Optimizing XGBoost Performance for Fish Weight Prediction through Parameter Pre-Selection

 ,
,  ,
,
Abstract
:1. Introduction
2. Related Work
3. Background
3.1. Min-Max Normalization
3.2. One-Hot Encoding
3.3. Machine Learning Regression Algorithms
3.3.1. Linear Regression
3.3.2. Ridge Regression
3.3.3. Decision Tree
3.3.4. Random Forest
3.3.5. eXtreme Gradient Boosting (XGBoost)
3.4. Metric Evaluation Models
3.4.1. MAE (Mean Absolute Error)
3.4.2. MSE (Mean Square Error)
3.4.3. R2_Score (Coefficient of Determination)
4. Methodology
4.1. Data Collection
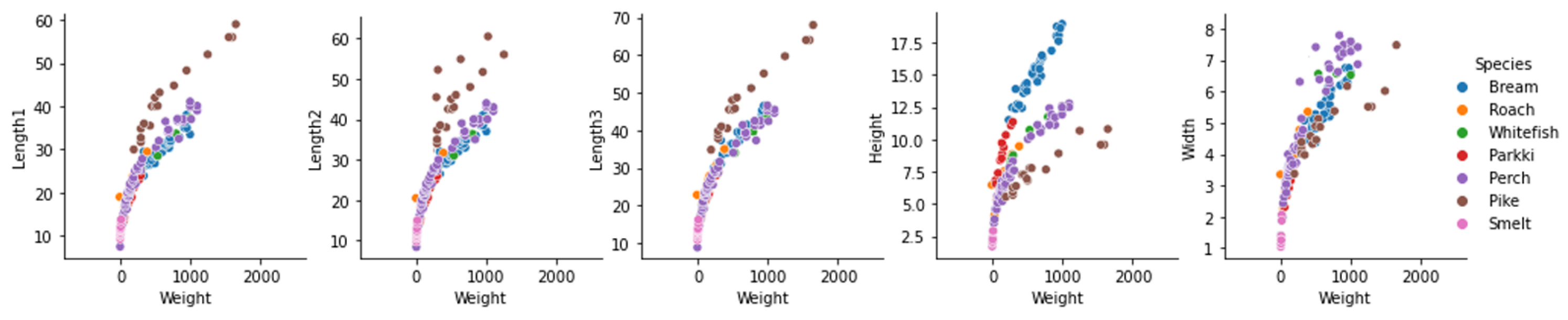
Dataset Composition
- Species: The specific fish species under consideration.
- Weight: The weight of the fish, typically measured in grams.
- Length1: The length of the body from the tip of the mouth to the base of the caudal fin, along its dorsal side, measured in centimeters.
- Length2: The measurement from the tip of the fish’s mouth to the tip of the tail fin along a diagonal line, measured in centimeters.
- Length3: This is the length of the line from the upper point of the tail to the lower point of the mouth, measured in centimeters.
- Height: The height of the fish, also measured in centimeters.
- Width: The width of the fish, measured in centimeters.
- Market Region: The geographic region or market where the fish was recorded.
- Market Category: The category of the market, such as retail or wholesale.
4.2. Data Preprocessing
4.3. Model Selection and Training
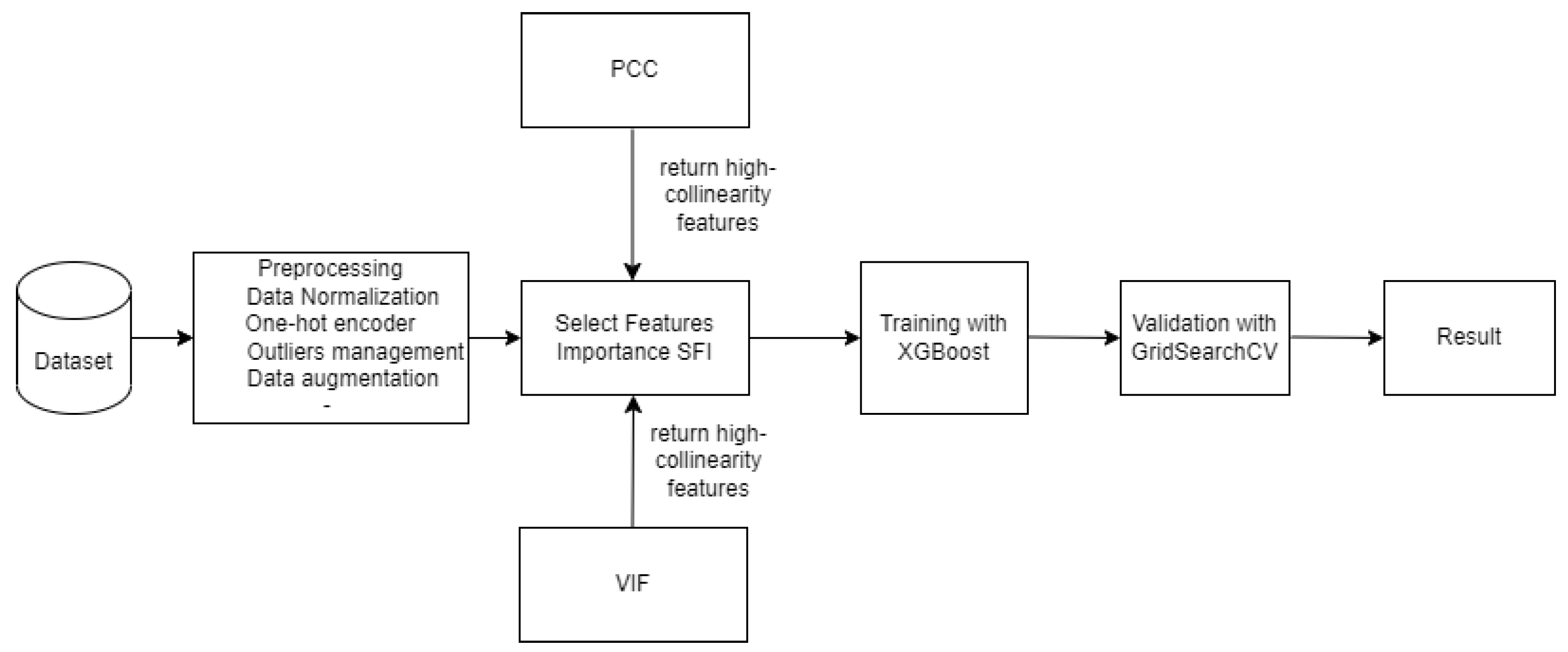
4.4. Multicollinearity Analysis Methods
4.4.1. Variance Inflation Factor Method (VIF)
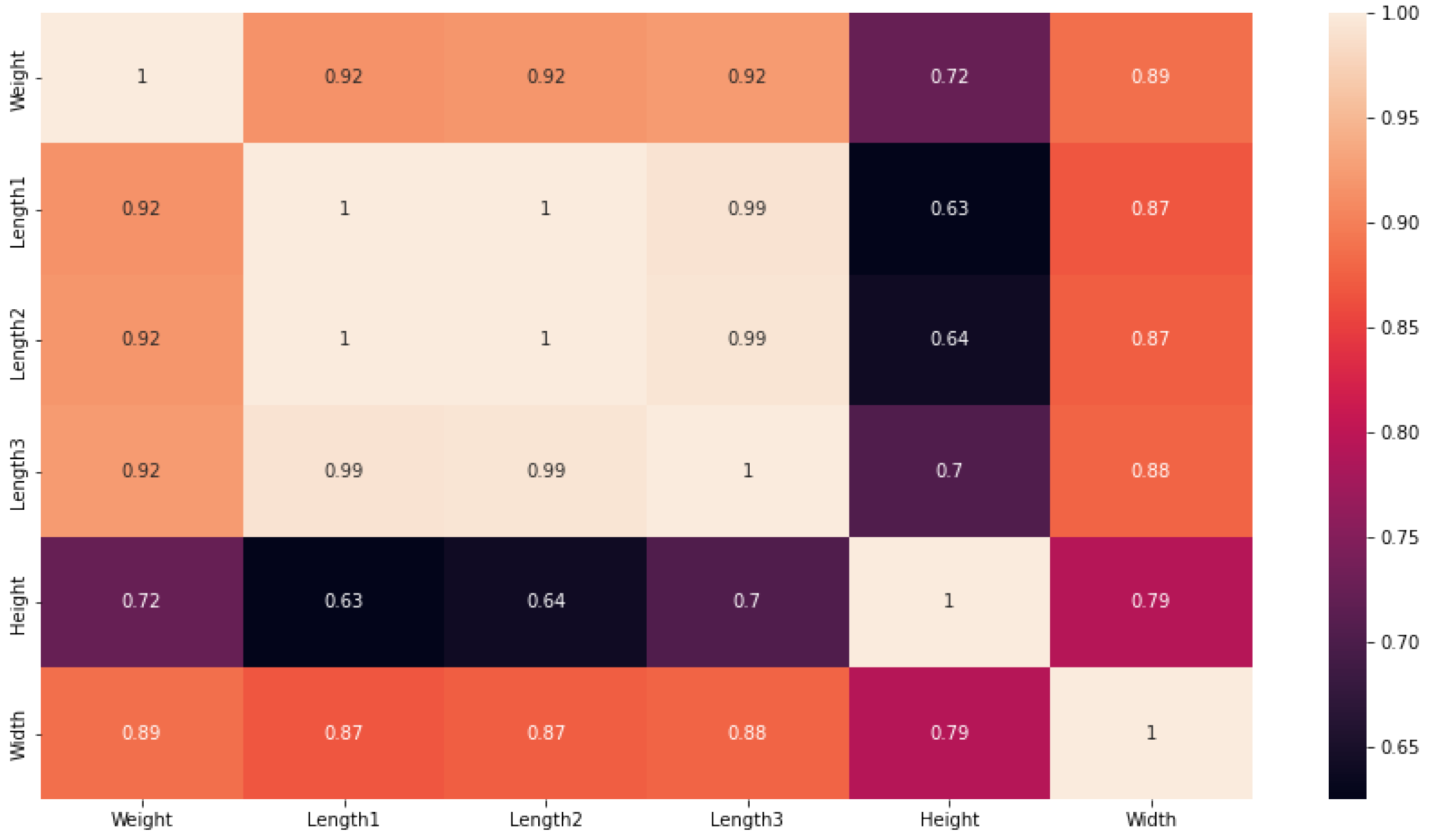
4.4.2. Pearson’s Correlation Coefficient Method (PCC)
4.4.3. Select Features Importance Method (SFI)
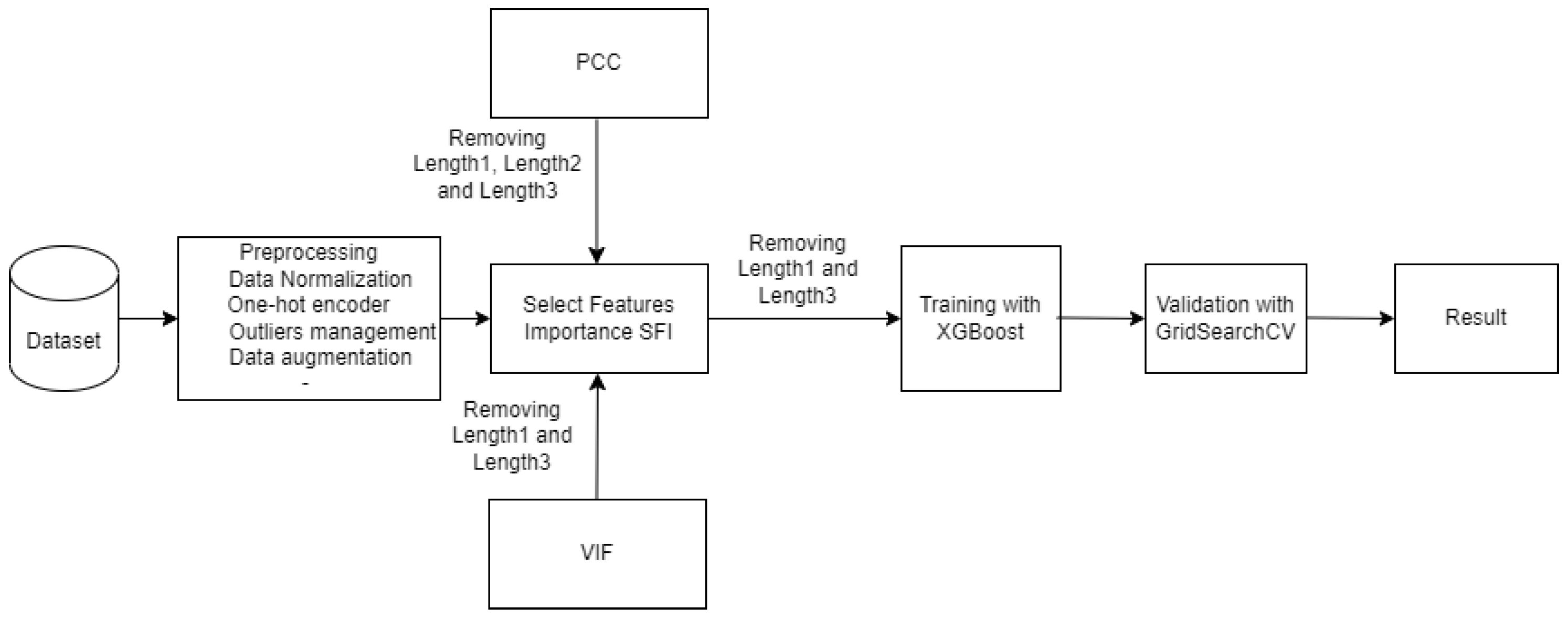
4.5. SFI-XGBoost Approach
5. Results and Discussion
5.1. Algorithms Evaluation
5.2. Data Analysis
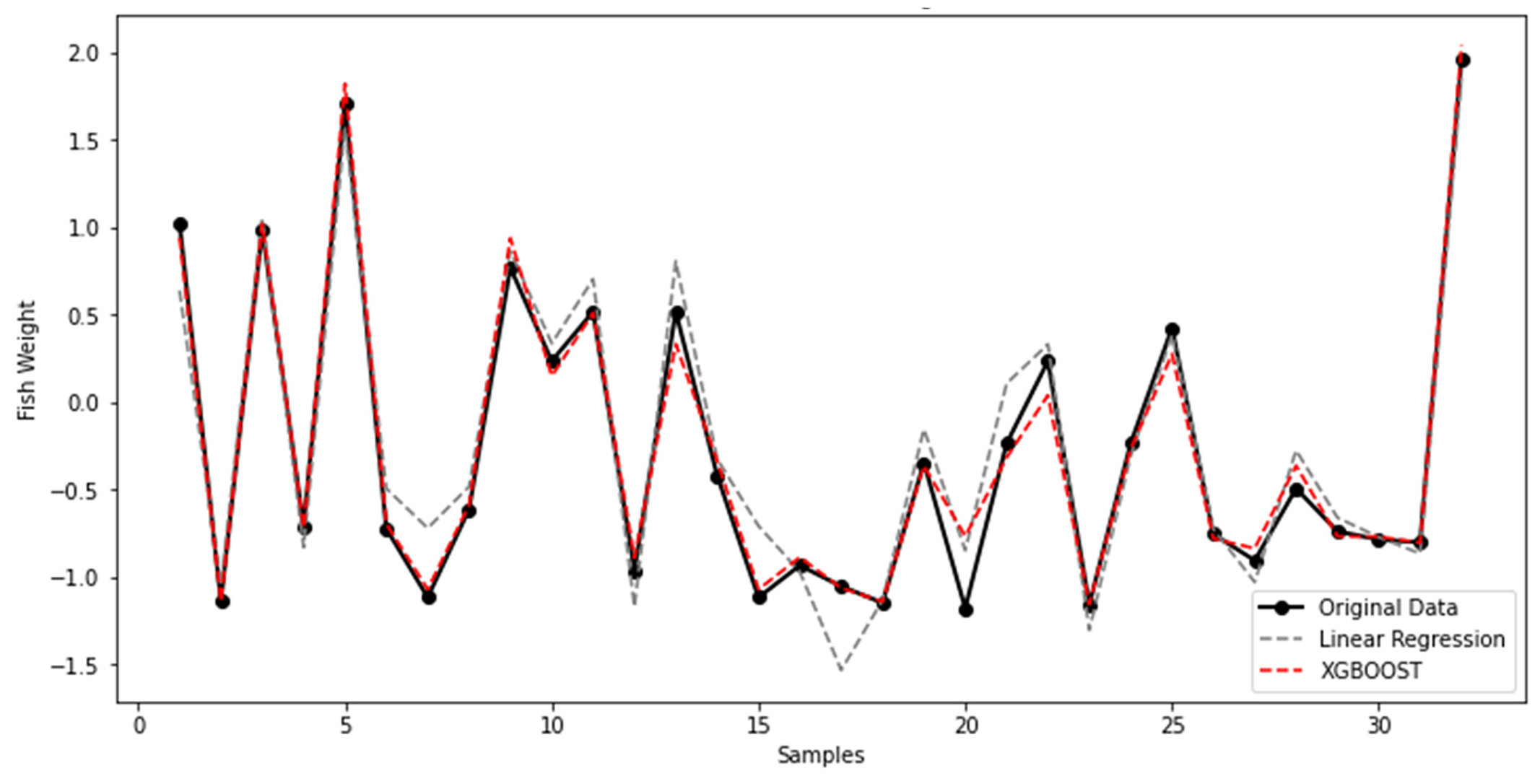
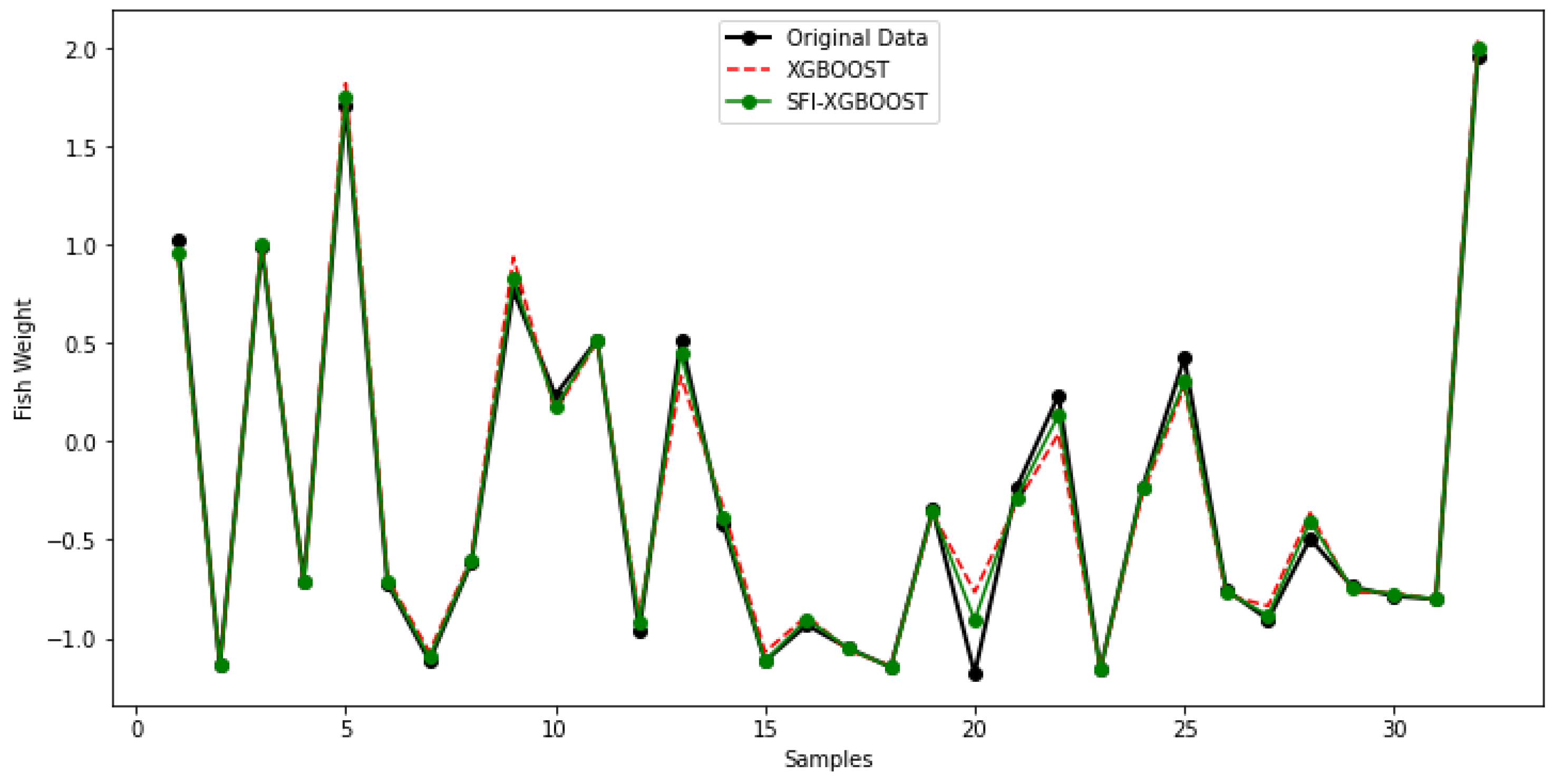
5.3. SFI-XGBoost Performances
5.4. Further Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- FAO. The State of World Fisheries and Aquaculture 2021; FAO: Rome, Italy, 2021; p. 254. [Google Scholar]
- Føre, M.; Frank, K.; Norton, T.; Svendsen, E.; Alfredsen, J.A.; Dempster, T.; Eguiraun, H.; Watson, W.; Stahl, A.; Sunde, L.M.; et al. Precision fish farming: A new framework to improve production in aquaculture. Biosyst. Eng. 2018, 173, 176–193. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, X.; Liu, J.; An, D.; Wei, Y. Dynamic feeding method for aquaculture fish using multi-task neural network. Aquaculture 2022, 551, 737913. [Google Scholar] [CrossRef]
- Kaur, G.; Adhikari, N.; Krishnapriya, S.; Wawale, S.G.; Malik, R.Q.; Zamani, A.S.; Perez-Falcon, J.; Osei-Owusu, J. Recent Advancements in Deep Learning Frameworks for Precision Fish Farming Opportunities, Challenges, and Applications. J. Food Qual. 2023, 2023, 4399512. [Google Scholar] [CrossRef]
- Ziarati, M.; Zorriehzahra, M.J.; Hassantabar, F.; Mehrabi, Z.; Dhawan, M.; Sharun, K.; Emran, T.B.; Dhama, K.; Chaicumpa, W.; Shamsi, S. Zoonotic diseases of fish and their prevention and control. Vet. Q. 2022, 42, 95–118. [Google Scholar] [CrossRef]
- Tengtrairat, N.; Woo, W.L.; Parathai, P.; Rinchumphu, D.; Chaichana, C. Non-intrusive fish weight estimation in turbid water using deep learning and regression models. Sensors 2022, 14, 5161. [Google Scholar] [CrossRef]
- Hao, M.; Yu, H.; Li, D. The measurement of fish size by machine vision-a review. In Proceedings of the Computer and Computing Technologies in Agriculture IX: 9th IFIP WG 5.14 International Conference, CCTA, Beijing, China, 27–30 September 2015; pp. 15–32. [Google Scholar]
- Froese, R.; Thorson, J.T.; Reyes, R.B., Jr. A Bayesian approach for estimating length-weight relationships in fishes. J. Appl. Ichthyol. 2014, 30, 78–85. [Google Scholar] [CrossRef]
- Kaka, R.M.; Jung’a, J.O.; Badamana, M.; Ruwa, R.K.; Karisa, H.C. Morphometric length-weight relationships of wild penaeid shrimps in Malindi-Ungwana Bay: Implications to aquaculture development in Kenya. Egypt. J. Aquat. Res. 2019, 45, 167–173. [Google Scholar] [CrossRef]
- Migiro, K.E.; Ogello, E.O.; Munguti, J.M. The length-weight relationship and condition factor of Nile tilapia (Oreochromis niloticus L.). Int. J. Adv. Res. 2014, 5, 777–782. [Google Scholar]
- Yang, Y.; Xue, B.; Jesson, L.; Zhang, M. Genetic programming for symbolic regression: A study on fish weight prediction. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC), Krakow, Poland, 28 June–1 July 2021; pp. 588–595. [Google Scholar]
- Li, H.; Chen, Y.; Li, W.; Wang, Q.; Duan, Y.; Chen, T. An adaptive method for fish growth prediction with empirical knowledge extraction. Biosyst. Eng. 2021, 212, 336–346. [Google Scholar] [CrossRef]
- Islamadina, R.; Pramita, N.; Arnia, F.; Munadi, K. Estimating fish weight based on visual captured. In Proceedings of the International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 6–7 March 2018; pp. 366–372. [Google Scholar]
- Hwang, K.H.; Choi, J.W. Machine vision based weight prediction for flatfish. In Proceedings of the 18th International Conference on Control, Automation and Systems (ICCAS), PyeongChang, Republic of Korea, 17–20 October 2018; pp. 1628–1631. [Google Scholar]
- Konovalov, D.A.; Saleh, A.; Efremova, D.B.; Domingos, J.A.; Jerry, D.R. Automatic weight estimation of harvested fish from images. In Proceedings of the Digital image computing: Techniques and applications (DICTA), Perth, WA, Australia, 2–4 December 2019; pp. 1–7. [Google Scholar]
- Yang, Y.; Xue, B.; Jesson, L.; Wylie, M.; Zhang, M.; Wellenreuther, M. Deep Convolutional Neural Networks for Fish Weight Prediction from Images. In Proceedings of the 36th International Conference on Image and Vision Computing New Zealand (IVCNZ), Tauranga, New Zealand, 9–10 December 2021; pp. 1–6. [Google Scholar]
- Tonachella, N.; Martini, A.; Martinoli, M.; Pulcini, D.; Romano, A.; Capoccioni, F. An affordable and easy-to-use tool for automatic fish length and weight estimation in mariculture. Sci. Rep. 2022, 12, 15642. [Google Scholar] [CrossRef] [PubMed]
- Sthapit, P.; Teekaraman, Y.; MinSeok, K.; Kim, K. Algorithm to estimation fish population using echosounder in fish farming net. In Proceedings of the International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Republic of Korea, 16–18 October 2019; pp. 587–590. [Google Scholar]
- Rezo, M.; Čagalj, K.M.; Ušljebrka, I.; Kovačić, Z. Collecting information for biomass estimation in mariculture with a heterogeneous robotic system. In Proceedings of the 44th International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 27 September–1 October 2021; pp. 1125–1130. [Google Scholar]
- Okamoto, M.; Morita, S.; Sato, T. Fundamental study to estimate fish biomass around coral reef using 3-dimensional underwater video system. In Proceedings of the OCEANS 2000 MTS/IEEE Conference and Exhibition, Conference Proceedings (Cat. No. 00CH37158), Providence, RI, USA, 11–14 September 2000; pp. 1389–1392. [Google Scholar]
- Chang, C.C.; Wang, J.H.; Wu, J.L.; Hsiehn, Y.Z.; Wu, T.D.; Cheng, S.C.; Chang, C.C.; Juang, J.G.; Liou, C.H.; Hsu, T.H.; et al. Applying artificial intelligence (AI) techniques to implement a practical smart cage aquaculture management system. J. Med. Biol. Eng. 2021, 41, 652–658. [Google Scholar] [CrossRef]
- Rossi, L.; Bibbiani, C.; Fronte, B.; Damianon, E.; Di Lieto, A. Application of a smart dynamic scale for measuring live-fish biomass in aquaculture. In Proceedings of the IEEE International Workshop on Metrology for Agriculture and Forestry (MetroAgriFor), Trento-Bolzano, Italy, 3–5 November 2021; pp. 248–252. [Google Scholar]
- Qin, H.; Li, X.; Liang, J.; Peng, Y.; Zhang, C. DeepFish: Accurate underwater live fish recognition with a deep architecture. Neurocomputing 2016, 187, 49–58. [Google Scholar] [CrossRef]
- Gajera, V.; Gupta, R.; Jana, P.K. An effective multi-objective task scheduling algorithm using min-max normalization in cloud computing. In Proceedings of the 2nd International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), Bangalore, India, 21–23 July 2016; pp. 812–816. [Google Scholar]
- Al-Shehari, T.; Alsowail, R.A. An insider data leakage detection using one-hot encoding, synthetic minority oversampling and machine learning techniques. Entropy 2021, 10, 1258. [Google Scholar] [CrossRef]
- Xue, G.; Song, L.; Sun, J.; Wu, M. Foreground estimation based on robust linear regression model. In Proceedings of the 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 3269–3272. [Google Scholar]
- Ahn, J.J.; Byun, H.W.; Oh, K.J.; Kim, T.Y. Using ridge regression with genetic algorithm to enhance real estate appraisal forecasting. Expert Syst. Appl. 2012, 39, 8369–8379. [Google Scholar] [CrossRef]
- Jalal, D.; Ezzedine, T. Decision tree and support vector machine for anomaly detection in water distribution networks. In Proceedings of the International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 1320–1323. [Google Scholar]
- Shahbazi, Z.; Hazra, D.; Park, S.; Byun, Y.C. Toward improving the prediction accuracy of product recommendation system using extreme gradient boosting and encoding approaches. Symmetry 2020, 12, 1566. [Google Scholar] [CrossRef]
- Hu, Z.; Zhang, Y.; Zhao, Y.; Xie, M.; Zhong, J.; Tu, Z.; Liu, J. A water quality prediction method based on the deep LSTM network considering correlation in smart mariculture. Sensors 2019, 6, 1420. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Shahid, F.; Zameer, A.; Muneeb, M. Predictions for COVID-19 with deep learning models of LSTM, GRU and Bi-LSTM. Chaos Solitons Fractals 2020, 140, 110212. [Google Scholar] [CrossRef]
- Kaggle. Available online: https://www.kaggle.com/datasets/likhitsudha/fishweights (accessed on 12 September 2023).
- Jongjaraunsuk, R.; Taparhudee, W. Weight estimation model for red tilapia (Oreochromis niloticus Linn.). Images. Agric. Nat. Resour. 2022, 56, 215–224. [Google Scholar]
- Tolentino, L.K.; De Pedro, C.P.; Icamina, J.D.; Navarro, J.B.; Salvacion, L.J.; Sobrevilla, G.C.; Villanueva, A.A.; Amado, T.M.; Padilla, M.V.; Madrigal, G.A. Weight prediction system for nile tilapia using image processing and predictive analysis. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 8. [Google Scholar] [CrossRef]
- Lopez-Tejeida, S.; Soto-Zarazua, G.M.; Toledano-Ayala, M.; Contreras-Medina, L.M.; Rivas-Araiza, E.A.; Flores-Aguilar, P.S. An Improved Method to Obtain Fish Weight Using Machine Learning and NIR Camera with Haar Cascade Classifier. Appl. Sci. 2023, 13, 69. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fish Species | Scientific Name | Count of Samples | Fish Shapes |
|---|---|---|---|
| European Bream | Abramis brama | 35 |  |
| Roach | Rutilus rutilus | 20 |  |
| WhiteFish | Coregoninae | 17 |  |
| Common Perch | Perca fluviatilis | 56 |  |
| Northern Pike | Esox lucius | 17 |  |
| Delta Smelt | Hypomesus olidus | 14 |  |
| Model | MSE | MAE | r2_Score (%) |
|---|---|---|---|
| Linear Regression | 0.0407 | 0.1649 | 94.52 |
| Ridge | 0.0385 | 0.1675 | 94.80 |
| Decision Tree | 0.0224 | 0.0998 | 97.01 |
| Random Forest | 0.0163 | 0.0795 | 97.76 |
| XGBoost | 0.0129 | 0.0745 | 98.24 |
| Features | VIF |
|---|---|
| Length3 | 2559.12 |
| Length1 | 2373.50 |
| Length2 | 136.50 |
| Width | 84.46 |
| Height | 74.50 |
| Model | MSE | MAE | r2_Score (%) |
|---|---|---|---|
| XGBoost | 0.0129 | 0.0745 | 98.24 |
| SFI-XGBoost | 0.0006 | 0.0175 | 99.94 |
| Reference | Method | Data Characteristics | Fish Species | Performance Indicators |
|---|---|---|---|---|
| [14] | The flatfish is characterized by its large surface area. After capturing the flatfish images, preprocessing operations were applied. Using image segmentation techniques, the tail was removed to obtain a more accurate estimate of the area. Using the formula W = 3.674 A − 2.145, where W is the weight and A is the area, the weight is estimated. | Flatfish Images captured. | Flatfish. | r2_score: 99.72% |
| [16] | The method used in this study is to train the convolutional neural network model with the external dataset. This training is performed with three different architectures of CNNs: VGG-11, ResNet18 and DenseNet-121. The results obtained with DenseNet-121 are the best. | A dataset containing images of fish and their weights which is produced by PFR. | Australasian Snapper. | r2_score: 96% |
| [34] | This method consists of collecting data (length and weight of fish) manually. According to the data found, the equation is established, where W is the weight and L is the length. Then, the length of the fish is determined from its image. Finally, the weight is estimated using the equation established at the beginning. | Fish lengths and fish weights are collected manually. Images of fish are captured to estimate the weight. | Red Tilapia. | ACC: 93.01% |
| [35] | An IoT system is used in this work. The collection of fish images is done from two positions (two cameras). The images are sent via a LoRa network to a web application. Fish image-processing operations are applied to determine the length. The weight estimation is made using the polynomial regression formula , where W is the weight and L is the length. | Fish images are captured from two cameras in an IoT system including a Raspberry Pi board, LoRaWAN and a web application. | Nile Tilapia. | Mean Percentage Error: 2.82% |
| [36] | In this study, a system composed of several hardware and software components is implemented. The detection of fish images is performed with videos captured with a NIR camera. The Haar Classifier is a tool that detects a fish object in real time. After processing the image, the detection of length and width allows to estimate the weight of the fish using the equation , where W is the weight and L is the length. | Videos captured with a NIR camera from an experiments tank. | Tilapia. | ACC: 92%. |
| This work | Our work consists of developing a new approach, SFI-XGBoost. It selects the most important features before passing them to XGBoost for training. SFI-XGBoost is based on the features Length1 Length2, Length3 and width to create the model. This model is applicable to several fish species. | The dataset is retained from the Kaggle web site. It contains the attributes species, Length1, Length2, Length3, width, height and weight. The number of records in this dataset is 159. | European Bream, Roach, WhiteFish, Common Perch, Northern Pike and Delta Smelt | r2_score: 99.94% |
| Reference | Proposed Formula for Calculating Fish Weight | Fish Species | r2_Score |
|---|---|---|---|
| [34] | where W: Weight and L: Length | Red Tilapia | 51.74 % |
| [35] | where W: Weight and L: Length. | Nile Tilapia | 63.17 % |
| [36] | where W: Weight and L: Length. | Tilapia | 50.52 % |
| This work | SFI-XGBoost approach | European Bream, Roach, WhiteFish, Common Perch, Northern Pike and Delta Smelt | 99.94% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hamzaoui, M.; Aoueileyine, M.O.-E.; Romdhani, L.; Bouallegue, R. Optimizing XGBoost Performance for Fish Weight Prediction through Parameter Pre-Selection. Fishes 2023, 8, 505. https://doi.org/10.3390/fishes8100505
Hamzaoui M, Aoueileyine MO-E, Romdhani L, Bouallegue R. Optimizing XGBoost Performance for Fish Weight Prediction through Parameter Pre-Selection. Fishes. 2023; 8(10):505. https://doi.org/10.3390/fishes8100505
Chicago/Turabian StyleHamzaoui, Mahdi, Mohamed Ould-Elhassen Aoueileyine, Lamia Romdhani, and Ridha Bouallegue. 2023. "Optimizing XGBoost Performance for Fish Weight Prediction through Parameter Pre-Selection" Fishes 8, no. 10: 505. https://doi.org/10.3390/fishes8100505
APA StyleHamzaoui, M., Aoueileyine, M. O. -E., Romdhani, L., & Bouallegue, R. (2023). Optimizing XGBoost Performance for Fish Weight Prediction through Parameter Pre-Selection. Fishes, 8(10), 505. https://doi.org/10.3390/fishes8100505