Task-Driven Learned Hyperspectral Data Reduction Using End-to-End Supervised Deep Learning

 , , ,
, , ,
Abstract
:
1. Introduction
2. Related Work
3. Materials and Methods
3.1. Notation and Concepts
3.1.1. Hyperspectral Imaging
3.1.2. Supervised Learning and Neural Networks
3.1.3. Spectral Data Reduction
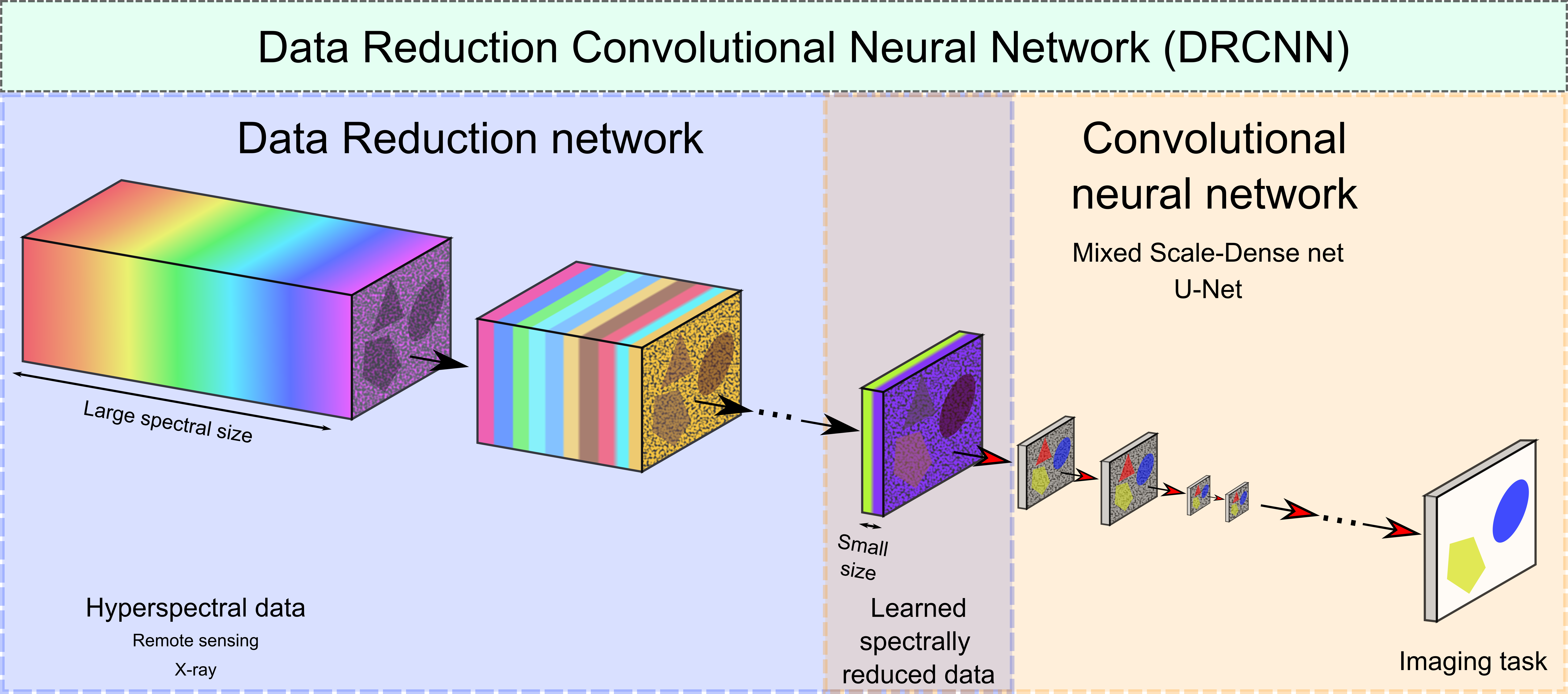
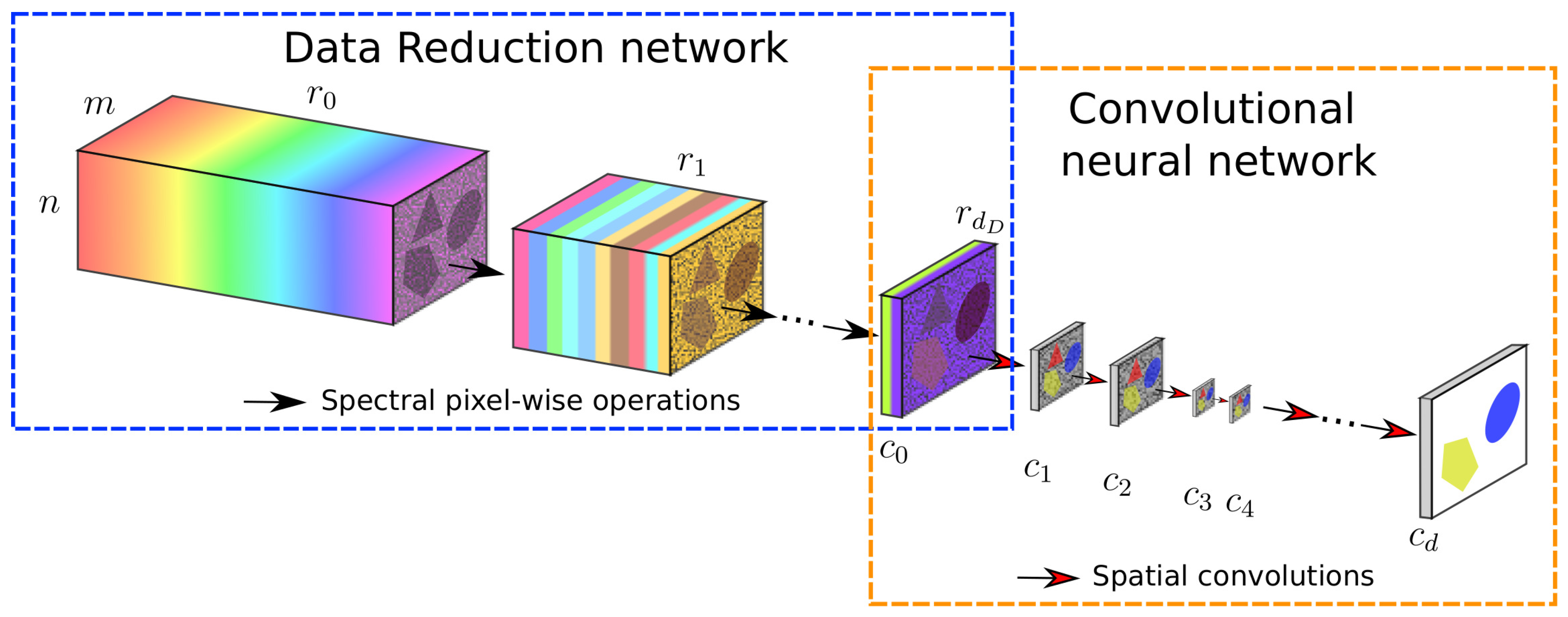
3.2. Learned Data Reduction Method
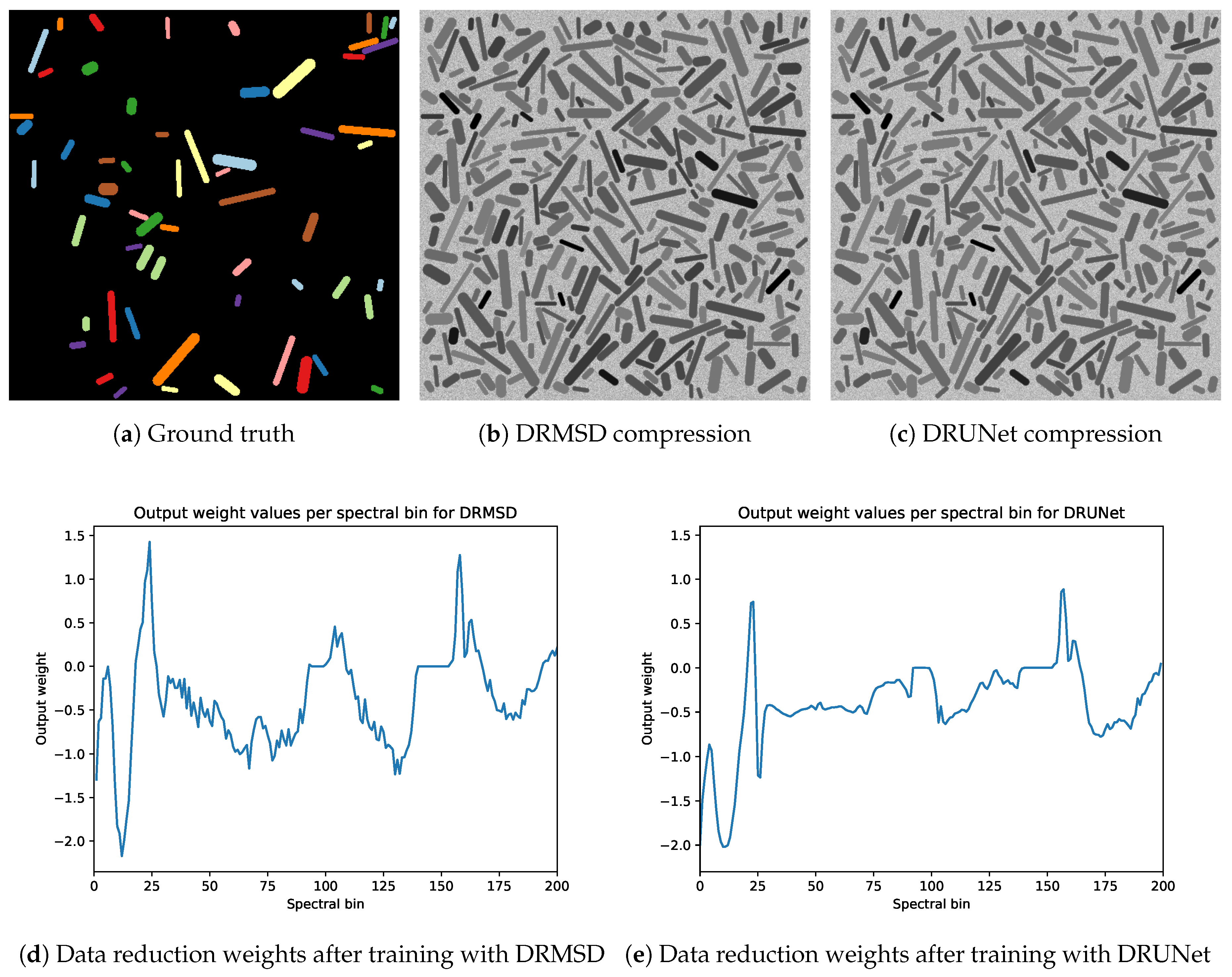
4. Experiments and Results
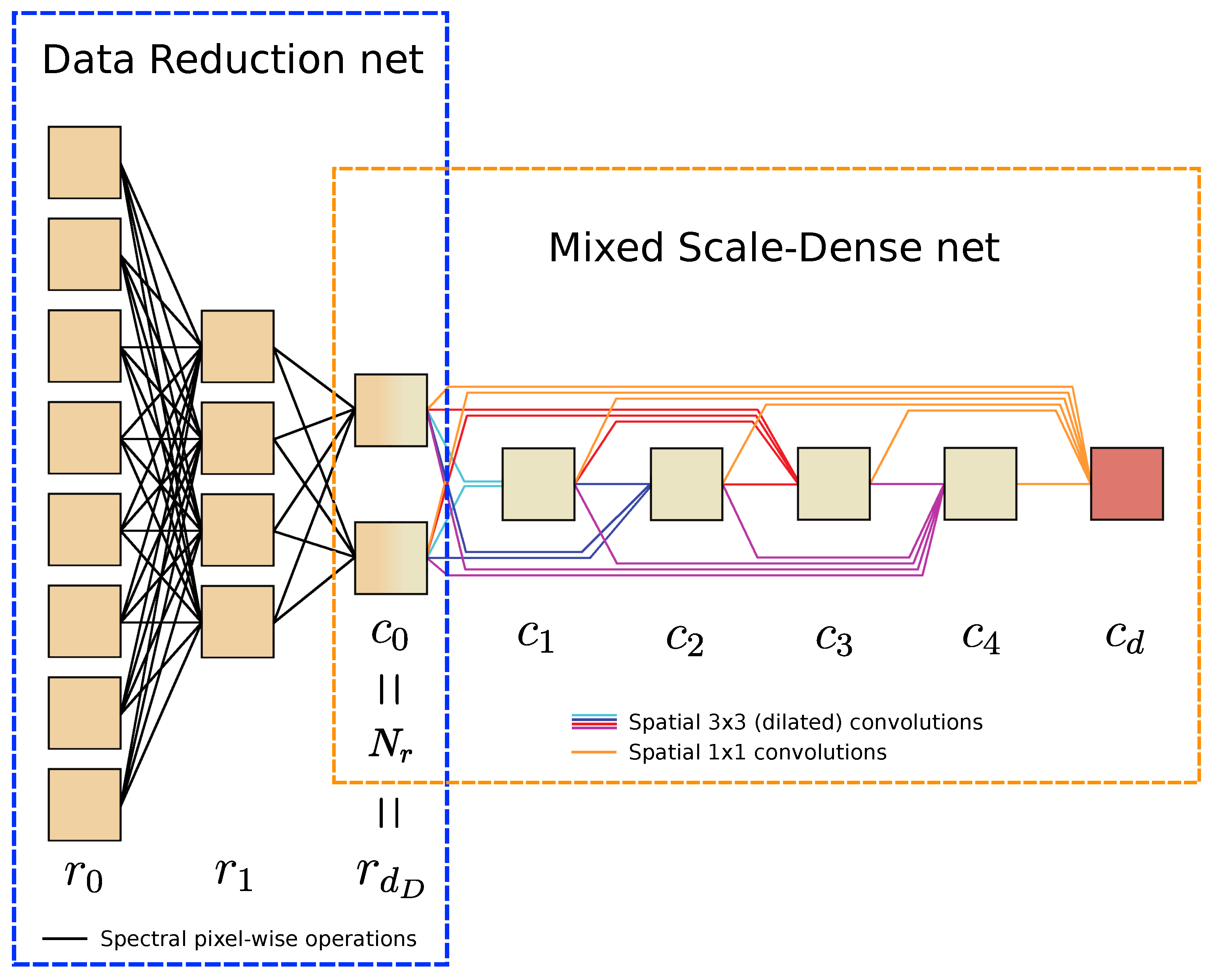
4.1. Data Reduction Network Architectures
4.1.1. Data Reduction Multi-Scale Dense Net
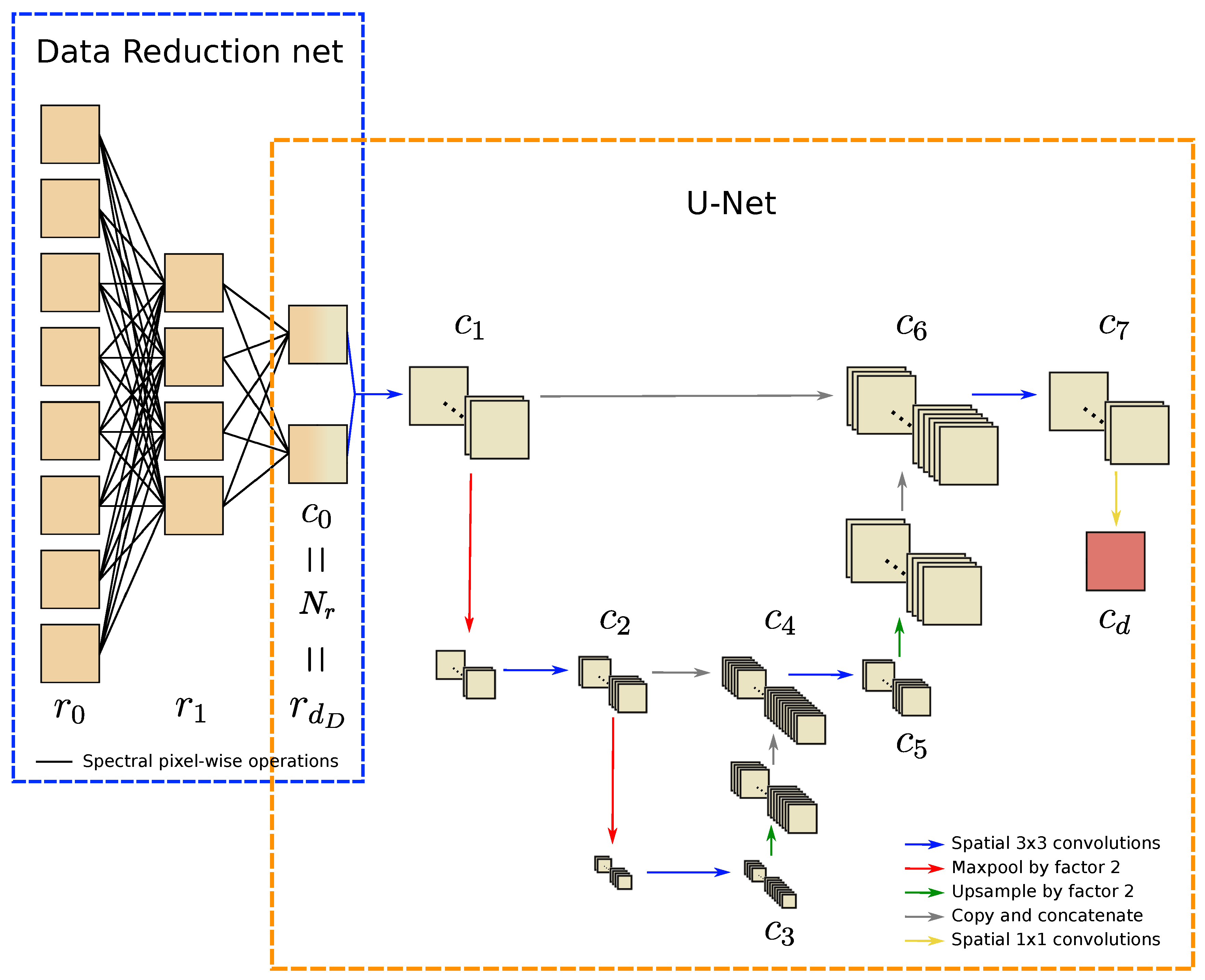
4.1.2. Data Reduction U-Net
4.2. Datasets
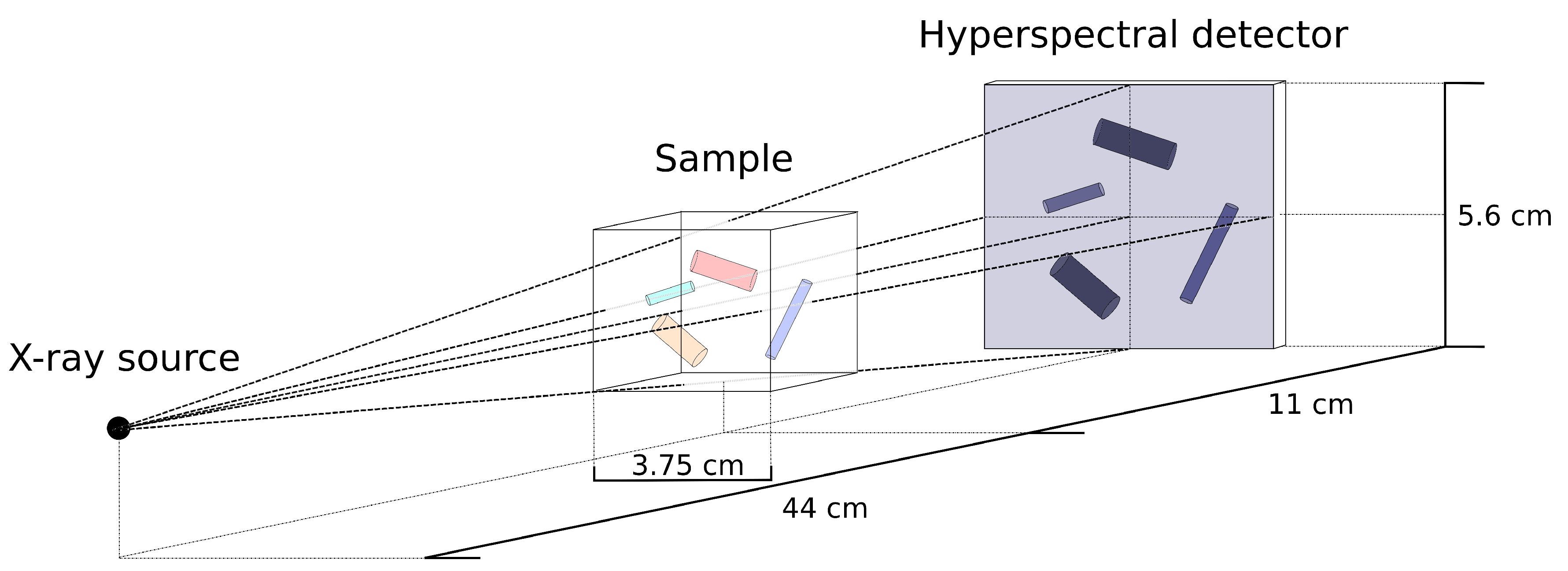
4.2.1. Simulated Attenuation-Based Hyperspectral X-ray Dataset
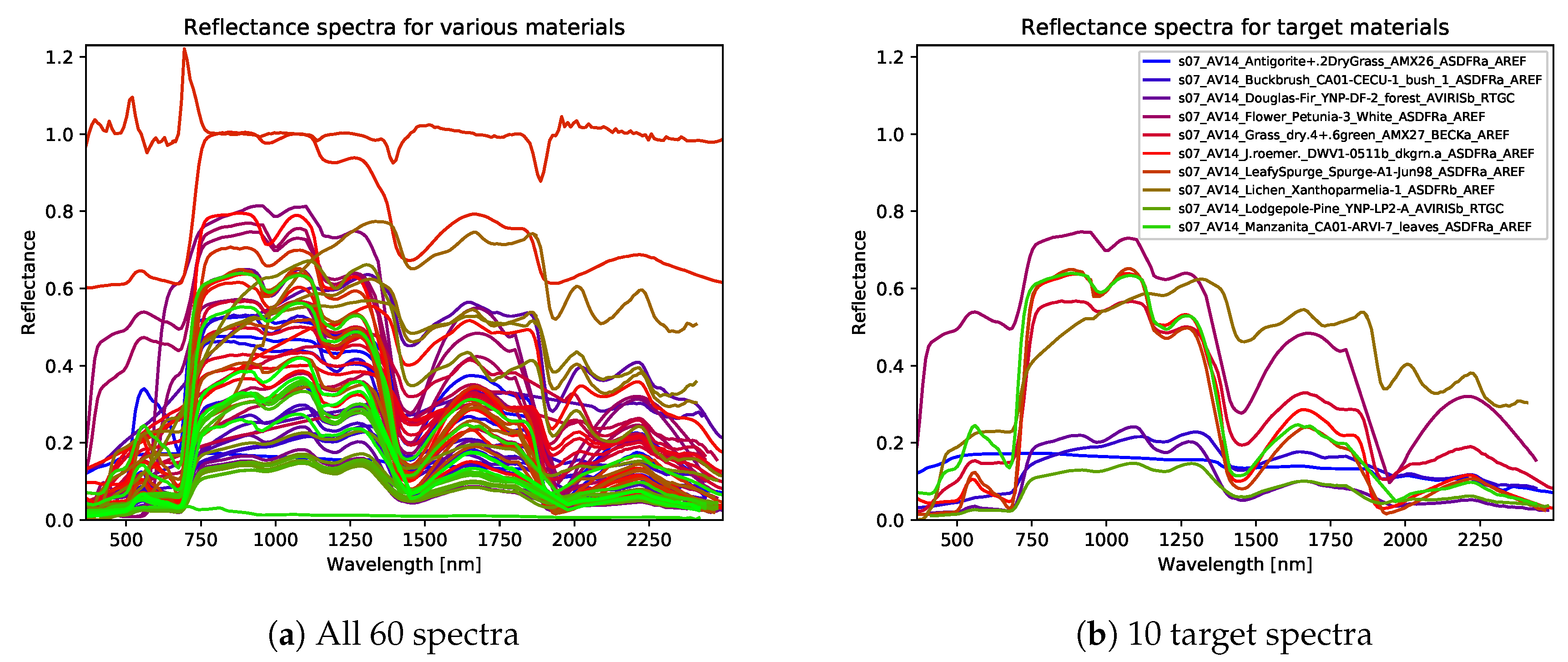
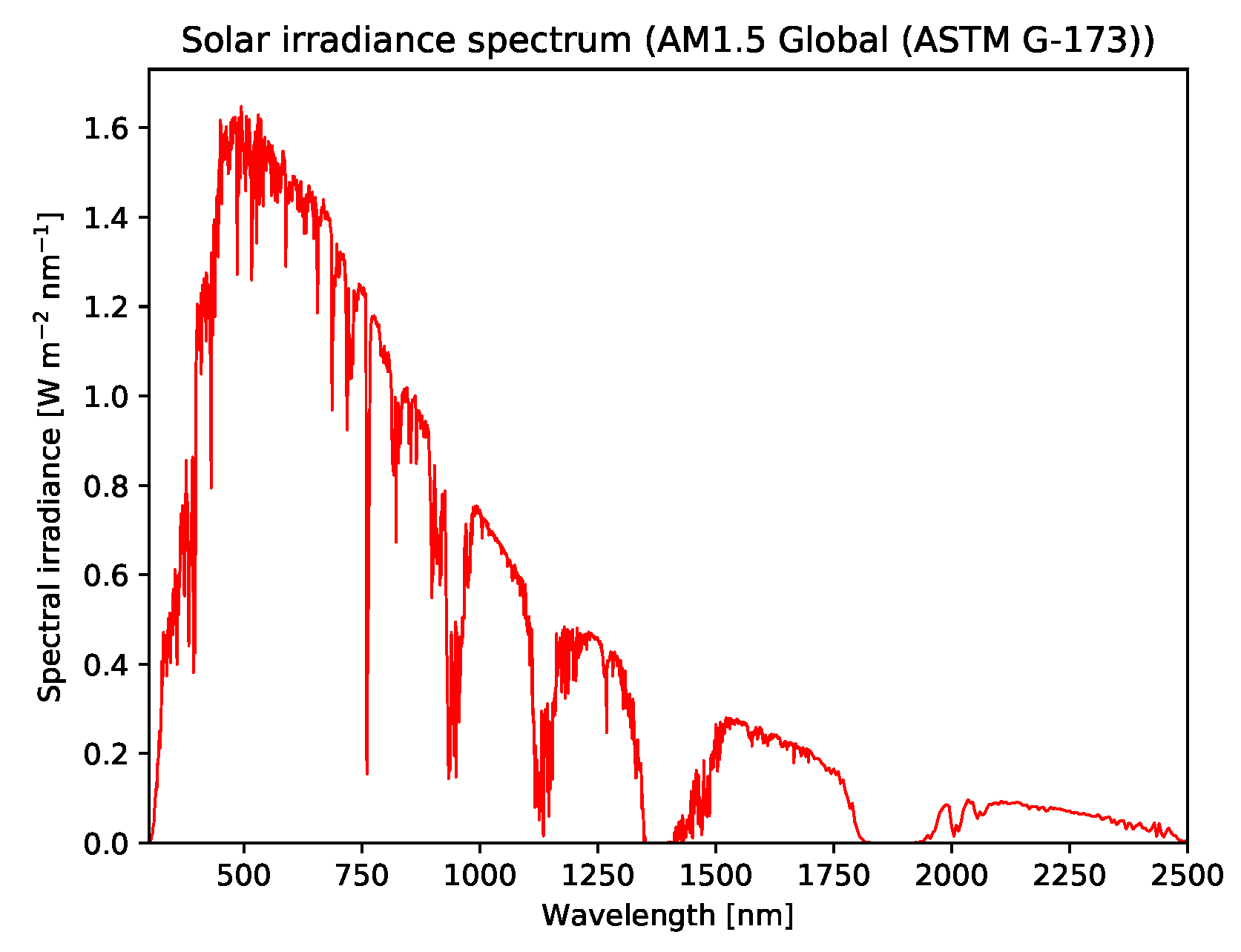
4.2.2. Simulated Reflectance-Based Hyperspectral Remote Sensing Dataset
4.3. Implementation of Standard Data Reduction Methods
4.4. Results
4.4.1. Noise and Multiple Materials
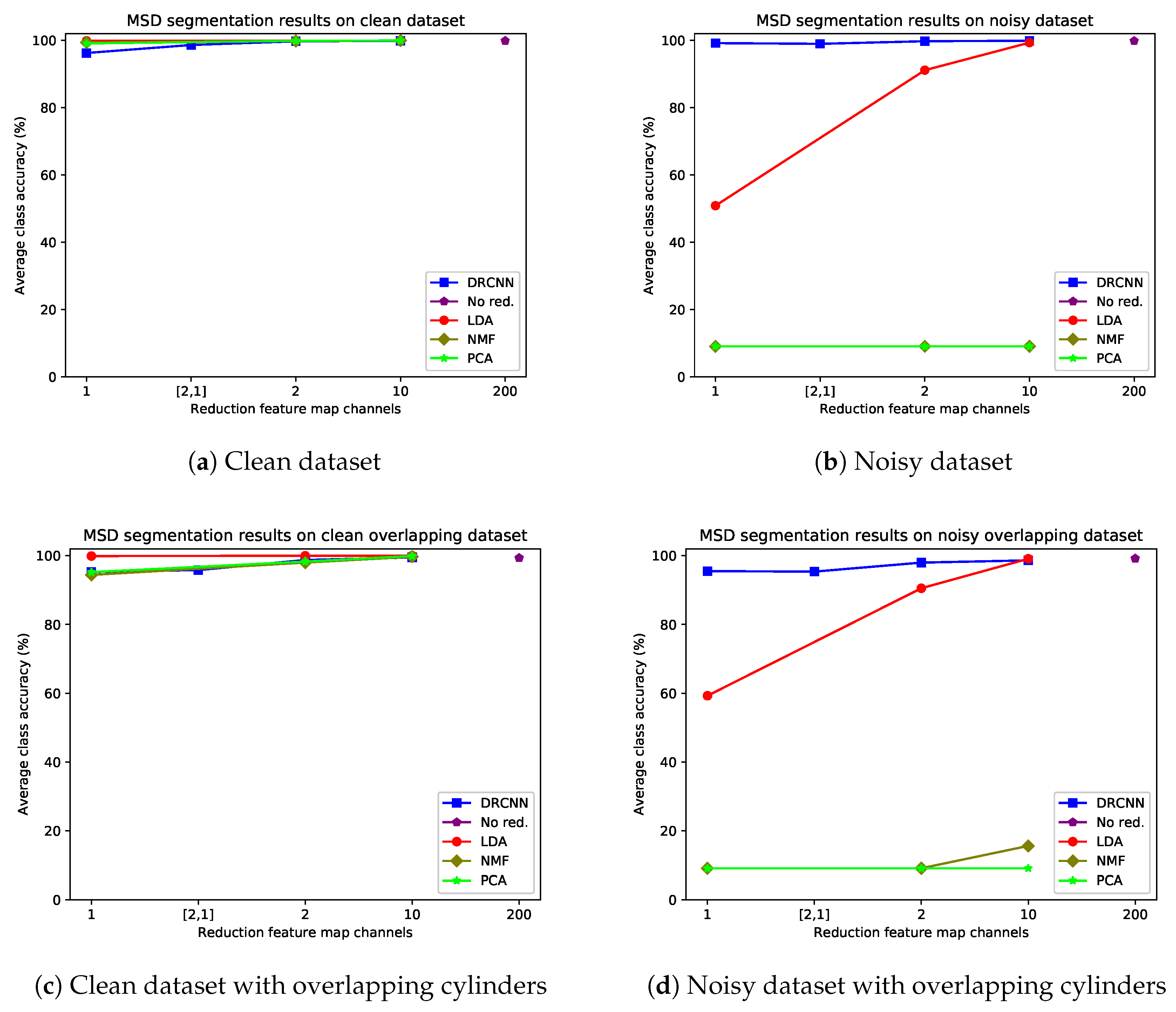
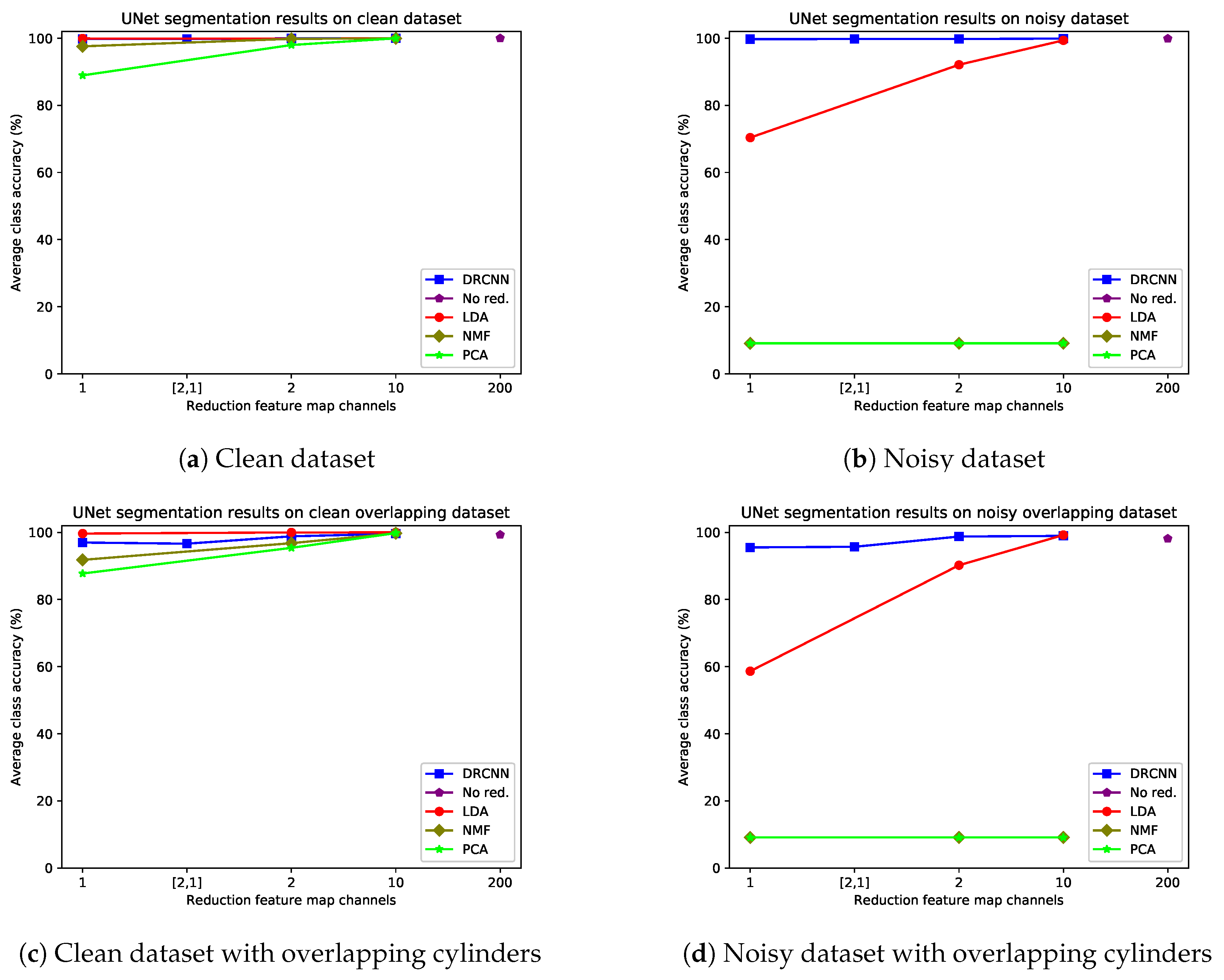
4.4.2. Number of Reduction Feature Map Channels
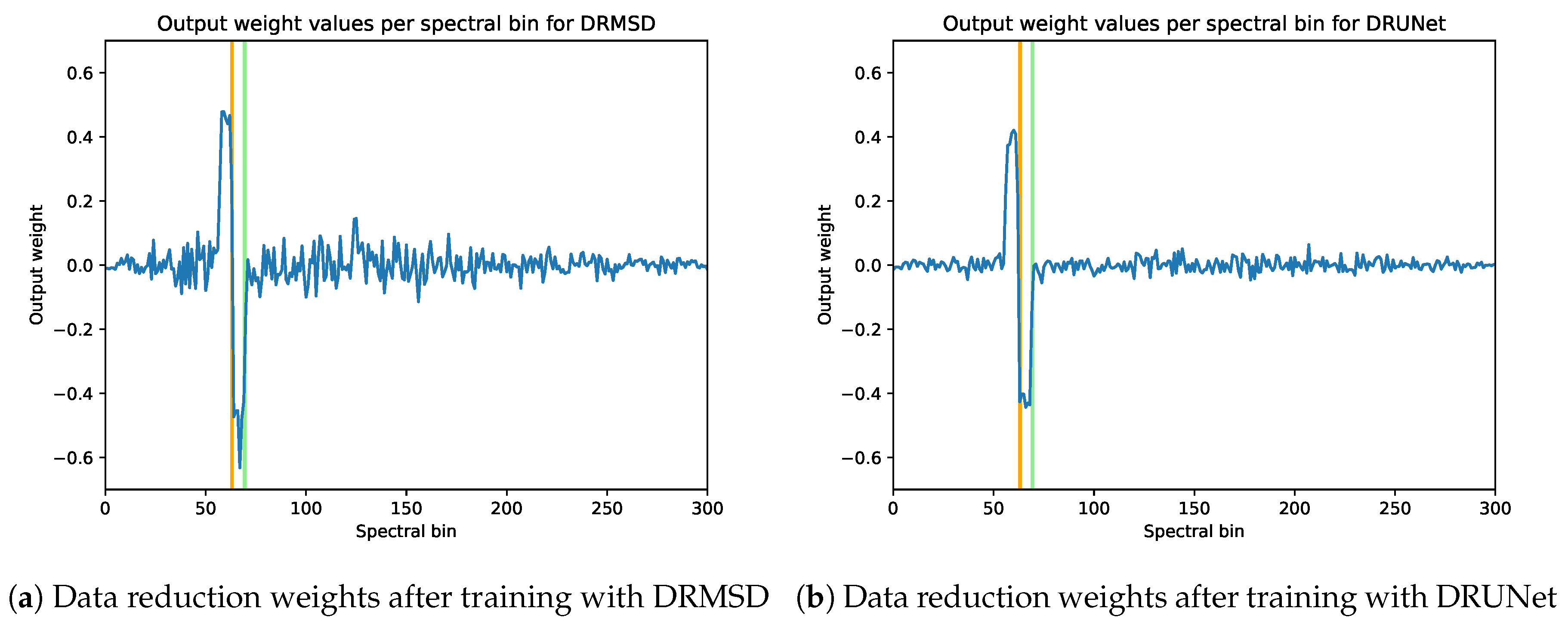
4.4.3. Dependence of Feature Map Properties on Data Reduction Method
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural network |
| DRCNN | Data Reduction CNN |
| PCA | Principal Component Analysis |
| NMF | Nonnegative Matrix Factorization |
| LDA | Linear Discriminant Analysis |
| MSD | Mixed-Scale Dense (network) |
| DRMSD | Data Reduction MSD |
| DRUNet | Data Reduction U-Net |
Appendix A. X-ray Projection Data Computation
Appendix B. Robustness

{kind=link}
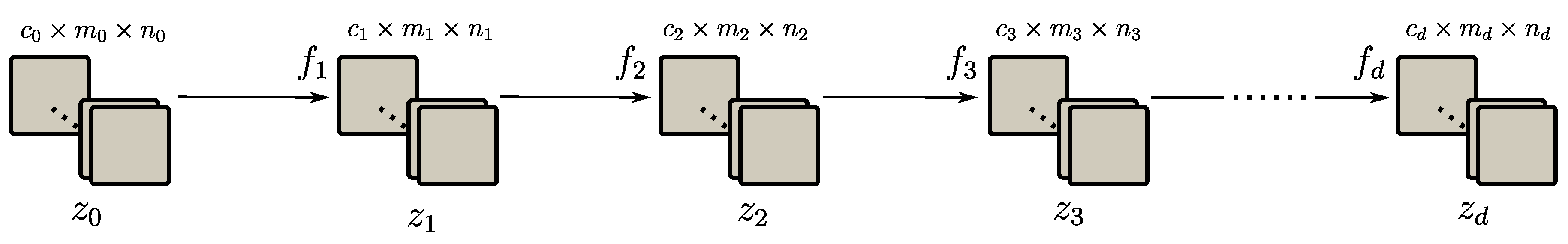{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Data Type | Red. Type | Red. Chan. | Avg. | Std. | Min. | Max. | Median |
|---|---|---|---|---|---|---|---|---|
| X-ray | Noisy Many materials | DRMSD | 2 | 99.30 | 0.0883 | 99.13 | 99.42 | 99.31 |
| X-ray | Noisy Many materials | DRUNet | 2 | 98.87 | 0.2937 | 98.36 | 99.29 | 98.97 |
| X-ray | Noisy Many materials | LDA + MSD | 2 | 94.09 | 0.7639 | 92.76 | 95.48 | 93.91 |
| X-ray | Noisy Many materials | LDA + UNet | 2 | 87.24 | 0.6757 | 86.10 | 88.21 | 87.36 |
| Remote sensing | Noisy Overlapping | DRMSD | 1 | 95.85 | 0.3642 | 95.28 | 96.34 | 95.86 |
| Remote sensing | Noisy Overlapping | DRUNet | 1 | 94.46 | 0.7250 | 93.27 | 95.58 | 94.65 |
| Remote sensing | Noisy Overlapping | LDA + MSD | 1 | 59.34 | 1.2328 | 56.27 | 60.60 | 59.78 |
| Remote sensing | Noisy Overlapping | LDA + UNet | 1 | 61.11 | 0.7674 | 60.03 | 62.48 | 61.05 |
References
- Elmasry, G.; Kamruzzaman, M.; Sun, D.W.; Allen, P. Principles and applications of hyperspectral imaging in quality evaluation of agro-food products: A review. Crit. Rev. Food Sci. Nutr. 2012, 52, 999–1023. [Google Scholar] [CrossRef] [PubMed]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Habermann, M.; Frémont, V.; Shiguemori, E.H. Feature selection for hyperspectral images using single-layer neural networks. In Proceedings of the 8th International Conference of Pattern Recognition Systems (ICPRS 2017), Madrid, Spain, 11–13 July 2017; pp. 1–6. [Google Scholar]
- Chang, C.I. Hyperspectral Data Processing: Algorithm Design and Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Lu, G.; Fei, B. Medical hyperspectral imaging: A review. J. Biomed. Opt. 2014, 19, 010901. [Google Scholar] [CrossRef] [PubMed]
- Eger, L.; Do, S.; Ishwar, P.; Karl, W.C.; Pien, H. A learning-based approach to explosives detection using multi-energy x-ray computed tomography. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 2004–2007. [Google Scholar]
- Fotiadou, K.; Tsagkatakis, G.; Tsakalides, P. Deep convolutional neural networks for the classification of snapshot mosaic hyperspectral imagery. Electron. Imaging 2017, 2017, 185–190. [Google Scholar] [CrossRef] [Green Version]
- Sun, D.W. Hyperspectral Imaging for Food Quality Analysis and Control; Elsevier: San Diego, CA, USA, 2010. [Google Scholar]
- Spiegelberg, J.; Rusz, J. Can we use PCA to detect small signals in noisy data? Ultramicroscopy 2017, 172, 40–46. [Google Scholar] [CrossRef]
- Bakker, E.J.; Schwering, P.B.; van den Broek, S.P. From hyperspectral imaging to dedicated sensors. In Targets and Backgrounds VI: Characterization, Visualization, and the Detection Process; International Society for Optics and Photonics: Orlando, FL, USA, 2000; Volume 4029, pp. 312–324. [Google Scholar]
- Signoroni, A.; Savardi, M.; Baronio, A.; Benini, S. Deep learning meets hyperspectral image analysis: A multidisciplinary review. J. Imaging 2019, 5, 52. [Google Scholar] [CrossRef] [Green Version]
- Sun, W.; Du, Q. Hyperspectral band selection: A review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 118–139. [Google Scholar] [CrossRef]
- Motta, G.; Rizzo, F.; Storer, J.A. Hyperspectral Data Compression; Springer Science & Business Media: Berlin, Germany, 2006. [Google Scholar]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef] [Green Version]
- Li, F.; Ng, M.K.; Plemmons, R.; Prasad, S.; Zhang, Q. Hyperspectral image segmentation, deblurring, and spectral analysis for material identification. In Visual Information Processing XIX; International Society for Optics and Photonics: Orlando, FL, USA, 2010; Volume 7701, p. 770103. [Google Scholar]
- Sharma, V.; Diba, A.; Tuytelaars, T.; Van Gool, L. Hyperspectral CNN for image classification & band selection, with application to face recognition. In Technical Report KUL/ESAT/PSI/1604; KU Leuven, ESAT: Leuven, Belgium, 2016. [Google Scholar]
- Nalepa, J.; Myller, M.; Kawulok, M. Validating hyperspectral image segmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1264–1268. [Google Scholar] [CrossRef] [Green Version]
- Pelt, D.M.; Sethian, J.A. A mixed-scale dense convolutional neural network for image analysis. Proc. Natl. Acad. Sci. USA 2018, 115, 254–259. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Vaddi, R.; Prabukumar, M. Comparative study of feature extraction techniques for hyperspectral remote sensing image classification: A survey. In Proceedings of the 2017 International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 15–16 June 2017; pp. 543–548. [Google Scholar]
- Kumar, B.; Dikshit, O.; Gupta, A.; Singh, M.K. Feature extraction for hyperspectral image classification: A review. Int. J. Remote Sens. 2020, 41, 6248–6287. [Google Scholar] [CrossRef]
- Huang, H.; Chen, M.; Duan, Y. Dimensionality Reduction of Hyperspectral Image Using Spatial-Spectral Regularized Sparse Hypergraph Embedding. Remote Sens. 2019, 11, 1039. [Google Scholar] [CrossRef] [Green Version]
- Joy, A.A.; Hasan, M.A.M.; Hossain, M.A. A Comparison of Supervised and Unsupervised Dimension Reduction Methods for Hyperspectral Image Classification. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’sBazar, Bangladesh, 7–9 February 2019; pp. 1–6. [Google Scholar]
- Li, W.; Feng, F.; Li, H.; Du, Q. Discriminant analysis-based dimension reduction for hyperspectral image classification: A survey of the most recent advances and an experimental comparison of different techniques. IEEE Geosci. Remote Sens. Mag. 2018, 6, 15–34. [Google Scholar] [CrossRef]
- Li, T.; Zhang, J.; Zhang, Y. Classification of hyperspectral image based on deep belief networks. In Proceedings of the 2014 IEEE international conference on image processing (ICIP), Paris, France, 27–30 October 2014; pp. 5132–5136. [Google Scholar]
- Qiao, T.; Ren, J.; Wang, Z.; Zabalza, J.; Sun, M.; Zhao, H.; Li, S.; Benediktsson, J.A.; Dai, Q.; Marshall, S. Effective denoising and classification of hyperspectral images using curvelet transform and singular spectrum analysis. IEEE Trans. Geosci. Remote Sens. 2016, 55, 119–133. [Google Scholar] [CrossRef] [Green Version]
- Kale, K.V.; Solankar, M.M.; Nalawade, D.B.; Dhumal, R.K.; Gite, H.R. A research review on hyperspectral data processing and analysis algorithms. Proc. Natl. Acad. Sci. India Sect. A Phys. Sci. 2017, 87, 541–555. [Google Scholar] [CrossRef]
- Rasti, B.; Hong, D.; Hang, R.; Ghamisi, P.; Kang, X.; Chanussot, J.; Benediktsson, J.A. Feature extraction for hyperspectral imagery: The evolution from shallow to deep. arXiv 2020, arXiv:2003.02822. [Google Scholar]
- Thilagavathi, K.; Vasuki, A. Dimension reduction methods for hyperspectral image: A survey. Int. J. Eng. Adv. Technol. 2018, 8, 160–167. [Google Scholar]
- Dai, Q.; Cheng, J.H.; Sun, D.W.; Zeng, X.A. Advances in feature selection methods for hyperspectral image processing in food industry applications: A review. Crit. Rev. Food Sci. Nutr. 2015, 55, 1368–1382. [Google Scholar] [CrossRef]
- Albon, C. Machine Learning with Python Cookbook: Practical Solutions from Preprocessing to Deep Learning; O’Reilly Media, Inc.: Sevastopol, CA, USA, 2018. [Google Scholar]
- Fauvel, M.; Chanussot, J.; Benediktsson, J.A. Kernel principal component analysis for the classification of hyperspectral remote sensing data over urban areas. EURASIP J. Adv. Signal Process. 2009, 783194, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Kouropteva, O.; Okun, O.; Pietikäinen, M. Selection of the optimal parameter value for the locally linear embedding algorithm. FSKD 2002, 2, 359–363. [Google Scholar]
- Van Der Maaten, L.; Postma, E.; Van den Herik, J. Dimensionality reduction: A comparative review. J. Mach. Learn. Res. 2009, 10, 13. [Google Scholar]
- Jaccard, N.; Rogers, T.W.; Morton, E.J.; Griffin, L.D. Detection of concealed cars in complex cargo X-ray imagery using deep learning. J. X-ray Sci. Technol. 2017, 25, 323–339. [Google Scholar] [CrossRef] [Green Version]
- Akcay, S.; Kundegorski, M.E.; Willcocks, C.G.; Breckon, T.P. Using deep convolutional neural network architectures for object classification and detection within x-ray baggage security imagery. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2203–2215. [Google Scholar] [CrossRef] [Green Version]
- Petersson, H.; Gustafsson, D.; Bergstrom, D. Hyperspectral image analysis using deep learning—A review. In Proceedings of the 2016 Sixth International Conference on Image Processing Theory, Tools and Applications (IPTA), Oulu, Finland, 12–15 December 2016; pp. 1–6. [Google Scholar]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Imani, M.; Ghassemian, H. An overview on spectral and spatial information fusion for hyperspectral image classification: Current trends and challenges. Inf. Fusion 2020, 59, 59–83. [Google Scholar] [CrossRef]
- Paoletti, M.; Haut, J.; Plaza, J.; Plaza, A. Deep learning classifiers for hyperspectral imaging: A review. ISPRS J. Photogramm. Remote Sens. 2019, 158, 279–317. [Google Scholar] [CrossRef]
- Paoletti, M.; Haut, J.; Plaza, J.; Plaza, A. A new deep convolutional neural network for fast hyperspectral image classification. ISPRS J. Photogramm. Remote Sens. 2018, 145, 120–147. [Google Scholar] [CrossRef]
- Valsesia, D.; Magli, E. High-Throughput Onboard Hyperspectral Image Compression With Ground-Based CNN Reconstruction. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9544–9553. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Yu, X.; Zhang, P.; Yu, A.; Fu, Q.; Wei, X. Supervised deep feature extraction for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1909–1921. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Deep learning for classification of hyperspectral data: A comparative review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 159–173. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Li, Y.; Li, G.; Liu, A. A spectral feature based convolutional neural network for classification of sea surface oil spill. ISPRS Int. J. Geo-Inf. 2019, 8, 160. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Wei, Z.; Xu, Y. A Lightweight Spectral-Spatial Feature Extraction and Fusion Network for Hyperspectral Image Classification. Remote Sens. 2020, 12, 1395. [Google Scholar] [CrossRef]
- Feng, F.; Wang, S.; Wang, C.; Zhang, J. Learning Deep Hierarchical Spatial-Spectral Features for Hyperspectral Image Classification Based on Residual 3D-2D CNN. Sensors 2019, 19, 5276. [Google Scholar] [CrossRef] [Green Version]
- Palsson, F.; Sveinsson, J.R.; Ulfarsson, M.O. Multispectral and hyperspectral image fusion using a 3-D-convolutional neural network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 639–643. [Google Scholar] [CrossRef]
- Adler, A.; Elad, M.; Zibulevsky, M. Compressed learning: A deep neural network approach. arXiv 2016, arXiv:1610.09615. [Google Scholar]
- Zhang, X.; Zheng, Y.; Liu, W.; Wang, Z. A hyperspectral image classification algorithm based on atrous convolution. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 1–12. [Google Scholar] [CrossRef]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the ICML 2013, Atlanta, GA, USA, 16–21 June 2013; Volume 30, p. 3. [Google Scholar]
- Kingma, D.P.; Ba, L. ADAM: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- GitHub–Dmpelt/Msdnet: Python Implementation of the Mixed-Scale Dense Convolutional Neural Network. Available online: https://github.com/dmpelt/msdnet (accessed on 24 November 2020).
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2017; pp. 240–248. [Google Scholar]
- Jadon, S. A survey of loss functions for semantic segmentation. arXiv 2020, arXiv:2006.14822. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the NIPS-W, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]
- Graña, M.; Veganzons, M.; Ayerdi, B. Hyperspectral Remote Sensing Scenes. Available online: http://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes (accessed on 15 September 2020).
- Yu, S.; Jia, S.; Xu, C. Convolutional neural networks for hyperspectral image classification. Neurocomputing 2017, 219, 88–98. [Google Scholar] [CrossRef]
- Van Aarle, W.; Palenstijn, W.J.; De Beenhouwer, J.; Altantzis, T.; Bals, S.; Batenburg, K.J.; Sijbers, J. The ASTRA Toolbox: A platform for advanced algorithm development in electron tomography. Ultramicroscopy 2015, 157, 35–47. [Google Scholar] [CrossRef] [Green Version]
- Van Aarle, W.; Palenstijn, W.J.; Cant, J.; Janssens, E.; Bleichrodt, F.; Dabravolski, A.; De Beenhouwer, J.; Batenburg, K.J.; Sijbers, J. Fast and flexible X-ray tomography using the ASTRA toolbox. Opt. Express 2016, 24, 25129–25147. [Google Scholar] [CrossRef]
- Hubbell, J.H.; Seltzer, S.M. Tables of X-ray Mass Attenuation Coefficients and Mass Energy-Absorption Coefficients 1 keV to 20 MeV for Elements Z = 1 to 92 and 48 Additional Substances of Dosimetric Interest; Technical Report; National Inst. of Standards and Technology-PL: Gaithersburg, MD, USA, 1995. [Google Scholar]
- Kokaly, R.; Clark, R.; Swayze, G.; Livo, K.; Hoefen, T.; Pearson, N.; Wise, R.; Benzel, W.; Lowers, H.; Driscoll, R.; et al. Usgs Spectral Library Version 7 Data: Us Geological Survey Data Release; United States Geological Survey (USGS): Reston, VA, USA, 2017. [Google Scholar]
- Kokaly, R.F.; Clark, R.N.; Swayze, G.A.; Livo, K.E.; Hoefen, T.M.; Pearson, N.C.; Wise, R.A.; Benzel, W.M.; Lowers, H.A.; Driscoll, R.L.; et al. USGS Spectral Library Version 7; Technical Report; US Geological Survey: Reston, VA, USA, 2017. [Google Scholar]
- Standard Solar Spectra | PVEducation. 2019. Available online: https://www.pveducation.org/pvcdrom/appendices/standard-solar-spectra (accessed on 8 July 2020).
- ASTM. G173—03: Standard Tables for Reference Solar Spectral Irradiances: Direct Normal and Hemispherical on 37° Tilted Surface; ASTM International: West Conshohocken, PA, USA, 2003. [Google Scholar]
- Griffin, M.K.; Burke, H.K. Compensation of hyperspectral data for atmospheric effects. Linc. Lab. J. 2003, 14, 29–54. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- X-ray Mass Attenuation Coefficients | NIST. Available online: https://www.nist.gov/pml/x-ray-mass-attenuation-coefficients (accessed on 24 February 2020).
- Siemens Healthineers, Simulation of X-Ray Spectra: Online Tool for the Simulation of X-ray Spectra. 2018. Available online: https://www.oem-xray-components.siemens.com/X-ray-spectra-simulation (accessed on 24 February 2020).



















| MSD | U-Net | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PCA | NMF | LDA | DRCNN | No Red. | PCA | NMF | LDA | DRCNN | No Red. | |||
| X-ray | Clean | 2 mat. | 99.70 | 99.73 | 99.73 | 99.73 | 99.37 | 99.66 | 99.67 | 99.67 | 99.69 | 99.72 |
| 60 mat. | 60.36 | 82.69 | 99.69 | 99.68 | 99.42 | 79.64 | 82.92 | 99.72 | 99.69 | 99.69 | ||
| Noisy | 2 mat. | 50.00 | 57.31 | 90.39 | 99.11 | 98.60 | 50.00 | 50.00 | 79.49 | 98.92 | 98.40 | |
| 60 mat. | 50.00 | 52.31 | 75.53 | 99.16 | 98.77 | 50.00 | 54.79 | 85.11 | 98.69 | 98.86 | ||
| Remote sensing | Clean | No overlap | 99.87 | 99.85 | 99.94 | 99.75 | 99.90 | 97.97 | 99.81 | 99.87 | 99.95 | 99.97 |
| Overlap | 98.29 | 97.99 | 99.97 | 98.74 | 99.33 | 95.39 | 96.78 | 99.98 | 98.82 | 99.28 | ||
| Noisy | No overlap | 9.09 | 9.09 | 91.15 | 99.76 | 99.86 | 9.09 | 9.09 | 92.10 | 99.76 | 99.87 | |
| Overlap | 9.09 | 9.09 | 90.53 | 97.98 | 99.17 | 9.09 | 9.09 | 90.20 | 98.76 | 98.13 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeegers, M.T.; Pelt, D.M.; van Leeuwen, T.; van Liere, R.; Batenburg, K.J. Task-Driven Learned Hyperspectral Data Reduction Using End-to-End Supervised Deep Learning. J. Imaging 2020, 6, 132. https://doi.org/10.3390/jimaging6120132
Zeegers MT, Pelt DM, van Leeuwen T, van Liere R, Batenburg KJ. Task-Driven Learned Hyperspectral Data Reduction Using End-to-End Supervised Deep Learning. Journal of Imaging. 2020; 6(12):132. https://doi.org/10.3390/jimaging6120132
Chicago/Turabian StyleZeegers, Mathé T., Daniël M. Pelt, Tristan van Leeuwen, Robert van Liere, and Kees Joost Batenburg. 2020. "Task-Driven Learned Hyperspectral Data Reduction Using End-to-End Supervised Deep Learning" Journal of Imaging 6, no. 12: 132. https://doi.org/10.3390/jimaging6120132
APA StyleZeegers, M. T., Pelt, D. M., van Leeuwen, T., van Liere, R., & Batenburg, K. J. (2020). Task-Driven Learned Hyperspectral Data Reduction Using End-to-End Supervised Deep Learning. Journal of Imaging, 6(12), 132. https://doi.org/10.3390/jimaging6120132