




How Well Do Self-Supervised Models Transfer to Medical Imaging?

 ,
,  ,
, 
Abstract
:1. Introduction
- i.
- ImageNet supervised pretrained features have been found to transfer very poorly to medical imaging tasks [19]. However, in [20], it is demonstrated that ImageNet self-supervised pretrained features tend to transfer much better than their supervised counterparts to a variety of downstream tasks, some with large domain shifts from ImageNet. It remains to be seen, however, if this improved transfer performance also applies to medical imaging.
- ii.
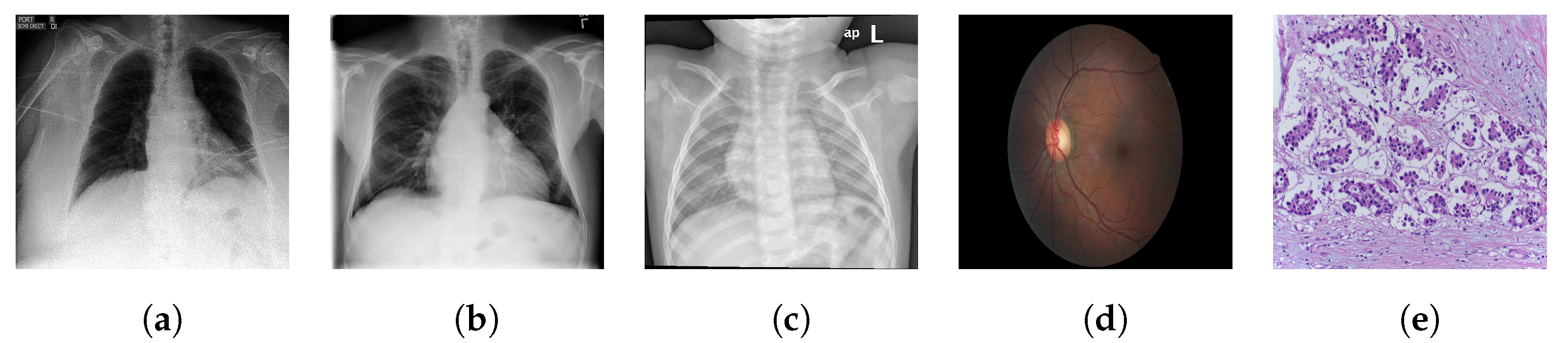
- Medical images differ significantly in their structure to the natural images found in ImageNet, which are non-cluttered and have a clear global object. Many medical images are extremely unstructured, such as skin lesions [21]. Even those with a clearer object-like structure, for example X-rays, have characteristic signatures associated with the different categorical labels (which in a medical context often correspond to different pathologies) that tend to be minute local textural variations [19]. Medical image analysis has therefore proven to be a difficult task for deep learning models. Consequently it provides a strong test of the generalisability and robustness of the features learned by self-supervised pretraining.
- iii.
- Refs. [16,17] find improved performance over supervised ImageNet pretrained features through performing self-supervised pretraining, as well as finetuning, on the target medical dataset. However, it is unclear whether such domain-specific self-supervised pretrained models significantly outperform similarly pretrained ImageNet alternatives.
- iv.
- Taking publicly available pretrained models and finetuning them is significantly less computationally expensive than pretraining from scratch, and therefore allows us to perform interesting, and, to the best of our knowledge, new analysis without massive resources.
- Q1.
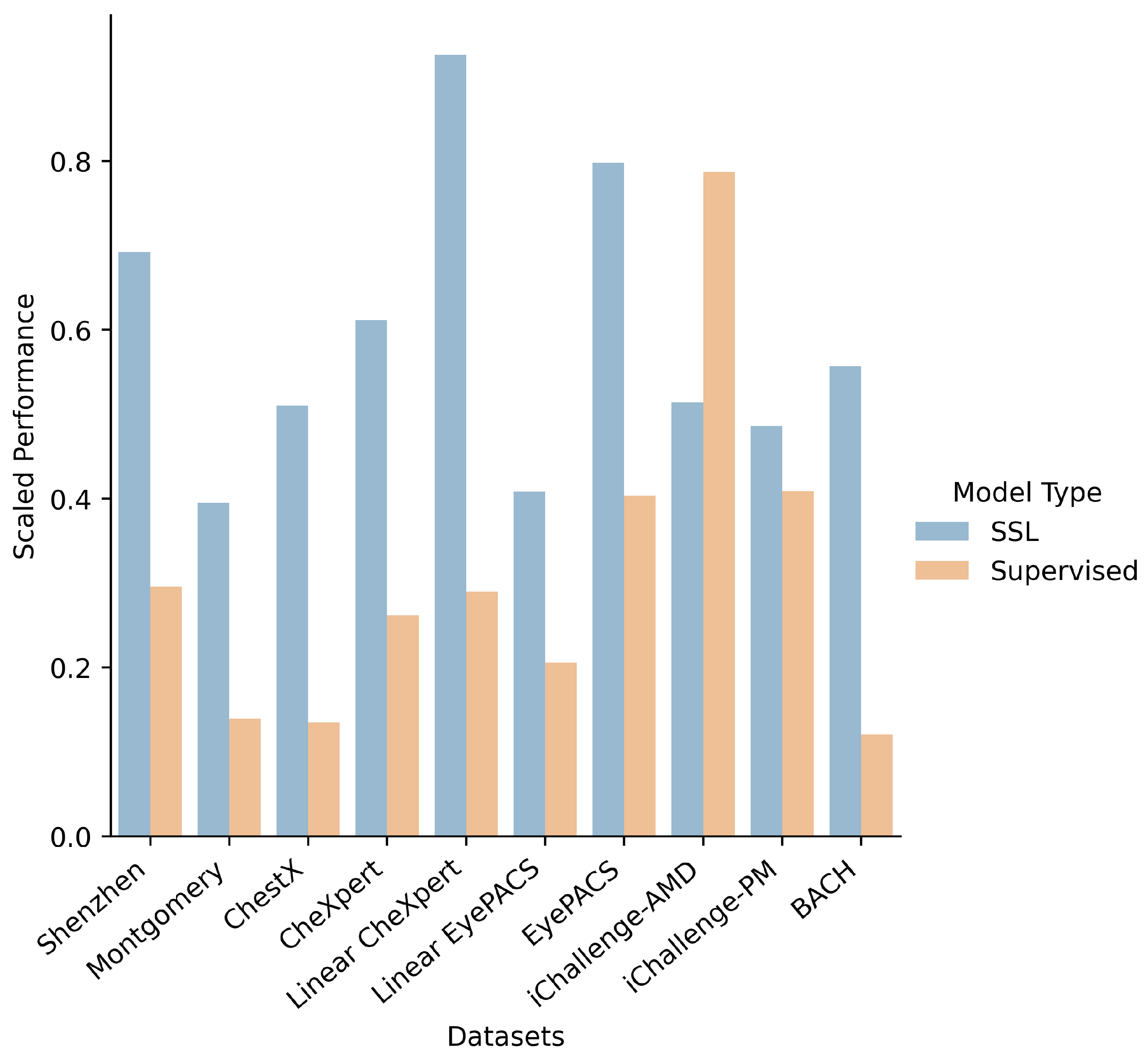
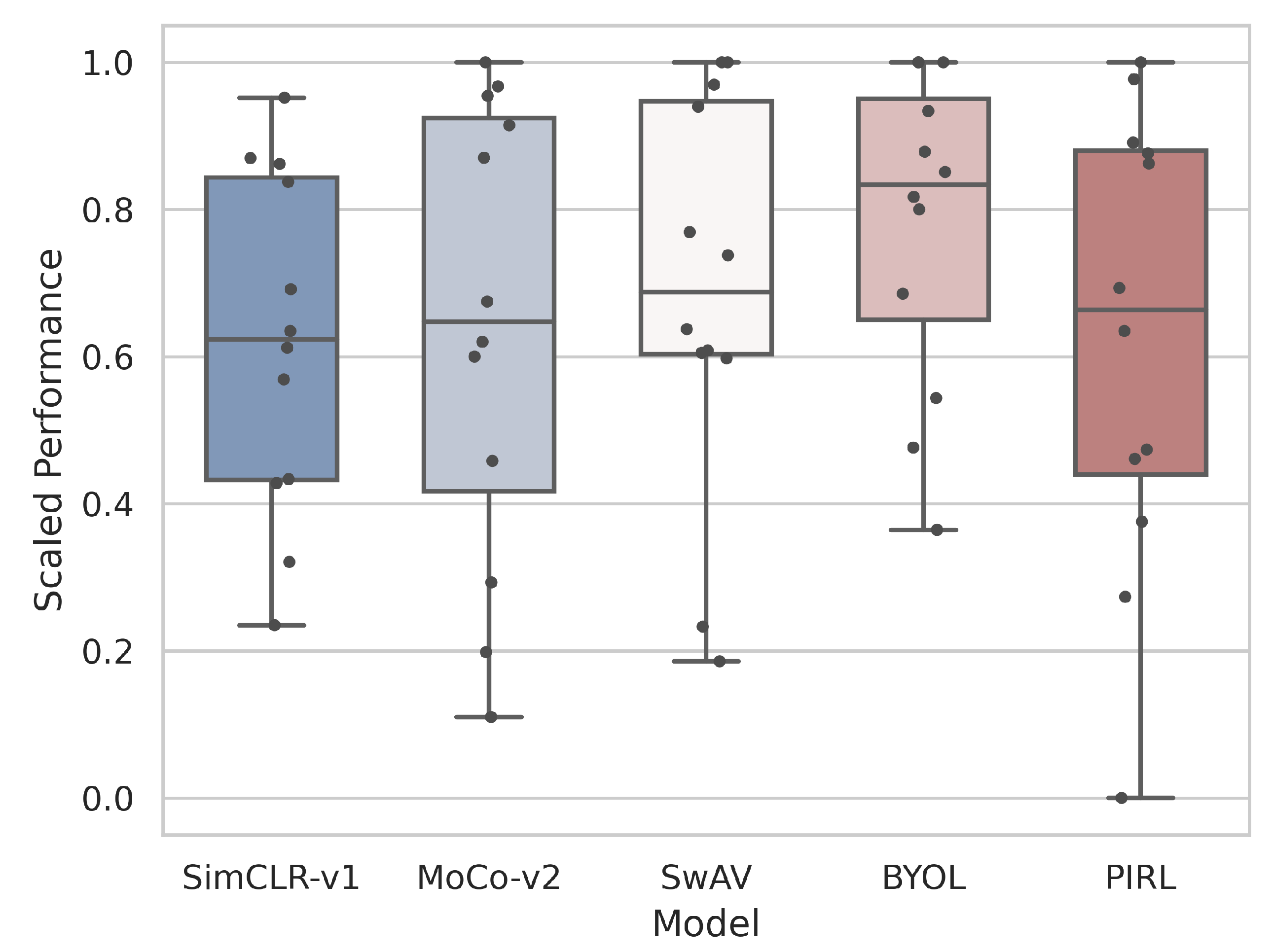
- How do supervised, self-supervised methods compare for medical downstream tasks? A: We find that self-supervised methods are able to outperform supervised methods across the vast majority of medical downstream tasks with few-shot and many-shot linear learning. Of the self-supervised methods, the Bootstrap Your Own Latent (BYOL) method was found to be the best overall performer. More careful treatment of hyperparameters is needed to come to conclusive results about many-shot finetune learning.
- Q2.
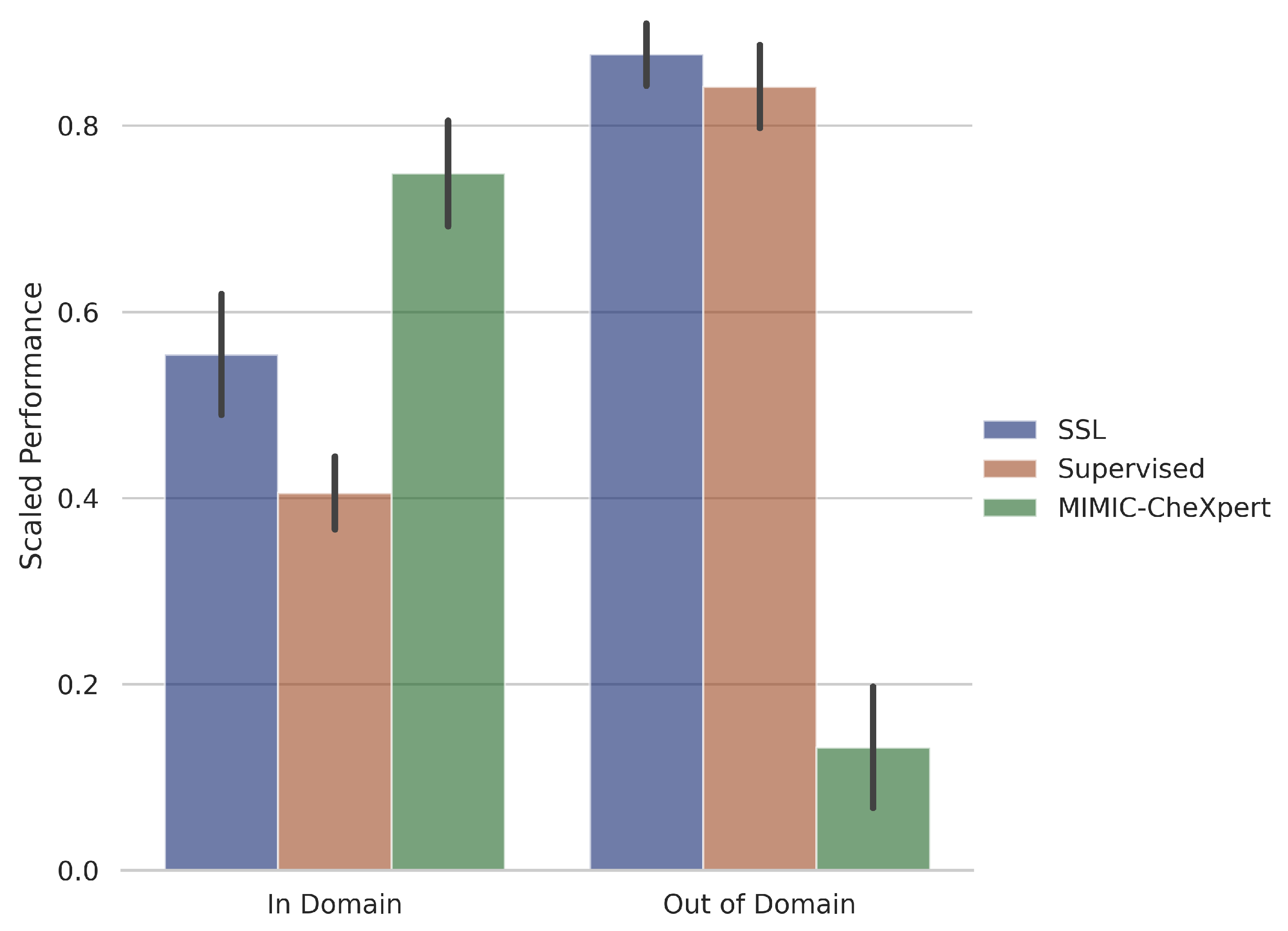
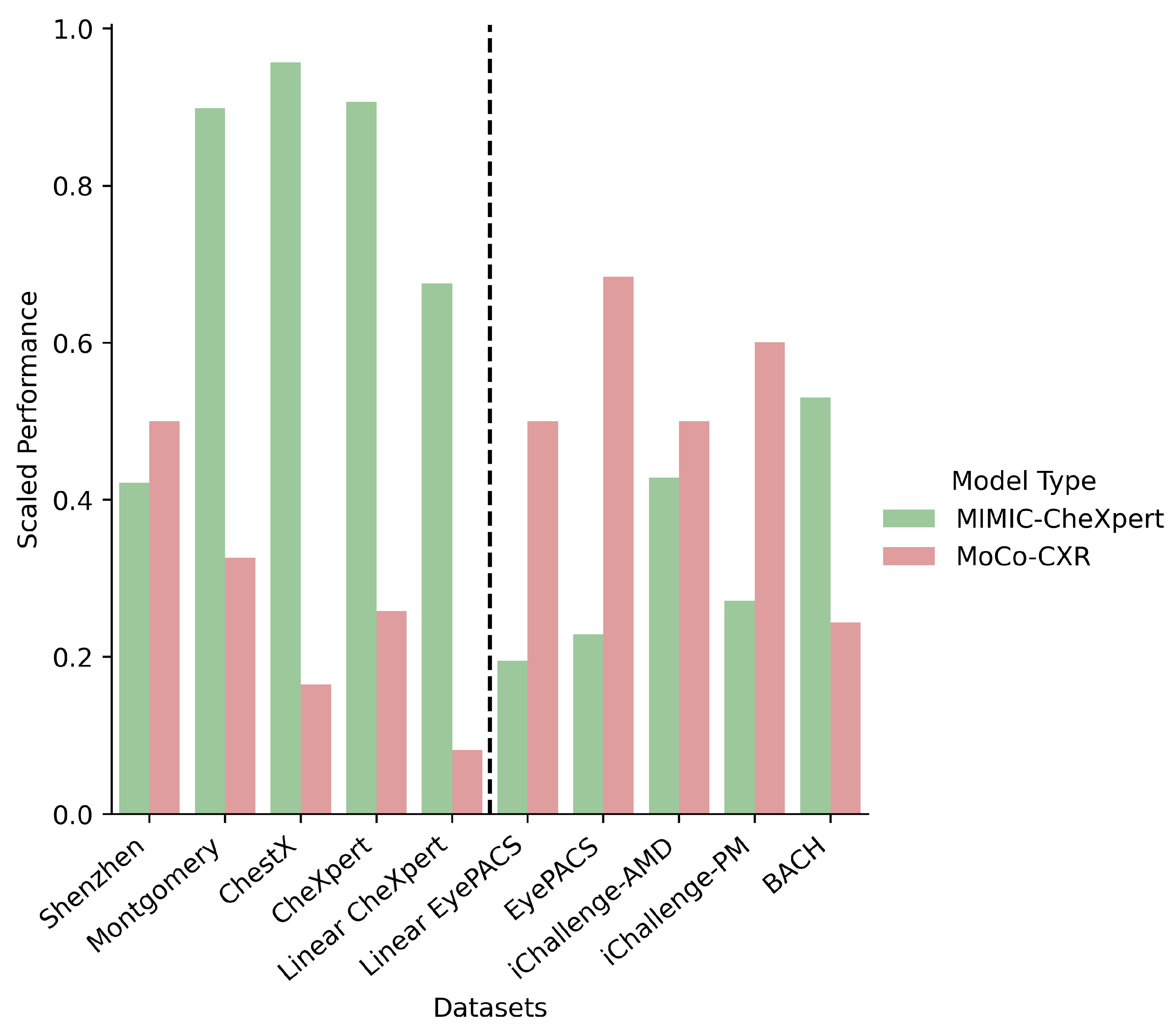
- Is there a clear benefit to domain-specific self-supervised pretraining?A: Yes, provided the downstream task is also in the same domain. Domain-specific pretrained self-supervised models, trained on chest X-rays, were much better than self-supervised or supervised models on two of the four chest X-ray datasets. However, it is observed that the performance drops off significantly as the domain of the dataset shifts, and hence even the slight shift in domain of the remaining two chest X-ray datasets was enough to drastically reduce the classification accuracy.
- Q3.
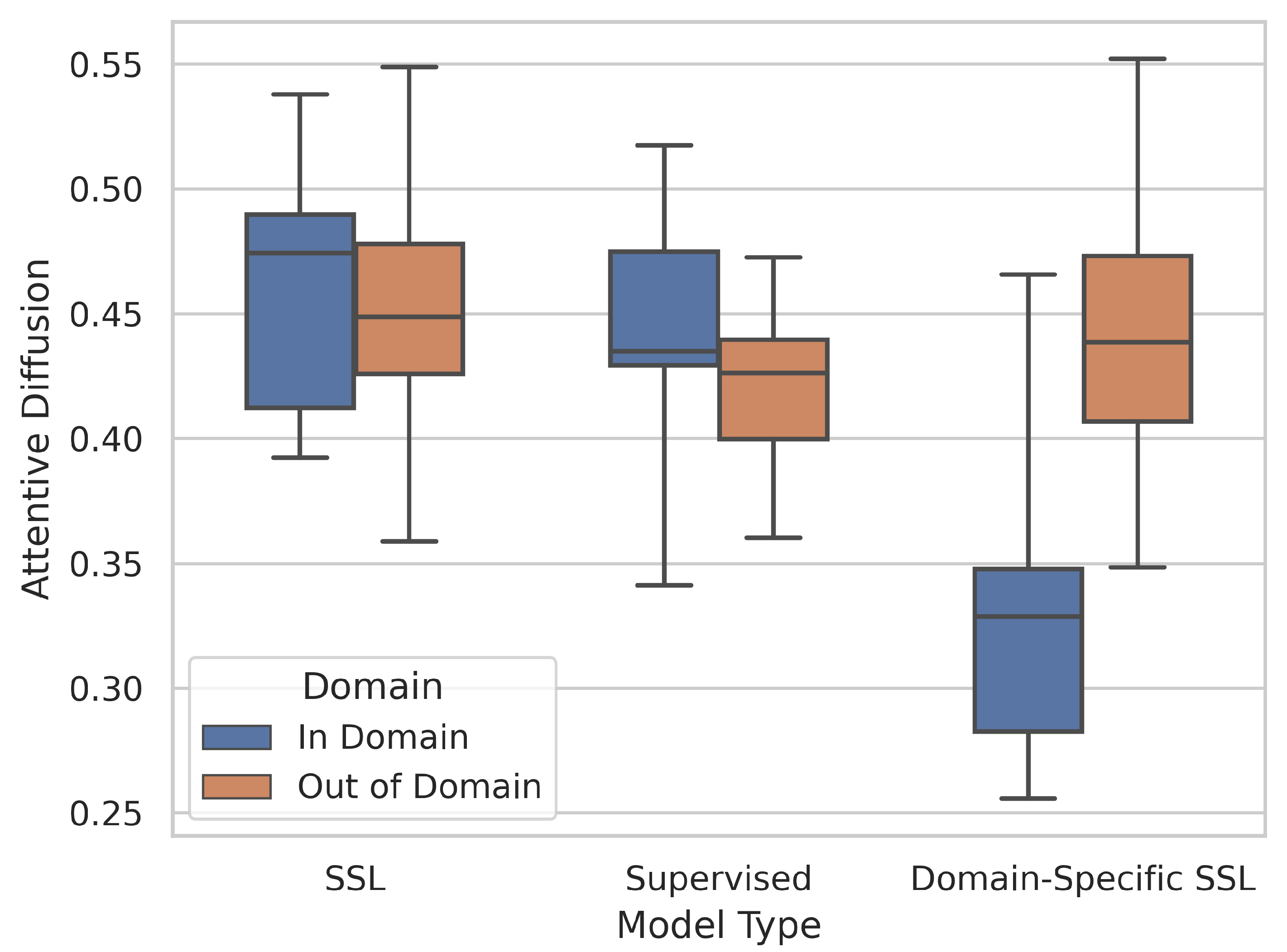
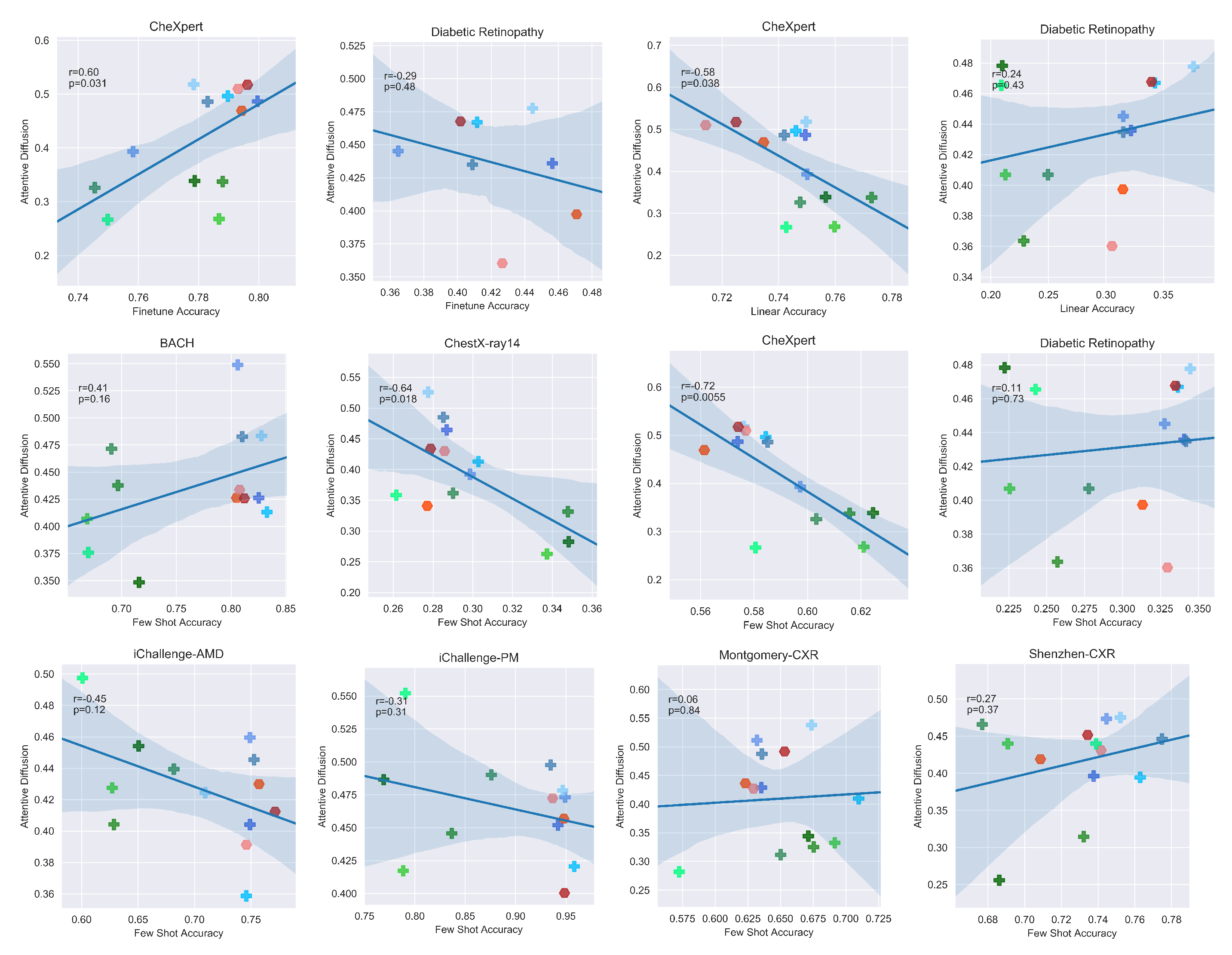
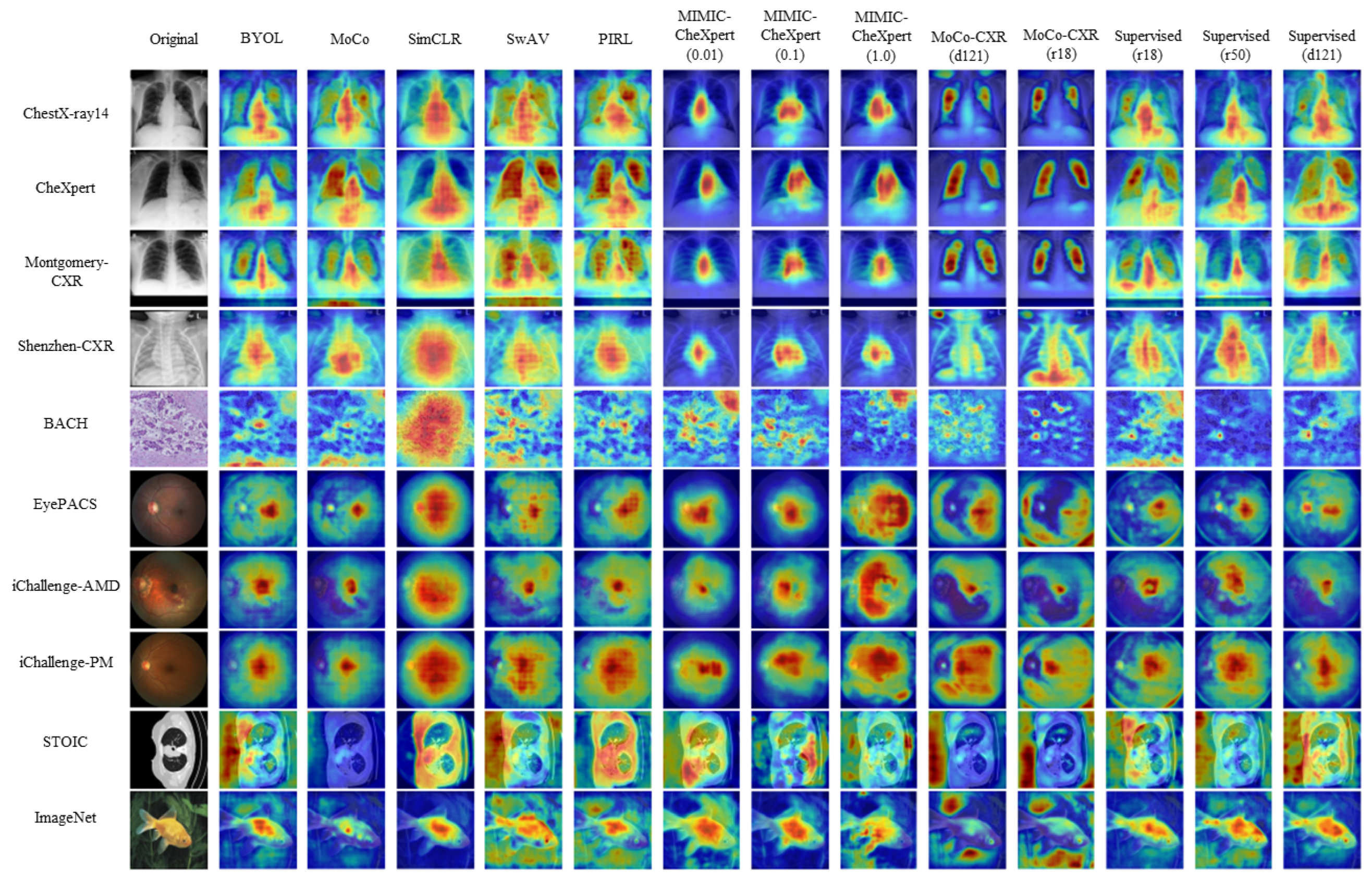
- What information is encoded in the pretrained features?A: The domain-specific models appear to encode only very specific areas for in-domain data with a significantly lower attentive diffusion than the other types of models. Due to the nature of disease manifestations occurring as small texture differences in medical images, this hyperfocus on key areas may help explain its improved performance compared to the more holistic approach of SSL and supervised models.
Contribution and Novelty
- 1.
- To the best of our knowledge, this is the first large scale comparison of pretrained SSL models to standard pretrained models for transferring to medical images.
- 2.
- This is also one of the first attempts to directly compare the transferability of SSL models pretrained on ImageNet vs. those pretrained on a medical domain specific task for a variety of different medical imaging datasets, allowing us to directly quantify the benefits of both approaches.
- 3.
- Finally, we are able to show through the analysis of the encoded features how in domain pretraining leads to a more focused feature extraction than standard ImageNet pretraining, which can massively boost performance for in domain tasks at the expense of generalisability.
2. Overview of Self-Supervised Learning
3. Related Work
3.1. Transfer Performance of Self-Supervised Models
3.2. Domain-Specific Self-Supervised Learning for Medical Image Analysis
3.3. Generalisability of Self-Supervised Features
4. Materials and Methods
4.1. Models
4.2. Datasets
4.2.1. Preliminaries
4.2.2. Preprocessing
4.3. Evaluation Setup
4.3.1. Few-Shot Learning
4.3.2. Many-Shot Learning
4.4. Analysis Tools
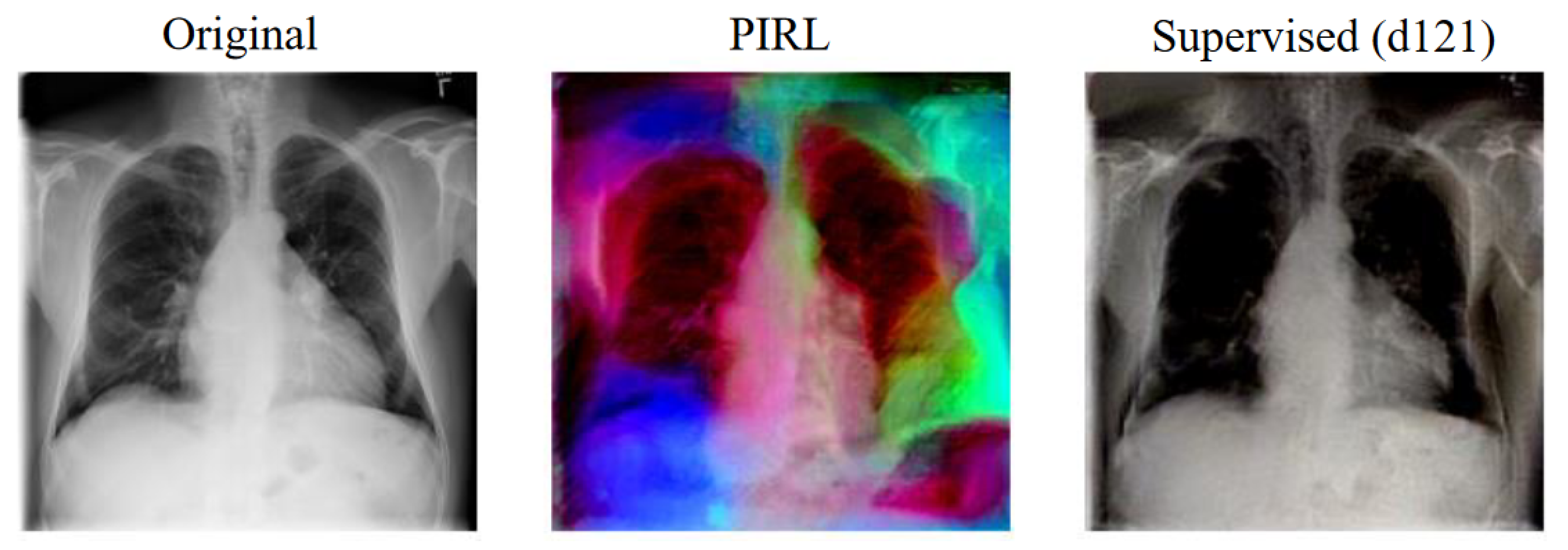
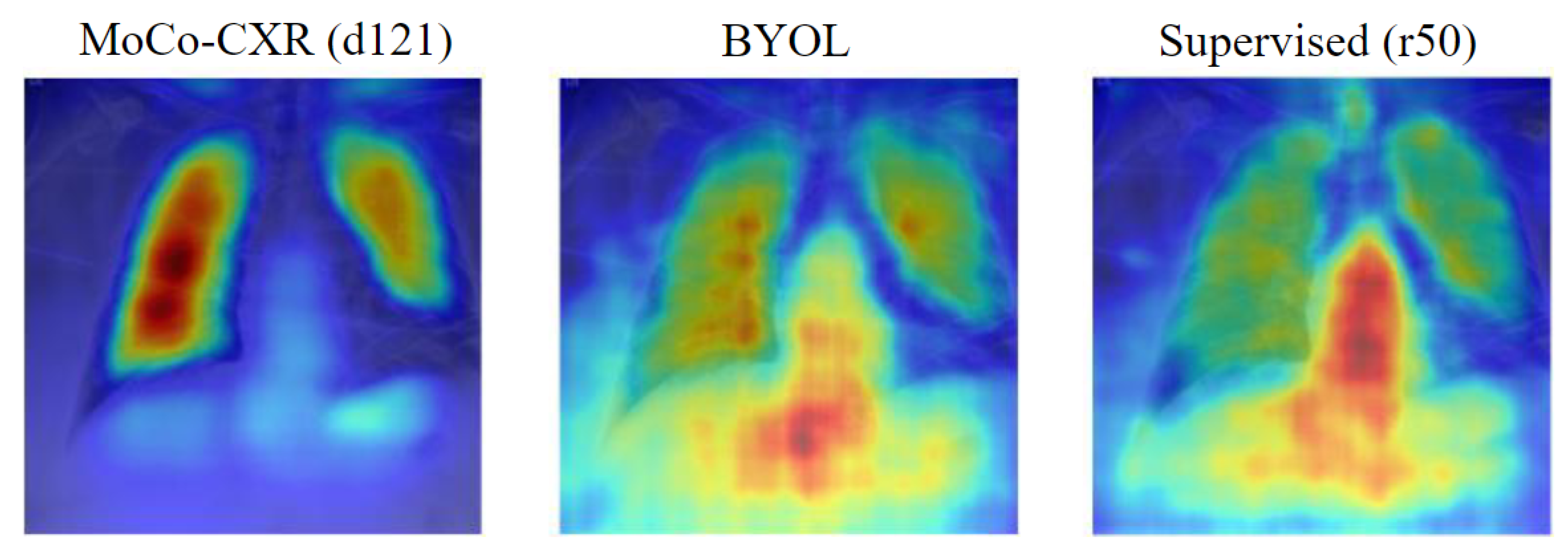
4.4.1. Saliency Maps
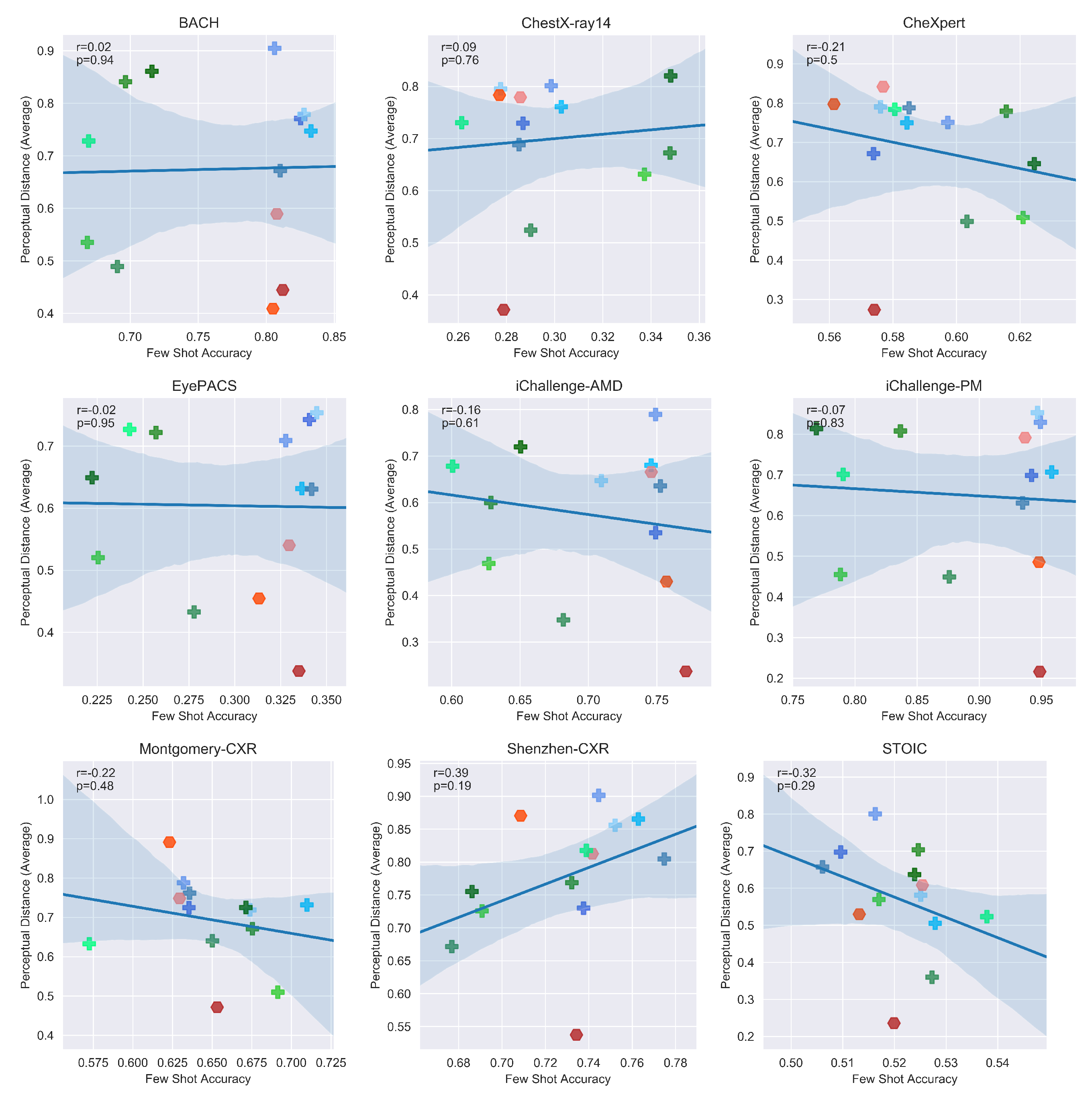
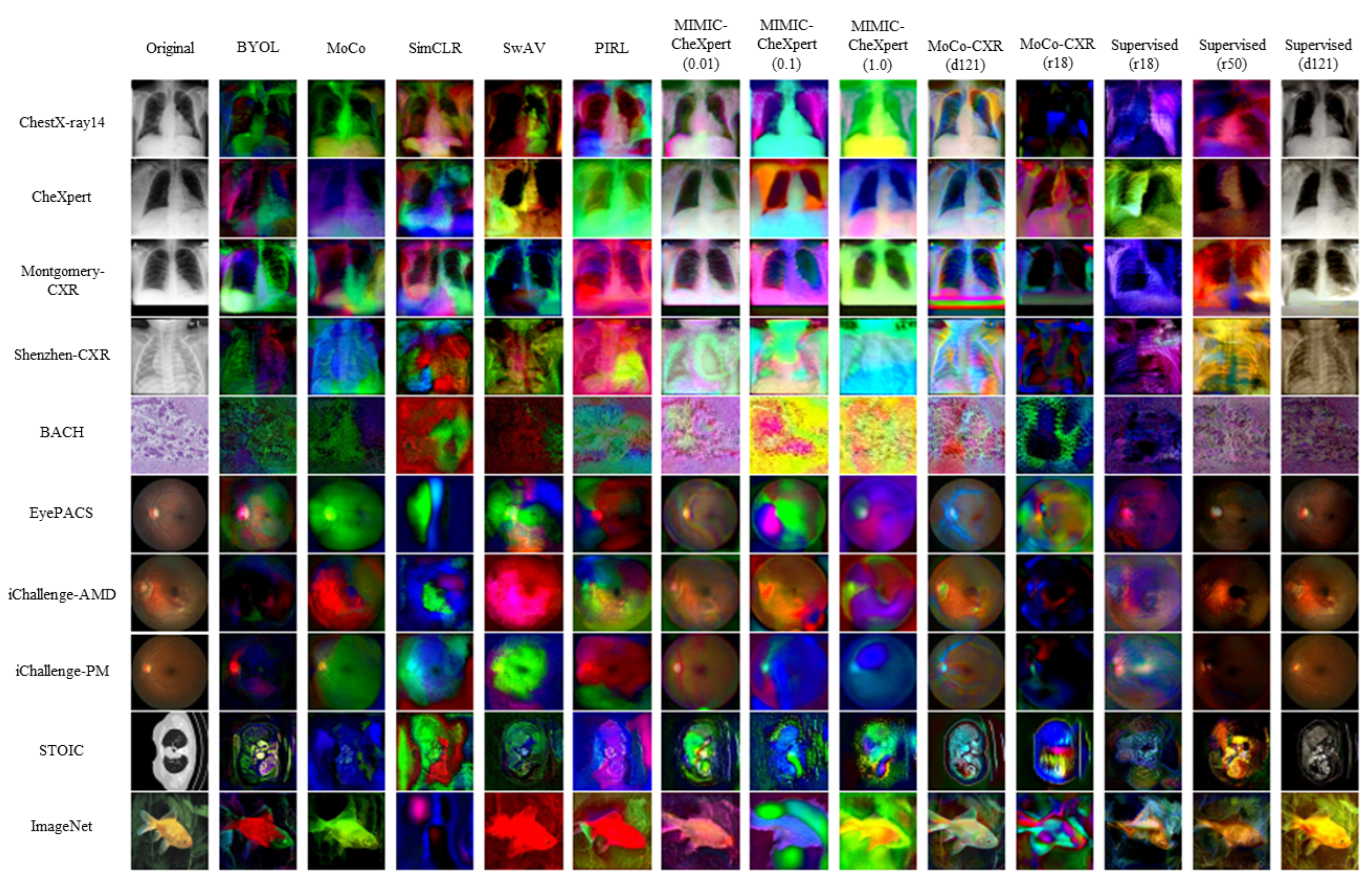
4.4.2. Deep Image Prior Reconstructions
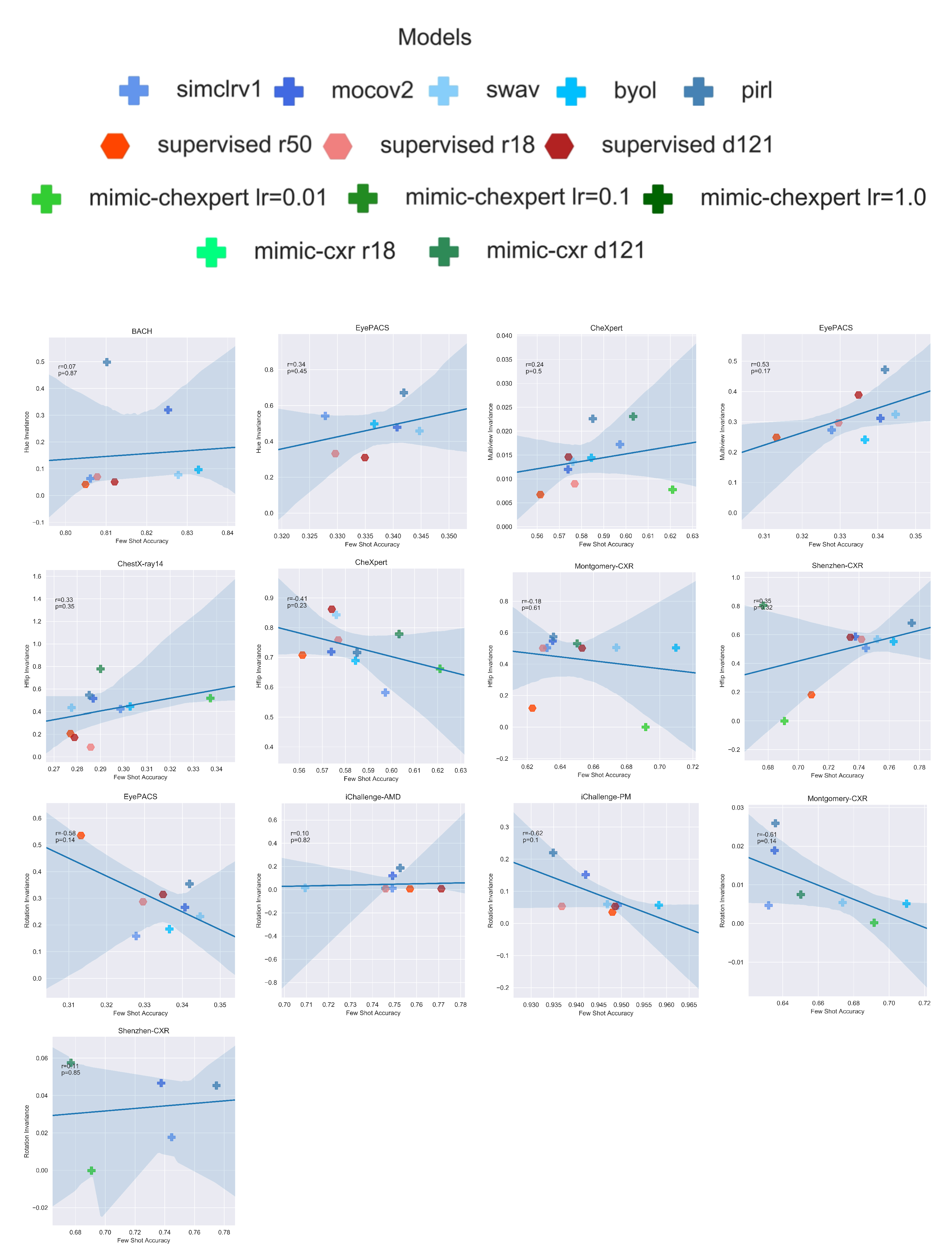
4.4.3. Invariances
5. Results
5.1. How Do Supervised, Self-Supervised Methods Compare for Medical Downstream Tasks?
5.2. Is There a Clear Benefit to Domain-Specific Self-Supervised Pretraining?
5.3. What Information Is Encoded in the Pretrained Features?
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SSL | Self-supervised learning |
| SimCLR | Simple framework for Contrastive Learning of visual representations |
| (see Section 2) | |
| PIRL | Pretext-Invariant Representation learning (see Section 2) |
| MOCO | Momentum Contrast (see Section 2) |
| BYOL | Bootstrap Your Own Latent (see Section 2) |
| SwAV | Swapping Assignments Between Views (see Section 2) |
| CXR | Chest X-rays |
| BHM | Breast Histology Microscopy slides |
| MIMIC-CheXpert | Self-supervised model pre-trained on chest X-rays dataset |
| (see Section 4.1) | |
| MoCo-CXR | Self-supervised model pre-trained on chest X-rays dataset |
| (see Section 4.1) | |
| iChalleng-PM | Pathological Myopia (PM) retinal fundus images dataset (see Section 4.2) |
| iChallenge-AMD | Age-related Macular degeneration (AMD) retinal images dataset |
| (see Section 4.2) | |
| EyePACS | Retinal images dataset for diabetic retinopathy detection (see Section 4.2) |
| BACH | Breast Cancer Histology images dataset (see Section 4.2) |
Appendix A. Invariances

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EyePACS | iChallenge-AMD | iChallenge-PM | BACH | |
|---|---|---|---|---|
| SimCLR | 0.159 | 0.011 | 0.056 | 0.063 |
| MoCo | 0.266 | 0.120 | 0.152 | 0.319 |
| SwAV | 0.232 | 0.015 | 0.059 | 0.077 |
| BYOL | 0.185 | 0.012 | 0.057 | 0.097 |
| PIRL | 0.354 | 0.187 | 0.220 | 0.498 |
| CheXpert | ChestX | Shenzhen | Montgomery | |
|---|---|---|---|---|
| SimCLR | 0.582 | 0.423 | 0.506 | 0.503 |
| MoCo | 0.719 | 0.517 | 0.587 | 0.547 |
| SwAV | 0.843 | 0.433 | 0.569 | 0.505 |
| BYOL | 0.689 | 0.445 | 0.551 | 0.504 |
| PIRL | 0.716 | 0.547 | 0.682 | 0.574 |
| MIMIC-CheXpert | 0.662 | 0.518 | 0.001 | 0.003 |
| MoCo-CXR | 0.997 | 0.778 | 0.803 | 0.530 |
| CheXpert | EyePACS | |
|---|---|---|
| SimCLR | 0.017 | 0.273 |
| MoCo | 0.012 | 0.312 |
| SwAV | 0.014 | 0.325 |
| BYOL | 0.014 | 0.241 |
| PIRL | 0.023 | 0.472 |
| MIMIC-CheXpert | 0.008 | |
| MoCo-CXR | 0.024 |
Appendix B. Perceptual Distances
| Shenzhen | Montomery | EyePACS | ChestX | BACH | iC-AMD | iC-PM | CheXpert | ImageNet | |
|---|---|---|---|---|---|---|---|---|---|
| SimCLR | 0.95 | 0.80 | 0.75 | 0.80 | 0.92 | 0.76 | 0.86 | 0.78 | 0.78 |
| MoCo | 0.79 | 0.74 | 0.72 | 0.70 | 0.74 | 0.54 | 0.77 | 0.70 | 0.50 |
| SwAV | 0.90 | 0.75 | 0.78 | 0.77 | 0.85 | 0.64 | 0.90 | 0.76 | 0.74 |
| BYOL | 0.96 | 0.76 | 0.66 | 0.76 | 0.80 | 0.73 | 0.72 | 0.77 | 0.60 |
| PIRL | 0.80 | 0.76 | 0.66 | 0.68 | 0.66 | 0.63 | 0.64 | 0.79 | 0.62 |
| Supervised (r50) | 0.84 | 0.89 | 0.47 | 0.76 | 0.37 | 0.46 | 0.50 | 0.80 | 0.51 |
| Supervised (r18) | 0.90 | 0.76 | 0.55 | 0.80 | 0.64 | 0.68 | 0.84 | 0.82 | 0.56 |
| Supervised (d121) | 0.51 | 0.45 | 0.33 | 0.34 | 0.49 | 0.22 | 0.19 | 0.23 | 0.48 |
| MIMIC-CheXpert | 0.79 | 0.70 | 0.71 | 0.81 | 0.79 | 0.74 | 0.84 | 0.72 | 0.75 |
| MoCo-CXR | 0.79 | 0.64 | 0.68 | 0.72 | 0.72 | 0.68 | 0.71 | 0.75 | 0.69 |
| Shenzhen | Montomery | EyePACS | ChestX | BACH | iC-AMD | iC-PM | CheXpert | ImageNet | |
|---|---|---|---|---|---|---|---|---|---|
| SimCLR | 0.92 | 0.77 | 0.64 | 0.79 | 0.87 | 0.72 | 0.73 | 0.69 | 0.80 |
| MoCo | 0.67 | 0.67 | 0.60 | 0.67 | 0.71 | 0.43 | 0.50 | 0.61 | 0.43 |
| SwAV | 0.83 | 0.68 | 0.65 | 0.81 | 0.65 | 0.56 | 0.71 | 0.75 | 0.76 |
| BYOL | 0.84 | 0.65 | 0.51 | 0.74 | 0.61 | 0.58 | 0.58 | 0.71 | 0.50 |
| PIRL | 0.85 | 0.76 | 0.52 | 0.66 | 0.56 | 0.50 | 0.49 | 0.68 | 0.59 |
| Supervised (r50) | 0.89 | 0.89 | 0.34 | 0.81 | 0.26 | 0.32 | 0.38 | 0.78 | 0.38 |
| Supervised (r18) | 0.79 | 0.73 | 0.46 | 0.76 | 0.47 | 0.57 | 0.68 | 0.79 | 0.46 |
| Supervised (d121) | 0.53 | 0.40 | 0.22 | 0.32 | 0.27 | 0.14 | 0.14 | 0.40 | 0.39 |
| MIMIC-CheXpert | 0.73 | 0.64 | 0.62 | 0.75 | 0.80 | 0.63 | 0.72 | 0.76 | 0.73 |
| MoCo-CXR | 0.88 | 0.60 | 0.63 | 0.72 | 0.65 | 0.62 | 0.61 | 0.78 | 0.64 |
| Shenzhen | Montomery | EyePACS | ChestX | BACH | iC-AMD | iC-PM | CheXpert | ImageNet | |
|---|---|---|---|---|---|---|---|---|---|
| SimCLR | 0.84 | 0.79 | 0.74 | 0.81 | 0.92 | 0.88 | 0.90 | 0.79 | 0.89 |
| MoCo | 0.73 | 0.77 | 0.91 | 0.81 | 0.87 | 0.64 | 0.83 | 0.70 | 0.64 |
| SwAV | 0.84 | 0.73 | 0.83 | 0.80 | 0.83 | 0.75 | 0.96 | 0.86 | 0.93 |
| BYOL | 0.79 | 0.78 | 0.73 | 0.78 | 0.82 | 0.74 | 0.82 | 0.76 | 0.74 |
| PIRL | 0.77 | 0.76 | 0.72 | 0.72 | 0.79 | 0.77 | 0.76 | 0.89 | 0.78 |
| Supervised (r50) | 0.88 | 0.89 | 0.56 | 0.77 | 0.59 | 0.51 | 0.57 | 0.81 | 0.61 |
| Supervised (r18) | 0.75 | 0.76 | 0.61 | 0.77 | 0.65 | 0.75 | 0.85 | 0.91 | 0.67 |
| Supervised (d121) | 0.57 | 0.56 | 0.46 | 0.45 | 0.57 | 0.35 | 0.32 | 0.19 | 0.59 |
| MIMIC-CheXpert | 0.82 | 0.85 | 0.84 | 0.91 | 1.00 | 0.79 | 0.89 | 0.86 | 0.87 |
| MoCo-CXR | 0.79 | 0.69 | 0.87 | 0.75 | 0.81 | 0.73 | 0.79 | 0.82 | 0.83 |
Appendix C. Attentive Diffusions
| Shenzhen | Montomery | EyePACS | ChestX | BACH | iC-AMD | iC-PM | CheXpert | ImageNet | |
|---|---|---|---|---|---|---|---|---|---|
| SimCLR | 0.47 | 0.51 | 0.45 | 0.39 | 0.55 | 0.46 | 0.47 | 0.39 | 0.26 |
| MoCo | 0.40 | 0.43 | 0.44 | 0.46 | 0.43 | 0.40 | 0.45 | 0.49 | 0.41 |
| SwAV | 0.48 | 0.54 | 0.48 | 0.53 | 0.48 | 0.42 | 0.48 | 0.52 | 0.49 |
| BYOL | 0.39 | 0.41 | 0.47 | 0.41 | 0.41 | 0.36 | 0.42 | 0.50 | 0.39 |
| PIRL | 0.45 | 0.49 | 0.43 | 0.49 | 0.48 | 0.45 | 0.50 | 0.49 | 0.47 |
| Supervised (r50) | 0.42 | 0.44 | 0.40 | 0.34 | 0.43 | 0.43 | 0.46 | 0.47 | 0.43 |
| Supervised (r18) | 0.43 | 0.43 | 0.36 | 0.43 | 0.43 | 0.39 | 0.47 | 0.51 | 0.35 |
| Supervised (d121) | 0.45 | 0.49 | 0.47 | 0.43 | 0.43 | 0.41 | 0.40 | 0.52 | 0.40 |
| MIMIC-CheXpert | 0.44 | 0.34 | 0.48 | 0.33 | 0.44 | 0.45 | 0.49 | 0.34 | 0.45 |
| MoCo-CXR | 0.47 | 0.31 | 0.47 | 0.36 | 0.47 | 0.50 | 0.55 | 0.33 | 0.42 |
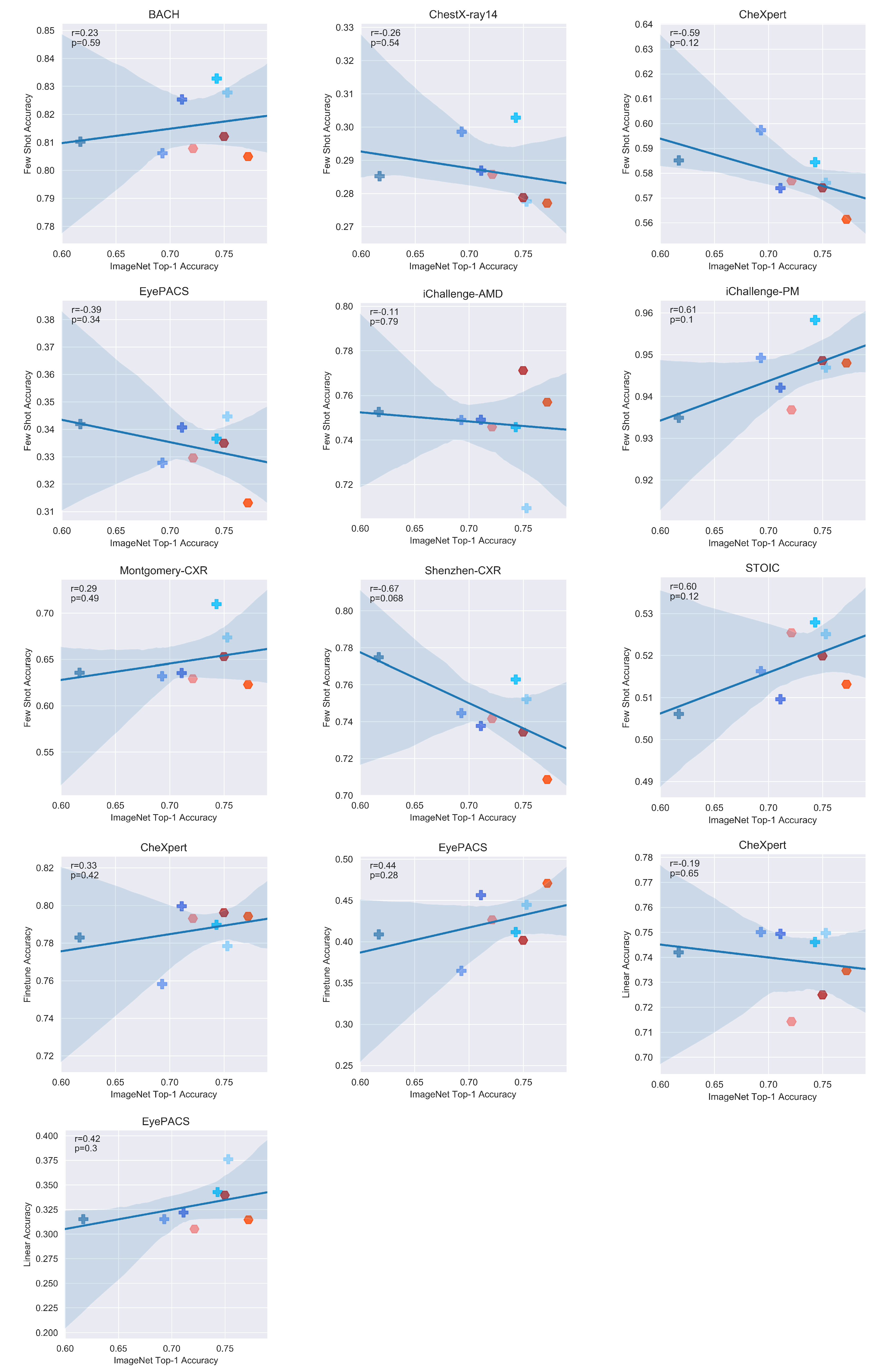
Appendix D. Additional Figures






References
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Girshick, R.B. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging Properties in Self-Supervised Vision Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 11–17 October 2021. [Google Scholar]
- Jain, J.; Singh, A.; Orlov, N.; Huang, Z.; Li, J.; Walton, S.; Shi, H. SeMask: Semantically Masked Transformers for Semantic Segmentation. arXiv 2021, arXiv:2112.12782. [Google Scholar] [CrossRef]
- Yuan, Z.; Yan, Y.; Sonka, M.; Yang, T. Large-scale Robust Deep AUC Maximization: A New Surrogate Loss and Empirical Studies on Medical Image Classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 11–17 October 2021. [Google Scholar]
- Li, T.; Bo, W.; Hu, C.; Hong, K.; Liu, H.; Wang, K.; Fu, H. Applications of Deep Learning in Fundus Images: A Review. Med. Image Anal. 2021, 69, 101971. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Kuprel, B.; Novoa, R.; Ko, J.; Swetter, S.; Blau, H.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lee, S.; Seo, J.B.; Yun, J.; Cho, Y.H.; Vogel-Claussen, J.; Schiebler, M.; Gefter, W.; Beek, E.; Goo, J.M.; Lee, K.; et al. Deep Learning Applications in Chest Radiography and Computed Tomography: Current State of the Art. J. Thorac. Imaging 2019, 34, 1. [Google Scholar] [CrossRef] [Green Version]
- Shurrab, S.; Duwairi, R. Self-supervised learning methods and applications in medical imaging analysis: A survey. Peer J Computer Sci. 2022, 8, e1045. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef]
- Sowrirajan, H.; Yang, J.; Ng, A.Y.; Rajpurkar, P. MoCo Pretraining Improves Representation and Transferability of Chest X-ray Models. In Proceedings of the 4th Conference on Medical Imaging with Deep Learning, Lubeck, Germany, 7–9 July 2021. [Google Scholar]
- Sriram, A.; Muckley, M.J.; Sinha, K.; Shamout, F.; Pineau, J.; Geras, K.J.; Azour, L.; Aphinyanaphongs, Y.; Yakubova, N.; Moore, W. COVID-19 Prognosis via Self-Supervised Representation Learning and Multi-Image Prediction. arXiv 2021, arXiv:2101.04909. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–21 June 2009; pp. 248–255. [Google Scholar]
- Raghu, M.; Zhang, C.; Kleinberg, J.M.; Bengio, S. Transfusion: Understanding Transfer Learning with Applications to Medical Imaging. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Ericsson, L.; Gouk, H.; Hospedales, T.M. How Well Do Self-Supervised Models Transfer? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 5414–5423. [Google Scholar]
- Li, Y.; Shen, L. Skin Lesion Analysis Towards Melanoma Detection Using Deep Learning Network. Sensors 2017, 18, 556. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G.E. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; pp. 1597–1607. [Google Scholar]
- Misra, I.; van der Maaten, L. Self-Supervised Learning of Pretext-Invariant Representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6707–6717. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R.B. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Grill, J.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.Á.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Ericsson, L.; Gouk, H.; Loy, C.C.; Hospedales, T.M. Self-Supervised Representation Learning: Introduction, Advances and Challenges. IEEE Signal Process. Mag. 2021, 39, 42–62. [Google Scholar] [CrossRef]
- Truong, T.; Mohammadi, S.; Lenga, M. How Transferable Are Self-supervised Features in Medical Image Classification Tasks? Proc. Mach. Learn. Res. 2021, 158, 54–74. [Google Scholar]
- Chaves, L.; Bissoto, A.; Valle, E.; Avila, S. An Evaluation of Self-Supervised Pre-Training for Skin-Lesion Analysis. arXiv 2021, arXiv:2106.09229. [Google Scholar] [CrossRef]
- Azizi, S.; Mustafa, B.; Ryan, F.; Beaver, Z.; Freyberg, J.; Deaton, J.; Loh, A.; Karthikesalingam, A.; Kornblith, S.; Chen, T.; et al. Big Self-Supervised Models Advance Medical Image Classification. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3458–3468. [Google Scholar] [CrossRef]
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.L.; Shpanskaya, K.S.; et al. CheXpert: A Large Chest Radiograph Dataset with Uncertainty Labels and Expert Comparison. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 590–597. [Google Scholar]
- Jaeger, S.; Candemir, S.; Antani, S.; Wáng, Y.X.; Lu, P.X.; Thoma, G. Two public chest X-ray datasets for computer-aided screening of pulmonary diseases. Quant. Imaging Med. Surg. 2014, 4, 475–477. [Google Scholar] [CrossRef]
- Johnson, A.E.W.; Pollard, T.J.; Berkowitz, S.J.; Greenbaum, N.R.; Lungren, M.P.; Deng, C.; Mark, R.G.; Horng, S. MIMIC-CXR: A large publicly available database of labeled chest radiographs. Sci. Data 2019, 6, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Navarro, F.; Watanabe, C.; Shit, S.; Sekuboyina, A.; Peeken, J.C.; Combs, S.E.; Menze, B.H. Self-Supervised Pretext Tasks in Model Robustness & Generalizability: A Revisit from Medical Imaging Perspective. In Proceedings of the 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Glasgow, UK, 11–15 July 2022; pp. 5074–5079. [Google Scholar]
- Zhao, N.; Wu, Z.; Lau, R.W.H.; Lin, S. What makes instance discrimination good for transfer learning? arXiv 2020, arXiv:2006.06606. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved Baselines with Momentum Contrastive Learning. arXiv 2020, arXiv:2003.04297. [Google Scholar] [CrossRef]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2097–2106. [Google Scholar]
- Fu, H.; Li, F.; Orlando, J.I.; Bogunović, H.; Sun, X.; Liao, J.; Xu, Y.; Zhang, S.; Zhang, X. PALM: PAthoLogic Myopia Challenge. 2019. Available online: https://ieee-dataport.org/documents/palm-pathologic-myopia-challenge (accessed on 14 April 2022).
- Aresta, G.; Araújo, T.; Kwok, S.; Chennamsetty, S.S.; Safwan, M.; Alex, V.; Marami, B.; Prastawa, M.; Chan, M.; Donovan, M.; et al. BACH: Grand challenge on breast cancer histology images. Med. Image Anal. 2019, 56, 122–139. [Google Scholar] [CrossRef]
- Li, L.; Qin, L.; Xu, Z.; Yin, Y.; Wang, X.; Kong, B.; Bai, J.; Lu, Y.; Fang, Z.; Song, Q.; et al. Using Artificial Intelligence to Detect COVID-19 and Community-acquired Pneumonia Based on Pulmonary CT: Evaluation of the Diagnostic Accuracy. Radiology 2020, 296, E65–E71. [Google Scholar] [CrossRef]
- Kwok, S. Multiclass Classification of Breast Cancer in Whole-Slide Images. In Proceedings of the Image Analysis and Recognition; Springer International Publishing: Cham, Switzerland, 2018; pp. 931–940. [Google Scholar]
- Guo, Y.; Codella, N.C.F.; Karlinsky, L.; Smith, J.R.; Rosing, T.; Feris, R.S. A New Benchmark for Evaluation of Cross-Domain Few-Shot Learning. arXiv 2019, arXiv:1912.07200. [Google Scholar] [CrossRef]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical Networks for Few-shot Learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. In Proceedings of the IEEE international Conference on Computer Vision, Venice, Italy, 22 – 29 October 2017; pp. 618–626. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V.S. Deep Image Prior. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Ericsson, L.; Gouk, H.; Hospedales, T.M. Why Do Self-Supervised Models Transfer? Investigating the Impact of Invariance on Downstream Tasks. arXiv 2021, arXiv:2111.11398. [Google Scholar] [CrossRef]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2016, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Zagoruyko, S.; Komodakis, N. Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar] [CrossRef]









| Dataset | Type | # Images | # Classes |
|---|---|---|---|
| CheXpert | CXR | 224,316 | 14 |
| Shenzhen-CXR | CXR | 662 | 2 |
| Montgomery-CXR | CXR | 138 | 2 |
| ChestX-ray14 | CXR | 112,120 | 14 |
| BACH | BHM | 400 | 4 |
| EyePACS | Fundus | 35,126 | 5 |
| iChallenge-AMD | Fundus | 400 | 2 |
| iChallenge-PM | Fundus | 400 | 2 |
| Models | |
|---|---|
| Supervised | Supervised pretrained on ImageNet (ResNet-50, ResNet-18, DenseNet-121) |
| Self-supervised | Self-Supervised pretrained on ImageNet (SimCLR-v1, MoCo-v2, PIRL, SwAV, BYOL) |
| Domain-specific Self-Supervised | Self-Supervised pretrained on chest X-rays (MIMIC-CheXpert, MoCo-CXR) |
| Datasets | |
| In-domain | All chest X-ray datasets (CheXpert, Shenzhen-CXR Montgomery-CXR, ChestX-ray14) |
| Out-of-domain | All non chest X-ray datasets (BACH, EyePACS, iChallenge-AMD, iChallenge-PM) |
| CheXpert | Shenzhen | Montgomery | ChestX | BACH | EyePACS | iC-AMD | iC-PM | |
|---|---|---|---|---|---|---|---|---|
| SimCLR-v1 | 59.73 ± 0.72 | 74.46 ± 0.66 | 63.20 ± 0.80 | 29.86 ± 0.46 | 80.61 ± 0.74 | 32.78 ± 0.42 | 47.90 ± 0.62 | 94.92 ± 0.32 |
| MoCo-v2 | 57.39 ± 0.75 | 73.76 ± 0.66 | 63.54 ± 0.74 | 28.69 ± 0.44 | 82.53 ± 0.71 | 34.07 ± 0.43 | 74.91 ± 0.64 | 94.21 ± 0.33 |
| SwAV | 57.61 ± 0.77 | 75.22 ± 0.65 | 67.38 ± 0.71 | 27.76 ± 0.44 | 82.78 ± 0.65 | 34.47 ± 0.43 | 70.94 ± 0.66 | 94.69 ± 0.31 |
| BYOL | 58.44 ± 0.74 | 76.29 ± 0.65 | 70.98 ± 0.67 | 30.28 ± 0.46 | 83.28 ± 0.66 | 33.66 ± 0.41 | 74.58 ± 0.61 | 95.83 ± 0.28 |
| PIRL | 58.51 ± 0.76 | 77.48 ± 0.60 | 63.58 ± 0.76 | 28.52 ± 0.44 | 81.02 ± 0.69 | 34.19 ± 0.41 | 75.26 ± 0.60 | 93.49 ± 0.35 |
| Supervised (r50) | 56.14 ± 0.76 | 70.86 ± 0.72 | 62.31 ± 0.75 | 27.71 ± 0.46 | 80.49 ± 0.68 | 31.32 ± 0.43 | 75.70 ± 0.64 | 94.80 ± 0.33 |
| Supervised (r18) | 57.69 ± 0.80 | 74.16 ± 0.66 | 62.94 ± 0.69 | 28.58 ± 0.40 | 80.78 ± 0.71 | 32.96 ± 0.41 | 74.59 ± 0.62 | 93.68 ± 0.35 |
| Supervised (d121) | 57.41 ± 0.78 | 73.43 ± 0.65 | 65.31 ± 0.67 | 27.88 ± 0.44 | 81.21 ± 0.70 | 33.49 ± 0.42 | 77.12 ± 0.60 | 94.86 ± 0.30 |
| MIMIC-CheXpert | 62.45 ± 0.75 | 73.22 ± 0.64 | 69.15 ± 0.66 | 34.82 ± 0.48 | 71.60 ± 0.98 | 25.71 ± 0.40 | 65.05 ± 0.72 | 83.66 ± 0.54 |
| MoCo-CXR | 60.33 ± 0.74 | 73.89 ± 0.64 | 65.02 ± 0.70 | 29.01 ± 0.46 | 69.07 ± 0.82 | 27.78 ± 0.41 | 68.17 ± 0.72 | 87.59 ± 0.47 |
| Linear | Finetune | |||
|---|---|---|---|---|
| CheXpert | EyePACS | CheXpert | EyePACS | |
| SimCLR | 75.01 | 31.51 | 75.82 | 36.48 |
| MoCo | 74.94 | 32.18 | 79.96 | 45.64 |
| SwAV | 74.97 | 37.61 | 77.84 | 44.47 |
| BYOL | 74.61 | 34.27 | 78.97 | 41.17 |
| PIRL | 74.20 | 31.51 | 78.30 | 40.89 |
| Supervised (r50) | 73.47 | 31.46 | 79.43 | 47.08 |
| Supervised (r18) | 71.43 | 30.52 | 79.31 | 42.66 |
| Supervised (d121) | 72.50 | 33.96 | 79.62 | 40.18 |
| MIMIC-CheXpert | 77.28 | 78.80 | ||
| MoCo-CXR | 74.76 | 74.98 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anton, J.; Castelli, L.; Chan, M.F.; Outters, M.; Tang, W.H.; Cheung, V.; Shukla, P.; Walambe, R.; Kotecha, K. How Well Do Self-Supervised Models Transfer to Medical Imaging? J. Imaging 2022, 8, 320. https://doi.org/10.3390/jimaging8120320
Anton J, Castelli L, Chan MF, Outters M, Tang WH, Cheung V, Shukla P, Walambe R, Kotecha K. How Well Do Self-Supervised Models Transfer to Medical Imaging? Journal of Imaging. 2022; 8(12):320. https://doi.org/10.3390/jimaging8120320
Chicago/Turabian StyleAnton, Jonah, Liam Castelli, Mun Fai Chan, Mathilde Outters, Wan Hee Tang, Venus Cheung, Pancham Shukla, Rahee Walambe, and Ketan Kotecha. 2022. "How Well Do Self-Supervised Models Transfer to Medical Imaging?" Journal of Imaging 8, no. 12: 320. https://doi.org/10.3390/jimaging8120320
APA StyleAnton, J., Castelli, L., Chan, M. F., Outters, M., Tang, W. H., Cheung, V., Shukla, P., Walambe, R., & Kotecha, K. (2022). How Well Do Self-Supervised Models Transfer to Medical Imaging? Journal of Imaging, 8(12), 320. https://doi.org/10.3390/jimaging8120320