
Brain Melody Interaction: Understanding Effects of Music on Cerebral Hemodynamic Responses



Abstract
:1. Introduction
- Can participants’ cerebral hemodynamic responses reflect what genre of music they are listening to?
- Are participants’ emotional reactions to music reflected in their hemodynamic responses?
- Are fNIRS signals suitable to train machine learning models to understand participants’ response to different music?
2. Background
2.1. FNIRS Devices Used in the Literature
2.2. Computation Methods Using Brain Activity Signals
3. Materials and Methods
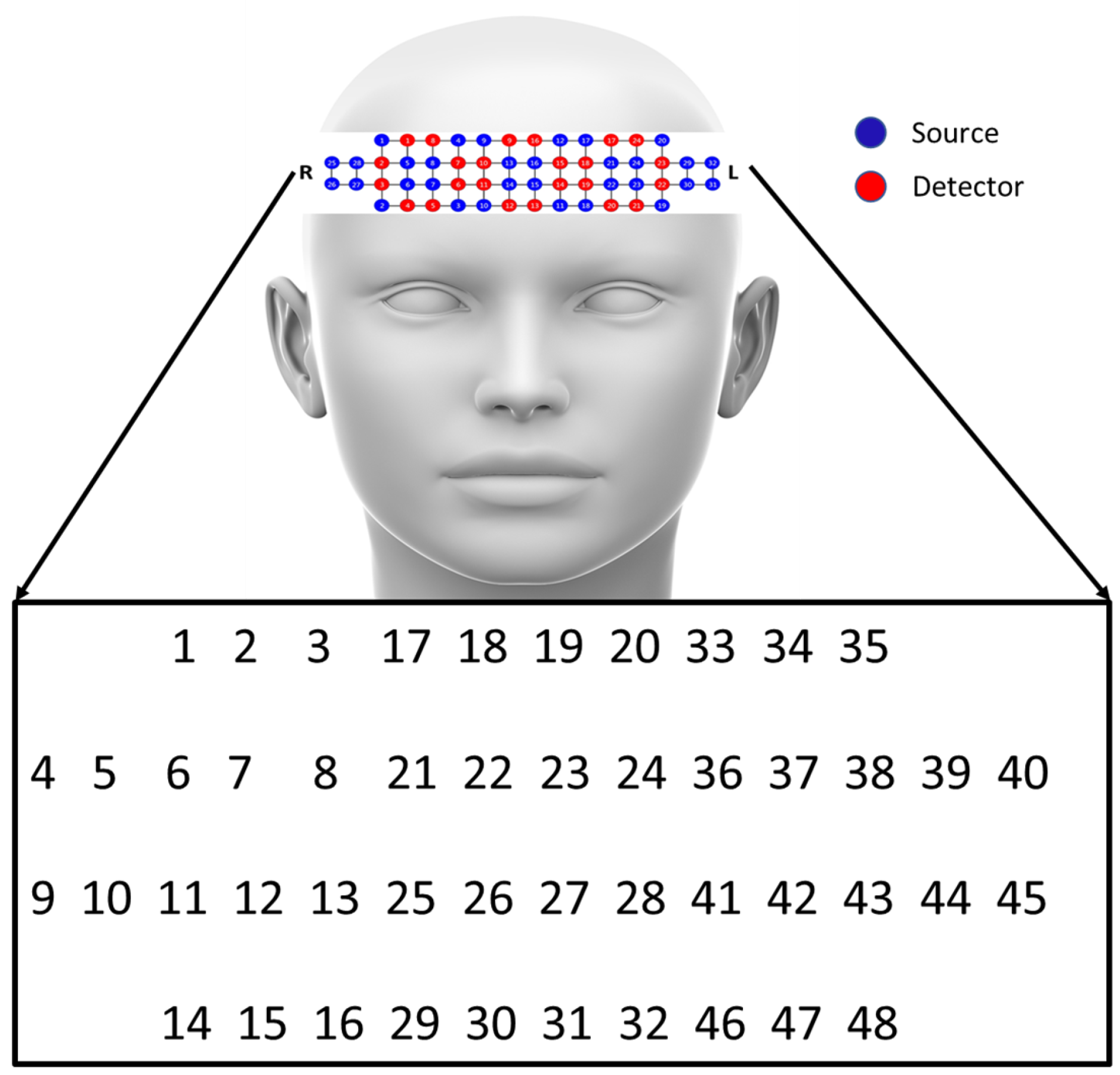
3.1. Participants and Stimuli
3.2. Experiment Design
3.3. Data Preprocessing
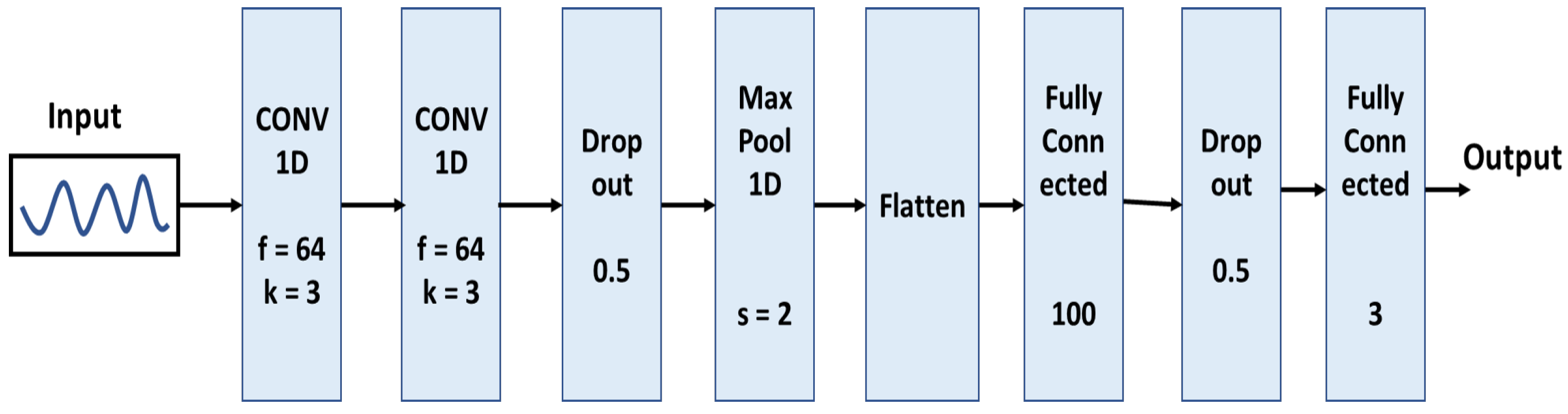
3.4. Feature Extraction
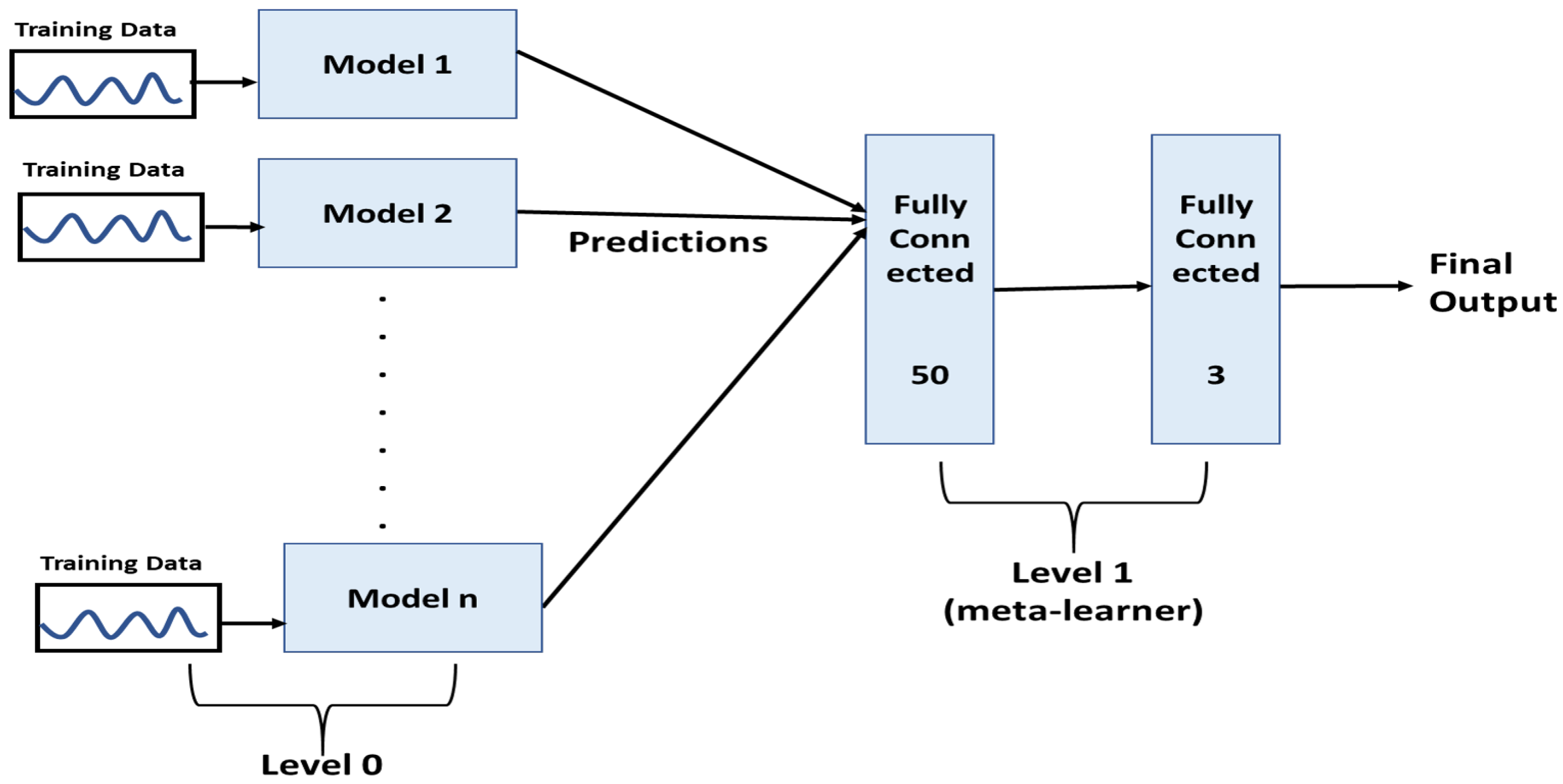
3.5. Classification Methods and Evaluation Measures
4. Results and Discussion
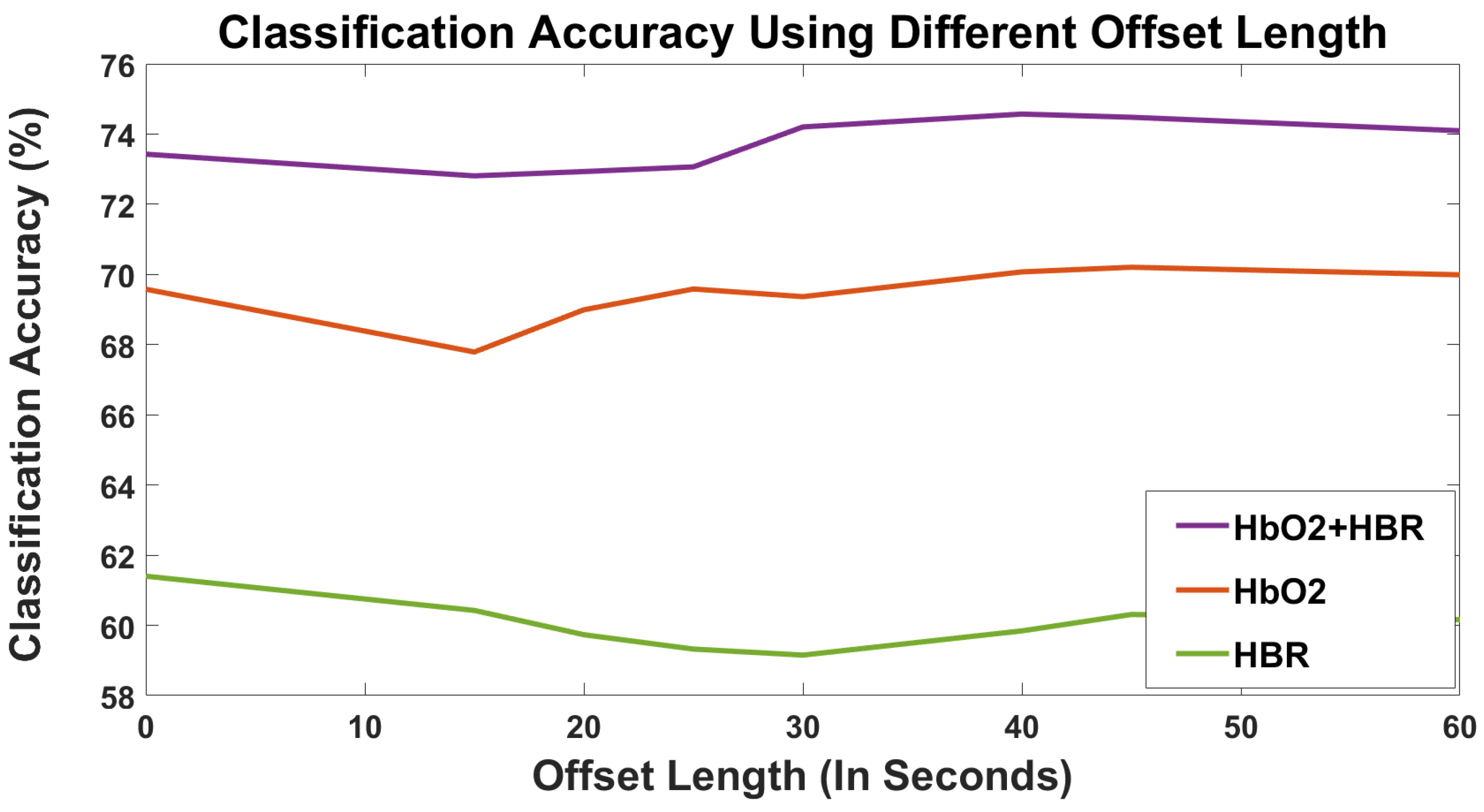
4.1. Automatic Feature Extraction Reduces Complexity and Performs Better Than Handcrafted Feature-Based Model
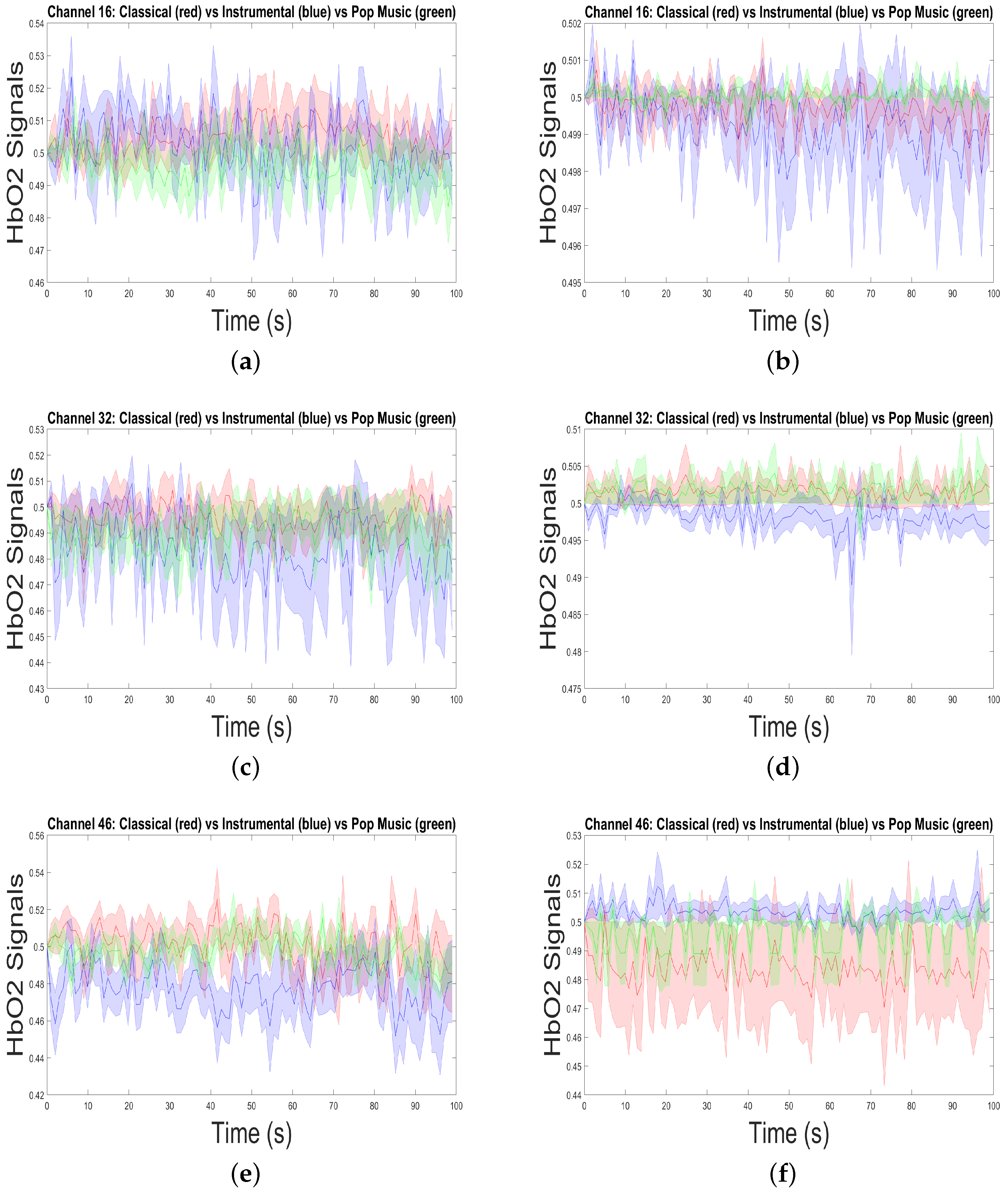
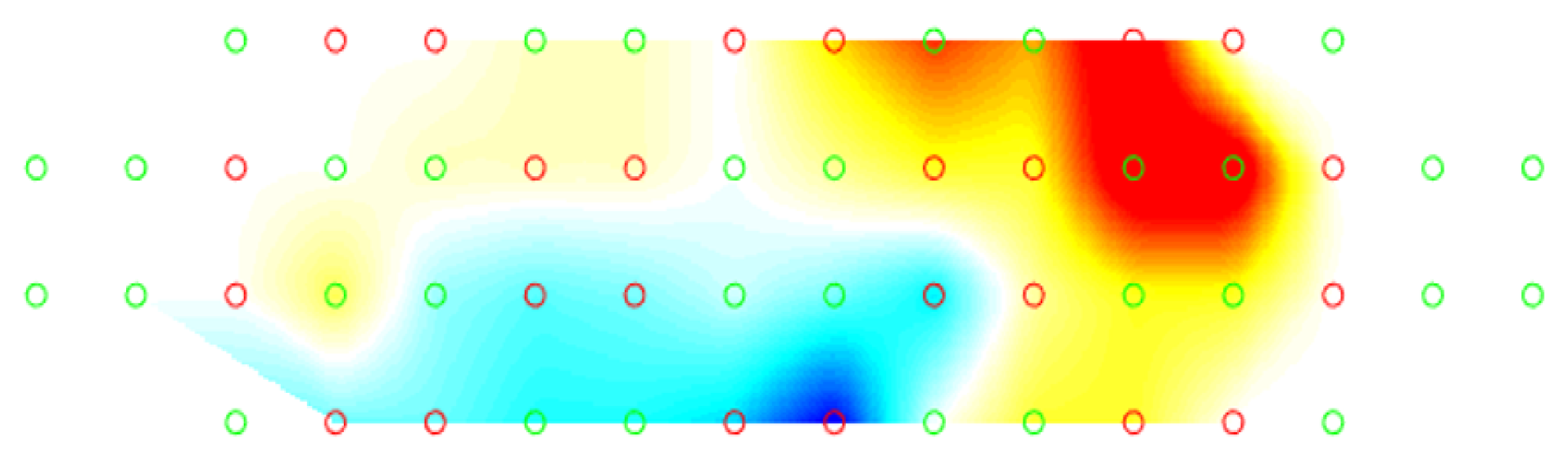
4.2. fNIRS Shows Differential Brain Responses to Music Genres
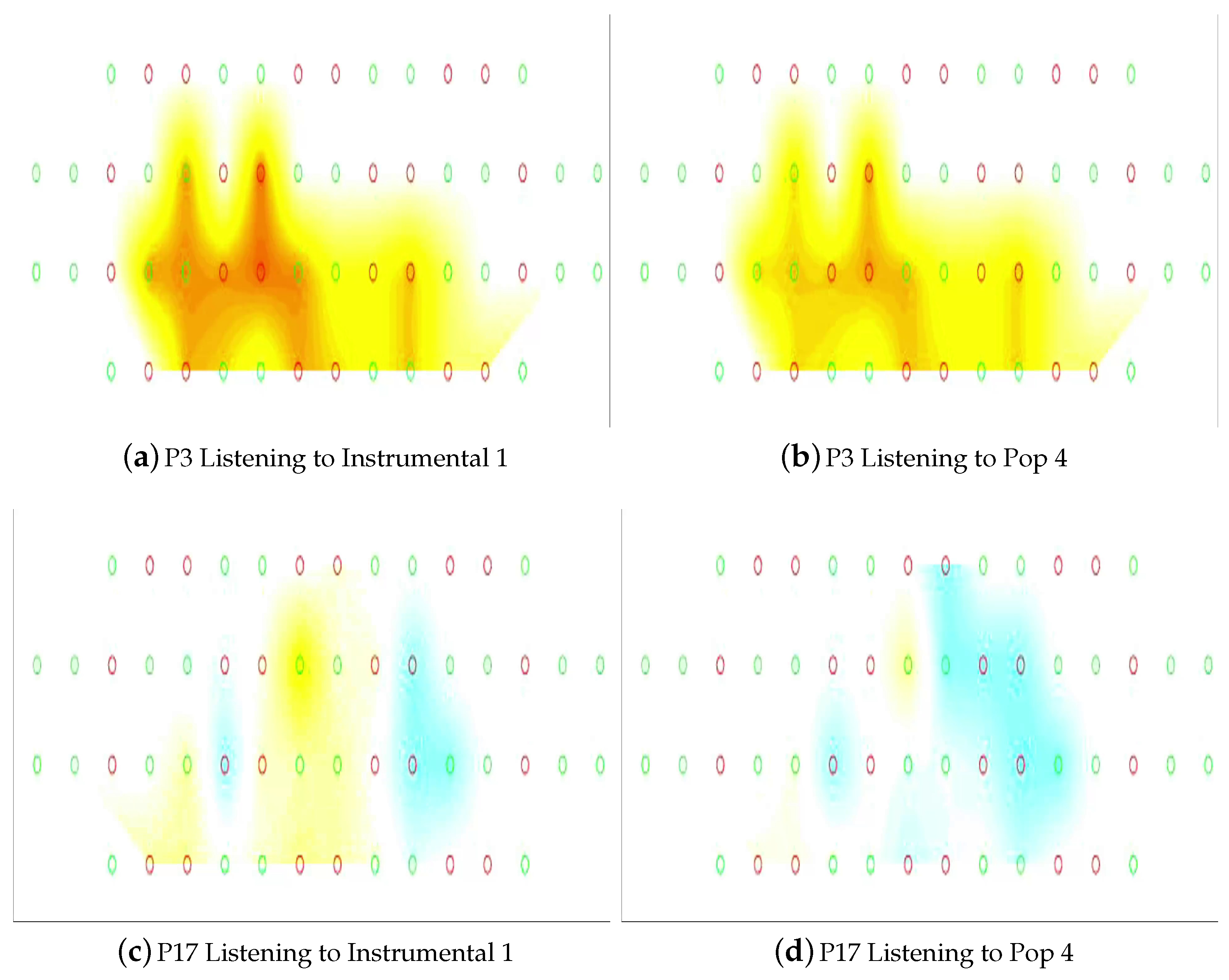
4.3. Hemodynamic Responses Are Slow Modality Signals and Show Similar Patterns While Reliving the Experience of Listening to a Music Genre
4.4. Common Assumptions about Music May Need to Be Revisited
4.5. Participants’ Verbal Responses on Emotional Reaction to Music Aligns with Their Hemodynamic Responses
5. Conclusions
- Creation of advanced wearable technology that will measure fNIRS signals and recommend music to improve participants’ emotional well-being.
- Identification of appropriate stimuli based on participants’ physiological response for various purposes such as music therapy and task performance. As mentioned in the discussion in Section 4.4, participants’ physiological and verbal responses often do not align with pre-assumptions about the stimuli. Using their physiological responses would yield more accurate results in such cases.
- Identification of music that has adverse effects on the brain which can be used to prevent musicogenic epilepsy.
- Creation of wearable devices using only the regions of interest (e.g., medial pre-frontal cortex) which can be used for longer-duration experiments and continuous measurements.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Juslin, P.N.; Sloboda, J.A. Music and Emotion: Theory and Research; Oxford University Press: Oxford, UK, 2001. [Google Scholar]
- Huang, R.H.; Shih, Y.N. Effects of background music on concentration of workers. Work 2011, 38, 383–387. [Google Scholar] [CrossRef] [PubMed]
- de Witte, M.; Pinho, A.d.S.; Stams, G.J.; Moonen, X.; Bos, A.E.; van Hooren, S. Music therapy for stress reduction: A systematic review and meta-analysis. Health Psychol. Rev. 2020, 16, 134–159. [Google Scholar] [CrossRef]
- Umbrello, M.; Sorrenti, T.; Mistraletti, G.; Formenti, P.; Chiumello, D.; Terzoni, S. Music therapy reduces stress and anxiety in critically ill patients: A systematic review of randomized clinical trials. Minerva Anestesiol. 2019, 85, 886–898. [Google Scholar] [CrossRef] [PubMed]
- Innes, K.E.; Selfe, T.K.; Khalsa, D.S.; Kandati, S. Meditation and music improve memory and cognitive function in adults with subjective cognitive decline: A pilot randomized controlled trial. J. Alzheimer’s Dis. 2017, 56, 899–916. [Google Scholar] [CrossRef] [PubMed]
- Feng, F.; Zhang, Y.; Hou, J.; Cai, J.; Jiang, Q.; Li, X.; Zhao, Q.; Li, B.A. Can music improve sleep quality in adults with primary insomnia? A systematic review and network meta-analysis. Int. J. Nurs. Stud. 2018, 77, 189–196. [Google Scholar] [CrossRef]
- Walden, T.A.; Harris, V.S.; Catron, T.F. How I feel: A self-report measure of emotional arousal and regulation for children. Psychol. Assess. 2003, 15, 399. [Google Scholar] [CrossRef]
- Cowen, A.; Keltner, D. Self-report captures 27 distinct categories of emotion bridged by continuous gradients. Proc. Natl. Acad. Sci. USA 2017, 114, E7900–E7909. [Google Scholar] [CrossRef] [Green Version]
- Dindar, M.; Malmberg, J.; Järvelä, S.; Haataja, E.; Kirschner, P. Matching self-reports with electrodermal activity data: Investigating temporal changes in self-regulated learning. Educ. Inf. Technol. 2020, 25, 1785–1802. [Google Scholar] [CrossRef] [Green Version]
- Ko, B.C. A brief review of facial emotion recognition based on visual information. Sensors 2018, 18, 401. [Google Scholar] [CrossRef]
- Shan, K.; Guo, J.; You, W.; Lu, D.; Bie, R. Automatic facial expression recognition based on a deep convolutional-neural-network structure. In Proceedings of the 2017 IEEE 15th International Conference on Software Engineering Research, Management and Applications (SERA), London, UK, 7–9 June 2017; pp. 123–128. [Google Scholar]
- Mellouk, W.; Handouzi, W. Facial emotion recognition using deep learning: Review and insights. Procedia Comput. Sci. 2020, 175, 689–694. [Google Scholar] [CrossRef]
- Huang, K.Y.; Wu, C.H.; Hong, Q.B.; Su, M.H.; Chen, Y.H. Speech emotion recognition using deep neural network considering verbal and nonverbal speech sounds. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5866–5870. [Google Scholar]
- Dhall, A.; Sharma, G.; Goecke, R.; Gedeon, T. Emotiw 2020: Driver gaze, group emotion, student engagement and physiological signal based challenges. In Proceedings of the 2020 International Conference on Multimodal Interaction, Virtual Event, 25–29 October 2020; pp. 784–789. [Google Scholar]
- Noroozi, F.; Kaminska, D.; Corneanu, C.; Sapinski, T.; Escalera, S.; Anbarjafari, G. Survey on emotional body gesture recognition. IEEE Trans. Affect. Comput. 2018, 12, 505–523. [Google Scholar] [CrossRef] [Green Version]
- Egermann, H.; Fernando, N.; Chuen, L.; McAdams, S. Music induces universal emotion-related psychophysiological responses: Comparing Canadian listeners to Congolese Pygmies. Front. Psychol. 2015, 5, 1341. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krumhansl, C.L. An exploratory study of musical emotions and psychophysiology. Can. J. Exp. Psychol. Can. Psychol. Exp. 1997, 51, 336. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sudheesh, N.; Joseph, K. Investigation into the effects of music and meditation on galvanic skin response. ITBM-RBM 2000, 21, 158–163. [Google Scholar] [CrossRef]
- Khalfa, S.; Isabelle, P.; Jean-Pierre, B.; Manon, R. Event-related skin conductance responses to musical emotions in humans. Neurosci. Lett. 2002, 328, 145–149. [Google Scholar] [CrossRef]
- Hu, X.; Li, F.; Ng, T.D.J. On the Relationships between Music-induced Emotion and Physiological Signals. In Proceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR 2018), Paris, France, 23–27 September 2018; pp. 362–369. [Google Scholar]
- Jaušovec, N.; Jaušovec, K.; Gerlič, I. The influence of Mozart’s music on brain activity in the process of learning. Clin. Neurophysiol. 2006, 117, 2703–2714. [Google Scholar] [CrossRef]
- Mannes, E. The Power of Music: Pioneering Discoveries in the New Science of Song; Bloomsbury Publishing: New York, NY, USA, 2011. [Google Scholar]
- Miendlarzewska, E.A.; Trost, W.J. How musical training affects cognitive development: Rhythm, reward and other modulating variables. Front. Neurosci. 2014, 7, 279. [Google Scholar] [CrossRef]
- Phneah, S.W.; Nisar, H. EEG-based alpha neurofeedback training for mood enhancement. Australas. Phys. Eng. Sci. Med. 2017, 40, 325–336. [Google Scholar] [CrossRef]
- Liao, C.Y.; Chen, R.C.; Liu, Q.E. Detecting Attention and Meditation EEG Utilized Deep Learning. In Proceedings of the International Conference on Intelligent Information Hiding and Multimedia Signal Processing; Springer: Berlin/Heidelberg, Germany, 2018; pp. 204–211. [Google Scholar]
- Coppola, G.; Toro, A.; Operto, F.F.; Ferrarioli, G.; Pisano, S.; Viggiano, A.; Verrotti, A. Mozart’s music in children with drug-refractory epileptic encephalopathies. Epilepsy Behav. 2015, 50, 18–22. [Google Scholar] [CrossRef]
- Forsblom, A.; Laitinen, S.; Sarkamo, T.; Tervaniemi, M. Therapeutic role of music listening in stroke rehabilitation. Ann. N. Y. Acad. Sci. 2009, 1169, 426–430. [Google Scholar] [CrossRef]
- Critchley, M. Musicogenic epilepsy. In Music and the Brain; Elsevier: Amsterdam, The Netherlands, 1977; pp. 344–353. [Google Scholar]
- Curtin, A.; Ayaz, H. Chapter 22—Neural Efficiency Metrics in Neuroergonomics: Theory and Applications. In Neuroergonomics; Ayaz, H., Dehais, F., Eds.; Academic Press: Cambridge, MA, USA, 2019; pp. 133–140. [Google Scholar] [CrossRef]
- Midha, S.; Maior, H.A.; Wilson, M.L.; Sharples, S. Measuring Mental Workload Variations in Office Work Tasks using fNIRS. Int. J. Hum.-Comput. Stud. 2021, 147, 102580. [Google Scholar] [CrossRef]
- Tang, T.B.; Chong, J.S.; Kiguchi, M.; Funane, T.; Lu, C.K. Detection of Emotional Sensitivity Using fNIRS Based Dynamic Functional Connectivity. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 894–904. [Google Scholar] [CrossRef] [PubMed]
- Ramnani, N.; Owen, A.M. Anterior prefrontal cortex: Insights into function from anatomy and neuroimaging. Nat. Rev. Neurosci. 2004, 5, 184–194. [Google Scholar] [CrossRef]
- Manelis, A.; Huppert, T.J.; Rodgers, E.; Swartz, H.A.; Phillips, M.L. The role of the right prefrontal cortex in recognition of facial emotional expressions in depressed individuals: FNIRS study. J. Affect. Disord. 2019, 258, 151–158. [Google Scholar] [CrossRef]
- Pinti, P.; Aichelburg, C.; Gilbert, S.; Hamilton, A.; Hirsch, J.; Burgess, P.; Tachtsidis, I. A review on the use of wearable functional near-infrared spectroscopy in naturalistic environments. Jpn. Psychol. Res. 2018, 60, 347–373. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- OEG-16 Product/Spectratech. Available online: https://www.spectratech.co.jp/En/product/productOeg16En.html (accessed on 15 February 2022).
- Brite23—Artinis Medical Systems|fNIRS and NIRS Devices-Blog. Available online: https://www.artinis.com/blogpost-all/category/Brite23 (accessed on 15 February 2022).
- LIGHTNIRS|SHIMADZU EUROPA-Shimadzu Europe. Available online: https://www.shimadzu.eu/lightnirs (accessed on 15 February 2022).
- OBELAB-fNIRS Devices. Available online: https://www.obelab.com/ (accessed on 15 February 2022).
- Hsu, Y.L.; Wang, J.S.; Chiang, W.C.; Hung, C.H. Automatic ecg-based emotion recognition in music listening. IEEE Trans. Affect. Comput. 2017, 11, 85–99. [Google Scholar] [CrossRef]
- Lin, Y.P.; Wang, C.H.; Jung, T.P.; Wu, T.L.; Jeng, S.K.; Duann, J.R.; Chen, J.H. EEG-based emotion recognition in music listening. IEEE Trans. Biomed. Eng. 2010, 57, 1798–1806. [Google Scholar]
- Rojas, R.F.; Huang, X.; Ou, K.L. A machine learning approach for the identification of a biomarker of human pain using fNIRS. Sci. Rep. 2019, 9, 5645. [Google Scholar] [CrossRef] [PubMed]
- Daly, I.; Williams, D.; Malik, A.; Weaver, J.; Kirke, A.; Hwang, F.; Miranda, E.; Nasuto, S.J. Personalised, multi-modal, affective state detection for hybrid brain-computer music interfacing. IEEE Trans. Affect. Comput. 2018, 11, 111–124. [Google Scholar] [CrossRef] [Green Version]
- Rahman, J.S.; Gedeon, T.; Caldwell, S.; Jones, R.; Jin, Z. Towards Effective Music Therapy for Mental Health Care Using Machine Learning Tools: Human Affective Reasoning and Music Genres. J. Artif. Intell. Soft Comput. Res. 2021, 11, 5–20. [Google Scholar] [CrossRef]
- Yang, D.; Yoo, S.H.; Kim, C.S.; Hong, K.S. Evaluation of neural degeneration biomarkers in the prefrontal cortex for early identification of patients with mild cognitive impairment: An fNIRS study. Front. Hum. Neurosci. 2019, 13, 317. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ho, T.K.K.; Gwak, J.; Park, C.M.; Song, J.I. Discrimination of mental workload levels from multi-channel fNIRS using deep leaning-based approaches. IEEE Access 2019, 7, 24392–24403. [Google Scholar] [CrossRef]
- Chiarelli, A.M.; Croce, P.; Merla, A.; Zappasodi, F. Deep learning for hybrid EEG-fNIRS brain–computer interface: Application to motor imagery classification. J. Neural Eng. 2018, 15, 036028. [Google Scholar] [CrossRef] [PubMed]
- Ma, T.; Lyu, H.; Liu, J.; Xia, Y.; Qian, C.; Evans, J.; Xu, W.; Hu, J.; Hu, S.; He, S. Distinguishing Bipolar Depression from Major Depressive Disorder Using fNIRS and Deep Neural Network. Prog. Electromagn. Res. 2020, 169, 73–86. [Google Scholar] [CrossRef]
- Hughes, J.R.; Fino, J.J. The Mozart effect: Distinctive aspects of the music—A clue to brain coding? Clin. Electroencephalogr. 2000, 31, 94–103. [Google Scholar] [CrossRef]
- Harrison, L.; Loui, P. Thrills, chills, frissons, and skin orgasms: Toward an integrative model of transcendent psychophysiological experiences in music. Front. Psychol. 2014, 5, 790. [Google Scholar] [CrossRef] [Green Version]
- Gamma Brain Energizer—40 Hz—Clean Mental Energy—Focus Music—Binaural Beats. Available online: https://www.youtube.com/watch?v=9wrFk5vuOsk (accessed on 10 March 2018).
- Serotonin Release Music with Alpha Waves—Binaural Beats Relaxing Music. Available online: https://www.youtube.com/watch?v=9TPSs16DwbA (accessed on 10 March 2018).
- Hurless, N.; Mekic, A.; Pena, S.; Humphries, E.; Gentry, H.; Nichols, D. Music genre preference and tempo alter alpha and beta waves in human non-musicians. Impulse 2013, 24, 1–11. [Google Scholar]
- Billboard Year End Chart. Available online: https://www.billboard.com/charts/year-end (accessed on 10 March 2018).
- Lin, L.C.; Chiang, C.T.; Lee, M.W.; Mok, H.K.; Yang, Y.H.; Wu, H.C.; Tsai, C.L.; Yang, R.C. Parasympathetic activation is involved in reducing epileptiform discharges when listening to Mozart music. Clin. Neurophysiol. 2013, 124, 1528–1535. [Google Scholar] [CrossRef]
- Fisher, R.A. Statistical methods for research workers. In Breakthroughs in Statistics; Springer: Berlin/Heidelberg, Germany, 1992; pp. 66–70. [Google Scholar]
- Peck, E.M.M.; Yuksel, B.F.; Ottley, A.; Jacob, R.J.; Chang, R. Using fNIRS brain sensing to evaluate information visualization interfaces. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 473–482. [Google Scholar]
- Walker, J.L. Subjective reactions to music and brainwave rhythms. Physiol. Psychol. 1977, 5, 483–489. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; André, E. Emotion recognition based on physiological changes in music listening. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 2067–2083. [Google Scholar] [CrossRef]
- Shin, J.; Kwon, J.; Choi, J.; Im, C.H. Performance enhancement of a brain-computer interface using high-density multi-distance NIRS. Sci. Rep. 2017, 7, 16545. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Delpy, D.T.; Cope, M.; van der Zee, P.; Arridge, S.; Wray, S.; Wyatt, J. Estimation of optical pathlength through tissue from direct time of flight measurement. Phys. Med. Biol. 1988, 33, 1433. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Picard, R.W.; Vyzas, E.; Healey, J. Toward machine emotional intelligence: Analysis of affective physiological state. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1175–1191. [Google Scholar] [CrossRef] [Green Version]
- Chowdhury, R.H.; Reaz, M.B.; Ali, M.A.B.M.; Bakar, A.A.; Chellappan, K.; Chang, T.G. Surface electromyography signal processing and classification techniques. Sensors 2013, 13, 12431–12466. [Google Scholar] [CrossRef] [PubMed]
- Triwiyanto, T.; Wahyunggoro, O.; Nugroho, H.A.; Herianto, H. An investigation into time domain features of surface electromyography to estimate the elbow joint angle. Adv. Electr. Electron. Eng. 2017, 15, 448–458. [Google Scholar] [CrossRef]
- Acharya, U.R.; Hagiwara, Y.; Deshpande, S.N.; Suren, S.; Koh, J.E.W.; Oh, S.L.; Arunkumar, N.; Ciaccio, E.J.; Lim, C.M. Characterization of focal EEG signals: A review. Future Gener. Comput. Syst. 2019, 91, 290–299. [Google Scholar] [CrossRef]
- Rahman, J.S.; Gedeon, T.; Caldwell, S.; Jones, R. Brain Melody Informatics: Analysing Effects of Music on Brainwave Patterns. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Palangi, H.; Deng, L.; Ward, R.K. Recurrent deep-stacking networks for sequence classification. In Proceedings of the 2014 IEEE China Summit & International Conference on Signal and Information Processing (ChinaSIP), Xi’an, China, 9–13 July 2014; pp. 510–514. [Google Scholar]
- Deng, L.; Platt, J.C. Ensemble deep learning for speech recognition. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Deng, L.; Tur, G.; He, X.; Hakkani-Tur, D. Use of kernel deep convex networks and end-to-end learning for spoken language understanding. In Proceedings of the 2012 IEEE Spoken Language Technology Workshop (SLT), Miami, FL, USA, 2–5 December 2012; pp. 210–215. [Google Scholar]
- Tur, G.; Deng, L.; Hakkani-Tür, D.; He, X. Towards deeper understanding: Deep convex networks for semantic utterance classification. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 5045–5048. [Google Scholar]
- Zvarevashe, K.; Olugbara, O.O. Recognition of Cross-Language Acoustic Emotional Valence Using Stacked Ensemble Learning. Algorithms 2020, 13, 246. [Google Scholar] [CrossRef]
- Malik, M.; Adavanne, S.; Drossos, K.; Virtanen, T.; Ticha, D.; Jarina, R. Stacked convolutional and recurrent neural networks for music emotion recognition. arXiv 2017, arXiv:1706.02292. [Google Scholar]
- Bagherzadeh, S.; Maghooli, K.; Farhadi, J.; Zangeneh Soroush, M. Emotion Recognition from Physiological Signals Using Parallel Stacked Autoencoders. Neurophysiology 2018, 50, 428–435. [Google Scholar] [CrossRef]
- Jiang, C.; Li, Y.; Tang, Y.; Guan, C. Enhancing EEG-based classification of depression patients using spatial information. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 566–575. [Google Scholar] [CrossRef]
- On Average, You’re Using the Wrong Average: Geometric & Harmonic Means in Data Analysis. Available online: https://tinyurl.com/3m2dmztn/ (accessed on 10 February 2022).
- Valverde-Albacete, F.J.; Peláez-Moreno, C. 100% classification accuracy considered harmful: The normalized information transfer factor explains the accuracy paradox. PLoS ONE 2014, 9, e84217. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bauernfeind, G.; Steyrl, D.; Brunner, C.; Müller-Putz, G.R. Single trial classification of fnirs-based brain-computer interface mental arithmetic data: A comparison between different classifiers. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 2004–2007. [Google Scholar]
- Pathan, N.S.; Foysal, M.; Alam, M.M. Efficient mental arithmetic task classification using wavelet domain statistical features and svm classifier. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’sBazar, Bangladesh, 7–9 February 2019; pp. 1–5. [Google Scholar]
- Euston, D.R.; Gruber, A.J.; McNaughton, B.L. The role of medial prefrontal cortex in memory and decision making. Neuron 2012, 76, 1057–1070. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Smith, R.; Lane, R.D.; Alkozei, A.; Bao, J.; Smith, C.; Sanova, A.; Nettles, M.; Killgore, W.D. The role of medial prefrontal cortex in the working memory maintenance of one’s own emotional responses. Sci. Rep. 2018, 8, 3460. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Morita, T.; Itakura, S.; Saito, D.N.; Nakashita, S.; Harada, T.; Kochiyama, T.; Sadato, N. The role of the right prefrontal cortex in self-evaluation of the face: A functional magnetic resonance imaging study. J. Cogn. Neurosci. 2008, 20, 342–355. [Google Scholar] [CrossRef]
- Henson, R.; Shallice, T.; Dolan, R.J. Right prefrontal cortex and episodic memory retrieval: A functional MRI test of the monitoring hypothesis. Brain 1999, 122, 1367–1381. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Leong, Y.C.; Honey, C.J.; Yong, C.H.; Norman, K.A.; Hasson, U. Shared memories reveal shared structure in neural activity across individuals. Nat. Neurosci. 2017, 20, 115–125. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kawakami, A.; Furukawa, K.; Katahira, K.; Okanoya, K. Sad music induces pleasant emotion. Front. Psychol. 2013, 4, 311. [Google Scholar] [CrossRef] [Green Version]
- Glaser, B.G.; Strauss, A.L. Discovery of Grounded Theory: Strategies for Qualitative Research; Routledge: London, UK, 2017. [Google Scholar]
- OBELAB - NIRSIT Analysis Tool. Available online: http://obelab.com/upload_file/down/%5BOBELAB%5DNIRSIT_Analysis_Tool_Manual_v3.6.1_ENG.pdf (accessed on 15 February 2022).
- Moghimi, S.; Kushki, A.; Guerguerian, A.M.; Chau, T. Characterizing emotional response to music in the prefrontal cortex using near infrared spectroscopy. Neurosci. Lett. 2012, 525, 7–11. [Google Scholar] [CrossRef]
- Hossain, M.Z.; Gedeon, T.; Sankaranarayana, R. Using temporal features of observers’ physiological measures to distinguish between genuine and fake smiles. IEEE Trans. Affect. Comput. 2018, 11, 163–173. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Genre and Stimuli No. | Music Stimulus Name |
|---|---|
| Classical 1 | Mozart Sonatas K.448 [26] |
| Classical 2 | Mozart Sonatas K.545 [54] |
| Classical 3 | F. Chopin’s “Funeral March” from Sonata in B flat minor Op. 35/2 [48] |
| Classical 4 | J.S Bach’s Suite for Orchestra No. 3 in D “Air” [48]. |
| Instrumental 1 | Gamma Brain Energizer [50] |
| Instrumental 2 | Serotonin Release Music with Alpha Waves [51] |
| Instrumental 3 | “The Feeling of Jazz” by Duke Ellington [52] |
| Instrumental 4 | “YYZ” by Rush [52] |
| Pop 1 | “Happy” by Pharrell Williams |
| Pop 2 | “Uptown Funk” by Mark Ronson featuring Bruno Mars |
| Pop 3 | “Love Yourself” by Justin Bieber |
| Pop 4 | “Shape of You” by Ed Sheeran |
| Feature Type | Feature Names |
|---|---|
| Time Domain (Linear) | Mean, maximum, minimum, standard deviation, interquartile range, variance, summation, skewness, kurtosis, number of peaks, root mean square, absolute summation, difference absolute standard deviation value, simple square integral, average amplitude change, means of the absolute values of the first and second differences |
| Time Domain (Non-Linear) | Hjorth parameters (mobility), Hurst exponent |
| Frequency Domain | Mean, minimum and maximum of the first 16 points from Welch’s power spectrum |
| KNN | RF | 1D CNN | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Label | Signal | ACC | PREC | REC | F1 | ACC | PREC | REC | F1 | ACC | PREC | REC | F1 |
| HbO2 | 0.342 | 0.34 | 0.342 | 0.334 | 0.327 | 0.326 | 0.327 | 0.321 | 0.696 | 0.724 | 0.696 | 0.689 | |
| HbR | 0.339 | 0.336 | 0.339 | 0.33 | 0.341 | 0.342 | 0.34 | 0.336 | 0.614 | 0.649 | 0.614 | 0.602 | |
| HbO2 + HbR | 0.371 | 0.378 | 0.371 | 0.369 | 0.376 | 0.374 | 0.376 | 0.368 | 0.734 | 0.762 | 0.734 | 0.731 | |
| HbO2 | 0.495 | 0.455 | 0.495 | 0.467 | 0.553 | 0.449 | 0.553 | 0.461 | 0.74 | 0.758 | 0.74 | 0.707 | |
| HbR | 0.49 | 0.452 | 0.491 | 0.466 | 0.56 | 0.46 | 0.56 | 0.466 | 0.67 | 0.66 | 0.67 | 0.614 | |
| HbO2 + HbR | 0.541 | 0.512 | 0.541 | 0.521 | 0.594 | 0.538 | 0.593 | 0.519 | 0.774 | 0.786 | 0.774 | 0.749 | |
| HbO2 | 0.437 | 0.424 | 0.437 | 0.427 | 0.464 | 0.422 | 0.464 | 0.428 | 0.694 | 0.716 | 0.694 | 0.668 | |
| HbR | 0.451 | 0.433 | 0.451 | 0.438 | 0.486 | 0.451 | 0.486 | 0.446 | 0.587 | 0.589 | 0.587 | 0.523 | |
| HbO2 + HbR | 0.489 | 0.476 | 0.489 | 0.479 | 0.517 | 0.478 | 0.517 | 0.481 | 0.734 | 0.748 | 0.734 | 0.717 | |
| HbO2 | 0.452 | 0.439 | 0.452 | 0.442 | 0.476 | 0.444 | 0.476 | 0.446 | 0.697 | 0.719 | 0.697 | 0.682 | |
| HbR | 0.442 | 0.425 | 0.442 | 0.429 | 0.472 | 0.437 | 0.472 | 0.435 | 0.619 | 0.638 | 0.619 | 0.597 | |
| HbO2 + HbR | 0.479 | 0.463 | 0.479 | 0.466 | 0.491 | 0.451 | 0.491 | 0.457 | 0.719 | 0.741 | 0.719 | 0.708 | |
| HbO2 | 0.517 | 0.512 | 0.516 | 0.513 | 0.541 | 0.505 | 0.54 | 0.493 | 0.708 | 0.734 | 0.708 | 0.674 | |
| HbR | 0.518 | 0.509 | 0.518 | 0.512 | 0.549 | 0.513 | 0.549 | 0.499 | 0.626 | 0.644 | 0.626 | 0.546 | |
| HbO2 + HbR | 0.539 | 0.533 | 0.538 | 0.533 | 0.544 | 0.511 | 0.544 | 0.496 | 0.718 | 0.743 | 0.718 | 0.684 | |
| HbO2 | 0.596 | 0.559 | 0.595 | 0.57 | 0.649 | 0.555 | 0.649 | 0.557 | 0.749 | 0.747 | 0.749 | 0.697 | |
| HbR | 0.595 | 0.556 | 0.595 | 0.568 | 0.651 | 0.544 | 0.651 | 0.55 | 0.692 | 0.674 | 0.692 | 0.605 | |
| HbO2 + HbR | 0.648 | 0.633 | 0.658 | 0.637 | 0.684 | 0.668 | 0.683 | 0.618 | 0.77 | 0.772 | 0.77 | 0.731 | |
| HbO2 | 0.706 | 0.638 | 0.706 | 0.659 | 0.744 | 0.631 | 0.742 | 0.653 | 0.794 | 0.791 | 0.794 | 0.734 | |
| HbR | 0.7 | 0.629 | 0.7 | 0.652 | 0.74 | 0.627 | 0.74 | 0.651 | 0.769 | 0.726 | 0.769 | 0.69 | |
| HbO2 + HbR | 0.748 | 0.727 | 0.747 | 0.73 | 0.769 | 0.749 | 0.768 | 0.702 | 0.805 | 0.799 | 0.805 | 0.753 | |
| Stimuli | Negative Comments | Neutral Comments | Positive Comments |
|---|---|---|---|
| Classical 1 | 2 | 6 | 19 |
| Classical 2 | 4 | 6 | 17 |
| Classical 3 | 9 | 6 | 12 |
| Classical 4 | 3 | 5 | 19 |
| Instrumental 1 | 19 | 3 | 5 |
| Instrumental 2 | 8 | 3 | 16 |
| Instrumental 3 | 5 | 1 | 21 |
| Instrumental 4 | 9 | 8 | 10 |
| Pop 1 | 2 | 10 | 15 |
| Pop 2 | 1 | 11 | 15 |
| Pop 3 | 3 | 8 | 16 |
| Pop 4 | 0 | 12 | 15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahman, J.S.; Caldwell, S.; Jones, R.; Gedeon, T. Brain Melody Interaction: Understanding Effects of Music on Cerebral Hemodynamic Responses. Multimodal Technol. Interact. 2022, 6, 35. https://doi.org/10.3390/mti6050035
Rahman JS, Caldwell S, Jones R, Gedeon T. Brain Melody Interaction: Understanding Effects of Music on Cerebral Hemodynamic Responses. Multimodal Technologies and Interaction. 2022; 6(5):35. https://doi.org/10.3390/mti6050035
Chicago/Turabian StyleRahman, Jessica Sharmin, Sabrina Caldwell, Richard Jones, and Tom Gedeon. 2022. "Brain Melody Interaction: Understanding Effects of Music on Cerebral Hemodynamic Responses" Multimodal Technologies and Interaction 6, no. 5: 35. https://doi.org/10.3390/mti6050035
APA StyleRahman, J. S., Caldwell, S., Jones, R., & Gedeon, T. (2022). Brain Melody Interaction: Understanding Effects of Music on Cerebral Hemodynamic Responses. Multimodal Technologies and Interaction, 6(5), 35. https://doi.org/10.3390/mti6050035