
Sentiment Analysis of Multilingual Dataset of Bahraini Dialects, Arabic, and English


Abstract
:1. Summary
2. Data Description
2.1. Dataset Repository
- E_MSA_BDs-PR-SA.csv: is composed of four columns. The first one is polarity, which is represented by 0 and 1. The second column is the “English review”, the third column is the “corresponding review in MSA”, and the fourth one is the “corresponding review in BDs”, as shown in Figure 1;
- Bahraini Dialects Dataset.csv: is composed of two columns: the polarity and the review text in Bahraini dialects, and 5000 rows of reviews;
- English Dataset.csv: is composed of two columns: the polarity and the review text in English, and 5000 rows of reviews;
- MSA Dataset.csv: is composed of two columns: the polarity and the review text in modern standard Arabic (MSA), and 5000 rows of reviews.
- 5
- BDs-StopWords.txt: contains a created list of Bahraini dialects stopwords. The stopwords are parts of the text that are not useful in sentiment analysis, such as punctuation, pronouns, and prepositions;
- 6
- MSA-Stopwords.txt: MSA-Stopwords.txt: contains a list of MSA stopwords. The included words in this list represent an extension to the built one in python software.
2.2. Dataset Pre-Processing
- 7.
- BDs_ PreProcessing.py: contains the coding of preprocessing of Bahraini dialects product reviews, including the augmenting of the 5000 reviews of the Bahraini dialect product dataset to 10,000;
- 8.
- MSA_ PreProcessing.py: contains the coding for preprocessing MSA product reviews, including the augmenting of the 5000 reviews of the standard Arabic product dataset to 10,000;
- 9.
- English_ PreProcessing.py: contains the coding for preprocessing English product reviews, including augmenting of the 5000 reviews of the English product dataset to 10,000.
3. Methods
3.1. Dataset Design and Preparation
- A dataset in English of Amazon product reviews for sentiment analysis was downloaded from [13]. The downloaded English Dataset is composed of two comma-separated values (CSV) training and testing files. They contain negative and positive reviews labeled as label_1 and label_2, respectively;
- A total of 5000 reviews, 2500 negative and 2500 positive, have been manually selected from the training and testing files of the English dataset of Amazon reviews to form a balanced dataset;
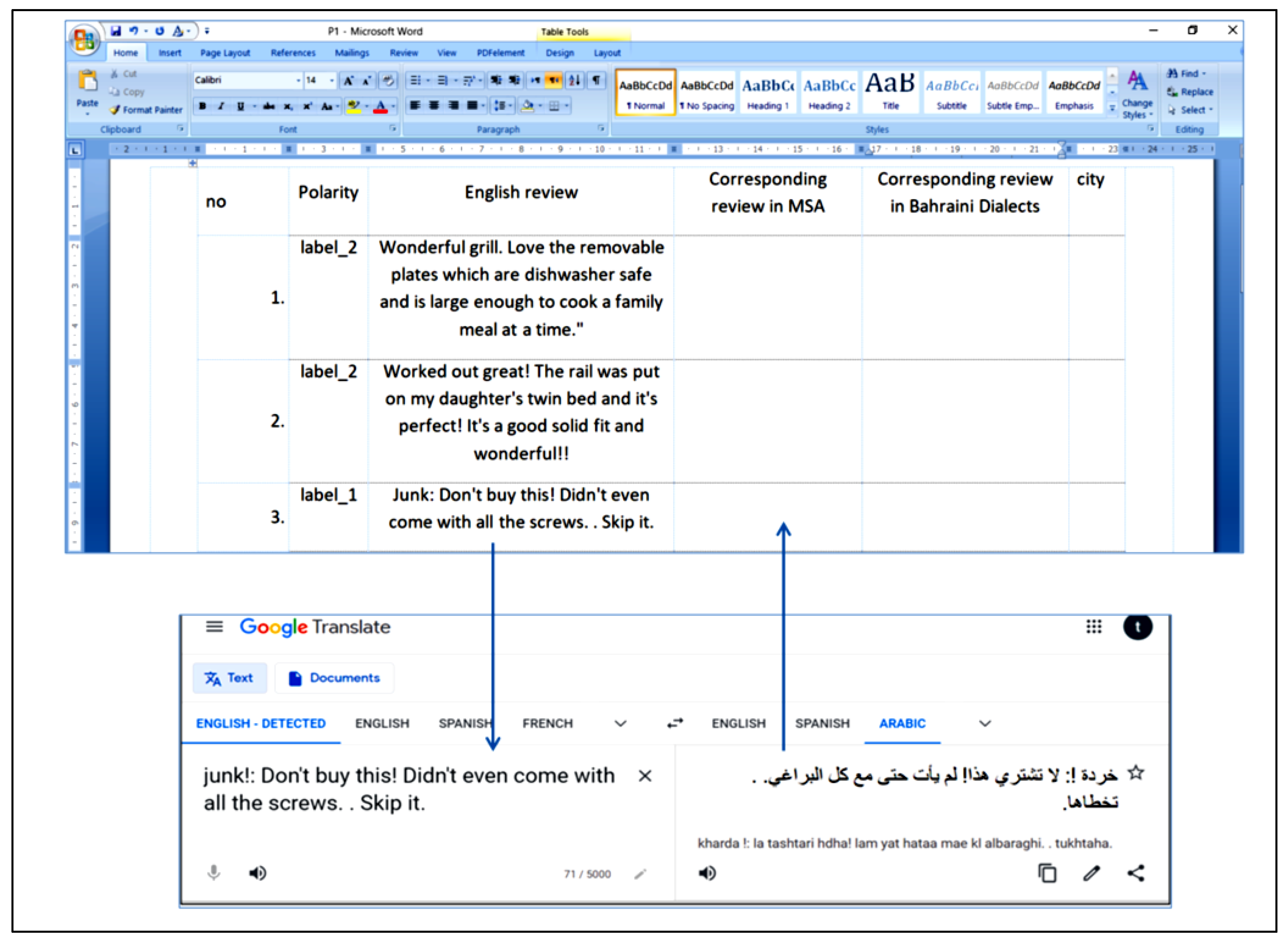
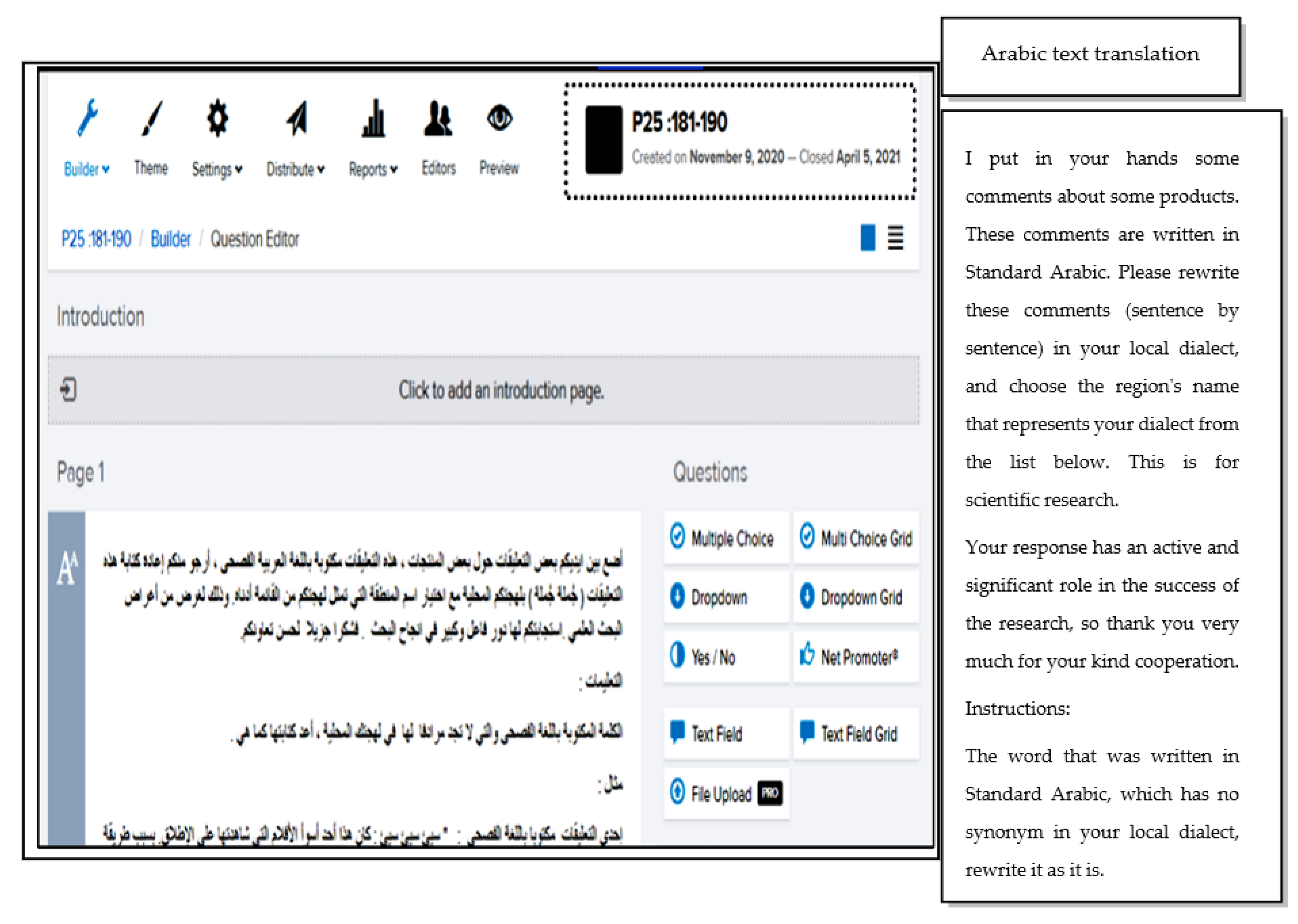
- The selected 5000 reviews were copied into 25 separate Ms-word files. The copied reviews have been validated manually by correcting the spelling and grammar errors, using a Ms-word grammar and spelling checker supported by a human checker specializing in English–Arabic–English translation, and by deleting the sentences that are not affecting the review sentiment. This deletion was aimed to provide reviews with a reasonable length, not exceeding 200 words, which aid the capturing of meaning by participants for a manual translation of MSA reviews to BDs. Each of the 25 files includes a template for a table composed of six columns: number, label, review in English, corresponding review in MSA, corresponding review in BDs, and a city, as shown in Figure 2. The Ms-word files have been saved as P1, P2, and P3…P25. Each Pi contains 200 balanced reviews. This numbering method helps in identifying each review in the stage of distributing the MSA reviews and collecting their corresponding ones in BDs, as will be explained later;
- The 200 reviews of Pi were translated one by one to MSA using https://translate.google.com/ (accessed on 1 December 2019). The MSA-translated review is copied to its dedicated cell in the table in the MS-word file, as shown in Figure 3. The resulting MSA reviews were manually validated by someone who specializes in English–Arabic–English translation to ensure meaning matching between the English reviews and their corresponding ones in MSA;
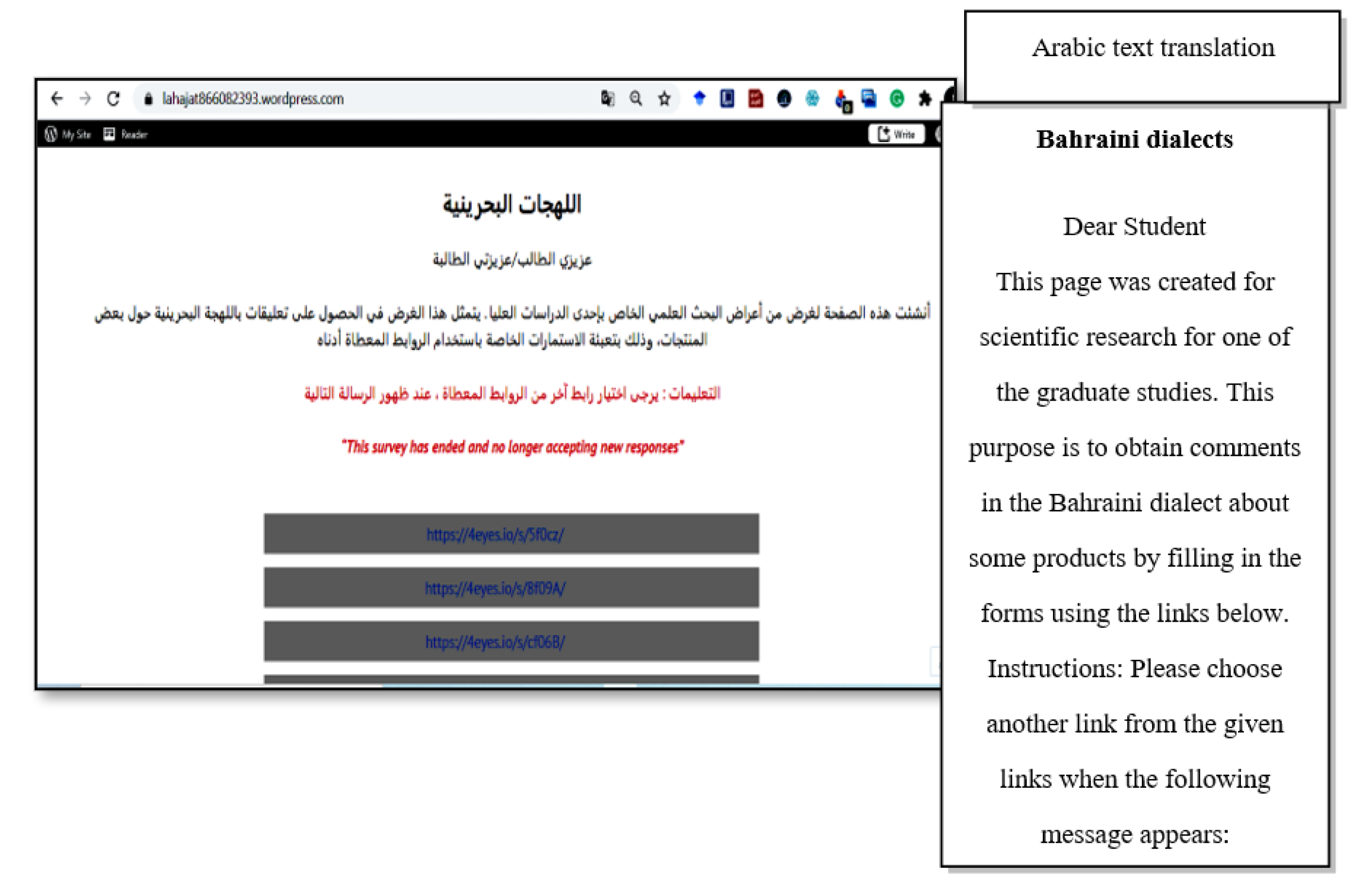
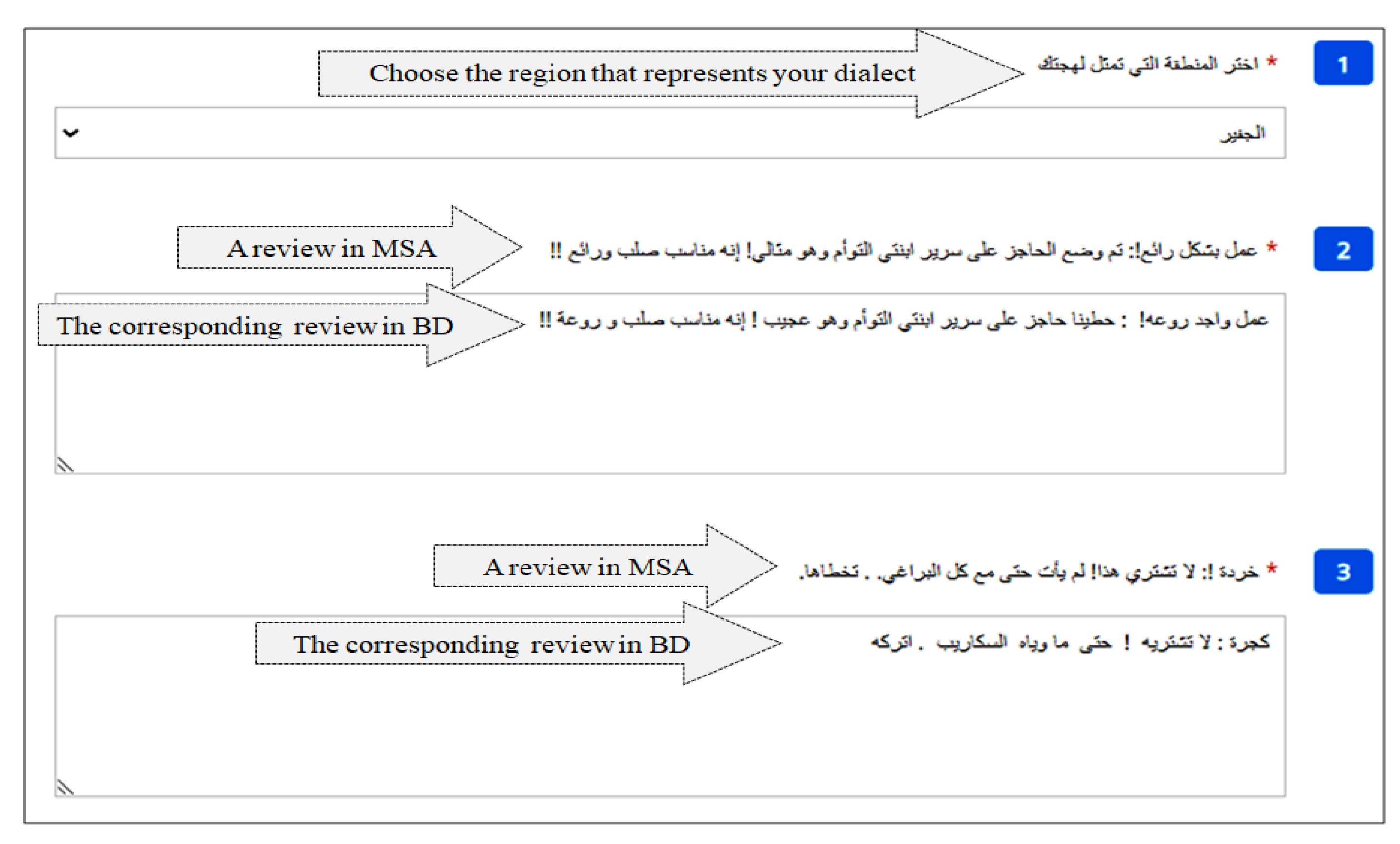
- The 5000 MSA reviews that resulted from the translation process were distributed to Bahraini dialect native speakers using 500 customized forms that were constructed through https://getfoureyes.com/ (accessed on 5 December 2019). Each form includes 10 different and unique MSA reviews. Below each review, a text box was provided where the respondent can rewrite the review in their spoken dialect, as depicted in Figure 4.
- 6
- The submitted forms were opened one by one by the data collector, a native speaker specializing in Arabic, to ensure semantic and spelling corrections. Each submitted form contains 10 MSA reviews and their corresponding ones in BDs. Figure 8 shows two out of ten reviews;
- 7
- After the checking, revising, and validation processes, the responses were collected by copying them to the dedicated cell in the table of the corresponding file, as shown in Figure 9.
- 8
- The resulting parallel dataset of English, MSA, and BDs of 5000 reviews was copied to the Ms-Excel file, where the polarity labels (label_1, label_2) were replaced by (0, 1), respectively. After the step of copying reviews and replacing the labels, the datasets have been put through one of the accuracy checks by checking the missing and null values of the polarity and the review text in English and its corresponding ones in MSA and BDs, using the count function that guaranteed the required numbers of rows are not empty;
- 9
- The Ms-Excel file was converted to a text file with UTF-8 encoding, a suitable format for processing Arabic text in Python;
- 10
- Each dataset was separated individually in a step to prepare them for the SA process.
3.2. Dataset Preprocessing
3.2.1. Modern Standard Arabic and Bahraini Dialect Datasets Preprocessing
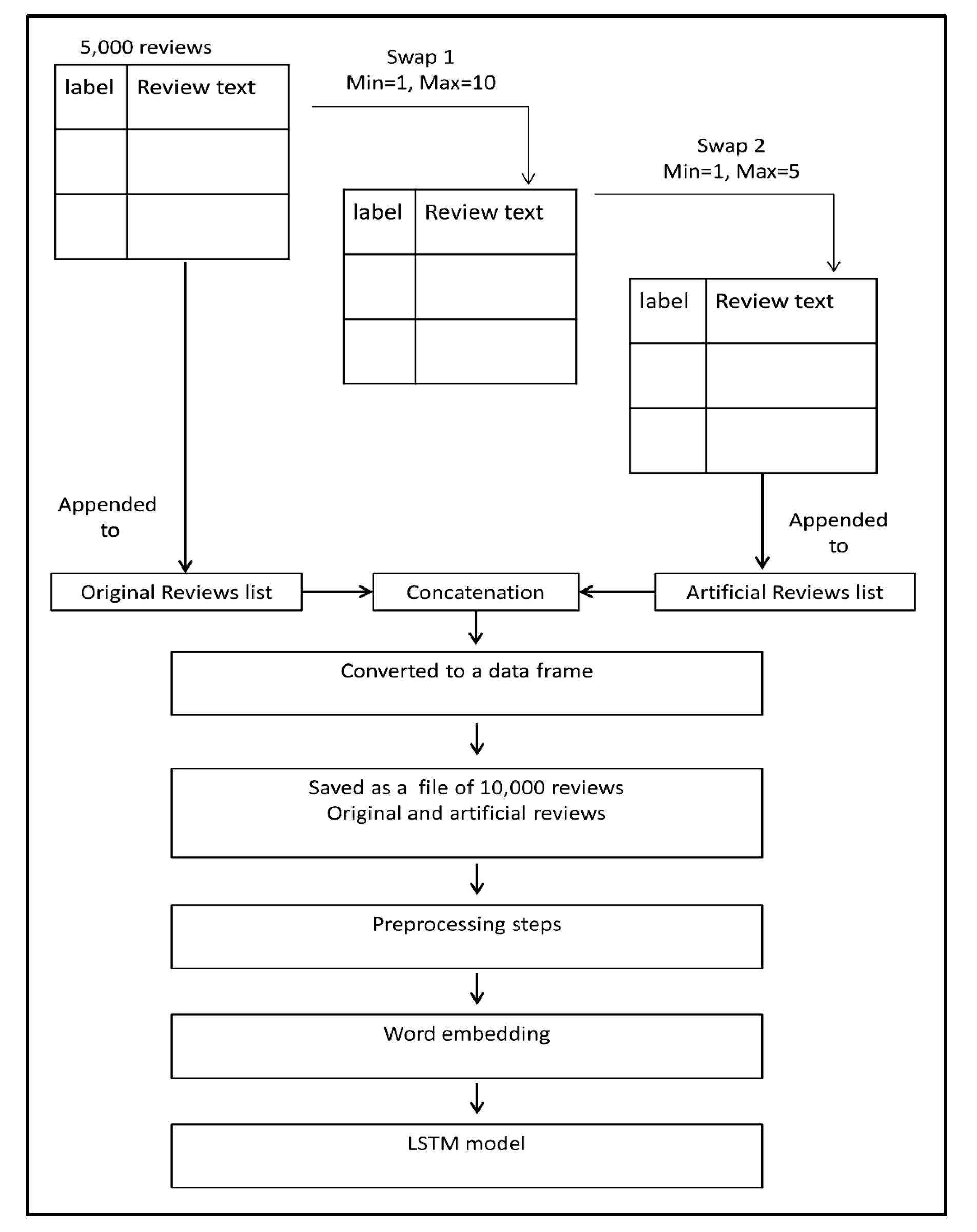
- Applying the “swap” augmentation technique twice on each review of the dataset. The first one with a minimum number of words to be swapped equals 1 and a maximum equals 10; in contrast, the second time applying the augmentation technique, a minimum number of words to be swapped equals 1 and a maximum equals 5;
- Normalizing some characters by replacing them with other ones; for example, the character “گ, whose spelling is “Ga” is replaced by “ك”, “ة” is replaced by “ه”, “ؤ” is replaced by “ء”, and “ئ” is replaced by “ء”;
- Removing the digits, repeated characters, punctuation, diacritics, and English words;
- Tokenizing the text by breaking it into chunks of words;
- Removing the stop words.
3.2.2. English Dataset Preprocessing
- Applying the “swap” augmentation technique twice on each review of the dataset. The first one with a minimum number of words to be swapped equals 1 and a maximum equals 10; in contrast, the second time applying the augmentation technique, a minimum number of words to be swapped equals 1 and a maximum equals 5;
- Normalizing text by converting uppercase characters to lower ones;
- Removing special characters such as “@”, hash, and digits;
- Removing the stop words.
4. Remarks for the User
- The dataset has been created to be analyzed at the document level;
- The dataset has been augmented using a random swap technique through the Python program;
- The dataset has been analyzed sentimentally using the LSTM model using different evaluation metrics such as accuracy, F1-score, and ROC AUC at different k-fold cross-validation values, in addition to the train-validate-test split. More details are in [12];
- The results showed slight differences in the LSTM model’s performance on all datasets. For example, the AUC value was 98.79% on the English dataset, 98.67% on the MSA, and 98.46% on the BDs;
- To obtain a more enhanced performance of the LSTM model, the model has been integrated into the ensemble learning technique as detailed in [17];
- The BDs dataset was utilized as a source in the transfer learning process to analyze a target dataset of movie comments in Bahraini dialects, as detailed in [12].
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Name of Town/Villagein in Arabic | Name of Town/Villagein in English | Number of Responses (Filled Forms) |
|---|---|---|---|
| 1 | أبو قوة | AbuQuwah | 3 |
| 2 | البديع | Al Budaiya | 2 |
| 3 | البلاد القديم | Al Bilad Al Qadeem | 3 |
| 4 | الجفير | Al Juffair | 4 |
| 5 | الحد | Al Hidd | 4 |
| 6 | الدراز | Al Diraz | 13 |
| 7 | الدير | Al Dair | 9 |
| 8 | الديه | Al Daih | 4 |
| 9 | الرفاع الشرقي | East Rifaa | 18 |
| 10 | السنابس | Al Sanabis | 8 |
| 11 | السهلة الشمالية | North Sehla | 2 |
| 12 | العكر | Al Eker | 1 |
| 13 | القرية | Al Qurrayah | 1 |
| 14 | الكورة | Al Kawarah | 6 |
| 15 | المالكية | Al Malikiyah | 6 |
| 16 | المحرق | Al Muharraq | 8 |
| 17 | المصلى | Al Musalla | 2 |
| 18 | المعامير | Al Ma’ameer | 19 |
| 19 | المنامة | Al Manama | 27 |
| 20 | النعيم | Al Naim | 3 |
| 21 | النويدرات | Al Nuwaidrat | 264 |
| 22 | أم الحصم | Umm AlHassam | 4 |
| 23 | بوري | Buri | 5 |
| 24 | توبلي | Tubli | 4 |
| 25 | جبلة حبشي | Jeblat Hebshi | 1 |
| 26 | جدحفص | Jidhafs | 3 |
| 27 | جدعلي | JidAli | 5 |
| 28 | دمستان | Damistan | 1 |
| 29 | رأس رمان | Ras Romman | 10 |
| 30 | سار | Saar | 4 |
| 31 | سترة | Sitra | 21 |
| 32 | سماهيج | Samaheej | 4 |
| 33 | سند | Sanad | 4 |
| 34 | عراد | Arad | 3 |
| 35 | كرانة | Karranah | 10 |
| 36 | كرزكان | Karzakkan | 5 |
| 37 | مدينة عيسى | Isa Town | 7 |
| 38 | مقابة | Maqabah | 2 |
References
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. In Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery; John Wiley & Sons Inc.: Hoboken, NJ, USA, 2018; Volume 8, p. 1253. [Google Scholar]
- El-Masri, M.; Altrabsheh, N.; Mansour, H.; Ramsay, A. A web-based tool for Arabic sentiment analysis. Procedia Comput. Sci. 2017, 117, 38–45. [Google Scholar] [CrossRef]
- Abdul-Mageed, M.; Alhuzali, H.; Elaraby, M. You tweet what you speak: A city-level dataset of Arabic dialects. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Abo, M.E.M.; Shah, N.A.K.; Balakrishnan, V.; Kamal, M.; Abdelaziz, A.; Haruna, K. SSA-SDA: Subjectivity and Sentiment Analysis of Sudanese Dialect Arabic. In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Aljouf, Saudi Arabia, 3–4 April 2019; pp. 1–5. [Google Scholar]
- Mohammed, A.; Kora, R. Deep learning approaches for Arabic sentiment analysis. Soc. Netw. Anal. Min. 2019, 9, 1–12. [Google Scholar] [CrossRef]
- Alahmary, R.M.; Al-Dossari, H.Z.; Emam, A.Z. Sentiment analysis of Saudi dialect using deep learning techniques. In Proceedings of the 2019 International Conference on Electronics, Information, and Communication (ICEIC), Auckland, New Zealand, 22–25 January 2019; pp. 1–6. [Google Scholar]
- Alsarsour, I.; Mohamed, E.; Suwaileh, R.; Elsayed, T. Dart: A large dataset of dialectal arabic tweets. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Al Shamsi, A.A.; Abdallah, S. A Systematic Review for Sentiment Analysis of Arabic Dialect Texts Researches. In Proceedings of International Conference on Emerging Technologies and Intelligent Systems: ICETIS 2021; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; Volume 2, pp. 291–309. [Google Scholar]
- Mdhaffar, S.; Bougares, F.; Esteve, Y.; Hadrich-Belguith, L. Sentiment analysis of tunisian dialects: Linguistic ressources and experiments. In Proceedings of the Third Arabic Natural Language Processing Workshop (WANLP), Valencia, Spain, 3 April 2017; pp. 55–61. [Google Scholar]
- Itani, M.; Roast, C.; Al-Khayatt, S. Developing resources for sentiment analysis of informal Arabic text in social media. Procedia Comput. Sci. 2017, 117, 129–136. [Google Scholar] [CrossRef]
- Al Shamsi, A.; Abdallah, S. Sentiment Analysis of Emirati Dialect. Big Data Cogn. Comput. 2022, 6, 57. [Google Scholar] [CrossRef]
- Omran, T.M.; Sharef, B.T.; Grosan, C.; Li, Y. Transfer learning and sentiment analysis of Bahraini dialects sequential text data using multilingual deep learning approach. Data Knowl. Eng. 2023, 143, 102106. [Google Scholar] [CrossRef]
- Amazon Reviews for Sentiment Analysis. 2022. Available online: https://www.kaggle.com/datasets/bittlingmayer/amazonreviews (accessed on 1 December 2019).
- Luque, F.M. Atalaya at tass 2019: Data augmentation and robust embeddings for sentiment analysis. arXiv 2019, arXiv:1909.11241. [Google Scholar]
- Wei, J.; Zou, K. Eda: Easy data augmentation techniques for boosting on text classification tasks. arXiv 2019, arXiv:1901.11196. [Google Scholar]
- Makcedward/Nlpaug. 2021. Available online: https://github.com/makcedward/nlpaug/blob/master/example/quick_example.ipynb (accessed on 6 April 2021).
- Omran, T.; Sharef, B.; Grosan, C.; Li, Y. Ensemble Learning for Sentiment Analysis of Translation-Based Textual Data. In Proceedings of the 2022 International Conference on Electrical, Computer, Communications and Mechatronics Engineering (ICECCME), online, 16–18 November 2022; pp. 1–9. [Google Scholar]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Omran, T.; Sharef, B.; Grosan, C.; Li, Y. Sentiment Analysis of Multilingual Dataset of Bahraini Dialects, Arabic, and English. Data 2023, 8, 68. https://doi.org/10.3390/data8040068
Omran T, Sharef B, Grosan C, Li Y. Sentiment Analysis of Multilingual Dataset of Bahraini Dialects, Arabic, and English. Data. 2023; 8(4):68. https://doi.org/10.3390/data8040068
Chicago/Turabian StyleOmran, Thuraya, Baraa Sharef, Crina Grosan, and Yongmin Li. 2023. "Sentiment Analysis of Multilingual Dataset of Bahraini Dialects, Arabic, and English" Data 8, no. 4: 68. https://doi.org/10.3390/data8040068
APA StyleOmran, T., Sharef, B., Grosan, C., & Li, Y. (2023). Sentiment Analysis of Multilingual Dataset of Bahraini Dialects, Arabic, and English. Data, 8(4), 68. https://doi.org/10.3390/data8040068