
A Semiautomatic Multi-Label Color Image Segmentation Coupling Dirichlet Problem and Colour Distances


Abstract
:1. Introduction
- The development of a similarity index/distance between pixel using a given colour space and involving pixels in a neighbourhood, in order to improve the random walker approach and a basic clustering step;
- A modified energy related to the random walker approach which improves the quality of the image segmentation and considers only the minimisation of a quadratic function;
- A combination of the above techniques, which overcomes the issues presented by those approaches when they are applied alone;
- A machine-learning approach to adapt the weights of the colour distance (modifying hence the Euclidean distance), acting as a preprocessing on the images.
2. An Improved Image Segmentation Method
- (a)
- The image contains a set of approximately homogeneous colour regions (avoid segmentation too granular or too noisy);
- (b)
- The colour information in each image region can be represented by a set of few quantised colours (we can consider some kind of colour categorisation model);
- (c)
- The colours between two neighbouring regions are distinguishable (a suitable definition for similarity between pixels).
2.1. The Random Walker Method
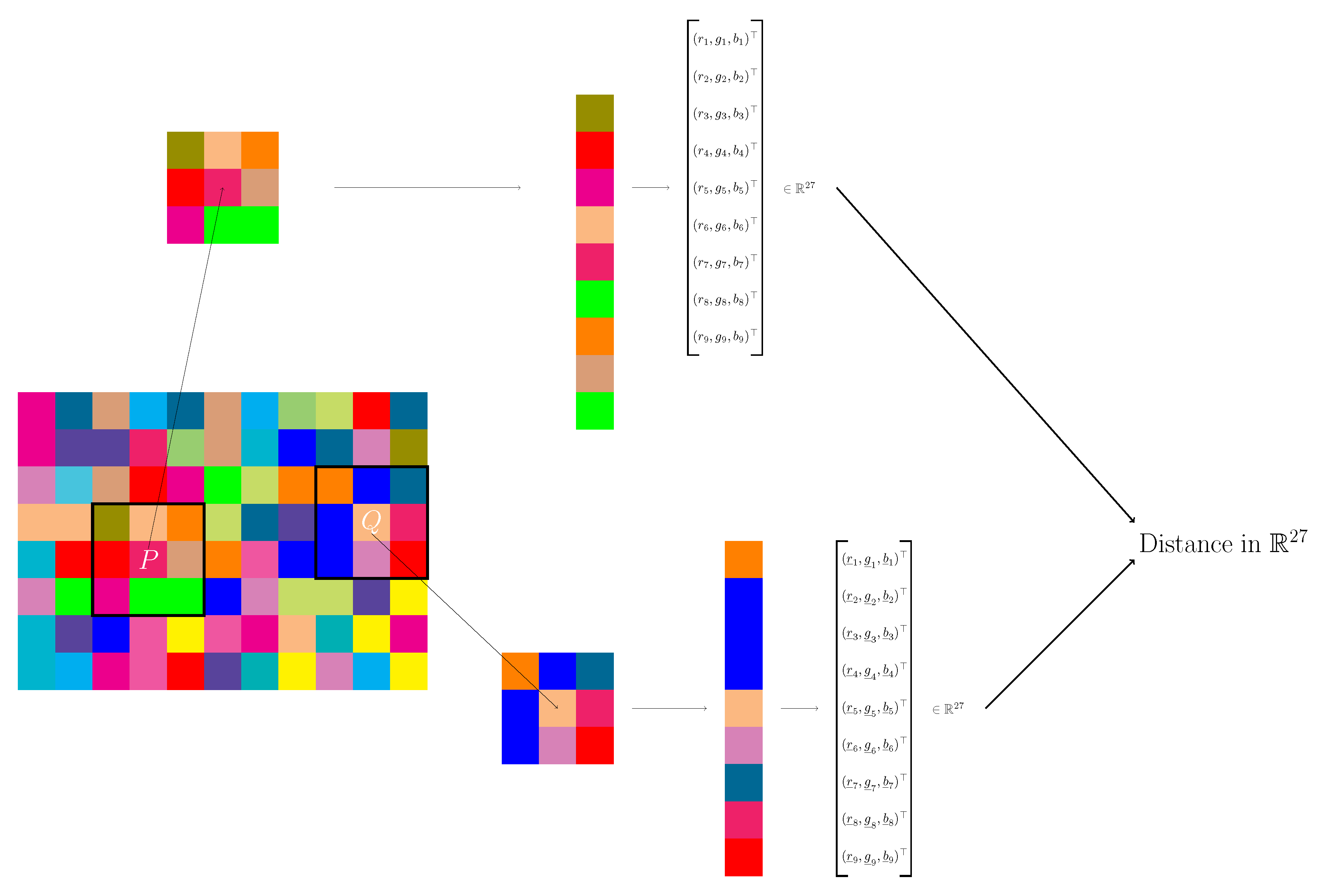
2.2. A Suitable Similarity Measure
| Algorithm 1 Random walk by colour similarity algorithm (RaWaCS) |
|
2.3. Combined Role of the Similarity Index and Random Walk Approach
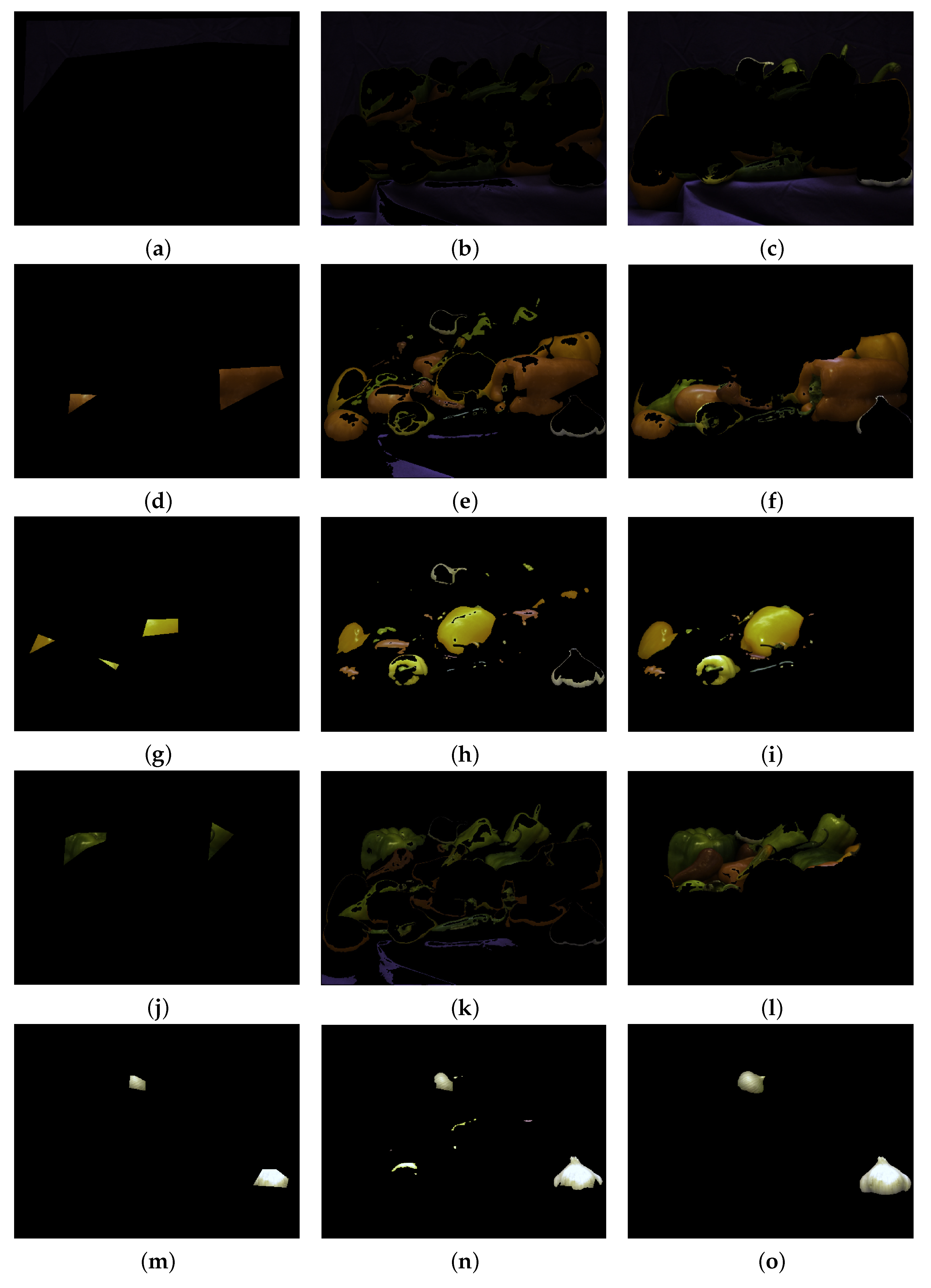
2.4. Peppers
3. Results
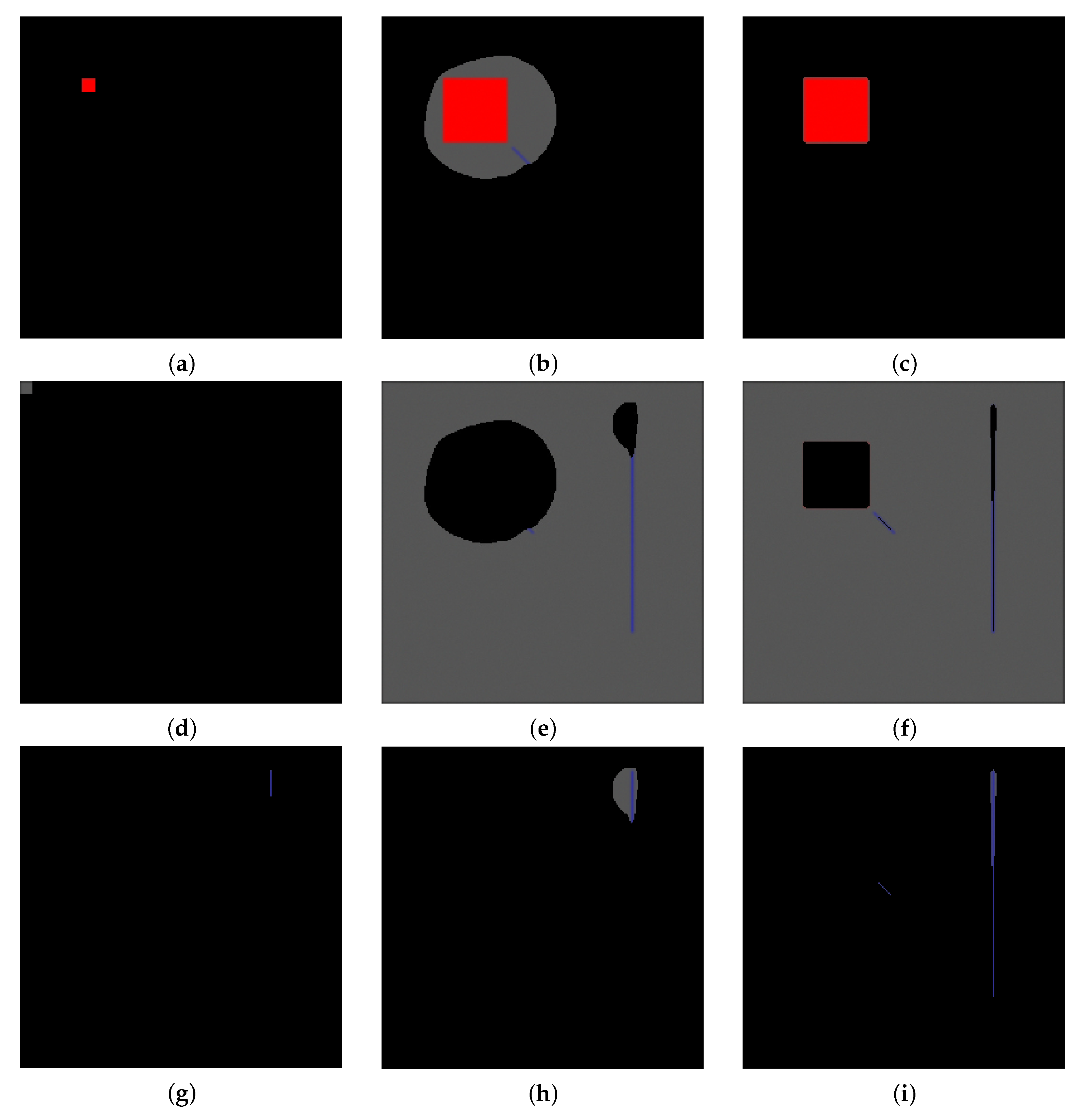
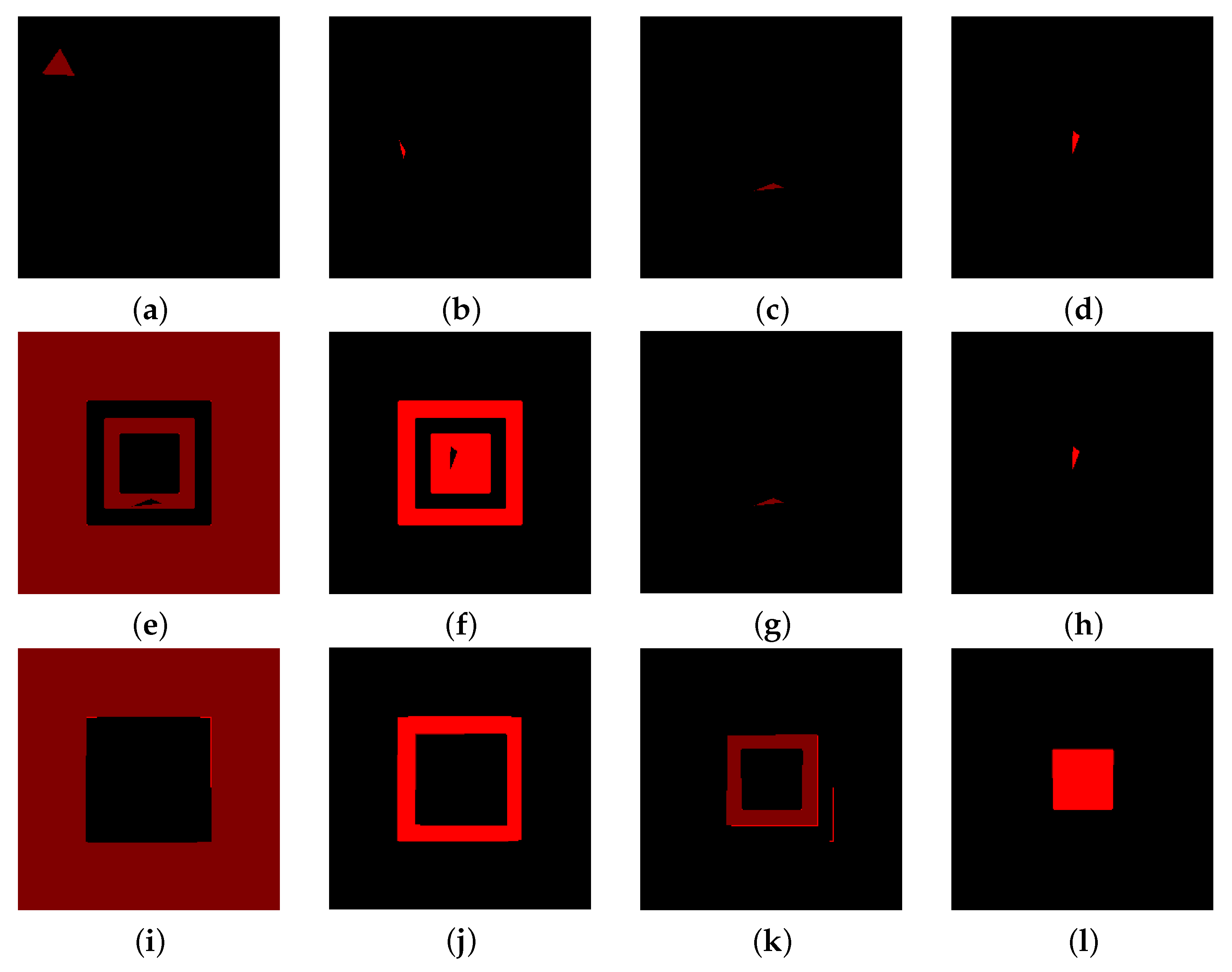
3.1. Comparison with k-Means and Classical Random Walk in Presence of Additive Noise
3.2. WBC and GrabCut Datasets
3.3. Different Colour Spaces
- Mark the regions of interest;
- Consider the original image in a new colourspace;
- Apply the proposed procedure to the transformed image;
- Visualise the computed labels, obtained on the transformed image, on the original RGB image.
3.4. Adapting the Distance’s Weights
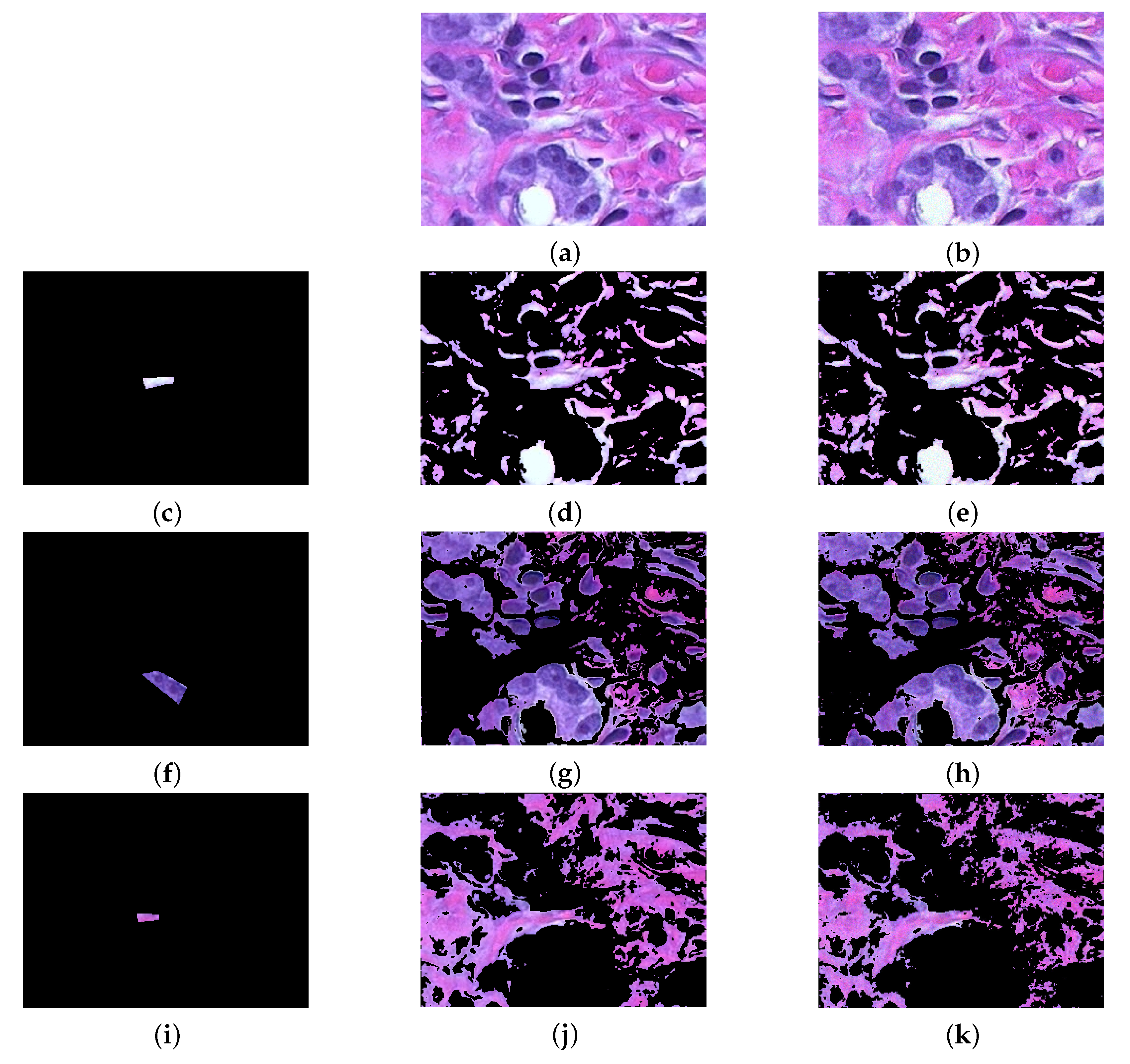
3.5. Biological Images
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer Scienze and Business Media: Berlin, Germany, 2010. [Google Scholar]
- Benfenati, A.; Bonacci, F.; Bourouina, T.; Talbot, H. Efficient Position Estimation of 3D Fluorescent Spherical Beads in Confocal Microscopy via Poisson Denoising. J. Math. Imaging Vis. 2021, 63, 56–72. [Google Scholar] [CrossRef]
- Aletti, G.; Naldi, G.; Parigi, G. Around the image analysis of the vessels remodelling during embryos development. In Proceedings of the 19th European Conference on Mathematics for Industry, Santiago de Compostela, Spain, 13–17 June 2016; p. 225. [Google Scholar]
- Palazzolo, G.; Moroni, M.; Soloperto, A.; Aletti, G.; Naldi, G.; Vassalli, M.; Nieus, T.; Difato, F. Fast wide-volume functional imaging of engineered in vitro brain tissues. Sci. Rep. 2017, 7, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Banfi, F.; Mandelli, A. Computer Vision Meets Image Processing and UAS PhotoGrammetric Data Integration: From HBIM to the eXtended Reality Project of Arco della Pace in Milan and Its Decorative Complexity. J. Imaging 2021, 7, 118. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Nock, R.; Nielsen, F. Statistical region merging. Trans. Pattern Anal. Mach. Intell. 2004, 26, 1452–1458. [Google Scholar] [CrossRef] [PubMed]
- Deshpande, A.; Dahikar, P.; Agrawal, P. An Experiment with Statistical Region Merging and Seeded Region Growing Image Segmentation Techniques. In Recent Trends in Image Processing and Pattern Recognition; Santosh, K.C., Hegadi, R.S., Eds.; Springer: Singapore, 2019; pp. 493–506. [Google Scholar]
- Dhanachandra, N.; Manglem, K.; Chanu, Y.J. Image segmentation using k-means clustering algorithm and subtractive clustering algorithm. Procedia Comput. Sci. 2015, 54, 764–771. [Google Scholar] [CrossRef] [Green Version]
- Najman, L.; Schmitt, M. Watershed of a continuous function. Signal Process. 1994, 38, 764–771. [Google Scholar] [CrossRef] [Green Version]
- Najman, L. Extending the Power Watershed Framework Thanks to Γ–Convergence. SIAM J. Imaging Sci. 2017, 10, 2275–2292. [Google Scholar] [CrossRef] [Green Version]
- Jordan, J.; Angelopoulou, E. Supervised multispectral image segmentation with power watersheds. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 1585–1588. [Google Scholar] [CrossRef]
- Couprie, C.; Grady, L.; Najman, L.; Talbot, H. Power Watershed: A Unifying Graph–Based Optimization Framework. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1384–1399. [Google Scholar] [CrossRef] [Green Version]
- Cousty, J.; Bertrand, G.; Najman, L.; Couprie, M. Watershed Cuts: Minimum Spanning Forests and the Drop of Water Principle. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1362–1374. [Google Scholar] [CrossRef] [Green Version]
- Wolf, S.; Pape, C.; Bailoni, A.; Rahaman, N.; Kreshuk, A.; Kothe, U.; Hamprecht, F. The Mutex Watershed: Efficient, Parameter-Free Image Partitioning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Kass, M.; Witkin, A. Snakes: Active contour models. Int. J. Comput. Vis. 1988, 1, 321–331. [Google Scholar] [CrossRef]
- Thias, A.H.; Al Mubarok, A.F.; Handayani, A.; Danudirdjo, D.; Rajab, T.E. Brain Tumor Semi-automatic Segmentation on MRI T1-weighted Images using Active Contour Models. In Proceedings of the 2019 International Conference on Mechatronics, Robotics and Systems Engineering (MoRSE), Bali, Indonesia, 4–6 December 2019; pp. 217–221. [Google Scholar] [CrossRef]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef] [Green Version]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut”: Interactive Foreground Extraction Using Iterated Graph Cuts. ACM Trans. Graph. 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Chen, X.; Pan, L. A Survey of Graph Cuts/Graph Search Based Medical Image Segmentation. IEEE Rev. Biomed. Eng. 2018, 11, 112–124. [Google Scholar] [CrossRef]
- Lermé, N.; Malgouyres, F. A reduction method for graph cut optimization. Pattern Anal. Applic. 2014, 17, 361–378. [Google Scholar] [CrossRef] [Green Version]
- Pizenberg, M.; Carlier, A.; Faure, E.; Charvillat, V. Outlining Objects for Interactive Segmentation on Touch Devices. In Proceedings of the 25th ACM International Conference on Multimedia MM ’17, Mountain View, CA, USA, 23–27 October 2017; pp. 1734–1742. [Google Scholar] [CrossRef]
- Kato, Z.; Zerubia, J. Markov Random Fields in Image Segmentation. Found. Trends Signal Process. 2012, 5, 1–155. [Google Scholar] [CrossRef]
- Starck, J.; Elad, M.; Donoho, D.L. Image decomposition via the combination of sparse representations and a variational approach. IEEE Trans. Image Process. 2005, 14, 1570–1582. [Google Scholar] [CrossRef] [Green Version]
- Casaca, W.; Gois, J.P.; Batagelo, H.C.; Taubin, G.; Nonato, L.G. Laplacian Coordinates: Theory and Methods for Seeded Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2665–2681. [Google Scholar] [CrossRef] [PubMed]
- Freedman, D. An improved image graph for semi-automatic segmentation. SIViP 2012, 6, 533–545. [Google Scholar] [CrossRef]
- Bampis, C.G.; Maragos, P.; Bovik, A.C. Graph-Driven Diffusion and Random Walk Schemes for Image Segmentation. IEEE Trans. Image Process. 2017, 26, 35–50. [Google Scholar] [CrossRef] [PubMed]
- Deshmukh, K.S. Color image segmentation: A review. In Proceedings of the Second International Conference on Digital Image Processing, Singapore, 26–28 February 2010; Jusoff, K., Xie, Y., Eds.; Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series. Volume 7546, p. 754624. [Google Scholar] [CrossRef]
- Busin, L.; Vandenbroucke, N.; Macaire, L. Color spaces and image segmentation. Adv. Imaging Electron Phys. 2008, 151, 65–168. [Google Scholar]
- Sàez, A.; Serrano, C.; Acha, B. Normalized Cut optimization based on color perception findings. A comparative study. Mach. Vis. Appl. 2014, 1813–1823. [Google Scholar] [CrossRef]
- Protiere, A.; Sapiro, G. Interactive Image Segmentation via Adaptive Weighted Distances. IEEE Trans. Image Process. 2007, 16, 1046–1057. [Google Scholar] [CrossRef] [Green Version]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Wang, X.; Hänsch, R.; Ma, L.; Hellwich, O. Comparison of different color spaces for image segmentation using graph-cut. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; Volume 1, pp. 301–308. [Google Scholar]
- Yi, F.; Moon, I. Image segmentation: A survey of graph-cut methods. In Proceedings of the 2012 International Conference on Systems and Informatics (ICSAI2012), Yantai, China, 19–20 May 2012; pp. 1936–1941. [Google Scholar] [CrossRef]
- Reza, M.N.; Na, I.S.; Baek, S.W.; Lee, K.H. Rice yield estimation based on K-means clustering with graph-cut segmentation using low-altitude UAV images. Biosyst. Eng. 2019, 177, 109–121. [Google Scholar] [CrossRef]
- Merkurjev, E.; Kostic, T.; Bertozzi, A.L. An MBO scheme on graphs for segmentation and image processing. SIAM J. Imaging Sci. 2013, 6, 1903–1930. [Google Scholar] [CrossRef]
- Hu, H.; Sunu, J.; Bertozzi, A.L. Multi-class Graph Mumford-Shah Model for Plume Detection using the MBO scheme. In Proceedings of the EMMCVPR, Hong Kong, China, 13–16 January 2015; Tai, X.C., Bae, E., Chan, T.F., Lysaker, M., Eds.; Springer Lecture Notes in Computer Science: Berlin/Heidelberg, Germany; Volume 8932, pp. 209–222. [Google Scholar]
- Bertozzi, A.L.; Flenner, A. Diffuse interface models on graphs for classification of high dimensional data. SIAM Rev. 2016, 58, 293–328. [Google Scholar] [CrossRef] [Green Version]
- Benfenati, A.; Chouzenoux, E.; Pesquet, J. Proximal approaches for matrix optimization problems: Application to robust precision matrix estimation. Signal Process. 2020, 169, 107417. [Google Scholar] [CrossRef] [Green Version]
- Benfenati, A.; Chouzenoux, E.; Pesquet, J.C. A nonconvex variational approach for robust graphical lasso. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing-Proceedings, Calgary, AB, Canada, 15–20 April 2018; pp. 3969–3973. [Google Scholar] [CrossRef] [Green Version]
- Maire, M.; Narihira, T.; Yu, S.X. Affinity CNN: Learning Pixel-Centric Pairwise Relations for Figure/Ground Embedding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 174–182. [Google Scholar] [CrossRef] [Green Version]
- Fowlkes, C.; Martin, D.; Malik, J. Learning affinity functions for image segmentation: Combining patch-based and gradient-based approaches. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; Volume 2, p. II-54. [Google Scholar] [CrossRef]
- Wolf, S.; Schott, L.; Köthe, U.; Hamprecht, F. Learned Watershed: End-to-End Learning of Seeded Segmentation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2030–2038. [Google Scholar] [CrossRef] [Green Version]
- Belkin, M.; Niyogi, P. Towards a theoretical foundation for Laplacian-based manifold methods. J. Comput. Syst. Sci. 2008, 74, 1289–1308. [Google Scholar] [CrossRef] [Green Version]
- Grady, L. Random walks for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1768–1783. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bertero, M.; Boccacci, P.; Ruggiero, V. Inverse Imaging with Poisson Data; IOP Publishing: Bristol, UK, 2018; pp. 2053–2563. [Google Scholar] [CrossRef]
- Boykov, Y. Graph cuts and efficient N-D image segmentation. Int. J. Comput. Vis. 2006, 70, 109–131. [Google Scholar] [CrossRef] [Green Version]
- McDonald, R.; Smith, K.J. CIE94-a new colour-difference formula. J. Soc. Dyers Colour. 1995, 111, 376–379. [Google Scholar] [CrossRef]
- Grady, L.; Polimeni, J.R. Discrete Calculus: Applied Analysis on Graphs for Computational Science; Springer: London, UK, 2010. [Google Scholar]
- Wang, X.; Zhu, C.; Bichot, C.E.; Masnou, S. Graph-based image segmentation using weighted color patch. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, VIC, Australia, 15–18 September 2013; pp. 4064–4068. [Google Scholar] [CrossRef] [Green Version]
- Cagli, E.; Carrera, D.; Aletti, G.; Naldi, G.; Rossi, B. Robust DOA estimation of speech signals via sparsity models using microphone arrays. In Proceedings of the 2013 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, 20–23 October 2013; pp. 1–4. [Google Scholar]
- Aletti, G.; Moroni, M.; Naldi, G. A new nonlocal nonlinear diffusion equation for data analysis. In Acta Applicandae Mathematicae; Springer: Berlin/Heidelberg, Germany, 2019; pp. 1–27. [Google Scholar]
- Hansen, P.; Nagy, J.; O’Leary, D. Deblurring Images: Matrices, Spectra, and Filtering; Fundamentals of Algorithms, Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2006. [Google Scholar]
- Grady, L. Available online: http://leogrady.net/software/ (accessed on 1 January 2021).
- Singaraju, D.; Grady, L.; Vidal, R. Interactive image segmentation via minimization of quadratic energies on directed graphs. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Wang, Y.; Wang, G.; Liu, J. Fast and Robust Segmentation of White Blood Cell Images by Self-supervised Learning. Micron 2018, 107, 55–71. [Google Scholar] [CrossRef]
- Bampis, C.G.; Maragos, P. Unifying the random walker algorithm and the SIR model for graph clustering and image segmentation. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 2265–2269. [Google Scholar] [CrossRef]
- Benfenati, A.; Ruggiero, V. Image regularization for Poisson data. In Journal of Physics: Conference Series; Rodet, T.V.E., Ed.; IOP Publishing: Bristol, UK, 2015; Volume 657. [Google Scholar] [CrossRef] [Green Version]
- Benfenati, A.; La Camera, A.; Carbillet, M. Deconvolution of post-adaptive optics images of faint circumstellar environments by means of the inexact Bregman procedure. Astron. Astrophys. 2016, 586, 9. [Google Scholar] [CrossRef] [Green Version]
- Benfenati, A.; Ruggiero, V. Inexact Bregman iteration for deconvolution of superimposed extended and point sources. Commun. Nonlinear Sci. Numer. Simul. 2015, 20, 882–896. [Google Scholar] [CrossRef]
- Zanni, L.; Benfenati, A.; Bertero, M.; Ruggiero, V. Numerical Methods for Parameter Estimation in Poisson Data Inversion. J. Math. Imaging Vis. 2015, 52, 397–413. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | RI | GCE | Err | Time |
|---|---|---|---|---|
| RaWaCs | 0.9557 | 0.0598 | 0.0349 | 0.0252 |
| RW | 0.9312 | 0.0827 | 0.0526 | 0.0131 |
| NRW | 0.8838 | 0.1134 | 0.2317 | 0.0494 |
| NLRW | 0.8921 | 0.0998 | 0.2212 | 0.0501 |
| Method | RI | GCE | Err | Time |
|---|---|---|---|---|
| RaWaCs | 0.9542 | 0.0427 | 0.0236 | 0.4734 |
| RW | 0.9499 | 0.0419 | 0.0277 | 0.2860 |
| NRW | 0.9493 | 0.0410 | 0.2428 | 8.0130 |
| NLRW | 0.9575 | 0.0361 | 0.2375 | 8.7822 |
| Colour Space | RI | GCE | Err | Time |
|---|---|---|---|---|
| RGB | 0.9557 | 0.0598 | 0.0349 | 0.0252 |
| LAB | 0.9524 | 0.0610 | 0.0363 | 0.0248 |
| XYZ | 0.9631 | 0.0598 | 0.0353 | 0.0260 |
| YCbCr | 0.9566 | 0.0580 | 0.0338 | 0.0256 |
| Dataset | RI | GCE | Err | Time |
|---|---|---|---|---|
| GrabCut | 0.9682 | 0.0303 | 0.0163 | 463.20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aletti, G.; Benfenati, A.; Naldi, G. A Semiautomatic Multi-Label Color Image Segmentation Coupling Dirichlet Problem and Colour Distances. J. Imaging 2021, 7, 208. https://doi.org/10.3390/jimaging7100208
Aletti G, Benfenati A, Naldi G. A Semiautomatic Multi-Label Color Image Segmentation Coupling Dirichlet Problem and Colour Distances. Journal of Imaging. 2021; 7(10):208. https://doi.org/10.3390/jimaging7100208
Chicago/Turabian StyleAletti, Giacomo, Alessandro Benfenati, and Giovanni Naldi. 2021. "A Semiautomatic Multi-Label Color Image Segmentation Coupling Dirichlet Problem and Colour Distances" Journal of Imaging 7, no. 10: 208. https://doi.org/10.3390/jimaging7100208
APA StyleAletti, G., Benfenati, A., & Naldi, G. (2021). A Semiautomatic Multi-Label Color Image Segmentation Coupling Dirichlet Problem and Colour Distances. Journal of Imaging, 7(10), 208. https://doi.org/10.3390/jimaging7100208