
A Soft Coprocessor Approach for Developing Image and Video Processing Applications on FPGAs


Abstract
:1. Introduction
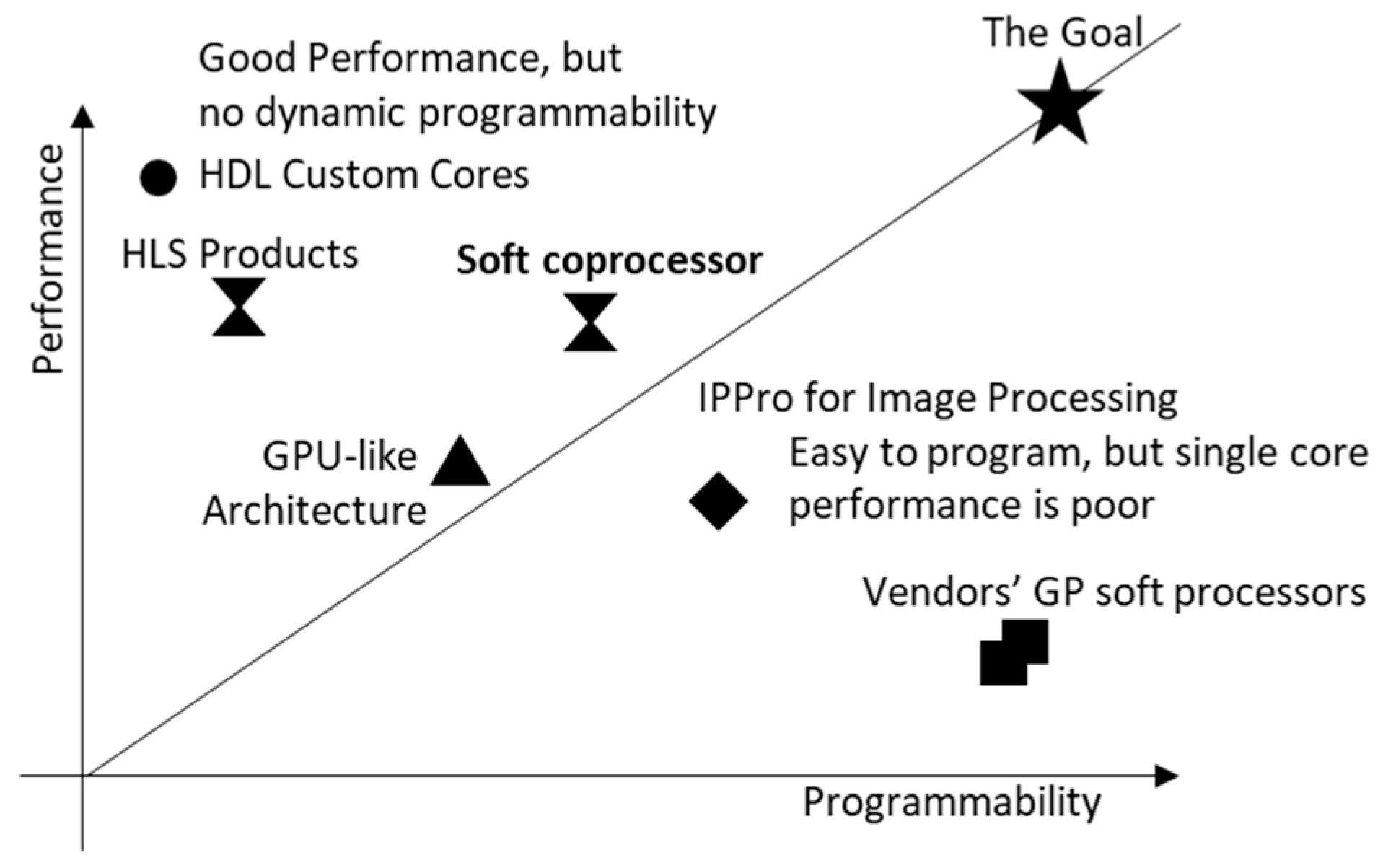
- It is hard to achieve both programmability and performance on FPGAs across all devices.
- Current vendors’ HLS tools still require users to be knowledgeable about hardware and the limitations of the tools.
- Lengthy synthesis time is a hindrance during experimental and iterative image processing system development.
- We propose the concept of customizable Soft Coprocessors (SCPs) as the basic building block for stream-based applications. We allow users to chain SCPs together so they can communicate directly with each other and not merely with the host. We use AXI4-Stream Interconnect to connect the SCPs in a system. In this way, we provide users with a flexible system that can be programmed as a Data Flow Graph (DFG). Users do not normally need to re-synthesize when they change the DFG.
- We provide a set of customizable Software Coprocessors based on the key concepts of Image Algebra (IA), including a range of point, neighborhood, and global operations.
- We provide a set of efficient hardware skeletons for defining new IA-like operations, where users need only supply their own C-based pixel-level function. This enables the creation of very efficient function-specific SCPs.
2. Background and Related Work
2.1. Current Tools for Designing FPGA Custom Cores in a High-Level Environment
2.2. Soft Processors
2.3. Image Algebra and Pixel Level Abstractions
2.4. FPGA-Based Image Processing
- Custom hardware designed using Verilog HDL or VHDL and combined with the vendor’s IPs.
- High-level synthesis tools used to convert a C-based representation of the algorithm to hardware.
- Algorithm mapped onto a network of soft processors.
2.5. Summary
3. User’s View of the Soft Coprocessor Approach
3.1. The Concept of Soft Coprocessors
- A standard interface for data transfer between soft coprocessors, allowing developers to add a soft coprocessor to a system without having to design custom I/O hardware.
- Each soft coprocessor can be parameterizable, allowing a degree of programmability and functional flexibility, but without requiring re-synthesis.
- The soft coprocessors should be able to interact with each other, and be formed into a DFG arrangement, to reduce communication and buffering overheads. This assumes a stream-based approach.
- Each soft coprocessor should be able to interact with the background control and communication system that manages the operation of the whole FPGA-based system.
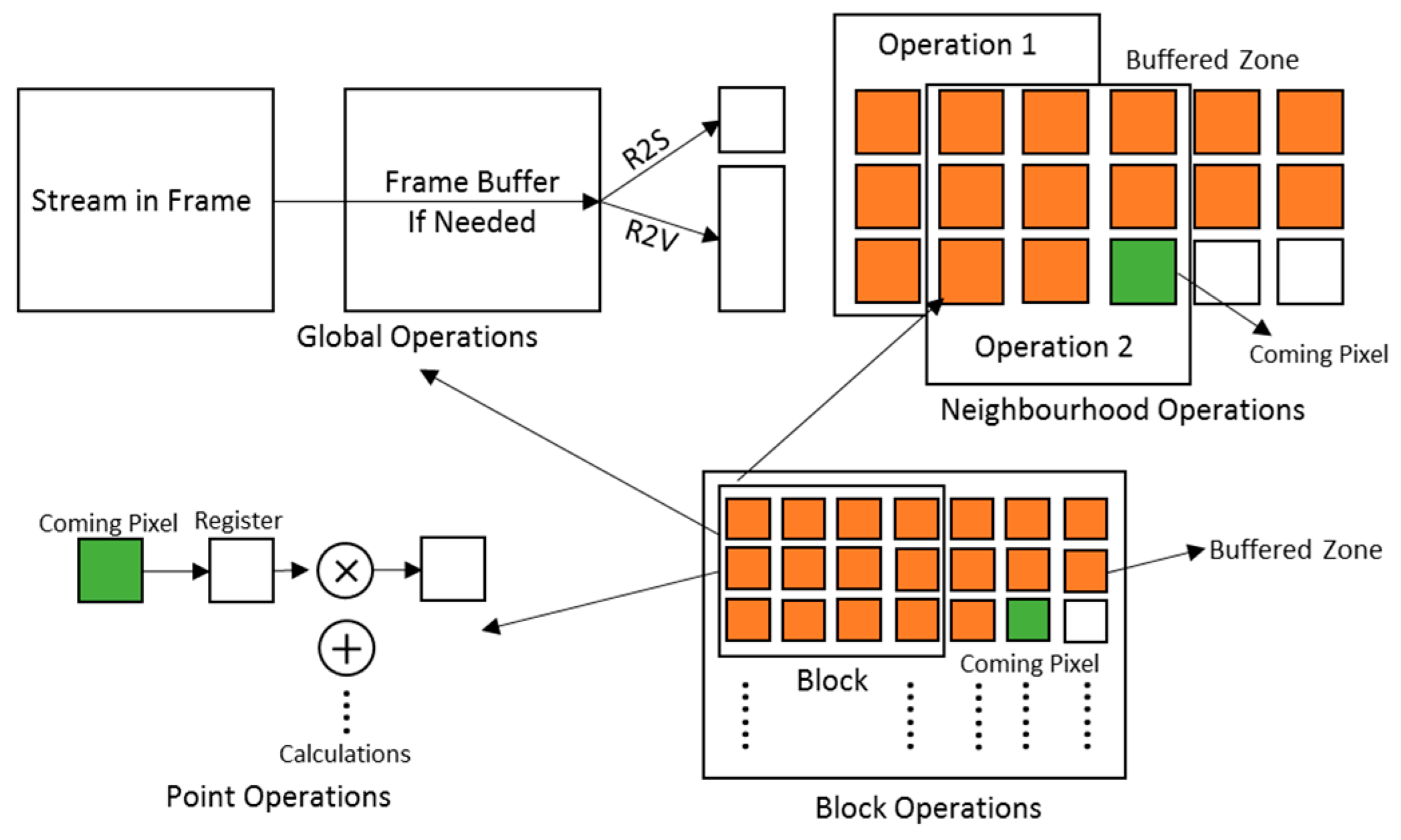
3.2. Soft Coprocessors for Stream-Based Image Processing
3.3. Single Image Algebra-Based SCPs
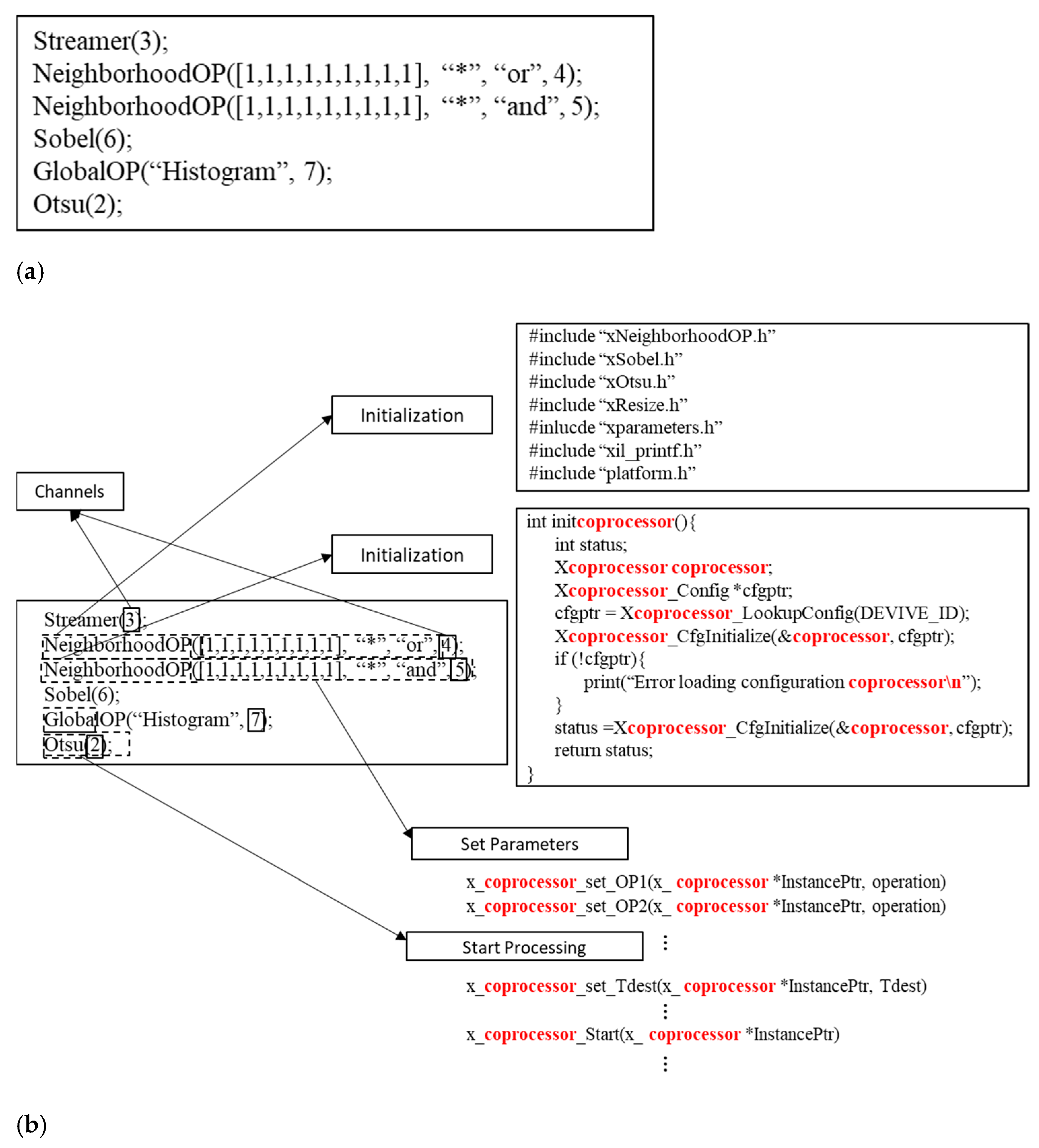
3.4. Chaining Multiple SCPs in a Data Flow Graph
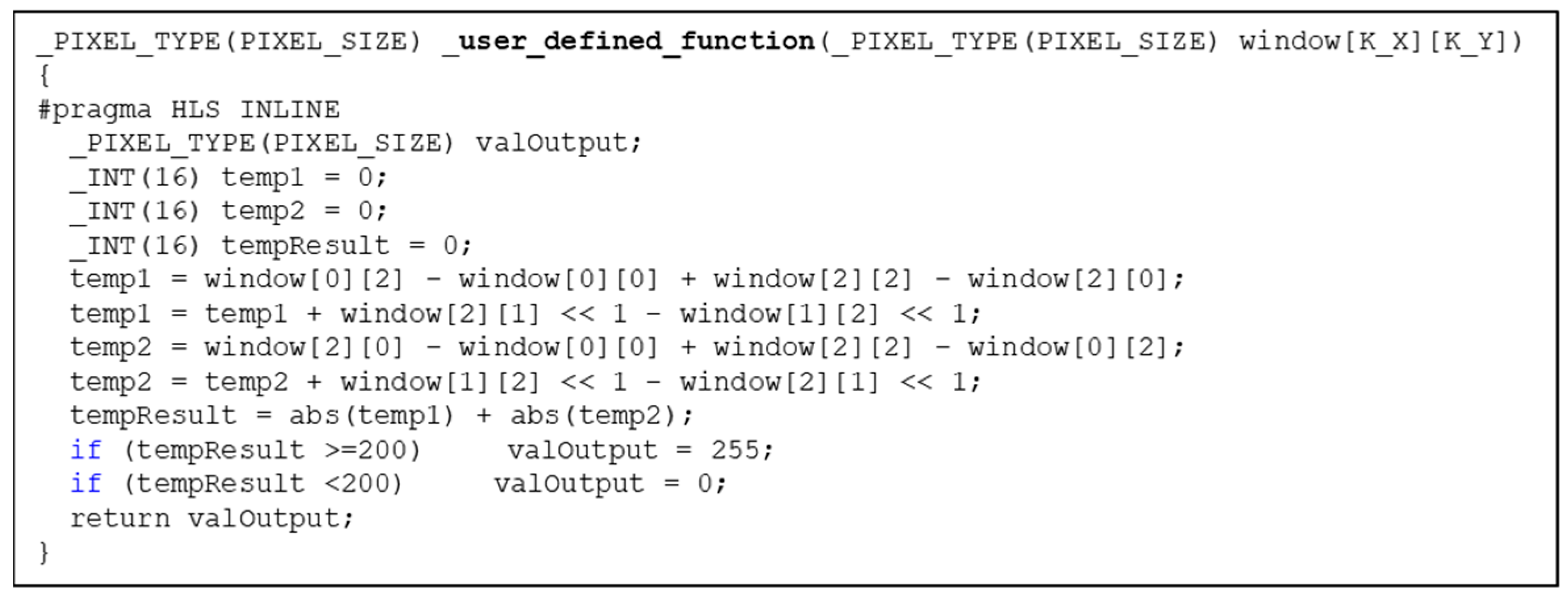
3.5. Skeleton SCPs for Function-Specific Coprocessors
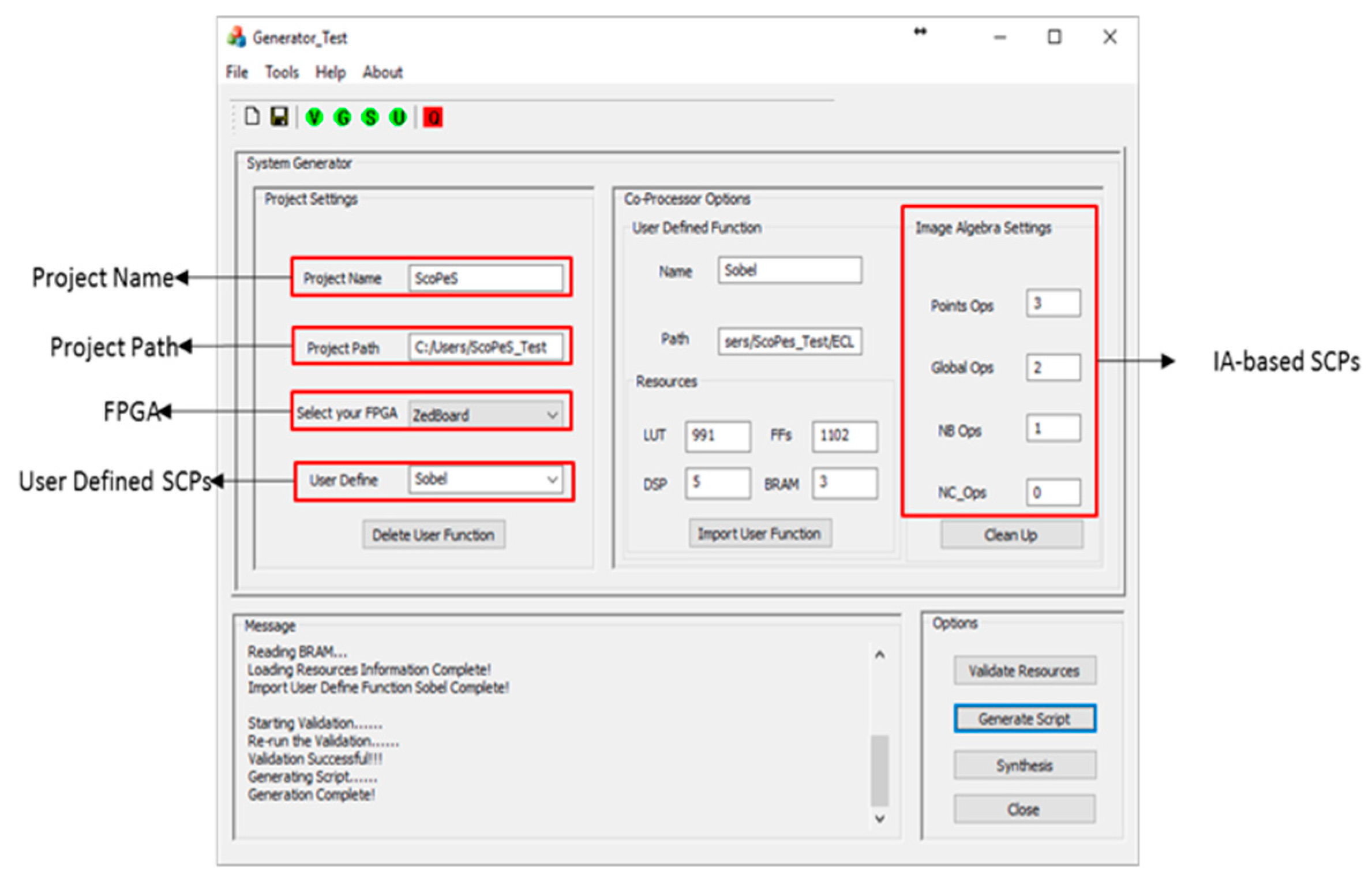
3.6. Generating SCP Configurations
3.7. Text-Based DFG Code Generator (TCG)
3.8. Using the SCoPeS Development Environment
- Decompose the desired algorithms into IA expressions.
- Select (or create) a suitable configuration from the Configuration library. (We can select a different one later if we run out of instances of a certain type of SCP).
- Define each algorithm as a Data Flow Graph (DFG) and use the TCG tool to set up the system defined by the DCG.
- Experiment with the system, until the functions and parameters are finalized.
- If necessary, design function-specific coprocessors to replace some of the IA-based SCPs selected in step 2.
- If step 5 was utilized, import the function-specific coprocessors into the system and resynthesize the system configuration.
4. Architectures and Implementations of Coprocessors
4.1. SCP Architectures for Image Algebra Operation Types
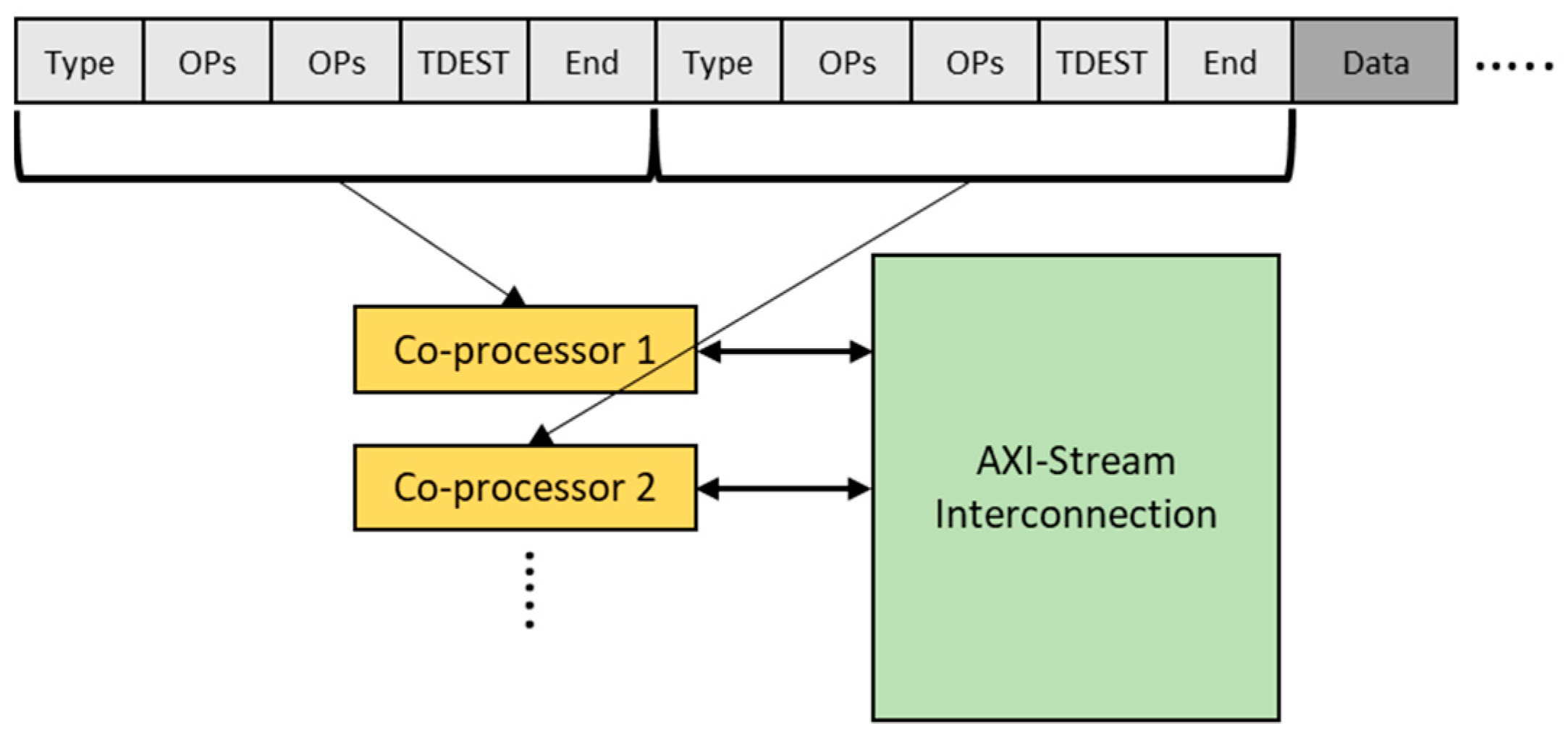
4.2. Communication between Coprocessors
4.3. Coding SCPs behind the Scenes
- Interface settings;
- Pipelining directives;
- Buffer settings;
- Special data types and hardware-level signal handling.
5. Evaluation and Comparisons
Performance and Hardware Utilization
6. Conclusions
- We propose the concept of soft coprocessors, which are single-instruction processors that can be parameterized to support a range of different functions. SCPs can be assembled into a DFG for efficient stream-based processing.
- The SCPs allow users to conveniently design and experiment with an image processing application by chaining SCPs together. We use AXI4-Stream Interconnect to connect all the SCPs in the system in a way that reflects the algorithm’s Data Flow Graph (DFG). In this way, we provide users with a flexible system that can be programmed as a textual DFG. Users do not need to re-synthesize when they change the DFG.
- We provide reusable SCP skeletons to allow developers to create efficient function-specific coprocessors without needing to know (much) about hardware structures.
- We have provided a set of generator tools which comprise the SCoPeS environment—a prototype IDE to support the SCP concept.
- Overall, we conclude that the soft coprocessor approach has the potential to deliver better performance than the soft processor approach, and can improve programmability over dedicated HDL cores for domain-specific applications while achieving competitive real-time performance and utilization.
- Our current work is designed only for image and video processing development, and is not a general-purpose tool. However, as a general rule, the coprocessor approach is suited to any application area that has an associated under-pinning algebra.
- Our implementation currently only supports relatively simple DFGs.
- Our tools do not yet support image partitioning for greater parallelism, which can be a useful additional technique for accelerating image processing applications. Updating our tools to include this option of a multi-core approach is a promising future development.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Wu, T.; Yang, Z. Animal tumor medical image analysis based on image processing techniques and embedded system. Microprocess. Microsyst. 2021, 81, 103671. [Google Scholar] [CrossRef]
- Khasanova, A.; Makhmutova, A.; Anikin, I. Image Denoising for Video Surveillance Cameras Based on Deep Learning Techniques. In Proceedings of the 2021 International Conference on Industrial Engineering, Applications and Manufacturing (ICIEAM), Sochi, Russia, 17–21 May 2021; pp. 713–718. [Google Scholar]
- Kalinowska, K.; Wojnowski, W.; Tobiszewski, M. Smartphones as tools for equitable food quality assessment. Trends Food Sci. Technol. 2021, 111, 271–279. [Google Scholar] [CrossRef]
- Nguyen, M.T.; Truong, L.H.; Le, T.T. Video surveillance processing algorithms utilizing artificial intelligent (AI) for unmanned autonomous vehicles (UAVs). MethodsX 2021, 8, 101472. [Google Scholar] [CrossRef] [PubMed]
- Aslan, S.; Güdükbay, U.; Töreyin, B.U.; Çetin, A.E. Deep convolutional generative adversarial networks based flame detection in video. arXiv 2019, arXiv:1902.01824. [Google Scholar] [CrossRef]
- Arvin, R.; Khattak, A.J.; Qi, H. Safety critical event prediction through unified analysis of driver and vehicle volatilities: Application of deep learning methods. Accid. Anal. Prev. 2021, 151, 105949. [Google Scholar] [CrossRef] [PubMed]
- Siska, J.; Jaeschke, T.; Wagner, J.; Pohl, N. FPGA-Accelerated Multispectral Ultra-High Resolution SAR-Imaging with Wideband FMCW Radars. In Proceedings of the 2019 IEEE Radio and Wireless Symposium (RWS), Orlando, FL, USA, 20–23 January 2019; pp. 1–4. [Google Scholar]
- Attaran, N.; Puranik, A.; Brooks, J.; Mohsenin, T. Embedded low-power processor for personalized stress detection. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 2032–2036. [Google Scholar] [CrossRef]
- Chen, X.; Tan, H.; Chen, Y.; He, B.; Wong, W.F.; Chen, D. ThunderGP: HLS-based graph processing framework on fpgas. In Proceedings of the 2021 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Online, 28 February–2 March 2021; pp. 69–80. [Google Scholar]
- Yuan, H.; Ding, D.; Fan, Z.; Sun, Z. A Real-Time Image Processing Hardware Acceleration Method based on FPGA. In Proceedings of the 2021 6th International Conference on Computational Intelligence and Applications (ICCIA), Xiamen, China, 11–13 June 2021; pp. 200–205. [Google Scholar]
- Xiao, Z.; Chamberlain, R.D.; Cabrera, A.M. HLS Portability from Intel to Xilinx: A Case Study. In Proceedings of the 2021 IEEE High Performance Extreme Computing Conference (HPEC), Greater Boston Area, MA, USA, 21–23 September 2021; pp. 1–8. [Google Scholar]
- Winterstein, F.; Bayliss, S.; Constantinides, G.A. High-level synthesis of dynamic data structures: A case study using Vivado HLS. In Proceedings of the 2013 International Conference on Field-Programmable Technology (FPT), Kyoto, Japan, 9–11 December 2013; pp. 362–365. [Google Scholar]
- Liu, S.; Lau, F.C.; Schafer, B.C. Accelerating FPGA prototyping through predictive model-based HLS design space exploration. In Proceedings of the 2019 56th ACM/IEEE Design Automation Conference (DAC), Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar]
- Coussy, P.; Gajski, D.D.; Meredith, M.; Takach, A. An introduction to high-level synthesis. IEEE Des. Test Comput. 2009, 26, 8–17. [Google Scholar] [CrossRef]
- O’Loughlin, D.; Coffey, A.; Callaly, F.; Lyons, D.; Morgan, F. Xilinx vivado high level synthesis: Case studies. In Proceedings of the 25th IET Irish Signals & Systems Conference 2014 and 2014 China-Ireland International Conference on Information and Communications Technologies (ISSC 2014/CIICT 2014), Limerick, Ireland, 26–27 June 2014; pp. 352–356. [Google Scholar]
- Gaide, B.; Gaitonde, D.; Ravishankar, C.; Bauer, T. Xilinx adaptive compute acceleration platform: VersalTM architecture. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 24–26 February 2019; pp. 84–93. [Google Scholar]
- Chatarasi, P.; Neuendorffer, S.; Bayliss, S.; Vissers, K.; Sarkar, V. Vyasa: A high-performance vectorizing compiler for tensor convolutions on the Xilinx AI Engine. In Proceedings of the 2020 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 22–24 September 2020; pp. 1–10. [Google Scholar]
- Kathail, V.; Hwang, J.; Sun, W.; Chobe, Y.; Shui, T.; Carrillo, J. SDSoC: A higher-level programming environment for Zynq SoC and Ultrascale+ MPSoC. In Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016. [Google Scholar] [CrossRef]
- Domingo, R.; Salvador, R.; Fabelo, H.; Madronal, D.; Ortega, S.; Lazcano, R.; Juárez, E.; Callicó, G.; Sanz, C. High-level design using Intel FPGA OpenCL: A hyperspectral imaging spatial-spectral classifier. In Proceedings of the 2017 12th International Symposium on Reconfigurable Communication-Centric Systems-on-Chip (ReCoSoC), Madrid, Spain, 12–14 July 2017; pp. 1–8. [Google Scholar]
- Canis, A.; Choi, J.; Fort, B.; Syrowik, B.; Lian, R.L.; Chen, Y.T.; Hsiao, H.; Goeders, J.; Brown, S.; Anderson, J. Legup high-level synthesis. In FPGAs for Software Programmers; Springer: Berlin, Germany, 2016; pp. 175–190. [Google Scholar]
- Wakabayashi, K. CyberWorkBench: Integrated design environment based on C-based behavior synthesis and verification. In Proceedings of the 2005 IEEE VLSI-TSA International Symposium on VLSI Design, Automation and Test, (VLSI-TSA-DAT), Hsinchu, Taiwan, 27–29 April 2005; pp. 173–176. [Google Scholar]
- Guo, L.; Chi, Y.; Wang, J.; Lau, J.; Qiao, W.; Ustun, E.; Zhang, Z.; Cong, J. AutoBridge: Coupling Coarse-Grained Floorplanning and Pipelining for High-Frequency HLS Design on Multi-Die FPGAs. In Proceedings of the 2021 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Online, 28 February–2 March 2021; pp. 81–92. [Google Scholar]
- Noronha, D.H.; Salehpour, B.; Wilton, S.J. LeFlow: Enabling flexible FPGA high-level synthesis of tensorflow deep neural networks. In Proceedings of the FSP Workshop 2018, Fifth International Workshop on FPGAs for Software Programmers, Dublin, Ireland, 31 August 2018; pp. 1–8. [Google Scholar]
- Hebbar SR, R.; Milenković, A. SPEC CPU2017: Performance, event, and energy characterization on the core i7–8700K. In Proceedings of the 2019 ACM/SPEC International Conference on Performance Engineering, Mumbai, India, 7–11 April 2019; pp. 111–118. [Google Scholar]
- Beutel, J.; Trüb, R.; Forno, R.D.; Wegmann, M.; Gsell, T.; Jacob, R.; Keller, M.; Sutton, F.; Thiele, L. The dual processor platform architecture: Demo abstract. In Proceedings of the 18th International Conference on Information Processing in Sensor Networks, Montreal, QC, Canada, 16–18 April 2019; pp. 335–336. [Google Scholar]
- Bellemou, A.; Benblidia, N.; Anane, M.; Issad, M. Microblaze-based multiprocessor embedded cryptosystem on FPGA for elliptic curve scalar multiplication over Fp. J. Circuits Syst. Comput. 2019, 28, 1950037. [Google Scholar] [CrossRef]
- Shamseldin, A.; Soubra, H.; ElNabawy, R. Performance of DSP operations implemented using a soft microprocessor: A case study based on Nios II. In Proceedings of the 2021 International Conference on Microelectronics (ICM), Cairo, Egypt, 19–22 December 2021; pp. 66–69. [Google Scholar]
- Mplemenos, G.G.; Papaefstathiou, I. Mplem: An 80-processor fpga based multiprocessor system. In Proceedings of the 2008 16th International Symposium on Field-Programmable Custom Computing Machines, Palo Alto, CA, USA, 14–15 April 15 2008; pp. 273–274. [Google Scholar]
- Siddiqui, F.; Amiri, S.; Minhas, U.I.; Deng, T.; Woods, R.; Rafferty, K.; Crookes, D. Fpga-based processor acceleration for image processing applications. J. Imaging 2019, 5, 16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kimura, Y.; Kikuchi, T.; Ootsu, K.; Yokota, T. Proposal of Scalable Vector Extension for Embedded RISC-V Soft-Core Processor. In Proceedings of the 2019 Seventh International Symposium on Computing and Networking Workshops (CANDARW), Nagasaki, Japan, 26–29 November 2019; pp. 435–439. [Google Scholar]
- Wilson, J.N.; Ritter, G.X. Handbook of Computer Vision Algorithms in Image Algebra; CRC Press: Boca Raton, FL, USA, 2000. [Google Scholar]
- Liu, G.; Luo, Q.; Liu, B.; Lu, B.; Guo, P. Embedded intelligent camera algorithm based on hardware IP. In Proceedings of the Tenth International Symposium on Precision Engineering Measurements and Instrumentation, Kunming, China, 8–10 August 2018. [Google Scholar] [CrossRef]
- Bailey, D.G. Image processing using FPGAs. J. Imaging 2019, 5, 53. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Palmer, J.F. The Intel 8087 numeric data processor. In Proceedings of the National Computer Conference, Anaheim, CA, USA, 19–22 May 1980; pp. 887–893. [Google Scholar]
- Li, Z.; Yang, W.; Peng, S.; Liu, F. A survey of convolutional neural networks: Analysis, applications, and prospects. arXiv 2004, arXiv:2004.02806. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SCPs | FFs | LUTs | BRAMs | DSPs | FPS |
| Point | 1659 | 2015 | 0 | 3 | 186 |
| Neighborhood Basic | 1104 | 1404 | 5 | 9 | 127 |
| Neighborhood Complex | 4963 | 7141 | 5 | 72 | 125 |
| Global | 622 | 998 | 0 | 0 | 189 |
| IPPro [30] | FFs | LUTs | BRAMs | DSPs | FPS |
| Point (8 core) | 12,279 | 10,941 | 18.5 | 8 | 120 |
| Neighborhood Basic (6 core) | 13,202 | 11,826 | 32.5 | 6 | 76 |
| SCPs | FFs | LUTs | BRAMs | DSPs | FPS |
|---|---|---|---|---|---|
| Point | 3346 | 2965 | 0 | 3 | 556 |
| Neighborhood Basic | 2309 | 1963 | 5 | 9 | 380 |
| Neighborhood Complex | 9862 | 12,368 | 5 | 72 | 374 |
| Global | 1432 | 1353 | 0 | 0 | 568 |
| Min Area | Operation | Performance | Utilization (>1 Is Worse) | ||||
| Freq | FPS | FFs | LUTs | BRAMs | DSPs | ||
| Point | SCP | 150 MHz | 1 | 1 | 1 | 1 | 1 |
| IPPro (8 core) | 150 MHz | 1.5 | 7.4 | 5.4 | --- | 2.7 | |
| Neighborhood | SCP | 150 MHz | 1 | 1 | 1 | 1 | 1 |
| IPPro (6 core) | 150 MHz | 2.4 | 8.0 | 5.9 | --- | 2.0 | |
| Max Performance | Operation | Performance | Utilization | ||||
| Freq | FPS | FFs | LUTs | BRAMs | DSPs | ||
| Point | SCP | 150 MHz | 1 | 1 | 1 | 1 | 1 |
| IPPro (8 core) | 150 MHz | 4.6 | 3.7 | 3.7 | --- | 2.7 | |
| Neighborhood | SCP | 150 MHz | 1 | 1 | 1 | 1 | 1 |
| IPPro (6 core) | 150 MHz | 7.3 | 5.7 | 6.0 | --- | 0.7 | |
| SCP Type | FFs | LUTs | BRAMs | DSPs | FPS |
|---|---|---|---|---|---|
| Generic | 9862 | 12,368 | 5 | 72 | 125 |
| Function-specific | 932 | 1107 | 2 | 3 | 128 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, T.; Crookes, D.; Woods, R.; Siddiqui, F. A Soft Coprocessor Approach for Developing Image and Video Processing Applications on FPGAs. J. Imaging 2022, 8, 42. https://doi.org/10.3390/jimaging8020042
Deng T, Crookes D, Woods R, Siddiqui F. A Soft Coprocessor Approach for Developing Image and Video Processing Applications on FPGAs. Journal of Imaging. 2022; 8(2):42. https://doi.org/10.3390/jimaging8020042
Chicago/Turabian StyleDeng, Tiantai, Danny Crookes, Roger Woods, and Fahad Siddiqui. 2022. "A Soft Coprocessor Approach for Developing Image and Video Processing Applications on FPGAs" Journal of Imaging 8, no. 2: 42. https://doi.org/10.3390/jimaging8020042
APA StyleDeng, T., Crookes, D., Woods, R., & Siddiqui, F. (2022). A Soft Coprocessor Approach for Developing Image and Video Processing Applications on FPGAs. Journal of Imaging, 8(2), 42. https://doi.org/10.3390/jimaging8020042