
Flexible and Efficient Multi-Keyword Ranked Searchable Attribute-Based Encryption Schemes



Abstract
:1. Introduction
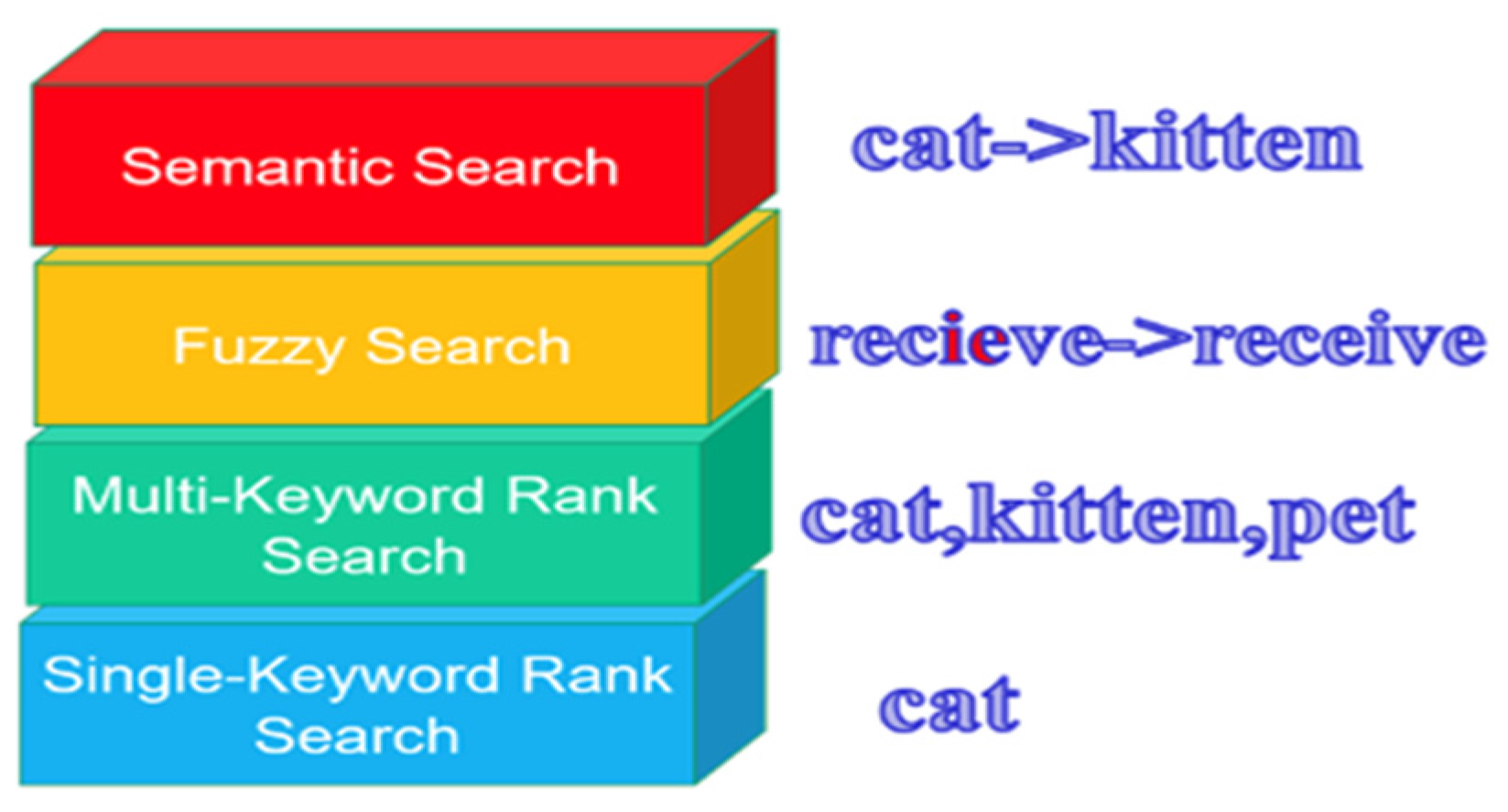
1.1. Motivations
1.2. Contributions of This Work
1.3. Organization
2. Related Work
2.1. Attribute-Based Encryption
2.2. Searchable Encryption
2.3. Searchable ABE Schemes
3. Preliminaries
3.1. Bilinear Pairing
- Bilinearity: For all and all holds. That is, the exponentiation operations inside pairings can be moved outside directly.
- Non-degeneracy:
- Computability: For all and any additive or multiplicative operations on it can be efficiently computed.
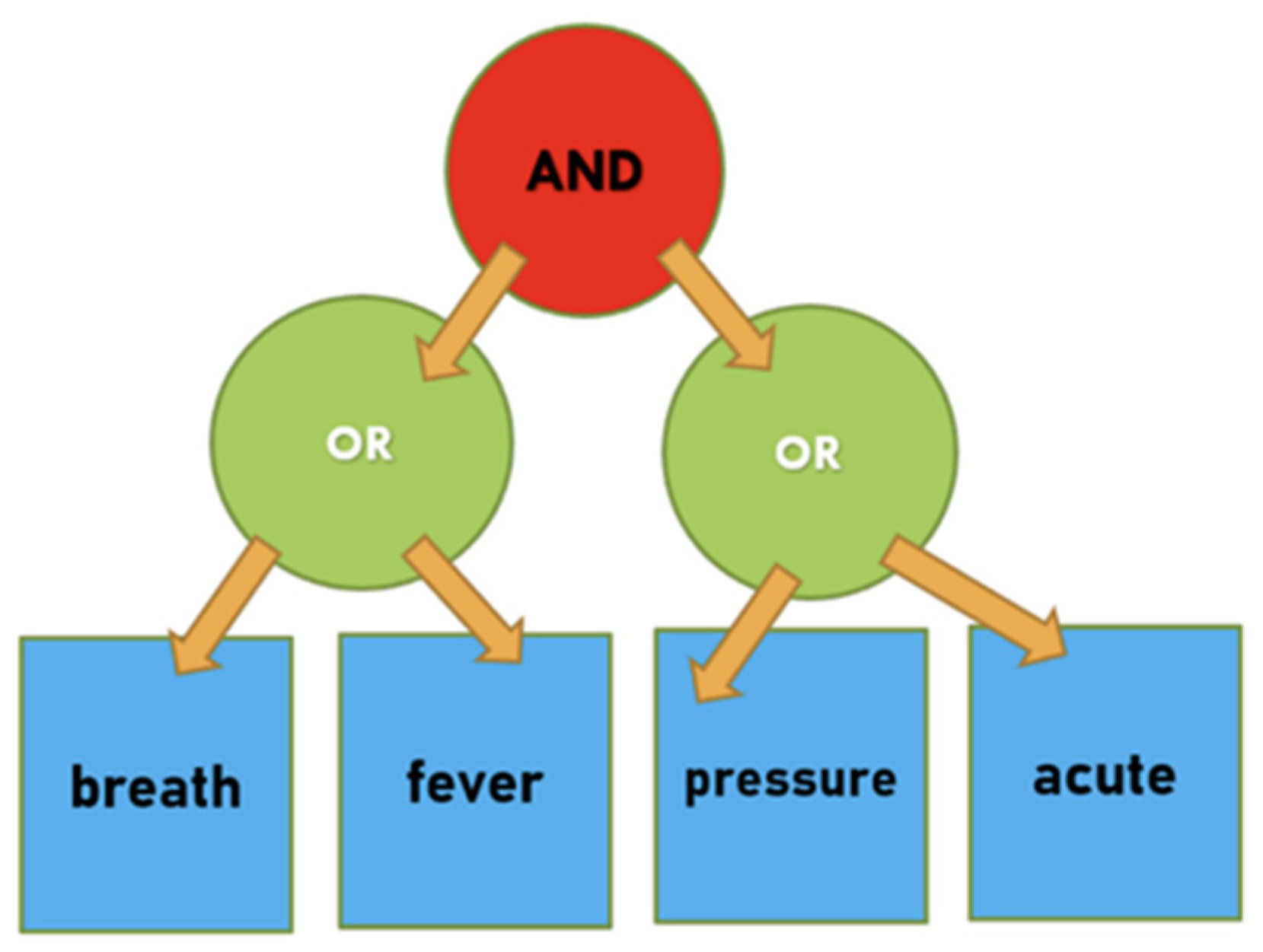
3.2. Access Structure
3.3. Linear Secret-Sharing Schemes
- The shares for each party form a vector over .
- There exists a matrix with is the vector of rows and columns called the share-generating matrix for . For the i-th row of M, we let the function define the party labeling row , for all as . When we consider the column vector , where is the secret to be shared, and are randomly chosen, then is the vector representing the shares of the secret according to the scheme . The share belongs to party .
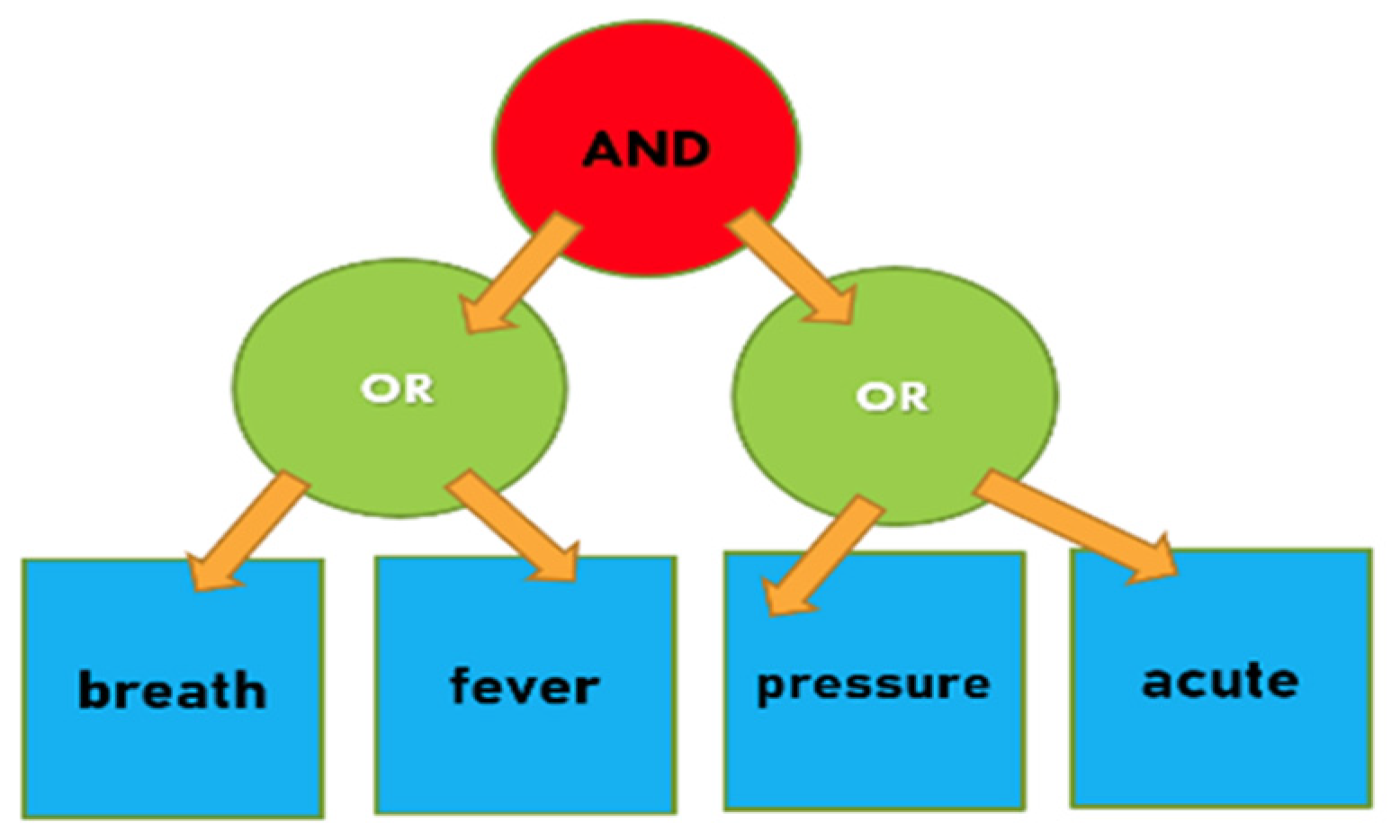
3.4. Relevance Score
4. Problem Definitions
4.1. Threat Model
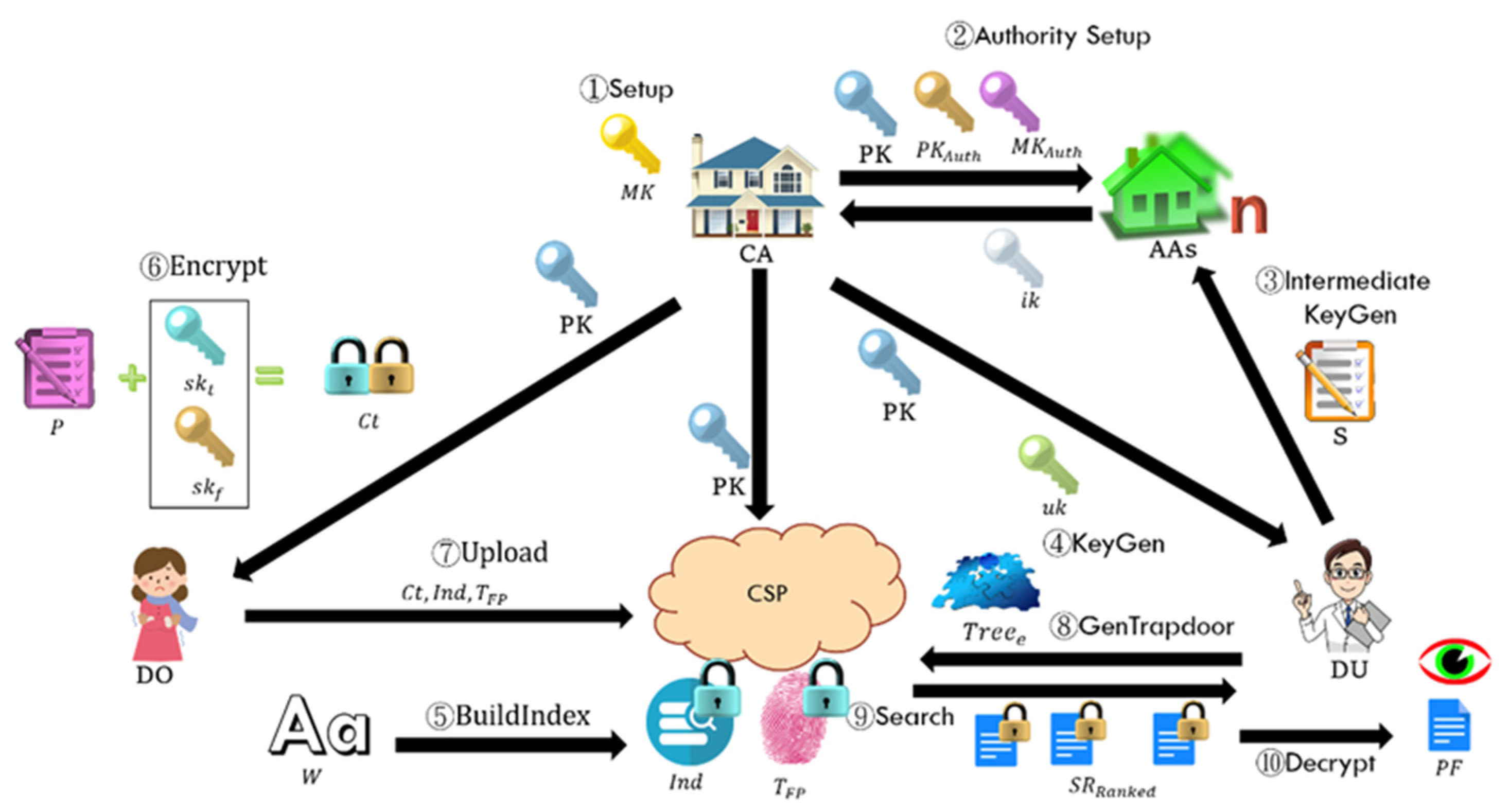
4.2. System Architecture
4.3. Security Model
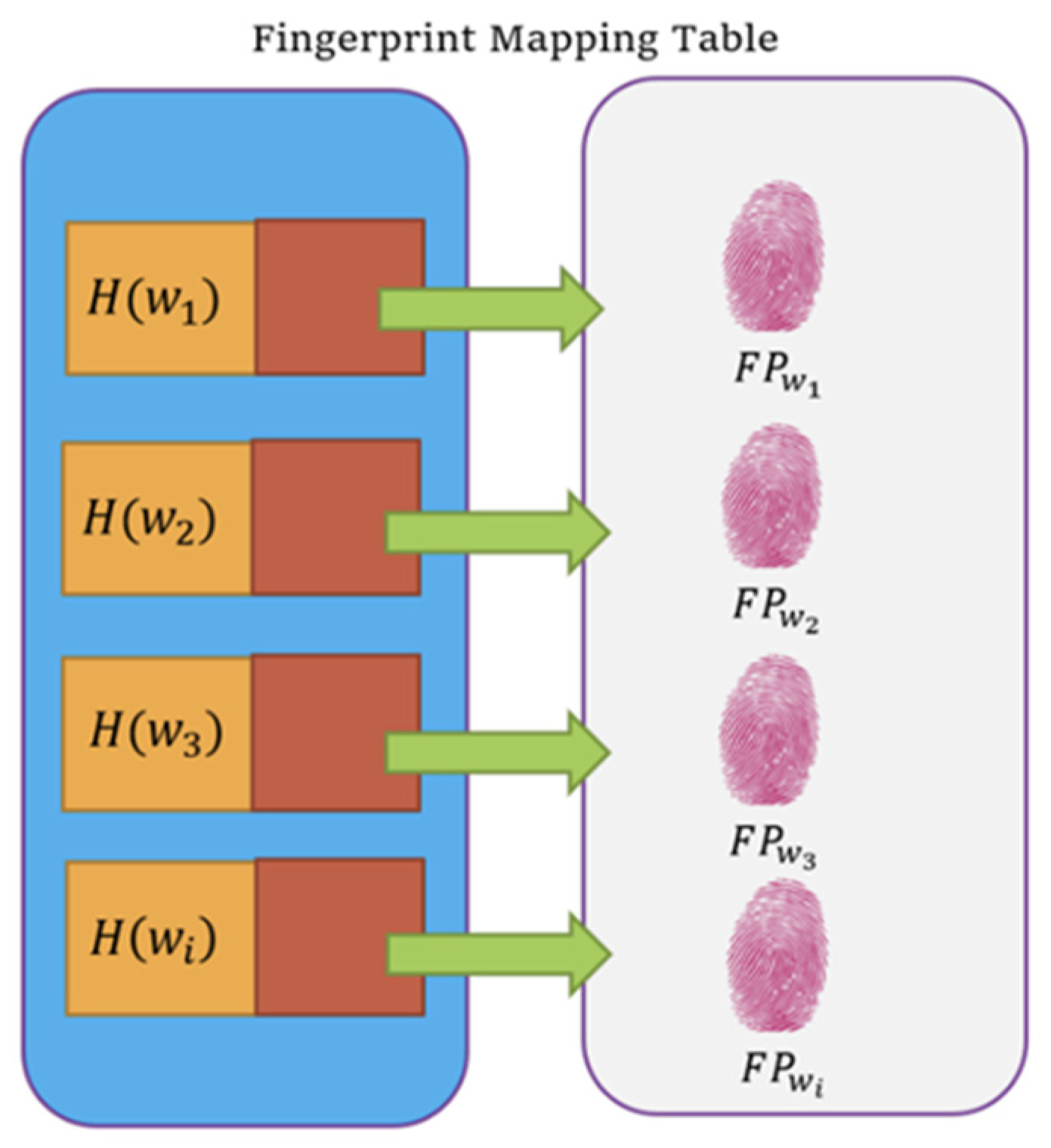
5. Concrete Construction
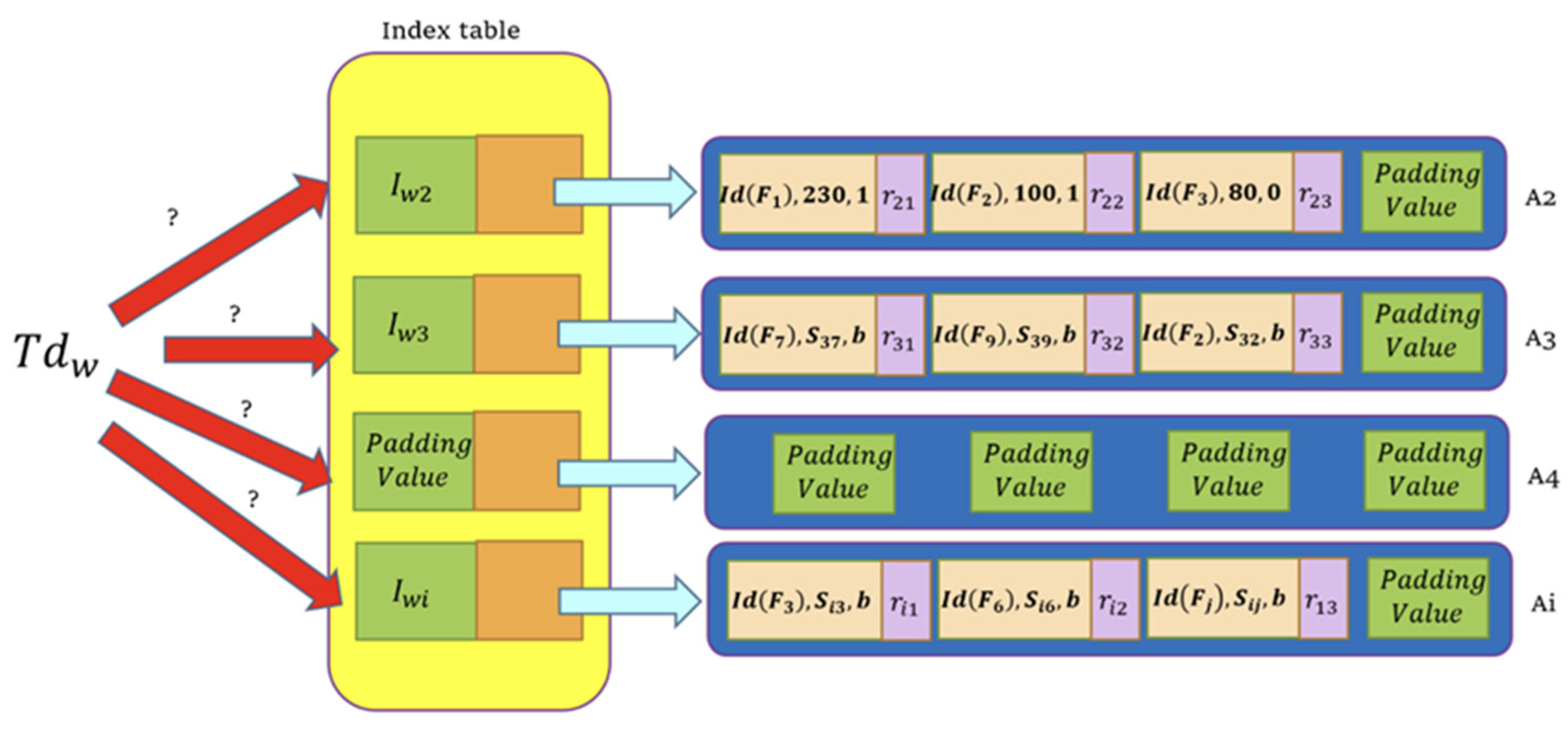
Construction of the Basic FERMSABE Scheme
- −
- : The identifier of the file, , which contains the keyword, .
- −
- : The relevance score of the keyword, and the file, . Notice that the blocks will not be sorted according to this score for confusion.
- −
- : Random strings of the same length. We use this field to prevent producing two identity blocks.
- −
- Padding values: We add padding values to every linked list to make them of the same size. This setting implies that some linked lists composed of all padding values may also be appended to the table.
6. Analyses
6.1. Security Analyses
- −
- : Assume that B received a secret key query for , in which does not match the access structure . B performs the following operations: if A has previously asked for , B retrieves from the list, , directly and returns it to A.
6.2. Functional Comparisons
6.3. Computational Complexity Analyses
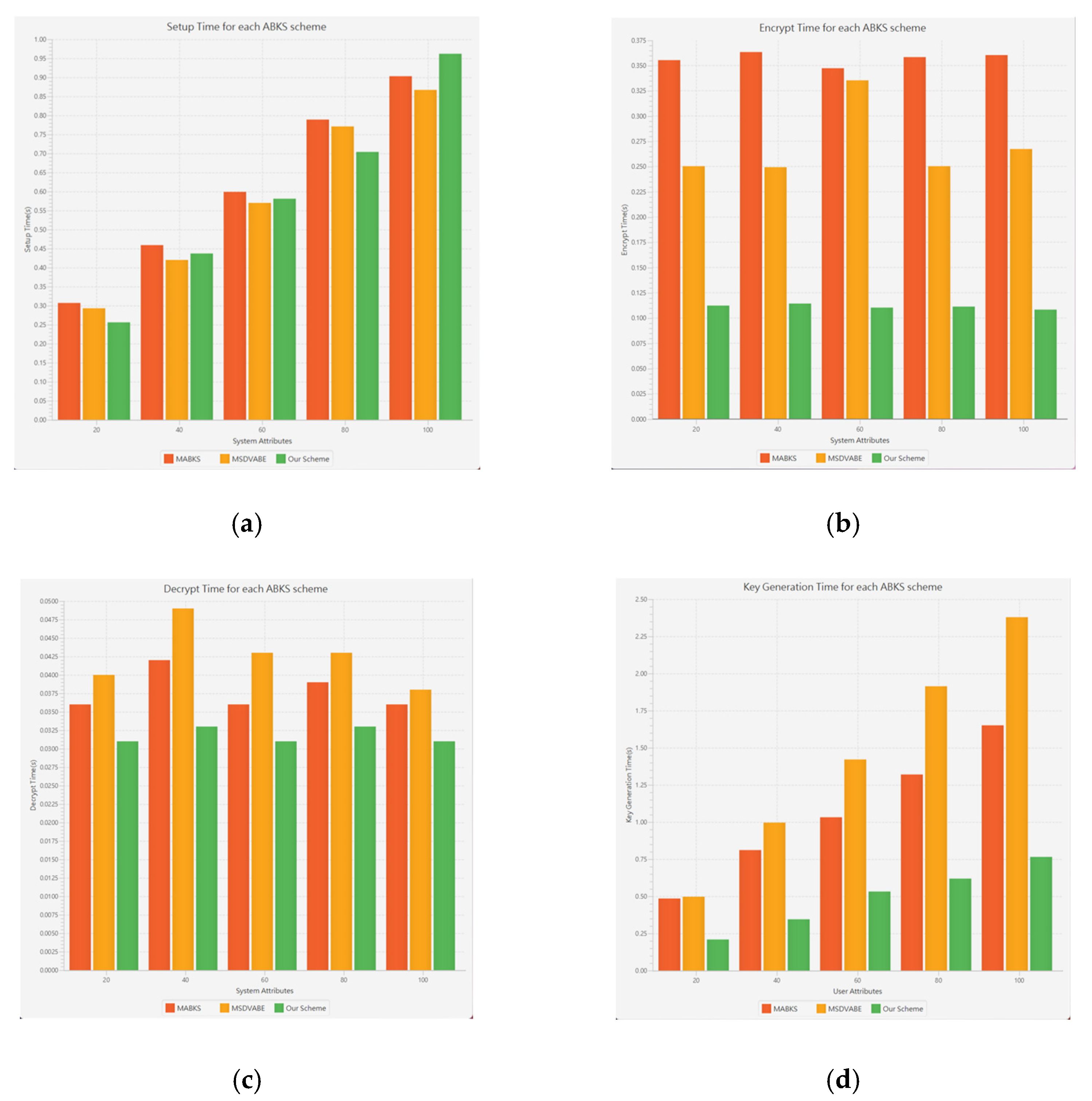
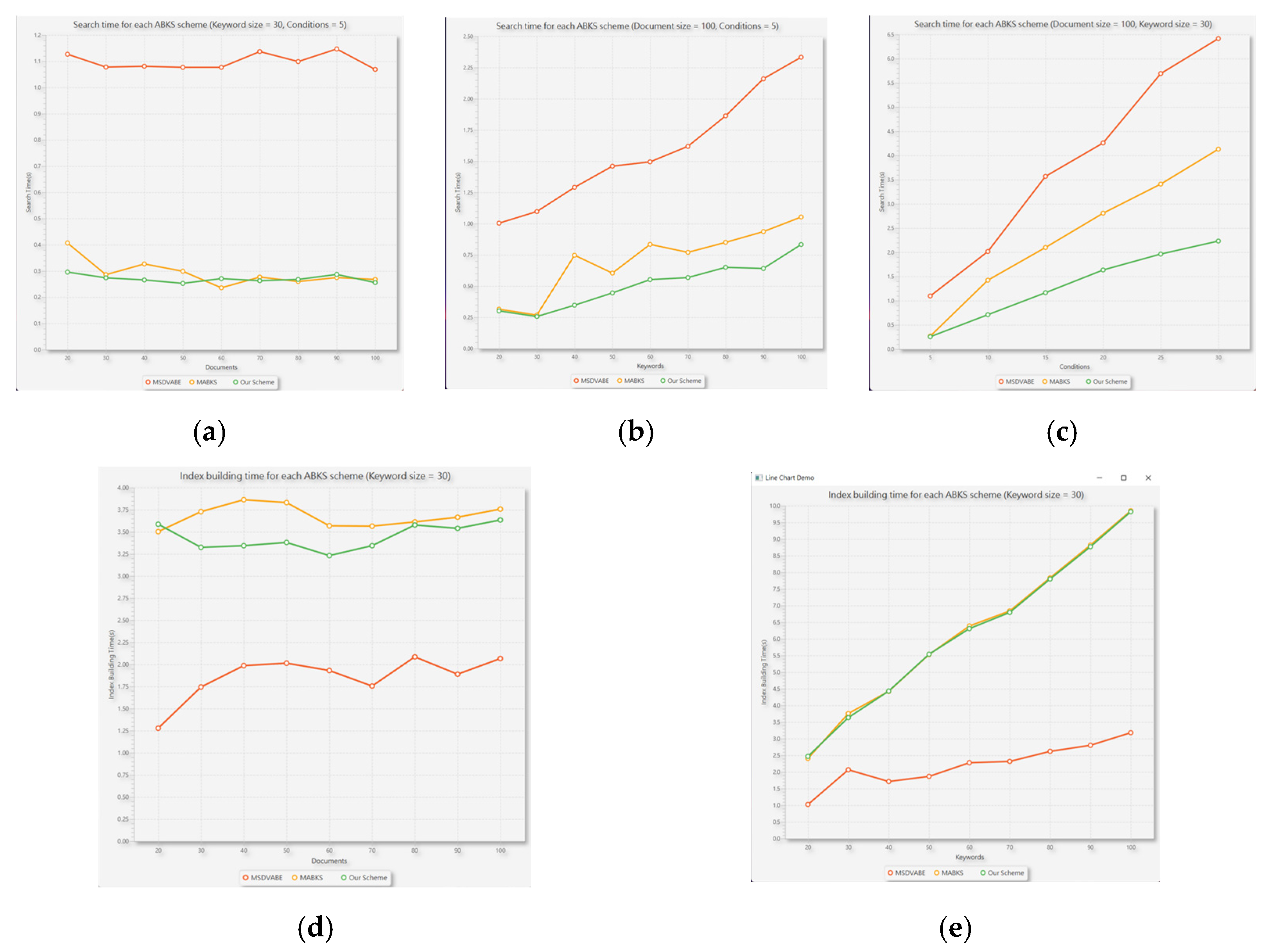
6.4. Experimental Analyses
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Saxena, A.; Shinghal, K.; Misra, R.; Agarwal, A. Automated Enhanced Learning System using IoT. In Proceedings of the 2019 4th International Conference on Internet of Things: Smart Innovation and Usages (IoT-SIU), Ghaziabad, India, 18–19 April 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Korupolu, M.; Jannabhatla, S.; Kommineni, V.S.; Kalyanam, H.; Vasantham, V. Video Streaming Platform Using Distributed Environment in Cloud Platform. In Proceedings of the 2021 7th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 19–20 March 2021; Volume 1, pp. 1414–1417. [Google Scholar] [CrossRef]
- Xiong, H.; Yao, T.; Wang, H.; Feng, J.; Yu, S. A Survey of Public-Key Encryption with Search Functionality for Cloud-Assisted IoT. IEEE Internet Things J. 2021, 9, 401–418. [Google Scholar] [CrossRef]
- Bethencourt, J.; Sahai, A.; Waters, B. Ciphertext-Policy Attribute-Based Encryption. In Proceedings of the 2007 IEEE Symposium on Security and Privacy (SP’07), Berkeley, CA, USA, 20–23 May 2007; pp. 321–334. [Google Scholar] [CrossRef]
- Chi, P.-W.; Wang, M.-H.; Shiu, H.-J. How to Hide the Real Receiver Under the Cover Receiver: CP-ABE with Policy Deniability. IEEE Access 2020, 8, 89866–89881. [Google Scholar] [CrossRef]
- Han, J.; Susilo, W.; Mu, Y.; Zhou, J.; Au, M.H.A. Improving Privacy and Security in Decentralized Ciphertext-Policy Attribute-Based Encryption. IEEE Trans. Inf. Forensics Secur. 2015, 10, 665–678. [Google Scholar] [CrossRef]
- Li, J.; Yao, W.; Han, J.; Zhang, Y.; Shen, J. User Collusion Avoidance CP-ABE with Efficient Attribute Revocation for Cloud Storage. IEEE Syst. J. 2017, 12, 1767–1777. [Google Scholar] [CrossRef]
- Moffat, S.; Hammoudeh, M.; Hegarty, R. A Survey on Ciphertext-Policy Attribute-based Encryption (CP-ABE) Approaches to Data Security on Mobile Devices and its Application to IoT. In Proceedings of the ICFNDS’17: Proceedings of the International Conference on Future Networks and Distributed Systems, Cambridge, UK, 19–20 July 2017; Association for Computing Machinery: New York, NY, USA, 2017; p. 34. [Google Scholar] [CrossRef]
- Yahiatene, Y.; Menacer, D.E.; Riahla, M.A.; Rachedi, A.; Tebibel, T.B. Towards a distributed ABE based approach to protect privacy on online social networks. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Fu, Z.; Shu, J.; Sun, X.; Zhang, D. Semantic keyword search based on tree over encrypted cloud data. In Proceedings of the SCC’14—Proceedings of the 2nd International Workshop on Security in Cloud Computing, Kyoto, Japan, 3 June 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 59–62. [Google Scholar] [CrossRef]
- Liu, G.; Yang, G.; Bai, S.; Zhou, Q.; Dai, H. FSSE: An Effective Fuzzy Semantic Searchable Encryption Scheme over Encrypted Cloud Data. IEEE Access 2020, 8, 71893–71906. [Google Scholar] [CrossRef]
- Tzouramanis, T.; Manolopoulos, Y. Secure reverse k-nearest neighbors search over encrypted mult-dimensional databases. In Proceedings of the IDEAS’18: Proceedings of the 22nd International Database Engineering & Applications Symposium, Calabria, Italy, 18–20 June 2018; Association for Computing Machinery: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Wang, B.; Hou, Y.; Li, M.; Wang, H.; Li, H. Maple: Scalable multi-dimensional range search over encrypted cloud data with tree-based index. In Proceedings of the 9th ACM Symposium on Information, Computer and Communications Security, Kyoto, Japan, 4–6 June 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 111–122. [Google Scholar] [CrossRef]
- Yoshino, M.; Naganuma, K.; Kunihiro, N.; Sato, H. Practical Query-based Order Revealing Encryption from Symmetric Searchable Encryption. In Proceedings of the 2020 15th Asia Joint Conference on Information Security (AsiaJCIS), Taipei, Taiwan, 20–21 August 2020; pp. 16–23. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, X.A.; Yang, X.; Cai, W. Efficient Predicate Encryption Supporting Construction of Fine-Grained Searchable Encryption. In Proceedings of the 2013 5th International Conference on Intelligent Networking and Collaborative Systems, Xi’an, China, 9–11 September 2013; pp. 438–442. [Google Scholar] [CrossRef]
- Cao, L.; Kang, Y.; Wu, Q.; Wu, R.; Guo, X.; Feng, T. Searchable encryption cloud storage with dynamic data update to support efficient policy hiding. China Commun. 2020, 17, 153–163. [Google Scholar] [CrossRef]
- Chaudhari, P.; Das, M.L. A2BSE: Anonymous attribute based searchable encryption. In Proceedings of the 2017 ISEA Asia Security and Privacy (ISEASP), Surat, India, 29 January–1 February 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Khan, S.; Khan, S.; Zareei, M.; Alanazi, F.; Kama, N.; Alam, M.; Anjum, A. ABKS-PBM: Attribute-Based Keyword Search with Partial Bilinear Map. IEEE Access 2021, 9, 46313–46324. [Google Scholar] [CrossRef]
- Li, H.; Liu, D.; Jia, K.; Lin, X. Achieving authorized and ranked multi-keyword search over encrypted cloud data. In Proceedings of the 2015 IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 7450–7455. [Google Scholar] [CrossRef]
- Liu, L.; Wang, S.; He, B.; Zhang, D. A Keyword-Searchable ABE Scheme from Lattice in Cloud Storage Environment. IEEE Access 2019, 7, 109038–109053. [Google Scholar] [CrossRef]
- Miao, Y.; Deng, R.; Liu, X.; Choo, K.-K.R.; Wu, H.; Li, H. Multi-authority Attribute-Based Keyword Search over Encrypted Cloud Data. IEEE Trans. Dependable Secur. Comput. 2019, 18, 1667–1680. [Google Scholar] [CrossRef]
- Sun, W.; Yu, S.; Lou, W.; Hou, Y.T.; Li, H. Protecting your right: Attribute-based keyword search with fine-grained owner-enforced search authorization in the cloud. In Proceedings of the IEEE INFOCOM 2014—IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 226–234. [Google Scholar] [CrossRef]
- Wang, H.; Ning, J.; Huang, X.; Wei, G.; Poh, G.S.; Liu, X. Secure Fine-grained Encrypted Keyword Search for e-Healthcare Cloud. IEEE Trans. Dependable Secur. Comput. 2019, 18, 1307–1319. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, D.; Zhang, Y.; Liu, L. Efficiently Revocable and Searchable Attribute-Based Encryption Scheme for Mobile Cloud Storage. IEEE Access 2018, 6, 30444–30457. [Google Scholar] [CrossRef]
- Zhang, L.; Su, J.; Mu, Y. Outsourcing Attributed-Based Ranked Searchable Encryption with Revocation for Cloud Storage. IEEE Access 2020, 8, 104344–104356. [Google Scholar] [CrossRef]
- Miller, G.A. Wordnet: A lexical database for English. Communications. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Wang, C.-J.; Luo, J.-F. A Key-policy Attribute-based Encryption Scheme with Constant Size Ciphertext. In Proceedings of the 2012 Eighth International Conference on Computational Intelligence and Security, Guangzhou, China, 17–18 November 2012; pp. 447–451. [Google Scholar] [CrossRef]
- Cao, N.; Wang, C.; Li, M.; Ren, K.; Lou, W. Privacy-Preserving Multi-Keyword Ranked Search over Encrypted Cloud Data. IEEE Trans. Parallel Distrib. Syst. 2013, 25, 222–233. [Google Scholar] [CrossRef]
- Aritomo, D.; Watanabe, C.; Matsubara, M.; Morishima, A. A Privacy-Preserving Similarity Search Scheme over Encrypted Word Embed-Dings; Association for Computing Machinery: New York, NY, USA, 2019; pp. 403–412, iiWAS2019. [Google Scholar] [CrossRef]
- Fan, J.; Vercauteren, F. Somewhat practical fully homomorphic encryption. IACR Cryptol. ePrint Arch. 2012, 144. [Google Scholar]
- Gentry, C. A Fully Homomorphic Encryption Scheme. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2009. aAI3382729. [Google Scholar]
- Yu, J.; Lu, P.; Zhu, Y.; Xue, G.; Li, M. Toward Secure Multikeyword Top-k Retrieval over Encrypted Cloud Data. IEEE Trans. Dependable Secur. Comput. 2013, 10, 239–250. [Google Scholar] [CrossRef]
- Sun, J.; Ren, L.; Wang, S.; Yao, X. Multi-Keyword Searchable and Data Verifiable Attribute-Based Encryption Scheme for Cloud Storage. IEEE Access 2019, 7, 66655–66667. [Google Scholar] [CrossRef]
- Waters, B. Ciphertext-policy attribute-based encryption: An expressive, efficient, and provably secure realization. In International Workshop on Public Key Cryptography; Springer: Berlin/Heidelberg, Germany, 2011; pp. 53–70. [Google Scholar]
- William, W.; Cohen, M.L.D.C. Enron Email Dataset. Tech. Rep. 2015. Available online: https://www.cs.cmu.edu/enron/ (accessed on 10 May 2023).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Description | Symbols | Description |
|---|---|---|---|
| Master secret key | Searching keyword | ||
| Public key | Keyword set | ||
| Authority master key | Plaintext files | ||
| Authority public key | A document | ||
| User secret key | Fingerprint | ||
| Intermediate user secret key | Ciphertexts | ||
| Session key | Relevance score | ||
| The universe of user attributes | Search condition string | ||
| User attribute set | Fingerprint table | ||
| An attribute | Trapdoor | ||
| Hash function | Search tree (plaintext) | ||
| Access policy | Search tree (encrypted) | ||
| User id | Maximum size of searching results | ||
| Attribute authority id | Searching results | ||
| Secure index | Ranked searching results |
| Function | MABKS [21] | MSDVABE [33] | FSSE [11] | Ours |
|---|---|---|---|---|
| Access control | - | |||
| Keyword search | ||||
| Multi-keyword | - | |||
| Ranked result | - | - | ||
| Fuzzy search | - | - | ||
| Semantic search | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, J.-K.; Lin, W.-T.; Wu, J.-L. Flexible and Efficient Multi-Keyword Ranked Searchable Attribute-Based Encryption Schemes. Cryptography 2023, 7, 28. https://doi.org/10.3390/cryptography7020028
Lin J-K, Lin W-T, Wu J-L. Flexible and Efficient Multi-Keyword Ranked Searchable Attribute-Based Encryption Schemes. Cryptography. 2023; 7(2):28. https://doi.org/10.3390/cryptography7020028
Chicago/Turabian StyleLin, Je-Kuan, Wun-Ting Lin, and Ja-Ling Wu. 2023. "Flexible and Efficient Multi-Keyword Ranked Searchable Attribute-Based Encryption Schemes" Cryptography 7, no. 2: 28. https://doi.org/10.3390/cryptography7020028
APA StyleLin, J. -K., Lin, W. -T., & Wu, J. -L. (2023). Flexible and Efficient Multi-Keyword Ranked Searchable Attribute-Based Encryption Schemes. Cryptography, 7(2), 28. https://doi.org/10.3390/cryptography7020028