1. Introduction
It is common knowledge that the cost of energy is most likely to rise in the years to come. Recent events such as the war in Ukraine have made clear that the cost of energy is a highly complex and flexible aspect dictated by economic and geopolitical criteria that cannot be estimated with precision [
1]. In the shipping industry, the cost of fuel has become the dominant factor in the operational costs of ships; therefore, all shipping companies are starting to adopt new technologies in order to reduce their operating expenses and become more competitive [
2]. This is also dictated by the international regulations regarding CO
2 emissions (the Carbon Intensity Indicator (CII) and the Energy Efficiency eXisting Ship Index (EEXI)).
A key strategy of shipping companies to compensate for the aforementioned variable economic environment is the adoption of modern systems that are based on IoT technologies and help to operate ships in a more efficient way [
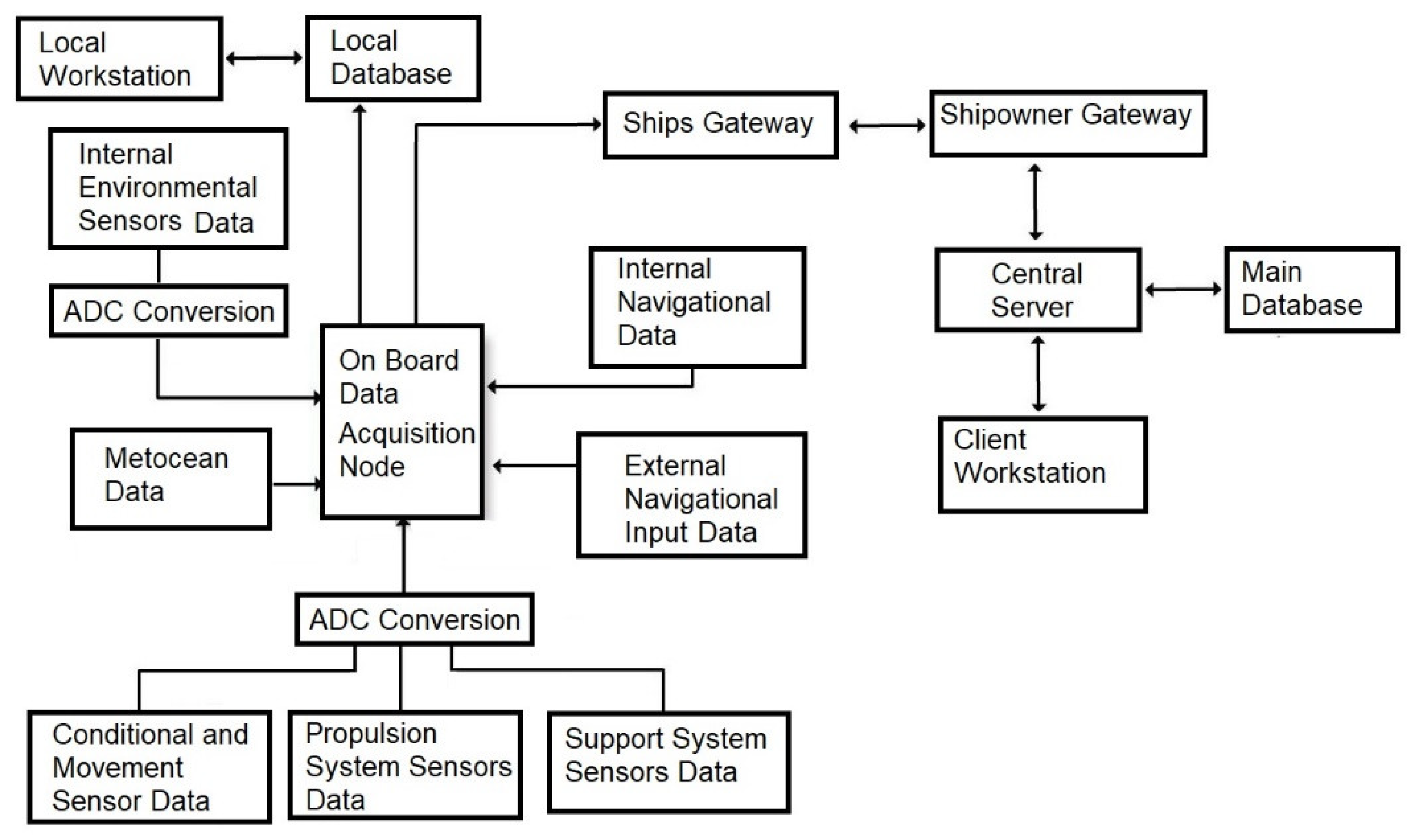
3]. State-of-the-art systems based on Industry 4.0 technologies are currently being installed on board ships. These systems collect data from various sensors, and process and store these data, to give insights to the crew, the shipping company personnel and the operators about the operating conditions of each ship and how they affect the ship’s performance and efficiency.
The “quality” of the data, in terms of consistency and accuracy, that are collected with these systems is probably the most important aspect of their overall performance. Missing or inaccurate data can lead to biased estimations or even the incapability to monitor performance. In the case of ships, this problem becomes more crucial when taking into account that while sailing, the resources (if any) to identify and repair sensors/data acquisition systems are limited.
Dealing with random missing data in log files is a common problem/challenge in all modern data acquisition, control and presentation systems (ADLMs) that are installed, but dealing with the complete missingness of a crucial sensor or compensating for sensor drift is a much more difficult and complex problem. The most common methods for data imputation that are usually implemented are the following [
4]:
Use of the next or previous value.
Unsupervised machine learning (ML) techniques such as K-Nearest Neighbors.
Use of the maximum, minimum, mean, moving average or median value.
Average or linear interpolation.
Use of a fixed value.
Unfortunately, all the above methods are not adequate to be used when we are missing a very large number of continuous data (a series of data) or when we cannot validate the accuracy of readings in order to calibrate the method used. In order to compensate for this problem, it has been proposed to use a type of Missing Value Prediction technique. A number of papers published recently deal with the sensor drift problem. In [
5], an LSTM and SVM Multi-Class Ensemble Learning model was used to deal with the drift of a gas sensor that improved the accuracy of the sensor over a 3-year period. Numerous algorithms have been proposed in the literature that are able to detect unreliable/drifted sensor data in a sensor network [
6]. In [
7], machine learning approaches to address IoT sensor drift are presented that need low computational power and, thus, can be implemented in any IoT sensor network. Time series forecasting algorithms are used to compensate for either the complete missingness of sensor data or sensor drift. Supervised ML used in time series forecasting is a very promising approach in order to deal with the missingness of a large amount of data. The missing data can be set as the label (dependent value), and all the other data can be set as attributes (independent data) in order to fill in the missing data. In general, all ML models learn with respect to the distribution of the features in the training data. If the feature space distribution of the data changes, there will be a mismatch between the model’s representation and the actual data, resulting in decreased performance. This inherent characteristic of ML models is used in the present study to detect and compensate for sensor drift.
The aim of this study is to examine the possibility to address and solve the aforementioned problem with the use of machine learning or deep learning techniques. We evaluate whether it is possible to compensate for sensor drift if we train an ML model to predict a sensor value when a sensor is new and in good condition and then transfer the model’s “knowledge” to actual conditions. Time series forecasting algorithms are used to compensate for either the complete missingness of sensor data or sensor drift. Supervised ML used in time series forecasting is a very promising approach in order to deal with the missingness of a large amount of data. The missing data can be set as the label (dependent value), and all the other data can be set as attributes (independent data) in order to fill in the missing data. In general, all ML models learn with respect to the distribution of the features in the training data. If the feature space distribution of the data changes, there will be a mismatch between the model’s representation and the actual data, resulting in decreased performance. This inherent characteristic of ML models is used in the present study to detect and compensate for sensor drift. The paper content is organized as follows: In
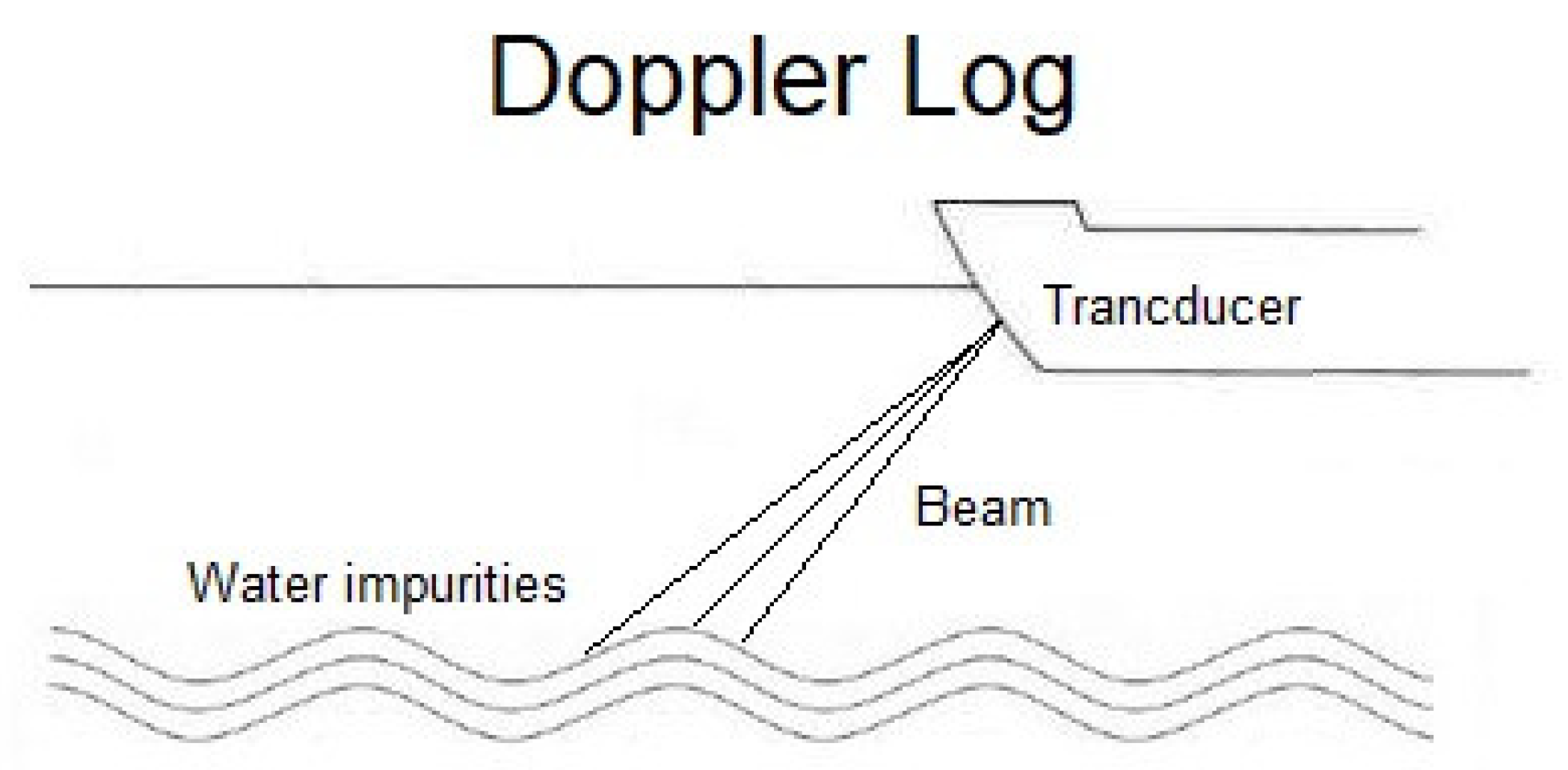
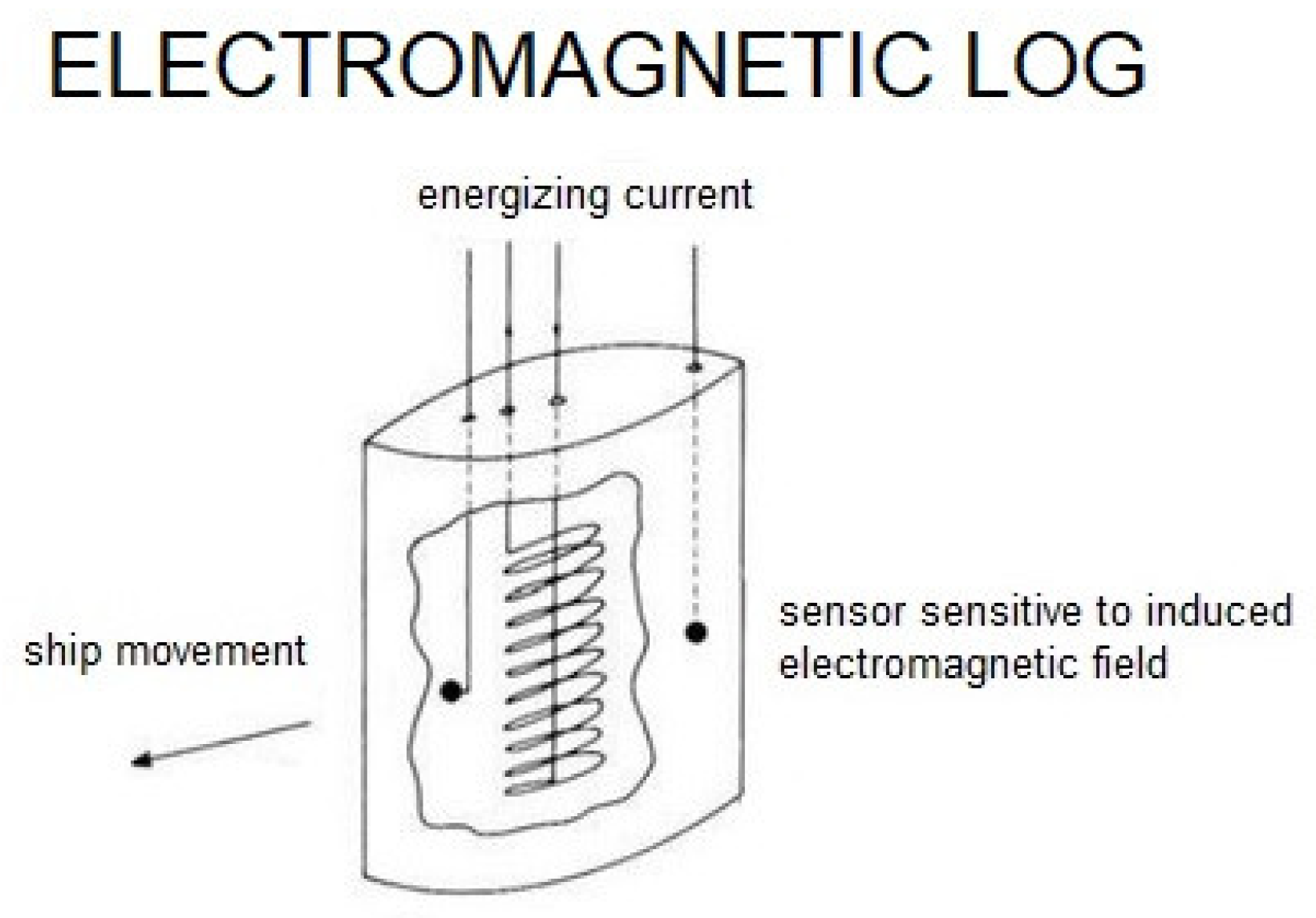
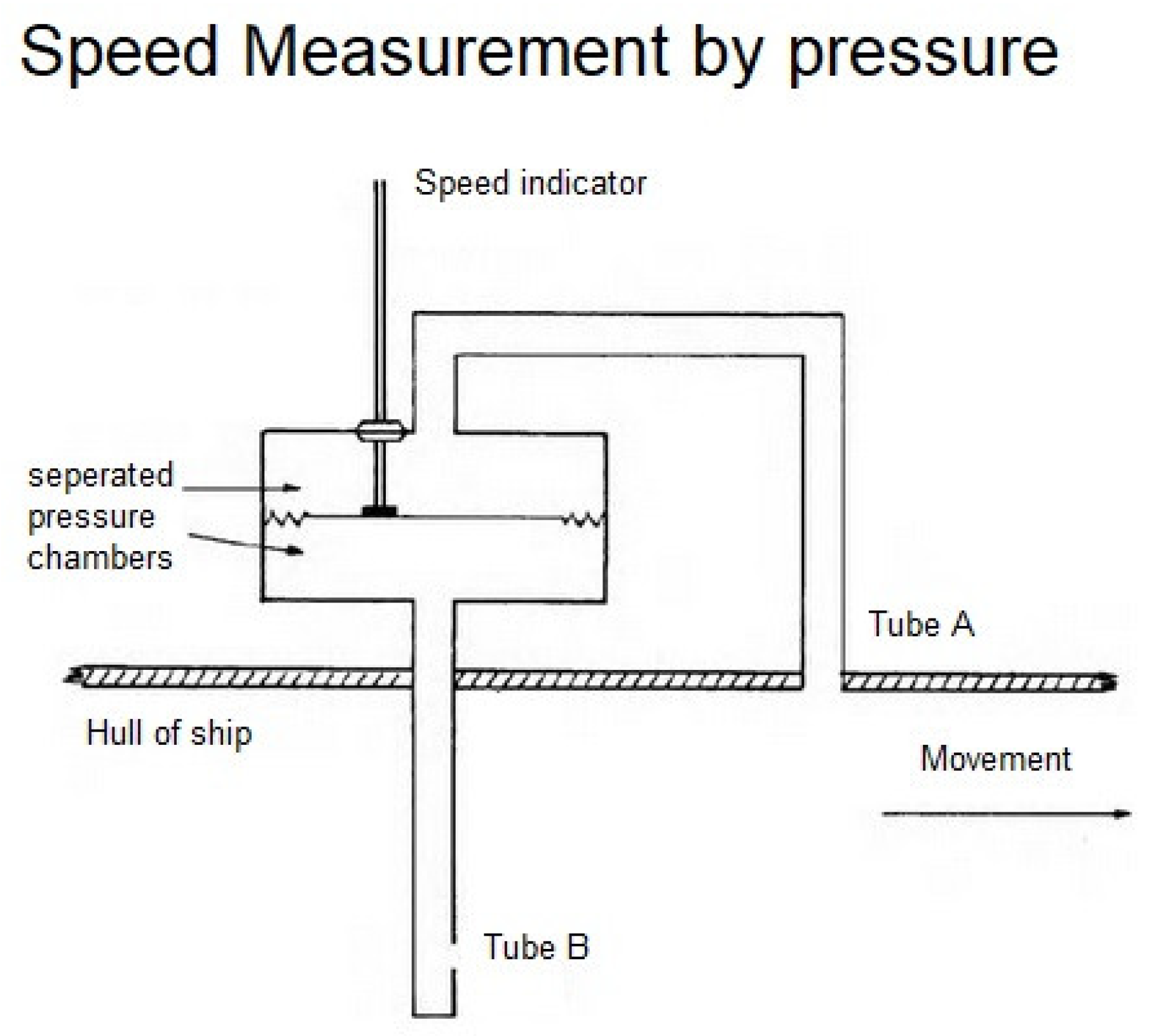
Section 2, the importance of the sea though water (STW) value in ship performance prediction is described. The different types of STW sensors that are installed in the majority of ships are presented. Their working principle is explained to support their high exposure to the possibility of drifting in their accuracy. The basic configuration of modern ADLM systems and the mechanisms of missing values are presented in
Section 3.
Section 4 is dedicated to the analysis of the proposed method. In
Section 5, the results of this study are presented, and in
Section 6, we conclude by briefly discussing the results and providing future perspectives/challenges.
4. Proposed Method for Compensating for Missing Data and Drift in Readings of STW Sensors
4.1. Use Case Vessel
To evaluate the proposed approach for compensating for missing data and drift in the readings of STW sensors, a typical dataset was used, provided by the onboard ADLM system installed on a crude oil tanker with a 165,000 tons displacement and built in 2015. This system gathers data from various on-board sensors and information received from external service providers (i.e., weather forecasting and navigational data) The raw dataset was generated from measurements/data covering a period of 6 months, from mid-February of 2020 until the end of July 2020 [
27]. The ship’s main specifications are presented in
Table 1.
The onboard ADLM system collects and stores data with a sampling frequency of 0.017 Hz (1 measurement every minute). With this frequency, a total number of 236,161 instances were collected in the period of 6 months. The number of data parameters (attributes) that the system collects is 178.
4.2. ML Algorithms/Time Series Forecasting
As mentioned, the dataset used in the present study to evaluate the proposed approach for compensating for missing data and drift in the readings of STW sensors covers a period of 6 months with data logging every 1 min. Each of the different attributes (parameters logged) has continuous values that are time-dependent (the value of each time instant is dependent on the past sequence of values). This kind of dataset is called a time series, and the method of predicting future values over a future time is called time series forecasting.
Analyzing past data helps us identify future trends. Most of the well-known machine learning (ML) algorithms can be used to solve this kind of problem in its original form or after some modifications. The most important characteristic of the algorithms that can be used in a time series is their ability to extrapolate patterns outside of the domain of the training data, which, by default, machine learning techniques are not able to perform. This is a very attractive feature, especially for applications in which the availability of data covering the whole range of possible values is limited or hard to make available.
For the scope of the present study, four algorithms with the capability to be implemented in time series data frames were applied and compared. These are detailed as follows:
These algorithms were selected because they are representatives of the three dominant categories of algorithms (linear regressors, tree-based and artificial neural networks) that have a wide field of application and have been widely used in the literature on these types of problems.
In Linear Regression, the relationships between dependent and independent variables are modeled using linear predictor functions. The goal is to estimate unknown parameters from the data (coefficients) that will form a linear equation that can best describe future data. Due to the assumption that unknown future data depend linearly on their unknown parameters, these models are easier to fit than models that are non-linearly related to their parameters because the statistical properties of the resulting estimators are easier to determine. The computation complexity of these models is relatively small, making them fast. On the other hand, the assumption of linear dependency deprives them of the ability to accurately estimate complex patterns [
28].
Random Forests are part of a group of ML algorithms that use ensemble learning methods for regression. These methods aim at improving the accuracy of predictions by combining multiple models instead of using a single model. Random Forests contract a multitude of decision trees at the training time, and all of them are used to predict future values. The mean or average prediction of these individual trees is returned as a result of the combined model. Decision trees (which are the structural elements of Random Forests), in general, outperform Linear Regression because of their ability to “capture” extremely complex patterns in data. The downside is that they are keen to overfit. Random Forests were created to compensate for this disadvantage [
29].
LSTMs are artificial neural networks that belong to a category named Recurrent Neural Networks (RNNs). This type of network can process not only single data points but also entire sequences of data. This characteristic makes them well-suited to making predictions based on time series data. RNNs can keep track of any arbitrary long-term dependencies in the input sequences in order to make predictions. The problem with RNNs is that by using back-propagation (which is the training technique for all ANNs), it is possible for the long-term (time-dependent) gradients to tend to zero or infinity, making training impossible. LSTMs were developed in order to solve the vanishing gradient problem. Due to their construction, they allow gradients to back-propagate and thus allow the training procedure to be completed [
30,
31].
The N-Beats (Neural Basis Expansion Analysis for Time Series) is a modern ANN model (first presented in the literature in 2019) created with a combination of stack sequences, whereby each of these stacks is a combination of multiple blocks. The blocks connect to form a feedforward network via forecast and back cast links. Each block removes irrelevant information from the dataset that cannot be approximated. Then, the block focusing on the residual error, which the preceding blocks could not disentangle, generates a partial forecast while focusing primarily on the local characteristics of the time series at hand. The stack aggregates the partial forecasts across all the blocks that constitute it, and the result is transferred as an input to the next stack. Each stack identifies any non-local patterns, and then all these partial forecasts are pieced together to form a global forecast at the model level. Based on a recent study [
32], the N-Beats model had an exceptional performance in M3, M4 and TOURISM competition datasets (that contain time series data), improving the forecast accuracy by 11% over a statistical benchmark. Due to this, it is assumed to be an excellent candidate for evaluation in the present study. The characteristics of the N-Beats model are extremely useful when dealing with time series data and especially in compensating for data drift since the algorithm is extremely adaptable due to the fact that it focuses primarily on the local characteristics of a time series sequence and thus does not “carry” long-term information that could be infected due to sensor drift.
4.3. Simulation Platform—Simcenter Amesim Configuration
In order to evaluate the proposed method for overcoming the problem of missing sensor values in the present study, a well-established mechatronic simulation software (Siemens Simcenter Amesim) was used. Amesim is an integrated simulation platform used primarily for the modeling and analysis of various multi-domain physical systems [
33]. With the use of this software, we can predict the multi-disciplinary performance of complex systems by connecting the valid analytical modeling blocks of electrical, hydraulic, pneumatic and mechanical subsystems into a comprehensive and schematic full-system model [
34]. The aforementioned modeling blocks are described using nonlinear time-dependent analytical equations. Using specific libraries that fall into the mechatronic engineering field, different physical domain behaviors can be analyzed and predicted.
Our use of such software as Amesim was dictated by the fact that there was no access to the “ground truth” of the STW values. A system able to approximate the real values of STW without being affected by the deviations caused by sensor drifting was required in order to test the hypothesis of this study. Modeling software like Amesim are not affected by sensor deviations since all the model blocks (ship, propeller, etc.) are implemented without taking into account the cause that generates these deviations, e.g., the ship model block does not simulate the hull degradation caused by marine fouling that distorts the seawater flow and can deviate the STW readings.
A digital twin of the case study ship was created with the use of Simcenter Amesim. Different modules from the marine library were implemented in order to simulate the behavior of the ship in actual conditions.
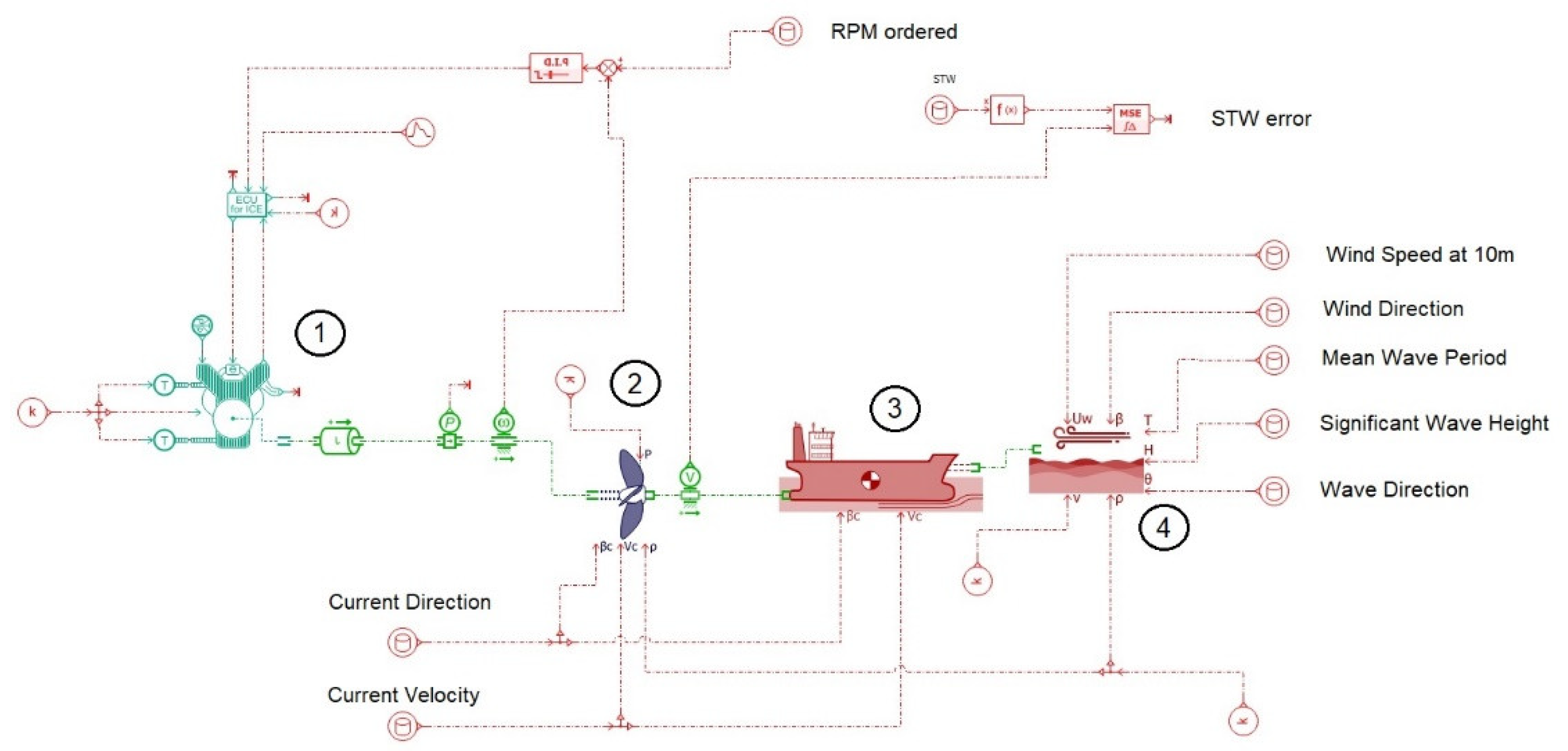
Figure 6 presents the Amesim configuration that is used in this study.
The main modules that form the digital twin of the ship are as follows:
The aforementioned blocks of models are interconnected according to the actual physical relations that exist between them, and based on the first principles (the equilibrium of mass, torque and energy), the integrated simulation model (the digital twin of the ship examined) can predict the ship through water (STW) velocity of the ship that corresponds to the input operating parameters provided at each time instant, based on the available dataset from the ADLM system used in the current study. Comparing the theoretical (predicted by the model) STW ship speed with the logged one (derived using the onboard speed log system), the mean square error is determined.
In order to validate the digital twin of the case study ship that we created using Amesim, we simulated the STW using data that belong to the first of the trips that are available to us. Using these data, we can check how close Amesim approximates the values of the measured STW in the case study reference conditions.
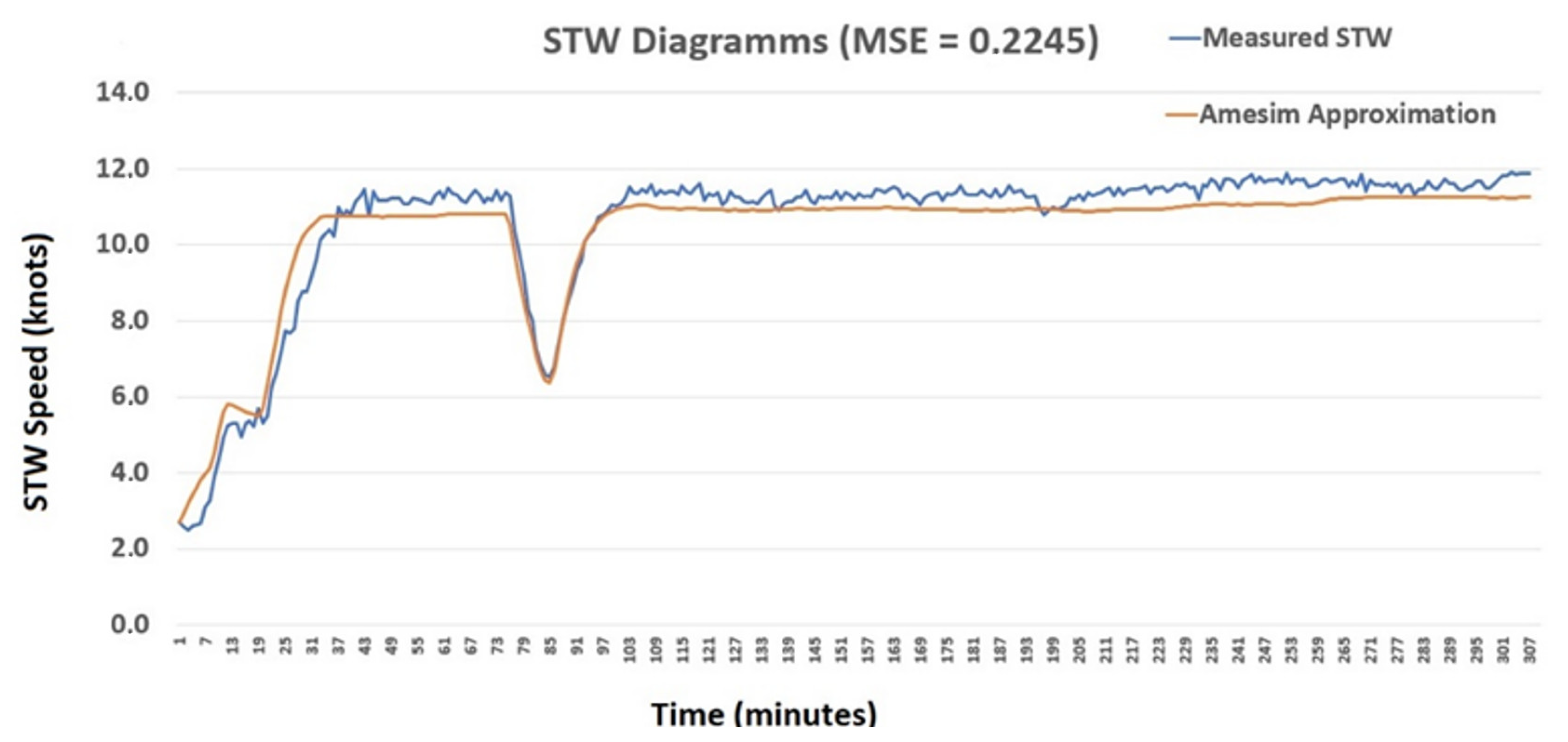
Figure 7 presents the comparison between the measured STW values with the onboard sensor and the corresponding predicted ones using the model developed with the Amesim platform, during the first time series being examined.
As observed, the predicted values are close to the measured ones during the whole time period examined, which is a strong indication that the developed model manages to correctly predict, at least qualitatively, the effect of operating conditions on the value of STW. Moreover, the absolute values are very close to the measured ones, with the MSE value being equal to 0.2245.
5. Results and Discussion
To evaluate the performance of the aforementioned time series forecasting algorithms to compensate for missing sensor values or drifted values in a real ship scenario, the ship’s speed through water (STW) was set as a label parameter since this has a dominant effect on a ship’s fuel consumption, which is of the utmost importance for ship operators and ship owners. Another very important reason for choosing STW as the label is the fact that any sensor responsible for measuring STW, regardless of its type, is outside of the hull and exposed to the harsh environment of the sea. This makes these sensors more prone to drift. One other note is that one can argue that since Amesim or any other simulation software can estimate the STW, why bother using time series forecasting models? The answer to this question is that exactly the same procedure that is proposed in this paper, with the same expected results, can be used to predict any other sensor data that might be completely missing, even the ones that are crucial inputs for the simulation software to work. Creating virtual sensors with time series forecasting models might be the answer to increasing the robustness of an overall performance monitoring system.
The aforementioned time series algorithms predict the STW speed of a ship using all the available logged data following a gradually time-evolving procedure covering the full time period of the available dataset. A total of three cases were examined: in the first case, each algorithm predicts at each time step the value of the STW speed based on all the previous data available until that time, and this value is assumed to be known in the next time step until all the time period under investigation is covered (forecast horizon = one). In each iteration, past (known/estimated) data are increased with the forecast horizon. This type of prediction takes place in real-time.
In the second case, the prediction of the STW speed is estimated in batches of five values (forecast horizon = five). After each group of 5 time instants (t = 5), the STW speed values corresponding to each one of the past 5 time instants (t = 0 to t = 4) are predicted. In the following iteration of the prediction procedure (i.e., at t = 10), the already predicted STW speed values of the last predicted group of data (until t = 4) are used to predict the following group of 5 values (i.e., from t = 5 to t = 9). This procedure is then repeated in the next batch and so on. This type of prediction is near to real-time but has the advantage that algorithms have future knowledge of all the independent attribute values.
The third case is similar to the second with the difference that each batch expands to nine values (forecast horizon = nine). The limit of the examined forecast horizon to values between five and nine was purposely set due to the high computational demand of ANN algorithms and the corresponding time needed to provide results. Taking into account that in the use case examined, the ADLM system has a sampling frequency of 0.017 Hz, the calculations should be completed in less than 60 s with a forecast horizon of 1. In the cases of forecast horizons of five and nine, the available time increases by a factor of five and nine, respectively. The latter is crucial, especially in cases where CPU power is limited (which is the case, for example, when these techniques should be applied for specific applications onboard).
The predicted values of STW speed according to each of the above three data interpretation approaches (with forecast horizons of one, five and nine) using each of the four algorithms presented (LR, RF, LSTM and N-Beats), along with the measured values from the o-board speed log sensor, were compared with the assumed as “true” value of the STW speed predicted via the digital twin of the ship (physical simulation model) for the corresponding operating conditions. The parameter used to compare these values and evaluate the performance of each of the approaches presented in compensating for the missing data and the drift in the readings of the STW sensors is the mean squared error (MSE). More specifically, considering that the predicted values of the STW speed based on the developed simulation model are independent of the possible causes that could lead to the STW log sensor’s failure or drift, it is suitable to assume that these predictions could be treated as being closest to the unbiased real STW speed value for each operating condition. Therefore, this value is used for the definition of the MSE when the various approaches proposed in the present study are evaluated, and high values of MSE could be attributed to the low effectiveness of a certain approach to compensate for STW sensor drift or loss of data. In this way, it becomes possible to compare the various approaches objectively, although it the actual/accurate value of the STW at each operating condition is unknown.
5.1. Data Pre-Processing—Time Series Forming
In the first step for all the instances, from the data collected with the ship’s ADLM system, speed over ground (SOG) values of less than 2 knots were discarded because they were considered to correspond to transition periods or periods in which the ship was in harbor.
From the original set of available attributes (logged parameters), only those related (directly or indirectly) to the parameter under study (STW) were taken into account. All other (irrelevant) attributes (e.g., parameters related to the auxiliary engines, or data used to monitor the operating conditions of the auxiliary pipe network) were excluded from the dataset in order to reduce the total volume of the data and thus maximize the prediction accuracy of the ML models that were used. Following this approach, the total number of attributes taken into account decreased from the original 178 entries to 49.
In the second step, all the attributes that have an extremely high correlation with STW and originate from the same sensor were excluded. Therefore, longitudinal water speed, transverse water speed and stern transverse water speed were excluded from the dataset since they could bias the results.
Afterward, all the instances that had missing values for attributes related to meteorological conditions and in which missingness was continuous for very long time spans were also excluded from the dataset used. This eliminated the possible bias of the dataset that would arise with any kind of interpolation technique applied.
Especially for the attribute “Water depth” (which might affect the way that an STW sensor works), interpolation was applied in cases where there was continuality between the last non-missing value and the first non-missing value. The criterion used for determining the continuality of the missing values was the percentage of the difference between the last and first consecutive non-missing values, which was set to be as high as 3%. The threshold of 3% was set since this is the typical accuracy of this type of sensor [
38]. For those entries where continuality criterion checks failed or the number of continuous missing values was high enough, they were excluded from the final dataset used.
5.2. Algorithm Training/Hyperparameter Optimization
After the above preprocessing, 53 separate time series data (each of them corresponding to a different trip of the ship) were created, with no missing values, that span from 13 February 2020 until 20 July 2020. These time series can be separated into two periods. The first 26 time series represent continuous trips with minimum harbor periods that span from February to April. From the 27th time series until the 53rd, the ship started to increase the periods of staying in harbors. Due to the fact that marine growth mainly develops when a ship is stationary and, thus, the possibility of affecting the accuracy of the STW sensor increases, we decided to use the first 26 time series for the training of all the algorithms and test with the dataset corresponding to the second period. In this way, the ability of the algorithms to compensate for both missingness and sensor drift can be evaluated.
The time series forecasting needed for this paper was conducted using Python scripts that utilize well-known and established libraries in the area of ML. A relatively new Python library (Darts) simplified the code to a great extent and has been proven to be very helpful. Darts is an open-source Python library created by Unit8 that uses scikit-learn as a back-bone and can be used for forecasting time series [
39].
The hardware/software used to perform the necessary calculations in this study were made common for all the algorithms examined to make the time comparisons reliable. The configuration that was used is presented in
Table 2. (It is worth noting that the intelligence that is now feasible to be implemented and integrated into our systems is mainly attributed to the hardware capabilities, which in the near past could not easily support protocol processing execution [
40].)
The training of any ML algorithm is, basically, the procedure in which a number of parameters are learned from the data. We used existing data in order to fit the model parameters. In every ML model (including the ones used for time series forecasting), there is another kind of parameter that cannot be directly learned from the regular training process. These parameters, which are called hyperparameters, are model-specific and must be determined before the learning process begins. These kinds of parameters determine the important properties of each model, such as its complexity or how fast it can learn from data. For this implementation, we determined the best hyperparameters using the grid search technique for the Linear Regression and Random Forest algorithms and the random search technique for LSTM and N-Beats in each of the 26 time series (1st period) that were used for algorithm training.
In the grid search hyperparameter tuning, we defined a search space as a grid of hyperparameter values and evaluated every position in the grid, while in the random search, we defined a search space as a bounded domain of hyperparameter values and randomly samples points in that domain [
41]. The above separation was dictated by the fact that the LSTM and N-Beats algorithms completed the grid search for the hyperparameters in a test time series over unacceptably long time periods due to the extensive calculations needed. In
Table 3, the average time needed for a grid hyperparameter search for the Linear Regression and Random Forest algorithms together with the corresponding time for a random time series when using LSTM and N-Beats are presented.
In
Table 3, we can witness the exponential increase in the computational time when using the ANN models. The final set of hyperparameters that were used for the combined model (the one that used all of the 26 time series for training) was constructed with the use of the median of each separate hyperparameter in the cases of the Linear Regression and Random Forest algorithms and the corresponding results of the random search in the cases of LSTM and N-Beats.
In each of the three test cases examined (i.e., with forecast horizons of one, five and nine) and for all of the time series that were used for training, we calculated the MSE that the algorithms had when predicting the STW. The last 10% of the values of STW in each time series were used for testing. This was carried out in order to evaluate the performance of the algorithms in terms of consistency.
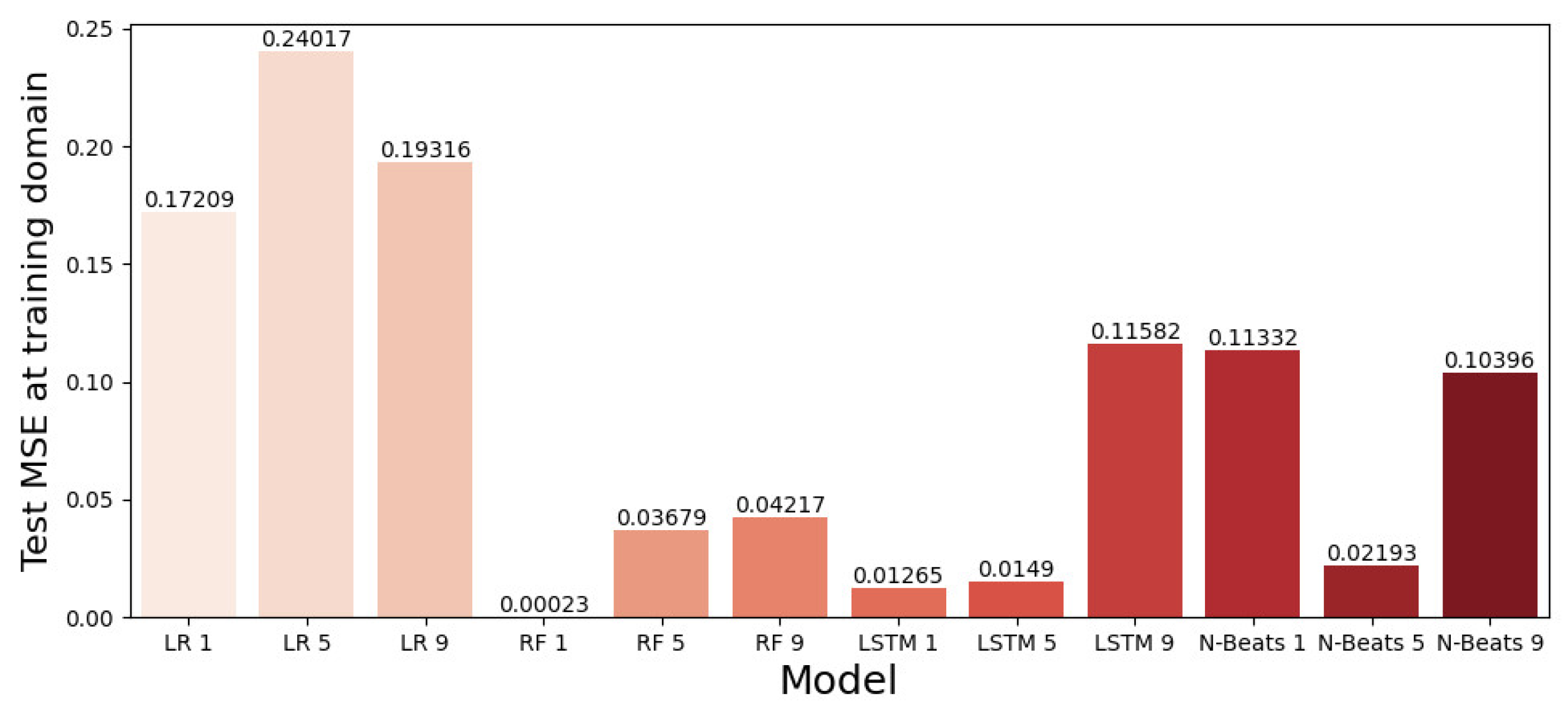
Figure 8 presents the allocation of mean MSE values for the prediction of STW for all four algorithms used (LR = Linear Regression model and RF = Random Forest model).
In
Figure 8, it is observed that the absolute best performance in terms of the MSE corresponds to the Random Forest (RF) algorithm when setting the forecasting horizon equal to one. The MSE = 0.00023 observed in this case is an exceptional value, meaning that the total amount of data from the 26 time series are sufficient enough to train this algorithm without overfitting the data. On the other hand, the Linear Regression algorithm (an algorithm that is commonly used for data imputation) is not able to fit the data very well, presenting by far the worst performance, regardless of the forecast horizon. The more sophisticated and computationally demanding ANN algorithms (LSTM and N-Beats) accomplished very good performances (with LSTM outperforming in all cases) but cannot outperform the Random Forest algorithm, which seems to be the most suitable algorithm of all. Finally, it is worth noting that, with the exception of the N-Beats algorithm, the best MSE value is achieved when the forecast horizon is set to one. This means that “future knowledge” of the attributes at the time of prediction (which is used in the case of the time horizon at five and nine) does not increase their performance.
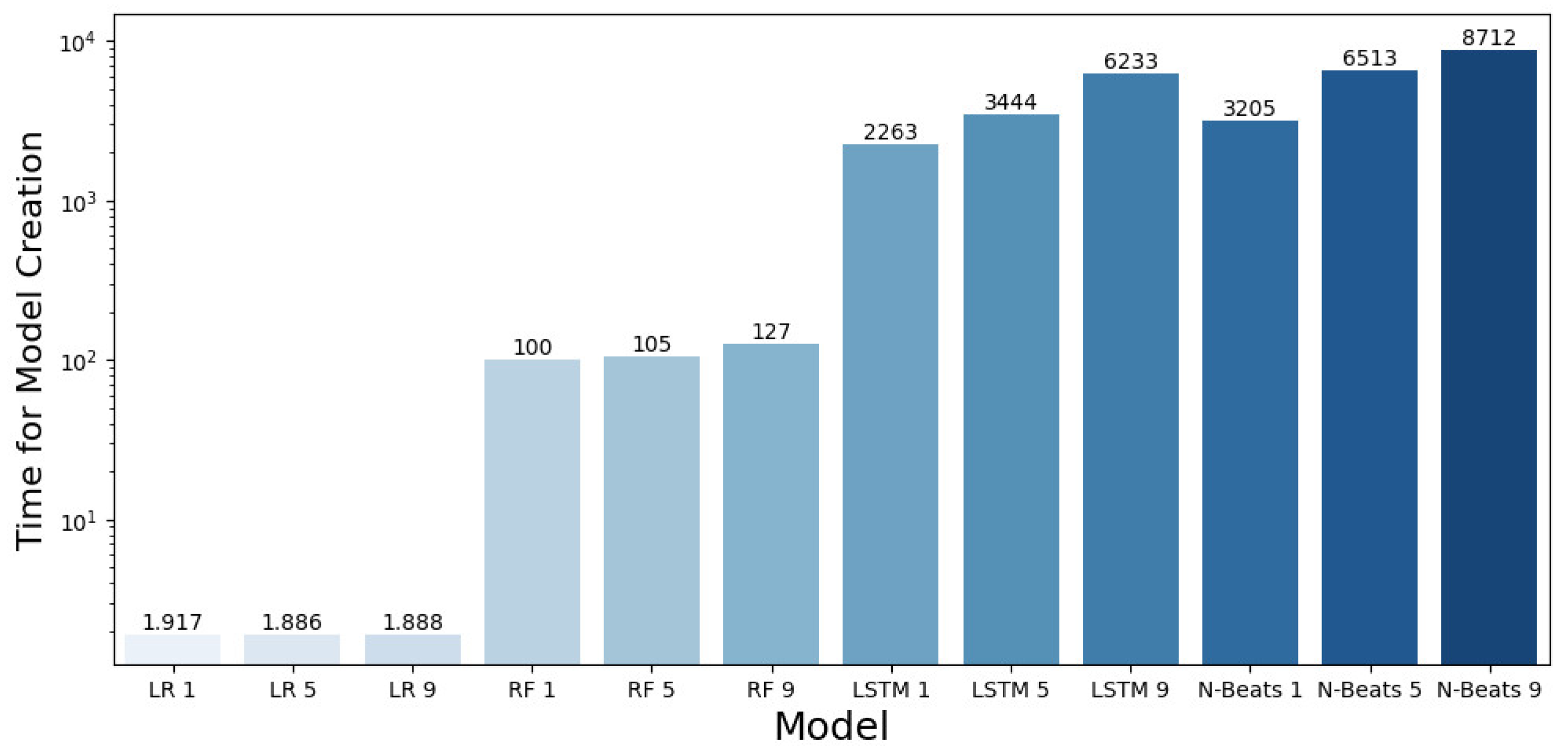
In
Figure 9, we present the CPU time needed for model creation in each of the twelve cases examined (three cases of time horizons for each of the four algorithms evaluated). It should be noted that the
y-axis (time spent in seconds) is on a log scale.
As expected, the increase in the model complexity resulted in more computational demands, which in turn led to an increase in the time needed to complete the necessary calculations for model creation. The increase in the time needed in the cases of LSTM and N-Beats is exponential compared with that in the LR and RF cases. The average time for completion of LSTM is one 1 h and 6 min, while Random Forest has an average time of 1 min and 50 s. Combining these results with the comparison of the MSE values shown in
Figure 8, it is concluded that Random Forest proved to be among the most accurate algorithms with the lowest CPU demand, which makes it preferable for the application examined. Moreover, from
Figure 8, it is observed that the increase in the forecast horizon does not improve the completion time as could be expected, although this leads to fewer iterations needed from the algorithms.
5.3. Algorithm Evaluation
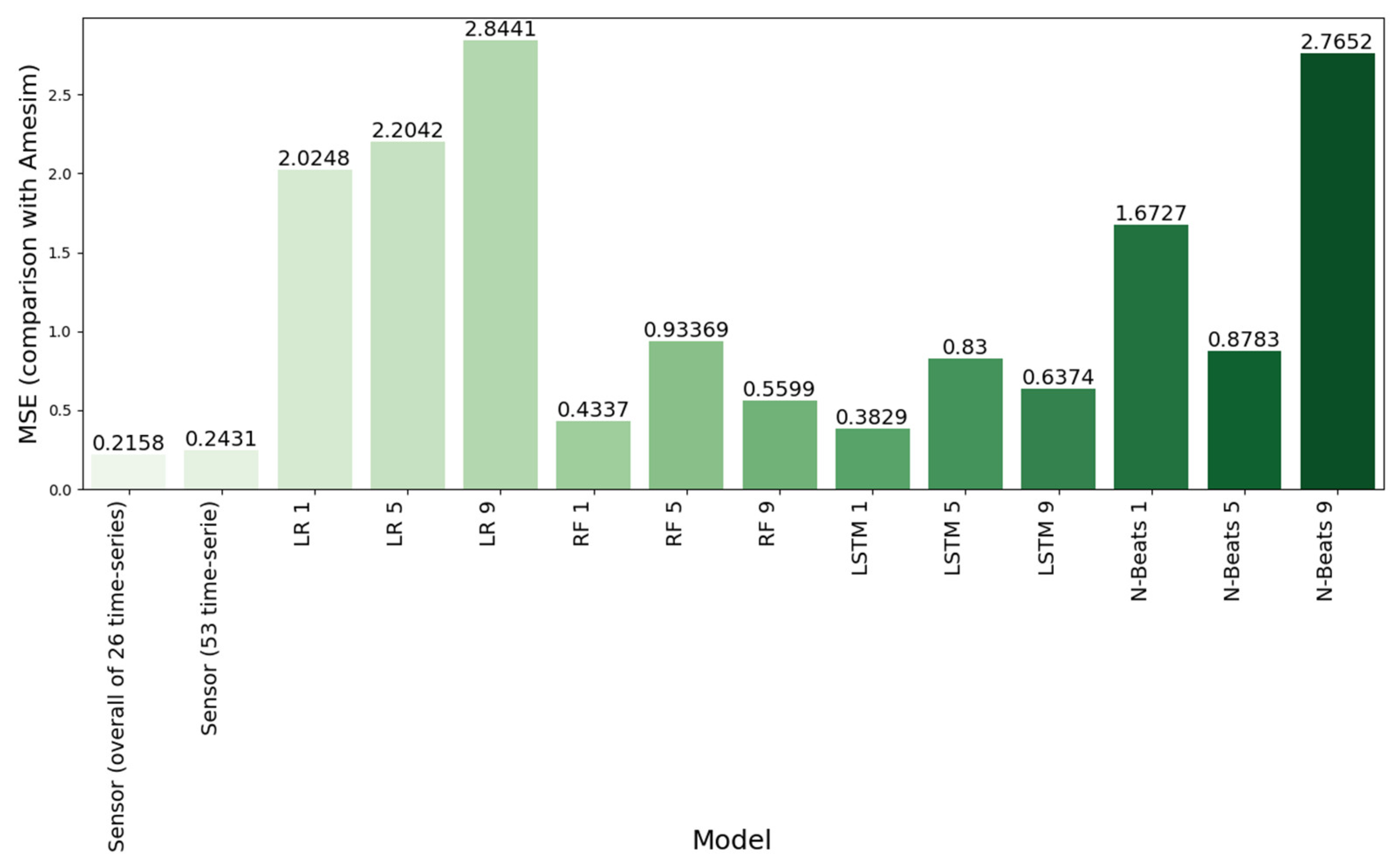
After validating the models’ performances, their evaluation in the 2nd period of the ship cruising data (and, specifically, the 53rd time series) is presented in
Figure 10. As already explained, the criterion for this evaluation is the MSE defined using the predicted value of the STW for each variant of the model being examined and the corresponding value predicted with the Ship Digital Twin model (Amesim) for the same conditions. Moreover, in the same figure, the MSE for the sensor is presented, which is derived using the recorded actual value with the onboard installed STW sensor and the corresponding value predicted with the physical model (Amesim), which is assumed to be independent of any parameter that could cause sensor drift or missing values. In
Figure 10, we can witness an increase in the MSE values between the digital twin and the STW values measured with the sensor when we switch from the first period to the test period (the MSE increases from 0.2158 to 0.2431), which indicates that there is a slightly increasing drift, as observed, and the MSE of the sensor is very low (equal to 0.2431), which is an indication that in the specific time period examined (2nd period), the STW sensor does not suffer from high drift.
On the other hand, when focusing on the performance of the Random Forest method with a forecast horizon of one (RF-1), which was identified as having the best performance in terms of MSE when tested in the first time domain (the twenty-six time series used for training), it seems that in the second time series (representing the actual test conditions), it has the second best MSE value and is outperformed by the LSTM model with the same forecast horizon (LSTM-1). This indicates that the LSTM model can generalize better in the domain adaptation. Both the Random Forest model and LSTM model achieved comparable MSE values with the sensor readings, which implies that both models can compensate for the complete missingness of STW data; however, this score is not considered good enough to indicate that these algorithms could also be used to compensate for the error induced by sensor drift. On the other hand, the LR model seems to have the worst performance, followed by N-Beats.
6. Conclusions and Future Perspectives
Most new ship buildings are equipped with modern data acquisition, control and monitoring systems that collect data from various sensors installed onboard, and analyze and combine these data with meteorological and geographical data provided by external sources, to assist shipping companies to minimize their operating expenses and become more competitive by optimizing ship performance. One of the most important metrics that is logged by the ADLM system and used for the analysis of ship performance is the ship’s speed through water (STW), which is directly related to the propulsion power needed during cruising. This is why this parameter was selected to evaluate the performance of four widely used time-series forecasting algorithms (with three variants for each) in compensating for missing data and drift in the readings of STW sensors, which is a common problem in real-life applications.
The four selected time series forecasting algorithms have escalating complexity in dealing with the complete missingness of STW data or the degradation of STW reading accuracy due to drift. All four algorithms were tested in three different configurations, i.e., in real-time prediction (forecast horizon = one) and near-to-real-time prediction (forecast horizon = five and forecast horizon = nine). The predictions as well as the onboard STW sensor readings were compared in terms of MSE with the assumed “ground truth” STW value predicted with the physical model of the ship developed using the Siemens Amesim simulation platform.
The results indicate that an ensemble model (Random Forest) and the LSTM Recurrent Neural Network, if used recurrently to predict only the next label value (forecast horizon = one), are able to generalize well and predict STW with adequate accuracy when trained in a certain domain (with the ship and STW sensor under certain reference conditions in terms of calibration and hull degradation) and tested in a different domain (with the ship and STW sensor in real-life operational test cases over a long time period).
The MSE scores for the STW for the above 2 algorithms (RF and LSTM) were 0.3829 and 0.4337, respectively, while the corresponding value for the sensor readings was equal to 0.2431. This high difference is an indication that these algorithms cannot be used or at least do not offer high confidence in solving the crucial problem faced in real-life occurrences of sensor drift or missing values. Based on the results, it seems that using a physical model could be a challenging alternative, at least in cases where this could be possible (i.e., the data required for the model are available). However, it should be noted that also in the case of using a physical simulation model, as was carried out in the present study to “generate” the unbiased reference value of STW for each operating condition, the effect of the model accuracy must be considered. In real-life applications, the STW value depends on many parameters, often being difficult to be precisely determined and simulated, especially if the results are needed in real-time. Even if using more detailed simulation approaches, using computational fluid dynamics (CFD) is not expected to provide a better solution to the scope of this study. Therefore, the use of simple physical models based on the first principles seems to be a fair compromise. The next steps include the investigation of more specialized techniques for domain adaptation, such as RNN autoencoders.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}