
Scaling Ethereum 2.0s Cross-Shard Transactions with Refined Data Structures



Abstract
:1. Introduction
- We propose a novel data structure for the Merkle tree used for address management in Ethereum, which we propose to combine with the Merkle tree used in rollups and the shard management lists to create a combined tree that allows for a reduction in field sizes.
- −
- We reduce the size of cross-shard TXs in rollups by up to 98% and 75% when compared to the conventional TX and state-of-the-art rollups.
- −
- We do this with minimal alterations to the rollup protocols as proposed for Ethereum 2.0 ensuring negligible system penalties.
- This reduction in TX size, for TX sent using our compression proposals for rollups, allows blocks to accommodate up to 98% and 65% more cross-shard TXs than when compared to the number of conventional TXs or state-of-the-art rollup TXs that can be sent per block [4].
2. Related Work
3. Preliminaries
3.1. Ethereum 1.0
Data Structure of Conventional TX
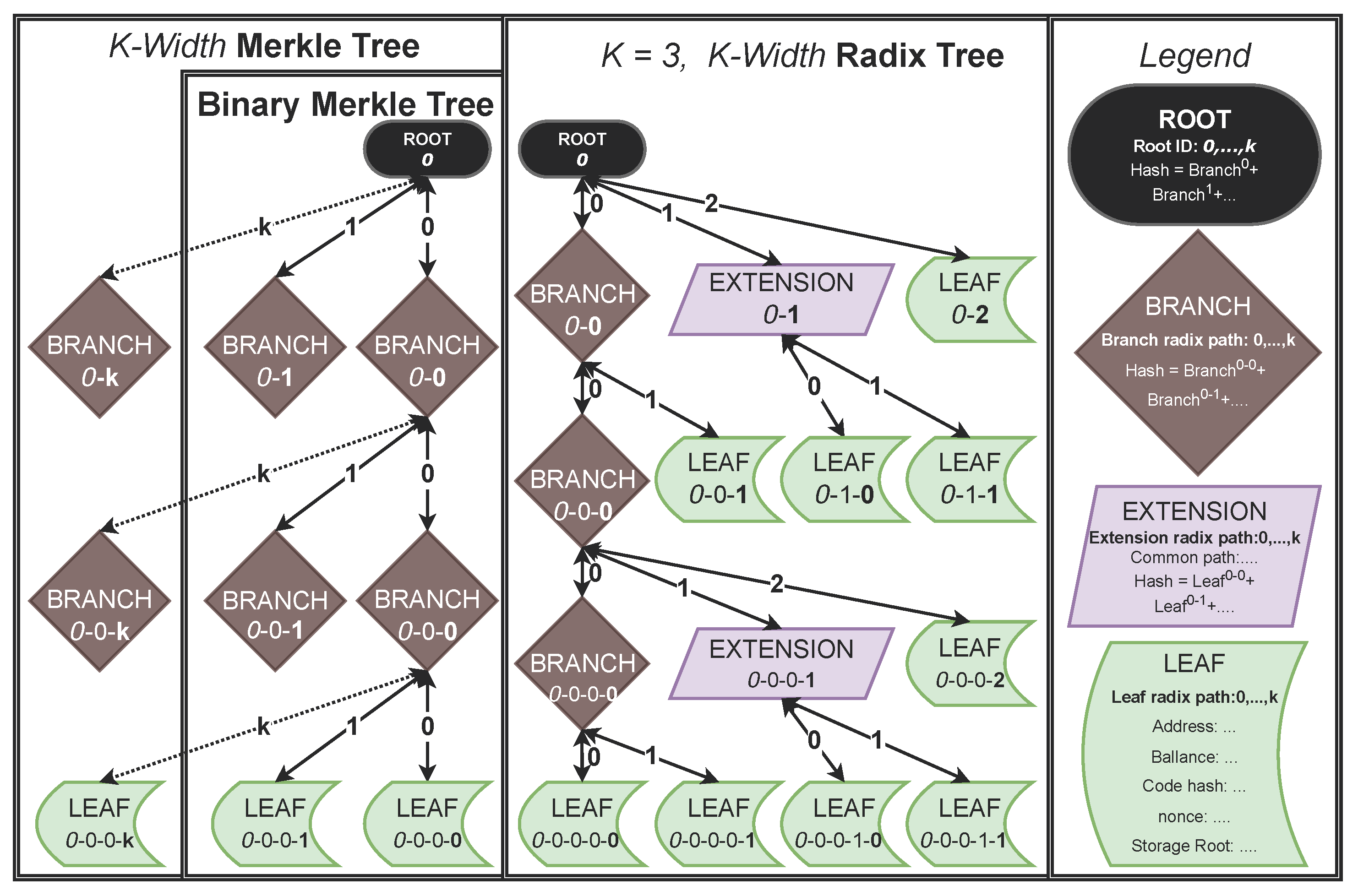
3.2. Types of Merkle Trees
3.2.1. Merkle Trees
3.2.2. Radix Trees
3.2.3. k-Merkle and Radix Trees
3.3. Ethereum 2.0
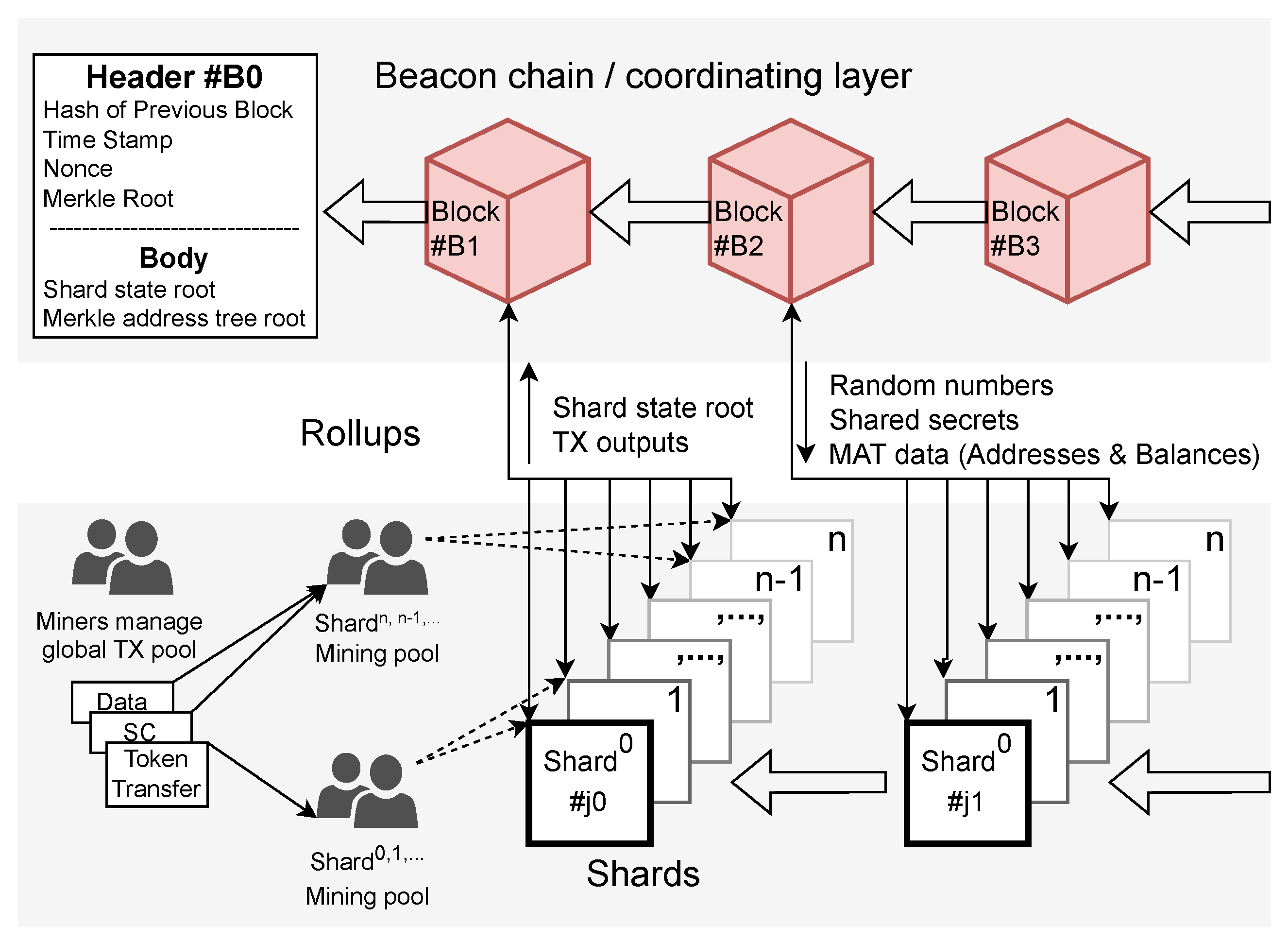
3.3.1. Sharding
3.3.2. Rollups
4. Problem Statement
5. Proposed Method
- (i)
- Address field compression (AC), we use our proposed Merkle tree structure to create commonality in the radix path used as an ID allowing the common path to be removed from the TX body;
- (ii)
- Address and gas field compression (AGC), we propose changes to when and how gas is validated to remove it from the TX body;
- (iii)
- Address, gas, and value field compression (AGVC), we propose changes to the rollup protocol, to instead of recording TXs, record the value change per user;
- (iv)
- Gas and value field compression without address field (GVCRO), we propose further changes to enable the elimination of the address field.
5.1. Address Field Compression
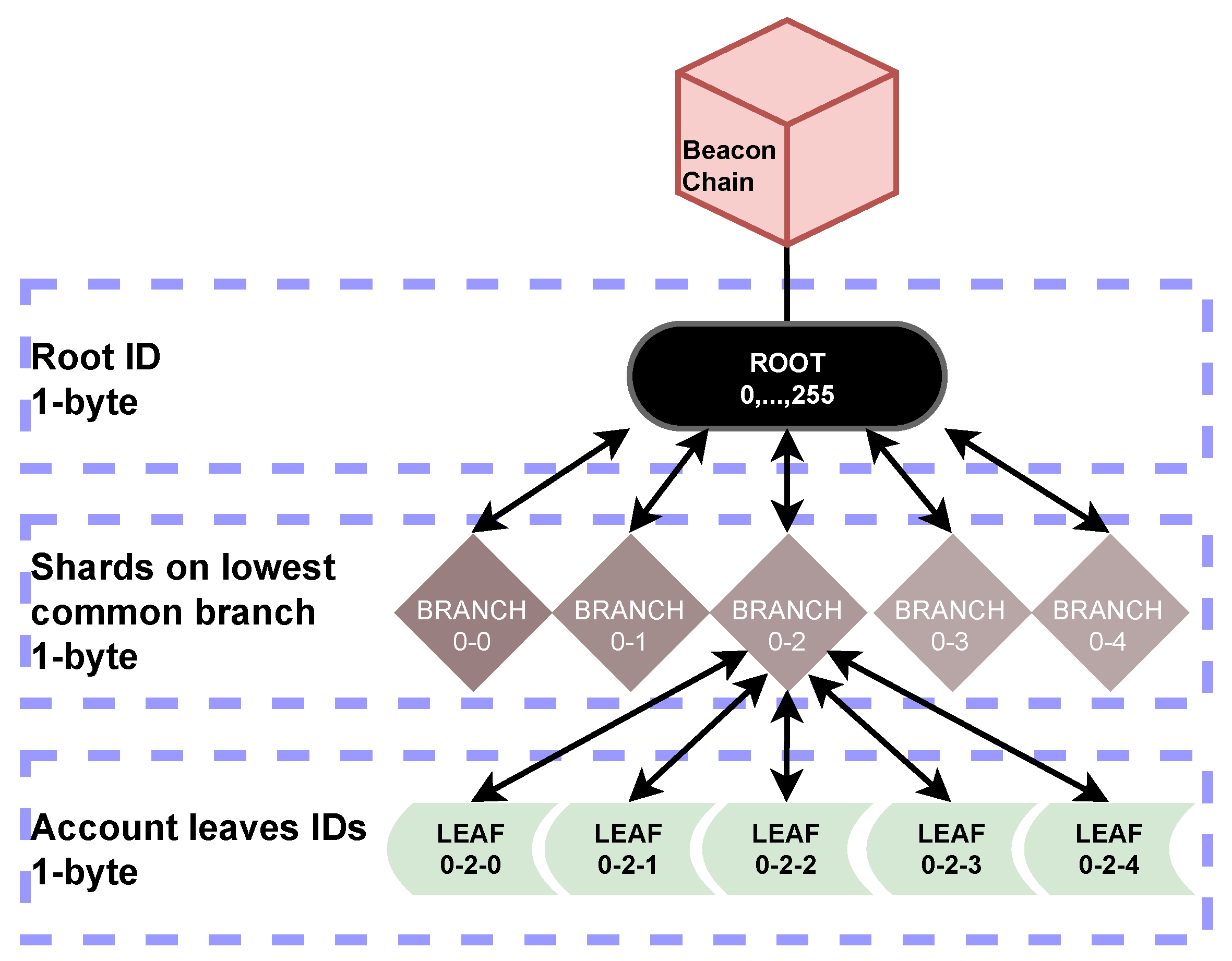
5.1.1. Merkle Tree Structure
- (i)
- Root ID, in the format, mod 256, is used to identify the k-Merkle tree across recent epochs, allowing the k-Merkle tree to be dynamically updated (Merkle trees outside this range can be identified by prefacing the ID with the coordinating layers’ block number to which the Merkle tree to be referenced has been committed.),
- (ii)
- Shard’s branch ID, which is the lowest branch node common to all of the c wide sharding committee, and
- (iii)
- Account IDs for the n accounts in the leaves.
5.1.2. Compressed ID Structure
5.1.3. Address Compression Procedure
| Algorithm 1 Address compression. |
Input: , valid TXs that have arrived at shardj, & Global Merkle address tree state Output: Shard and account IDs with opcodes for senders(s) and recipient(s)
|
5.2. Gas Compression
Gas Compression Procedure
5.3. Address and Gas Compression with Value Batching
| Algorithm 2 Gas compression. |
Input: The output of Algorithm 1, Valid TXs that have arrived at shard and have had their shard and account IDs generated. Output: Rollups with only one gas field, denoted in gas per byte, in the header.
|
Value Batching Procedure
| Algorithm 3 Value batching. |
| Input: , transactions arriving at a shards’ rollup SC and, depending on if the keypair or ordered list output is desired. Output: V, an ordered list of the total value change per user or U:V, User: Total Value change key pairs.
|
5.4. Omission of the Radix IDs
5.4.1. GVCRO’s Assumptions
5.4.2. Potential Use Cases for GVCRO
6. Performance Evaluation
6.1. Parameters for Performance Evaluation
6.1.1. Evaluation Categories for Performance Evaluation
6.1.2. System Parameters for Performance Evaluation
6.1.3. Evaluation Parameters for Performance Evaluation
6.1.4. Evaluation Process Used for Performance Evaluation
6.1.5. Message Parameters Used for Performance Evaluation
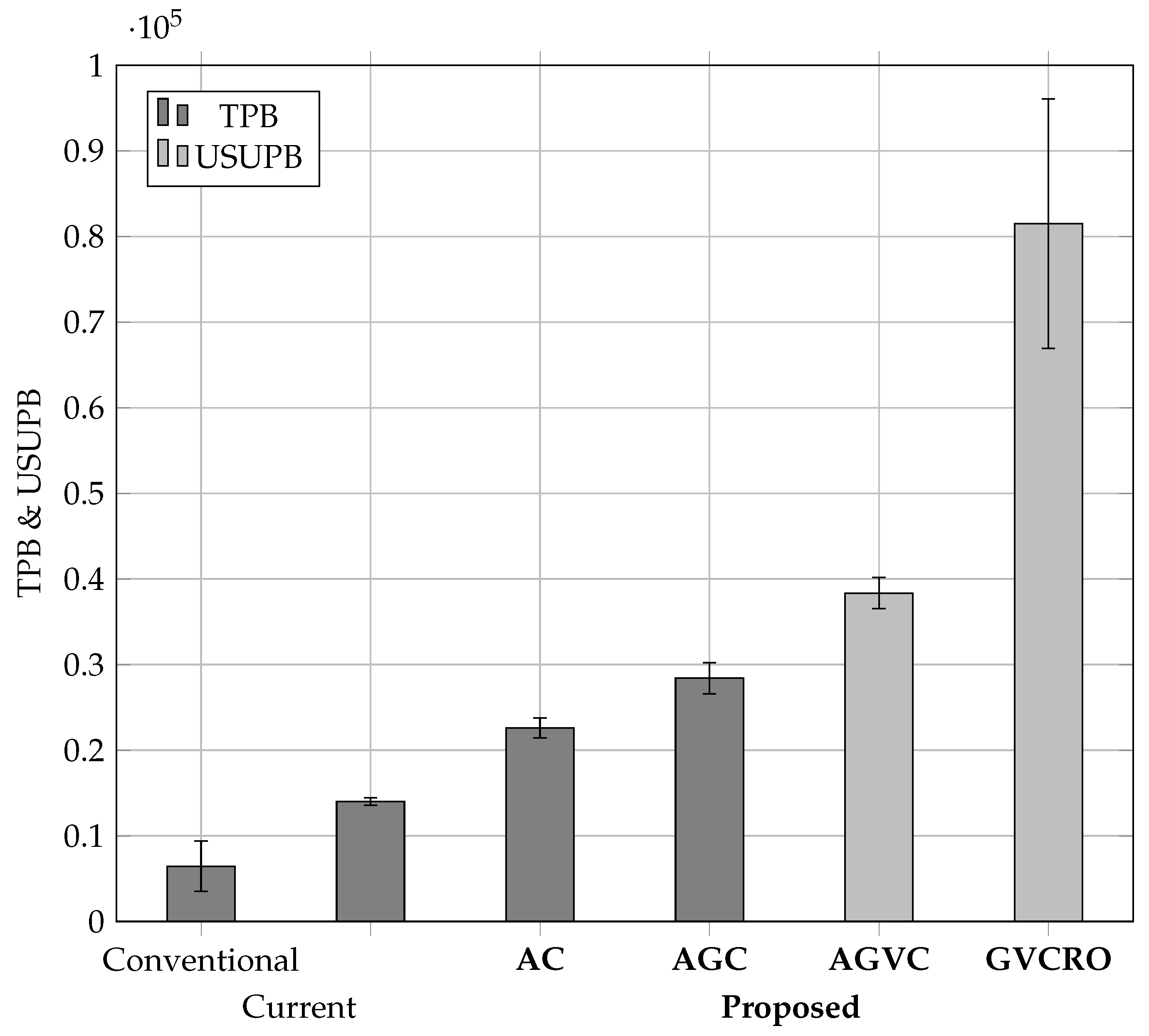
6.2. TPB
6.2.1. Evaluation Parameters
6.2.2. Conventional TX
6.2.3. State-of-the-Art Rollups
6.2.4. AC and AGC
6.3. USUPB
6.3.1. Evaluation Parameters
6.3.2. Assumptions
6.3.3. Evaluation of AGVC and GVCRO
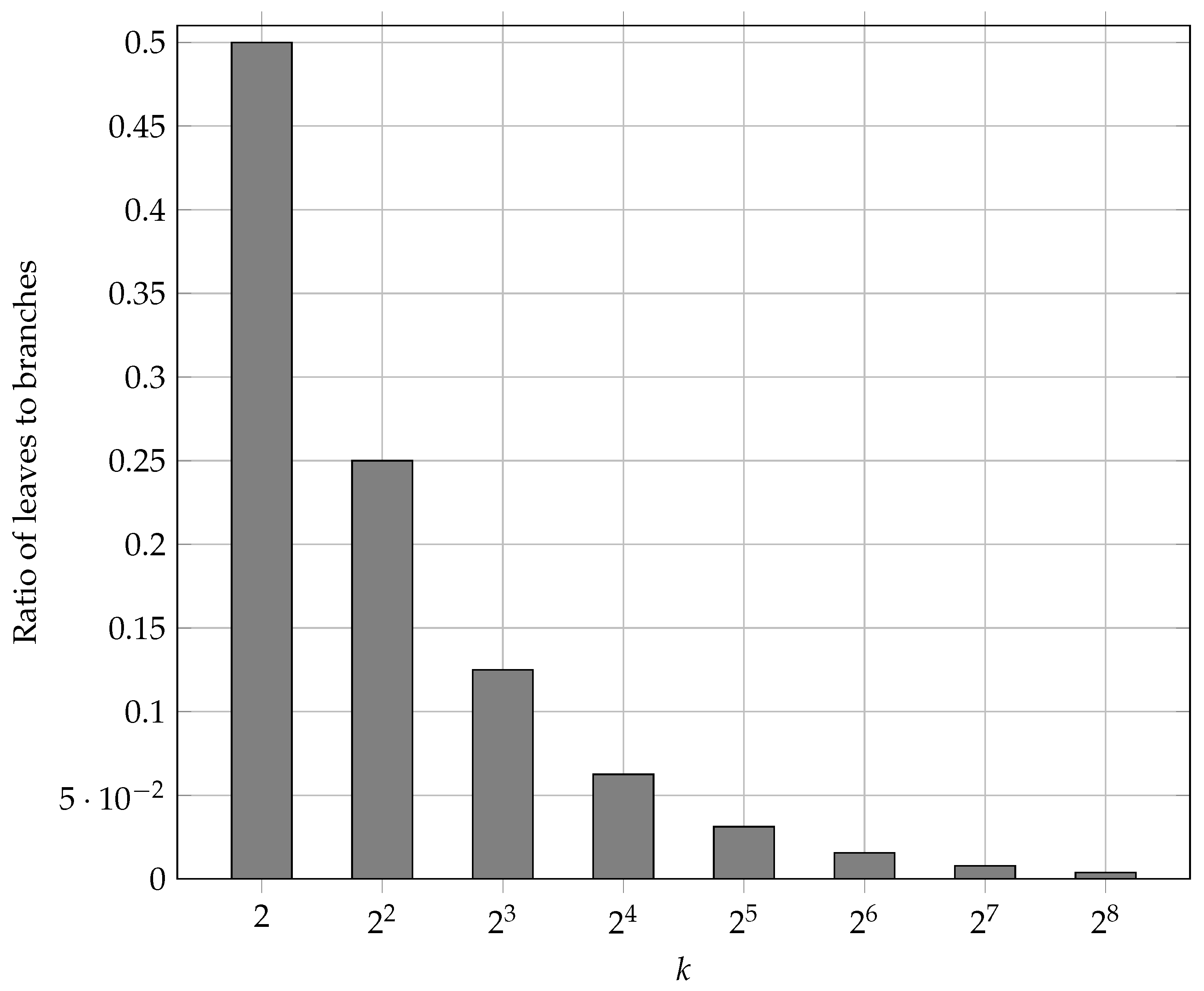
6.4. Impact of k-Ary Trees k Value on Performance
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| TPS | Transactions per Second |
| TPB | Transactions per Block |
| USUPB | User States Updated per Block |
| TX | Transactions |
| AC | Address Compression |
| AGC | Address and Gas Compression |
| AGVC | Address, Gas, and Value Compression |
| GVCRO | Gas and Value Compression no Radix ID |
| EMS | Energy Management System (for an electrical grid) |
| KZG | Kate, Zaverucha, and Goldberg’s constant-sized polynomial commitments |
| PoW | Proof of Work |
| PoS | Proof of Share |
| PoA | Proof of Authority |
| SC | Smart Contract |
| EVM | Ethereum Virtual Machine |
References
- Chauhan, A.; Malviya, O.; Verma, M.; Singh Mor, T. Blockchain and Scalability. In Proceedings of the IEEE International Conference on Software Quality, Reliability and Security Companion (QRS-C), Lisbon, Portugal, 16–20 July 2018; pp. 122–128. [Google Scholar]
- Hafid, A.; Hafid, A.S.; Samih, M. Scaling blockchains: A comprehensive survey. IEEE Access 2020, 8, 125244–125262. [Google Scholar] [CrossRef]
- Zamani, M.; Movahedi, M.; Raykova, M. Rapidchain: Scaling blockchain via full sharding. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security (CCS), Toronto, ON, Canada, 15–19 October 2018; pp. 931–948. [Google Scholar]
- Buterin, V. An Incomplete Guide to Rollups. 2021. Available online: https://vitalik.ca/general/2021/01/05/rollup.html (accessed on 10 September 2022).
- Sguanci, C.; Spatafora, R.; Vergani, A.M. Layer 2 Blockchain Scaling: A Survey. arXiv 2021, arXiv:2107.10881. [Google Scholar]
- Croman, K.; Decker, C.; Eyal, I.; Gencer, A.E.; Juels, A.; Kosba, A.; Miller, A.; Saxena, P.; Shi, E.; Gün Sirer, E.; et al. On Scaling Decentralized Blockchains. In Financial Cryptography and Data Security, Proceedings of the International Conference on Financial Cryptography and Data Security, Christ Church, Barbados, 26 February 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 106–125. [Google Scholar] [CrossRef]
- Marukhnenko, O.; Khalimov, G. The Overview of Decentralized Systems Scaling Methods. Comput. Inf. Syst. Technol. 2021. [Google Scholar] [CrossRef]
- Cai, S.; Zhou, H.; Yang, N.; Ming, Z. A TPS Model of Block-Generating Method Based on PoW. In Proceedings of the IEEE International Conference on Smart Cloud (SmartCloud), Tokyo, Japan, 10–12 December 2019; pp. 80–85. [Google Scholar] [CrossRef]
- Gobel, J.; Krzesinski, A. Increased block size and Bitcoin blockchain dynamics. In Proceedings of the 2017 27th International Telecommunication Networks and Applications Conference (ITNAC), Melbourne, VIC, Australia, 22–24 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Zhao, C.; Zhang, S.; Wang, T.; Liew, S.C. Bodyless Block Propagation: TPS Fully Scalable Blockchain with Pre-Validation. arXiv 2022, arXiv:2204.08769. [Google Scholar]
- Wang, K.; Kim, H.S. FastChain: Scaling Blockchain System with Informed Neighbor Selection. In Proceedings of the IEEE International Conference on Blockchain (Blockchain), Atlanta, GA, USA, 14–17 July 2019; pp. 376–383. [Google Scholar] [CrossRef]
- Chen, J.; Qin, Y. Reducing Block Propagation Delay in Blockchain Networks via Guarantee Verification. In Proceedings of the 2021 IEEE 29th International Conference on Network Protocols (ICNP), Dallas, TX, USA, 1–5 November 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Marchesi, L.; Marchesi, M.; Destefanis, G.; Barabino, G.; Tigano, D. Design Patterns for Gas Optimization in Ethereum. In Proceedings of the 2020 IEEE International Workshop on Blockchain Oriented Software Engineering (IWBOSE), London, ON, Canada, 18 February 2020; pp. 9–15. [Google Scholar] [CrossRef]
- Li, C. Gas Estimation and Optimization for Smart Contracts on Ethereum. In Proceedings of the IEEE/ACM International Conference on Automated Software Engineering (ASE), Melbourne, Australia, 15–19 November 2021; pp. 1082–1086. [Google Scholar] [CrossRef]
- Oyinloye, D.P.; Teh, J.S.; Jamil, N.; Alawida, M. Blockchain Consensus: An Overview of Alternative Protocols. Symmetry 2021, 13, 1363. [Google Scholar] [CrossRef]
- Toyoda, K.; Machi, K.; Ohtake, Y.; Zhang, A.N. Function-Level Bottleneck Analysis of Private Proof-of-Authority Ethereum Blockchain. IEEE Access 2020, 8, 141611–141621. [Google Scholar] [CrossRef]
- Khan, N.; State, R. Lightning Network: A Comparative Review of Transaction Fees and Data Analysis. In Blockchain and Applications, Proceedings of the International Congress on Blockchain and Applications, Ávila, Spain, 26–28 June 2019; Springer: Cham, Switzerland, 2020; pp. 11–18. [Google Scholar] [CrossRef]
- Gudgeon, L.; Moreno-Sanchez, P.; Roos, S.; McCorry, P.; Gervais, A. Sok: Layer-two blockchain protocols. In Financial Cryptography and Data Security, Proceedings of the International Conference on Financial Cryptography and Data Security, Kota Kinabalu, Malaysia, 10–14 February 2020; Springer: Cham, Switzerland, 2020; pp. 201–226. [Google Scholar]
- Vispute, A.; Patel, S.; Patil, Y.; Wagh, S.; Shirole, M. Scaling Blockchain by Autonomous Sidechains. In Proceedings of the International Conference on Microelectronics, Computing and Communication Systems; Springer: Singapore, 2021; pp. 459–473. [Google Scholar] [CrossRef]
- Avarikioti, G.; Kokoris-Kogias, E.; Wattenhofer, R. Divide and Scale: Formalization of Distributed Ledger Sharding Protocols. arXiv 2019, arXiv:1910.10434. [Google Scholar]
- Dang, H.; Dinh, T.T.A.; Loghin, D.; Chang, E.C.; Lin, Q.; Ooi, B.C. Towards Scaling Blockchain Systems via Sharding. In Proceedings of the 2019 International Conference on Management of Data, Amsterdam, The Netherlands, 30 June–5 July 2019; ACM: New York, NY, USA, 2019; pp. 123–140. [Google Scholar] [CrossRef] [Green Version]
- Buterin, V. Ethereum Whitepaper. 2021. Available online: https://ethereum.org/en/whitepaper/ (accessed on 10 September 2022).
- Aiyar, K.; Halgamuge, M.N.; Mohammad, A. Probability Distribution Model to Analyze the Trade-off between Scalability and Security of Sharding-Based Blockchain Networks. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Kokoris-Kogias, E.; Jovanovic, P.; Gasser, L.; Gailly, N.; Syta, E.; Ford, B. OmniLedger: A Secure, Scale-Out, Decentralized Ledger via Sharding. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 583–598. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, L.N.; Nguyen, T.D.T.; Dinh, T.N.; Thai, M.T. OptChain: Optimal Transactions Placement for Scalable Blockchain Sharding. In Proceedings of the IEEE International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 525–535. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, J.; Yin, J.; Li, G.; Yu, H.; Wu, Q. Cross-shard Transaction Processing in Sharding Blockchains. In Algorithms and Architectures for Parallel Processing, Proceedings of the International Conference on Algorithms and Architectures for Parallel Processing, New York, NY, USA, 2–4 October 2020; Springer: Cham, Switzerland, 2020; pp. 324–339. [Google Scholar] [CrossRef]
- Li, S.; Yu, M.; Yang, C.S.; Avestimehr, A.S.; Kannan, S.; Viswanath, P. PolyShard: Coded Sharding Achieves Linearly Scaling Efficiency and Security Simultaneously. IEEE Trans. Inf. Forensics Secur. 2021, 16, 249–261. [Google Scholar] [CrossRef]
- Das, S.; Krishnan, V.; Ren, L. Efficient Cross-Shard Transaction Execution in Sharded Blockchains. arXiv 2020, arXiv:2007.14521. [Google Scholar]
- Wang, C.; Raviv, N. Low Latency Cross-Shard Transactions in Coded Blockchain. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Melbourne, Australia, 12–20 July 2021; pp. 2678–2683. [Google Scholar] [CrossRef]
- Wang, J.; Wang, H. Monoxide: Scale out blockchains with asynchronous consensus zones. In Proceedings of the USENIX Symposium on Networked Systems Design and Implementation (NSDI), Boston, MA, USA, 26–28 February 2019; pp. 95–112. [Google Scholar]
- Whinfrey, C. Hop: Send Tokens Across Rollups. 2021. Available online: https://hop.exchange/whitepaper.pdf (accessed on 10 September 2022).
- Drake, J. Registrations, Shard Count and Shuffling. 2018. Available online: https://ethresear.ch/t/registrations-shard-count-and-shuffling/2129/1 (accessed on 10 September 2022).
- Sen, S.; Freedman, M.J. Commensal cuckoo. ACM SIGOPS Oper. Syst. Rev. 2012, 46, 33–39. [Google Scholar] [CrossRef]
- Buterin, V. On-Chain Scaling to Potentially 500 tx/sec through Mass tx Validation. 2018. Available online: https://ethresear.ch/t/on-chain-scaling-to-potentially-500-tx-sec-through-mass-tx-validation/3477 (accessed on 10 September 2022).
- Kate, A.; Zaverucha, G.M.; Goldberg, I. Polynomial Commitments. Ph.D. Thesis, Waterloo University, Waterloo, ON, Canada, 2010. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TX FIELD | DESCRIPTION | FIELD LENGTH & OPCODE IN BYTES |
|---|---|---|
| CHAIN ID | Blockchain ID (e.g., 1 for the main Ethereum network) | 1 + 1 |
| RECIPIENT, SENDER | Recipient’s and sender’s addresses | 32 + 1 per address |
| VALUE | Value to be sent in Wei, the base unit of Ethereum where Wei | ≤32 + 1 |
| GAS PRICE | Cost of a unit of computation as determined by Ethereum’s gas tables in gWei where 1 ETH = gWei | ≤32 + 1 |
| GAS PRIORITY FEE | These are priority fees much like tips which are paid to the miners | ≤32 + 1 |
| GAS LIMIT | The maximum gas a user is willing to pay to process a TX | ≤32 + 1 |
| NONCE | Counter for the number of TXs sent by the user | ≤32 + 1 |
| ACCESS LIST | Optional list of accounts the TX will interact with | 32 + 1 per address |
| SIGNATURE | The TX data are taken and signed using the user’s private key | 68 + 1 |
| V | A part of a signature used to prevent a replay attack | 1 |
| DATA | Used to deploy data or SC as well as to make a function call to a SC. Typically empty for currency transfer | ≤block size + 1 |
| TX FIELD | DESCRIPTION | FIELD LENGTH & OPCODE IN BYTES |
|---|---|---|
| HEADER | ||
| SHARD ID | The ID of the sending shard | 1 + 1 |
| ROLLUP SIZE | The size of the rollup in bytes | byte length + 1 |
| POST-STATE-ROOT | The Merkle root of the shard after the TXs | 4 + 1 |
| SIGNATURE | Signed by miners private key or rollup SC using a polynomial | 68 + 1 |
| BODY (repeated per TX) | ||
| SENDER RADIX PATH | The radix path from the Merkle root to the senders account leaf | 4 + 1 |
| RECIPIENT RADIX PATH | The radix path from the Merkle root to the recipients account leaf | 4 + 1 |
| VALUE | The value being sent is encoded as | Up to |
| GAS | Gas is replaced with a reference to a gas table | 1 + 1 |
| TX FIELD | BYTES | OPCODE IN BYTES |
|---|---|---|
| HEADER | ||
| SHARD ID | 1 byte (root ID) + 1 byte (shard ID) for up to 256 shards per layer & 1 byte per layer in the Merkle tree | 1 |
| ROLLUP SIZE | 1 byte per 256 bytes in rollup | 1 |
| POST-STATE-ROOT | 4 | 1 |
| SIGNATURE | 68 | 1 |
| BODY | ||
| SENDER ACCOUNT ID | 1 | 1 |
| RECIPIENT ACCOUNT ID | 1 | 1 |
| VALUE | Typically 2 or 3 | 1 |
| GAS | 1 | 1 |
| TX FIELD | BYTES | OPCODE IN BYTES |
|---|---|---|
| HEADER | ||
| SHARD ID | 1 byte + 1 byte for up to 256 shards per layer | 1 |
| & 1 byte per layers in Merkle tree | ||
| ROLLUP SIZE | 1 byte per 256 bytes in rollup | 1 |
| GAS | 1 | 1 |
| POST-STATE-ROOT | 4 | 1 |
| SIGNATURE | 68 | 1 |
| BODY | ||
| SENDER ACCOUNT ID | 1 | 1 |
| RECIPIENT ACCOUNT ID | 1 | 1 |
| VALUE | typically 2 or 3 | 1 |
| TX FIELD | BYTES | OPCODE IN BYTES |
|---|---|---|
| HEADER | ||
| SHARD ID | 1 byte for up to 256 shards per layer | 1 |
| & 1 byte per layers in Merkle tree | ||
| ROLLUP SIZE | 1 byte per 256 bytes in rollup | 1 |
| GAS | 1 | 1 |
| POST-STATE-ROOT | 4 | 1 |
| SIGNATURE | 68 | 1 |
| BODY | ||
| PARTICIPANT RADIX PATH | 1 | 1 |
| VALUE | typically 2 or 3 | 1 |
| TX FIELD | BYTES | OPCODE IN BYTES |
|---|---|---|
| HEADER | ||
| SHARD ID | 1 byte for up to 256 shards per layer | 1 |
| & 1 byte per layer in a Merkle tree | ||
| ROLLUP SIZE | 1 byte per 256 bytes in rollup | 1 |
| GAS | 1 | 1 |
| POST-STATE-ROOT | 4 | 1 |
| SIGNATURE | 68 | 1 |
| BODY | ||
| VALUE for radix ID 0 | typically 2 or 3 | |
| ... | ... | |
| VALUE for radix ID n | typically 2 or 3 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kudzin, A.; Toyoda, K.; Takayama, S.; Ishigame, A. Scaling Ethereum 2.0s Cross-Shard Transactions with Refined Data Structures. Cryptography 2022, 6, 57. https://doi.org/10.3390/cryptography6040057
Kudzin A, Toyoda K, Takayama S, Ishigame A. Scaling Ethereum 2.0s Cross-Shard Transactions with Refined Data Structures. Cryptography. 2022; 6(4):57. https://doi.org/10.3390/cryptography6040057
Chicago/Turabian StyleKudzin, Alexander, Kentaroh Toyoda, Satoshi Takayama, and Atsushi Ishigame. 2022. "Scaling Ethereum 2.0s Cross-Shard Transactions with Refined Data Structures" Cryptography 6, no. 4: 57. https://doi.org/10.3390/cryptography6040057
APA StyleKudzin, A., Toyoda, K., Takayama, S., & Ishigame, A. (2022). Scaling Ethereum 2.0s Cross-Shard Transactions with Refined Data Structures. Cryptography, 6(4), 57. https://doi.org/10.3390/cryptography6040057