1. Introduction
Understanding breakthroughs in chemistry is both challenging and important. Through the systematic matrix of advances in structure and transformation of matter, its relevance translates into important technological gains. In the last decade, the popularization of chemical discoveries in the production of vaccines [
1,
2], consumable hi-tech [
3] and pollution mitigation [
4] showed knowledge dynamics whose civilizational advances are embedded in the description and explanation of chemical concepts. It is not surprising that these developments captured scientists’ attention regarding their conceptual structure. Particularly, when asked how to introduce into public discourse so many new discoveries, the importance of the public’s understanding of science is highlighted [
5]. Is it possible for dense and rich language intended for fellow scientists to be comprehensive for both decision-makers and the public?
To address this question, it is important to be objective when designing chemical information. An element that must be clear in such communication is how knowledge is produced. In this digital age, where many experiments are fast-paced (literally, at the click of a button), the mystique of the scientist’s work is jeopardized in favor of computational algorithms that read, document, and interpret experimental data [
6]. And chemistry is no exception. Entire fields of research, such as drug design, determination of chemical properties, and reaction troubleshooting, are dominantly mediated by computers [
7,
8]. However, complex instruments go beyond sample reading and can solve chemical questions in real time [
9]. Although these are important and egalitarian methods of conducting science, to whom can we attribute its conclusions? To the scientist who designed the computer algorithm? The one who coded it? Or to the one who executed it? Are they all responsible? This can be a trivial issue when we only want to ‘do science’ and achieve a breakthrough in current knowledge. However, as others may say it formally, I do not take this as a minor issue. Understanding how knowledge is produced not only implies directing its ownership but also facilitates its explanation. We certainly remember ongoing issues when, in the name of a better understanding, scientific discoveries are reduced to the minimum necessary [
10]. This was clear in the recent skepticism of the announcement of vaccines for SARS-CoV-2, likely because of how swiftly they emerged [
11]. Communication missteps, partially explained by knowledge novelty, have caused a public perception that overlooks the structures, experiences, and scientific collaborations behind this achievement. Only a clear identification of how scientific discovery takes place can help build a communicative framework towards a comprehensive audience.
My position on this subject is not only advocated by the emergence of computational methods in chemistry. It is also backed by a historical matrix that should not be ignored. There are several examples of the history of science in which a failure in the explanation of a scientific phenomenon can identify a clear flaw in the logic of the scientific discovery. For example, at the end of the 19th century, Portugal faced a severe economic crisis, largely due to the massive drop in exports of one of its most valuable agricultural assets [
12]. Port wine sales were halted by the reported presence of large quantities of a prohibited substance—salicylic acid—detected by foreign scientists using a recent analytical chemistry method. The wine’s producers, who never tampered with their product (and were aware of its suitability), sponsored scientists to refute these criticisms. In the many years in which this quarrel took place, it was indeed proven that salicylic acid was present in the Port wines. However, it was only in very small quantities, well within the acceptable limits for human consumption. How can we explain this finding? Not because the experts acted in bad faith, purposely claiming the wines as adulterated, but due to a frank misinterpretation of the analytical method used, as it could not determine the source nor correctly quantify the salicylic acid. This method’s employment would even be criticized by the method’s author, as this flaw perfectly illustrates that when science is concerned with using new methods, the discovery workflow is essential (in particular, for correcting these ‘errors’). The confirmation of a method is a logical part of science, and it can change based on new information and its ability to describe reality [
13]. Since this is a statement far from philosophical consensus, it reveals that science greatly benefits from a clarification of all of these concepts.
It is in this context that I intend to invoke the tools of the philosophy of science. Although it may be rhetorical to ask a chemist what philosophy can do for his work, I venture to answer affirmatively. I would say that the philosophy of science addresses the scientific explanation of a chemical phenomenon [
14]. By understanding what is involved, at different levels of perception, it expands the comprehensibility of the scientific act [
15]. It reveals the conceptual implications in the scientific sphere which, more than ever, require its understanding outside the laboratory. I do not hide the humble origins of the philosophy of chemistry, but in this work, I will only focus on questions beyond chemistry’s internal dimension: on the nature of substances, synthesis, and interactions. It is important to clarify key philosophical issues on the dissemination and public understanding of science. Beyond realism vs. reductionism, I intend to focus on the problem of ‘explanation in chemistry’. Better chemistry communication and education depend on how both explain the essentials of the underlying scientific phenomenon. In this context, I support myself using the notion of constructive realism that is generally invoked in the relevance of explanation in science [
16]. It does not compromise the empirical and constructive characterization of chemistry, as it balances a pragmatic notion of explanation with the realistic chemist’s perspective.
What are we talking about when we talk about ‘chemical explanation’? In the eyes of philosophy, we must face various perspectives of looking at the scientific process. What should we require in our communication for an explanation to be valid? If chemistry itself intends to have a self-explanatory mechanism, what differentiates a scientific explanation from an event description? To this end, several authors have written on the adequate framing of scientific explanation which clarifies this issue [
17]. However, recognizing the multiplicity of opinions on this subject also testifies that current philosophical models often fail to clarify ‘explanation in chemistry’. It is precisely this notion that I intend to address. I have reasons to believe that recent methods in chemistry embody logical conceptual structures in the statistically-based process of chemistry discovery. Thus, an incursion (albeit brief) of current philosophical models in scientific explanation is justified. To this end, I analyze the case of high-end computational artificial intelligence (AI) tools applied in chemistry research, whose results range from theory generation to chemical behavior prediction of certain systems. I intend to demonstrate that, contrary to the general convention on the discovery of chemical phenomena, there are cases for which we can argue a logic in chemistry explanation. By clarifying how cutting-edge discoveries are characterized using complex statistical tools, I aim to show a series of a trade-off patterns in chemical explanation which complement its logic of discovery.
To this end, this paper is divided in the following manner. I will begin by framing scientific explanation in chemistry and then report on the current views on the logic of discovery in chemistry. Subsequent sections will address a particular example of AI methodologies in chemistry discovery and then introduce several cases of identified logic structures on the quoted scientific explanation.
2. Is There a Logic of Discovery in Chemistry?
Can we have a formula to make any chemistry-based discovery? As in, a thoughtful playbook to conduct science? Reichenbach formulated this simple but methodologically dense question [
18]. In his perspective, the generation of scientific hypotheses comes from the scientists’ creative process, removing the possibility of a logical procedure. That is, only the analysis of the explanation would be approached by scientific logic, as confirmation or rejection of the analyzed theory. Conceptually, this truism fits the assumption that there is a univocal motivation in the process of scientific explanation: it will always have to start from a conceptual invocation of previous knowledge, the formulation of which invariably depends on individual experience. There is no prior ‘recipe’ for the discovery of a phenomenon as each event, although comparable, has its own circumstances.
Historically, the evolution of modern chemistry into the contemporary period shows the adequacy of this reasoning. Reconsider the example of the ‘Salicylic acid poisoning of Port wines’. Given the uniqueness of each wine, it would be wrong to assume that the generic analytical method that implicated the Port wines could provide a logical hypothesis that they were ‘poisoned’ with salicylic acid. They deemed any presence of salicylic acid as ‘poisonous’ for human consumption, a credence debunked at the time by other chemists. As salicylic acid of a natural source could be present in ‘normal’ wines producing no health effects, the method’s hypothesis was incorrectly generated, as they were not designed to distinguish between salicylic acid of natural/external sources, nor were they prepared to discriminate health-negligible concentrations. Therefore, the origin of the mechanism of scientific discovery that described wine as unfit for consumption was not conceptually prepared to do so correctly. If it were today, before establishing the hypothesis that a wine is deemed adulterated, counter-analyses would have to be carried out with other methods and operators, as only a diverse array of experimental data could draw a conclusion regarding the ‘discovery’ [
19]. As such, scientists’ creativity is always present, as they would have to analyze and compare the experimental data with previous knowledge. It is this notion that prompts the emergence of modern scientific decisions, as including scientists’ creativity in knowledge creation prevents incorrect generalizations and the use of circumstantial realities. This is what the scientists’ activity intends to address: the entropic nature of experience.
With the development of chemical practice, does it make sense today to speak of a logic of discovery? The development of new methods, combined with the precision and accuracy provided by emerging technologies, makes it possible to expedite the experimental process, simplifying hypothesis generation through increasing speed and density of information. Here, one can quote some voices that almost assume that in a computerized process, there is only a figurative nature of the ideal scientific verdict [
20]. If instrumental advancement helps with scientific endeavor, the biggest problem may be assessing the complexity of the division between human and machine intervention.
It is precisely with the concentration of efforts on the massification of scientific knowledge production, largely since the end of the 20th century, that it has been possible to talk about this. A pivotal example is the synthesis and discovery of new molecules. Since Corey [
21] proposed the ‘retrosynthetic hypothesis of organic molecules’, many have followed his suggested systematization of a reaction process, planned according to experimental logic. Instead of thinking of the process from beginning to end, Corey proposed the reverse. Knowing that we wish to produce a particular molecule but do not know how, a good strategy would be to start from the end, designing the steps needed, and continue towards the beginning of the process. This backwards reasoning eases the establishment of theoretical links between concepts that can outline the complete synthetic process. The evaluation of the viability of these hypotheses is carried out by their theoretical plausibility, or simply by experiments in the laboratory. We can also speak of a logic of discovery in the innovation of new targets for chemical synthesis [
22]. The most obvious case is in the creation of molecules for therapeutic purposes, where it is common to research active principles that are analogous to already-existing ones. Whether for economic reasons (cheaper synthesis) or pharmacological motives (less toxicity), with the chemical study of an existing molecule through computational methods, it is possible to simulate three-dimensional structures of new molecules. Then, with a trial-and-error methodology where the outcome of the molecule is biologically evaluated, the chemical structure of the eventual drug is modeled until the desired activity is achieved. These methodologies in chemical synthesis are strategically mentioned as examples of discovery logic, something that is not consensual in other areas of science. Since the goal of chemists is to identify reaction features, there are situations in which dense mechanistic detail does not add any relevant explanatory information. This is true in areas such as neuroscience and functional biology, especially in situations where experimental confirmation is more difficult [
23]. Thus, even if one can think of different sources for mechanisms in chemistry, the final stage of process discovery should not depend so much on the density level of knowledge, but rather on the interconnection of explanatory information between chemical actors and their incumbent steps. I base this assumption on the concept of ‘logic of discovery’ conveyed by Carmichael [
19]. A summary of this argument is presented in
Figure 1.
Assuming that the essential step in the discovery process is the act of building a hypothesis from which the proposition tested originates, achieving the logical explanation establishes a dependency relationship between discovery and explanation. Therefore, the logic of discovery can be discussed in the explanation of the phenomenon, being necessary for specific concepts, but also for fundamental questions in which the explanation must be inferred by logical deduction. It is only by an explanatory apparatus that one can identify the basic components of a logic nature of a phenomenon. It is with this motto I will discuss the following scientific example.
3. Scientific Explanation in Chemistry
How important is explanation in chemistry? Since this is one of the primary objectives of the philosophy of science, the act of explaining a scientific phenomenon must be restricted from other concepts of scientific enterprise [
24], understood as other projects that scientists can undertake. As it is important to distinguish explanation from other endeavors, I intend to go beyond cataloguing conceptual advances in science. This proves to be a difficult exercise, but let us consider the following case of three important scientific activities.
The first is description. This concept is concerned with describing things in the world through arrays of unique characteristics of objects. A second activity is to classify these objects. We can put them in categories based on their characteristics, as Linnaeus did with his taxonomy proposal, in which one classifies different living organisms into groups. From a chemistry standpoint, the periodic table of elements is probably the most discussed example of accounts on description and classification. It is a system that classifies different elements, currently doing so based on their atomic number. Previous iterations were based on element description, well before scientists studied atomic particles and theorizing about protons, neutrons or electrons. The third endeavor is forecasting. Different from explanation, one can make a prediction about what is going on and will happen in the future. This differs from explaining why it happened, because someone will need to make several correlations to make a prediction. This is the case of chemical biomarkers in medicine. Sometimes, before we know the cause of a disease, we can see what correlates with it and use it as a guide for a medical forecast (although one might not know what is involved) [
25,
26].
These are examples suggested to differ from explanation. But how are they different [
27]? Scientific explanation should give us a deep understanding of the process at hand (as an answer to a question). It is known that one can identify the characteristics of things in the world in order to describe and classify them. One might also make predictions if they have a little more information. However, it is a totally different conception to explain why a certain event has these specific types of characteristics. For this, it is necessary to involve more information, as most people expect an explanation to give them a deeper understanding, focused on comprehending rather than diverging from prediction. This is clear with what occurred with the Periodic Table, when Mendeleev predicted the missing elements in its first version [
28]. His layout of how elements were organized allowed future scientists to discover the missing elements. It represents one of the most impressive examples of prediction, because it is difficult to grasp the mental web that was established when chemists started ordering elements, which eventually allowed to predict them. This is different from an occasional one-off event where one might get lucky and find a random connection. It is a systematic feature, almost like a rule, letting an individual to make an explanation while also making a prediction.
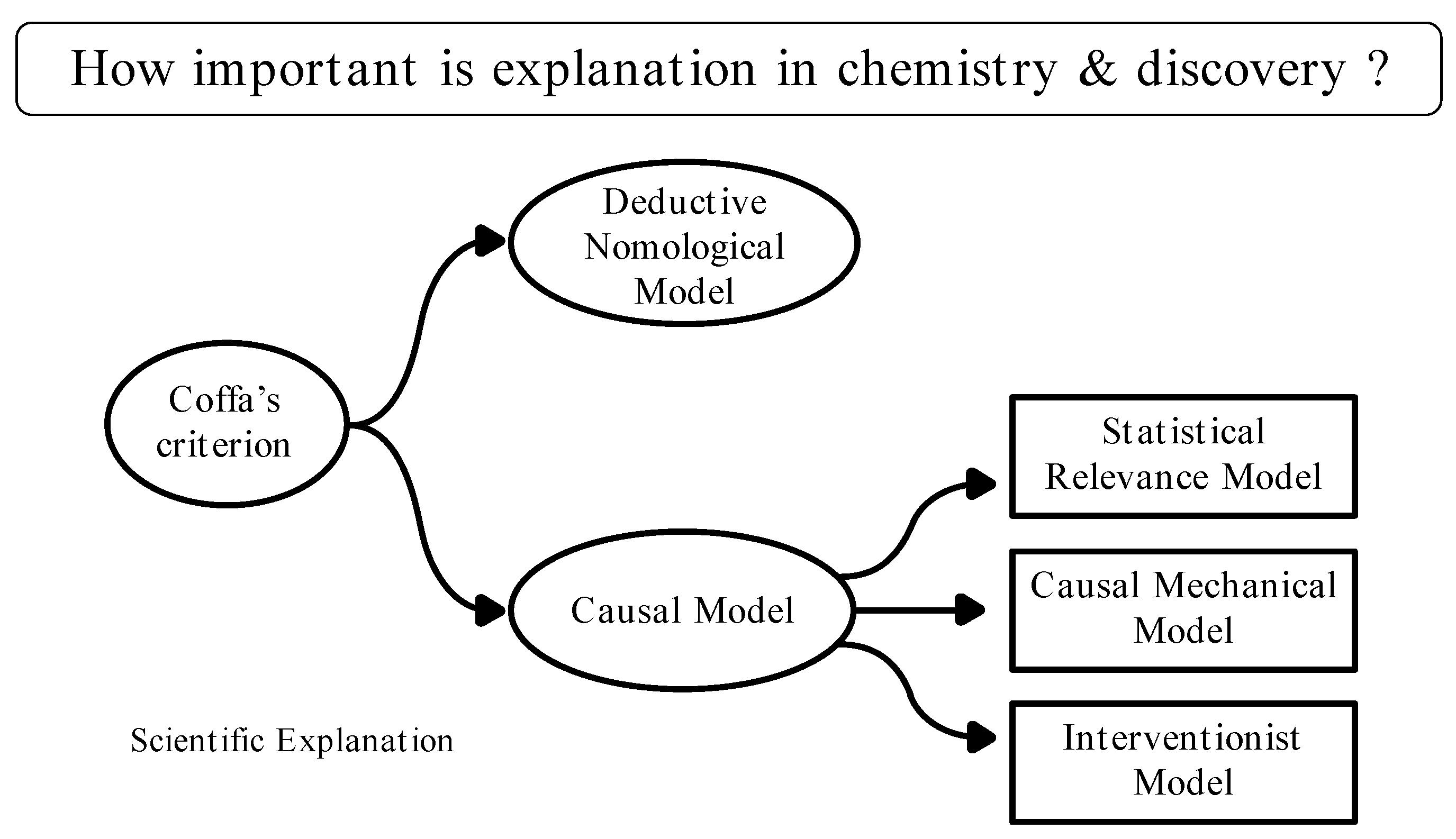
To establish a link between discovery and explanation, we turn to the philosophical discussion of these models in the chemical sciences. We can start by the classic classification of scientific explanations according to Coffa’s criterion [
29], which states the presence of two large families of models (
Figure 2). The epistemic group is represented by the deductive-nomological [
13] model (DN), and the ontic group is exemplified by the causal model of explanation. The DN model states that an event’s explanation, called explanandum, must be deduced from several empirically established laws of logic which explain the phenomenon, called explanans. It is important to note that there are restrictions to this interpretation, such as the impossibility of performing accidental generalizations of the same laws (thus, explaining its empirical condition). The explanations provide valid reasons for a certain phenomenon or observed fact without restricting the dynamics of the laws cited for scientific explanation. It is understood that the epistemic models of explanation are less dogmatic. Instead, the ontic models assume that the world works in a certain way, marked by a constructive structure in which the world is organized by a causal link [
30]. This sprung an extensive philosophical literature on the role of causation in the explanation of scientific phenomena.
Contemporary philosophy discussion on scientific explanation often starts from the inception of the DN model, as advocated by Hempel (legitimized by other influential works [
31,
32]), and its dichotomy with the ontic models. By exploiting descriptive gaps in the DN model, alternative models of scientific explanation have been proposed, especially framing the role of causation in explanation and how it structures scientific explanation. As it is not the aim of this work to discuss and compare these models, I highlight three ontic models that attempt to describe the relevance of causation in scientific explanation: Salmon’s Statistical Relevance model; the Causal Mechanical model; and Woodward’s interventionist account of causation. These iterations support my argument for a structured logic of discovery of a chemistry problem, overlapping with the presented elements of AI-assisted chemical discovery.
Before going in depth with the experimental example, we must first clarify the nomenclature intricacies in this question. Most scientists are familiar with the dichotomy of inductive and deductive reasoning. While deduction describes a line of thought where a conclusion is derived from factual grounds, inductive reasoning yields a conclusion though a general probabilistic degree [
33]. Thus, the main difference between these two traditional standpoints lies in how someone reaches a solution to a particular problem. Say a chemist wants to discover an adulterant in a foodstuff. If he had directly seen the contaminant molecule in the sample, he could deduce its presence. However, if he detected its presence using an analytical method that yielded a 90% certainty on its result, then he would have inductively reasoned that the foodstuff was poisoned. Ergo, the explanatory difference in these examples stem from the scientist’s factual (as an absolute truth) or probabilistic conclusion.
Beyond these two cases, scientific practice dynamics are not always black and white. Sometimes, rational reasoning can be achieved from an alternative model that encompasses characteristics from both previous takes. Abductive reasoning embodies this by reaching a conclusion with a degree of certainty while supporting it with several explanatory considerations [
34]. Unlike pure induction, abductive reasoning yields a statistically based verdict using premises that guide and support a stated degree of certainty. Circling back to the adulteration example, the chemist will now use all available information before reaching a conclusion: knowledge of how the foodstuff was produced, who commissioned it, or what molecular interactions in the food matrix could yield a false positive. It works like a filter that selects the best explanation beyond pure statistical probability.
Considering these three types of reasoning, I raise them as starting points for the main argument in the next section.
4. An Artificial Intelligence-Based Model: The ‘Catalyst Problem’
Artificial intelligence tools have been increasingly used to help solve scientific problems [
35]. In chemistry, many of the works carried out with AI use Machine Learning (ML) algorithms [
36]. The aim of these techniques is to obtain a model capable of making predictions according to the input data. The wide adherence of chemists to these methods is understood by the large typology of data that can be applied to the ML models. From numerical values, to images, to even quantitative and qualitative variables, there are several inputs that can be translated into a prediction. This can also become a simulation of a result, either a numerical figure or the spatial distribution of a particular molecule. Another trending example is the use of ML for calculating thermodynamic properties intended for the development of new chemical processes. However, as with this and other examples, the reported computational cost and accuracy of these calculations, coupled with the costly resources needed, often refrain from high expectations of these methodologies.
The ML concept of statistical analysis enables the causal relationship in computational learning, framing knowledge advancement by making a novel discovery. However, the concept of causal knowledge creation has been used cautiously in the literature, particularly in the application of AI techniques to scientific discovery [
37,
38]. Through a current of thought that warns about its struggling ability to manage counterfactuals, causal learning is explained in its need to require symbiotic collaboration of data and models. Hence, the following critique is made of AI methodologies as representative of scientific discovery: input data are not an end in themselves, as an algorithm may find associative patterns without describing actual causal meaning.
In this paper, I seek to describe a methodology that uses AI tools, but whose causal payoff is not given by its output. We add a mechanistic layer that uses the algorithm’s conclusions to establish causal relationships between the input data and the chemical features of a given molecule. In other words, the discovery is performed using information gathered by a ML algorithm. However, to reinforce the idea of an absence of arbitrariness in knowledge creation, I emphasize the statistical confirmation given in each iteration of the process. Results are guaranteed through a mathematical function describing the chemical outcome. The causality conceived herein is strengthened by statistical information, which is directly proportional to the amount of data introduced in the algorithm. In this way, the mechanism and the chemical activity given by a computational method is supported by the information given by the data, corroborated by its statistical score.
Let us discuss an emergent application using AI to solve a chemical problem. We will refer to this as the ‘Catalyst Problem’. The inverse Quantitative Structure–Activity Relationships method (iQSAR) is an increasingly popular framework for creating new molecules [
39,
40]. It works by overturning the basic concept of traditional QSAR methods: instead of designing a molecule from structural features, iQSAR lays out new structures from mathematical descriptors calculated from chemical properties. To formally clarify, we can describe a QSAR relationship as:
An iQSAR approach would be described as:
Take, for example, the design of a novel catalyst for a specific chemical reaction. From a desired target property, it is possible to tailor-make a chemical structure to act on the catalytic site [
41]. This strategy is based on a framework of a QSAR model and constrains it, allowing descriptor values of a specific property to generate targets for potential new molecules [
39]. As a relatively recent alternative, this is a creative approach to molecular design, as it bypasses a major issue with traditional molecule discovery methods. It avoids the often-time-consuming database screening for a potential molecule that could still be unknown. Consider that the active site is a lock, and the catalyst is a particular key. Instead of using the traditional QSAR method of trying multiple keys to open a lock, iQSAR designs a key from the lock itself. Using this ‘inverted take’ on molecular design, different chemical optimizations have been successfully made using this approach [
42]. This still demands fine-tuning consolidation methods to perfect the structure design, which is why iQSAR tools are only used in specific cases. This means that if we want to ‘train’ an algorithm to produce an output from specific data, we always must adapt its network weight matrix. This is carried out by an attractive adaptation process.
Going forward with the ‘Catalyst Problem’ example, let us suppose that our goal is to have a catalyst that can generate higher production yields. This chemical process is well known, and we have a substantial amount of raw data from previous reaction routes—for example, data information on the performance of several chemical descriptors of other reactions’ catalysts. If we could have a readout of the most important descriptors needed to describe the ‘perfect’ candidate for a potential catalyst, we could then use an iQSAR model to design the corresponding chemical structure. And here is where AI becomes useful. With ML tools, it is possible to use the pre-existing reaction data to develop a computer algorithm that can learn without being programmed in advance [
43,
44]. Concerning the development of iQSAR models, ML can correlate the best chemical property/activity with molecular features using an algorithm. This leads to the creation of models which are able to predict the activities of molecules possessing similar descriptor values for the targeted specific chemical space (here, the catalytic site) [
39]. Thus, it is possible to generate new chemical entities that resemble the best binding structure while displaying prime values for the chemical descriptors of the reaction’s catalyst. In short, it is conceptually possible to generate a new chemical entity from data observations of past reactions to produce an ideal catalyst to solve a chemistry reaction problem.
This previous description seems to recall an old philosophic axiom that stipulates that ‘all scientific data is theory laden’ [
45]. If we could argue that all raw data are facts with no interpretation until connected by a theory, what can we say about this structure generation? One might say that the collected data emerged from a logical process where the scientific discovery is an object to our endeavor, whose knowledge generation is bounded by theory-laden scientific practice. The quantification of the descriptors themselves has a subjacent theory, created from scientists’ intuition and creative work and then used to record the reaction data. However, when we input this data into a ML model instructed to correlate the ideal catalytic descriptors, the outcome is a product of several steps of data treatment. The subsequent step taken by the iQSAR model, using this information as input to design a new molecule from its constraint equations, describes an induction process where the output is the desired structure. Narrowing the construction of new compounds limits the hypothesis solution space, using independent variables in adequate algorithms. The workflow of this procedure consists of a logical process for generating a theory on the chemical behavior of this catalytic system, as the new catalyst is structured without a textbook creative practice. In this iteration, both hypothesis and justification for the chemical discovery are assured by a logic procedure. Ergo, this poses another threat to Reichenbach’s claims of a duality of contexts in scientific discovery.
Another postulate regarding the pertinence of this example rises when we compare with another challenge to Reichenbach’s claims. Traditional trial-and-error drug discovery methodology, using a stage-bound process pathway, also displays a logic process. Even here, we can claim that in these stages there is some room for scientists’ creativity. Say, in the last stage, where it is necessary to try different substitutes for a certain scaffold, there are different subjective criteria to guide this design (unless these criteria are automated by a computer). We can then say that the ‘Catalyst Problem’ is more robust than this objection, giving momentum to ML methods.
5. Scientific Explanation on AI-Based Chemical Discovery
In this section, I will outline the connection between different models of scientific explanation and the proposed model for the ‘Catalyst Problem’. Starting with framing and explaining the models using a causation structure, I will enumerate the three exemplified models that shape the argument of a possible logical course in theory generation.
As discussed, we are dealing with computational predictions that provide answers stemming from statistical patterns between data and models. Considering this logical reasoning which will be discussed further (bearing this as an exploratory hypothesis), I will only consider inductive and deductive reasoning in its inception. This decision is based on the quantitative results that are used in these computational models, which rely on statistical power to support their conclusions.
5.1. Statistical Relevance Model
Let us start with the classic DN model. It comprises two different components: the explanandum (defining the explanatory target which describes the chemical phenomenon) and the explanans (based on the premise used to explain the phenomenon). According to Hempel, to connect these concepts a ‘logical deduction’ between both must be established, similar to a cause/effect dichotomy, which is governed by some postulates. It also states that individual explanation sentences included in the explanandum must be true.
However, if the DN model illustrates the explanation through a deduction of laws, this assertion may be compatible with the example of induction by AI. Perhaps in the same way, this also does not explain a certain type of laws: the laws of statistics. But are statistical laws really laws? Hempel answers this by stating that there is room for a particular form of explanation [
24]. Inductive–statistical explanation (IS) embraces a set of individual events that are ruled under a statistical ‘law’. For example, using a classical model of quantum chemistry, the event of finding a particle moving freely inside a box with impenetrable walls (event), is given a probability according to a mathematical rule (law) [
46]. In this type of scientific explanation, the relationship between the explanans and the explanandum is of an inductive nature and the justification for the event is given by the probability of its outcome. If the possibility of finding a particle in a closed box is high (given by a probability law), and if the particle is indeed in the box, then this information can explain the discovery of the particle. However, the same cannot be inferred from a negative induction. If the probability of finding it is low, even if the particle stuck in the box can be found, it is not possible to use this information to explain the event.
Like in the exploration of the IS model, the directional features of an event are important for considering a logic model for explanation, as there are different ways of explanation between the explanans and the explanandum. Motivated by the difficulty of the Hempelian model in encompassing multiple examples from the philosophy of science, and seeking to address its limitations, Salmon proposed the following model [
47]: for cases in which Hempel’s explanatory model does not hold, the notion of statistical relevance or conditional dependency relationship between the explanandum and explanans is introduced [
48]. If this relationship is statistically relevant, the explanation is considered, and if it is not, it ceases to be. In other words, the notion of a fundamental property to the explanation is highlighted in the form of relevant statistical correlations between the explanandum and explanans.
This form of explanation has, essentially, two assumptions. The first is that explanation is the gathering of information that is statically relevant to the explanandum. The second is that the causal relation between the two elements of the explanation depends on a purely (or partially) statistical relationship. This is the case in the ‘Catalyst’ example. There is a clear statistical dependence on the success of the discovery of the molecule, which translates into the input data introduced in the algorithm. The equations leading to this discovery are solved by limiting the solutions within the analyzed chemical space, using independent variables in the appropriate algorithms, whose affinity is assessed by fitness with respect to a desired value of catalytic activity. In other words, the success of the newly generated structure depends on this probability function, which considers the previous elements of the explanandum. It should be recognized that this is a link specifically drawn for this problem, and one must be careful when applying this notion to other AI problems where the outcome is purely a statistical result.
5.2. Causal Mechanical Model
Concluding his fundamental change to scientific explanation, Salmon also sought to introduce a model based on a statistical assumption [
48,
49]. This new iteration, called the ‘Causal Mechanics of explanation’ (CM), aimed to deepen the causal and explanatory relation in scientific discovery beyond the statistical relevance of the event [
50]. In this sense, the ‘causal process’ would be a mechanical procedure, such as the movement of a ball (or particle) in space. The identification of this phenomenon would occur through the possibility of continuously transferring a mark [
48,
51]. For example, one could make a modification in the spatial structure of an object that moves in space; introducing an ink mark into a ball does not prevent it from being kicked by a football player. That is, the mark transmitted in one spatial–temporal location (on the ball), will persist in other spatial–temporal locations (throughout its movement), even if there are no further modifications to the process. Modification is neither lost nor found etiologically for the explanation of motion, although there are some objections to how a ‘mark is measured’.
Although one may consider the transmission of a mark a counterfactual condition, in this context a causal interaction superimposes a spatial–temporal intersection between the two processes. By modifying each one’s structure, they come to possess characteristics that would be absent if no interaction had occurred. Assuming the ‘Catalyst’ example, the explanation by which a viable catalyst is discovered will discriminate the process and causal interactions that lead to the final breakthrough. In addition to this etiological aspect of the explanation, the CM model should also describe the processes and interactions that make up the event, showing the causal nexus of the discovery. When the dataset is integrated into the algorithm, the generation of each molecular component with a specific feature (determined by the initial data) can be viewed as a causal interaction. Explaining molecule discovery involves determining the interactions made by the algorithm’s data, as well as the generation of the final structure (involving both interactions).
The explanation of the criterion of the ‘transmission of a mark’, can also be incorporated into the example here presented. Without prejudice to the final discovery, the mark introduction may be a given value for a descriptor which was not contemplated in the initial data pool. Assuming this occurs by the set of interactions of the initial data and all data are optimized considering holistic characteristics prior to structure generation, the introduction of a single value is not an impediment to the explanation of the event. It is assumed, however, that if there were modifications to the associated error with this discovery, this value would be negligible in contrast to the final payoff of the molecule generation process (it would require a great number of marks to achieve a statistically different outcome in structure generation).
5.3. Interventionist Model
An interventionist approach claims that causes are the properties that decisively influence their effects [
52,
53]. These are defined by discrete variables that can take different values. For example, a broad definition can be made by a binary behavior: in a chemical reaction mediated by a catalyst, its absence in the reaction medium causes it not to take place. In other words, the presence of the catalyst in the reaction is an essential condition for the chemical process to begin. Assuming that ‘0’ indicates the absence of the catalyst and ‘1’ indicates its presence, we can verify that only with its addition (number 1) does the reaction change. By manipulating the presence of this molecule, control is provided over the progression of the reaction, imposing a gatekeeping status on the effect.
To document this change in cause and effect, the assumed variables need to have two or more different states (or distinct numbers). This variation needs to be governed by an intervening criterion, as these changes to the effect need to be made equal in the values of the variable’s cause (on which the effect depends). In turn, this invalidates the notion that the presence of counterfactual dependence is not sufficient for a causal relationship between the explanatory elements. To succeed in interpreting a phenomenon with this hypothesis, it is necessary to make three assumptions: that variables take on different values depending on the cause; that there is an effect variable dependent on different causes; and that cause and effect are related in an intervening sense. That is, only the presence/absence of causation determines the occurrence of the observed effect.
What is the link between causation and chemical explanation [
54]? In all of these perspectives, we find that the cause underlying the effect has a special importance. It ‘makes the difference’, being particularly relevant for controlling and manipulating the explanation. However, the presence of such information is not a sine qua non condition for any scientific explanation. Besides the different forms it may take, there are cases cited in the philosophy of science that advocate this without prejudice to the explicative value they convey. These formal structures give meaning to the intervening aspects of explanation, validating the notion of causation of an explanation formed by its elements. In other words, the framing of the ‘Catalyst’ example in these models advocates for its logical establishment in the occurrence of these elements, and may interact as a logical event in the discovery for which it is proposed.
The example of the ‘Catalyst Problem’ specifies some cause variables (the numerical values of descriptors) and effect variables (the property and chemical structure of the designed molecule). They confirm an interventionist association in which the values of the cause variables are simultaneously related with the effect variables. In fact, this relationship is verified whenever representations are used to capture a scientific concept or a phenomenon of interest. In this case, the causal structure criteria serve the purpose of distinguishing the values that contribute (or not) to the explanation within the context in which a relationship between the two is verified. An advantage of this form is that it works through representational plasticity, i.e., which representation of variables can take other forms depending on the type of example (if there is an overlap of information between cause and effect). The most pragmatic case of this situation of the periodic table [
28]. It fulfills the purpose of conveying causal information while accommodating various representation formats in which this can be achieved by a causal structure (by containing causal information present in chemistry explanations). Nevertheless, this is not the only way in which the periodic table is explanatory.
6. Structuring a Logic of Chemistry Discovery
Integrating this example of logical induction in chemistry research in the context of scientific explanation, provided solid arguments for arguing (at least partially) a logic of discovery. In particular, the causal structure demonstrated by generating a hypothesis for solving a chemical problem using ML algorithms not only is compatible with established methods of explanation in science, but also underlines the possibility of its integration into contemporary types of research development. The example also suggests that there are overlapping concepts and methodologies of inductive origin in classic chemistry problems, and that there is a depreciation of the deductive component in hypothesis formulation, ensured by an inductive structure in innovative discoveries.
It is not surprising that there is an increasingly ‘autonomous’ perception when identifying the structure of the scientific process. While deductive patterns in hypothesis generation can be recognized, hypothesis decision-making by deterministic methodologies must also be acknowledged. If in the historical example of the ‘Salicylic Acid Poisoning’ the new chemical analysis methods lacked explanation because of poor robustness in their deduction process, obtaining hypotheses in these new chemistry challenges should be object of equal attention. While, of course, assuming that induction plays a pivotal role in describing the process of discovery. The introduced statistical certainty, which embraces the calculated risks of each iteration of the problem, makes the identification of the molecule that solves the chemical problem no longer a creative endeavor. Although not significant enough to set aside chemical deduction from other problems, it raises an important question regarding the explanation of future technological discoveries. The difficulty of making the scientific process understandable by a traditional format of science popularization, forces one to approach cases such as the AI example with particular care. Therefore, I establish the corollary of this article using the dynamics of a computational trade-off according to the logic of chemical discovery (
Figure 3).
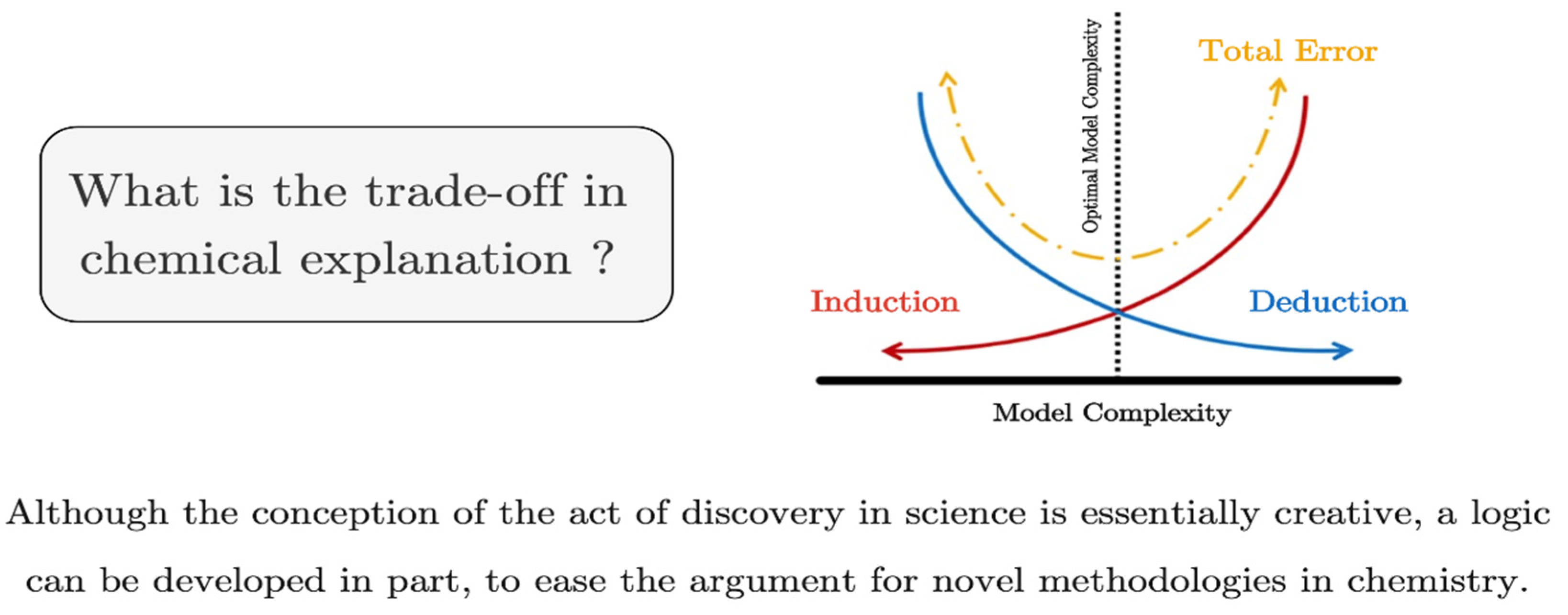
While the conceptual deconstruction of the creative side of science can be made easier with a superior algorithm that embraces this structure, its conclusions may be more difficult to understand. For example, the material speed (of hypothesis realization) and conceptual speed (of concept-theoretic generation) are substantially reduced compared to previous findings. Additionally, through the previously cited examples where speed was a factor in scientific dissemination, one can predict that a logical characterization will be a difficult reduction target. An instructive flaw in realizing how important hypothesis generation is in chemistry is not understanding how the tools for ‘making science’ are evolving. This becomes clear when we consider the schematic relation (in
Figure 3) between induction and deduction in model complexity. A successful computational model will provide results or predictions with the lowest margin of error. However, to explain its findings, one cannot simply rule out deductive or inductive arguments. It is in this trade-off of explanation tools that the explanatory power of the model’s outcome resides, ensuring a successful scientific confirmation and further public dissemination. Given the complexity of the AI-based models here presented, it is by using the compatible co-existence of deductive and inductive reason that facilitates scientific explanation, in the transition of experimentation from the real to the virtual world.
If it is true that there was a period of abundant fundamental discoveries with little practical effect on our everyday lives, this situation has now been reversed. The speed at which new hypotheses are tested and proven with new technological advances is growing swiftly. We cannot speak of a ‘great leap’ as the one made in the transition from 19th to 20th century chemistry, but we may witness an event rarely seen in modern science. This underlines the importance of hypotheses in the process of technological evolution. It seems reasonable, however, that new efforts should be made to develop models of explanation increasingly able to clarify this change. Otherwise, they will fail to keep up with methodological advances in chemistry decision-making.
7. Conclusions
Establishing an unambiguous logic in the discovery process in chemistry is not an easy task. Still, technological development allows science to advance in such a way that there is an opportunity to state examples that advocate for such logic. As explained in this article, the dissemination of AI methodologies in formulating a chemical hypothesis allows us to reach conclusions that, without them, would be difficult to achieve. More than that, it allows the creative part of this process to be progressively aided by a procedural logic, the subjectivity of which (especially in science) has its limitations. There is an urgent need for an enlightening debate about this development in scientific practice, during which we need to rethink whether it makes sense to speak of a universal way of perceiving discovery in chemistry. And it is important that this new content dissemination should be made assertively, also engaging with the public’s perception of science.
I fully accept that the present conception of the act of discovery in science is essentially creative. But a certain logic can be partially developed, although it is easier to argue particular cases (as in this example from computational chemistry). Nevertheless, a logic of discovery would be difficult to separate conceptually from a logic of pure demonstration. If discovery is something related to our point of view, this assumption loses some strength when we invoke methodologies that point to a logic of that same discovery. Its usefulness is easily measurable in computational method explanation, given the complex trade-off for a quasi-logic discovery in chemistry. This is why subsequent studies on other chemistry research ventures are needed to fully understand the scope of the logic presented herein. Recent impactful works on chemistry’s digital transition (both in academia and in industry), are good candidates for such a task. Being able to explain how ‘science is made’ is only important as long as we understand how it explains itself.



{kind=link}
{kind=link}
{kind=link}


