1. Introduction
Stock price forecasting is surely one of the most important issues in finance and it has become one of the serious concerns of investors and shareholders since accurate and authentic forecasts of stock prices have attractive rewards and profitable advantages, and inaccurate and unreliable predictions can have irreparable consequences. Hence, it is essential to provide a precise and efficient model for predicting stock prices.
Stock price forecasting strategies are categorized into three wide classes that could overlap. The three classes are, respectively, fundamental analysis, technical analysis, and technological approaches [
1]. Fundamental analysis analyzes economic, monetary, and financial variables which affect a company’s value and attempt to calculate it through financial statements [
2]. Technical analysis is an analysis strategy for predicting the trend of prices and it reveals this concept that prices fluctuate in patterns that are determined by investors’ changing tendencies in the direction of various economic, commercial, financial, political, and psychological factors [
3]. The philosophy of the technical analysis is the opinion that all of the variables which affect market price are instantly impressed in the market process. This means that the effect of these external variables will immediately cause fluctuations in stock prices. Technical analysts work with different analytical instruments like technical indicators to analyze a security’s strength or weakness and forecast future price variations. This is in contrast to fundamental experts, who examine the intrinsic value of securities.
The technical indicators are definitely one of the major criteria for investing in the stock market and they play an important task in buy/sell stocks signals. Technical indicators are typically utilized by dynamic investors and traders because they are planned to evaluate short period price trends; however, long term traders can also apply technical indicators to recognize entry and exit positions. Technical indicators are mathematical computations on the basis of the price, volume, etc. By evaluating historical information, technical analysts employ indicators to forecast upcoming price fluctuations. Conventional time series approaches in statistics have also been employed to stock price forecasting [
4].
In this article, a novel approach integrating Artificial Bee Colony (ABC), Adaptive Neuro-Fuzzy Inference System (ANFIS), and Support Vector Machine (SVM) has been planned for stock price forecasting and technical analysis in the U.S. Stock Exchange.
The model includes three modules:
The ABC module for multi-objective optimization of technical indicators.
The ANFIS module to predict the upcoming price of stocks.
The SVM module to create the nexus between the stock price and technical indicator and to further decrease the forecasting errors.
The ABC is a metaheuristic algorithm for optimizing numerical problems and it is precisely on the basis of the model for the foraging behavior of honey bee colonies. It contains three necessary parts: employed and unemployed foraging bees, and food sources [
5]. ANFIS is an adaptive network that employs supervised learning on the learning algorithm and there are two groups of the diverse parameter in the framework of ANFIS: hypothesis and result. Training ANFIS implies the determination of these parameters applying the optimization algorithms [
6]. Given that ANFIS has been extended, it is employed in modeling and simulation of many mechanisms and efficient outcomes have been attained. SVM is one of the discriminative classifiers wherein classification is dependent on the decision levels and their borders and it is a collection of supervised learning procedures which applied for classification and regression [
7]. The principal idea of SVM is to build a hyperplane as the decision surface in ways that the margin of separation between positive and negative instances is maximized [
8]. SVM has been used in different areas such as time series and financial forecasting, the approximation of complicated engineering examines, convex quadratic programming, selection of loss functions, and so on. Lately, the SVM has been effectively employed on stock price forecasting and its trends.
In this investigation, our model employs three methods including ABC, ANFIS, and SVM and combines them. Each of the methods has benefits and drawbacks. One strategy to overcome challenging real-world issues, particularly in the finance and investment field, is to incorporate the application of several techniques in an effort to merge their various strong points and deal with a single technique’s weak point. This strategy creates hybrid models which provide more desirable outcomes compared to the ones reached with the application of each separated technique.
Certainly, stock price forecasting is difficult due to stock market fluctuations resulting from the fact that the prices of stock are extremely unstable, complicated, and dynamic.
Based on the abovementioned items, it is an essential issue for financial experts and portfolio managers, and is presently getting substantial consideration from both investigators and practitioners.
In this paper, the “Mathworks MATLAB R2019” software has been utilized for the presentation and test of the model.
The remainder of this article is arranged as follows: beginning with this introduction and in the next section, the literature reviews are carried out on the previous studies. The materials and methods are explained in
Section 3, and
Section 4 describes the results and evaluation of the proposed model. The conclusions are then discussed in the last section.
2. Related Works
Due to the importance of stock price forecasting, many researchers have studied this matter. Recently, there have been an increasing number of scientific researches presenting the forecasting models for future trends of different types of securities. In the following, we concentrate on the review of former investigations in line with this topic.
The first paper dealing with this subject, by Kimoto, Asakawa et al. [
9], utilized modular NN to forecast the timing of buying or selling for the TOPIX. The outcomes demonstrated that a great profit was attained.
Kamijo and Tanigawa [
10] improved a style identification method to forecast the stock prices in the Tokyo stock market. Their approach has been introduced to examine the recurrent networks to reduce the mismatching forms.
Yoon and Swale [
11] offered a four-layered NN to forecast stock prices in the USA. The outcomes demonstrated that their technique works better than the MDA procedure.
Baba and Kozaki [
12] suggested the BPNN method along with a random optimization strategy to forecast stock exchange in Japan. The outcomes confirmed that their method assisted to stock price forecasting.
Cheung, Lai et al. [
13] applied an adaptive rival penalized competitive learning approach and a combined linear forecasting model to predict both the Shanghai stock and the US Dollar to the German exchange rate. The outcomes verified that their method enhanced profits along with time.
Saad, Prokhorov et al. [
14] performed comparison research of TDNN, PNN, and RNN in forecasting daily closing prices in stock exchanges. The outcomes demonstrated that all networks are equally achievable but the simplest network is more suitable.
Takahashi, Tamada et al. [
15] suggested a NN that embodied a multiple line-segments regression method to forecast stock prices. The tangent and length of multiple line-segments regression were determined as outputs of the NN neural networks. The outcomes demonstrated that their method worked properly in stock price predicting.
Kim [
16] utilized SVM to forecast the trend of daily stock price alterations in the KOSPI. This research chose twelve technical indicators to design primary features and then assessed the possibility of implementing SVM in the financial forecast by comparing it with BPN and CBR. The outcomes verified that SVM works better than BPN and CBR.
Pai and Lin [
17] utilized the advantages of the ARIMA and SVM to improve a hybrid method. The ARIMA approach utilized to design the linear dataset, while the SVMs were used to manage the nonlinear information pattern in time series predicting. Their outcomes revealed that their introduced strategy can noticeably improve the predicting capabilities of the single ARIMA or SVM model.
Manish and Thenmozhi [
18] utilized SVM and random forest to forecast the daily volatility of trend of S&P CNX NIFTY Market Index of the National Stock Exchange and compared the outcomes with the traditional discriminant and logit methods and ANN. They utilized the same technical indicators as input factors which used by Kim (2003). The outcomes revealed that SVM operate better than random forest, artificial neural network (ANN), and other traditional methods.
Huang, Nakamori et al. [
19] examined the predictability of financial changes trend with SVM by forecasting the weekly changes trend of NIKKEI 225 Index. To examine the forecast capability of SVM, they contrasted its functionality with the linear discriminant analysis, quadratic discriminant analysis and BPNN. The outcomes indicated that SVM works better than the other approaches.
Kumar and Thenmozhi [
20] presented the SVM method to forecasting the S&P CNX NIFTY Index returns. They utilized the different criteria to evaluate the functionality of the SVM model and finally observed that the SVM method obtained higher precision and quality in comparison with other methods.
Chang and Liu [
21] offered a TSK type fuzzy rule-based system to deal with stock price predicting troubles. They applied stepwise regression to examine and choose technical indicators which are more important to the stock price. Their offered method was examined on the Taiwan Stock Market and the outcomes outperformed other strategies and multiple regression analysis.
Ince and Trafalis [
22] suggested a method for stock price predicting by two techniques, depending on the presumption which the upcoming value of a stock price relies on its technical indicators. The investigations were performed on the daily stock prices of the ten firms exchanged on the NASDAQ. The outcomes demonstrated that the SVR method generated more desirable achievements compared to the MLPN for short-term forecast concerning the MSE. Besides, they concluded that If the risk premium is utilized as a comparison measure, then the SVR method is as good as the MLP approach or better.
Huang and Tsai [
23] presented a hybrid method utilizing filter-based feature selection, SOFM, and SVR, as a way to predict the stock price. Firstly, the filter-based feature selection was utilized to figure out crucial input technical indicators. After that, the SOFM was employed to cluster the training data into a number of disjointed clusters in ways that the components in every cluster are analogous. Lastly, the SVR was utilized to build an individual predicting approach for every cluster. Their approach was showed via a case study on predicting the price of next day in the Taiwan stock exchange and the outcomes demonstrated that their strategy can enhance predicting precision and decrease the training time over the traditional single SVR.
Hsu, Hsieh et al. [
24] improved the two-phase structure by combining a self-organizing map and SVR for stock price forecasting. They analyzed seven main stock market indices. The outcomes indicated that their method presents a successful substitute for stock price forecasting.
Atsalakis and Valavanis [
25,
26] reviewed the related papers which working with techniques for stock market forecasting. In part I, they reviewed the conventional methods and in part II, the soft computing approaches were researched.
Liang, Zhang et al. [
27] introduced a two-phase method to develop option price predicting by utilizing NN and SVR. In their research, NNs and SVRs were utilized to carry out nonlinear curve approximation to more decrease the predicting errors. Their method was revealed by tests on the information taken from the Hong Kong stock exchange. The outcomes indicated that the NN and SVR methods could substantially decrease the average predict errors, therefore increasing the predicting precision.
Hadavandi, Shavandi et al. [
28] suggested a hybrid strategy by combining stepwise regression analysis, ANN, and genetic fuzzy systems. Firstly, they utilized the stepwise regression analysis to choose variables which could considerably impact stock prices. Then a SOM-NN was utilized to divide the real information into many clusters in ways wherein the components in every cluster are more uniform. Ultimately, information in every cluster was given into a genetic fuzzy system for stock price prediction. Their method was revealed via a test on predicting the closing prices of the next day for two IT companies and two airlines, and outcomes demonstrated that the recommended method performs better than other prior procedures.
Lu [
29] offered a stock price predicting strategy by utilizing ICA and BPN. The ICA was utilized to the forecasting factors and the filtered predicting factors acted as the input factors of the BPN to create the predicting model. Their strategy was revealed by a case study on predicting the TAIEX closing cash and Nikkei 225 opening cash indicators. The outcomes showed that their strategy operates superior to the integrated wavelet-BPN model, the BPN model without filtered predicting factors, and the random walk model.
Cheng, Chen et al. [
30] applied the CDPA, MEPA, RST, and GA to improve a hybrid method for stock price predicting. The CDPA and MEPA were implemented to partition technical indicator values and RST was implemented to produce linguistic rules. Ultimately, the GA was implemented to improve the rules. Their technique was approved by a case study on predicting the TAIEX.
Kara, Boyacioglu et al. [
31] tried to improve two models which are based on the ANN and SVM. Ten technical indicators and daily stock price for the ISE National 100 Index were chosen to evaluate the model functionality. The outcomes demonstrated that the ANN method performs better than the SVM method. Their study also both the ANN and SVM methods revealed considerable functionality in the forecasting the trends of the stock price.
Svalina, Galzina et al. [
32] were utilized ANFIS to forecast the closing stock price of the Zagreb Stock Exchange. The authors utilized information during the years 2010 to 2012. Their method forecast the close price for CRO in the five upcoming days. It was revealed that the forecasts have enhanced their errors for each day ahead.
Wei [
33] presented a hybrid method utilizing GA and ANFIS for stock price forecasting. The method has been evaluated by RMSE during the six-year period of the TAIEX. The outcomes indicated that the method functioned better than the other three methods.
Chen and Kao [
34] offered a hybrid PSO-SVM method with fuzzy time series. They demonstrated that their method works better than conventional approaches for stock market prediction.
Xiong, Bao et al. [
35] presented a new hybrid method called FA-MSVR which utilized to predicting the three internationally traded market indexes including the S&P 500, the FTSE 100, and the Nikkei 225. The outcomes demonstrated that their method worked better than counterparts and it was a favorable substitute for predicting interval-valued financial time series.
Hafezi, Shahrabi et al [
36] offered a novel smart model in a multi-agent structure named the BNNMAS for stock price forecasting. The model worked in a four-layer multi-agent structure to forecast eight years of DAX stock price. The ability of their method is examined by utilizing fundamental and technical DAX stock price information and compared the results with the various other approaches, for instance, GANN and GRNN, and so on. Their outcomes indicated that the BNNMAS works precisely and reliably, and therefore it is an appropriate method for stock price forecasting, particularly in long-time intervals.
Khuat, Le et al. [
37] presented a method for stock price forecasting based on Haar wavelet transform and ANN which optimized by DABC. The method was examined on the historical price information for various corporations. The outcome was favorable that it could help the stock traders efficiently.
Pyo, Lee et al. [
38] investigated the movements of the KOSPI 200 prices applying the ANN and SVM. Their outcomes proved the instability and high variability of machine-learning approaches on market predictions that are explained in [
39] and various other studies, by way of hypothesis tests utilizing the KOSPI 200 index market.
Zhang, Aggarwal et al. [
40] presented a new SFM-RN to record the multi-frequency exchanging templates from past market information to get a long-run and short-run forecasts. In their study, the future stock prices are forecasted as a nonlinear mapping of the composition of the elements in an Inverse Fourier Transform (IFT) fashion. The findings on the actual market information revealed more competitive capabilities by the SFM versus the state-of-the-art approaches.
Nguyen [
41] employed the Hidden Markov Model (HMM), to forecast a daily stock price of three dynamic stocks—Apple, Google, and Facebook—depending on their historical information. Thus, the models to forecast close prices of these stocks applying single observation information and multiple observation information have utilized. This study utilized the forecasts as signals for stock dealing. The outcomes revealed that the HMM functioned better than the naïve approach in stock price predicting. Furthermore, the outcomes revealed that active dealers applying HMM obtained a higher return compared to applying the naïve predict for Facebook and Google stocks.
In another paper, Nguyen [
42] presented the application of HMM in stocks dealing depending on the stock price forecasting. The process begins by employing four metrics as a way to identify an optimal number of states for the HMM. Next, it was utilized to forecast the monthly closing prices of the S&P 500 index. The outcomes obviously confirmed that the HMM operated more desirably than the traditional approach in the stocks dealing and forecasting.
Shah, Tairan et al. [
43] offered a method named QGGABC-FFNN that depended on the ABC and NN to reduce the error in the stock price forecasting. Their method has been confirmed and examined to forecast the precise trend of Saudi Stock Market. The outcomes indicated that the QGGABC-FFNN works better than typical computational algorithms.
Dinh and Kwon [
44] presented a developed technique for the stock price forecasting by taking into account the limitations and then created input variables by considering price and volume data. They also determined three modeling parameters: the input and the target window sizes and the profit threshold which the underlying functions are learned by multilayer perceptrons and the SVM. They examined their method by 6 stocks for 15 years and the expected functionality by the considered parameters were compared. Their method considerably enhanced the forecast precision more than the expected functionality and also the outcomes indicated that the method provided more stable profitability than other strategies.
Chandar [
45] proposed a new hybrid method called WANFIS, which employed on past information of several firms. The outcomes demonstrated that the method received higher precision of the prediction compared to other methods.
After investigating the past studies, there are several negative aspects in the previous approaches, namely: (1) stringent statistical hypotheses are essential; (2) human interventions take part in predicting process; and (3) an appropriate range is complex to be discovered.
As mentioned, in the past scientific research, many models have been presented to predict stock prices, but each of the models presented in the previous researches has different advantages and disadvantages. With this in mind, we plan to improve the disadvantages of the previous models and fix their problems as much as possible.
In this paper, we intend to provide a robust and efficient hybrid model based on ABC, ANFIS, and SVM without human interference. Employing hybrid models or integrating numerous models has become a universal technique to enhance forecasting accuracy and the literature on this matter has extended noticeably [
46].
3. Materials and Methods
In this section, a novel hybrid model for the stock price forecasting is created by using ABC, ANFIS, and SVM to achieve a more precise approach compared to previous approaches.
In the following, the detailed description of the different sections of our model is expressed.
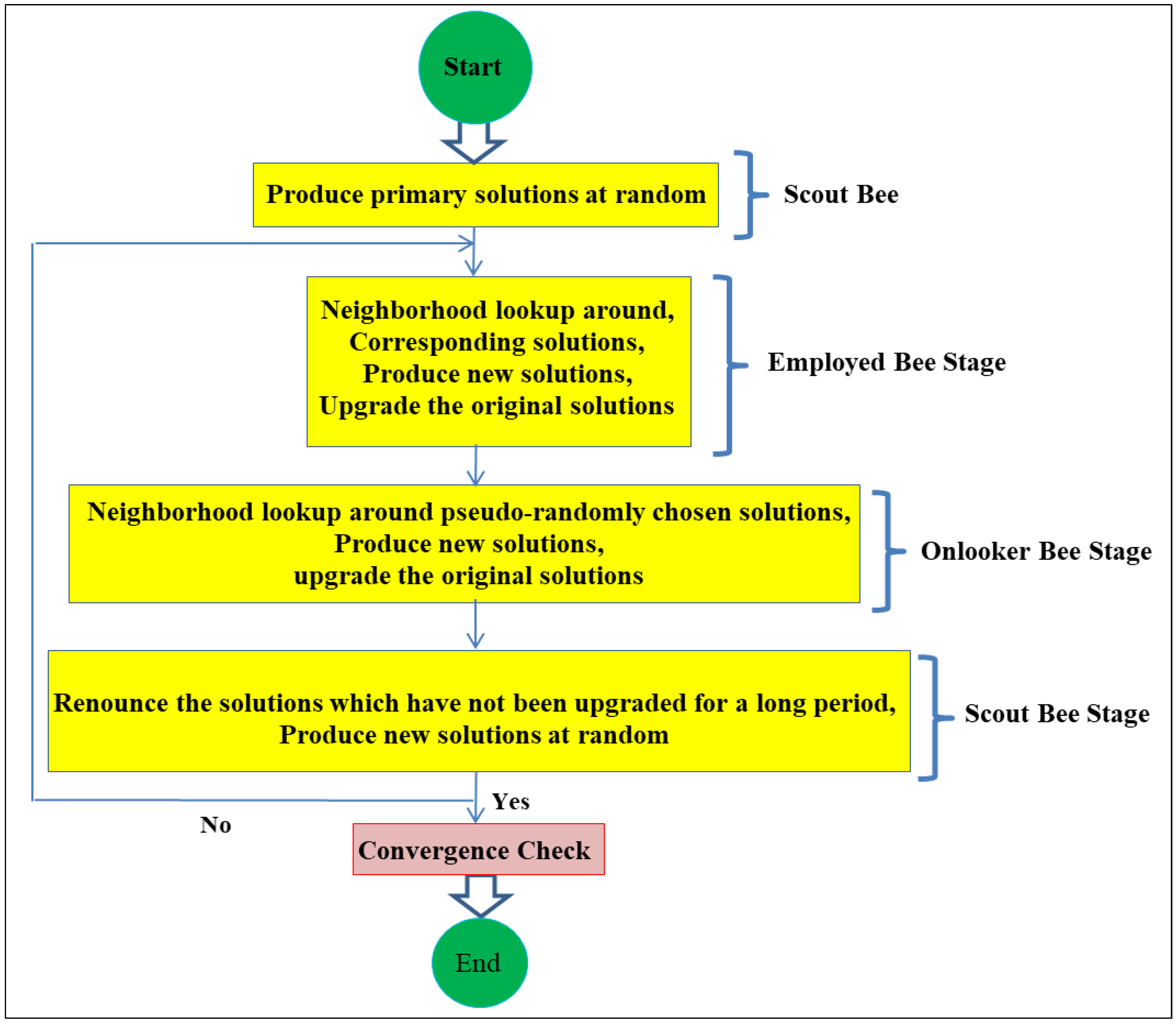
3.1. Artificial Bee Colony (ABC)
The ABC algorithm is a recently improved swarm intelligence approach on the basis of the natural food searching behaviour of bees [
47]. In the ABC algorithm, the colony of artificial bees includes three types of bees: (1) employed bees, (2) onlooker bees, (3) scouts bees. Half of the swarm includes employed bees and other half includes the onlooker bees. The number of employed bees or onlooker bees is equivalent to the number of solutions in the swarm. The ABC produces a randomly dispersed primary population of SN solutions wherein SN indicates the swarm size. In a D-dimensional lookup area, every solution (
) is indicated in the following:
Wherein i and j ∈ {1, 2, 3, … , D}
D: The dimension size
The indicator for solutions of a population
The possibility value that is depending on the individuals’ fitness value to summation of fitness values of every food sources and determines whether a particular food source has potential to obtain position of a new food source is measured by:
Wherein , the fitness and possibility of the food source i.
After sharing the nectar information between the present onlookers and applied bees, for greater fitness compared to the earlier one, the situation of the new food source is computed as follows:
Wherein: k ∈ {1, 2, 3, … , SN} is a randomly chosen indicator and has to be varying from i. n is the optimization variables indicator. (n) is the food source situation at nth iteration, wherein is its modified situation in (n + 1)th iteration.
φn is a random number in the area of [−1, 1]. The parameter
is set to meet the appropriate value and is improved as:
Wherein:
(0, 1): A random number within [0, 1]
The maximum, minimum y-th parameter values
The steps of the ABC algorithm and the flowchart of the ABC are as follows:
Step 1: Initialize stage
Step 2: Repeat
Step 3: Employed bees stage
Step 4: Onlooker bees stage
Step 5: Scout bees stage
Step 6: Memorize the best food source
Step 7: Until cycle = Maximum cycle number
The detailed procedures of the ABC are displayed in
Figure 1.
3.2. Adaptive Neuro-Fuzzy Inference System (ANFIS)
ANFIS was first released by Jang [
48]. The ANFIS integrates the features of artificial neural networks (ANN) and Fuzzy Inference Systems (FIS). Hence, it has quick learning capability, the potential of achieving the nonlinear framework of a system, and ability of adaptation. The quick learning capability is utilized for automatic fuzzy if-then principle generation and parameter optimization in ANFIS. Its inference system matches with a collection of fuzzy if-then principles which have learning capability to estimate nonlinear functions [
48,
49].
The ANFIS has been effectively applied to a wide range of issues in many different matters such as finance, accounting, financial engineering, economics, and management in ways that various objectives which includes analysis, assessment, and forecasting. The use of ANFIS for high-frequency data trading is highly effective.
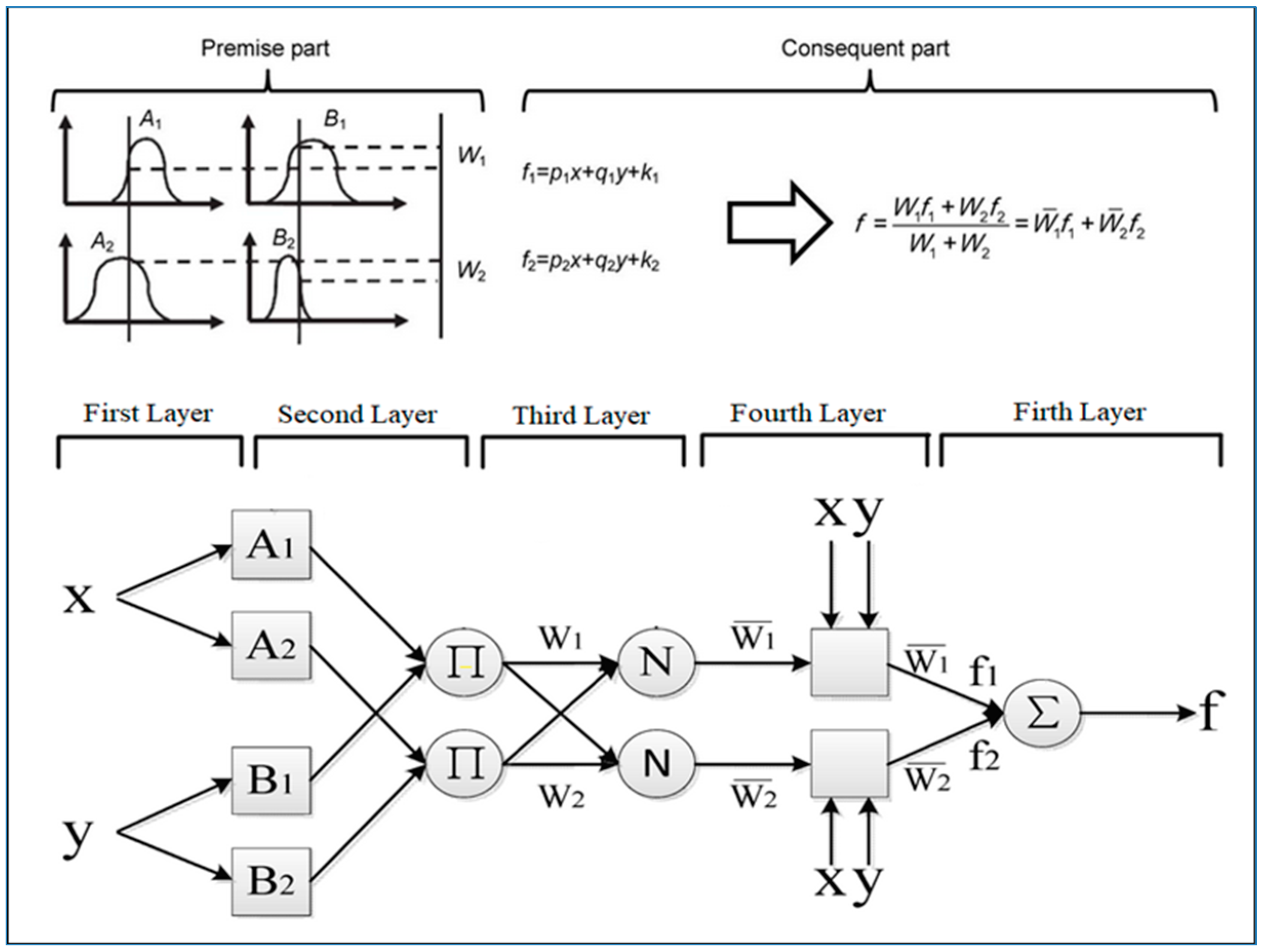
ANFIS Structure
The ANFIS could solve any type of complex and nonlinear issue successfully by integrating the benefits of the ANN and FIS, and it leads to fewer errors. The structure of ANFIS is displayed in
Figure 2. The ANFIS is basically the rule-based fuzzy modeling. Two rules which have employed in this structure are stated below:
Wherein:
: Membership functions of each input x and y
: Linear parameters in part-Then (consequent part)
As shown in
Figure 2, the ANFIS structure has five layers that the formulas of the layers are defined in Equations (5)–(12).
: The normalized firing power from the previous layer
: A parameter in the node
3.3. Support Vector Machine (SVM)
SVM is a learning machine applying structural risk and minimizing inductive principle to get beneficial generalization on a restricted number of learning patterns. Firstly, SVM has been released by Vapnik [
50] and it is a learning program utilizing a high dimensional feature space.
SVM executes a learning algorithm and it is beneficial for identifying delicate patterns in complicated information collections. This algorithm runs discriminative category learning by instance to forecast the categories of earlier unobserved information.
Figure 3 illustrates the SVM structure.
SVM evolved from studies in statistical learning theory on how to adjust generalization, and discover an optimum trade-off between structural intricacy and empirical risk.
SVM categorize points by allocating them to one of two disjoint half areas, either in the pattern area or in a higher-dimensional characteristic area [
51,
52]. The equation of standard SVM as follows:
Considering the
f(x), the classification is obtained as:
Considering a linearly separable data-collection, the role of learning coefficients and of decreases to fixing the following constrained optimization issue:
Find w and b that minimize:
Subject to constraints:
This optimization issue could be fixed by applying the Lagrangian function determined as:
Wherein ,, … are Lagrange multipliers and = [,, … ]T.
The answer of original limited optimization issue is specified by the saddle point of that has to be minimized with regards to and and maximized with regards to .
Consider the following about Lagrange multipliers:
If , the value of that maximizes is = 0.
If , the value of that maximizes is = +∞.
Considering that and are attempting to minimize , they will be modified in such a way to make X at least equal to +1.
Data points with > 0 are known as the support vectors.
3.3.1. Optimality Conditions
The essential statuses for the saddle point of
L (
w,
b,
α) are:
Or expressed several procedures,
Solving for the essential conditions leads to:
By changing into the Lagrangian function and by applying as a new limitation, the dual optimization issue could be designed as follow:
Find α that maximizes:
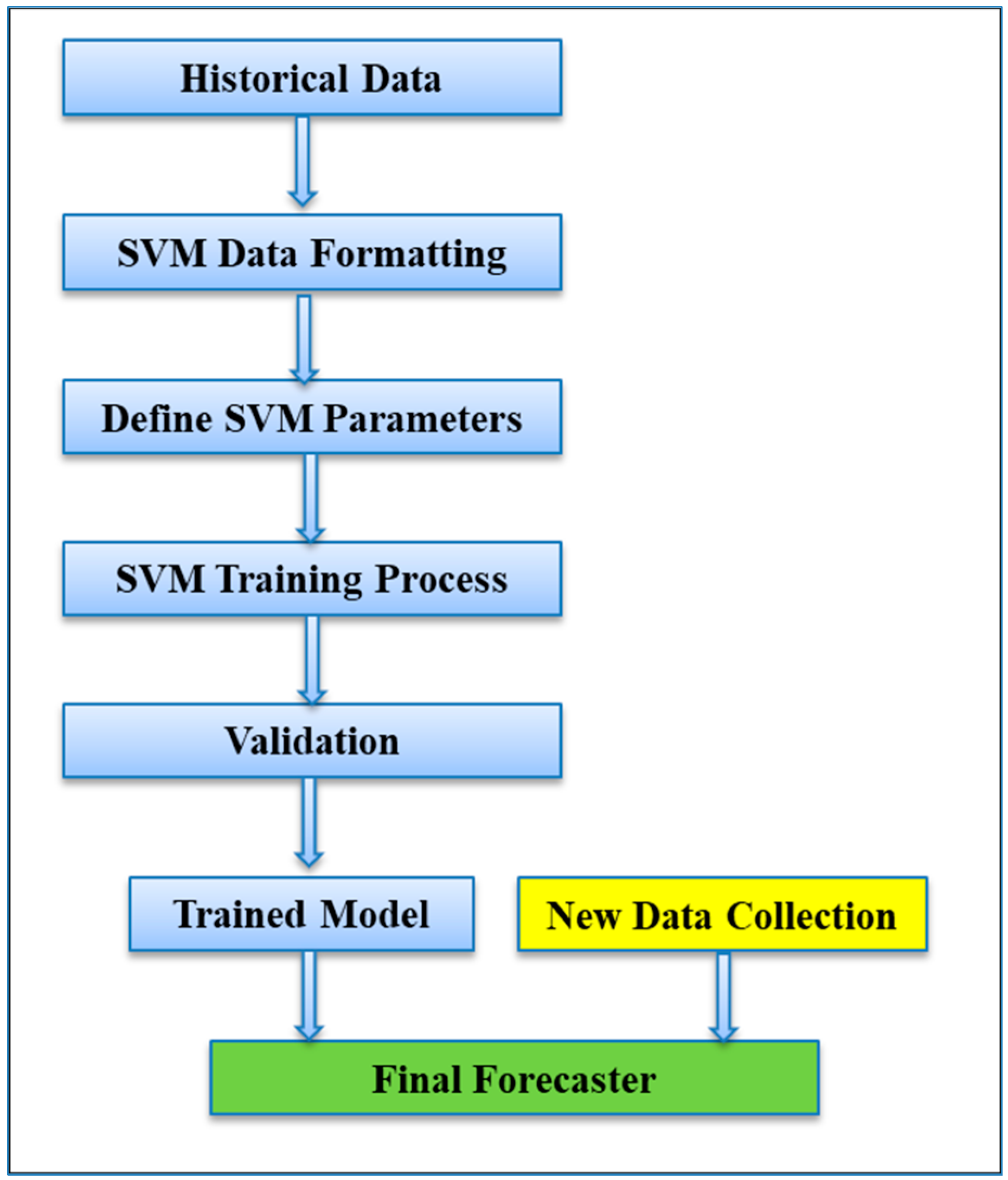
3.3.2. Final Forecaster
Since the values
,
, …
acquired by the answer of the dual issue, the final SVM forecaster could be given from Equation (17) as:
: The set of support vectors.
We consider the following about support vectors:
Given that ≠ 0 merely for the support vectors, just support vectors are employed in achieving to forecasting model.
Notice that is a scalar.
3.4. Technical Indicators
Technical indicators are concentrated on historical information, for instance, price and volume, instead of the fundamental analysis of the trade. There are plenty of indicators in the market that can be utilized to reveal the momentum, trend, volatility, etc., and they are based on mathematical equations, which are the interpreters of the market. They check out price data and convert it into easy and useful signals which can assist investors and traders to specify when to buy or sell. Any technical indicator presents exclusive data and check out historical price information. They could be utilized as numerous indicators in combination with other indicators.
After the review of the past studies and related papers, we selected twenty original technical indicators that have major roles in the technical analysis and stock price forecasting. These technical indicators, which are listed in
Table 1, could cover all stock data by considering the four classes including Oscillator, Index, Overlay, and Cumulative. Based on previous researches and viewpoints of technical experts and professionals, the twenty chosen technical indicators are the most essential indicators in the technical analysis.
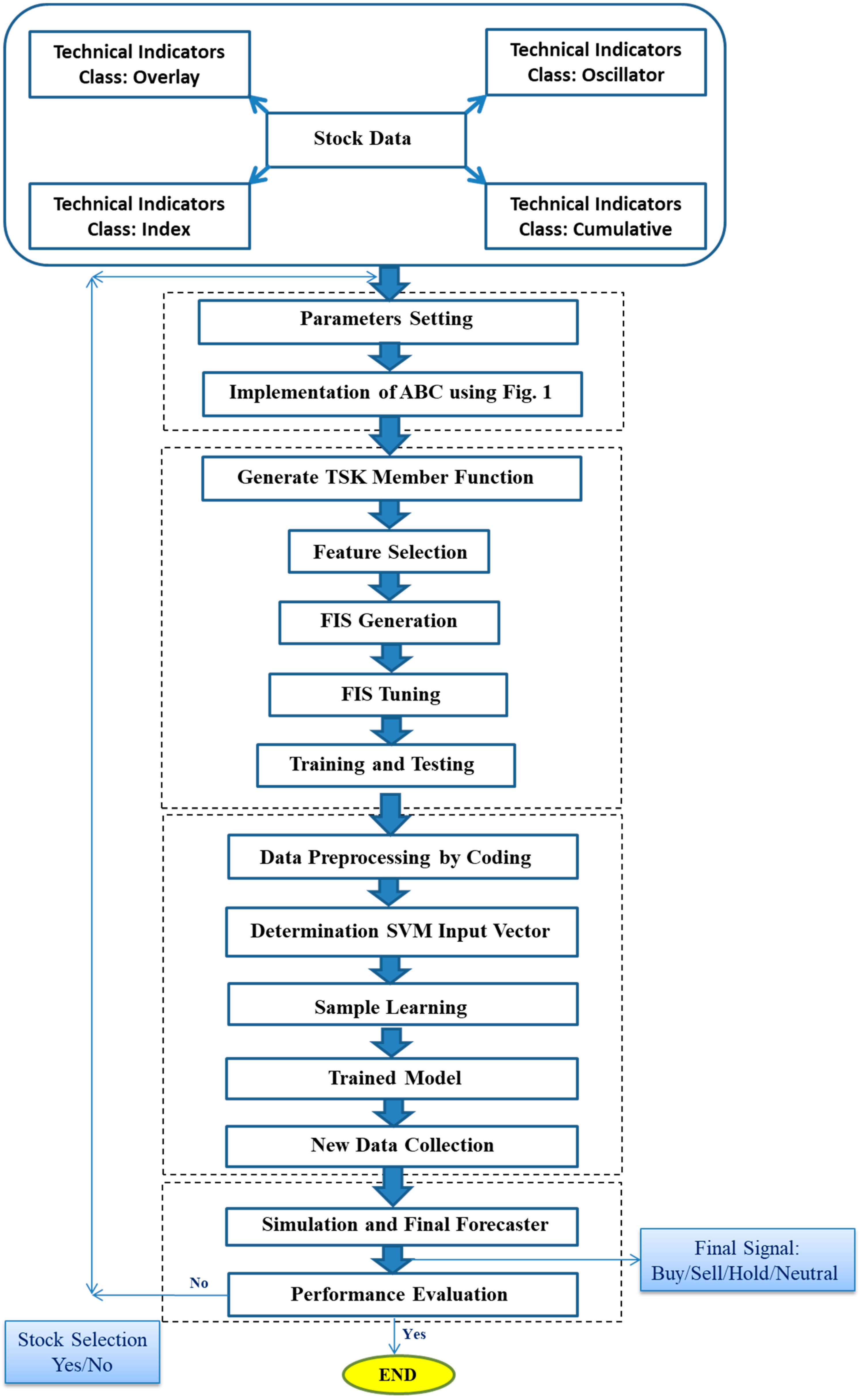
3.5. Proposed Model
Figure 4 illustrates the architecture of the presented model for the stock price forecasting. This figure shows that the ABC and ANFIS modules have been employed to multi-objective optimization of technical indicators, and the SVM module has been used to produce trading signals (Buy/Sale/Hold/Neutral).
After the calculations of the technical indicators outlined in
Table 1, they have been applied in the model as input variables. At the first stage, the ABC is applied to optimize the technical indicators for forecasting tools. At the second stage, the ANFIS is implemented to predict the future price of stocks. At the third stage, the SVM has been used to data preprocessing by coding and then the data have been normalized. The determination of the input vector and sample learning are the last phases of the SVM. Eventually, the final signal will be obtained from the model.
3.6. Data and Parameter Setting
The periods of our research are adequate for testing and validation of the model because the boom and bust cycle and the economic fluctuations and important political events have happened during the years 2008–2018. To increase accuracy and avoid mistakes, sample selection in the training and testing data is divided into five periods of two years.
The details about the training and testing data are provided in
Table 2. Approximately 80% of the data was intended for training, and 20% for testing. Four parameters from the stock exchange are employed to create the vectors and explanations of the parameters are mentioned in
Table 3.
The parameter adjustments are essential since they can have a negative impact on the model performance if they are not correctly regulated. The adjustments of parameters are detailed in
Table 4 and
Table 5. The best-suited adjustments are planned for comparison with the other methods.
The technical indicators are the input variables and the output objectives are stock’s future price and the signals for buy/hold/sell.
4. Results and Evaluation
In this section, we evaluate the performance of the offered model and compare it with the other approaches. To enhance the credibility of the proposed model, five criteria for accuracy and quality are evaluated. These criteria determine the deviation between observed and forecasted values. These measures include RMSE, MAE, MAPE, and Theil’s U (U
1, U
2) and the formulas for them are as follows:
Wherein indicates the observed price and shows the forecasted price at time t.
Theil suggested two U statistics contains U
1 and U
2, employed in finance. The U
1 is a criterion of prediction accuracy [
53]. The U
2 is a criterion of prediction quality [
54]. The interpretation of the Theil’s U is mentioned in
Table A2 (see
Appendix A).
The comparison outcomes of three key indexes in the U.S. Stock Exchange are shown in
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10, which prove that our technique has increased the forecasting precision and quality for all the three indexes.
To validation the model, the final results have been revealed in
Table 6,
Table 7,
Table 8,
Table 9,
Table 10 and
Table 11. According to the outcomes in these tables, it can be observed that the ABC-ANFIS-SVM could provide the lowest error and the topmost accuracy under the testing model.
Table 11 indicates that the RMSE, MAE, and MAPE for the ABC-ANFIS-SVM are less than the other models. Moreover, U
1 and U
2 for our method are higher than the other methods.
When implementing ANFIS the articles cited in the references were used [
55,
56]. All of the methods have been executed in “Mathworks MATLAB R2019” software. All in all, according to RMSE, MAE, MAPE, U
1, and U
2 criteria, we derived that ABC-ANFIS-SVM functions best in terms of accuracy and quality. The ABC-ANFIS-SVM is evaluated to other methods which are proved by five criteria. All values of our model are higher than other methods for all indices. For SVM implementations, all tests were executed on “Mathworks MATLAB” software utilizing LIBSVM [
57].
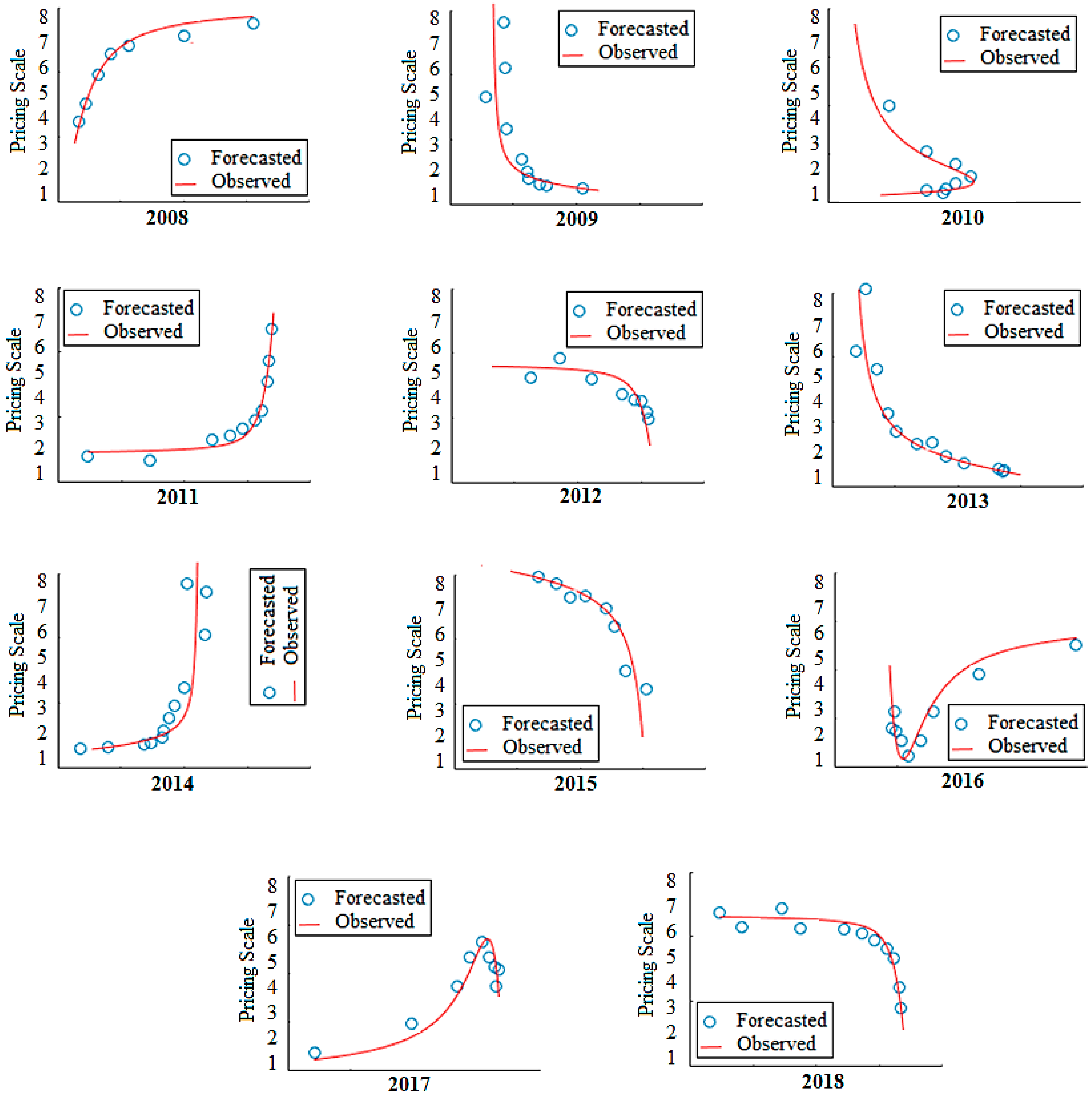
The functionality for every year is computed and the outcomes have been displayed in
Figure 5.
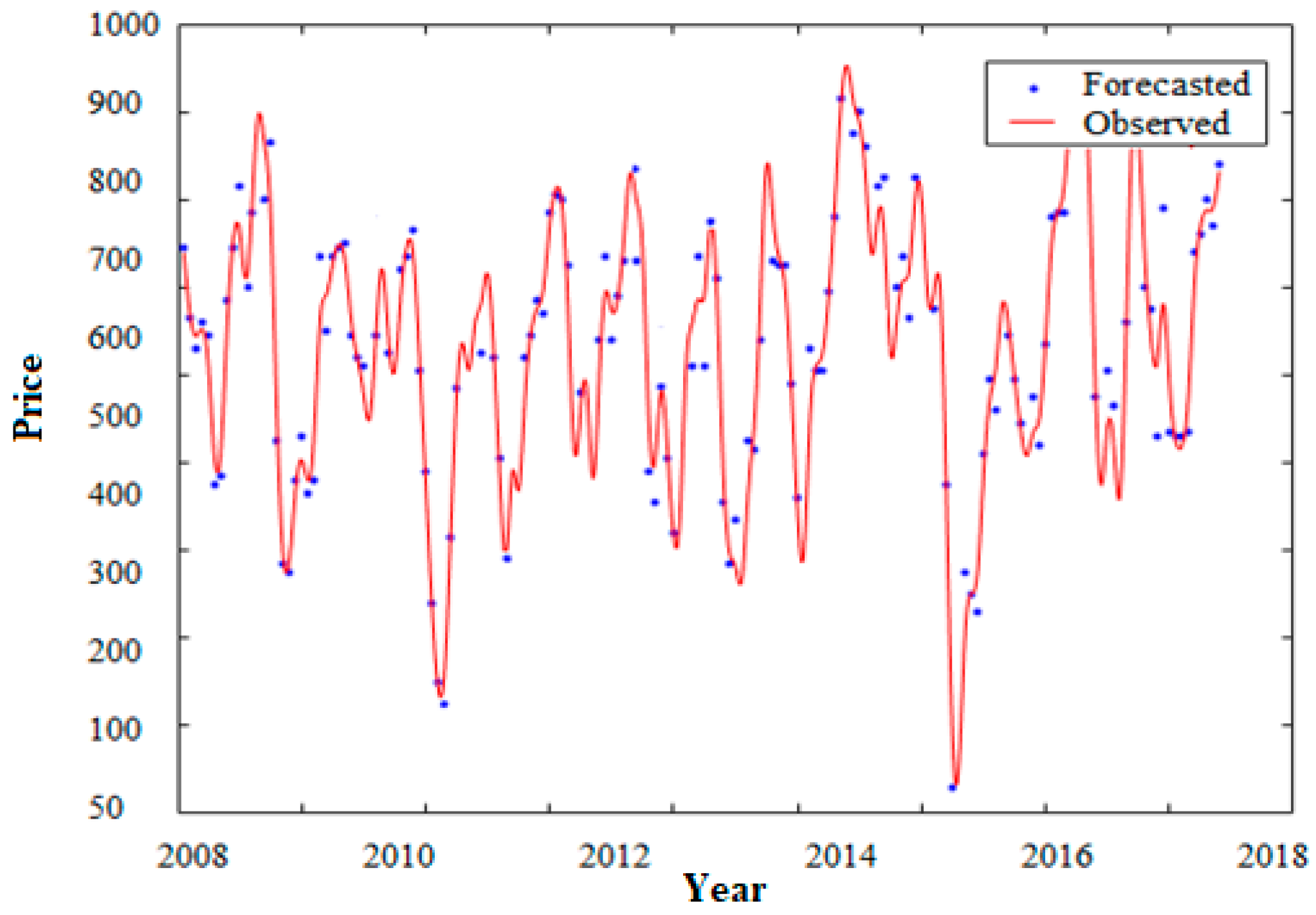
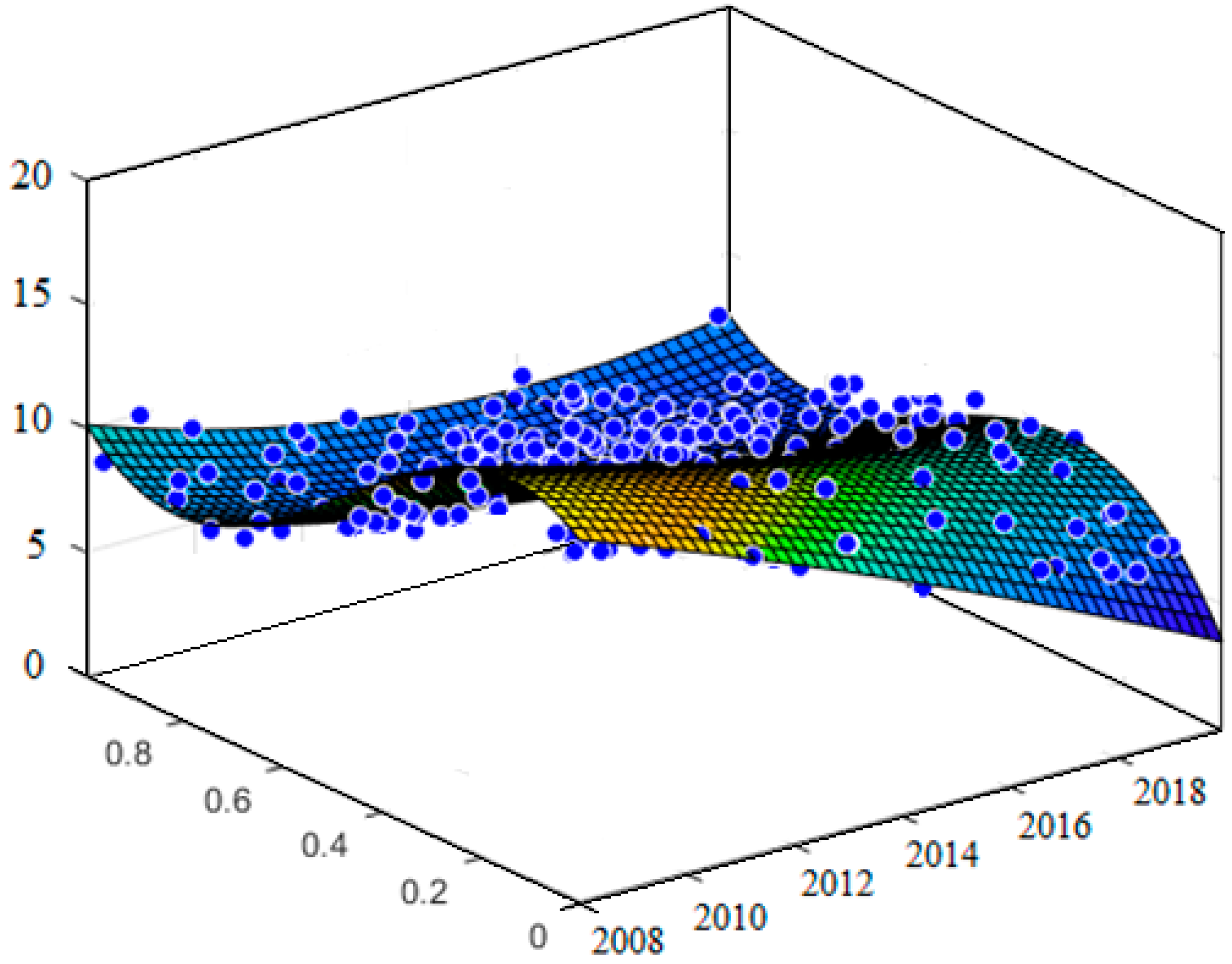
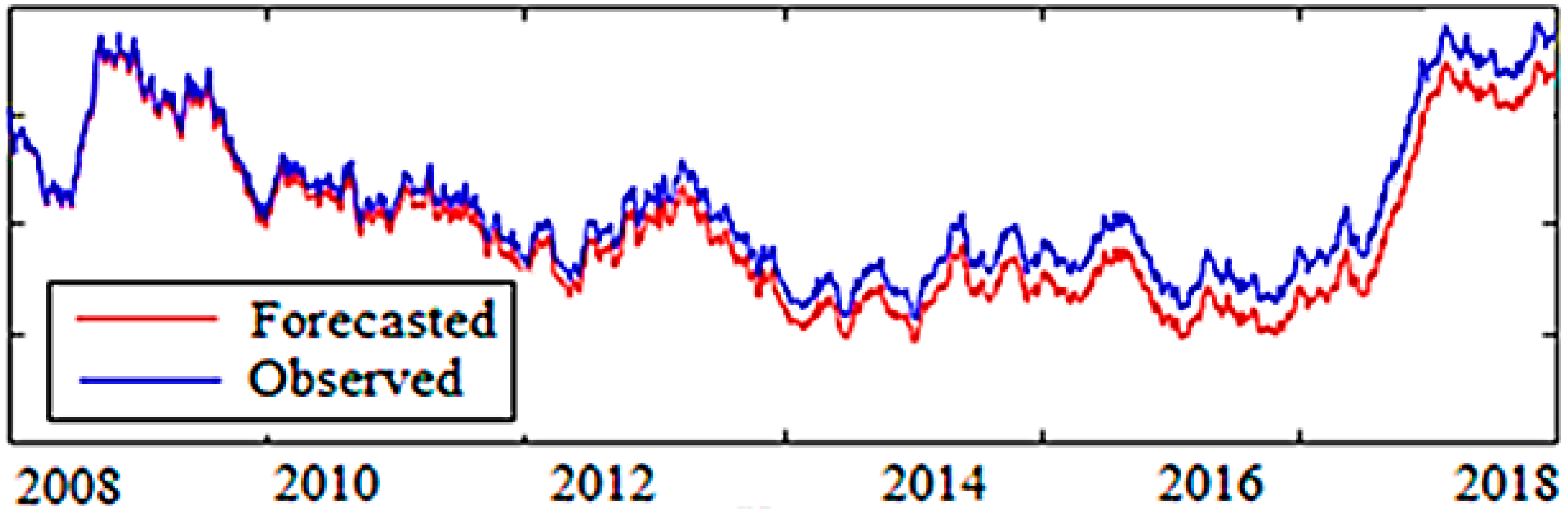
Figure 6 illustrates the performance evaluation of ABC-ANFIS-SVM that corroborates the best performance. The forecasted prices approximately correspond with the trend of the observed prices.
Figure 7 and
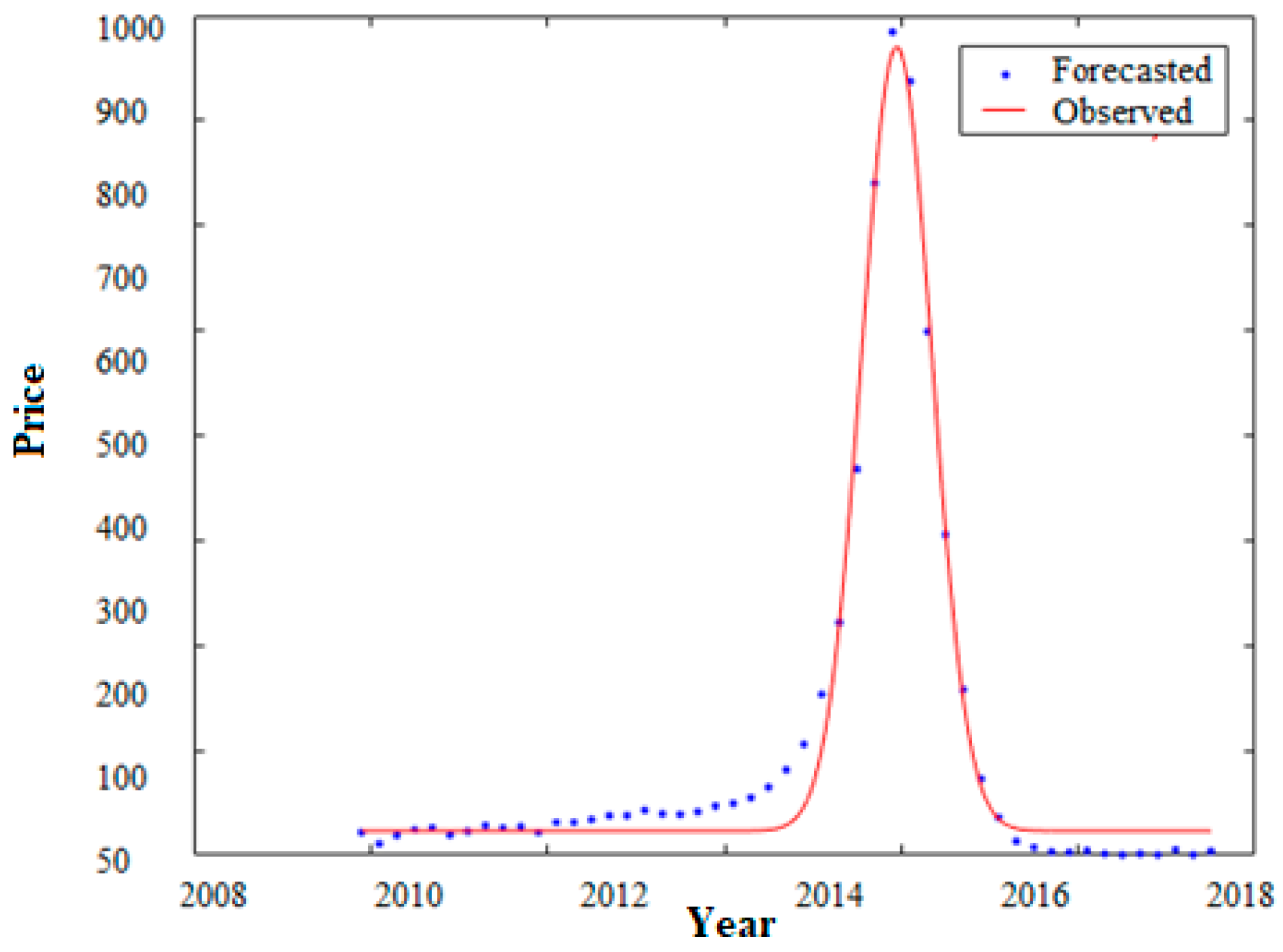
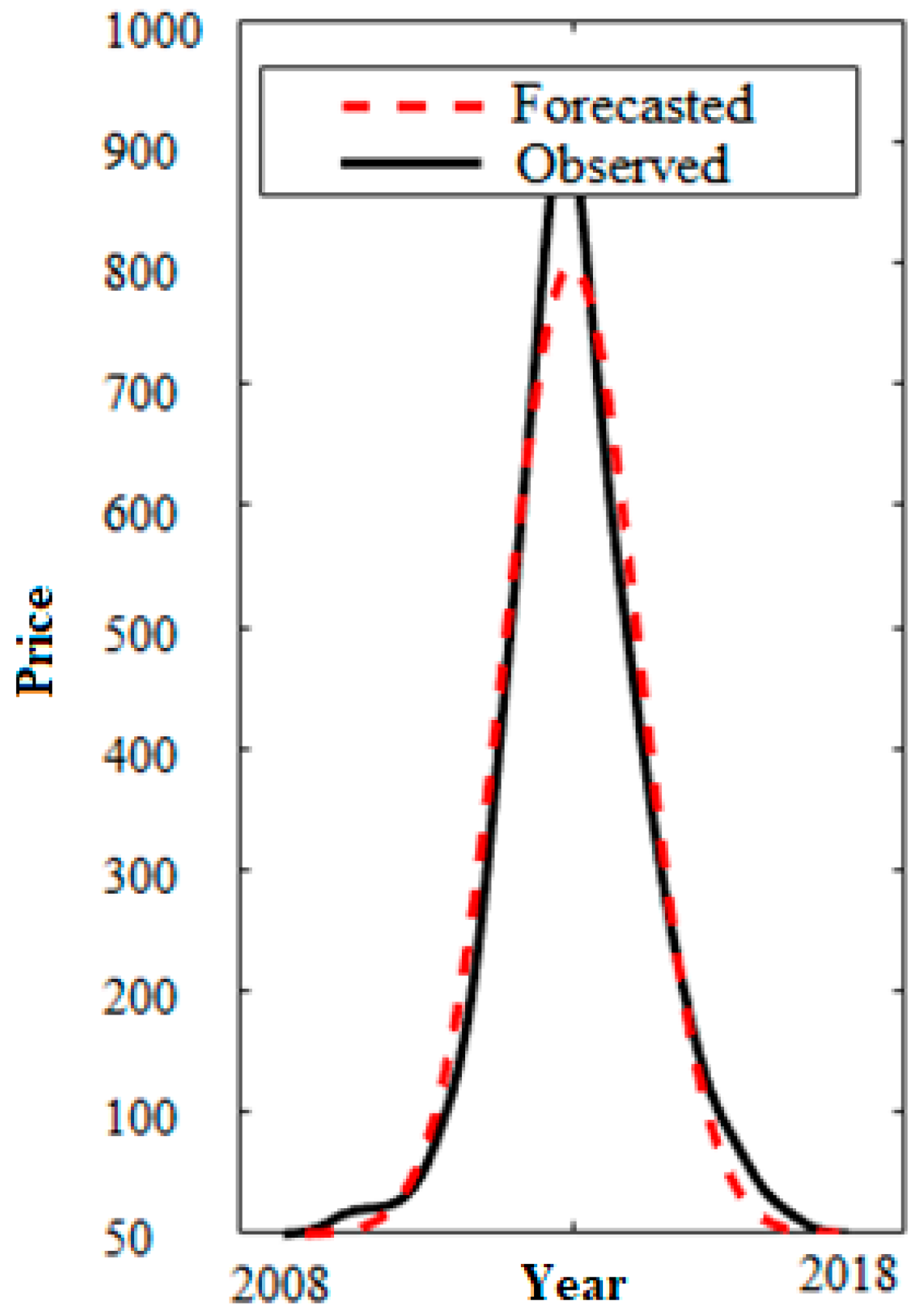
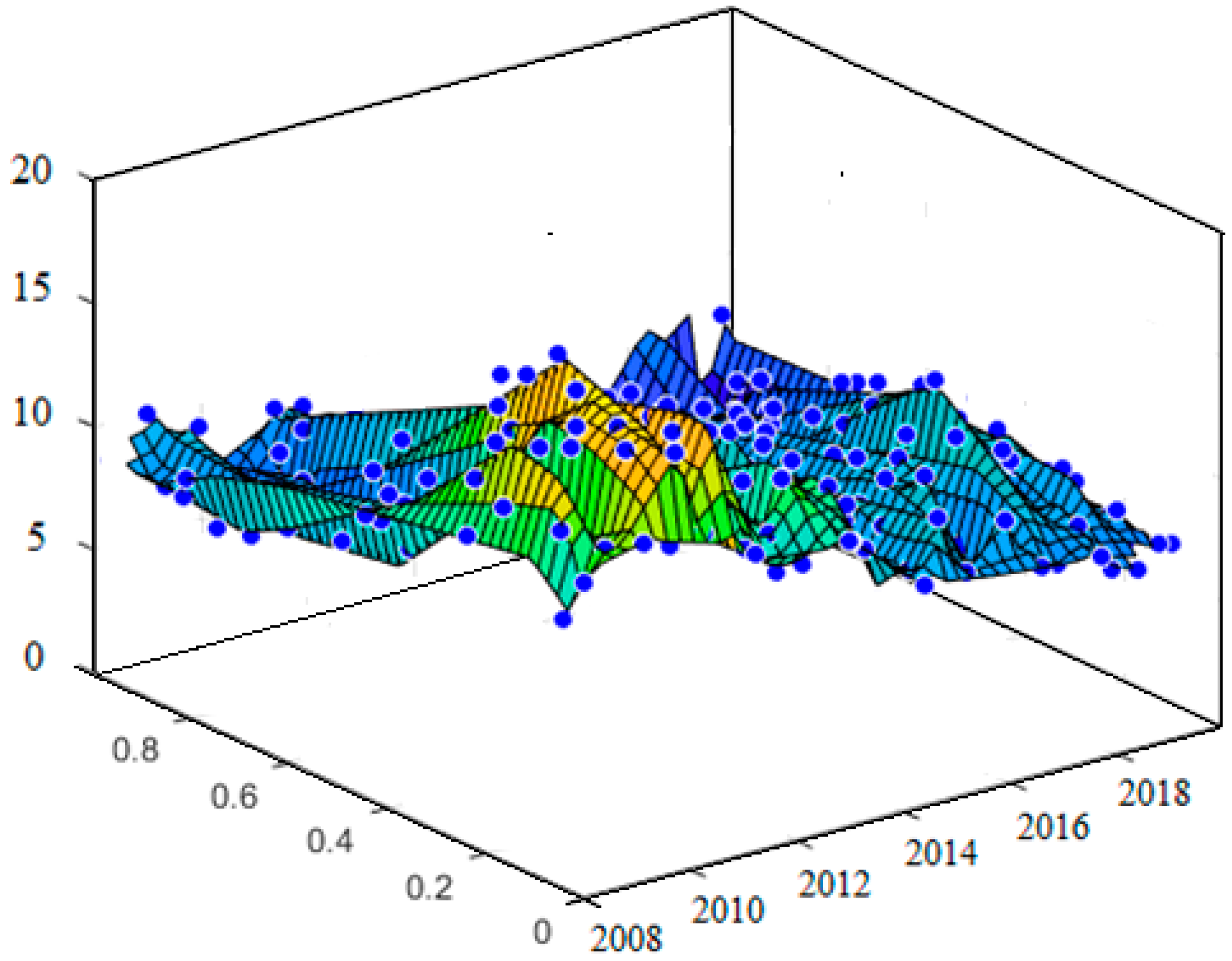
Figure 8 indicate the model performance for both training data and testing data which confirmed that our model is a prosperous tool for stock price forecasting. The results of the testing model and model matching are displayed in
Figure 9,
Figure 10 and
Figure 11 which are so satisfactory and adequate.
Table 12,
Table 13,
Table 14,
Table 15,
Table 16,
Table 17,
Table 18,
Table 19,
Table 20,
Table 21,
Table 22 and
Table 23 show the final signals of ABC-ANFIS-SVM model, which will offer trading signals to investors and financial analysts after calculating technical indicators and accurate stock price forecasts. These tables are provided as examples for the 12 largest American companies for the validation and verification of the presented model. Consequently, all the signals are approved according to the period of a particular transaction.
5. Conclusions
In this paper, a new approach for the stock price forecasting was created by integrating ABC, ANFIS, and SVM to more precisely predict the stock prices. Forecasting the trends of activities of the stock price is crucial for the progress of efficient investment policies. In this investigation, we have integrated the ABC-ANFIS into the SVM forecasting model to optimize the technical indicators. We have tried with ABC-ANFIS-SVM to achieve an approximation of the topmost attainable accuracy and quality for stock price forecasting. With the purpose to analyze the ABC-ANFIS-SVM, we employed it on stock price data of the U.S. Stock Exchange from 2008 to 2018, which has been applied as the case study. Twenty technical indicators were employed in our model as input variables.
To display the functionality and superiority of the model, five criteria were examined. After examining the experimental results, we unmistakably have noticed that the presented approach is designed to simulate the active unpredictable stock markets efficiently, which produces a more accurate and high-quality model as compared with other methods. It is obvious that the outcomes authenticate that the novel approach substantially boosts the reliability of the ABC-ANFIS-SVM model. In fact, our approach is the first hybrid model that combines three modules ABC, ANFIS, and SVM together with performance evaluation by the criteria of accuracy and quality. It implies that the model has lesser diversions between forecasted and observed prices than the other methods. Furthermore, the output signals confirmed that the twenty selected technical indicators were absolutely appropriate and comprehensive. The key advantages of our model include enhancing speed and precision in computation, reaching the most optimal technical indicators and the ability to obtain an active strategy to invest in the stock exchange and portfolio building. In future works, the presented model can be further studied by using other soft computing methods or by attaching other techniques or additional input variables. Additionally, the model can be employed for other financial markets.
The computational analysis has revealed that ABC-ANFIS-SVM is the most efficient approach for stock price forecasting and it could be employed in other challenges associated with financial predicting. From the point of view of the authors, the overall functionality of the presented model in the stock price forecasting works better than related studies in the previous investigations. Nevertheless, the function of our model may be developed by two ideas. Firstly, by setting the model parameters by running more sensitive and extensive variables adjustment, which can be subsequent articles for research workers. Secondly, the supplementary or alternative variables can be used as inputs of the model, for instance: foreign exchange rates, interest rates, and many others.
According to the results of the model evaluation and its performance, we conclude that the investigation aims have been achieved. Even so, we are encountered with two limitations about forces that move stock prices. Besides the technical factors, there are two other important factors that can affect stock prices: (1) Fundamental factors and (2) market sentiment. Our model can be improved considerably by taking into account these two items. In our future work, we intend to take into account these items and will present a newer model.
The unique attributes of this work:
Proposing a novel efficient hybrid model based on ABC, ANFIS, and SVM
Applying the comprehensive and major technical indicators
Multi-objective optimization of technical indicators
Ultimately, we summarize the key outcomes of the article in the following cases:
This study indicates that the challenge of stock price forecasting can be solved by employing ABC-ANFIS-SVM.
This study indicates that the forecasting accuracy and reliability of the ABC-ANFIS-SVM is more accurate than the other models.
This study indicates the strength of the ABC-ANFIS-SVM model by comparing its predicting quality with different methods.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










