1. Introduction
The field of explainable AI focuses on improving the interpretability of machine learning model behavior. In recent years, exciting developments have taken place in this area, such as the emergence of the LIME [
1] and SHAP [
2] algorithms, which have become popular. These algorithms take a data point and its classification according to a trained machine learning model and provide an explanation for the classification by analyzing the importance of each feature for that specific classification. This is interesting for a researcher, but a layman using the AI system is unlikely to understand the reasoning of the machine learning model.
Instead, Van der Waa et al. [
3] created an algorithm called
local foil trees that explains why something was classified as class
A instead of a different class
B by providing a set of decision rules that need to apply for that point to be classified as class
B. This increases understanding of the AI system [
4] and can, for instance, be used to infer what can be done to change the classification. This is particularly relevant for decision support systems, for which the AI system should provide advice to the user. An example could be that the AI system advises a user to have lower blood pressure and higher body weight in order to go from high risk of a certain illness to a lower risk.
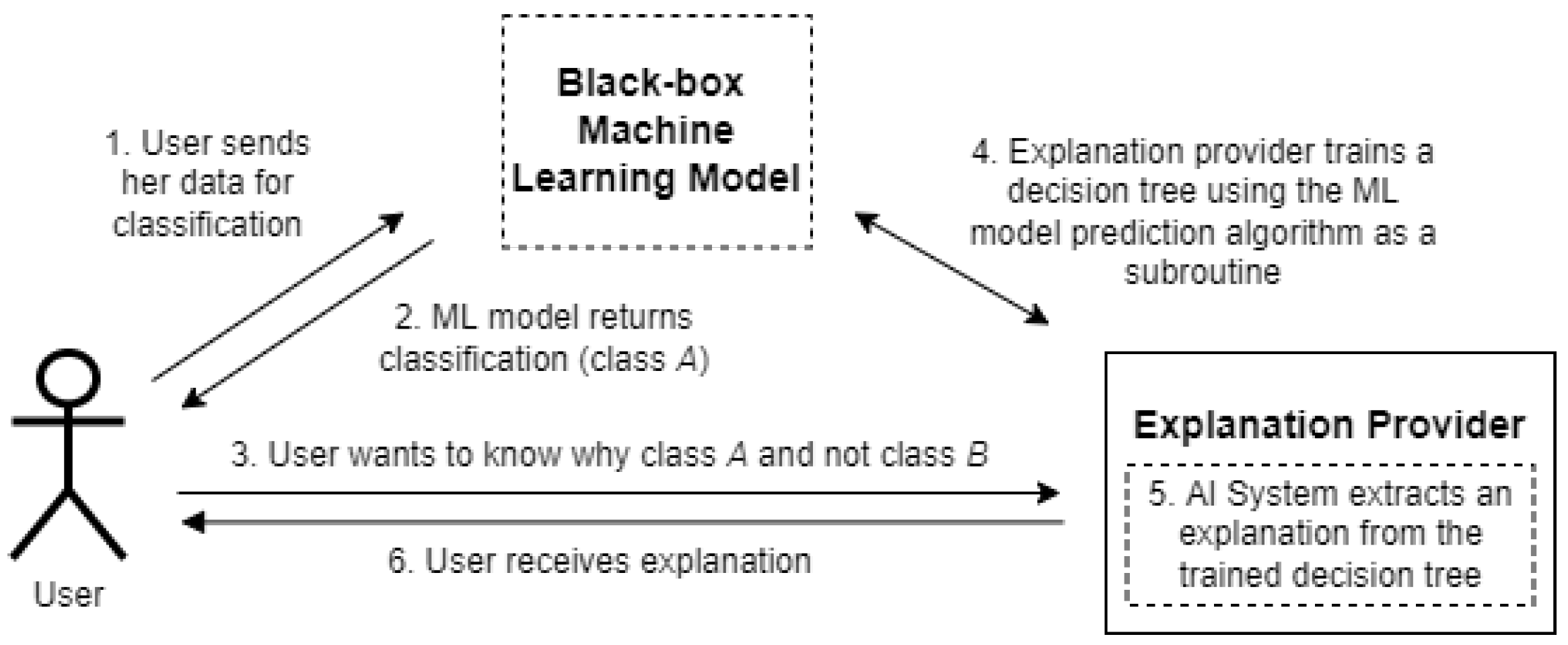
Our work focuses on creating a secure algorithm that provides the same functionality as the local foil tree algorithm in a setting where the black-box machine learning model needs to remain secret to protect the confidentiality of the machine learning model and the training data. Before we explain why this assumption is realistic, we provide a rough overview of the algorithm and interactions in the local foil tree algorithm.
As shown in
Figure 1, the user first submits her data to the machine learning model to retrieve a classification. The user then wants to know why she was classified as class
A and not as class
B. To create an explanation for this, the explanation provider trains a decision tree and uses the machine learning model as a black-box subroutine within that process. This decision tree is then used to generate an explanation.
In practice, we often see that it can be very valuable to train machine learning models on personal data: for example, in the medical domain to prevent diseases [
5], or to detect possible money laundering [
6]. Due to the sensitive nature of personal data, however, it is challenging for organizations to share and combine data. Legal frameworks such as the General Data Protection Regulation (
https://gdpr-info.eu, accessed on 20 October 2022) (GDPR) and the Health Insurance Portability and Accountability Act (
https://www.govinfo.gov/content/pkg/PLAW-104publ191/pdf/PLAW-104publ191.pdf, accessed on 20 October 2022) (HIPAA) further restrict the usage and exchange of personal data.
In order to avoid violating privacy when we want to use personal data as training data for a machine learning algorithm, it is possible to apply cryptographic techniques to securely train the machine learning model, which results in a hidden model [
5,
7,
8]. This ensures that the privacy of the personal data is preserved while it is used to train the model. In order to enable explainable AI with the hidden model, we could simply reveal the model and apply, e.g., the original local foil tree algorithm. However, there are various reasons why it could be undesirable to reveal the trained model. Firstly, if one or more organizations involved have a commercial interest in the machine learning model, the model could be used in ways that were not originally intended. Keeping the model secret then ensures control of model usage. Secondly, sensitive data are used to train the machine learning model, and recent research has shown that it is feasible to reconstruct training data from a trained model [
9,
10,
11]. The whole reason to securely train the model is to avoid leaking sensitive data, but if the machine learning model is known, it is still possible that sensitive data are leaked when such reconstruction attacks are used. In these cases, we should therefore assume that the model stays hidden to protect the confidentiality of the machine learning model and the training data.
This poses a new challenge for black-box explainable AI. In step 2 of
Figure 1, the classification
A can be revealed to the user without problems, but it is unclear how steps 4 and 5 from
Figure 1 would work when the model is hidden. There is a variety of cryptographic techniques that can be used to securely train models. When multiple organizations are involved, common techniques are secret sharing [
12] and homomorphic encryption [
13]. In this work, we address the aforementioned challenge and provide an algorithm that can produce contrastive explanations when the model is either secret-shared or homomorphically encrypted. Practically, this means that the explanation provider, as shown in
Figure 1, does not have the model locally, but that it is owned by a different party or even co-owned by multiple parties. The arrows in the figure then imply that communication needs to happen with the parties that (jointly) own the model.
An additional challenge comes from the fact that explainable AI works best when rule-based explanations, as provided through the local foil tree algorithm, are accompanied by an example-based explanation, such as a data point that is similar to the user but is classified as class
B instead of
A [
4]. The use of a (class B) data point from the sensitive training data would violate privacy in the worst way possible. As we discuss in
Section 3, we address this challenge using synthetic data.
In summary, we present a privacy-preserving solution to explain an AI system, consisting of:
A cryptographic protocol to securely train a binary decision tree when the target variable is hidden;
An algorithm to securely generate synthetic data based on numeric sensitive data;
A cryptographic protocol to extract a rule-based explanation from a hidden foil tree and construct an example data point for it.
The target audience for this work is twofold. One the one hand, our work is relevant for data scientists who want to provide explainable, data-driven insights using sensitive (decentralized) data. It gives access to new sources of data without violating privacy when explainability is essential. On the other hand, our work provides a new tool for cryptographers to improve the interpretability of securely trained machine learning models that have applications in the medical and financial domain.
In the remainder of this introduction, we discuss related work and briefly introduce secure multi-party computation. In the following sections, we explain the local foil tree algorithm [
3] and present a secure solution. Thereafter, we discuss the complexity of the proposed solution and share experimental results. Finally, we provide closing remarks in the conclusion.
1.1. Related Work
This work is an extended version of [
14]. Our solution is based on the local foil tree algorithm by Van der Waa et al. [
3], for which we design a privacy-preserving solution based on MPC. There is related work in the area of securely training decision trees, but these results are never applied to challenges in explainable AI. As we elaborate further in
Section 3, we have a special setting for which the feature values of the synthetic data to train the decision tree are not encrypted, but the classifications of these data points are encrypted. As far as we know, no training algorithm using such a setting has been proposed yet.
We mention the work of de Hoogh et al. [
15], who present a secure variant of the well-known ID3 algorithm (with discrete variables). Their training data points remain hidden, whereas in our case, that is not necessary. Furthermore, as the number of children of an ID3 decision node reflects the number of categories of the chosen feature, the decision tree is not completely hidden. The authors implement their solution using Shamir sharing with VIFF, which is a predecessor of the MPyC [
16] framework that we use.
A more recent paper on secure decision trees is by Abspoel et al. [
17], who implement C4.5 and CART in the MP-SPDZ framework. We also consider CART since this leads to a binary tree, which does not reveal information on (the number of categories of) the feature chosen in a decision node. Abspoel et al. use both discrete and continuous variables, similar to our settings. However, since Abspoel et al. work with encrypted feature values, they need a lot of secure comparisons to determine the splitting thresholds.
In a similar approach, Adams et al. [
18] scale the continuous features to a small domain to avoid the costly secure comparisons at the expense of a potential drop in accuracy.
Only one article was found on privacy-preserving explainable AI. The work of [
19] presents a new class of machine learning models that are interpretable and privacy-friendly with respect to the training data. Our work does not introduce new models but provides an algorithm to improve the interpretability of existing complex models that have been securely trained on sensitive data.
1.2. Secure Multi-Party Computation
We use secure multi-party computation (MPC) to protect secret data such as the ML classification model and its training data. MPC is a cryptographic tool to extract information from the joint data of multiple parties without needing to share their private data with other parties. Introduced by Yao in 1982 [
20], the field has developed quickly, and various platforms are available now for arbitrary secure computations on secret data, such as addition, subtraction, multiplication and comparison. We use the MPyC platform [
16] that uses Shamir secret sharing in the semi-honest model, where all parties are curious but are assumed to follow the rules of the protocol.
Like many MPC platforms, MPyC follows the share–compute–reveal paradigm. Each party first uploads its inputs by generating non-revealing shares for the other parties. When the inputs have been uploaded as secrets, the parties can then perform joint computations without learning the inputs. Finally, the output that is eventually computed is revealed to the entitled parties.
1.3. Notation
Due to the inherent complexity of both explainable AI and cryptographic protocols, we require many symbols in our presentation. These symbols are all introduced in the body of this paper; however, for the reader’s convenience, we also summarize the most important symbols in
Table 1.
Sets are displayed in curly font, e.g., , and vectors in bold font, e.g., . The vector represents the j-th elementary vector of appropriate, context-dependent length. The notation is used to denote the Boolean result of the comparison . Any symbol between square brackets represents a secret-shared version of that symbol. Finally, a reference to line y of Protocol x is formulated as line x.y.
2. Explainable AI with Local Foil Trees
In this section, we present the local foil tree method of Van der Waa et al. [
3] and discuss the challenges that arise when the black-box classifier does not yield access to its training data and provides classifications in secret-shared (or encrypted) form to the explanation provider.
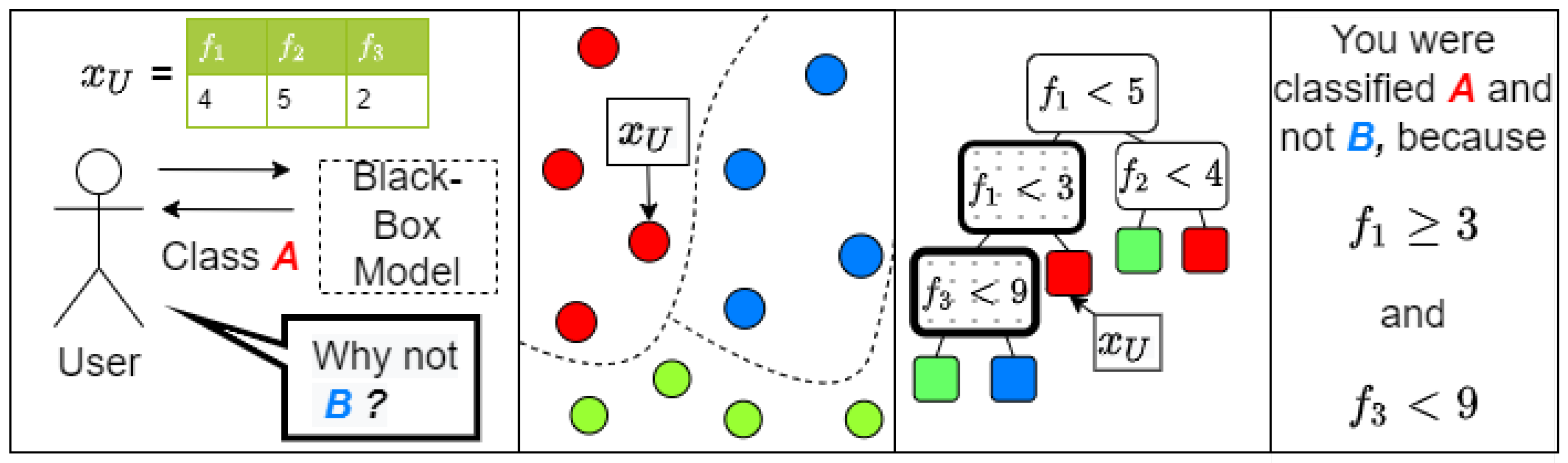
We assume that we have black-box access to a classification model. If a user-supplied data point
is classified as some class
A, our goal is to construct an explanation why
was not classified as a different class
B. The explanation will contain decision rules in the form that a certain feature of
is less (or greater) than a certain threshold value. An overview of the different steps is illustrated in
Figure 2 and formalized in Protocol 1. Note that we deviate from Van der Waa et al. by providing an example data point in the final step. In each step of the protocol, we also refer to the section of our work where we present secure protocols for that step.
| Protocol 1 Foil-tree based explanation | |
| Input: Data point that is classified as class A; foil class B | |
| Output: Explanation why was not classified as the foil class | |
| 1: Obtain a classification for the user | ▹ cf. Section 3.1 |
| 2: Prepare the synthetic data points for the foil tree | ▹ cf. Section 3.2 |
| 3: Classify all synthetic data points through the black-box | ▹ cf. Section 3.3 |
| 4: Train a decision tree | ▹ cf. Section 3.4 |
| 5: Locate fact leaf (leaf node of ) | ▹ cf. Section 3.5 |
| 6: Determine the foil leaf (leaf node of class B closest to fact leaf) | ▹ cf. Section 3.6 |
| 7: Determine the decision node at which the root-leaf paths of the fact and foil leaf split ▹ cf. Section 3.7 |
| 8: Construct the explanation (and provide example data point). | ▹ cf. Section 3.7 |
Both limitations that the model owner introduced help to better preserve the privacy of the training data and to secure the model itself, but they also hinder us in generating an explanation. In particular, if we cannot access training data, we need to generate synthetic data that can be used to train a decision tree. Training a decision tree in itself is complicated by the fact that the classifications are hidden, which most notably implies that during the recursive procedure, we need to securely keep track of the synthetic data samples that end up in each branch of the tree.
Information can also be revealed through the structure of the decision tree; in particular, it may disclose the splitting feature. For example, if a certain categorical feature can assume six values and a decision node splits into six new nodes, it is likely that this node represents that feature. For this reason, we do not use the commonly used ID3 or its successor C4.5 for training the decision tree. We instead generate a binary decision tree with the CART (Classification and Regression Trees) algorithm [
21]. The CART algorithm greedily picks the best decision rule for a node. In case of classification trees, this materializes as the rule with the lowest Gini index. The Gini index measures the impurity, i.e., the probability of incorrectly classifying an observation, so the lowest Gini index results in the best class purity.
The result of the training procedure is a decision tree whose decision rules and leaf classification are secret-shared. As a consequence we need a secure protocol for determining the position of a foil data point and all nodes that are relevant for the explanation. With help from the model owner(s), among all secret values in the process, only these nodes and the user classification are revealed.
Compared to secure protocols for training decision trees on hidden data points with hidden classification, the fact that we use synthetic data also has some benefits. First, since the (synthetic) data points are known, we can still access their features directly, improving the efficiency of the protocol. Second, since we already trained the decision tree on synthetic data, we can also supplement our explanation with a synthetic data point, and thereby increase user acceptance [
4].
Although our goal is only to provide a privacy-preserving implementation of the local foil tree method, we also mention an evaluation of the method on three benchmark classification tasks [
3]. Van der Waa et al. tested the local foil tree method on the Iris dataset, as depicted in
Table 2. The column “Mean length” denotes the average length of the explanation in terms of decision nodes, with the total number of features as an upper bound. The accuracy is the
score of the foil-tree for its binary classification task on the test set compared to the true labels, and the fidelity score is the
of the foil-tree on the test set compared to the model output. For more explanations on this evaluation, we refer to [
3].
3. Secure Solution
In this section, we describe the secure version of the local foil tree algorithm, which reveals negligible information about the sensitive training data and black-box model. In the rest of this work, we refer to training data when we talk about the data used to train the black-box machine learning model and to synthetic data when we refer to the synthetically generated data that we use to train the foil tree.
The secure protocol generates N synthetic data points , with P features that each can be categorical or continuous. To increase the efficiency of the secure solution, we make use of one-hot or integer encoding to represent categorical values. We assume that the class of data point is represented by a secret binary indicator vector such that if data point is classified as class k by the black-box, and otherwise.
During the decision training, we maintain an indicator vector of length N such that if and only if the i-th synthetic data point is still present in this branch.
3.1. Classify User Data
We assume that the user is allowed to learn the black-box classification of her own data point , so this step is trivial. Without loss of generality, we assume that the user received classification A.
3.2. Generating Synthetic Data
Van der Waa et al. [
3] mention that synthetic data could be used to train the local foil trees, and they suggest using normal distributions. In this section, we apply that suggestion and provide a concrete algorithm for generating a local dataset around the data point for which an explanation is being generated.
We first take a step back and list what requirements the synthetic data should adhere to:
The synthetic data should reveal negligible information about the features of the training data.
The synthetic data should be local, in the sense that all data points are close to , the data point to be explained.
The synthetic data should be realistic, such that they can be used in an explanation and still make sense in that context.
State-of-the-art synthetic data generation algorithms such as GAN [
22] and SMOTE [
23] can generate very realistic data, but they need more than one data point to work, so we cannot apply them to the single data point to be explained. One could devise a secure algorithm for GAN or SMOTE and securely apply it to the sensitive data, but this would affect the efficiency of our solution. In this article, we pursue the simpler approach that was suggested by Van der Waa et al.
Ideally, one would securely calculate some statistics of the sensitive training data for the black-box model and reveal these statistics. Based on these statistics, one could generate a synthetic dataset by sampling from an appropriate distribution. Our implementation securely computes the mean and variance of every feature in the training data and samples synthetic data points from a truncated normal distribution. The reason for truncating is two-fold: first, it allows us to sample close to the user’s data point
, and second, features may not assume values on the entire real line. Using a truncated normal distribution allows us to generate slightly more realistic data that is similar to
. The details are presented in Protocol 2.
| Protocol 2 Synthetic data generation. |
Input: Encrypted black-box training set , integer N, target data point Output: Synthetic dataset with cardinality N - 1:
fordo ▹ Compute mean and variance of feature p. - 2:
; - 3:
end for - 4:
Reveal and - 5:
- 6:
fordo - 7:
for do - 8:
repeat Draw from - 9:
until - 10:
end for - 11:
- 12:
end for - 13:
Return
|
To generate more realistic data, one could also incorporate correlation between features, or go even further and sample from distributions that better represent the training data than a normal distribution.
In our experiments, we noticed that an interval of generally yielded a synthetic dataset that was still close to but also provided a variety of classifications for the data points. A smaller interval (for example of size ) often resulted in a dataset for which the distribution of classifications was quite unbalanced. The foil class might then not be present in the foil tree, breaking the algorithm. Larger intervals would result in data points that are not local anymore and would therefore yield a less accurate decision tree.
3.3. Classify Synthetic Data
All synthetic training data points can now be classified securely by the model owner(s). This results in secret-shared classification vectors . The secure computation depends on the model, and it is beyond our scope.
3.4. Training a Decision Tree
In this section, we explain the secure CART algorithm that we use to train a secure decision tree, which is formalized in Protocol 3. The inputs to this algorithm are:
- (1)
: a set of synthetic data points.
- (2)
: a set of splits to use in the algorithm. Each split is characterized by a pair that indicates that the feature with index is at least .
- (3)
: the convergence fraction used in the stopping criterion.
- (4)
: a secret binary availability vector of size N. Here, equals 1 if the i-th synthetic data point is available and 0 otherwise.
| Protocol 3 cart—Secure CART training of a binary decision tree. | |
| Input: Training set , split set , convergence parameter , secret-shared binary availability vector |
| Output: Decision tree | |
| 1: | |
| 2: | |
| 3: while is not fully constructed do | |
| 4: for do | |
| 5: | ▹ nr available data points per class |
| 6: end for | |
| 7: | ▹ nr available data points |
| 8: | |
| 9: | ▹ indicates most common class |
| 10: if or then | ▹ branch fully constructed |
| 11: Extend with leaf node with class indicator | |
| 12: else | ▹ branch splits |
| 13: for do | |
| 14: | |
| 15: end for | |
| 16: | |
| 17: | ▹ indicates best split |
| 18: | ▹ feature of optimal split |
| 19: | ▹ threshold of optimal split |
| 20: decision node that corresponds with split | |
| 21: | |
| 22: | |
| 23: Extend b to the left with result of cart( | |
| 24: Extend b to the right with the result of cart( | |
| 25: Extend with b | |
| 26: end if | |
| 27: end while | |
| 28: Return | |
We start with an empty tree and all training data points marked as available. First, the stopping criterion uses the number of elements of the most common class (line 3.8) and the total number of elements in the availability vector (line 3.7). The stopping criterion from line 3.10 is securely computed by and consequently revealed.
If the stopping condition is met, i.e., equal to one, a leaf node with the secret-shared indicator vector of the most common class is generated. In order to facilitate the efficient extraction of a foil data point as mentioned at the start of
Section 3, we also store the availability vector
in this leaf node. How this indicator vector is used to securely generate a foil data point is discussed in
Section 3.8.
If the stopping criterion is not met, a decision node is created by computing the best split (lines 3.13–19) using the adjusted Gini indices of each split in . We elaborate on computing the adjusted Gini index (lines 3.13–15) later on in this section.
After determining the optimal split, an availability vector is constructed for each child based on this split in lines 3.21–22. For the left child, this is done using the availability vector , the indicator vector indicating the feature of the best split and the threshold of the best split, as explained in Protocol 4. The resulting availability vector has a in index i if . The entry-wise difference with then gives the availability vector for the right child. The CART algorithm is then called recursively with the new availability vectors to generate the children of the decision node.
In Protocol 3, we use two yet-unexplained subroutines, namely
max and
find. The
max subroutine securely computes the maximum value in a list using secure comparisons. Thereafter, the
find subroutine finds the location of the maximum computed by
max in the list that was input to
max, which is returned as a secret-shared indicator vector indicating this location. The functions
max and
find are already implemented in MPyC. However, since we always use the two in junction, we implemented a slight variation that is presented in
Appendix A.
| Protocol 4 left_child_availability—Indicate the data points that flow into the left child. |
Input: Synthetic dataset , availability vector for the current node, feature indicator vector , threshold Output: Availability vector for the left child - 1:
fordo - 2:
- 3:
- 4:
- 5:
end for - 6:
Return
|
3.4.1. Compute the Gini Index for Each Possible Split
We aim to find the split
with the highest class purity, which is equivalent to the lowest Gini index
. As such, we first need to compute the Gini index for all splits. The Gini index of a split is the weighted sum of the Gini value of the two sets that are induced by the split,
Here,
n is again the number of available data points in the current node,
is the number of available data points in the left set that is induced by split
, and
is the Gini value of the left set that is induced by split
,
where
denotes the number of available data points in the left node with class
k. The symbols
,
and
are defined analogously for the right set. For notation convenience, justified as the upcoming derivations concern a fixed index
s, we drop the superscripts
s from the symbol
n.
We now derive a more convenient expression for the Gini index. Substituting expression (
2) into (
1) and rewriting yields
Now, since
is independent of the split, minimizing the Gini index over all possible splits is equivalent to
maximizing the
adjusted Gini index,
We represent
as a rational number to avoid an expensive secure (integer) division. Both the numerator
and the denominator
are non-zero if the split
separates the available data points, e.g., the split induces at least one available data point in each set. Otherwise, either
or
, and
, such that
is not properly defined. In line 3.16, one could naively let
max evaluate
by computing
. However, this may yield an undesired outcome if one of the denominators equals zero.
Appendix B presents two possible modifications that handle this situation.
Protocol 5 shows how the adjusted Gini index can be computed securely. Observe that
and
were already computed for the CART stopping criterion, so they come for free. The computation
can be implemented efficiently as a secure inner product. The computations of
n,
,
and
do not require any additional communication. Because the total number of possible spits
is much larger than the number
N of data points, it makes sense to precompute
for each
i and
k such that the computation of
for each split requires no additional communication.
| Protocol 5 adjusted_gini—Compute the adjusted Gini index of a split. |
Input: Synthetic dataset , vector of available transactions , split Output: Encrypted numerator and denominator of adjusted Gini index - 1:
fori = 1, …, N do - 2:
▹ 1 if data point meets split criterion, else 0 - 3:
end for - 4:
, , - 5:
, , - 6:
Return and
|
3.4.2. Convergence
In theory, it is possible that at some point during training, the CART algorithm has not yet met the stopping criterion and has no splits available that actually separate the set of available data points. In this case, the algorithm keeps adding useless decision nodes and does not make any actual progress. To prevent ending up in this situation, we can detect it by revealing and can take appropriate action. Additionally, a maximum number of nodes or a maximum depth can be set.
3.5. Locate the Fact Leaf
Once the decision tree has been constructed, we need to find the leaf that contains the fact . As the fact leaf is revealed, the path from the root to the fact leaf is revealed as well. Therefore, we can traverse the decision tree from the root downwards and reveal each node decision. The decision for data point at a given node can be computed similarly to Protocol 4. First, the feature value that is relevant for the current decision node is determined through . Second, the secure comparison is performed and revealed. The result directly indicates the next decision node that needs to be evaluated. This process is repeated until a leaf is encountered: the fact leaf.
3.6. Locate the Foil Leaf
Since we know the fact leaf and the structure of the decision tree, we can create an ordered list of all tree leaves, starting with the closest leaf and ending with the farthest leaf. We can traverse this list and find the first leaf that is classified as class
B without revealing the classes but only whether they equal
B, i.e., by revealing the Boolean
for every leaf. This does not require any extra computations, as these vectors have already been computed and stored during the training algorithm. We use the number of steps between nodes within the decision tree as our distance metric, but as Van der Waa et al. [
3] note, there are more advanced options.
3.7. Construct the Explanation
Once the fact leaf and the foil leaf have been determined, the lowest common node can be found without any secure computations since the structure of the decision tree is known. We traverse the decision tree from this lowest common node to the foil leaf and reveal the feature and threshold for each of the nodes on that path (the nodes with a thick border and dotted background in
Figure 2). For each rule, we determine whether it applies to
. For instance, if a rule says that
and indeed
satisfies this rule, then it is not relevant for the explanation.
After this filter is applied, we combine the remaining rules where applicable. For example, if one rule requires and another rule requires , we take the strictest rule, which in this case is .
3.8. Retrieving a Foil Data Point
Finally, we wish to complement the explanation by presenting the user with a synthetic data point that is similar to the user’s data point but that is (correctly) classified as a foil by the foil tree. We refer to such a data point as a foil data point. Note that it is possible for samples in a foil leaf to have a classification different from B, so care needs to be taken in determining the foil sample.
As mentioned in
Section 3.4, we assume that for each leaf node we saved the secret-shared availability vector
that indicates which data points are present in the leaf node. In
Section 3.6, we determined the foil leaf, so we can retrieve the corresponding binary availability vector
. Recall that the
i-th entry in this vector equals 1 if data point
is present in the foil leaf and 0 otherwise. All foil data points
therefore satisfy
and are classified as
B by the foil tree.
A protocol for retrieving a foil data point is presented in Protocol 6. It conceptually works as follows. First, it constructs a indicator vector for the position of the foil data point. This vector is constructed in an element-wise fashion with a helper variable
that indicates whether we already found a foil data point earlier. Second, the secure indicator vector is used to construct the foil data point
, which is then revealed to the user.
| Protocol 6 retrieve_foil—Retrieve foil data point. |
Input: Availability vector of the foil leaf, class index Output: Foil data point - 1:
▹ flips to when a foil data point is found - 2:
fordo - 3:
- 4:
- 5:
end for - 6:
fordo - 7:
- 8:
end for - 9:
Reveal to the user
|
It is important that the foil data point is only revealed to the user and not to the computing parties since the foil data point can leak information on the classifications of the synthetic data points according to the secret-shared model, which are the values we are trying to protect. In practice, this means that all computing parties send their shares of the feature values in vector to the user, who can then combine them to obtain the revealed values.
4. Security
We use the MPyC platform [
16], which is known to be passively secure. The computing parties jointly form the Explanation Provider (see
Figure 1) that securely computes an explanation, which is revealed to the user, who is typically not one of the computing parties. The machine learning model is out of scope; we simply assume secret classifications of synthetic data points are available as secret-sharings of the Explanation Provider without any party learning the classifications.
During the protocol, the Explanation Provider learns data point of the user, its class A, and the foil class B, together with the average and variance of each feature used to generate synthetic dataset . Furthermore, the (binary) structure of the decision tree, including the fact leaf, foil leaf, and therefore also the lowest common node, are revealed. Other than this, no training data or model information is known by the Explanation Provider.
The explanation—consisting of the feature index and threshold for each node on the path from the lowest common node to the fact or foil leaf—and the foil data point s are revealed only to the user.
5. Complexity
For generation of the binary decision tree, the number of all possible splits is large and determines the runtime. For each node, we need to compute the Gini index for all possibilities and identify the maximum. If we can compute secure inner products at the cost of one secure multiplication, as in MPyC, the node complexity is linear in and K and more or less equal to the costs of secure comparisons per node. A secure comparison is roughly linear in the number of input bits, which in our case is .
However, we can always precompute for all and , such that the node complexity is linear in N and K. The secure comparisons per node cannot be avoided though.
The number of nodes of the decision tree varies between 1 (no split) and (full binary tree). Therefore, the total computational (and communication) complexity is . Although the aim is to obtain a tree of depth , the depth d of the tree will vary between 1 (no split) and (only extremely unbalanced splits). At each tree level, we can find the best splits in parallel, such that the number of communication rounds is limited to (assuming a constant round secure comparison).
Given the decision tree, completing the explanation is less complex and costs at most d secure comparisons.
6. Experiments
We implemented our secure foil tree algorithm in the MPyC framework [
16], which was also used for most earlier work on privacy-preserving machine learning [
5,
8,
15,
24]. This framework functions as a compiler to easily implement protocols that use Shamir secret sharing. It has efficient protocols for scalar–vector multiplications and inner products. In our experiments, we ran MPyC with three parties and used secure fixed point numbers with a 64-bit integer part and 32-bit fractional part. For the secret-shared black-box model, we secret-shared a neural network with three hidden layers of size 10 each. We used the iris dataset [
25] as our training data for the neural network (using integer encoding for the target variable) and generated three synthetic datasets based on the iris dataset of sizes 50, 100 and 150, respectively.
Table 3 shows the results of our performance tests. We report the timing in seconds of our secure foil tree training algorithm under ‘Tree Training’, for explanation construction under ‘Explanation’, and for extraction of the data point under ‘Data Point’. For each of these, we report the average, minimum and maximum times that we observed. The column ‘Accuracy’ denotes the accuracy of the foil tree with respect to the neural network. This accuracy is computed as the number of samples from the synthetic dataset for which the classifications according to the neural network and the foil tree are equal, divided by the total number of samples (
N). We do not provide any performance results on the training algorithm or classification algorithm of the secret-shared black-box model (in this case, the neural network), as the performance of the model highly depends on which model is used, and our solution is model-agnostic.
We see that the accuracy does not necessarily increase when we use more samples. A synthetic dataset size of 50 seems to suffice for the Iris dataset and shows performance numbers of less than half a minute for the entire algorithm.






{kind=link}
{kind=link}