

High Throughput PRESENT Cipher Hardware Architecture for the Medical IoT Applications

Abstract
:1. Introduction
2. Related Works
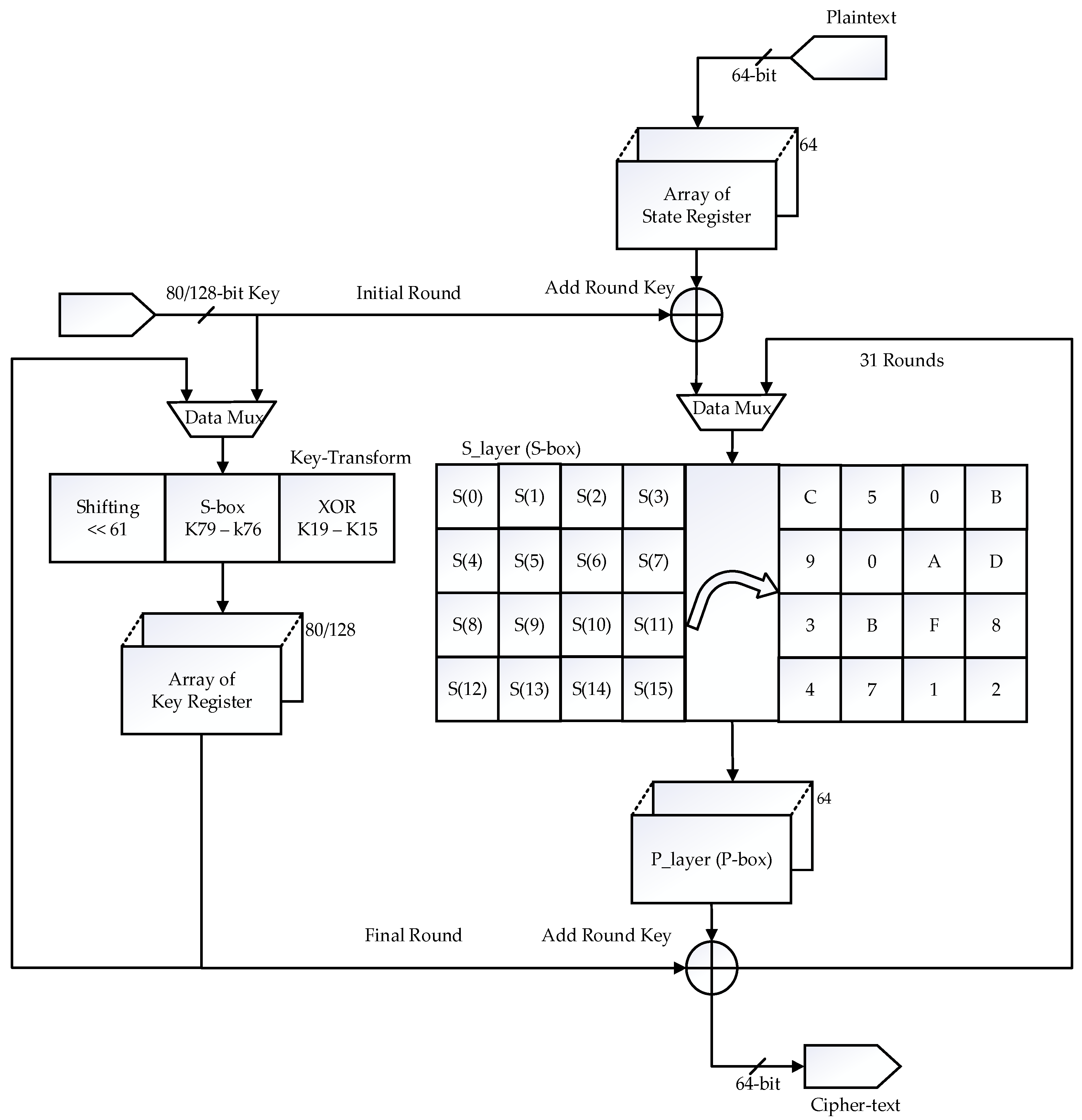
3. Overview of Symmetric-Key Block Cipher-PRESENT Cipher SP-Box Algorithm
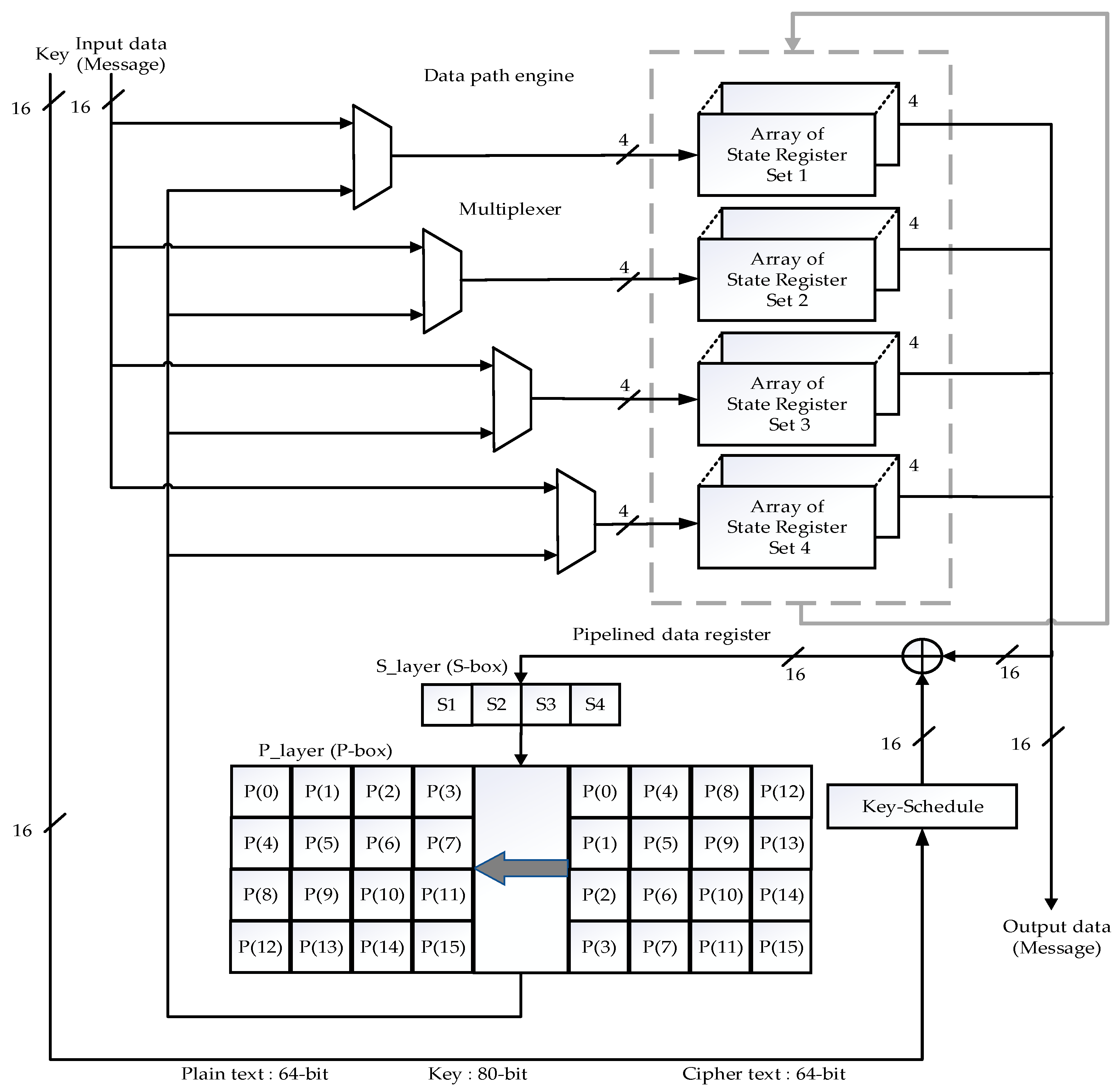
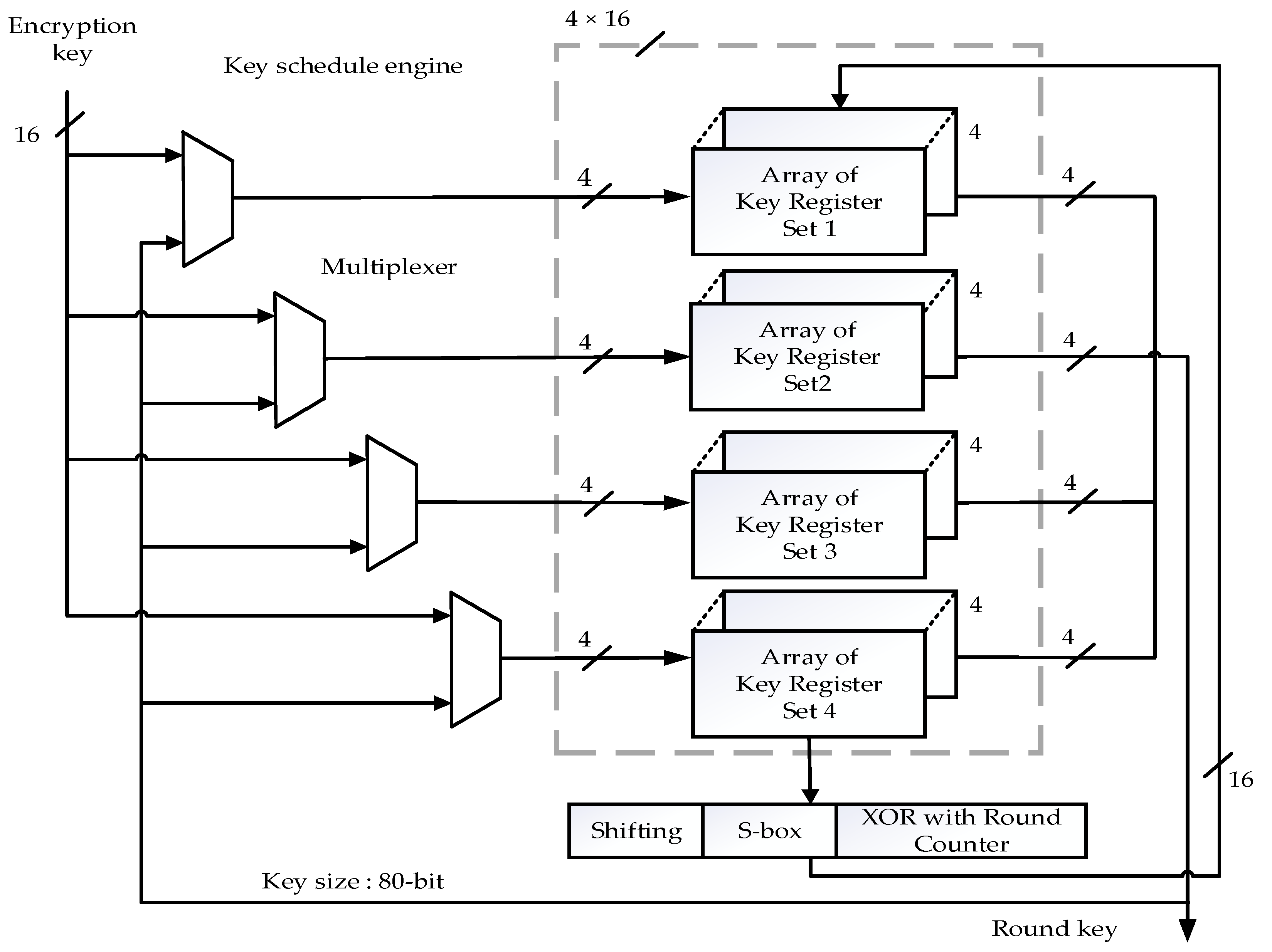
4. Existing 16-Bit Data Path and Key Schedule Architecture
- Step 1: Add Round Key
- aj is the current state (input plain text message)
- kj is the round key
- i is the number of rounds
- aj is directly assigned to S(in)
- Step 2: S-layer (S-box)
- Step 3: P-layer (P-box)
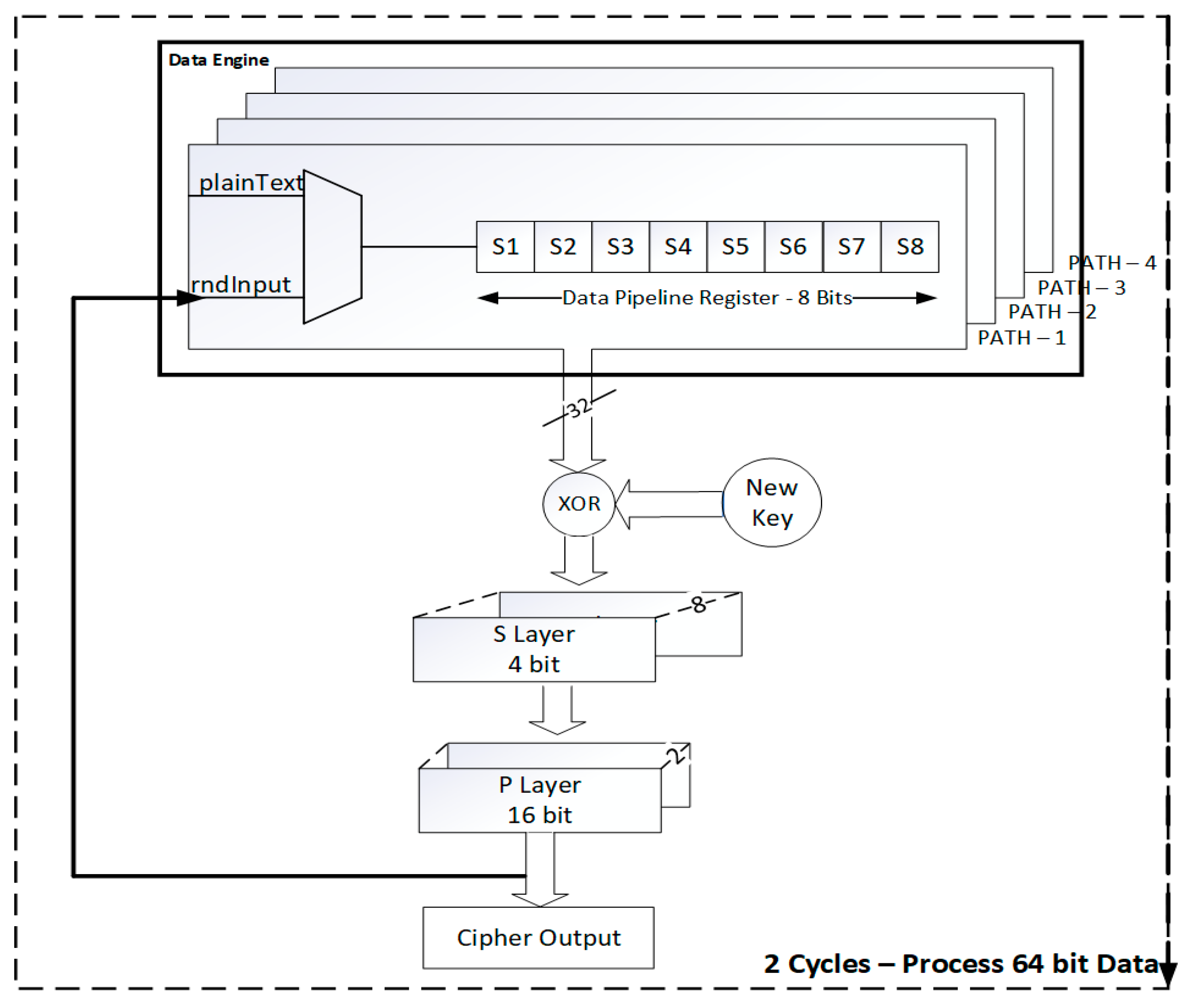
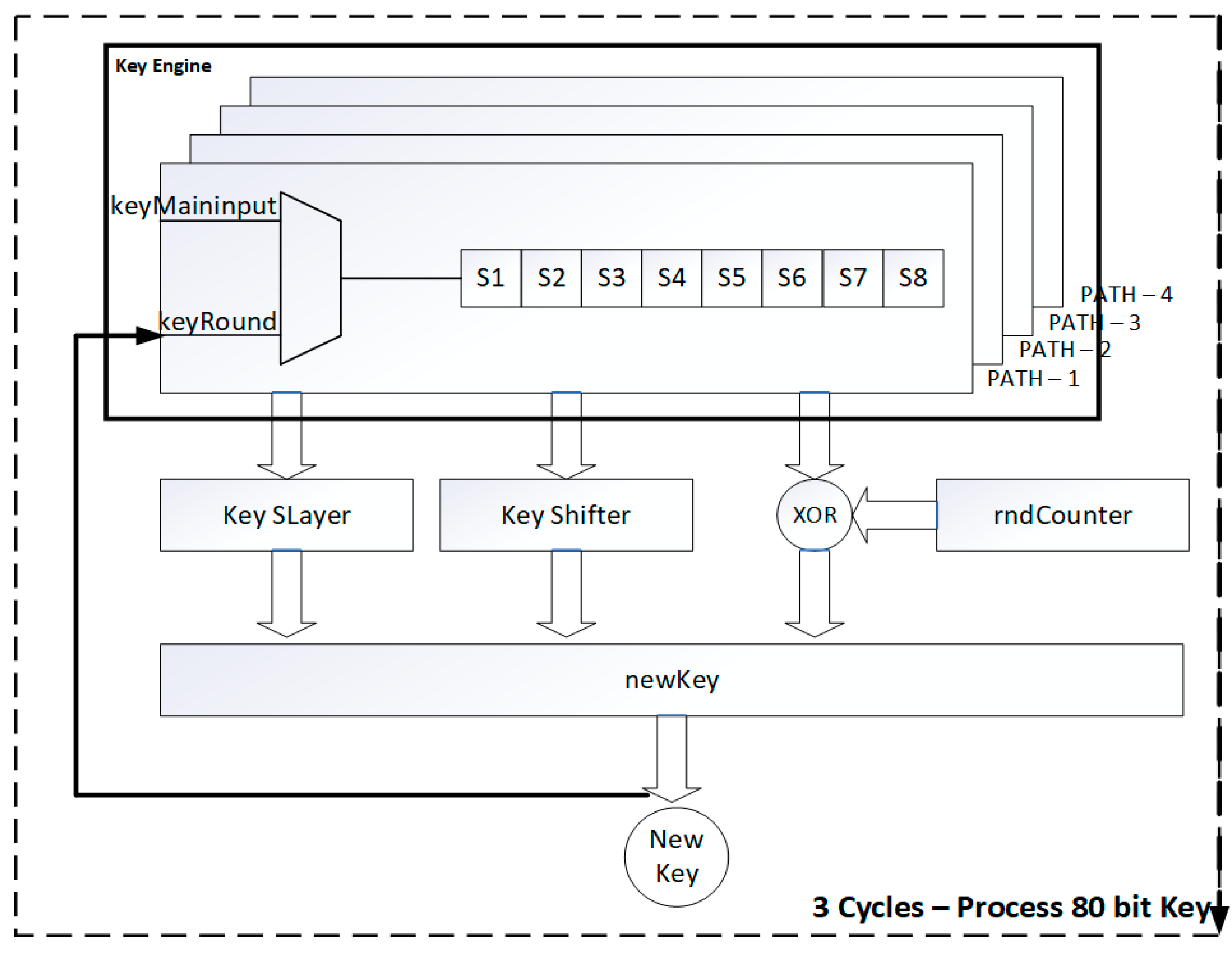
5. Proposed Low Latency 32-Bit Data Path and Key Schedule Architecture
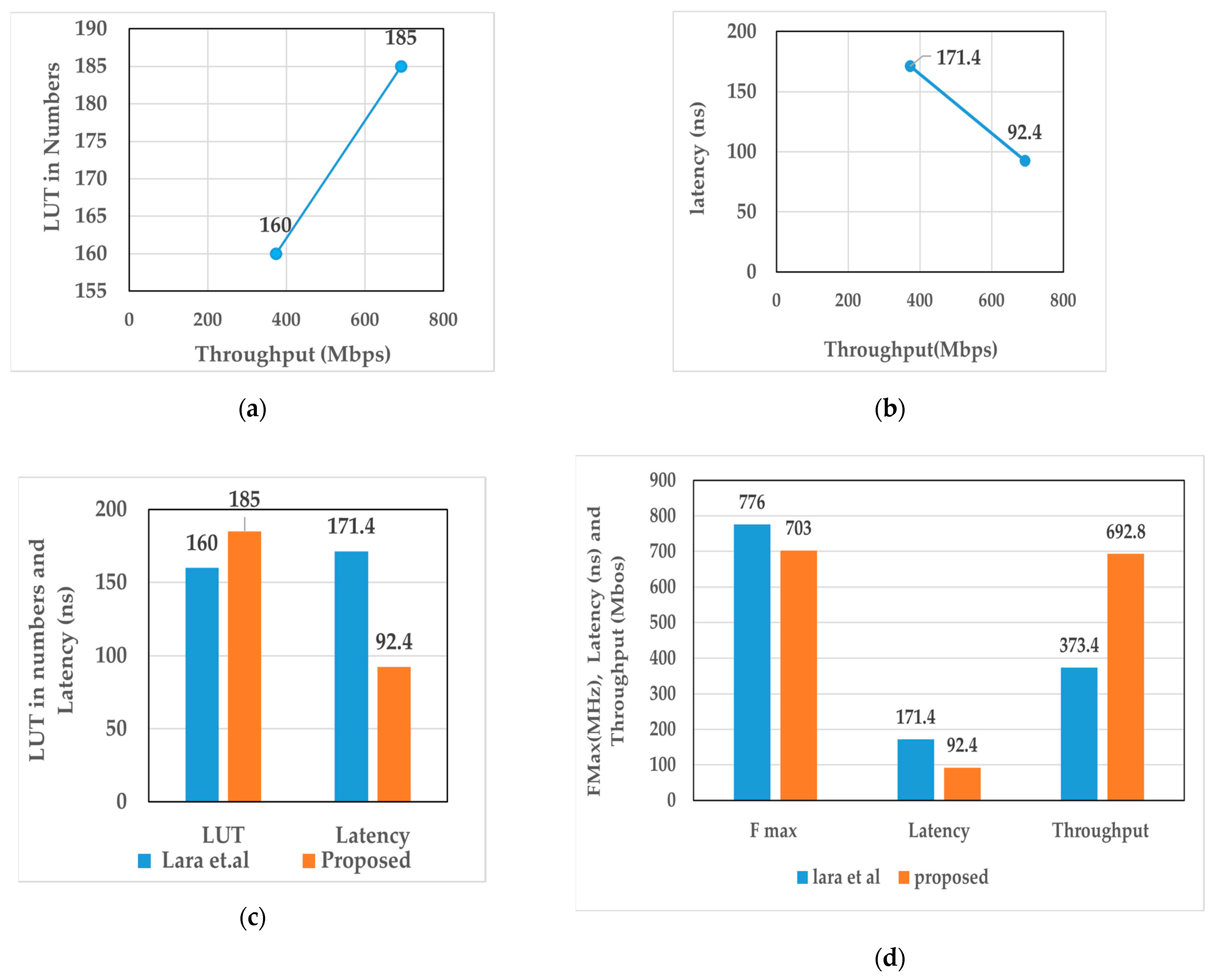
6. Result and Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ullah, I.; Mahmoud, Q.H. Design and Development of Deep Learning-Based Model for Anomaly Detection in IoT Networks. IEEE Access 2021, 9, 103906–103926. [Google Scholar] [CrossRef]
- Arul Murugan, C.; Karthigai Kumar, P.; Sathya Priya, S. FPGA implementation of hardware architecture with AES encryptor using sub-pipelined S-box techniques for compact applications. Automatika 2020, 61, 682–693. [Google Scholar] [CrossRef]
- Marzouqi, H.; Al-Qutayri, M.; Salah, K.; Schinianakis, D.; Stouraitis, T. A high-speed FPGA implementation of an RSD-based ECC processor. IEEE Trans. Very-Large-Scale Integr. (VLSI) Syst. 2015, 24, 151–164. [Google Scholar] [CrossRef]
- Bani-Hani, R.; Harb, S.; Mhaidat, K.; Taqieddin, E. High-throughput and area-efficient FPGA implementations of data encryption standard (DES). Circuits Syst. 2014, 5, 45–46. [Google Scholar] [CrossRef]
- Ahmad, R.; Kho, D.; Ismail, W. Parallel-Pipelined-Memory-Based Blowfish Design with Reduced FPGA Utilization for Secure Zig Bee Real-Time Transmission. Wirel. Pers. Commun. 2019, 104, 471–489. [Google Scholar] [CrossRef]
- Tarus, M.S.; McKay, K.A.; Calik, C.; Chang, D.; Bassham, L. Status Report on the First Round of the NIST Lightweight Cryptography Standardization Process; National Institute of Standards and Technology, NIST Interagency/Internal Rep. (NISTIR): Gaithersburg, MD, USA, 2019. [Google Scholar]
- Thakor, V.A.; Razzaque, M.A.; Khandaker, M.R.A. Lightweight cryptography algorithms for resource-constrained IoT devices: A review, comparison, and research opportunities. IEEE Access 2021, 9, 28177–28193. [Google Scholar] [CrossRef]
- Tao, H.; Bhuiyan, M.Z.A.; Abdullah, A.N.; Hassan, M.M.; Zain, J.M.; Hayajneh, T. Secured Data Collection with Hardware-Based Ciphers for IoT-Based Healthcare. IEEE Internet Things J. 2019, 6, 410–420. [Google Scholar] [CrossRef]
- Jamuna Rani, D.; Emalda Roslin, S. Lightweight cryptographic algorithms for medical internet of things (IoT)-a review. In Proceedings of the Online International Conference on Green Engineering and Technologies (IC-GET), Coimbatore, India, 19 November 2016. [Google Scholar]
- Bogdanov, A.; Knudsen, L.R.; Leander, G.; Paar, C.; Poschmann, A.; Robshaw, M.J.; Seurin, Y.; Vikkelsoe, C. RESENT: An ultra-lightweight block cipher. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Vienna, Austria, 10–13 September 2007; Springer: Berlin/Heidelberg, Germany, 2007; Volume LNCS 4127, pp. 450–466. [Google Scholar]
- Abbas, Y.A.; Jidin, R.; Jamil, N.; Zaba, M.R.; Rusli, M.E.; Tariq, B. Implementation of PRINCE Algorithm in FPGA. In Proceedings of the International Conference on Information Technology and Multimedia (ICIMU), Putrajaya, Malaysia, 18–20 November 2014. [Google Scholar]
- Kolbl, S.; Leander, G.; Tiessen, T. Observations on the SIMON block cipher family. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 16–18 August 2015; Springer: Berlin/Heidelberg, Germany, 2015; Volume LNCS 9215, pp. 161–185. [Google Scholar]
- Banik, S.; Pandey, S.K.; Peyrin, T.; Sasaki, Y.; Sim, S.M.; Todo, Y. GIFT: A small present. In Proceedings of the International Conference on Cryptographic Hardware and Embedded Systems, Taipei, Taiwan, 25–28 September 2017; Springer: Cham, Switzerland, 2017; pp. 321–345. [Google Scholar]
- Jamuna Rani, D.; Emalda Roslin, S. Optimized Implementation of Gift Cipher. Wirel. Pers. Commun. 2021, 119, 2185–2195. [Google Scholar] [CrossRef]
- Beierle, C.; Jean, J.; Stefan, K.; Leander, G.; Moradi, A.; Peyrin, T.; Sasaki, Y.; Sasdrich, P.; Sim, S.M. The SKINNY family of block ciphers and its low-latency variant MANTIS. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 123–153. [Google Scholar]
- Nallathambi, B.; Palanivel, K. Fault diagnosis architecture for SKINNY family of block ciphers. Microprocess. Microsyst. 2020, 77, 103202. [Google Scholar] [CrossRef]
- Guo, J.; Peyrin, T.; Poschmann, A. The PHOTON family of lightweight hash functions. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 222–239. [Google Scholar]
- Suzaki, T.; Minematsu, K.; Morioa, S.; Kobayashi, E. A Lightweight Block Cipher for Multiple Platforms. In Proceedings of the International Conference on Selected Areas in Cryptography, Windsor, ON, Canada, 15–16 August 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 339–354. [Google Scholar]
- Beaulieu, R.; Shors, D.; Smith, J.; Treatman-Clark, S.; Weeks, B.; Wingers, L. The SIMON and SPECK lightweight block ciphers. In Proceedings of the 52nd Annual Design Automation Conference, San Francisco, CA, USA, 8–12 June 2015; pp. 1–6. [Google Scholar]
- Rolfes, C.; Poschmann, A.; Leander, G.; Paar, C. Ultra-lightweight implementations for smart devices—Security for 1000 gate equivalents. In Proceedings of the International Conference on Smart Card Research and Advanced Applications, London, UK, 8–11 September 2008; Volume LNCS 5189, pp. 89–103. [Google Scholar]
- Sbeiti, M.; Silbermann, M.; Poschmann, A.; Paar, C. Design space exploration of PRESENT implementations for FPGAs. In Proceedings of the 2009 5th Southern Conference on Programmable Logic (SPL), IEEE, Sao Carlos, Brazil, 1–3 April 2009; pp. 141–145. [Google Scholar]
- Yalla, P.; Kaps, J.P. Lightweight cryptography for FPGA. In Proceedings of the International Conference on Reconfigurable Computing and FPGAs, IEEE, Cancun, Mexico, 9–11 December 2009; pp. 225–230. [Google Scholar]
- Kavun, E.B.; Yalcin, T. RAM-based ultra-lightweight FPGA implementation of PRESENT. In Proceedings of the International Conference on Reconfigurable Computing and FPGAs, IEEE, Cancun, Mexico, 30 November–2 December 2011; pp. 280–285. [Google Scholar]
- Hanley, N.; Neill, O.M. RAM-based ultra-lightweight FPGA implementation of PRESENT. In Proceedings of the IEEE Computer Society Annual Symposium on VLSI, Amherst, MA, USA, 19–21 August 2012; pp. 57–62. [Google Scholar]
- Tay, J.J.; Wong, M.D.; Wong, M.M.; Zhang, C.; Hijazin, I. Compact FPGA Implementation of PRESENT with Boolean S-Box. In Proceedings of the 6th Asia Symposium on Quality Electronic Design (ASQED), IEEE, Kula Lumpur, Malaysia, 4–5 August 2015; pp. 144–148. [Google Scholar]
- Lara-Nino, C.A.; Morales-Sandoval, M.; Diaz-Perez, A. Novel FPGA-based low-cost hardware architecture for the PRESENT block cipher. In Proceedings of the Euro micro-Conference on Digital System Design (DSD), Limassol, Cyprus, 31 August–2 September 2016. [Google Scholar]
- Lara-Nino, C.A.; Diaz-Perez, A.; Morales-Sandoval, M. Lightweight hardware architectures for the present cipher in FPGA. Trans. Circuits Syst. 2017, 64, 2544–2555. [Google Scholar] [CrossRef]
- Moosavi, S.R.; Rahmani, A.M.; Westerlund, T.; Yang, G.; Liljeberg, P.; Hannu, T. Pervasive health monitoring based on internet of things: Two case studies. In Proceedings of the 4th International Conference on Wireless Mobile Communication and Healthcare-Transforming Healthcare Through Innovations in Mobile and Wireless Technologies (MOBIHEALTH), IEEE, Athens, Greece, 3–5 November 2014; pp. 275–278. [Google Scholar]
- Xilinx, X. Zynq-7000 All Programmable SoC Overview, DS190. Prod. Specif. 2018, 1–25. [Google Scholar]
- Finkenzeller, K. Identification Cards—Contactless Integrated Circuit Cards—Proximity Cards—Part 2: Radio Frequency Power and Signal Interface, Document ISO/IEC 14, 3rd ed.; John Wiley and Sons: German, UK, 2010; pp. 443–452. [Google Scholar]
- Farahmand, F.; Ferozpuri, A.; Diehl, W.; Gaj, K. Minerva: Automated hardware optimization tool. In Proceedings of the International Conference on Reconfigurable Computing and FPGAs (Re ConFig), Cancun, Mexico, 4–6 December 2017; pp. 1–8. [Google Scholar]
- Pandey, J.G.; Goel, T.; Karmakar, A. A high-performance and area-efficient VLSI architecture for the PRESENT lightweight cipher. In Proceedings of the 31st International Conference on VLSI Design and 2018 17th International Conference on Embedded Systems (VLSID), IEEE, Pune, India, 6–10 January 2018; pp. 392–397. [Google Scholar]
- Maro, E. Modelling of power consumption for Advanced Encryption Standard and PRESENT ciphers. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1155, 012060. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Existing Architecture [27] | Proposed Architecture |
|---|---|---|
| Block size | 64 | 64 |
| Key size | 80 | 80 |
| Number of slices | 48 | 59 |
| Number of LUT | 160 | 185 |
| Number of flip-flops | 153 | 169 |
| Latency (ns) | 171.392 | 92.46 |
| Latency (Cycles) | 133 | 65 |
| Max. frequency (MHz) | 776 | 703 |
| Throughput (Mbps) | 373.413 | 692.846 |
| Throughput/Slice (kbps) | 7.779 | 11.743 |
| Throughput* (kbps) | 6.578 | 13.459 |
| Total power (W) | 0.157 | 2.754 |
| Static power (W) | 0.123 | 2.62 |
| Dynamic power (W) | 0.034 | 0.134 |
| Plain Text Message (Input Data) (64-Bit) | Key Data (80-Bit) | Cipher Text Message (Output Data) (64-Bit) |
|---|---|---|
| 00000001F708E9B8 | 0000000008FB8F50f7E0 | 661B90DFD32CB83C |
| 00001DE63A028FEB | 00000000000291056CF3 | EBA17AB44B0CA503 |
| 018EB8895EED0E10 | D005A30380E380000000 | F269C4A6405880B3 |
| 7CB547399FFD1400 | 95100D1BF3D0C8000000 | 5102C10A4646A2A0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Damodharan, J.; Susai Michael, E.R.; Shaikh-Husin, N. High Throughput PRESENT Cipher Hardware Architecture for the Medical IoT Applications. Cryptography 2023, 7, 6. https://doi.org/10.3390/cryptography7010006
Damodharan J, Susai Michael ER, Shaikh-Husin N. High Throughput PRESENT Cipher Hardware Architecture for the Medical IoT Applications. Cryptography. 2023; 7(1):6. https://doi.org/10.3390/cryptography7010006
Chicago/Turabian StyleDamodharan, Jamunarani, Emalda Roslin Susai Michael, and Nasir Shaikh-Husin. 2023. "High Throughput PRESENT Cipher Hardware Architecture for the Medical IoT Applications" Cryptography 7, no. 1: 6. https://doi.org/10.3390/cryptography7010006
APA StyleDamodharan, J., Susai Michael, E. R., & Shaikh-Husin, N. (2023). High Throughput PRESENT Cipher Hardware Architecture for the Medical IoT Applications. Cryptography, 7(1), 6. https://doi.org/10.3390/cryptography7010006