
Emotion Classification from Speech and Text in Videos Using a Multimodal Approach




Abstract
:1. Introduction
- The authors represent the features of emotions related to multimodal data extracted from videos (e.g., prosodic features from audio, and postures, gestures, and expressions from video) in the form of a sequences of several types of modal information, using a linguistic approach.
- The authors formalize the emotion detection process as a multi-class classification problem and model each emotion detection process using a hidden Markov model (HMM). This model allows the authors to capture the discrete features (e.g., opinion words, prosody, facial expressions, gestures) that characterize emotions, and hence which features characterize the sequences of structured data of the multimodal sentence. The authors chose to use HMM because this model achieves good classification accuracy on multi-dimensional and discrete or categorical features.
2. Problem Definition
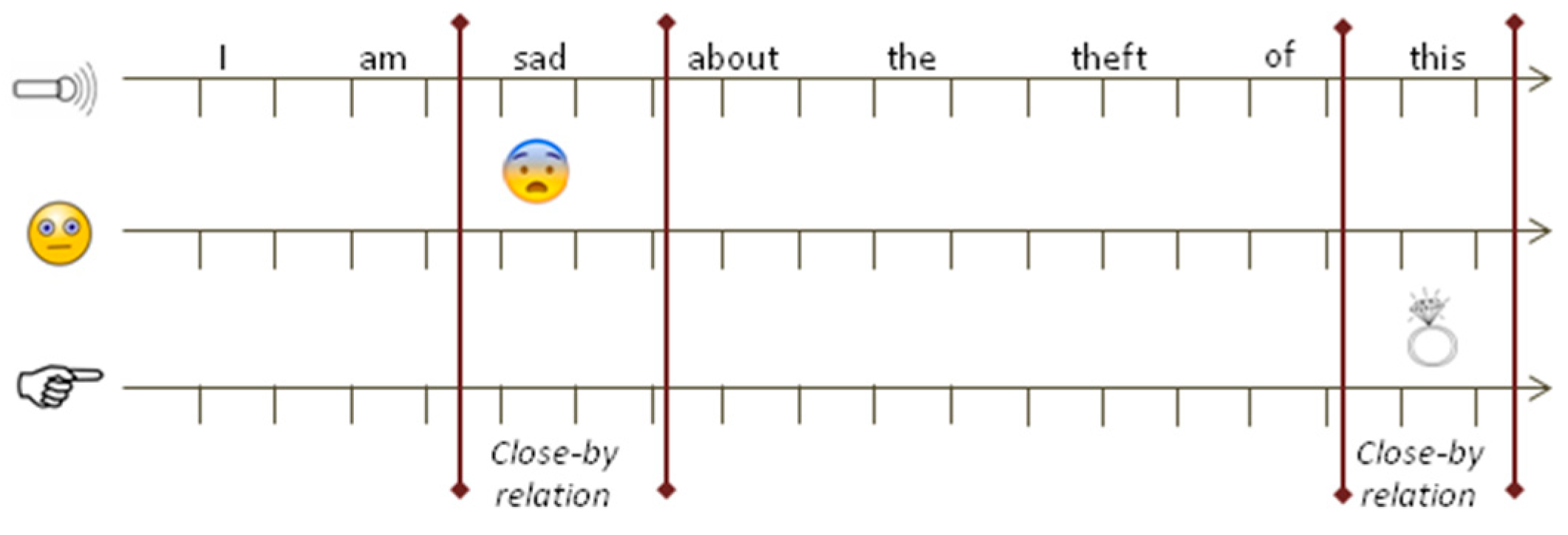
“I am sad about the theft of this.”
3. Textual Data and Emotion Classification
4. Audio Data and Emotion Classification
5. Video Data and Emotion Classification
6. Open Challenges
7. Multimodal Emotion Classification
7.1. Dataset Construction
7.2. Representation
while showing a fearful facial expression and gesturing towards a picture of a jewel, as illustrated in the timeline in Figure 1. The authors start from the hypothesis that all the multimodal elements described above are extracted using tools for gesture classification, facial expression, and handwriting classification. Our method is applied downstream of these tools. All the elements defined through the interaction modalities (in this example, the authors have speech, facial expressions, and gestures) are combined in the multimodal sentence. The authors can use the definitions of complementarity and redundancy [7] to show that the speech element ““I am sad about the theft of this.”
 sad” and the facial expression element “
sad” and the facial expression element “  ” (fearful) are redundant, whereas the speech element “this” and the gesture element indicate that the jewel in the picture are complementary.
” (fearful) are redundant, whereas the speech element “this” and the gesture element indicate that the jewel in the picture are complementary. sad” and the facial expression element “
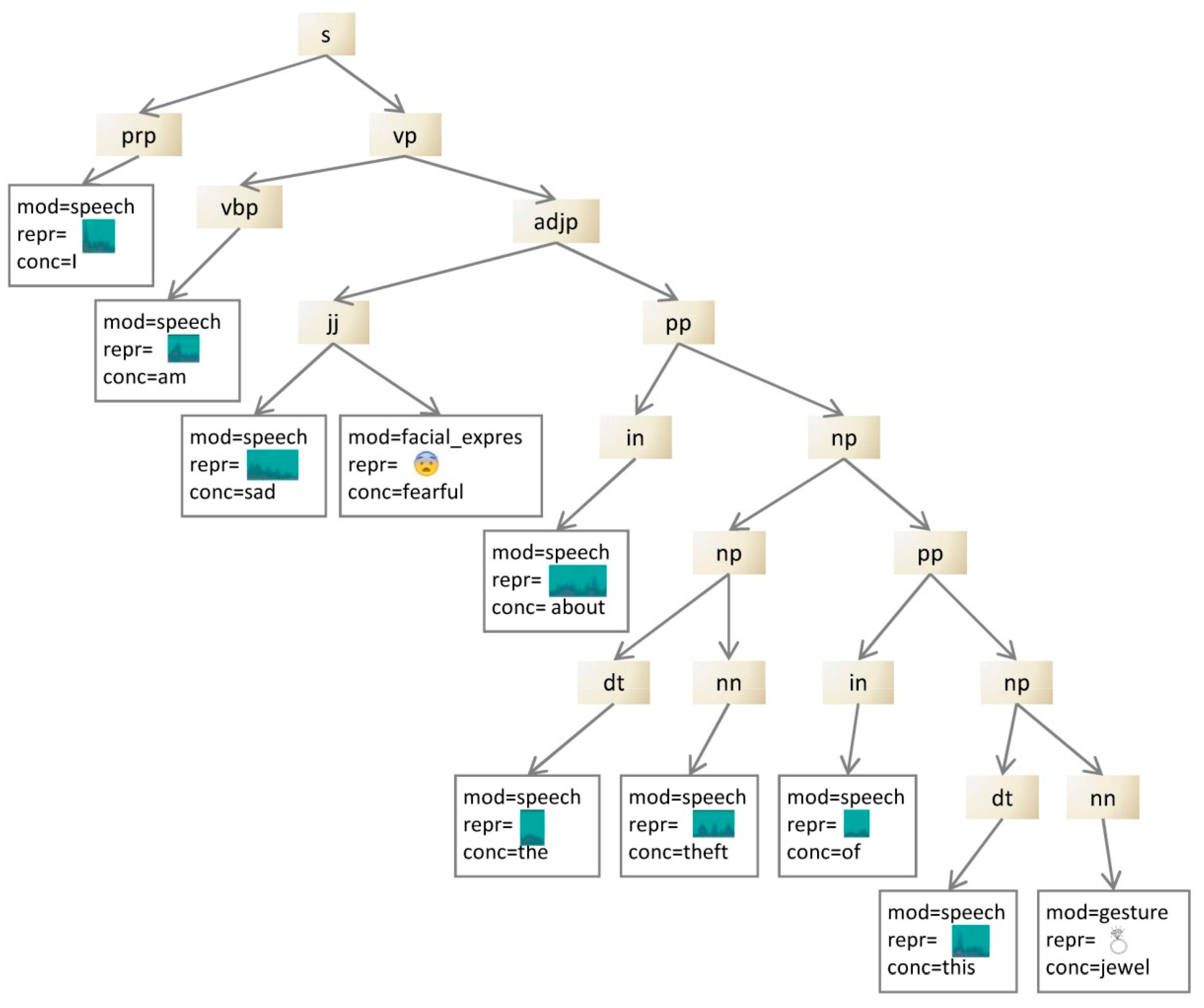
sad” and the facial expression element “  ” have a close relationship [7] and are combined into the same syntactic role (see Figure 2), they express two different emotions (sadness and fear). To unambiguously identify the emotion conveyed, the two modal elements need to refer to the same emotion. In this case, there are two possible interpretations of the multimodal sentence (“I am sad about the theft of this jewel” and “I am fearful about the theft of this jewel”).
” have a close relationship [7] and are combined into the same syntactic role (see Figure 2), they express two different emotions (sadness and fear). To unambiguously identify the emotion conveyed, the two modal elements need to refer to the same emotion. In this case, there are two possible interpretations of the multimodal sentence (“I am sad about the theft of this jewel” and “I am fearful about the theft of this jewel”). ,
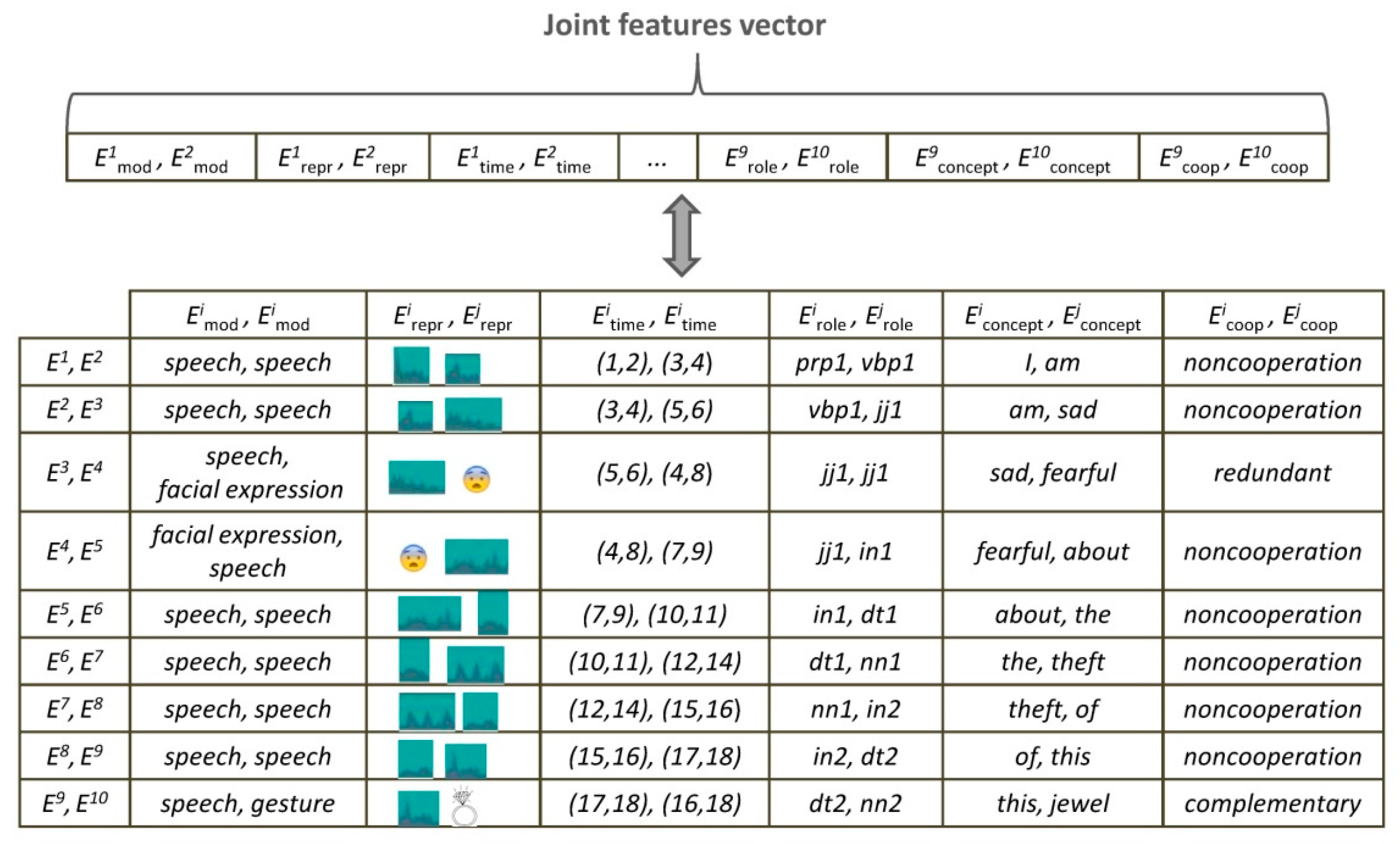
,  ), (1–2, 3–4), (prp1, vbp1), (I, am), (noncooperation,
), (1–2, 3–4), (prp1, vbp1), (I, am), (noncooperation,noncooperation) … (speech, gesture), (
 ,
,  ), (17–18, 16–18), (dt2, nn2), (this, jewel),
), (17–18, 16–18), (dt2, nn2), (this, jewel),(complementary, complementary)]
7.3. Proposed Model
for i = 1, …, m and k ϵ K and K = {mod, repr, time, role, concept, coop}
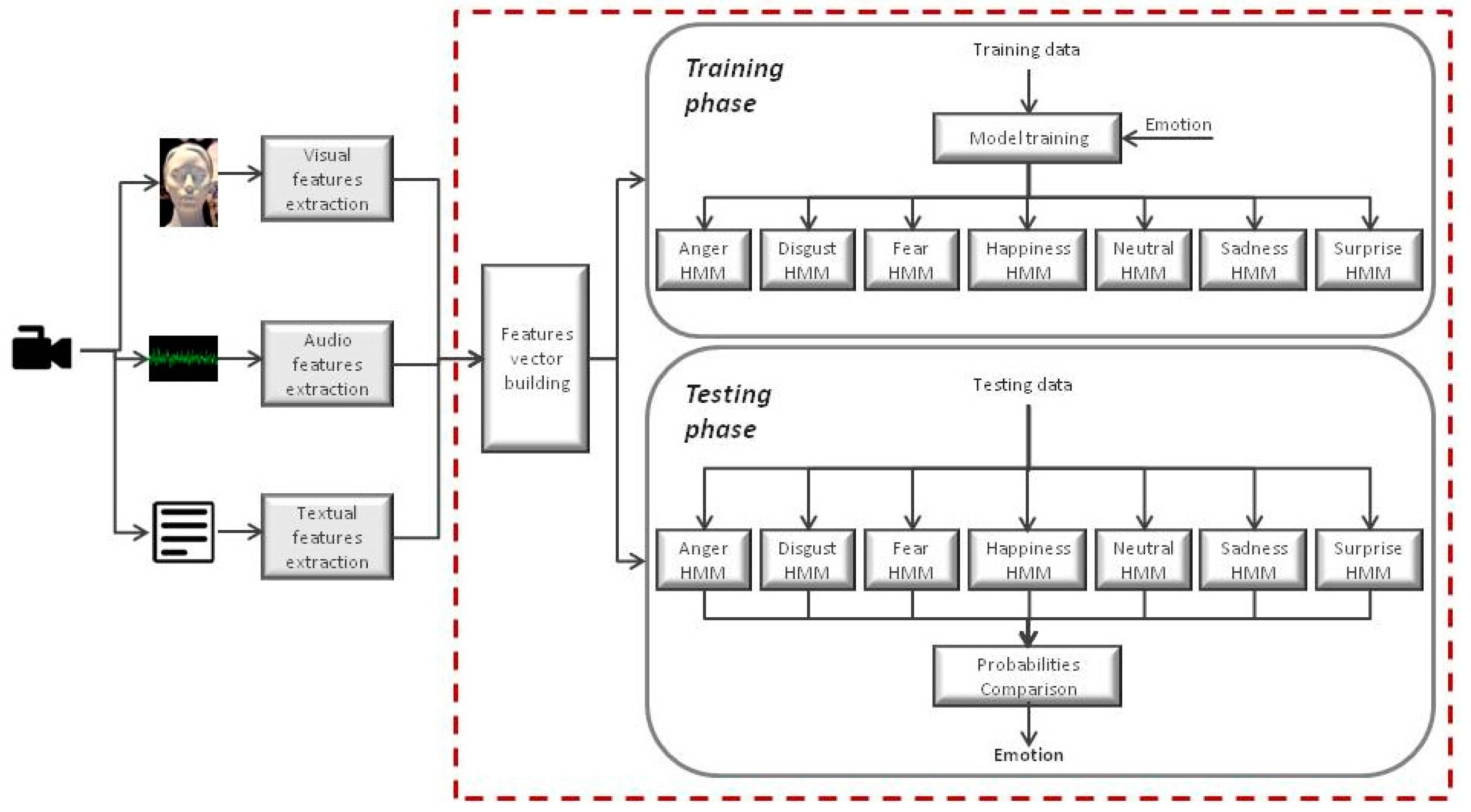
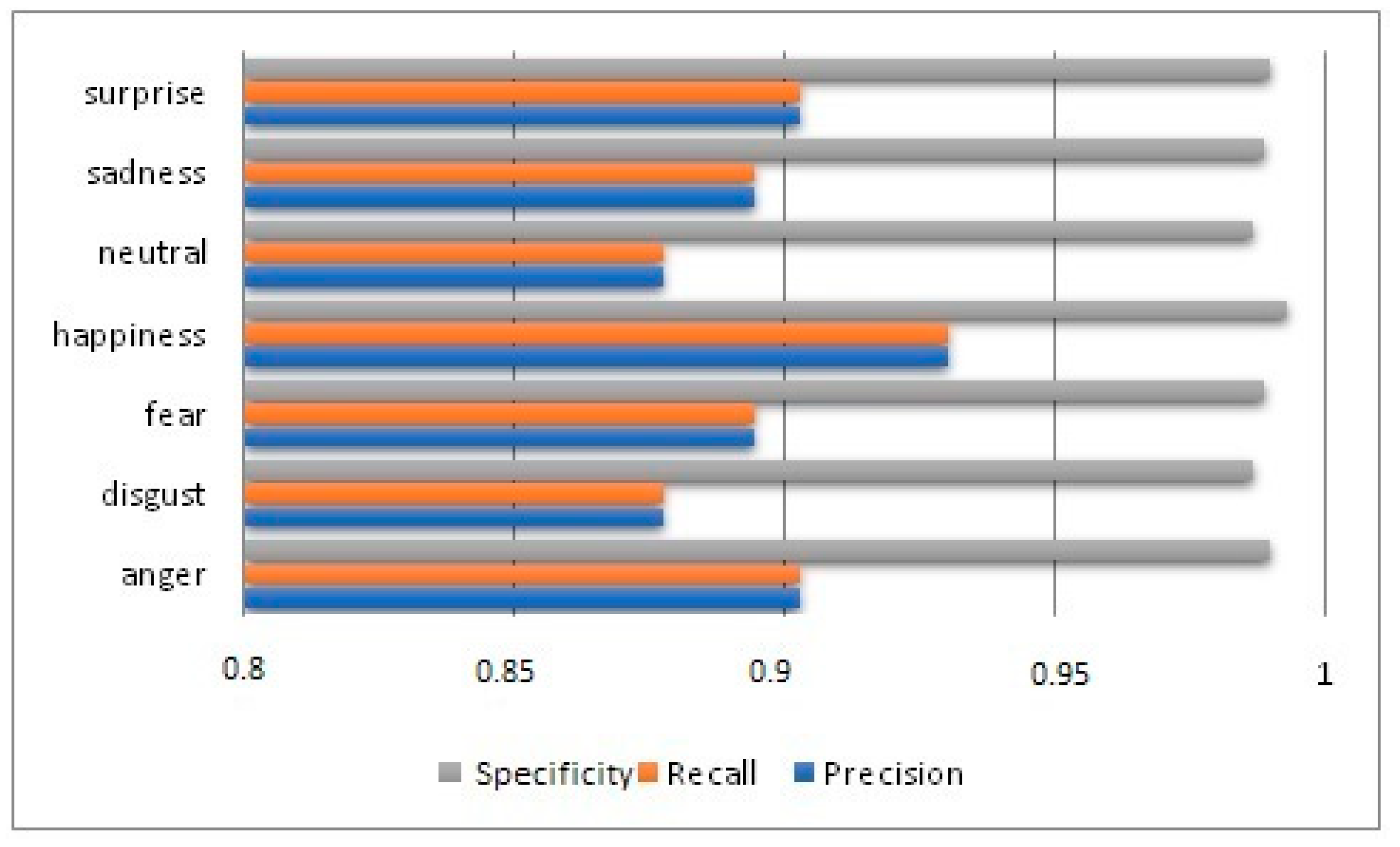
8. Evaluation
- Precision (Pi): This gives a score for each emotion class and is defined as the ratio of the multimodal sentences that are correctly classified by the model as belonging to the given emotion class to the total number of multimodal sentences classified by the model as belonging to the given emotion class.
- Recall (Ri): This gives a score for a particular class and is defined as the ratio of the number of multimodal sentences correctly classified by the model as belonging to the given emotion class to the total number of multimodal sentences actually belonging to the given emotion class.
- Specificity (Si): This measures the proportion of no true emotion classes that are correctly identified as false.
9. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ekman, P. Basic emotions. In Handbook of Cognition and Emotion; Dalgleish, T., Power, T., Eds.; John Wiley & Sons: New York, NY, USA, 1999. [Google Scholar]
- Plutchik, R. The Nature of Emotions; American Scientist Vol. 89, No. 4 (JULY-AUGUST 2001); Sigma Xi, The Scientific Research Honor Society. 2001, pp. 344–350. Available online: https://www.jstor.org/stable/27857503 (accessed on 22 February 2017).
- Russell, J.A. Core affect and the psychological construction of emotion. Psychol. Rev. 2003, 110, 145. [Google Scholar] [CrossRef] [PubMed]
- Rubin, D.C.; Talarico, J.M. A comparison of dimensional models of emotion: Evidence from emotions, prototypical events, autobiographical memories, and words. Memory 2009, 17, 802–808. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, D.; Mooney, R. Panning for gold: Finding relevant semantic content for grounded language learning. In Proceedings of the Symposium Machine Learning in Speech and Language Processing, Bellevue, WA, USA, 27 June 2011; Available online: www.cs.utexas.edu/~ml/papers/chen.mlslp11.pdf (accessed on 18 February 2016).
- Paleari, M.; Chellali, R.; Huet, B. Features for multimodal emotion recognition: An extensive study. In Proceedings of the 2010 IEEE Conference on Cybernetics and Intelligent Systems (CIS), Berks, UK, 1–2 September 2010; pp. 90–95. [Google Scholar] [CrossRef]
- Caschera, M.C.; Ferri, F.; Grifoni, P. Multimodal interaction systems: Information and time features. Int. J. Web Grid Serv. 2007, 3, 82–99. [Google Scholar] [CrossRef]
- Caschera, M.C.; Ferri, F.; Grifoni, P. Sentiment analysis from textual to multimodal features in digital environments. In Proceedings of the 8th International Conference on Management of Digital EcoSystems (MEDES), ACM, New York, NY, USA, 1–4 November 2016; pp. 137–144. [Google Scholar] [CrossRef]
- Lee, S.; Narayanan, S. Audio-visual emotion recognition using Gaussian mixture models for face and voice. In Proceedings of the IEEE International Symposium on Multimedia, Berkeley, CA, USA, 15–17 December 2008. [Google Scholar]
- Caschera, M.C. Interpretation methods and ambiguity management in multimodal systems. In Handbook of Research on Multimodal Human Computer Interaction and Pervasive Services: Evolutionary Techniques for Improving Accessibility; Grifoni, P., Ed.; IGI Global: Hershey, PA, USA, 2009; pp. 87–102. [Google Scholar]
- Tepperman, J.; Traum, D.; Narayanan, S. Yeah right: Sarcasm recognition for spoken dialogue systems. In Proceedings of the InterSpeech-ICSLP, Pittsburgh, PA, USA, 17–21 September 2006. [Google Scholar]
- Frank, M.G.; O’Sullivan, M.; Menasco, M.A. Human behavior and deception detection. In Handbook of Science and Technology for Homeland Security; Voeller, J.G., Ed.; John Wiley & Sons: New York, NY, USA, 2009. [Google Scholar]
- Abouelenien, M.; Perez-Rosas, V.; Mihalcea, R.; Burzo, M. Deception detection using a multimodal approach. In Proceedings of the 16th ACM International Conference on Multimodal Interaction, ICMI 2014, Istanbul, Turkey, 12–16 November 2014. [Google Scholar]
- Ma, M.D. Methods of detecting potential terrorists at airports. In Security Dimensions and Socio-Legal Studies; CEEOL: Frankfurt am Main, Germany, 2012; pp. 33–46. [Google Scholar]
- Butalia, M.A.; Ingle, M.; Kulkarni, P. Facial expression recognition for security. Int. J. Mod. Eng. Res. (IJMER) 2012, 2, 1449–1453. [Google Scholar]
- Lim, T.B.; Husin, M.H.; Zaaba, Z.F.; Osman, M.A. Implementation of an automated smart home control for detecting human emotions via facial detection. In Proceedings of the 5th International Conference on Computing and Informatics, ICOCI 2015, Istanbul, Turkey, 11–13 August 2015; pp. 39–45. [Google Scholar]
- Bollen, J.; Mao, H.; Zeng, X. Twitter mood predicts the stock market. J. Comput. Sci. 2011, 2, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Williamson, J.R.; Quatieri, T.F.; Helfer, B.S.; Ciccarelli, G.; Mehta, D.D. Vocal and facial biomarkers of depression based on motor in coordination and timing. In Proceedings of the 4th International Workshop on Audio/Visual Emotion Challenge, Orlando, FL, USA, 7 November 2014; ACM: New York, NY, USA, 2014; pp. 65–72. [Google Scholar]
- Yang, Y.; Fairbairn, C.; Cohn, J.F. Detecting depression severity from vocal prosody. IEEE Trans. Affect. Comput. 2013, 4, 142–150. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sivasangari, A.; Ajitha, P.; Rajkumar, I.; Poonguzhali, S. Emotion recognition system for autism disordered people. J. Ambient Intell. Humaniz. Comput. 2019, 1–7. [Google Scholar] [CrossRef]
- De Silva, L.C.; Miyasato, T.; Nakatsu, R. Facial emotion recognition using multimodal information. In Proceedings of the IEEE Int. Conf. on Information, Communications and Signal Processing (ICICS’97), Singapore, 12 September 1997; pp. 397–401. [Google Scholar]
- Massaro, D.W. Illusions and issues in bimodal speech perception. In Proceedings of the Auditory Visual Speech Perception’98, Sydney, Australia, 4–7 December 1998; pp. 21–26. [Google Scholar]
- Cowie, R.; Douglas-Cowie, E.; Tsapatsoulis, N.; Votsis, G.; Kollias, S.; Taylor, J.G. Emotion recognition in human computer interaction. IEEE Signal Process. Mag. 2001, 18, 32–80. [Google Scholar] [CrossRef]
- Busso, C.; Deng, Z.; Yildirim, S.; Bulut, M.; Lee, C.M.; Kazemzadeh, A.; Lee, S.; Neumann, U.; Narayanan, S. Analysis of emotion recognition using facial expressions, speech and multimodal information. In Proceedings of the 6th International Conference on Multimodal Interfaces (ICMI’04), State College, PA, USA, 14–15 October 2004; ACM: New York, NY, USA, 2004; pp. 205–211. [Google Scholar]
- Chen, L.S.; Huang, T.S.; Miyasato, T.; Nakatsu, R. Multimodal human emotion/expression recognition. In Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998. [Google Scholar]
- Pantic, M.; Rothkrantz, L.J.M. Toward an affect-sensitive multimodal human-computer interaction. Proc. IEEE 2003, 91, 1370–1390. [Google Scholar] [CrossRef] [Green Version]
- Vinodhini, G.; Chandrasekaran, R.M. Sentiment analysis and opinion mining: A survey. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2012, 2, 282–292. [Google Scholar]
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef] [Green Version]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef] [Green Version]
- Rustamov, S.; Mustafayev, E.; Clements, M.A. Sentiment analysis using neuro-fuzzy and hidden Markov models of text. In Proceedings of the IEEE Southeastcon 2013, Jacksonville, FL, USA, 4–7 April 2013; pp. 1–6. [Google Scholar]
- Kamps, J.; Marx, M.; Mokken, R.; Rijke, M. Using WordNet to measure semantic orientations of adjectives. In Proceedings of the Fourth International Conference on Language Resources and Evaluation, Lisbon, Portugal, 26–28 May 2004; pp. 1115–1118. [Google Scholar]
- Wu, C.; Shen, L.; Wang, X. A new method of using contextual information to infer the semantic orientations of context dependent opinions. In Proceedings of the International Conference on Artificial Intelligence and Computational Intelligence, Shanghai, China, 7–8 November 2009. [Google Scholar]
- Peng, T.C.; Shih, C.C. An unsupervised snippet-based sentiment classification method for Chinese unknown phrases without using reference word pairs. In Proceedings of the 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Toronto, ON, Canada, 31 August–3 September 2010. [Google Scholar]
- Li, G.; Liu, F. A clustering-based approach on sentiment analysis. In Proceedings of the IEEE International Conference on Intelligent System and Knowledge Engineering, Hangzhou, China, 15–16 November 2010; pp. 331–337. [Google Scholar]
- Adam, A.; Blockeel, H. Dealing with overlapping clustering: A constraint-based approach to algorithm selection. In Proceedings of the 2015 International Conference on Meta-Learning and Algorithm Selection (MetaSel’15), Porto, Portugal, 7 September 2015; Volume 1455, pp. 43–54. [Google Scholar]
- Shetty, P.; Singh, S. Hierarchical clustering: A Survey. Int. J. Appl. Res. 2021, 7, 178–181. [Google Scholar] [CrossRef]
- Maddah, M.; Wells, W.M.; Warfield, S.K.; Westin, C.F.; Grimson, W.E. Probabilistic clustering and quantitative analysis of white matter fiber tracts. In Proceedings of the 2007 Conference on Information Processing in Medical Imaging, Kerkrade, The Netherlands, 2–6 July 2007; Volume 20, pp. 372–383. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez, M.Z.; Comin, C.H.; Casanova, D.; Bruno, O.M.; Amancio, D.R.; Costa, L.D.F.; Rodrigues, F. Clustering algorithms: A comparative approach. PLoS ONE 2019, 14, e0210236. [Google Scholar] [CrossRef] [PubMed]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef] [Green Version]
- Ruiz, M.; Srinivasan, P. Hierarchical neural networks for text categorization. In Proceedings of the ACM SIGIR Conference 1999, Berkeley, CA, USA, 15–19 August 1999. [Google Scholar]
- Tung, A.K.H. Rule-based classification. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009. [Google Scholar] [CrossRef]
- Garg, A.; Roth, D. Understanding probabilistic classifiers. In Machine Learning: ECML 2001; De Raedt, L., Flach, P., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2167. [Google Scholar] [CrossRef] [Green Version]
- Melville, P.; Gryc, W. Sentiment analysis of blogs by combining lexical knowledge with text classification. In Proceedings of the KDD’09, Paris, France, 28 June–1 July 2009. ACM 978-1-60558-495-9/09/06. [Google Scholar]
- Aggarwal, C.C.; Zhai, C.X. Mining Text Data; Springer Science + Business Media: New York, NY, USA; Dordrecht, The Netherlands; Heidelberg, Germany; London, UK, 2012. [Google Scholar]
- Jian, Z.; Chen, X.; Wu, H.-S. Sentiment classification using the theory of ANNs. J. China Univ. Posts Telecommun. 2010, 17, 58–62. [Google Scholar]
- Moraes, R.; Valiati, J.F.; Neto, W.P.G. Document-level sentiment classification: An empirical comparison between SVM and ANN. Expert Syst. Appl. 2013, 40, 621–633. [Google Scholar] [CrossRef]
- Kang, H.; Yoo, S.J.; Han, D. Senti-lexicon and improved Naïve Bayes algorithms for sentiment analysis of restaurant reviews. Expert Syst. Appl. 2012, 39, 6000–6010. [Google Scholar] [CrossRef]
- Zhang, Z.; Ye, Q.; Zhang, Z.; Li, Y. Sentiment classification of Internet restaurant reviews written in Cantonese. Expert Syst. Appl. 2011, 38, 7674–7682. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. In Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing, Philadelphia, PA, USA, 6–7 July 2002; Volume 10, pp. 79–86. [Google Scholar]
- Singh, P.K.; Husain, M.S. Methodological study of opinion mining and sentiment analysis techniques. Int. J. Soft Comput. (IJSC) 2014, 5, 11–21. [Google Scholar] [CrossRef]
- Patil, P.; Yalagi, P. Sentiment analysis levels and techniques: A survey. Int. J. Innov. Eng. Technol. (IJIET) 2016, 6, 523–528. [Google Scholar]
- Stalidis, P.; Giatsoglou, M.; Diamantarasa, K.; Sarigiannidis, G.; Chatzisavvas, K.C. Machine learning sentiment prediction based on hybrid document representation. arXiv 2015, arXiv:1511.09107v1. [Google Scholar]
- Prakash, C.; Gaikwad, V.B.; Singh, R.R.; Prakash, O. Analysis of emotion recognition system through speech signal using KNN and GMM classifier. IOSR J. Electron. Commun. Eng. (IOSR-JECE) 2015, 10, 55–61. [Google Scholar]
- Schuller, B.; Rigoll, G.; Lang, M. Hidden Markov model-based speech emotion recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2003, Hong Kong, China, 6–10 April 2003; Volume 2. [Google Scholar]
- Nwe, T.; Foo, S.; De Silva, L. Speech emotion recognition using hidden Markov models. Speech Commun. 2003, 41, 603–623. [Google Scholar] [CrossRef]
- Hu, H.; Xu, M.; Wu, W. GMM supervector based SVM with spectral features for speech emotion recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, Honolulu, HI, USA, 15–20 April 2007. [Google Scholar]
- Davis, S.; Mermelstein, P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 57–366. [Google Scholar] [CrossRef] [Green Version]
- Pao, T.; Chen, Y.; Yeh, J. Emotion recognition from Mandarin speech signals. In Proceedings of the International Symposium on Chinese Spoken Language Processing, Hong Kong, China, 15–18 December 2004. [Google Scholar]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. In Readings in Speech Recognition; Waibel, A., Lee, K.-F., Eds.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1990; pp. 267–296. [Google Scholar]
- Ayadi, M.E.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Lee, C.; Yildrim, S.; Bulut, M.; Kazemzadeh, A.; Busso, C.; Deng, Z.; Lee, S.; Narayanan, S. Emotion recognition based on phoneme classes. In Proceedings of the ICSLP 2004, Jeju Island, Korea, 4–8 October 2004; pp. 2193–2196. [Google Scholar]
- Reshma, M.; Singh, A. Speech emotion recognition by Gaussian mixture model. Int. J. Comput. Sci. Inf. Technol. 2015, 6, 2969–2971. [Google Scholar]
- Hendy, N.A.; Farag, H. Emotion recognition using neural network: A comparative study. World Acad. Sci. Eng. Technol. 2013, 7, 433–439. [Google Scholar]
- Navas, E.; Hernáez, I.; Luengo, I. An objective and subjective study of the role of semantics and prosodic features in building corpora for emotional TTS. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1117–1127. [Google Scholar] [CrossRef] [Green Version]
- Atassi, H.; Esposito, A. A speaker independent approach to the classification of emotional vocal expressions. In Proceedings of the Twentieth International Conference on Tools with Artificial Intelligence, ICTAI 2008, Dayton, OH, USA, 3–5 November 2008; IEEE Computer Society: Washington, DC, USA, 2008; pp. 147–152, ISBN 978-0-7695-3440-4. [Google Scholar]
- Lugger, M.; Yang, B. The relevance of voice quality features in speaker independent emotion recognition. In Proceedings of the ICASSP 2007, Honolulu, HI, USA, 15–20 April 2007. [Google Scholar]
- Huang, Y.; Tian, K.; Wu, A.; Zhang, G. Feature fusion methods research based on deep belief networks for speech emotion recognition under noise condition. J. Ambient Intell. Hum. Comput. 2019, 10, 1787–1798. [Google Scholar] [CrossRef]
- Sikandar, M. A survey for multimodal sentiment analysis methods. Int. J. Comput. Technol. Appl. 2014, 5, 1470–1476. [Google Scholar]
- Ekman, P.; Oster, H. Facial expressions of emotion. Ann. Rev. Psychol. 1979, 30, 527–554. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Hussain, A.; Huang, G.-B. Towards an intelligent framework for multimodal affective data analysis. Neural Netw. 2015, 63, 104–116. [Google Scholar] [CrossRef] [PubMed]
- Cerezo, E.; Hupont, I.; Baldassarri, S.; Ballano, S. Emotional facial sensing and multimodal fusion in a continuous 2D affective space. J. Ambient Intell. Hum. Comput. 2012, 3, 31–46. [Google Scholar] [CrossRef]
- Morency, L.-P.; Mihalcea, R.; Doshi, P. Towards multimodal sentiment analysis: Harvesting opinions from the web. In Proceedings of the 13th International Conference on Multimodal Interfaces, ICMI 2011, Alicante, Spain, 14–18 November 2011; pp. 169–176. [Google Scholar]
- Ramos Pereira, M.H.; CardealPádua, F.L.; Machado Pereira, A.C.; Benevenuto, F.; Dalip, D.H. Fusing audio, textual, and visual features for sentiment analysis of news videos. In Proceedings of the ICWSM 2016, Cologne, Germany, 17–20 May 2016; pp. 659–662. [Google Scholar]
- Kahou, S.E.; Bouthillier, X.; Lamblin, P.; Gulcehre, C.; Michalski, V.; Konda, K.; Jean, S.; Froumenty, P.; Dauphin, Y.; Boulanger-Lewandowski, N.; et al. Emonets: Multimodaldeeplearningapproachesforemotionrecognitioninvideo. J. Multimodal User Interfaces 2016, 10, 99–111. [Google Scholar] [CrossRef] [Green Version]
- Wollmer, M.; Metallinou, A.; Eyben, F.; Schuller, B.; Narayanan, S.S. Context-sensitive multimodal emotion recognition from speech and facial expression using bidirectional LSMT modeling. In Proceedings of the Interspeech, Makuhari, Japan, 26–30 September 2010; pp. 2362–2365. [Google Scholar]
- Poria, S.; Cambria, E.; Howard, N.; Huang, G.-B.; Hussain, A. Fusing audio, visual and textual clues for sentiment analysis from multimodal content. Neurocomputing 2016, 174, 50–59. [Google Scholar] [CrossRef]
- Cid, F.; Manso, L.J.; Núñez, P. A novel multimodal emotion recognition approach for affective human robot interaction. In Proceedings of the FinE-R 2015 IROS Workshop, Hamburg, Germany, 28 September–3 October 2015; pp. 1–9. [Google Scholar]
- Datcu, D.; Rothkrantz, L. Multimodal recognition of emotions in car environments. In Proceedings of the Second Driver Car Interaction & Interface Conference (DCI&I-2009), Praag, Czech Republic, 2–3 November 2009. [Google Scholar]
- Meftah, I.T.; Le Thanh, N.; Ben Amar, C. Multimodal approach for emotion recognition using a formal computational model. Int. J. Appl. Evol. Comput. (IJAEC) 2013, 4, 11–25. [Google Scholar] [CrossRef]
- Zeng, Z.; Pantic, M.; Roisman, G.I.; Huang, T.S. A survey of affect recognition methods: Audio, visual, and spontaneous expressions. PAMI 2009, 31, 39–58. [Google Scholar] [CrossRef]
- Zeng, Z.; Tu, J.; Pianfetti, B.M.; Huang, T.S. Audio–visual affective expression recognition through multistream fused HMM. Trans. Multimed. 2008, 10, 570–577. [Google Scholar] [CrossRef]
- Fragopanagos, N.; Taylor, J.G. Emotion recognition in human–computer interaction. Neural Netw. 2005, 18, 389–405. [Google Scholar] [CrossRef]
- Caridakis, G.; Malatesta, L.; Kessous, L.; Amir, N.; Paouzaiou, A.; Karpouzis, K. Modeling naturalistic affective states via facial and vocal expressions recognition. In Proceedings of the 8th International Conference on Multimodal Interfaces (ICMI ’06), Banff, AB, Canada, 2–4 November 2006; pp. 146–154. [Google Scholar]
- You, Q.; Luo, J.; Jin, H.; Yang, J. Cross-modality consistent regression for joint visual-textual sentiment analysis of social multimedia. In Proceedings of the Ninth ACM International Conference on Web Search and Data Mining (WSDM’16), San Francisco, CA, USA, 22–25 February 2016; ACM: New York, NY, USA, 2016; pp. 13–22. [Google Scholar]
- Siddiqui, M.F.H.; Javaid, A.Y. A multimodal facial emotion recognition framework through the fusion of speech with visible and infrared images. Multimodal Technol. Interact. 2020, 4, 46. [Google Scholar] [CrossRef]
- Zhou, W.; Cheng, J.; Lei, X.; Benes, B.; Adamo, N. Deep Learning-Based Emotion Recognition from Real-Time Videos; HCI: Jacksonville, FL, USA, 2020. [Google Scholar]
- Pandeya, Y.R.; Bhattarai, B.; Lee, J. Deep-learning-based multimodal emotion classification for music videos. Sensors 2021, 21, 4927. [Google Scholar] [CrossRef] [PubMed]
- Khorrami, P.; Le Paine, T.; Brady, K.; Dagli, C.; Huang, T.S. How deep neural networks can improve emotion recognition on video data. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 619–623. [Google Scholar] [CrossRef] [Green Version]
- Ranganathan, H.; Chakraborty, S.; Panchanathan, S. Multimodal emotion recognition using deep learning architectures. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Abdullah, S.M.A.; Ameen, S.Y.A.; Sadeeq, M.A.M.; Zeebaree, S. Multimodal emotion recognition using deep learning. J. Appl. Sci. Technol. Trends 2021, 2, 52–58. [Google Scholar] [CrossRef]
- Salido Ortega, M.; Rodríguez, L.; Gutierrez-Garcia, J.O. Towards emotion recognition from contextual information using machine learning. J. Ambient Intell. Human Comput. 2019, 11, 3187–3207. [Google Scholar] [CrossRef]
- Perifanos, K.; Goutsos, D. Multimodal hate speech detection in Greek social media. Multimodal Technol. Interact. 2021, 5, 34. [Google Scholar] [CrossRef]
- Caschera, M.C.; Ferri, F.; Grifoni, P. InteSe: An integrated model for resolvingambiguities in multimodalsentences. IEEE Trans. Syst. Man Cybern. Syst. 2013, 43, 911–931. [Google Scholar] [CrossRef]
- Sapiński, T.; Kamińska, D.; Pelikant, A.; Ozcinar, C.; Avots, E.; Anbarjafari, G. Multimodal Database of Emotional Speech, Video and Gestures. World Acad. Sci. Eng. Technol. Int. J. Comput. Inf. Eng. 2018, 12, 809–814. [Google Scholar]
- Caschera, M.C.; D’Ulizia, A.; Ferri, F.; Grifoni, P. MCBF: Multimodal Corpora Building Framework. In Human Language Technology: Challenges for Computer Science and Linguistics; Volume 9561 of the Series Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 177–190. [Google Scholar]
- Available online: https://cdn.crowdemotion.co.uk (accessed on 22 February 2017).
- crowdemotion api. Available online: https://cdn.crowdemotion.co.uk/demos/api-demo/index.html (accessed on 22 February 2017).
- Available online: http://apidemo.theysay.io/ (accessed on 22 February 2017).
- Criptodivisas en Pruebas. Available online: http://www.theysay.io/ (accessed on 22 February 2017).
- Eyben, F.; Weninger, F.; Groß, F.; Schuller, B. Recent developments in opensmile, the munich open-source multimedia feature extractor. In Proceedings of the ACMMM’13, Barcelona, Spain, 21–25 October 2013; pp. 835–838. [Google Scholar]
- Software of the Stanford Natural Language Processing Group. Available online: http://Nlp.stanford.edu/software/ (accessed on 8 March 2017).
- Caschera, M.C.; Ferri, F.; Grifoni, P. An approach for managing ambiguities in multimodal interaction. In OTM-WS 2007, Part I: LNCS; Meersman, R., Tari, Z., Eds.; Springer: Heidelberg, Germany, 2007; Volume 4805, pp. 387–397. [Google Scholar]
- Marcus, M.P.; Santorini, B.; Marcinkiewicz, M.A. Building a large annotated corpus of English: The Penn Treebank. Comput. Linguist. 1994, 19, 313–330. [Google Scholar]
- Caschera, M.C.; Ferri, F.; Grifoni, P. Ambiguity detection in multimodal systems. In Advanced Visual Interfaces 2008; ACM Press: New York, NY, USA, 2008; pp. 331–334. [Google Scholar]
- Murray, I.R.; Arnott, J.L. Toward the simulation of emotion in synthetic speech: A review of the literature on human vocal emotion. J. Acoust. Soc. Am. 1993, 93, 1097–1108. [Google Scholar] [CrossRef]
- Caschera, M.C.; Ferri, F.; Grifoni, P. From modal to multimodal ambiguities: A classification approach. JNIT 2013, 4, 87–109. [Google Scholar]
- Grifoni, P.; Caschera, M.C.; Ferri, F. Evaluation of a dynamic classification method for multimodal ambiguities based on Hidden markov models. Evol. Syst. 2021, 12, 377–395. [Google Scholar] [CrossRef]
- Grifoni, P.; Caschera, M.C.; Ferri, F. DAMA: A dynamic classification of multimodal ambiguities. Int. J. Comput. Intell. Syst. 2020, 13, 178–192. [Google Scholar] [CrossRef]
- Yakhnenko, O.; Silvescu, A.; Honavar, V. Discriminatively trained Markov model for sequence classification. In Proceedings of the ICDM’05: Fifth IEEE International Conference on Data Mining, Houston, TX, USA, 27–30 November 2005; pp. 498–505. [Google Scholar]
- Doan, A.E. Type I and Type II Error. In Encyclopedia of Social Measurement; Kempf-Leonard, K., Ed.; Elsevier: Amsterdam, The Netherlands, 2005; pp. 883–888. ISBN 9780123693983. [Google Scholar] [CrossRef]
- Manliguez, C. Generalized Confusion Matrix for Multiple Classes. 2016. Available online: https://www.researchgate.net/publication/310799885_Generalized_Confusion_Matrix_for_Multiple_Classes (accessed on 22 February 2017). [CrossRef]
- Mesquita, B.; Boiger, M.; De Leersnyder, J. Doing emotions: The role of culture in everyday emotions. Eur. Rev. Soc. Psychol. 2017, 28, 95–133. [Google Scholar] [CrossRef]
- Martin-Krumm, C.; Fenouillet, F.; Csillik, A.; Kern, L.; Besancon, M.; Heutte, J.; Paquet, Y.; Delas, Y.; Trousselard, M.; Lecorre, B.; et al. Changes in emotions from childhood to young adulthood. Child Indic. Res. 2018, 11, 541–561. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emotions | Number of Samples |
|---|---|
| Anger | 60 |
| Disgust | 60 |
| Fear | 60 |
| Happiness | 60 |
| Neutral | 60 |
| Sadness | 60 |
| Surprise | 60 |
| Anger | Disgust | Fear | Happiness | Neutral | Sadness | Surprise |
|---|---|---|---|---|---|---|
| 36 | 36 | 36 | 36 | 36 | 36 | 36 |
| Anger | Disgust | Fear | Happiness | Neutral | Sadness | Surprise |
|---|---|---|---|---|---|---|
| 24 | 24 | 24 | 24 | 24 | 24 | 24 |
| Predicted | ||||||||
|---|---|---|---|---|---|---|---|---|
| True | Anger | Disgust | Fear | Happiness | Neutral | Sadness | Surprise | |
| Anger | 0.58 | 0.17 | 0.08 | 0.00 | 0.04 | 0.13 | 0.00 | |
| Disgust | 0.08 | 0.46 | 0.17 | 0.00 | 0.13 | 0.08 | 0.08 | |
| Fear | 0.08 | 0.21 | 0.54 | 0.00 | 0.04 | 0.08 | 0.04 | |
| Happiness | 0.00 | 0.00 | 0.00 | 0.71 | 0.13 | 0.00 | 0.17 | |
| Neutral | 0.17 | 0.04 | 0.04 | 0.13 | 0.46 | 0.13 | 0.04 | |
| Sadness | 0.04 | 0.08 | 0.08 | 0.04 | 0.13 | 0.54 | 0.08 | |
| Surprise | 0.04 | 0.04 | 0.08 | 0.13 | 0.08 | 0.04 | 0.58 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Caschera, M.C.; Grifoni, P.; Ferri, F. Emotion Classification from Speech and Text in Videos Using a Multimodal Approach. Multimodal Technol. Interact. 2022, 6, 28. https://doi.org/10.3390/mti6040028
Caschera MC, Grifoni P, Ferri F. Emotion Classification from Speech and Text in Videos Using a Multimodal Approach. Multimodal Technologies and Interaction. 2022; 6(4):28. https://doi.org/10.3390/mti6040028
Chicago/Turabian StyleCaschera, Maria Chiara, Patrizia Grifoni, and Fernando Ferri. 2022. "Emotion Classification from Speech and Text in Videos Using a Multimodal Approach" Multimodal Technologies and Interaction 6, no. 4: 28. https://doi.org/10.3390/mti6040028
APA StyleCaschera, M. C., Grifoni, P., & Ferri, F. (2022). Emotion Classification from Speech and Text in Videos Using a Multimodal Approach. Multimodal Technologies and Interaction, 6(4), 28. https://doi.org/10.3390/mti6040028