
Weakly Supervised Tumor Detection in PET Using Class Response for Treatment Outcome Prediction



Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
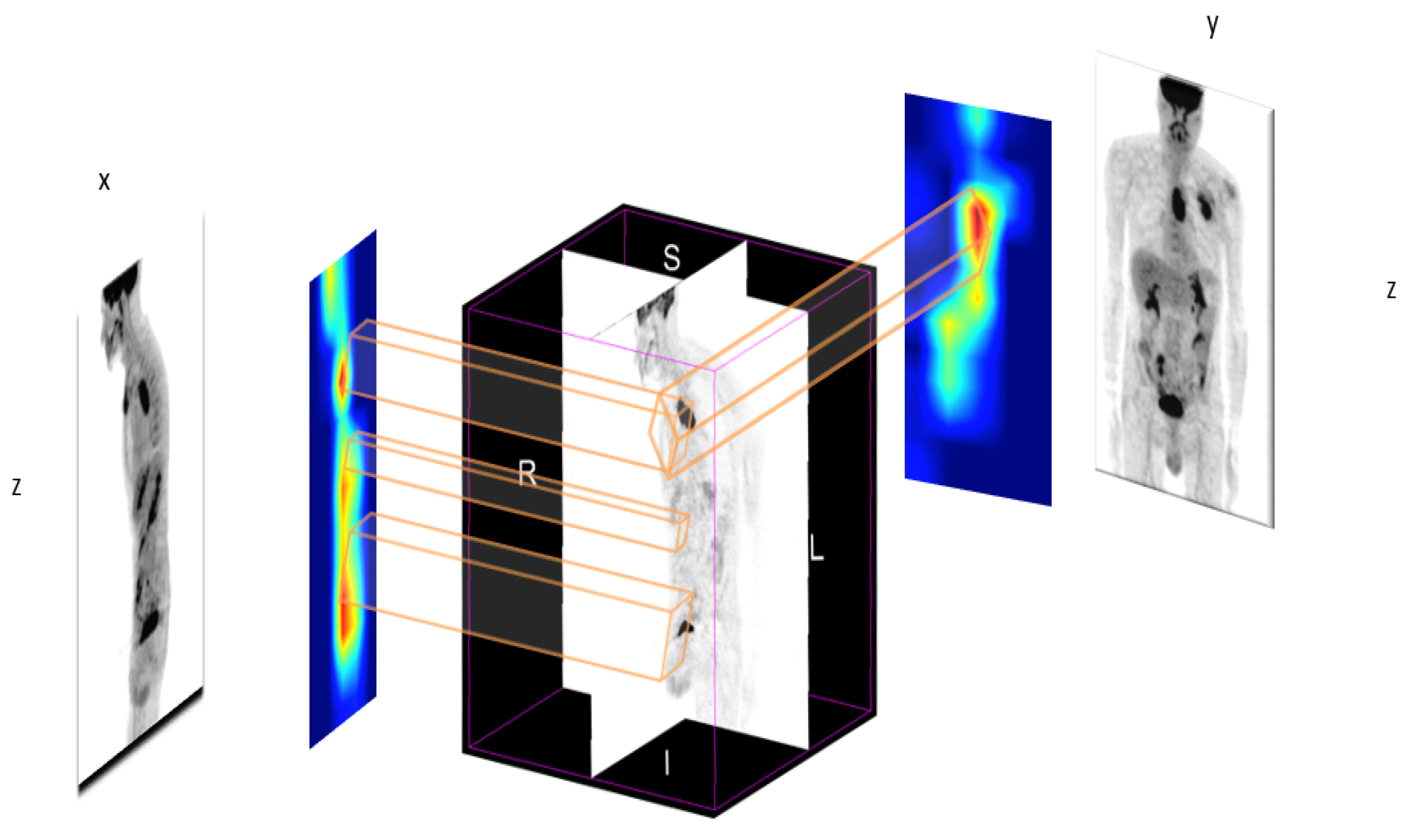
2.2. Maximum Intensity Projection
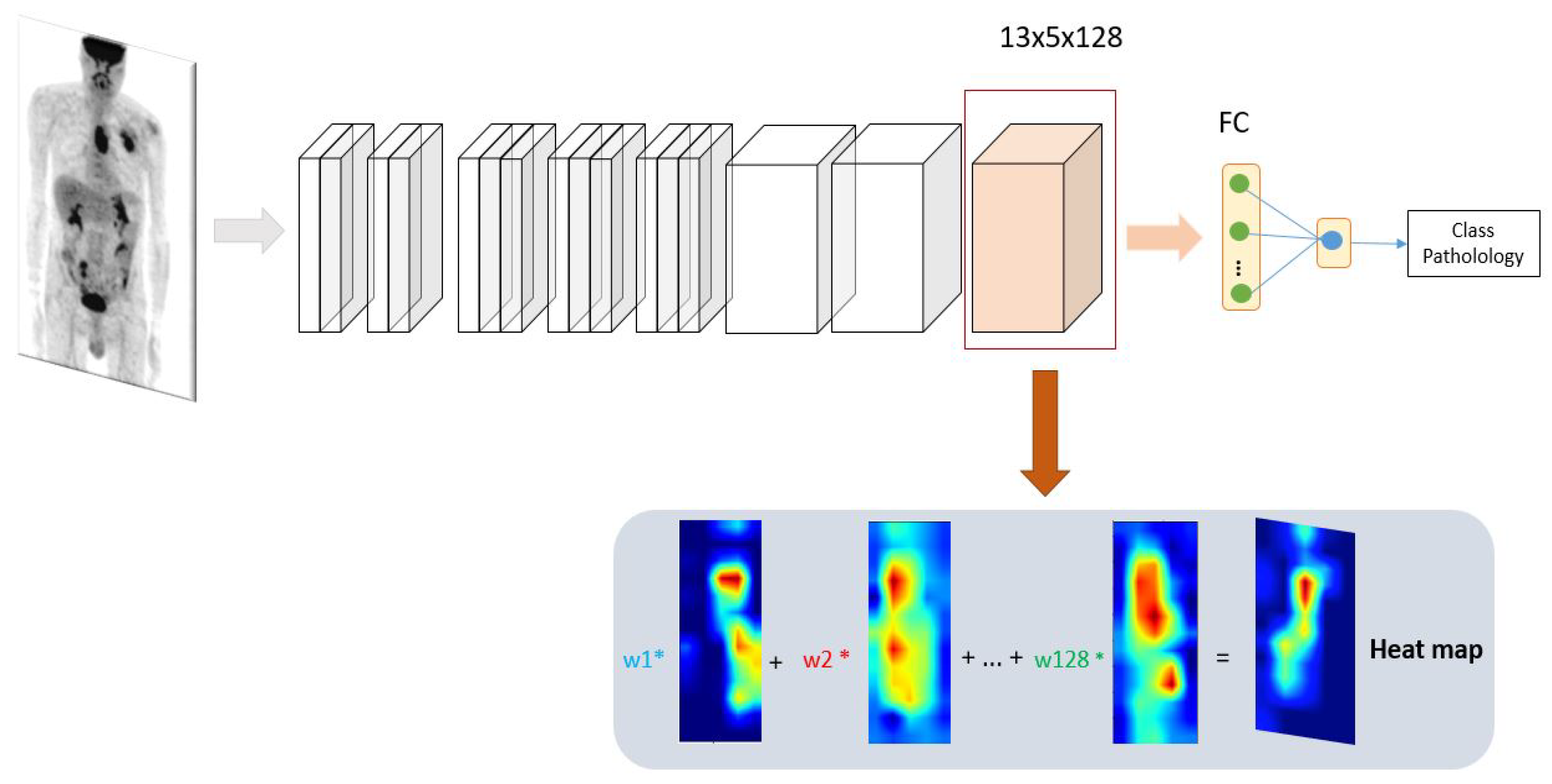
2.3. New Design of Class Activation Map (CAM)
2.3.1. Classification
2.3.2. Distance Constraint Using Prior Knowledge
2.4. Segmentation
2.5. Prediction
3. Experiments
3.1. Setup
3.2. Implementation
4. Evaluation Methodology
5. Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PET | positron emission tomography |
| MIP | maximum intensity projection |
| CAD | computer-aided detection |
| WSL | weakly supervised learning |
| CNN | convolutional neural network |
| FCN | convolutional neural networks |
| NN | Network in Network |
| CAM | class attention maps |
| RF | random forests |
| SVM | support vector machines |
| SUV | standard uptake value |
| WPk | without prior knowledge |
| Ms | manual segmentation |
| OS | overall survival |
| ACC | accuracy |
| Sens | sensitivity |
| Spec | specificity |
| AUC | area under the ROC curve |
References
- Gillies, R.J.; Kinahan, P.E.; Hricak, H. Radiomics: Images are more than pictures, they are data. Radiology 2016, 278, 563–577. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amyar, A.; Ruan, S.; Gardin, I.; Herault, R.; Clement, C.; Decazes, P.; Modzelewski, R. Radiomics-net: Convolutional neural networks on FDG PET images for predicting cancer treatment response. J. Nucl. Med. 2018, 59, 324. [Google Scholar]
- Lian, C.; Ruan, S.; Denœux, T.; Jardin, F.; Vera, P. Selecting radiomic features from FDG-PET images for cancer treatment outcome prediction. Med. Image Anal. 2016, 32, 257–268. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K.; et al. Chexnet: Radiologist-level pneumonia detection on chest X-rays with deep learning. arXiv 2017, arXiv:1711.05225. [Google Scholar]
- Hannun, A.Y.; Rajpurkar, P.; Haghpanahi, M.; Tison, G.H.; Bourn, C.; Turakhia, M.P.; Ng, A.Y. Cardiologist-level arrhythmia detection and classification in ambulatory electrocardiograms using a deep neural network. Nat. Med. 2019, 25, 65. [Google Scholar] [CrossRef]
- Yousefirizi, F.; Decazes, P.; Amyar, A.; Ruan, S.; Saboury, B.; Rahmim, A. AI-Based Detection, Classification and Prediction/Prognosis in Medical Imaging: Towards Radiophenomics. PET Clin. 2022, 17, 183–212. [Google Scholar] [CrossRef]
- Mahendran, A.; Vedaldi, A. Understanding deep image representations by inverting them. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5188–5196. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Object detectors emerge in deep scene cnns. arXiv 2014, arXiv:1412.6856. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Amyar, A.; Decazes, P.; Ruan, S.; Modzelewski, R. Contribution of class activation map on WB PET deep features for primary tumour classification. J. Nucl. Med. 2019, 60, 1212. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Bazzani, L.; Bergamo, A.; Anguelov, D.; Torresani, L. Self-taught object localization with deep networks. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar]
- Cinbis, R.G.; Verbeek, J.; Schmid, C. Weakly supervised object localization with multi-fold multiple instance learning. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 189–203. [Google Scholar] [CrossRef] [PubMed]
- Ahn, J.; Cho, S.; Kwak, S. Weakly supervised learning of instance segmentation with inter-pixel relations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2209–2218. [Google Scholar]
- Zhou, Y.; Zhu, Y.; Ye, Q.; Qiu, Q.; Jiao, J. Weakly supervised instance segmentation using class peak response. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3791–3800. [Google Scholar]
- Paul, D.; Su, R.; Romain, M.; Sébastien, V.; Pierre, V.; Isabelle, G. Feature selection for outcome prediction in oesophageal cancer using genetic algorithm and random forest classifier. Comput. Med. Imaging Graph. 2017, 60, 42–49. [Google Scholar] [CrossRef] [PubMed]
- Leger, S.; Zwanenburg, A.; Pilz, K.; Lohaus, F.; Linge, A.; Zöphel, K.; Kotzerke, J.; Schreiber, A.; Tinhofer, I.; Budach, V.; et al. A comparative study of machine learning methods for time-to-event survival data for radiomics risk modelling. Sci. Rep. 2017, 7, 13206. [Google Scholar] [CrossRef] [PubMed]
- Cameron, A.; Khalvati, F.; Haider, M.A.; Wong, A. MAPS: A quantitative radiomics approach for prostate cancer detection. IEEE Trans. Biomed. Eng. 2015, 63, 1145–1156. [Google Scholar] [CrossRef] [PubMed]
- Hatt, M.; Tixier, F.; Pierce, L.; Kinahan, P.E.; Le Rest, C.C.; Visvikis, D. Characterization of PET/CT images using texture analysis: The past, the present… any future? Eur. J. Nucl. Med. Mol. Imaging 2017, 44, 151–165. [Google Scholar] [CrossRef]
- Zhou, Y.; Xu, J.; Liu, Q.; Li, C.; Liu, Z.; Wang, M.; Zheng, H.; Wang, S. A radiomics approach with CNN for shear-wave elastography breast tumor classification. IEEE Trans. Biomed. Eng. 2018, 65, 1935–1942. [Google Scholar] [CrossRef]
- Hosny, A.; Parmar, C.; Coroller, T.P.; Grossmann, P.; Zeleznik, R.; Kumar, A.; Bussink, J.; Gillies, R.J.; Mak, R.H.; Aerts, H.J. Deep learning for lung cancer prognostication: A retrospective multi-cohort radiomics study. PLoS Med. 2018, 15, e1002711. [Google Scholar] [CrossRef] [Green Version]
- Amyar, A.; Ruan, S.; Gardin, I.; Chatelain, C.; Decazes, P.; Modzelewski, R. 3-d rpet-net: Development of a 3-d pet imaging convolutional neural network for radiomics analysis and outcome prediction. IEEE Trans. Radiat. Plasma Med. Sci. 2019, 3, 225–231. [Google Scholar] [CrossRef]
- Prokop, M.; Shin, H.O.; Schanz, A.; Schaefer-Prokop, C.M. Use of maximum intensity projections in CT angiography: A basic review. Radiographics 1997, 17, 433–451. [Google Scholar] [CrossRef]
- Valencia, R.; Denecke, T.; Lehmkuhl, L.; Fischbach, F.; Felix, R.; Knollmann, F. Value of axial and coronal maximum intensity projection (MIP) images in the detection of pulmonary nodules by multislice spiral CT: Comparison with axial 1-mm and 5-mm slices. Eur. Radiol. 2006, 16, 325–332. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Dice | IOU | |
|---|---|---|---|
| Esophageal cancer | U-NET [31] | 0.42 ± 0.16 | 0.32 ± 0.03 |
| SegNet [32] | 0.57 ± 0.14 | 0.45 ± 0.05 | |
| ResUnet [33] | 0.55 ± 0.19 | 0.45 ± 0.03 | |
| CAMsWPK | 0.53 ± 0.17 | 0.42 ± 0.04 | |
| CAMs & FCNs | 0.73 ± 0.12 | 0.63 ± 0.05 | |
| PET-CAM | 0.73 ± 0.09 | 0.62 ± 0.03 | |
| Lung cancer | U-NET [31] | 0.57 ± 0.19 | 0.45 ± 0.04 |
| SegNet [32] | 0.69 ± 0.12 | 0.59 ± 0.04 | |
| ResUnet [33] | 0.66 ± 0.14 | 0.55 ± 0.03 | |
| CAMsWPK | 0.63 ± 0.14 | 0.51 ± 0.05 | |
| CAMs & FCNs | 0.73 ± 0.12 | 0.63 ± 0.04 | |
| PET-CAM | 0.77 ± 0.07 | 0.65 ± 0.03 |
| Method | Accuracy | Sensitivity | Specificity | AUC | |
|---|---|---|---|---|---|
| Esophageal cancer | U-NET [31] | 0.47 ± 0.07 | 0.67 ± 0.22 | 0.31 ± 0.21 | 0.48 ± 0.24 |
| SegNet [32] | 0.57 ± 0.05 | 0.69 ± 0.19 | 0.44 ± 0.22 | 0.55 ± 0.10 | |
| ResUnet [33] | 0.53 ± 0.08 | 0.57 ± 0.23 | 0.47 ± 0.23 | 0.55 ± 0.17 | |
| CAMsWPK | 0.57 ± 0.03 | 0.61 ± 0.28 | 0.56 ± 0.24 | 0.53 ± 0.26 | |
| MS | 0.72 ± 0.08 | 0.79 ± 0.17 | 0.62 ± 0.21 | 0.70 ± 0.04 | |
| CAMs & FCNs | 0.57 ± 0.04 | 0.69 ± 0.21 | 0.47 ± 0.22 | 0.51 ± 0.24 | |
| PET-CAM | 0.69 ± 0.04 | 0.80 ± 0.14 | 0.59 ± 0.26 | 0.67 ± 0.08 | |
| Lung cancer | U-NET [31] | 0.52 ± 0.14 | 0.64 ± 0.23 | 0.36 ± 0.19 | 0.53 ± 0.25 |
| SegNet [32] | 0.60 ± 0.09 | 0.69 ± 0.14 | 0.50 ± 0.17 | 0.57 ± 0.19 | |
| ResUnet [33] | 0.59 ± 0.12 | 0.67 ± 0.17 | 0.52 ± 0.19 | 0.57 ± 0.21 | |
| CAMsWPK | 0.61 ± 0.07 | 0.59 ± 0.21 | 0.57 ± 0.15 | 0.55 ± 0.24 | |
| MS | 0.68 ± 0.17 | 0.72 ± 0.09 | 0.54 ± 0.07 | 0.61 ± 0.03 | |
| CAMs & FCNs | 0.59 ± 0.07 | 0.63 ± 0.12 | 0.57 ± 0.19 | 0.57 ± 0.17 | |
| PET-CAM | 0.65 ± 0.05 | 0.65 ± 0.18 | 0.58 ± 0.15 | 0.59 ± 0.04 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amyar, A.; Modzelewski, R.; Vera, P.; Morard, V.; Ruan, S. Weakly Supervised Tumor Detection in PET Using Class Response for Treatment Outcome Prediction. J. Imaging 2022, 8, 130. https://doi.org/10.3390/jimaging8050130
Amyar A, Modzelewski R, Vera P, Morard V, Ruan S. Weakly Supervised Tumor Detection in PET Using Class Response for Treatment Outcome Prediction. Journal of Imaging. 2022; 8(5):130. https://doi.org/10.3390/jimaging8050130
Chicago/Turabian StyleAmyar, Amine, Romain Modzelewski, Pierre Vera, Vincent Morard, and Su Ruan. 2022. "Weakly Supervised Tumor Detection in PET Using Class Response for Treatment Outcome Prediction" Journal of Imaging 8, no. 5: 130. https://doi.org/10.3390/jimaging8050130
APA StyleAmyar, A., Modzelewski, R., Vera, P., Morard, V., & Ruan, S. (2022). Weakly Supervised Tumor Detection in PET Using Class Response for Treatment Outcome Prediction. Journal of Imaging, 8(5), 130. https://doi.org/10.3390/jimaging8050130