1. Introduction
Probabilistic theories posed a challenge for Popper’s falsificationism. But, on first glance, there are strong analogies between “naive” falsificationism, and standard practice in frequentist hypothesis testing. For example, a standard frequentist test of a sharp null hypothesis rejects upon observing an event that would be highly improbable if the null hypothesis were true. Such a test has a very low chance of erroneously rejecting the null hypothesis. That falls short of, but is closely analogous to, the infallibility of rejecting a universal law upon observing a countervailing instance. Alternatively, a standard frequentist test of a sharp null hypothesis has a high chance of erroneously
failing to reject if the null hypothesis is subtly false. That is similar to the fallibility of inferring a universal hypothesis from finitely many instances. Such analogies are natural and sometimes made explicitly by statisticians. Here are Gelman and Shalizi [
1]:
Extreme p-Values indicate that the data violate regularities implied by the model, or approach doing so. If these were strict violations of deterministic implications, we could just apply modus tollens …as it is, we nonetheless have evidence and probabilities. Our view of model checking, then, is firmly in the long hypothetico-deductive tradition, running from Popper (1934/1959) back through Bernard (1865/1927) and beyond (Laudan, 1981).
Statistical falsification, Gelman and Shalizi suggest, is
all but deductive.
1 But how extremal, exactly, does a
p-Value have to be for a test to count as a falsification? Popper was loathe to draw the line at any particular value: “It is fairly clear that this ‘practical falsification’ can be obtained only through a methodological decision to regard highly improbable events as ruled out …But with what right can they be so regarded? Where are we to draw the line? Where does this ‘high improbability’ begin?” ([
3], p. 182) The problem of when to consider a statistical hypothesis to be falsified has engendered a significant literature [
4,
5,
6] but no universally accepted answer.
A natural idea, due to Fisher [
7] and Gillies [
4], is to pick some canonical event that is highly improbable if the hypothesis is true. The problem with this idea, pointed out by Neyman [
8] and given dramatic expression by Redhead [
9], is that there is no unique methodological convention satisfying this property; indeed there may be competing conventions giving conflicting verdicts on every sample.
2 Neyman and Pearson [
11] attempt to solve this uniqueness problem by requiring the falsifying event to have maximum probability if the hypothesis is false. Falsificationists like Gillies [
4] object that this strategy involves restricting the set of alternatives in artifical ways. But even if we grant the basics of the Neyman–Pearson framework, there is typically no way to choose a single falsifying event with “uniformly” maximum probability in all the alternative possibilities in which the hypothesis is false: one must always favor some alternative over others (See Casella and Berger [
12], p. 393). In short, the question of when to consider an event falsifying seems to have no answer entirely free of arbitrariness.
Our response to this situation is two-fold. The first response is nicely summarized by Redhead [
9]: “Popper demands in science refutability, not refutation”. The question of which hypotheses are refutable is at least as important as the question of when data should be taken to have refuted a hypothesis.
3 The existence of a univocal methodological convention is not necessary for refutability; indeed, if there were a univocal answer, the problem would no longer have any conventional or methodological aspect. The results of this work allow us to be fairly ecumenical about which methodology of falsification should be adopted without losing any clarity about which hypotheses are falsifiable: Theorem 2 says that a variety of different methodologies of falsification—ranging from the permissive to the stringent—give rise to exactly the same collection of falsifiable hypotheses. Moreover, it provides a relatively simple mathematical criterion for identifying the falsifiable hypotheses. That means scientific controversies about the testability of hypotheses can be adjudicated without awaiting a precise resolution of the problem of statistical falsification.
Although the existence of a univocal methodological convention is not necessary for refutability, what is important is the existence of a coherent set of methodological decisions exhibiting some desirable properties. Statistical tests are implicit proposals for such a convention, proposing a falsifying event (rejection region) for every sample size. To the extent possible, these tests should exhibit the synchronic virtues sought after by Fisher, Neyman, Pearson and others: at every sample size, if the hypothesis is true, the chance that it is rejected should be small; and if it is false, the chance that it is rejected should be large. But excessive focus on these synchronic virtues tends to obscure the social dimensions of these decisions. Our second response is a plea to consider another axis on which competing methodological proposals can be compared. If it were adopted by researchers conducting independent investigations of the same hypothesis, the method should also exhibit certain diachronic virtues: if the hypothesis is true, the chance that it is falsely rejected should shrink as monotonically as possible as the investigation is replicated at larger sample sizes; and similarly, if the hypothesis is false, the chance that it is correctly rejected should grow as monotonically as possible. In other words: a good methodological convention would, if adopted, support a pattern of successful replication by independent investigators. Crucially, possessing the synchronic virtues at every sample size is not sufficient to ensure the diachronic virtues: care must be taken such that the methodological decisions for different sample sizes cohere in a particular way.
4 Finally, falsifiable hypotheses would be those for which a methodological convention exhibiting all of these virtues exists.
We end this introductory section with a few comments on routes not taken in the following. The work of Mayo and Spanos [
6] is in its own way a mathematical elaboration of Popperian falsifiability. It is natural to equate falsifiability with Mayo and Spanos’ severe testability. Although severe testability is an important notion of independent interest, we do not adopt this identification—it would be too radical a revision of falsifiability. Roughly, a hypothesis is severely tested by some evidence if, were the hypothesis false, then with high probability evidence less favorable to the hypothesis would have been observed. On that stringent notion, hypotheses like
the coin is precisely fair are not severely testable, since whatever sequence of flips has been observed, a sequence equally favorable to the
precisely fair hypothesis could have been generated by a subtly biased coin. But we take sharp null hypotheses like
the coin is precisely fair as archetypical falsifiable hypotheses. Finally, it might be justly said that any contemporary philosophical discussion of statistics should say something about the Bayesian point of view. We do not attempt to fully satisfy a philosophical Bayesian. But although this work is inspired by a rival philosophical tradition, it should not be understood as incompatible with Bayesianism. On any of a number of reasonable correspondence principles, any hypothesis falsifiable by a Bayesian method will be falsifiable in our sense. Although the question of whether the converse is true is an interesting one, we do not pursue it here.
2. In Search of Statistical Falsifiability
Accordingly, instead of asking ‘when should a statistical hypothesis be regarded as falsified?’, we are guided in the following by the question: ‘when should a statistical hypothesis be regarded falsifiable?’. We suggest that statistical falsifiability will be found by analogy with exemplars from philosophy of science and the theory of computation. We have in mind universal hypotheses like ‘all ravens are black’, or co-semidecidable formal propositions like ‘this program will not halt’. Although there is no a priori bound on the amount of observation, computation, or proof search required, these hypotheses may be falsified by suspending judgement until the hypothesis is decisively refuted by the provision of a non-black raven or a halting event. We wish to call the reader’s attention to several paradigmatic properties of these falsification methods. We do not claim that these properties are typically achievable in empirical inquiry; rather, they should be seen as regulative ideals that falsification methods ought to approximate.
By suspending judgement until the hypothesis is logically incompatible with the evidence, falsification methods never have to “stick their neck out" by making a conjecture that might be false.
5Exemplary falsification methods never have to retract their previous conclusions; their conjecture at any later time always entails their conjecture at any previous time. In the ornithological context, conjectures made on the basis of more observations always entail conjectures made on the basis of fewer; once a non-black raven has been observed, the hypothesis is decisively falsified. (We appeal here to an idealization that we later discharge in the statistical setting: an exemplary method never mistakes a black raven for a non-black raven). In the computational context, conjectures made on the basis of more computation always entail conjectures made on the basis of less; once the program has entered a halting state, it will never exit again.
If all ravens are black, the falsification method may suspend judgement forever; but if there is some non-black raven, diligent observation will turn up a falsifying instance eventually. Similarly, if the program eventually halts, the patient observer will notice.
6We propose that statistical falsifiability will be found if we look for the minimal weakening of these paradigmatic properties that is feasible in statistical contexts. First, some definitions.
7 Inference methods output conjectures on the basis of input information. Here “information" is understood broadly. One conception of information, articulated explicitly by Bar-Hillel and Carnap [
19] and championed by Floridi [
20,
21], is true, propositional semantic content, logically entailing certain relevant possibilities, and logically refuting others. This notion is prevalent in epistemic logic and many related formal fields—call it the
propositional notion of information. A second conception, ubiquitous in the natural sciences, is random samples, typically independent and identically distributed, and logically consistent with all relevant possibilities, although more probable under some, and less probable under others. Call that the
statistical notion of information. Of course, statistical information can be expressed propositionally. The trouble is that—at least so far as the relevant possibilities are concerned—the proposition is always the same, since every proposition about the observed data is logically consistent with every probabilistic proposition.
Statistical methods cannot be expected to be infallible. We liberalize that requirement as follows:
The -error avoidance property is closely related to frequentist statistical inference. A confidence interval with coverage probability is straightforwardly -error avoiding: the chance that the interval excludes the true parameter is bounded by . A hypothesis test with significance level is also -error avoiding, so long as one understands failure to reject the null hypothesis as recommending suspension of judgment, rather than concluding that the null hypothesis is true. The chance of falsely rejecting the null is bounded by , and failing to reject outputs only the trivially true, or tautological, hypothesis.
We first define a weaker notion. A
method is a function from information to conjectures. A method
falsifies hypothesis H in the limit by converging, on increasing information, to not-
H iff
H is false. In statistical settings, that means that in all and only the worlds in which
H is false, the chance that
outputs not-
H converges to 1 as sample size increases.
8 A method
verifies H in the limit if it falsifies not-
H in the limit. A method
decides H in the limit if it verifies
H and not-
H in the limit. Hypothesis
H is verifiable, refutable, or decidable in the limit iff there exists a method that verifies, refutes or decides it in the limit.
Falsification
in the limit is a relatively undemanding concept of success—it is consistent with any finite number of errors and volte-faces prior to convergence. Falsification is a stronger success notion. Consider the following cycle of definitions.
9- F1.
Hypothesis H is falsifiable iff there is a monotonic, error avoiding method M that falsifies H in the limit;
- F1.5.
Hypothesis H is falsifiable iff there is a method M that falsifies H in the limit, and for every , M is -error avoiding;
- F2.
Hypothesis H is falsifiable iff for every there is an -error evoiding method that falsifies H in the limit.
Concept F1 is the familiar one from epistemology, the philosophy of science, and the theory of computation. Our motivating examples are all of this type. These may be falsified by suspending judgement until the relevant hypothesis is logically refuted by information. Although there is no a priori bound on the amount of information (or computation) required, the outputs of a falsifier are guaranteed to be true, without qualification.
Concept F1.5 weakens concept F1 by requiring only that there exist a method that avoids error with probability one. Hypotheses of type F1.5 are less frequently encountered in the wild.
10 Concept F1.5 is introduced here to smooth the transition to F2.
F2 weakens F1.5 by requiring only that for every bound on the chance of error, there exists a method that achieves the bound. Hypotheses of this type are ubiquitous in statistical settings. The problem of falsifying that a coin is fair by flipping it indefinitely is an archetypical problem of the third kind. For any
, there is a consistent hypothesis test with significance level
that falsifies, in the third sense, that the coin is fair. Moreover, it is hard to imagine a more stringent notion of falsification that could actually be implemented in digital circuitry. Electronics operating outside the protective cover of Earth’s atmosphere are often disturbed by space radiation—energetic ions can flip bits or change the state of memory cells and registers [
22]. Even routine computations performed in space are subject to non-trivial probabilities of error, although the error rate can be made arbitrarily small by redundant circuitry, error-correcting codes, or simply by repeating the calculation many times and taking the modal result. Electronics operating on Earth are less vulnerable, but are still not immune to these effects.
Since issues of monotonicity are ignored, F2 provides only a partial statistical analogue for F1. A statistical analogue of monotonicity is suggested by considerations of replication. Suppose that researchers write a grant to study whether NewDrug is better at treating migraine than OldDrug. They perform a pre-trial analysis of their methodology and conclude that if NewDrug is indeed better OldDrug, the objective chance that they will reject the null hypothesis of “no improvement” is greater than 50%. The funding agency is satisfied, providing enough funding to perform a pilot study with N = 100. Elated, the researchers perform the study, and correctly reject the null hypothesis. Now suppose that a replication study is proposed at sample size 150, but the chance of rejecting has decreased to 40%. The chance of rejecting correctly, and thereby replicating successfully, has gone down, even though the first study was correct. Nevertheless, investigators propose going to the trouble and expense of collecting a larger sample! Such methods are epistemically defective. They may even be immoral: why expose more patients to potential side effects for no epistemic gain? Accordingly, consider the following statistical norm:
Unfortunately, strict monotonicity is often infeasible (see Lemma 1). Nevertheless, it should be a regulative ideal that we strive to approximate. The following principle expresses that aspiration:
That property ensures that collecting a larger sample is never a disastrously bad idea. Equipped with a notion of statistical monotonicity, we state the final definition in our cycle:
- F3.
Hypothesis H is falsifiable iff for every there is an -error avoiding and -monotonic method that falsifies H in the limit.
F3 seems like a rather modest strengthening of F2. Surprisingly, many standard frequentist methods satisfy F2, but not F3. Chernick and Liu [
23] noticed non-monotonic behavior in the power function of standard hypothesis tests of the binomial proportion, and proposed heuristic software solutions. That defect would have precisely the bad consequences that inspired our statistical notion of monotonicity: attempting replication with a larger sample might actually be a bad idea. That issue has been raised in consumer safety regulation, vaccine studies, and agronomy [
24,
25,
26]. But Chernick and Liu [
23] have noticed only the tip of the iceberg—similar considerations attend all statistical inference methods. One of the results of this paper (Theorem A1) is that F3 is feasible whenever F2 is. That suggests that stasticial feasibility is a robust notion; many different formulations yield the same collection of falsifiable hypotheses.
It is sometimes more natural to speak not in terms of falsifiability but its dual: verifiability. The falsifiability notions F1, F2, F3 give rise to corresponding notions of verifiability V1, V2, V3 by letting H be verifiable (in the relevant sense) iff its logical complement ¬H is falsifiable (in the relevant sense). Then, such archetypical hypotheses as, ‘not all ravens are black’, or semidecidable formal proposition like ‘this program will halt’ are verifiable in the sense of V1. The statistical hypotheses that typically serve as composite alternatives to sharp null hypotheses turn out to be verifiable in the sense of V2 and V3.
Both verifiability and falsifiability are one-sided notions. They can be symmetrized by defining
H to be decidable (in the relevant sense) iff
H is both verifiable and falsifiable (in the relevant sense). That gives rise to the three corresponding decidability concepts D1, D2 and D3. Finite-horizon empirical hypotheses such as ‘the first hundred observed ravens will be black’ and formal propositions like ‘this program will halt in under a hundred steps’ are decidable in the sense of D1. Typically, simple vs. simple hypothesis testing problems turn out to be decidable in the sense of D3. However, some more interesting problems also turn out to be statistically decidable (see Genin and Mayo-Wilson [
27]).
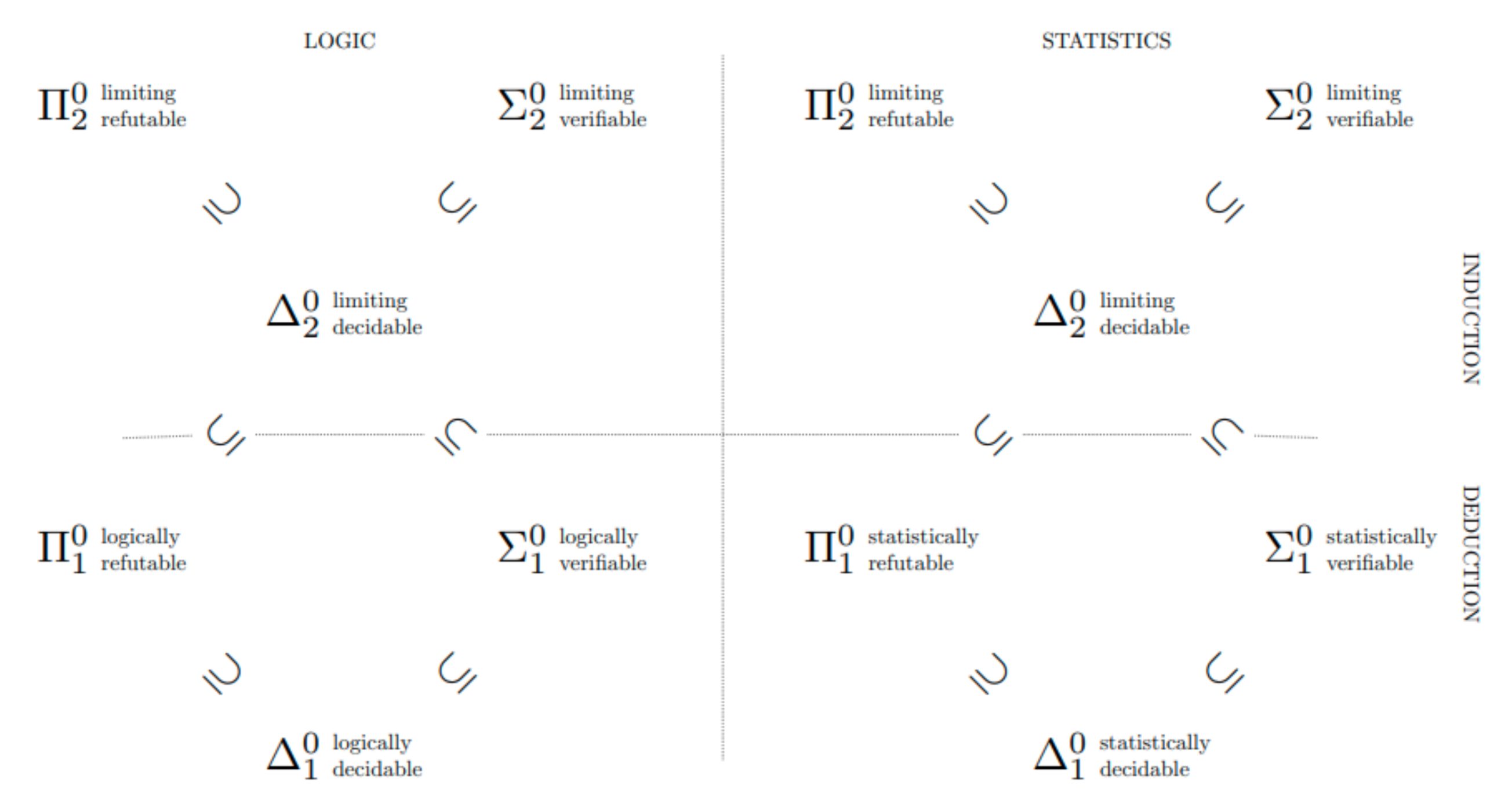
3. The Topology of Inquiry
A central insight of Abramsky [
28], Vickers [
29], Kelly [
30] is that falsifiable propositions of type F1 enjoy the following properties:
- C1.
If are falsifiable, then so is their disjunction, ;
- C2.
If is a (potentially infinite) collection of falsifiable propositions, then their conjunction, , is also falsifiable.
Together, C1 and C2 say that falsifiable propositions of type F1 are closed under conjunction, and finite disjunction. Why the asymmetry? For the same reason that it is possible to falsify that bread will cease to nourish sometime next week, but not possible to falsify that it will cease to nourish on some day in the future. It is also important to notice what C1 and C2 do not say: if H is falsifiable, its negation may not be. To convince yourself of this it suffices to notice that it is possible to falsify that bread will always nourish, but not that it will cease to nourish on some day in the future.
For their part, verifiable propositions of type V1 satisfy the dual properties:
- O1.
If and are verifiable, then so is their conjunction, ;
- O2.
If is a (potentially infinite) collection of verifiable propositions, then their disjunction, , is also verifiable.
O1 and O2 express the characteristic asymmetries of verifiability. Although it is possible to verify that bread nourishes for any finite number of days, it is not possible to verify that bread will continue to nourish into the indefinite future. Moreover, if H is verifiable, its negation may not be: if bread will cease to nourish, we will read about it in the newspaper; but nothing we can observe about bread will ever rule out the possibility of a future dereliction of duty.
Jointly, C1 and C2 ensure that the collection of all propositions of type F1 constitute the
closed sets of a
topological space.
11 The collection of all propositions of type V1 constitute the
open sets of the topology; and the propositions of type D1 constitute the
clopen sets of the topology. Sets of greater topological complexity are formed by set-theoretic operations on open and closed sets. The central point of Kelly [
30] is that degrees of methodological accessibility correspond exactly to increasingly ramified levels of topological complexity, corresponding to elements of the
Borel hierarchy. Roughly speaking, the Borel complexity of a hypothesis measures how complex it is to construct the hypothesis out of logical combinations of verifiable and falsifiable propositions. Higher levels of Borel complexity correspond to
inductive notions of methodological success, where by inductive we mean any success notion where the chance of error is unbounded in the short run (see
Figure 1).
Taking falsifiability of type F1 as the fundamental notion, the view sketched above was worked out in its essentials by Kelly [
30] and further generalized by de Brecht and Yamamoto [
31], Genin and Kelly [
32] and Baltag et al. [
33]. Genin and Kelly [
34] exhibit a topology on probability measures in which the closed sets are exactly the propositions falsifiable in the sense of F2. That shows that the structure of statistical verifiability is
also topological, at least when issues of monotonicity are ignored. The characteristic asymmetries are all present: while it is possible to falsify that the coin is fair, it is not possible to falsify that it is biased.
In this work, we show that hypotheses of type F3 also enjoy a topological structure; in fact, under a weak assumption, every hypothesis falsifiable in the sense of F2 is also falsifiable in the sense of F3 (Theorem A1). Imposing the demands of monotonicity does not make any fewer hypotheses falsifiable. That result provides a kind of cross-check on our notion of statistical falsifiability: it enjoys the same algebraic closure properties as the traditional notion F1, familiar from classical philosophy of science.
4. The Statistical Setting
4.1. Models, Measures and Samples
A model characterizes the contextually relevant features of a data-generating process. Models may be quite simple, as when they specify the bias of a coin. Models may also be elaborate structural hypotheses, as when they specify a set of structural equations expressing the causal processes by which data are generated. Inquiry typically begins with the specification of a set of possible models , any one of which, for all the inquirers know, may characterize the true data-generating process. Each model determines a probability measure, over a common sample space . A sample space is a set of possible random samples , together with a -algebra of events over the set of samples. Each probability measure is a possible assignments of probabilities to events in that is consistent with the axioms of probability and with the constraints specified by the model . We let W be the set i.e., the set of all probability measures on the sample space generated by possibilities in .
A set of models
is said to be
identified if the map
is one-to-one, i.e., if no two models generate the same probability measure over the space of observable outcomes
If two models
generate the same probability measure over the observables, then no amount of random sampling can possibly distinguish them and the question of whether
or
is the generating mechanism is, in a sense, hopeless from a statistical perspective.
12 In the following, we will assume that the set of models is identified. Since each probability measure uniquely determines a model, we can identify the model with its probabilistic consequences and drop the subscript
from our notation.
Call the triple consisting of a set of probability measures W on a sample space , a statistical setup. The inquirer observes events in , but the hypotheses she is interested in are typically propositions over W. In paradigmatic cases, an event A in is logically consistent with all probability measures in W.
Although measures in W assign probabilities to all events in not all these events are the kinds of events than an agent can observe. No one can tell whether a real-valued sample point is rational or irrational, or if it is exactly For another example, suppose that region A is the closed interval , and that the sample happens to land right on the boundry-point of A. Suppose, furthermore, that given enough time and computational power, the sample can be specified to arbitrary, finite precision. No finite degree of precision: ; ; ; … suffices to determine that is truly in A. But the mere possibility of a sample hitting the boundary of A does not matter statistically, if the chance of obtaining such a sample is zero, as it typically is, unless there is discrete probability mass on the point . Both these examples hinge on an implicit underlying topology on the sample space .
The topology the sample space reflects what is formally verifiable about the sample itself. For example, if is the real line, then it is typically verifiable whether a sample point is greater or less than ; and whether it lies in the interval It is typically not verifiable whether the sample is rational or irrational, or whether it is exactly We assume that these formally verifiable propositions over are closed under finite conjunctions and arbitrary disjunctions and therefore, form the open sets of a topological space. Then, the formally decidable proposition in form the clopen sets of the same topological space. Furthermore, we assume that the -algebra contains all the verifiable proposition and in fact that it is the least such -algebra, i.e., that it is generated by closing the verifiable propositions under countable unions and negations. A -algebra that arises from a topology in this way is called a Borel algebra and its members are called Borel sets.
A Borel set
A for which
is said to be
almost surely clopen (decidable) in μ.
13 Say that a collection of Borel sets
is almost surely clopen in
iff every element of
is almost surely clopen in
. We say that a Borel set
A is almost surely decidable iff it is almost surely decidable in every
in
W. Similarly, we say that a collection of Borel sets
is almost surely clopen iff every element of
is almost surely clopen.
A topological basis on is a collection of subsets of such that (1) the elements of cover ; and (2) if are elements of then for each there is containing and contained in Closing a topological basis under unions generates a topology, and every topology is generated by some basis. In the following, we will assume that the topology on is generated by a basis that is at most countably infinite and almost surely clopen. Say that a statistical setup is feasibly based if is a Borel -algebra arising from a countable, almost surely clopen basis. That assumption is satisfied, for example, in the standard case in which the worlds in W are Borel measures on , and all measures are absolutely continuous with respect to Lebesgue measure, i.e., when all measures have probability density functions, which includes normal, chi-square, exponential, Poisson, and beta distributions. It is also satisfied for discrete distributions like the binomial, for which the topology on the sample space is the discrete (power set) topology, so every region in the sample space is clopen. It is satisfied in the particular cases of Examples 1 and 2.
Example 1. Consider the outcome of a single coin flip. The set Ω of possible outcomes is . Since every outcome is decidable, the appropriate topology on the sample space is , the discrete topology on Ω. Let W be the set of all probability measures assigning a bias to the coin. Since every element of is clopen, every element is also almost surely clopen.
Example 2. Consider the outcome of a continuous measurement. Then, the sample space Ω is the set of real numbers. Let the basis of the sample space topology be the usual interval basis on the real numbers. That captures the intuition that it is verifiable that the sample landed in some open interval, but it is not verifiable that it landed exactly on the boundary of an open interval. There are no non-trivial decidable (clopen) propositions in that topology. However, in typical statistical applications, W contains only probability measures μ that assign zero probability to the boundary of an arbitrary open interval. Therefore, every open interval E is almost surely decidable, i.e., .
Product spaces represent the outcomes of repeated sampling. Let
I be an index set, possibly infinite. Let
be sample spaces, each with basis
. Define the
product of the
as follows: let
be the Cartesian product of the
; let
be the product topology, i.e., the topology in which the open sets are unions of Cartesian products
, where each
is an element of
, and all but finitely many
are equal to
. When
I is finite, the Cartesian products of basis elements in
are the intended basis for
. Let
be the
-algebra generated by
. Let
be a probability measure on
, the Borel
-algebra generated by the
. The
product measure is the unique measure on
such that, for each
expressible as a Cartesian product of
, where all but finitely many of the
are equal to
,
. (For a simple proof of the existence of the infinite product measure, see Saeki [
37].) Let
denote the
-fold product of
with itself. If
W is a set of measures, let
denote the set
If
is a Borel
-algebra generated by
, let
be the Borel
-algebra generated by
n-fold product of
with itself.
4.2. Statistical Tests
A statistical
method is a measurable function
from random samples to propositions over
W, i.e., for every
A in the range of
its preimage
is an element of
. A
test of a statistical hypothesis
is a statistical method
. Call
the
acceptance region, and
the
rejection region of the test.
14 The
power of test
is the worst-case probability that it rejects truly, i.e.,
. The
significance level of a test is the worst-case probability that it rejects falsely, i.e.,
.
A test is feasible in μ iff its acceptance region is almost surely decidable in . Say that a test is feasible iff it is feasible in every world in W. More generally, say that a method is feasible iff the preimage of every element of its range is almost surely decidable in every world in W. Tests that are not feasible in are impossible to implement—as described above, if the acceptance region is not almost surely clopen in , then with non-zero probability, the sample lands on the boundary of the acceptance region, where one cannot decide whether to accept or reject. If one were to draw a conclusion at some finite stage, that conclusion might be reversed in light of further computation. Tests are supposed to solve inductive problems, not to generate new ones.
Considerations of feasibility provide a new perspective on the assumption that appears throughout this work: that the basis is almost surely clopen. If that assumption fails, then it is not an a priori matter whether geometrically simple zones are suitable acceptance zones for statistical methods. But if that is not determined a priori, then presumably it must be investigated by statistical means. That suggests a methodological regress in which we must use statistical methods to decide which statistical methods are feasible to use. Therefore, we consider only feasible methods in the following development.
4.3. The Weak Topology
A sequence of measures converges weakly to , written , iff for every A almost surely clopen in . It is immediate that iff for every -feasible test , . It follows that no feasible test of achieves power strictly greater than its significance level. Furthermore, every feasible method that correctly infers H with high chance in , exposes itself to a high chance of error in “nearby” .
It is a standard fact that one can topologize
W in such a way that weak convergence is exactly convergence in the topology.
15 That topology is called the
weak topology, n.b.: the weak topology is a topology on
probability measures, whereas all previously mentioned topologies were topologies on
random samples. In other words, the open sets of the weak topology are propositions over
W, not over
If we interpret the closure operator in terms of the weak topology,
iff there is a sequence
lying in
A such that
.
If
A is an almost surely decidable event in the appropriate
-algebra then it is immediate from the definition of weak convergence that
and
are open in the weak topology over
. In this case, it is also true that
and
are open in the weak topology over
W. That observation will often be appealed to in the following. For a proof, see Theorem 2.8 in Billingsley [
38].
5. Statistical Falsifiability
Hypothesis H was said to be falsifiable (in the sense of if there is an error avoiding method that converges on increasing information to not-H iff H is false. That condition implies that there is a method that achieves every bound on chance of error, and converges to not-H iff H is false. In statistical settings, one cannot insist on such a high standard of infallibility. Instead, we say that H is falsifiable in chance iff for every bound on error, there is a method that achieves it, and that converges in probability to not-H iff H is false. The reversal of quantifiers expresses the fundamental difference between statistical and propositional falsifiability. The central point in this section is encapsulated in Theorem 1: for feasibly based statistical setups, the statistically falsifiable propositions (in the sense of F2) are exactly the closed sets in the weak topology.
Say that a family of feasible tests of H is an α-falsifier in chance of iff for all :
BndErr. , if ;
LimCon. , if .
Say that H is α-falsifiable in chance iff there is an -falsifier in chance of H. Say that H is falsifiable in chance iff H is -falsifiable in chance for every .
Several strengthenings of falsifiability in chance immediately suggest themselves. One could demand that, in addition to BndErr, the chance of error vanishes to zero:
A strengthening of this requirement will be taken up in the following section.
Defining statistical verifiability requires no new ideas. Say that H is α-verifiable in chance iff there is an -falsifier in chance of . Say that H is verifiable in chance iff is -falsifiable in chance for every .
The central theorem of Genin and Kelly [
34] states that, for feasibly based statistical setups, falsifiability in chance is equivalent to being closed in the weak topology.
Theorem 1. (Fundamental Characterization Theorem). Suppose that the statistical setup is feasibly based. Then, for the following are equivalent:
H is α-falsifiable in chance for some
H is falsifiable in chance;
H is closed in the weak topology on W.
Since a hypothesis is verifiable iff its complement is refutable, the characterization of statistical verifiability follows immediately.
Since a topological space is determined uniquely by its closed sets, Theorem 1 implies that the weak topology is the unique topology that characterizes statistical falsifiability (in the sense of ), at least under the weak conditions stated in the antecedent of the theorem. Thus, under those conditions, the weak topology is not merely a convenient formal tool; it is the fundamental topology for statistical inquiry.
6. Monotonic Falsifiability
In
Section 5, we said that
is a statistical falsifier of
H if it converges to not-
H if
H is false, and otherwise has a small chance of drawing an erroneous conclusion. But that standard is consistent with a wild see-sawing in the chance of producing the informative conclusion not-
H as sample sizes increase, even if
H is false. Of course, it is desirable that the chance of correctly rejecting
H increases with the sample size, i.e., that for all
and
,
Failing to satisfy Mon has the perverse consequence that collecting a larger sample might be a bad idea. Researchers would have to worry whether a failure of replication was due merely to a clumsily designed statistical method that converges to the truth along a needlessly circuitous route. Unfortunately, Mon is infeasible in typical cases, so long as we demand that verifiers satisfy VanErr. Lemma 1 expresses that misfortune.
Say that a statistical setup is purely statistical iff for all and all events such that This is the formal expression of the idea that almost surely clopen sample events have no logical bearing on statistical hypotheses and is easily seen to be a weakening of mutual absolute continuity.
Lemma 1. Suppose that the statistical setup is feasibly based and purely statistical. Let H be closed, but not open in the weak topology. If is an α-falsifier in chance of H, then, satisfiesVanErronly if it does not satisfy Mon.
Proof of Lemma 1. Suppose for a contradiction that
is an
-falsifier in chance of
H satisfying
VanErr. Since
H is not open, there is
Since the statistical setup is purely statistical and
satisfies
LimCon, there must be a sample size
such that
Let
By construction,
Since
satisfies
VanErr, there is
such that
Let
By construction,
Since
is feasible, both
are open in the weak topology (see the observation at the end of
Section 4.3). Since open sets are closed under finite conjunction,
O is open in the weak topology. But since
there is
But then,
whereas
Therefore,
does not satisfy
Mon. □
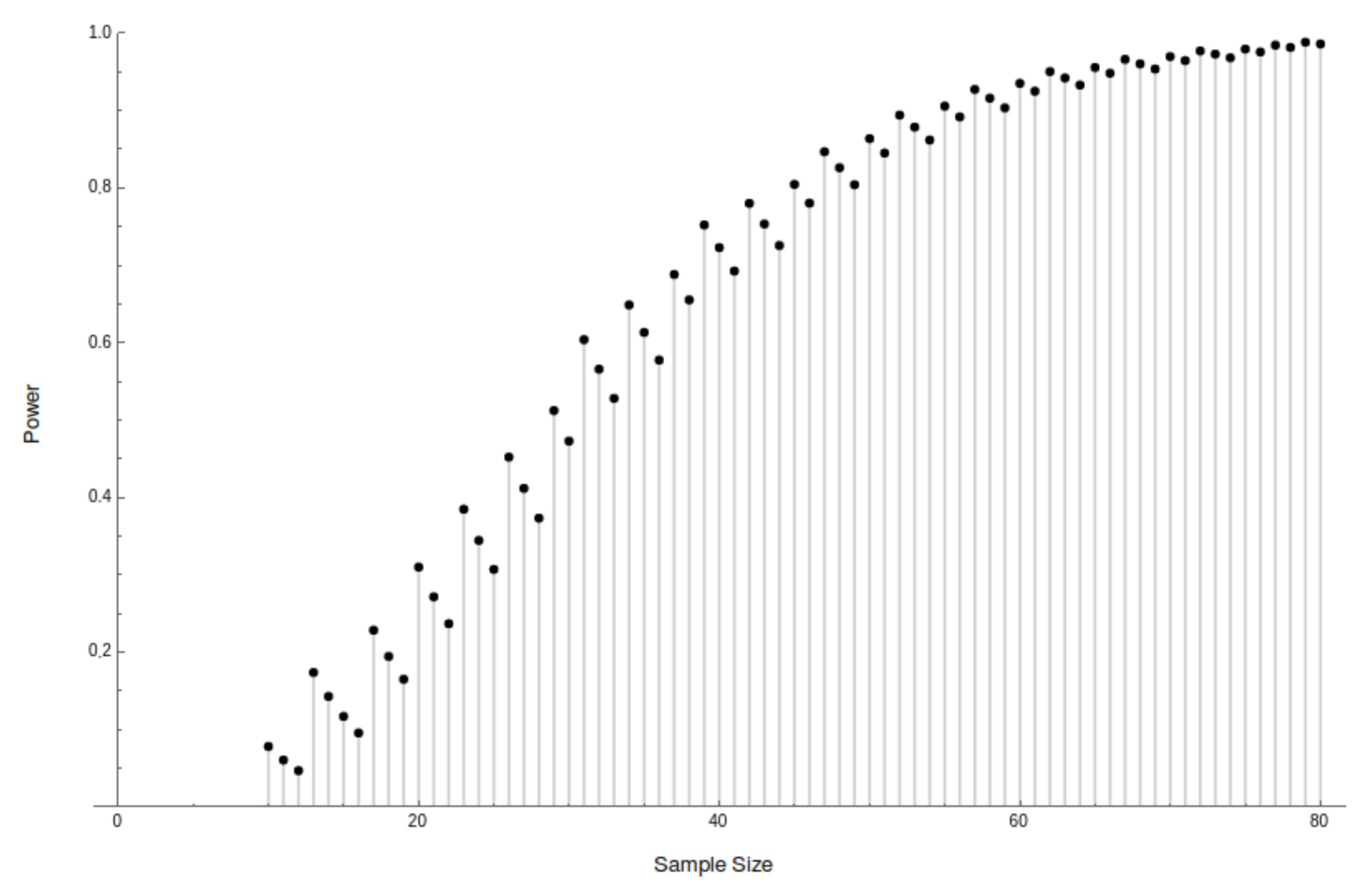
But even if strict monotonicity of power is infeasible, it ought to be our regulative ideal. Say that an -falsifier of H, whether in chance, or almost sure, is α-monotonic iff for all and :
Satisfying
-
Mon ensures that collecting a larger sample is not a disastrously bad idea. Surprisingly, some standard hypothesis tests fail to satisfy even this weak requirement. Chernick and Liu [
23] noticed non-monotonic behavior in the power function of textbook tests of the binomial proportion, and proposed heuristic software solutions. The test exhibited in the Genin and Kelly’s proof of Theorem 1 also displays dramatic non-monotonicity (
Figure 2). Others have raised worries of non-monotonicity in consumer safety regulation, vaccine studies, and agronomy [
24,
25,
26].
We now articulate a notion of statistical falsifiability that requires -monotonicity. Write if the sequence converges monotonically to zero. Say that a family of feasible tests of is an α-monotonic falsifier of H iff
MVanEee. For all , there exists a sequence such that each , and ;
LimCon., ;
α-Mon., , if .
Say that H is α-monotonically falsifiable iff there is an -monotonic falsifier of H. Say that H is monotonically falsifiable iff H is -monotonically falsifiable, for every . It is clear that every -monotonic falsifier of H is also an -falsifier in chance. However, not every -monotonic falsifier of H is an almost sure -falsifier. The converse also does not hold.
Defining monotonic verifiability requires no new ideas. Say that H is α-monotonically verifiable in chance iff there is an -monotonic falsifier of . Say that H is montonically verifiable iff is -monotonically refutable for every .
The central theorem of this section states that every statistically falsifiable hypothesis is also monotonically falsifiable. The proof is provided in the
Appendix A.
Theorem 2. Suppose that the statistical setup is feasibly based. Then, for the following are equivalent:
H is α-falsifiable in chance for some ;
H is statistically falsifiable;
H is monotonically falsifiable;
H is closed in the weak topology on W.
The characterization of monotonic verifiability follows immediately.
7. Conclusions: Falsifiability and Induction
This work is inspired by Popper’s falsificationism and its difficulties with statistical hypotheses. We have proposed several different notions of statistical falsifiability and proven that, whichever definition we prefer, the same hypotheses turn out to be falsifiable. That shows that the notion enjoys a kind of conceptual robustness. Finally, we have demonstrated that, under weak assumptions, the statistically falsifiable hypotheses correspond precisely to the closed sets in a standard topology on probability measures. That means that standard techniques from statistics and measure theory can be used to determine exactly which hypotheses are statistically falsifiable. Hopefully, this result will be a boon to statistical practice by providing a simple diagnostic for statistical falsifiability—controversies about testability may be resolved while maintaining an ecumenical attitude about what, precisely, statistical falsification consists in.
However, this work should not be taken as a wholesale endorsement of Popperian falsificationism. It is easy to generate respectable statistical hypotheses that are not falsifiable or, for that matter, verifiable. Indeed, many pressing scientific hypotheses are of this nature, especially when researchers are interested in answering causal questions (see [
39]). These should by no means be regarded as unscientific. The hallmark of these kinds of hypotheses is that, although it is possible to converge to the truth as sample sizes increase, it is not possible to do so with finite sample bounds on the probability of error. This fact should be faced squarely—and not necessarily by searching for stronger assumptions that make it possible to provide finite sample guarantees.
A large class of scientific problems can be reconstructed in the following way: we enumerate a collection of disjoint hypothesis
in such a way that that
is falsifiable no matter how large
n is.
16 Then, we test longer and longer initial segments, conjecturing the first hypothesis that we fail to reject. Since the procedure involves nesting tests, we cannot expect finite sample bounds on the probability of conjecturing a false hypothesis. Nevertheless, this procedure answers pretty closely to a Popperian methodology of conjectures and refutations. Unlike Popper, we have no problem calling the outcome of such a procedure—belief in, or acceptance of, the first unrejected hypothesis in the enumeration—an induction. But is there anything to be said in favor of this natural and commonplace scientific procedure? Popper hoped that it would produce theories of greater and greater
truthlikeness or
verisimilitude. That notion has had a troubled and fascinating career, which we do not review here.
17 There is, so far as we know, no demonstration that this procedure must produce theories of increasing truthlikeness.
18Let us briefly consider a different idea. Call such a procedure
progressive if (1) it converges in chance to the true
(if any is true) and (2) if
is true, then the objective chance of conjecturing
increases monotonically with sample size. It should come as no surprise that this kind of strict monotonicity is not usually feasible. However, it should be a regulative ideal: say that such a procedure is
-
progressive if (1’) it converges in chance to the true
(if any is true) and (2’) if
is true, then the objective chance of conjecturing
never decreases by more than
as sample sizes increase. The latter is a natural generalization of
-
Mon to problems of theory choice and precludes egregious backsliding. It should be intuitive that such a procedure can only be
-progressive if the constituent test are themselves
-monotonic in chance. Genin [
45] Theorem 3.6.3, shows that, for all
it is possible to produce an
-progressive solution to this problem, so long as the consitutent tests are chosen to be sufficiently monotonic in chance. The existence of such tests is guaranteed by Theorem 2. That means that a carefully calibrated methodology of conjectures and refutations is conducive to progress—it converges to the right answer (if any candidate is right) with an arbitrarily low degree of backsliding. We hope that these remarks suggest to some degree the relevance of this work to a positive theory of induction.


{kind=link}
{kind=link}
{kind=link}


