An Experimental Evaluation of Fault Diagnosis from Imbalanced and Incomplete Data for Smart Semiconductor Manufacturing



Abstract
:1. Introduction
2. Background
2.1. Semiconductor Manufacturing Processes and the Data Volume
2.2. Fault Detection in Semiconductor Manufacturing
2.3. SECOM Dataset
- Overall 1567 trials were recorded, with only 104 of which resulted in failure. This creates a near 1:14 relation between the number of failures and successes recorded, resulting in a highly imbalanced dataset.
- Not all the signals that are recorded are useful for classification. Features exist in the SECOM dataset that present little to no data and do not change throughout the trials, moreover, some features exist that are very noisy or have no effect on the outcome of the test.
- Nearly 7 percent of the data in the SECOM dataset is missing. These data points were either never measured, or somehow lost and never made it to the final records.
3. Methodology
3.1. Classification System Architecture
Cross-Validation and the Proper Way to Do It
3.2. Data Pruning
3.3. Data Imputation
3.3.1. Image In-Painting
3.3.2. Our Approach: In-Painting KNN-Imputation
| Algorithm 1 The Flow of Inpainting KNN Imputation. |
| Input Parameters: Input Data and Number of Neighbors (K-Param) Output Parameters: Filled Data Fetching Input: Data ← Read input data from file Calculating Number of Missing Values: for i in Columns do: NullSum[i] ← Sum(IsMissing(Data[:,i]) Iteration ← Sum(NullSum) Calculation of Confidence Value (Sum of Missing Values in Rows and Columns): Confidence ← 360 360 OneArray(DataDimension): for i in Rows do: RowSum ← Sum(IsMissing(Data[i,:])) ColumnSum ← Sum(IsMissing(Data[:,j])) for i in Rows do: for j in Columns do: if IsMissing(Data[0]) do: Confidence[i,j] ← RowSum[i] + ColumnSum[j] Familiarity = Sum(KNeighborsDistances): NNB ← NearestNeighbors(NeighborsNumber = KParam, DistanceOption = "Euclidean") FitForNNB(XArray) for i in Rows do: Distances = SumofDistances (KNeighborsForNNB (Data[i,:])) Familiarity[i] ← Distances Normalize Familiarity: FamiliarityNorm ← Normalized Familiarity Between [6, 360] Loop for Filling Missing Values: for Counter in Range(Iteration) do Order ← Confidence FamiliarityNorm Target ← argmin(Order): (x, y) ← Location of Target Extract Target Row for XTest: XTest ← Data[x,:] XTrain ← Remove row of "x" and column "y" from Data YTrain ← Extract column "y" from Data Delete Instances with Missing Values in the Target Column: Let Index be an empty array for Element in YTrain do: if IsMissing(Element) do: Removing row of element Filling Remained Part of XTest By Mean Values of Features: MeanTrain ← Mean(XTrain, Column) for FeatureCounter in Columns do: for InstanceCounter in Rows do: if IsMissing(XTrain [InstanceCounter, FeatureCounter]) do: XTrain [InstanceCounter, FeatureCounter] ← MeanTrain [FeatureCounter] for FeatureCounter in Range(Length(XTest)) do: if IsMissing(XTest [FeatureCounter]) do: XTest [FeatureCounter] ← MeanTrain [FeatureCounter] Predicting the Missing Value with KNN: Classifier ← KNeighborsRegressor(NeighborsNumber = KParam) FitForClassifier(XTrain,YTrain) Prediction ← ClassifierPrediction(XTest) for j in Column y do: Confidence[x,j] ← Confidence[x,j] − 1 for i in Row x do: Confidence[i,y] ← Confidence[i,y] − 1 Confidence[x,y] ← 360 360 Data[x,y] ← Prediction |
3.4. Feature Selection
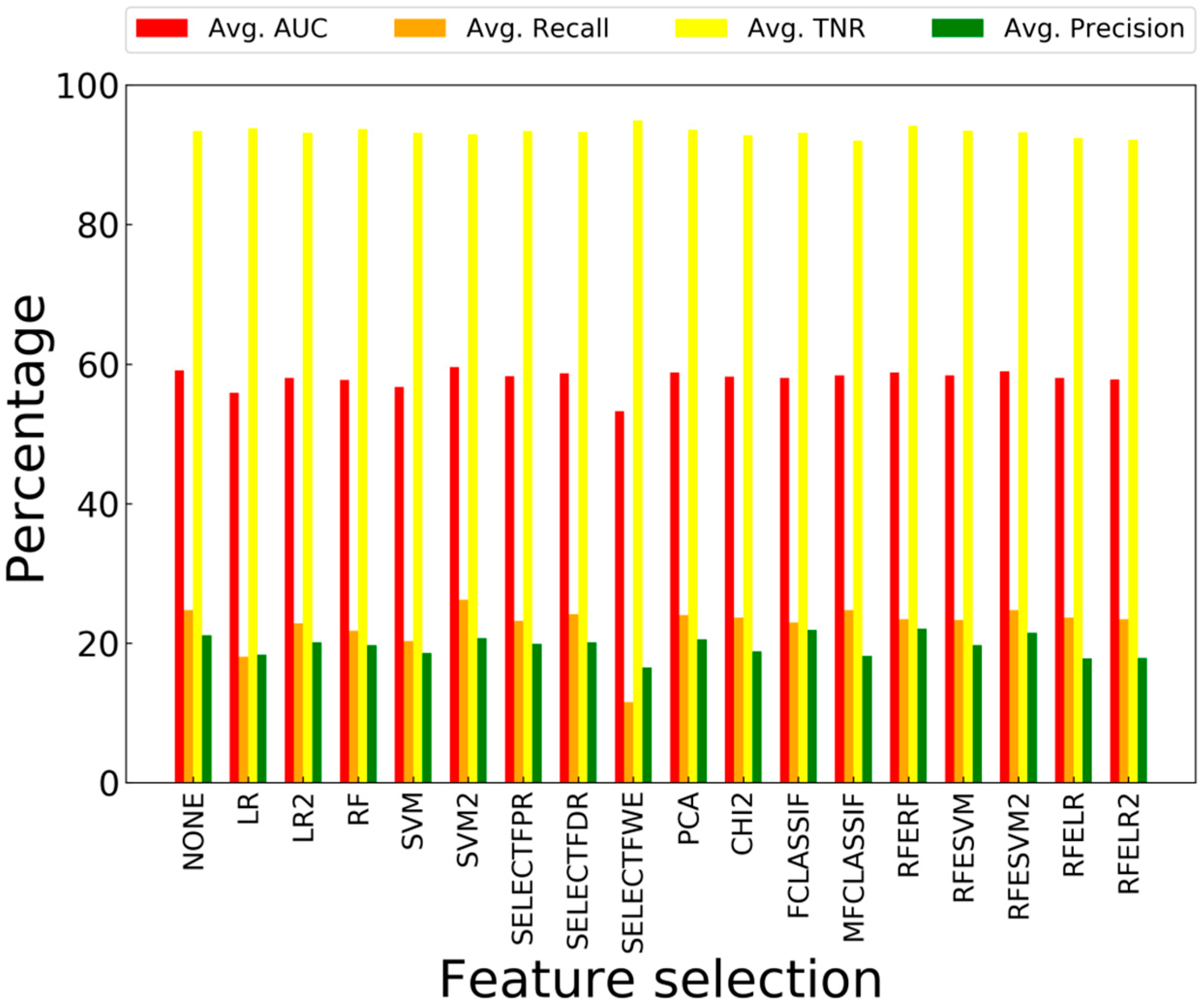
- Univariate feature selection: This type of feature selection performs univariate statistical tests on the input data and selects the ones with the highest scores. The scoring functions used in this work are Chi-squared (CHI2), ANOVA F-value between label and feature (FCLASSIF), mutual information (MFCLASSIF), false positive rate test (SELECTFPR), estimated false discovery rate (SELECTFDR), family-wise error rate (SELECTFWE).
- Selecting from a model: a group of estimators can output feature importance after they have been trained on the data. Using this feature importance, the highest-ranking features are selected from models such as RF, Logistic Regression with L1 (LR) and L2 (LR2) regularization, and Support Vector Machine with L1 (SVM) and L2 (SVM2) regularization.
- Recursive Feature Elimination (RFE): Similar to the previous approach, a model that outputs feature importance is fitted on the training data; however, the features with the lowest importance are removed. This process is repeated, and model is trained on the new data, until the features with the highest importance are remaining. The same models used for the previous approach are used for this approach (RFERF, RFELR, RFELR2, RFESVM, and RFESVM2).
- Dimensionality reduction: In this work Principle Component Analysis (PCA) is used to linearly reduce the dimensionality of the data, using Singular Value Decomposition of the data matrix to project each data vector to a space with lower dimensions.
3.5. Synthetic Data Generation
3.6. Classification
4. Results
4.1. Experimental Setup
4.2. Results
4.2.1. Classification Results
4.2.2. Feature Selection Results
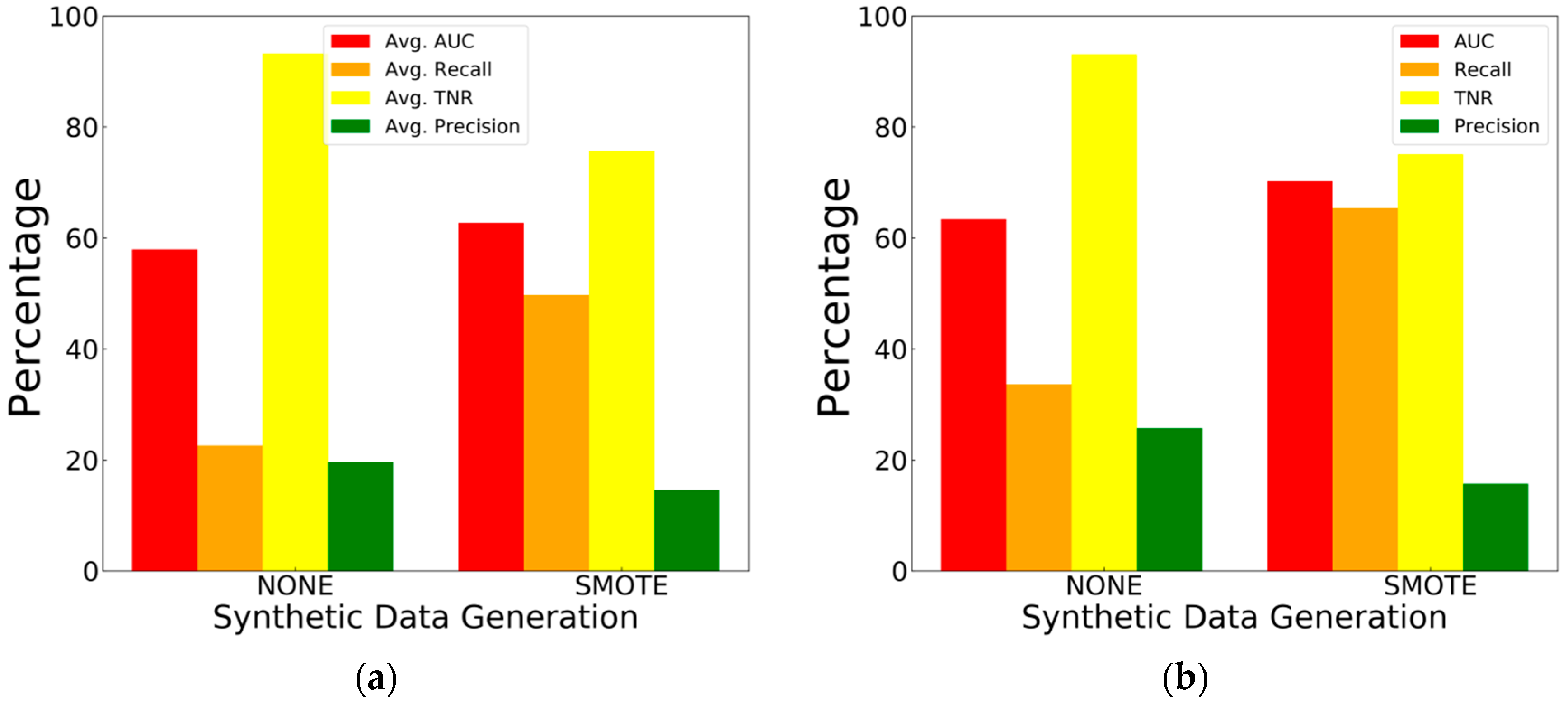
4.2.3. Synthetic Data Generation Results
4.2.4. Data Imputation Results
4.2.5. Feature Importance
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kim, J.; Han, Y.; Lee, J. Data Imbalance Problem solving for SMOTE Based Oversampling: Study on Fault Detection Prediction Model in Semiconductor Manufacturing Process. Adv. Sci. Technol. Lett. 2016, 133, 79–84. [Google Scholar]
- Kim, J.K.; Cho, K.C.; Lee, J.S.; Han, Y.S. Feature Selection Techniques for Improving Rare Class Classification in Semiconductor Manufacturing Process; Springer: Cham, Switzerland, 2017; pp. 40–47. [Google Scholar]
- Moldovan, D.; Cioara, T.; Anghel, I.; Salomie, I. Machine learning for sensor-based manufacturing processes. In Proceedings of the 13th IEEE International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 7–9 September 2017; pp. 147–154. [Google Scholar]
- Kerdprasop, K.; Kerdprasop, N. A Data Mining Approach to Automate Fault Detection Model Development in the Semiconductor Manufacturing Process. Int. J. Mech. 2011, 5, 336–344. [Google Scholar]
- Wang, J.; Feng, J.; Han, Z. Discriminative Feature Selection Based on Imbalance SVDD for Fault Detection of Semiconductor Manufacturing Processes. J. Circuits Syst. Comput. 2016, 25, 1650143. [Google Scholar] [CrossRef]
- Kim, J.; Han, Y.; Lee, J. Euclidean Distance Based Feature Selection for Fault Detection Prediction Model in Semiconductor Manufacturing Process. Adv. Sci. Technol. Lett. 2016, 133, 85–89. [Google Scholar]
- Subramaniam, S.K.; Husin, S.H.; Singh, R.S.S. Production monitoring system for monitoring the industrial shop floor performance. Int. J. Syst. Appl. Eng. Dev. 2009, 3, 28–35. [Google Scholar]
- Caputo, G.; Gallo, M.; Guizzi, G. Optimization of Production Plan through Simulation Techniques. WSEAS Trans. Inf. Sci. Appl. 2009, 6, 352–362. [Google Scholar]
- Munirathinam, S.; Ramadoss, B. Predictive Models for Equipment Fault Detection in the Semiconductor Manufacturing Process. Int. J. Eng. Technol. 2016, 8, 273–285. [Google Scholar] [CrossRef]
- McCann, M.; Li, Y.; Maguire, L.; Johnston, A. Causality Challenge: Benchmarking relevant signal components for effective monitoring and process control. J. Mach. Learn. Res. 2010, 6, 277–288. [Google Scholar]
- Kim, J.K.; Han, Y.S.; Lee, J.S. Particle swarm optimization-deep belief network-based rare class prediction model for highly class imbalance problem. Concurr. Comput. Pract. Exp. 2017, 29, e4128. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar]
- Gelman, A.; Hill, J. Missing-data imputation. In Data Analysis Using Regression and Multilevel/Hierarchical Models; Cambridge University Press: Cambridge, UK, 2006; pp. 529–544. [Google Scholar]
- Mockus, A. Missing Data in Software Engineering. In Guide to Advanced Empirical Software Engineering; Springer: London, UK, 2008; pp. 185–200. [Google Scholar]
- De Silva, H.; Perera, A.S. Missing data imputation using Evolutionary k- Nearest neighbor algorithm for gene expression data. In Proceedings of the 2016 Sixteenth International Conference on Advances in ICT for Emerging Regions (ICTer), Negombo, Sri Lanka, 1–3 September 2016; pp. 141–146. [Google Scholar]
- Troyanskaya, O.; Cantor, M.; Sherlock, G.; Brown, P.; Hastie, T.; Tibshirani, R.; Botstein, D.; Altman, R.B. Missing value estimation methods for DNA microarrays. Bioinformatics 2001, 17, 520–525. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guillemot, C.; Le Meur, O. Image Inpainting: Overview and Recent Advances. IEEE Signal Process. Mag. 2014, 31, 127–144. [Google Scholar] [CrossRef]
- Biradar, R.L.; Kohir, V.V. A novel image inpainting technique based on median diffusion. Sadhana 2013, 38, 621–644. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chomboon, K.; Kerdprasop, K.; Kerdprasop, N.K. Rare class discovery techniques for highly imbalance data. In Proceedings of the International MultiConference of Engineers and Computer Scientists, Hong Kong, China, 13–15 March 2013. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Imputation | Feature Selection | True Positive | True Negative | False Positive | False Negative | TNR | Precision | Recall | AUC |
|---|---|---|---|---|---|---|---|---|---|---|
| LR | In-painting | SELECTFDR | 68 | 1098 | 365 | 36 | 75.05 | 15.70 | 65.38 | 70.22 |
| SVM | In-painting | SELECTFDR | 67 | 1104 | 359 | 37 | 75.46 | 15.72 | 64.42 | 69.94 |
| KNN | In-painting | SVM | 81 | 791 | 672 | 23 | 54.07 | 10.75 | 77.88 | 65.96 |
| RF | In-painting | SELECTFWE | 48 | 1152 | 311 | 56 | 78.74 | 13.37 | 46.15 | 62.45 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salem, M.; Taheri, S.; Yuan, J.-S. An Experimental Evaluation of Fault Diagnosis from Imbalanced and Incomplete Data for Smart Semiconductor Manufacturing. Big Data Cogn. Comput. 2018, 2, 30. https://doi.org/10.3390/bdcc2040030
Salem M, Taheri S, Yuan J-S. An Experimental Evaluation of Fault Diagnosis from Imbalanced and Incomplete Data for Smart Semiconductor Manufacturing. Big Data and Cognitive Computing. 2018; 2(4):30. https://doi.org/10.3390/bdcc2040030
Chicago/Turabian StyleSalem, Milad, Shayan Taheri, and Jiann-Shiun Yuan. 2018. "An Experimental Evaluation of Fault Diagnosis from Imbalanced and Incomplete Data for Smart Semiconductor Manufacturing" Big Data and Cognitive Computing 2, no. 4: 30. https://doi.org/10.3390/bdcc2040030
APA StyleSalem, M., Taheri, S., & Yuan, J. -S. (2018). An Experimental Evaluation of Fault Diagnosis from Imbalanced and Incomplete Data for Smart Semiconductor Manufacturing. Big Data and Cognitive Computing, 2(4), 30. https://doi.org/10.3390/bdcc2040030