2.1. Data Preparation
We utilized a LoD2 CityGML dataset of Rostock, Germany to model our buildings. Even though software support for CityGML is sometimes lacking, there are simple ways to transform its boundary representation (B-Rep) model into a polygon mesh that is usable by modern game engines. The problem is that this step usually removes any metadata. We wanted to circumvent this to retain all the useful information that a CityGML dataset may have for accurate noise simulations, like information about building materials and absorption coefficients defined by the NoiseADE extension. To achieve this, we wrote a Python script to split the city-wide dataset into individual buildings. Then we converted each building into a COLLADA 3D model and gave it the same name as the CityGML file. We then loaded both files for each building into Unity, where we could now query for additional information simply by loading the same resource name with a different file ending.
Within Unity, we made use of the Mapbox mapping extension [
8]. It supports dynamic loading of terrain height maps and a collection of basemaps and handles the accuracy problems that we would usually encounter when using georeferenced data in 32-bit floating point accuracy. The problem is that Mapbox in Unity only works with the popular Web Mercator projection instead of arbitrary reference systems. While that precision is fine for placement of buildings on a street (the noise simulation itself only runs at a limited accuracy), reprojecting our CityGML data point-by-point introduced noticeable distortions within the individual building geometries, especially in multipart buildings. To fix this, we introduced a reference point into each CityGML building file by selecting the highest corner point. If multiple points are at the same height, we take the northernmost and then the easternmost of that subset. The same Python script from earlier selects this point, reprojects it to Web Mercator (EPSG:4326), and writes it into the file. Later, in Unity, we found that same point in the mesh data and can now place the buildings according to the correct projection, while retaining all the accuracy in the geometry itself.
2.2. Hardware
Mostly driven by the gaming industry, there is a plethora of commodity VR hardware on the market today. The idea realized in this paper is in principle not limited to any one system, but the choice of hardware sets the performance and interaction constraints for the implementation. To cover as many use cases as possible, we decided to use a modern head-mounted display, which typically does not require an expert on-site to set up the system. Other options can be found in [
1,
9]. The former describes projector-based stereo viewing of noise data, while the latter a CAVE system with a main focus on accurate audio playback.
Once in the head-mounted display (HMD) product space, the most important choice is whether tracking is done in three or in six degrees of freedom (DOF). While a 6-DOF system might increase presence and interaction capabilities, especially because current 6-DOF systems usually feature two motion controllers for hand tracking, the 3-DOF system lowers the barrier of entry, both in terms of price and the amount of set-up and instruction required before use. The latter also corresponds well with the limitations set by the noise standard: Noise has to be recomputed for each position, and in a 3-DOF environment, this does not continuously change due to body movements; instead, it only does so at the users prompt. Furthermore, noise results in the Common Noise Assessment Methods in Europe (CNOSSOS-EU) standard are said to be only valid for observer points that are two meters or more above the ground [
10]. If we want the user position to stay close to their real-world height, a 6-DOF system would allow them to duck down into a nondefined area. In a 3-DOF system, we can instead set their virtual head at two meters high and keep it there. 3-DOF systems are also more affordable, do not require the user to move around, and thus currently have the lowest barrier of entry into the VR space. Recently, they have even been utilized and validated for other VR soundscape research [
11].
2.3. Input & Interactions
The problem with 3-DOF HMDs is that they are limited in what kind of interactions they allow. Some 3-DOF VR systems come with their own controller, while others rely fully on the HMD itself as an input modality. In the latter case, the common interaction methods are viewing direction combined with a single button or a touchpad. This will hardly be enough to cover all the interactions that are needed. To avoid visual clutter and distraction through unwanted audio cues, the user needs to be able to dynamically switch certain features on and off. We identified the following basic set of interactions:
Movement through the virtual environment (locomotion);
Switch the noise map on/off;
Switch the propagation visualization on/off;
Play the current noise level;
Allow the user to set a multitude of parameters.
It is evident that we need more than one button/touchpad to cover these use cases if we do not want to force the user to do an excessive amount of head gestures. Thus, we either have to use a system equipped with a controller or use voice recognition. While the latter is an interesting research direction, we settled on the controller-based approach, as there is already a large body of research and consumer experience that has accumulated over the years.
For the actual implementation, we utilized a 3-DOF tracked motion controller as found in common standalone VR systems like GearVR. Other types of controllers, even those without motion tracking, should also be able to handle the required interactions without much issue.
The first interaction on our list is simultaneously the most critical for any VR application: User movement and agency, ranging from simple head rotations to continuous movement in large environments. For that reason, we look at this interaction in more detail. Different techniques have been extensively researched, especially since the resurgence of consumer-level VR HMDs over the last few years. Some require the user to actually walk in the physical world, others are based on keyboard, joystick or motion controller input. Reference [
12] discusses the most common of these approaches in detail and presents a point and teleport system. Here, the user does not have to move through space and is instead directly snapped to a location that is selected with a motion controller that acts as a pointer. The experimental data show that this is a low-friction method that most users enjoy working with. It also remains usable even when seated, as it does not require anything but arm movement and, depending on the specific implementation, body rotation, which can be accomodated with a swiveling chair.
For our purposes, the main contender of the point and teleport method is joystick locomotion, which continously moves the user position in the direction indicated with the joystick. Reference [
12] shows this to be a viable approach. The reason we settled on teleportation is performance-related—we only have to recompute user noise levels after every snap, whereas for joystick locomotion, it would have to be continously updated in real-time. We do not believe that the advantages of joystick locomotion outweigh this advantage in performance.
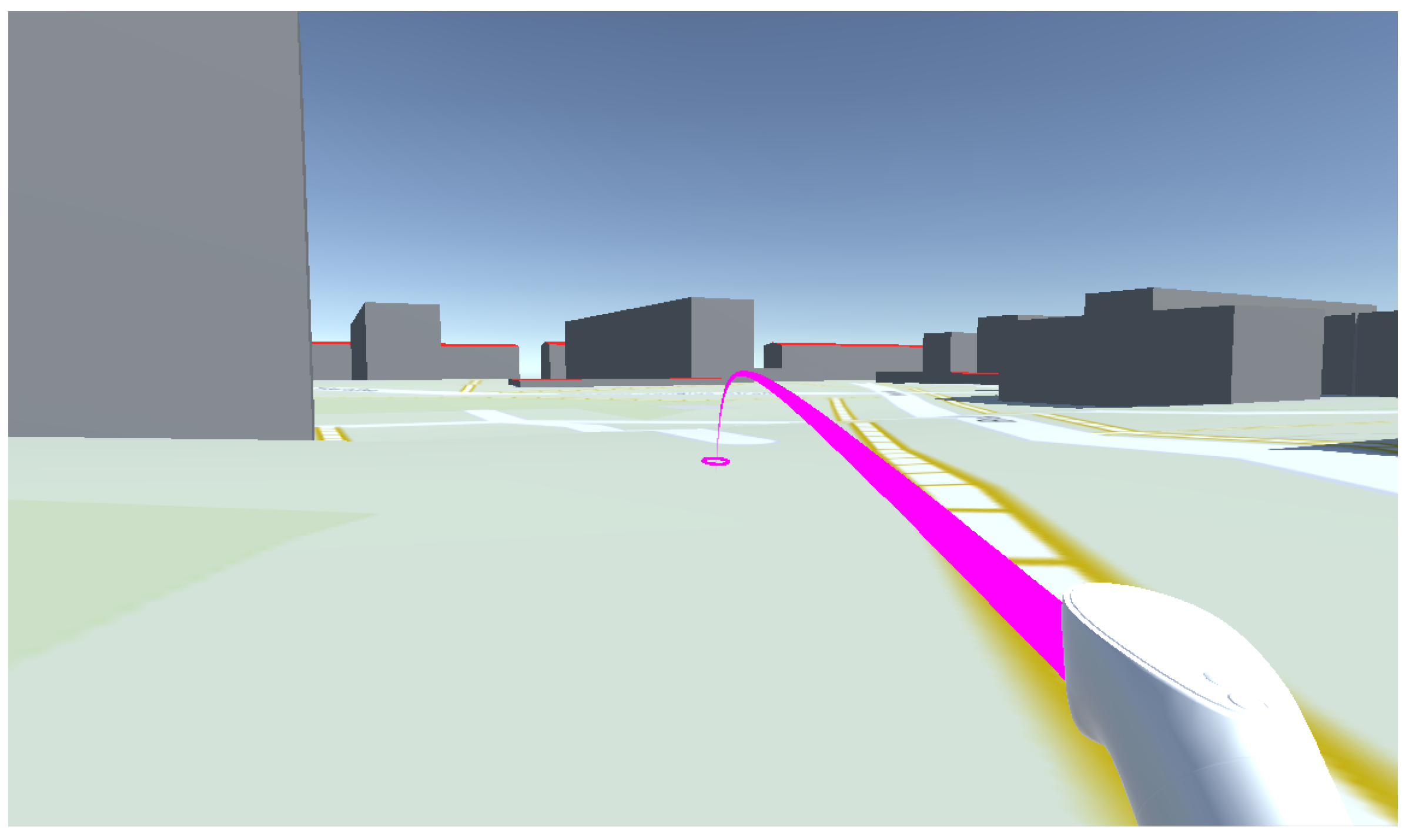
Following the results from [
12], we settled on a point and teleport system with a visual indicator, in which the user can decide whether they want to keep their rotation or realign their view on teleport. Because of how common this form of locomotion is in current VR applications, we did not have to implement this interaction ourselves. Almost every VR framework contains a prototypical rendition of this interaction, which also means that many users will be immediately familiar (see
Figure 1).
One problem with common teleportation approaches is the lack of altitude control. In joystick locomotion, the user can easily launch into flight and explore the environment at different heights. In terms of directly experiencing the noise data, this would not offer large benefits, as noise maps are usually calulated as a 2D grid at a fixed height over the ground plane and vertically over every building surface, not in a full 3D volumetric fashion. What upward movement could enable is easier navigation through the urban environment, especially as the user could simply hop on or over buildings that are in the way. We found that users get easily lost in the highly abstracted, very uniformly rendered environments, even if they had extensive knowledge of the areas being displayed. It thus became a necessity to offer some sort of overview map to regain spatial context throughout the exploration.
To our knowledge, there are no current studies testing the effectiveness of different exploration aids for larger, city-scale immersive virtual environments from a first-person perspective. There exists some research in the Augmented Reality (AR) space concerning how city environments can be explored, but here, the navigation tasks are usually limited to wayfinding and navigating to a specific position, as seen, for example, in [
13]. We require a method that helps with free exploration of the virtual urban space, while maintaining a focus on the data.
For this, we identified the following methods, most of them common interactions from non-immersive mapping appications:
A minimap, or any kind of overview shown in addition to the actual surroundings;
Upward teleportation, or any way to change player position away from the ground plane;
Zooming out, which in a VR context would equal a change of scale for either user or environment;
Environment deformation, like bending terrain upwards at a distance (see [
14]).
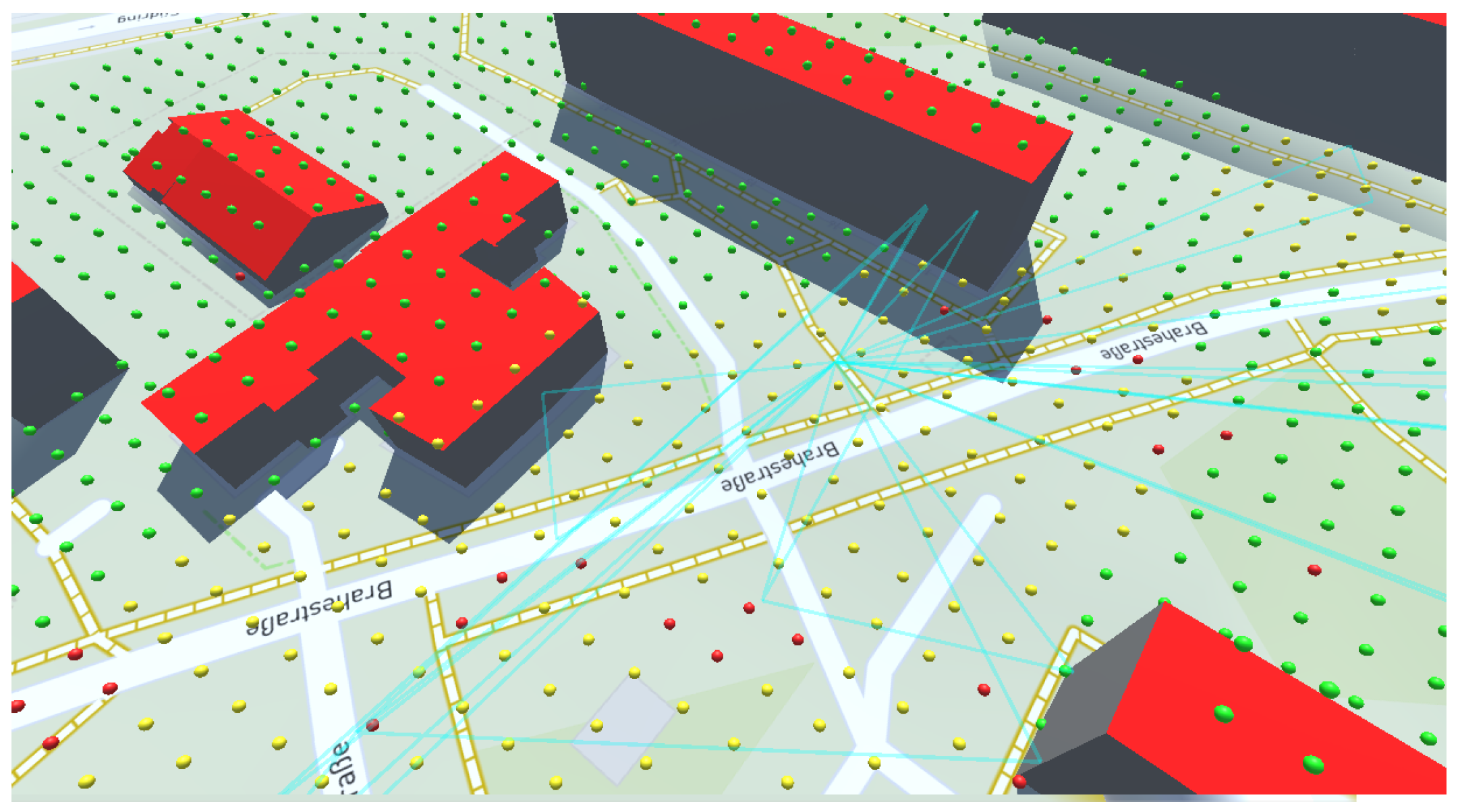
Comparing these approaches might be an interesting direction for future research. For our purposes, option four has a relatively high implementation overhead. Option one opens up a host of other questions, such as how to place the minimap, whether and how to present the 3D data on this representation, and how to interact with it. There is no immediate disadvantage apparent in options two and three. We settled on a variant of option three, an immediate snap of the current map extent to a lower scale, because it requires only one input action and should be easy for users to understand (see
Figure 2).
A side note that may be interesting for some readers: During the development of Google Earth VR, the designers grappled with similar problems and held a talk about their results [
15]. Their interaction design contains a combination of options one, two, and three and is generally well regarded by users.
2.4. Cnossos-Eu in Unity
Now that we have an environment that the user can explore and navigate, we need to populate it with the noise data. The CNOSSOS-EU [
10] standard describes a 2.5D method to compute noise propagation but mentions at several points where a 3D implementation is possible or necessary. In Unity, we have the choice between using a 2D and a 3D physics engine. In order to correctly handle different roof shapes, we settled on using the 3D physics and adapting the 2.5D method as accurately as possible.
The foremost problem in implementing these standards is the pathfinding for the noise propagation paths. Reference [
10] defines four types of paths—direct paths with diffractions over horizontal edges, reflections on vertical walls, diffractions on vertical edges, and a combination of the latter two paths. Reference [
16] describes how to efficiently construct noise propagation paths of the first type over LoD2 CityGML data and notes some difficulties with the other path types. Accurate handling of reflections and diffractions is indeed costly, not always solvable in the general case, and requires some knowledge about surface materials. Still, we wanted the user to have the option of including them, especially because they can potentially improve the realism of the sound simulation.
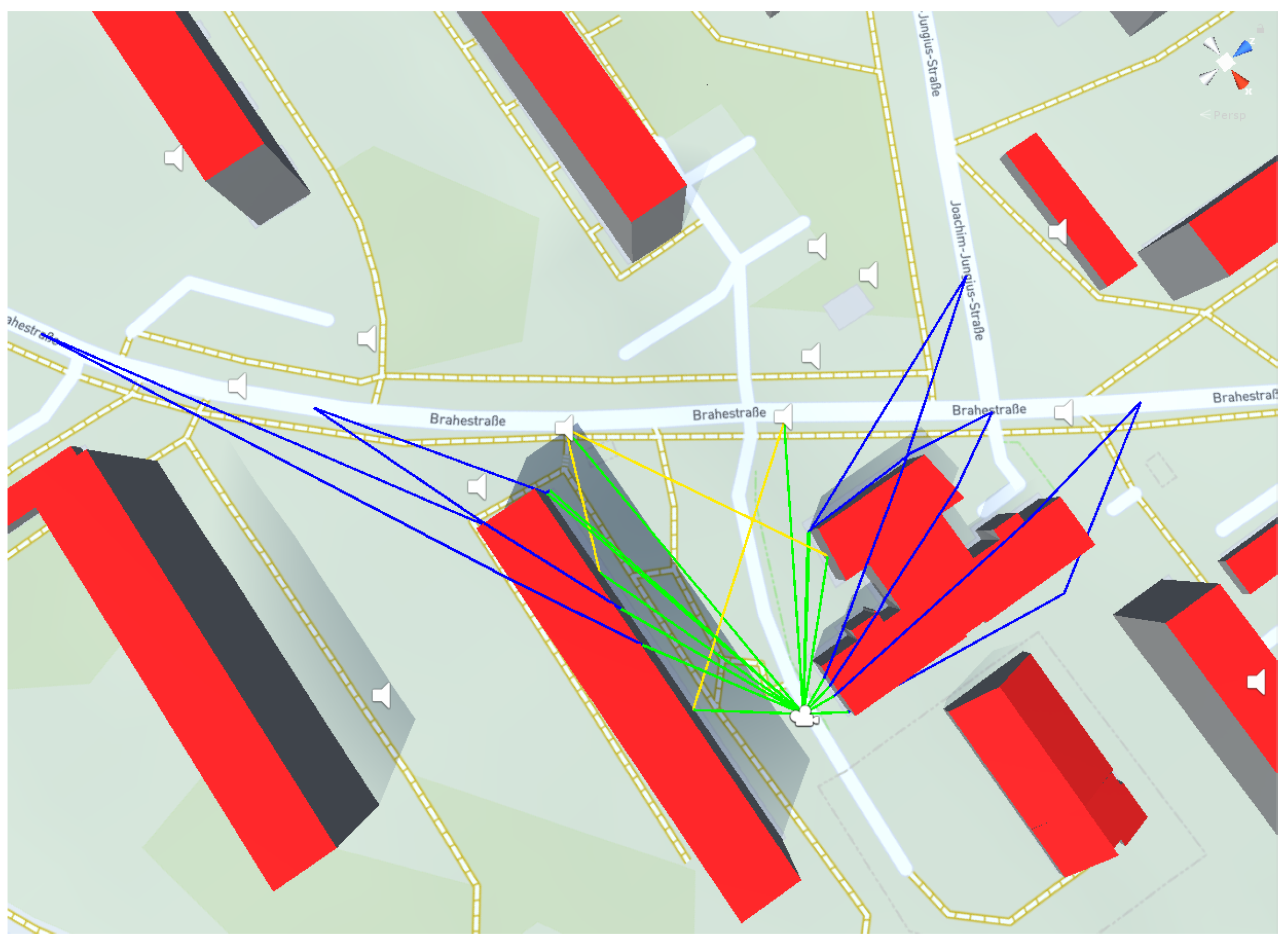
Considering that the large majority of urban buildings have a very simple shape in LoD2 data and are made out of some form of concrete or steel, we were able to implement a heuristic approach that manages to construct all four types of paths in most cases. A rendering of a common propagation situation is depicted in
Figure 3. For performance reasons, we only allowed specular, first-order reflections. The way we achieve this is by casting a ray from observer to source. If the ray hits an obstacle, we fire three new rays, the target of each shifted one meter left, right, or up from the obstacle impact point. If they miss the obstacle at that point, we have a diffraction and can retry the raycast from there. If they still hit the obstacle, we shift them further in their direction. This only assumes that the user is not surrounded by geometry on all sides (to handle that case, we limit the number of steps in each direction) and usually constructs two vertical and one horizontal diffraction if no direct path is present. (We could then make another assumption about building shape and construct a simple rectangle of paths to fill out the spaces between the three that we have, though this is not currently included.) Reflections are handled by raycasting in every direction (at one degree steps) on a plane between source and observer (this is where we utilize the 2D nature of the standard—full 3D reflections would increase the complexity drastically). At the impact point, we tested whether the direction of the target and the impact angle would end up describing a specular reflection. We allowed some room for error in this test, so we do not miss too many reflections, which would have happened between two angle steps.
This approach finds its way around most building shapes. What it does not do is conform precisely to the roof shape—the very reason we are utilizing CityGML LoD2 data instead of the less performance-intensive LoD1. To make use of roof shapes, we moved from full 3D space to 2.5D space. We traveled along every path and raycast downwards at a regular interval. This turns every path into a 2D approximation of the slice of ground that it travelled over. Reflections and vertical diffractions are simply folded open. The result conforms exactly to the way propagation paths are described in [
10]—the intersection between the terrain and a vertical plane that is spanned between observer and source points. Although we do not currently include it in our prototype, because our data do not carry this information, this is also the step where information about ground materials would be collected.
After we defined all the propagation geometry, we computed the sound pressure level (SPL) for each path. For this, we first took the sound power level of the source point (which depends on the type of vehicle, see [
10] for details) and then calculated several attenuation coefficients as shown in Equation (
1):
where
is the SPL in homogeneous conditions,
is the sound power in a given frequency band (we currently exclude both favourable conditions and directionality),
is the attenuation due to geometrical divergence,
is the attenuation due to atmospheric absorption, and
is the attenuation due to ground and/or diffraction (depending on path type) in homogenous conditions.
Once the SPL for each path and octave band is calculated, everything can be summed up and A-weighted to get the total sound pressure at an observer point. Details about how to do these summations can be found in [
10].
2.5. Visualization
In accordance with the previous sections, we have to visualize three sets of data:
The noise levels over the terrain;
The propagation paths used in the noise calculations;
The terrain and city model.
There are several approaches commonly used for mapping noise or other continuous data over 3D city environments and terrain. Reference [
1] shows a system for an immersive context, which interpolates results and textures the building facades accordingly. This does not extend to the terrain. Reference [
17] extends a similar visualization over the terrain but does not specifically focus on VR. Reference [
18] uses 3D contour lines to cover terrain, facades, and rooftops to arrive at a similar result. It is questionable whether an environment uniformly covered with data would be easy to navigate in immersive virtual reality. Instead, we want to retain as much spatial context as possible. Ideally, the user should be able to see streets and some terrain information on the ground.
With that limitation in mind, we found it a better idea to look at AR visualizations, as they, by their nature, have to preserve some degree of spatial context. Situated Analytics is a rising research topic grappling exactly with these issues. Current research is limited but often focuses on scatterplots in a volumetric space, for example, [
19,
20]. This kind of visualization serves our purpose well, as the actual output of the noise standard used here is a grid of points in 3D space and thus shares some of the attributes of immersive scatterplots, e.g., depth, occlusion, point representation, and more. Visualizations like the ones shown in [
1,
17,
18] are interpolations over this point grid and try to give an overview of a noise situation, while in our case, we want to only show exactly what is being calculated by the standard.
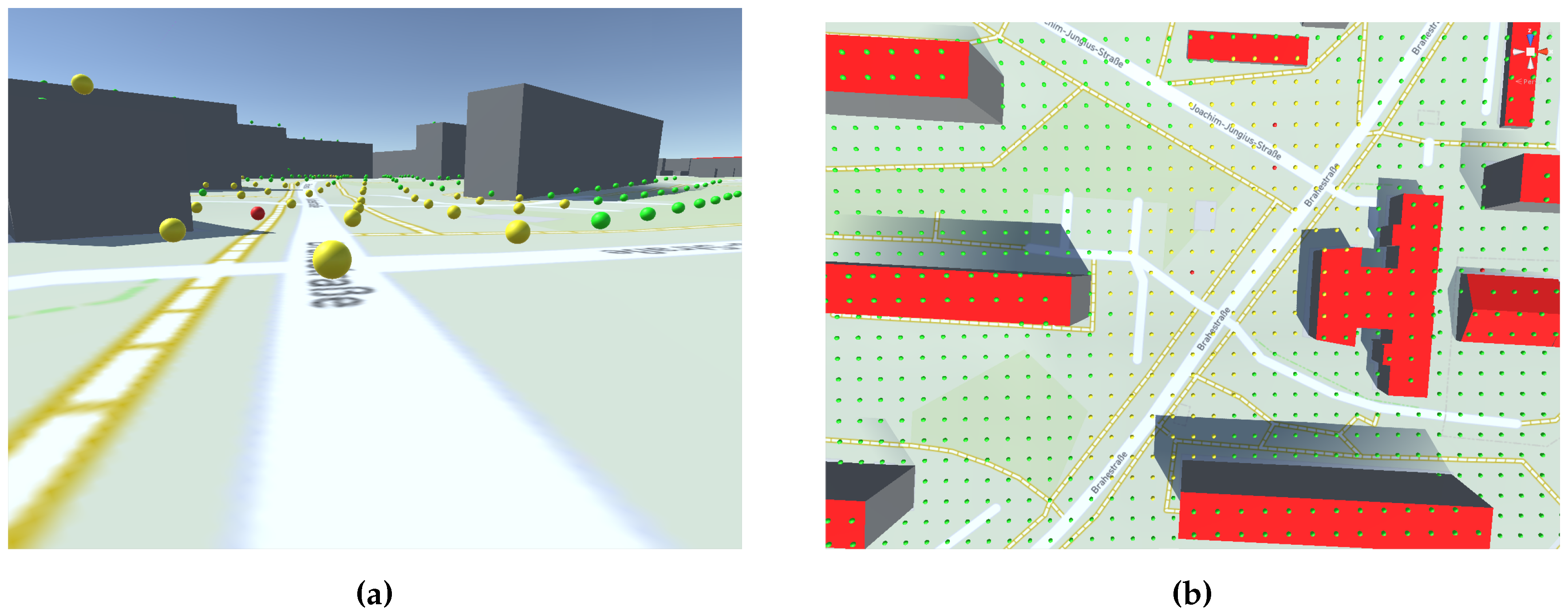
Showing several different techniques, reference [
19] concluded that many perceptual questions remain open in how exactly to display volumetric data in an immersive environment. What an ideal visualization for our case would look like will hopefully be answered by future immersive analytics research. For now, we use simple spheres draped over the terrain that represent a grid of observer points. We colored them to represent the level of annoyance their output values indicate (see
Figure 4).
For point two and point three, we remained as close to the actual geometry as possible. Propagation paths are transparent 3D lines, and the terrain is textured with a thematic street map for further geospatial context. In the current prototype, the terrain information was supplied by the Mapbox extension.
2.6. Sonification
In addition to the visualization, we wanted to make use of the multisensory nature of VR and let the noise data be audible. This process is called sonification, as defined in [
21]. While in our case, the mapping from data input to sound output seems very straightforward, as we are essentially turning a virtual dB value into a real output dB value, there are a few things to consider. First, the dB levels that leave the user’s speakers or headphones are influenced by many hardware and software factors. Without calibration for one specific system, we can never be sure whether input and output sound level are even close to each other. Our usage of a standalone VR headset makes this calibration process easier, as there are fewer unknown factors (like having only one systemwide volume control), and we might be able to carry over calibration results between multiple headsets of the exact same type with some reasonable accuracy. On the other hand, sonification can be useful for the user even without calibration—it allows them to compare relative values while traveling through the environment, without the need for additional visual feedback. In this case, we mapped the differences in the input dB values to differences in the output dB values.
Related to mapping accuracy is the question of spatialization. Modern game engines integrate complex 3D sound frameworks that allow factors like room reverberations, doppler effects, and attenuation through obstacles to influence the sound playback. We do not want to make use of most of these features, as they are either rough approximations of real sound propagation effects that we already simulated by taking into account the full scene geometry, or they distort our results for cinematic effect. Instead, we utilized the most basic level of audio spatialization offered in modern game engines. In Unity, this includes a nonpersonalized binaural head related transfer function (HRTF) that makes use of the sound position in relation to the listener. In the case of HTRFs, spatialization of the sound is achieved through filtering of the audio signal for each ear in such a way that important real life cues are simulated: Mentioned in Unity’s manual [
22] specifically are microdelays between both ears and filtering of sound waves as they travel through the human head. In order to make use of this spatialization, we need the correct positioning and directionality of both the audio source and the user’s head. The latter is known to us because of the VR HMD’s head tracking, while the computation of the former is already included in the noise standard in the form of image sources [
10]. For each image source in the standard, we positioned one audio source in the virtual environment.
Next, we needed to set the volume for each source. One issue here is that the attenuation of the sound level over distance is part of both the noise standard and Unity’s audio spatialization. The noise standard calls this
geometric divergence and calculates it according to Equation (
2), where
is the geometric divergence and d is the distance from source to receiver [
10].
Meanwhile, Unity uses a curve that models distance to a factor that is applied to the sound volume. Fortunately for us, the divergence described in Equation (
2) describes a simple logarithmic curve that can be adapted as a distance falloff curve. To utilize this, we removed the geometric divergence from the final noise calculation result as soon as it was supposed to be played back to the user. This does not result in the exact output value, especially because the divergence is subtracted from the end result, while the falloff curve is a multiplier. However, if the curve is set with care, then this should lead to a result that corresponds reasonably well with reality for the dB(A) value range we expect in urban noise environments.
If absolute precision is required, then some engines, including Unity, have the capability to implement a custom audio spatializer with customizable distance falloff functions. Such an implementation would have to go hand in hand with extensive calibration of the HMD’s audio output.
Once we removed the geometric divergence and A-weighted the resulting sound pressure levels, we had the final noise that we wanted to play back to the user. To achieve this, we transformed the dB value into a linear value between zero and one, to conform to the way Unity represents volume. In our prototype, we did this by converting the SPL back to sound pressure. Sound pressure is what the A-weighted SPL that we are using is derived from. All the dB values we are using here are in reference to 20
Pa, which is the minimum sound pressure in Pascal (Pa) that a young ear can detect [
23]. To get to our linear value, we converted our SPL, which if written in full has the unit ”dB re 20
Pa”, back to Pa. We then divided it by two, as shown in Equation (
3). The division by two is done so that 100 dB maps to one. We do not expect much higher sound pressure levels than 100 dB in traffic noise situations, so we simply turned every value that goes above 100 back to one.
where
is the in-engine volume of the image source
i and
is the sound pressure of the image source in Pascal.
At this point, we only need to select an appropriate audio clip (for example of a passing car) and play it with calculated volume level.
This will not output the actual physical SPL value in the user’s headphones. If this is the goal, then calibration data should be taken into account in this step. The used clip should also be a recording made with specialized equipment, or entirely synthesized.
If we instead want to move further in a cinematic direction, we could now apply appropriate filters to the audio clip, as we know how many reflections and diffractions each path went through. This would of course further alter our results in ways not always predictable—in order to increase immersion and realism with what we have, and without any further distortion, we delay audio playback by the time it would take sound to travel over the whole path. This way, diffractions and reflections play later than direct hits and create reverberations and echoes without any audio filtering. Especially diffractions and reflections on vertical edges may not contribute much to the total noise level at an observer point [
10], but they can drastically change what the user hears in an environment with many buildings.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}