
Dual Autoencoder Network with Separable Convolutional Layers for Denoising and Deblurring Images


Abstract
:1. Introduction
- In image segmentation, in which noise in pixels can appear when dividing a single digital image into multiple portions called image segments or image regions to facilitate or modify the image presentation into a form, which is more significant and more comfortable to investigate and analyze [12,13].
2. Basic Types of Noise on Images
2.1. Gaussian Noise
2.2. Poisson Noise
2.3. Speckle Noise
2.4. Impulse Noise
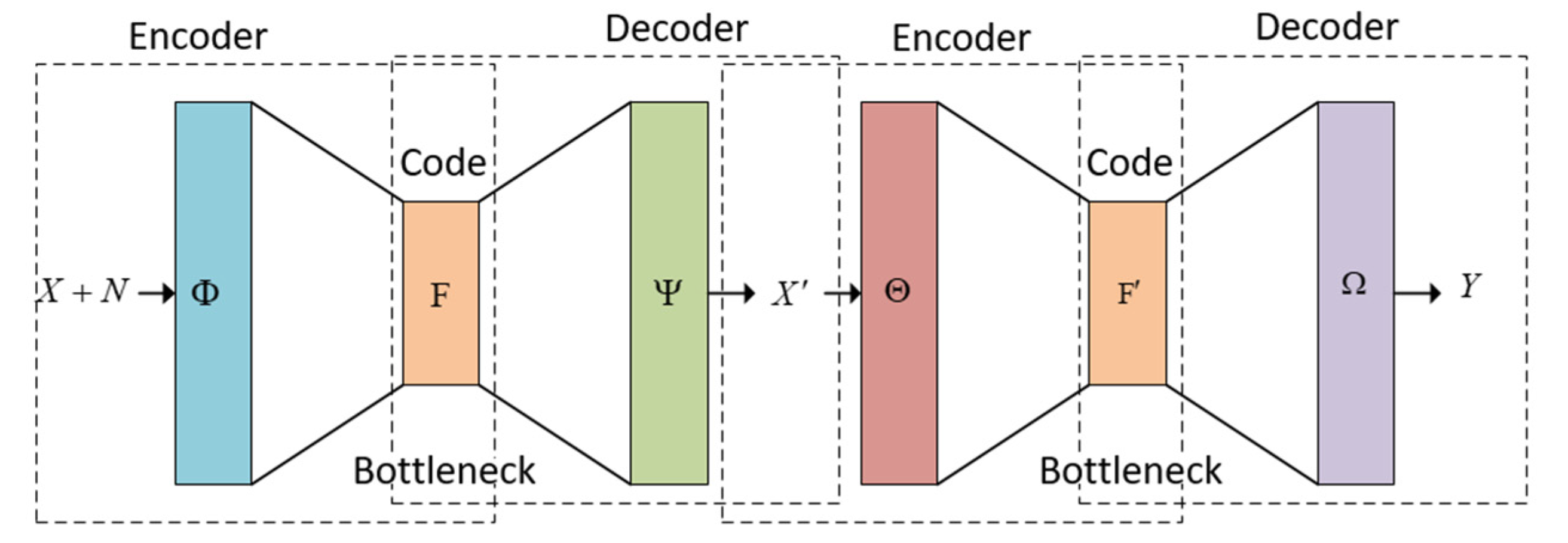
3. Dual Autoencoder with Convolutional and Separable Convolutional Neural Networks
4. Results of Image Denoising
- Image denoising for Gaussian noise (Gaussian blur) with a dual autoencoder achieved better results with both convolutional and separable convolutional neural networks where it raised the mode of the similarities of the testing dataset with the original by approximately 5% for convolution layers and 9% for separable convolution layers and the average PSNR by approximately 8 dB for convolution layers and 9 dB for separable convolution layers. A dual autoencoder with separable convolution layers achieved the higher accuracy with a value of 89% and with a high rate of performance, spending 0.019 s to denoise each image.
- Image denoising for Poisson noise with a dual autoencoder achieved better results for both the use of a convolutional neural network and separable convolutional neural network. Both kinds of neural networks achieved similar accuracy. However, the separable convolution layers enabled it faster with a lower number of parameters.
- Image denoising for speckle noise with a dual autoencoder raised the mode of the accuracies by approximately 6%, where a separable convolutional neural network and convolutional neural network achieved the same results, but the performance of the separable neural network was faster. The average PSNR increased by approximately 2 dB for convolution layers and 4 dB for separable convolution layers. In the dual autoencoder, it took 0.02 s to denoise each image.
- Image denoising for impulse noise due to a dual autoencoder with both a convolutional neural network and separable convolutional neural network raised the M by 6% and the average PSNR by approximately 3 dB. Both kinds of neural networks achieved the same accuracy, but the separable convolutional neural network performed faster, where it took 0.023 s to denoise each image.
- -
- A dual autoencoder ensures higher accuracy on increasing the total time of training and the time of denoising in comparison with one autoencoder. Thus, to reach a high accuracy of image denoising, we should use a more complicated device and spend a higher computational cost;
- -
- In the mentioned situation, it would be better to have the approach that decreases computational cost without reducing the accuracy of restoring images. This way is a separable convolution in neural networks. In the cases of Poisson noise, speckle noise, and impulse noise, we kept the accuracy gained by the dual autoencoder and got a higher performance of this device by means of separable convolutional neural networks. In the case of Gaussian noise (Gaussian blur), we obtained both a higher accuracy and performance of the device, which is built on the basis of separable convolutional neural networks.
5. Discussion
- The ability of feature extraction from non-linear processes and performing non-linear transformations, for instance, image denoising.
- The ability of dimensionality reduction in the autoencoder network process of compressing the data and the feature of information retrievals in the autoencoder network process of decompressing the data.
- Reducing the training parameters decreases the training and performing time of the autoencoder’s network and saves more memory on the user device.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Roy, A.; Maity, P. A Comparative Analysis of Various Filters to Denoise Medical X-Ray Images. In Proceedings of the 2020 4th International Conference on Electronics, Materials Engineering & Nano-Technology (IEMENTech), Kolkata, India, 2–4 October 2020. [Google Scholar] [CrossRef]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Virtual Conference, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar] [CrossRef]
- Liu, X.; Suganuma, M.; Sun, Z.; Okatani, T. Dual Residual Networks Leveraging the Potential of Paired Operations for Image Restoration. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H.; Shao, L. Multi-Stage Progressive Image Restoration. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Solovyeva, E. Cellular Neural Network as a Non-linear Filter of Impulse Noise. In Proceedings of the 2017 20th Conference of Open Innovations Association FRUCT (FRUCT20), St. Petersburg, Russia, 3–7 April 2017; pp. 420–426. [Google Scholar] [CrossRef]
- Solovyeva, E.B.; Degtyarev, S.A. Synthesis of Neural Pulse Interference Filters for Image Restoration. Radioelectron. Commun. Syst. 2008, 51, 661–668. [Google Scholar] [CrossRef]
- Solovyeva, E. Types of Recurrent Neural Networks for Non-linear Dynamic System Modelling. In Proceedings of 2017 IEEE International Conference on Soft Computing and Measurements (SCM2017), St. Petersburg, Russia, 24–26 May 2017; pp. 252–255. [Google Scholar] [CrossRef]
- Kim, J.S.; Chang, D.S.; Choi, Y.S. Enhancement of Multi-Target Tracking Performance via Image Restoration and Face Embedding in Dynamic Environments. Appl. Sci. 2021, 11, 649. [Google Scholar] [CrossRef]
- Yang, L.; Fan, J.; Huo, B.; Li, E.; Liu, Y. Image Denoising of Seam Images With Deep Learning for Laser Vision Seam Tracking. IEEE Sens. J. 2022, 22, 6098–6107. [Google Scholar] [CrossRef]
- Leng, C.; Zhang, H.; Cai, G.; Chen, Z.; Basu, A. Total Variation Constrained Non-Negative Matrix Factorization for Medical Image Registration. IEEE/CAA J. Autom. Sin. 2021, 8, 1025–1037. [Google Scholar] [CrossRef]
- Jia, X.; Thorley, A.; Chen, W.; Qiu, H.; Shen, L.; Styles, I.B.; Duan, J. Learning a Model-Driven Variational Network for Deformable Image Registration. IEEE Trans. Med. Imaging 2022, 41, 199–212. [Google Scholar] [CrossRef]
- Kollem, S.; Reddy, K.R.L.; Rao, D.S. A Review of Image Denoising and Segmentation Methods Based on Medical Images. Int. J. Mach. Learn. Comput. 2019, 9, 288–295. [Google Scholar] [CrossRef]
- Tian, C.; Chen, Y. Image Segmentation and Denoising Algorithm Based on Partial Differential Equations. IEEE Sens. J. 2020, 20, 11935–11942. [Google Scholar] [CrossRef]
- Garg, A.; Khandelwal, V. Combination of Spatial Domain Filters for Speckle Noise Reduction in Ultrasound Medical Images. Adv. Electr. Electron. Eng. 2018, 15, 857–865. [Google Scholar] [CrossRef]
- Arabi, H.; Zaidi, H. Improvement of image quality in PET using post-reconstruction hybrid spatial-frequency domain filtering. Phys. Med. Biol. 2018, 63, 215010. [Google Scholar] [CrossRef]
- Huang, Z.; Zhang, Y.; Li, Q.; Zhang, T.; Sang, N. Spatially adaptive denoising for X-ray cardiovascular angiogram images. Biomed. Signal Processing Control 2018, 40, 131–139. [Google Scholar] [CrossRef]
- Suresh, S.; Lal, S.; Chen, C.; Celik, T. Multispectral Satellite Image Denoising via Adaptive Cuckoo Search-Based Wiener Filter. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4334–4345. [Google Scholar] [CrossRef]
- Hasan, M.; El-Sakka, M.R. Improved BM3D image denoising using SSIM-optimized Wiener filter. EURASIP J. Image Video Processing 2018, 25, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Ishikawa, A.; Tajima, H.; Fukushima, N. Halide implementation of weighted median filter. In Proceedings of the International Workshop on Advanced Imaging Technology (IWAIT) 2020, Yogyakarta, Indonesia, 5–7 January 2020. [Google Scholar] [CrossRef]
- Mafi, M.; Rajaei, H.; Cabrerizo, M.; Adjouadi, M. A Robust Edge Detection Approach in the Presence of High Impulse Noise Intensity Through Switching Adaptive Median and Fixed Weighted Mean Filtering. IEEE Trans. Image Processing 2018, 27, 5475–5490. [Google Scholar] [CrossRef]
- Iqbal, N.; Ali, S.; Khan, I.; Lee, B. Adaptive Edge Preserving Weighted Mean Filter for Removing Random-Valued Impulse Noise. Symmetry 2019, 11, 395. [Google Scholar] [CrossRef]
- Ben Said, A.; Hadjidj, R.; Foufou, S. Total Variation for Image Denoising Based on a Novel Smart Edge Detector: An Application to Medical Images. J. Math. Imaging Vis. 2018, 61, 106–121. [Google Scholar] [CrossRef]
- Hanh, D.N.H.; Thanh, L.T.; Hien, N.N.; Prasath, S. Adaptive total variation L1 regularization for salt and pepper image denoising. Optik 2020, 208, 163677. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, L.; He, W.; Zhang, L. Hyperspectral Image Denoising With Total Variation Regularization and Nonlocal Low-Rank Tensor Decomposition. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3071–3084. [Google Scholar] [CrossRef]
- Bal, A.; Banerjee, M.; Chaki, R.; Sharma, P. An efficient method for PET image denoising by combining multi-scale transform and non-local means. Multimed. Tools Appl. 2020, 79, 29087–29120. [Google Scholar] [CrossRef]
- Wang, G.; Liu, Y.; Xiong, W.; Li, Y. An improved non-local means filter for color image denoising. Optik 2018, 173, 157–173. [Google Scholar] [CrossRef]
- Heo, Y.-C.; Kim, K.; Lee, Y. Image Denoising Using Non-Local Means (NLM) Approach in Magnetic Resonance (MR) Imaging: A Systematic Review. Appl. Sci. 2020, 10, 7028. [Google Scholar] [CrossRef]
- Ravishankar, S.; Ye, J.C.; Fessler, J.A. Image Reconstruction: From Sparsity to Data-Adaptive Methods and Machine Learning. Proc. IEEE 2020, 108, 86–109. [Google Scholar] [CrossRef] [PubMed]
- Madathil, B.; George, S.N. DCT based weighted adaptive multi-linear data completion and denoising. Neurocomputing 2018, 318, 120–136. [Google Scholar] [CrossRef]
- Kuttan, D.B.; Kaur, S.; Goyal, B.; Dogra, A. Image Denoising: Pre-processing for enhanced subsequent CAD Analysis. In Proceedings of the 2021 2nd International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 7–9 October 2021. [Google Scholar] [CrossRef]
- Sawant, A.; Kulkarni, S. Hybrid Filtering Techniques For Medical Image Denoising. In Proceedings of the International Conference on Business Management, Innovation, and Sustainability (ICBMIS-2020), Dubai, United Arab Emirates, 13–14 April 2020; pp. 1–10. [Google Scholar] [CrossRef]
- Zhou, L.; Schaefferkoetter, J.D.; Tham, I.W.K.; Huang, G.; Yan, J. Supervised learning with cyclegan for low-dose FDG PET image denoising. Med. Image Anal. 2020, 65, 101770. [Google Scholar] [CrossRef] [PubMed]
- Tian, C.; Fei, L.; Zheng, W.; Xu, Y.; Zuo, W.; Lin, C.-W. Deep learning on image denoising: An overview. Neural Netw. 2020, 131, 251–275. [Google Scholar] [CrossRef]
- Tian, C.; Xu, Y.; Fei, L.; Yan, K. Deep Learning for Image Denoising: A Survey. Genet. Evol. Comput. 2019, 834, 563–572. [Google Scholar] [CrossRef]
- Pang, T.; Zheng, H.; Quan, Y.; Ji, H. Recorrupted-to-Recorrupted: Unsupervised Deep Learning for Image Denoising. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Ignatov, A.; Byeoung-Su, K.; Timofte, R.; Pouget, A.; Song, F.; Li, C.; Chen, F. Fast Camera Image Denoising on Mobile GPUs with Deep Learning, Mobile AI 2021 Challenge: Report. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021. [Google Scholar] [CrossRef]
- Cui, J.; Gong, K.; Guo, N.; Wu, C.; Meng, X.; Kim, K.; Li, Q. PET image denoising using unsupervised deep learning. Eur. J. Nucl. Med. Mol. Imaging 2019, 46, 2780–2789. [Google Scholar] [CrossRef]
- Hong, I.; Hwang, Y.; Kim, D. Efficient deep learning of image denoising using patch complexity local divide and deep conquer. Pattern Recognit. 2019, 96, 106945. [Google Scholar] [CrossRef]
- Islam, M.T.; Rahman, S.M.; Ahmad, M.O.; Swamy, M.N.S. Mixed Gaussian-impulse noise reduction from images using convolutional neural network. Signal Processing Image Commun. 2018, 68, 26–41. [Google Scholar] [CrossRef]
- Ilesanmi, A.E.; Ilesanmi, T.O. Methods for image denoising using convolutional neural network: A review. Complex Intell. Syst. 2021, 7, 2179–2198. [Google Scholar] [CrossRef]
- Paul, E.; Sabeenian, R.S. Modified convolutional neural network with pseudo-CNN for removing nonlinear noise in digital images. Displays 2022, 74, 102258. [Google Scholar] [CrossRef]
- Munir, N.; Park, J.; Kim, H.-J.; Song, S.-J.; Kang, S.-S. Performance enhancement of convolutional neural network for ultrasonic flaw classification by adopting autoencoder. NDT E Int. 2020, 111, 102218. [Google Scholar] [CrossRef]
- Singha, S.; Sk. Imran Hossain, M.A.H.; Murase, K. A Robust System for Noisy Image Classification Combining Denoising Autoencoder and Convolutional Neural Network. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 224–235. [Google Scholar] [CrossRef]
- Paul, A.; Kundu, A.; Chaki, N.; Dutta, D.; Jha, C.S. Wavelet enabled convolutional autoencoder based deep neural network for hyperspectral image denoising. Multimed. Tools Appl. 2021, 81, 2529–2555. [Google Scholar] [CrossRef]
- Saleh Ahmed, A.; El-Behaidy, W.H.; Youssif, A.A.A. Medical image denoising system based on stacked convolutional autoencoder for enhancing 2-dimensional gel electrophoresis noise reduction. Biomed. Signal Processing Control 2021, 69, 102842. [Google Scholar] [CrossRef]
- Kang, G.; Gao, S.; Yu, L.; Zhang, D. Deep Architecture for High-Speed Railway Insulator Surface Defect Detection: Denoising Autoencoder With Multitask Learning. IEEE Trans. Instrum. Meas. 2019, 68, 2679–2690. [Google Scholar] [CrossRef]
- Awad, A. Denoising images corrupted with impulse, Gaussian, or a mixture of impulse and Gaussian noise. Eng. Sci. Technol. 2019, 22, 746–753. [Google Scholar] [CrossRef]
- Abubakar, A.; Zhao, X.; Li, S.; Takruri, M.; Bastaki, E.; Bermak, A. A Block-Matching and 3-D Filtering Algorithm for Gaussian Noise in DoFP Polarization Images. IEEE Sens. J. 2018, 18, 7429–7435. [Google Scholar] [CrossRef]
- Kumain, S.C.; Singh, M.; Singh, N.; Kumar, K. An efficient Gaussian Noise Reduction Technique For Noisy Images using optimized filter approach. In Proceedings of the 2018 First International Conference on Secure Cyber Computing and Communication (ICSCCC), Jalandhar, India, 15–17 December 2018. [Google Scholar] [CrossRef]
- Khan, K.B.; Shahid, M.; Ullah, H.; Rehman, E.; Khan, M.M. Adaptive trimmed mean autoregressive model for reduction of poisson noise in scintigraphic images. IIUM Eng. J. 2018, 19, 68–79. [Google Scholar] [CrossRef] [Green Version]
- Kumar, P.G.; Sahay, R.R. Low Rank Poisson Denoising (LRPD): A Low Rank Approach Using Split Bregman Algorithm for Poisson Noise Removal From Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar] [CrossRef]
- Kumar, M.; Mishra, S.K. Jaya based functional link multilayer perceptron adaptive filter for Poisson noise suppression from X-ray images. Multimed. Tools Appl. 2018, 77, 24405–24425. [Google Scholar] [CrossRef]
- Duarte-Salazar, C.A.; Castro-Ospina, A.E.; Becerra, M.A.; Delgado-Trejos, E. Speckle Noise Reduction in Ultrasound Images for Improving the Metrological Evaluation of Biomedical Applications: An Overview. IEEE Access 2020, 8, 15983–15999. [Google Scholar] [CrossRef]
- Kumar Pal, S.; Bhardwaj, A.; Shukla, A. A Review on Despeckling Filters in Ultrasound Images for Speckle Noise Reduction. In Proceedings of the 2021 International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 4–5 March 2021. [Google Scholar] [CrossRef]
- Chen, Z.; Zeng, Z.; Shen, H.; Zheng, X.; Dai, P.; Ouyang, P. DN-GAN: Denoising generative adversarial networks for speckle noise reduction in optical coherence tomography images. Biomed. Signal Processing Control 2020, 55, 101632. [Google Scholar] [CrossRef]
- Garg, B. Restoration of highly salt-and-pepper-noise-corrupted images using novel adaptive trimmed median filter. Signal Image Video Processing 2020, 14, 1555–1563. [Google Scholar] [CrossRef]
- Solovyeva, E. A Split Signal Polynomial as a Model of an Impulse Noise Filter for Speech Signal Recovery. J. Phys. Conf. Ser. (JPCS) 2017, 803, 012156. [Google Scholar] [CrossRef]
- Solovyeva, E. Operator Approach to Nonlinear Compensator Synthesis for Communication Systems. In Proceedings of the 2016 International Siberian Conference on Control and Communications (SIBCON), Moscow, Russia, 12–14 May 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Garg, B.; Arya, K.V. Four stage median-average filter for healing high density salt and pepper noise corrupted images. Multimed. Tools Appl. 2020, 79, 32305–32329. [Google Scholar] [CrossRef]
- Varatharajan, R.; Vasanth, K.; Gunasekaran, M.; Priyan, M.; Gao, X.Z. An adaptive decision based kriging interpolation algorithm for the removal of high density salt and pepper noise in images. Comput. Electr. Eng. 2018, 70, 447–461. [Google Scholar] [CrossRef]
- Choi, H.; Kim, M.; Lee, G.; Kim, W. Unsupervised learning approach for network intrusion detection system using autoencoders. J. Supercomput. 2019, 75, 5597–5621. [Google Scholar] [CrossRef]
- Park, S.; Yu, S.; Kim, M.; Park, K.; Paik, J. Dual Autoencoder Network for Retinex-Based Low-Light Image Enhancement. IEEE Access 2018, 6, 22084–22093. [Google Scholar] [CrossRef]
- Drozdov, A.; Rongali, S.; Chen, Y.-P.; O’Gorman, T.; Iyyer, M.; McCallum, A. Unsupervised Parsing with S-DIORA: Single Tree Encoding for Deep Inside-Outside Recursive Autoencoders. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual Conference, Punta Cana, Dominican Republic, 16–20 November 2020. [Google Scholar] [CrossRef]
- Dong, G.; Liao, G.; Liu, H.; Kuang, G. A Review of the Autoencoder and Its Variants: A Comparative Perspective from Target Recognition in Synthetic-Aperture Radar Images. IEEE Geosci. Remote Sens. Mag. 2018, 6, 44–68. [Google Scholar] [CrossRef]
- Lopez Pinaya, W.H.; Vieira, S.; Garcia-Dias, R.; Mechelli, A. Autoencoders. In Machine Learning; Mechelli, A., Vieira, S., Eds.; Elsevier Science: Amsterdam, The Netherland, 2019; pp. 193–208. [Google Scholar] [CrossRef]
- Solovyeva, E.; Abdullah, A. Binary and Multiclass Text Classification by Means of Separable Convolutional Neural Network. Inventions 2021, 6, 70. [Google Scholar] [CrossRef]
- Gao, H.; Yuan, H.; Wang, Z.; Ji, S. Pixel Transposed Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1218–1227. [Google Scholar] [CrossRef]
- Rothe, R.; Timofle, R.; Gool, L.V. IMDB-WIKI Dataset. 2015. Available online: https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/ (accessed on 11 July 2022).
- Sambare, M. FER-2013 Dataset. 2020. Available online: https://www.kaggle.com/msambare/fer2013 (accessed on 11 July 2022).
- Lundqvist, D.; Flykt, A.; Ohman, A. KDEF Dataset. 1998. Available online: https://www.kdef.se/download-2/index.html (accessed on 11 July 2022).
- Mahoor, M.H. AffectNet Dataset. 2017. Available online: http://mohammadmahoor.com/affectnet/ (accessed on 11 July 2022).
- Shukla, R.K.; Agarwal, A.; Malviya, A.K. An Introduction of Face Recognition and Face Detection for Blurred and Noisy Images. Int. J. Sci. Res. Comput. Sci. Eng. 2018, 6, 39–43. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, Y.; Li, Y.; Chen, Z.; Wang, Z. Spherical Structural Similarity Index for Objective Omnidirectional Video Quality Assessment. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018. [Google Scholar] [CrossRef]
- Luo, J.; Lei, W.; Hou, F.; Wang, C.; Ren, Q.; Zhang, S.; Luo, S.; Wang, Y.; Xu, L. GPR B-Scan Image Denoising via Multi-Scale Convolutional Autoencoder with Data Augmentation. Electronics 2021, 10, 1269. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device of Image Denoising | Neural Network | Number of Parameters | Total Time of Training (s) | Time of Denoising(s) | M (%) | Average PSNR (dB) |
|---|---|---|---|---|---|---|
| Autoencoder | CNN | 29,626 | 24,085 | 446 | 76 | 24.52 |
| SCNN | 14,910 | 20,804 | 167 | 80 | 25.53 | |
| Dual Autoencoder | CNN | 81,052 | 54,757 | 440 | 81 | 32.79 |
| SCNN | 51,595 | 43,038 | 374 | 89 | 34.60 |
| Device of Image Denoising | Neural Network | Number of Parameters | Total Time of Training (s) | Time of Denoising(s) | M (%) | Average PSNR (dB) |
|---|---|---|---|---|---|---|
| Autoencoder | CNN | 29,626 | 22,001 | 60 | 71 | 27.38 |
| SCNN | 14,910 | 19,412 | 58 | 71 | 27.77 | |
| Dual Autoencoder | CNN | 81,052 | 56,324 | 55 | 76 | 30.59 |
| SCNN | 51,595 | 41,207 | 49 | 77 | 31.11 |
| Device of Image Denoising | Neural Network | Number of Parameters | Total Time of Training (s) | Time of Denoising(s) | M (%) | Average PSNR (dB) |
|---|---|---|---|---|---|---|
| Autoencoder | CNN | 29,626 | 22,348 | 209 | 84 | 54.48 |
| SCNN | 14,910 | 19,360 | 161 | 84 | 54.62 | |
| Dual Autoencoder | CNN | 81,052 | 53,964 | 457 | 89 | 56.02 |
| SCNN | 51,595 | 40,912 | 398 | 90 | 58.93 |
| Device of Image Denoising | Neural Network | Number of Parameters | Total Time of Training (s) | Time of Denoising(s) | M (%) | Average PSNR (dB) |
|---|---|---|---|---|---|---|
| Autoencoder | CNN | 29,626 | 24,052 | 184 | 78 | 54.93 |
| SCNN | 14,910 | 20,293 | 173 | 79 | 55.07 | |
| Dual Autoencoder | CNN | 81,052 | 55,708 | 480 | 85 | 58.34 |
| SCNN | 51,595 | 42,007 | 460 | 85 | 58.03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Solovyeva, E.; Abdullah, A. Dual Autoencoder Network with Separable Convolutional Layers for Denoising and Deblurring Images. J. Imaging 2022, 8, 250. https://doi.org/10.3390/jimaging8090250
Solovyeva E, Abdullah A. Dual Autoencoder Network with Separable Convolutional Layers for Denoising and Deblurring Images. Journal of Imaging. 2022; 8(9):250. https://doi.org/10.3390/jimaging8090250
Chicago/Turabian StyleSolovyeva, Elena, and Ali Abdullah. 2022. "Dual Autoencoder Network with Separable Convolutional Layers for Denoising and Deblurring Images" Journal of Imaging 8, no. 9: 250. https://doi.org/10.3390/jimaging8090250
APA StyleSolovyeva, E., & Abdullah, A. (2022). Dual Autoencoder Network with Separable Convolutional Layers for Denoising and Deblurring Images. Journal of Imaging, 8(9), 250. https://doi.org/10.3390/jimaging8090250