1. Introduction
Faults occurring in a computer system have historically been related to integrated circuit (IC) fabrication defects. However, with the advent of hardware Trojan-based attacks, there is a high probability of defects being intentionally induced in the circuit. The trend of outsourcing fabrication has increased the vulnerability of ICs to Trojan attacks. These hardware Trojans alter not only the functionality of the circuit but also degrade their reliability. Hence, they are difficult to identify during the IC testing phase. Special attention must be given to preventing and identifying such attacks. Split fabrication has proven effective in reducing the Trojan attacks on the critical parts of the IC. However, if such an attack has occurred, it must be identified as early as possible in the manufacturing cycle.
Methods mentioned in the literature for Trojan detection can be classified broadly as destructive and non-destructive [
1]. Destructive methods include physical inspection and advanced image processing techniques. The major disadvantages of this method are low detection speed, high cost and poor coverage of Trojan types. The non-destructive methods include logic testing-based approaches and side channel analysis. In the logic testing-based approach, the activation probability of a hardware Trojan is usually low. Hence, standard test patterns have low chances of detecting a Trojan. For this reason, researchers focused on improving the existing testing techniques to increase Trojan detection. The advantage of the testing-based approach is that it is non-invasive and can identify Trojans inserted at different design flow levels. The side channel analysis method is also powerful to detect malicious modifications in an IC. This technique uses an IC’s physical characteristics (power and EM radiations) to detect a Trojan’s presence. However, this method requires a golden IC for comparison. Factors other than hardware Trojans can also alter the physical characteristics. Hence, it is difficult to determine the cause behind the abnormal behavior [
2,
3,
4]. Hardware Trojan or malicious modifications in a circuit include:
- (a)
Modification of the functional behavior: Inserting logic gates at an intermediate node of the IC.
- (b)
Electrical modifications: Adding extra load capacitance at the output of logic gates, thereby increasing the delay of the path.
- (c)
Transistor ageing: Increasing the threshold voltage by inducing Negative-Bias Temperature Instability (NBTI).
Figure 1 shows examples of the three types of hardware Trojans that affect the functionality and reliability of a circuit. The functional modifications in a circuit can be easily detected using test patterns generated by any standard Automatic Test Pattern Generator (ATPG) tool. However, detecting electrical modifications and transistor ageing requires specific patterns that can trigger such attacks. This paper refers to such patterns as Trojan Triggering Patterns (TTP). These attacks have an adverse effect on the reliability of the IC. Hence, they are commonly termed as reliability attacks. It is nearly impossible to identify them during destructive physical analysis. This paper proposes a novel Trojan detection technique using Transition Delay Fault (TDF) identification. The proposed method can identify reliability attacks without using any hardware overhead.
It is mentioned in [
5,
6] that the Trojan-infected nodes tend to cluster. Detection of clustered Trojans becomes a laborious task as the output responses interact and obscure some faulty responses. Hence, the proposed method enhances the Trojan detection accuracy by using K-means clustering algorithm.
Every hardware Trojan has malicious intent. If the Trojan attack aims at leaking safety critical information from the IC, then the Trojans will be targeted on specific modules in the IC. Hence, clustering of Trojans is possible. Since the clustered Trojans interact and lead to masking and reinforcement effects, it is difficult to detect them. Moreover, the clustered Trojan signatures are entirely different, making their identification more time-consuming. The probability of clustered hardware Trojans may be less, but once clustered it requires a special procedure for proper identification [
5,
6].
The remainder of the paper is arranged as follows:
Section 2 gives a brief overview of the related work in the detection of reliability attacks, and
Section 3 provides a detailed understanding of the proposed TTP generation algorithm.
Section 4 gives the necessary details on the proposed clustered Trojan detection procedure.
Section 5 discusses the results and comparisons with existing methodologies, and finally,
Section 6 concludes the paper.
3. Proposed TDF-Based TTP Generation Algorithm
An algorithm to generate TTPs for detecting Trojans without adding additional gates into the circuit model is explained here. The algorithm consists of two main parts: Trojan triggering condition and TDF-pair grouping. A detailed description of the proposed algorithm is given below.
3.1. Trojan Triggering Condition
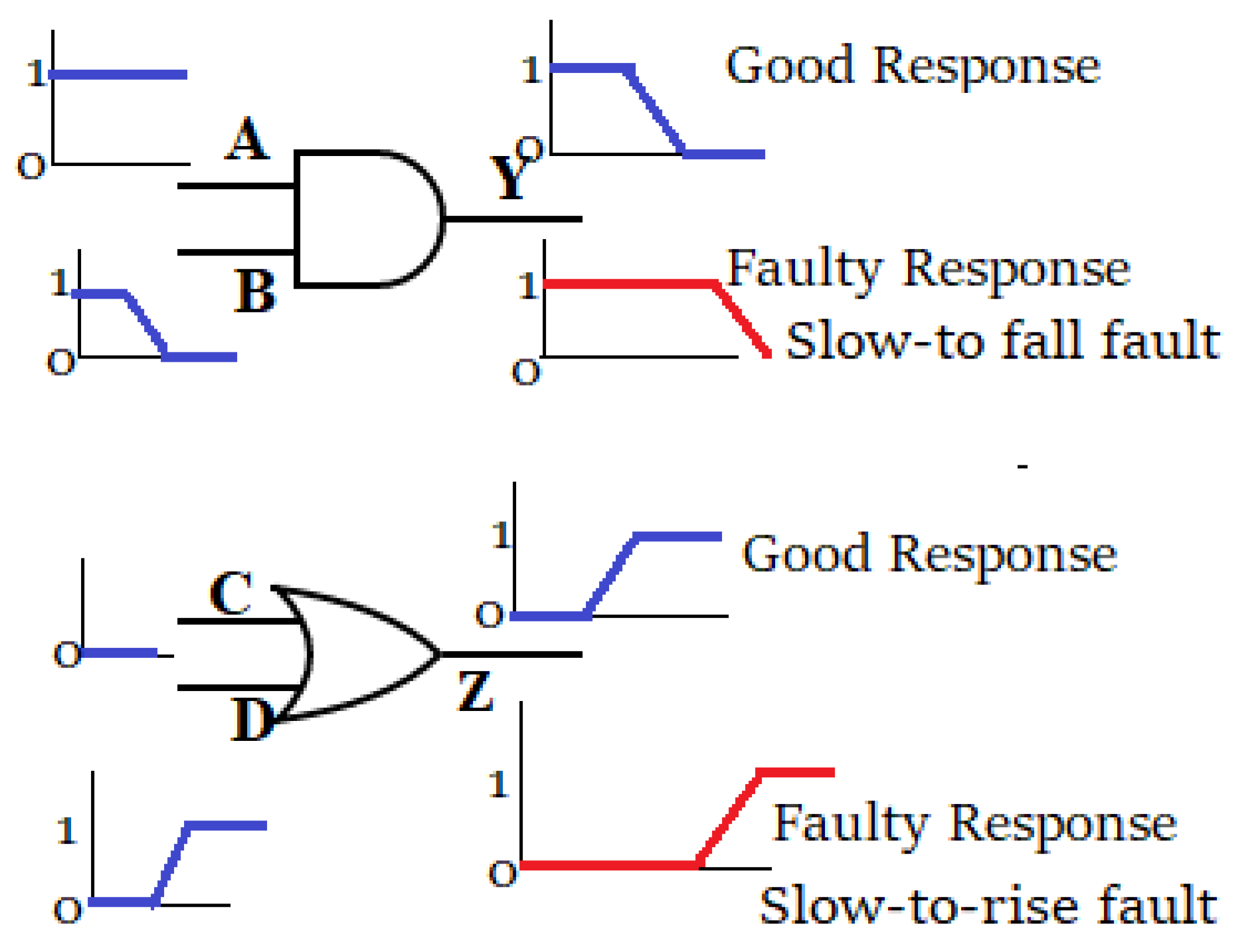
Generally, a two-pattern set is used to test TDFs. Here, the first pattern initializes the faulty node, and the second pattern sets the transition at the node. Consider the circuit shown in
Figure 4. To detect a slow-to-rise fault at node 5, represented as 5/01, a test vector pair that ensures a logic ‘0’ to logic ‘1’ transition at node 5 must be applied. To increase the probability of detecting a Trojan, patterns that can activate a Trojan at a node while deactivating the transition in the nearby nodes are considered. Since such conditions occur rarely, they are suitable for triggering a Trojan. This can be treated as a rare event capable of triggering a Trojan. Hence, for generating the triggering condition for a Trojan, a pattern that can activate a TDF at the Trojan node while deactivating TDFs in the nearby nodes can be used. For example, to deactivate the 5/01 TDF, any test vector pair that activates a ‘10’, ‘11’, ‘10’ transition at node 5 can be used.
On further investigation, it can be observed that if the value of node 5 in the first time-frame is logic ‘1’, then irrespective of the second time-frame value, the TDF 5/01 gets deactivated. Similarly, if the value of node 5 at time-frame 2 is logic ‘0’, then irrespective of the first time-frame values, the TDF 5/01 gets deactivated. The proposed method selects the Trojan triggering patterns based on the second time-frame information only. Thus, generating TTPs using only one time-frame value makes the proposed method faster than the existing methods [
8,
12], which use two time-frame values.
The patterns that satisfy the constraints for transition deactivation are obtained using Zero Suppressed Binary Decision Diagram (ZBDD) based SAT-solvers [
13]. In this approach, the ZBDDs are used as the fundamental data structure. ZBDDs are proven to be efficient compared to lists and tries [
12,
13]. ZBDD can represent Boolean expressions in a compressed form, resulting in much faster search times. The results in [
12,
13,
14] show that ZBDDs work well for digital benchmark circuits such as ISCAS’89, ITC’99 and IWLS’05.
3.2. TDF-Pair Grouping
In the proposed method, multiple TDF pairs are considered simultaneously for generating compact test patterns that trigger multiple Trojans. The TDF pairs that can be considered in one cycle are grouped together. TDF pairs can be grouped together if at least one fault in a pair has a disjoint observation cone with other pairs of the group. Fault pairs that satisfy the above constraint can be of the following two types:
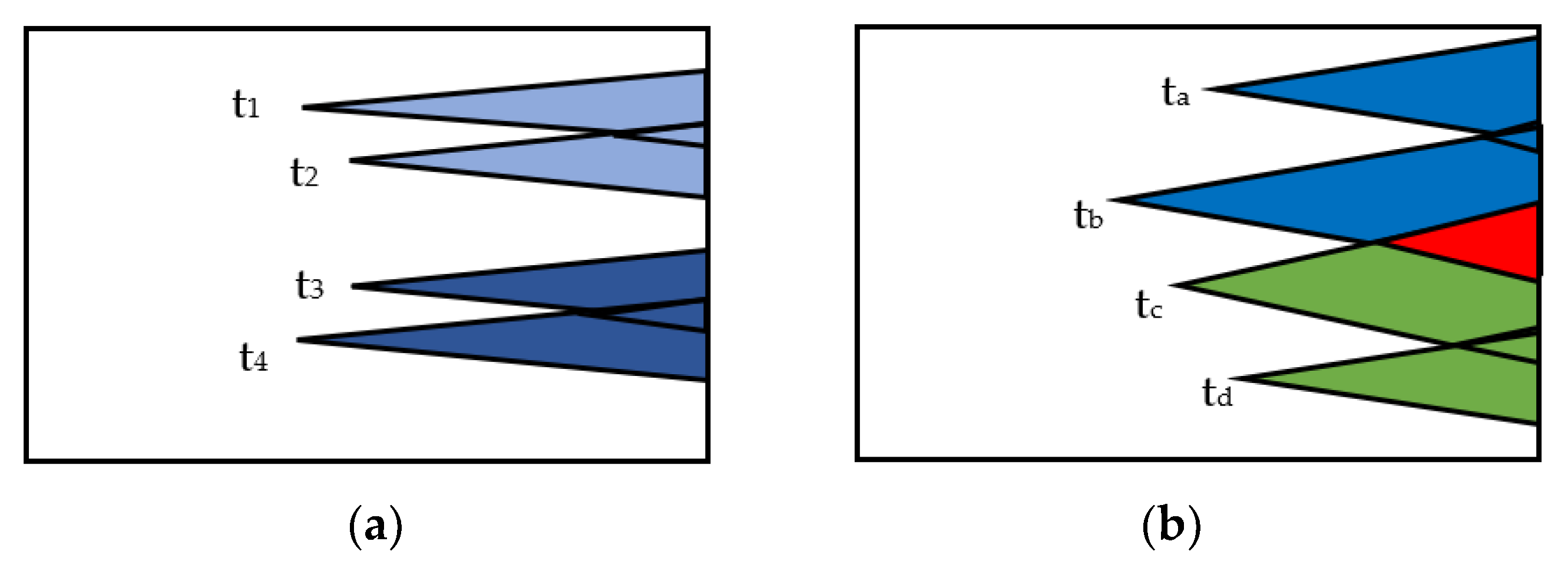
Type 1: Two fault pairs that have non-overlapping observation cones. For example,
Figure 5a shows two fault pairs P1 = (t
1, t
2) and P2 = (t
3, t
4). The faults pairs P1 and P2 have disjoint observation cones. Hence, the pairs do not interact. Hence, P1 and P2 can be grouped.
Type 2: Two fault pairs have overlapping observation cones. Consider the fault pairs P3 = (t
a, t
b) and P4 = (t
c, t
d), shown in
Figure 5b. Here, t
a has no common nodes with pair P4. Similarly, t
d does not have any common nodes with pair P3. Thus, the pairs P3 and P4 satisfy the criterion for grouping.
When type 2 faults are grouped, an additional grouping constraint must be satisfied. For example, tb and tc cannot be activated simultaneously, as they have common propagation nodes.
The pseudocode for the proposed Algorithm 1 for TTP generation is shown below. The following terms are used: TDF List is the list of Transition Delay Faults, FP is the list of fault pairs. TTP is the set of Trojan Triggering Patterns, and TP is the set of Test Patterns. EQFP indicates the fault pairs which cannot be distinguished as they produce a similar response at the output. Hence, they are termed Equivalent Fault Pairs. OP is the set of primary outputs to which a fault or a group of faults are propagating. ‘G’ indicates the group of fault pairs that are considered simultaneously.
To avoid detection, the Trojans are inserted in the non-critical path. General ATPG methods are constrained to generate patterns for critical path. Cha and Gupta [
15] have addressed this issue and have proved that shorter paths can increase detection sensitivity. The delay added by the HT has a larger fractional impact on the path delay as compared to the longer paths. For example, if Δt is the delay added due to a HT in a path with total delay T, then Δt/T is the fractional delay induced by the HT. If T is smaller, then Δt/T will be a higher value thereby increasing its detection probability. Hence, HT at shorter paths can be detected by using an appropriate test vector generation strategy. In [
15], the existing ATPG tool is modified by leveraging the TDF model since it is assumed as a delay on an individual node.
A similar approach is used in the proposed method. Here, in addition to the test patterns generated using a standard ATPG tool, Trojan triggering patterns are generated after obtaining the delay of each sensitized path. The path delays are computed using the Prime-Time tool in Synopsys. The ATPG tool is then adjusted for the required delay.
| Algorithm 1. Pseudocode for proposed TTP Generation |
INPUT: Netlist, TDF List, FP
OUTPUT: TTP, TP, EQFP
for i in TDF
Generate test pattern tpi using an ATPG tool
Add the pattern to TP
Remove fault pairs from FP which can be distinguished using tpi
Remove the faults from TDF which can be detected using tpi
for i in FP //Remaining fault pair grouping
OPi <= ɸ
OPi <= set of Primary Outputs in the observation cone of fpi
Compute the delay for each path;
FP= FP-fpi
Gi = fpi
for j in FP
OPj <= set of Primary Outputs in the observation cone of fpj
If (fpi and fpj satisfy the grouping criterion)
Gi = Gi + fpj
FP = FP- fpj
OPi = OPi + OPj
for i in G // Transition Deactivation Condition
Generate ZBDD for the set of outputs in OPi
Select the patterns which satisfy the Transition Deactivation and delay Condition
Add the patterns to TTP
Add the remaining Fault pairs to EQFP |
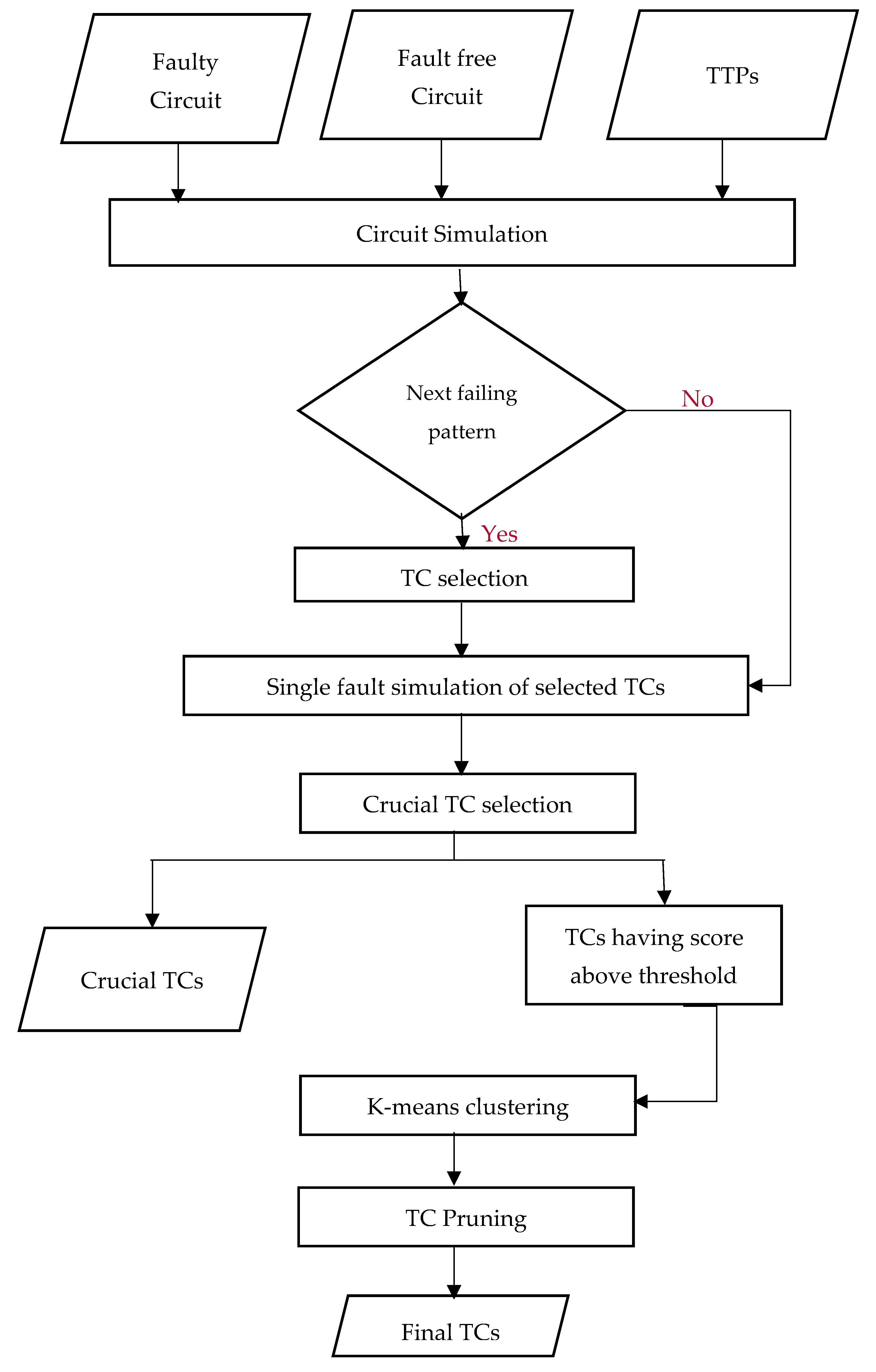
4. Proposed Detection of Clustered Trojans
The overall flow of the proposed clustered Trojan detection is shown in
Figure 6. A set of clustered Trojans are injected into the CUT. The TTPs obtained using the method explained in
Section 3 are used to perform the circuit simulation. The obtained response is then compared with the golden response of the fault-free circuit to obtain the list of Trojan Candidates (TCs) using the proposed TC selection algorithm explained in
Section 4.1. Single fault simulations of the selected TCs are performed to assign a score to the TCs. The TCs with the highest scores are named crucial TCs. This procedure is called Crucial TC selection, details of which are given in
Section 4.2. Finally, the K-means clustering algorithm, with the optimal number of clusters discussed in
Section 4.3, is used to prune the list of TCs.
4.1. TC Selection Algorithm
In the proposed Algorithm 2, a list of TCs is obtained with the help of generated TTPs as explained in
Section 3. TTPs are highly efficient in triggering Trojans. However, the fault-masking and fault reinforcement due to the presence of multiple Trojans would affect the efficiency of TTPs. Hence the TC selection algorithm is followed by crucial TC selection and the K-means clustering algorithm.
During the TC selection algorithm, a list of nodes connected to each failing output is obtained. The second time-frame values of these nodes are compared with the second time-frame values of the fault-free circuit. Each node with a mismatch in the second time-frame value is listed as a TC.
The advantage of the proposed TC selection algorithm is that it needs only one time-frame value to obtain the list of TCs. Thus, the algorithm is comparatively faster and requires less memory. The pseudocode for the algorithm is shown below. The following terms are used in the algorithm: FO is the list of failing outputs for the Failing Test Patterns (FTPs).
| Algorithm 2. Algorithm: TC Selection |
Input: FO, FTP
Output: List of TC
for i in FO
Obtain the list of nodes connected directly or indirectly to foi
Update N
for i in FTP
for j in N
If (faultfree response of njϵ N ≠Actual response of nj)
Add nj to TC |
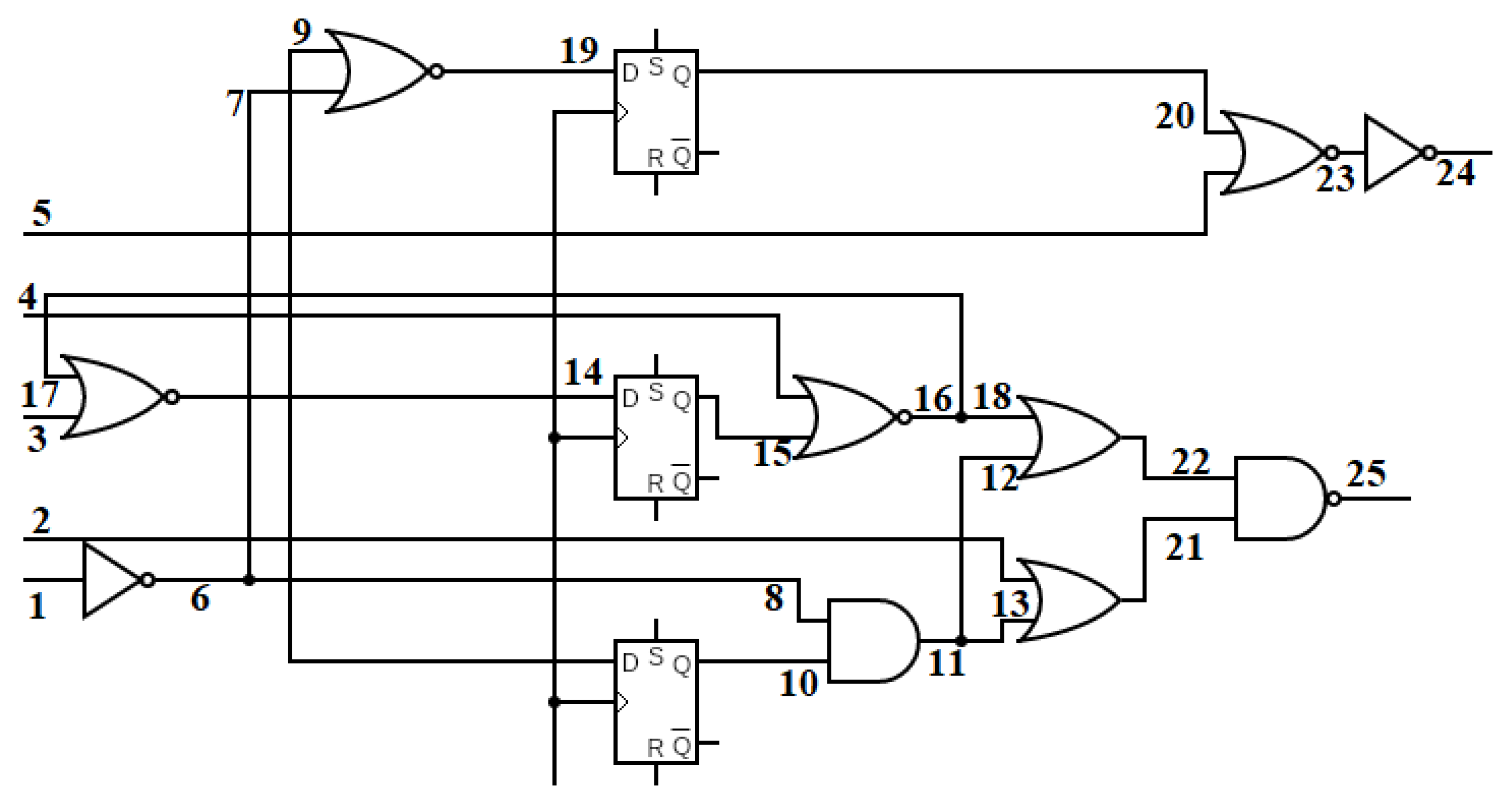
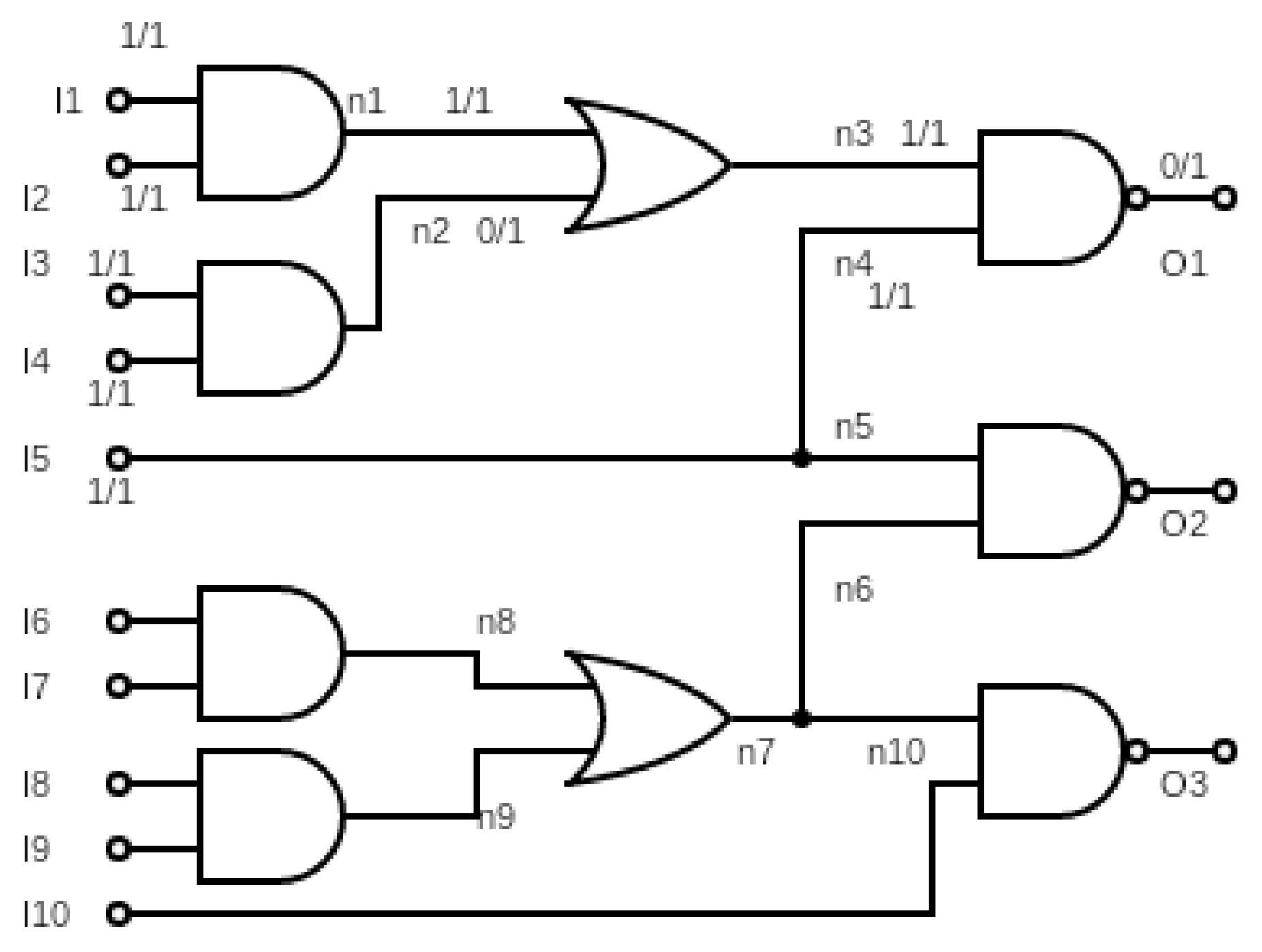
Consider an example circuit shown in
Figure 7 where the primary inputs are denoted as I1, I2, … I10, primary outputs as O1, O2, O3 and intermediate nodes are represented as n1, n2, … n10, etc. Assume that, after circuit simulation, output O1 shows a faulty response in the second time-frame. The true response and the actual response are shown in the circuit as 0/1, where ‘0’ is the true response or expected value and ‘1’ is the faulty response. In the first step, the list of nodes to which the output propagates are obtained. In this example, the list is
N = {n3, n4, I5, n1, n2, I1, I2, I3, I4}. In the second iterative loop of the proposed algorithm, the nodes which have a conflicting true response and actual response for the second time-frame are selected. These nodes indicate possible Trojan locations. Hence, they are added to the list of TCs.
4.2. Crucial TC Selection
Algorithm 3 explains the crucial TC selection process. A single fault simulation is performed on each fault in the list of TCs. The fault simulation responses are obtained only for the failing test patterns reported during the simulation of the faulty circuit. The obtained single-fault simulation responses are then compared with the actual faulty circuit responses. The TC, which can explain the maximum number of failed outputs, will have the highest score. The score for each TC is computed using the Equation (1):
Here, FTP is the set of Failing Test Patterns, and FO is the set of failing outputs. SFS indicates the single fault simulation procedure. AFS indicates the actual fault simulation after injecting a clustered fault into the circuit. The score is the sum of the intersection of the failing outputs for SFS and AFS for each failing pattern. The TCs with maximum scores are named crucial TCs. Among the remaining TCs, those that cross a threshold of 0.9 × max_score are considered as viable TCs. Here, 0.9 is a user-defined value for the threshold. Considering faults with less than the maximum score attempts to include the fault-masking and fault reinforcement effects. The pseudocode for crucial TC selection is shown below. Inputs to the algorithm 3 are the list of TCs and the list of Failing Test Patterns (FTPs)
| Algorithm 3. Crucial TC Selection |
Inputs: TC, FTP
Outputs: Crucial_TC, Final_TC
Max_score = 0;
for i in TC
Scorei = 0
for j in FTP
SFSj <= Failing outputs for single fault Simulation
AFSj <= Failing outputs of Actual fault simulation
Current_scorej = |SFSj ∩ AFSj|
Scorei = scorei + current_scorej
if (scorei > Max_score)
Max_score = scorei
for i in TC
if (scorei = = Max_score)
Crucial_TC = crucial_TC ∪ TCi
if (scorei > 0.9 × Max_score)
Final_TC=Final_TC ∪ DCi |
4.3. K-Means Clustering Algorithm
K-Means clustering is used when a set of n-samples are grouped into K clusters. The CUT must be converted into a 2-Dimensional plane for applying the K-means clustering algorithm. Hence, the ‘x’ and ‘y’ coordinate values are extracted for each TC node using the layout information. Various methods can be used for searching a TC node in a layout. A Horizontal Vertical Tree (HVT)-based data structure mentioned in [
14] is used in the proposed method. A binary search algorithm is used to search for the given TC. These coordinates represent the physical position of the possible Trojan nodes.
An important parameter that affects the algorithm’s efficacy is the optimum Number of Clusters (NC). This paper uses the Elbow-Curve method to obtain the Optimum Number of Clusters (ONC). In this method, the K-means clustering is run on the combined list of Crucial TCs and viable TCs, for a range of K (from K = 1 to K = N), where 1 is the minimum and N is the maximum number of clusters. For each value of K, the average distance to the centroid of all DCs in a cluster is computed. These values are plotted in a graph. The point where the average distance to the centroid drops suddenly (elbow) is selected as the optimum NC.
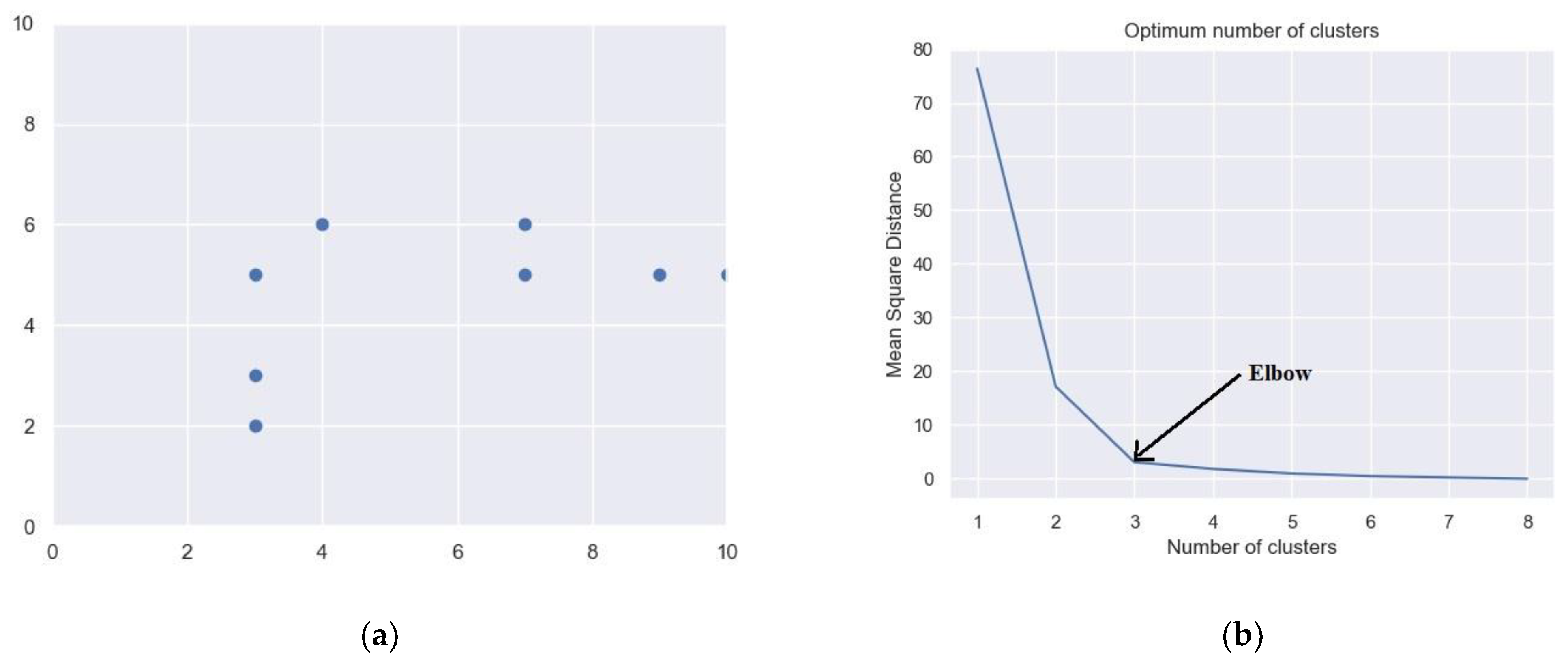
Figure 8 shows the result of applying the K-means clustering algorithm on the ISCAS’89-s27 benchmark circuit.
Figure 8a indicates the 2-Dimensional plot of the list of TCs when four TDFs belonging to the α-cluster were injected into the circuit.
Figure 8b shows the plot for obtaining the ONC. The
x-axis shows the number of clusters ranging from one to eight (number of TCs).
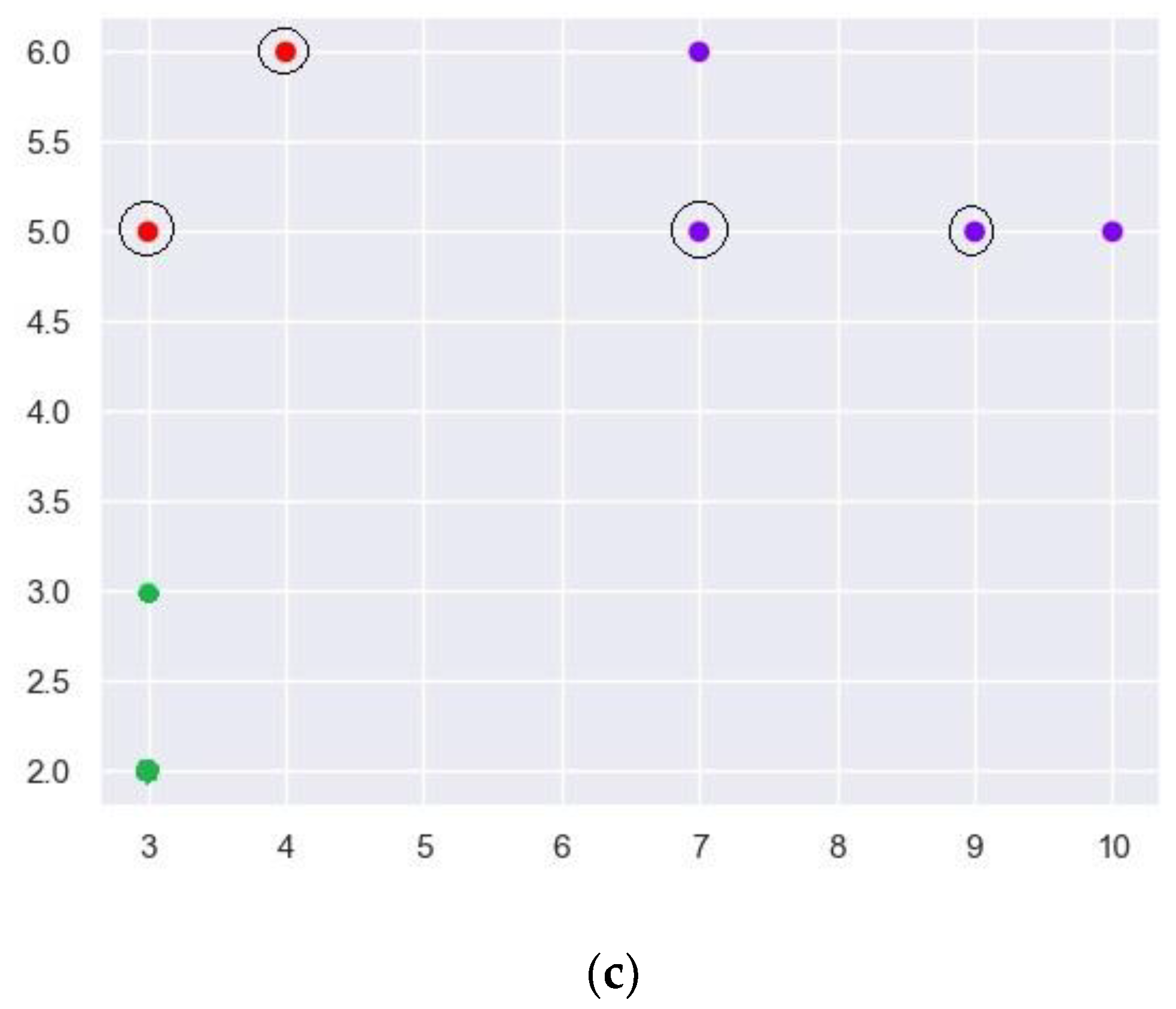
Y-axis shows the mean square distance of the centroid of each cluster to the TCs in the respective clusters. It is observed that at NC = 3, the mean square distance drops drastically. Hence, K-means clustering is applied for K = 3, and the obtained clusters are shown in
Figure 8c. Cluster C1 with 4 TCs are represented using ‘Blue’ color dots. Clusters C2 and C3, with two members each, are represented using ‘Red’ and ‘Green’ color dots, respectively.
After clustering, TC pruning is performed to remove the scattered TCs. A user-defined parameter ‘s = 0.6’ is used for pruning. All the clusters with a size less than 0.6 times the biggest cluster are removed. However, the crucial suspects are retained, even if they belong to a cluster to be removed. In
Figure 8c, the crucial suspects are indicated using black circles enclosing the dot. The maximum size of the cluster is 4. Hence any cluster with a size less than 0.6 × 4 = 2.4 is to be removed. Since both the elements of cluster C2 are crucial suspects, they are retained, and cluster C3 is removed. Hence, the final list of TCs will have six entries where four are the actual injected Trojans, and only two are incorrectly identified TCs. Hence, in this case, the accuracy is 1, and the resolution is 0.67. Accuracy and resolution are computed using Equations (2) and (3), respectively.
Accuracy indicates the number of Trojans identified out of the total number of injected Trojans. Resolution indicates the number of correctly identified Trojans among the list of TCs reported at the end of the diagnostic procedure. 100% accuracy indicates there are no false negative cases. As resolution increases, the false negative cases decrease. The accuracy and resolution when a single TDF is injected are observed to be maximum. This also indicates the efficiency of the TTPs in identifying the Trojans.
5. Results and Discussion
To validate the proposed Trojan detection procedure for single and clustered Trojans, experiments were conducted on various ISCAS’89, ITC’99 and IWLS’05 benchmark circuits. SYNOPSYS TMAX was used to generate the LOC and LOS test patterns for the TDFs. The circuit netlist was derived from SYNOPSYS Design Compiler, with 90 nm standard cell library. The Colorado University Decision Diagram (CUDD) tool [
16] was used to manipulate the ZBDDs. The script for the proposed TDF-based TTP generation algorithm and detection of clustered Trojans was written in Python 3.0. All experiments were conducted on Intel
® Core i5, 1.8 GHz processor and Linux operating system. The proposed method works best when high resolution delay measurement technique is used.
Table 1 shows the consolidated results for the proposed TDF-based TTP generation algorithm. The first column lists the benchmark circuits on which the proposed algorithm was applied. #TDF is the number of Transition Delay faults reported by the Synopsys TMAX tool. #FP is the total number of fault pairs. If ‘n’ is the number of TDFs in a circuit, then nC2 is the number of possible fault pairs. #TP indicates the number of test patterns. INDIS indicates the number of fault pairs that could not be distinguished using only the TPs. To generate TTPs the Trojan triggering condition and TDF-pair grouping methods are applied on these fault pairs that cannot be distinguished (referred to as indistinguished in this paper). These patterns are listed in the column labelled #TTP. The fault pairs which cannot be distinguished, as they have a similar response at the output, are grouped as Equivalent faults (EQU). The fault pairs for which the fault effects do not reach the output are listed under the column labelled ‘#Aborted’. The Next column shows the Detection Ratio (DR). Equation (4) is used to compute DR. No false positives were reported; however, some of the fault pairs were aborted in s15850 and s38584 circuits; hence false negatives are reported in these two cases.
Table 2 compares the results of the proposed TTP generation algorithm [
17]. The columns labelled #EQU in
Table 2 show the number of equivalent fault pairs in [
17] and the proposed TTP generation algorithm. The results indicate a 32.1% decrease in the number of equivalent fault-pairs. In the proposed algorithm, a novel Trojan triggering condition is used. Moreover, multiple fault pairs with overlapping observation cones are considered simultaneously, thus reducing the number of equivalent faults as compared to [
17]. Reduced equivalent faults indicate that the TTPs generated using the proposed method can trigger Trojans more effectively.
In the proposed TTP generation algorithm, high detection capability is achieved at the expense of a slight increase (4.2%) in the total number of patterns. The number of patterns (#TP + #TTP) is high for two ISCAS’89 circuits, namely s15850 and s35932. However, it can be observed that the number of aborted faults reported in the proposed TTP generation algorithm is only ‘7’ as compared to ‘11’ in [
17] for s15850. The number of aborted faults are reported in the columns labelled ‘Ab’ in
Table 2 for [
17] and the proposed TTP generation algorithm, respectively. Overall, the proposed TTP generation algorithm efficiently generates patterns with high Trojan Triggering capability.
The proposed Clustered Trojan procedure was applied on ISCAS’89 circuit s38584 and ITC’99 circuits b17 and b18. One to ten Trojans were injected into each circuit. Clustered Trojans belonging to α, β and ϒ clusters were injected. Hence, in total 3 × 10 × 3 = 90 faulty circuits were analyzed. The HTs were inserted based on their physical closeness. These clusters can be on the critical as well as non-critical paths. The HTs on the critical paths can be detected using the standard ATPG patterns, and for those on the non-critical paths, the patterns generated using the TTP generation algorithm are used. A Gaussian delay distribution is generally assumed when path delay fault models are considered. However, in the proposed method a transition fault model is considered. It assumes that the delay is on a single node in the excited path.
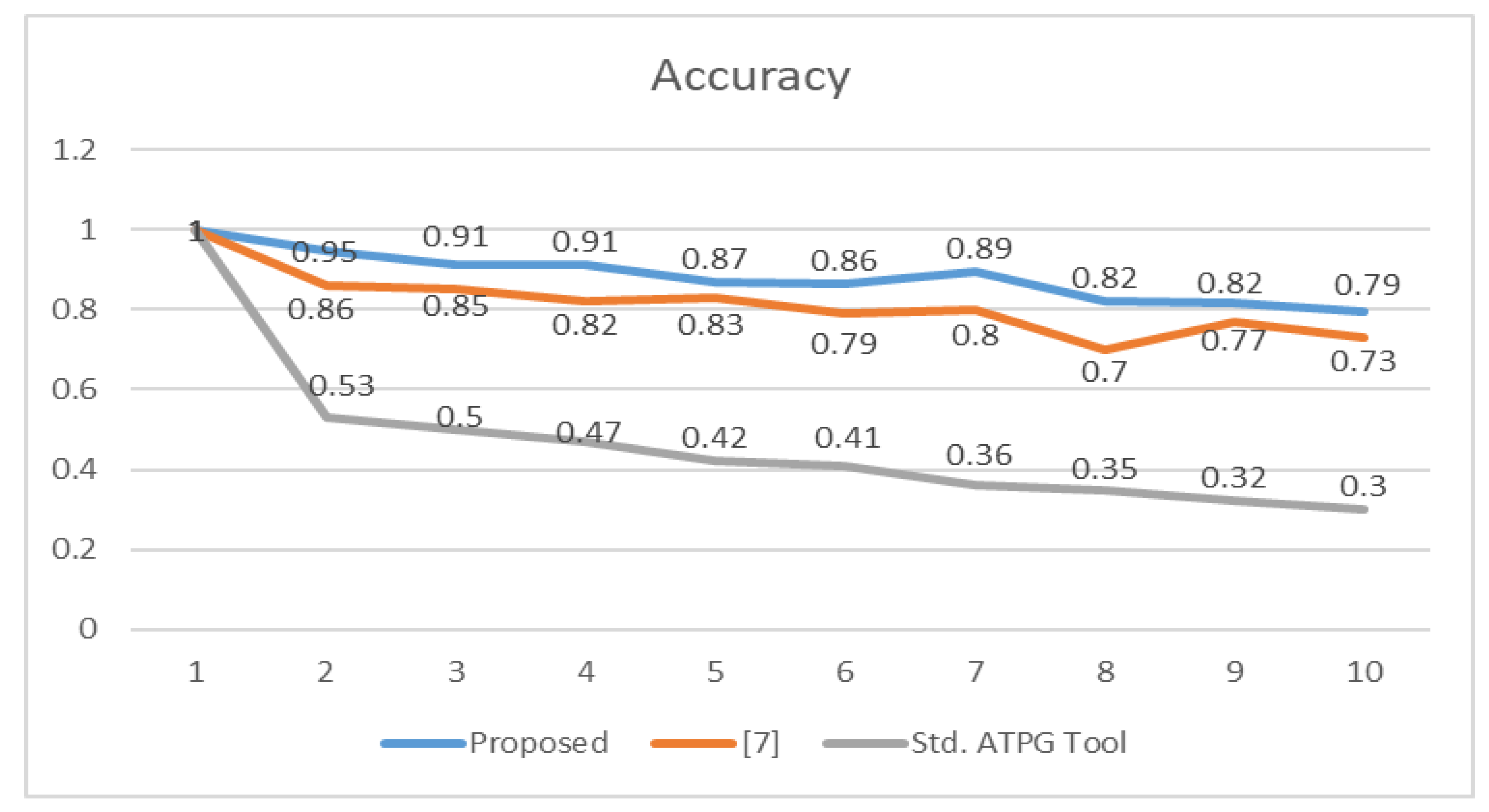
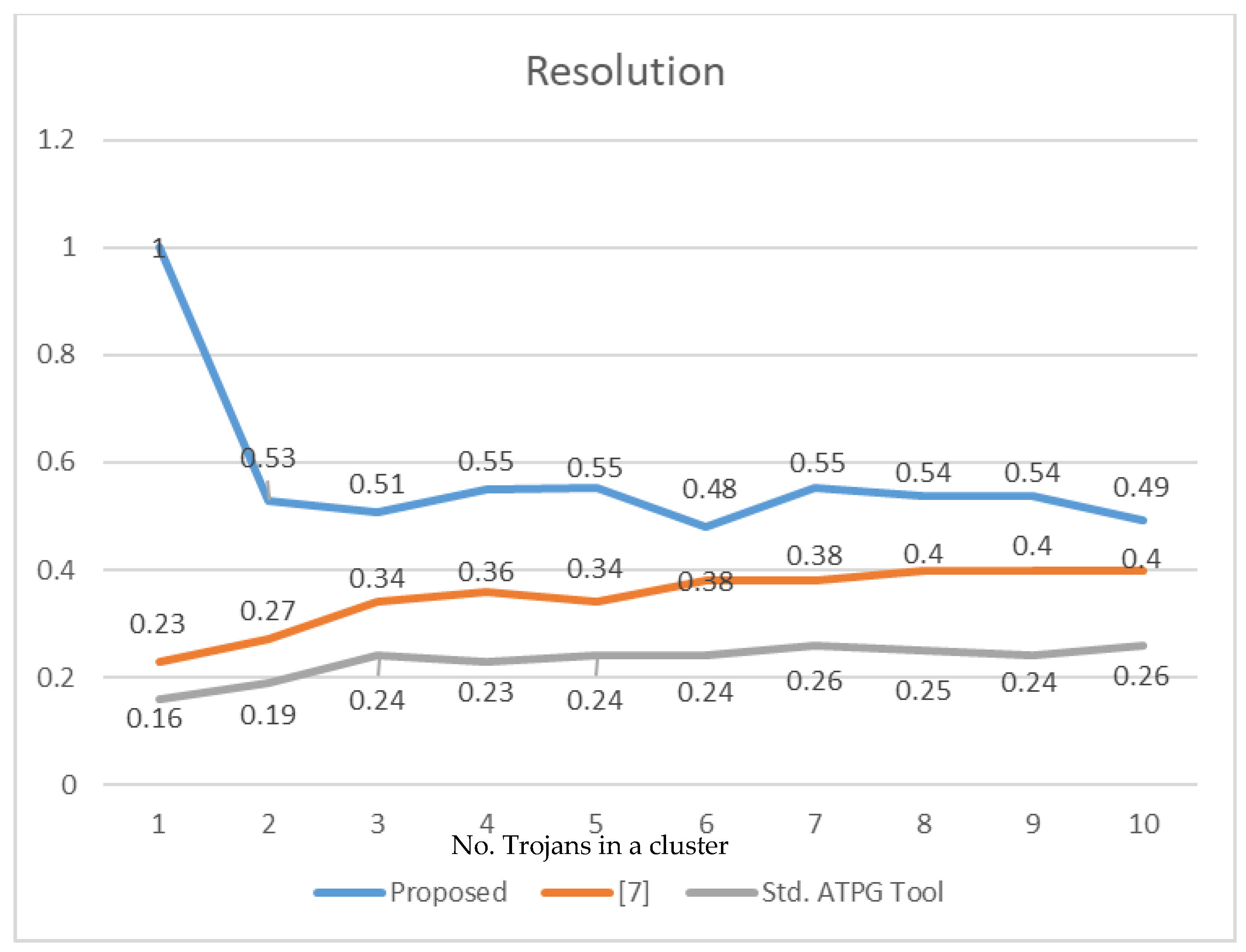
The accuracy and resolution of the proposed method for clustered multiple TDF diagnosis are reported in
Table 3 and
Table 4, respectively. It is observed that the accuracy and resolution decrease as the number of faults increases due to fault-masking and fault-reinforcement effects. However, the proposed method maintains a minimum accuracy of 0.79 even when ten clustered Trojans are injected into the CUDs. Similarly, the resolution also decreases as the number of clustered Trojans increases.
Figure 9 and
Figure 10 compare the average accuracy and resolution of the proposed clustered Trojan procedure with [
7] and Synopsys ATPG tool TMAX. There is a 46% increase in accuracy and a 34% increase in resolution compared to the ATPG tool. There is a 7% increase in accuracy and a 22% increase in resolution compared to [
7]. The use of TTPs with high distinguishing capability followed by the crucial TC selection and K-means clustering algorithm has improved the accuracy and resolution of the proposed clustered multiple TDF diagnosis.
Table 5 compares the Trojan coverage (TrC) of the proposed method with [
18]. The proposed method reports zero false positive cases. False negatives are reported only in s15850 and s38584 benchmark circuits. The false positives reported for s35932 are comparatively higher in [
18]. This has reduced the TrC to 27%. The proposed method provides an average of 83% improvement in TrC.
Table 6 compares the Trojan coverage, number of test patterns and test pattern generation time of the proposed method with [
15] for ISCAS’89 benchmark circuit s5378. The proposed method tries to generate patterns that can activate multiple Trojans simultaneously. Hence there is a 2.4 times reduction in the number of patterns and over 25 times reduction in pattern generation time. Test cost is directly proportional to the number of test patterns and test generation time. Thus, the proposed method is cost efficient as compared to [
15].
6. Conclusions
This paper proposes a Trojan Triggering pattern generation approach to detect Trojans that manifest as delays in the circuit. These Trojans cannot be necessary triggered by the test patterns as they can be injected in the non-critical path. The proposed method uses a novel approach to generate patterns by sensitizing the non-critical paths. This paper also considers the effect of clustered Trojan detection. Since the clustered Trojans cannot be activated using standard test patterns, the proposed method detects clustered Trojans using additional patterns generated for distinguishing TDFs. The proposed method uses only single fault simulation responses for predicting the clustered Trojans. Hence, any commercial ATPG tool with single fault simulation capability for TDFs can be used to implement the proposed procedure. A TTP generation algorithm generates the patterns required for testing and activating a Trojan circuit. These patterns are then used for clustered Trojan detection.
The accuracy and resolution of the proposed clustered Trojan detection procedure are improved further by applying crucial TC selection and K-means clustering algorithms. Some of the less significant TCs are neglected, thereby improving the resolution. It is also observed that keeping the crucial TCs improves the accuracy, thereby reducing the false positives and false negatives.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}