1. Introduction
Mobile robots are widely used in aerospace, entertainment, agriculture, the military, mining, and rescue operations [
1]. They have attracted the attention of many scholars. Meltem Eyuboglu [
2] proposed a novel collaborative path planning algorithm for a 3-wheel omnidirectional Autonomous Mobile Robot, Arash Marashian [
3] proposed a method for solving mobile robots’ path-planning and path-tracking in static and dynamic environments. Nina Majer [
4] proposed a Game-Theoretic Trajectory Planning of Mobile Robots in Unstructured Intersection Scenarios, Guangxin Li [
5] solved the path planning of a mobile robot by mixing the algorithms of ACO and ABC. Zhiheng Yu [
6] proposed a path planning algorithm for mobile robots based on the water flow potential field method and the beetle antennae search algorithm. De Zhang [
7] proposed Multi-objective path planning for mobile robots in nuclear accident environments based on improved ant colony optimization with modified A*, Patrick F. and Charles P. [
8] proposed the kinematic modeling of wheeled mobile robots, and Junlin Ou proposed a hybrid path planning based on adaptive visibility graph initialization and edge computing for mobile robots [
9]. In many fields of its application, path planning is the most important part. Path planning aims to find a collision-free, optimally safe path from the starting point to the target point in the environment with obstacles according to certain performance indicators, such as planning time, path smoothness, and walking convenience.
Many methods have been applied to mobile robot path planning (MRPP), such as those of Guodong Zhu and Peng Wei, who use dynamic geofencing to solve the path planning problem [
10]. Elie Hermand [
11] proposes a constrained control scheme to steer an UAV to the desired position while ensuring constraint satisfaction at all times. Joseph Kim and Ella Atkins [
12] use airspace Geofencing to solve path planning problems. With the development of research, the swarm-based algorithm has been applied to the MRPP. Unlike traditional algorithms, swarm-based algorithms can perform many intelligent tasks accurately and robustly, which is due to the inspiration of biological intelligence. Therefore, the swarm-based algorithm improves the accuracy of the solution, and lots of scholars use the swarm-based algorithm to solve the MRPP. V. Sathiya [
13] proposed a FIMOPSO to solve mobile robot path planning. A. Lazarowska [
14] uses the Discrete Artificial Potential Field algorithm (DAPF) to solve the MRPP. Zhang Chungang [
15] solved the mobile robot rolling path planning problem. Guangsheng Li [
16] uses self-adaptive learning particle swarm optimization to solve the MRPP. These optimization methods show that MRPP has attracted the attention of many scholars (See
Table 1).
A swarm-based algorithm is a kind of metaheuristic algorithm. Other metaheuristic optimization algorithms include biological evolution-based, Swarm-based, physical- and chemistry-based, and human-based algorithms. Swarm-based algorithm is a kind of classical algorithm, such as the Hunting search algorithm (HSA) [
17], the Grasshopper optimisation Algorithm (GOA) [
18], Cat Swarm Optimization (CSA) [
19], particle swarm optimization (PSO) [
20], Firefly algorithm (FA) [
21], Salp Swarm Algorithm (SSA) [
22], Whale optimization algorithm (WOA) [
23], and gray wolf optimization algorithm (GWO) [
24]. Because of its simple concept and remarkable performance, this kind of algorithm is widely studied and applied. Whale optimization algorithm (WOA) [
23] is a famous swarm-based algorithm proposed by Mirjalili in 2016. The algorithm solves the problem by simulating the hunting behavior of whales. The hunting process is the optimization process. Because of its remarkable performance in solving problems, the algorithm has been widely studied in the academic community.
The main contributions of this paper are as follows: In order to improve the accuracy of MRPP and WOA’s performance and broaden the application of WOA, a hybrid whale-firefly optimization algorithm based on multi-population and Opposition-Based Learning is proposed in this paper. Firstly, to improve the exploration ability and balance exploitation and exploration, the multiple population mechanism is introduced for the division of labor and cooperation. Secondly, aim to solve the problem of poor accuracy of the algorithm by introducing the Opposition-Based Learning (OBL) and improving the optimization ability of the algorithm through symmetric mapping. The performance of the algorithm is improved by the above two methods. On this basis, in order to better conform to the biological mechanism, the Perception of the food population of whales is introduced to expand the search space and further improve the exploration ability.
The rest of this paper is set as follows:
Section 2 introduces the classical whale optimization algorithm.
Section 3 introduces the FWOA.
Section 4 introduces the verification of FWOA, and
Section 5 introduces the MRPP model.
Section 6 describes the simulation results and analysis.
Section 7 contains conclusions and future work.
2. Whale Optimization Algorithm
Whale optimization algorithm (WOA) is based on the hunting behavior of humpback whales. It mainly includes three phases: Encircling prey, Bubble-net attacking method (exploitation phase), and Search for prey.
2.1. Encircling Prey
Humpback whales can locate their prey and encircle them. The WOA defines the current best candidate solution as the best solution [
23]. The other search agents will update the position toward the leader whales (the best solution defined); the equations of this behavior are expressed as follows:
where
t is the current iteration,
and
are coefficient vectors,
indicates the position vector of the best solution obtained so far,
is the position vector, | | is the absolute value, and • is an element-by-element multiplication. Notes that
should be updated in each iteration if there is a better solution.
The vectors
and
are calculated as follows:
The is linearly decreased from 2 to 0 over the course of iterations and is a random vector in [0,1].
2.2. Bubble-Net Attacking Method (Exploitation Phase)
Bubble-net attacking method includes the shrinking encircling mechanism and the spiral updating position method. The search agents will choose a method to update their position.
Shrinking encircling mechanism: By decreasing the value of
in Equation (3), whales can shrink and encircle prey [
23]. Spiral updating position: This mechanism firstly calculates the distance between the whale position and the prey position, then, by establishing an equation between the search agents and the prey, the update of position is achieved. To mimic this method, the equations are as follows:
The is the distance of the ith whale to the prey, b is a constant for defining the shape of the logarithmic spiral, l is a random number in [−1, 1], and is an element-by-element multiplication.
A parameter
p is introduced to control the switch between the shrink encircling mechanism and the spiral updating position method. The equation is as follows:
The p is a random number in [0,1].
2.3. Search for Prey
For the exploration phase, agents update the position by randomly selecting whales. The random value of
A that is greater than 1 or less than −1 can let them move far away from the prey. This mechanism and |
A| < 1 together let the algorithm perform a global search. The equations are expressed as follows:
where
indicated a random position vector chosen from the current population.
The WOA algorithm starts with a random population and then updates the solution at each iteration. While the condition is satisfied, the algorithm concludes that the solution is the best solution.
3. The Proposed FWOA
Based on classical WOA, this section proposes a hybrid whale-firefly optimization algorithm based on multi-populations and Opposition-Based Learning. The FWOA has three improvements: multi-populations, hybrids with the firefly algorithm (FA), and the perception of food.
3.1. The Multi-Populations
Like primitive humans, all social creatures will divide and cooperate according to the task type. The division and cooperation of ants ensure the stability of their society, and the division and cooperation of wolves ensure the efficiency of hunting prey. Research shows that the whale will also carry out division and cooperation, dividing the total population into several subpopulations. Each subpopulation has its own task, and the entire whale population will predate in this way.
In order to make the algorithm more consistent with the natural mechanism and improve its performance while balancing its exploitation and exploration, this paper divides the initial whale population into two subpopulations: (1) the Search Population (SP) and (2) the Hunt Population (HP). The number of whales in each population accounts for half of the total population. Assign different tasks to different populations to achieve the goal of division of labor and cooperation.
The main task of the search population (SP) is to search (exploration). Through its fast exploration of the search space, it can find the region that is most likely to have the optimal solution. After each search, it will continue to look for other possible locations for the best solution. Through this mechanism, the exploration ability of the algorithm is greatly improved, which enables the algorithm to quickly find the location of the optimal solution.
The main task of the hunt population (HP) is to hunt (exploitation). After the search population has locked down the optimal value area, the hunt population will be exploited in this area to find the optimal value. This mechanism ensures the exploitation ability of the classic WOA. Furthermore, different tasks make the two populations focus on different aspects at the same time. The hunt population focuses on exploitation, and the search population focuses on exploration, realizing the balance between exploitation and exploration. The tasks of the hunt population and search population in different phases are described as follows:
3.1.1. Search Prey
In the search for prey phase, in order to reflect the independence between populations, two populations randomly select a leader whale from their own populations and update the position according to the position of their own leader whale. The position update method for the search population is as follows:
where
is the distance between the current whale and the leader whale randomly selected in the search population,
is the leader whale selected in the search population, and
is the position of the whale in the search population.
The position update method for the hunt population is as follows:
where
is the distance between the current whale and the leader whale randomly selected in the hunt population,
is the leader whale selected in the hunt population, and
is the position of the whale in the hunt population.
3.1.2. Encircling Prey
In the encircling prey phase, in order to reflect the cooperation of the population and to improve the efficiency of the algorithm, the search population and the hunt population in this phase are merged to form a combined population (CP). The search method for combined population (CP) is according to the phase of Encircling prey in classic WOA. In this phase, the combination of populations is realized, thus improving the computational efficiency of the algorithm. The position update method for the population is as follows:
where
is the distance between the current whale and the best whale in the combined population,
is the position of the leader whale, and
is the position of the current whale.
3.1.3. Bubble-Net Attacking Method (Exploitation Phase)
In contrast to the above phases, in the bubble-net attacking method, the two populations were assigned different tasks. To emphasize the exploration behavior, the search population first randomly selects a leader whale from the search population, and other whales in the population update the position of the whale to perform a search behavior to improve the exploration ability of the algorithm. The method is expressed as Equation (10).
The hunt population uses the position update method of classical WOA, and it is as follows:
where
is the distance between the current whale and the best whale,
is the best whale position, and
is the position of the hunt population.
3.2. Bubble-Net Attacking Method
3.2.1. The Perception of Food
Nature is full of magic. Spider sensing can help spiders avoid danger. Like spiders, studies have found that whales also have a perception, but it is the perception of food, which may be based on smell or temperature. This perception allows whales to quickly explore areas where food may exist when hunting, improve hunting efficiency, and provide more food for the whales. Compared with the excellent exploitation ability of classical WOA, its exploration ability is slightly inferior. Due to its unique exploration mechanism, WOA does not have a good search direction during exploration but randomly selects the direction. Although this exploration mechanism provides good randomness for the algorithm, it shows a relatively inferior ability in terms of efficiency. To improve this weakness, this section applies the whale’s perception ability to classical WOA to improve the exploration ability and efficiency of classic WOA.
The focus of food perception is to guide whales in the direction of predation, so after each iteration of the algorithm, the entire population will conduct a food perception. Through this perception, the optimal population search direction will be found. At the same time, in order to ensure the randomness of the algorithm and avoid getting stuck at local optimal, the perception direction of the optimal population will be compared with the current optimal searcher after each perception, and the best one of the two will be found, and this direction will become the position update direction of the entire population, so as to improve the exploration ability and enable the algorithm to quickly find the optimal value.
3.2.2. Firefly Algorithm (FA)
The Firefly algorithm (FA) [
21] was proposed by Xin She Yang in 2008. It is an idealized behavior based on the flicker characteristics of fireflies [
25]. There are several important parameters in the firefly algorithm: (1) Light intensity and attraction
; (2) Firefly in horizontal position
x; (3) Firefly in vertical position
; (4) Distance between firefly
i and
j ; (5) Intensity of light source
.
The brightness of the firefly at a certain position or position
(represented by
) can be calculated as follows:
The attraction must be adjusted as a function of absorption. Thus, the change in light intensity
follows the inverse square law:
Meanwhile, consider the static light absorption coefficient
; the intensity
of light varies with position or distance
, thus:
where
indicates the actual intensity of light.
The attraction of fireflies
can be approximated as:
where
is the attractiveness level when
.
Then, the distance between two fireflies can be calculated. Let firefly
i and firefly
j be
and
on the horizontal axis, and on the vertical
axis, the distance between them can be calculated as:
As mentioned above, the navigation of firefly
i is attracted by another highly attractive firefly
j, and the movement of firefly
i towards firefly
j is expressed mathematically as follows:
where
rand is a random number in the interval [0,1],
. The coefficient of the random displacement vector,
the light absorption coefficient of the environment,
and the Euclidean distance between two fireflies.
For the maximization problem, the brightness can be simply proportional to the objective function. Other forms of brightness can be defined in a way similar to the fitness function in a genetic algorithm or bacterial foraging algorithm (BFA) (Algorithm 1).
| Algorithm 1 Pseudocode of the Firefly Algorithm |
| Define target function which is presented as: |
| Generate or develop preliminary or pilot population of fireflies: |
| Define expression for intensity of light (1) so that it is linked with |
| Define the light adsorption, represented by y |
| While (t < maximum generation of light) |
| For (for all fireflies in the sample space) |
| For (for all fireflies in the sample space) |
| If () |
| Firefly i move towards firefly j |
|
End if |
| Express attractiveness of firefly based on the separation point (r) distance |
| Estimate original value and present the final value in terms of light intensity |
|
End for |
|
End for |
| Find the best possible firefly |
| End while |
3.2.3. The Hybrid of WOA and FA
Similar to fireflies’ perception of light, food perception is a whale’s ability, so in the food perception phase, let the search agent perceive according to the FA method to find the optimal food direction. At the beginning of perception, everyone in the population randomly generates a positional perception of food.
Position food is not perceived according to the current position of the individual, which is set to ensure the randomness of the individual population. In order to improve the performance of the algorithm, a probability selection is made during food perception to make the algorithm targeted. Therefore, a random number
q is generated after the random food location is generated. If the value of the random number
q is less than 0.5, the food perception is updated as follows:
where
is the Euclidean distance between food perception location
i and food perception location
j, and other parameters are as shown above.
If the value of q is greater than 0.5, a random position perception is performed to regenerate a new food position, so as to greatly improve the randomness of the algorithm while ensuring performance improvement and keeping the algorithm in a steadily improving state.
3.3. Opposition-Based Learning
Opposition-Based Learning is a strategy proposed by Hamid R. tizhoosh in 2005 [
26]. The main idea of this strategy is: when people are solving the solution
x of a given problem, they usually need to estimate a solution
In many cases, learning starts at random points (initialization of the population). In algorithms, it starts with a random population and moves the solution towards the optimal solution. Based on this thinking, it is beneficial to improve the efficiency of the algorithm if the opposite number is calculated when searching for x
Suppose
. The opposite number
of
x is calculated as follows:
The formula is extended to the multi-dimensional case.
. Defined, the equation is as follows:
When it comes to FWOA,
which
is the lower bound and the upper bound of the problem, and
the search agents, the equation is as follows::
where
is the opposite population of search agents.
Figure 1 shows the computer system for antisymmetric learning. Based on this mechanism, the detection ability of the algorithm can be improved, and the traversal of the search space by the algorithm can be increased.
The Pseudocode of the FWOA is as follow (Algorithm 2):
| Algorithm 2 Pseudocode of the FWOA |
| Initialize the whale populations: The search population and The hunt population: |
| Calculate the fitness of each search agent |
| = the best search agent |
| while (t < maximum number of iterations) |
| for each search agent |
| Update , |
| if1 () |
| if2 () |
| The combined population updates the position of the current search agent by the Equation (15). |
| else if2 () |
| Search population selects a random search agent by Equation (10) |
| Search population updates the position of the current search agent by the Equation (11). |
| Hunt population selects a random search agent by Equation (12) |
| Hunt population updates the position of the current search agent by the Equation (13) |
| end if2 |
| else if1 () |
| Search population selects a random search agent by Equation (10) |
| Search population updates the position of the current search agent by the Equation (11) |
| Hunt population updates the position of the current search agent by the Equation (17) |
|
end if1 |
|
end for |
| Initialize the perception of food population |
| Update |
| If3 () |
| The combined population updates the perception of food position by Equation (24) |
| Else if3 () |
| Initialize a new position of food |
|
end if3 |
| Find the opposite population by Equation (27) |
| Check if any search agent goes beyond the search space and amend it |
| Calculate the fitness of each search agent |
| Update if there is a better solution |
|
| End while |
| Return |
4. Verification of FWOA
In this section, the FWOA algorithm has been tested on 23 benchmark functions. The 23 benchmark functions are classical functions used by many researchers [
27,
28,
29,
30,
31]. Although these functions are simple, we chose them to compare our algorithm with the current metaheuristic method to verify the performance of FWOA.
Table 2,
Table 3 and
Table 4 list these benchmark functions. Generally speaking, the reference functions used can be divided into three groups: Uni-modal functions, Multi-modal functions, and Fixed-dimension multi-modal functions.
Table 2,
Table 3 and
Table 4 show these groups of functions, respectively. Different types of functions place different emphasis on performance. Dimension in the table represents the dimension of the function, Range is the boundary of the function search space and
is the best value.
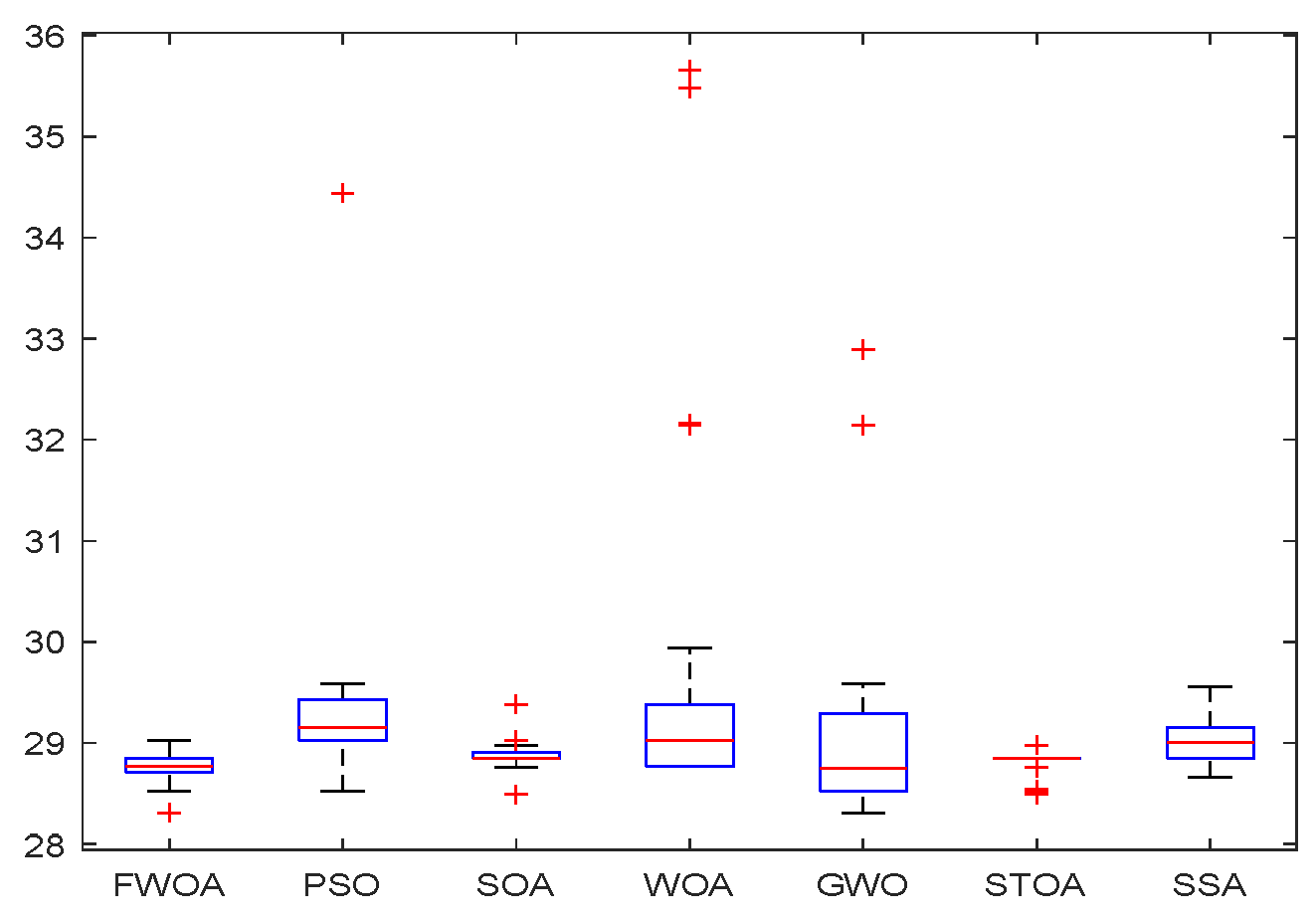
4.1. Experiment Setting
The maximum number of iterations of the algorithm is 1000, and the number of search agents is 100. Each algorithm runs independently on each benchmark function 30 times. In order to verify the results, the FWOA algorithm is compared with classic PSO [
20], SSA [
22], WOA [
23], GWO [
24], STOA [
32], and SOA [
33]. The statistical results (average, minimum, maximum, and standard deviation) are shown in
Table 5,
Table 6 and
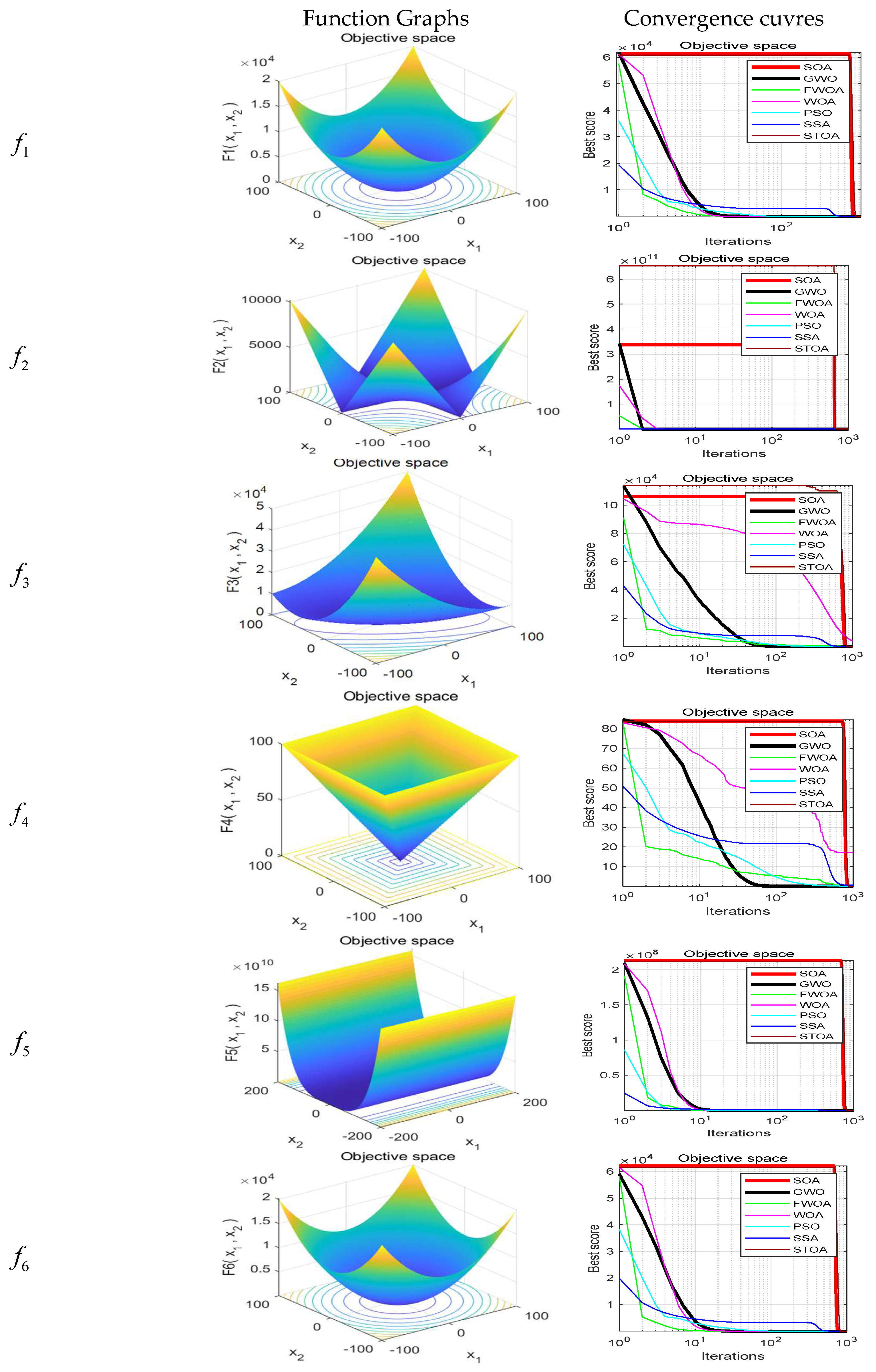
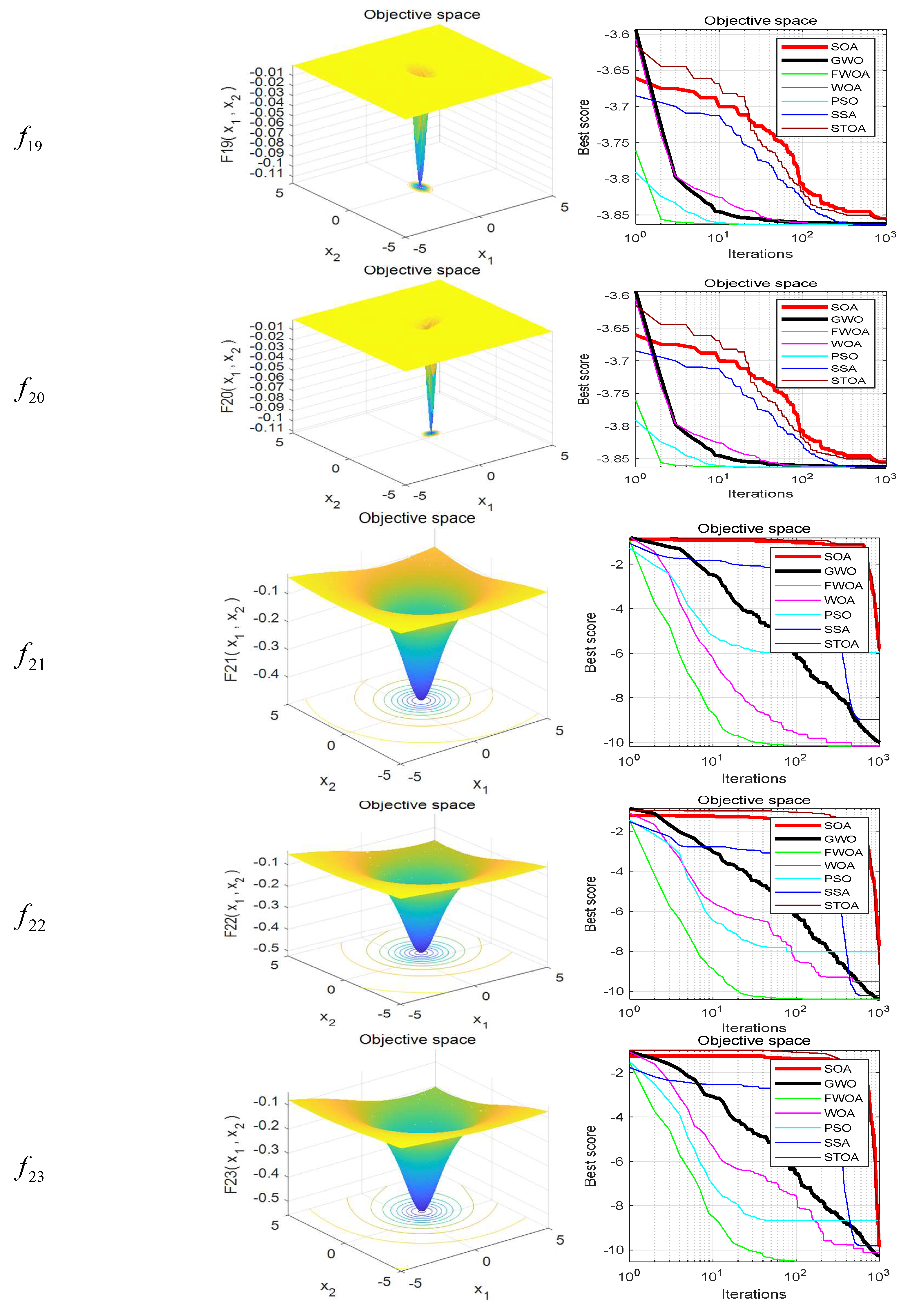
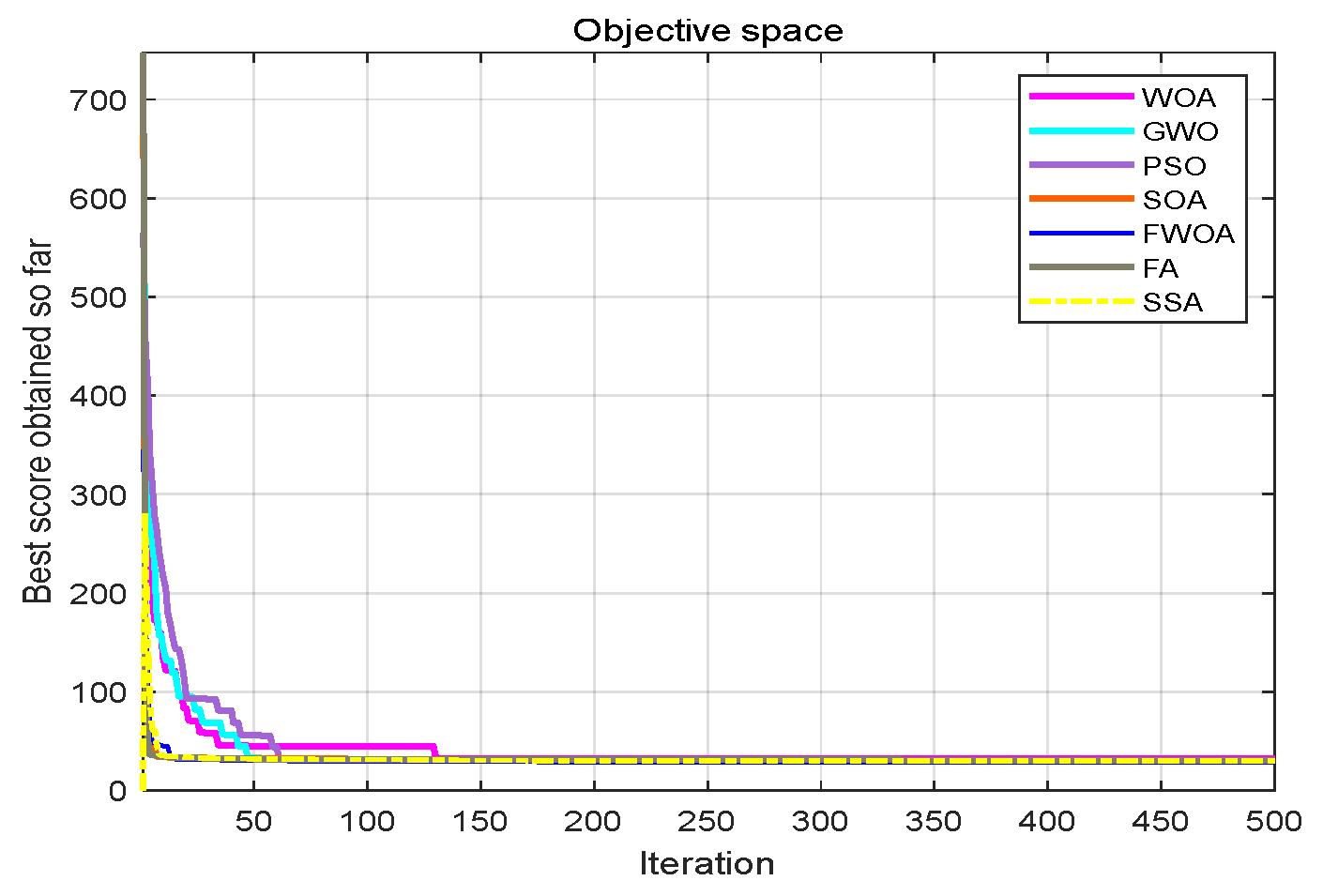
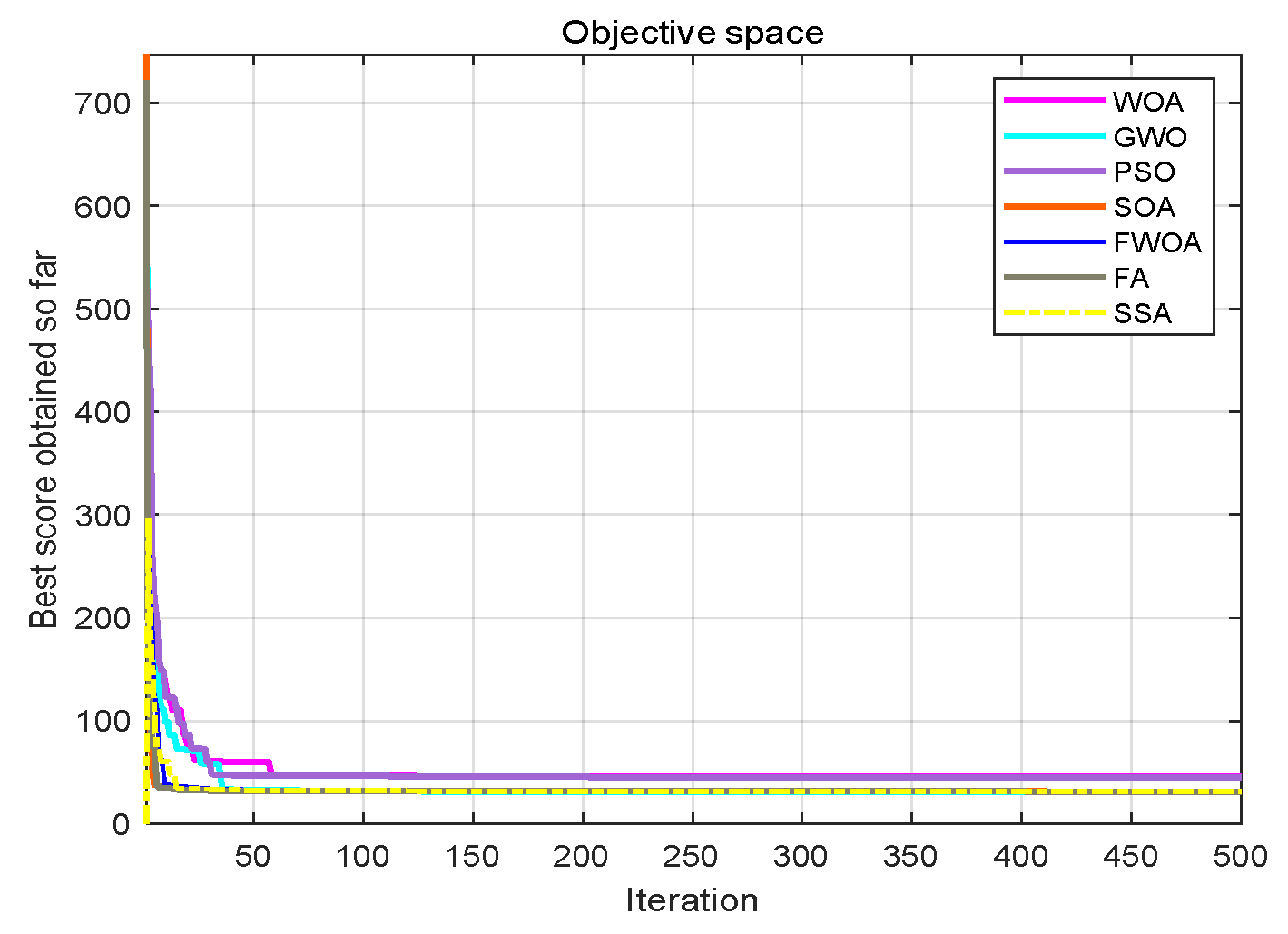
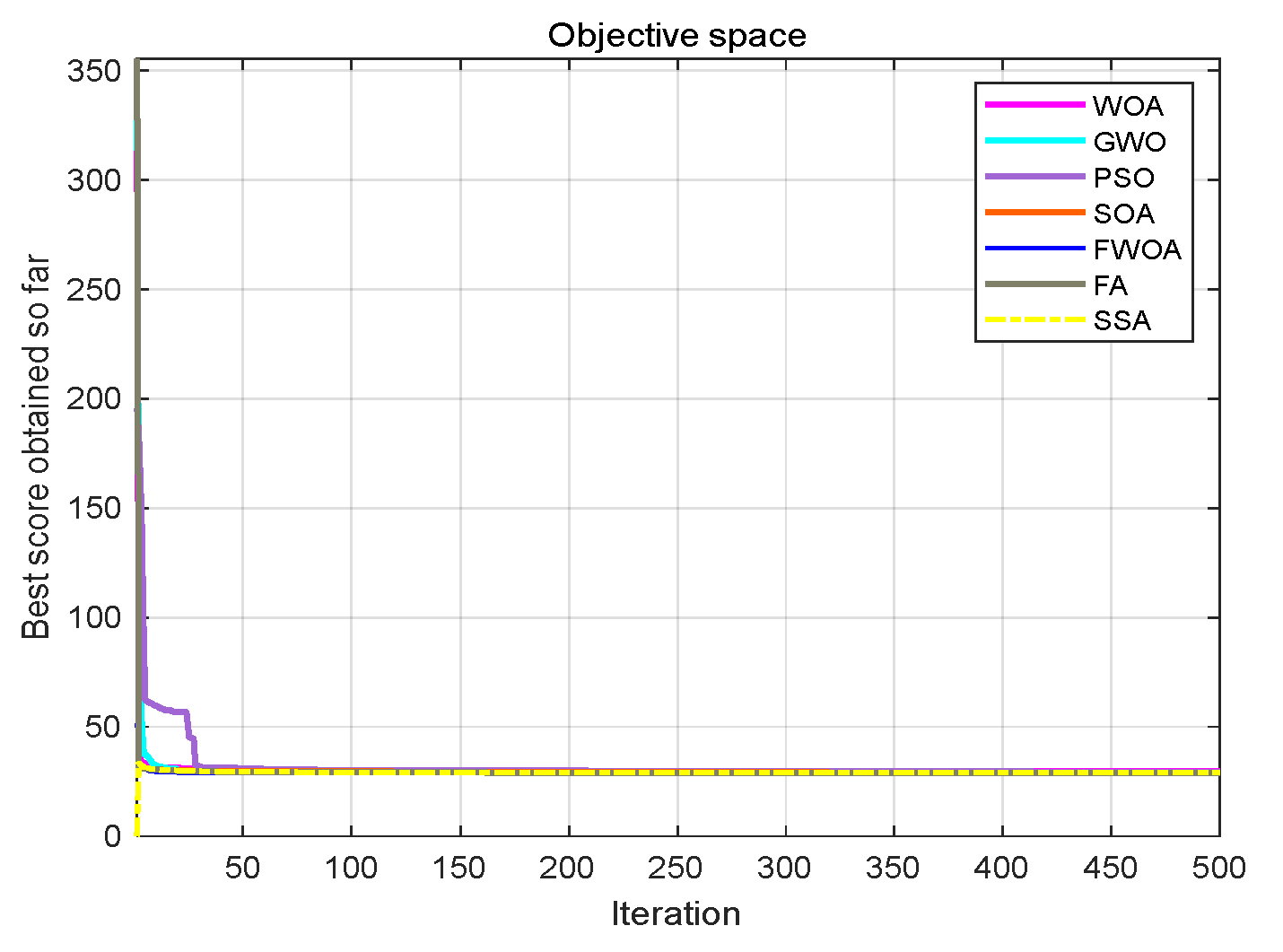
Table 7. The function graphs and algorithm convergence graphs are shown in
Figure 2.
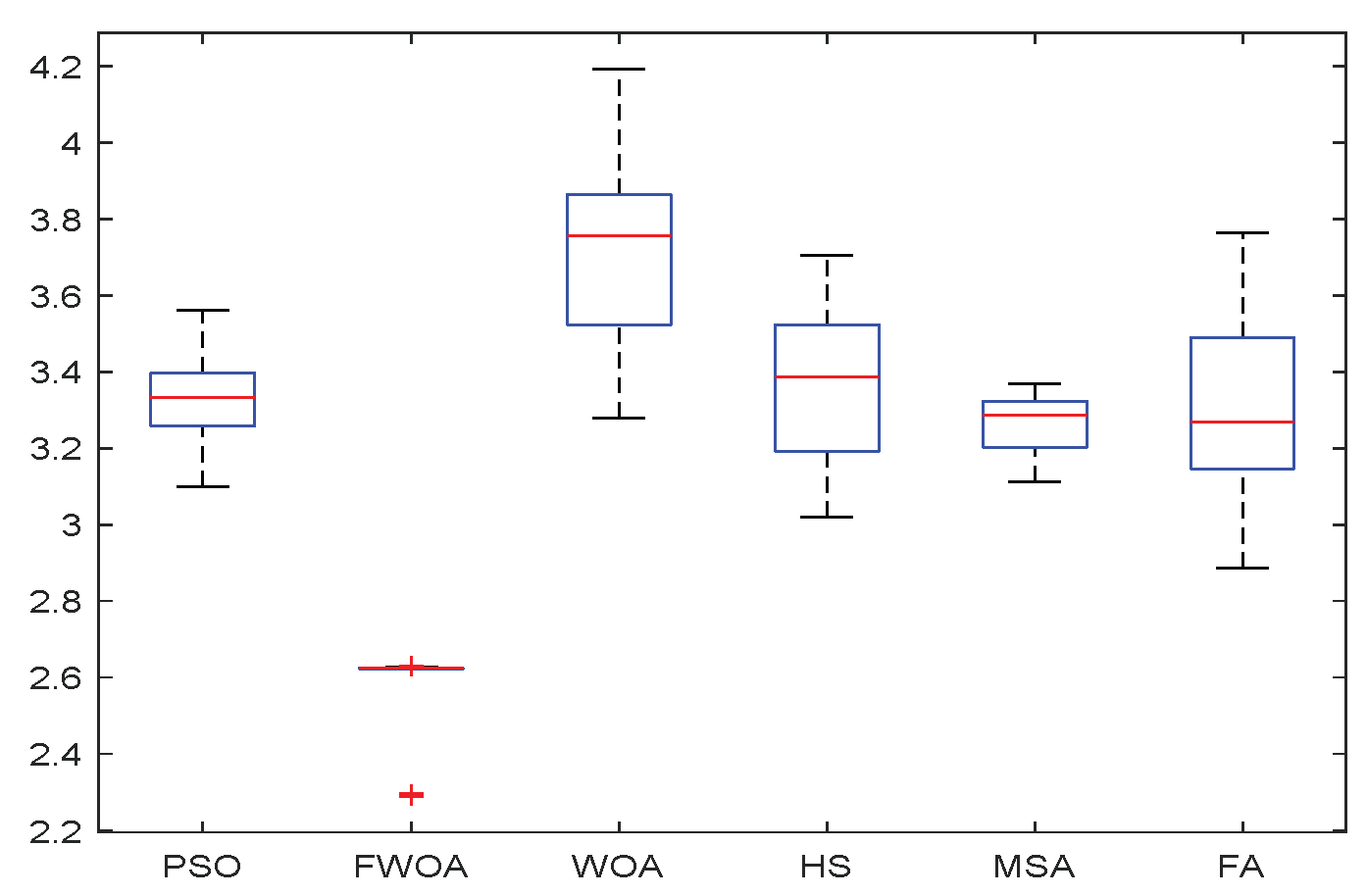
4.2. Exploitation Analysis
According to the results in
Table 5, FWOA can provide very competitive results. This algorithm is superior to other algorithms in
. It should be noted that unimodal functions focus on benchmark exploitation. Therefore, these results show that FWOA has better performance in finding the optimal value of the function. This is due to the food perception mechanism discussed earlier.
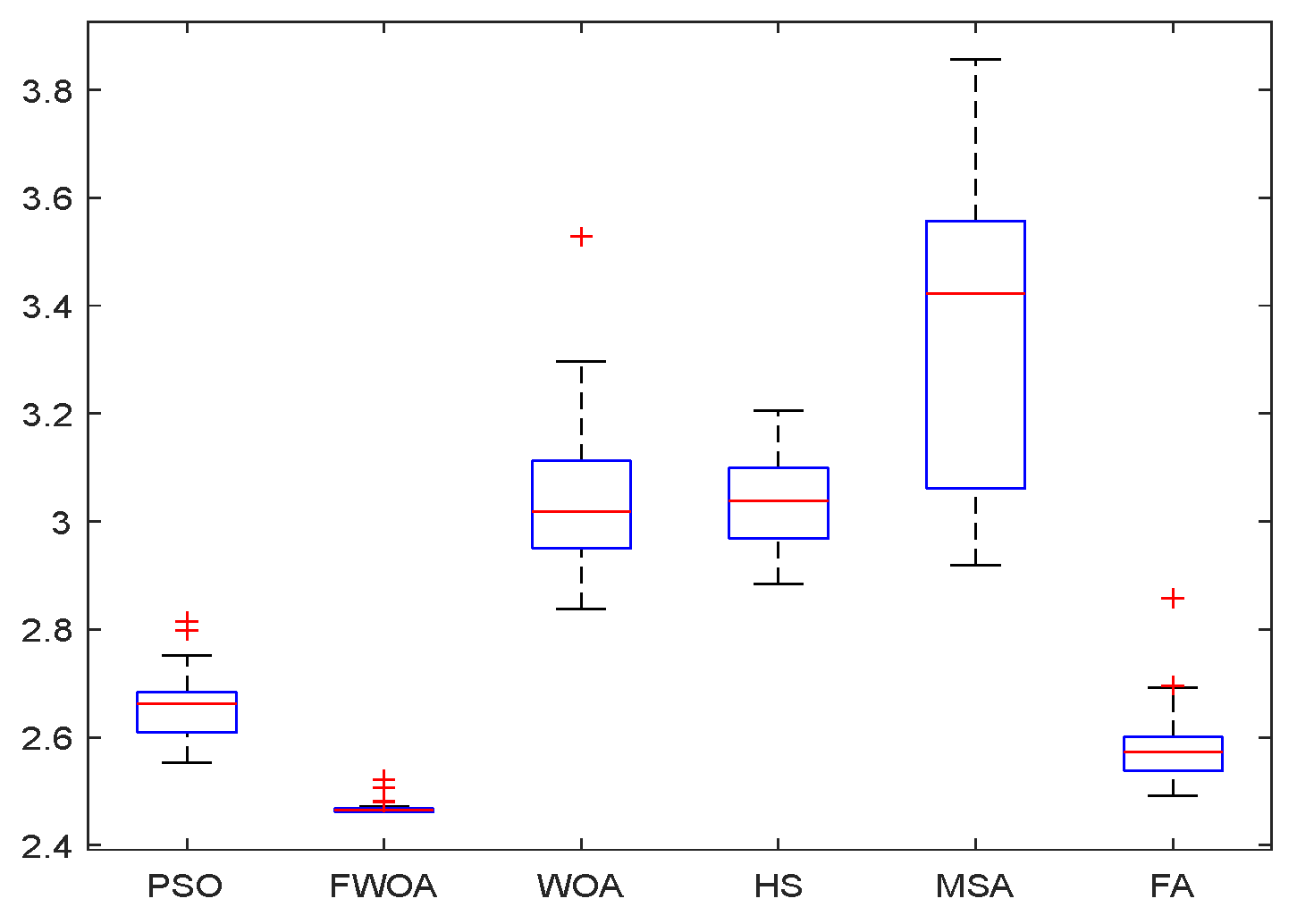
4.3. Exploration Analysis
Compared with unimodal functions, multi-modal functions have many local optimal values, and their complexity grows exponentially with the dimension, so the requirements for algorithm performance of multi-modal functions are stricter. Therefore, they are suitable for benchmarking the exploration abilities of algorithms.
According to the results in
Table 6, FWOA can also provide very competitive results on Fixed-dimension multi-modal functions. The FWOA is superior to other algorithms in most functions
. This phenomenon is reflected in the fact that FWOA can find the best value smaller than the results of all test algorithms, and the maximum value found by FWOA is also the smallest of all algorithms. In addition, compared with GWO and PSO, which have good exploration capabilities, FWOA shows remarkable performance and can often surpass them. These results show that the FWOA algorithm has certain research value.
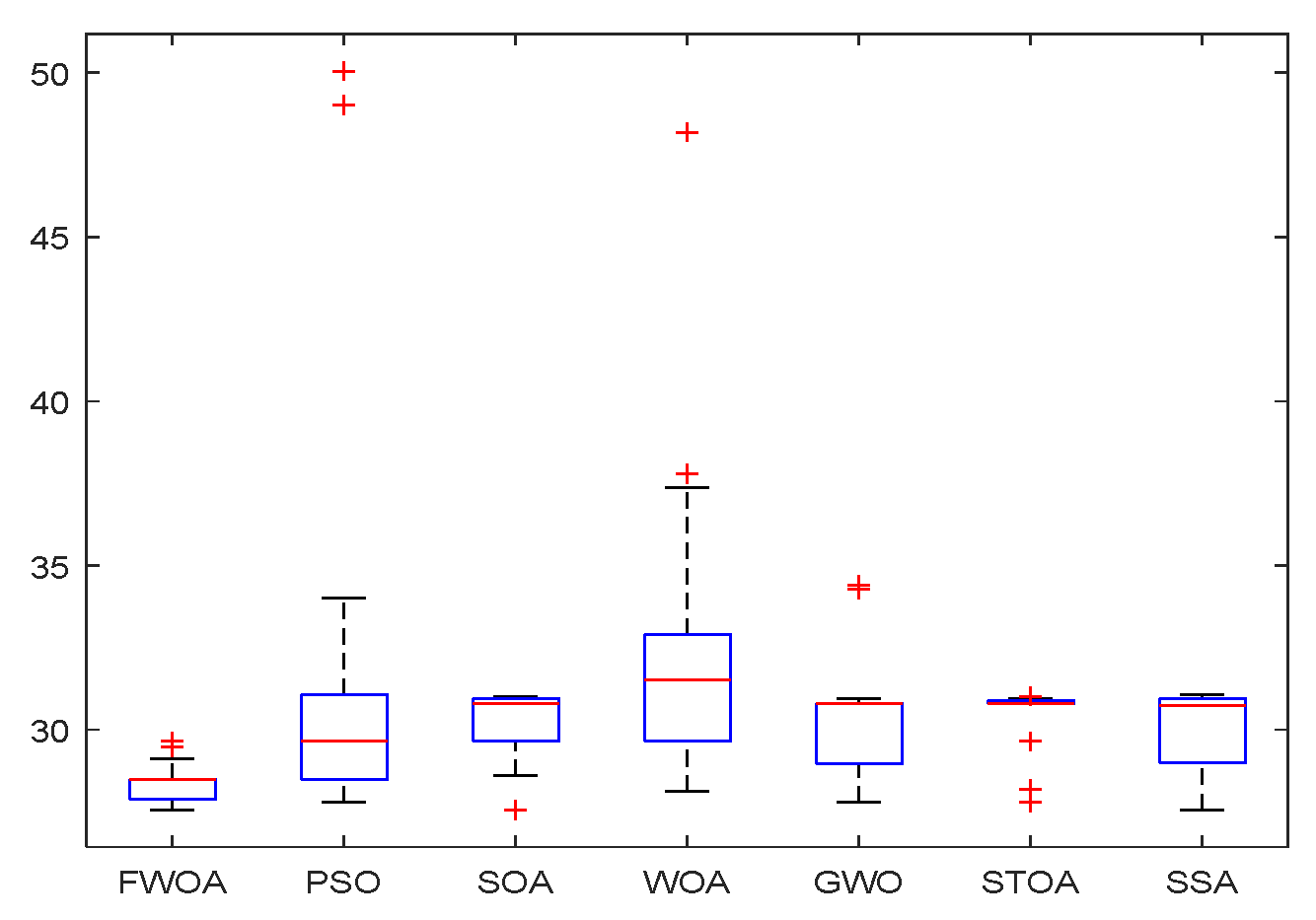
4.4. The Standard Deviation Analysis
The standard deviation is the arithmetic square root of the variance. The standard deviation can reflect the degree of dispersion of a data set. It is most commonly used in probability statistics as a measure of the degree of statistical distribution. A large standard deviation represents a large difference between most values and their average values; a small standard deviation means that these values are close to the average value, so the difference between the data are small. The smaller the standard deviation in algorithm analysis, the better the stability and robustness of the algorithm.
According to the results in
Table 5,
Table 6 and
Table 7, the standard deviation of FWOA is the smallest in most cases, which means that FWOA has strong stability and can provide a relatively stable calculation. This is due to the multi-population mechanism of the algorithm. The division and cooperation of different populations enable the algorithm to achieve the balance between development and detection, so it can also ensure its stability while maintaining good performance.
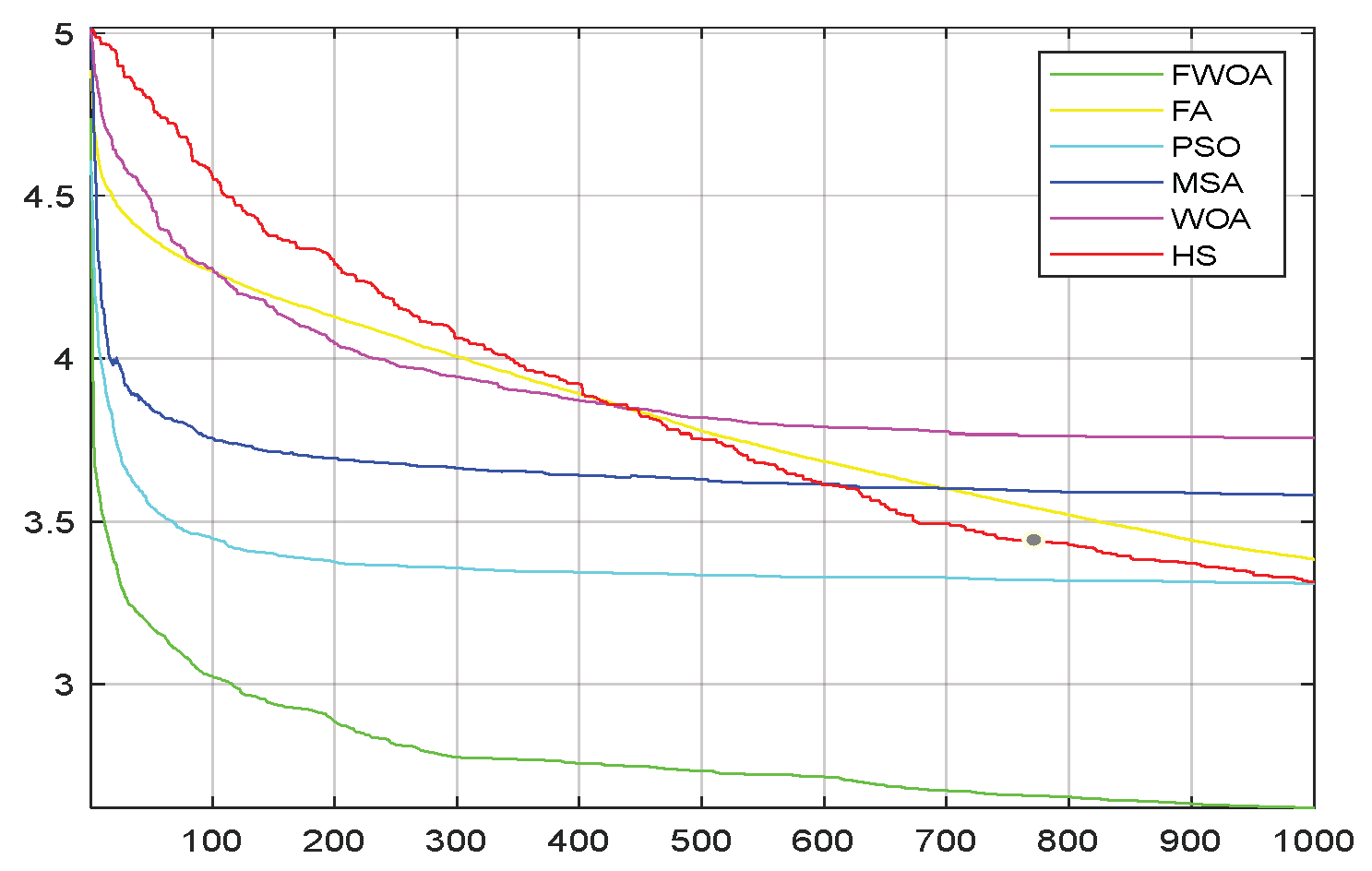
4.5. The Convergence Analysis
This section shows the convergence of the FWOA. According to Digalakis [
28], in the initial step of optimization, the movement of search agents should undergo mutation, which helps metaheuristics widely explore the search space. Then, these changes should be reduced to emphasize exploitation at the end of optimization. To observe the convergence behavior of the FWOA algorithm, the convergence graph of the algorithm is shown in
Figure 2. In most cases, FWOA converges first, due to the search population discussed before.
To sum up, compared with the well-known metaheuristic algorithm, the experimental results verify the performance of the FWOA algorithm in solving various benchmark functions. In order to further study the performance of the proposed algorithm, a practical problem (two different problem environments) is used in the following section.
The algorithm is compared with different well-known algorithms to verify its effectiveness.
5. Using FWOA to Solve the Mobile Robot Path Planning Problem
The mobile robot path planning problem (MRPP) is a famous research problem. There are lots of different methods to solve it, such as Zhang Z [
34] who proposed a method based on A-star and Dijkstra Algorithm, Z Cen [
35] who proposed a method based on genetic algorithms and the A* algorithm; Y Lü [
36] who proposed a method based on a directional relationship with uncertain environmental information; and Y Cheng [
37] who proposed a distributed snake algorithm for mobile robot path planning with curvature constraints. Kurihara K [
38] proposed a mobile robot path planning method with the existence of moving obstacles; Msg A [
39] proposed an intelligent approach for autonomous mobile robot path planning based on an adaptive neuro-fuzzy inference system; and Zhang Z [
40] proposed a method based on the dynamic movement primitives library.
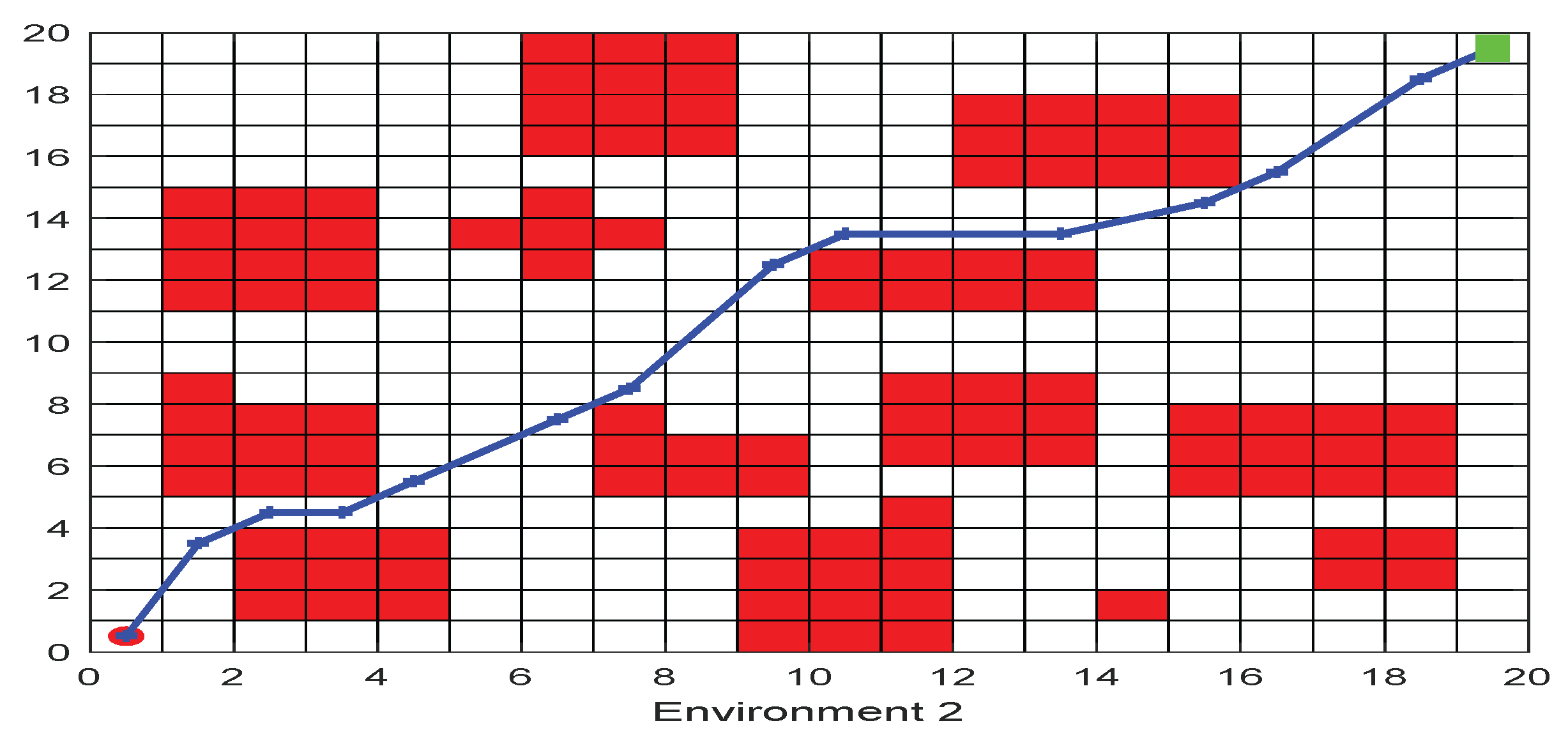
The experimental environment of this study is divided into two parts: (1) The irregular obstacle environment with no influence range; (2) The regular obstacle environment with influence range The irregular obstacle environment with no influence range simulates the shapes of different obstacles in the real environment, and the robot searches for the optimal path to avoid collision in this environment. The obstacle of the regular obstacle environment experiment with influence range is circular. This environment simulates the real environment in which objects of different shapes will produce an influence range. When the robot approaches, there may be different degrees of collision, resulting in different motion conditions. (1: Do not affect the robot’s motion. 2: Slightly affect the motion. 3: Collision to immovable). The influence range of obstacles in this environment is subject to the center of the circle. The influence decreases linearly with the distance between the robot position and the center of the circle, so as to simulate the real environment. The method of solving MRPP by FWOA is introduced as follows:
5.1. Irregular Obstacles Environment with None Influence Range
Mobile robot path planning is an important task of intelligent robot research. The first step is to model the environment. In an obstacle-free environment, this paper uses the grid method to model. The grid method decouples the workspace into several simple areas to establish an environment model that is convenient for compute path planning; in this way, the physical space is mapped into an abstract space. The free grid point is represented by , and the obstacle point is represented by . Through this mechanism, the modeling of irregular obstacles can be realized, and it is also convenient for computation.
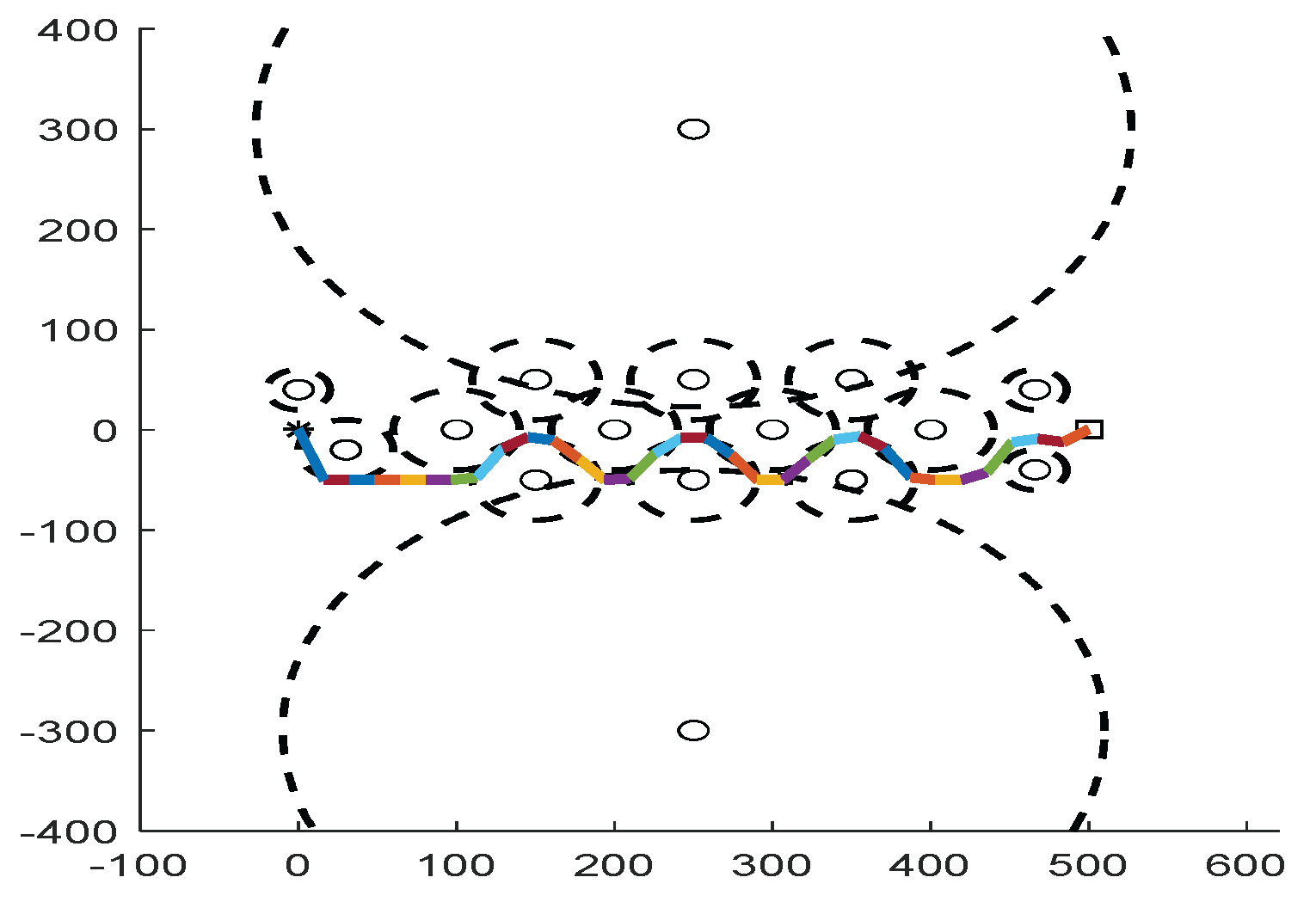
On the two-dimensional map, as shown in
Figure 3. in order to solve the path planning problem, we make the following assumptions: (1) The mobile robot only moves in the set search space; (2) There are
different-shape static irregular obstacles in the robot motion space, which are described by the grid method. The obstacles have no influence range, and the path is unavailable when the robot hits the obstacles. (3) Mobile robot is regarded as a particle [
41], and its size is ignored. According to the above assumptions, the obstacles are expanded to
. This
is obtained by:
where
is the safe distance, which is artificially selected to prevent the mobile robot from contacting obstacles.
The robot moves in eight directions, as shown in
Figure 4. Through different moving directions, we can realize the path planning of the mobile robot when moving to any grid point in the search space [
41]. The cost function of this model is the motion distance of the robot in two-dimensional space.
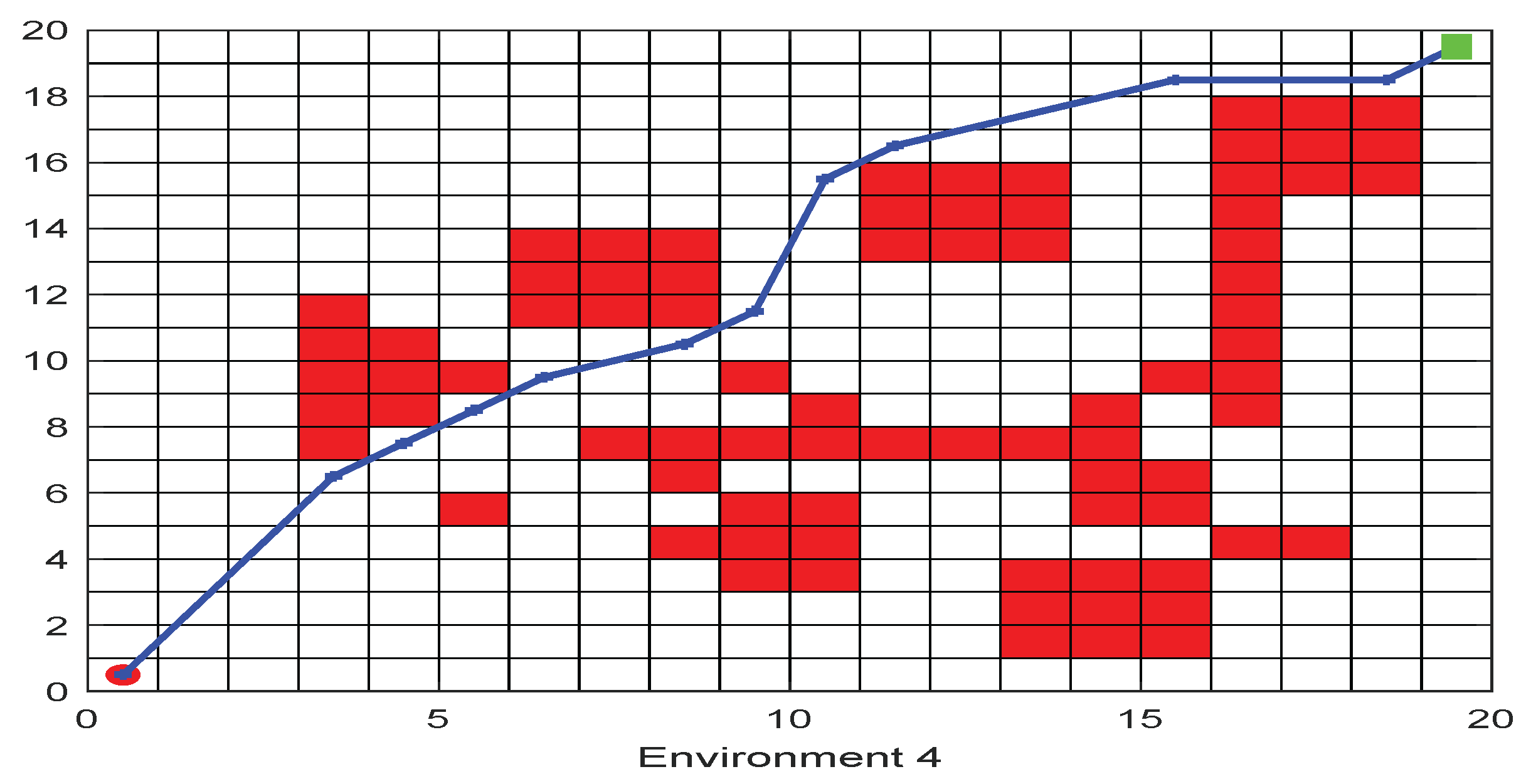
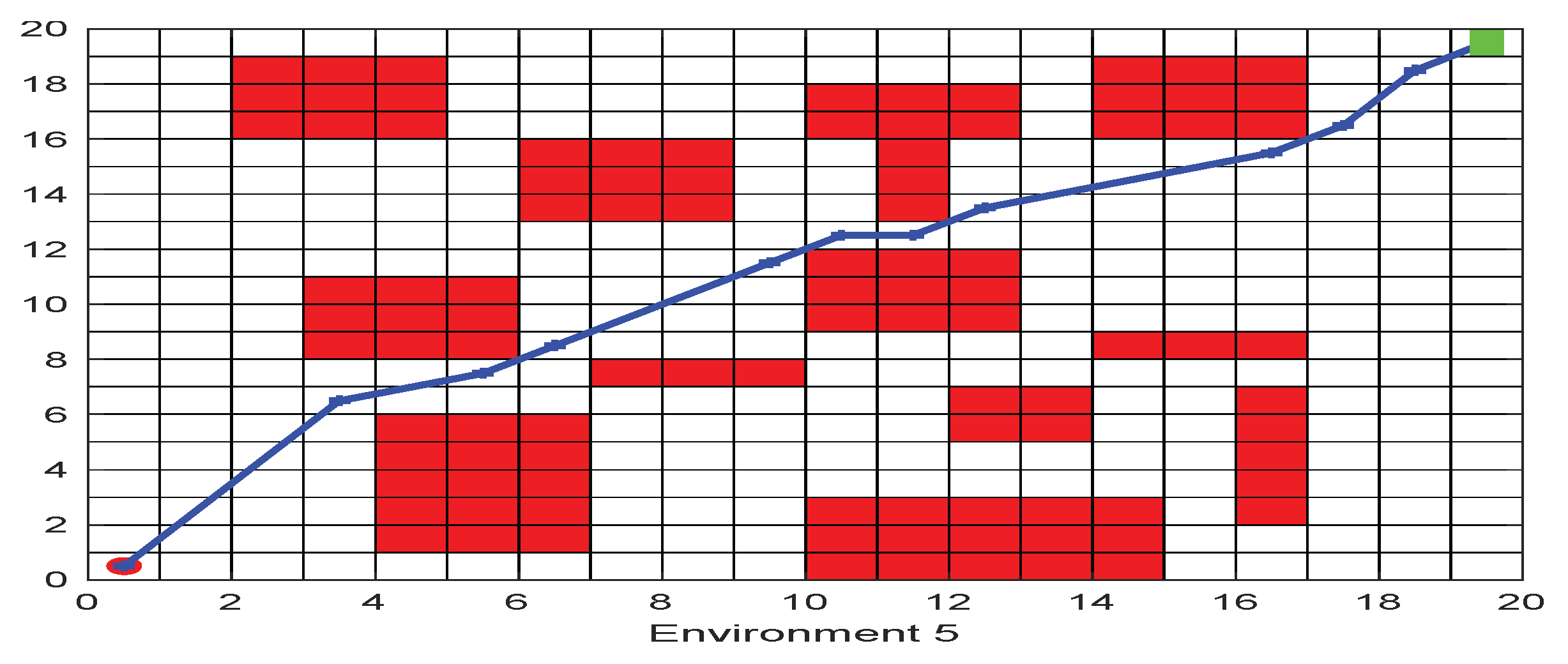
5.2. Regular Obstacle Environment with Influence Range
Due to the irregular shape of obstacles, their influence ranges are different. When a robot encounters an obstacle while moving in the environment, three situations may occur: (1) stop moving; (2) affect but do not stop moving; and (3) do not affect moving. Based on these situations, this section introduces the obstacle environment with a regular influence range that is more realistic.
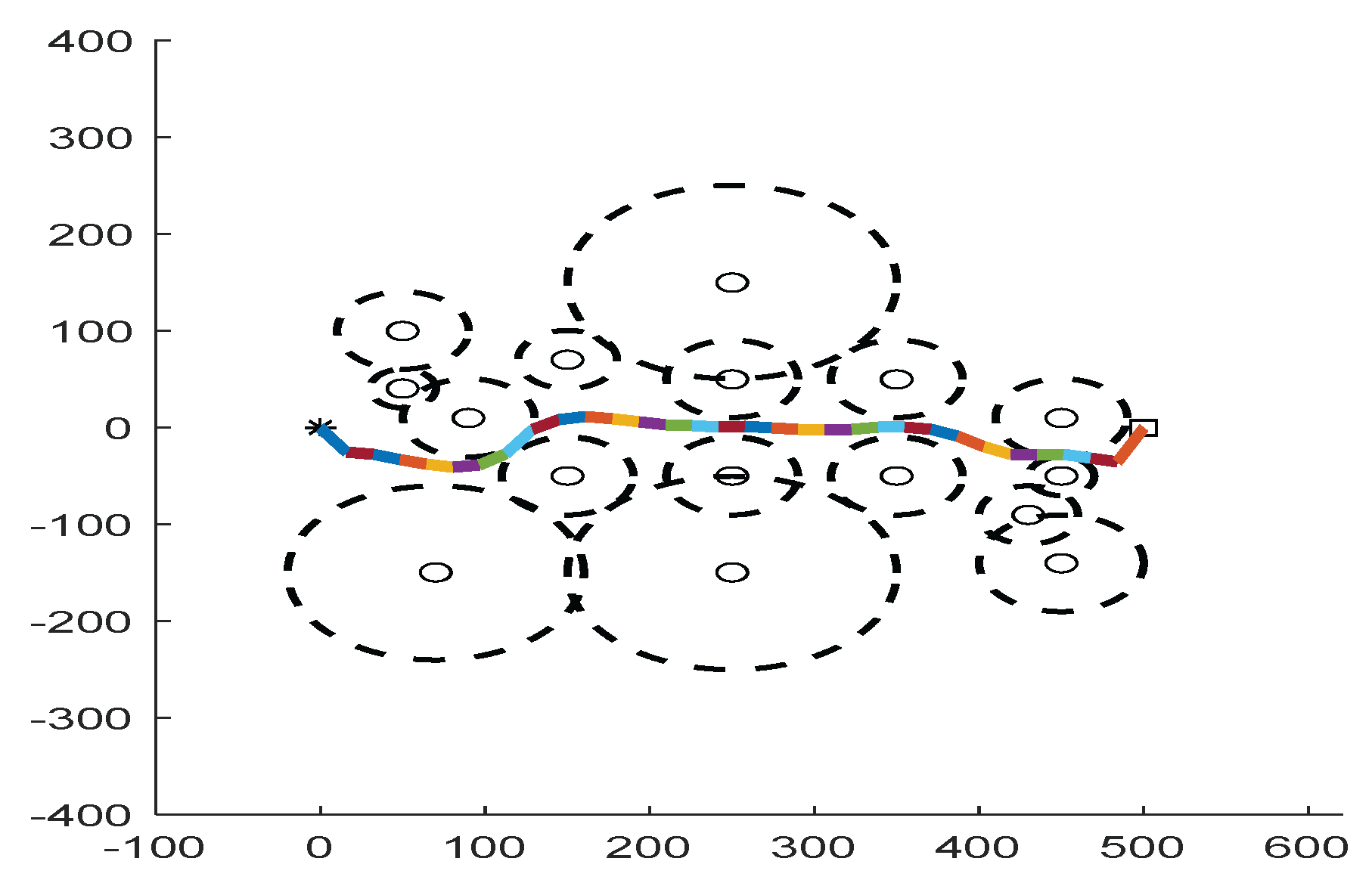
The path planning problem in this environment is to find a connection between the starting point and the target point with the least threat, as shown in
Figure 3. The point
is the starting point, and the point
is the target point. In order to simplify the problem, the general problem is divided into several sub-problems by using the deconstruction method. Thus, the starting point and the target point are connected by a line, and the connection is divided into 𝑚 segments. The path planning is carried out for each segment, and the path length is the sum of the subpaths.
In [
42], an obstacle probability density model based on UAV movement is introduced. The model describes that the influence range of obstacles will not have a boundary when the UAV is moving but will decrease with the increase in distance between the UAV and the obstacle center, but will never be zero. Based on this theory, the probability density model is proposed as follows:
where
is a parameter that controls the shape of the density function,
indicates the distance from the moving object to the
ith bstacle.
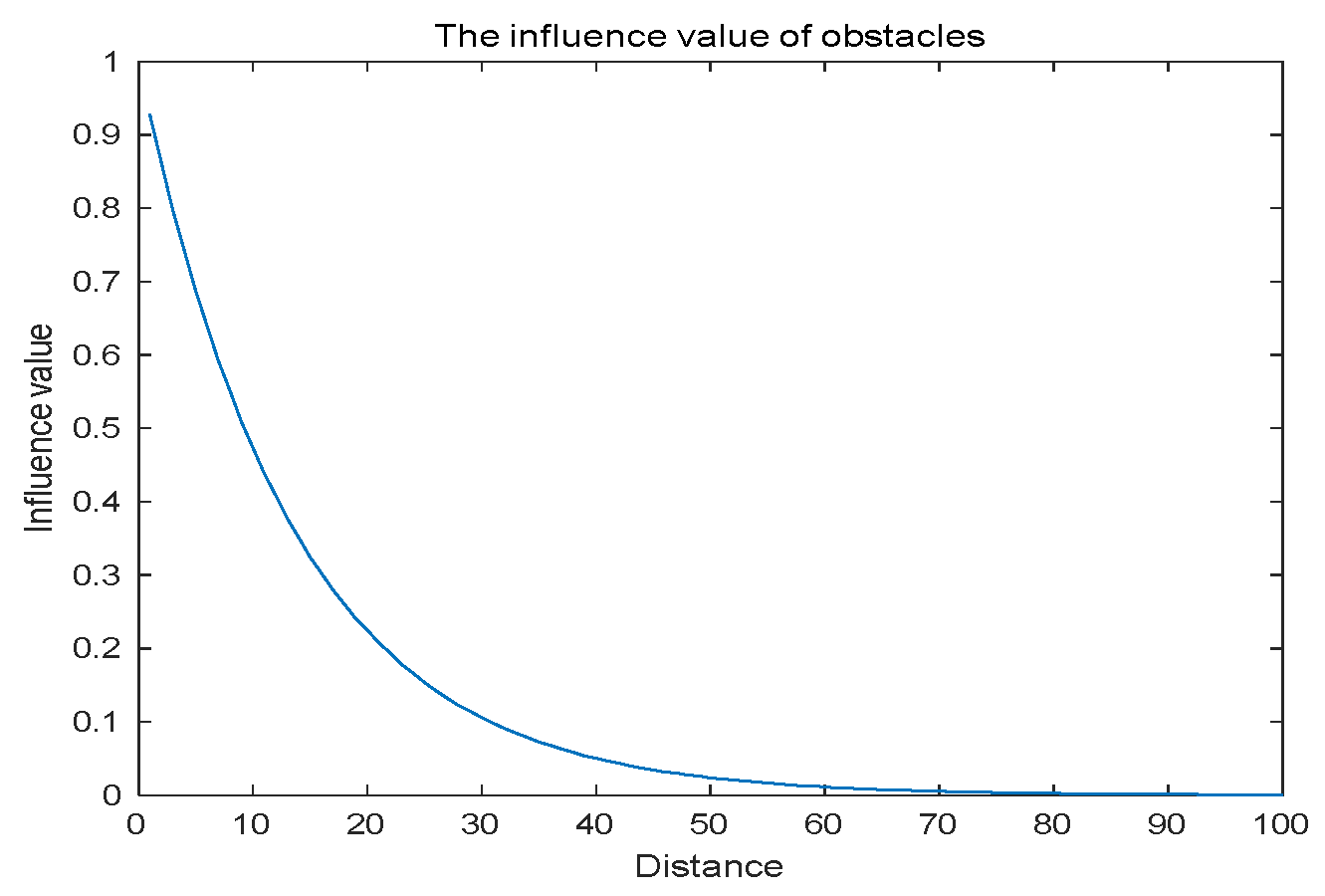
For the robot, it can be known that the impact of obstacles in the environment on the robot also decreases with the distance from the center of the obstacle, so the model can be used to model the robot path planning problem. However, collision has a great impact on the robot to a certain extent, which is much greater than the impact of obstacles on the UAV. But the probability density value drops too fast to truly simulate the environment. In order to solve this problem, the probability model is improved as follows.
Figure 5 shows the improved probability density value, which is smoother than the original probability density curve:
The descent speed of the improved probability model becomes slower, which is more in line with the robot situation. Based on this probability density model and in combination with the path planning model in article [
3], let the parameter
D be the length of the motion path, the parameter
S be the distance of the subproblem segment, and the parameter
be the weight. The following model is proposed to find the shortest distance while considering the influence range:
Based on this objective function, the path planning problem can be modeled to solve this problem.











































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}