1. Introduction
PET (Positron Emission Tomography) is a medical imaging modality that reconstructs the 3D distribution of metabolic activity by detecting the photons emitted during the in vivo annihilation of free electrons with positrons from an injected radioactive tracer. In principle, cancer lesions should be visible in the reconstructed image with high contrast compared to the surrounding healthy tissue thanks to their particular metabolic fingerprints (e.g., higher sugar metabolism in fluorodeoxyglucose PET). However, the long acquisition time required to collect projection data with an acceptable noise level leads to motion artefacts that strongly affect lesions’ contrast-to-noise-ratio and, therefore, the diagnostic power of PET images. This is of particular relevance when trying to image lesions with sizes comparable to the system resolution and that are continuously moving around during data acquisition.
As an example, a current challenge in the PET diagnosis of lung cancer at an early stage is the visibility of lesions of dimensions of one centimetre or less, which will be displaced by a few times their dimension during the respiratory cycle.
One way of avoiding motion blurring is to divide projection data into a number of different data subsets (gates) in which the patient (and, therefore, the activity distribution) can be considered stationary. Gating can be achieved by means of an external gate-triggering device or by analysing the data itself. Once gated data is available, one can choose to reconstruct each gate separately or simply one of the gates (usually the one with more counts) avoiding, in this way, motion artefacts. The drawback with this approach is the higher noise level of the reconstructed images that can, especially for smaller lesions, result in scarce visibility and, consequently, uncertain diagnosis. For this reason, attempts have been made to jointly estimate the image and motion in order to reconstruct a single stationary image with the full statistics of the entire projection data set. On passing, please note that, in this work, only changes in the radiotracers distribution due to patient movement are considered and the kinetics of the radiotracer distribution during the acquisition is not taken into consideration. However, the two problems have many features in common and can be tackled using similar methods [
1]. Similar ideas of minimising an objective function that depends on the parameters of both the image and of a prior motion model can be applied also to cardiac or respiratory gated data, as reported by the authors of reference [
2]. Instead of assuming a parameterised motion model, one can try to jointly estimate image and motion by minimising a cost function depending on the likelihood of the image and motion and a regularisation part depending on the smoothness and size of the deformation. This kind of approach has been attempted by many authors [
3,
4,
5] and has its main drawback in the computational cost of the minimisation.
We apply, here, a method that uses reconstructed gates for estimating the deformation fields among them and then reconstructs the entire data set in a chosen reference gate by incorporating the deformation fields in the reconstruction algorithm. A similar approach was already proposed in 2006 by Qiao and co-authors [
6] using CT-gated images for gate registration. Pouchol et al., in reference [
7], instead, proposed to use PET gate registration by means of a deep-learning-based algorithm [
7]. This approach has the advantages of not requiring an extra dose to the patient and to be computationally inexpensive enough to be adopted in clinical practice. We improve the results obtained in reference [
7], by using SynthMorph [
8] for the estimation of the registration fields. SynthMorph has the advantage of being able to estimate the deformation field at low computational cost compared to traditional methods and, most importantly, to be contrast and modality agnostic [
9]. In other words, SynthMorph is capable of registering gates with substantially different numbers of events and can also register PET images to X-ray CT images (or Magnetic Resonance images).
There is a further complication in the reconstruction of the entire data set in a chosen reference gate that is due to the photon attenuation by the patient. PET scanners can only detect photons that exit the patient; in fact, a substantial amount of photons will be absorbed by the patient tissues and will depose a dose. In order to estimate the radiotracer distribution, projections, therefore, have to be corrected for this attenuation, which is strongly dependent on the specific tissues encountered by the emitted photons along the path of the different projection lines. For this reason, it is, at present, customary to perform an X-ray Computed Tomography (CT) in concomitance with a PET scan. The CT reconstruction is then used to estimate an attenuation map for attenuation correction. The challenge in the case of respiratory or cardiac gating resides in the fact that, in general, none of the emission gates will exactly correspond to the position in which the X-ray CT scan has been taken and the misalignment between the attenuation map and the various gates will introduce serious artefacts in the reconstruction.
In this paper, two algorithms for performing the appropriate attenuation correction of the data are proposed. In one of the proposed algorithms (referred to as M-MLEM with CT-based attenuation correction or, in short M-MLEM+CT in the following) a CT-image is scaled to PET photon energies (that is 511 keV) and registered to each of the gates via Synthmorph, whereas, in the second proposed approach (referred to as
M-MLAA in the remainder of this paper), Synthmorph is composed with the forward projector in a morphed version of the Maximum Likelihood Activity and Attenuation (MLAA) [
10] algorithm. Both of these proposed methods will be described in more detail in the next section.
2. Materials and Methods
In this paper, the algorithm proposed in reference [
7] and reported for convenience in Algorithm 1, is extended to 3D and the attenuation correction of the projections is included in the reconstruction in two different ways.
| Algorithm 1 M-MLEM algorithm |
Require:
Require:
Require:
▹ Radon transform
▹ adjoint operator of Radon transform
▹ learned parameters of Synthmorph network
▹ nb of MLEM iterations
▹ nb of M-MLEM iterations
▹ nb total of gates
▹ init of the distribution estimation
▹ data for every gates
▹ Init registration fields
for
do
for do
▹ MLEM iteration
end for
if then
▹ vector field between two close gates
▹ approximate estimation of inverse
end if
end for
fordo
▹ M-MLEM iteration
end for |
2.1. Proposed Algorithms: M-MLEM with CT-Based Attenuation Correction and M-MLAA
Let us consider the case of gated sinogram data with gates , in each of which the patient is assumed to be stationary. The corresponding images of the activity distribution are going to be denoted by and the relative attenuation maps by , whereas the attenuation map obtained from an X-ray CT scan will be indicated by .
Data acquisition is modelled by a
forward operator,
A, such that:
It is here worth noting that Equation (
1) refers to the expectation values of
and
, which are both, in fact, Poisson-distributed random variables.
Finally, let
be the registration action between gates
and
:
and let us define
as the composition of the forward operator with the registration action:
, so that
.
Disregarding the effect of attenuation, the reconstruction of all data in the reference gate,
, can be performed using the Morphed-Maximum Likelihood Expectation Maximisation, M-MLEM, introduced in reference [
7] and reported in Algorithm 1.
2.1.1. M-MLEM with CT-Based Attenuation Correction
The first algorithm proposed in this paper performs the attenuation correction by deforming the CT-based attenuation map,
, to the reference gate and will be called the Morphed-Maximum Likelihood Expectation Maximisation with CT-based attenuation map (
MLEM + CT) in the remainder of this work. The activity distribution is updated as reported in Algorithm 2, where
denotes the CT-based attenuation map after it has been morphed to the reference gate.
| Algorithm 2 M-MLEM + CT algorithm |
Require:
Require:
Require:
Require:
▹ Radon transform
▹ adjoint operator of Radon transform
▹ learned parameters of Synthmorph network
▹ nb of MLAA iterations
▹ nb of M-MLEM iterations
▹ nb total of gates
▹ init of the distribution estimation
▹ data for every gates
▹ init registration fields
for
do
▹ MLAA iteration - MLEM step
▹ MLAA iteration - MLTR step
▹ vector field between CT attenuation map and
▹ approximate estimation of inverse
▹ attenuation map deformed in gate0
for
do
for do
▹ MLAA iteration: MLEM step
▹ MLAA iteration: MLTR step
end for
if then
▹ vector field between two close gates
▹ vector field between two close gates
▹ approximate estimation of inverse
end if
end for
for
do
▹ M-MLEM iteration
end for |
2.1.2. M-MLAA
The second proposed algorithm will be called the Morphed-Maximum Likelihood Activity and Attenuation (
M-MLAA). It follows the interleaved updates of activity distribution and attenuation map as in its original version [
10], but the forward and backward operators are composed with the registration fields evaluated by Synthmorph, as described in
Section 2.1. The two update steps will be, consequently, called
M-MLEM and
M-MLTR, and are reported in Algorithm 3.
| Algorithm 3 M-MLAA |
Require:
Require:
Require:
▹ Radon transform
▹ adjoint operator of Radon transform
▹ learned parameters of Synthmorph network
▹ nb of MLAA iterations
▹ nb of M-MLAA iterations
▹ nb total of gates
▹ init of the distribution estimation
▹ data for every gates
▹ init registration fields
for
do
for do
▹ MLAA iteration: MLEM step
▹ MLAA iteration: MLTR step
end for
if then
▹ vector field between two close gates
▹ vector field between two close gates
▹ approximate estimation of inverse
end if
end for
for
do
▹ MMLAA iteration: MMLEM step
▹ MMLAA iteration: MMLTR step
end for |
2.2. Implementation of the Algorithms
Forward and backward operators are implemented from the Time of Flight (TOF) branch of the Synergistic Image Reconstruction Framework (SIRF) library [
11], and are wrapped in the Operator Discretization Library (ODL) [
12] in which all the algorithms are implemented. The operators are defined according to the geometry of the Siemens mCT scanner.
Registration fields are computed using the pre-trained convolutional neural network Synthmorph [
8]. Synthmorph is trained on synthetic, semantic segmented images and provides modality-agnostic and contrast-invariant registration. Registration fields,
, registering
, and
are computed from images obtained with two initial MLAA iterations.
Inverse diffeomorphisms,
, are computed by the first-order approximation of
, as:
. For both approaches, two sets of diffeomorphisms for the activity distributions and the attenuation map are evaluated. In order to enhance the Synthmorph registration performances, the attenuation map reconstructions are segmented to remove the artifacts in the region of the field of view not covered by the object. These artifacts are commonly seen whenever applying an MLTR-MLAA update [
13]. For
M-MLEM + CT, Synthmorph is further deployed as a first step in the registration of the CT-based attenuation map,
, to the reconstruction of the reference gate,
obtained after the same number of initial MLAA iterations.
2.3. Synthetic Data Generation
In order to assess the performance of the proposed algorithms, synthetic projection data have been generated from the digital 4D extended cardiac-torso XCAT phantom [
14] in which five lesions have been added.
The voxel size of the generated XCAT phantom is 0.316 × 0.316 × 0.16 cm
and four respiratory and cardiac gates have been used in this study. Please note that the proximity to the real respiratory and cardiac motion of the XCAT phantoms is ensured by the fact that they were obtained from X-ray CT and Magnetic Resonance measurements of healthy male volunteers. In particular, 4D-tagged Magnetic Resonance Imaging data and 4D high-resolution respiratory-gated CT data are used [
14].
The size, relative uptake, and positioning of the lesions have been carefully chosen. The size is almost the same for all of the lesions and comparable to the system resolution.
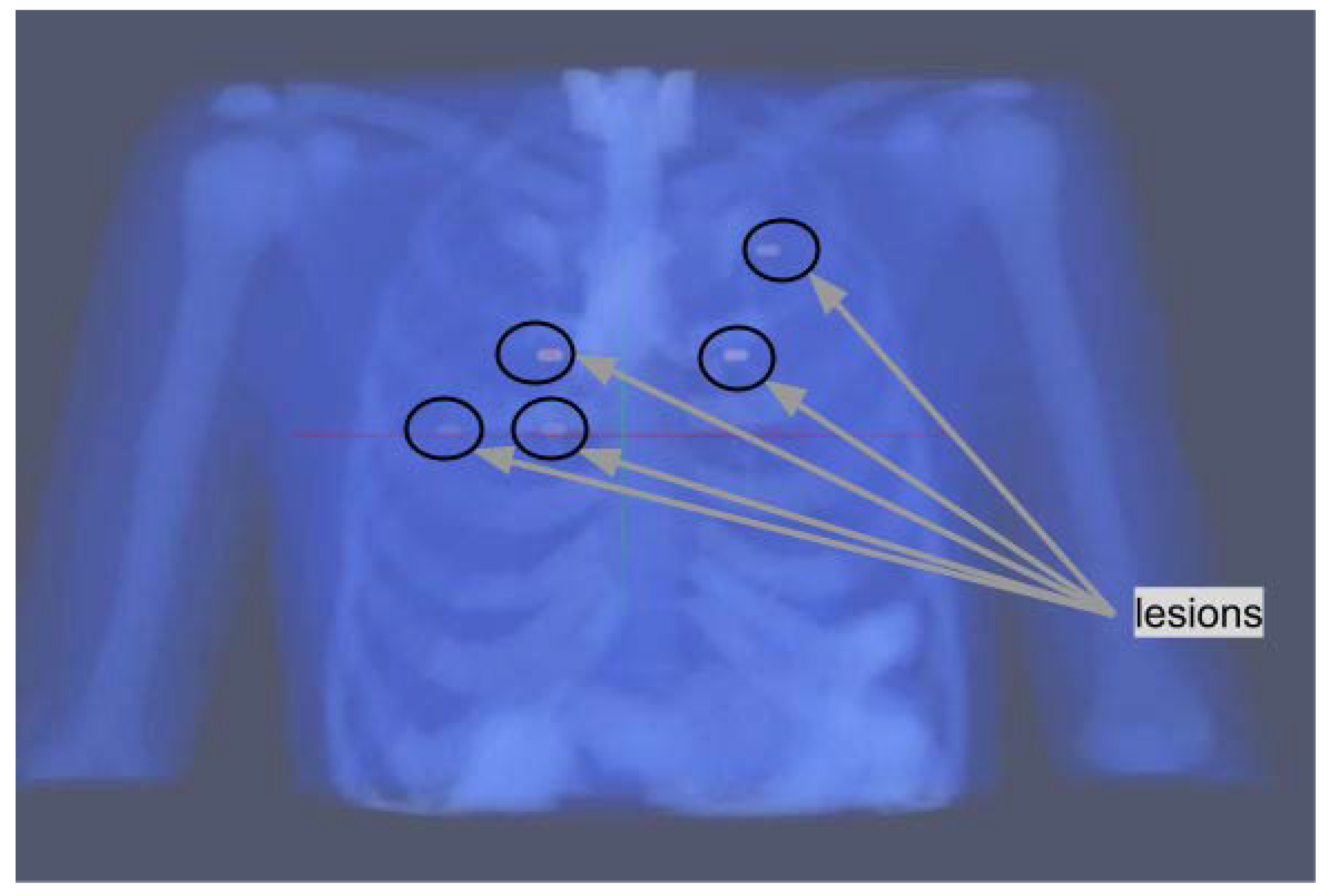
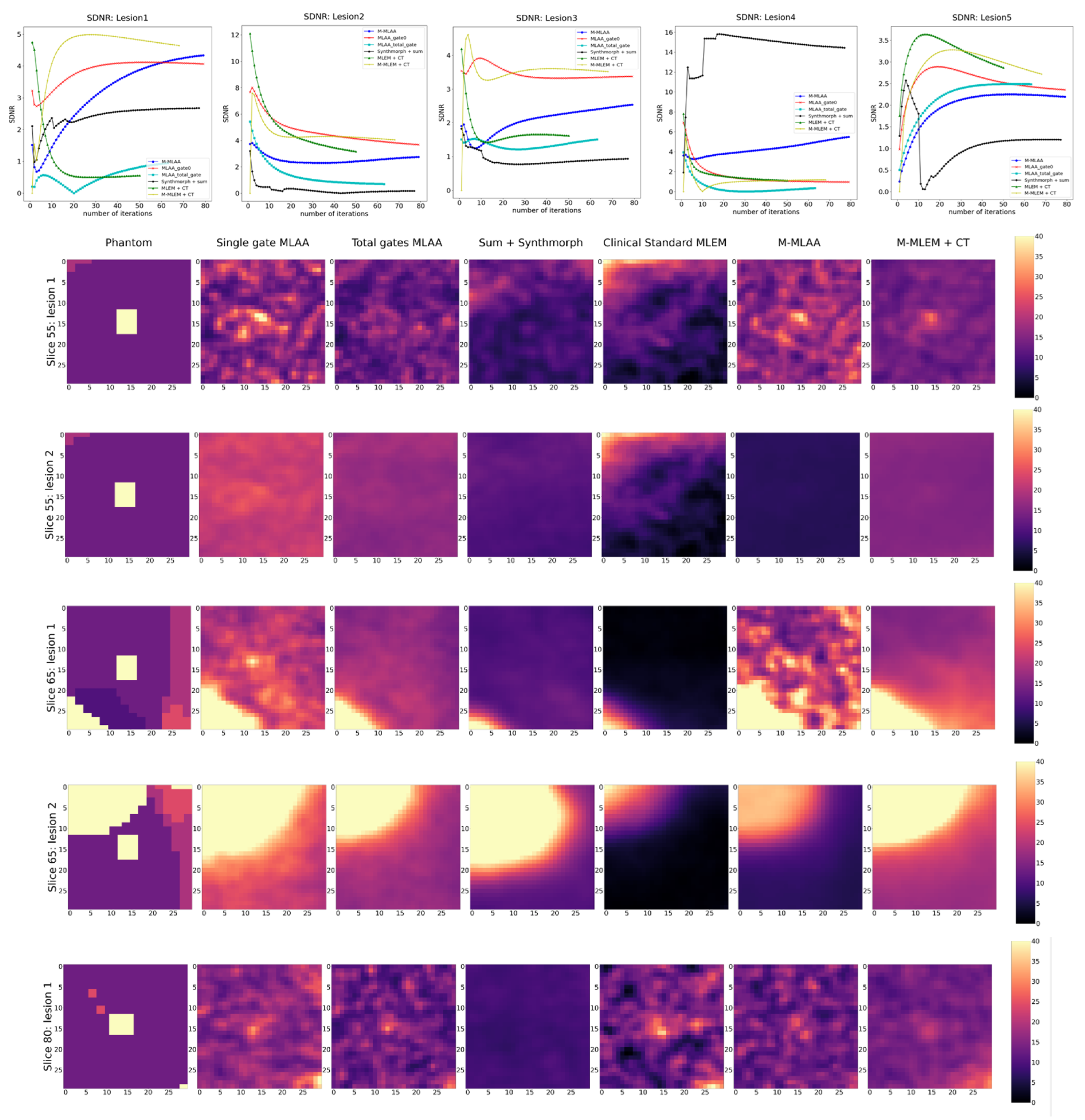
Their position is shown in
Figure 1; two lesions are localized in slice 55, two lesions in slice 65, and one lesion in slice 80. The rationale for their positioning is described in the following. One of the lesions is placed in the upper part of the lungs, this should be the easiest one to detect as respiratory motion is lower in that region. Two of them are placed in proximity to the heart, which has an high uptake through the blood pool, and are therefore expected to have a lower contrast compared to their surroundings. The remaining two lesions are placed around the middle of the lungs, one on each side.
Uptake is chosen to be either 4:1 or 6:1 compared to the blood pool, reflecting the typical standard uptake values in fluorodeoxyglucose PET.
From the labels in the XCAT phantom, a radiotracer distribution and an attenuation map have been estimated in the way described in the following:
Radiotracer distribution: Uptake for healthy tissues has been taken from reference [
15] with an educated guess for tissues not present in the reference. The activity in reference [
15] has been scaled to a level consistent to the dose injected at Karolinska Hospital in Huddinge (3 MBq/kg up to a max of 400 MBq total). The scaling has been done considering a mass of 70 kg for the full-body XCAT-phantom and by setting the average uptake per voxel to be equal to the total injected dose divided by the number of voxels in the XCAT-phantom. Lungs uptake is considered to be 0.75 of the average uptake and the scaling factors for remaining organs are derived from Table 2 in reference [
15] by dividing the median activity concentration in the organ (column 2) by the median activity of lungs divided by 0.75. The five lesions were given an activity corresponding to 4 or 6 times that of the blood pool. One of the lesions in slice 55 has a dimension of 6 × 5 voxels, whereas the other is 6 × 4 and the lesions in slice 80 and 65 are all 6 × 5 voxels in dimension.
Attenuation map: The attenuation map has been estimated from the labels of the XCAT using the values from the National Institute of Standards and Technology tables [
16]. Since, at the energy of interest, most human tissues, apart from bone and lung tissues, have similar attenuation, we only used the x different value for the linear attenuation coefficients reported in
Table 1.
Once the activity distribution and the attenuation map have been created, attenuated sinograms are generated with forward projection and Poisson noise is added.
2.4. Hardware and Software
The hardware used is an Intel(R) Xeon(R) CPU E5-2690 v3 @ 2.60 GHz with one GPU from the ASPEED Graphics Family, with 500 Gigabyte memory and 8 Terabyte hard disk. All computations are run in Python 3.7.4, using TOF capabilities of the Synergistic Image Reconstruction Framework (SIRF 3.4) library and the Operator Discretization Library (ODL 0.7.0). Voxelmorph 0.2 and Tensorflow 2.11.0 are used for Synthmorph registration.
2.5. Evaluation of M-MLAA and M-MLEM + CT Reconstructions
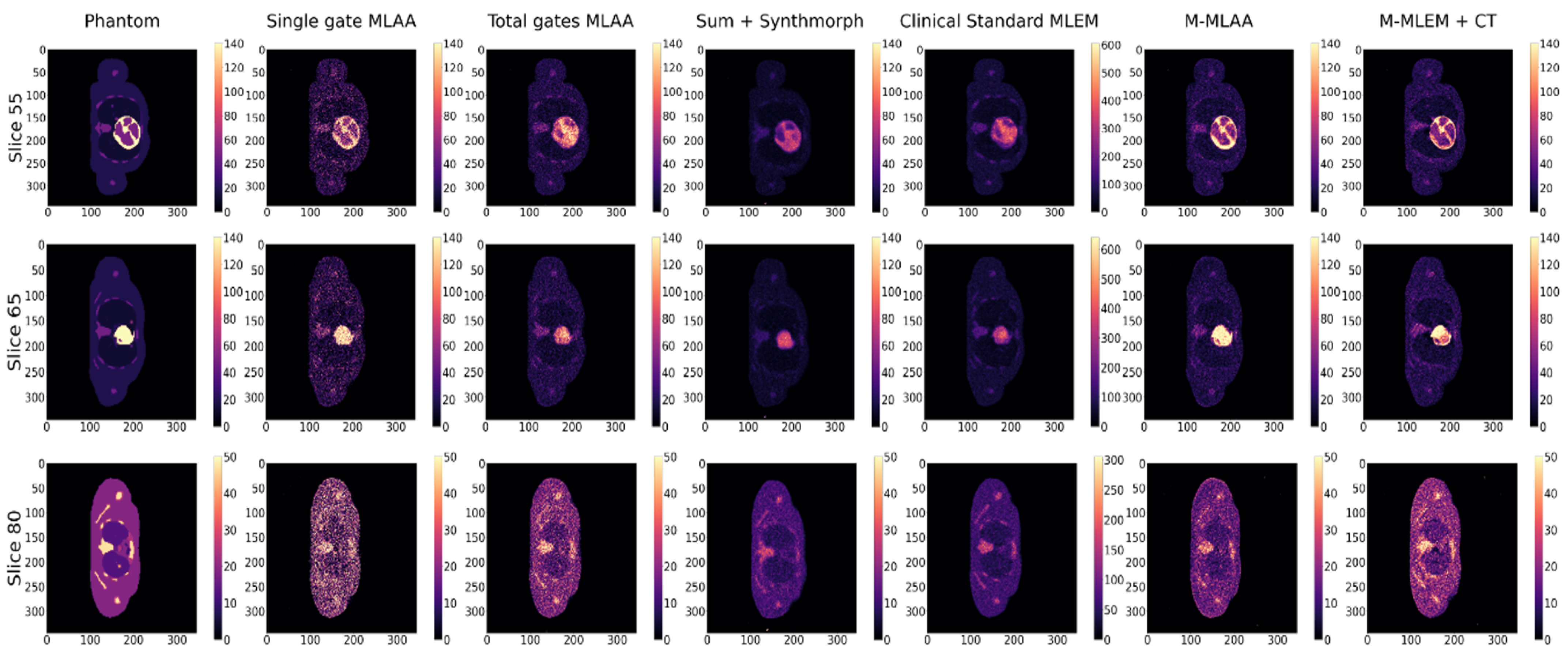
M-MLAA and M-MLEM + CT reconstructions have been compared against:
MLAA reconstruction of reference gate, ; this corresponds to the situation in which a large amount of projection data are thrown away in order to avoid motion blurring (called, in the remainder of this study, Single-gate MLAA);
MLAA reconstruction from the sum of the data in all of the four gates; this corresponds to disregarding the motion correction (called, in the remainder of this study, Total-gate MLAA);
MLAA single-gate reconstructions summed after registration in the reference gate with Synthmorph (called, in the remainder of this study, Sum + Synthmorph);
MLEM reconstruction of the reference gate, , with attenuation correction performed through a CT-derived attenuation map. This corresponds to the most common clinical practice and disregards motion correction (called, in the remainder of this study, Clinical Standard MLEM).
The comparison of the algorithm performances is carried out through the evaluation of chosen Figures of Merit (FOMs) and a Channelised Hotelling Observer (CHO).
2.5.1. Figures of Merit (FOMs)
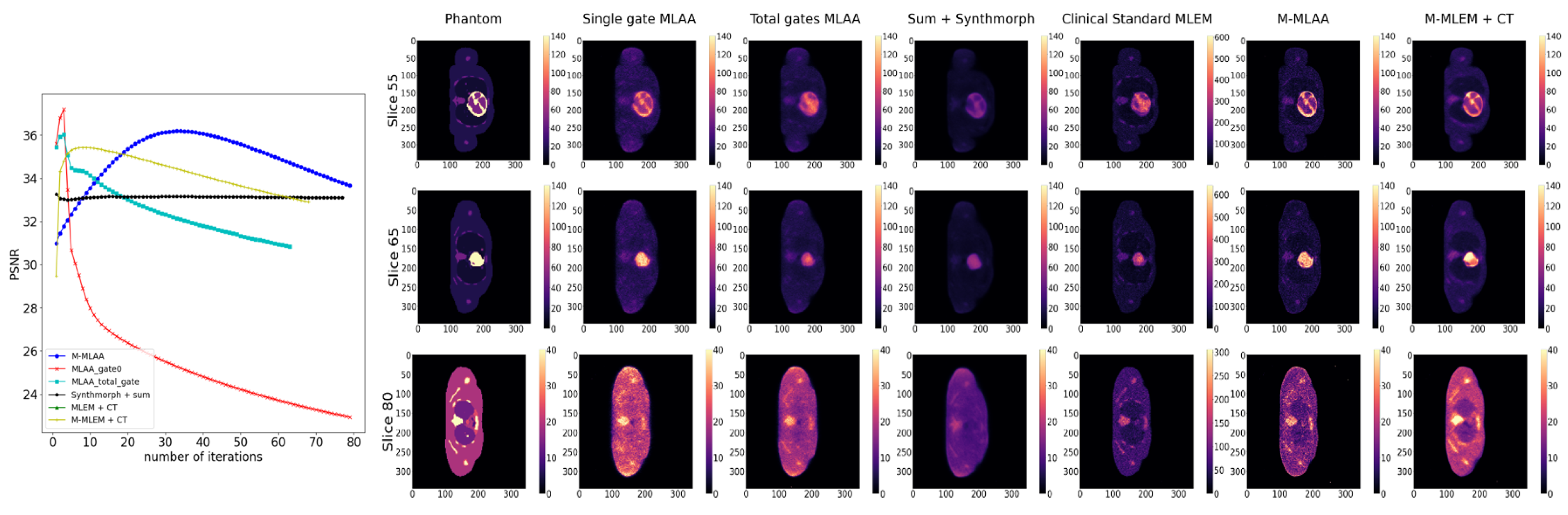
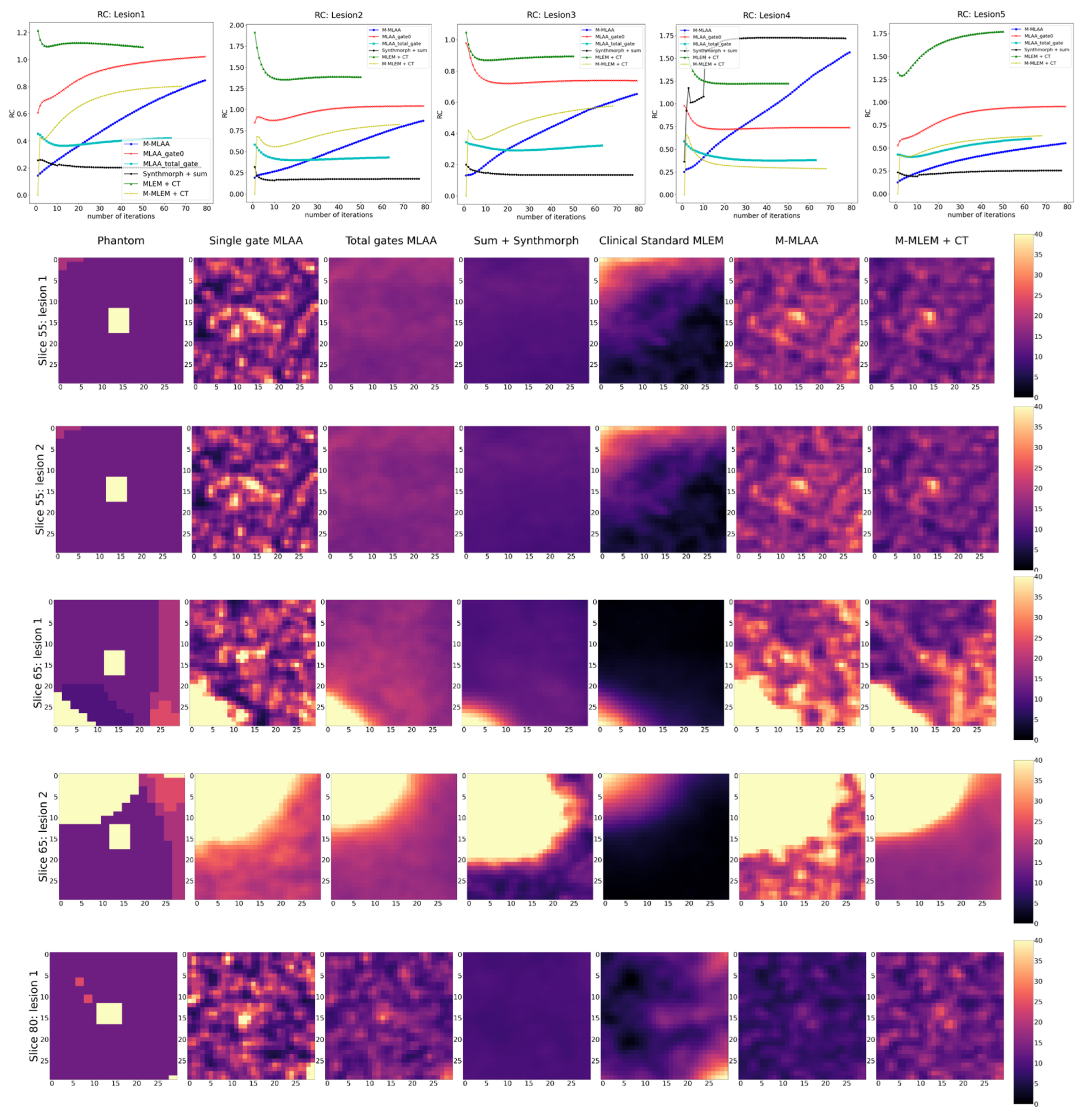
The FOMs that have been evaluated are: Peak Signal-to-Noise Ratio (PSNR), Recovery Coefficient (RC), and Signal Difference-to-Noise Ratio (SDNR). PSNR has been evaluated, on the whole, using reconstructed images with a data range equal to 500; RC and SDNR have been evaluated within Regions of Interest (i.e., ROIs) around the five lesions in the phantom.
With indicating the phantom, the reconstructed image from noisy and attenuated sinograms, the ROI around the lesion, and the ROI within the background, the chosen FOMs have been evaluated as follows:
Here,
d is the maximum fluctuation in the input image data type and
is the Mean Squared Error, computed as follows:
2.5.2. Channelised Hotelling Observer
Model observers are used to assess the quality of medical images with respect to a clinical task of interest, which, in our case, is a lesion detection task. They function as a powerful surrogate of human performance [
17,
18]. The Channelised Hotelling Observer, CHO, belongs to the class of linear model observers, which act by applying a linear template
to the image data vector
to compute a scalar test statistic
t as a decision variable, according to the following:
The decision variable is, then, compared against a threshold to determine if the lesion is present (
) or absent (
). By varying the threshold, it is possible to compute the Receiver Operating Characteristic (ROC) Curve and the Area Under the Curve (AUC) and use those to compare the performances of the tested algorithms [
18,
19]. The CHO operates through a set of channels, which allow for extracting specific features from the images, such as the ones that can be extracted by the human visual system. The outputs of the channels are then linearly combined using the
Fisher–Hotelling rule in order to achieve the optimal CHO template. The Fisher–Hotelling rule states that the vector
, containing the best linear combination of the channel weights, is to be computed as follows [
20]:
Here, is the covariance matrix of the output of the channels to the images, is the mean signal plus background, as seen by each channel, and is the mean background only, as seen by each channel. The optimal template is, finally, used to compute the test statistic and evaluate the ROC and AUC for each of the algorithms tested.
In this paper, the CHO is implemented through 4 Gabor filters. Gabor filters have been chosen since they are a validated model to mimic the response of the cells in the visual cortex [
19,
20]. The parameters of the Gabor filters have been set to a spatial frequency that varies between 0.01 and 0.02 pixels, an orientation that varies between 0.01 and 0.05 radians, a bandwidth of 0.9 octaves, and with standard deviation set to 3. Twenty-five ROIs have been considered, each with a dimension of
pixels. Five ROIs are evaluated around the lesions of interest and twenty in the background only; they are taken within the slices 55, 65, and 80. Before feeding in the CHO and extracting features through the channels, a Gaussian filter with
is used to reduce the noise within the reconstructed images.
4. Discussion
Looking at
Figure 4,
Figure 5 and
Figure 6, it is evident that the response from the chosen FOMs does not correlate with the visual assessment of the lesion visibility and fidelity to the phantom. In
Figure 4, it is possible to observe that the maximum PSNR values are obtained by the
single-gate MLAA after only a few iterations. However, the corresponding image seems to be of inferior quality compared to both
M-MLEM + CT and
M-MLAA at their best PSNR value, which is obtained for a larger number of iterations.
Similarly, in
Figure 5, the RC value for each of the algorithms as a function of the number of iterations is shown together with the corresponding reconstructions of an ROI around the lesions at the optimal number of iterations. For all lesions, RC favours
and
. However, this does not seems to be the case when looking at the corresponding reconstructions.
Finally, SDNR shows rather inconsistent behaviour over the different lesions, making it difficult to establish which algorithm offers the best performance in reconstructing the lesions.
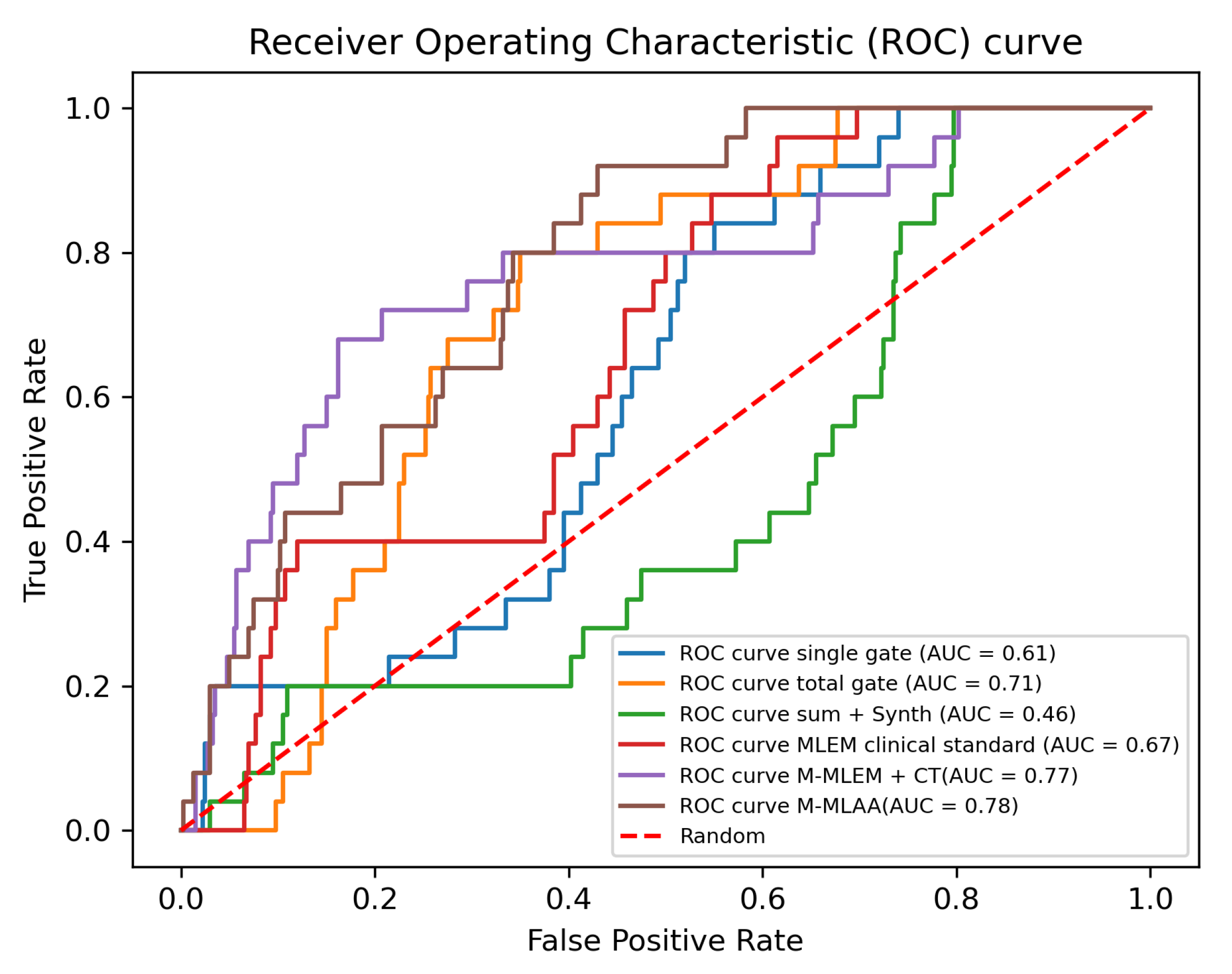
The results obtained with the CHO are, instead, more compatible with what the visual inspection suggests (see
Figure 7), with
M-MLEM + CT and
M-MLAA outperforming the other algorithms and having similar performances (
of
and of
, respectively).
According to the CHO, and give the worst reconstructions, with exhibiting a worse performance than simple random guessing. On passing, let us here point out that we are aware of the fact that, in cases like the one here presented, it is always possible to improve the performance of an observer that is performing under the 0.5 AUC threshold (corresponding to random guessing), by simply reversing the observer predictions. This is, however, not relevant in the present case as the above inversion would still yield an AUC value of 0.54, which is still close to random guessing.
As a last note, it is worth noting that scatter and random corrections have not being considered in this study and need to be included before applying the two proposed algorithms to clinical data. This does not constitute a substantial challenge, since the algorithms can be easily extended to account for those two corrections, just as is routinely done with MLEM. Also, the hyperparameters of both M-MLEM + CT and M-MLAA can be further optimised, in particular regarding the optimal number of initial iterations before feeding reconstructed images in Synthmorph for the evaluation of the registration fields.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}