1. Introduction
A neurodevelopmental condition known as autism spectrum disorder (ASD) is characterised by differences in neurological functioning. People who are diagnosed as autistic might exhibit a variety of behavioural patterns, interests, and behaviours such as engaging in repetitive behaviours or exhibiting a strong fixation on specific objects. People with ASD may have trouble communicating and interacting with others. Furthermore, it is important to point out that people with ASD may exhibit different learning and attention patterns from typically developing people. There is a notable global increase in the prevalence of autism spectrum disorder, with a continuous annual rise in the number of individuals diagnosed with this neurodevelopmental disorder. According to the Centre for Disease Control and Prevention (CDC), the prevalence of ASD among 8-year-olds in the United States is 1 in 36. According to data from the autism and developmental disabilities monitoring (ADDM) network, the percentage of children diagnosed with ASD at age 8 increased by 100 percent between 2000 and 2020 (Maenner, et al., 2023 [
1]). For this reason, the importance of early ASD detection lies in its capacity to expedite precise diagnoses, thus enabling timely interventions during critical developmental stages. This temporal alignment enhances the effectiveness of therapeutic protocols and educational interventions. Moreover, the early identification of ASD creates a foundation for families to avail themselves of specialised services and engage with support networks, subsequently enhancing the development trajectory of affected children. Importantly, support groups serve as crucial resources for families navigating the challenges posed by Autism, offering advice, collective wisdom, and emotional reinforcement (Øien; Salgado-Cacho; Zwaigenbaum, et al. [
2,
3,
4]).
Traditional methods of diagnosing ASD include behavioural observations, historical records, parental reports, and statistical analysis (Wan et al., 2019 [
5]). Advanced technology can be used such as eye-tracking technologies that can capture gaze patterns such as gaze fixation, blinking, and saccadic eye movements. In light of this capability, our research endeavours to make a distinctive contribution by developing a model tailored to scrutinise divergences in gaze patterns and attentional mechanisms between individuals diagnosed with autism and those without. The application of this model seeks to illuminate nuances in gaze-related behaviours, shedding light on potential markers that differentiate the two cohorts. Nonetheless, the diagnostic facet of autism presents a complex landscape. A pressing demand emerges for refined diagnostic tools that efficaciously facilitate accurate and efficient assessments. This diagnostic accuracy, in turn, serves as the bedrock for informed interventions and personalised recommendations. Our investigation bridges this exigency by delving into the symbiotic potential between eye-tracking technology and deep learning algorithms.
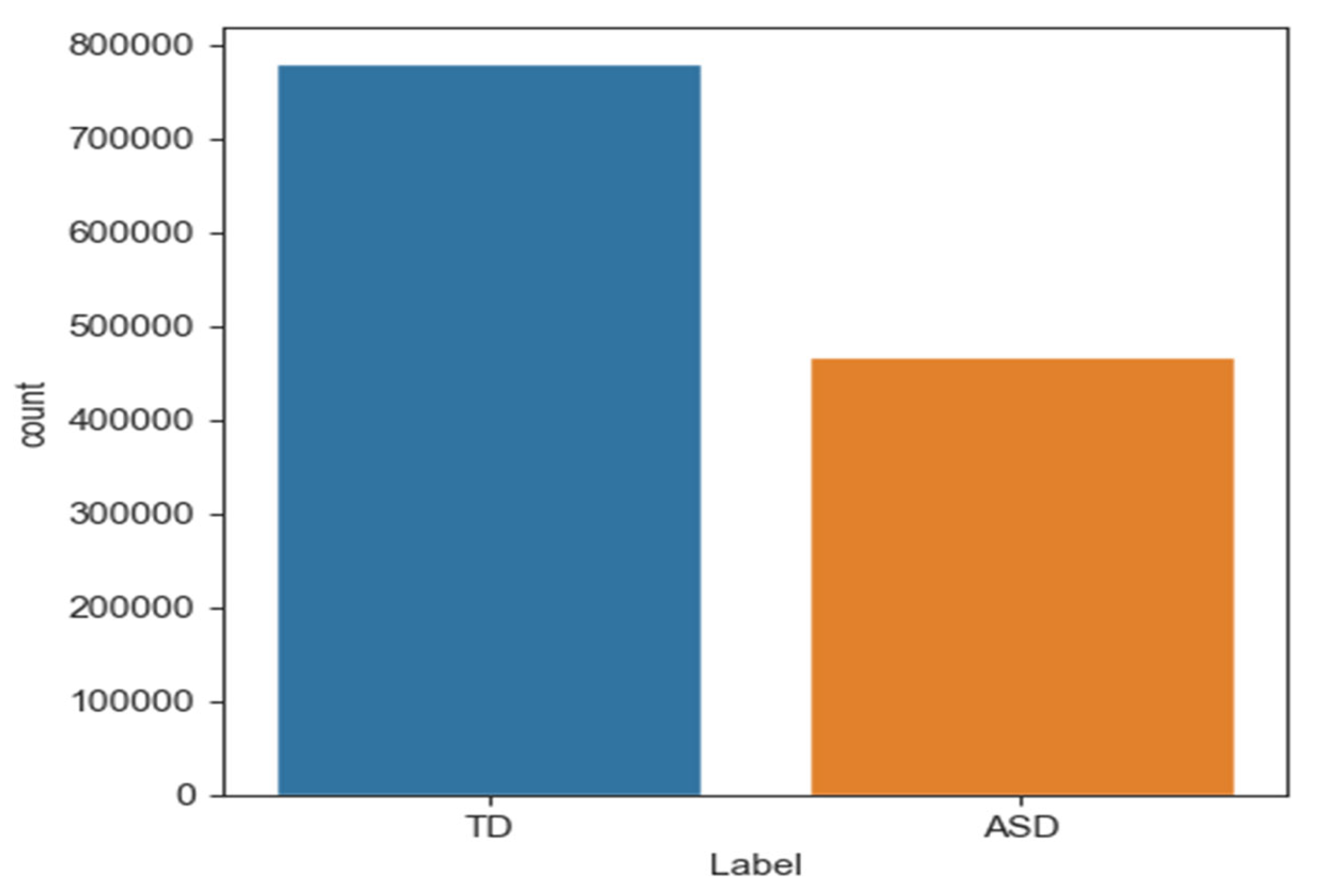
A fundamental aspect of the contributions presented in this study encompasses the deep learning-based model meticulously designed to discern autism through analysing gaze patterns. This study is one of the first studies to use the dataset after it was released as a standard dataset available to the public. The dataset comprises raw eye-tracking data collected from 29 children diagnosed with autism spectrum disorder (ASD) and 30 typically developing (TD) children. The visual stimuli used to engage the children during data collection included both static images (balloons and cartoon characters) and dynamic videos. In total, the dataset contains approximately 2,165,607 rows of eye-tracking data recorded while the children viewed the stimuli.
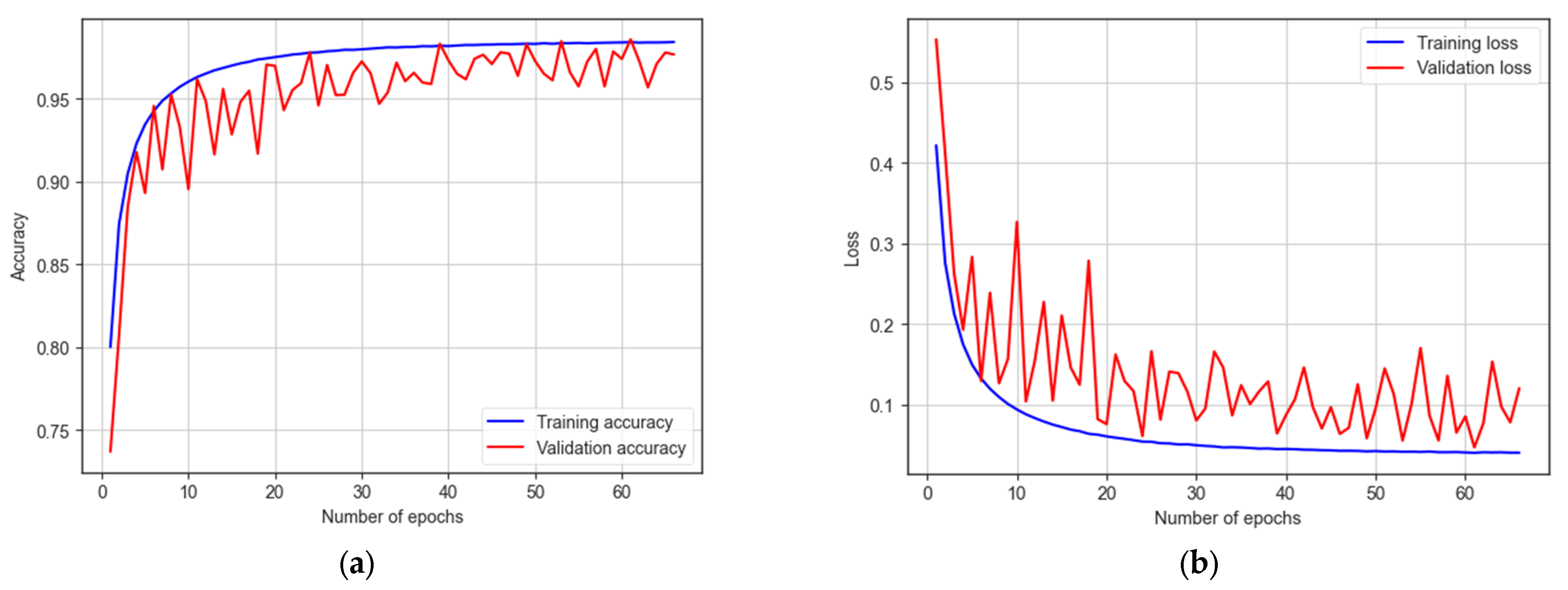
This study presented an impressive accuracy level of 98%, marking a notable stride in innovative advancement. This achievement is primarily attributed to the strategic implementation of the long short-term memory (LSTM) architecture, a sophisticated computational framework. The discernible success achieved substantiates the effectiveness of the rigorous preprocessing methodologies meticulously applied to the dataset, thereby underlining the robustness and integrity of the research outcomes.
This paper is organised as follows: section two discusses related work and previous studies that pertain to our research; section three presents the description of the data and the architecture of the models; section four provides the experimental results of the models and provides a detailed discussion. Finally, the conclusions of the study are presented.
2. Related Work
Neuroscience and psychology researchers employ eye-tracking equipment to learn crucial things about human behaviour and decision making. This equipment also aids in the identification and management of psychological problems like autism. For instance, people with autism may exhibit atypical gaze patterns and attention, such as a protracted focus on non-social things and issues synchronising their attention with social interactions. Eye-tracking technology can detect three main types of eye movements: fixation, saccade, and blinking. During fixation, the eyes briefly pause while the brain processes visual information. Fixation duration usually lasts between 150 ms and 300 ms, depending on the context. For instance, the duration differs when reading on paper (230 ms) compared to on a screen (553 ms) or when watching a naturalistic scene on a computer (330 ms) [
6]. Saccades are rapid eye movements that continuously scan the object to ensure accurate perception, taking about (30–120 ms) each [
7]. When the eye-tracking system fails to track gaze, a blink occurs.
This section provides a comprehensive review of previous study efforts that have utilised eye-tracking technology to examine disparities in gaze patterns and attentional mechanisms between individuals who have received a diagnosis of ASD and those who have not been diagnosed with ASD. This study focuses on the utilisation of artificial intelligence algorithms to diagnose autism through the analysis of gaze patterns. By combining eye-tracking technology with AI algorithms, this can help in the early detection of autism by analysing and classifying these gaze patterns (Ahmed and Jadhav, 2020; Kollias et al., 2021 [
8,
9]).
Eye-tracking technology has played a pivotal role in discerning the unique gaze and face recognition patterns exhibited by individuals with ASD. This subsection delves into how individuals with ASD and TD children differ in their visual attention toward faces. A study investigated whether children with ASD exhibit different face fixation patterns compared to TD children when viewing various types of faces, as proposed by (Kang et al., 2020a [
10]). The study involved 77 children with low-functioning ASD and 80 TD children, all between the ages of (3 and 6) years. A Tobii TX300 eye-tracking system was used to collect data. The children sat 60 cm away from the screen and viewed a series of random facial photos, including own-race familiar faces, own-race unfamiliar faces, and other-race unfamiliar faces. The features were extracted using the K-means algorithm and selected based on minimal redundancy and maximal relevance. The SVM classifier was then used, with the highest accuracy of 72.50% achieved when selecting 32 features out of 64 from unfamiliar other-race faces. For own-race unfamiliar faces, the highest accuracy was 70.63% when selecting 18 features and 78.33% when selecting 48 features. The classification result AUC was 0.89 when selecting 120 features. The machine learning analysis indicated differences in the way children with ASD and TD processed own-race and other-race faces.
An approach to identify autism in children using their eye-movement patterns during face scanning was proposed by (Liu et al., 2016 [
11]). A dataset was collected from 29 children with ASD and 29 TD children aged (4–11) years, using a Tobii T60 eye tracker with a sample rate of 60 Hz. During the stimuli procedure, the children were asked to memorise six faces and were then tested by showing them 18 faces and asking if they had seen that face before. The eye tracker recorded the children’s eye-scanning patterns on the faces. The K-means algorithm was used to cluster the eye-tracking data according to fixation coordinates. A histogram was then used to represent the features, and SVM was used for classification, resulting in an accuracy of 88.51%. The study found that eye-movement patterns during face scanning can be used to discriminate between children with ASD and TD children.
The study differentiation of ASD and TD was based on gaze fixation times as proposed by (Wan et al., 2019 [
5]). The study included 37 participants with ASD and 37 TD individuals, all between the ages of (4 and 6) years. The researchers employed a portable eye-tracking system, specifically the SMI RED250 to collect data. The participants were placed in a dark, soundproof room and asked to view a 10 s silent video of a young Asian woman speaking the English alphabet on a 22-inch widescreen LCD display. The researchers used an SVM classifier, which yielded an accuracy of 85.1%. Analysis of the results revealed that the ASD group had significantly shorter fixation periods in various areas, including the eyes, mouth, nose, person, face, outer person, and body.
A validation of eye tracking as a tool for detecting autism was proposed by (Murias et al., 2018 [
12]). Their study involved 25 children with ASD between the ages of (24 and 72) months, and eye tracking was conducted using a Tobii TX300 eye tracker. The Tobii TX300 Eye Tracker is a product of Tobii AB (Stockholm, Sweden) a Swedish technology company that develops and sells products for eye tracking and attention computing. The children were seated on their parent’s lap while watching a 3 min video of an actor speaking in a child-directed manner while four toys surrounded him. The researchers analysed the children’s eye gaze on the actor, toys, face, eyes, and mouth. The results suggest that eye-tracking social attention measurements are valid and comparable to caregiver-reported clinical indicators.
The gaze patterns of toddlers and preschoolers with and without ASD were compared as they watched static and dynamic visualisations as proposed by (Kong et al., 2022 [
13]). The authors employed the SMI RED250 portable eye-tracking system to collect data from both ASD and TD children. The sample included 55 ASD and 40 TD toddlers aged between 1 and 3 years and 37 ASD and 41 TD preschoolers aged between 3 and 5 years. Participants were shown a video of a person moving his mouth while their eye movements were recorded. The study’s outcome indicated that the SVM achieved an 80% classification rate for both ASD and TD toddlers and 71% for preschoolers. The findings suggested that eye-tracking patterns for ASD in both toddlers and preschoolers were typical and distinctive.
The integration of eye-tracking technology with web browsing and searching provides a perceptive lens into people’s digital conduct, especially when comparing people with ASD and TD individuals. The investigation of eye-gaze patterns of TD and ASD individuals while browsing and searching web pages was introduced by (Yaneva et al., 2018 [
14]). The study utilised several web pages like Yahoo, Babylon, Apple, AVG, Godaddy, and BBC. The participants included 18 TD and 18 ASD individuals under the age of 18 who were familiar with the web pages. The researchers employed the Gazepoint GP3 eye-tracking device to collect data on various gaze features, including time to first view, time viewed, fixations, and revisits. The collected data were then used to train a logistic regression model that included both gaze and non-gaze features. The results showed that the search task elicited more significant between-group differences, with a classifier trained on these data achieving 0.75 accuracy, compared to 0.71 for the browse task. The differences in eye tracking between web users with ASD and TD individuals were observed as proposed by (Eraslan et al., 2019 [
15]). The participants’ eye movements were recorded while searching for specific information on various web pages. The study found that participants with ASD had longer scan paths and tended to focus on more irrelevant visual items and had shorter fixation durations compared to TD participants. The researchers also discovered different search patterns in participants with ASD. In a related study by (Deering 2013), eye-movement data were collected from four individuals with ASD and ten individuals without ASD while evaluating web content. The study examined eye fixation and movement patterns on various websites, including Amazon, Facebook, and Google. The findings indicated no significant differences between the two groups. However, (Eraslan et al., 2019 [
15]) noted that the study’s sample size was limited.
The difference between ASD and TD groups was investigated in the reading task (Yaneva et al., 2016 [
16]). The dataset was collected from 20 adults with ASD (mean age = 30.75) and 20 TD adults (mean age = 30.81) using the Gazepoint GP3 with a 60 Hz sampling rate. The study formulated several hypotheses, including the average number of fixations and longer fixations. The results showed that the ASD group had longer fixations on long words compared to the TD group. However, the study’s limitation was the eye tracker’s 60 Hz sampling rate, which may not be sufficient to accurately record the fixations while reading each word.
The study conducted by (Eraslan et al., 2021 [
17]) aimed to evaluate the web accessibility rules related to the visual complexity of websites and the distinguishability of web page components, such as WCAG 2.1 Guideline 1.3 and Guideline 1.4. Gaze data were collected from two different types of information processing activities involving web pages: browsing and searching. Participants included 19 individuals with ASD with a mean age of 41.05 and 19 TD individuals with a mean age of 32.15. The Gazepoint GP3 eye tracker was used, and stimulating web pages such as BCC and Amazon were presented. The results revealed that the visual processing of the two groups differed for the synthesis and browsing tasks. The ASD group made considerably more fixations and transitions between items when completing synthesis tasks. However, when participants freely navigate the sites and concentrate on whatever aspects they find fascinating, the numbers of fixations and transitions are comparable across the two groups, but those with autism had longer fixations. The study found that there were significant differences between the two groups for the mean fixation time in browsing tasks and the total fixation count and number of transitions between items in synthesis tasks.
This subsection related to fixation time and visualising patterns within eye tracking delves into the specific metrics and patterns that characterise how eyes engage with visual stimuli. Carette et al. (2018 [
18]) presented a method for transforming eye-tracking data into a visual pattern. They collected data from 59 participants, 30 TD and 29 ASD, using the SMI RED mobile eye tracker, which records eye movements at a 60 Hz frequency. Their dataset contains 547 images: 328 belonged to the TD class and 219 to the ASD class. They used these data to develop a binary classifier using a logistic regression model and achieved an AUC of approximately 81.9%. Subsequent work on this dataset employed deep learning and machine learning models, including random forests, SVM, logistic regression, and naive Bayes, with AUCs ranging from 0.7% to 92%. Unsupervised techniques such as deep autoencoders and K-means clustering were proposed by Elbattah et al. (2019 [
19]), with clustering results ranging from 28% to 94%. A CNN-based model by Cilia et al. (2021 [
20]) achieved an accuracy of 90%. Transfer learning models like VGG-16, ResNet, and DenseNet were evaluated, with VGG-16 having the highest AUC at 0.78% (Elbattah et al., 2022 [
21]). The collective work underscores the growing interest and success in employing eye-tracking technology and various machine learning techniques to detect Autism, and highlights the need for improved sample sizes and dataset variations.
The eye movement was converted into text sequences using NLP as proposed by (Elbattah et al., 2020 [
22]). To achieve this, the authors employed a deep learning model for processing sequence learning on raw eye-tracking data using various NLP techniques, including sequence extraction, sequence segmentation, tokenisation, and one-hot encoding. The authors utilised CNN and LSTM models. The LSTM model achieved 71% AUC, while the CNN achieved an AUC of 84%.
The Gaze–Wasserstein approach for autism detection is presented by (Cho et al., 2016 [
23]). The data were collected using Tobii EyeX from 16 TD and 16 ASD children aged between 2 and 10 years. During the experiment, the children were seated in front of a screen and shown eight social and non-social stimuli scenes, each lasting for 5 s. The study utilised the KNN classifier and performance was measured using F score matrices. The overall classification scored 93.96%, with 91.74% for social stimuli scenes and 89.52% for non-social stimuli scenes. The results suggest that using social stimuli scenes in the Gaze–Wasserstein approach is more effective than non-social stimuli scenes.
The study employed machine learning to analyse EEG and eye-tracking (Kang et al., 2020b [
24]) data from children, focusing on their reactions to facial photos of different races. Various features were analysed using a 128-channel system for EEG and the TX300 system for eye tracking. Feature selection was conducted using the minimum redundancy maximum relevance method. The SVM classifier achieved 68% accuracy in EEG analysis, identifying differences in power levels in children with autism spectrum disorder (ASD) compared to typically developing children. Eye-tracking analysis achieved up to 75.89% accuracy and revealed that children with ASD focused more on hair and clothing rather than facial features when looking at faces of their own race.
In recent years, there have been substantial advancement researches for classification and identifying ASD using different machine leaning algorithms based on the features of ASD people like face and eye tracking [
25,
26,
27,
28,
29]. Thabtah et al. [
30] proposed a study that collected a dataset from ASD newborns, children, and adults. The ASD was developed based on the Q-CHAT and AQ-10 assessment instruments. Omar et al. [
31] used the methodology based on random forest (RF), regression tree (CART), and random forest iterative for detecting the ASD. The system used AQ-10 and 250 real-world datasets using the ID3 algorithm. Sharma et al. [
32] proposed NB, stochastic gradient descent (SGD), KNN, RT, and K-star, in conjunction with the CFS-greedy stepwise feature selector.
Satu et al. [
33] used a number of methods to detect ASD in order to determine the distinguishing features that differentiate between autism and normal development with different ages from 16 to 30 years. Erkan et al. [
34] used the KNN, SVM, and RF algorithms to assess the efficacy of each technique in diagnosing autism spectrum disorders (ASDs). Akter et al. [
35] used the SVM algorithm to demonstrate the superior performance of both toddlers and older children and adult datasets.
Despite the advancements in the amalgamation of eye-tracking methodologies with artificial intelligence techniques, a discernible research lacuna persists. This underscores the necessity for developing a model with superior performance capabilities to enhance classification precision, thereby ensuring a reliable early diagnosis of autism.
Table 1 displays the most important previous studies.
5. Discussion
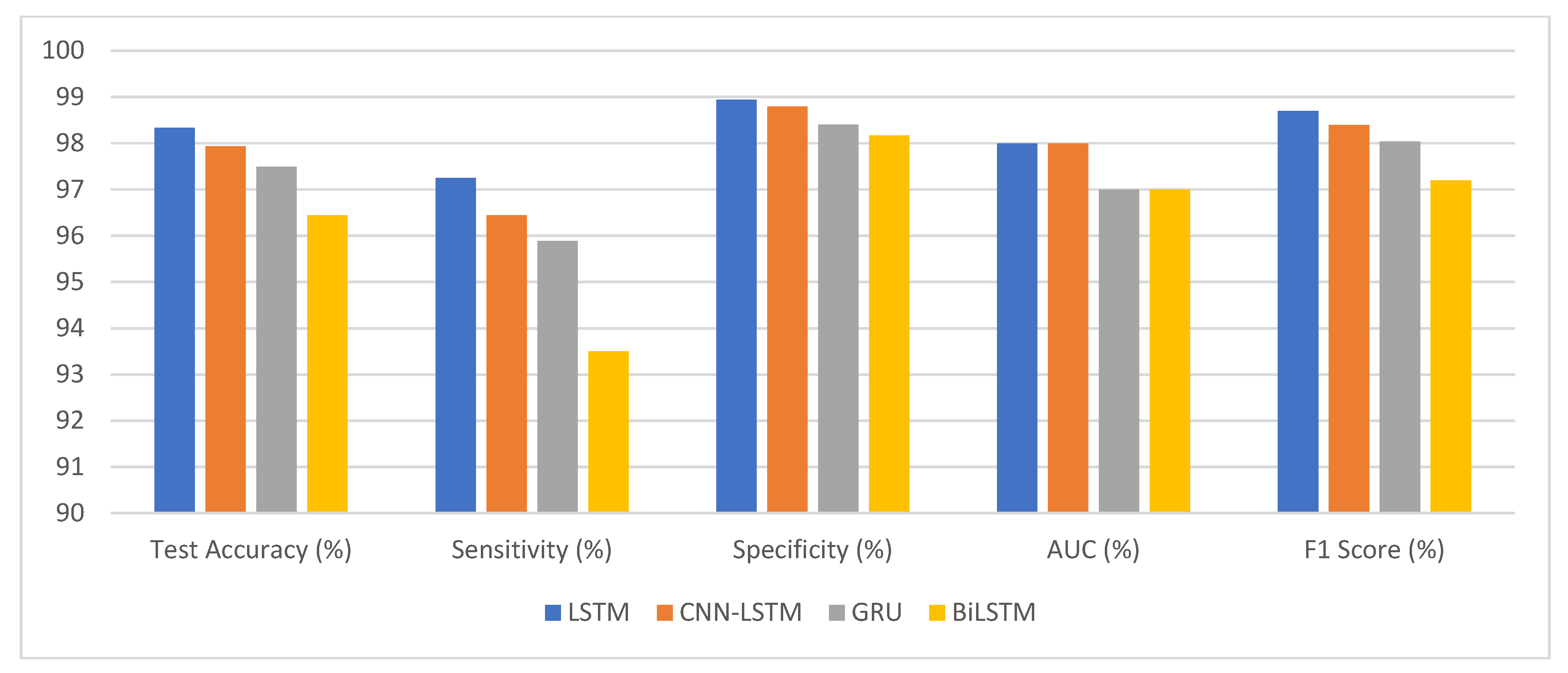
This research paper aims to enhance the diagnostic process of the ASD by combining eye-tracking data with deep learning algorithms. It investigates different eye-movement patterns in individuals with ASD compared to TD individuals. This approach can enhance ASD diagnosis accuracy and pave the way for early intervention programs that benefit children with ASD. The experimental work investigated the effectiveness of deep learning models, specifically LSTM, CNN-LSTM, GRU, and BiLSTM, in detecting autism using a statistical eye-tracking dataset. The findings shed light on the performance of these models in accurately classifying individuals with autism. Among the models, the LSTM model achieved an impressive test accuracy of 98.33%. It successfully identified 81,760 true positive samples, while maintaining a low false positive rate of 1577, out of the 84,075 ASD samples. With a high sensitivity of 97.25%, the model demonstrated its ability to detect individuals with autism accurately. Moreover, it exhibited a specificity of 98.94%, effectively identifying non-autistic individuals. The F1 score of 98.70% further emphasises the model’s effectiveness in autism detection.
The deep learning models performed well on a statistical eye-tracking dataset for autism detection as presented in
Table 9 and
Figure 18. Accuracy rates, sensitivities, and specificities all point to their usefulness in identifying autistic people. These results proposed that deep learning models may be useful in autism diagnosis. They could help advance efforts towards better screening for autism and more timely treatments for those on the spectrum.
In the evolving domain of research aimed at distinguishing autism spectrum disorder (ASD) from typically developing (TD) individuals, various methodologies have emerged, offering rich insights. Liu et al. (2016), employing an SVM-based model focused on facial recognition, achieved an accuracy of 88.51%, hinting at significant neural disparities in processing between ASD and TD children. Similarly, Wan et al. (2019) leveraged visual stimuli, specifically videos, to attain an accuracy of 85.1% with SVM, emphasising the diagnostic potential of the visual modality. An intriguing age-centric variation was observed in Kong et al. (2022), where SVM-analysed toddlers and preschoolers demonstrated accuracies of 80% and 71%, respectively, underscoring the necessity for age-adaptive diagnostic strategies. Shifting focus, Yaneva et al. (2018) delved into eye-gaze pat terns, achieving results of 0.75 and 0.71 for search and browsing tasks through logistic regression, suggesting that gaze metrics could be pivotal in ASD diagnostics. Meanwhile, Elbattah et al., 2020 used CNN and LSTM models to analyse static and dynamic scenes, obtaining accuracies of 0.84% and 71%.
Upon a comprehensive examination and comparison of extant literature, it is evident that our proposed model exhibits marked efficacy and superiority as presented in
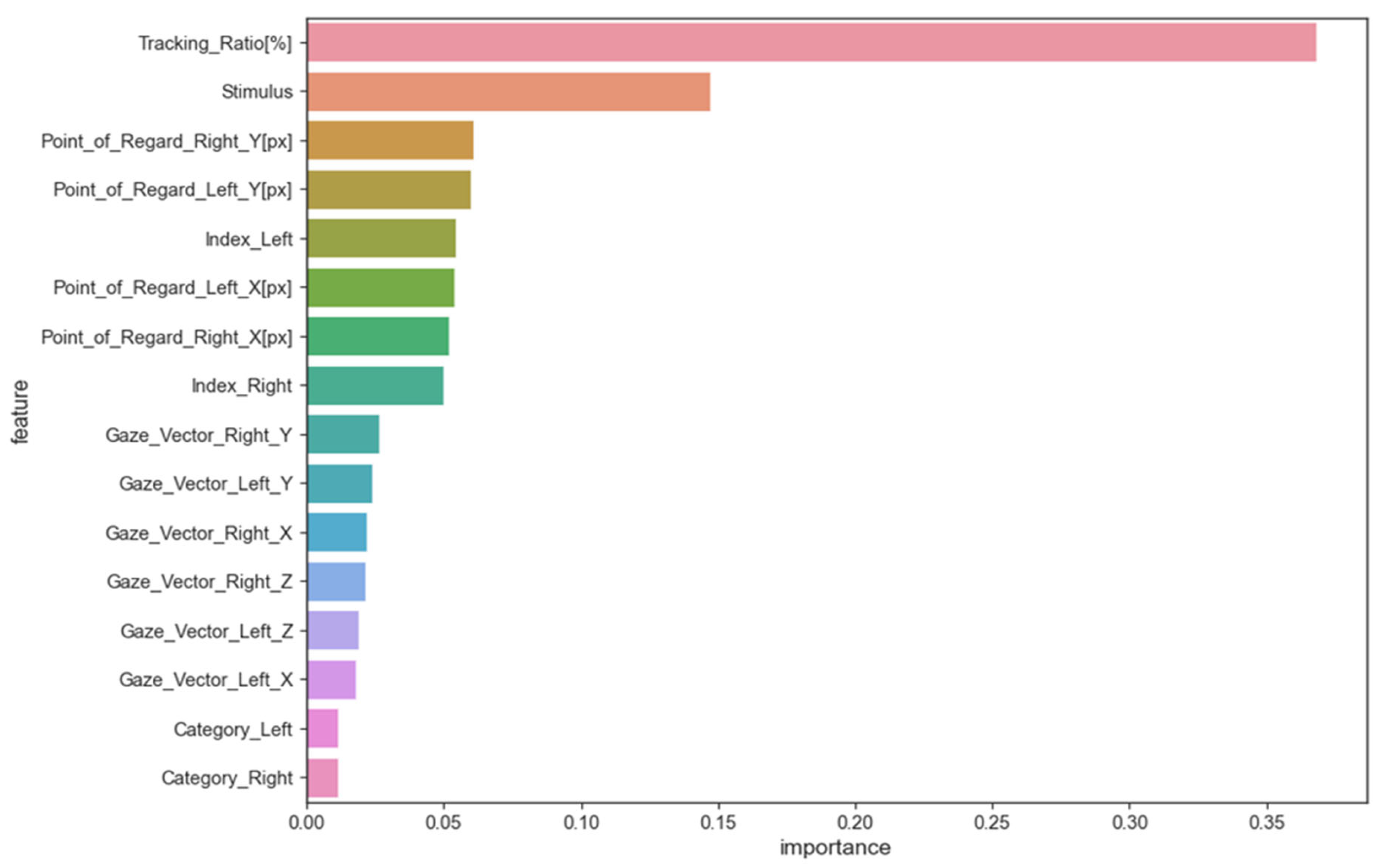
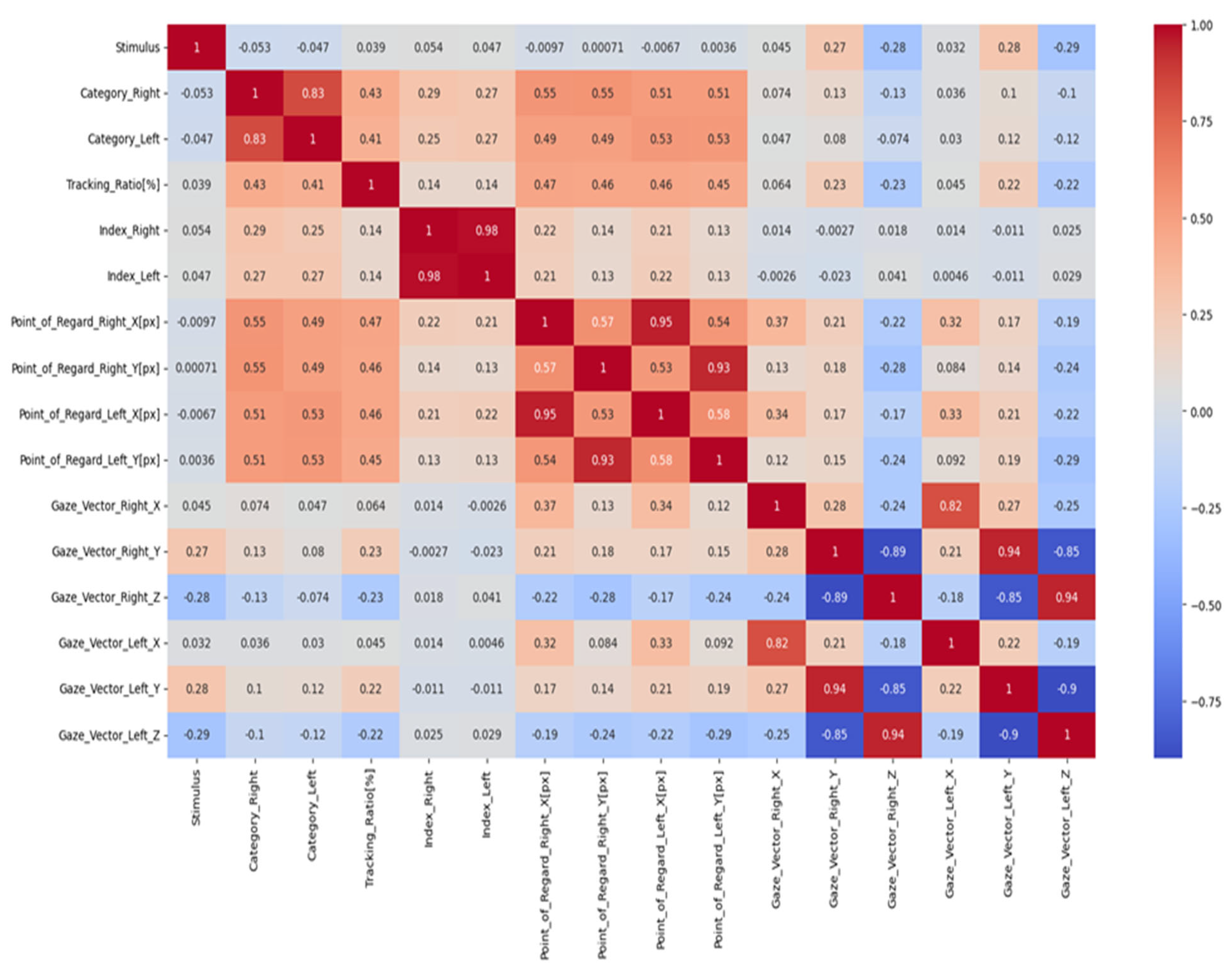
Table 10. This can be attributed to the meticulous data preprocessing procedures employed, coupled with the judicious selection of salient features that underscore the distinctions between individuals with autism and those without. The model we have advanced achieved a commendable accuracy of 98% utilising the LSTM methodology.
6. Conclusions
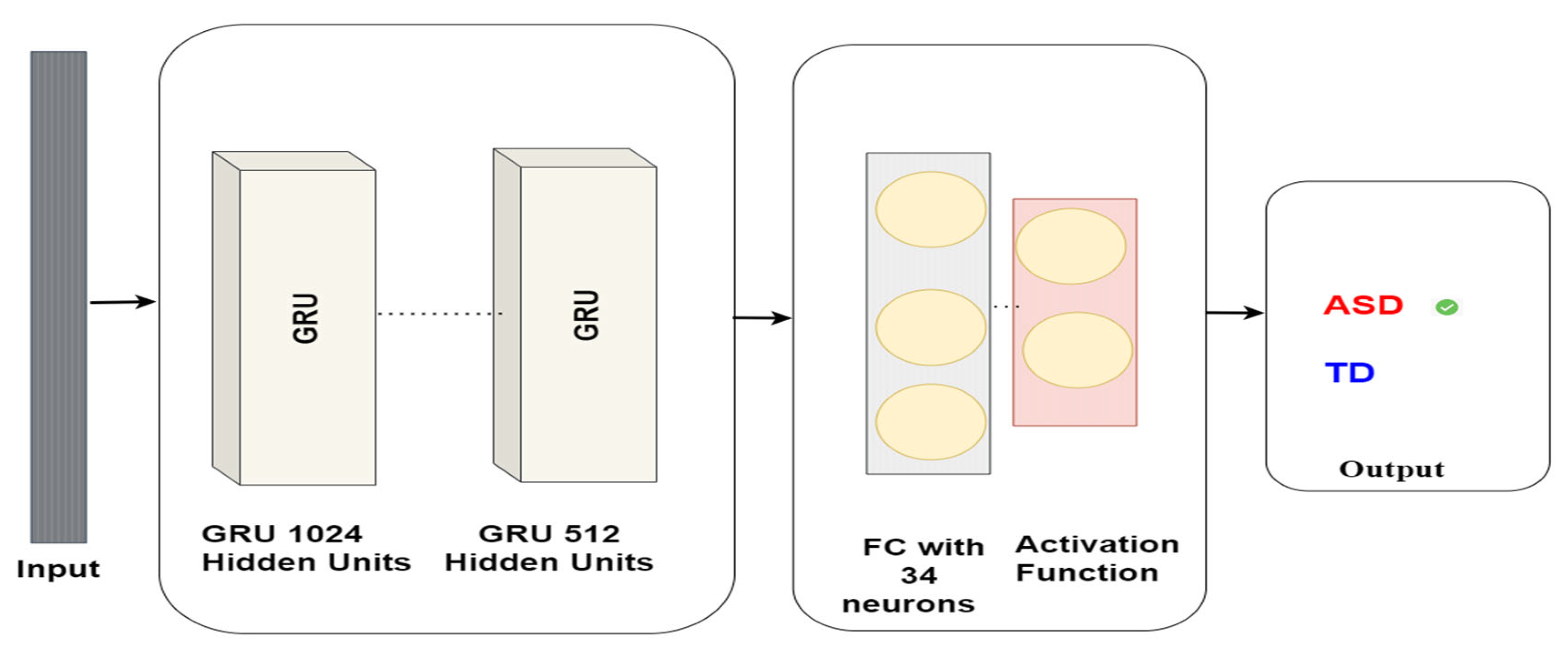
In the dynamic tapestry of contemporary ASD research, this study firmly posits itself as a beacon of innovative methodologies and impactful outcomes. Navigating the intricate labyrinth of ASD diagnosis, the research underscores the critical imperative of early detection, a tenet foundational to effective intervention strategies. At the methodological core lies our deployment of deep learning techniques, uniquely integrating CNN and RNN with an eye-tracking dataset. The performance metrics offer a testament to this integration’s success. Specifically, the BiLSTM yielded an accuracy of 96.44%, the GRU achieved 97.49%, the CNN-LSTM hybrid model secured 97.94%, and the LSTM model notably excelled with an accuracy of 98.33%.
Upon a systematic scrutiny of extant literature, it becomes unequivocally evident that our proposed model stands unparalleled in its efficacy. This prowess can be attributed to our meticulous data preprocessing techniques and the discerning selection of features. It is worth emphasising that the judicious feature selection played a pivotal role in accentuating the distinctions between individuals with autism and their neurotypical counterparts, leading our LSTM model to realize a remarkable 98% accuracy. This research converges rigorous scientific exploration with the overarching goal of compassionate care for individuals with ASD. It reiterates the profound significance of synergising proactive diagnosis, community engagement, and robust advocacy. As a beacon for future endeavours, this study illuminates a path where, through holistic approaches, children with ASD can truly realize their innate potential amidst the multifaceted challenges presented by Autism.
There is a definite path forward for future research to include a larger and more diverse sample, drawing from a larger population of people with ASD and TD individuals. Increasing the size of the sample pool could help researchers spot more patterns and details in the data. Importantly, a larger sample size would strengthen the statistical validity of the results, increasing the breadth with which they can be applied to a wider population.


 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}