
Pitch It Right: Using Prosodic Entrainment to Improve Robot-Assisted Foreign Language Learning in School-Aged Children

 , ,
, ,  and
and
Abstract
:1. Introduction
2. Materials and Method
2.1. Participants
2.2. Research Design
2.3. Materials
2.3.1. The Word-Learning Task
2.3.2. Implementation of Entrainment
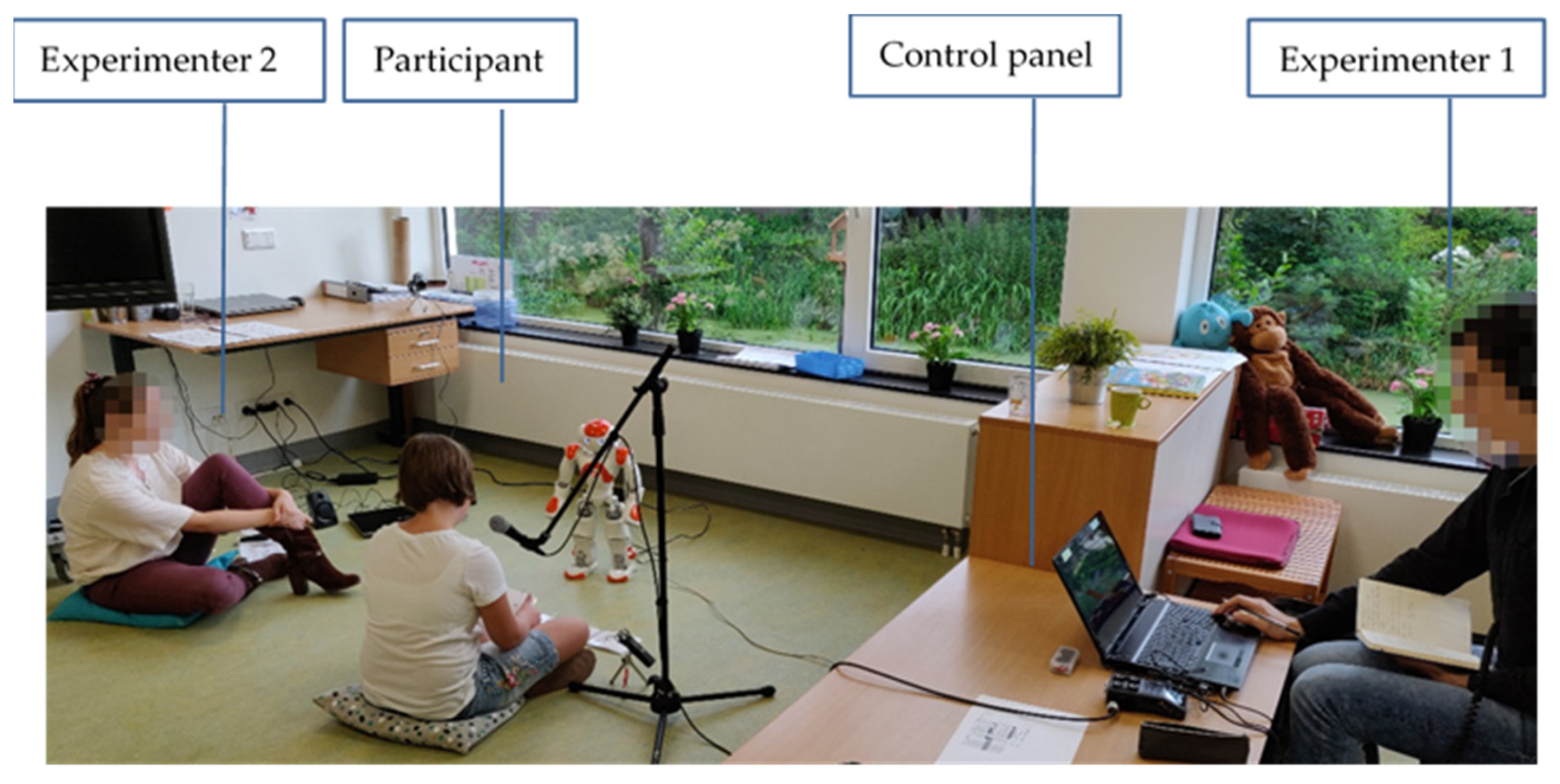
2.4. Procedure
- Phase 1. Introduction: The participant was introduced to the robot and the task.
- Phase 2. Testing (pre-test): The familiarity of the participant with the English words from the learning task was tested.
- Phase 3. Practice round: The participant was prepared for the learning task.
- Phase 4. Training (part 1): The first half of the word learning task was conducted.
- Phase 5. Break: The robot told stories and showed the participant a few tricks (e.g., mimicking a sneeze, mimicking an orchestra conductor).
- Phase 6. Training (part 2): The second half of the word learning task was conducted.
- Phase 7. Testing (post-test): The participants’ knowledge of the words was assessed again.
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bloom, B.S. The 2-sigma problem: The search for methods of group instruction as effective as one-to-one tutoring. Educ. Res. 1984, 13, 4–16. [Google Scholar] [CrossRef]
- Lester, J.C.; Converse, S.A.; Kahler, S.E.; Barlow, S.T.; Stone, B.A.; Bhogal, R.S. The persona effect: Affective impact of animated pedagogical agents. In Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 22–27 March 1997; pp. 359–366. [Google Scholar] [CrossRef]
- Riether, N.; Hegel, F.; Wrede, B.; Horstmann, G. Social facilitation with social robots? In Proceedings of the 2012 7th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Boston, MA, USA, 5–8 March 2012; p. 41. [Google Scholar] [CrossRef]
- Song, H.; Barakova, E.; Ham, J.; Markopoulos, P. Personalizing HRI in Musical Instrument Practicing: The Influence of Robot Roles (Evaluative versus Non-evaluative) on the Child’s Motivation for Children in Different Learning Stages. Front. Robot. AI 2021, 8, 282. [Google Scholar] [CrossRef] [PubMed]
- Randall, N. A Survey of Robot-Assisted Language Learning (RALL). ACM Trans. Hum. Robot Interact. 2019, 9, 7:1–7:36. [Google Scholar] [CrossRef] [Green Version]
- van den Berghe, M.A.J. Social Robots as Second-Language Tutors for Young Children: Challenges and Opportunities. Doctoral Dissertation, Universiteit Utrecht, Utrecht, The Netherlands, 2019. [Google Scholar]
- Ghazali, A.S.; Ham, J.; Barakova, E.; Markopoulos, P. Assessing the effect of persuasive robots interactive social cues on users’ psychological reactance, liking, trusting beliefs and compliance. Adv. Robot. 2019, 33, 325–337. [Google Scholar] [CrossRef] [Green Version]
- Belpaeme, T.; Kennedy, J.; Ramachandran, A.; Scassellati, B.; Tanaka, F. Social robots for education: A review. Sci. Robot. 2018, 3, eaat5954. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Giles, H.; Coupland, J.; Coupland, N. (Eds.) Contexts of Accommodation: Developments in Applied Sociolinguistics; Editions de la Maison des Sciences de l’Homme; Cambridge University Press: Cambridge, UK, 1991. [Google Scholar] [CrossRef]
- Reitter, D.; Keller, F.; Moore, J.D. Computational modelling of structural priming in dialogue. In Proceedings of the Human Language Technology Conference of the NAACL, Companion Volume: Short Papers, New York, NY, USA, 4–9 June 2006; pp. 121–124. [Google Scholar] [CrossRef] [Green Version]
- Reitter, D.; Keller, F.; Moore, J.D. A Computational Cognitive Model of Syntactic Priming. Cogn. Sci. 2011, 35, 587–637. [Google Scholar] [CrossRef] [Green Version]
- Brennan, S.E.; Clark, H.H. Conceptual pacts and lexical choice in conversation. J. Exp. Psychol. Learn. Mem. Cogn. 1996, 22, 1482–1493. [Google Scholar] [CrossRef] [PubMed]
- Levitan, R.; Hirschberg, J. Measuring acoustic-prosodic entrainment with respect to multiple levels and dimensions. In Proceedings of the 12th Annual Conference of the International Speech Communication Association, Florence, Italy, 27–31 August 2011. [Google Scholar]
- Benuš, Š. Social aspects of entrainment in spoken interaction. Cogn. Comput. 2014, 6, 802–813. [Google Scholar] [CrossRef]
- Mitchell, C.; Boyer, K.; Lester, J. From strangers to partners: Examining convergence within a longitudinal study of task-oriented dialogue. In Proceedings of the 13th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Seoul, Korea, 5–6 July 2012; pp. 94–98. [Google Scholar]
- Ward, A.; Litman, D.J. Dialog Convergence and Learning. In Proceedings of the Conference on Artificial Intelligence in Education: Building Technology Rich Learning Contexts That Work, Amsterdam, The Netherlands, 8 June 2007; pp. 262–269. [Google Scholar]
- Thomason, J.; Nguyen, H.V.; Litman, D. Prosodic entrainment and tutoring dialogue success. In Proceedings of the International Conference on Artificial Intelligence in Education, Memphis, TN, USA, 9–13 July 2013; pp. 750–753. [Google Scholar]
- Michel, M.; Cappellini, M. Alignment During Synchronous Video Versus Written Chat L2 Interactions: A Methodological Exploration. Annu. Rev. Appl. Linguist. 2019, 39, 189–216. [Google Scholar] [CrossRef] [Green Version]
- Lubold, N.; Walker, E.; Pon-Barry, H.; Ogan, A. Automated Pitch Convergence Improves Learning in a Social, Teachable Robot for Middle School Mathematics. Artif. Intell. Educ. 2018, 10947, 282–296. [Google Scholar] [CrossRef]
- Kory-Westlund, J.M.; Breazeal, C. Exploring the Effects of a Social Robot’s Speech Entrainment and Backstory on Young Children’s Emotion, Rapport, Relationship, and Learning. Front. Robot. AI 2019, 6, 54. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sadoughi, N.; Pereira, A.; Jain, R.; Leite, I.; Lehman, J.F. Creating Prosodic Synchrony for a Robot Co-player in a Speech-controlled Game for Children. In Proceedings of the 2017 12th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Vienna, Austria, 6–9 March 2017; pp. 91–99. [Google Scholar] [CrossRef]
- Xia, Z.; Levitan, R.; Hirschberg, J. Prosodic Entrainment in Mandarin and English: A Cross-Linguistic Comparison. Proc. Speech Prosody 2014, 5, 65–69. [Google Scholar] [CrossRef]
- Podesva, R.J.; Sharma, D. Research Methods in Linguistics; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar]
- Dunn, L.M.; Dunn, D.M. Peabody Picture Vocabulary Test IV; American Guidance Service: Circle Pines, MN, USA, 2007. [Google Scholar]
- Soliño Fernández, B. 2019-Speech-Entrainment (Version 1.1.1). 2021. Available online: https://zenodo.org/record/5330715#.YaWLe7oRWHt (accessed on 29 August 2021). [CrossRef]
- Boersma, P.; Weenink, D. Praat: Doing Phonetics by Computer (Version 6.0). 2019. Available online: http://www.praat.org/ (accessed on 16 April 2019).
- Weise, A. Cuny-Gc-Entrainment (Commit: ddc93b82f8352074eb23a839a583dea1c1d54d49). 2016. Available online: https://github.com/andreas-weise/cuny-gc-entrainment/ (accessed on 4 July 2019).
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models Using lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.R-project.org/ (accessed on 4 November 2020).
- Alemi, M.; Meghdari, A.; Ghazisaedy, M. Employing Humanoid Robots for Teaching English Language in Iranian Junior High-Schools. Int. J. Hum. Robot. 2014, 11, 1450022. [Google Scholar] [CrossRef]
- Eimler, S.; von der Pütten, A.; Schächtle, U.; Carstens, L.; Krämer, N. Following the White Rabbit—A Robot Rabbit as Vocabulary Trainer for Beginners of English. In Proceedings of the 6th Symposium of the Workgroup Human-Computer Interaction and Usability Engineering in Work and Learning, Life and Leisure, Klagenfurt, Austria, 4–5 November 2010; Volume 6389, pp. 322–339. [Google Scholar] [CrossRef]
- Mazzoni, E.; Benvenuti, M. A Robot-Partner for Preschool Children Learning English Using Socio-Cognitive Conflict. J. Educ. Technol. Soc. 2015, 18, 474–485. [Google Scholar]
- van Straten, C.L.; Smeekens, I.; Barakova, E.; Glennon, J.; Buitelaar, J.; Chen, A. Effects of robots’ intonation and bodily appearance on robot-mediated communicative treatment outcomes for children with autism spectrum disorder. Pers. Ubiquitous Comput. 2018, 22, 379–390. [Google Scholar] [CrossRef] [Green Version]
- Carini, R.M.; Kuh, G.D.; Klein, S.P. Student Engagement and Student Learning: Testing the Linkages. Res. High. Educ. 2006, 47, 1–32. [Google Scholar] [CrossRef]
- de Wit, J.; Schodde, T.; Willemsen, B.; Bergmann, K.; de Haas, M.; Kopp, S.; Krahmer, E.; Vogt, P. The effect of a robot’s gestures and adaptive tutoring on children’s acquisition of second language vocabularies. In Proceedings of the 2018 ACM/IEEE International Conference on Human-Robot Interaction, Chicago, IL, USA, 5–8 March 2018; pp. 50–58. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Control (N = 15) | Entrainment (N = 15) | |
|---|---|---|
| Pre-test | 0.43 (0.50) | 0.46 (0.50) |
| Post-test | 0.75 (0.44) | 0.59 (0.50) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Molenaar, B.; Soliño Fernández, B.; Polimeno, A.; Barakova, E.; Chen, A. Pitch It Right: Using Prosodic Entrainment to Improve Robot-Assisted Foreign Language Learning in School-Aged Children. Multimodal Technol. Interact. 2021, 5, 76. https://doi.org/10.3390/mti5120076
Molenaar B, Soliño Fernández B, Polimeno A, Barakova E, Chen A. Pitch It Right: Using Prosodic Entrainment to Improve Robot-Assisted Foreign Language Learning in School-Aged Children. Multimodal Technologies and Interaction. 2021; 5(12):76. https://doi.org/10.3390/mti5120076
Chicago/Turabian StyleMolenaar, Bo, Breixo Soliño Fernández, Alessandra Polimeno, Emilia Barakova, and Aoju Chen. 2021. "Pitch It Right: Using Prosodic Entrainment to Improve Robot-Assisted Foreign Language Learning in School-Aged Children" Multimodal Technologies and Interaction 5, no. 12: 76. https://doi.org/10.3390/mti5120076
APA StyleMolenaar, B., Soliño Fernández, B., Polimeno, A., Barakova, E., & Chen, A. (2021). Pitch It Right: Using Prosodic Entrainment to Improve Robot-Assisted Foreign Language Learning in School-Aged Children. Multimodal Technologies and Interaction, 5(12), 76. https://doi.org/10.3390/mti5120076