Towards Identifying Author Confidence in Biomedical Articles



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background
3. Data Set
4. Methodology
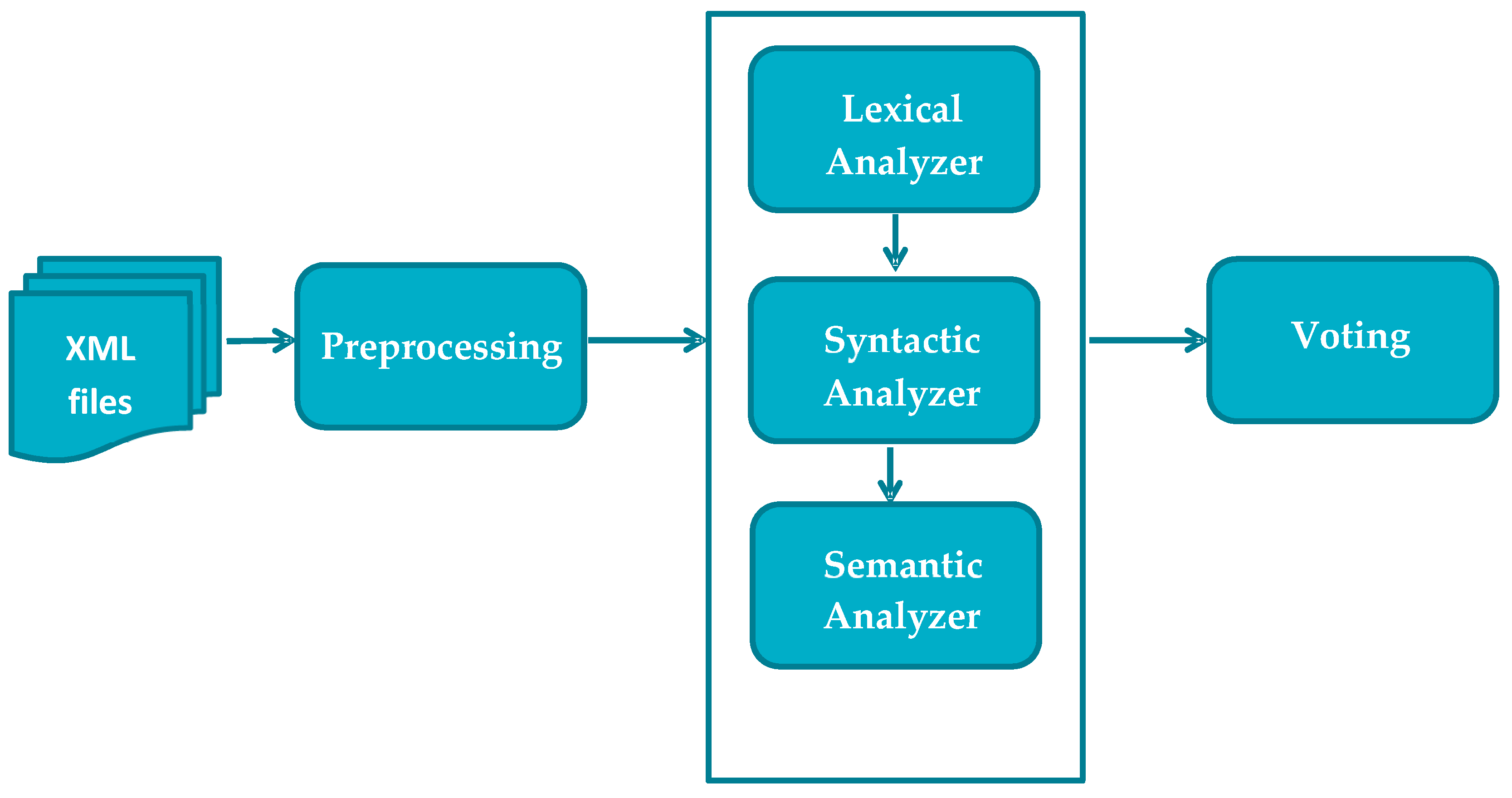
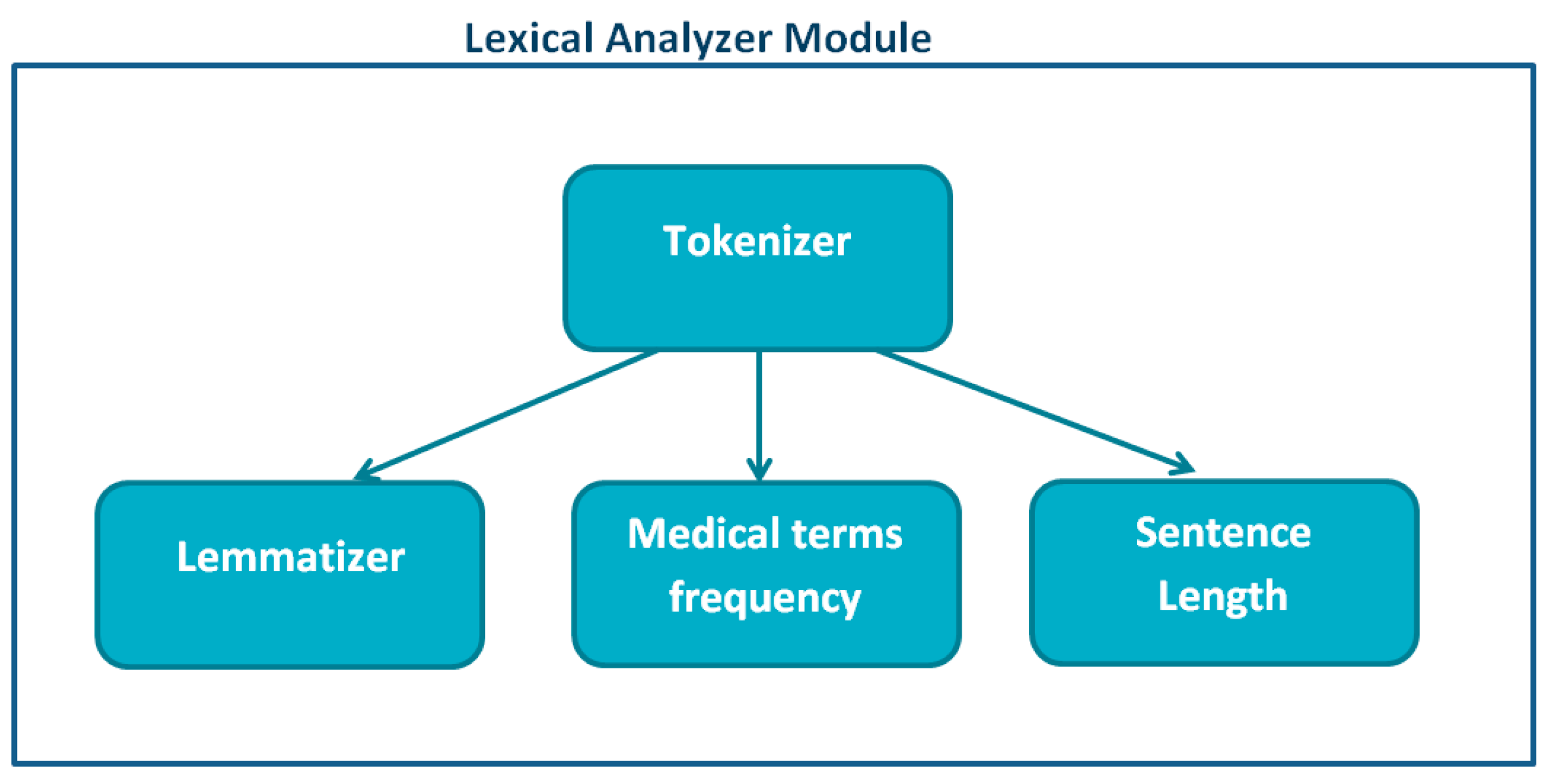
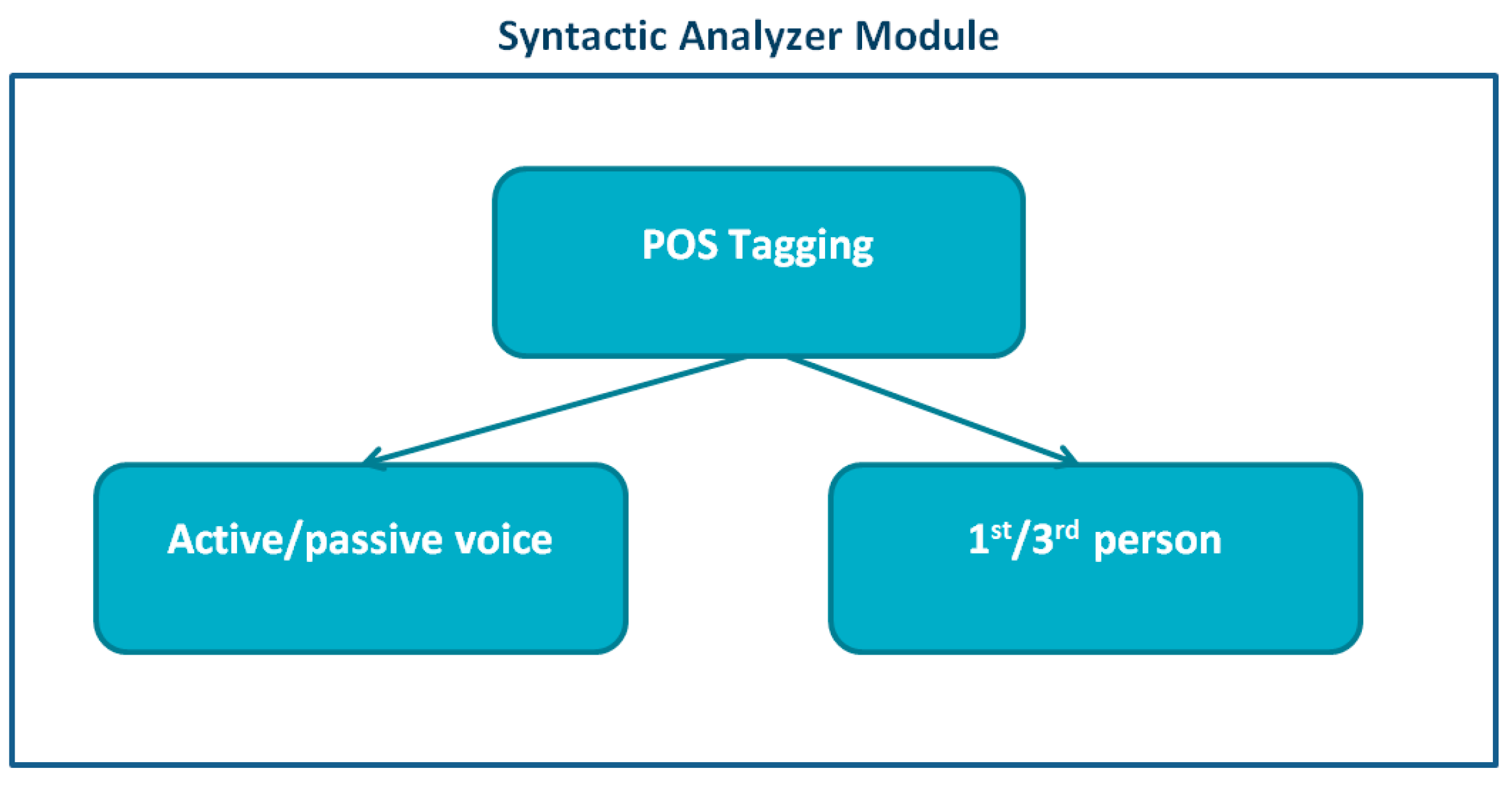
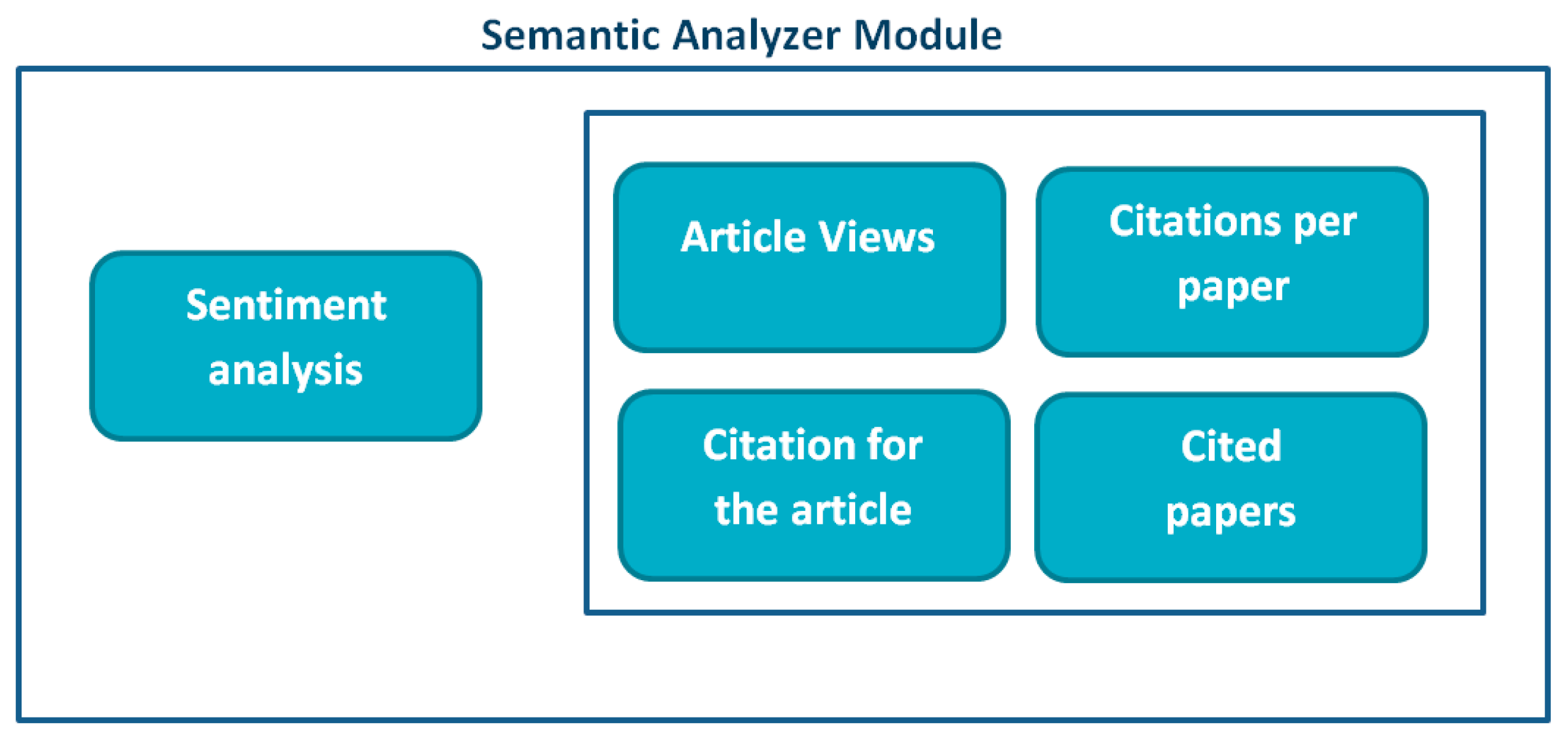
5. System Description
6. Results
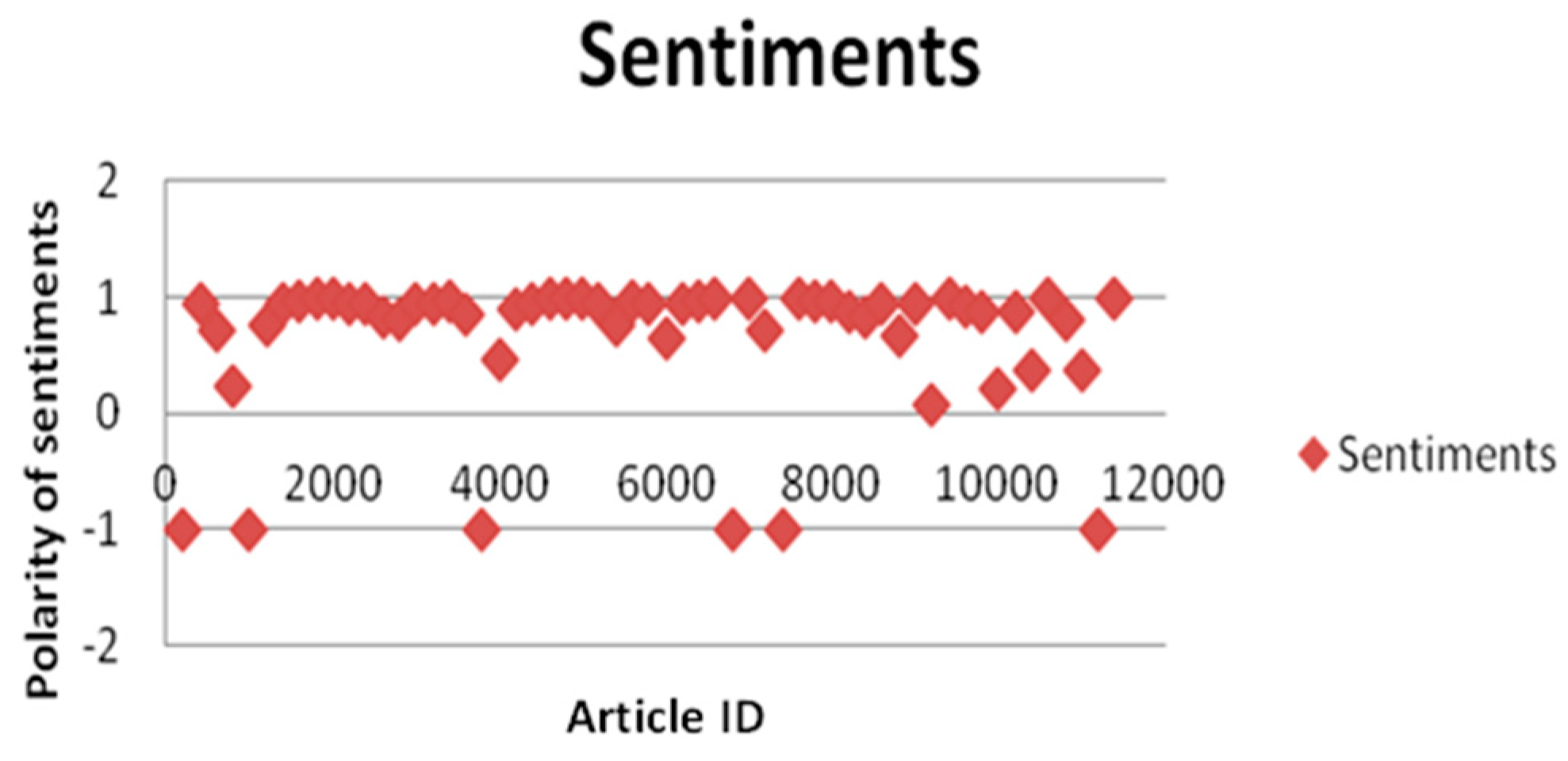
6.1. Sentiment Analysis
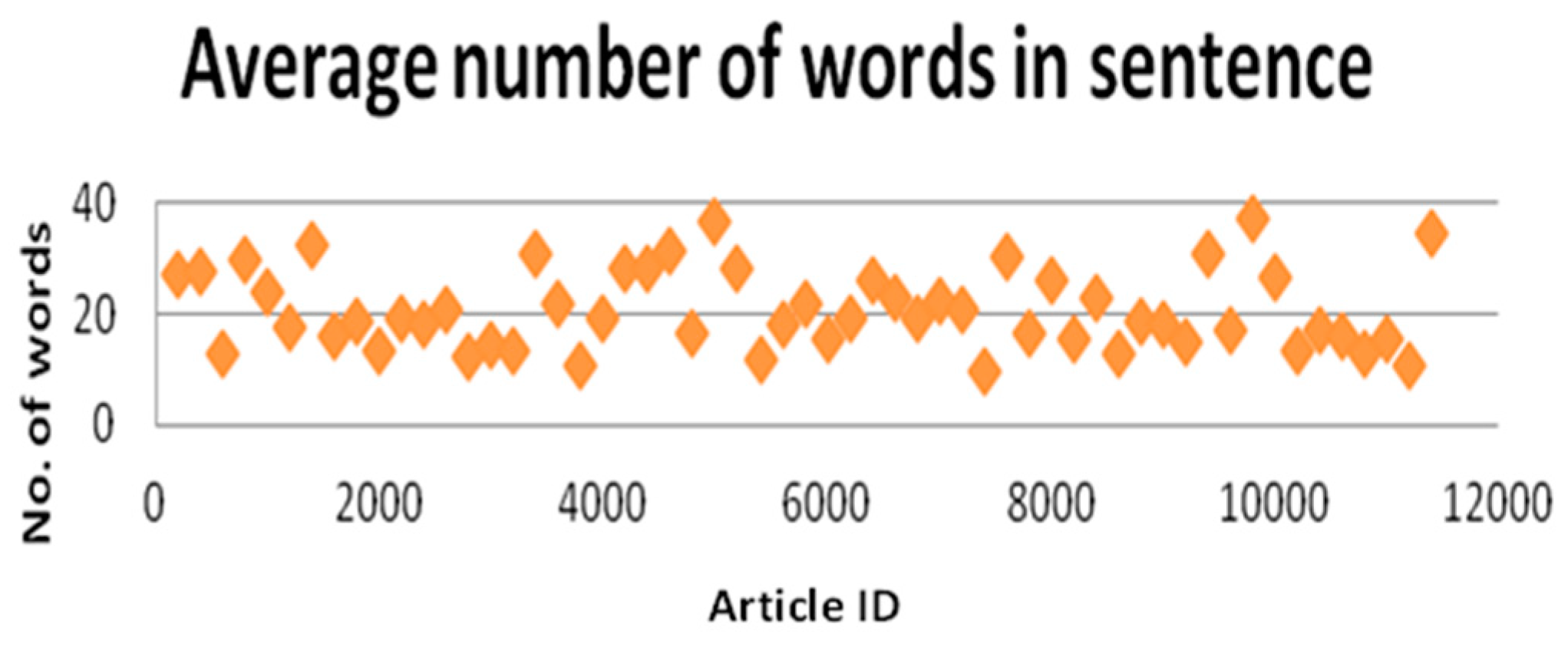
6.2. Average Words Per Sentence
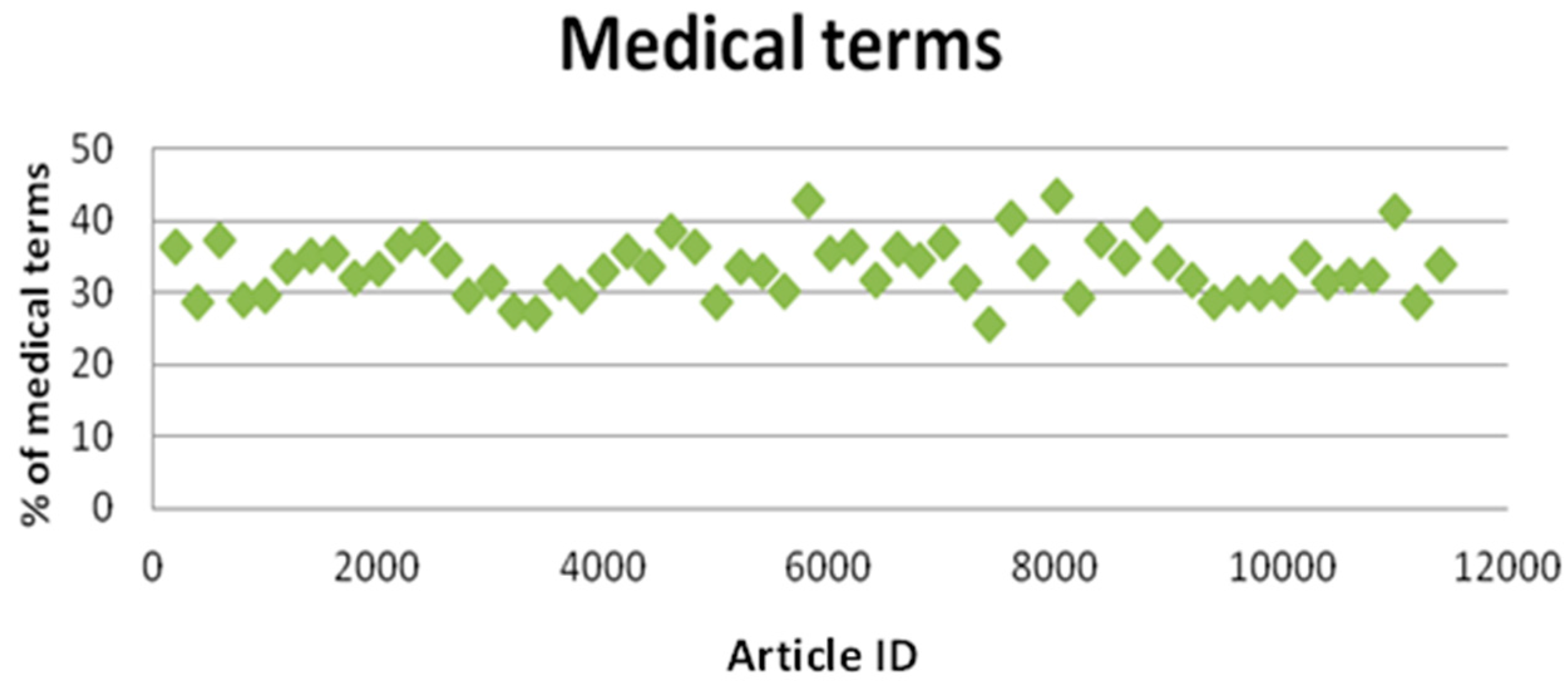
6.3. Medical Frequency Terms
7. Discussion
Author Contributions
Funding
Conflicts of Interest
Appendix A. An Example of Chapters Analyzed, Results and Conclusion, in XML Format
| <title>Conclusion</title> |
| <p>This paper studied multiple affiliations of authors in research publications. Results for three scientific fields (biology, chemistry and engineering) and three countries (Germany, Japan and the UK) showed that multiple affiliations are widespread and have increased in all fields and countries during the period 2008–2014.</p> |
| <p>We found that multiple affiliations reflect the dynamics of the research sector in specific countries and proposed a classification of the cross-sector and international dimension of author affiliations. To summarize, we find three types of multiple affiliations that can be classified as (A) a highly internationalized, HEI cantered affiliation distribution as represented by researchers in the UK, (B) a balanced affiliation distribution as seen in Germany, and (C) a domestic, cross-sector affiliation distribution as seen in Japan. These results suggest that cross-sector affiliations are highest in countries and fields with a large non-university research sector, while cross-country affiliations are highest in countries with an international research base. An analysis of other countries may find additional types. However, the occurrence of low cross-sector affiliations paired with low internationalization, that is, where academic authors are primarily affiliated with other domestic universities, may be limited by academic employment contracts which generally still limit such arrangements.</p> |
| <p>These observed differences have consequences for the types of networking that can be achieved through multiple affiliations in different countries. For example, international affiliations may help to preserve links to ‘frontline’ research institutions, while cross-sector affiliations may be more conducive to knowledge transfer and mobility between sectors (ESF <xref ref-type=“bibr” rid=“CR5”>2013</xref>). Our results did, however, show that most multiple affiliations of academics are with other universities or with PROs, including in the cases of Japan and Germany. The role of multiple affiliations as a facilitator for knowledge transfer between distinct sectors (ESF <xref ref-type=“bibr” rid=“CR5”>2013</xref>) may therefore be rather limited.</p> <title>Results</title> |
| <p>Table <xref rid=“Tab1” ref-type=“table”>1</xref> shows the total number of authors reported on the selected publications by country and field, as well as the number and proportion of authors that report more than one institutional address. Of the more than 118,000 authors in the sample, 7.2% have more than one institution attached, with some differences across countries and subject areas.<xref ref-type=“fn” rid=“Fn5”>5</xref> The proportion of authors with multiple institutional addresses is highest with more than 9% of authors in biology and chemistry in the case of Germany, and biology in the case of the UK. This already suggests some country and subject-specific differences regarding the extent of multiple affiliations.</p> |
Appendix B. An Example of Metadata for a Scientific Article on Malaria Issue, in XML Format

References
- Gifu, D. Malaria Detection System. In Institute of Mathematics and Computer Science, Proceedings of the International Conference on Mathematical Foundations of Informatics (MFOI-2017), Chișinău, Moldova, 9–11 November 2017; Cojocaru, S., Gaindric, C., Druguș, I., Eds.; Academy of Sciences of Moldova: Chișinău, Moldova, 2017; pp. 74–78. [Google Scholar]
- Dashevskiy, M.; Luo, Z. Predictions with Confidence in Applications. In Proceedings of the Machine Learning and Data Mining in Pattern Recognition, Leipzig, Germany, 23–25 July 2009; pp. 775–786. [Google Scholar]
- De Keizer, N.F.; Abu-Hanna, A.; Zwetsloot-Schonl, J.H.M. Understanding terminological systems I: Terminology and typology. Method. Inf. Med. 2000, 39, 16–21. [Google Scholar]
- De Keizer, N.F.; Abu-Hanna, A. Understanding terminological systems II: Terminology and typology. Method Inf. Med. 2000, 39, 22–29. [Google Scholar]
- Cornet, R.; de Keizer, N.F.; Abu-Hanna, A. A framework for characterizing terminological systems. Method. Inf. Med. 2006, 45, 253–266. [Google Scholar]
- Rexha, A.; Kröll, M.; Ziak, H.; Kern, R. Extending Scientific Literature Search by Including the Author’s Writing Style. In Proceedings of the BIR@ ECIR, Abeerden, UK, 8–12 April 2017; pp. 93–100. [Google Scholar]
- Hangyo, M.; Kawahara, D.; Kurohashi, S. Japanese Zero. Reference Resolution Considering Exophora and Author/ReaderMentions. Available online: http://aclweb.org/anthology/D/D13/D13-1095.pdf (accessed on 20 January 2019).
- Nguyen, D.; Smith, N.A.; Rose, C.P. Author Age Prediction from Text using Linear Regression. In Proceedings of the 5th ACL-HLT Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities, Portland, OR, USA, 24 June 2011; Available online: http://aclweb.org/anthology/W/W11/W11-1515.pdf (accessed on 20 January 2019).
- Qian, T.; Liu, B. Identifying Multiple Userids of the Same Author. In Proceedings of the Conference on Empirical Methods in Natural Language, Seattle, WA, USA, 18–21 October 2013; Available online: http://aclweb.org/anthology/D/D13/D13-1113.pdf (accessed on 20 January 2019).
- Hyland, K. Humble servants of the discipline? Self-mention in research articles in English for Specific Purposes. Engl. Specif. Purp. 2001, 20, 207–226. [Google Scholar] [CrossRef]
- Friedman, C.; Alderson, P.; Austin, J.; Cimino, J.J.; Johnson, S.B. A general natural-language text processor for clinical radiology. J. Am. Med. Info. Assoc. 1994, 1, 161–174. [Google Scholar] [CrossRef]
- Wilbur, W.J.; Rzhetsky, A.; Shatkay, H. New directions in biomedical text annotations: Definitions, guidelines and corpus construction. BMC Bioinform. 2006, 7, 356. [Google Scholar] [CrossRef] [PubMed]
- Light, M.; Qiu, X.Y.; Srinivasan, P. The Language of Bioscience: Facts, Speculations, and Statements in Between. In Proceedings of the BioLINK 2004: Linking Biological Literature, Ontologies and Databases, Boston, MA, USA, 6 May 2004; pp. 17–34. [Google Scholar]
- Thompson, P.; Venturi, G.; McNaught, J.; Montemagni, S.; Ananiadou, S. Categorising Modality in Biomedical Texts. In Proceedings of the LREC 2008 Workshop on Building and Evaluating Resources for Biomedical Text Mining, Maarakech, Morocco, 26 May 2008; pp. 27–34. [Google Scholar]
- Medlock, B.; Briscoe, T. Weakly Supervised Learning for Hedge Classification in Scientific Literature. In Proceedings of the 45th Meeting of the Association for Computational Linguistics, Prague, Czech Republic, 25–27 June 2007; pp. 992–999. [Google Scholar]
- Sim, Y.; Routledge, B.R.; Smith, N.A. A Utility Model of Authors in the Scientific Community. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1510–1519. Available online: http://aclweb.org/anthology/D/D15/D15-1175.pdf (accessed on 20 January 2019).
- Szarvas, G. Hedge Classification in Biomedical Texts with a Weakly Supervised Selection of Keywords. In Proceedings of the 46th Meeting of the Association for Computational Linguistics, Columbus, OH, USA, 16 June 2008; pp. 281–289. [Google Scholar]
- Zarnoth, P.; Sniezek, J. The social influence of confidence in group decision making. J. Exp. Soc. Psychol 1997, 33, 345–366. [Google Scholar] [CrossRef] [PubMed]
- Partridge, D.; Bailey, T.C.; Everson, R.M.; Fieldsend, J.E.; Hernandez, A.; Krzanowski, W.J.; Schetinin, V. Classification with Confidence for Critical Systems. In Developments in Risk-Based Approaches to Safety; Springer: London, UK, 2007; pp. 231–239. [Google Scholar]
- Cyra, L.; Gorski, J. Supporting Compliance with Security Standards by Trust Case Templates. In Proceedings of the 2nd International Conference on Dependability of Computer Systems (DepCoS-RELCOMEX 2007), Szklarska Poreba, Poland, 14–16 June 2007; pp. 91–98. [Google Scholar]
- Hawkins, R.; Kelly, T.; Knight, J.; Graydon, P. A New Approach to Creating Clear Safety Arguments. In Advances in Systems Safety; Springer: Berlin, Germany, 2011; pp. 3–23. [Google Scholar]
- Wang, R.; Guiochet, J.; Motet, G.; Schön, W. D-S Theory for Argument Confidence Assessment. In Proceedings of the 4th International Conference on Belief Functions (BELIEF 2016), Prague, Czech Republic, 21–23 September 2016; pp. 190–200. [Google Scholar]
- Derntl, M. Basics of Research Paper Writing and Publishing. J. Technol. Enhan. Learn. 2014, 6, 105–123. Available online: http://dbis.rwth-aachen.de/~derntl/papers/misc/paperwriting.pdf (accessed on 20 January 2019). [CrossRef]








© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Onofrei Plămadă, M.; Trandabăț, D.; Gîfu, D. Towards Identifying Author Confidence in Biomedical Articles. Data 2019, 4, 18. https://doi.org/10.3390/data4010018
Onofrei Plămadă M, Trandabăț D, Gîfu D. Towards Identifying Author Confidence in Biomedical Articles. Data. 2019; 4(1):18. https://doi.org/10.3390/data4010018
Chicago/Turabian StyleOnofrei Plămadă, Mihaela, Diana Trandabăț, and Daniela Gîfu. 2019. "Towards Identifying Author Confidence in Biomedical Articles" Data 4, no. 1: 18. https://doi.org/10.3390/data4010018
APA StyleOnofrei Plămadă, M., Trandabăț, D., & Gîfu, D. (2019). Towards Identifying Author Confidence in Biomedical Articles. Data, 4(1), 18. https://doi.org/10.3390/data4010018