LNSNet: Lightweight Navigable Space Segmentation for Autonomous Robots on Construction Sites




Abstract
:1. Introduction
2. Research Objectives and Contributions
3. Literature Review
3.1. Vision-Based Object Recognition in Construction
3.2. State-of-the-Art Object Recognition
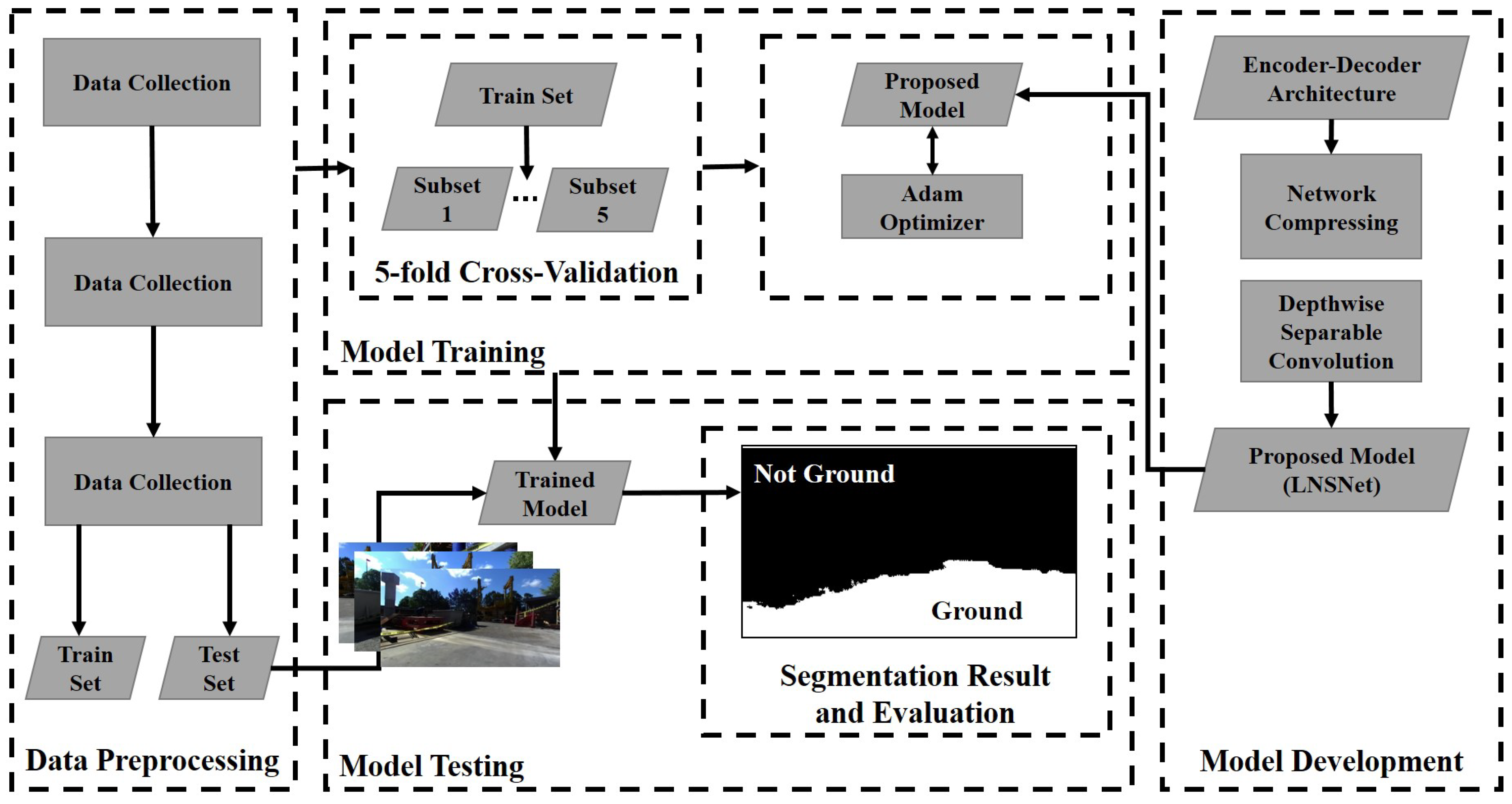
4. Method
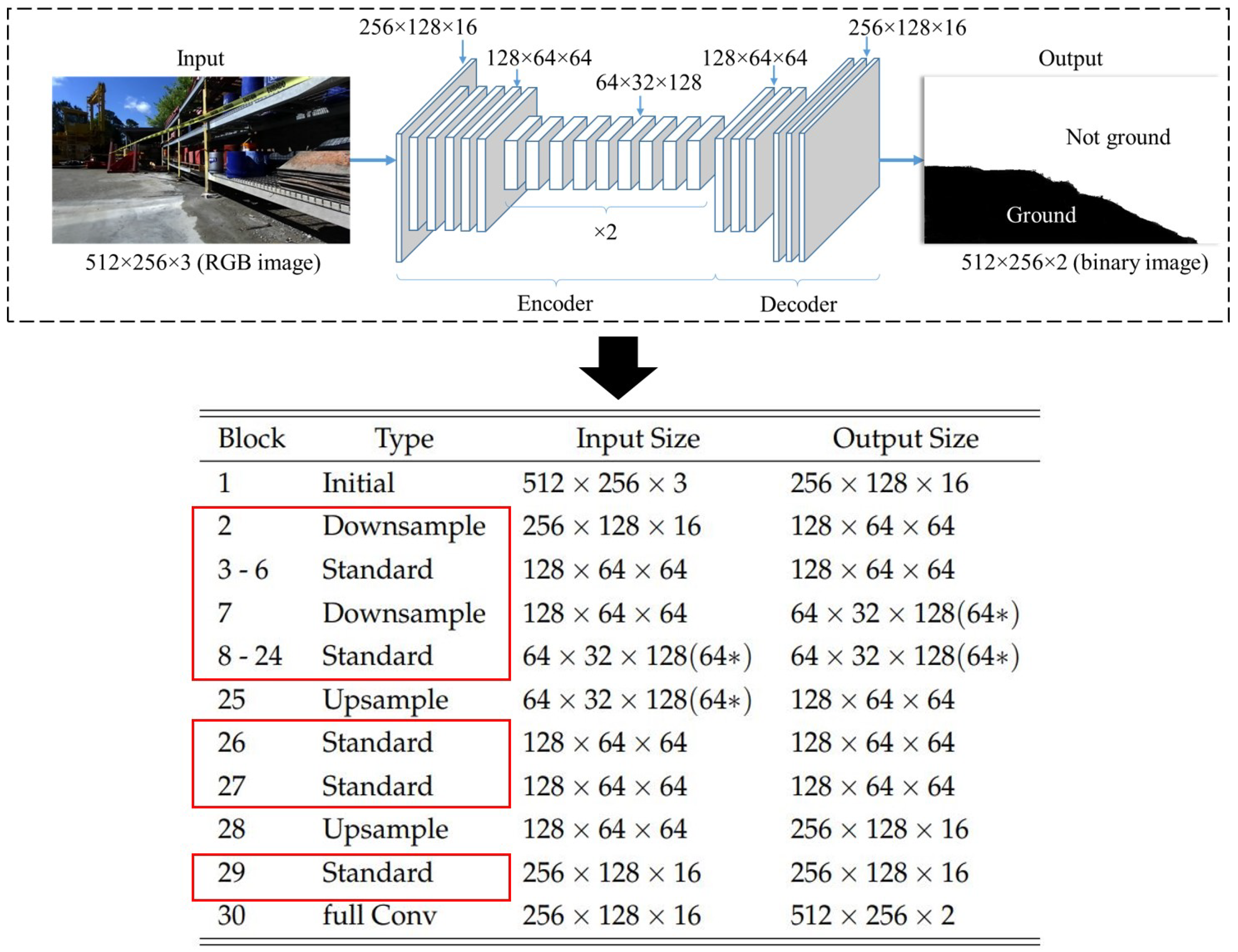
4.1. Model Architecture
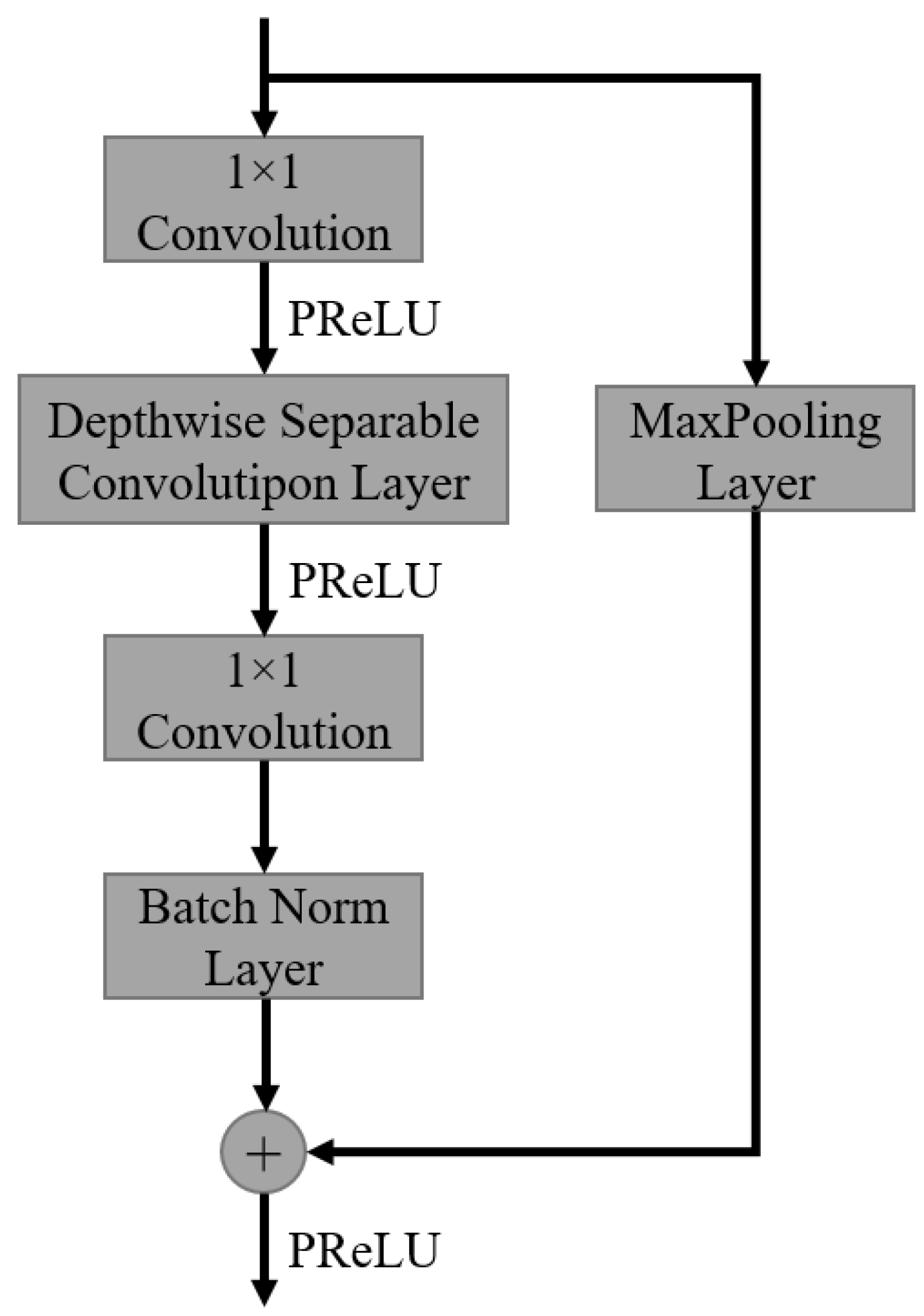
4.1.1. Factorized Convolution Block
4.1.2. Architecture Design
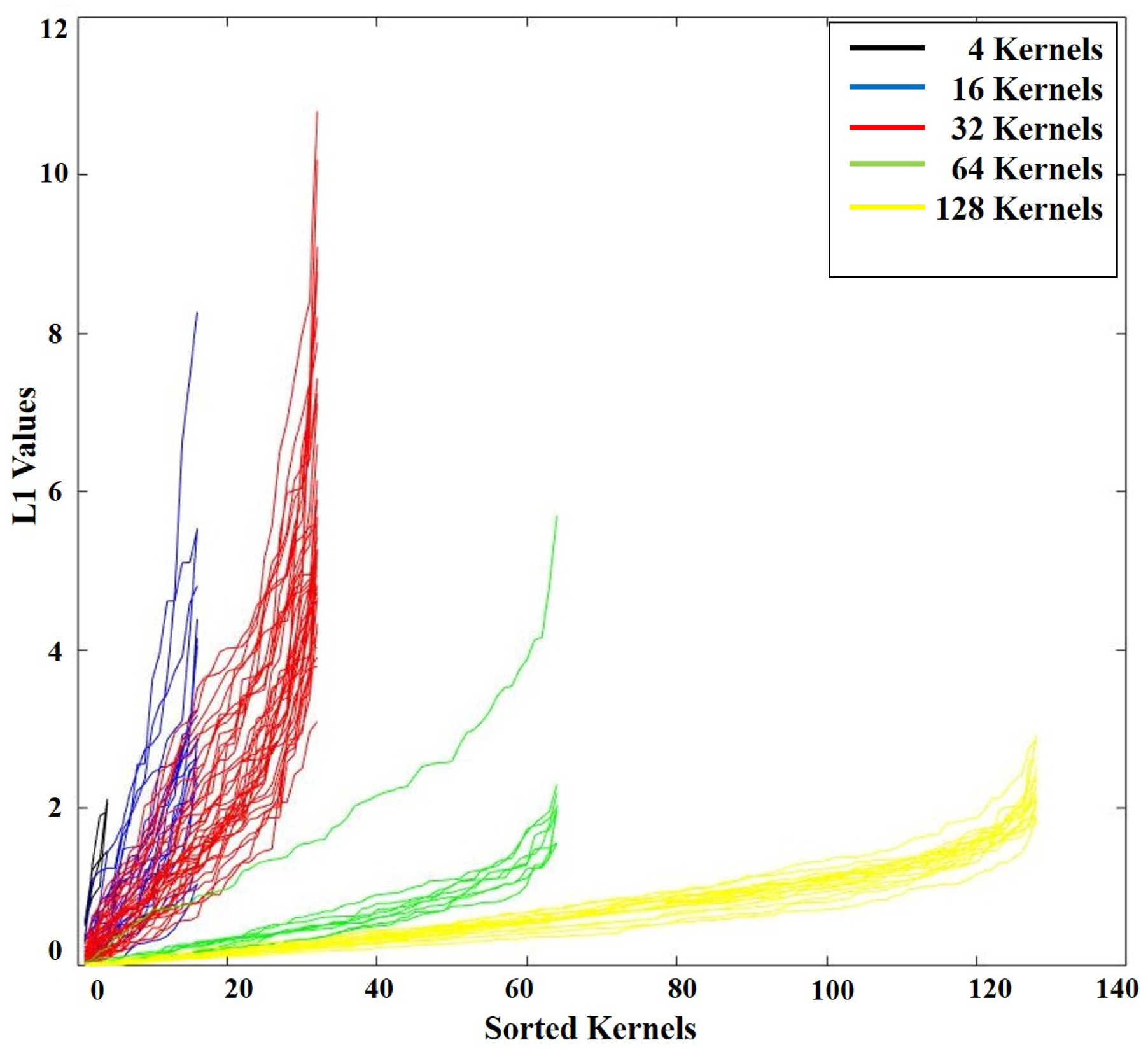
4.1.3. Model Compressing
- (1)
- For each filter, calculate the value.
- (2)
- Sort filters by values calculated in Step1.
- (3)
- Remove the filters and corresponding feature maps.
- (4)
- Fine-tune the whole network.
4.2. Optimizer and Loss Function
5. Experimental Setup
5.1. Dataset Construction and Training Strategy
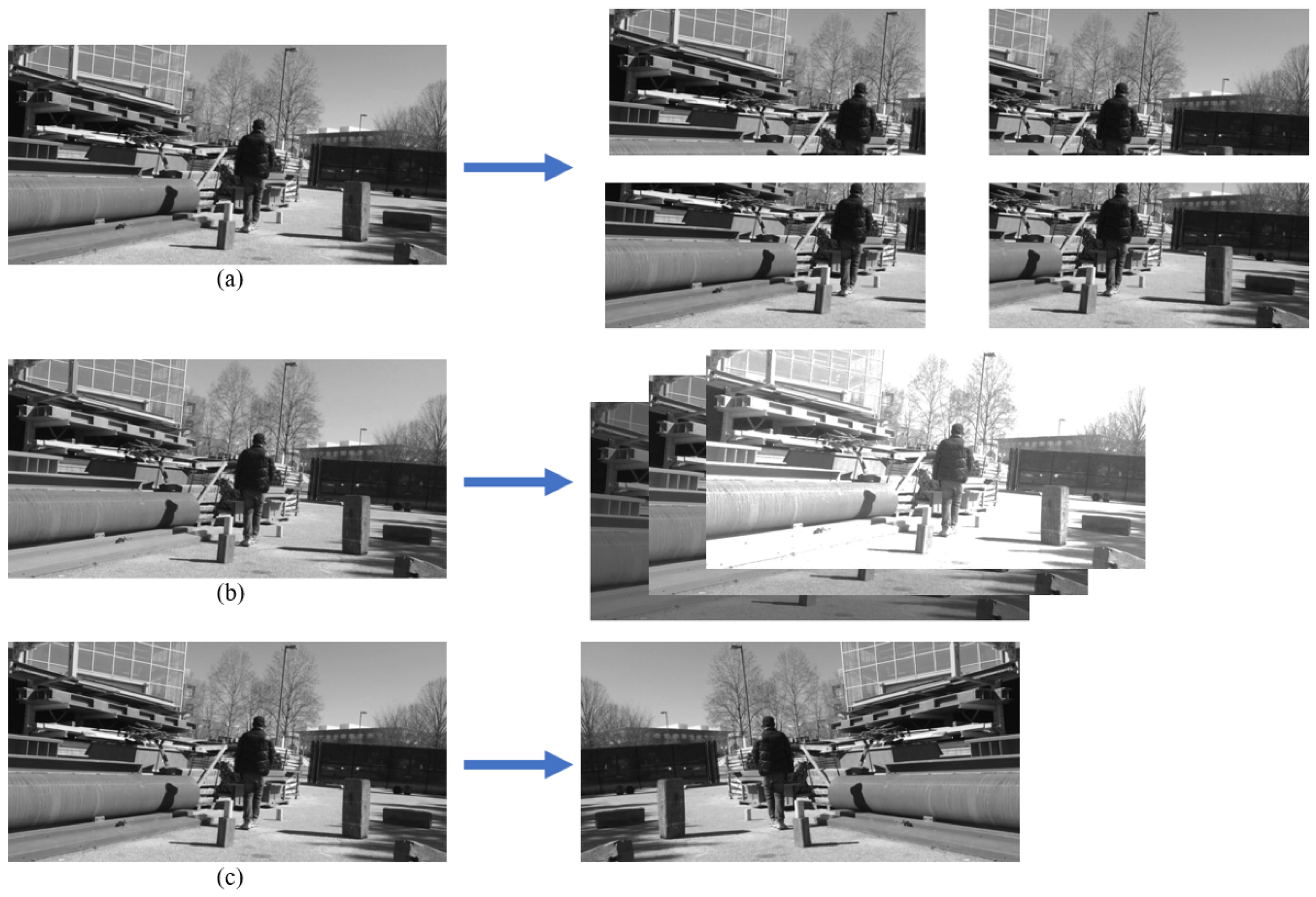
5.2. Data Augmentation
6. Experimental Results
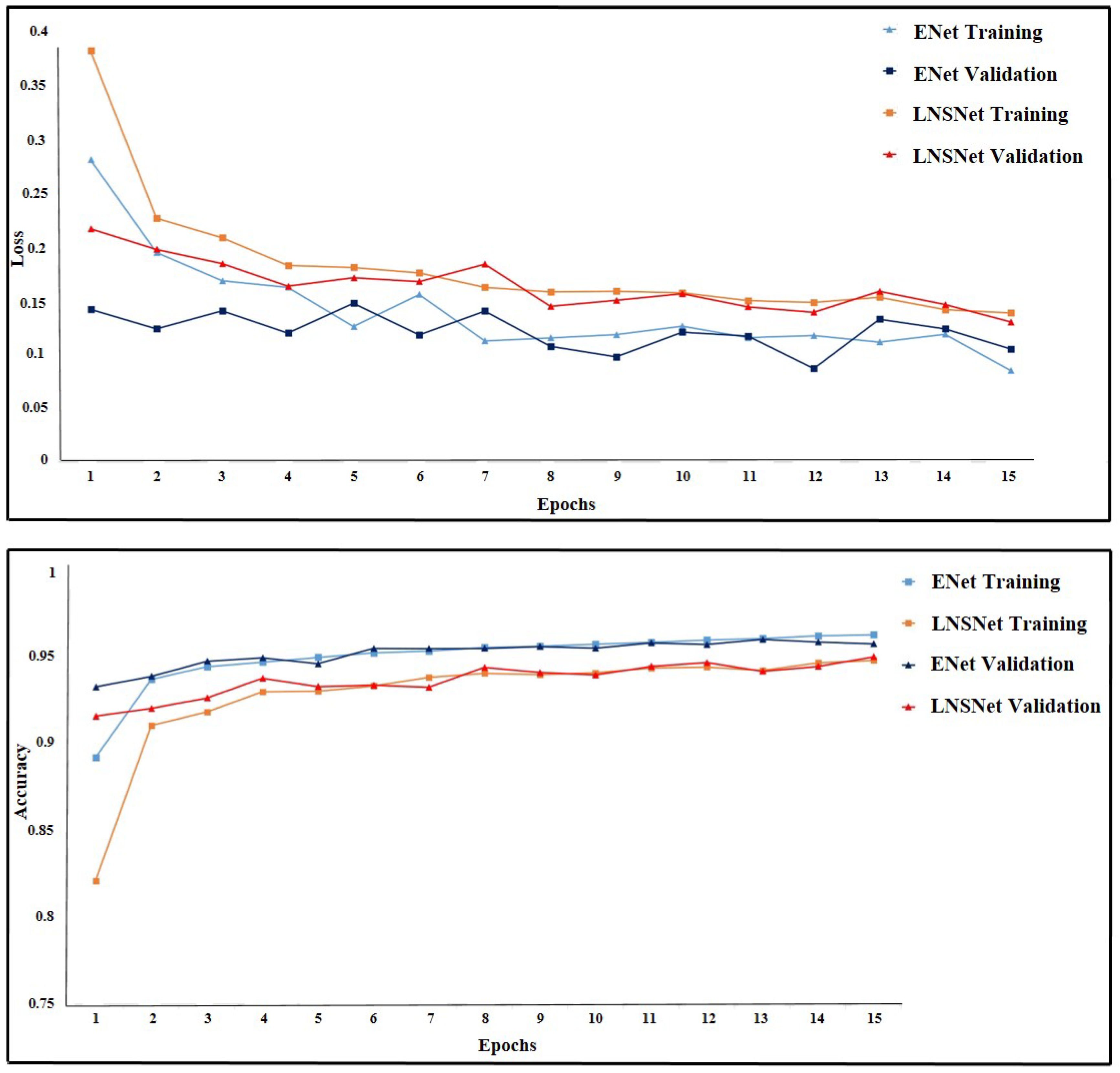
6.1. Training Results
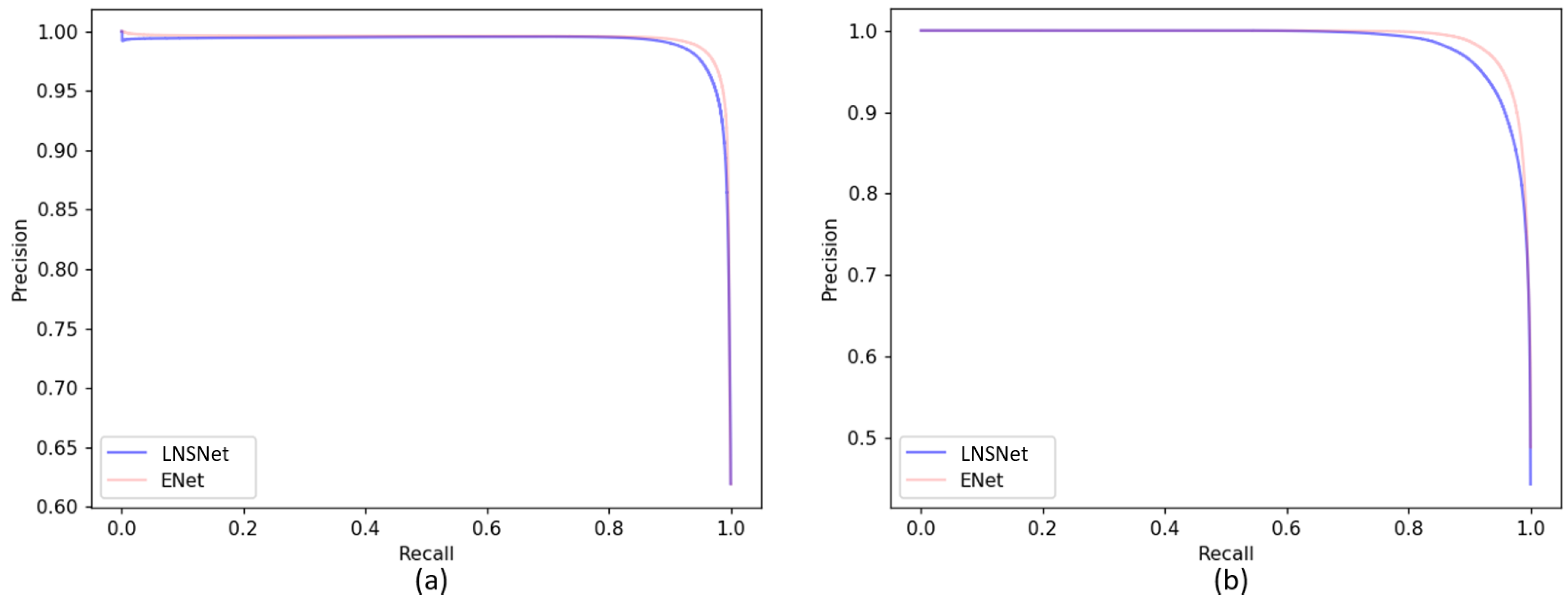
6.2. Test Results
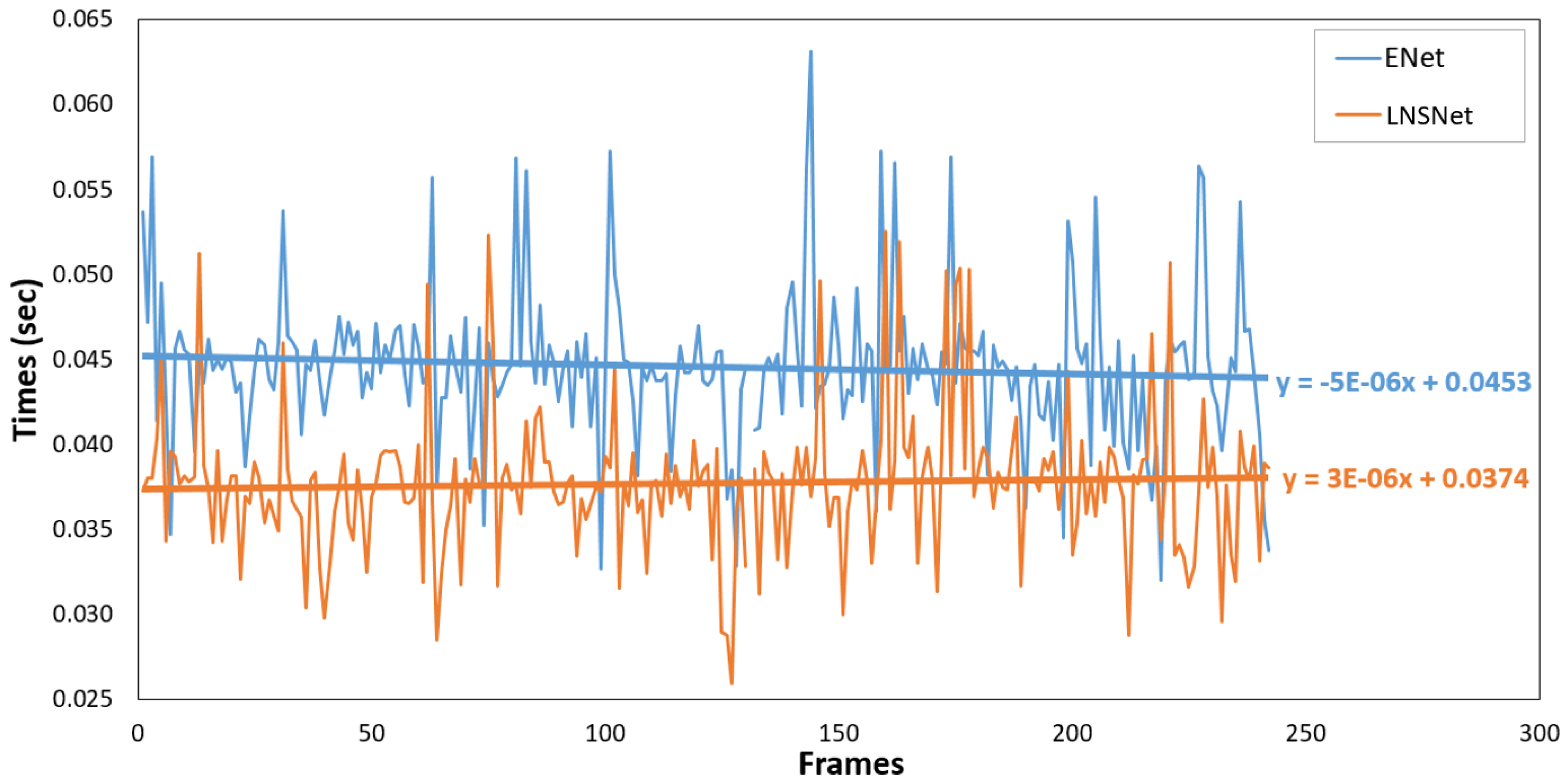
6.3. Model Comparison
7. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Changali, S.; Mohammad, A.; van Nieuwl, M. The Construction Productivity Imperative; McKinsey & Company: Brussels, Belgium, 2015. [Google Scholar]
- Kangari, R.; Yoshida, T. Automation in construction. Robot. Auton. Syst. 1990, 6, 327–335. [Google Scholar] [CrossRef]
- Chan, A.P.; Scott, D.; Chan, A.P. Factors affecting the success of a construction project. J. Construct. Eng. Manag. 2004, 130, 153–155. [Google Scholar] [CrossRef]
- Asadi, K.; Ramshankar, H.; Noghabaee, M.; Han, K. Real-time Image Localization and Registration with BIM Using Perspective Alignment for Indoor Monitoring of Construction. J. Comput. Civ. Eng. 2019. [Google Scholar]
- Han, K.K.; Golparvar-Fard, M. Potential of big visual data and building information modeling for construction performance analytics: An exploratory study. Autom. Constr. 2017, 73, 184–198. [Google Scholar] [CrossRef]
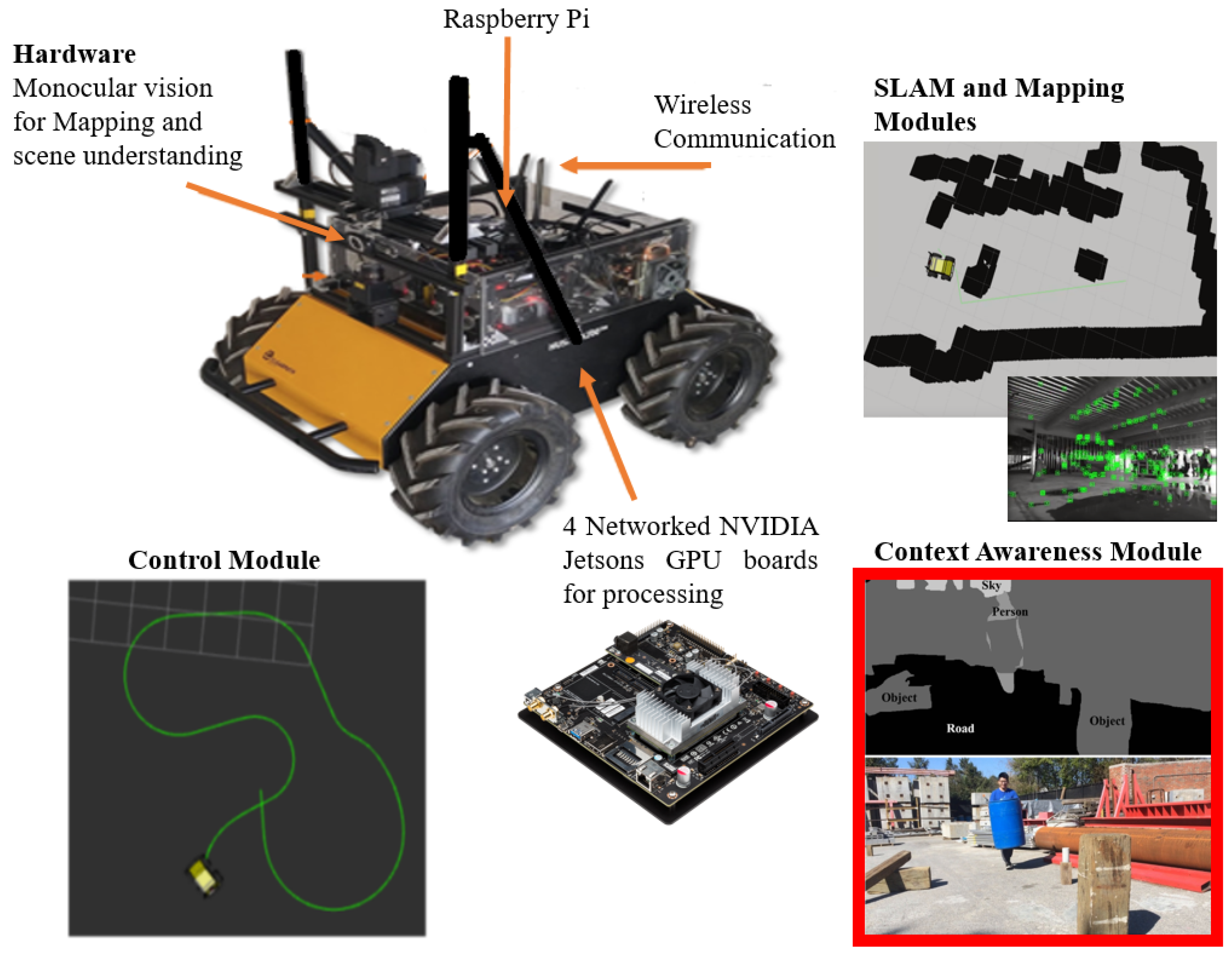
- Asadi, K.; Ramshankar, H.; Pullagurla, H.; Bhandare, A.; Shanbhag, S.; Mehta, P.; Kundu, S.; Han, K.; Lobaton, E.; Wu, T. Building an Integrated Mobile Robotic System for Real-Time Applications in Construction. arXiv, 2018; arXiv:1803.01745. [Google Scholar]
- Asadi, K.; Han, K. Real-Time Image-to-BIM Registration using Perspective Alignment for Automated Construction Monitoring. In Construction Research Congress 2018, New Orleans, LA, USA, 2–4 April 2018; ASCE: Reston, VA, USA, 2018; pp. 388–397. [Google Scholar]
- Kropp, C.; Koch, C.; König, M. Interior construction state recognition with 4D BIM registered image sequences. Autom. Constr. 2018, 86, 11–32. [Google Scholar] [CrossRef]
- Asadi Boroujeni, K.; Han, K. Perspective-Based Image-to-BIM Alignment for Automated Visual Data Collection and Construction Performance Monitoring. In Computing in Civil Engineering 2017, Seattle, WA, USA, 25–27 June 2017; ASCE: Reston, VA, USA, 2017; pp. 171–178. [Google Scholar]
- Yang, J.; Park, M.W.; Vela, P.A.; Golparvar-Fard, M. Construction performance monitoring via still images, time-lapse photos, and video streams: Now, tomorrow, and the future. Adv. Eng. Informat. 2015, 29, 211–224. [Google Scholar] [CrossRef]
- Ham, Y.; Han, K.K.; Lin, J.J.; Golparvar-Fard, M. Visual monitoring of civil infrastructure systems via camera-equipped Unmanned Aerial Vehicles (UAVs): A review of related works. Vis. Eng. 2016, 4, 1. [Google Scholar] [CrossRef]
- Liu, P.; Chen, A.Y.; Huang, Y.N.; Han, J.Y.; Lai, J.S.; Kang, S.C.; Wu, T.; Wen, M.; Tsai, M. A review of rotorcraft unmanned aerial vehicle (UAV) developments and applications in civil engineering. Smart Struct. Syst. 2014, 13, 1065–1094. [Google Scholar] [CrossRef]
- Asadi, K.; Ramshankar, H.; Pullagurla, H.; Bhandare, A.; Shanbhag, S.; Mehta, P.; Kundu, S.; Han, K.; Lobaton, E.; Wu, T. Vision-based integrated mobile robotic system for real-time applications in construction. Autom. Constr. 2018, 96, 470–482. [Google Scholar] [CrossRef]
- ClearPathRobotics. husky-unmanned-ground-vehicle-robot. Available online: https://www.clearpathrobotics.com/husky-unmanned-ground-vehicle-robot/ (accessed on 29 November 2017).
- NVIDIA. Unleash Your Potential with the Jetson TX1 Developer Kit. Available online: https://developer.nvidia.com/embedded/buy/jetson-tx1-devkit (accessed on 29 November 2017).
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. CoRR, 2016; arXiv:1606.02147. [Google Scholar]
- Quigley, M.; Gerkey, B.; Conley, K.; Faust, J.; Foote, T.; Leibs, J.; Berger, E.; Wheeler, R.; Ng, A. ROS: An open-source Robot Operating System. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) Workshop on Open Source Robotics, Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Golparvar-Fard, M.; Peña-Mora, F.; Savarese, S. D4AR–a 4-dimensional augmented reality model for automating construction progress monitoring data collection, processing and communication. J. Inf. Technol. Construct. 2009, 14, 129–153. [Google Scholar]
- Kim, H.; Kim, K.; Kim, H. Data-driven scene parsing method for recognizing construction site objects in the whole image. Autom. Constr. 2016, 71, 271–282. [Google Scholar] [CrossRef]
- Brilakis, I.; Park, M.W.; Jog, G. Automated vision tracking of project related entities. Adv. Eng. Informat. 2011, 25, 713–724. [Google Scholar] [CrossRef]
- Teizer, J.; Vela, P. Personnel tracking on construction sites using video cameras. Adv. Eng. Informat. 2009, 23, 452–462. [Google Scholar] [CrossRef]
- Yang, J.; Arif, O.; Vela, P.A.; Teizer, J.; Shi, Z. Tracking multiple workers on construction sites using video cameras. Adv. Eng. Informat. 2010, 24, 428–434. [Google Scholar] [CrossRef]
- Chi, S.; Caldas, C.H. Automated object identification using optical video cameras on construction sites. Comput.-Aided Civ. Infrastruct. Eng. 2011, 26, 368–380. [Google Scholar] [CrossRef]
- Park, M.W.; Brilakis, I. Construction worker detection in video frames for initializing vision trackers. Autom. Constr. 2012, 28, 15–25. [Google Scholar] [CrossRef]
- Escorcia, V.; Dávila, M.A.; Golparvar-Fard, M.; Niebles, J.C. Automated vision-based recognition of construction worker actions for building interior construction operations using RGBD cameras. In Construction Research Congress 2012: Construction Challenges in a Flat World; 21–23 May 2012; West Lafayette, IN, USA; ASCE: Reston, VA, USA, 2012; pp. 879–888. [Google Scholar]
- Memarzadeh, M.; Golparvar-Fard, M.; Niebles, J.C. Automated 2D detection of construction equipment and workers from site video streams using histograms of oriented gradients and colors. Autom. Constr. 2013, 32, 24–37. [Google Scholar] [CrossRef]
- Cho, Y.K.; Gai, M. Projection-recognition-projection method for automatic object recognition and registration for dynamic heavy equipment operations. J. Comput. Civ. Eng. 2013, 28, A4014002. [Google Scholar] [CrossRef]
- Zhu, Z.; Ren, X.; Chen, Z. Integrated detection and tracking of workforce and equipment from construction jobsite videos. Autom. Constr. 2017, 81, 161–171. [Google Scholar] [CrossRef]
- Park, M.W.; Brilakis, I. Continuous localization of construction workers via integration of detection and tracking. Autom. Constr. 2016, 72, 129–142. [Google Scholar] [CrossRef]
- Kang, D.; Cha, Y.J. Autonomous UAVs for Structural Health Monitoring Using Deep Learning and an Ultrasonic Beacon System with Geo-Tagging. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 885–902. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Comput.-Aided Civ. Infrastruct. Eng. 2017, 33, 731–747. [Google Scholar] [CrossRef]
- Gao, Y.; Mosalam, K.M. Deep Transfer Learning for Image-Based Structural Damage Recognition. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 748–768. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Zhu, Z.; Paal, S.; Brilakis, I. Detection of large-scale concrete columns for automated bridge inspection. Autom. Constr. 2010, 19, 1047–1055. [Google Scholar] [CrossRef]
- Wu, Y.; Kim, H.; Kim, C.; Han, S.H. Object recognition in construction-site images using 3D CAD-based filtering. J. Comput. Civ. Eng. 2009, 24, 56–64. [Google Scholar] [CrossRef]
- Son, H.; Kim, C.; Kim, C. Automated color model–based concrete detection in construction-site images by using machine learning algorithms. J. Comput. Civ. Eng. 2011, 26, 421–433. [Google Scholar] [CrossRef]
- Han, K.K.; Golparvar-Fard, M. Appearance-based material classification for monitoring of operation-level construction progress using 4D {BIM} and site photologs. Autom. Constr. 2015, 53, 44–57. [Google Scholar] [CrossRef]
- Hamledari, H.; McCabe, B.; Davari, S. Automated computer vision-based detection of components of under-construction indoor partitions. Autom. Constr. 2017, 74, 78–94. [Google Scholar] [CrossRef]
- Li, H.; Chan, G.; Wong, J.K.W.; Skitmore, M. Real-time locating systems applications in construction. Autom. Constr. 2016, 63, 37–47. [Google Scholar] [CrossRef]
- Asadi, K.; Jain, R.; Qin, Z.; Sun, M.; Noghabaei, M.; Cole, J.; Han, K.; Lobaton, E. Vision-based Obstacle Removal System for Autonomous Ground Vehicles Using a Robotic Arm. arXiv, 2019; arXiv:cs.RO/1901.08180. [Google Scholar]
- Han, K.; Degol, J.; Golparvar-Fard, M. Geometry- and Appearance-Based Reasoning of Construction Progress Monitoring. J. Construct. Eng. Manag. 2018, 144, 04017110. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv, 2015; arXiv:1511.00561. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv, 2017; arXiv:1704.04861. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv, 2016; arXiv:1608.08710. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Van Merriënboer, B.; Bahdanau, D.; Dumoulin, V.; Serdyuk, D.; Warde-Farley, D.; Chorowski, J.; Bengio, Y. Blocks and fuel: Frameworks for deep learning. arXiv, 2015; arXiv:1506.00619. [Google Scholar]
- Nickolls, J.; Buck, I.; Garland, M.; Skadron, K. Scalable Parallel Programming with CUDA. Queue 2008, 6, 40–53. [Google Scholar] [CrossRef]
- Chetlur, S.; Woolley, C.; Vandermersch, P.; Cohen, J.; Tran, J.; Catanzaro, B.; Shelhamer, E. cudnn: Efficient primitives for deep learning. arXiv, 2014; arXiv:1410.0759. [Google Scholar]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv, 2017; arXiv:1706.02677. [Google Scholar]
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection; Ijcai: Montreal, QC, Canada, 1995; Volume 14, pp. 1137–1145. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Proposed Dataset Labels | Cityscapes Labels |
|---|---|
| Ground | road, sidewalk, parking |
| Not Ground | person, rider, car, truck, bus, on rails, motorcycle, bicycle, caravan, trailer, fence, guard rail, bridge, tunnel, pole, pole group, traffic sign, traffic light, rail track, sky, building, wall, vegetation, terrain, void(ground), void(dynamic), void(static) |
| ENet | LNSNet | |
|---|---|---|
| Recall | 0.9664 | 0.9442 |
| Precision | 0.9367 | 0.9290 |
| Accuracy | 0.9659 | 0.9551 |
| ENet | LNSNet | |
|---|---|---|
| Recall | 0.9890 | 0.9908 |
| Precision | 0.8855 | 0.8384 |
| Accuracy | 0.9435 | 0.9231 |
| LNSNet | ENet | |
|---|---|---|
| Average inference time per frame (ms) | 36.5 | 44.7 |
| Total parameters | 227,393 | 371,116 |
| Max input frame rate for real-time performance | 27.4 | 22.4 |
| Model size (KB) | 1068 | 2225 |
| Mean (s) | Std (s) | df | t-Value | p-Value | |
|---|---|---|---|---|---|
| ENet | 0.0447 | 0.0048 | 473.98 | 17.036 | 4.0602 |
| LNSNet | 0.0365 | 0.0042 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asadi, K.; Chen, P.; Han, K.; Wu, T.; Lobaton, E. LNSNet: Lightweight Navigable Space Segmentation for Autonomous Robots on Construction Sites. Data 2019, 4, 40. https://doi.org/10.3390/data4010040
Asadi K, Chen P, Han K, Wu T, Lobaton E. LNSNet: Lightweight Navigable Space Segmentation for Autonomous Robots on Construction Sites. Data. 2019; 4(1):40. https://doi.org/10.3390/data4010040
Chicago/Turabian StyleAsadi, Khashayar, Pengyu Chen, Kevin Han, Tianfu Wu, and Edgar Lobaton. 2019. "LNSNet: Lightweight Navigable Space Segmentation for Autonomous Robots on Construction Sites" Data 4, no. 1: 40. https://doi.org/10.3390/data4010040
APA StyleAsadi, K., Chen, P., Han, K., Wu, T., & Lobaton, E. (2019). LNSNet: Lightweight Navigable Space Segmentation for Autonomous Robots on Construction Sites. Data, 4(1), 40. https://doi.org/10.3390/data4010040