
Beetle Antennae Search: Using Biomimetic Foraging Behaviour of Beetles to Fool a Well-Trained Neuro-Intelligent System



Abstract
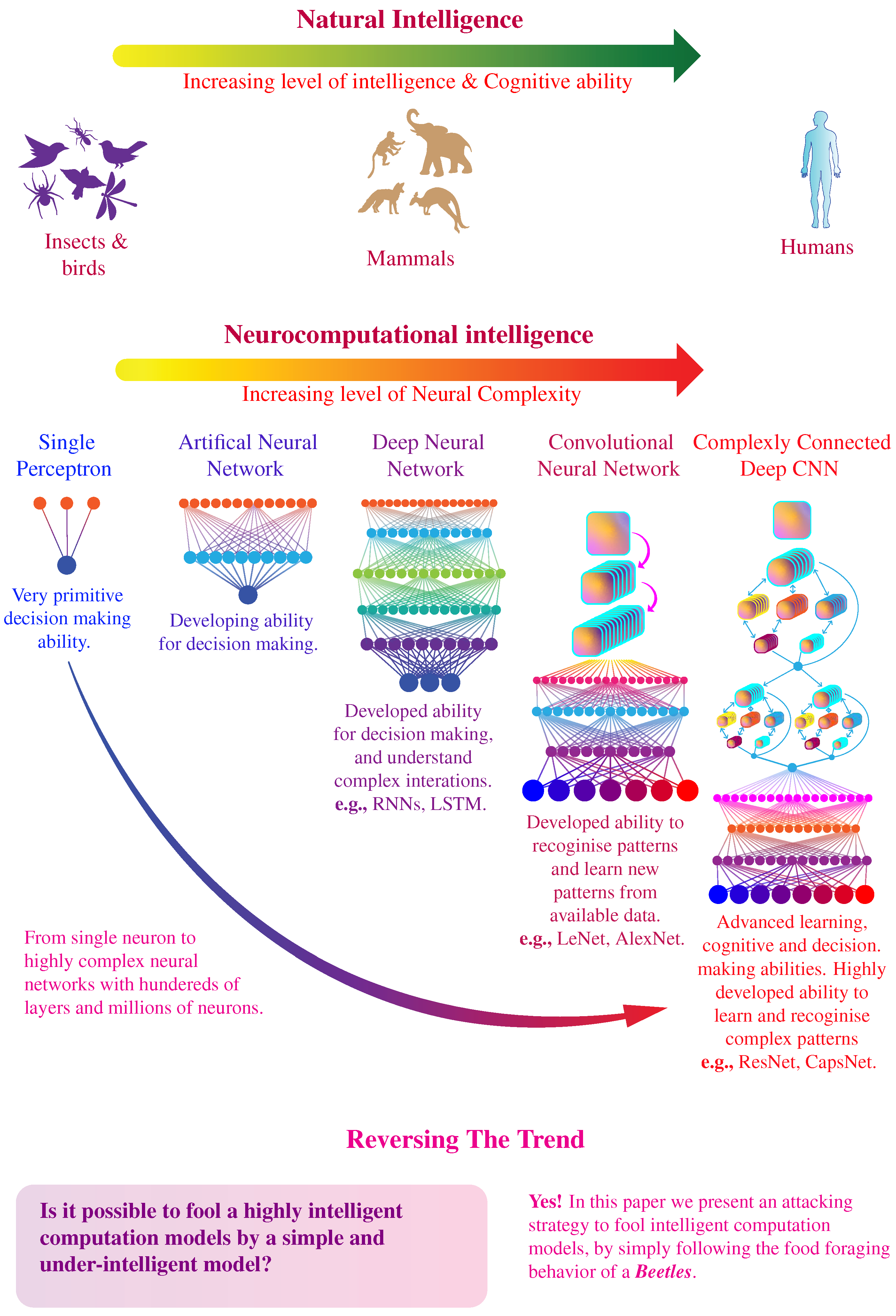
:1. Introduction
- A pixel-level fooling attack algorithm for CNN, by just using a single search particle.
- The algorithm is independent of the architecture of the CNN. It treats the CNN as a black-box and just relies on the output prediction of the CNN. Therefore, the algorithm is general enough to be applied to different CNN architectures.
- The algorithm is very efficient since it relies on only a single search particle.
- Extensive experimental results using two CNN architectures; LeNet-5 and ResNet are presented to demonstrate the efficacy of the proposed algorithm.
2. Problem Formulation
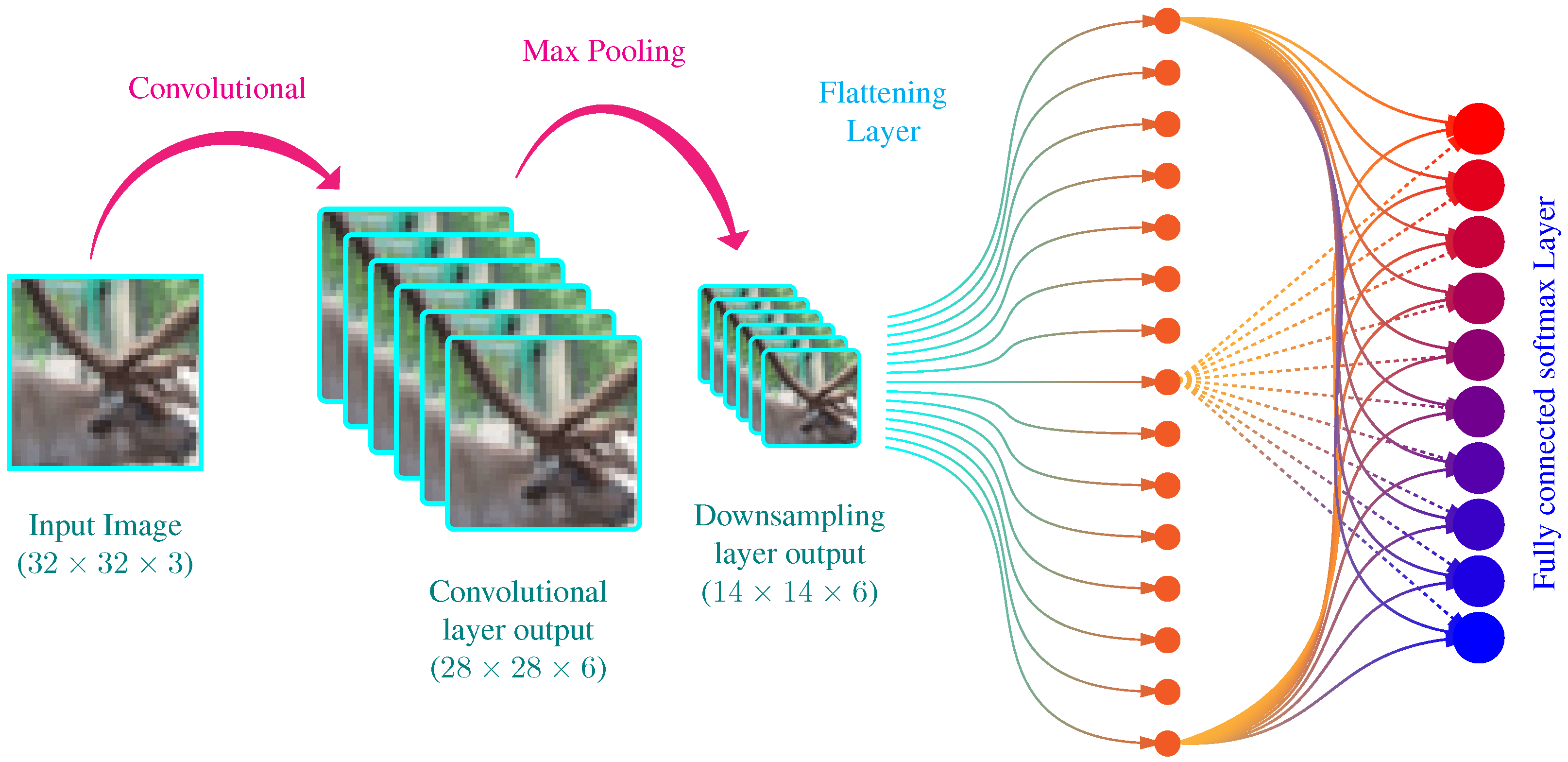
2.1. Convolutional Neural Networks
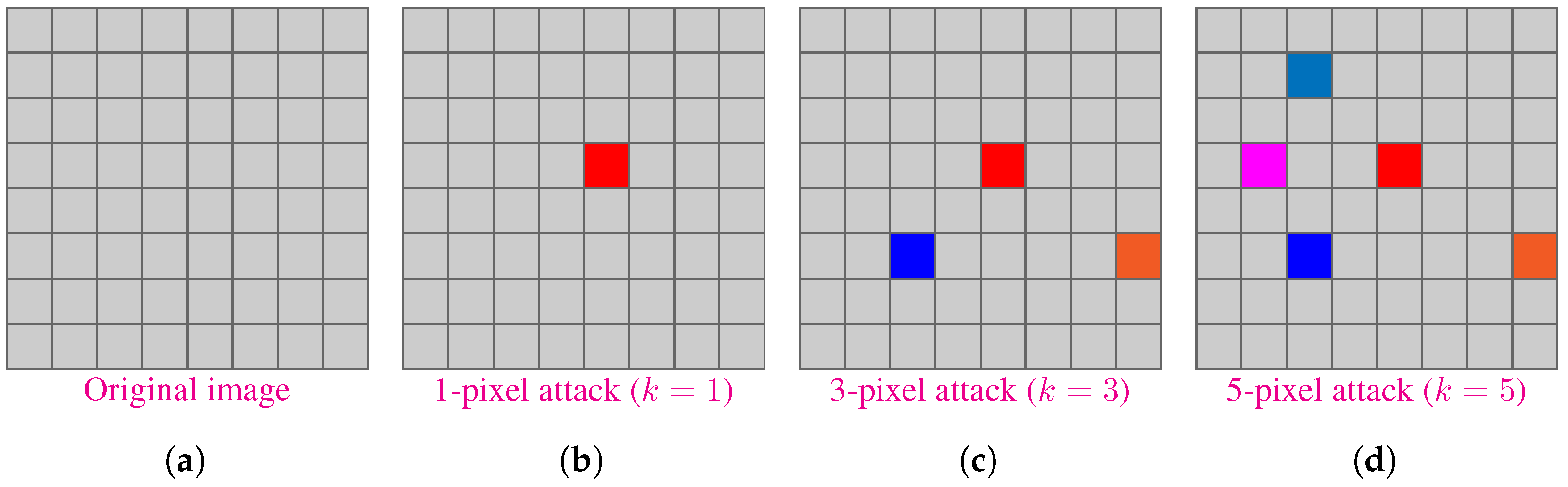
2.2. Image Perturbation
2.3. Untargeted Attack
2.4. Targeted Attack
3. Algorithm
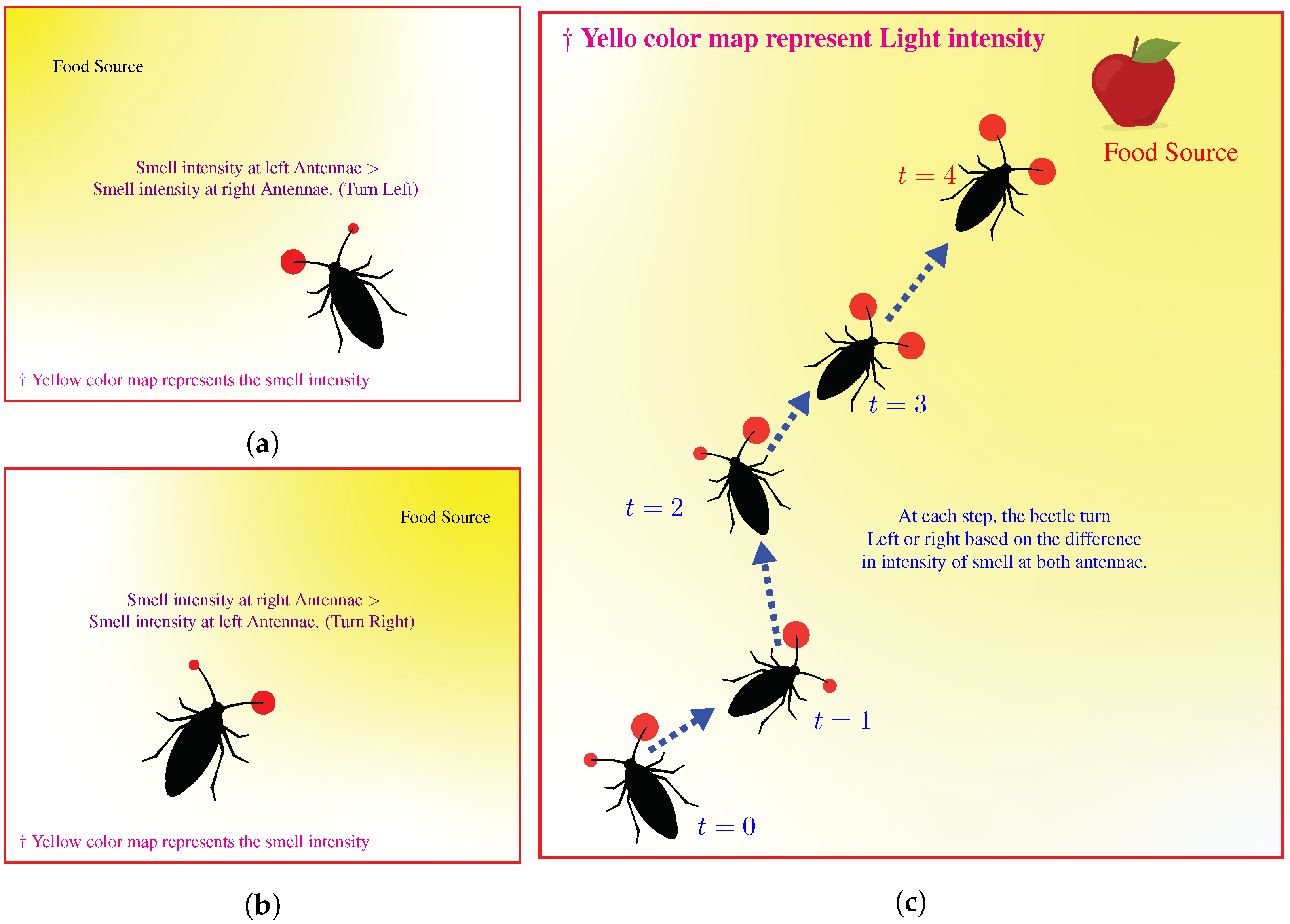
3.1. Mathematically Modelling Behavior of Beetle
3.2. Optimization Algorithm
- Start from random location .
- Generate a random direction vector for left antennae relative to current position of the beetle.
- Calculate the position of left and right antennae ( and ) using (12).
- If reached goal position , stop. Otherwise, return to step 2.
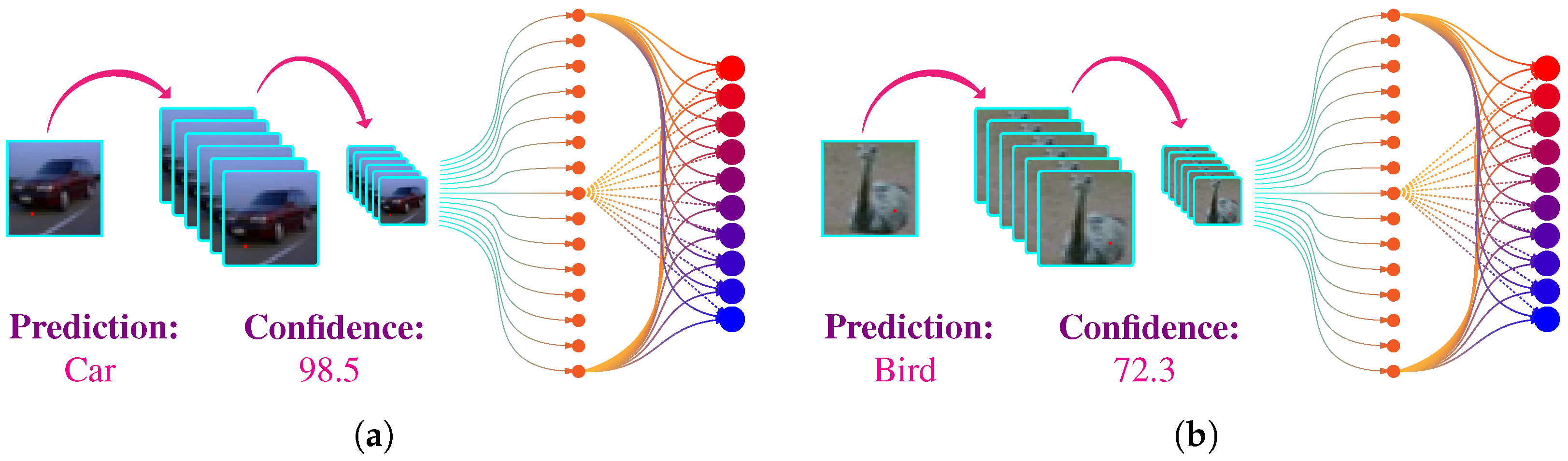
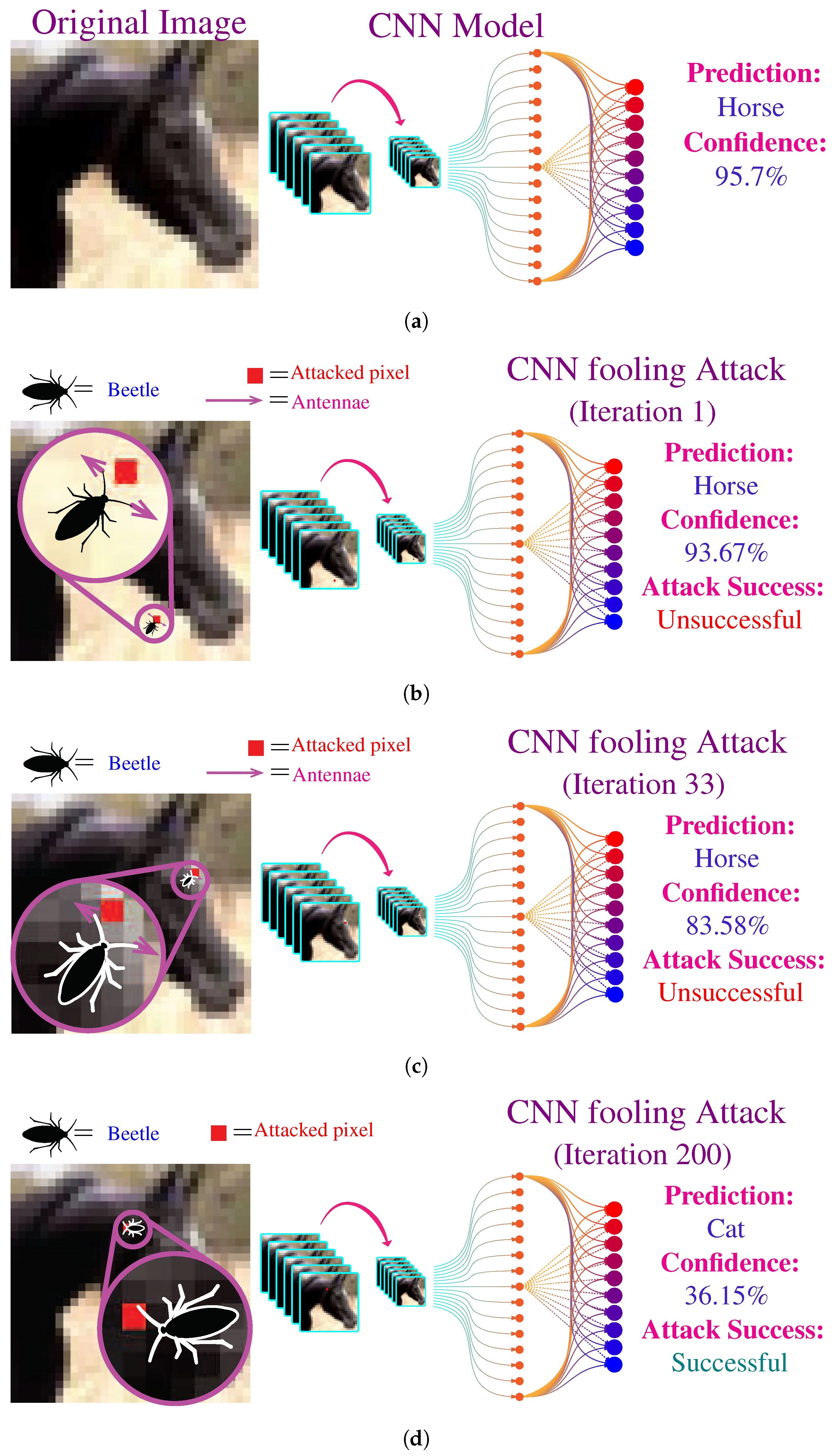
3.3. Illustration of Attacking Algorithm
3.4. Computational Complexity
| Algorithm 1: Attacking Algorithm. |
 |
4. Experiment Methodology and Results
4.1. Evaluation Methodology
4.1.1. Image Dataset
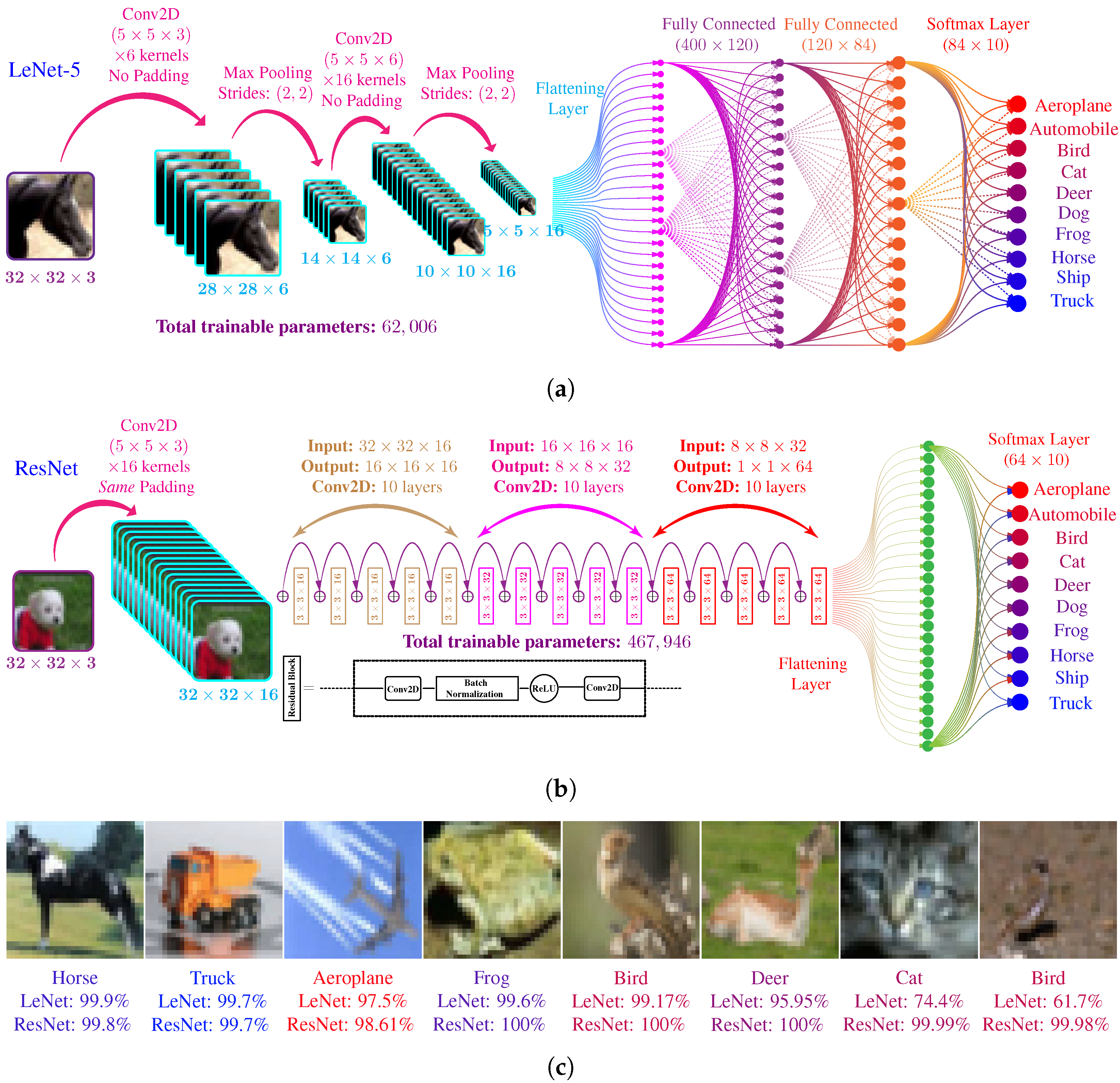
4.1.2. LeNet-5 Architecture
- The first hidden layer of LeNet is a 2D convolutional layer with six kernels, each of dimension . Each kernel uses a rectified linear unit (ReLU) as an activation function. The total tunable parameter in this layer, including the bias parameters, are . A max-pooling layer follows the convolutional layer with a stride of .
- The second hidden layer is similar 2D convolutional layer with 16 kernels, each of dimension . Total number of tunable parameters in this layer are .
- The output of the second convolutional layer is flattened from a to a vector. The flattened layer is connected to a fully connected later with 120 neurons with ReLU activation. The total trainable parameters in this layer are 48,120.
- The fourth layer is also a fully connected layer with a total of 84 neurons with ReLU activation. Connection with layer three makes the total trainable parameters in this layer to be 10,164.
- The last layer is a fully-connected layer with ten neurons using softmax activation. The connection with fourth layer makes a total of trainable parameters. The output is vector.
4.1.3. ResNet Architecture
- The first hidden layer is a 2D convolutional layer with 16 kernels, each of dimension . This convolutional layer uses zero paddings; therefore, the output of this layer has a dimension of .
- The first convolutional layer is followed by a set of 5 similar residual blocks. Each residual block contains two convolutional layers. Each of the convolutional layers contains 16 kernels of dimension and uses zero paddings to maintain the dimension between its input and output. Each convolutional layers outputs a 3D-matrix of dimension , except the output of fifth residual block which apply max polling with stride , making output dimension .
- After the fifth residual block, we have another set of 5 residual blocks. For this set of the block, each convolutional layer has a total of 32 kernels of dimension . Each convolutional layer outputs a 3D-matrix of dimension , except the output of the tenth block, which employs a max-pooling layer and outputs a 3D-matrix of dimension .
- The residual blocks from eleventh to fifteenth are also similar to each other. The convolutional layers in these blocks have a total of 64 kernels of dimension . The output of each convolutional layers is a 3D-matrix of dimension .
- The output of the fifteenth residual block is passed through a global average pooling layer and outputs a 3D-matrix of dimension .
- The tensor is flattened into vector and connected with a fully connected layer of 10 neurons with softmax activation.
4.1.4. Training of CNNs
4.2. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hilger, K.; Ekman, M.; Fiebach, C.J.; Basten, U. Intelligence is associated with the modular structure of intrinsic brain networks. Sci. Rep. 2017, 7, 16088. [Google Scholar] [CrossRef] [Green Version]
- Genç, E.; Fraenz, C.; Schlüter, C.; Friedrich, P.; Hossiep, R.; Voelkle, M.C.; Ling, J.M.; Güntürkün, O.; Jung, R.E. Diffusion markers of dendritic density and arborization in gray matter predict differences in intelligence. Nat. Commun. 2018, 9, 1905. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.J.; McGue, M.; Iacono, W.G.; Michael, A.M.; Chabris, C.F. The causal influence of brain size on human intelligence: Evidence from within-family phenotypic associations and GWAS modeling. Intelligence 2019, 75, 48–58. [Google Scholar] [CrossRef] [PubMed]
- Gibson, K.R. Evolution of human intelligence: The roles of brain size and mental construction. Brain Behav. Evol. 2002, 59, 10–20. [Google Scholar] [CrossRef] [PubMed]
- Pietschnig, J.; Penke, L.; Wicherts, J.M.; Zeiler, M.; Voracek, M. Meta-analysis of associations between human brain volume and intelligence differences: How strong are they and what do they mean? Neurosci. Biobehav. Rev. 2015, 57, 411–432. [Google Scholar] [CrossRef] [PubMed]
- Mattson, M.P. Superior pattern processing is the essence of the evolved human brain. Front. Neurosci. 2014, 8, 265. [Google Scholar] [CrossRef] [PubMed]
- Jaeger, H. Artificial intelligence: Deep neural reasoning. Nature 2016, 538, 467. [Google Scholar] [CrossRef]
- Vargas, D.V.; Murata, J. Spectrum-diverse neuroevolution with unified neural models. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 1759–1773. [Google Scholar] [CrossRef] [Green Version]
- Hassabis, D.; Kumaran, D.; Summerfield, C.; Botvinick, M. Neuroscience-inspired artificial intelligence. Neuron 2017, 95, 245–258. [Google Scholar] [CrossRef] [Green Version]
- Kar, K.; Kubilius, J.; Schmidt, K.; Issa, E.B.; DiCarlo, J.J. Evidence that recurrent circuits are critical to the ventral stream’s execution of core object recognition behavior. Nat. Neurosci. 2019, 22, 974–983. [Google Scholar] [CrossRef] [Green Version]
- Bingul, Z. Adaptive genetic algorithms applied to dynamic multiobjective problems. Appl. Soft Comput. 2007, 7, 791–799. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3856–3866. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Boisseau, R.P.; Vogel, D.; Dussutour, A. Habituation in non-neural organisms: Evidence from slime moulds. Proc. R. Soc. Biol. Sci. 2016, 283, 20160446. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.H.; Li, S.; Cao, X. Tracking control of redundant manipulator under active remote center-of-motion constraints: An RNN-based metaheuristic approach. Sci. China Inf. Sci. 2021, 64, 1–18. [Google Scholar] [CrossRef]
- Khan, A.H.; Cao, X.; Li, S.; Luo, C. Using social behavior of beetles to establish a computational model for operational management. IEEE Trans. Comput. Soc. Syst. 2020, 7, 492–502. [Google Scholar] [CrossRef] [Green Version]
- Zivkovic, M.; Bacanin, N.; Venkatachalam, K.; Nayyar, A.; Djordjevic, A.; Strumberger, I.; Al-Turjman, F. COVID-19 cases prediction by using hybrid machine learning and beetle antennae search approach. Sustain. Cities Soc. 2021, 66, 102669. [Google Scholar] [CrossRef]
- Xie, S.; Chu, X.; Zheng, M.; Liu, C. Ship predictive collision avoidance method based on an improved beetle antennae search algorithm. Ocean Eng. 2019, 192, 106542. [Google Scholar] [CrossRef]
- Levi, G.; Hassner, T. Age and gender classification using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 34–42. [Google Scholar]
- Svoboda, P.; Hradiš, M.; Maršík, L.; Zemcík, P. CNN for license plate motion deblurring. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3832–3836. [Google Scholar]
- Zhang, Z.; Chen, P.; McGough, M.; Xing, F.; Wang, C.; Bui, M.; Xie, Y.; Sapkota, M.; Cui, L.; Dhillon, J.; et al. Pathologist-level interpretable whole-slide cancer diagnosis with deep learning. Nat. Mach. Intell. 2019, 1, 236. [Google Scholar] [CrossRef]
- zu Belzen, J.U.; Bürgel, T.; Holderbach, S.; Bubeck, F.; Adam, L.; Gandor, C.; Klein, M.; Mathony, J.; Pfuderer, P.; Platz, L.; et al. Leveraging implicit knowledge in neural networks for functional dissection and engineering of proteins. Nat. Mach. Intell. 2019, 1, 225. [Google Scholar] [CrossRef]
- Pasquale, G.; Ciliberto, C.; Odone, F.; Rosasco, L.; Natale, L. Real-world Object Recognition with Off-the-shelf Deep Conv Nets: How Many Objects can iCub Learn? arXiv 2015, arXiv:1504.03154. [Google Scholar]
- Ding, Y.; Zhang, W.; Yu, L.; Lu, K. The accuracy and efficiency of GA and PSO optimization schemes on estimating reaction kinetic parameters of biomass pyrolysis. Energy 2019, 176, 582–588. [Google Scholar] [CrossRef]
- Whitley, D. A genetic algorithm tutorial. Stat. Comput. 1994, 4, 65–85. [Google Scholar] [CrossRef]
- Dorigo, M.; Di Caro, G. Ant colony optimization: A new meta-heuristic. In Proceedings of the 1999 Congress on Evolutionary Computation-CEC99 (Cat. No. 99TH8406), Washington, DC, USA, 6–9 July 1999; IEEE: Piscataway, NJ, USA, 1999; Volume 2, pp. 1470–1477. [Google Scholar]
- Neshat, M.; Sepidnam, G.; Sargolzaei, M.; Toosi, A.N. Artificial fish swarm algorithm: A survey of the state-of-the-art, hybridization, combinatorial and indicative applications. Artif. Intell. Rev. 2014, 42, 965–997. [Google Scholar] [CrossRef]
- Yang, X.S.; Deb, S. Engineering optimisation by cuckoo search. arXiv 2010, arXiv:1005.2908. [Google Scholar] [CrossRef]
- Mehrabian, A.R.; Lucas, C. A novel numerical optimization algorithm inspired from weed colonization. Ecol. Inform. 2006, 1, 355–366. [Google Scholar] [CrossRef]
- Nakrani, S.; Tovey, C. On honey bees and dynamic server allocation in internet hosting centers. Adapt. Behav. 2004, 12, 223–240. [Google Scholar] [CrossRef]
- Yang, X.S. Firefly algorithms for multimodal optimization. In Proceedings of the International Symposium on Stochastic Algorithms, Sapporo, Japan, 26–28 October 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 169–178. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Połap, D.; Woźniak, M. Red fox optimization algorithm. Expert Syst. Appl. 2021, 166, 114107. [Google Scholar] [CrossRef]
- Zhang, M.; Xu, Z.; Lu, X.; Liu, Y.; Xiao, Q.; Taheri, B. An optimal model identification for solid oxide fuel cell based on extreme learning machines optimized by improved Red Fox Optimization algorithm. Int. J. Hydrogen Energy 2021, 46, 28270–28281. [Google Scholar] [CrossRef]
- Hayyolalam, V.; Kazem, A.A.P. Black widow optimization algorithm: A novel meta-heuristic approach for solving engineering optimization problems. Eng. Appl. Artif. Intell. 2020, 87, 103249. [Google Scholar] [CrossRef]
- Hu, G.; Du, B.; Wang, X.; Wei, G. An enhanced black widow optimization algorithm for feature selection. Knowl. Based Syst. 2022, 235, 107638. [Google Scholar] [CrossRef]
- Maqsood, M.; Ghazanfar, M.A.; Mehmood, I.; Hwang, E.; Rho, S. A Meta-Heuristic Optimization Based Less Imperceptible Adversarial Attack on Gait Based Surveillance Systems. J. Signal Process. Syst. 2022, 1–23. [Google Scholar] [CrossRef]
- Msika, S.; Quintero, A.; Khomh, F. SIGMA: Strengthening IDS with GAN and Metaheuristics Attacks. arXiv 2019, arXiv:1912.09303. [Google Scholar]
- Zang, Y.; Qi, F.; Yang, C.; Liu, Z.; Zhang, M.; Liu, Q.; Sun, M. Word-level textual adversarial attacking as combinatorial optimization. arXiv 2019, arXiv:1910.12196. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef] [Green Version]
- Su, J.; Vasconcellos, V.D.; Prasad, S.; Daniele, S.; Feng, Y.; Sakurai, K. Lightweight classification of IoT malware based on image recognition. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; Volume 2, pp. 664–669. [Google Scholar]
- Pasquale, G.; Ciliberto, C.; Rosasco, L.; Natale, L. Object identification from few examples by improving the invariance of a deep convolutional neural network. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 4904–4911. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 565–571. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3929–3938. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 2574–2582. [Google Scholar]
- Xu, X.; Chen, X.; Liu, C.; Rohrbach, A.; Darrell, T.; Song, D. Fooling vision and language models despite localization and attention mechanism. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4951–4961. [Google Scholar]
- Sun, Y.; Zhang, J.; Li, G.; Wang, Y.; Sun, J.; Jiang, C. Optimized neural network using beetle antennae search for predicting the unconfined compressive strength of jet grouting coalcretes. Int. J. Numer. Anal. Methods Geomech. 2019, 43, 801–813. [Google Scholar] [CrossRef]
- Jiang, X.; Li, S. BAS: Beetle Antennae Search Algorithm for Optimization Problems. Int. J. Robot. Control 2018, 1, 1–5. [Google Scholar] [CrossRef]
- Khan, A.H.; Li, S.; Luo, X. Obstacle avoidance and tracking control of redundant robotic manipulator: An rnn based metaheuristic approach. IEEE Trans. Ind. Inform. 2019, 16, 4670–4680. [Google Scholar] [CrossRef] [Green Version]
- Khan, A.T.; Li, S.; Zhou, X. Trajectory optimization of 5-link biped robot using beetle antennae search. IEEE Trans. Circuits Syst. II Express Briefs 2021, 68, 3276–3280. [Google Scholar] [CrossRef]
- Wu, Q.; Shen, X.; Jin, Y.; Chen, Z.; Li, S.; Khan, A.H.; Chen, D. Intelligent beetle antennae search for UAV sensing and avoidance of obstacles. Sensors 2019, 19, 1758. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, J.; Huang, Y.; Ma, G.; Nener, B. Multi-objective beetle antennae search algorithm. arXiv 2020, arXiv:2002.10090. [Google Scholar]
- Khan, A.H.; Li, S.; Chen, D.; Liao, L. Tracking Control of Redundant Mobile Manipulator: An RNN based Metaheuristic Approach. Neurocomputing 2020, 400, 272–284. [Google Scholar] [CrossRef]
- Khan, A.T.; Cao, X.; Li, Z.; Li, S. Enhanced beetle antennae search with zeroing neural network for online solution of constrained optimization. Neurocomputing 2021, 447, 294–306. [Google Scholar] [CrossRef]
- Khan, A.T.; Li, S.; Cao, X. Human guided cooperative robotic agents in smart home using beetle antennae search. Sci. China Inf. Sci. 2022, 65, 1–17. [Google Scholar] [CrossRef]
- Ren, Z.; Li, P.; Fang, J.; Li, H.; Chen, Q. SBA: An efficient algorithm for address assignment in ZigBee networks. Wirel. Pers. Commun. 2013, 71, 719–734. [Google Scholar] [CrossRef]
- Khan, A.H.; Cao, X.; Katsikis, V.N.; Stanimirović, P.; Brajević, I.; Li, S.; Kadry, S.; Nam, Y. Optimal Portfolio Management for Engineering Problems Using Nonconvex Cardinality Constraint: A Computing Perspective. IEEE Access 2020, 8, 57437–57450. [Google Scholar] [CrossRef]
- Khan, A.H.; Cao, X.; Li, S.; Katsikis, V.N.; Liao, L. BAS-ADAM: An ADAM based approach to improve the performance of beetle antennae search optimizer. IEEE/CAA J. Autom. Sin. 2020, 7, 461–471. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; Citeseer: Princeton, NJ, USA, 2009. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Nature-Inspired | Attacked Model | Dataset Type | Number Search Particles |
|---|---|---|---|---|
| Grey wolf optimization [38] | Yes | AlexNet | Image sequences | Several |
| SIGMA [39] | No | Neural Networks | Network Intrusion detection dataset | 30 |
| PSO [40] | Yes | BiLSTM and BERT | Text (Natural Language) | 8 |
| Differential Evolution [41] | No | VGG16 and AlexNet | Images (CIFAR-10) | 400 |
| BAS (proposed) | Yes | LeNet and ResNet | Images (CIFAR-10) | 2 |
| × | No. of Parameters | Training Samples | Training Accuracy | Testing Samples | Testing Accuracy |
|---|---|---|---|---|---|
| LeNet-5 | 50,000 | 50,000 | 78.47% | 10,000 | 74.88% |
| ResNet | 50,000 | 50,000 | 99.83% | 10,000 | 92.31% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, A.H.; Cao, X.; Xu, B.; Li, S. Beetle Antennae Search: Using Biomimetic Foraging Behaviour of Beetles to Fool a Well-Trained Neuro-Intelligent System. Biomimetics 2022, 7, 84. https://doi.org/10.3390/biomimetics7030084
Khan AH, Cao X, Xu B, Li S. Beetle Antennae Search: Using Biomimetic Foraging Behaviour of Beetles to Fool a Well-Trained Neuro-Intelligent System. Biomimetics. 2022; 7(3):84. https://doi.org/10.3390/biomimetics7030084
Chicago/Turabian StyleKhan, Ameer Hamza, Xinwei Cao, Bin Xu, and Shuai Li. 2022. "Beetle Antennae Search: Using Biomimetic Foraging Behaviour of Beetles to Fool a Well-Trained Neuro-Intelligent System" Biomimetics 7, no. 3: 84. https://doi.org/10.3390/biomimetics7030084
APA StyleKhan, A. H., Cao, X., Xu, B., & Li, S. (2022). Beetle Antennae Search: Using Biomimetic Foraging Behaviour of Beetles to Fool a Well-Trained Neuro-Intelligent System. Biomimetics, 7(3), 84. https://doi.org/10.3390/biomimetics7030084