Feedforward Neural Network-Based Architecture for Predicting Emotions from Speech



Abstract
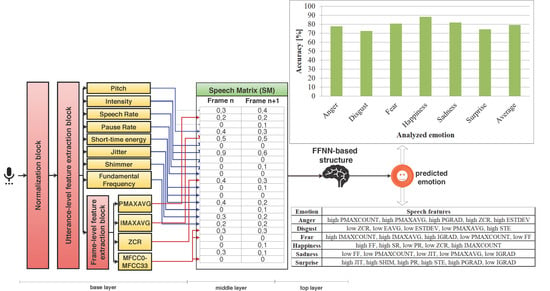
:
1. Introduction
2. Results
2.1. Databases Used
- -
- Dataset Controlled (DSC): Utterances are collected in the presence of an emotional stimulus;
- -
- Dataset Random (DSR): Utterances are collected in the absence of an emotional stimulus.
- -
- Accuracy (ACC):
- -
- Sensitivity or True Positive Rate (TPR):
- -
- Specificity or True Negative Rate (TNR):
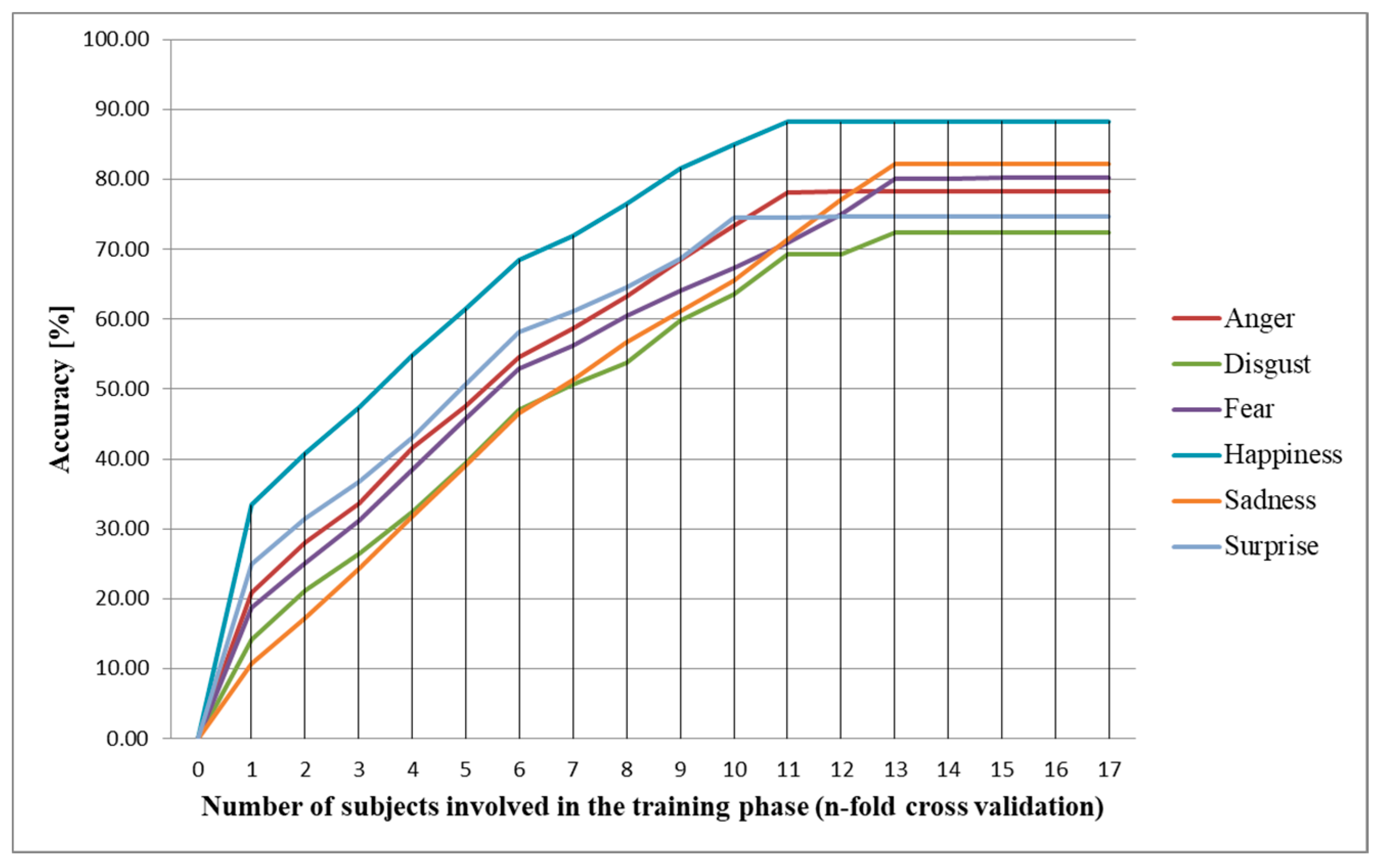
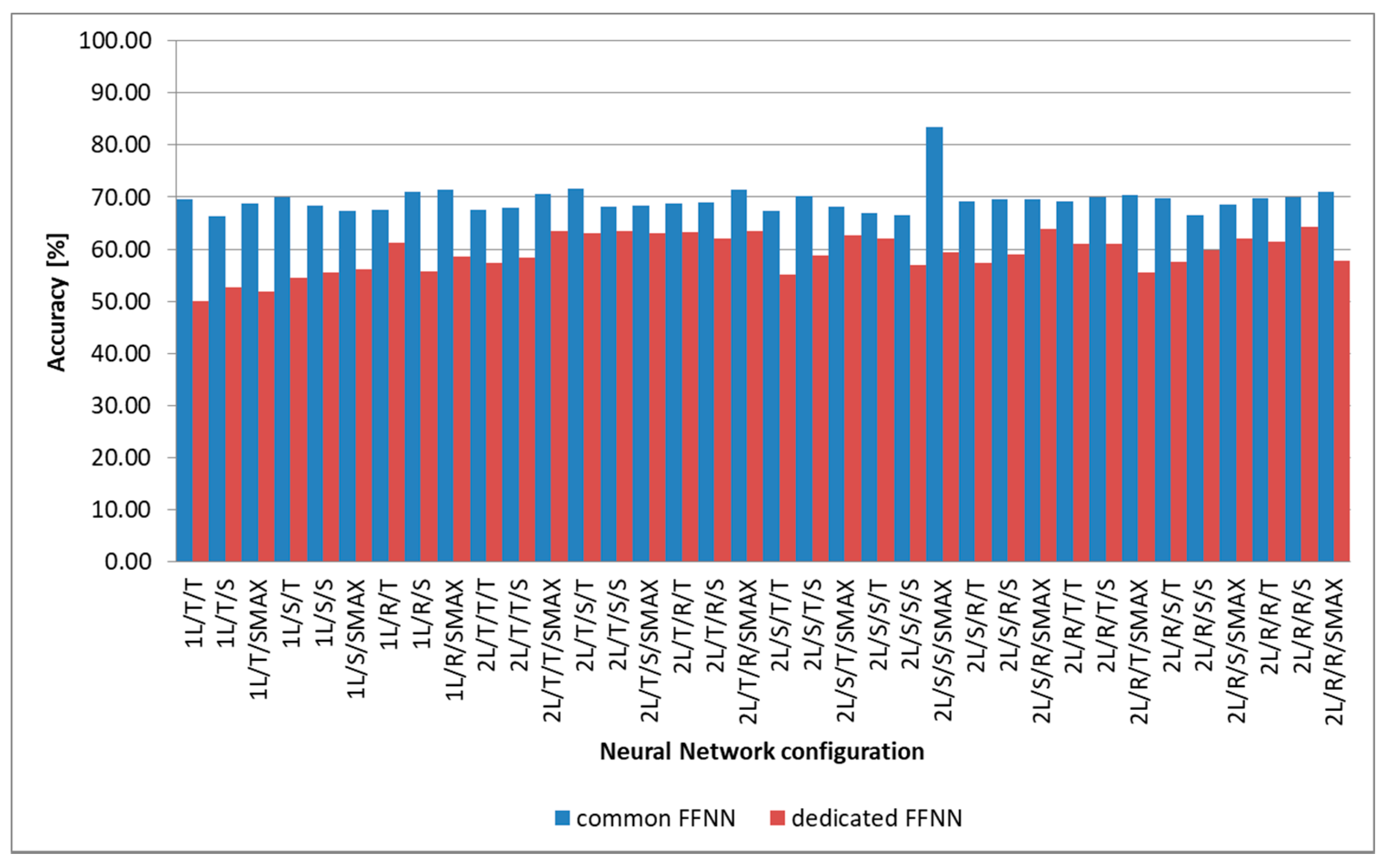
2.2. Intra-Subject Methodology
2.3. Inter-Subject Methodology
2.4. Correlations Between Speech Features and Emotions
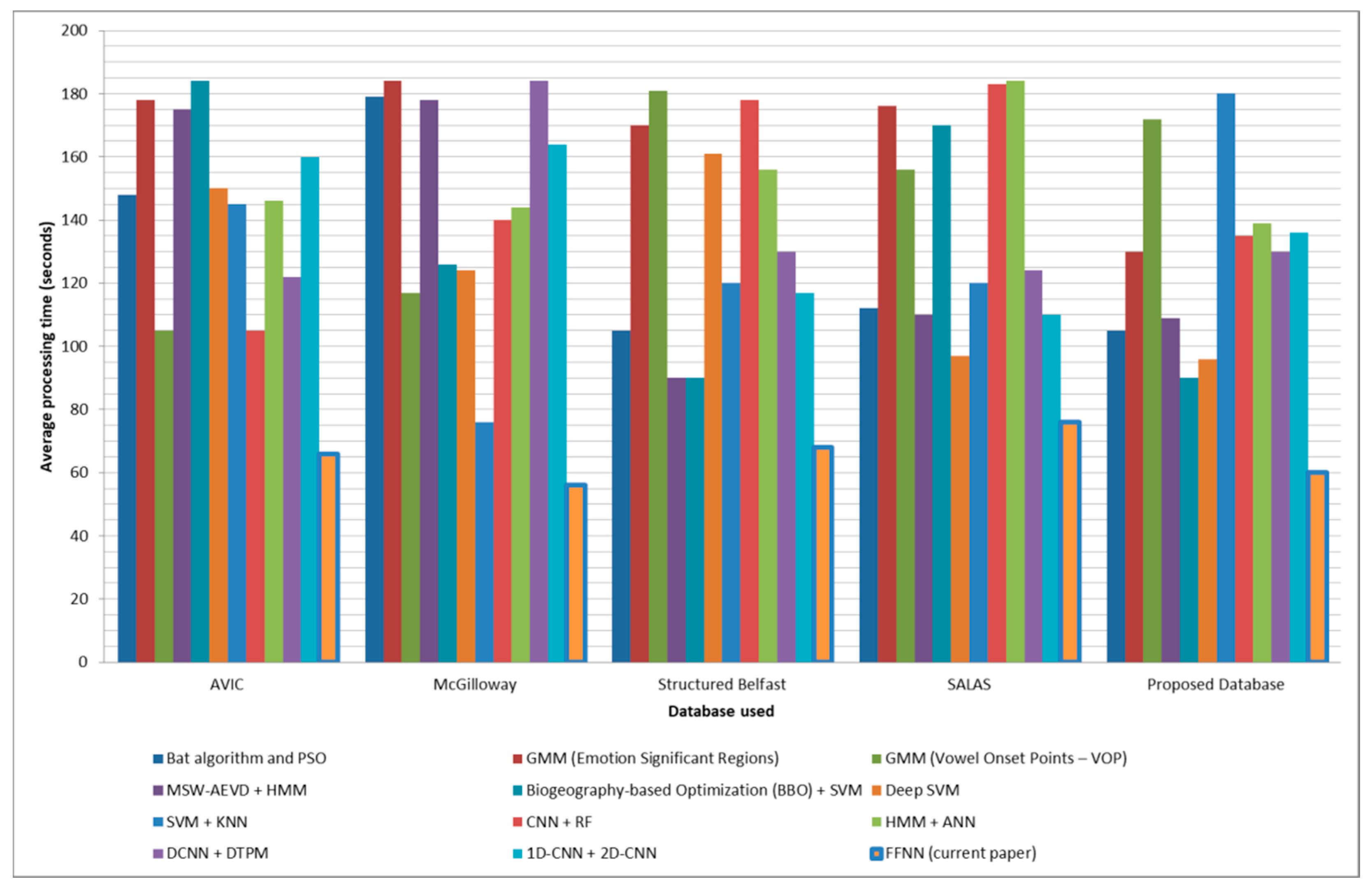
2.5. Comparison with State-of-the-Art Methods
3. Discussion
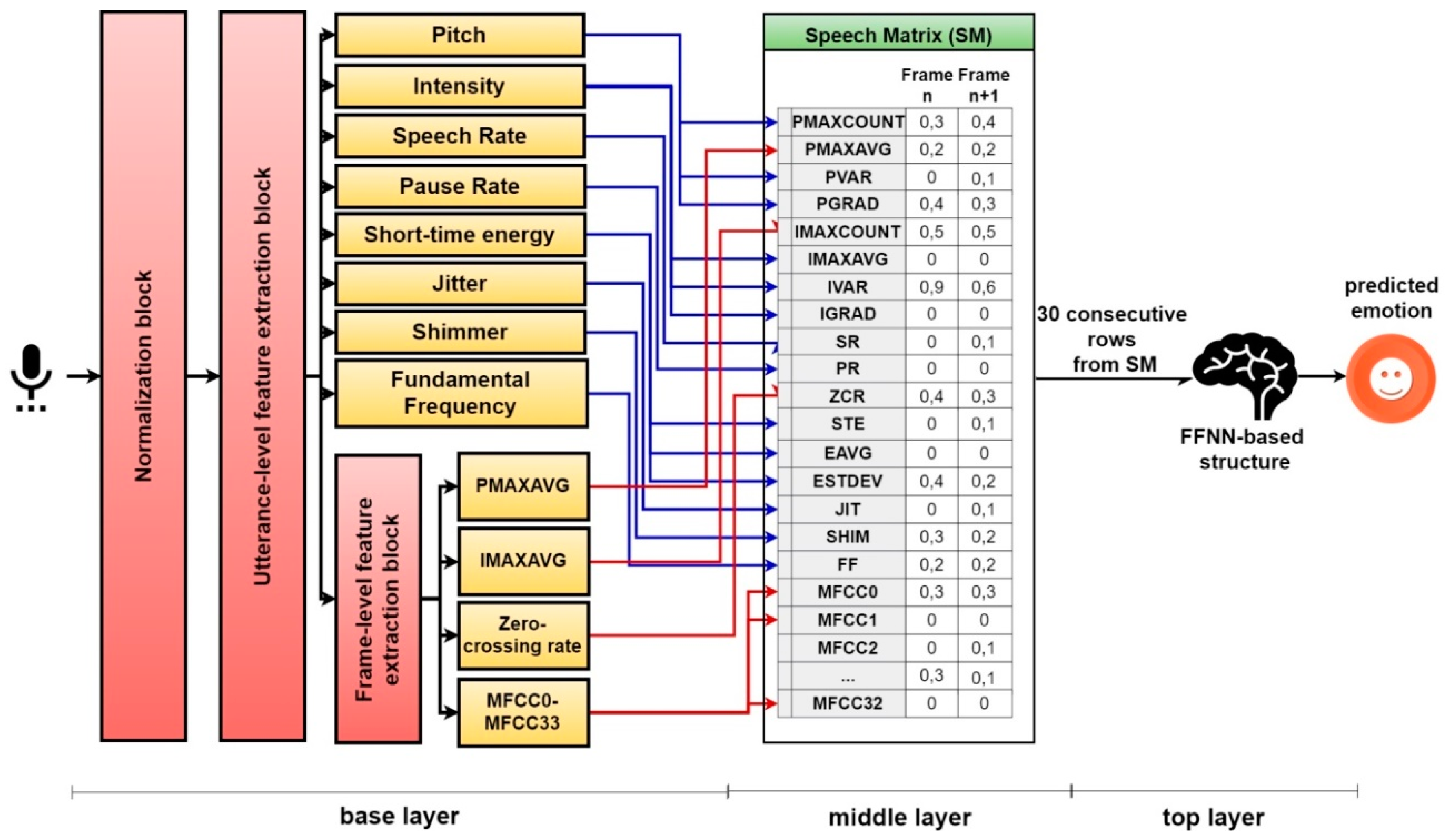
4. Materials and Methods
4.1. Base Layer
4.2. Middle Layer
4.3. Top Layer
4.4. Training and Testing Phases
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liebenthal, E.; Silbersweig, D.A.; Stern, E. The Language, Tone and Prosody of Emotions: Neural Substrates and Dynamic of Spoken-Word Emotion Perception. Front. Neurosci. 2016, 10, 506. [Google Scholar] [CrossRef] [PubMed]
- Koolagudi, S.G.; Sreenivasa Rao, K. Emotion recognition from speech: A review. Int. J. Speech Tech. 2012, 15, 99–117. [Google Scholar] [CrossRef]
- Al-Talabani, A.; Sellahewa, H.; Jassim, S.A. Emotion recognition from speech: Tools and challenges. In Proceedings of the SPIE 9497, Mobile Multimedia/Image Processing, Security, and Applications 2015, Baltimore, MD, USA, 21 May 2015. [Google Scholar]
- Partila, P.; Tovarek, J.; Frnda, J.; Voznak, M.; Penhaker, M.; Peterek, T. Emotional Impact on Neurological Characteristics and Human Speech. In Proceedings of the First Euro-China Conference on Intelligent Data Analysis and Applications, Shenzhen, China, 13–15 June 2014; pp. 527–533. [Google Scholar]
- Guoth, I.; Chmulik, M.; Polacky, J.; Kuba, M. Two-dimensional cepstrum analysis approach in emotion recognition from speech. In Proceedings of the 39th International Conference on Telecommunications and Signal Processing, Vienna, Austria, 27–29 June 2016. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. J. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Vydana, H.K.; Vikash, P.; Vamsi, T.; Kumar, K.P.; Vuppala, A.K. Detection of emotionally significant regions of speech for emotion recognition. In Proceedings of the 2015 Annual IEEE India Conference, New Delhi, India, 17–20 December 2015. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the 9th European Conference on Speech Communication and Technology, Lisboa, Portugal, 4–8 September 2005; pp. 1517–1520. [Google Scholar]
- Fan, Y.; Xu, M.; Wu, Z.; Cai, L. Automatic Emotion Variation Detection in continuous speech. In Proceedings of the Signal and Information Processing Association Annual Summit and Conference (APSIPA), 2014 Asia-Pacific, Siem Reap, Cambodia, 9–12 December 2014. [Google Scholar]
- Shami, M.T.; Kamel, M.S. Segment-based approach to the recognition of emotions in speech. In Proceedings of the IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6–8 July 2005. [Google Scholar]
- Fu, L.; Wang, C.; Zhang, Y. Classifier fusion for speech emotion recognition. In Proceedings of the IEEE International Conference on Intelligent Computing and Intelligent Systems, Xiamen, China, 29–31 October 2010. [Google Scholar]
- Zhang, C.; Yu, C.; Hansen, J.H.L. An Investigation of Deep-Learning Frameworks for Speaker Verification Antispoofing. IEEE J. Selected Topics Signal Process. 2017, 11, 684–694. [Google Scholar] [CrossRef]
- Basu, S.; Chakraborty, J.; Aftabuddin, M. Emotion recognition from speech using convolutional neural network with recurrent neural network architecture. In Proceedings of the 2nd International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 19–20 October 2017. [Google Scholar]
- Parthasarathy, S.; Tashev, I. Convolutional Neural Network Techniques for Speech Emotion Recognition. In Proceedings of the 16th International Workshop on Acoustic Signal Enhancement, Tokyo, Japan, 17–20 September 2018. [Google Scholar]
- Zhang, S.; Zhang, S.; Huang, T.; Gao, W. Speech emotion recognition using deep convolutional neural network and discriminant temporal pyramid matching. IEEE Trans. Multimed. 2018, 30, 1576–1590. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, X.; Chen, L. Learning deep features to recognize speech emotion using merged deep CNN. IET Signal Process. 2018, 12, 713–721. [Google Scholar] [CrossRef]
- Shahin, I.; Nassif, A.B.; Hamsa, S. Emotion Recognition using hybrid Gaussian mixture model and deep neural network. IEEE Access 2019, 26777–26787. [Google Scholar] [CrossRef]
- Shahin, I. Emirati speaker verification based on HMMIs, HMM2s, and HMM3s. In Proceedings of the IEEE 13th International Conference on Signal Processing (ICSP), Chengdu, China, 6–10 November 2016. [Google Scholar]
- Lotfidereshgi, R.; Gournay, P. Biologically inspired speech emotion recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Clynes, M. Sentics: The Touch of the Emotions; Anchor Press: New York, NY, USA, 1978. [Google Scholar]
- Ekman, P. Are there basic emotions? Psychol. Rev. 1992, 99, 550–553. [Google Scholar] [CrossRef]
- Vidrascu, L.; Devillers, L. Real-Life Emotion Representation and Detection in Call Centers Data. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction, Beijing, China, 22–24 October 2005; pp. 739–746. [Google Scholar]
- Vaudable, C.; Devillers, L. Negative emotions detection as an indicator of dialogs quality in call centers. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Kyoto, Japan, 25–30 March 2012. [Google Scholar]
- Park, C.; Rosenblat, J.D.; Lee, Y.; Pan, Z.; Cao, B.; Iacobucci, M.; McIntyre, R.S. The neural system of emotion regulation and abnormalities in major depressive disorder. Behav. Brain Res. 2019, 367, 181–188. [Google Scholar] [CrossRef] [PubMed]
- Jakubczyk, A.; Trucco, E.M.; Kopera, M.; Kobylinski, P.; Suszek, H.; Fudalej, S.; Brower, K.J.; Wojnar, M. The association between impulsivity, emotion regulation, and symptoms of alcohol use disorder. J. Subst. Abuse Treat. 2018, 91, 49–56. [Google Scholar] [CrossRef] [PubMed]
- Fowler, J.C.; Madan, A.; Oldham, J.M.; Frueh, B.C. Differentiating bipolar disorder from borderline personality disorder: Diagnostic accuracy of the difficulty in emotion regulation scale and personality inventory for DSM-5. J. Affect. Disord. 2019, 245, 856–860. [Google Scholar] [CrossRef] [PubMed]
- Trudel-Fitzgerald, C.; Qureshi, F.; Appleton, A.A.; Kubzansky, L.D. A healthy mix of emotions: Underlying biological pathways linking emotions to physical health. Curr. Opin. Behav. Sci. 2017, 15, 16–21. [Google Scholar] [CrossRef]
- Brook, M.; Brieman, C.L.; Kosson, D.S. Emotion processing in Psychopathy Checklist - assessed psychopathy: A review of the literature. Clin. Psycho. Rev. 2013, 33, 979–995. [Google Scholar] [CrossRef] [PubMed]
- Baumann, F.; Benndorf, V.; Friese, M. Loss-induced emotions and criminal behavior: An experimental analysis. J. Econom. Behav. Organ. 2019, 159, 134–145. [Google Scholar] [CrossRef]
- Wan, P.; Wu, C.; Lin, Y.; Ma, X. On-road experimental study on driving anger identification model based on physiological features by ROC curve analysis. IET Intell. Transp. Syst. 2017, 11, 290–298. [Google Scholar] [CrossRef]
- Drury, D.A.; Dorrian, J.; Ferguson, S.A.; Thomas, M.J.W. Detection of heightened emotional activity in commercial airline crews: A reliability study. Aviat. Psychol. Appl. Human Fact. 2013, 3, 83–91. [Google Scholar] [CrossRef]
- Schuller, B.; Vlasenko, B.; Eyben, F.; Wollmer, M.; Stuhlzatz, A.; Wendemuth, A.; Rigoll, G. Cross-Corpus Acoustic Emotion Recognition: Variances and Strategies. IEEE Trans. Affect. Comput. 2010, 1, 119–131. [Google Scholar] [CrossRef]
- Martin, O.; Kotsia, I.; Macq, B.; Pitas, I. The eNTERFACE’ 05 Audio-Visual Emotion Database. In Proceedings of the 22nd International Conference on Data Engineering Workshops, Atlanta, GA, USA, 3–7 April 2006. [Google Scholar]
- Douglas-Cowie, E.; Campbell, N.; Cowie, R.; Roach, P. Emotional speech: Towards a new generation of databases. Speech Commun. 2003, 40, 33–60. [Google Scholar] [CrossRef] [Green Version]
- Sneddon, I.; McRorie, M.; McKeown, G.; Hanratty, J. The Belfast Induced Natural Emotion Database. IEEE Trans. Affect. Comput. 2012, 3, 32–41. [Google Scholar] [CrossRef]
- Balomenos, T.; Raouzaiou, A.; Karpouzis, K.; Kollias, S.; Cowie, R. An Introduction to Emotionally Rich Man-Machine Intelligent System. In Proceedings of the Third European Symposium on Intelligent Technologies, Hybrid Systems and their implementation on Smart Adaptive Systems, Oulu, Finland, 10–12 July 2013. [Google Scholar]
- World Medical Association, World Medical Association Declaration of Helsinki: Ethical principles for medical research involving human subjects. JAMA 2013, 310, 2191–2194. [CrossRef] [PubMed]
- Harmon-Jones, C.; Bastian, B.; Harmon-Jones, E. The Discrete Emotions Questionnaire: A New Tool for Measuring State Self-Reported Emotions. PLoS One 2016, 11, e0159915. [Google Scholar] [CrossRef] [PubMed]
- Baveye, Y.; Dellandrea, E.; Chamaret, C.; Chen, L. LIRIS-ACCEDE: A Video Database for Affective Content Analysis. IEEE Trans. Affect. Comput. 2015, 6, 43–55. [Google Scholar] [CrossRef] [Green Version]
- Simundic, A.M. Measures of Diagnostic Accuracy: Basic Definitions. Electr. J. Int. Federation Clin. Chem. Lab. Med. 2009, 19, 203–211. [Google Scholar]
- Bertrand, M.; Mullainathan, S. Do People Mean What They Say? Implications for Subjective Survey Data. Am. Econom. Rev. 2001, 91, 67–72. [Google Scholar] [CrossRef]
- Paidi, G.; Kadiri, S.R.; Yegnanarayana, B. Analysis of Emotional Speech—A Review. In Toward Robotic Socially Believable Behaving Systems—Volume I: Modeling Emotions; Springer: Berlin/Heidelberg, Germany, 2016; pp. 205–238. [Google Scholar]
- Banse, R.; Scherer, K.R. Acoustic profiles in vocal emotion expression. J. Person. Soc. Psychol. 1996, 70, 614. [Google Scholar] [CrossRef]
- Koolagudi, S.G.; Rao, K.S. Real life emotion classification using VOP and pitch based spectral features. In Proceedings of the Annual IEEE India Conference, Kolkata, India, 17–19 December 2011. [Google Scholar]
- Ding, N.; Ye, N.; Huang, H.; Wang, R.; Malekian, R. Speech emotion features selection based on BBO-SVM. In Proceedings of the 10th International Conference on Advanced Computational Intelligence, Xiamen, China, 29–31 March 2018. [Google Scholar]
- Aouani, H.; Ayed, Y.B. Emotion recognition in speech using MFCC with SVM, DSVM and auto-encoder. In Proceedings of the 4th International Conference on Advanced Technologies for Signal and Image Processing, Susah, Tunisia, 21–24 March 2018. [Google Scholar]
- Kolakowska, A.; Landowska, A.; Szwoch, M.; Szwock, W.; Wrobel, M. Emotion Recognition and Its Applications. In Human-Computer Systems Interaction: Backgrounds and Applications; Springer: Cham, Switzerland, 2014; Volume 3, pp. 51–62. [Google Scholar]
- Philip, R.C.; Whalley, H.C.; Stanfield, A.C.; Sprengelmeyer, R.; Santos, I.M.; Young, A.W.; Atkinson, A.P.; Calder, A.J.; Johnstone, E.C.; Lawrie, S.M.; et al. Deficits in facial, body movement and vocal emotional processing in autism spectrum disorders. Psychol. Med. 2010, 40, 1919–1929. [Google Scholar] [CrossRef] [Green Version]
- Stewart, M.E.; McAdam, C.; Ota, M.; Peppe, S.; Cleland, J. Emotional recognition in autism spectrum conditions from voices and faces. Autism 2013, 17, 6–14. [Google Scholar] [CrossRef]
- Schelinski, S.; von Kriegstein, K. The relation between vocal pitch and vocal emotion recognition abilities in people with Autism Spectrum Disorder and Typical Development. J. Autism Dev. Disord. 2019, 49, 68–82. [Google Scholar] [CrossRef]
- Ekpenyong, M.; Obot, O. Speech Quality Enhancement in Digital Forensic Voice Analysis. Comput. Intell. Digit. Forensics: Forensic Invest. Appl. 2014, 555, 429–451. [Google Scholar]
- Upadhyay, N.; Karmakar, A. Speech Enhancement using Spectral Subtraction-type Algorithms: A comparison and simulation study. Procedia Comput. Sci. 2015, 54, 574–588. [Google Scholar] [CrossRef]
- Prasad, N.V.; Umesh, S. Improved cepstral mean and variance normalization using Bayesian framework. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013. [Google Scholar]
- Nolan, F. Intonational equivalence: An experimental evaluation of pitch scales. In Proceedings of the 15th International Congress of Phonetic Sciences, Barcelona, Spain, 3–9 August 2003. [Google Scholar]
- Gurban, M.; Thiran, J.P. Information Theoretic Feature Extraction for Audio-Visual Speech Recognition. IEEE Trans. Signal Process. 2009, 57, 4765–4776. [Google Scholar] [CrossRef] [Green Version]
- Ayadi, M.E.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Aksoy, S.; Haralick, R.M. Feature normalization and likelihood-based similarity measures for image retrieval. Pattern Recogn. Lett. 2001, 22, 563–582. [Google Scholar] [CrossRef] [Green Version]
- Saxen, H.; Petterson, F. A methodology for developing Nonlinear Models by Feedforward Neural Networks. In Proceedings of the International Conference on Adaptive and Natura Computing Algorithms, Kuopio, Finland, 23–25 April 2009; pp. 72–78. [Google Scholar]
- Hara, K.; Saito, D.; Shouno, H. Analysis of function of rectified linear unit used in deep learning. In Proceedings of the International Joint Conference on Neural Network, Killarney, Ireland, 11–16 July 2015. [Google Scholar]
- Bridle, J.S. Probabilistic Interpretation of Feedforward Classification Network Outputs, with Relationships to Statistical Pattern Recognition. Neurocomputing 1990, 68, 227–236. [Google Scholar]
- Li, J.; Cheng, J.H.; Huang, F. Brief Introduction of Back Propagation BP) Neural Network Algorithm and Its Improvement. Adv. Comput. Sci. Inf. Eng. 2012, 169, 553–558. [Google Scholar]
- Masood, S.; Doja, M.N.; Chandra, P. Analysis of weight initialization techniques for gradient descent. In Proceedings of the Annual IEEE India Conference 2015, New Delhi, India, 17–20 December 2015. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TRDT | TEDT | AVGD | MM | A | D | F | H | S | SPR | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|
| DSC | DSC | 10 | AC | 83.20 ± 0.05 | 76.20 ± 0.14 | 84.30 ± 0.12 | 91.10 ± 0.03 | 86.40 ± 0.12 | 78.90 ± 0.16 | 83.35 ± 0.15 |
| SE | 77.40 | 70.90 | 78.40 | 85.50 | 82.40 | 73.70 | 78.04 | |||
| SP | 74.10 | 67.10 | 76.40 | 84.10 | 78.30 | 70.70 | 75.12 | |||
| DSC | DSR | 12 | AC | 82.30 ± 0.10 | 75.40 ± 0.23 | 83.20 ± 0.21 | 90.40 ± 0.03 | 84.30 ± 0.16 | 77.20 ± 0.21 | 82.13 ± 0.19 |
| SE | 77.10 | 70.80 | 78.00 | 85.40 | 80.00 | 73.00 | 77.44 | |||
| SP | 73.30 | 67.02 | 75.20 | 84.02 | 77.70 | 70.54 | 75.04 | |||
| DSR | DSC | 16 | AC | 70.80 ± 0.34 | 65.10 ± 0.34 | 71.60 ± 0.39 | 78.20 ± 0.43 | 71.30 ± 0.37 | 66.30 ± 0.39 | 70.55 ± 0.38 |
| SE | 65.10 | 60.80 | 67.60 | 73.30 | 67.30 | 61.40 | 65.90 | |||
| SP | 63.70 | 57.50 | 64.70 | 70.70 | 62.40 | 59.20 | 63.02 | |||
| DSR | DSR | 15 | AC | 68.20 ± 0.46 | 62.40 ± 0.64 | 69.20 ± 0.62 | 75.30 ± 0.65 | 68.60 ± 0.56 | 63.60 ± 0.55 | 67.88 ± 0.58 |
| SE | 63.00 | 57.40 | 63.90 | 70.40 | 64.60 | 57.90 | 62.86 | |||
| SP | 61.10 | 54.10 | 60.00 | 67.80 | 61.50 | 57.40 | 60.31 | |||
| DSC + DSR | DSC + DSR | 13 | AC | 81.30 ± 0.43 | 74.20 ± 0.45 | 81.80 ± 0.43 | 89.10 ± 0.49 | 83.20 ± 0.47 | 76.10 ± 0.42 | 80.95 ± 0.45 |
| SE | 77.00 | 68.40 | 76.70 | 83.30 | 79.00 | 70.20 | 75.76 | |||
| SP | 73.20 | 65.40 | 72.70 | 82.60 | 76.80 | 69.90 | 73.60 |
| Predicted Output | Expected Output | |||||||
| Anger | Disgust | Fear | Happiness | Sadness | Surprise | |||
| Train: DSC Test: DSC | Anger | 83.20 | 0.00 | 9.20 | 0.00 | 7.60 | 0.00 | |
| Disgust | 11.20 | 76.20 | 1.20 | 0.00 | 11.40 | 0.00 | ||
| Fear | 0.00 | 4.50 | 84.30 | 0.00 | 0.00 | 11.20 | ||
| Happiness | 0.00 | 0.00 | 0.00 | 91.10 | 0.00 | 8.90 | ||
| Sadness | 1.50 | 12.10 | 0.00 | 0.00 | 86.40 | 0.00 | ||
| Surprise | 1.30 | 0.00 | 9.60 | 10.20 | 0.00 | 78.90 | ||
| Train: DSC Test: DSR | Anger | 82.30 | 0.00 | 10.20 | 0.00 | 7.50 | 0.00 | |
| Disgust | 14.30 | 75.40 | 2.70 | 0.00 | 7.60 | 0.00 | ||
| Fear | 0.00 | 5.40 | 83.20 | 0.00 | 0.00 | 11.40 | ||
| Happiness | 0.00 | 0.00 | 0.00 | 90.40 | 0.00 | 9.60 | ||
| Sadness | 4.40 | 11.30 | 0.00 | 0.00 | 84.30 | 0.00 | ||
| Surprise | 1.70 | 0.00 | 9.90 | 11.20 | 0.00 | 77.20 | ||
| Train: DSR Test: DSC | Anger | 70.80 | 0.00 | 16.50 | 0.00 | 10.20 | 2.50 | |
| Disgust | 21.20 | 65.10 | 1.80 | 1.40 | 10.50 | 0.00 | ||
| Fear | 0.00 | 7.20 | 71.60 | 0.00 | 0.00 | 21.20 | ||
| Happiness | 1.50 | 3.80 | 0.00 | 78.20 | 0.00 | 16.50 | ||
| Sadness | 7.60 | 18.50 | 0.00 | 2.60 | 71.30 | 0.00 | ||
| Surprise | 3.80 | 0.00 | 11.40 | 18.50 | 0.00 | 66.30 | ||
| Train: DSR Test: DSR | Anger | 68.20 | 0.00 | 17.60 | 0.00 | 11.20 | 3.00 | |
| Disgust | 24.30 | 62.40 | 1.00 | 1.00 | 11.30 | 0.00 | ||
| Fear | 0.00 | 7.60 | 69.20 | 0.00 | 0.00 | 23.20 | ||
| Happiness | 2.30 | 4.20 | 0.00 | 75.30 | 0.00 | 18.20 | ||
| Sadness | 8.10 | 21.20 | 0.00 | 2.10 | 68.60 | 0.00 | ||
| Surprise | 4.00 | 0.00 | 12.20 | 20.20 | 0.00 | 63.60 | ||
| Train: DSC+DSR Test: DSC+DSR | Anger | 81.30 | 0.00 | 10.80 | 0.00 | 7.90 | 0.00 | |
| Disgust | 14.40 | 74.20 | 3.10 | 0.00 | 8.30 | 0.00 | ||
| Fear | 0.00 | 5.80 | 81.80 | 0.00 | 0.00 | 12.40 | ||
| Happiness | 0.00 | 0.00 | 0.00 | 89.10 | 0.00 | 10.90 | ||
| Sadness | 4.60 | 11.40 | 0.00 | 0.00 | 83.20 | 0.80 | ||
| Surprise | 1.80 | 0.00 | 10.40 | 11.70 | 0.00 | 76.10 | ||
| TRDT | TEDT | AVGD | NTS | MM | A | D | F | H | S | SUP | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DSC | DSC | 2 | 64 | AC | 68.71 ± 0.48 | 62.21 ± 0.45 | 68.91 ± 0.43 | 75.25 ± 0.49 | 71.51 ± 0.47 | 64.21 ± 0.43 | 68.51 ± 0.41 |
| SE | 65.42 | 59.72 | 66.72 | 71.71 | 69.41 | 61.42 | 65.74 | ||||
| SP | 61.11 | 53.43 | 60.01 | 67.02 | 63.61 | 56.74 | 60.33 | ||||
| DSC | DSC | 1 | 96 | AC | 74.74 ± 0.34 | 69.15 ± 0.33 | 77.72 ± 0.31 | 84.73 ± 0.34 | 78.14 ± 0.37 | 71.93 ± 0.39 | 76.01 ± 0.35 |
| SE | 71.95 | 65.84 | 74.11 | 80.81 | 74.85 | 68.31 | 72.61 | ||||
| SP | 66.34 | 61.41 | 70.63 | 77.53 | 70.56 | 63.84 | 68.43 | ||||
| DSC | DSC | 0.5 | 127 | AC | 79.31 ± 0.21 | 74.23 ± 0.21 | 82.15 ± 0.23 | 89.44 ± 0.23 | 83.25 ± 0.22 | 76.26 ± 0.21 | 80.75 ± 0.21 |
| SE | 76.23 | 70.51 | 79.24 | 86.81 | 80.21 | 73.34 | 77.74 | ||||
| SP | 71.22 | 65.82 | 73.71 | 82.00 | 75.85 | 68.21 | 72.83 | ||||
| DSR | DSR | 18 | 64 | AC | 61.31 ± 0.95 | 57.81 ± 0.91 | 62.35 ± 0.92 | 73.01 ± 0.95 | 64.34 ± 0.97 | 56.70 ± 0.94 | 62.51 ± 0.92 |
| SE | 57.33 | 55.01 | 58.84 | 70.41 | 60.71 | 52.90 | 59.24 | ||||
| SP | 53.24 | 49.42 | 54.01 | 65.00 | 55.35 | 47.82 | 54.15 | ||||
| DSR | DSR | 15 | 96 | AC | 64.35 ± 0.65 | 60.11 ± 0.65 | 65.71 ± 0.67 | 74.61 ± 0.65 | 68.02 ± 0.65 | 59.23 ± 0.53 | 65.34 ± 0.61 |
| SE | 62.14 | 56.74 | 63.33 | 72.32 | 65.51 | 56.54 | 62.71 | ||||
| SP | 56.61 | 52.73 | 57.82 | 65.91 | 59.55 | 51.64 | 57.35 | ||||
| DSR | DSR | 8 | 127 | AC | 66.61 ± 0.56 | 63.11 ± 0.54 | 68.61 ± 0.54 | 76.71 ± 0.52 | 70.94 ± 0.54 | 62.53 ± 0.54 | 68.14 ± 0.53 |
| SE | 63.42 | 59.24 | 65.33 | 73.25 | 68.51 | 58.71 | 64.72 | ||||
| SP | 59.34 | 55.55 | 61.01 | 69.63 | 62.85 | 53.94 | 60.41 | ||||
| DSC | DSR | 1.5 | 127 | AC | 77.63 ± 0.29 | 72.33 ± 0.28 | 80.51 ± 0.31 | 88.11 ± 0.27 | 81.84 ± 0.22 | 74.35 ± 0.27 | 79.13 ± 0.26 |
| SE | 74.31 | 68.31 | 76.74 | 85.73 | 79.31 | 72.20 | 76.14 | ||||
| SP | 70.23 | 64.21 | 72.63 | 79.73 | 74.65 | 65.51 | 71.15 | ||||
| DSR | DSC | 7 | 127 | AC | 68.75 ± 0.59 | 65.14 ± 0.55 | 71.01 ± 0.54 | 79.21 ± 0.52 | 73.14 ± 0.54 | 64.52 ± 0.56 | 70.34 ± 0.55 |
| SE | 66.66 | 62.12 | 68.31 | 76.73 | 70.01 | 62.24 | 67.71 | ||||
| SP | 61.01 | 57.41 | 63.34 | 70.54 | 65.32 | 57.35 | 62.54 | ||||
| DSC + DSR | DSC + DSR | 5 | 127 | AC | 76.81 ± 0.49 | 71.75 ± 0.50 | 79.63 ± 0.51 | 87.41 ± 0.48 | 81.14 ± 0.45 | 73.61 ± 0.54 | 78.35 ± 0.51 |
| SE | 73.44 | 69.23 | 75.91 | 84.02 | 77.35 | 71.55 | 75.24 | ||||
| SP | 68.53 | 63.41 | 72.15 | 79.31 | 73.01 | 66.34 | 70.51 |
| Predicted Output | Expected Output | |||||||
| Anger | Disgust | Fear | Happiness | Sadness | Surprise | |||
| Train: DSC Test: DSC | Anger | 79.31 | 0.00 | 14.30 | 0.00 | 6.39 | 0.00 | |
| Disgust | 10.20 | 74.23 | 5.07 | 0.00 | 10.50 | 0.00 | ||
| Fear | 0.00 | 6.65 | 82.15 | 0.00 | 0.00 | 11.20 | ||
| Happiness | 0.00 | 0.00 | 0.00 | 89.44 | 0.00 | 10.56 | ||
| Sadness | 6.95 | 9.80 | 0.00 | 0.00 | 83.25 | 0.00 | ||
| Surprise | 2.84 | 0.00 | 10.50 | 10.40 | 0.00 | 76.26 | ||
| Train: DSC Test: DSR | Anger | 77.63 | 0.00 | 15.40 | 0.00 | 6.97 | 0.00 | |
| Disgust | 16.50 | 72.33 | 4.67 | 0.00 | 6.50 | 0.00 | ||
| Fear | 0.00 | 4.09 | 80.51 | 0.00 | 0.00 | 15.40 | ||
| Happiness | 0.00 | 0.00 | 0.00 | 88.11 | 0.00 | 11.89 | ||
| Sadness | 3.86 | 14.30 | 0.00 | 0.00 | 81.84 | 0.00 | ||
| Surprise | 5.95 | 0.00 | 6.50 | 13.20 | 0.00 | 74.35 | ||
| Train: DSR Test: DSC | Anger | 68.75 | 0.00 | 15.40 | 0.00 | 9.50 | 6.35 | |
| Disgust | 16.50 | 65.14 | 5.60 | 4.26 | 8.50 | 0.00 | ||
| Fear | 0.00 | 9.49 | 71.01 | 0.00 | 0.00 | 19.50 | ||
| Happiness | 3.59 | 6.70 | 0.00 | 79.21 | 0.00 | 10.50 | ||
| Sadness | 7.60 | 15.40 | 0.00 | 3.86 | 73.14 | 0.00 | ||
| Surprise | 5.60 | 0.00 | 10.48 | 19.40 | 0.00 | 64.52 | ||
| Train: DSR Test: DSR | Anger | 66.61 | 0.00 | 16.50 | 0.00 | 10.20 | 6.69 | |
| Disgust | 18.20 | 63.11 | 4.50 | 4.59 | 9.60 | 0.00 | ||
| Fear | 0.00 | 9.89 | 68.61 | 0.00 | 0.00 | 21.50 | ||
| Happiness | 4.30 | 3.59 | 0.00 | 76.71 | 0.00 | 15.40 | ||
| Sadness | 8.70 | 16.50 | 0.00 | 3.86 | 70.94 | 0.00 | ||
| Surprise | 7.67 | 0.00 | 10.40 | 19.40 | 0.00 | 62.53 | ||
| Train: DSC+DSR Test: DSC+DSR | Anger | 76.81 | 0.00 | 15.40 | 0.00 | 7.79 | 0.00 | |
| Disgust | 14.30 | 71.75 | 4.30 | 0.00 | 9.65 | 0.00 | ||
| Fear | 0.00 | 6.17 | 79.63 | 0.00 | 0.00 | 14.20 | ||
| Happiness | 0.00 | 0.00 | 0.00 | 87.41 | 0.00 | 12.59 | ||
| Sadness | 2.96 | 10.50 | 0.00 | 0.00 | 81.14 | 5.40 | ||
| Surprise | 4.29 | 0.00 | 6.70 | 15.40 | 0.00 | 73.61 | ||
| Emotion | Speech Features | AC | SE | SP | APT |
|---|---|---|---|---|---|
| Anger | high PMAXCOUNT, high PMAXAVG, high PGRAD, high ZCR, high ESTDEV | 83.5 | 80.2 | 78.4 | 55 |
| Disgust | low ZCR, low EAVG, low ESTDEV, low PMAXAVG, low STE | 78.3 | 76.2 | 75.4 | 55 |
| Fear | high IMAXCOUNT, high IMAXAVG, high IGRAD, low PMAXCOUNT, low FF | 86.4 | 83.2 | 81.4 | 55 |
| Happiness | high FF, high SR, low PR, low ZCR, high IMAXCOUNT | 92.1 | 90.1 | 89.4 | 34 |
| Sadness | low FF, low PMAXCOUNT, low JIT, low PMAXAVG, low IGRAD | 88.2 | 84.5 | 82.3 | 60 |
| Surprise | low JIT, low SHIM, high PR, high STE, high PGRAD, low IGRAD | 80.1 | 77.6 | 75.9 | 55 |
| Method Used | Measurement Method | Avic [32] | Mcgilloway [34] | Structured Belfast [35] | Salas [36] | Proposed Database | |
|---|---|---|---|---|---|---|---|
| Non NN-Based Methods | Bat algorithm and PSO [5] | Accuracy [%] | 80.66 | 64.31 | 72.91 | 67.47 | 72.37 |
| Sensitivity [%] | 75.57 | 59.54 | 68.14 | 64.44 | 66.01 | ||
| Specificity [%] | 76.85 | 59.04 | 67.58 | 61.56 | 68.09 | ||
| GMM (Emotion Significant Regions) [7] | Accuracy [%] | 71.15 | 64.67 | 72.71 | 68.20 | 77.12 | |
| Sensitivity [%] | 68.53 | 58.95 | 67.64 | 63.53 | 73.12 | ||
| Specificity [%] | 66.84 | 58.67 | 69.17 | 63.97 | 74.01 | ||
| GMM (Vowel Onset Points – VOP) [44] | Accuracy [%] | 66.92 | 65.84 | 69.46 | 68.25 | 75.41 | |
| Sensitivity [%] | 62.91 | 62.96 | 65.04 | 65.47 | 70.47 | ||
| Specificity [%] | 60.13 | 60.84 | 64.42 | 63.89 | 69.94 | ||
| MSW-AEVD + HMM [9] | Accuracy [%] | 68.61 | 69.68 | 72.51 | 79.63 | 70.12 | |
| Sensitivity [%] | 65.02 | 64.74 | 69.82 | 75.21 | 65.89 | ||
| Specificity [%] | 62.43 | 63.18 | 66.04 | 74.61 | 65.31 | ||
| Biogeography-based Optimization (BBO) + SVM [45] | Accuracy [%] | 71.03 | 68.63 | 71.11 | 70.18 | 76.12 | |
| Sensitivity [%] | 67.04 | 63.11 | 66.18 | 67.41 | 73.24 | ||
| Specificity [%] | 66.51 | 64.26 | 65.78 | 65.02 | 70.93 | ||
| Deep SVM [46] | Accuracy [%] | 66.56 | 71.31 | 68.72 | 71.93 | 72.71 | |
| Sensitivity [%] | 61.31 | 65.41 | 66.55 | 66.31 | 67.44 | ||
| Specificity [%] | 62.14 | 63.73 | 62.81 | 65.48 | 66.93 | ||
| SVM + KNN [10] | Accuracy [%] | 64.61 | 68.12 | 74.19 | 73.64 | 73.26 | |
| Sensitivity [%] | 61.62 | 64.37 | 70.32 | 69.64 | 69.86 | ||
| Specificity [%] | 59.32 | 63.96 | 69.44 | 68.84 | 67.84 | ||
| NN-Based Methods | CNN + RF [12] | Accuracy [%] | 64.54 | 70.22 | 74.31 | 69.82 | 70.77 |
| Sensitivity [%] | 61.56 | 69.54 | 73.97 | 67.78 | 68.42 | ||
| Specificity [%] | 60.83 | 69.75 | 73.57 | 65.01 | 67.37 | ||
| HMM + ANN [11] | Accuracy [%] | 68.14 | 65.48 | 69.14 | 74.12 | 70.59 | |
| Sensitivity [%] | 65.86 | 60.67 | 65.22 | 71.27 | 68.11 | ||
| Specificity [%] | 62.81 | 61.12 | 63.18 | 69.81 | 64.43 | ||
| DCNN + DTPM [15] | Accuracy [%] | 71.74 | 71.11 | 72.50 | 71.64 | 80.22 | |
| Sensitivity [%] | 69.51 | 66.14 | 67.42 | 68.71 | 76.48 | ||
| Specificity [%] | 62.40 | 64.92 | 63.94 | 67.68 | 76.37 | ||
| 1D-CNN + 2D-CNN [16] | Accuracy [%] | 68.34 | 69.34 | 74.86 | 69.53 | 77.01 | |
| Sensitivity [%] | 64.33 | 59.78 | 63.62 | 69.26 | 74.01 | ||
| Specificity [%] | 64.47 | 65.17 | 65.05 | 72.84 | 72.62 | ||
| FFNN (current paper) | Accuracy [%] | 73.03 | 73.67 | 76.88 | 81.21 | 84.8 | |
| Sensitivity [%] | 70.46 | 67.64 | 71.13 | 74.08 | 81.9 | ||
| Specificity [%] | 67.51 | 66.47 | 70.59 | 73.61 | 80.5 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gavrilescu, M.; Vizireanu, N. Feedforward Neural Network-Based Architecture for Predicting Emotions from Speech. Data 2019, 4, 101. https://doi.org/10.3390/data4030101
Gavrilescu M, Vizireanu N. Feedforward Neural Network-Based Architecture for Predicting Emotions from Speech. Data. 2019; 4(3):101. https://doi.org/10.3390/data4030101
Chicago/Turabian StyleGavrilescu, Mihai, and Nicolae Vizireanu. 2019. "Feedforward Neural Network-Based Architecture for Predicting Emotions from Speech" Data 4, no. 3: 101. https://doi.org/10.3390/data4030101
APA StyleGavrilescu, M., & Vizireanu, N. (2019). Feedforward Neural Network-Based Architecture for Predicting Emotions from Speech. Data, 4(3), 101. https://doi.org/10.3390/data4030101