grupo-bimbo-inventory-demand/discussion/23863 (accessed on 3 November 2018).
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Kaggle Competition ’Grupo Bimbo Inventory Demand’ Bimbo XGBoost R Script LB:0.457. Available online: https://www.kaggle.com/bpavlyshenko/bimbo-xgboost-r-script-lb-0-457 (accessed on 3 November 2018).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Validation Error | Out-of-Sample Error |
|---|---|---|
| ExtraTree | 14.6% | 13.9% |
| ARIMA | 13.8% | 11.4% |
| RandomForest | 13.6% | 11.9% |
| Lasso | 13.4% | 11.5% |
| Neural Network | 13.6% | 11.3% |
| Stacking | 12.6% | 10.2% |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pavlyshenko, B.M. Machine-Learning Models for Sales Time Series Forecasting. Data 2019, 4, 15. https://doi.org/10.3390/data4010015
Pavlyshenko BM. Machine-Learning Models for Sales Time Series Forecasting. Data. 2019; 4(1):15. https://doi.org/10.3390/data4010015
Chicago/Turabian StylePavlyshenko, Bohdan M. 2019. "Machine-Learning Models for Sales Time Series Forecasting" Data 4, no. 1: 15. https://doi.org/10.3390/data4010015
APA StylePavlyshenko, B. M. (2019). Machine-Learning Models for Sales Time Series Forecasting. Data, 4(1), 15. https://doi.org/10.3390/data4010015