Constrained Optimization-Based Extreme Learning Machines with Bagging for Freezing of Gait Detection


Abstract
:1. Introduction
Contribution and Organization
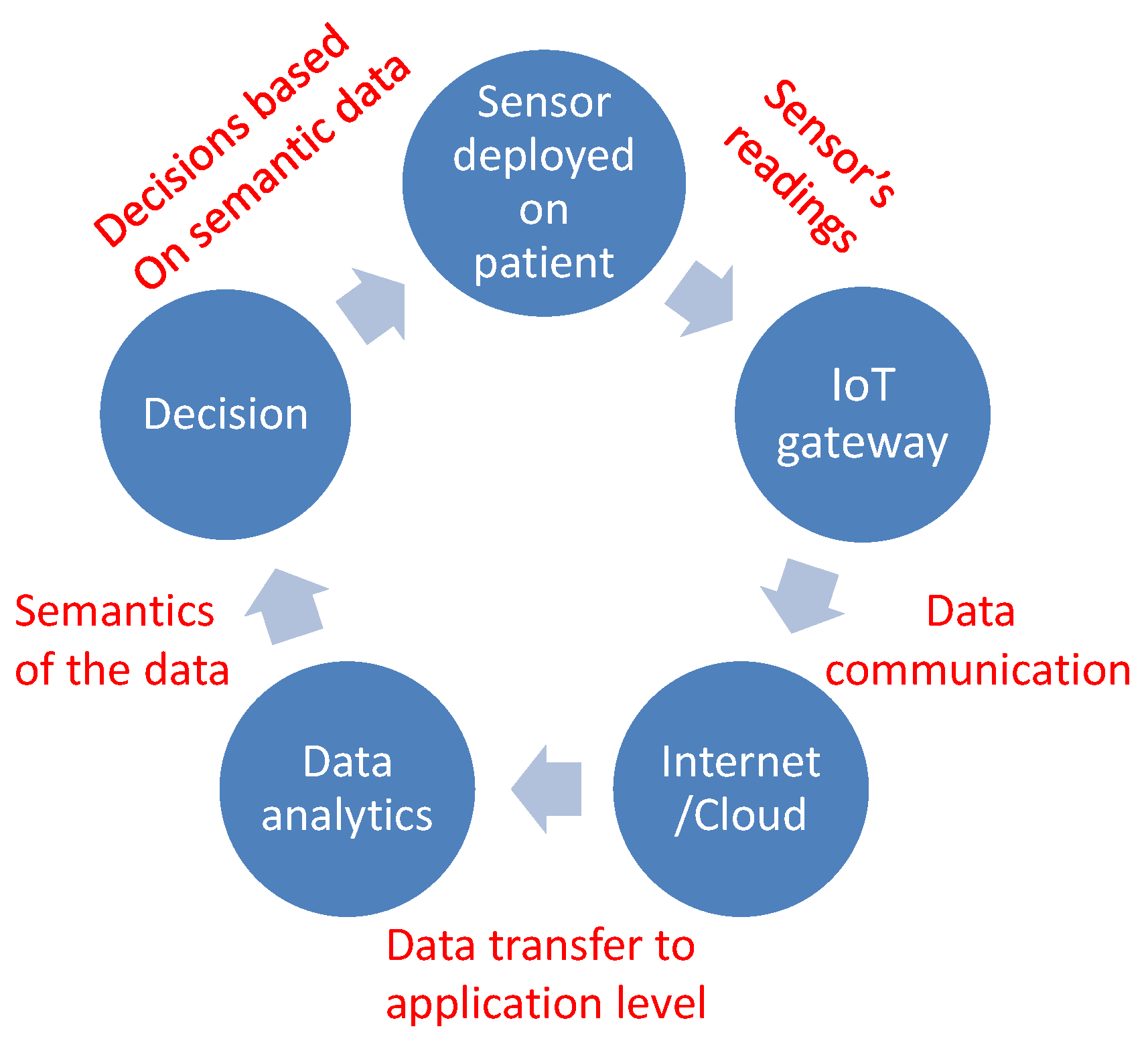
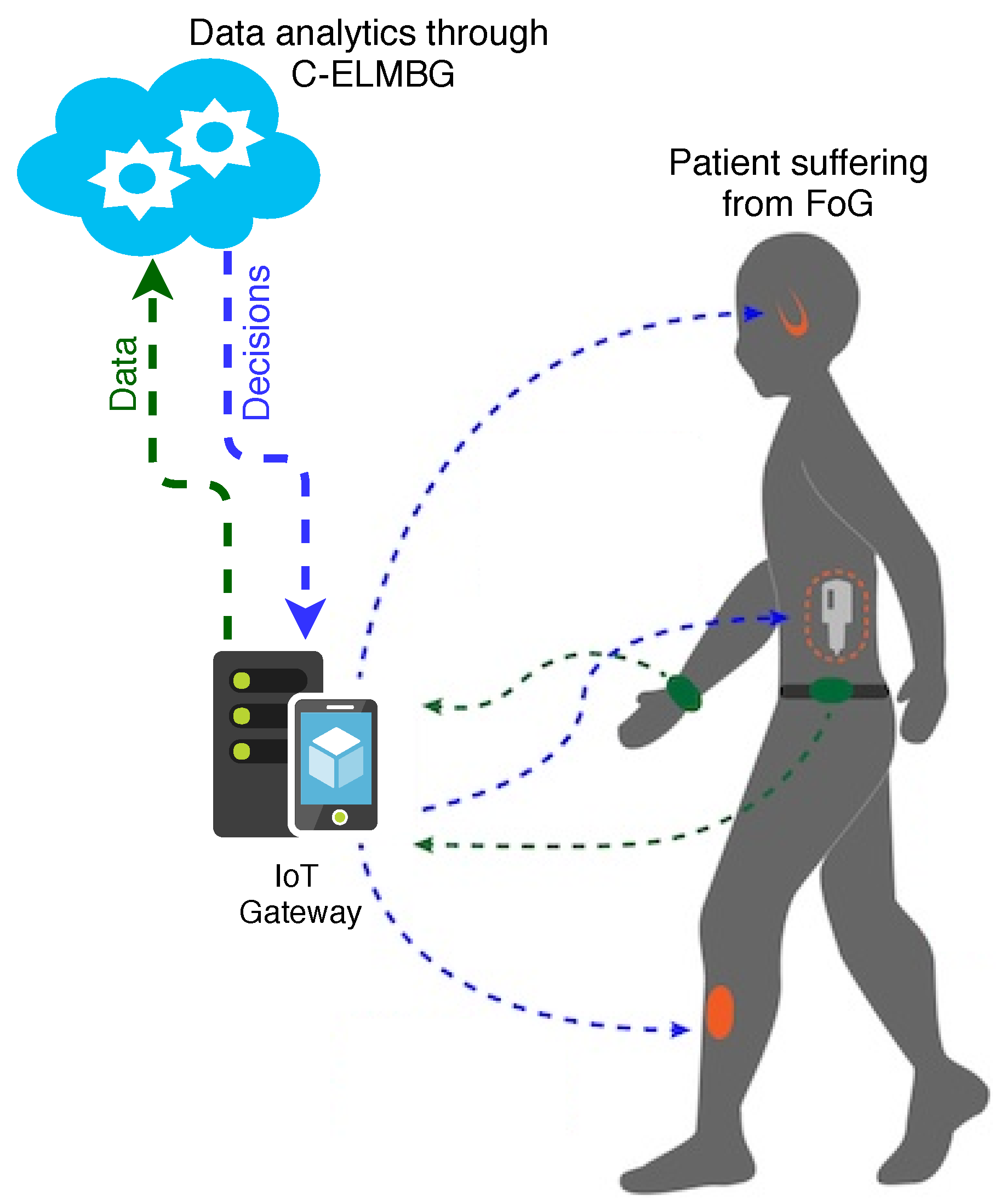
2. Freezing of Gait Detection Using IoT
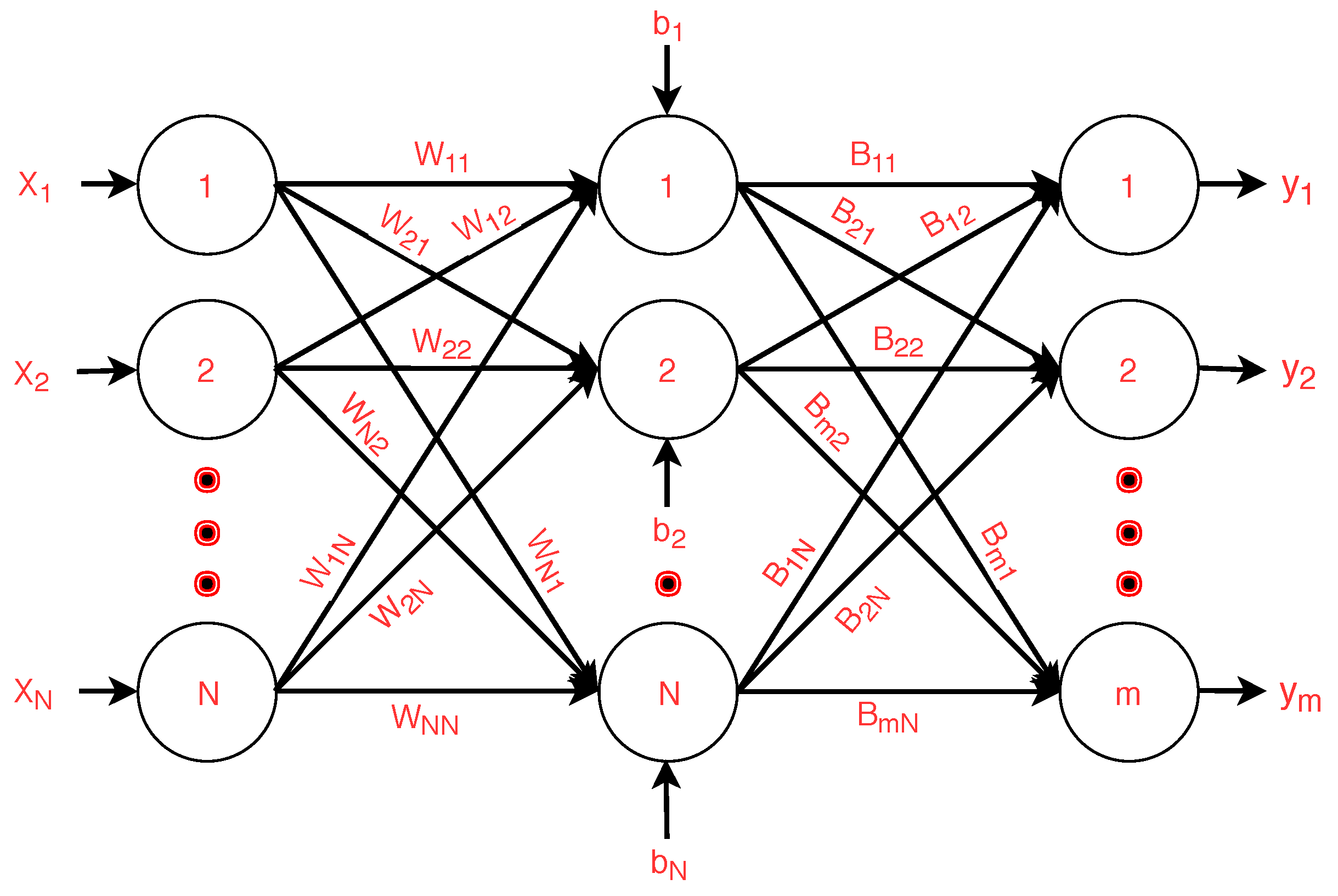
3. Constrained Optimization-Based Extreme Learning Machine with Bagging
| Algorithm 1: C-ELM with bagging (C-ELMBG). |
 |
4. Experimental Analysis
4.1. Simulation Setup
Description of the FoG Dataset
4.2. Simulation Results
4.2.1. Metrics for Evaluation of a Classifier
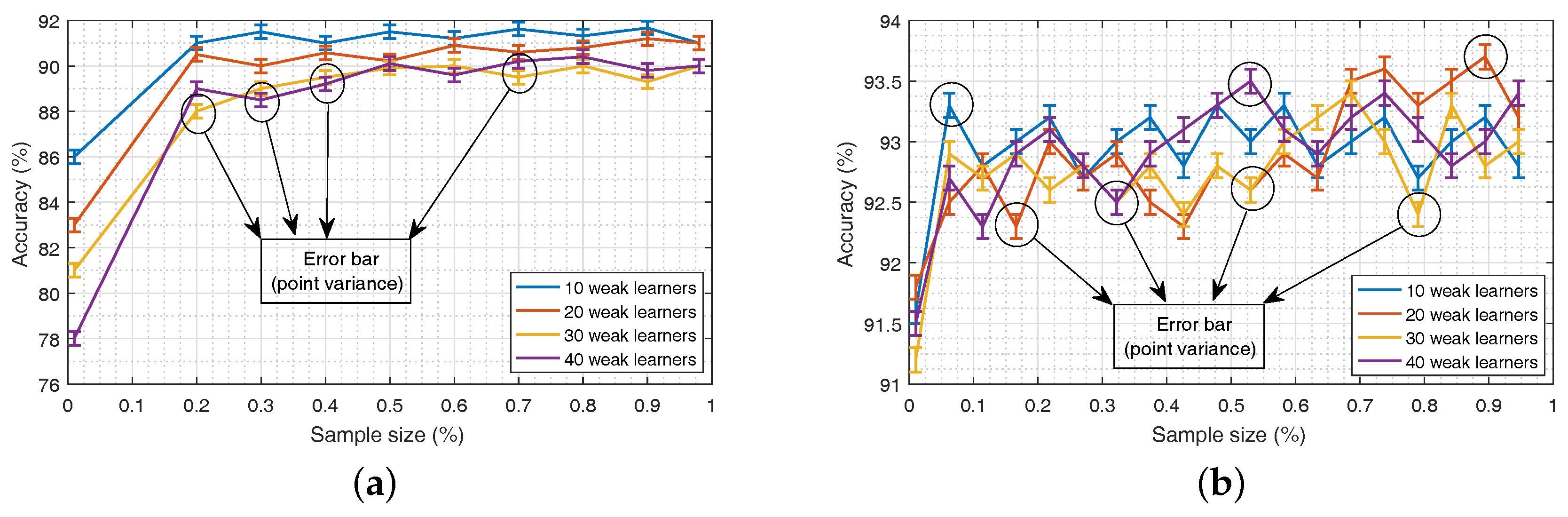
4.2.2. Parameter Settings
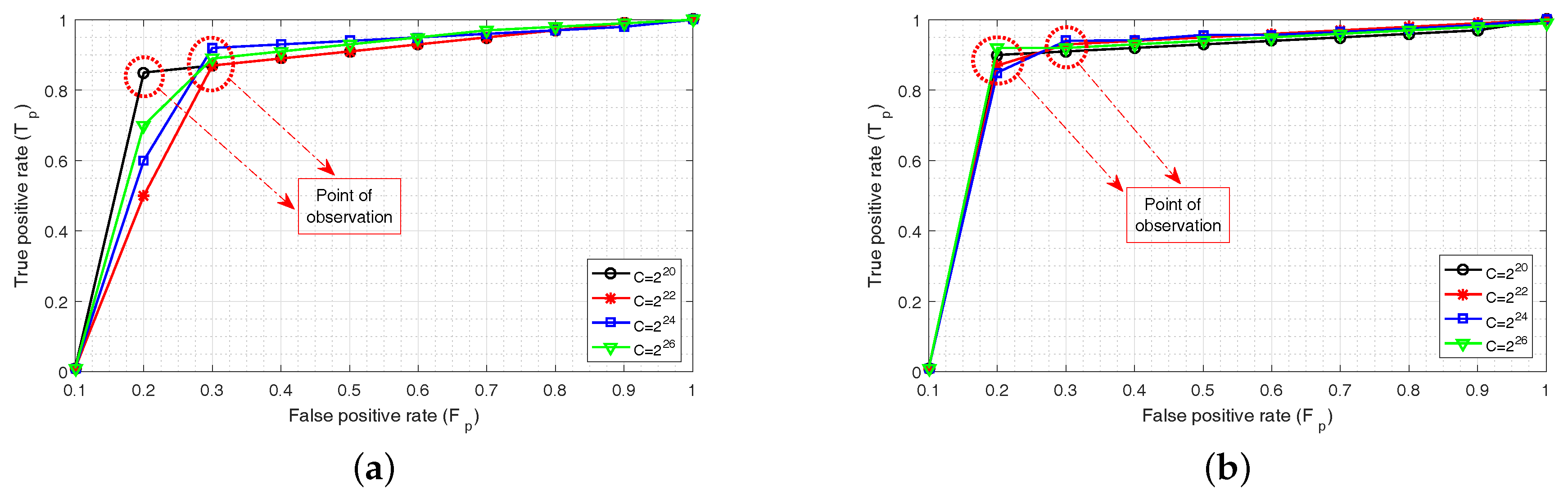
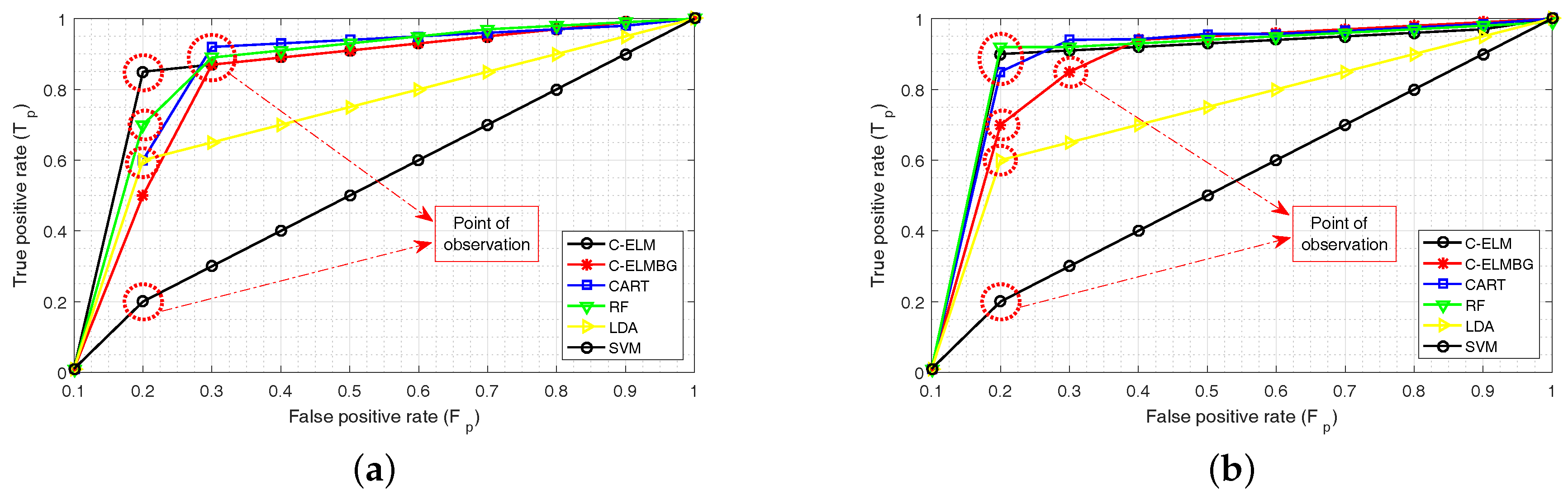
4.2.3. Comparison with Other Classifiers
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Handte, M.; Foell, S.; Wagner, S.; Kortuem, G.; Marrón, P.J. An internet-of-things enabled connected navigation system for urban bus riders. IEEE Internet Things J. 2016, 3, 735–744. [Google Scholar] [CrossRef]
- Xu, G.; Yu, W.; Griffith, D.; Golmie, N.; Moulema, P. Toward integrating distributed energy resources and storage devices in smart grid. IEEE Internet Things J. 2017, 4, 192–204. [Google Scholar] [CrossRef] [PubMed]
- Yu, T.; Wang, X.; Shami, A. Recursive principal component analysis-based data outlier detection and sensor data aggregation in IoT systems. IEEE Internet Things J. 2017, 4, 2207–2216. [Google Scholar] [CrossRef]
- Pringsheim, T.; Jette, N.; Frolkis, A.; Steeves, T.D. The prevalence of Parkinson’s disease: A systematic review and meta-analysis. Mov. Disord. 2014, 29, 1583–1590. [Google Scholar] [CrossRef] [PubMed]
- Islam, S.R.; Kwak, D.; Kabir, M.H.; Hossain, M.; Kwak, K.S. The internet of things for health care: A comprehensive survey. IEEE Access 2015, 3, 678–708. [Google Scholar] [CrossRef]
- Bloem, B.R.; Hausdorff, J.M.; Visser, J.E.; Giladi, N. Falls and freezing of gait in Parkinson’s disease: A review of two interconnected, episodic phenomena. Mov. Disord. 2004, 19, 871–884. [Google Scholar] [CrossRef] [PubMed]
- Bachlin, M.; Plotnik, M.; Roggen, D.; Maidan, I.; Hausdorff, J.M.; Giladi, N.; Troster, G. Wearable assistant for Parkinson’s disease patients with the freezing of gait symptom. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 436–446. [Google Scholar] [CrossRef] [PubMed]
- Mazilu, S.; Hardegger, M.; Zhu, Z.; Roggen, D.; Troster, G.; Plotnik, M.; Hausdorff, J.M. Online detection of freezing of gait with smartphones and machine learning techniques. In Proceedings of the 6th IEEE International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth), San Diego, CA, USA, 21–24 May 2012; pp. 123–130. [Google Scholar]
- Kubota, K.J.; Chen, J.A.; Little, M.A. Machine learning for large-scale wearable sensor data in Parkinson’s disease: Concepts, promises, pitfalls, and futures. Mov. Disord. 2016, 31, 1314–1326. [Google Scholar] [CrossRef] [PubMed]
- Pepa, L.; Ciabattoni, L.; Verdini, F.; Capecci, M.; Ceravolo, M. Smartphone based fuzzy logic freezing of gait detection in parkinson’s disease. In Proceedings of the IEEE/ASME 10th International Conference on Mechatronic and Embedded Systems and Applications (MESA), Senigallia, Italy, 10–12 September 2014; pp. 1–6. [Google Scholar]
- Rodriguez-Martin, D.; Sama, A.; Perez-Lopez, C.; Catala, A.; Arostegui, J.M.M.; Cabestany, J.; Bayes, A.; Alcaine, S.; Mestre, B.; Prats, A.; et al. Home detection of freezing of gait using support vector machines through a single waist-worn triaxial accelerometer. PLoS ONE 2017, 12, e0171764. [Google Scholar] [CrossRef] [PubMed]
- Lawrence, S.; Giles, C.L.; Tsoi, A.C.; Back, A.D. Face recognition: A convolutional neural-network approach. IEEE Trans. Neural Netw. 1997, 8, 98–113. [Google Scholar] [CrossRef] [PubMed]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv, 2014; arXiv:1404.2188. [Google Scholar]
- Liu, F.; Zhong, D. GSOS-ELM: An RFID-Based Indoor Localization System Using GSO Method and Semi-Supervised Online Sequential ELM. Sensors 2018, 18, 1995–2010. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, 3–5 December 2012; pp. 1097–1105. [Google Scholar]
- Uzair, M.; Shafait, F.; Ghanem, B.; Mian, A. Representation learning with deep extreme learning machines for efficient image set classification. Neural Comput. Appl. 2018, 30, 1211–1223. [Google Scholar] [CrossRef]
- Camps, J.; Sama, A.; Martin, M.; Rodriguez-Martin, D.; Perez-Lopez, C.; Alcaine, S.; Mestre, B.; Prats, A.; Crespo, M.C.; Cabestany, J.; et al. Deep Learning for Detecting Freezing of Gait Episodes in Parkinson’s Disease Based on Accelerometers. In International Work-Conference on Artificial Neural Networks; Springer: Cham, Switzerland, 2017; pp. 344–355. [Google Scholar]
- Hagan, M.T.; Demuth, H.B.; Beale, M.H.; De Jesús, O. Neural Network Design; PWS Pub.: Boston, MA, USA, 1996; Volume 20. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef] [Green Version]
- Wong, C.M.; Vong, C.M.; Wong, P.K.; Cao, J. Kernel-based multilayer extreme learning machines for representation learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 757–762. [Google Scholar] [CrossRef] [PubMed]
- Han, F.; Huang, D.S. Improved extreme learning machine for function approximation by encoding a priori information. Neurocomputing 2006, 69, 2369–2373. [Google Scholar] [CrossRef]
- Rong, H.J.; Huang, G.B.; Sundararajan, N.; Saratchandran, P. Online sequential fuzzy extreme learning machine for function approximation and classification problems. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2009, 39, 1067–1072. [Google Scholar] [CrossRef] [PubMed]
- Rumelhart, D.E.; McClelland, J.L. Parallel Distributed Processing: Explorations in the Microstructure of Cognition; Foundations; MIT Press: Cambridge, MA, USA, 1986; Volume 1. [Google Scholar]
- Zhu, Y.; Liang, J.; Chen, J.; Ming, Z. An improved NSGA-III algorithm for feature selection used in intrusion detection. Knowl. Based Syst. 2017, 116, 74–85. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Mao, K.; Siew, C.K.; Saratchandran, P.; Sundararajan, N. Can threshold networks be trained directly? IEEE Trans. Circ. Syst. II Express Briefs 2006, 53, 187–191. [Google Scholar] [CrossRef]
- Huang, G.B.; Ding, X.; Zhou, H. Optimization method based extreme learning machine for classification. Neurocomputing 2010, 74, 155–163. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.; Kwong, S.; Wang, D.D. An analysis of ELM approximate error based on random weight matrix. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2013, 21, 1–12. [Google Scholar] [CrossRef]
- Huang, G.B.; Chen, L.; Siew, C.K. Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans. Neural Netw. 2006, 17, 879–892. [Google Scholar] [CrossRef] [PubMed]
- Ma, C.; Ouyang, J.; Chen, H.L.; Zhao, X.H. An efficient diagnosis system for Parkinson’s disease using kernel-based extreme learning machine with subtractive clustering features weighting approach. Comput. Math. Methods Med. 2014, 2014, 985789. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.L.; Wang, G.; Ma, C.; Cai, Z.N.; Liu, W.B.; Wang, S.J. An efficient hybrid kernel extreme learning machine approach for early diagnoses of Parkinson’s disease. Neurocomputing 2016, 184, 131–144. [Google Scholar] [CrossRef]
- Huang, G.B.; Chen, L. Enhanced random search based incremental extreme learning machine. Neurocomputing 2008, 71, 3460–3468. [Google Scholar] [CrossRef] [Green Version]
- Feng, G.; Huang, G.B.; Lin, Q.; Gay, R.K.L. Error minimized extreme learning machine with growth of hidden nodes and incremental learning. IEEE Trans. Neural Netw. 2009, 20, 1352–1357. [Google Scholar] [CrossRef] [PubMed]
- Wong, S.Y.; Yap, K.S.; Yap, H.J. A Constrained Optimization based Extreme Learning Machine for noisy data regression. Neurocomputing 2016, 171, 1431–1443. [Google Scholar] [CrossRef]
- Tao, W.; Liu, T.; Zheng, R.; Feng, H. Gait analysis using wearable sensors. Sensors 2012, 12, 2255–2283. [Google Scholar] [CrossRef] [PubMed]
- Mathie, M.J.; Coster, A.C.; Lovell, N.H.; Celler, B.G. Accelerometry: Providing an integrated, practical method for long-term, ambulatory monitoring of human movement. Physiol. Meas. 2004, 25, R1–R20. [Google Scholar] [CrossRef] [PubMed]
- Roggen, D.; Bächlin, M.; Schumm, J.; Holleczek, T.; Lombriser, C.; Tröster, G.; Widmer, L.; Majoe, D.; Gutknecht, J. An educational and research kit for activity and context recognition from on-body sensors. In Proceedings of the IEEE Internation Conference on Body Sensor Networks (BSN), Singapore, 7–9 June 2010; pp. 277–282. [Google Scholar]
- Pothuganti, K.; Chitneni, A. A comparative study of wireless protocols: Bluetooth, UWB, ZigBee, and Wi-Fi. Adv. Electron. Electr. Eng. 2014, 4, 655–662. [Google Scholar]
- Siekkinen, M.; Hiienkari, M.; Nurminen, J.K.; Nieminen, J. How low energy is bluetooth low energy? comparative measurements with zigbee/802.15.4. In Proceedings of the IEEE Wireless Communications and Networking Conference Workshops (WCNCW), Paris, France, 1 April 2012; pp. 232–237. [Google Scholar]
- Soyata, T.; Ba, H.; Heinzelman, W.; Kwon, M.; Shi, J. Accelerating mobile-cloud computing: A survey. In Cloud Technology: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2015; pp. 1933–1955. [Google Scholar]
- Kuhn, H.W.; Tucker, A.W. Nonlinear programming. In Traces and Emergence of Nonlinear Programming; Springer: Basel, Switzerland, 2014; pp. 247–258. [Google Scholar]
- Daphnet Freezing of Gait Dataset. Available online: https://archive.ics.uci.edu/ml/datasets/Daphnet+Freezing+of+Gait (accessed on 20 May 2018).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) List of Common Acronyms Used | |
| Abbreviation | Description |
| AUROC | Area under the receiver operating characteristic curve |
| CART | Classification and regression trees |
| C-ELM | Constrained optimization-based extreme learning machines |
| C-ELMBG | Constrained optimization-based extreme learning machines with bagging |
| CNN | Convolutional neural networks |
| FoG | Freezing of gait |
| IoT | Internet-of-Things |
| LDA | Linear discriminant analysis |
| MCC | Matthews’ correlation coefficient |
| ML | Machine learning |
| RF | Random forests |
| ROC | Receiver operating characteristic |
| SVM | Support vector machines |
| (b) Mathematical Notations | |
| Notation | Description |
| N | Size of training dataset |
| P | Number of weak learners |
| Hidden layer matrix | |
| Final predicted vector | |
| Predicted error of instance k | |
| C | Regularization parameter |
| Identity matrix of size | |
| Target output vector | |
| Vector of input weights | |
| Vector of output weights | |
| Input observation vector | |
| Accuracy | |
| Sensitivity | |
| Specificity | |
| MCC | |
| Sr. No. | Features | Description |
|---|---|---|
| 1. | Ankle acceleration | horizontal forward acceleration (mg) |
| 2. | Ankle acceleration | vertical acceleration (mg) |
| 3. | Ankle acceleration | horizontal lateral acceleration (mg) |
| 4. | Upper leg acceleration | horizontal forward acceleration (mg) |
| 5. | Upper leg acceleration | vertical acceleration (mg) |
| 6. | Upper leg acceleration | horizontal lateral acceleration (mg) |
| 7. | Trunk acceleration | horizontal forward acceleration (mg) |
| 8. | Trunk acceleration | vertical acceleration (mg) |
| 9. | Trunk acceleration | horizontal lateral acceleration (mg) |
| 10. | Annotation | 1–> no freeze 2–> freeze |
| (a) Dataset Description | |||
| Classification | Total | ||
| Freeze | Not Freeze | ||
| Test dataset | 5120 | 4262 | 9382 |
| Training dataset 1 | 2907 | 8121 | 11,028 |
| Training dataset 2 | 12,145 | 5865 | 18,010 |
| (b) Confusion Matrix | |||
| Predicted | |||
| Yes | No | ||
| Actual | Yes | True positive () | False negative () |
| No | False positive () | True negative () | |
| (a) Training Set 1 | ||||||
| LDA | CART | C-ELM | C-ELMBG | RF | SVM | |
| 3298 | 4106 | 4704 | 4802 | 4559 | 0 | |
| 4112 | 3675 | 3746 | 3815 | 3713 | 4263 | |
| 151 | 587 | 517 | 447 | 549 | 0 | |
| 1821 | 1014 | 415 | 318 | 561 | 5119 | |
| (%) | 78.98 | 82.94 | 90.12 | 91.87 | 88.17 | 45.43 |
| (%) | 64.42 | 80.21 | 91.89 | 93.79 | 89.05 | 0 |
| (%) | 96.46 | 86.22 | 87.99 | 89.51 | 87.10 | 100 |
| 0.7968 | 0.8368 | 0.9103 | 0.9262 | 0.8914 | NaN | |
| 0.6287 | 0.6615 | 0.8005 | 0.8354 | 0.7614 | NaN | |
| AUROC | 0.8044 | 0.8322 | 0.8994 | 0.9165 | 0.8806 | 0.5 |
| (b) Training Set 2 | ||||||
| LDA | CART | C-ELM | C-ELMBG | RF | SVM | |
| 2948 | 4898 | 5087 | 5119 | 5120 | 5119 | |
| 4154 | 3147 | 3648 | 3697 | 3157 | 0 | |
| 108 | 1115 | 614 | 566 | 1105 | 4263 | |
| 2172 | 221 | 33 | 0 | 0 | 0 | |
| (%) | 75.7 | 85.76 | 93.11 | 93.97 | 88.23 | 54.57 |
| (%) | 57.58 | 95.68 | 99.37 | 100 | 100 | 100 |
| (%) | 97.47 | 73.83 | 85.59 | 86.73 | 74.08 | 0 |
| 0.7212 | 0.88 | 0.9402 | 0.9476 | 0.9026 | 0.706 | |
| 0.5849 | 0.7215 | 0.8663 | 0.8873 | 0.7806 | NaN | |
| AUROC | 0.7753 | 0.8476 | 0.9248 | 0.9336 | 0.8704 | 0.5 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haider Shah, S.W.; Iqbal, K.; Riaz, A.T. Constrained Optimization-Based Extreme Learning Machines with Bagging for Freezing of Gait Detection. Big Data Cogn. Comput. 2018, 2, 31. https://doi.org/10.3390/bdcc2040031
Haider Shah SW, Iqbal K, Riaz AT. Constrained Optimization-Based Extreme Learning Machines with Bagging for Freezing of Gait Detection. Big Data and Cognitive Computing. 2018; 2(4):31. https://doi.org/10.3390/bdcc2040031
Chicago/Turabian StyleHaider Shah, Syed Waqas, Khalid Iqbal, and Ahmad Talal Riaz. 2018. "Constrained Optimization-Based Extreme Learning Machines with Bagging for Freezing of Gait Detection" Big Data and Cognitive Computing 2, no. 4: 31. https://doi.org/10.3390/bdcc2040031
APA StyleHaider Shah, S. W., Iqbal, K., & Riaz, A. T. (2018). Constrained Optimization-Based Extreme Learning Machines with Bagging for Freezing of Gait Detection. Big Data and Cognitive Computing, 2(4), 31. https://doi.org/10.3390/bdcc2040031