Statistical Modeling of Trivariate Static Systems: Isotonic Models



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- by taking in better account ‘the border effects’ at the periphery of the mesh: this improvement will lead to more accurate model inference results at the periphery of the data-domain;
- by filling-in empty bins of the numerical, histogram-based, estimations of the joint probability density functions and with small non-zero values: this improvement to the original algorithm solves the problem of missing statistical information in some areas of the data-domain mostly due to the scarcity of data samples in those areas;
- by smoothing out the inferred model through linear interpolation by neighboring values: this improvement over the original version of the algorithm mitigates the discontinuity of the model due to a discretized meshing of the data-domain.
2. Modeling Principle and Implementation Details
2.1. Details on an Earlier Implementation
2.2. Refined Implementation
3. Numerical Experimental Results
- the synthetic datasets comprise data generated from a known deterministic function of two variables added with random noise to simulate indeterminacy, and by three synthetic datasets drawn from publicly available databases;
- the natural datasets comprise five cases-of-study drawn from publicly available databases and represent different modeling challenges about data variability and physical meaning of the involved variables.
3.1. Experiments on Synthetic Datasets
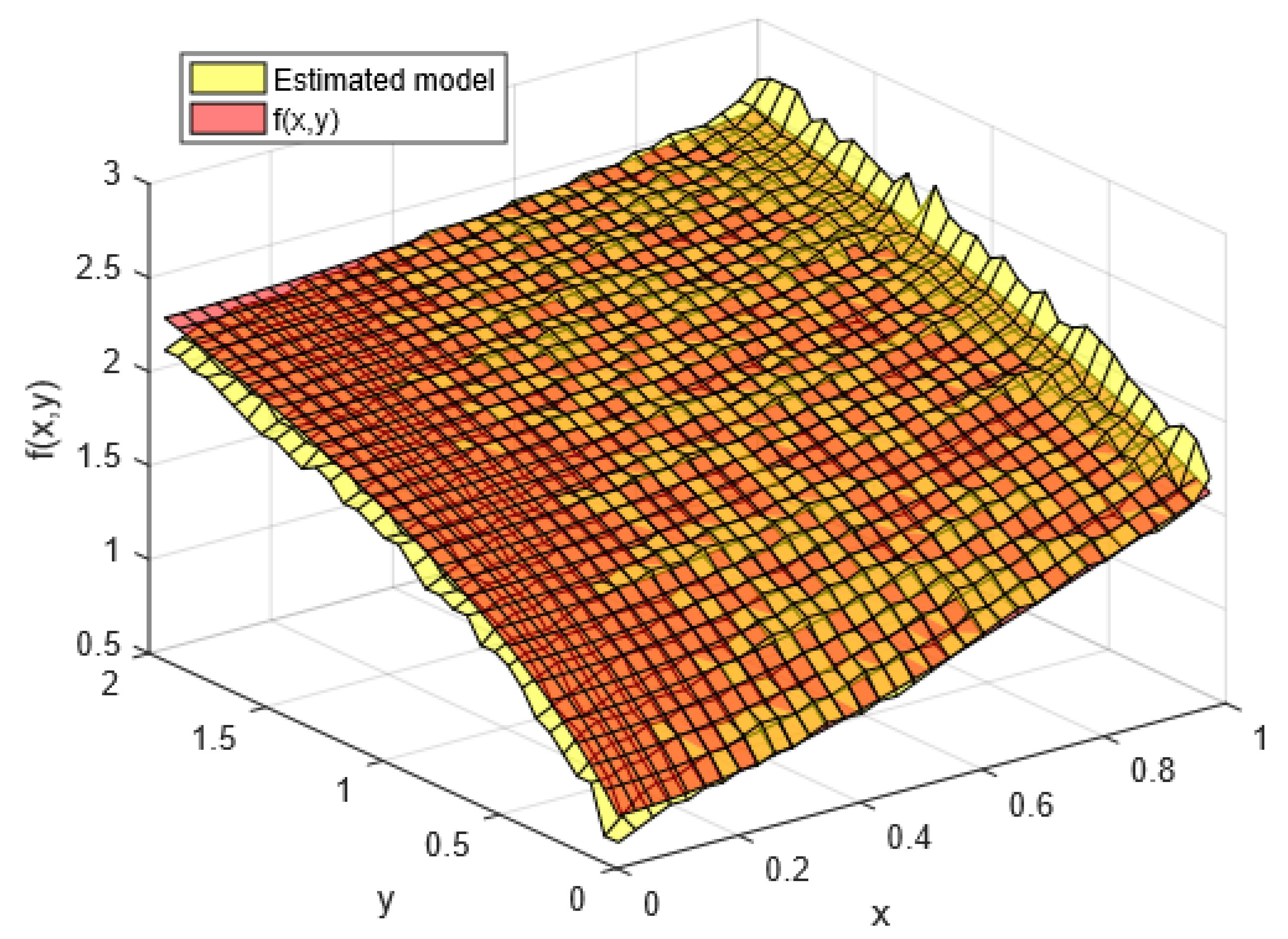
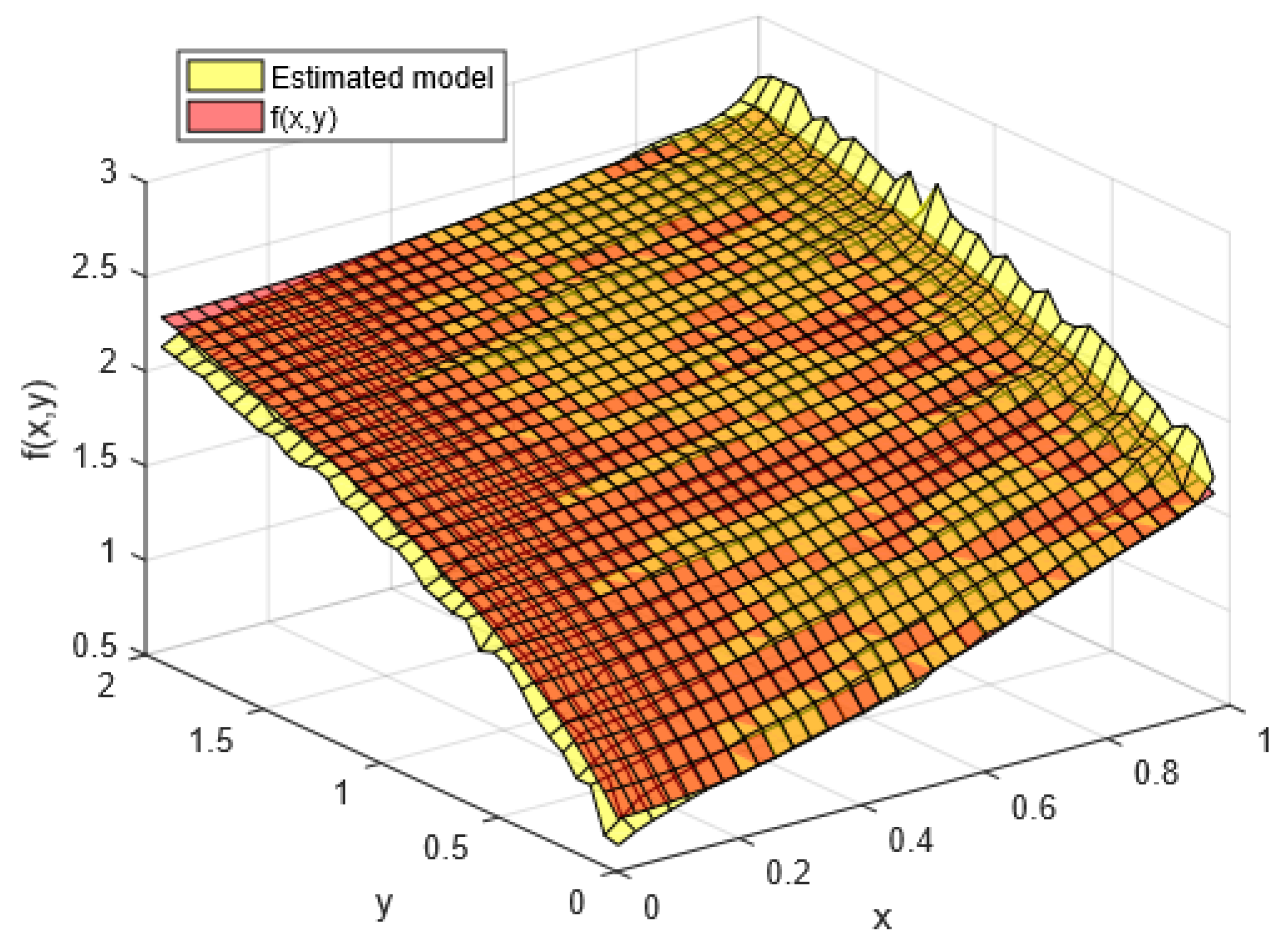
3.1.1. Synthetic Dataset 1: Know Mathematical Function
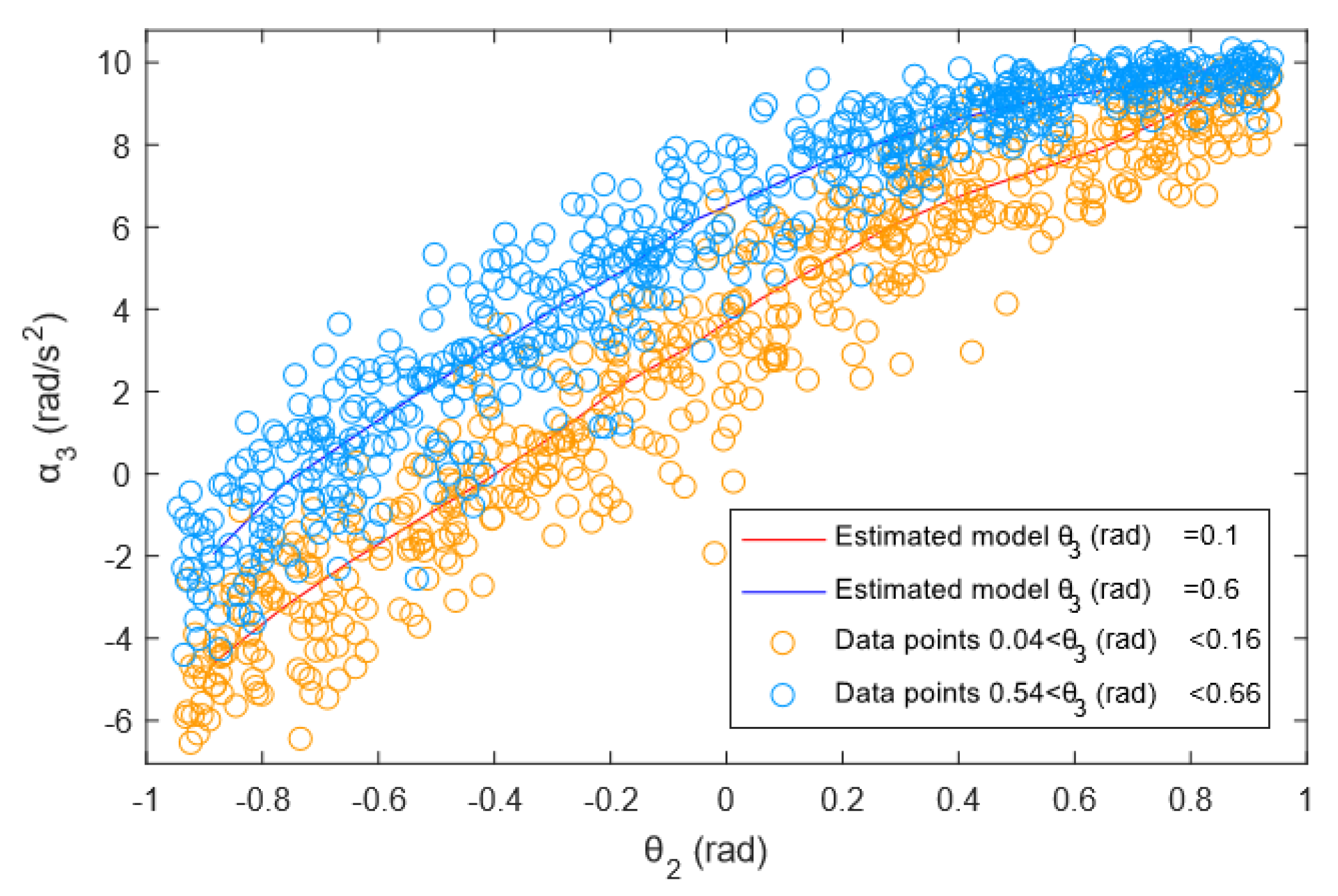
3.1.2. Synthetic Datasets 2—PUMA Robot
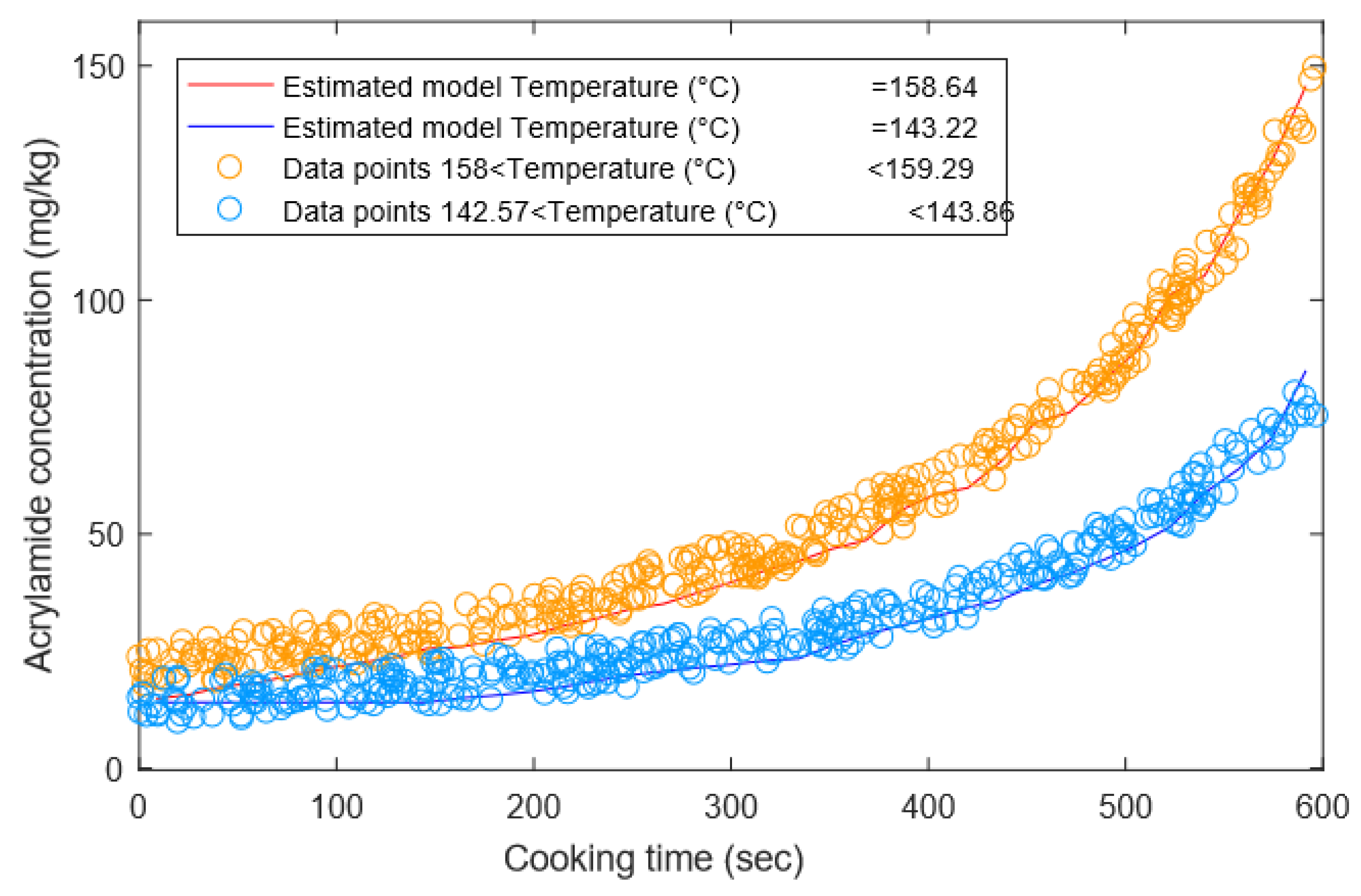
3.1.3. Synthetic Dataset 3—Acrylamide Formation in French Fries
3.1.4. Synthetic Dataset 4—Pollen Grains
3.2. Experiments on Natural Datasets
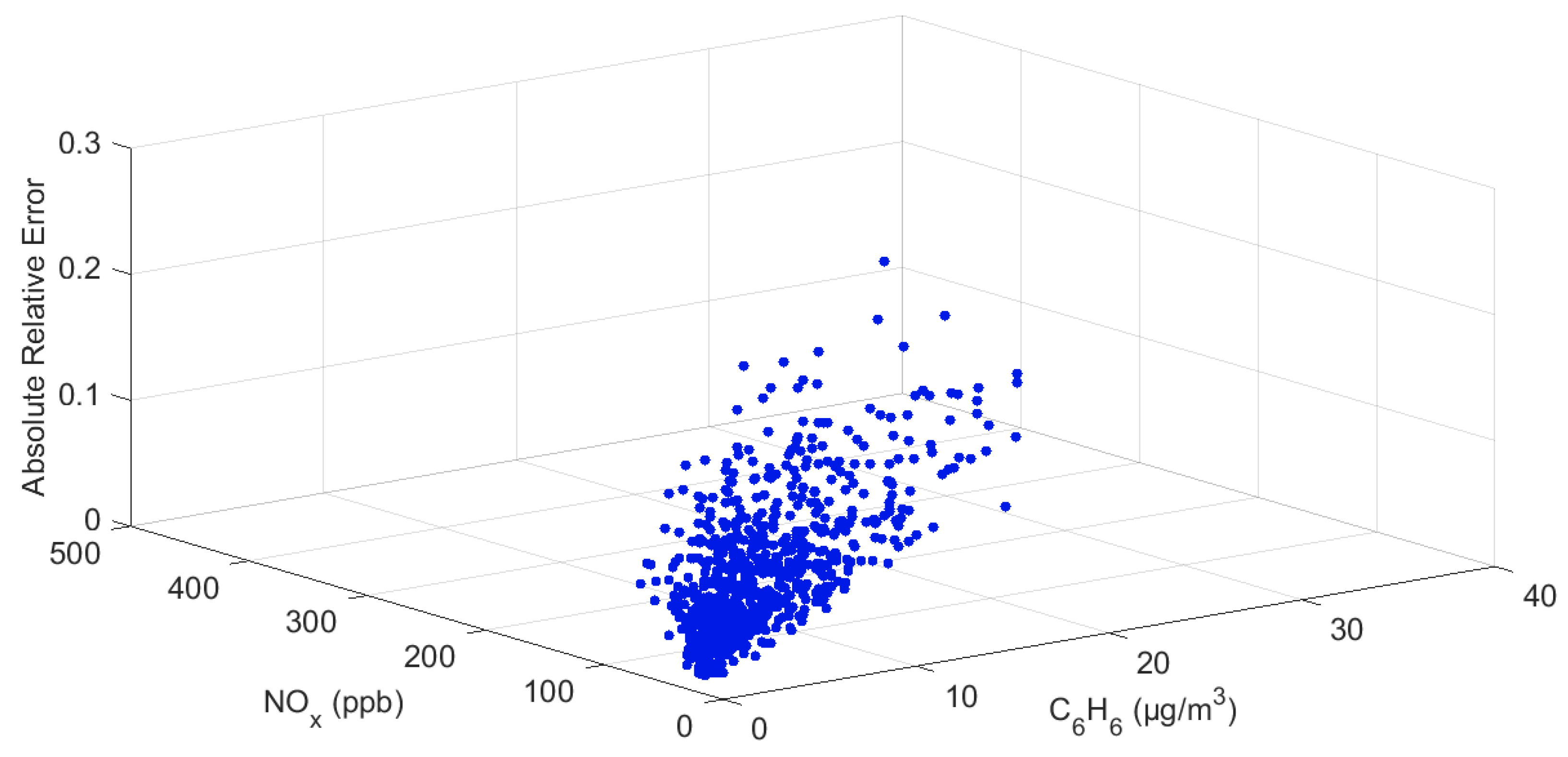
3.2.1. Natural Dataset 1—Air Quality
3.2.2. Natural Dataset 2—Baseball Players Salary
- Combination 1: Modeling ‘Number of runs’ (Runs during player’s career) as a function of ‘Number of times at bat’ (AB during player’s career) and ‘Number of runs batted in’ (RBI during player’s career). These three variables range in , and , respectively.
- Combination 2: Modeling ‘Annual salary in 1987’ as a function of ‘Number of runs batted in’ (RBI in 1986) and ‘Number of hits’ (H in 1986). These three variables range in $, and , respectively.
3.2.3. Natural Dataset 3—Body Fat
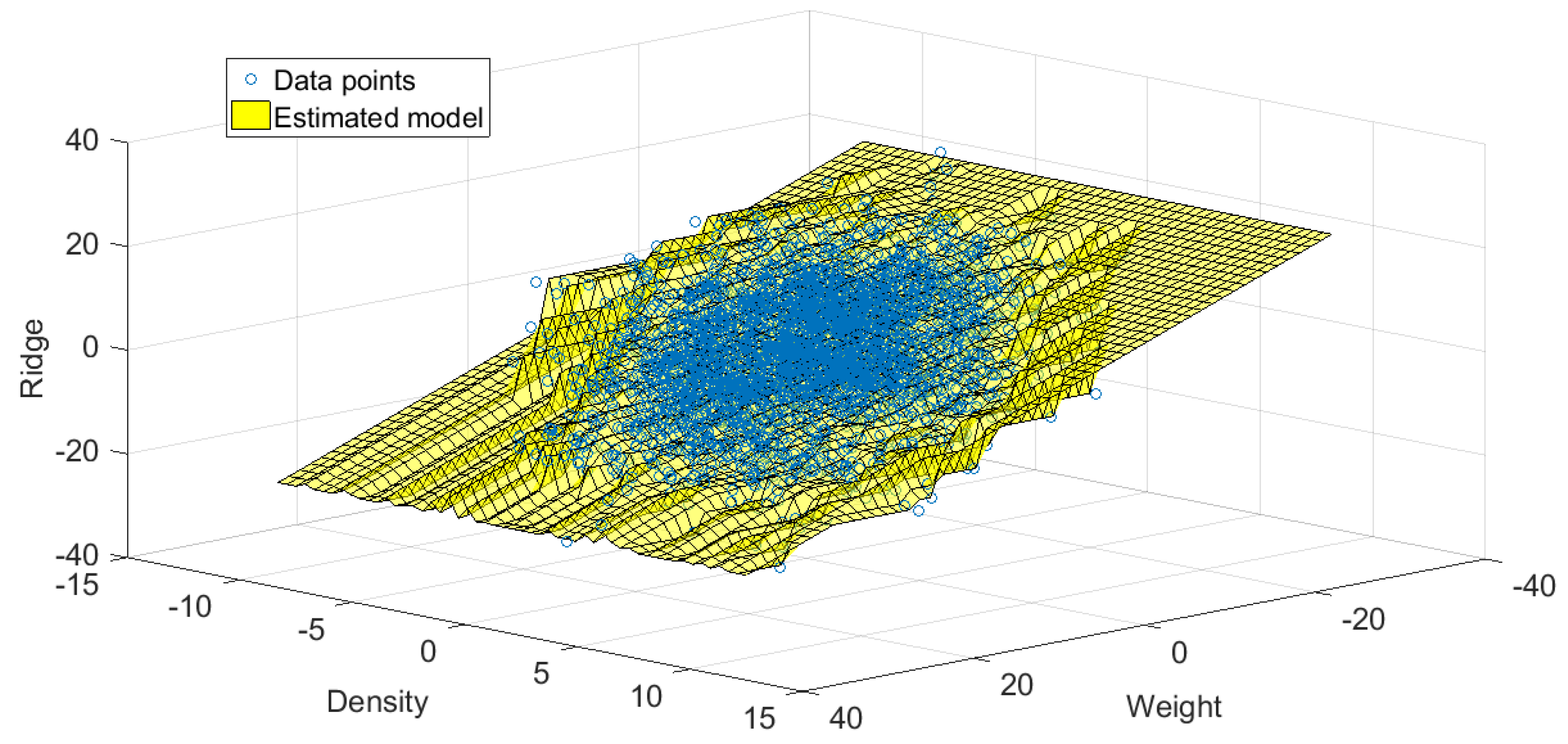
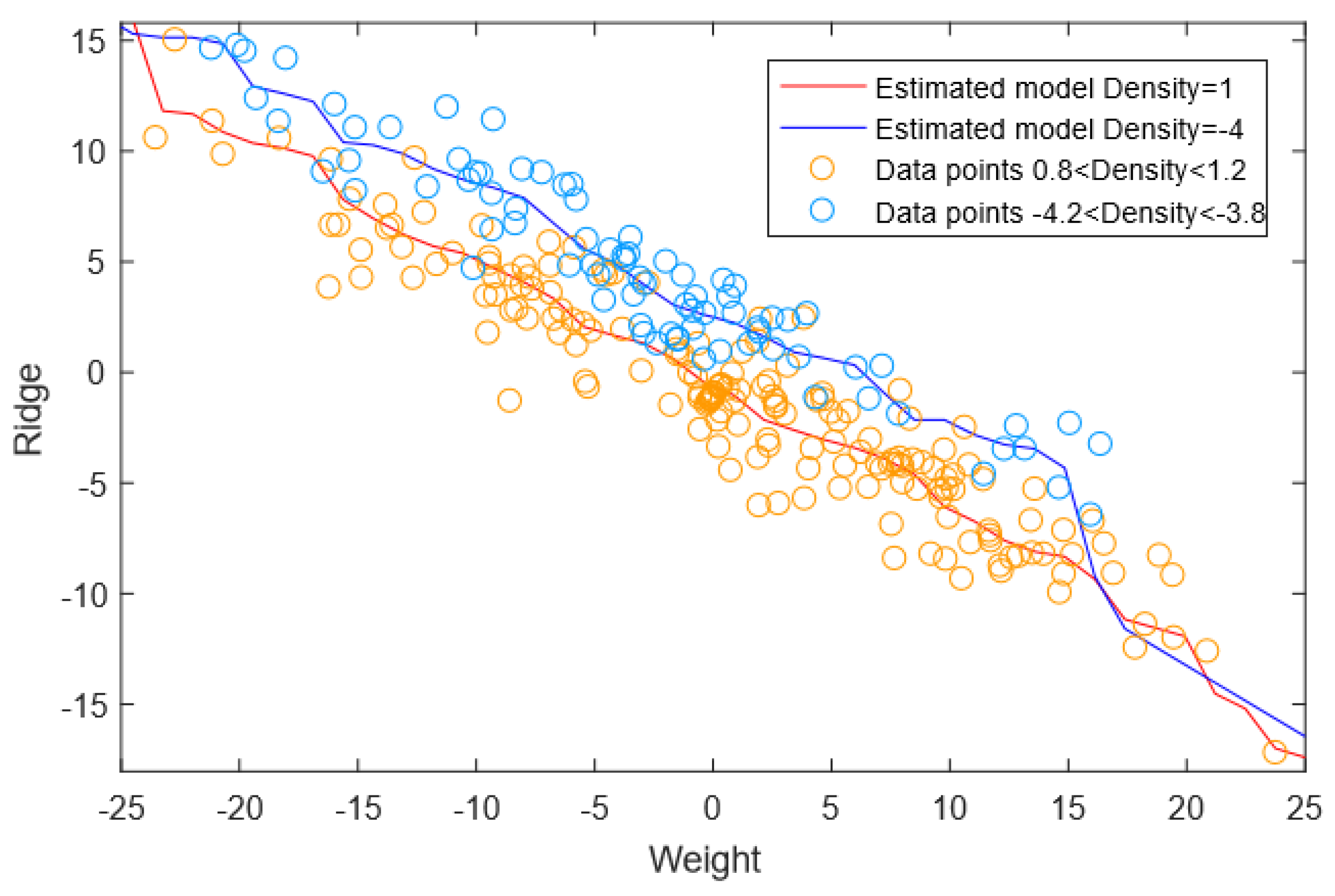
3.2.4. Natural Dataset 4—Vertebral Column
3.2.5. Natural Dataset 5—White Wine Characteristics
4. Conclusions
- The proposed algorithm does not make direct use of the data samples but rather extracts collective information from the data and represent such information by second-order joint probability functions. As a consequence, the model does not fit the data samples (which may be unreliable due to measurement errors or unknown hidden/nuisance variables) but rather captures the overall structure of the underlying physical system.
- The principle informing the discussed modeling procedure is drawn from a probability conservation law, which differentiates the proposed modeling concept from the classical deterministic linear/non-linear fitting schemes. The underlying probability conservation law holds true irrespective of the shape of the involved probability density functions and model, provided that continuity and monotonicity hold.
- The proposed procedure does not make any assumption on the shape of the model, except for continuity and monotonicity. As a result, the model is unrestricted and there is no need to choose any functional dependency beforehand, which differentiates the proposed modeling from the parametric/maximum-likelihood estimation methods.
- The involved quantities, namely, the probability density functions and the inferred model, are represented by simple numerical tables. The probability density functions are estimated by constructing occurrence histograms and the associated marginal cumulative distribution functions are estimated by cumulative sums. The model is estimated by proximity search within the tables, which only require basic mathematical operations. The resulting procedure is computationally light and very fast to execute.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kroese, D.P.; Chan, J.C.C. Statistical Modeling and Computation; Springer: Berlin, Germany, 2014. [Google Scholar]
- Carrara, P.; Altamura, E.; D’Angelo, F.; Mavelli, F.; Stano, P. Measurement and numerical modeling of cell-free protein synthesis: combinatorial block-variants of the PURE system. Data 2018, 3, 41. [Google Scholar] [CrossRef]
- Chu, P.C. World ocean isopycnal level absolute geostrophic velocity (WOIL-V) inverted from GDEM with the P-Vector method. Data 2018, 3, 1. [Google Scholar] [CrossRef]
- Hoseinie, S.H.; Al-Chalabi, H.; Ghodrati, B. Comparison between Simulation and Analytical Methods in Reliability Data Analysis: A Case Study on Face Drilling Rigs. Data 2018, 3, 12. [Google Scholar] [CrossRef]
- Reed, F.J.; Gaughan, A.E.; Stevens, F.R.; Yetman, G.; Sorichetta, A.; Tatem, A.J. Gridded population maps informed by different built settlement products. Data 2018, 3, 33. [Google Scholar] [CrossRef]
- Stein, M.; Janetzko, H.; Seebacher, D.; Jäger, A.; Nagel, M.; Hölsch, J.; Kosub, S.; Schreck, T.; Keim, D.A.; Grossniklaus, M. How to make sense of team sport data: From acquisition to data modeling and research aspects. Data 2017, 2, 2. [Google Scholar] [CrossRef]
- Torbati, M.E.; Mitreva, M.; Gopalakrishnan, V. Application of taxonomic modeling to microbiota data mining for detection of helminth infection in global populations. Data 2016, 1, 19. [Google Scholar] [CrossRef] [PubMed]
- Vakanski, A.; Jun, H.-P.; Paul, D.; Baker, R. A data set of human body movements for physical rehabilitation exercises. Data 2018, 3, 2. [Google Scholar] [CrossRef]
- Vorster, A.G.; Woodward, B.D.; West, A.M.; Young, N.E.; Sturtevant, R.G.; Mayer, T.J.; Girma, R.K.; Evangelista, P.H. Tamarisk and Russian olive occurrence and absence dataset collected in select tributaries of the Colorado River for 2017. Data 2018, 3, 42. [Google Scholar] [CrossRef]
- Archontoulis, S.; Miguez, F. Nonlinear regression models and applications in agricultural research. Agron. J. 2015, 107, 786–798. [Google Scholar] [CrossRef]
- Bates, D.; Watts, D. Nonlinear Regression Analysis and Its Applications, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- He, X.; Ng, P.; Portnoy, S. Bivariate quantile smoothing splines. J. R. Stat. Soc. 1998, 60, 537–550. [Google Scholar] [CrossRef] [Green Version]
- Kravtsov, S.; Kondrashov, D.; Ghil, M. Multilevel regression modeling of nonlinear processes: Derivation and applications to climatic variability. J. Clim. 2005, 18, 4404–4424. [Google Scholar] [CrossRef]
- Payandeh, B. Some applications of nonlinear regression models in forestry research. For. Chron. 1983, 59, 244–248. [Google Scholar] [CrossRef]
- Rusov, J.; Misita, M.; Milanovic, D.D.; Milanovic, D.L. Applying regression models to predict business results. FME Trans. 2017, 45, 198–202. [Google Scholar] [CrossRef] [Green Version]
- Biagiotti, J.; Fiori, S.; Torre, L.; López-Manchado, M.A.; Kenny, J.M. Mechanical properties of polypropylene matrix composites reinforced with natural fibers: A statistical approach. Polym. Compos. 2004, 25, 26–36. [Google Scholar] [CrossRef]
- Maheshwari, N.; Balaji, C.; Ramesh, A. A nonlinear regression based multi-objective optimization of parameters based on experimental data from an IC engine fueled with biodiesel blends. Biomass Bioenergy 2011, 35, 2171–2183. [Google Scholar] [CrossRef]
- Parthimos, D.; Haddock, R.E.; Hill, C.E.; Griffith, T.M. Dynamics of a three-variable nonlinear model of vasomotion: Comparison of theory and experiment. Biophys. J. 2007, 93, 1534–1556. [Google Scholar] [CrossRef] [PubMed]
- Van Echelpoel, W.; Goethals, P.L.M. Variable importance for sustaining macrophyte presence via random forests: Data imputation and model settings. Sci. Rep. 2018, 8, 14557. [Google Scholar] [CrossRef]
- Mitsis, G.D. Nonlinear, data-driven modeling of cerebrovascular and respiratory control mechanisms. In Proceedings of the 2009 9th International Conference on Information Technology and Applications in Biomedicine, Larnaca, Cyprus, 4–7 November 2009; pp. 1–4. [Google Scholar] [CrossRef]
- Zhang, Y.; Holt, T.A.; Khovanova, N. A data driven nonlinear stochastic model for blood glucose dynamics. Comput. Methods Programs Biomed. 2016, 125, 18–25. [Google Scholar] [CrossRef] [Green Version]
- Mitra, S.; Goldstein, Z. Designing early detection and intervention techniques via predictive statistical models—A case study on improving student performance in a business statistics course. Commun. Stat. 2015, 1, 9–21. [Google Scholar] [CrossRef]
- Underhill, G.H.; Khetani, S.R. Bioengineered liver models for drug testing and cell differentiation studies. Cell. Mol. Gastroenterol. Hepatol. 2018, 5, 426–439. [Google Scholar] [CrossRef]
- Cattaert, T.; Calle, M.L.; Dudek, S.M.; Mahachie John, J.M.; Van Lishout, F.; Urrea, V.; Ritchie, M.D.; Van Steen, K. Model-based multifactor dimensionality reduction for detecting epistasis in case-control data in the presence of noise. Ann. Hum. Genet. 2011, 75, 78–89. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.A. A trivariate Bernoulli regression model. Cogent Math. Stat. 2017, 5. [Google Scholar] [CrossRef]
- Breiman, L. Statistical modeling: the two cultures. Stat. Sci. 2001, 16, 199–231. [Google Scholar] [CrossRef]
- Fiori, S. An isotonic trivariate statistical regression method. Adv. Data Anal. Classif. 2013, 7, 209–235. [Google Scholar] [CrossRef]
- Li, H.; Aviran, S. Statistical modeling of RNA structure profiling experiments enables parsimonious reconstruction of structure landscapes. Nat. Commun. 2018, 9, 606. [Google Scholar] [CrossRef]
- Chen, M.-J.; Hsu, H.-T.; Lin, C.-L.; Ju, W.-Y. A statistical regression model for the estimation of acrylamide concentrations in French fries for excess lifetime cancer risk assessment. Food Chem. Toxicol. 2012, 50, 3867–3876. [Google Scholar] [CrossRef] [PubMed]
- De Vito, S.; Piga, M.; Martinotto, L.; Di Francia, G. CO, NO2 and NOx urban pollution monitoring with on-field calibrated electronic nose by automatic Bayesian regularization. Sens. Actuators B 2009, 143, 182–191. [Google Scholar] [CrossRef]
- Carpentier, A.; Schlueter, T. Learning relationships between data obtained independently. In Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; Volume 51, pp. 658–666. [Google Scholar]
- Domínguez-Menchero, J.S.; González-Rodríguez, G. Analyzing an extension of the isotonic regression problem. Metrika 2007, 66, 19–30. [Google Scholar] [CrossRef]
- Fiori, S. Fast closed form trivariate statistical isotonic modelling. Electron. Lett. 2014, 50, 708–710. [Google Scholar] [CrossRef]
- Papoulis, A.; Unnikrishna Pillai, S. Probability, Random Variables and Stochastic Processes, 4th ed.; McGraw-Hill: New York, NY, USA, 2002. [Google Scholar]
- Scott, D.W.; Sain, S.R. Multi-dimensional density estimation. In Handbook of Statistics, Data Mining and Data Visualization; Elsevier: San Diego, CA, USA, 2005; Volume 24, pp. 229–261. [Google Scholar]
- Fiori, S. Fast statistical regression in presence of a dominant independent variable. Neural Comput. Appl. 2013, 22, 1367–1378. [Google Scholar] [CrossRef]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Deen, M.J.; Kazemeini, M. Photosensitive polymer thin-film FETs Based on poly(3-octylthiophene). Proc. IEEE 2005, 93, 1312–1320. [Google Scholar] [CrossRef]
- Ghahramani, Z. Pumadyn Family of Datasets; Department of Engineering, University of Cambridge: Cambridge, UK, 1996. [Google Scholar]
- Becker, R.A.; Denby, L.; McGill, R.; Wilks, A. Datacryptanalysis: A Case Study. In Proceedings of the Section on Statistical Graphics; American Statistical Association: Boston, MA, USA, 1986; pp. 92–97. [Google Scholar]
- Slomka, M. The analysis of a synthetic data set. In Proceedings of the Section on Statistical Graphics; American Statistical Association: Boston, MA, USA, 1986; pp. 113–116. [Google Scholar]
- Coleman, D. Pollen Data. RCA Laboratories in Princeton, N.J. 1986. Available online: https://www.openml.org/d/529 (accessed on 5 December 2018).
- Hoaglin, D.C.; Velleman, P.F. A critical look at some analyses of Major League Baseball salaries. Am. Stat. 1995, 49, 277–285. [Google Scholar]
- Johnson, R.W.; College, C. Fitting percentage of body fat to simple body measurements. J. Stat. Educ. 1996, 4. [Google Scholar] [CrossRef]
- Barreto, G.; Neto, A. Vertebral Column Data Set; Department of Teleinformatics Engineering, Federal University of Ceara: Fortaleza, Brazil, 2011. [Google Scholar]
- Cortez, P. Wine Quality Data Set; University of Minho: Guimarães, Portugal, 2009. [Google Scholar]








































© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fiori, S.; Vitali, A. Statistical Modeling of Trivariate Static Systems: Isotonic Models. Data 2019, 4, 17. https://doi.org/10.3390/data4010017
Fiori S, Vitali A. Statistical Modeling of Trivariate Static Systems: Isotonic Models. Data. 2019; 4(1):17. https://doi.org/10.3390/data4010017
Chicago/Turabian StyleFiori, Simone, and Andrea Vitali. 2019. "Statistical Modeling of Trivariate Static Systems: Isotonic Models" Data 4, no. 1: 17. https://doi.org/10.3390/data4010017
APA StyleFiori, S., & Vitali, A. (2019). Statistical Modeling of Trivariate Static Systems: Isotonic Models. Data, 4(1), 17. https://doi.org/10.3390/data4010017