2.1. Face Aging
Before the advent of deep learning, age progression and regression methods were primarily divided into physical model and prototype approaches. Physical model techniques [
20,
21] were focused on modeling the physical attributes of face aging, such as the alterations in hair, mouth, and skin texture, over time. These methods required a substantial amount of matched data and were time-consuming. Prototype-based approaches were focused on investigating the differences in facial images among different age classes to determine the aging patterns of each age class. Typically, these methods involved averaging the faces of individuals within the same age range to identify common features [
22,
23]. The face rejuvenation/progression process involved removing/adding textures that exhibited signs of aging, which was accomplished by applying a learned transformation across facial surfaces. Since this procedure produced smoothed facial images for each age class, maintaining identity information was challenging.
The success of GANs in image synthesis and translation tasks has led to remarkable progress in face aging techniques. The training process of GANs involves training two models simultaneously: the generator
G, which learns to generate new samples that resemble the training samples and captures their distribution, and the discriminator
D, which distinguishes the synthetically generated samples from the real training ones. Let the data distribution be
, i.e., the training data
∼
. If
is sampled from the distribution
,
G and
D engage in the min-max game [
6]
where
denotes the expectation operator. To circumvent the prohibitive cost of longitudinal collection of multiple face images for each subject, GAN-based methods resort to unpaired face aging data for training and primarily focus on modeling mappings between image contents. It is crucial to enforce identity consistency to prevent matching ambiguities when trying to simulate the aging process in an unpaired training scenario. This way, key semantic conditional information of the input, such as the unique facial features of each individual, are maintained. It should be noted that most GAN-based face aging algorithms do not enforce constraints in regions that are particularly relevant to age changes. Still, the generator re-estimates the pixel at each spatial location of the synthetical image.
In [
24], a GAN-based framework for Attribute-Aware Attentive Face Aging (A
3GAN) was proposed. By integrating facial attribute vectors into the generator and discriminator, semantic conditional information from the input was employed to train the model to create elderly face images with attributes faithful to the corresponding input. An attention mechanism that limited the alterations to age-related regions improved the visual quality of the synthesized face images. Since wrinkles, eye bags, and laugh lines are represented mainly by local textures, a wavelet packet transform extracted features at several scales in the frequency space, increasing aging details.
The effects of aging within a specific age class are related to the effects of aging in neighboring age classes, as aging is a gradual and continuous process. Moreover, aging transformations between distant age classes are likely more drastic and intense than those between nearby age classes. In [
25], face aging was addressed as an unsupervised image-to-image translation problem. The Pyramid Face Aging-GAN (PFA-GAN) was suggested in particular, which contains a pyramid weight-sharing method. Face aging effects are therefore learned hierarchically, beginning with the subtle changes necessary between neighboring age classes and progressing to the more conspicuous and drastic changes required between distant age classes. No paired examples showing how the person looks at the target age class were needed, alleviating a severe limitation of many face-aging approaches.
In [
26], a framework was developed to simulate aging in three dimensions. The framework consisted of three components—a 3D estimator for vertices and textures, a texture-aging GAN, and a module for rendering 2D and 3D faces. The 3D vertex and texture estimator determined the spatial vertices and textures of the face. The GAN applied aging effects to the estimated texture map. Finally, the rendering module produced 2D or 3D faces using the vertex map and the aged facial texture map.
A GAN network termed Age Gap Reducer-Generative Adversarial Network was introduced in [
27] to reduce the age gap between face images using automatic age estimation. The network took into account both the gender of the individual in the input image and the desired age group to which the input face needed to be adjusted. This enabled the network to either regress the input image to a younger age group or progress it to an older age group, depending on the desired outcome.
Face aging depends on accurate age estimation. Age estimation is a challenging task because it is affected by gender, race, and various intrinsic or extrinsic attributes. An age estimation architecture was developed in [
28], which included three convolutional neural networks (CNNs) and two extreme learning machine structures. There is a lack of large and reliably annotated datasets for training deep neural networks to estimate age. Knowledge distillation was exploited for accurate age estimation in [
29] to address this problem. In a nutshell, class probability vectors were derived by a large model comprising multiple CNNs applied to a reference annotated dataset. The resulting predictions were then exploited as target labels to train a smaller model on a face dataset without age annotations.
2.2. Basic Elements of Explainable AI
The paper’s main contribution is to enrich CAAE, described in
Section 2.3, with explainable artificial intelligence (xAI) techniques by adding an explanation system into its training procedure. In the following, the basic xAI techniques are briefly reviewed.
Pixel and feature attribution techniques attempt to explain individual predictions by crediting each input feature according to how much it alters the prediction. Pixel attribution techniques are known by various names, one of which is Saliency maps. Typical examples of feature attribution techniques include SHAP and LIME. Input pixels, tabular data, or text are used as features. There are two sorts of attribution techniques:
- 1.
Gradient-based: These techniques compute the gradient of the prediction (or classification score) concerning input features. The key distinction between various gradient-based techniques lies in the method they use to calculate the gradient.
- 2.
Occlusion-based: These techniques, such as SHAP and LIME, manipulate image regions to produce model-agnostic explanations.
Both techniques provide explanations in the context of a Saliency map that is the same size as the input image or at least projected onto the input image. Each pixel is given a value, which can be interpreted as its importance for the prediction or categorization task.
2.2.1. Saliency
Saliency maps [
12] determine the significance of each feature in a given input for subsequent classification using a deep neural network inspired by how animals focus their attention. A nonlinear score function
is used to determine whether an image belongs to a particular class. This function is linearized using a first-order Taylor expansion around a specific image
It is seen that the first term represents the classification score when the input is not perturbed, while the gradient term weighs the impact of perturbations. By reshaping the gradient to a two-dimensional matrix (i.e., an image), the Saliency map is produced. The Saliency map is frequently normalized. Accordingly, will refer to the normalized Saliency map hereafter. If more than one channels are present in the input image, the maximum Saliency map across all channels is considered. One can create a visual representation by taking the absolute values of the elements in the Saliency map or by distinguishing between the negative and positive contributions. The process of computing the Saliency map is not costly, as it only necessitates a single back-propagation step and does not assume the existence of any further annotations beyond the labels employed during the initial model training.
2.2.2. LIME
LIME [
14] selectively activates or deactivates certain super-pixels in an image and then examines how these perturbations impact the predictions made by a classifier. To achieve this, LIME creates a synthetic neighborhood, denoted by
, around the input instance to be explained, denoted by
, i.e.,
where
is a local perturbation, and
denotes the zero-mean multivariate normal distribution with diagonal covariance matrix
estimated from the training set. Let
denote a binary vector for the interpretable representation of
, i.e., a binary vector indicating the “presence” or “absence” of a super-pixel. Let
be the model to be explained.
can be either a probability value or a binary indicator that indicates whether
belongs to a specific class. To learn a potentially interpretable linear model
, LIME samples instances
from
by randomly selecting non-zero elements. Given a perturbed sample
for
that contains the fraction of non-zero elements in
, the ridge regression method is used to learn
by defining a locally weighted square loss function as
where
is an exponential kernel with width
. Next, the function
is sought that minimizes
where the minimization is performed over the set of linear models, and
is a measure of interpretability (i.e., the number of non-zero weights for linear models). To solve the optimization problem (
5), the least absolute shrinkage and selection operator (LASSO) is employed.
LIME utilizes a sequential feature selection [
30,
31] to fit multiple ridge regressors and select a subset of
F features for the model
g repeatedly. The kernel width used is
, which is chosen during the process.
2.2.3. SHAP
Shapley’s values, which came from cooperative game theory, are the cornerstone of SHAP [
13]. In SHAP, features are considered actors that can potentially form coalitions to maximize future profits in a collaborative ecosystem. This approach has served as the foundation for several fields due to its adaptability. KernelSHAP (abbreviated as SHAP) is one of these branches.
SHAP approximates the original model with the surrogate model, chosen as a linear one. Let the original black-box model (i.e., GAN) be
f and the surrogate model be denoted as
g. Moreover, let
be a reduced vector of ones and zeros that enables or disables certain features of
, also known as the coalition vector. If
m denotes the size of
and
is the number of ones in
, SHAP’s loss function is defined as
where
reshapes the reduced vector
to
and
Z denotes the set of all possible reduced vectors to be generated by taking subsets of features from
. The SHAP kernel
in (
6) is given by:
The SHAP kernel is critical for giving tiny or big coalitions greater weight than coalitions that merely combine half of the traits (or close to it). The idea behind these behaviors is that we can learn more about individual features if we can analyze them separately (small coalitions) or if we have nearly all features except one (big coalitions).
The SHAP method is a reliable approach that can yield results equivalent to, if not better than, that of LIME. It also draws on well-established notions such as Shapley values, game theory, and LIME’s intuitive reasoning. However, similar to other permutation-based methods, SHAP has the issue of creating unrealistic data points by replacing missing attributes with random ones, which might lead to exaggerated interpretations.
2.2.4. Overview of xAI-Enhanced Approaches
This research parallels other initiatives to equip GANs with explainable techniques. In [
32], a study was conducted to investigate the similarity of the inner structure of CNN-based generators employed in CycleGAN. The CycleGAN was previously used for face aging in [
33]. The study introduced a cross-GAN filter similarity index to analyze the similarity of CNN filters across different GANs. Another explainable methodology called GAN-based Model EXplainability (GANMEX) was developed in [
34] by incorporating the classifier into the GAN to generate one versus many explanations. By using Principal Component Analysis in the latent feature space, important latent directions were identified, which enabled a large number of interpretable controls through layer-wise perturbation [
35]. In [
36], an xAI-enhanced version of a baseline machine learning model is proposed that is proved to outperform the original model in terms of interpretability and classification accuracy. The SHAP technique was used to extract high-contributed features that led to more accurate identification of vegetation pixels in [
37].
2.3. Proposed Workflow
The baseline CAAE network is depicted in
Figure 2. The CAAE model includes the encoder
E, the generator
G, and two discriminators, namely,
and
.
G is implemented as an autoencoder. Given an input face image, the encoder
E generates an encoded
(also known as a latent vector), preserving the high-level personal feature of the input face. The generator
G uses the encoded
and the target age information as a label to generate a facial image conditioned on the age. Two discriminator networks are imposed on the encoder
E and the generator
G, respectively.
regularizes
to be uniformly distributed to smooth the age transformation.
enforces
G to generate photo-realistic and plausible faces for arbitrary
and age label. The objective function contains three terms: (1) the
norm of the reconstruction error between the input image and the generated image by the generator plus the total variation loss of the generated image to remove ghosting artifacts; (2) the min-max objective function to train the encoder and
; and (3) the min-max function to train
. Let
denote the input face image,
l refer to an age label, and
be the encoded variable in the output of the encoder
. Moreover, let
and
be the
error norm and the total variation, respectively. If
is the distribution of the training face images,
denotes the prior distribution, and
implies random sampling from the prior distribution, the objective function optimized by CAAE is defined in (
8), i.e.,
where the coefficients
and
balance the smoothness and high-resolution terms.
CAAE is capable of generating highly realistic face images with both regressive and progressive effects. Unlike other methods, CAAE does not need paired examples of data for training or labeled faces in the testing data, making it more flexible. The separation of age and personality information in the latent space of results in maintained individual personalities and the elimination of any ghosting artifacts. Finally, CAAE is not influenced by alterations in pose, emotions, or occlusion.
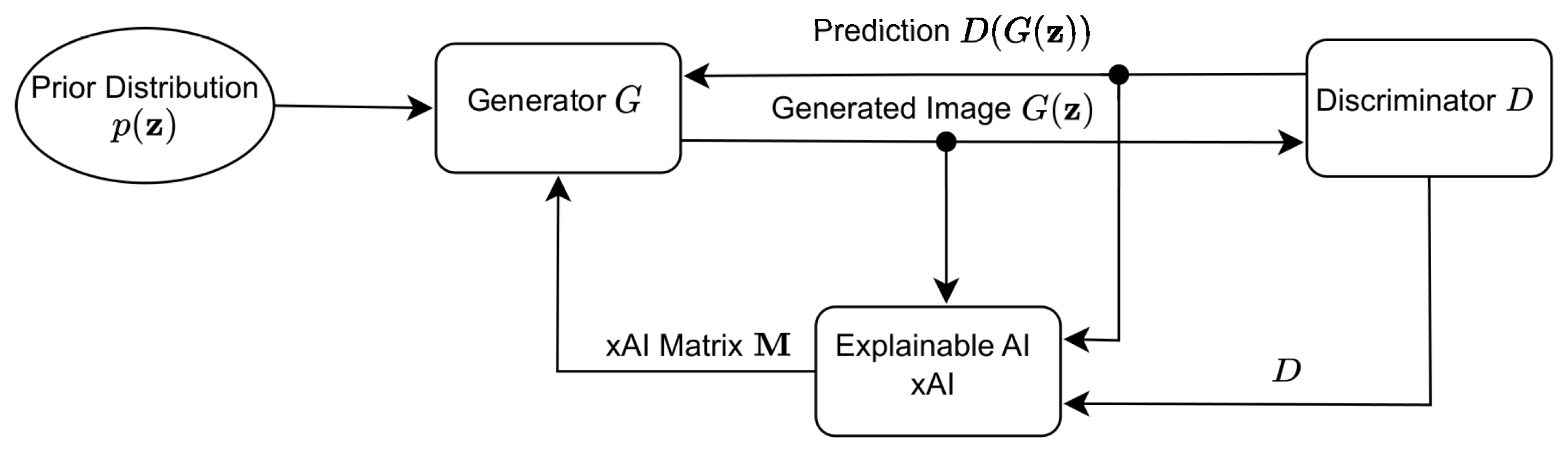
Another network termed xAI-GAN refers to the technique that aims to enhance GANs to provide better synthetic or reconstructed images through the incorporation of an xAI system [
38]. In this way, corrective explanatory feedback is provided during training from the discriminator to the generator.
Figure 3 depicts the system architecture of xAI-GAN.
Given a noise sample from a noise distribution, the untrained generator G creates an image that is then fed to discriminator D. The output of the discriminator , the generated image , and the discriminator network D are channeled to the xAI system seeking an explanation of the loss incurred by the synthetic image . The general idea behind the xAI-guided training process of a GAN is that the xAI system works as a guide. The xAI system acts by structuring the gradient descent in such a manner that generator training is focused on the most essential input features that the discriminator identifies.
The proposed framework follows the network structure in CAAE, which includes an encoder
E that converts RGB images to latent vectors
, a generator
G that converts
to RGB images, a discriminator
that enforces a uniform distribution on the encoder’s output, and a discriminator
that ensures the generator creates realistic images. CAAE incorporates two discriminators to improve the realistic properties of the generated facial images. The proposed xAI-CAAE aims to leverage xAI systems to strengthen and enrich the age progression and regression accomplished by CAAE. In CAAE, the discriminator offers feedback to the generator using a single loss value per generated image. The aim of xAI-guided training is to enhance this feedback by providing the xAI system’s “reasoning” for the discriminator’s decision. The architecture of xAI-CAAE is depicted in
Figure 4.
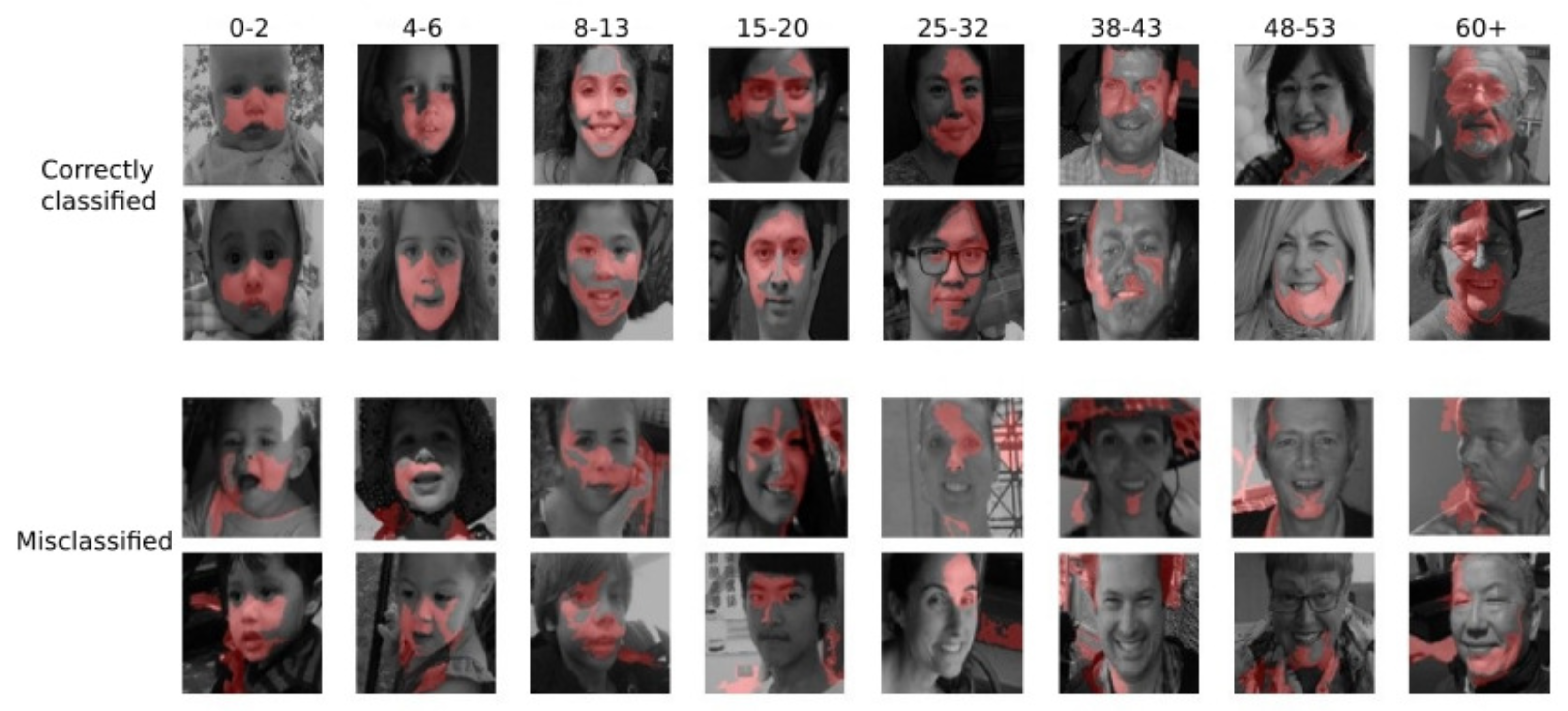
In xAI-CAAE, a modified gradient descent generator training process is established so that generator training focuses on the most significant features for the discriminator’s prediction. An xAI system employs a score function to determine the explanation matrix after propagating the loss through the discriminator to find . The matrix , which refers to pixels, is made up of real numbers in the range [0, 1], with greater values indicating more important features for the discriminator’s prediction. More specifically, in Saliency maps, if the pixel is given a value of 0 or near 0 in , the pixel under consideration does not influence the discriminator’s classification decision. On the contrary, the pixel is considered extremely essential if given a value of 1 or near 1. These values, when approaching 1, also show high-quality classification by the discriminator. In SHAP, the Shapley value can be described as the mean incremental impact of each pixel that is excluded in the discriminator’s output. This is computed by taking an average of all the different combinations of pixels that form the complete image, starting from an empty set of pixels. Accordingly, the explanation matrix allows us to concentrate the learning process on the most important qualities, regardless of whether they were favorable or harmful to the classification.
The proposed framework utilizes
to update the generator’s weights in a modified gradient descent method. In CAAE, the adjustment of generator weights typically involves calculating the gradient of the generator’s output with respect to the loss and then applying the chain rule. This method is enhanced by first computing the explanation matrix
and then multiplying it by the gradient of the generator’s output with respect to the loss. The explanation matrix
is used to mask the latter gradient and the pixels that contributed to the discriminator’s classification. As described, the modified gradient
is obtained by taking the Hadamard product (element-wise multiplication) between
and
, denoted as
, which serves as a mask for
and restricts the gradient to the most significant elements. Finally, the generator’s gradients
are computed using the modified gradient as
where
is a parameter that determines the degree to which the xAI system affects the original gradients.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}