
Masked Face Analysis via Multi-Task Deep Learning




Abstract
:1. Introduction
2. Related Work
2.1. Face Datasets
2.2. Face Recognition
2.3. Masked Face Analysis
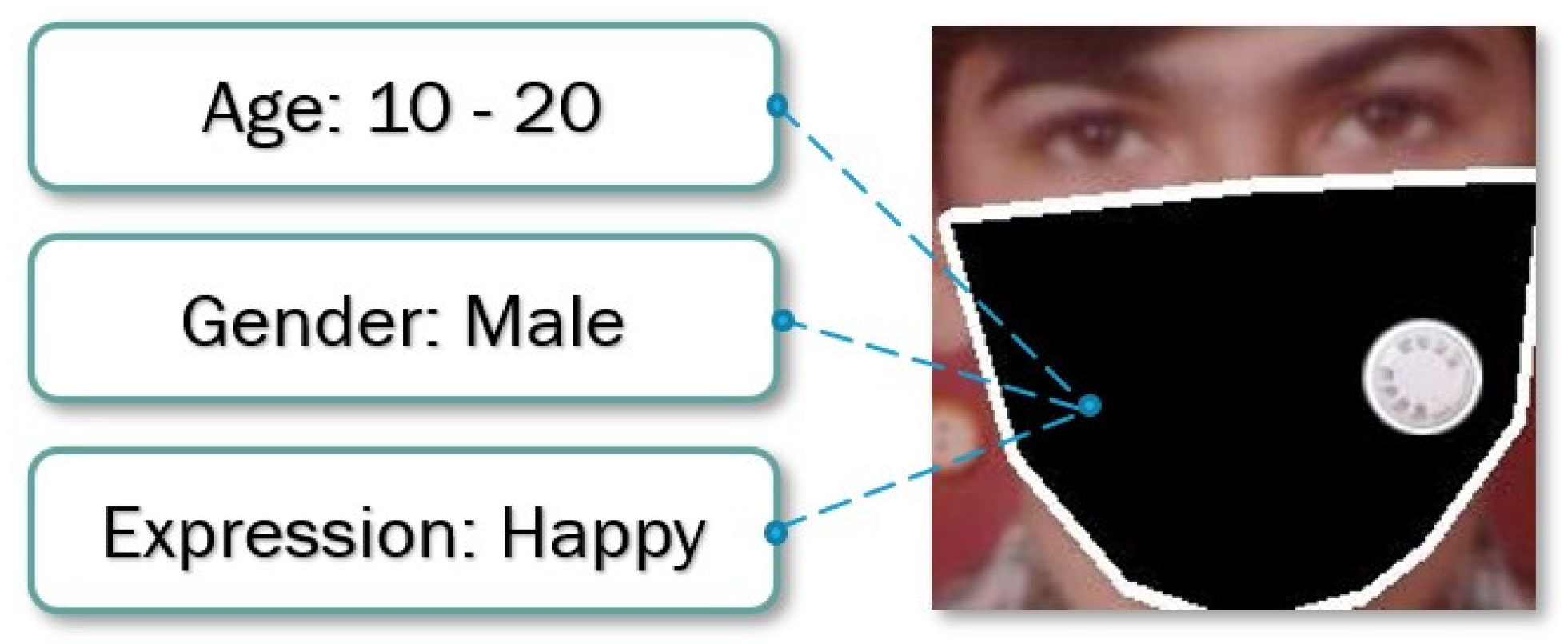
3. Data Collection and the Proposed Framework
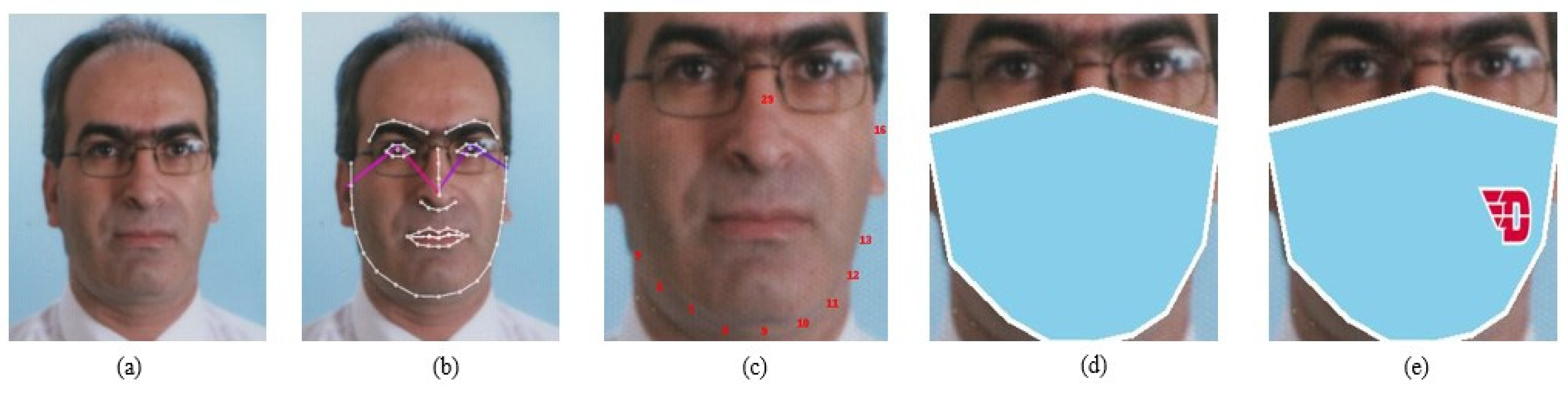
3.1. FGNET-MASK Dataset Collection
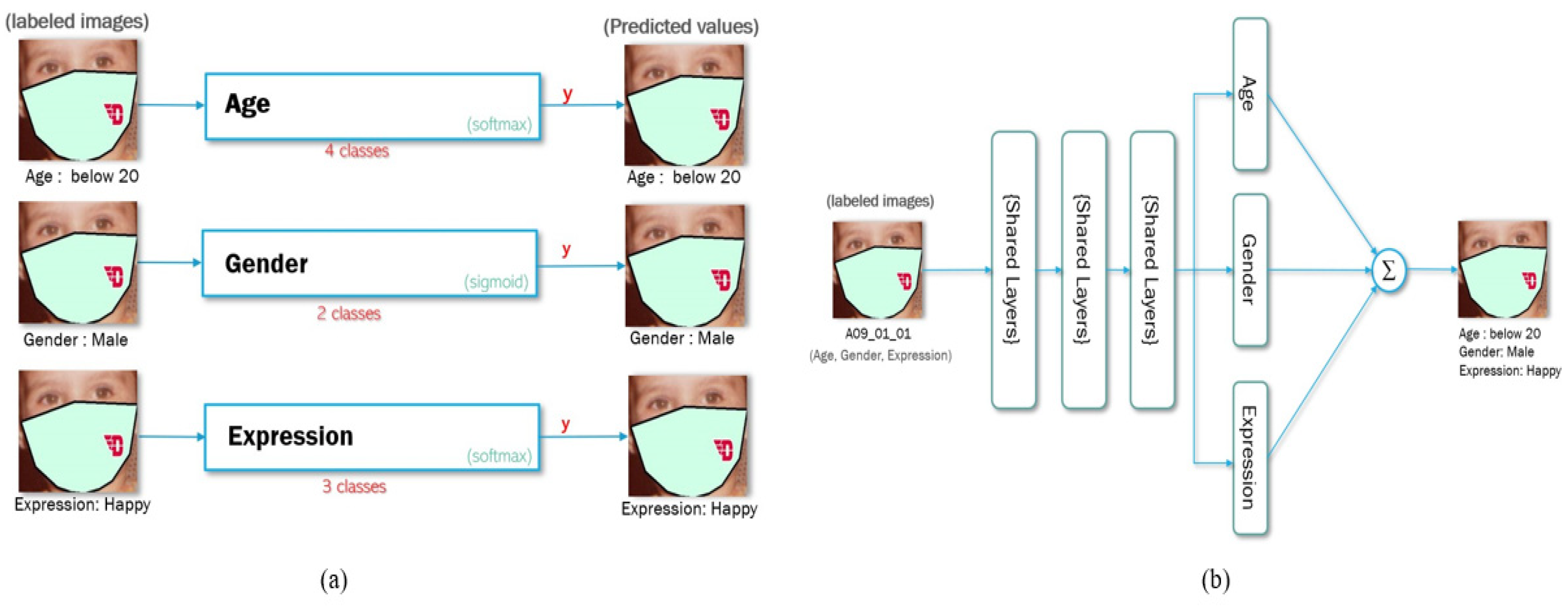
3.2. Single Models
3.3. Multi-Task Deep Learning
4. Experimental Results
4.1. Single Model
4.1.1. Support Vector Machine (SVM)
4.1.2. Simple Convolutional Neural Network (CNN)
4.1.3. ResNet-152
4.2. Multitask Deep Learning Model
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Guo, G.; Guowang, M.; Fu, Y.; Huang, T.S. Human age estimation using bio-inspired features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 112–119. [Google Scholar] [CrossRef]
- Cao, D.; He, R.; Zhang, M.; Sun, Z.; Tan, T. Real-world gender recognition using multi-order LBP and localized multi-boost learning. In Proceedings of the IEEE International Conference on Identity, Security and Behavior Analysis (ISBA 2015), Hong Kong, China, 23–25 March 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, K.; Nguyen, T.V.; Feng, J.; Sepulveda, J. Sense Beyond Expressions: Cuteness. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1067–1070. [Google Scholar]
- Nguyen, T.V.; Liu, L. Smart Mirror: Intelligent Makeup Recommendation and Synthesis. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA USA, 23–27 October 2017; pp. 1253–1254. [Google Scholar]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, Present, and Future of Face Recognition: A Review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, G.; Huang, B.; Xiong, Z.; Hong, Q.; Wu, H.; Yi, P.; Jiang, K.; Wang, N.; Pei, Y.; et al. Masked face recognition dataset and application. arXiv 2020, arXiv:2003.09093. [Google Scholar]
- Chaudhuri, B.; Vesdapunt, N.; Wang, B. Joint face detection and facial motion retargeting for multiple faces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9719–9728. [Google Scholar]
- Kortli, Y.; Jridi, M.; Falou, A.A.; Atri, M. Face Recognition Systems: A Survey. Sensors 2020, 20, 342. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ge, S.; Li, J.; Ye, Q.; Luo, Z. Detecting masked faces in the wild with lle-cnns. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2682–2690. [Google Scholar]
- Cao, J.; Li, Y.; Zhang, Z. Partially shared multi-task convolutional neural network with local constraint for face attribute learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–23 June 2018; pp. 4290–4299. [Google Scholar]
- Dmitry, Y.; Tamir, B.; Roman, V. MaskFace: Multi-task face and landmark detector. arXiv 2020, arXiv:2005.09412. [Google Scholar]
- Vandenhende, S.; Georgoulis, S.; Gansbeke, V.; Proesmans, W.; Dai, M.D.; Van, G.L. Multi-task learning for dense prediction tasks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1–20, Early Access. [Google Scholar] [CrossRef]
- Najibi, M.; Samangouei, P.; Chellappa, R.; Davis, L.S. Ssh: Single stage headless face detector. In Proceedings of the IEEE international conference on computer vision, Venice, Italy, 22–29 October 2017; pp. 4875–4884. [Google Scholar]
- Mundial, I.Q.; Ul Hassan, M.S.; Tiwana, M.I.; Qureshi, W.S.; Alanazi, E. Towards Facial Recognition Problem in COVID-19 Pandemic. In Proceedings of the 4rd International Conference on Electrical, Telecommunication and Computer Engineering (ELTICOM), Medan, Indonesia, 3–4 September 2020; pp. 210–214. [Google Scholar] [CrossRef]
- Yang, H.; Huang, D.; Wang, Y.; Jain, A.K. Learning face age progression: A pyramid architecture of gans. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake, UT, USA, 18–23 June 2018; pp. 31–39. [Google Scholar]
- Nithyashri, J.; Kulanthaivel, G. Classification of human age based on Neural Network using FG-NET Aging database and Wavelets. In Proceedings of the Fourth International Conference on Advanced Computing (ICoAC), Chennai, India, 13–15 December 2012; pp. 1–5. [Google Scholar] [CrossRef]
- Santarcangelo, V.; Farinella, G.M.; Battiato, S. Gender recognition: Methods, datasets and results. In Proceedings of the IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Levi, G.; Hassncer, T. Age and gender classification using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 34–42. [Google Scholar] [CrossRef]
- Tivatansakul, S.; Ohkura, M.; Puangpontip, S.; Achalakul, T. Emotional healthcare system: Emotion detection by facial expressions using Japanese database. In Proceedings of the 6th Computer Science and Electronic Engineering Conference (CEEC), Colchester, UK, 25–26 September 2014; pp. 41–46. [Google Scholar] [CrossRef]
- Arriaga, O.; Valdenegro-Toro, M.; Ploger, P. Real-time convolutional neural networks for emotion and gender classification. arXiv 2017, arXiv:1710.07557. [Google Scholar]
- Yang, L.; Ma, J.; Lian, J.; Zhang, Y.; Liu, H. Deep representation for partially occluded face verification. EURASIP J. Image Video Process. 2018, 1, 1–10. [Google Scholar] [CrossRef]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.-E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 172–186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Napoléon, T.; Alfalou, A. Local binary patterns preprocessing for face identification/verification using the VanderLugt correlator. In Optical Pattern Recognition XXV; International Society for Optics and Photonics, SPIE: Baltimore, MD, USA, 2014; p. 909408. [Google Scholar]
- Alfalou, A.; Brosseau, C. Understanding Correlation Techniques for Face Recognition: From Basics to Applications. In Face Recognition; Oravec, M., Ed.; IntechOpen: Rijeka, Croatia, 23 March 2011. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Chen, K.; Gong, S.; Xiang, T.; Chang Loy, C. Cumulative attribute space for age and crowd density estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments; Technical Report for University of Massachusetts: Amherst, MA, USA, 2007. [Google Scholar]
- Fu, Y.; Huang, T. Human Age Estimation With Regression on Discriminative Aging Manifold. IEEE Trans. Multimedia 2008, 10, 578–584. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition(CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Annalakshmi, M.S.; Roomi, M.M.; Naveedh, A.S. A hybrid technique for gender classification with SLBP and HOG features. Clust. Comput. 2019, 22, 11–20. [Google Scholar] [CrossRef]
- Yang, H.; Wang, X.A. Cascade classifier for face detection. J. Algorithms Comput. Technol. 2016, 10, 187–197. [Google Scholar] [CrossRef] [Green Version]
- Napoléon, T.; Alfalou, A. Pose invariant face recognition: 3D model from single photo. Opt. Lasers Eng. 2017, 89, 150–161. [Google Scholar] [CrossRef]
- HajiRassouliha, A.; Gamage, T.P.B.; Parker, M.D.; Nash, M.P.; Taberner, A.J.; Nielsen, P.M. FPGA implementation of 2D cross-correlation for real-time 3D tracking of deformable surfaces. In Proceedings of the IVCNZ, Wellington, New Zealand, 27–29 November 2013; pp. 352–357. [Google Scholar]
- Seo, H.J.; Milanfar, P. Face verification using the lark representation. IEEE Trans. Inf. Forensics Secur. 2011, 6, 1275–1286. [Google Scholar] [CrossRef] [Green Version]
- Shah, J.H.; Sharif, M.; Raza, M.; Azeem, A. A Survey: Linear and Nonlinear PCA Based Face Recognition Techniques. Int. Arab J. Inf. Technol. 2013, 10, 536–545. [Google Scholar]
- Liu, S.Q.; Lan, X.; Yuen, P.C. Remote photoplethysmography correspondence feature for 3D mask face presentation attack detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 558–573. [Google Scholar]
- Ulrich, L.; Vezzetti, E.; Moos, S.; Marcolin, F. Analysis of RGB-D camera technologies for supporting different facial usage scenarios. Multimed. Tools Appl. 2020, 79, 1–24. [Google Scholar] [CrossRef]
- Bock, R.D. Low-cost 3D security camera. In Autonomous Systems: Sensors, Vehicles, Security, and the Internet of Everything; International Society for Optics and Photonics: Orlando, FL, USA, 2018; p. 106430E. [Google Scholar]
- Ruiqin, L.; Wenan, T.; Zhenyu, C. Design of Face Recognition Access Entrance Guard System with Mask Based on Embedded Development. In Journal of Physics: Conference Serie; IOP Publishing Ltd.: Guilin, China, 2021; Volume 1883, p. 012156. [Google Scholar]
- Dagnes, N.; Marcolin, F.; Nonis, F.; Tornincasa, S.; Vezzetti, E. 3D geometry-based face recognition in presence of eye and mouth occlusions. Int. J. Interact. Des. Manuf. (IJIDeM) 2019, 13, 1617–1635. [Google Scholar] [CrossRef]
- Shi, Y.; Yu, X.; Sohn, K.M.; Jain, A.K. Towards universal representation learning for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 6817–6826. [Google Scholar]
- Chen, Z.; Xu, T.; Han, Z. Occluded face recognition based on the improved SVM and block weighted LBP. In Proceedings of the International Conference on Image Analysis and Signal Processing, Wuhan, China, 21–23 October 2011; pp. 118–122. [Google Scholar] [CrossRef]
- Nie, Z.; Mattey, A.; Huang, Z.; Nguyen, T.V. Revisit of Region-Feature Combinations in Facial Analysis. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 2347–2352. [Google Scholar] [CrossRef]
- COVID-19 Face Mask Detector with Open CV, Keras, Tensorflow, and Deep Learning. Available online: https://www.pyimagesearch.com/2020/05/04/covid-19-face-mask-detector-with-opencv-keras-tensorflow-and-deep-learning/ (accessed on 18 May 2021).
- Pillow Package. Available online: https://pillow.readthedocs.io/en/stable/ (accessed on 18 May 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Torralba, A.; Fergus, R.; Freeman, W. 80 Million Tiny Images: A Large Data Set for Nonparametric Object and Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1958–1970. [Google Scholar] [CrossRef] [PubMed]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015; pp. 41.1–41.12. [Google Scholar]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Jaques, S. Multi-Block Color-Binarized Statistical Images for Single-Sample Face Recognition. Sensors 2021, 21, 728. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | Age | Gender | Expression |
|---|---|---|---|
| Method | |||
| Eigenface | 0.59 | 0.68 | 0.58 |
| LBP [18] | 0.53 | 0.64 | 0.55 |
| TinyImage [47] | 0.73 | 0.82 | 0.70 |
| VGG Face [48] | 0.84 | 0.89 | 0.75 |
| MB-C-BSIF [49] | 0.48 | 0.64 | 0.53 |
| Single task (simple CNN) | 0.68 | 0.77 | 0.60 |
| Single task (ResNet) | 0.91 | 0.95 | 0.82 |
| MTDL (simple CNN) | 0.74 | 0.83 | 0.70 |
| MTDL (ResNet) | 0.95 | 0.98 | 0.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Patel, V.S.; Nie, Z.; Le, T.-N.; Nguyen, T.V. Masked Face Analysis via Multi-Task Deep Learning. J. Imaging 2021, 7, 204. https://doi.org/10.3390/jimaging7100204
Patel VS, Nie Z, Le T-N, Nguyen TV. Masked Face Analysis via Multi-Task Deep Learning. Journal of Imaging. 2021; 7(10):204. https://doi.org/10.3390/jimaging7100204
Chicago/Turabian StylePatel, Vatsa S., Zhongliang Nie, Trung-Nghia Le, and Tam V. Nguyen. 2021. "Masked Face Analysis via Multi-Task Deep Learning" Journal of Imaging 7, no. 10: 204. https://doi.org/10.3390/jimaging7100204
APA StylePatel, V. S., Nie, Z., Le, T. -N., & Nguyen, T. V. (2021). Masked Face Analysis via Multi-Task Deep Learning. Journal of Imaging, 7(10), 204. https://doi.org/10.3390/jimaging7100204