A Dataset of Vietnamese Junior High School Students’ Reading Preferences and Habits

 ,
, 
 , and
, and 
Abstract
:1. Summary
2. Data Description
2.1. Group (1) Questions
2.2. Group (2) Questions
2.3. Potential Research Questions
- What socio-economic and socio-cultural factors that could affect reading habits of students?
- How habits, preferences and wishes of students influence the efficacy of reading promotion campaigns and events?
- How does the birth order associate with reading habits?
- How does reading habits associate with academic performance and professional orientation?
- Is there any difference in reading habits conditioned on biological sex? For example, do female students behave differently when coming across interesting content?
- How does students’ perception of classrooms’ bookshelves associate with reading habits?
3. Methods
3.1. Materials and Methods
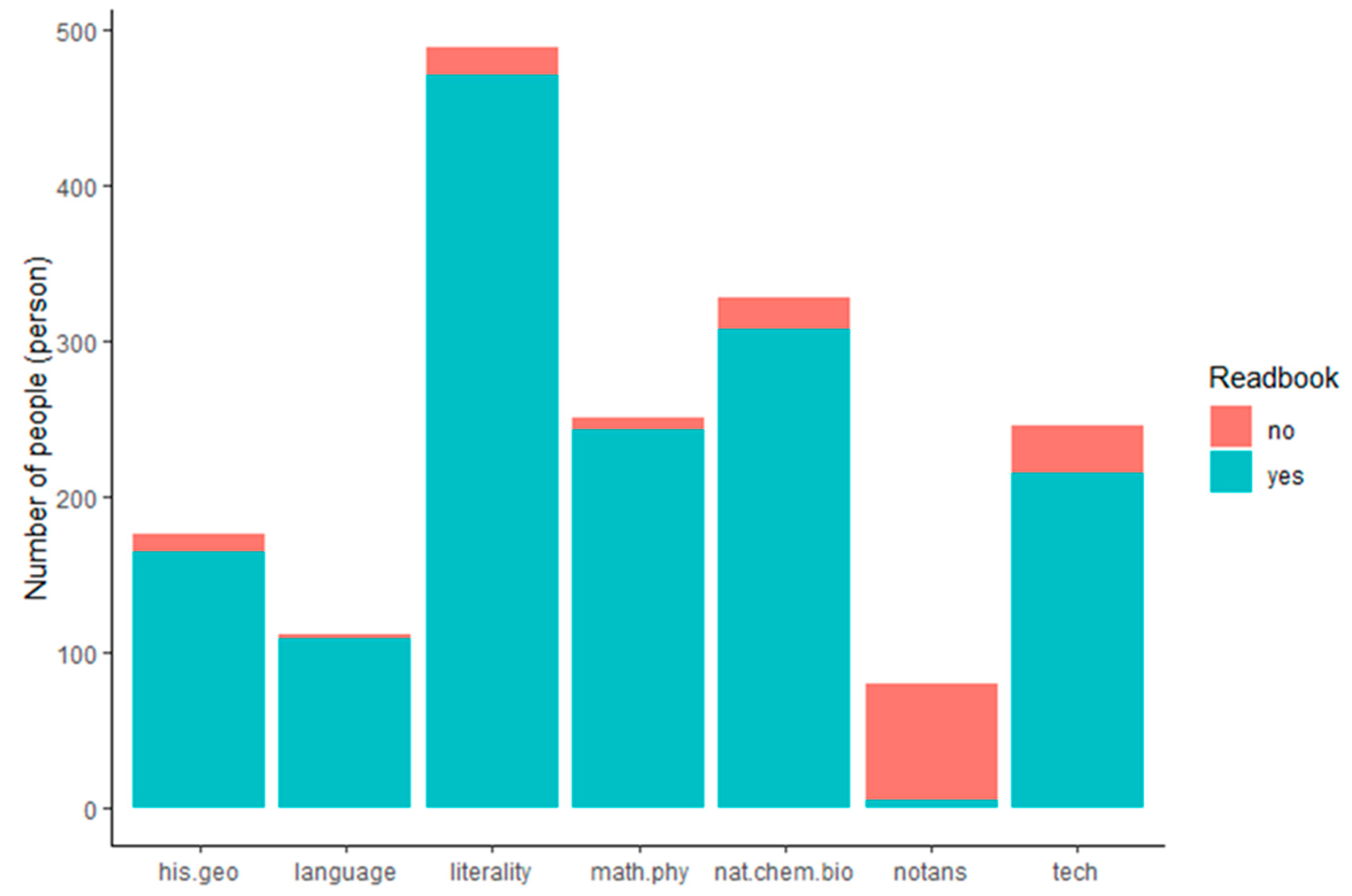
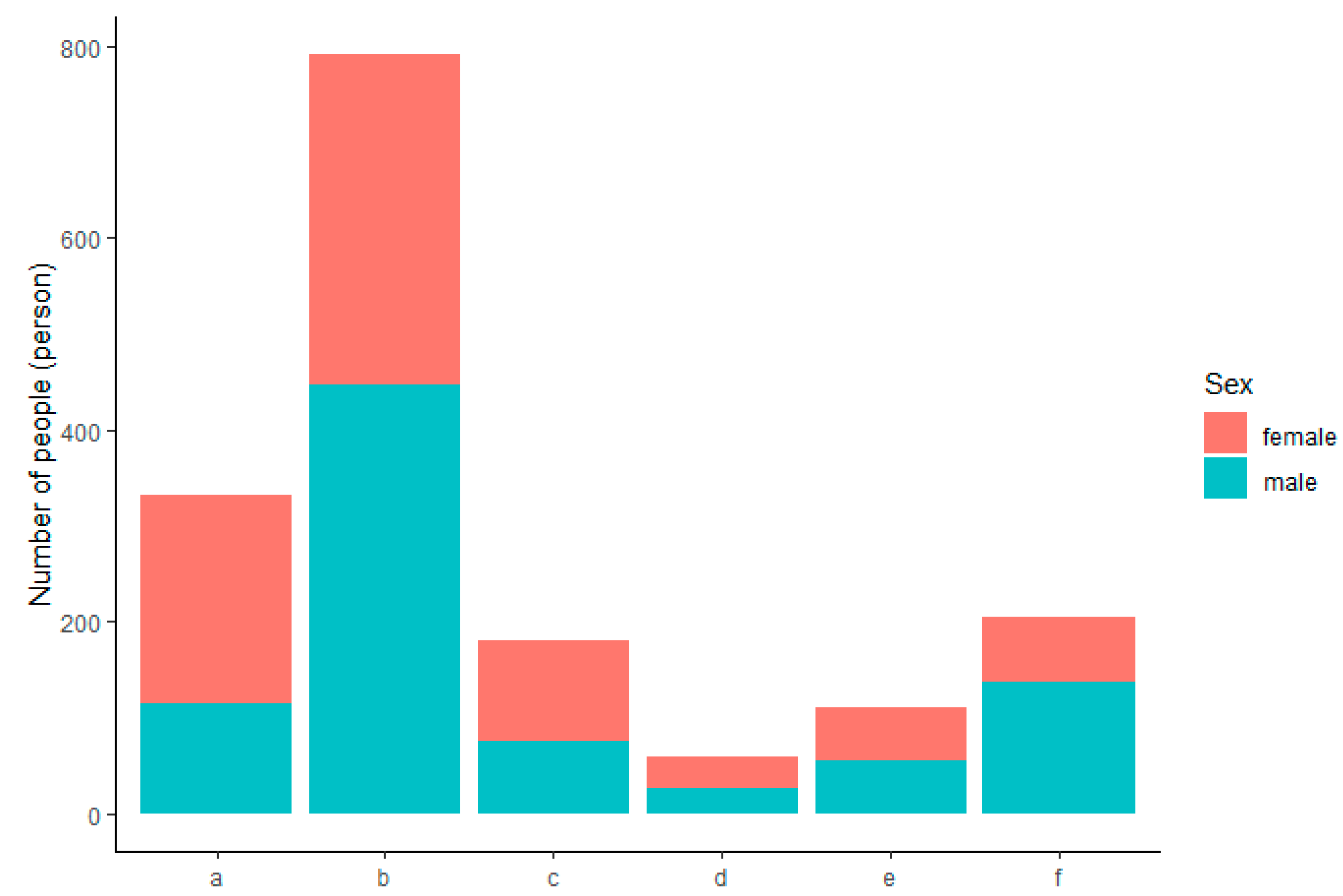
3.2. Examples of Data Analysis
| > tab=read.csv("D:/VA/Data in Brief/tab.csv",header=T) > attach(tab) > fit.md=vglm(cbind(yes,no)~Sex+Grade,data=tab,family=multinomial) > summary(fit.md) |
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | School | Number of Surveyed Students | Female | Male |
|---|---|---|---|---|
| 1 | Yên Hòa junior high school | 348 | 51.72% | 48.28% |
| 2 | Khánh Dương junior high school | 133 | 45.11% | 54.89% |
| 3 | Khánh Thượng junior high school | 281 | 54.09% | 45.91% |
| 4 | Yên Mỹ junior high school | 187 | 44.39% | 55.61% |
| 5 | Yên Phong junior high school | 221 | 48.87% | 51.13% |
| 6 | Yên Thái junior high School | 246 | 47.56% | 52.44% |
| 7 | Khánh Thịnh junior high School | 91 | 48.35% | 51.65% |
| 8 | Mai Sơn junior high School | 170 | 47.06% | 52.94% |
| Expanded list of schools from the second phase: (9) Yên Thắng junior high School. (10) Yên Nhân junior high School. (11) Yên Đồng junior high School. (12) Yên Từ junior high School. (13) Yên Thành junior high School. (14) Yên Hưng junior high School. (15) Vũ Phạm Khải junior high School. (16) Yên Lâm junior high School | ||||
Appendix B:
| ‘Sex’| ‘Grade’ | ‘Readbook’ | |||||||
|---|---|---|---|---|---|---|---|---|
| ‘Yes’ | ‘No’ | |||||||
| ‘Grade6’ | ‘Grade7’ | ‘Grade8’ | ‘Grade9’ | ‘Grade6’ | ‘Grade7’ | ‘Grade8’ | ‘Grade9’ | |
| ‘Male’ | 0.941 | 0.837 | 0.878 | 0.753 | 0.059 | 0.163 | 0.122 | 0.247 |
| ‘Female’ | 0.978 | 0.941 | 0.957 | 0.904 | 0.022 | 0.059 | 0.043 | 0.096 |
References
- Perfetti, C.A. Reading Ability; Oxford University Press: Oxford, UK, 1985. [Google Scholar] [CrossRef]
- Cheng, K.-H.; Tsai, C.-C. Children and parents’ reading of an augmented reality picture book: Analyses of behavioral patterns and cognitive attainment. Comput. Educ. 2014, 72, 302–312. [Google Scholar] [CrossRef]
- Farrant, B.M.; Zubrick, S.R. Early vocabulary development: The importance of joint attention and parent-child book reading. First Lang. 2011, 32, 343–364. [Google Scholar] [CrossRef]
- Manolitsis, G.; Georgiou, G.K.; Tziraki, N. Examining the effects of home literacy and numeracy environment on early reading and math acquisition. Early Child. Res. Q. 2013, 28, 692–703. [Google Scholar] [CrossRef]
- Whitehurst, G.J.; Falco, F.L.; Lonigan, C.J.; Fischel, J.E.; DeBaryshe, B.D.; Valdez-Menchaca, M.C.; Caulfield, M. Accelerating language development through picture book reading. Dev. Psychol. 1988, 24, 552–559. [Google Scholar] [CrossRef]
- Fountas, I.C.; Pinnell, G.S.; Le Verrier, R. Guided Reading; Heinemann: Portsmouth, UK, 2001. [Google Scholar]
- Smith, F. Understanding Reading: A Psycholinguistic Analysis of Reading and Learning to Read; Routledge: London, UK, 2004. [Google Scholar] [CrossRef]
- Daneman, M.; Carpenter, P.A. Individual differences in working memory and reading. J. Verbal Learn. Verbal Behav. 1980, 19, 450–466. [Google Scholar] [CrossRef]
- Krashen, S.D. The Power of Reading: Insights from the Research; ABC-CLIO: Stan Barbara, CA, USA, 2004. [Google Scholar]
- Hargrave, A.C.; Sénéchal, M. A book reading intervention with preschool children who have limited vocabularies: The benefits of regular reading and dialogic reading. Early Child. Res. Q. 2000, 15, 75–90. [Google Scholar] [CrossRef]
- Sikora, J.; Evans, M.; Kelley, J. Scholarly culture: How books in adolescence enhance adult literacy, numeracy and technology skills in 31 societies. Soc. Sci. Res. 2019, 77, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Marinak, B.A.; Gambrell, L.B. Reading motivation: Exploring the elementary gender gap. Lit. Res. Instr. 2010, 49, 129–141. [Google Scholar] [CrossRef]
- Anderson, M.A.; Tollefson, N.A.; Gilbert, E.C. Giftedness and reading: A cross-sectional view of differences in reading attitudes and behaviors. Gift. Child Q. 1985, 29, 186–189. [Google Scholar] [CrossRef]
- Pigliucci, M. The Case for More Science and Philosophy Books for Children. Available online: http://nautil.us/blog/-the-case-for-more-science-and-philosophy-books-for-children (accessed on 21 March 2019).
- Vuong, Q.-H. Survey data on Vietnamese propensity to attend periodic general health examinations. Sci. Data 2017, 4, 170142. [Google Scholar] [CrossRef]
- Vuong, Q.H. Survey data on entrepreneurs’ subjective plan and perceptions of the likelihood of success. Data Brief 2016, 6, 858–864. [Google Scholar] [CrossRef]
- Vuong, Q.-H.; Nguyen, T.-K. Data on Vietnamese patients’ financial burdens and risk of destitution. Data Brief 2016, 9, 543–548. [Google Scholar] [CrossRef] [PubMed]
- Vuong, Q.H. Data on Vietnamese patients’ behavior in using information sources, perceived data sufficiency and (non)optimal choice of health care provider. Data Brief 2016, 7, 1687–1695. [Google Scholar] [CrossRef] [PubMed]
- Agresti, A. Categorical Data Analysis, 3rd ed.; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Fienberg, S.E.; Junker, B.W. Categorical Data Analysis. In International Encyclopedia of Education, 3rd ed.; Peterson, P., Baker, E., McGaw, B., Eds.; Elsevier: Oxford, UK, 2010; pp. 58–65. [Google Scholar] [CrossRef]
- Tansey, R.; White, M.; Long, R.G.; Smith, M. A comparison of loglinear modeling and logistic regression in management research. J. Manag. 1996, 22, 339–358. [Google Scholar] [CrossRef]
- Vuong, Q.H. The (ir)rational consideration of the cost of science in transition economies. Nat. Hum. Behav. 2018, 2, 5. [Google Scholar] [CrossRef] [PubMed]




| Coded Name | Explanation | Items | Frequency | Proportion |
|---|---|---|---|---|
| Grade | Current grade where students are studying | Grade 6 | 467 | 27.86% |
| Grade 7 | 443 | 26.43% | ||
| Grade 8 | 410 | 24.46% | ||
| Grade 9 | 356 | 21.24% | ||
| Sex | Biological sex of the students | Male | 853 | 50.89% |
| Female | 823 | 49.11% | ||
| RankinF | Subjects’ birth order in the family | First child | 695 | 41.47% |
| Second child | 617 | 36.81% | ||
| Third child | 251 | 14.98% | ||
| Forth child | 79 | 4.71% | ||
| Fifth child | 26 | 1.55% | ||
| Sixth child | 5 | 0.30% | ||
| Seventh child | 3 | 0.18% | ||
| NumberofChi | Number of children in the family | 1 child | 78 | 4.65% |
| 2 children | 744 | 44.39% | ||
| 3 children | 629 | 37.53% | ||
| 4 children | 159 | 9.49% | ||
| 5 children | 45 | 2.68% | ||
| 6 children | 15 | 0.89% | ||
| 7 children | 5 | 0.30% | ||
| 8 children | 1 | 0.06% | ||
| Source | Main source of supply for books | Personal expense/Parents | 617 | 36.81% |
| Borrowed from friends/library | 1016 | 60.62% | ||
| Gift/Reward | 43 | 2.57% | ||
| PrioAct | Prioritized actions when coming across interesting content | Tell friends or family | 796 | 47.49% |
| Note down | 349 | 20.82% | ||
| Apply the content to daily life | 111 | 6.62% | ||
| Reflect and connect with personal knowledge | 420 | 25.06% | ||
| AftAct | Actions after finished a good book | Find more books with the same topic | 825 | 49.22% |
| Find books on related topics | 277 | 16.53% | ||
| Find books on new topics | 242 | 14.44% | ||
| Read again | 332 | 19.81% | ||
| EncourAct | Preferences on joining reading promotion activities | Yes | 1493 | 89.10% |
| No | 183 | 10.90% | ||
| MostlikedAct | Favorite book-related activities and events | Book exhibition | 637 | 39.69% |
| Storytelling competition | 427 | 26.60% | ||
| Story-writing competition | 187 | 11.65% | ||
| Creating book illustrations | 354 | 22.06% | ||
| Bookcase | Evaluating classrooms’ public bookshelves | Diverse and interesting | 637 | 38.01% |
| Missing good titles | 455 | 27.15% | ||
| Lacking books | 225 | 13.42% | ||
| No bookshelf | 359 | 21.42% |
| Intercept | “Sex” | “Grade” | |||
|---|---|---|---|---|---|
| “Male” | “Grade7” | “Grade8” | “Grade9” | ||
| β0 | β1 | β2 | β3 | β4 | |
| Logit (yes|no) | 3.888 *** [14.147] | −1.124 *** [−6.011] | −1.125 *** [−3.986] | −0.786 ** [−2.648] | −1.650 *** [−6.003] |
| Intercept | “Sex” | “EcoStt” | ||
|---|---|---|---|---|
| “Male” | “poor” | “rich” | ||
| β0 | β1 | β2 | β3 | |
| Logit (yes|no) | 2.860 *** [17.936] | −1.107 *** [−5.980] | −0.014 [−0.045] | 0.464 [1.529] |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vuong, Q.-H.; Le, A.-V.; La, V.-P.; Vuong, T.-T.; Do, T.-H.; Vuong, H.-M.; Do, D.-L.; Hoang, P.-H.; Vu, T.-H.; Ho, M.-T.; et al. A Dataset of Vietnamese Junior High School Students’ Reading Preferences and Habits. Data 2019, 4, 49. https://doi.org/10.3390/data4020049
Vuong Q-H, Le A-V, La V-P, Vuong T-T, Do T-H, Vuong H-M, Do D-L, Hoang P-H, Vu T-H, Ho M-T, et al. A Dataset of Vietnamese Junior High School Students’ Reading Preferences and Habits. Data. 2019; 4(2):49. https://doi.org/10.3390/data4020049
Chicago/Turabian StyleVuong, Quan-Hoang, Anh-Vinh Le, Viet-Phuong La, Thu-Trang Vuong, Thu-Hang Do, Ha-My Vuong, Duc-Lan Do, Phuong-Hanh Hoang, Thi-Hanh Vu, Manh-Tung Ho, and et al. 2019. "A Dataset of Vietnamese Junior High School Students’ Reading Preferences and Habits" Data 4, no. 2: 49. https://doi.org/10.3390/data4020049
APA StyleVuong, Q. -H., Le, A. -V., La, V. -P., Vuong, T. -T., Do, T. -H., Vuong, H. -M., Do, D. -L., Hoang, P. -H., Vu, T. -H., Ho, M. -T., & Ho, M. -T. (2019). A Dataset of Vietnamese Junior High School Students’ Reading Preferences and Habits. Data, 4(2), 49. https://doi.org/10.3390/data4020049