This section presents an extensive evaluation of face detection schemes, such as VJ, MTCNN, Face-SDD, and YOLOFace, to determine which is more suitable to be used in the proposed face recognition system. Firstly, extensive experiments are conducted on challenging face detection benchmarks: the Face Detection Data Set and Benchmark (FDDB) [
65], CelebA dataset [
66], WIDER FACE dataset [
67] (see
Figure 7), and Honda/UCSD dataset [
68] to verify the effectiveness of YOLO Face. As for the face recognition stage, we verify the proposed models on two challenging benchmarks: Labeled Faces in the Wild (LFW) dataset [
47] and YouTube Faces (YTF) dataset [
69].
4.1. Datasets
In this subsection, we briefly describe the datasets used for evaluation of the proposed system.
FDDB. The FDDB dataset contains annotations for 5171 face images in a set of 2845 pictures, designed to study the problem of an unconstrained face detection. It includes a wide variety of challenges such as: low image resolutions, severe occlusions, and difficult poses.
CelebA. The CelebA dataset contains 202,599 face images of celebrities, each one with 40 annotations of attributes with large variations of pose and changes in the background.
WIDER FACE. The WIDER Face is a set of images for face detection with a high degree of facial expressions, occlusion, and illumination conditions. It contains 32,203 images and annotations of 393,703 faces. These images are split into three subsets: training (40%), validation (10%), and testing (50%) sets. Each subset contains three levels of difficulty: Easy, Medium, and Hard.
Honda/UCSD. The Honda/UCSD is a set of a standard video dataset used to evaluate the performance of face detection and tracking. This dataset offers a large amount of facial expressions and poses such as rotation in the 2D and 3D plane.
LFW. The LFW is a widely used dataset for evaluating face recognition systems, which contains more than 13,000 face images captured from the web of 1680 persons, with two or more different images per person.
YTF. The YouTube Faces is a video face dataset designed to study the unconstrained face recognition problem. This set contains 3425 videos of 1595 different persons.
4.2. Face Detection
The YOLO-Face, MTCNN, Face-SSD, and traditional methods are evaluated under the same conditions, using challenging datasets over our proposed system. Face detection methods are configured to find faces in input images with a possible facial object size of 20 px; facial objects smaller than that are ignored. To evaluate the performance of YOLO-Face and other detection methods, different metrics for evaluation of machine learning are used such as: precision, recall, accuracy, and average precision (AP). The metric employed in the dataset PASCAL VOC [
70], IOU, an evaluation metric for the models developed for object localization, was also used. The IOU is defined as:
where
=
is the face region and
is the face detected region. Using Equation (
1), a threshold was established as 0.5, such that, if the relation between the detected region and the labeled one is larger than the threshold, it is assumed that a face exists in the detected region; otherwise, it can be considered that a face in the detected region does not exist. The estimated values are expressed in percentage terms such that, when the system output approach to 100%, the face detection and face recognition accuracy improve.
4.2.1. Main Results
YOLO-Face method was compared with other state-of-the-art methods [
16,
25,
29] using FDDB, CelebA, and WIDER FACE. Although the YOLO-Face network has proven its accuracy in detecting faces, experimental results show some drawbacks with non-annotated faces. In such a way as to solve this problem, we propose a modification in the decision-making of the face detection stage. The proposal consists of an evaluation process to determine if the prediction was incorrect by comparing the confidence value of the YOLO-Face method. First, the comparison of the bounding box of the face and the annotated ground-truth is carried out, if it is determined that the bounding box is a false positive, it proceeds to a second comparison. Then, it is evaluated if the prediction is a false positive through the confidence value that YOLO-Face delivers; if the confidence value of the prediction is greater than or equal to 80%, it is determined that there is a face within the bounding box. Therefore, double comparison prevents unnoted faces from being evaluated as false positives.
Table 1 shows the results obtained using the images contained in the FDDB dataset. Our experiments demonstrate that YOLO-Face provides a 99.8%, 72.9%, and 72.8% on precision, recall, and accuracy, only overcome by the MTCNN [
25] with an accuracy of 81.5%. Additionally, the same face detection models were evaluated using the CelebA dataset which contains 19,962 image faces, whose detection results are shown in
Table 2. Results show that, using the CelebA dataset, all the models obtain high performance. However, Face-SSD gets 99.7% accuracy over YOLO-Face with 99.6%. Finally, YOLO-Face obtains 95.8%, 94.2%, and 87.4% on the Easy, Medium, and Hard subsets of WIDER FACE validation are used, as highlighted in
Table 3.
Figure 8 shows some example face detection results on the WIDER dataset. We can easily see that the YOLO-Face detector performs better with small-scale faces.
We also evaluate YOLO-Face on a challenge video dataset [
68] and compare it against some state-of-the-art methods [
16,
25,
29].
Table 4 shows that the YOLO-Face method consistently outperforms all the previous approaches with the exception of video number 5 where Face-SSD has better performance.
4.2.2. Face Detection Inference Time
Inference time was measured to demonstrate the efficiency of YOLO-Face compared with state-of-the-art methods using a single NVIDIA GTX 2080-TI with CUDA 10.2 and cuDNN 7.6.5. Frame-per-second (FPS) and milliseconds (ms) are used to compare the speed. As pictured in
Table 5, the performance of YOLO-Face is better than the recent state of-the-art models with real-time speed. YOLO-Face spends 38 ms when detecting faces and can achieve about 26 fps for VGA-resolution (640 × 480) images. This method is 1.4 times faster than Refine Face [
28] with better performance on the WIDER FACE validation and 9 ms faster than the other real-time method, Face-SSD.
Additionally, using an Intel(R) Core (TM) i7-7700HQ CPU, the measure of inference time of YOLO-Face was compared with state-of-the-art methods. Results are provided in
Table 6. YOLO-Face can run at 2 FPS approximately using CPU, discarding it for CPU usage. Face-SSD achieves promising performance, and it can run at 24 FPS (50 ms) with an accuracy higher than 88% of detected faces on Honda/UCSD. In case the facial recognition application is limited by computational resources, the YOLO-Face used for face detection in the proposed scheme may be replaced by the Face-SSD scheme, with low performance degradation.
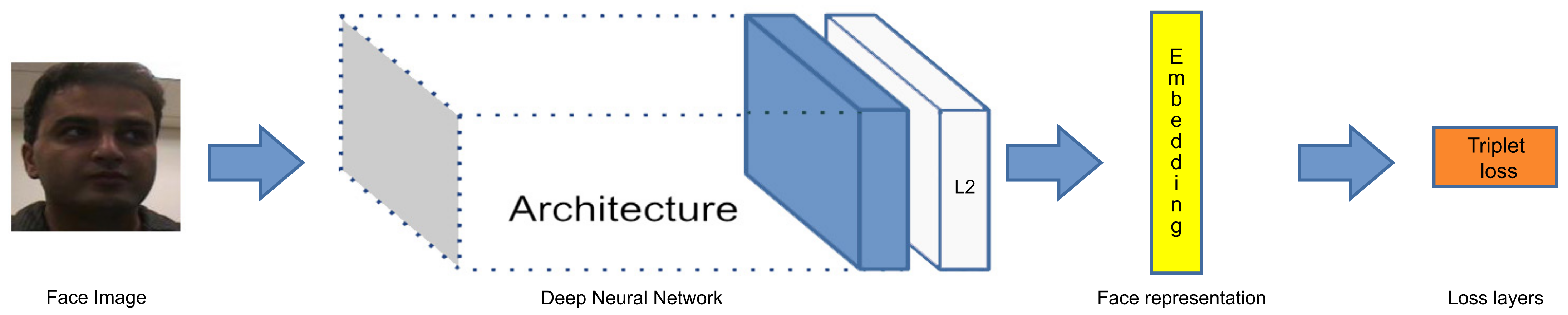
4.3. Face Recognition
At this stage, the baseline for the proposed methods is presented and provides the evaluation of the recognition performance. Our baseline is trained using the representations learned from CASIA-WebFace [
71]. This training set consists of a total of 453,453 images of about 10 K (ten thousand) of different identities after face detection. Consequently, the adagrad optimizer was employed for an optimizer with learning rate of
.
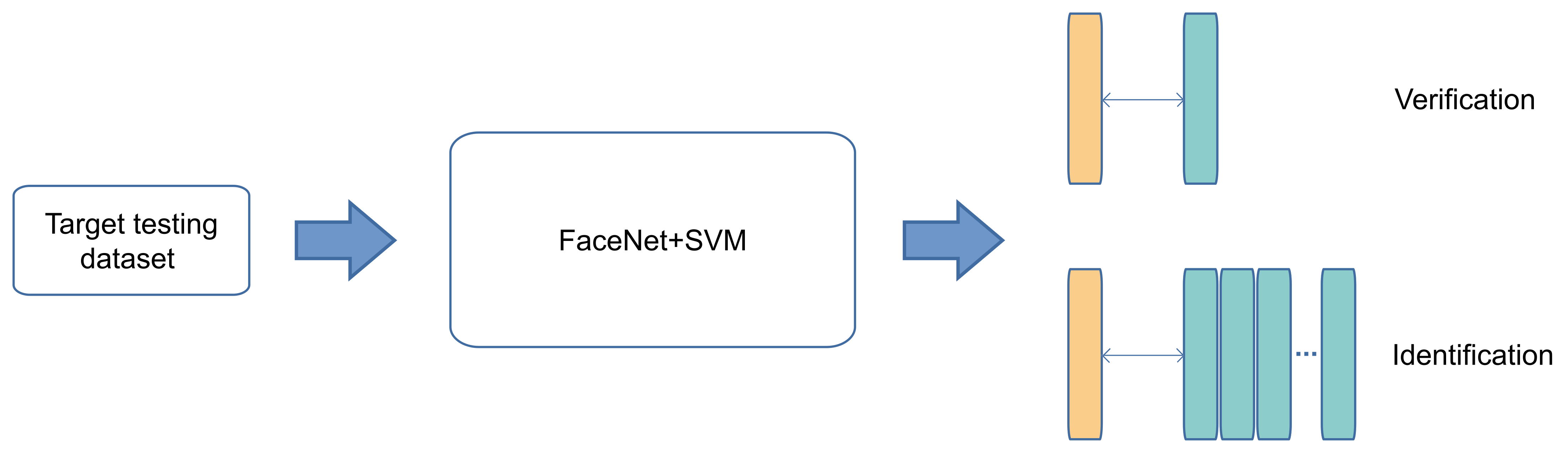
To measure the face recognition performance, proposed methods were evaluated for solving face recognition problems. Three different tasks of face recognition were considered: close-set face identification, open-set face identification, and face verification. In the tasks of face identification; three scenarios were defined. For each scenario, a training subset using the LFW dataset is defined, and
Table 7 shows the training size for each of the scenarios. The methods for Scenario A were trained using 500 images of five different identities, the methods for Scenario B were trained using 960 images of 32 different identities, and the methods for Scenario C were trained using 1270 images of 127 identities.
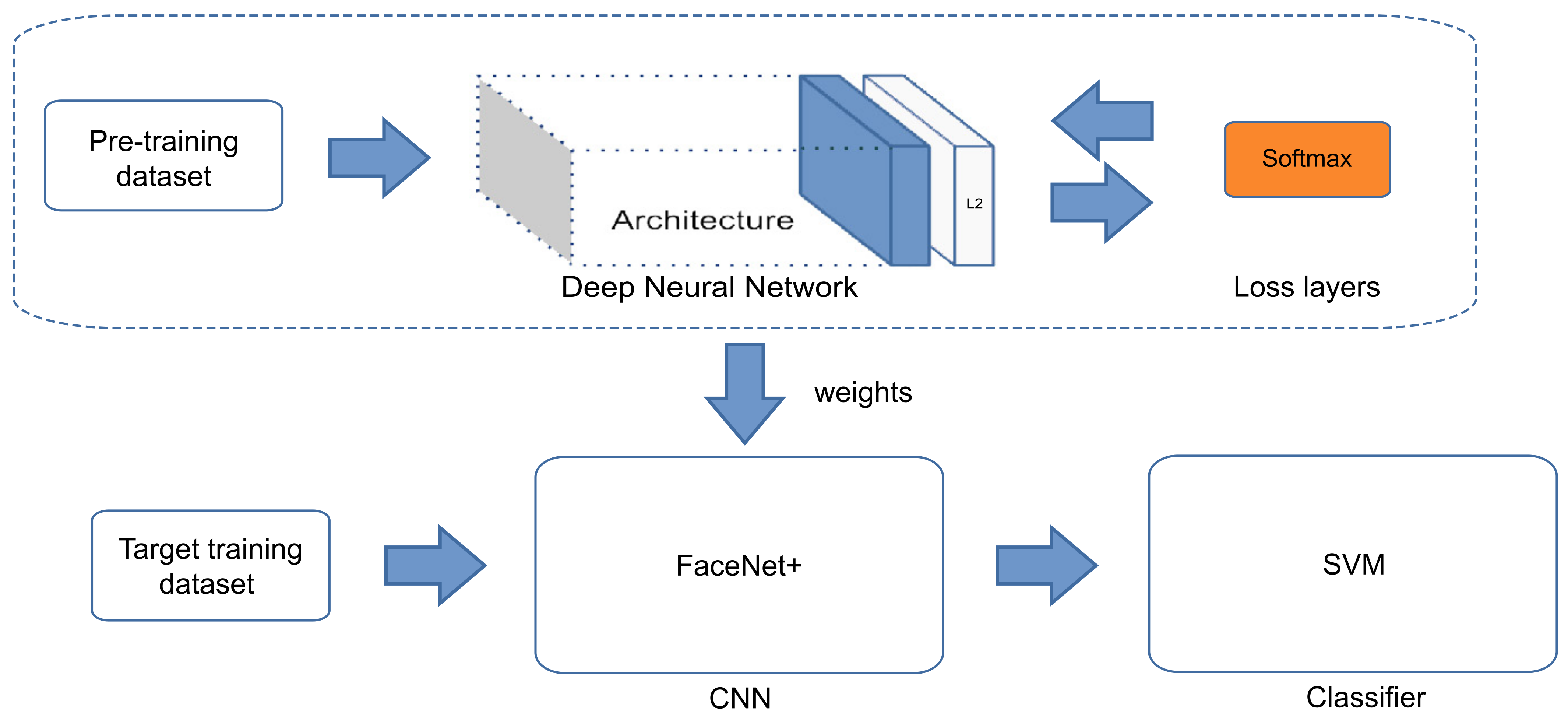
The proposed methods FaceNet+SVM, FaceNet+KNN, and FaceNet+RF were compared against the baseline (FaceNet+) which are evaluated in scenarios A, B, and C for the face identification tasks.
Table 8 shows the size of the testing subsets for each of the scenarios for the closed-set face identification.
Table 9 shows the accuracy results of the evaluation in the three scenarios. In Scenario C, the evaluation results show that the FaceNet+SVM model was able to achieve an accuracy of 99.7% using the LFW dataset. On the other hand, the FaceNet+KNN and FaceNet+RF were able to achieve an accuracy of 99.5% and 89.1%, respectively, using the same scenario, whereas the FaceNet+ was able to achieve an accuracy of 99.6% with the same scenario.
The evaluation results show that the proposed methods outperform the performance for identification even with a few images per person. The evaluation conditions are Area Under ROC Curve (AUC) and Average Precision (AP) are given in
Table 10 with the SVM, k-Nearest Neighbor (KNN), Random Forest (RF) classifiers, and L2-Softmax loss. Each row in
Table 10 corresponds to a compared facial recognition solution. Furthermore,
Table 9 shows that, among the analyzed classifiers, the SVM provides better performance, followed by RF and finally KNN.
Figure 9 and
Figure 10 are the ROC (Receiver Operating Characteristic) and Precision–Recall comparison, respectively, for the proposed methods. In the identification task for the ROC curve, it is necessary to binarize the problem by using a one vs. all approach and calculating the operating points for each class (identity) and then perform micro or macro averaging of true positive (TP) and false negative (FN) ratios through the different classes, which measures the macro average of the proposed methods, giving equal weight to the classification of each class. Moreover, Precision–Recall calculates the trade-off between precision and recall using micro or macro averaging for each class through different thresholds. The macro average is used because the micro average might not represent the performance of our proposed methods at all classes.
Additionally, the best method, FaceNet+SVM, is evaluated for the task of open-set face identification on the LFW dataset with 12,733 images of 5749 different identities. The FaceNet+SVM is measured in terms of the accuracy with 5, 32, and 127 enrolled identities and different confidence scores (conf); the results on LFW are as listed in
Table 11. Confidence scores are used to minimize the risk of mistakenly identifying the wrong person. Introducing confidence thresholds are important in the open-set contexts where the probes include non-enrolled identities.
The proposed FaceNet+SVM method on the face verification task according to the experiment presented by Schroff et al. is also evaluated [
48] for independent subjects. Given a pair of face images, the Euclidean distance is computed to determine if the images are the same or different. In addition, 99.7% and 94.7% classification accuracy were achieved on LFW and YTF datasets, respectively.
Table 12 shows the accuracy as compared with the previously mentioned state-of-the-art approaches on the most popular LFW benchmark for face verification tasks. These results show that our FaceNet+SVM relatively improves FaceNet [
48] and diverse solutions such DeepID3 [
49], Cosface [
51], and Ring loss [
52]. In the same way,
Table 13 shows the accuracy of different methods evaluated on another challenging dataset, YTF.
Table 14 and
Table 15 show the accuracy of some methods trained with the same database. In addition,
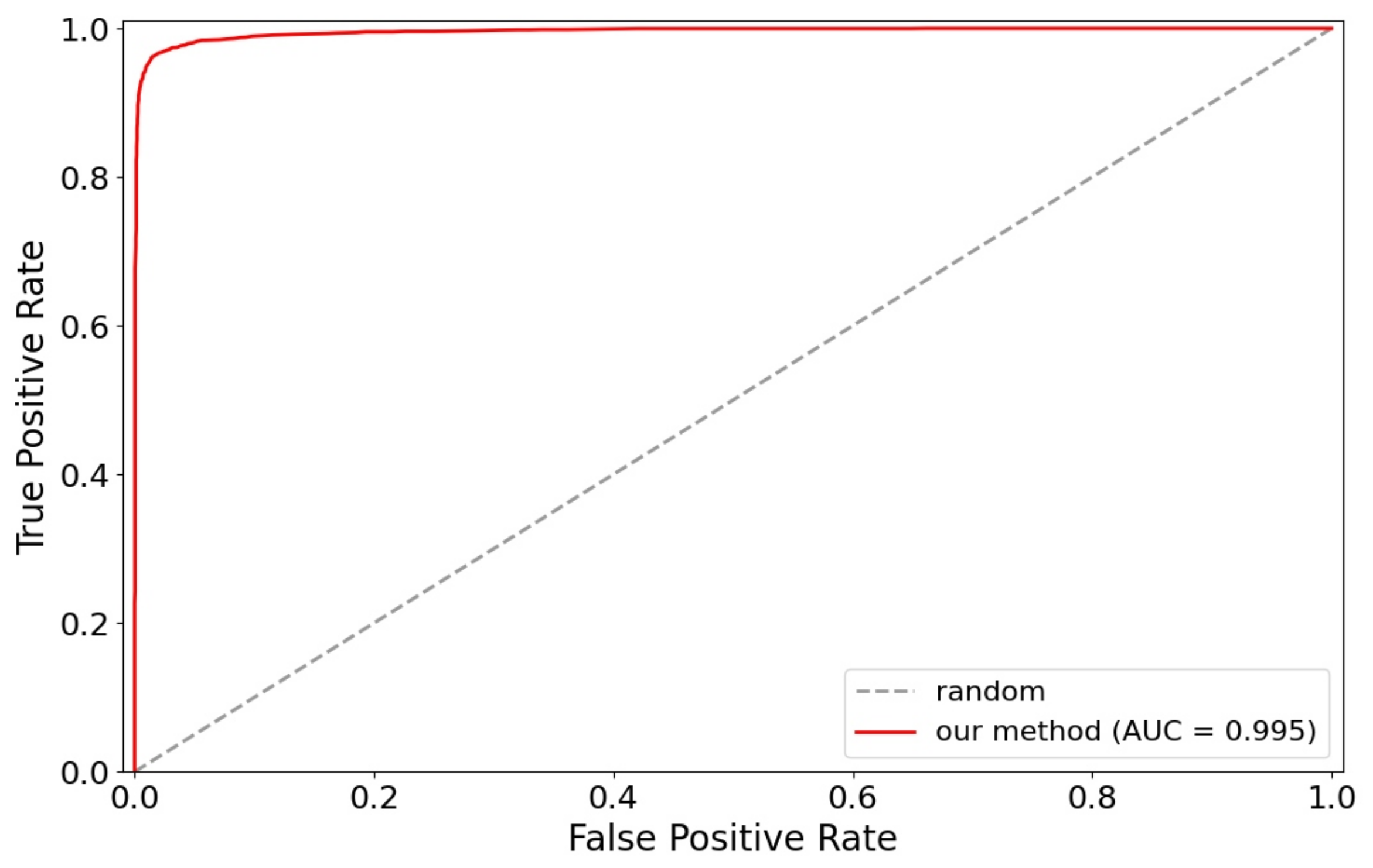
Figure 11 shows the ROC curve with our FaceNet+SVM method for verification tasks on the LFW dataset.
During testing, the face recognition stage spends 12 ms for an VGA image on the GPU, of which 11.5 ms are required for preprocessing and feature extraction, and 0.5 ms is required for face matching using our proposed method, FaceNet+SVM. In the proposed system, when combining face detection and face recognition stages, 99.1% recognition accuracy was obtained on the YTF dataset and real-time speed of 24 FPS at GPU using the YOLO-Face method and the FaceNet+SVM method. Additionally, the identification rate is evaluated, with the number of faces correctly identified (true positive rate) and the number of faces that are not correctly identified (false negative rate), using videos of the YTF dataset and YOLO-Face method and the FaceNet+SVM method; the results are shown in
Table 16. These results show that, in a closed set environment, when the face detection is wrong, that is, it detects a fake face or a bounding box that contains an object that is not really a face, the recognition rate worsens. For example, in videos 3, 7 and even in video 10, the detection system clearly fails to correctly detect the faces contained in the videos and then, in such situations, the achieved recognition or verification rates become too low. This limitation of the proposed system can be solved if some confidence thresholds are inserted, which are explained in
Table 16.
Complete System Inference Time
The inference time of the complete system was measured with the proposed pipeline by comparing the methods proposed in the detection stage and one of the best models in the recognition stage, FaceNet+SVM, using a single NVIDIA GTX 2080-TI with CUDA 10.2 and cuDNN 7.6.5. Frame-per-second (FPS) and millisecond (ms) are used to compare the speed; the results are provided in
Table 17. The results show a shorter execution time using the YOLO-Face and FaceNet+SVM methods; our framework can run at 24 FPS (49 ms) with the possibility of being used in real-time applications.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}