
A Direct-Forcing Immersed Boundary Method for Incompressible Flows Based on Physics-Informed Neural Network



Abstract
:1. Introduction
2. Methods
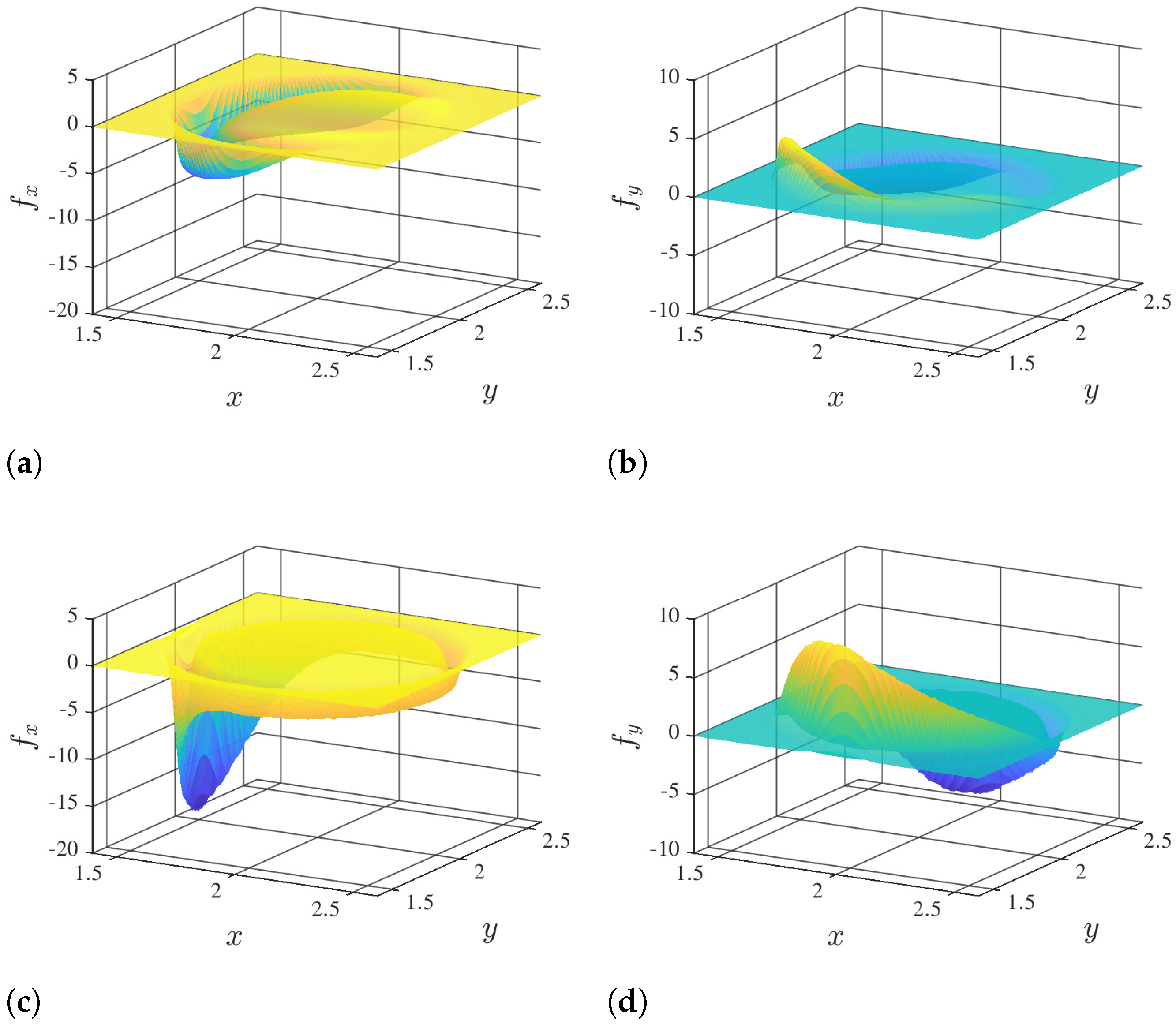
2.1. Direct-Forcing Immersed Boundary Method
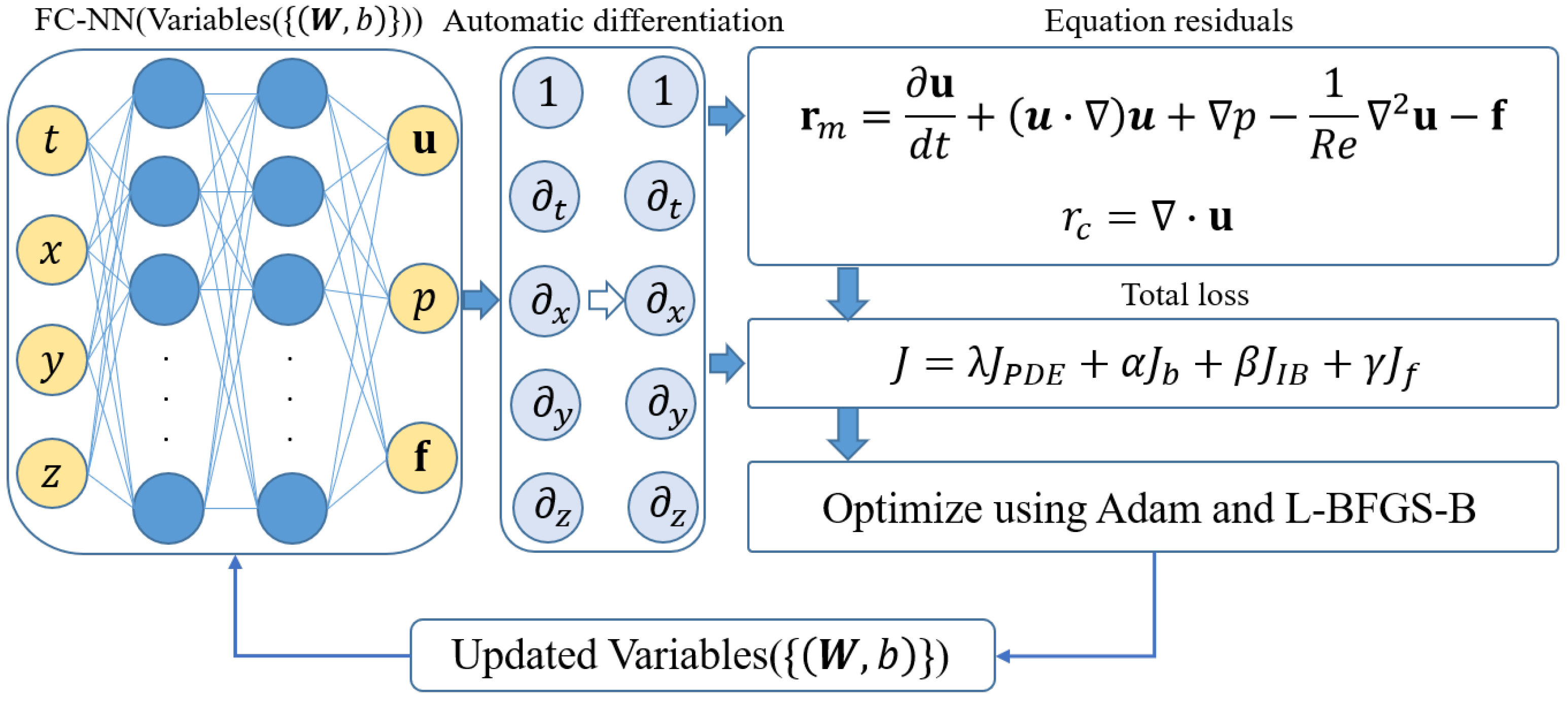
2.2. Physics-Informed Neural Network
3. Results
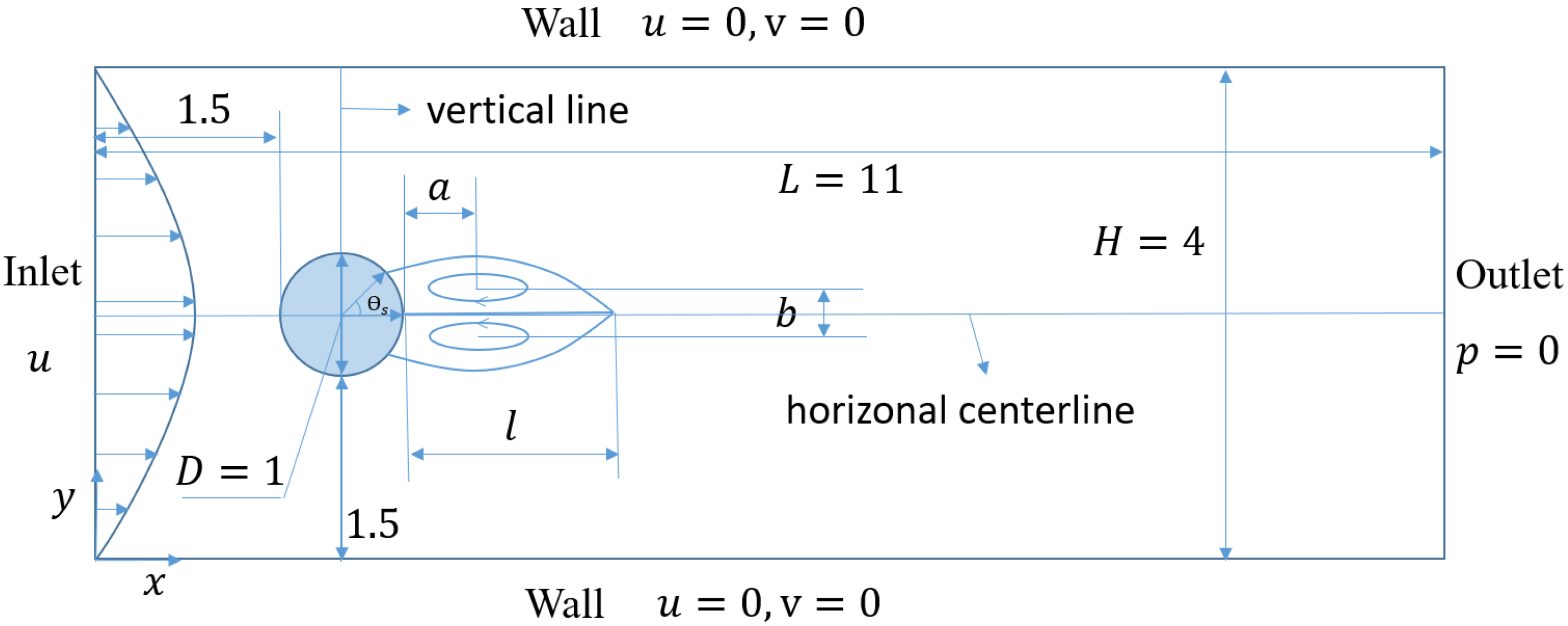
3.1. Problem Description and Numerical Settings
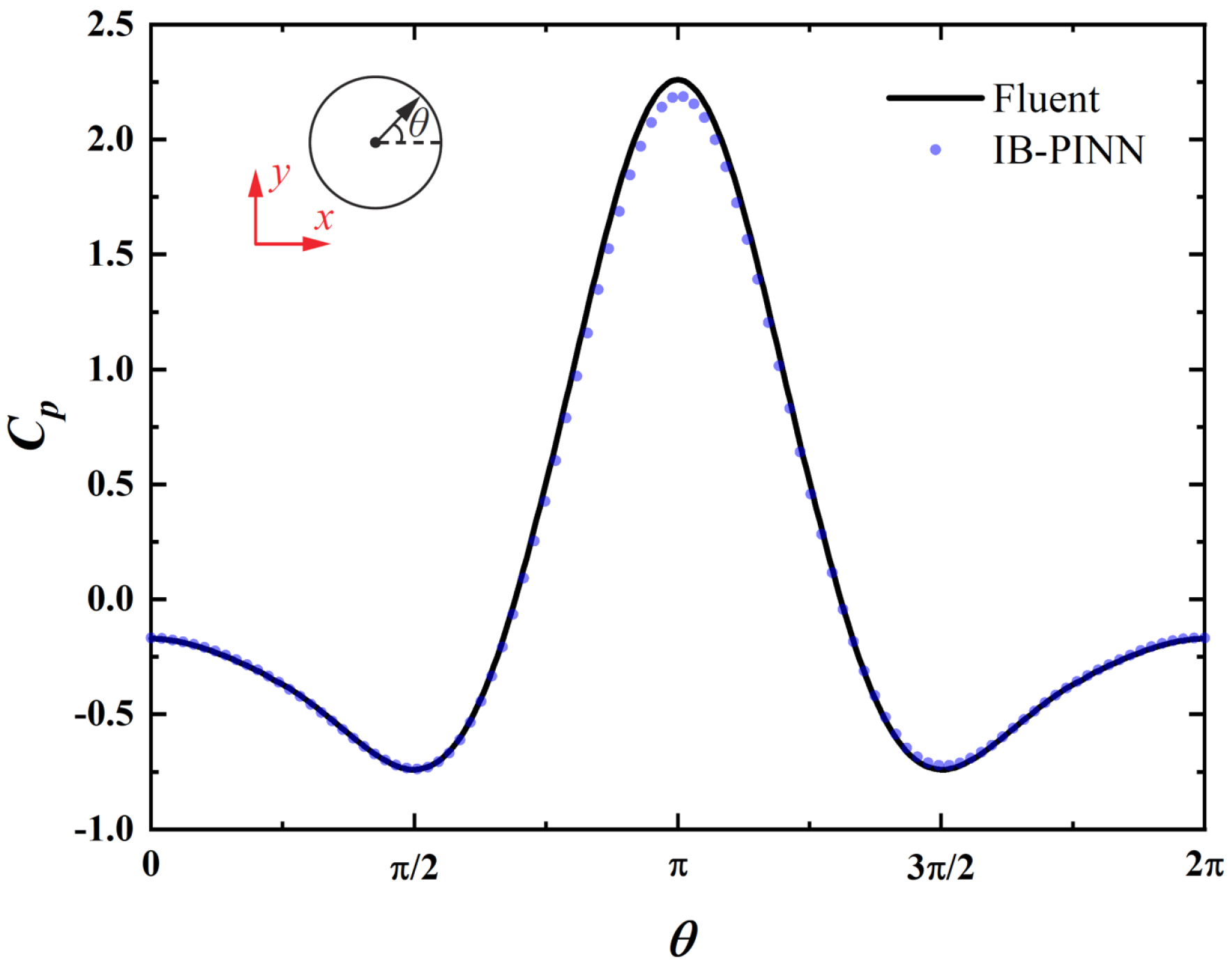
3.2. Predicted Solution vs. Reference Solutions
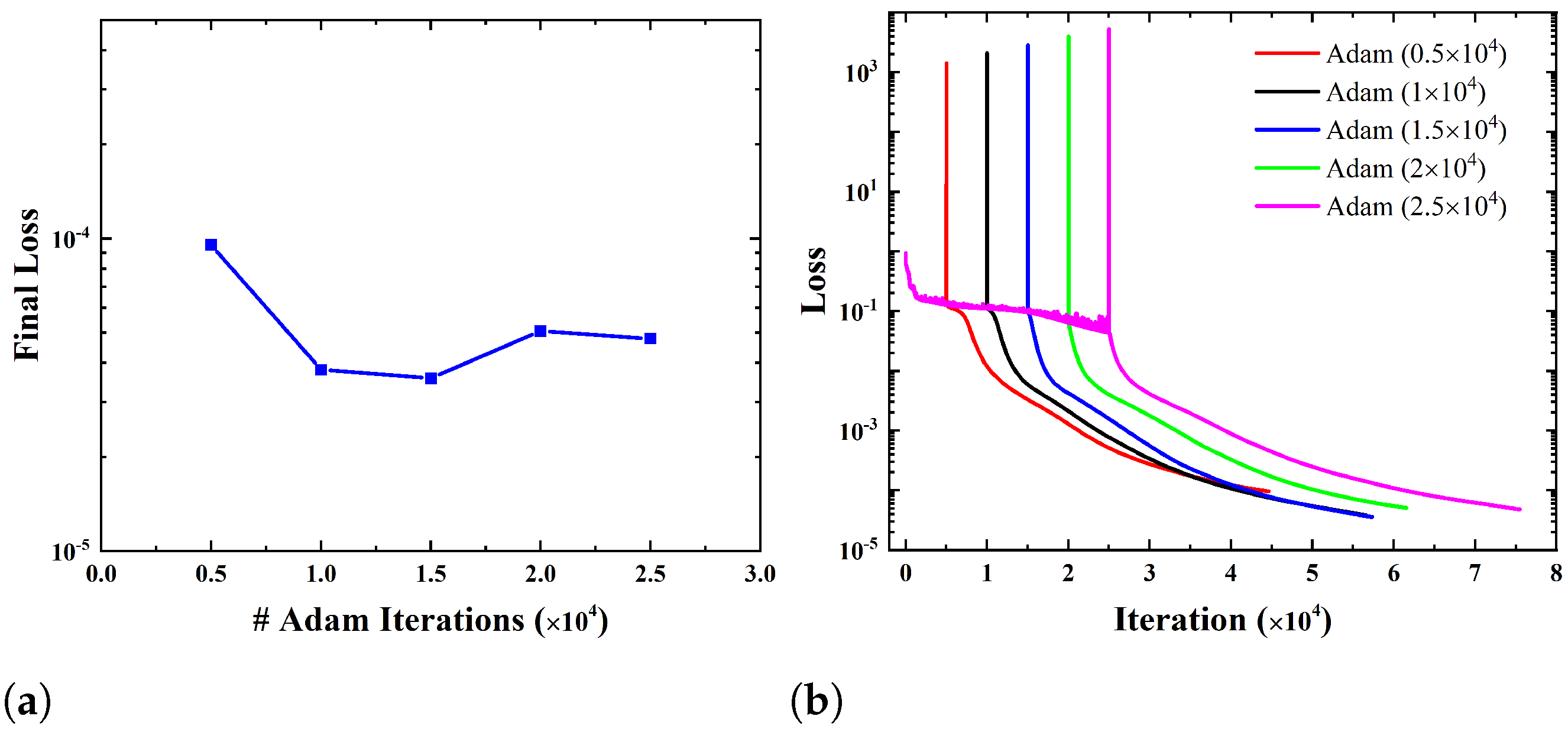
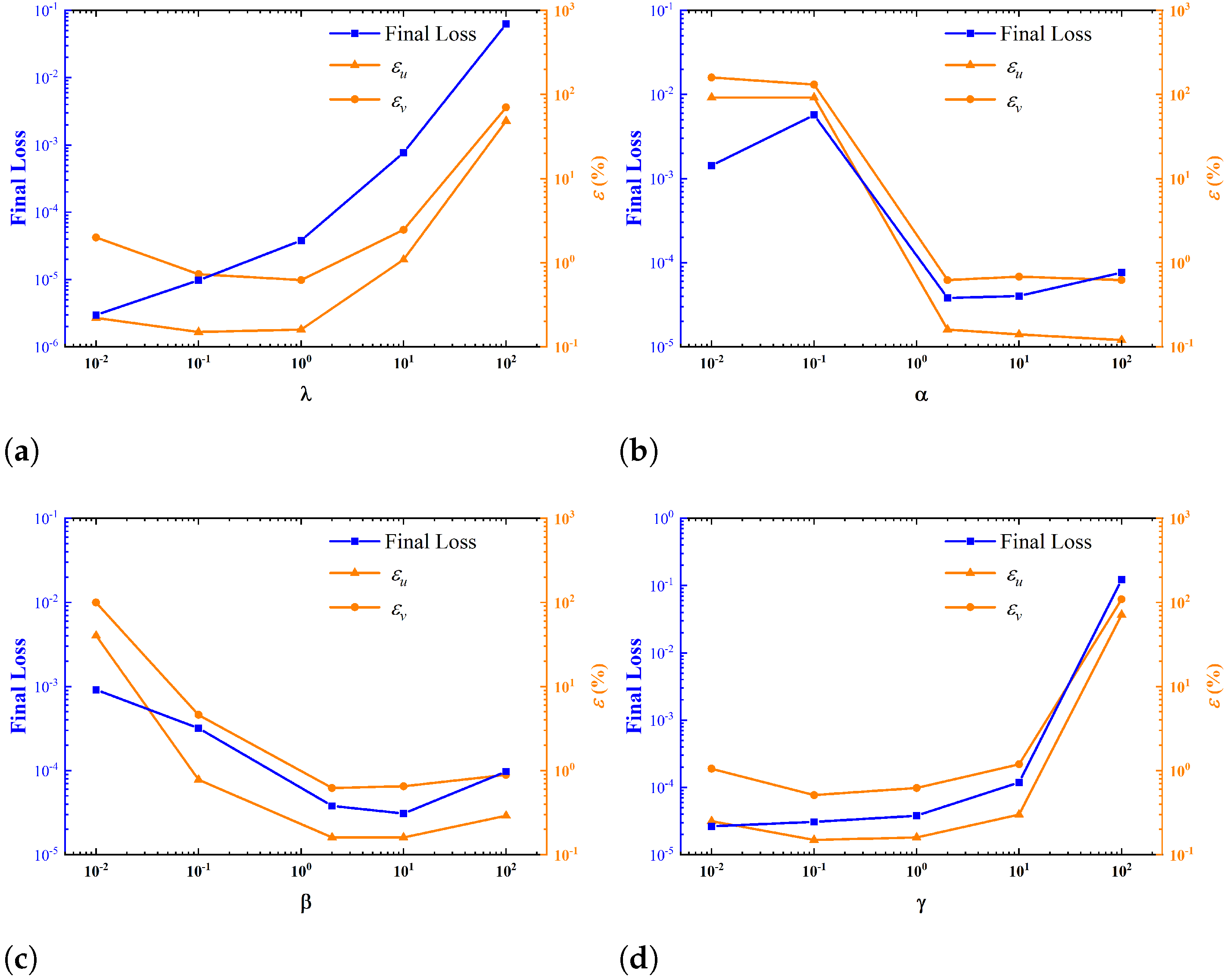
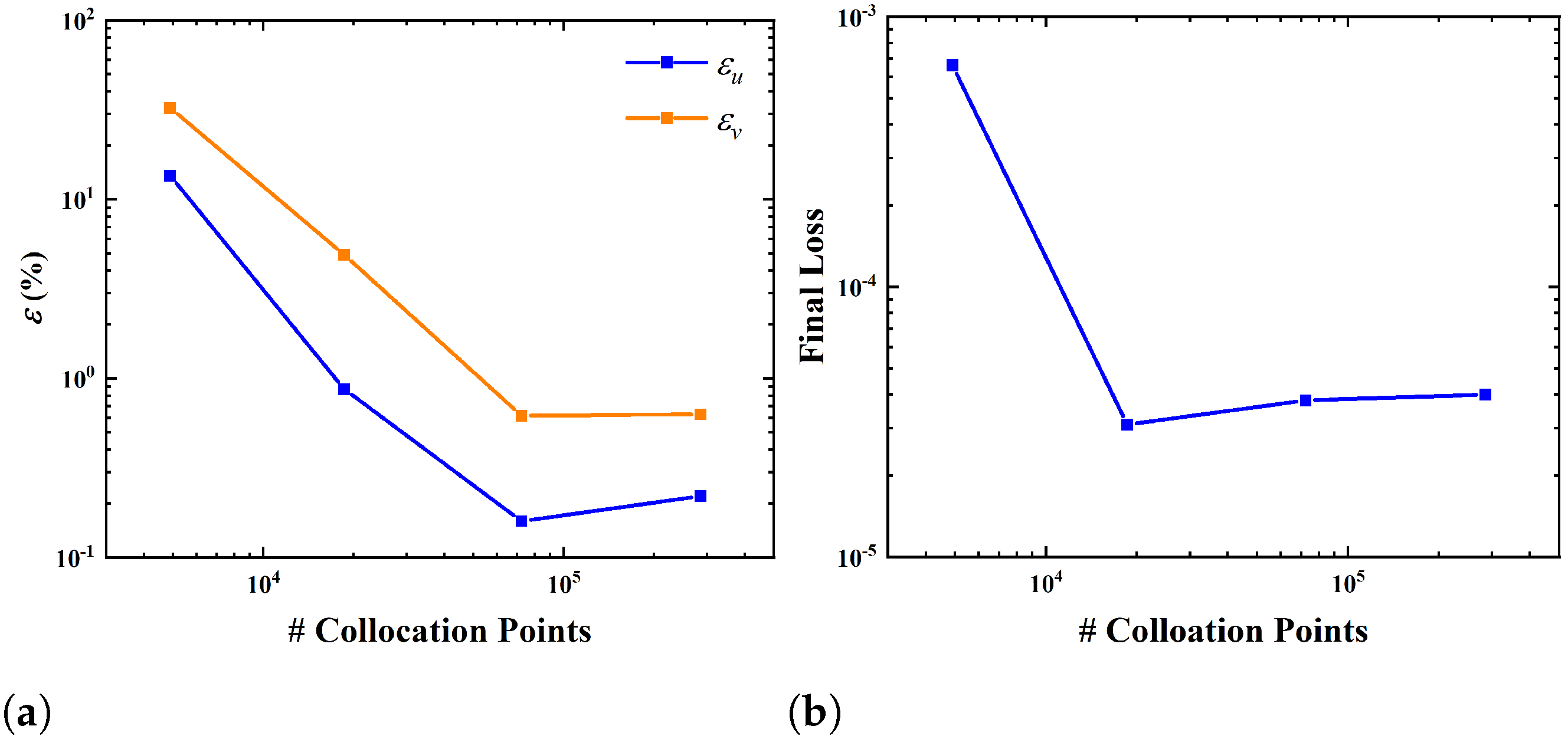
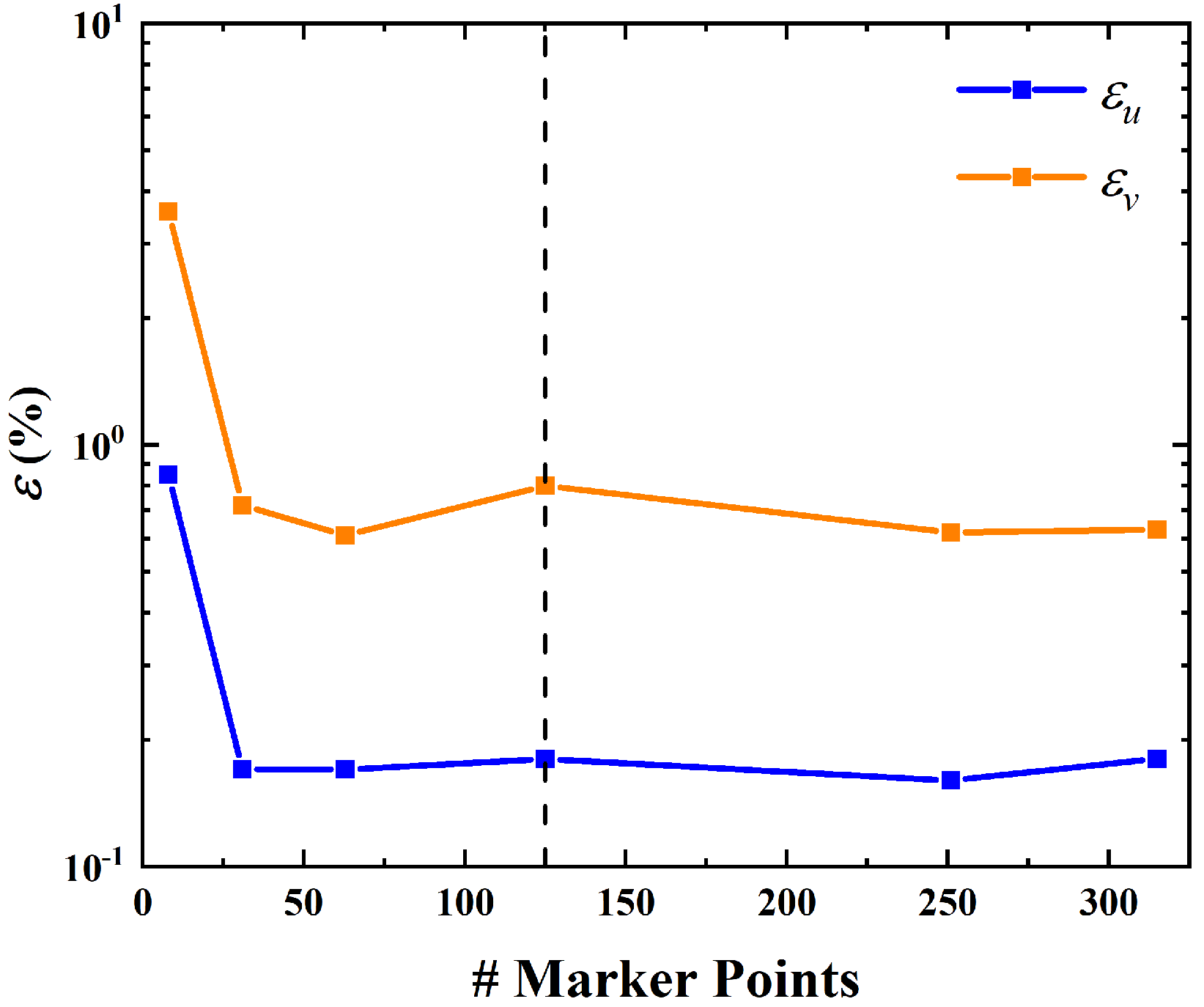
3.3. Influences of Some Parameters on the Performance of IB-PINN
3.4. Transfer Learning
4. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Simulation by Using Ansys Fluent

References
- Brunton, S.L.; Noack, B.R.; Koumoutsakos, P. Machine learning for fluid mechanics. Annu. Rev. Fluid Mech. 2020, 52, 477–508. [Google Scholar] [CrossRef] [Green Version]
- San, O.; Maulik, R.; Ahmed, M. An artificial neural network framework for reduced order modeling of transient flows. Commun. Nonlinear Sci. Numer. Simul. 2019, 77, 271–287. [Google Scholar] [CrossRef] [Green Version]
- Fresca, S.; Manzoni, A. Real-time simulation of parameter-dependent fluid flows through deep learning-based reduced order models. Fluids 2021, 6, 259. [Google Scholar] [CrossRef]
- Colvert, B.; Alsalman, M.; Kanso, E. Classifying vortex wakes using neural networks. Bioinspir. Biomim. 2018, 13, 025003. [Google Scholar] [CrossRef] [Green Version]
- Alsalman, M.; Colvert, B.; Kanso, E. Training bioinspired sensors to classify flows. Bioinspir. Biomim. 2019, 14, 016009. [Google Scholar] [CrossRef]
- Li, B.L.; Zhang, X.; Zhang, X. Classifying wakes produced by self-propelled fish-like swimmers using neural networks. Theor. Appl. Mech. Lett. 2020, 10, 149–154. [Google Scholar] [CrossRef]
- Calvet, A.G.; Dave, M.; Franck, J.A. Unsupervised clustering and performance prediction of vortex wakes from bio-inspired propulsors. Bioinspir. Biomim. 2021, 16, 046015. [Google Scholar] [CrossRef]
- Ling, J.; Kurzawski, A.; Templeton, J. Reynolds averaged turbulence modelling using deep neural networks with embedded invariance. J. Fluid Mech. 2016, 807, 155–166. [Google Scholar] [CrossRef]
- Xiao, H.; Wu, J.L.; Wang, J.X.; Sun, R.; Roy, C.J. Quantifying and reducing model-form uncertainties in Reynolds-averaged Navier—Stokes simulations: A data-driven, physics-informed Bayesian approach. J. Comput. Phys. 2016, 324, 115–136. [Google Scholar] [CrossRef] [Green Version]
- Singh, P.; Medida, S.; Duraisamy, K. Machine-Learning-Augmented Predictive Modeling of Turbulent Separated Flows over Airfoils. AIAA J. 2017, 55, 2215–2227. [Google Scholar] [CrossRef]
- Verma, S.; Novati, G.; Koumoutsakos, P. Efficient collective swimming by harnessing vortices through deep reinforcement learning. Proc. Natl. Acad. Sci. USA 2018, 115, 5849–5854. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rabault, J.; Kuchta, M.; Jensen, A.; Reglade, U.; Cerardi, N. Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control. J. Fluid Mech. 2019, 865, 281–302. [Google Scholar] [CrossRef] [Green Version]
- Viquerat, J.; Rabault, J.; Kuhnle, A.; Ghraieb, H.; Larcher, A.; Hachem, E. Direct shape optimization through deep reinforcement learning. J. Comput. Phys. 2021, 428, 110080. [Google Scholar] [CrossRef]
- Ghraieb, H.; Viquerat, J.; Larcher, A.; Meliga, P.; Hachem, E. Single-step deep reinforcement learning for open-loop control of laminar and turbulent flows. Phys. Rev. Fluids 2021, 6, 053902. [Google Scholar] [CrossRef]
- Ren, F.; Rabault, J.; Tang, H. Applying deep reinforcement learning to active flow control in weakly turbulent conditions. Phys. Fluids 2021, 33, 037121. [Google Scholar] [CrossRef]
- Ren, F.; Wang, C.L.; Tang, H. Bluff body uses deep-reinforcement-learning trained active flow control to achieve hydrodynamic stealth. Phys. Fluids 2021, 33, 093602. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Karniadakis, G.E.; Kevrekidis, I.G.; Lu, L.; Perdikaris, P.; Wang, S.F.; Yang, L. Physics-informed machine learning. Nat. Rev. Phys. 2021, 3, 422–440. [Google Scholar] [CrossRef]
- Cai, S.Z.; Mao, Z.P.; Wang, Z.C.; Yin, M.L.; Karniadakis, G.E. Physics-informed neural networks (PINNs) for fluid mechanics: A review. arXiv 2021, arXiv:2105.09506. [Google Scholar] [CrossRef]
- Sun, L.N.; Gao, H.; Pan, S.W.; Wang, J.X. Surrogate modeling for fluid flows based on physics-constrained deep learning without simulation data. Comput. Meth. Appl. Mech. Eng. 2020, 361, 112732. [Google Scholar] [CrossRef] [Green Version]
- Jin, X.W.; Cai, S.Z.; Li, H.; Karniadakis, G.E. NSFnets (Navier-Stokes Flow nets): Physics-informed neural networks for the incompressible Navier-Stokes equations. J. Comput. Phys. 2021, 426, 109951. [Google Scholar] [CrossRef]
- Rao, C.P.; Sun, H.; Liu, Y. Physics-informed deep learning for incompressible laminar flows. Theor. Appl. Mech. Lett. 2020, 10, 207–212. [Google Scholar] [CrossRef]
- Raissi, M.; Yazdani, A.; Karniadakis, G.E. Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations. Science 2020, 367, 1026–1030. [Google Scholar] [CrossRef] [PubMed]
- Mao, Z.P.; Jagtap, A.D.; Karniadakis, G.E. Physics-informed neural networks for high-speed flows. Comput. Meth. Appl. Mech. Eng. 2020, 360, 112789. [Google Scholar] [CrossRef]
- Hieber, S.E.; Koumoutsakos, P. An immersed boundary method for smoothed particle hydrodynamics of self-propelled swimmers. J. Comput. Phys. 2008, 227, 8636–8654. [Google Scholar] [CrossRef]
- Balam, I.R.; Hernandez-Lopez, F.; Trejo-Sánchez, J.; Zapata, U.M. An immersed boundary neural network for solving elliptic equations with singular forces on arbitrary domains. Math. Biosci. Eng. 2021, 18, 22–56. [Google Scholar] [CrossRef]
- Uhlmann, M. An immersed boundary method with direct forcing for the simulation of particulate flows. J. Comput. Phys. 2005, 209, 448–476. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.Z.; Zhang, X. An immersed boundary method based on discrete stream function formulation for two- and three-dimensional incompressible flows. J. Comput. Phys. 2011, 230, 3479–3499. [Google Scholar] [CrossRef] [Green Version]
- Taira, K.; Colonius, T. The immersed boundary method: A projection approach. J. Comput. Phys. 2007, 225, 2118–2137. [Google Scholar] [CrossRef]
- Colonius, T.; Taira, K. A fast immersed boundary method using a nullspace approach and multi-domain far-field boundary conditions. Comput. Methods Appl. Mech. Eng. 2008, 197, 2131–2146. [Google Scholar] [CrossRef]
- Peskin, C.S. The immersed boundary method. Acta Numer. 2002, 11, 479–517. [Google Scholar] [CrossRef] [Green Version]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Wang, S.Z.; He, G.W.; Zhang, X. Parallel computing strategy for a flow solver based on immersed boundary method and discrete stream-function formulation. Comput. Fluids 2013, 88, 210–224. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.J.; He, G.W.; Zhang, X. An improved direct-forcing immersed boundary method for fluid-structure interaction simulations. J. Fluids Eng. Trans. ASME 2014, 126, 040903. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.L.; Zhang, X.; Li, Z.L.; He, G.W. A smoothing technique for discrete delta functions with application to immersed boundary method in moving boundary simulations. J. Comput. Phys. 2009, 228, 7821–7836. [Google Scholar] [CrossRef]
- Chen, X.H.; Gong, C.Y.; Wan, Q.; Deng, L.; Wan, Y.B.; Liu, Y.; Chen, B.; Liu, J. Transfer learning for deep neural network-based partial differential equations solving. Adv. Aerodyn. 2021, 3, 36. [Google Scholar] [CrossRef]
- Meng, X.H.; Li, Z.; Zhang, D.K.; Karniadakis, G.E. PPINN: Parareal physics-informed neural network for time-dependent PDEs. Comput. Methods Appl. Mech. Eng. 2020, 370, 113250. [Google Scholar] [CrossRef]
- Shukla, K.; Jagtap, A.D.; Karniadakis, G.E. Parallel physics-informed neural networks via domain decomposition. J. Comput. Phys. 2021, 447, 110683. [Google Scholar] [CrossRef]
- ANSYS Fluent 18.1. ANSYS FLUENT Theory Guide; ANSYS Inc.: Canonsburg, PA, USA, 2018. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fluent | 1.19 | 0.45 | 0.48 | 47.7° | 2.17 |
| IB | 1.19 | 0.46 | 0.48 | 46.7° | 2.21 |
| IB-PINN | 1.17 | 0.45 | 0.48 | 46.7° | 2.18 |
| 90 | 100 | 110 | ||
|---|---|---|---|---|
| 5 | Final Loss | 7.3764 × 10 | 8.1033 × 10 | 5.4935 × 10 |
| (%) | 0.28 | 0.27 | 0.26 | |
| (%) | 0.64 | 0.84 | 2.65 | |
| 6 | Final Loss | 5.8943 × 10 | 3.8017 × 10 | 4.4175 × 10 |
| (%) | 0.28 | 0.16 | 0.25 | |
| (%) | 0.87 | 0.62 | 0.82 | |
| 7 | Final Loss | 3.4572 × 10 | 4.1086 × 10 | 3.2451 × 10 |
| (%) | 0.20 | 0.22 | 0.20 | |
| (%) | 1.18 | 0.96 | 0.60 |
| Final Loss | (%) | (%) | ||
|---|---|---|---|---|
| With interior constraint | 2.5749 × 10 −3 | 3.10 | 6.77 | 1.96 |
| Without interior constraint | 3.8017 × 10 −5 | 0.16 | 0.62 | 2.21 |
| Original | Tranfer Learning | |||||||
|---|---|---|---|---|---|---|---|---|
| # Iterations | Final Loss | (%) | (%) | # Iterations | Final Loss | (%) | (%) | |
| Re = 10 | 45011 | 8.7173 × 10 −4 | 1.62 | 2.50 | 38258 | 2.7832 × 10 −4 | 0.79 | 1.36 |
| Re = 20 | 81341 | 2.1812 × 10 −4 | 0.47 | 1.23 | 25420 | 7.3278 × 10 −5 | 0.27 | 0.82 |
| Re = 30 | 53915 | 4.7878 × 10 −5 | 0.19 | 0.78 | 11500 | 5.6311 × 10 −5 | 0.24 | 0.78 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Zhang, Z.; Zhang, X. A Direct-Forcing Immersed Boundary Method for Incompressible Flows Based on Physics-Informed Neural Network. Fluids 2022, 7, 56. https://doi.org/10.3390/fluids7020056
Huang Y, Zhang Z, Zhang X. A Direct-Forcing Immersed Boundary Method for Incompressible Flows Based on Physics-Informed Neural Network. Fluids. 2022; 7(2):56. https://doi.org/10.3390/fluids7020056
Chicago/Turabian StyleHuang, Yi, Zhiyu Zhang, and Xing Zhang. 2022. "A Direct-Forcing Immersed Boundary Method for Incompressible Flows Based on Physics-Informed Neural Network" Fluids 7, no. 2: 56. https://doi.org/10.3390/fluids7020056
APA StyleHuang, Y., Zhang, Z., & Zhang, X. (2022). A Direct-Forcing Immersed Boundary Method for Incompressible Flows Based on Physics-Informed Neural Network. Fluids, 7(2), 56. https://doi.org/10.3390/fluids7020056