

Hybrid of Deep Learning and Word Embedding in Generating Captions: Image-Captioning Solution for Geological Rock Images



Abstract
:1. Introduction
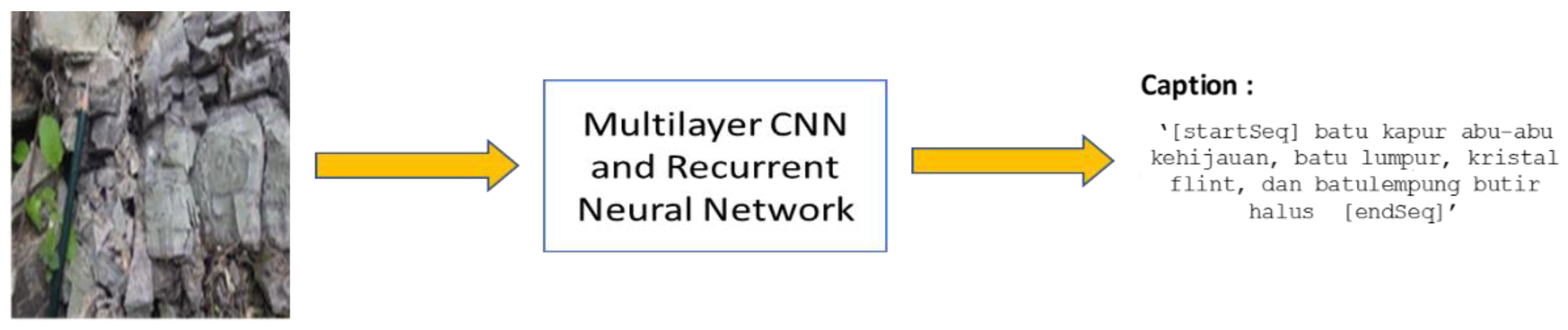
- Using geological field exploration to support captioning and build a model that produces a caption from an image. We collected that geological knowledge and used it to construct an algorithm and the architecture of the captioning model.
- Building the corpus for captioning that contains the pairwise images of rocks and their captions.
- Building a captioning model that can interpret images of rocks and achieve outcomes with an accuracy that is similar to a geologist’s annotation. Our models can outperform the baseline model relating to the BLEU score and acquire captions that are similar to a geologist’s annotation.
2. Methods
2.1. Long Short-Term Memory (LSTM)
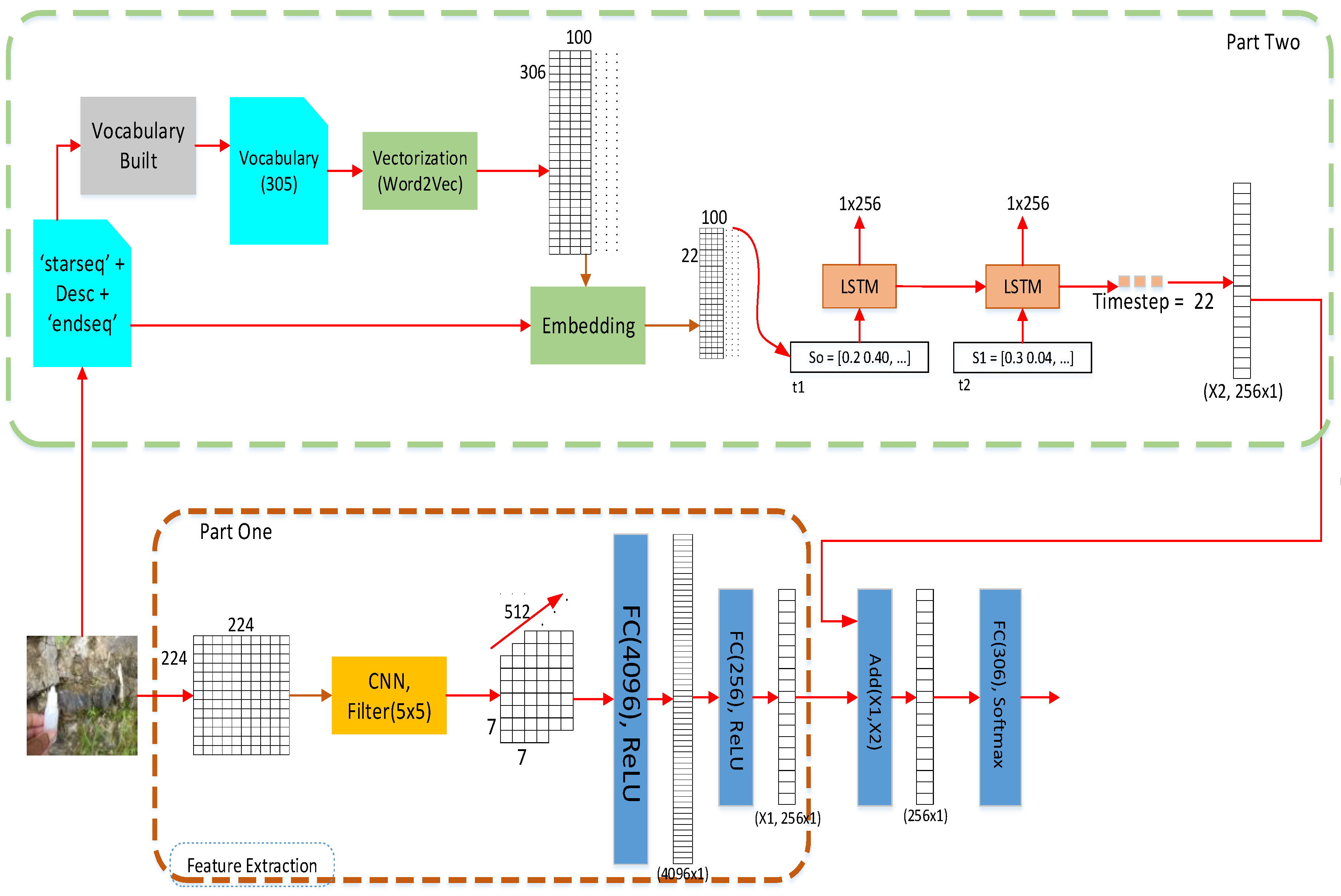
2.2. Part One Architectures
- Input Image (i1, i2, i3,…, in)—n stands for collecting the image, i;
- Reduce image; function for reduction of image to a size of 224 × 224;
- For I —I is the collection of the image:
- Image_feature = CNN(I, C, F)—I is the image with a size of 224 × 224; C represents the channels of convolutions; F is the filter matrix size that can be 3 × 3 or 5 × 5;
- Feature_Pooling = MaxPooling(Image_feature)—operation of the MaxPooling function;
- Feature_ReLu = ReLu Activation (Feature Pooling)—run of the ReLu activation;
- Feature_Dense = Dense(Feature_ReLu)—provides outcome units with 256 dense units.
- Return (Feature_Dense).
2.3. Part Two Architectures
- C = Input (caption)—input the corpus from the geologist’s annotation;
- X = ‘start_seq’—initialization of the word;
- U = unique_word(C)—building a unique word into a vocabulary that attaches from the corpus, C;
- C_Index = Making_Index(C)—providing the index for each word of the vocabulary;
- C_vector = Word2Vec(C_Index)—achieving the feature vector from the pre-trained model. The outcomes were 306 × 100 dimensions;
- W_embedding = Embedding (Vector word ‘Start_seq’ + C_vector);
- Word_predict = LSTM (w_embedding);
- Return (feature Length = 256 units).
2.4. Word Embedding
3. Results
3.1. Dataset
3.2. Experiments
- Tokenize each caption ;
- Calculate the variable “count” and “clip_count” from the reference token and candidate token, see Figure 7;
- Compute precision modification with formula ,
- If length of candidate <= reference, calculate brevity penalty (BP) with , else BP = 1;
- Calculate BLEU-1 and the result can be seen in Table 2.
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012; Volume 25, pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Karpathy, A.; Fei-Fei, L. Deep Visual-Semantic Alignments for Generating Image Descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 664–676. [Google Scholar] [CrossRef] [Green Version]
- Lebret, R.; Pinheiro, P.O.; Collobert, R. Phrase-Based Image Captioning. In Proceedings of the 32nd International Conference on Machine Learning, ICML, Lille, France, 6–11 July 2015; pp. 2085–2094. [Google Scholar]
- Boureau, Y.; Ponce, J.; Fr, J.P.; Lecun, Y. A Theoretical Analysis of Feature Pooling in Visual Recognition. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 111–118. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Batra, V.; He, Y.; Vogiatzis, G. Neural Caption Generation for News Images. In Proceedings of the LREC 2018—11th International Conference on Language Resources and Evaluation, Miyazaki, Japan, 7–12 May 2019; pp. 1726–1733. [Google Scholar]
- Chen, X.; Zhang, M.; Wang, Z.; Zuo, L.; Li, B.; Yang, Y. Leveraging Unpaired Out-of-Domain Data for Image Captioning. Pattern Recognit. Lett. 2020, 132, 132–140. [Google Scholar] [CrossRef]
- Qi, M.; Qin, J.; Li, A.; Wang, Y.; Luo, J.; Van Gool, L. StagNet: An Attentive Semantic RNN for Group Activity Recognition. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2018, 11214 LNCS, 104–120. [Google Scholar] [CrossRef]
- He, X.; Yang, Y.; Shi, B.; Bai, X. Neurocomputing VD-SAN: Visual-Densely Semantic Attention Network for Image Caption Generation. Neurocomputing 2019, 328, 48–55. [Google Scholar] [CrossRef]
- Chen, S.; Zhao, Q. Boosted Attention: Leveraging Human Attention for Image Captioning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 1, pp. 68–84. [Google Scholar]
- Ghosh, S.; Das, N.; Das, I.; Maulik, U. Understanding Deep Learning Techniques for Image Segmentation. ACM Comput. Surv. 2019, 52, 1–35. [Google Scholar] [CrossRef] [Green Version]
- Armi, L.; Fekri-ershad, S. Texture image analysis and texture classification methods—A review. arXiv 2019, arXiv:1904.06554. [Google Scholar]
- Soh, M. Learning CNN-LSTM Architectures for Image Caption Generation; Stanford University: Stanford, CA, USA, 2016; pp. 1–9. [Google Scholar]
- Bhatia, Y.; Bajpayee, A.; Raghuvanshi, D.; Mittal, H. Image Captioning Using Google’s Inception-Resnet-v2 and Recurrent Neural Network. In Proceedings of the 2019 Twelfth International Conference on Contemporary Computing (IC3), Noida, India, 8–10 August 2019; Volume 2019, pp. 1–6. [Google Scholar]
- Mao, J.; Yuille, A. Deep captioning with multimodal recurrent neural networks (M-RNN). arXiv 2015, arXiv:1412.6632. [Google Scholar]
- Junhua, M.; Wei, X.; Yi, Y.; Jiang, W.; Zhiheng, H.; Yuille, A. Deep Captioning with Multimodal Recurrent Neural Networks (m-RNN). In Proceedings of the ICLR, San Diego, CA, USA, 7–9 May 2015; pp. 1–17. [Google Scholar]
- Xiao, X.; Wang, L.; Ding, K.; Xiang, S.; Pan, C. Dense Semantic Embedding Network for Image Captioning. Pattern Recognit. 2019, 90, 285–296. [Google Scholar] [CrossRef]
- Xu, K.; Ba, J.L.; Kiros, R.; Courville, A. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6 July–11 July 2015; pp. 2048–2057. [Google Scholar]
- Donahue, J.; Hendricks, L.A.; Rohrbach, M.; Venugopalan, S.; Guadarrama, S.; Saenko, K.; Darrell, T. Long-Term Recurrent Convolutional Networks for Visual Recognition and Description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–14. [Google Scholar]
- He, X.; Shi, B.; Bai, X.; Xia, G.; Zhang, Z. Image Caption Generation with Part of Speech Guidance. Pattern Recognit. Lett. 2017, 119, 229–237. [Google Scholar] [CrossRef]
- Wang, L.; Chu, X.; Zhang, W.; Yiwei, W.; Weichen, S.; Chunlei, W. Social Image Captioning: Exploring Visual Attention and User Attention. Sensors 2018, 18, 646. [Google Scholar] [CrossRef]
- Lee, H.; Yoon, S.; Dernoncourt, F.; Kim, D.S.; Bui, T.; Jung, K. ViLBERTScore: Evaluating Image Caption Using Vision-and-Language BERT. In Proceedings of the First Workshop on Evaluation and Comparison of NLP Systems; Eval4NLP; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 34–39. [Google Scholar]
- Weijie, S.; Xizhou, Z.; Yue, C.; Bin, L.; Lewei, L. Vl-Bert: P Re-Training of G Eneric V Isual. In Proceedings of the ICLR, Addis Ababa, Ethiopia, 26–30 April 2020; pp. 1–16. [Google Scholar]
- Plummer, B.A.; Liwei, W.; Cervantes, C.M.; Caicedo, J.C.; Hockenmaier, J.; Lazebnik, S. Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–17 December 2015; pp. 2641–2649. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Qiu, Z.; Mei, T. Boosting Image Captioning with Attributes. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4904–4912. [Google Scholar]
- Nur, K.; Effendi, J.; Sakti, S.; Adriani, M.; Nakamura, S. Corpus Construction and Semantic Analysis of Indonesian Image Description. In Proceedings of the 6th Workshop on Spoken Language Technologies for Under-Resourced Languages, Gurugram, India, 29–31 August 2018; pp. 20–24. [Google Scholar]
- Su, J.; Tang, J.; Lu, Z.; Han, X.; Zhang, H. A Neural Image Captioning Model with Caption-to-Images Semantic Constructor. Neurocomputing 2019, 367, 144–151. [Google Scholar] [CrossRef]
- Wang, C.; Yang, H.; Meinel, C. Image Captioning with Deep Bidirectional LSTMs and Multi-Task Learning. ACM Trans. Multimed. Comput. Commun. Appl. 2018, 14, 3115432. [Google Scholar] [CrossRef]
- Ordenes, F.V.; Zhang, S. From Words To Pixels: Text And Image Mining Methods For Service Research. J. Serv. Manag. 2019, 30, 593–620. [Google Scholar] [CrossRef]
- Nezami, O.M.; Dras, M.; Wan, S.; Nov, C.V. SENTI-ATTEND: Image Captioning Using Sentiment and Attention. arXiv 2018, arXiv:1811.09789. [Google Scholar]
- Aneja, J.; Deshpande, A.; Schwing, A.G. Convolutional Image Captioning. In Computer Vision and Pattern Recognition; Computer Vision Foundation, 2017; pp. 5561–5570. Available online: https://arxiv.org/abs/1711.09151 (accessed on 12 September 2022).
- Wang, A.; Hu, H.; Yang, L. Image Captioning with Affective Guiding and Selective Attention. ACM Trans. Multimed. Comput. Commun. Appl. 2018, 14, 1–15. [Google Scholar] [CrossRef]
- Tan, Y.H.; Chan, C.S. Phrase-Based Image Caption Generator with Hierarchical LSTM Network. Neurocomputing 2019, 333, 86–100. [Google Scholar] [CrossRef]
- Li, N.; Chen, Z. Image Captioning with Visual-Semantic LSTM. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 793–799. [Google Scholar]
- Tan, E.; Lakshay, S. “Neural Image Captioning”. Available online: https://arxiv.org/abs/1907.02065 (accessed on 12 September 2022).
- Zhu, Z.; Xue, Z.; Yuan, Z. Think and Tell: Preview Network for Image Captioning. In Proceedings of the British Machine Vision Conference 2018 (BMVC 2018), Newcastle, UK, 3–6 September 2018; pp. 1–12. [Google Scholar]
- He, C.; Hu, H. Image Captioning with Visual-Semantic Double Atention. ACM Trans. Multimed. Comput. Commun. Appl. 2019, 15, 1–16. [Google Scholar] [CrossRef]
- Mullachery, V.; Motwani, V. Image Captioning. arXiv 2018, arXiv:1805.09137. [Google Scholar]
- Li, X.; Song, X.; Herranz, L.; Zhu, Y.; Jiang, S. Image Captioning with Both Object and Scene Information. In Proceedings of the 24th ACM International Conference on Multimedia; ACM: Amsterdam, The Netherlands, 2016; pp. 1107–1110. [Google Scholar]
- Mathews, A. Automatic Image Captioning with Style; ANU Open Research, 2018. Available online: https://openresearch-repository.anu.edu.au/bitstream/1885/151929/1/thesis_apm_01_11_18.pdf (accessed on 12 September 2022).
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and Tell: Lessons Learned from the 2015 MSCOCO Image Captioning Challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 652–663. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mun, J.; Cho, M.; Han, B. Text-Guided Attention Model for Image Captioning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4233–4239. [Google Scholar]
- Tran, A.; Mathews, A.; Xie, L. Transform and Tell: Entity-Aware News Image Captioning. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13032–13042. [Google Scholar] [CrossRef]
- Herdade, S.; Kappeler, A.; Boakye, K.; Soares, J. Image Captioning: Transforming Objects into Words. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Zhu, Y.; Li, X.; Li, X.; Sun, J.; Song, X.; Jiang, S. Joint Learning of CNN and LSTM for Image Captioning. In Proceedings of the CEUR Workshop Proceedings, Évora, Portugal, 5–8 September 2016; Volume 1609, pp. 421–427. [Google Scholar]
- Gan, C.; Gan, Z.; He, X.; Gao, J. StyleNet: Generating Attractive Visual Captions with Styles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 955–964. [Google Scholar]
- Kinghorn, P.; Zhang, L.; Shao, L. A Region-Based Image Caption Generator with Refined Descriptions. Neurocomputing 2018, 272, 416–424. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Kocarev, L.; Makraduli, J.; Amato, P. Rock classification in petrographic thin section images based on concatenated convolutional neural networks. Earth Sci. Inform. 2005, 9, 497–517. [Google Scholar]
- Lepistö, L. Rock Image Classification Using Color Features in Gabor Space. J. Electron. Imaging 2005, 14, 040503. [Google Scholar] [CrossRef]
- Lepistö, L.; Kunttu, I.; Autio, J.; Visa, A. Rock Image Classification Using Non-Homogenous Textures and Spectral Imaging. WSCG. 2003, pp. 1–5. Available online: http://wscg.zcu.cz/wscg2003/Papers_2003/D43.pdf (accessed on 12 September 2022).
- Nursikuwagus, A. Multilayer Convolutional Parameter Tuning Based Classification for Geological Igneous Rocks. In Proceedings of the International Conference on ICT for Smart Society (ICISS); Information Technology Research Group of the School of Electrical Engineering and Informatics, Bandung, Indonesia, 10–11 August 2021. [Google Scholar]
- Ran, X.; Xue, L.; Zhang, Y.; Liu, Z.; Sang, X.; He, J. Rock Classification from Field Image Patches Analyzed Using a Deep Convolutional Neural Network. Mathematics 2019, 7, 755. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the 1st International Conference on Learning Representations, ICLR 2013—Workshop Track Proceedings, Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–12. [Google Scholar]
- David, T.A. The University of South Alabama GY480 Field Geology Course; University of South Alabama: Mobile, AL, USA, 2021. [Google Scholar]
- Chen, J.; Yang, T.; Zhang, D.; Huang, H.; Tian, Y. Deep Learning Based Classification of Rock Structure of Tunnel Face. Geosci. Front. 2021, 12, 395–404. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arxiv 2015, arXiv:1409.1556. [Google Scholar]
- Ren, W.; Zhang, M.; Zhang, S.; Qiao, J.; Huang, J. Identifying Rock Thin Section Based on Convolutional Neural Networks. In Proceedings of the 2019 9th International Workshop on Computer Science and Engineering (WCSE 2019), Hong Kong, China, 15–17 June 2019; pp. 345–351. [Google Scholar] [CrossRef]
- Wu, C.; Wei, Y.; Chu, X.; Su, F.; Wang, L. Modeling Visual and Word-Conditional Semantic Attention for Image Captioning. Signal Process. Image Commun. 2018, 67, 100–107. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Wei-Jing, Z. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Wang, C.; Yang, H.; Bartz, C.; Meinel, C. Image Captioning with Deep Bidirectional LSTMs. In Proceedings of the MM 2016-ACM Multimedia Conference, New York, NY, USA, 15–19 October 2016; pp. 988–997. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Shlens, J. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the Computer Vision Fundation, Columbus, OH, USA, 23–28 June 2014; pp. 2818–2826. [Google Scholar]
- Fan, G.; Chen, F.; Chen, D.; Li, Y.; Dong, Y. A Deep Learning Model for Quick and Accurate Rock Recognition with Smartphones. Mob. Inf. Syst. 2020, 2020, 7462524. [Google Scholar] [CrossRef]
- Robson, B.A.; Bolch, T.; MacDonell, S.; Hölbling, D.; Rastner, P.; Schaffer, N. Automated Detection of Rock Glaciers Using Deep Learning and Object-Based Image Analysis. Remote Sens. Environ. 2020, 250, 112033. [Google Scholar] [CrossRef]
- Feng, J.; Qing, G.; Huizhen, H.; Na, L. Feature Extraction and Segmentation Processing of Images Based on Convolutional Neural Networks. Opt. Mem. Neural Netw. (Inf. Opt.) 2021, 30, 67–73. [Google Scholar] [CrossRef]
- Nursikuwagus, A.; Munir, R.; Khodra, M.L. Multilayer Convolutional Parameter Tuning Based Classification for Geological Igneous Rocks. In Proceedings of the ICISS, Patna, India, 16–20 December 2021. [Google Scholar]
- Wu, Q.; Shen, C.; Wang, P.; Dick, A.; Van Den Hengel, A. Image Captioning and Visual Question Answering Based on Attributes and External Knowledge. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1367–1381. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015-Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image Captioning with Semantic Attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4651–4659. [Google Scholar]
- Ding, G.; Chen, M.; Zhao, S.; Chen, H.; Han, J. Neural Image Caption Generation with Weighted Training and Reference. Cogn. Comput. 2018, 11, 763–777. [Google Scholar] [CrossRef] [Green Version]
- Cao, P.; Yang, Z.; Sun, L.; Liang, Y.; Yang, M.Q.; Guan, R. Image Captioning with Bidirectional Semantic Attention-Based Guiding of Long Short-Term Memory. Neural Process. Lett. 2019, 50, 103–119. [Google Scholar] [CrossRef] [Green Version]
- Contreras, J.V. Supervised Learning Applied to Rock Type Classification in Sandstone Based on Wireline Formation Pressure Data; AAPG/Datapages, Inc., 2020. Available online: https://www.searchanddiscovery.com/pdfz/documents/2020/42539contreras/ndx_contreras.pdf.html (accessed on 12 September 2022). [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Layer | Filter | Parameters | Size | Time(s) |
|---|---|---|---|---|---|
| VGG16 | 16 | 1 × 1, 3 × 3 | 134,260,544 | 224 × 224 | 1845 |
| Ours_CNN-A | 7 | 3 × 3 | 12,746,112 | 224 × 224 | 1860 |
| Ours_CNN-B | 7 | 3 × 3 | 2,397,504 | 224 × 224 | 1230 |
| Ours_CNN-C | 7 | 5 × 5 | 20,482,432 | 224 × 224 | 1885 |
| Ours_CNN-D | 2 | 5 × 5 | 104,867,300 | 224 × 224 | 1230 |
| Model Caption | BLEU-1 (Unigram) | BLEU-2 (bi-gram) | BLEU-3 (3-gram) | BLEU-4 (4-gram) |
|---|---|---|---|---|
| VGG16 + LSTM + word2vec | 0.5516 | 0.6048 | 0.6414 | 0.6526 |
| ResNet50 +LSTM + Word2Vec | 0.3990 | 0.3830 | 0.4030 | 0.3440 |
| InceptionV3 +LSTM + Word2Vec | 0.3320 | 0.3120 | 0.3300 | 0.2730 |
| Ours_CNN-A + LSTM + word2vec | 0.6464 | 0.6508 | 0.6892 | 0.6504 |
| Ours_CNN-B + LSTM + word2vec | 0.7012 | 0.7083 | 0.7312 | 0.7345 |
| Ours_CNN-C + LSTM + word2vec | 0.7620 | 0.8757 | 0.8861 | 0.8250 |
| Ours_CNN-D+ LSTM + word2vec | 0.5620 | 0.6578 | 0.7307 | 0.7537 |
| CNN + LSTM + One-Hot, adapted from [2], Copyright 2015, Karpathy et al. | 0.3990 | 0.3830 | 0.4050 | 0.3470 |
| InceptionV3 + LSTM + One-Hot [14] | 0.3760 | 0.3410 | 0.3540 | 0.2960 |
| ResNet50 + LSTM + One-Hot [14] | 0.4030 | 0.3920 | 0.4150 | 0.3590 |
| Evaluation | CNN-A | CNN-B | CNN-C | CNN-D | VGG16 |
|---|---|---|---|---|---|
| Accuracy | 0.9137 | 0.9148 | 0.9178 | 0.9206 | 0.9228 |
| Loss | 0.1763 | 0.1764 | 0.1638 | 0.1457 | 0.1464 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nursikuwagus, A.; Munir, R.; Khodra, M.L. Hybrid of Deep Learning and Word Embedding in Generating Captions: Image-Captioning Solution for Geological Rock Images. J. Imaging 2022, 8, 294. https://doi.org/10.3390/jimaging8110294
Nursikuwagus A, Munir R, Khodra ML. Hybrid of Deep Learning and Word Embedding in Generating Captions: Image-Captioning Solution for Geological Rock Images. Journal of Imaging. 2022; 8(11):294. https://doi.org/10.3390/jimaging8110294
Chicago/Turabian StyleNursikuwagus, Agus, Rinaldi Munir, and Masayu Leylia Khodra. 2022. "Hybrid of Deep Learning and Word Embedding in Generating Captions: Image-Captioning Solution for Geological Rock Images" Journal of Imaging 8, no. 11: 294. https://doi.org/10.3390/jimaging8110294
APA StyleNursikuwagus, A., Munir, R., & Khodra, M. L. (2022). Hybrid of Deep Learning and Word Embedding in Generating Captions: Image-Captioning Solution for Geological Rock Images. Journal of Imaging, 8(11), 294. https://doi.org/10.3390/jimaging8110294