1. Introduction
Open contests have become a preferred method for selecting cryptographic standards in the U.S. and worldwide, beginning with the Advanced Encryption Standard (AES) contest organized by the NIST in 1997–2000. Four typical criteria taken into account in the evaluation of candidates in such contests are security, performance in software, performance in hardware, and flexibility [
1]. Security, though crucial, is complex to assess quickly in contests. Hardware performance often serves as a tiebreaker when other criteria fail to declare a clear winner among cryptographic algorithms. In this survey, we focus on Secure Hash Algorithm 3 (SHA-3). It is a cryptographic hash function standard selected by the National Institute of Standards and Technology (NIST) in 2015. It emerged victorious in a rigorous competition organized by the NIST to find a successor to the aging SHA-2.
Among the contenders, Keccak, designed by Guido Bertoni, Joan Daemen, Micha
l Peeters, and Gilles Van Assche, stood out for its innovative design and strong security properties, ultimately earning its place as the foundation of SHA-3. This achievement marked a significant milestone in modern cryptography, ensuring robust and efficient hash functions for various security applications. While it currently stands as the leader in resisting recent cryptanalysis attacks and excels in hardware performance, there is a continuous demand for developing an efficient implementation, be it software, e.g., Central Processing Unit (CPU), or hardware, e.g., Field-Programmable Gate Array (FPGA) and Application-Specific Integrated Circuit (ASIC). Common software implementations on a microcontroller offer high flexibility, but they may not provide the required performance for cryptographic algorithms with high computational demands. Microcontrollers are versatile and programmable, making them suitable for a wide range of applications, but they may struggle with the computational intensity of modern cryptographic algorithms. Moving up the spectrum, an extensible processor, such as an application microprocessor, co-processors (i.e., [
2]), or a Digital Signal Processor (DSP), offers more significant performance potential than fixed ones. These processors can be optimized for specific cryptographic operations, providing better throughput and efficiency than a generic microcontroller. However, they are still limited by their general-purpose architecture, which may not match the specialized requirements of specific cryptographic algorithms. A programmable datapath takes the customization a step further by allowing users to design custom hardware accelerators for cryptographic tasks. This approach offers a balance between flexibility and performance. Programmable datapaths enable the efficient execution of cryptographic algorithms through parallel processing and custom hardware instructions (i.e., [
3]). Finally, the least flexible but most efficient solution is the hardwired datapath, typically implemented in ASICs (Application-Specific Integrated Circuits). ASICs are designed specifically for a particular cryptographic algorithm or set of algorithms, making them highly efficient in terms of speed and power consumption. However, their lack of flexibility means that any changes or updates to cryptographic algorithms require a new hardware design.
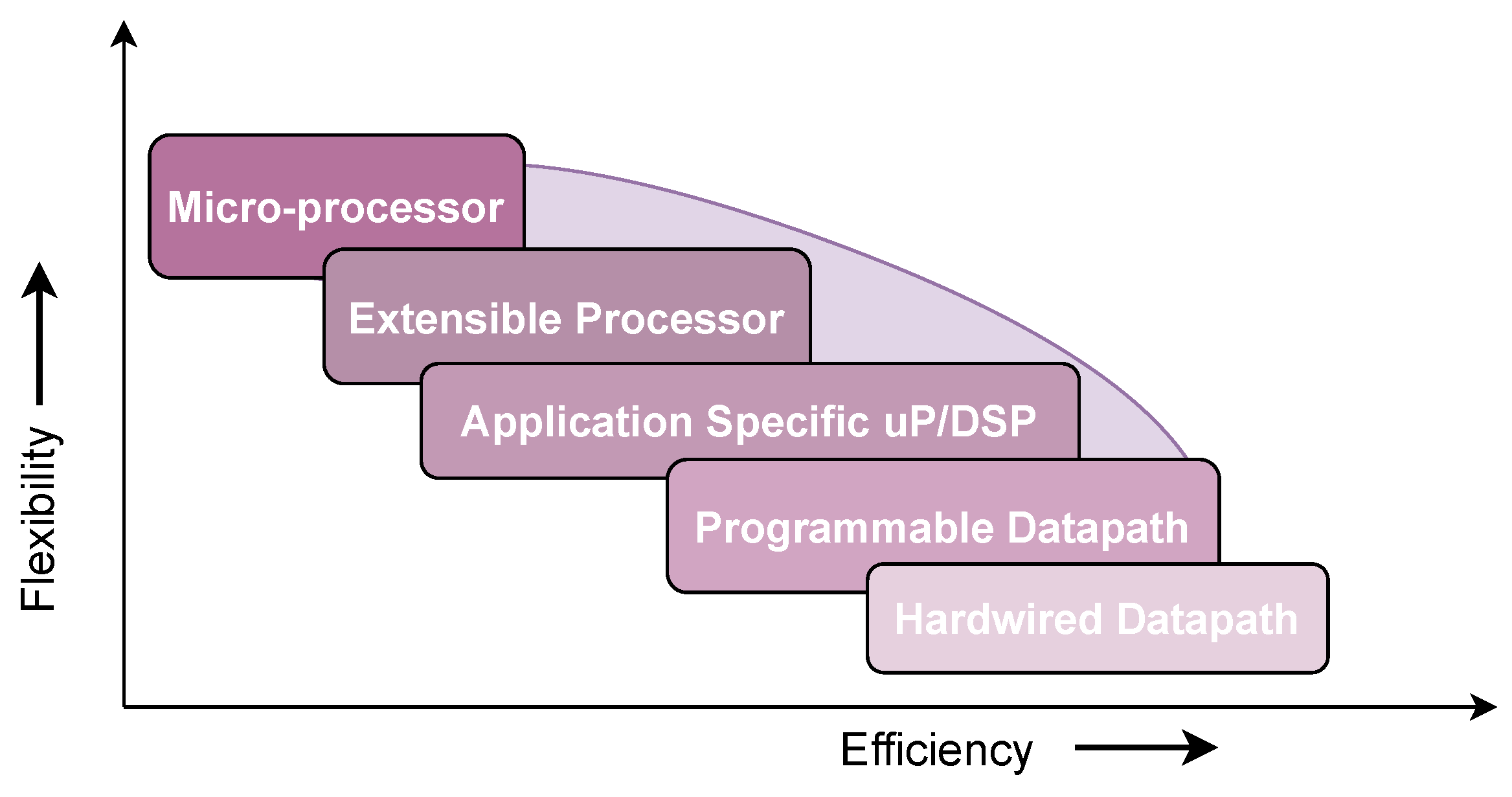
In summary, the choice of implementation approach for cryptographic algorithms depends on the trade-off between flexibility and efficiency, as shown in
Figure 1. Selecting the most suitable implementation space depends on the specific cryptographic requirements and application constraints.
The rest of the article is organized as follows:
Section 2 reports a background about SHA-3 construction.
Section 3 describes Keccak structure.
Section 4 is developed to report all of the solutions found in the state of the art for implementing SHA-3, compared with each other, while, in
Section 6, there are comments and examinations of different hardware implementation solutions more in details;
Section 6 reports implementations results, and
Section 7 the conclusion of this analysis.
2. SHA-3
SHA-3 is a subset of the Keccak family standardized by the NIST. The standard lists four specific instances of SHA-3 and two extendable-output functions (SHAKE128 and SHAKE256). While the SHA-3 functions have a specified output length, the two SHAKE variants permit extraction of a variable length of output data, which makes SHA-3 a suitable candidate for pseudo-random bit generation [
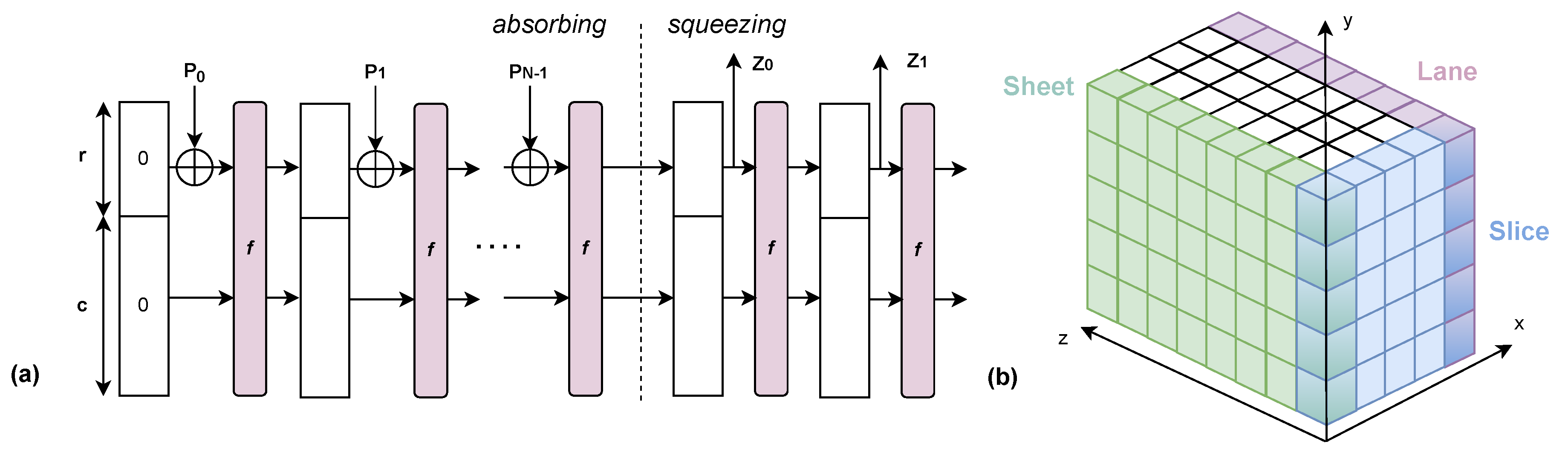
4]. All SHA-3 functions operate within a shared foundational framework known as the sponge construction (as shown in
Figure 2a). This framework is highly adaptable and allows for the generation of hash values with variable length, making it well suited for diverse applications.
The NIST standard defines four versions of the Keccak sponge function [
5] for a message
M and an output length
d, as shown in
Table 1. The algorithm uses two parameters for the sponge construction: the bitrate with
r-bits, which determines the number of bits absorbed in each step, and the capacity with
c-bits, which determines the attainable security level (
Figure 2a).
The flow of a sponge function can be understood through the following steps:
Initialization: the sponge function is initialized depending on r and c parameters.
Padding: The input message is padded to ensure that length is a multiple of
r. Most of the architectures utilize a software scheduler for preparing the input by splitting and padding long messages into blocks of 1600 bits (multi-block messages) for truncating, if necessary, the output of the hash computation in the appropriate size of the selected mode of operation and for updating the state matrix in the case of multi-block messages. As an example, in [
4,
6,
7,
8] the input to the SHA-3 block is assumed to be already padded.
In other works, i.e., [
8], the hardware block is not performing only the
f-transform, but it also has a Versioning and XOR-iring module (VSX) that is responsible for forming the appropriate state per algorithm version.
There are some implementations in which all the steps of the sponge function are supported (padding, mapping, and truncation), but, generally, these architectures assume that the input can only be of a certain length (i.e., [
9] considers input messages whose length is fixed to 64 bits), or have a precise application (i.e., [
10] considers only the CRYSTALS-Kyber 768 algorithm).
Absorbing Phase: Here, the padded message is divided into blocks of a size of r bits each, and each block is XORed with the current state of the sponge function. The resulting state is then processed through a series of bitwise operations, typically using a permutation function, to mix the input data with the current state. The function f acts on the state, with a width of .
Squeezing Phase: After all of the message blocks have been absorbed, the function produces the hash output by repeatedly extracting r bits from the state. These bits are concatenated to form the final hash value. The squeezing phase continues until the desired hash length is achieved.
Finalization: in the end, the sponge function may perform additional operations to finalize the hash value, such as truncating it to the desired length or applying additional cryptographic transformations.
Central to the sponge construction is the concept of state. The state has a length of 1600 bits and consists of a three-dimensional
table, as shown in
Figure 2b. Each bit of this cube can be addressed with
. In order to facilitate the description of the applied functions, the following conventions are used: the part of the state that presents the word is also called a lane, a two-dimensional part of the state with a fixed z is called a slice, and all lanes with the same x-coordinate form a sheet.
3. Keccak
The most important part of the SHA-3 and SHAKE primitives is the Keccak permutation function, which calls for 24 rounds of the f-1600 function. Each round is characterized by the five consecutive steps
, and
. These steps have a state array
A as input and an output
B, which is a processed new state array. As shown in Equation (
1),
consists of a parity computation, a rotation of one position, and a bitwise XOR.
In Equation (
2),
is a rotation by an offset that depends on the word position, and
is a permutation.
In Equation (
3),
consists of bitwise XOR, NOT, and AND gates.
Lastly,
, in Equation (
4) is a constant round addition.
When these five are completed, a round is completed.
Table 2 reports the round constant function
RC[i], which is a 24-value permutation that assigns 64-bit data to the Keccak function.
Table 3 reports the cyclic shift offset
r[x,y].
More information about the Keccak algorithm can be found in [
11].
4. Implementation
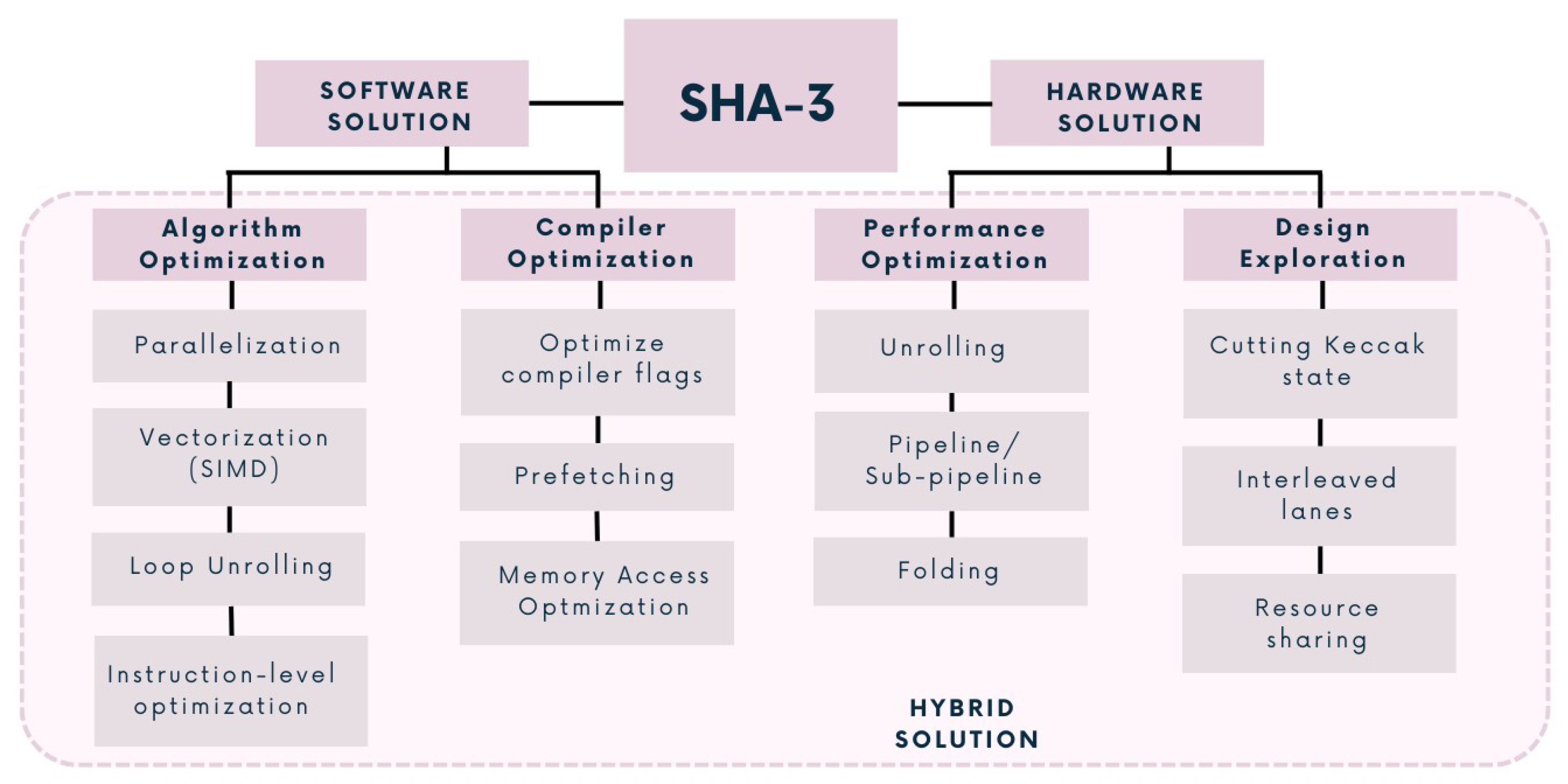
When developing a real implementation, a diverse array of possibilities within the design space is available. These options encompass entirely hardware-based solutions, pure software implementations, and hybrid approaches, such as Integrated Software Environments (ISE) or Application-Specific Instruction Processor (ASIP). Strictly hardware-based solutions involve dedicated IP cores, while pure software implementations rely solely on software resources. ISEs (Integrated Software Environment) or ASIP, representing a hybrid solution, enhance general-purpose processor cores with specialized hardware and instructions.
Figure 3 shows the different aspects covered in the next sections and proposes for each implementation approach a choice of proper references. Let us now delve into the intricacies of each conceivable approach.
4.1. Hardware Solutions
Hardware implementations of Keccak demand careful consideration of trade-offs. When implementing Keccak in hardware, the choice of design parameters and strategies heavily depends on the specific goals and constraints of the target application. These objectives typically revolve around factors such as speed, power efficiency, and area utilization. In this section, we will explore the various aspects that can be considered during the hardware implementation of Keccak, with a focus on these key parameters.
Unrolling. Unrolling is particularly efficient in improving the throughput for single-message hashing. Considering Keccak, the f-permutation block can be replicated and unrolled in the SHA-3 hash function. As an example, Refs. [
6,
12] implement SHA-3 considering an unrolling factor of two, while, in [
7], an even higher degree of unrolling has been analyzed. Moumni et al. [
9] and Nannipieri et al. [
13] have made several attempts, instantiating from a single instance to twelve, going from 24 clock cycles to 2; however, this resulted in an onerous increase in area.
Pipelining. Pipelining brings the advantages of combined data throughput enhancement in multi-message hashing, where the function processes more than one message concurrently. In addition, two different types of pipelining can be distinguished:
Classic pipelining, generally used between one round and another;
Sub-pipelining, inserted instead between two steps of the same round.
For instance, in [
8,
14], the pipeline is inserted between the
and
steps, while, in [
12], it is inserted between the
and
steps.
Folding. Towards a more compact SHA-3 structure, folding of the round computation can be considered. In the case of [
15], each round is computed over multiple clock cycles, depending on the folding factor.
Cutting the Keccak state. The efficient management of the Keccak state is of paramount importance [
16]. There are multiple alternatives, namely using slice-wise, plane-wise, and bit-interleaving techniques. Jungk et al. [
17] propose a very compact slice-oriented Keccak hardware, based on the observation that all Keccak steps except
can be performed efficiently with slice-wise processing. However, since input messages for absorption generally arrive in a lane-oriented fashion, the plane-wise partitioning is favorable (adjacent bits in a register belong to the same lane).
Interleaved lanes. Bit-interleaving is a technique that can be used to break large 64-bit lanes of Keccak into smaller chunks [
18].
Resource Sharing. Resource area sharing is a crucial optimization technique employed in hardware design, particularly in the context of FPGAs and ASICs. It aims to maximize the efficient utilization of available resources while minimizing the overall hardware footprint, which can lead to cost savings, improved performance, and reduced power consumption. An interesting example is the co-processor presented in [
2], named AE
$HA-3, which combines two of the NIST’s standardized algorithms, i.e., Advance Encryption Standard (AES) and SHA-3. Maache et al. [
3] also present a multi-purpose cryptographic system performing both AES and SHA-3, implementing it on the IntelFPGA Cyclone-V device.
To sum up, the hardware implementation of Keccak is a multifaceted task that necessitates careful consideration of various trade-offs and objectives. The specific design choices will be heavily influenced by the unique demands of the target application, whether it be a high-performance cryptographic accelerator, a low-power embedded system, or any other use case in which Keccak is employed. Each implementation will strike a balance between speed, power efficiency, area utilization, and security to meet its intended purpose effectively.
4.2. Software Solutions
Enhancing the software implementation of an algorithm holds the key to unlocking superior performance. By optimizing code, leveraging hardware-specific features, and minimizing resource overhead, software improvements can significantly boost algorithmic efficiency, resulting in faster execution and better utilization of available hardware resources. Accelerating the SHA-3 algorithm on FPGA devices, RISC-V, or ARM without dedicated hardware accelerators involves optimizing the software implementation to maximize performance. Here are some techniques to achieve this.
Parallelization. Using parallelization for implementing multi-threading or multi-processing when having multiple CPU cores can significantly improve performances. Each core can work on a separate chunk of data, improving overall throughput. Pereira et al. [
19] present a technique for parallel processing on Graphics Processing Units (GPUs) of the Keccak hash algorithm. They provide the core functionality, and the evaluation is performed on a Xilinx Virtex 5 FPGA.
Vectorization (SIMD). Utilize the SIMD (Single Instruction, Multiple Data) instructions available in modern processors (e.g., ARM NEON, RISC-V RVV) to process multiple data elements in parallel. This can significantly speed up the hashing process, especially when dealing with large datasets. For example, Ref. [
20] proposes a set of six custom instructions for Keccak-
[1600, 800, 400, 200] primitives, and, similarly to other crypto-instructions (e.g., Intel AES-NI and SHA), they exploit the wide SIMD (Single Instruction, Multiple Data) registers. Li et al. [
21] explore the full potential of parallelization of Keccak-
f[1600] in RISC-V-based processors through custom vector extensions on 32-bit and 64-bit architectures.
Loop Unrolling. Unroll loops in the SHA-3 algorithm code to reduce loop overhead and enable the compiler to optimize the code more effectively. This can result in faster execution, especially on CPUs with pipelined execution units. Ref. [
22] reports several analyses about security versus area versus the timing of PQC decapsulation algorithms, after loop unrolling, showing how, in most cases, this brings a significant reduction in latency.
Instruction-Level Optimization. Hand-tune critical sections of the code to use processor-specific instructions and features. This may include using assembly language or intrinsic to access specialized instructions for SHA-3 operations. Ref. [
23] presents two new techniques for the fast implementation of the Keccak permutation on the A-profile of the Arm architecture: the elimination of explicit rotations in the Keccak permutation through barrel shifting, and the construction of hybrid implementations concurrently leveraging both the scalar and the Neon instruction sets of AArch64.
Optimized Compiler Flags. Use compiler optimization flags (
-O2,
-O3, i.e., in [
24]) to instruct the compiler to apply various optimizations, including loop unrolling, inline function expansion, and instruction scheduling. Ref. [
25] uses
-On command line flags during GCC compilation to improve performance at the cost of increased compilation times.
Memory Access Optimization. Minimize memory access latency by optimizing data structures and memory access patterns. Cache-friendly data structures and efficient memory layouts can reduce the number of cache misses. Choi et al. [
26] discuss optimizations, memory management strategies, and parallelization schemes, aiming to enhance the performance and throughput of SHA-3 operations on graphics processing units (GPUs).
Prefetching. Use prefetching techniques to load data into the cache before it is actually needed, reducing memory access stalls and improving data processing speed. Lee et al. [
27], using NVIDIA GPU, exploit the feature for which arithmetic instructions and memory load/store instructions can be executed concurrently, as long as there is no dependency between the executing instruction and data being loaded/stored. They prefetch the input data of Keccak before XORing it into the state, so that address calculation and bitwise XOR operation can run in parallel with the memory copy operation.
The effectiveness of these techniques will depend on the specific platform, compiler, and workload, so thorough testing and profiling are essential to achieve optimal results. Continuously profiling and benchmarking the software implementation will help identify performance bottlenecks and areas for improvement. This iterative process can lead to significant performance gains.
4.3. Hybrid Solutions
Hybrid solutions, which combine both software and hardware components, represent a versatile approach to solving complex problems by harnessing the strengths of each domain. These solutions essentially encompass all of the techniques discussed in the previous section and merge them into a cohesive, integrated system.
In the realm of technology and problem-solving, software and hardware have traditionally been seen as separate entities. Software provides flexibility and adaptability, while hardware offers raw processing power and efficiency. A hybrid solution brings together the computational capabilities of hardware and the logic and adaptability of software to create a powerful and agile system. It allows optimization of the performance by distributing tasks between software and hardware according to their respective strengths. This means that computationally intensive tasks can be offloaded to dedicated hardware accelerators, while software can handle tasks that require flexibility and frequent updates. This balance ensures that the system operates efficiently without bottlenecks. Moreover, being that software is inherently adaptable, it is easier to implement changes and updates to meet evolving requirements. Fritzmann et al. [
4] present RISQ-V, an enhanced RISC-V architecture that integrates a set of powerfully coupled accelerators. Here, hardware/software co-design techniques have been combined to develop complex and highly customized solutions, designing tightly and loosely coupled accelerators and Instruction Set Architecture (ISA) extensions. This is an example of how combining the hardware and software provides the flexibility to adjust algorithms, logic, or functionality in response to changing needs while maintaining the stability and speed of the hardware.
5. Micro-Architecture Details
The Keccak permutation, which consists of five main steps (, , , , and ), is designed to be highly parallelizable, which means that the order of these steps can affect synthesis results and performance on an FPGA. The reasons are manifold.
Different FPGA architectures have distinct types and quantities of resources, and, therefore, the order of the permutation steps can influence how these resources are utilized. Additionally, the timing requirements of the FPGA may vary depending on the order of the steps. Certain steps may introduce longer or shorter critical paths, impacting the maximum achievable clock frequency. Some steps of the Keccak permutation are inherently more parallelizable than others. For example, the and steps can be parallelized more easily than the step, which involves shifting bits. The order in which these steps are arranged can determine how effectively parallelism can be exploited, affecting overall performance.
Obviously, FPGA synthesis tools must be considered too, since they employ various algorithms and optimization techniques to map the design onto the target FPGA.
Considering these factors, it is useful to explore different combinations of the permutation steps during FPGA design to find the optimal arrangement for a given FPGA platform. Some syntheses have been performed on Cyclone V (5CEFA9F31C8), with a time constraint of 6
. In this analysis, only performance is considered. As can be observed from
Table 4, the best results are in cases 2, 3, 4, 7, 8, and 9, which have in common the sequence
. Obviously, changing the rotation order disrupts the dependencies between steps, requiring additional clock cycles to ensure data integrity and correctness, thus increasing the overall processing time by at least one clock cycle (as can be seen from the fifth column of
Table 4).
Moreover, there are different possible options for what concerns implementation of the round constant generator (constants reported in
Table 2). There are three plausible implementations. First, a circuit constructed using Linear Feedback Shift Register (LFSR) can be employed to perform on-the-fly generation of the round constant values. Another solution is storing all of the 24 pre-calculated round constants of a 64-bit length in memory forms (such as registers or circular buffers) and transferring them to the
module via a multiplexer [
8]. Since efficient resource utilization is vital for hardware implementations, it has been proved that the length of the
RC values can be reduced to less than a byte size (see
Table 5) by storing only the non-zero bits in each of the round constant values [
12,
28]. This will also save 55–56 XORs in the
step.
In addition, a combinatorial circuit using a series of logical gates can be realized to compute the round constant value upon every iteration. For example, the counter value, which was used within SHA-3 to keep track of the number of iterations, was used as input to calculate on-the-fly
RC values.
In particular, considering A as the MSB of the counter and E as the LSB, seven logical expressions were constructed to obtain the constants shown in
Table 5. This solution has been synthesized by targeting an ASIC on 65
technology with a time constraint of 0.73
. Area results are reported in
Table 6: the second and third solutions provide a slight improvement in terms of area occupancy without changing the critical path of the entire circuit.
These kinds of exploration help achieve the best balance between resource utilization, performance, and power consumption, ultimately leading to a more efficient and effective hardware implementation of the Keccak permutation for a specific FPGA target or a particular technology. Additionally, it allows designers to adapt the design to different platforms without starting from scratch, saving time and effort in the development process.
7. Conclusions
In conclusion, this paper has undertaken a thorough and insightful journey into the world of SHA-3 implementations, examining a diverse array of solutions across hardware, software, and hybrid domains. By critically evaluating their strengths, weaknesses, and performance metrics, we have contributed valuable knowledge to the field of modern cryptography. Our research has shed light on the critical factors that shape the selection and optimization of Keccak SHA-3 implementations, emphasizing computational efficiency, scalability, and flexibility in various use cases. Through a meticulous analysis of speed and resource utilization, we have provided a comprehensive view of how these implementations fare in real-world scenarios.
The outcomes of this study have far-reaching implications, enhancing the understanding of cryptographic systems and facilitating the design and deployment of efficient solutions. Professionals and researchers alike are now better equipped to make informed decisions when navigating the intricate landscape of SHA-3 implementations, ultimately contributing to the advancement of secure and resilient cryptographic practices.
As the realm of cryptography continues to evolve, our commitment to rigorous evaluation and informed decision-making remains paramount. This research stands as a testament to our dedication to strengthening the foundations of cryptographic knowledge, ensuring that we continue to safeguard the digital world with ever more robust and efficient cryptographic solutions.









{kind=link}
{kind=link}
{kind=link}
{kind=link}