
A High-Efficiency Modular Multiplication Digital Signal Processing for Lattice-Based Post-Quantum Cryptography


Abstract
:1. Introduction
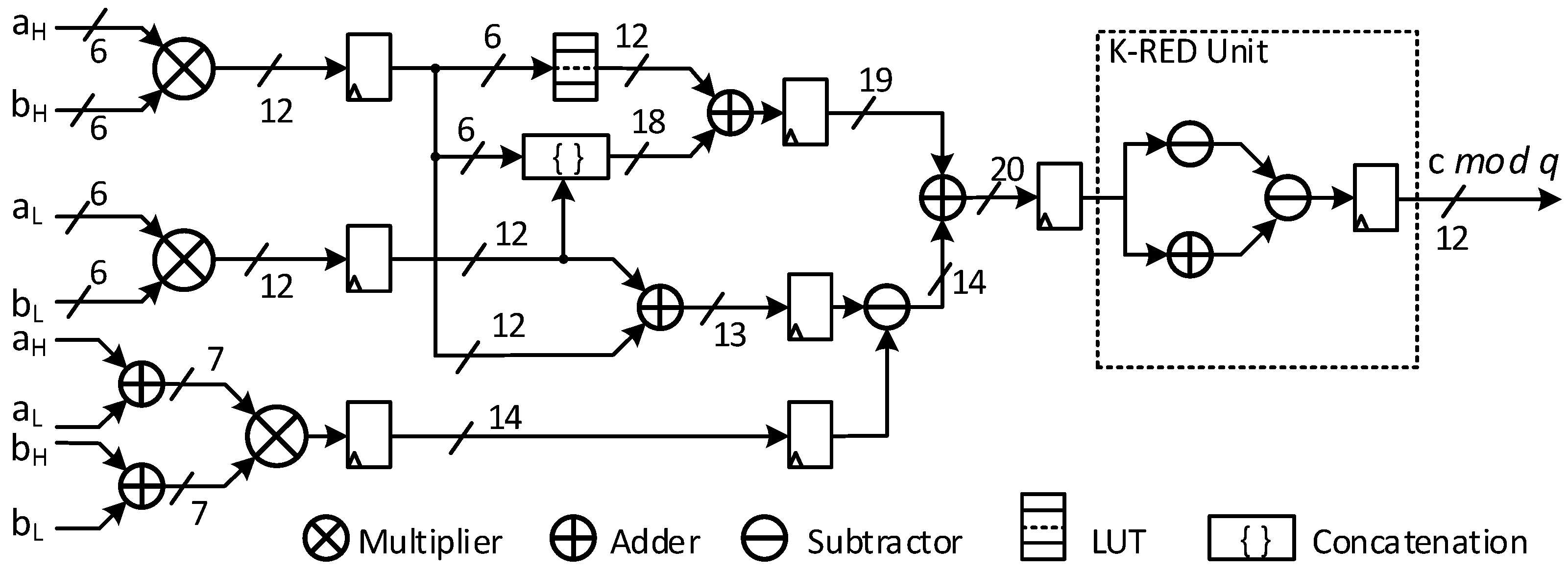
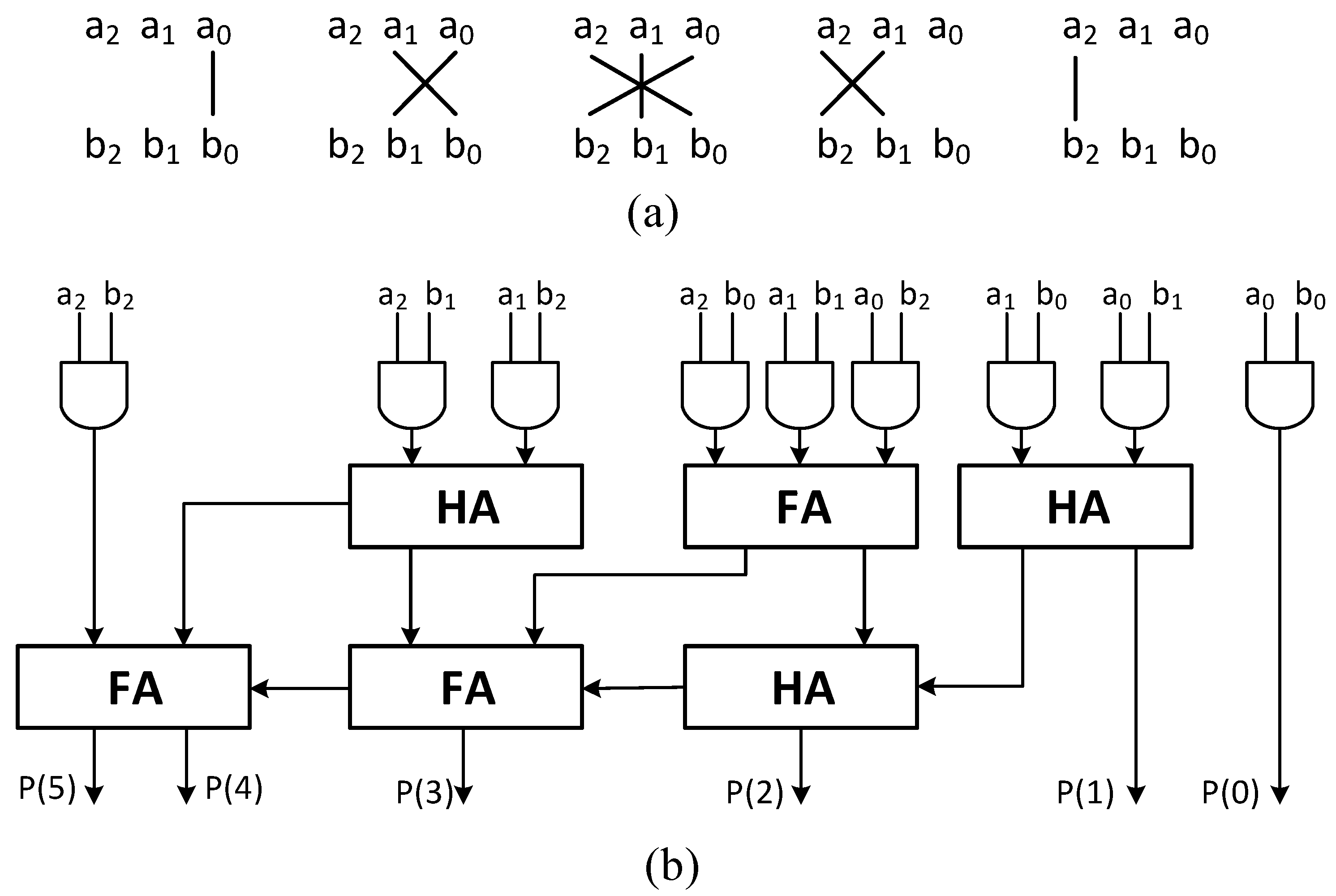
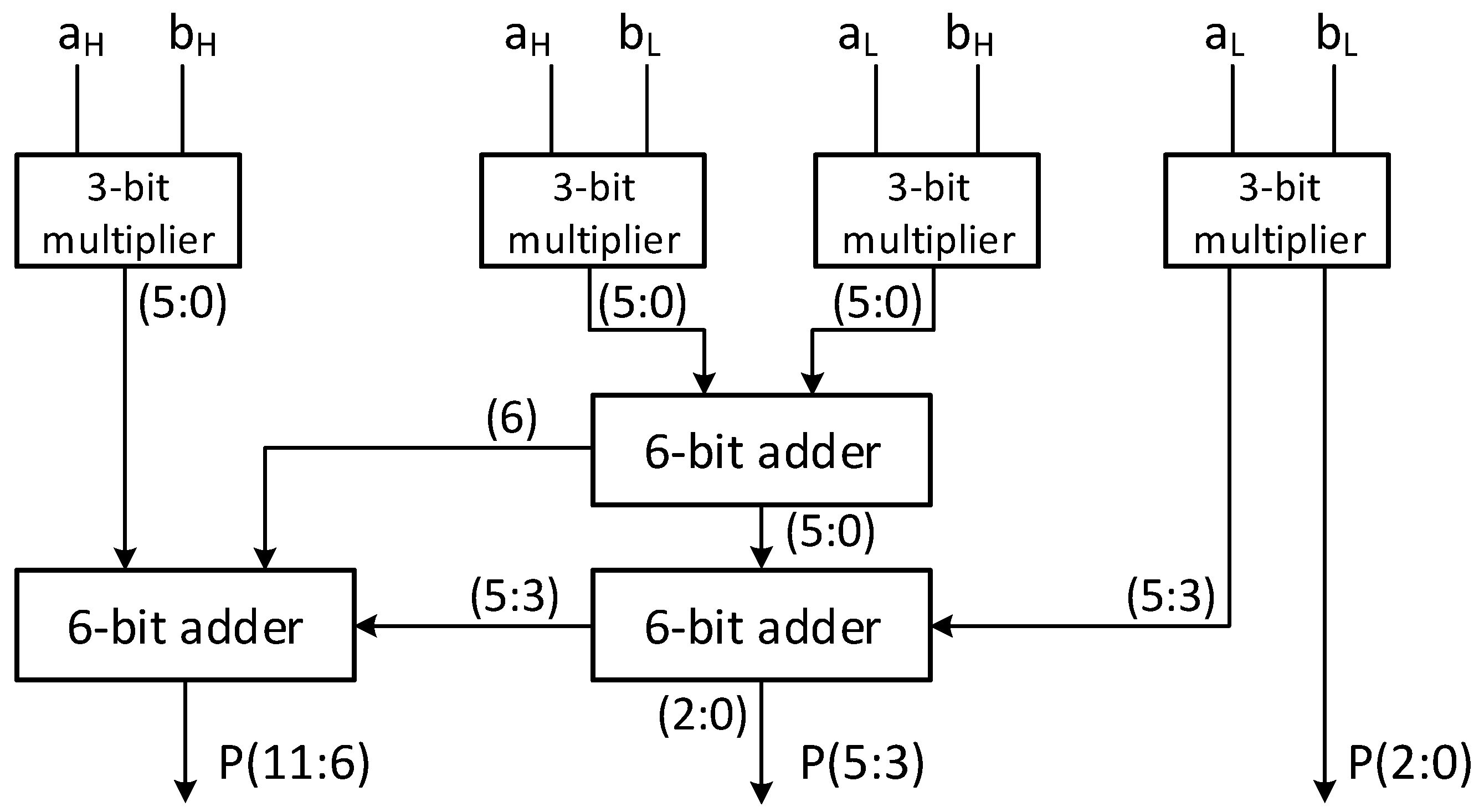
- Proposes the first specialized DSP that performs modular multiplication for the CRYSTAL-Kyber PQC algorithm, called Kyber-DSP (K-DSP).The K-DSP performs the multiplication of two input integers and modular reduction for the prime q = 3329. The architecture reaches a high frequency of 283 MHz, and the area is only 77 SLICEs, equivalent to 77% of a typical DSP. This result completely outperforms traditional methods of modular multiplication that rely on DSP.
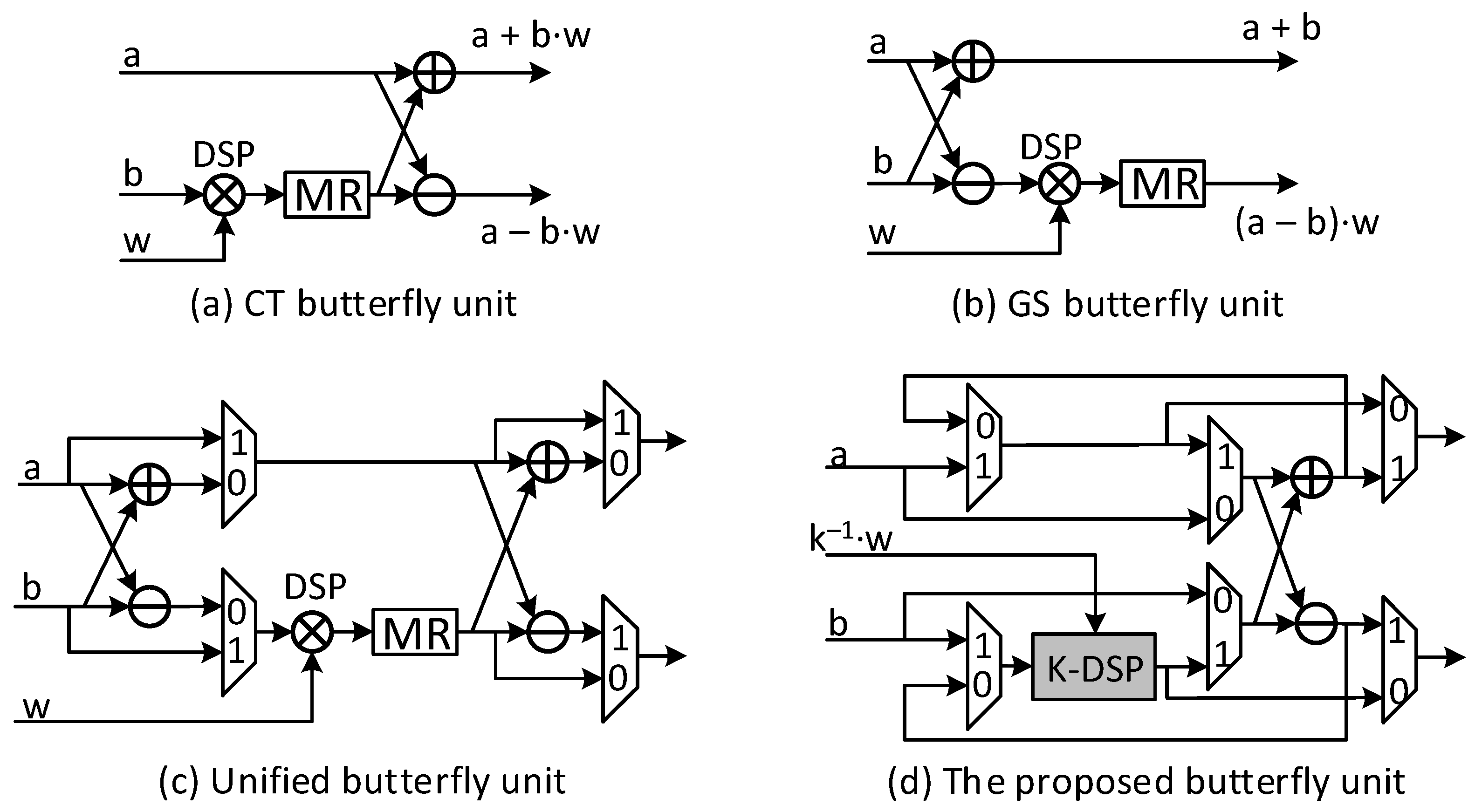
- The proposed Lattice-DSP (L-DSP) configuration optimizes the BU in NTT/INTT.In addition to saving on hardware resources, using the proposed L-DSP also eliminates the multiplication in the INTT process. As a result, the BU architecture requires minimal hardware resources. Choosing the architecture for NTT accelerators based on Decimation-In-Time (DIT), Decimation-In-Frequency (DIF), or both has become more flexible and easier. In CRYSTAL-Kyber, the BU architecture reaches a high frequency of 283 MHz while occupying an area equivalent to one DSP.
- Designs a K-DSP-based PWMM architecture designed for CRYSTAL-Kyber.PWM calculation in CRYSTAL-Kyber is more complicated than other LBC algorithms, requiring at least four multiplications for two PWM results. This study introduces a specific PWM structure for CRYSTAL-Kyber that uses K-DSP. Furthermore, the cumulative computation of matrix multiplication is combined with PWM while maintaining the same hardware cost for all three Kyber security levels (1, 3, and 5). The architecture that implements PWMM on the NTT domain includes PWM and Point-Wise Addition (PWA). The proposed PWMM operating frequency reaches 275 MHz with a hardware area of 386 SLICEs, equivalent to closely 4 DSPs.
- Extended with L-DSP design for prime numbers q = 7681 and 12,289.The proposed DSP design method is ideal for NTT-friendly algorithms with a prime factor . By applying this design to the case where q = 7681 and 12,889, it has been proven that the method still allows for a high operating frequency of 272 MHz and 256 MHz while using 87 SLICEs and 101 SLICEs of hardware resources.
2. The Background
2.1. CRYSTAL-Kyber
2.2. NTT-Based Polynomial Multiplication
3. Related Works
| Algorithm 1 Modular Multiplication by Barret Reduction [7] |
|
| Algorithm 2 K-RED Modular Reduction Algorithm [17] |
|
4. Proposed Hardware Design
4.1. K-DSP
4.2. Butterfly Unit
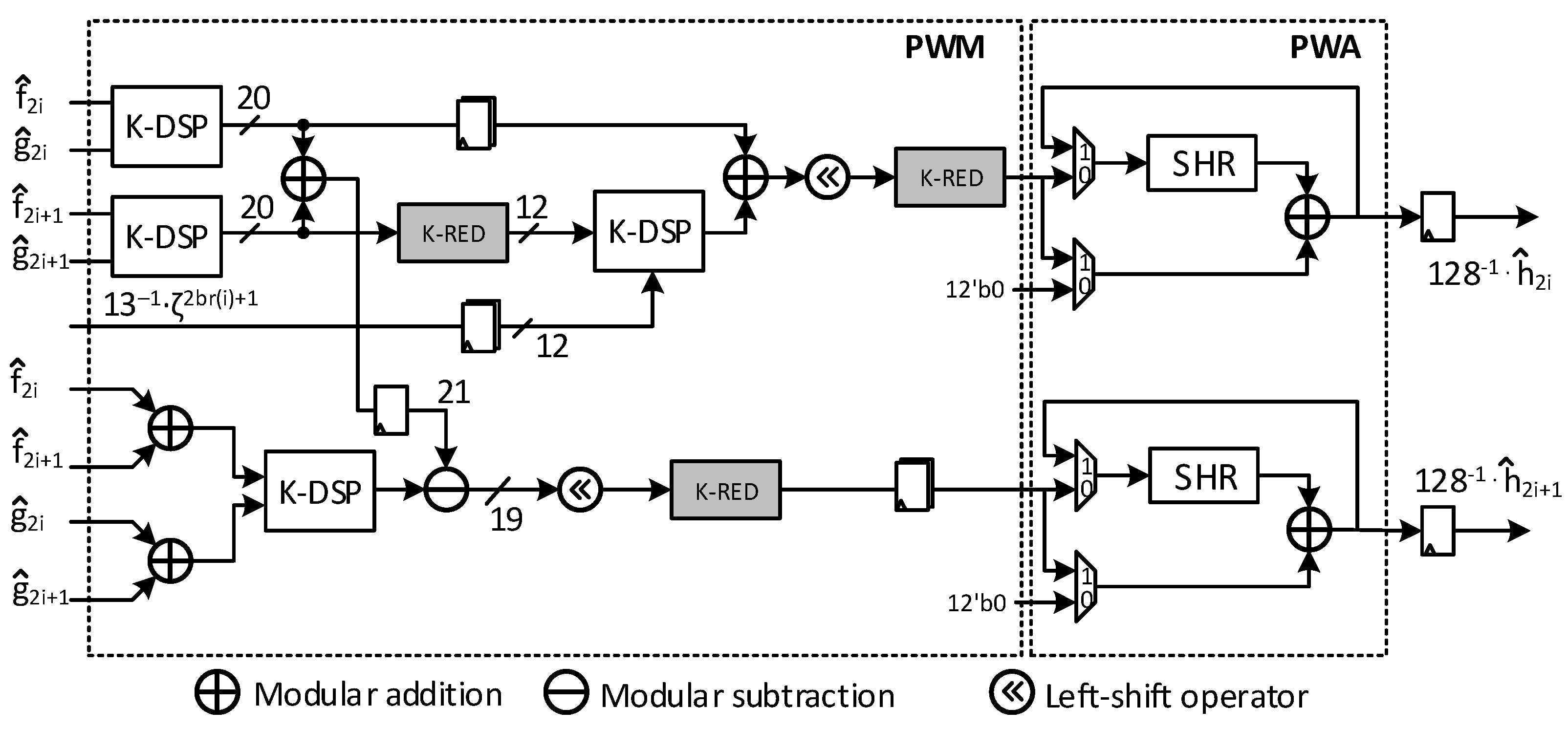
4.3. Point-Wise Matrix Multiplication Unit
4.4. L-DSPs
| Algorithm 3 L-DSP for Butterfly Unit |
|
| Algorithm 4 L-DSP for PWM Unit |
|
5. Implementation Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alagic, G.; Apon, D.; Cooper, D.; Dang, Q.; Dang, T.; Kelsey, J.; Lichtinger, J.; Liu, Y.K.; Miller, C.; Moody, D.; et al. Status Report on the Third Round of the NIST Post-Quantum Cryptography Standardization Process; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2022. [CrossRef]
- Avanzi, R.; Bos, J.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schanck, J.M.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS-Kyber: Algorithm Specifications And Supporting Documentation (Version 3.01). January 2021. Available online: https://pq-crystals.org/kyber/data/kyber-specification-round3-20210131.pdf (accessed on 15 September 2023).
- Bai, S.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS-Dilithium: Algorithm Specifications And Supporting Documentation (Version 3.01). February 2021. Available online: https://pq-crystals.org/dilithium/data/dilithium-specification-round3-20210208.pdf (accessed on 15 September 2023).
- Fouque, P.-A.; Hoffstein, J.; Kirchner, P.; Lyubashevsky, V.; Pornin, T.; Prest, T.; Ricosset, T.; Seiler, G.; Whyte, W.; Zhang, Z. Falcon: Fast-Fourier Lattice-Based Compact Signatures over NTRU (v1.2). October 2020. Available online: https://falcon-sign.info/falcon.pdf (accessed on 15 September 2023).
- Montgomery, P.L. Modular Multiplication Without Trial Division. Math. Comput. 1985, 44, 519–521. [Google Scholar] [CrossRef]
- Barrett, P. Implementing the Rivest Shamir and Adleman Public Key Encryption Algorithm on a Standard Digital Signal Processor. In Proceedings of the Advances in Crypto (CRYPTO), Santa Barbara, CA, USA, 16–20 August 1987; pp. 311–323. [Google Scholar]
- Satriawan, A.; Syafalni, I.; Mareta, R.; Anshori, I.; Shalannanda, W.; Barra, A. Conceptual Review on Number Theoretic Transform and Comprehensive Review on Its Implementations. IEEE Access 2023, 11, 70288–70316. [Google Scholar] [CrossRef]
- Liu, Z.; Seo, H.; Sinha Roy, S.; Großschädl, J.; Kim, H.; Verbauwhede, I. Efficient Ring-LWE Encryption on 8-Bit AVR Processors. In Proceedings of the Cryptographic Hardware and Embedded Systems (CHES), Saint-Malo, France, 13–16 September 2015; pp. 663–682. [Google Scholar]
- Renteria-Mejia, C.P.; Velasco-Medina, J. High-Throughput Ring-LWE Cryptoprocessors. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2017, 25, 2332–2345. [Google Scholar] [CrossRef]
- Liu, W.; Fan, S.; Khalid, A.; Rafferty, C.; O’Neill, M. Optimized Schoolbook Polynomial Multiplication for Compact Lattice-Based Cryptography on FPGA. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 2459–2463. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Khalid, A.; O’Neill, M.; Liu, W. Ultra High-Speed Polynomial Multiplications for Lattice-Based Cryptography on FPGAs. IEEE Trans. Emerg. Top. Comp. 2022, 10, 1993–2005. [Google Scholar]
- Plantard, T. Efficient Word Size Modular Arithmetic. IEEE Trans. Emerg. Top. Comp. 2021, 9, 1506–1518. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, J.; Zhao, H.; Liu, Z.; Cheung, R.C.; Koç, Ç.K.; Chen, D. Improved Plantard Arithmetic for Lattice-based Cryptography. IACR Trans. Cryptogr. Hardw. Embed. Syst. (TCHES) 2022, 2022, 614–636. [Google Scholar] [CrossRef]
- Banerjee, U.; Ukyab, T.S.; Chandrakasan, A.P. Sapphire: A Configurable Crypto-Processor for Post-Quantum Lattice-based Protocols. IACR Trans. Cryptogr. Hardw. Embed. Syst. (TCHES) 2019, 2019, 17–61. [Google Scholar] [CrossRef]
- Yaman, F.; Mert, A.C.; Öztürk, E.; Savaş, E. A Hardware Accelerator for Polynomial Multiplication Operation of CRYSTALS-KYBER PQC Scheme. In Proceedings of the 2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 1–5 February 2021; pp. 1020–1025. [Google Scholar]
- Zhang, C.; Liu, D.; Liu, X.; Zou, X.; Niu, G.; Liu, B.; Jiang, Q. Towards Efficient Hardware Implementation of NTT for Kyber on FPGAs. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Republic of Korea, 22–28 May 2021; pp. 1–5. [Google Scholar]
- Longa, P.; Naehrig, M. Speeding up the Number Theoretic Transform for Faster Ideal Lattice-Based Cryptography. In Proceedings of the International Conference on Cryptology and Network Security (CANS), Milan, Italy, 14–16 November 2016; pp. 124–139. [Google Scholar]
- Bisheh-Niasar, M.; Azarderakhsh, R.; Mozaffari-Kermani, M. High-Speed NTT-based Polynomial Multiplication Accelerator for Post-Quantum Cryptography. In Proceedings of the IEEE ymposium on Computer Arithmetic (ARITH), Lyngby, Denmark, 14–16 June 2021; pp. 94–101. [Google Scholar]
- Lil, M.; Tian, J.; Hu, X.; Cao, Y.; Wang, Z. High-Speed and Low-Complexity Modular Reduction Design for CRYSTALS-Kyber. In Proceedings of the IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Shenzhen, China, 11–13 November 2022; pp. 1–5. [Google Scholar]
- Kim, Y.; Song, J.; Seo, S.C. Accelerating Falcon on ARMv8. IEEE Access 2022, 10, 44446–44460. [Google Scholar] [CrossRef]
- Alagic, G.; Alagic, G.; Alperin-Sheriff, J.; Apon, D.; Cooper, D.; Dang, Q.; Liu, Y.-K.; Miller, C.; Moody, D.; Peralta, R.; et al. Status Report on the First Round of the NIST Post-Quantum Cryptography Standardization Process; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2019. [CrossRef]
- Alagic, G.; Alperin-Sheriff, J.; Apon, D.; Cooper, D.; Dang, Q.; Kelsey, J.; Liu, Y.-K.; Miller, C.; Moody, D.; Peralta, R.; et al. Status Report on the Second Round of the NIST Post-Quantum Cryptography Standardization Process; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2020. [CrossRef]
- Lyubashevsky, V.; Seiler, G. NTTRU: Truly Fast NTRU Using NTT. IACR Trans. Cryptogr. Hardw. Embed. Syst. (TCHES) 2019, 2019, 180–201. [Google Scholar] [CrossRef]
- Lyubashevsky, V.; Micciancio, D.; Peikert, C.; Rosen, A. SWIFFT: A Modest Proposal for FFT Hashing. In Proceedings of the Fast Software Encryption (FSE), Lausanne, Switzerland, 10–13 February 2008; pp. 54–72. [Google Scholar]
- Seiler, G. Faster AVX2 Optimized NTT Multiplication for Ring-LWE Lattice Cryptography. Cryptology ePrint Archive, Paper 2018/039. 2018. Available online: https://eprint.iacr.org/2018/039 (accessed on 15 September 2023).
- Chung, C.M.M.; Hwang, V.; Kannwischer, M.J.; Seiler, G.; Shih, C.J.; Yang, B.Y. NTT Multiplication for NTT-unfriendly Rings: New Speed Records for Saber and NTRU on Cortex-M4 and AVX2. IACR Trans. Cryptogr. Hardw. Embed. Syst. (TCHES) 2021, 2021, 159–188. [Google Scholar] [CrossRef]
- Dang, V.B.; Mohajerani, K.; Gaj, K. High-Speed Hardware Architectures and FPGA Benchmarking of CRYSTALS-Kyber, NTRU, and Saber. IEEE Trans. Comp. 2023, 72, 306–320. [Google Scholar] [CrossRef]
- Knezevic, M.; Vercauteren, F.; Verbauwhede, I. Faster Interleaved Modular Multiplication Based on Barrett and Montgomery Reduction Methods. IEEE Trans. Comp. 2010, 59, 1715–1721. [Google Scholar] [CrossRef]
- Botros, L.; Kannwischer, M.J.; Schwabe, P. Memory-Efficient High-Speed Implementation of Kyber on Cortex-M4. Cryptology ePrint Archive, Paper 2019/489. 2019. Available online: https://eprint.iacr.org/2019/489 (accessed on 15 September 2023).
- Alkim, E.; Alper Bilgin, Y.; Cenk, M.; Gérard, F. Cortex-M4 optimizations for R,M LWE schemes. IACR Trans. Cryptogr. Hardw. Embed. Syst. (TCHES) 2020, 2020, 336–357. [Google Scholar] [CrossRef]
- Abdulrahman, A.; Hwang, V.; Kannwischer, M.J.; Sprenkels, A. Faster Kyber and Dilithium on the Cortex-M4. Cryptology ePrint Archive, Paper 2022/112. 2022. Available online: https://eprint.iacr.org/2022/112 (accessed on 15 September 2023).
- Aikata, A.; Mert, A.C.; Imran, M.; Pagliarini, S.; Roy, S.S. KaLi: A Crystal for Post-Quantum Security Using Kyber and Dilithium. IEEE Trans. Circuits Syst. I Regul. Pap. 2023, 70, 747–758. [Google Scholar] [CrossRef]
- Guo, W.; Li, S.; Kong, L. An Efficient Implementation of KYBER. IEEE Trans. Circ. Syst. II Express Briefs (TCAS-II) 2022, 69, 1562–1566. [Google Scholar] [CrossRef]
- Guo, W.; Li, S. Highly-Efficient Hardware Architecture for CRYSTALS-Kyber with a Novel Conflict-Free Memory Access Pattern. IEEE Trans. Circuits Syst. I Regul. Pap. 2023, 1–11. [Google Scholar] [CrossRef]
- Li, M.; Tian, J.; Hu, X.; Wang, Z. Reconfigurable and High-Efficiency Polynomial Multiplication Accelerator for CRYSTALS-Kyber. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2023, 42, 2540–2551. [Google Scholar] [CrossRef]
- Ni, Z.; Khalid, A.; Liu, W.; O’Neill, M. Towards a Lightweight CRYSTALS-Kyber in FPGAs: An Ultra-lightweight BRAM-free NTT Core. In Proceedings of the 2023 IEEE International Symposium on Circuits and Systems (ISCAS), Monterey, CA, USA, 23 May 2023; pp. 1–5. [Google Scholar]
- Ye, Z.; Cheung, R.C.; Huang, K. PipeNTT: A Pipelined Number Theoretic Transform Architecture. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 4068–4072. [Google Scholar] [CrossRef]
- Bansal, Y.; Madhu, C.; Kaur, P. High Speed Vedic Multiplier Designs—A Review. In Proceedings of the Recent Advances in Engineering and Computational Sciences (RAECS), Chandigarh, India, 6–8 March 2014; pp. 1–6. [Google Scholar]
- James, A.P.; Kumar, D.S.; Ajayan, A. Threshold Logic Computing: Memristive-CMOS Circuits for Fast Fourier Transform and Vedic Multiplication. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2015, 23, 2690–2694. [Google Scholar] [CrossRef]
- Chen, H.; Yang, H.; Song, W.; Lu, Z.; Fu, Y.; Li, L.; Yu, Z. Symmetric-Mapping LUT-Based Method and Architecture for Computing XY-Like Functions. IEEE Trans. Circ. Syst. I Regul. Papers (TCAS-I) 2021, 68, 1231–1244. [Google Scholar] [CrossRef]
- Cooley, J.W.; Tukey, J.W. An Algorithm for the Machine Calculation of Complex Fourier Series. Math. Comput. 1965, 19, 297–301. [Google Scholar] [CrossRef]
- Gentleman, W.M.; Sande, G. Fast Fourier Transforms: For Fun and Profit. In Proceedings of the Fall Joint Computer Conference (AFIPS), San Francisco, CA, USA, 7–10 November 1966; pp. 563–578. [Google Scholar]
- Roy, S.S.; Vercauteren, F.; Mentens, N.; Chen, D.D.; Verbauwhede, I. Compact Ring-LWE Cryptoprocessor. In Proceedings of the Cryptographic Hardware and Embedded Systems (CHES), Busan, Republic of Korea, 23–26 September 2014; pp. 371–391. [Google Scholar]
- Pöppelmann, T.; Oder, T.; Güneysu, T. High-Performance Ideal Lattice-Based Cryptography on 8-Bit ATxmega Microcontrollers. In Proceedings of the Progress in Cryptology (LATINCRYPT), Guadalajara, Mexico, 23–26 August 2015; pp. 346–365. [Google Scholar]
- Zhang, N.; Yang, B.; Chen, C.; Yin, S.; Wei, S.; Liu, L. Highly efficient architecture of NewHope-NIST on FPGA using low-complexity NTT/INTT. IACR Trans. Cryptogr. Hardw. Embed. Syst. (TCHES) 2020, 2020, 49–72. [Google Scholar] [CrossRef]
- Duong-Ngoc, P.; Lee, H. Configurable Mixed-Radix Number Theoretic Transform Architecture for Lattice-Based Cryptography. IEEE Access 2022, 10, 12732–12741. [Google Scholar] [CrossRef]
- Ni, Z.; Khalid, A.; O’Neill, M.; Liu, W. HPKA: A High-Performance CRYSTALS-Kyber Accelerator Exploring Efficient Pipelining. IEEE Trans. Comp. 2023, 1–14. [Google Scholar] [CrossRef]
- Xing, Y.; Li, S. A Compact Hardware Implementation of CCAsecure Key Exchange Mechanism CRYSTALS-Kyber on FPGA. IACR Trans. Cryptogr. Hardw. Embed. Syst. (TCHES) 2021, 328–356. [Google Scholar] [CrossRef]
- Yao, K.; Wang, C.; O’Neill, M.; Liu, W. Towards CRYSTALS-Kyber: A M-LWE Cryptoprocessor with Area-Time Trade-Off. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Republic of Korea, 22–28 May 2021; pp. 1–5. [Google Scholar]
- Itabashi, Y.; Ueno, R.; Homma, N. Efficient Modular Polynomial Multiplier for NTT Accelerator of Crystals-Kyber. In Proceedings of the Euromicro Conference on Digital System Design (DSD), Maspalomas, Spain, 31 August–2 September 2022; pp. 528–533. [Google Scholar]
- Nannipieri, P.; Di Matteo, S.; Zulberti, L.; Albicocchi, F.; Saponara, S.; Fanucci, L. A RISC-V Post Quantum Cryptography Instruction Set Extension for Number Theoretic Transform to Speed-Up CRYSTALS Algorithms. IEEE Access 2021, 9, 150798–150808. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N | q | k | |||
|---|---|---|---|---|---|
| Kyber512 | 256 | 3329 | 2 | 3 | 2 |
| Kyber768 | 256 | 3329 | 3 | 2 | 2 |
| Kyber1024 | 256 | 3329 | 4 | 2 | 2 |
| Typical Algorithm | N | q |
|---|---|---|
| CRYSTAL-Kyber (v2,v3) | 256 | 3329 |
| CRYSTAL-Kyber (v1) | 256 | 7681 |
| FALCON | 512/1024 | 12,289 |
| Method | Freq (MHz) | LUTs | FFs | SLICEs | DSP | Eff. (Kbps/L) | |
|---|---|---|---|---|---|---|---|
| Proposed DSP | K-DSP | 283 | 228 | 174 | 77 | 0 | 14,895 |
| [18] | K-RED | 222 | 59 (+400) | 33 | 19 (+100) | 1 | 5804 |
| [19] | K-RED | N/A | 54 (+400) | 30 | 18 (+100) | 1 | N/A |
| [33] | Bit-reduce | 159 | 142 (+400) | 79 | 0 (+100) | 1 | 3520 |
| [36] | K-RED, LUT | 300 | 50 (+400) | 34 | 15 (+100) | 1 | 8000 |
| [46] | Barret | 265 | 81 (+400) | 112 | 0 (+100) | 1 | 6611 |
| [48] | Barret | 161 | 135 (+400) | 96 | 0 (+100) | 1 | 3611 |
| [50] | K-RED | 232 | 59 (+400) | 70 | 24 (+100) | 1 | 6065 |
| Freq (MHz) | LUTs | FFs | SLICEs | DSPs | Eff. (Kbps/L) | |
|---|---|---|---|---|---|---|
| This work | 283 | 304 | 234 | 104 | 0 | 931 |
| [18] | 222 | 200 (+400) | 179 | 0 (+100) | 1 | 370 |
| [27] | 229 | 440 (+400) | 499 | 0 (+100) | 1 | 286 |
| [33] | 159 | 774 (+800) | 394 | 317 (+200) | 2 | 101 |
| [46] | 265 | 186 (+400) | 172 | 0 (+100) | 1 | 452 |
| [48] | 161 | 647 (+800) | 501 | 0 (+200) | 2 | 111 |
| [50] | 208 | 274 (+400) | 181 | 0 (+100) | 1 | 309 |
| [51] | N/A | 177 (+2000) | 0 | 0 (+500) | 5 | N/A |
| Architecture | Prime Number q | Freq (MHz) | LUTs | FFs | SLICEs |
|---|---|---|---|---|---|
| L-DSP | 3329 | 283 | 228 | 174 | 77 |
| 7681 | 272 | 277 | 188 | 87 | |
| 12,289 | 256 | 306 | 262 | 101 | |
| BU | 3329 | 283 | 304 | 234 | 104 |
| 7681 | 260 | 362 | 253 | 120 | |
| 12,289 | 250 | 393 | 332 | 136 |
| Freq (MHz) | LUTs | FFs | SLICEs | DSPs | Cycles | ATP | Modes | |
|---|---|---|---|---|---|---|---|---|
| This work 1 | 275 | 1123 | 1061 | 386 | 0 | 128 | 180 | PWM, PWA |
| This work 2 | 275 | 2297 | 2081 | 797 | 0 | 64 | 185 | PWM, PWA |
| [34] | 200 | 1740 (+1600) | 643 | 575 (+400) | 4 | 128 | 624 | PWM |
| [35] | 300 | 1154 (+800) | 1031 | 445 (+200) | 2 | 256 | 550 | PWM |
| [36] | 303 | 1170 (+1600) | 1164 | 416 (+400) | 4 | 128 | 345 | PWM |
| [46] | 265 | 749 (+3200) | 1103 | 325 (+800) | 8 | 64 | 272 | PWM |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, T.-H.; Pham, C.-K.; Hoang, T.-T. A High-Efficiency Modular Multiplication Digital Signal Processing for Lattice-Based Post-Quantum Cryptography. Cryptography 2023, 7, 46. https://doi.org/10.3390/cryptography7040046
Nguyen T-H, Pham C-K, Hoang T-T. A High-Efficiency Modular Multiplication Digital Signal Processing for Lattice-Based Post-Quantum Cryptography. Cryptography. 2023; 7(4):46. https://doi.org/10.3390/cryptography7040046
Chicago/Turabian StyleNguyen, Trong-Hung, Cong-Kha Pham, and Trong-Thuc Hoang. 2023. "A High-Efficiency Modular Multiplication Digital Signal Processing for Lattice-Based Post-Quantum Cryptography" Cryptography 7, no. 4: 46. https://doi.org/10.3390/cryptography7040046
APA StyleNguyen, T. -H., Pham, C. -K., & Hoang, T. -T. (2023). A High-Efficiency Modular Multiplication Digital Signal Processing for Lattice-Based Post-Quantum Cryptography. Cryptography, 7(4), 46. https://doi.org/10.3390/cryptography7040046