Degraded Historical Document Binarization: A Review on Issues, Challenges, Techniques, and Future Directions


Abstract
:1. Introduction
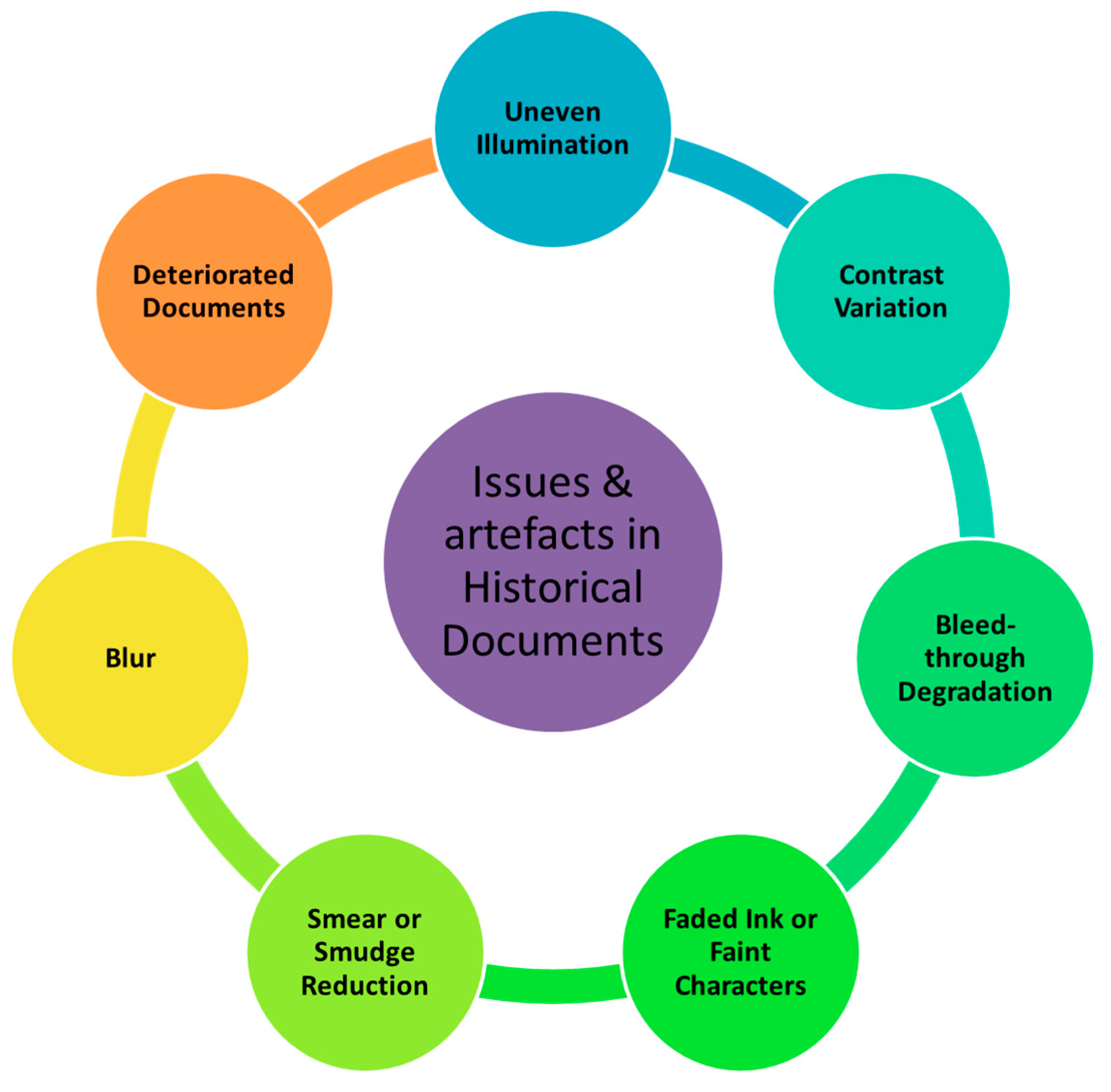
2. Challenges in Historical Documents
2.1. Uneven Illumination
2.2. Contrast Variation
2.3. Bleed-Through Degradation
2.4. Faded Ink or Faint Characters
2.5. Smear or Show Through
2.6. Blur
2.7. Thin or Weak Text
2.8. Deteriorated Documents
3. Handling Historical Document Degradation Issues
4. Document Binarization
4.1. Degraded Document Binarization Methods
4.1.1. Global Thresholding-Based Binarization Methods
4.1.2. Local/Adaptive Thresholding-Based Binarization Methods
4.1.3. Hybrid Thresholding-Based Binarization Methods
4.1.4. Machine Learning-Based Binarization Methods
5. Performance Metrics and Advanced Document Binarization
5.1. Performance Metrics to Evaluate Binarization Methods
5.1.1. F-Measure
5.1.2. Pseudo-F-Measure
5.1.3. Peak Signal-to-Noise Ratio (PSNR)
5.1.4. Negative Rate Metric (NRM)
5.1.5. Multi-Classification Penalty Metric (MPM)
5.1.6. Distance Reciprocal Distortion (DRD)
5.1.7. Average Quality Score
6. Advances in Binarization Methods
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Antonacopoulos, A.; Karatzas, D. Document image analysis for World War II personal records. In Proceedings of the 1st International Workshop on Document Image Analysis for Libraries (DIAL’04), Palo Alto, CA, USA, 23–24 January 2004; pp. 336–341. [Google Scholar]
- Marinai, S.; Marino, E.; Cesarini, F.; Soda, G. A general system for the retrieval of document images from digital libraries. In Proceedings of the 1st International Workshop on Document Image Analysis for Libraries (DIAL’04), Palo Alto, CA, USA, 23–24 January 2004; pp. 150–173. [Google Scholar]
- Govindaraju, V.; Xue, H. Fast handwriting recognition for indexing historical documents. In Proceedings of the 1st International Workshop on Document Image Analysis for Libraries, Palo Alto, CA, USA, 23–24 January 2004; pp. 314–320. [Google Scholar]
- Baird, H.S. Difficult and Urgent Open Problems in Document Image Analysis for Libraries. In Proceedings of the 1st International Workshop on Document Image Analysis for Libraries (DIAL’04), Palo Alto, CA, USA, 23–24 January 2004; pp. 25–32. [Google Scholar]
- Burie, J.-C.; Coustaty, M.; Hadi, S.; Kesiman, M.W.A.; Ogier, J.-M.; Paulus, E.; Sok, K.; Sunarya, I.M.G.; Valy, D. ICFHR2016 competition on the analysis of handwritten text in images of balinese palm leaf manuscripts. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 596–601. [Google Scholar]
- Calvo-Zaragoza, J.; Vigliensoni, G.; Fujinaga, I. Pixel-wise binarization of musical documents with convolutional neural networks. In Proceedings of the Fifteenth IAPR International Conference on Machine Vision Applications, Nagoya, Japan, 8–12 May 2017; pp. 362–365. [Google Scholar]
- Dodge, S.; Xu, J.; Stenger, B. Parsing floor plan images. In Proceedings of the Fifteenth IAPR International Conference on Machine Vision Applications, Nagoya, Japan, 8–12 May 2017; pp. 358–361. [Google Scholar]
- Sulaiman, A.; Omar, K.; Nasrudin, M.F. A database for degraded Arabic historical manuscripts. In Proceedings of the 2017 6th International Conference on Electrical Engineering and Informatics (ICEEI), Langkawi, Malaysia, 25–27 November 2017; pp. 1–6. [Google Scholar]
- Ploem, J.S.; Tanke, H.J. Introduction to Fluorescence Microscopy; Wiley Liss, Inc.: New York, NY, USA, 2001. [Google Scholar]
- Van der Kempen, G.M.P.; van Vliet, L.J.; Verveer, P.J.; Van der Voort, H.T.M. A quantitative comparison of image restoration methods for confocal microscopy. J. Microsc. 1997, 185, 354–365. [Google Scholar] [CrossRef]
- Mustafa, W.A.; Yazid, H. Image Enhancement Technique on Contrast Variation: A Comprehensive Review. J. Telecommun. Electron. Comput. Eng. 2017, 9, 199–204. [Google Scholar]
- Mustafa, W.A.; Yazid, H. Illumination and Contrast Correction Strategy using Bilateral Filtering and Binarization Comparison. J. Telecommun. Electron. Comput. Eng. 2016, 8, 67–73. [Google Scholar]
- Hadjadj, Z.; Meziane, A.; Cheriet, M.; Cherfa, Y. An active contour-based method for image binarization: Application to degraded historical document images. In Proceedings of the 14th International Conference on Frontiers in Handwriting Recognition (ICFHR’14), Crete Island, Greece, 1–4 September 2014; pp. 655–660. [Google Scholar]
- Huangy, Y.; Brown, M.S.; Xuy, D. A Framework for Reducing Ink-Bleed in Old Documents. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Leedham, G.; Varma, S.; Patankar, A.; Govindaraju, V. Separating text and background in degraded document images—A comparison of global thresholding techniques for multi-stage thresholding. In Proceedings of the 8th International Workshop on Frontiers in Handwriting Recognition, Niagara-on-the-Lake, ON, Canada, 6–8 August 2002; pp. 244–249. [Google Scholar]
- Hadjadj, Z.; Meziane, A.; Cherfa, Y.; Cheriet, M.; Setitra, I. ISauvola: Improved Sauvola’s algorithm for document image binarization. In Proceedings of the 2016 International Conference Image Analysis and Recognition (ICIAR 2016), Póvoa de Varzim, Portugal, 13–15 July 2016; pp. 737–745. [Google Scholar]
- Smigiel, E.; Belaid, A.; Hamza, H. Self-organizing Maps and Ancient Documents. In Proceedings of the 6th International Workshop on Document Analysis Systems VI, Florence, Italy, 8–10 September 2004; pp. 125–134. [Google Scholar]
- Sehad, A.; Chibani, Y.; Cheriet, M.; Yaddaden, Y. Ancient degraded document image binarization based on texture features. In Proceedings of the 2013 8th International Symposium on Image and Signal Processing and Analysis (ISPA), Trieste, Italy, 4–6 September 2013. [Google Scholar]
- Quraishi, M.I.; De, M.; Dhal, K.G.; Mondal, S.; Das, G. A novel hybrid approach to restore historical degraded documents. In Proceedings of the 2013 International Conference on Intelligent Systems and Signal Processing (ISSP), Gujarat, India, 1–2 March 2013; Volume 1, pp. 185–189. [Google Scholar]
- Shirani, K.; Endo, Y.; Kitadai, A.; Inoue, S.; Kurushima, N. Character Shape Restoration of Binarized Historical Documents by Smoothing via Geodesic Morphology. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; Volume 12, pp. 1285–1289. [Google Scholar]
- Xu, L.; Yan, Q.; Xia, Y.; Jia, J. Structure extraction from texture via relative total variation. ACM Trans. Graphics 2012, 31, 139:1–139:10. [Google Scholar] [CrossRef]
- Nagendhar, G.; Rajani, D. China Venkateswarlu SonagiriV.Sridhar. Text Localization in Video Data Using Discrete Wavelet Transform. Int. J. Innov. Res. Sci. Eng. Technol. 2012, 1, 118–127. [Google Scholar]
- Oakley, J.P.; Satherley, B.L. Improving image quality in poor visibility conditions using a physical model for degradation. IEEE Trans. Image Process. 1998, 7, 167–179. [Google Scholar] [CrossRef] [PubMed]
- Tan, C.L.; Cao, R.; Shen, P. Restoration of Archival Documents Using a Wavelet Technique. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1399–1404. [Google Scholar]
- Tan, C.L.; Cao, R.; Shen, P.; Chee, J.; Chang, J. Text extraction from historical handwritten documents by edge detection. In Proceedings of the 6th International Conference on Control, Automation, Robotics and Vision, ICARCV2000, Singapore, 5–8 December 2000. [Google Scholar]
- Schechner, Y.Y.; Karpel, N. Clear underwater vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2004), Washington, DC, USA, 27 June–2 July 2004; pp. 536–543. [Google Scholar]
- Kubecka, L.; Jan, J.; Kolar, R. Retrospective illumination correction of retinal images. Int. J. Biomed. Imaging 2010, 2010, 1–10. [Google Scholar] [CrossRef]
- Ghabousian, R.; Allahbakhshi, N. Survey of Contrast Enhancement Techniques based on Histogram Equalization. Int. J. Rev. Life Sci. 2015, 5, 901–908. [Google Scholar]
- Baird, H.S. State of the Art of Document Image Degradation Modelling, invited talk. In Proceedings of the IAPR 2000 Workshop on Document Analysis Systems, Rio de Janeiro, Brazil, 10–13 December 2000. [Google Scholar]
- Sharma, G. Cancellation of show-through in duplex scanning. In Proceedings of the International Conference on Image Processing (ICIP), Vancouver, BC, Canada, 10–13 September 2000; Volume 2, pp. 609–612. [Google Scholar]
- Kaur, R.; Kaur, A. An Effective Algorithm for Ink-Bleed through Removal in Document Images. Int. J. Comput. Sci. Technol. 2011, 2, 330–335. [Google Scholar]
- Dubois, E.; Pathak, A. Reduction of bleed-through in scanned manuscripts documents. In Proceedings of the IS&T Conference on Image Processing, Image Quality, Image Capture Systems, Montreal, QC, Canada, 22–25 April 2001; pp. 177–180. [Google Scholar]
- Wang, X. Recovery of Blurring Scanned Manuscript Image Based on Wavelets Transform Algorithm. In Proceedings of the 3rd International Congress on Image and Signal Processing, Yantai, China, 16–18 October 2010. IEEE 978-1-4244-6516-3/10. [Google Scholar]
- Leydier, Y.; LeBourgeois, F.; Emptoz, H. Serialized K-means for adaptative color image segmentation—Application to Document Images and Others. In Document Analysis Systems VI; DAS 2004. Lecture Notes in Computer Science, vol 3163; Springer: Berlin/Heidelberg, Germany, 2004; pp. 252–263. [Google Scholar]
- Wang, W.; Cui, X. A Background Correction Method for Particle Image under Non-uniform Illumination Conditions. In Proceedings of the 2nd International Conference on Signal Processing Systems (ICSPS), Dalian, China, 5–7 July 2010; pp. 695–699. [Google Scholar]
- Gatos, B.; Pratikakis, I.; Perantonis, S.J. An Adaptive Binarization Technique for Low Quality Historical Documents. In Proceedings of the 6th International Workshop on Document Analysis Systems VI (DAS2004), Florence, Italy, 8–10 September 2004; pp. 102–113. [Google Scholar]
- Ebrahimi Moghaddam, M.; Jamzad, M. Linear motion blur parameter estimation in noisy images using fuzzy sets and power. EURASIP J. Adv. Signal Process. 2006, 2007, 068985. [Google Scholar] [CrossRef]
- Ebrahimi Moghaddam, M. A mathematical model to estimate out of focus blurs. In Proceedings of the 5th IEEE International Symposium on Image and Signal Processing and Analysis (ISPA), Istanbul, Turkey, 27–29 September 2007; pp. 278–281. [Google Scholar] [CrossRef]
- Cannon, M.; Hochberg, J.; Kelly, P. QUARC: A Remarkably Effective Method for Increasing the OCR Accuracy of Degraded Typewritten Documents. In Proceedings of the 1999 Symposium on Document Image Understanding Technology (SDIUT’99), Annapolis, MD, USA, 14–16 April 1999; pp. 154–158. [Google Scholar]
- Antonacopoulos, A.; Karatzas, D. Semantics-Based Content Extraction in Typewritten Historical Documents. In Proceedings of the Eighth International Conference on Document Analysis and Recognition (ICDAR’05), Seoul, Korea, 31 August–1 September 2005; pp. 48–53. [Google Scholar]
- Antonacopoulos, A.; Casado Castilla, C. Flexible Text Recovery from Degraded Typewritten Historical Documents. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR2006), Hong Kong, China, 20–24 August 2006; pp. 1062–1065. [Google Scholar]
- Pletschacher, S. Representation of Digitized Documents Using Document Specific Alphabets and Fonts. In Archiving Conference; Society for Imaging Science and Technology: Springfield, VA, USA, 2008. [Google Scholar]
- Hu, J.; Singh, M.; Mojsilovic, A. Categorization Using Semi-Supervised Clustering. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008. [Google Scholar]
- Kitadai, A.; Nakagawa, M.; Baba, H.; Watanabe, A. Similarity evaluation and shape feature extraction for character pattern retrieval to support reading historical documents. In Proceedings of the 2012 10th IAPR International Workshop on Document Analysis Systems, Queensland, Australia, 27–29 March 2012; pp. 359–363. [Google Scholar]
- Wu, S.; Lin, W.; Jiang, L.; Xiong, W.; Chen, L.; Ong, S.H. An objective out-of-focus blur measurement. In Proceedings of the IEEE 5th International Conference on Information, Communications and Signal Processing ICICS 2005, Bangkok, Thailand, 6–9 December 2005; pp. 334–338. [Google Scholar]
- Shoa, T.; Thomas, G.; Shafai, C.; Shoa, A. Extracting a focused image from several out of focus micromechanical structure images. In Proceedings of the 2004 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Montreal, QC, Canada, 17–21 May 2004; Volume 3. [Google Scholar]
- Vivirito, P.; Battiato, S.; Curti, S.; La Cascia, M.; Pirrone, R. Restoration of out of focus images based on circle of confusion estimate. In Proceeding of the SPIE 47th Annual Meeting (Applications of Digital Image Processing XXV Conference), Seattle, WA, USA, 7–11 July 2002; pp. 408–416. [Google Scholar]
- Rooms, F.; Pizurica, A.; Philips, W. Estimating image blur in the wavelet domain. In Proceeding of the IEEE International Conference on Acoustics, Speech and Signal Processing, Orlando, FL, USA, 13–17 May 2002; Volume 4, pp. 4190–4194. [Google Scholar]
- Lagendijk, R.L.; Biemond, J. Basic Methods for Image Restoration and Identification. In Hand Book of Image and Vedio Processing; Academic Press: Delft, The Netherlands, 2000; Chapter B; pp. 125–140. [Google Scholar]
- Serdouk, Y.; Nemmour, H.; Chibani, Y. New off-line handwritten signature verification method based on artificial immune recognition system. Expert Syst. Appl. 2016, 51, 186–194. [Google Scholar] [CrossRef]
- Pratikakis, I.; Zagoris, K.; Barlas, G.; Gatos, B. ICDAR2017 competition on document image binarization (DIBCO 2017). In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1395–1403. [Google Scholar]
- Nagasudha, D.; Madhaveelatha; Pratap Reddy, Y. Telugu Document Image Segmentation Methods. Int. J. Res. Appl. 2014, 1, 76–79. [Google Scholar]
- Shi, Z.; Govindaraju, V. Line Separation for Complex Document Images Using Fuzzy Runlength. In Proceedings of the 1st International Workshop on Document Image Analysis for Libraries (DIAL’04), Washington, DC, USA, 23–24 January 2004; pp. 306–312. [Google Scholar]
- Surinta, O.; Chamchong, R. Image segmentation of historical handwriting from palm leaf manuscript. In Proceedings of the 8th IFIP International Federation for Information Processing, Beijing, China, 19–22 October 2008; Volume 288, pp. 370–375. [Google Scholar]
- Otsu, N. A thresholding selection method from gray-level histogram. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Kittler, J.; Illingworth, J. Minimum error thresholding. Pattern Recognit. 1986, 19, 41–47. [Google Scholar] [CrossRef]
- Bernsen, J. Dynamic thresholding of gray-level images. In Proceedings of the 8th International Conference on Pattern Recognition (ICPR), Paris, France, 27–31 October 1986; pp. 1251–1255. [Google Scholar]
- Niblack, W. An Introduction to Digital Image Processing; Prentice-Hall: Englewood Cliffs, NJ, USA, 1986; Volume 34. [Google Scholar]
- Sauvola, J.; Pietikainen, M. Adaptive document image binarization. Pattern Recognit. 2000, 33, 225–236. [Google Scholar] [CrossRef]
- Gatos, B.; Pratikakis, I.; Perantonis, S.J. Adaptive degraded document image binarization. Pattern Recognit. 2006, 39, 317–327. [Google Scholar] [CrossRef]
- Khurshid, K.; Siddiqi, I.; Faure, C.; Vincent, N. Comparison of Niblack inspired Binarization methods for ancient documents. In Proceedings of the Document Recognition and Retrieval XVI, San Jose, CA, USA, 20–22 January 2009; Volume 7247, p. 72470U. [Google Scholar]
- Pratikakis, I.; Zagoris, K.; Barlas, G.; Gatos, B. ICFHR2016 handwritten document image binarization contest (H-DIBCO 2016). In Proceedings of the 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 619–623. [Google Scholar]
- Su, B.; Lu, S.; Tan, C.L. Combination of document image binarization techniques. In Proceedings of the 11th International Conference on Document Analysis and Recognition (ICDAR), Beijing, China, 18–21 September 2011; pp. 22–26. [Google Scholar]
- Sokratis, V.; Kavallieratou, E.; Paredes, R.; Sotiropoulos, K. A Hybrid Binarization Technique for Document Images. In Learning Structure and Schemas from Documents, Volume 375 of Studies in Computational Intelligence; Biba, M., Xhafa, F., Eds.; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 2011; pp. 165–179. [Google Scholar]
- Moghaddam, R.F.; Moghaddam, F.F.; Cheriet, M. Unsupervised ensemble of experts (EoE) framework for automatic binarization of document images. In Proceedings of the 12th International Conference on Document Analysis and Recognition (ICDAR), Washington, DC, USA, 25–28 August 2013; pp. 703–707. [Google Scholar]
- Moghaddam, R.F.; Cheriet, M. A multi-scale framework for adaptive binarization of degraded document images. Pattern Recognit. 2010, 43, 2186–2198. [Google Scholar] [CrossRef]
- Mitianoudis, N.; Papamarkos, N. Document image binarization using local features and Gaussian mixture modeling. Image Vis. Comput. 2015, 38, 33–51. [Google Scholar] [CrossRef]
- Yan, H.; Wu, J. Character and line extraction from color map images using a multi-layer neural network. Pattern Recognit. Lett. 1994, 15, 97–103. [Google Scholar] [CrossRef]
- Chi, Z.; Wong, K.W. A Two-Stage Binarization Approach for Document Images. In Proceedings of the International Symposium on Intelligent Multimedia, Video and Speech Processing (ISIMP 2001), Hong Kong, China, 24 May 2001. [Google Scholar]
- Hidalgo, J.L.; Espana, S.; Castro, M.J.; Pérez, J.A. Enhancement and Cleaning of Handwritten Data by Using Neural Networks; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Feng, S. A novel variational model for noise robust document image binarization. Neurocomputing 2019, 325, 288–302. [Google Scholar] [CrossRef]
- Kefali, A.; Sari, T.; Bahi, H. Foreground-background separation by feed-forward neural networks in old manuscripts. Informatica 2014, 38, 329–339. [Google Scholar]
- Pastor-Pellicer, J.; España-Boquera, S.; Zamora-Martínez, F.; Afzal, M.Z.; Castro-Bleda, M.J. Insights on the use of convolutional neural networks for document image binarization. In Proceedings of the 13th International Work-Conference on Artificial Neural Networks (IWANN 2015), Palma de Mallorca, Spain, 10–12 June 2015; Springer: Cham, Switzerland, 2015; pp. 115–126. [Google Scholar]
- Westphal, F.; Lavesson, N.; Grahn, H. Document image binarization using recurrent neural networks. In Proceedings of the 2018 13th IAPR International Workshop on Document Analysis Systems (DAS), Vienna, Austria, 24–27 April 2018; pp. 263–268. [Google Scholar]
- Kalchbrenner, N.; Danihelka, I.; Graves, A. Grid long short-term memory. arXiv 2015, arXiv:1507.01526. [Google Scholar]
- Calvo-Zaragoza, J.; Gallego, A.J. A selectional auto-encoder approach for document image binarization. arXiv 2017, arXiv:1706.10241. [Google Scholar]
- Tensmeyer, C.; Martinez, T. Document image binarization with fully convolutional neural networks. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR 2017), Kyoto, Japan, 13–15 November 2017; Volume 1, pp. 99–104. [Google Scholar]
- Vo, Q.N.; Kim, S.H.; Yang, H.J.; Lee, G. Binarization of degraded document images based on hierarchical deep supervised network. Pattern Recognition. 2018, 74, 568–586. [Google Scholar] [CrossRef]
- Gatos, B.; Ntirogiannis, K.; Pratikakis, I. ICDAR 2009 document image binarization contest (DIBCO 2009). In Proceedings of the 2009 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; pp. 1375–1382. [Google Scholar]
- Ntirogiannis, K.; Gatos, B.; Pratikakis, I. An objective evaluation methodology for handwritten image document binarization techniques. In Proceedings of the 2008 the Eighth IAPR International Workshop on Document Analysis Systems, Nara, Japan, 16–19 September 2008; pp. 217–224. [Google Scholar]
- Powers, D.M. Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing; Addison-Wesley: New York, NY, USA, 1992. [Google Scholar]
- Young, D.P.; Ferryman, J.M. Pets metrics: On-line performance evaluation service. In Proceedings of the 14th International Conference on Computer Communications and Networks, San Diego, CA, USA, 17–19 October 2005; pp. 317–324. [Google Scholar]
- Lu, H.; Kot, A.C.; Shi, Y.Q. Distance-reciprocal distortion measure for binary document images. IEEE Signal Process. Lett. 2004, 11, 228–231. [Google Scholar] [CrossRef]
- Ye, P.; Doermann, D. Document image quality assessment: A brief survey. In Proceedings of the 12th International Conference on Document Analysis and Recognition (ICDAR 2013), Washington, DC, USA, 25–28 August 2013; pp. 723–727. [Google Scholar]
- Yahya, S.R.; Abdullah, S.N.H.S.; Omar, K.; Zakaria, M.S.; Liong, C.Y. Review on image enhancement methods of old manuscript with the damaged background. In Proceedings of the 2009 International Conference on Electrical Engineering and Informatics, Selangor, Malaysia, 5–7 August 2009; pp. 62–67. [Google Scholar]
- Li, C.H.; Lee, C.K. Minimum cross entropy thresholding. Pattern Recognit. 1993, 26, 617–625. [Google Scholar] [CrossRef]
- Sauvola, J.; Seppanen, T.; Haapakoski, S.; Pietikainen, M. Adaptive document binarization. In Proceedings of the 4th International Conference on Document Analysis and Recognition (ICDAR’ 97), Ulm, Germany, 18–20 August 1997. [Google Scholar]
- Cheng, H.D.; Chen, J.R.; Li, J. Threshold selection based on fuzzy c-partition entropy approach. Pattern Recognit. 1997, 31, 857–870. [Google Scholar] [CrossRef]
- Wolf, C.; Jolion, J.M.; Chassaing, F. Extraction de texte dans des vidéos: Le cas de la binarisation. Proc. RFIA 2002, 1, 145–152. [Google Scholar]
- Kavallieratou, E.; Stathis, S. Adaptive binarization of historical document images. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’ 06), Hong Kong, China, 20–24 August 2006. [Google Scholar]
- Kuo, T.Y.; Lai, Y.Y.; Lo, Y.C. A novel image binarization method using hybrid thresholding. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME’ 10), Singapore, 19–23 July 2010. [Google Scholar]
- Lu, S.; Su, B.; Tan, C.L. Document image binarization using background estimation and stroke edges. Int. J. Doc. Anal. Recognit. 2010, 13, 303–314. [Google Scholar] [CrossRef]
- Pai, Y.T.; Chang, Y.F.; Ruan, S.J. Adaptive thresholding algorithm: Efficient computation technique based on intelligent block detection for degraded document images. Pattern Recognit. 2010, 43, 3177–3187. [Google Scholar] [CrossRef]
- Bataineh, B.; Abdullah, S.N.H.S.; Omar, K. An adaptive local binarization method for document images based on a novel thresholding method and dynamic windows. Pattern Recognit. Lett. 2011, 32, 1805–1813. [Google Scholar] [CrossRef]
- Howe, N. Document binarization with automatic parameter tuning. Int. J. Doc. Anal. Recognit. 2013, 16, 247–258. [Google Scholar] [CrossRef]
- Neves, R.F.P.; Mello, C.A.B. A local thresholding algorithm for images of handwritten historical documents. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Anchorage, AK, USA, 9–12 October 2011; IEEE Xplore Press: Anchorage, AK, USA, 2011. [Google Scholar] [CrossRef]
- Singh, T.R.; Roy, S.; Singh, O.I.; Sinam, T.; Singh, K. A new local adaptive thresholding technique in binarization. IJCSI Int. J. Comput. Sci. Issues 2011, 8, 271–277. [Google Scholar]
- Moghaddam, R.F.; Cheriet, M. AdOtsu: An adaptive and parameterless generalization of Otsu’s method for document image binarization. Pattern Recognit. 2012, 45, 2419–2431. [Google Scholar] [CrossRef]
- Ntirogiannis, K.; Gatos, B.; Pratikakis, I. A combined approach for the binarization of handwritten document images. Pattern Recognit. Lett. 2014, 35, 3–15. [Google Scholar] [CrossRef]
- AL-Khatatneh, A.M.; Pitchay, S.A.; Al-qudah, M.K. Compound binarization for degraded document images. ARPN J. Eng. Appl. Sci. 2015, 6608, 594–599. [Google Scholar]
- Lu, D.; Huang, X.; Liu, C.; Lin, X.; Zhang, H.; Yan, J. Binarization of degraded document image based on contrast enhancement. In Proceedings of the 35th Chinese Control Conference, Chengdu, China, 27–29 July 2016; pp. 4894–4899. [Google Scholar] [CrossRef]
- Bataineh, B.; Abdullah, S.H.S.; Omar, K. Adaptive binarization method for degraded document images based on surface contrast variation. Pattern Anal. Appl. 2017, 20, 639. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, L. Broken and degraded document images binarization. Neurocomputing 2017, 237, 272–280. [Google Scholar] [CrossRef]
- Hadjadj, Z.; Cheriet, M.; Meziane, A.; Cherfa, Y. A new efficient binarization method: Application to degraded historical document images. Signal Image Video Process. 2017, 11, 1155–1162. [Google Scholar] [CrossRef]
- Lu, D.; Huang, X.; Sui, L. Binarization of degraded document images based on contrast enhancement. Int. J. Doc. Anal. Recognit. (IJDAR) 2018, 21, 123–135. [Google Scholar] [CrossRef]
- Khitas, M.; Ziet, L.; Bouguezel, S. Improved Degraded Document Image Binarization Using Median Filter for Background Estimation. Elektronika ir Elektrotechnika 2018, 24, 82–87. [Google Scholar] [CrossRef]
- Xiong, W.; Xu, J.; Xiong, Z.; Wang, J.; Liu, M. Degraded historical document image binarization using local features and support vector machine (SVM). Optik 2018, 164, 218–223. [Google Scholar] [CrossRef]
- Boudraa, O.; Hidouci, W.K.; Michelucci, D. Degraded Historical Documents Images Binarization Using a Combination of Enhanced Techniques. arXiv 2019, arXiv:1901.09425. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Studies Conducted | Outcomes/Performance |
|---|---|
| Niblack, 1985 [59] | Performance is measured in terms of distance calculated from results and ground truth. The distance was 146. |
| Li and Lee, 1993 [88] | Average quality score was measured as 0.114 which shows good performance |
| Sauvola et al., 1997 [89] | Performance is measured in terms of distance calculated from results and ground truth. The distance was 28.7. |
| Cheng et al., 1998 [90] | Qualitative measure shows preservation of main features of the component image |
| Sauvola et al., 2000 [60] | Performance in evaluated based on the ranking/scoring in terms of weighted distance from base pixels. Overall weighted performance was 93.2% as compared to other methods that results in less than 90%. |
| Wolf et al., 2002 [91] | Performance is measured in terms of distance calculated from results and ground truth. The distance was 53.16. |
| Kavallieratou and Stathis, 2006 [92] | Performance in measured in terms of precision from 43 good-quality images that shows high values as 97.67% |
| Gatos et al., 2009 [79] | Performance in measured in terms of calculating F-measure and values obtained are 91.9% |
| Kuo et al., 2010 [92] | Performance in visually measured and results shows competitive visual result compare to Niblack, Sauvola, Chang, and Otsu methods |
| Lu et al., 2010 [94] | Performance in measured in terms of calculating F-measure and values obtained are 91.24% |
| Pai et al., 2010 [95] | Performance is measured in terms of time and recognition rates and the values obtained are:Average processing time = 0.351; Average recognition rate = 98.22% |
| Bataineh et al., 2011 [96] | F-mean, PSNR, NRM respectively are 10.5, 6.16 and 89.34 |
| Neves and Mello, 2011 [98] | Values obtained for F-measure, PSNR, NRM, MPM, and GA are 88.7052, 18.7090, 0.0576, 0.6823, and 0.9360, respectively |
| Su et al., 2011 [64] | F-Measure was calculated and combined results of Otsu’s and Sauvola’s are 86.62% while combined results of Lu’s method and Su’s are 93.18% |
| Singh et al., 2011 [99] | Computational Time is measured as ~0.234 Sec. Achieved lowest computational time compared Niblack, Sauvola, and Bernsen methods |
| Moghaddam and Cheriet, 2012 [100] | Using the F-measure method automatic mode = 91.57%. Grid-based AdOtsu = 92.01%. Multiscale grid-based AdOtsu = 92.06% |
| Howe, 2013 [97] | Performance is measured in terms of F-measure (%) PSNR and DRD are 89.47, 21.80, and 3.44, respectively. |
| Kefali et al.2014 [72] | Performance increase according to PSNR, DRD, etc. Metrics. |
| Ntirogiannis et al. 2014 [101] | F-measure, PSNR, NRM, MPM, p-F-measure (p-FM) and Distance Reciprocal Distortion (DRD), top performance in most cases. |
| Hadjadj et al. 2014 [13] | F-measure method = 91.24% |
| Mitianoudia and Papamarkos, 2015 [67] | Performance in measured by calculating PSNR, MSE, Recall, Precision, F-mean, NRM with the values obtained as 15.29, 0.0295, 0.8331, 0.9466, 0.8862, and 0.0872, respectively |
| Al-Khatatneh et al. 2015 [102] | Performance of this method is measured for handwritten and printed documents. For handwritten document, F-mean and PSNR are 79.63% and 16.56 respectively while for printed document F-mean and PSNR are 87.6% and 15.94 respectively |
| Lu et al., 2016 [103] | This method was evaluated in terms of F-mean, PSNR and NRM for both the printed and handwritten document. For handwritten images, F-mean, PSNR and NRM are 82.82%, 11.86, and 8.76, respectively while for printed documents values are 87.12%, 10.44, and 8.92, respectively |
| Calvo-Zaragoza et al. 2017 [76] | Remarkable accuracy rate achieved by the deep Binarization algorithm. 7.9% increase in the accuracy rate vs. state-of-the-art method |
| Bataineh et al., 2017 [104] | Measured F-mean, PSNR, NRM and obtained the results as 17.5, 5.14, and 88%, respectively |
| Tensmeyer et al. 2017 [77] | Performance is measured with various metrics demonstrated an improvement in final performance on two public datasets |
| Chen et al., 2017 [105] | The performance in measured in terms of PSNR and F-mean that shows the values as 18.2381 and 95.7, respectively. |
| Hadjadj et al. 2017 [106] | Performance is measured in terms of F-measure (%) PSNR and DRD are 91.67, 19.96 and 2.76 respectively. |
| Westphal et al.2018 [74] | Performance increase in terms of PSNR and BRD metrics against state-of-the-art models |
| Quang Nhat Vo et al. 2018 [78] | Significant improvement achieved by evaluating different metrics: F-measure 94.4, PSNR 21.4, BRD 1.8 |
| Lu et al. 2018 [107] | Performance in measured in terms of FP, FN, TP, TN, FP + FN, F-measure (%) and NRM and values obtained are 3180, 8968, 37,013, 747,992, 12,148, 85.90%, and 0.0996 respectively that shows better performance as compared to Otsu, Niblack and Sauvola methods. |
| Khitas et al. 2018 [108] | Best Results obtained on BICKLEY DIARY Dataset. Values obtained for the Fm (%) PSNR, NRM and MPM are 79.11, 13.24, 12.85, and 23.99, respectively. This method has achieved comparatively less significant results for DIBCO database |
| Xiong et al. 2018 [109] | Superior performance in terms of F-measure, PSNR, NRM, DRD, and MPM that is obtained as 89.967, 18.640, 0.054, 3.757, and 1.979 respectively that shows far better performance |
| Boudraa et al. 2019 [110] | They used terms of FM (%), FMp (%), DRD and PSNR are 85.08, 89.81, 5.08, and 17.47 respectively |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sulaiman, A.; Omar, K.; Nasrudin, M.F. Degraded Historical Document Binarization: A Review on Issues, Challenges, Techniques, and Future Directions. J. Imaging 2019, 5, 48. https://doi.org/10.3390/jimaging5040048
Sulaiman A, Omar K, Nasrudin MF. Degraded Historical Document Binarization: A Review on Issues, Challenges, Techniques, and Future Directions. Journal of Imaging. 2019; 5(4):48. https://doi.org/10.3390/jimaging5040048
Chicago/Turabian StyleSulaiman, Alaa, Khairuddin Omar, and Mohammad F. Nasrudin. 2019. "Degraded Historical Document Binarization: A Review on Issues, Challenges, Techniques, and Future Directions" Journal of Imaging 5, no. 4: 48. https://doi.org/10.3390/jimaging5040048
APA StyleSulaiman, A., Omar, K., & Nasrudin, M. F. (2019). Degraded Historical Document Binarization: A Review on Issues, Challenges, Techniques, and Future Directions. Journal of Imaging, 5(4), 48. https://doi.org/10.3390/jimaging5040048