


Evaluating Task-Level CPU Efficiency for Distributed Stream Processing Systems



Abstract
:1. Introduction
- One reason is the growing popularity of the “edge computing” paradigm. Edge computing involves the processing of data at the edge of a network and closer to the actual data sources. This is an important concept because the volume of generated raw data, usually in the context of IoT, can be too large to be transmitted to a cloud data center and also because the latency requirements of the business case can be too strict [7]. However, a challenge of this paradigm is the limited CPU resources of many edge devices. These devices are often constrained by factors such as size, power, and cost, which can limit the computational resources that are available for stream processing [8]. Therefore, ensuring CPU efficiency is critical because it allows these systems to make the most effective use of the limited CPU resources that are available [9].
- In addition, in the context of cloud computing, CPU efficiency becomes increasingly important [10]. As these systems often operate at scale to process large volumes of data and are based on a pay-per-use model, the operating cost can be significant. By ensuring that the CPU is used efficiently, it is possible to reduce the number of resources required to process a given workload and, in turn, achieve significant cost savings;
- Finally, improving CPU efficiency also results in reduced power consumption, which is a key concern nowadays because the production and use of electricity often cause the emission of greenhouse gases. Hence, optimizing CPU efficiency can help to mitigate the environmental impact of these systems [10].
- First, it is independent of the actual stream processing engine (SPE) being used, does not require proprietary APIs, and even supports DSPSs that are based on different programming languages (e.g., Java/C). Hence, it offers a single approach for multiple systems;
- Second, the measurement toolchain does not significantly impact performance or introduce overheads, which is an issue associated with traditional profiling and tracing approaches. Therefore, our approach is even applicable to production environments;
- Finally, this approach can be adapted and integrated into any DSPS as long as it is based on a recent Linux kernel (≥V3.18).
- We describe the conceptual basis of our approach and demonstrate how it can be integrated using the Yahoo Streaming Benchmark as an example. (YSB) [11];
- We provide open-source tool support for this approach;
- We evaluate the consistency of the yielded measurement results and the performance overheads of our approach and show that it can be used under high CPU load and in production environments without significantly distorting the results;
- We extensively demonstrate the potential of this approach by analyzing the task-level CPU efficiency of the three popular open source SPEs Apache Spark Structured Streaming (Spark STR), Apache Spark Continuous Processing (Spark CP), and Apache Flink (Flink) in various experiments.
2. Related Work
- We extend the concept to support distributed systems;
- We present the details of our technical implementation;
- We evaluate the consistency of the measurement results and the performance overheads of the approach;
- We integrate the prototype into an existing benchmark;
- We perform extensive experiments to analyze the performance of three open-source streaming frameworks;
- We provide our prototype open-source, including installation scripts that ease the setup.
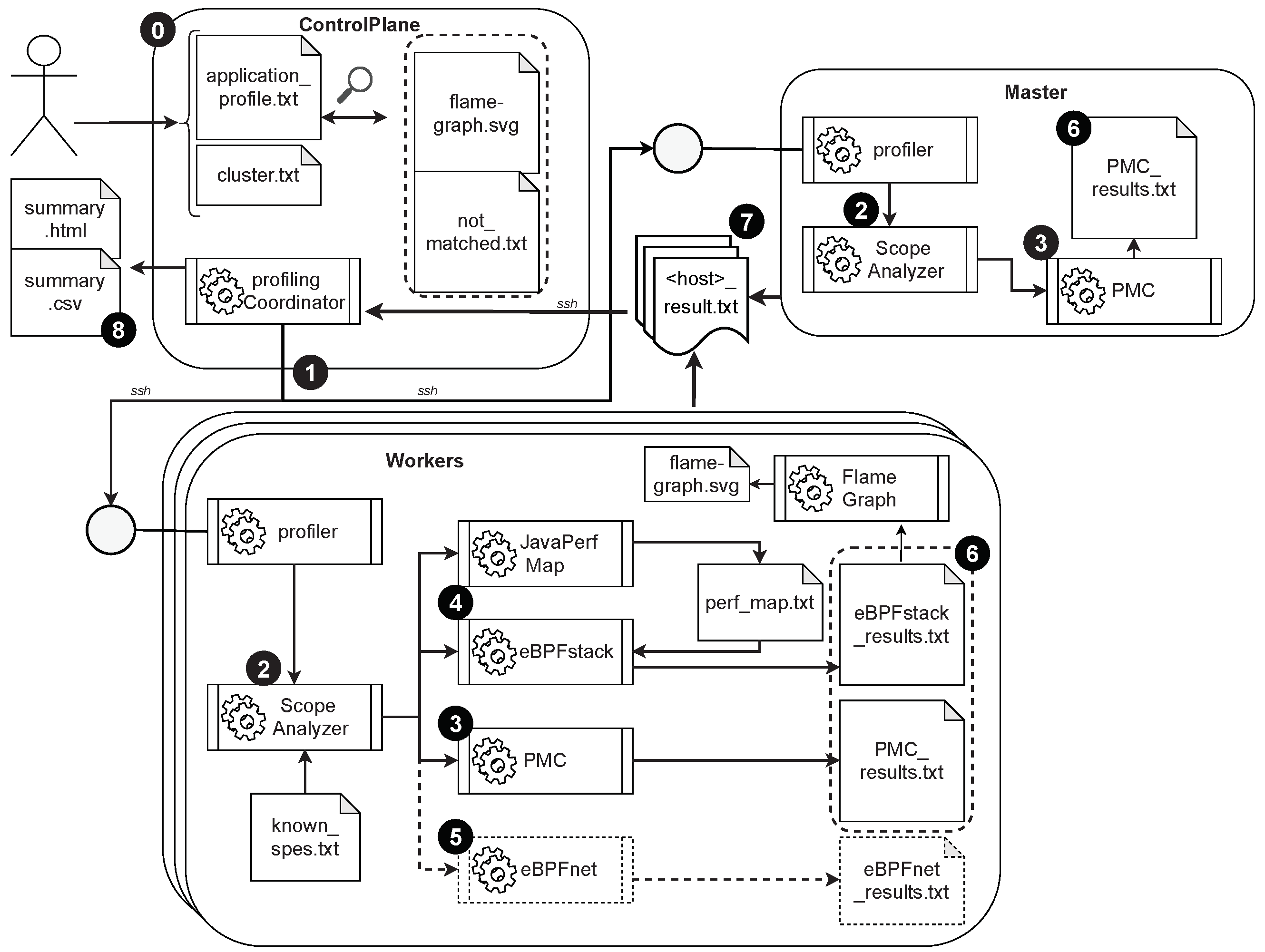
3. Task-Level Performance Measurement
3.1. Enabling Technologies
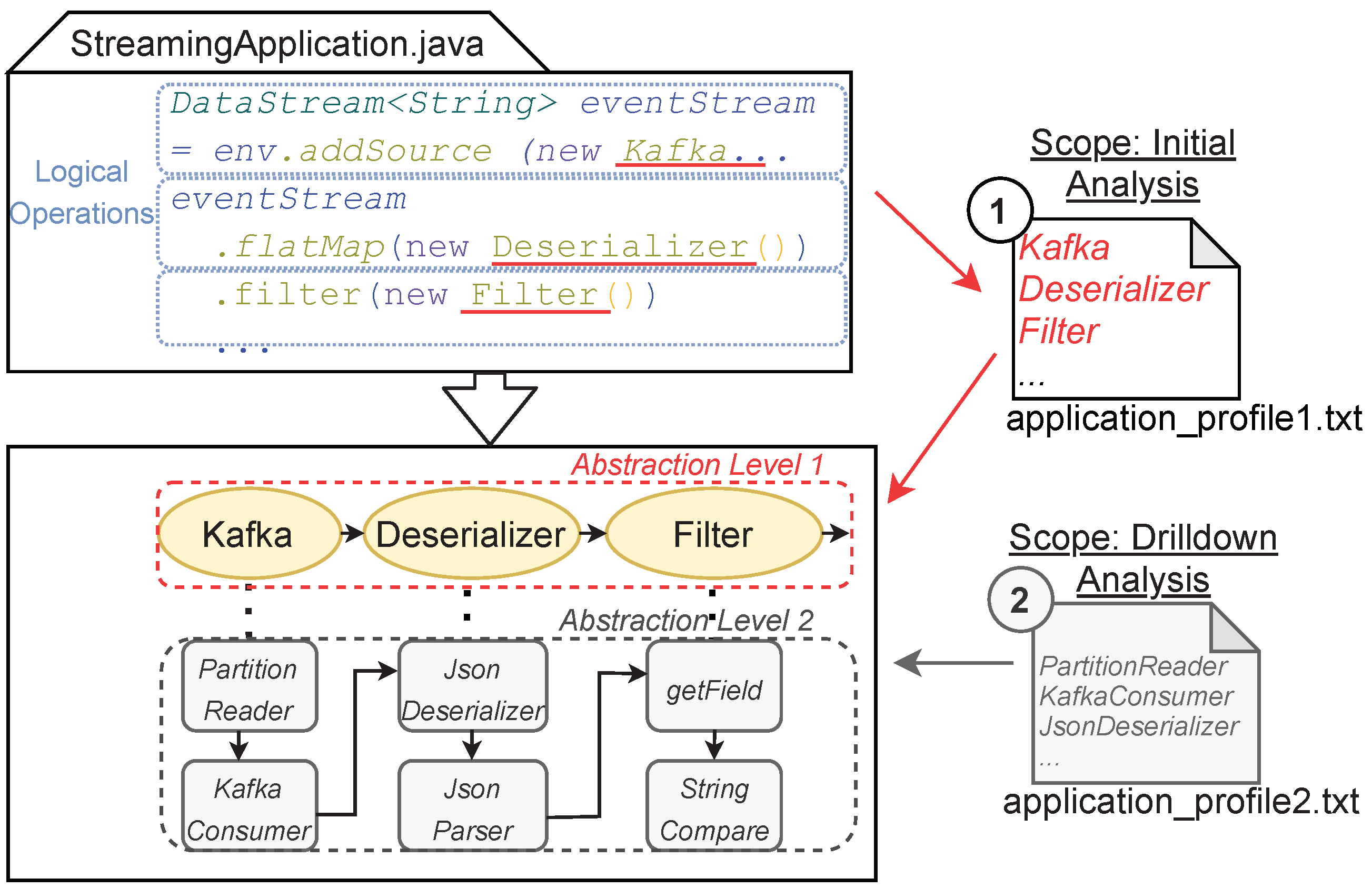
3.2. Conceptual Approach
3.3. Stack Trace Analysis
| Algorithm 1: Stack trace analysis to identify the code paths associated with each streaming task and aggregate the number of CPU cycles consumed for each task |
 |
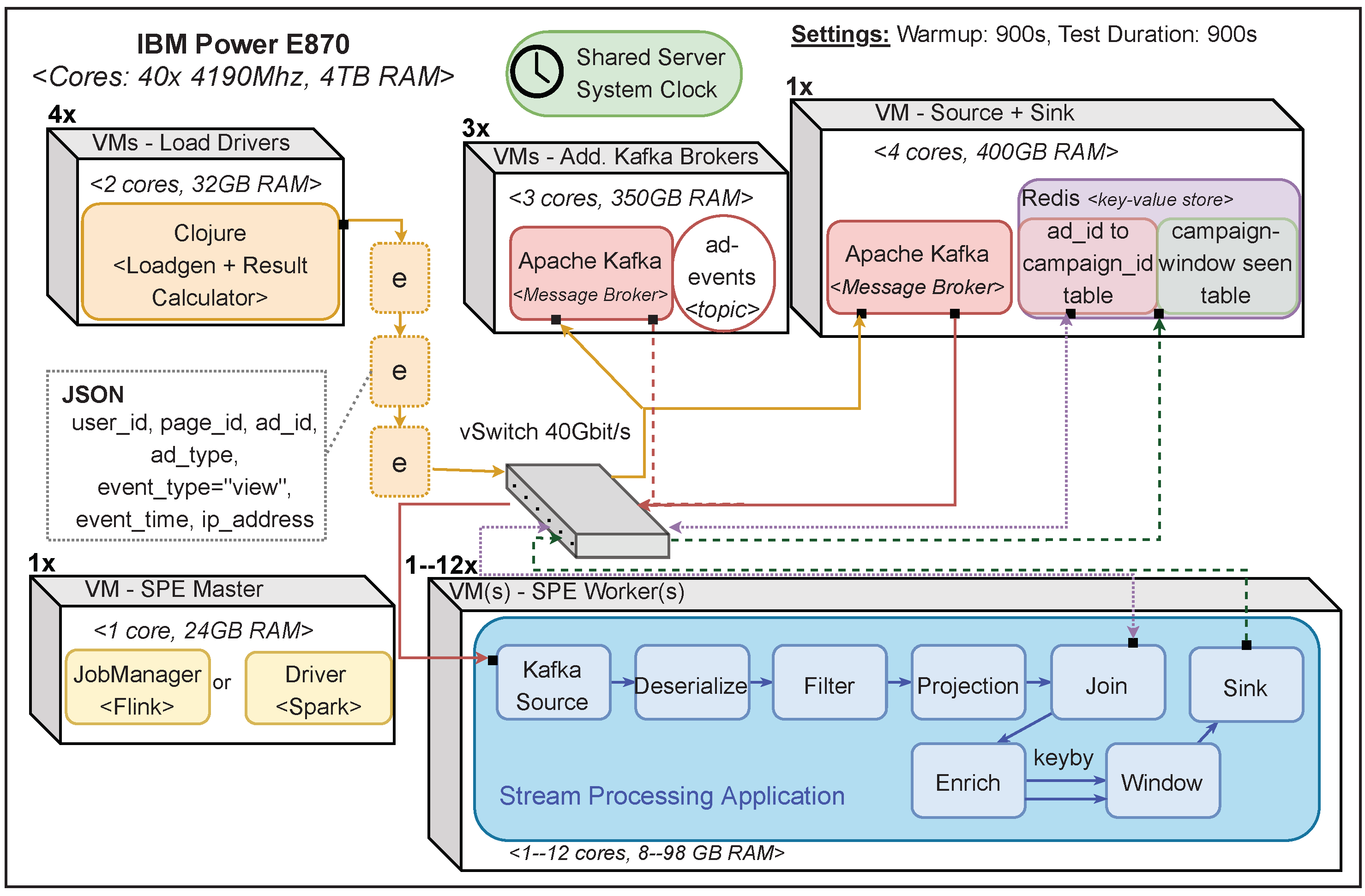
4. Testing Approach
4.1. YSB Extensions
4.2. Testbed
5. Approach Quality
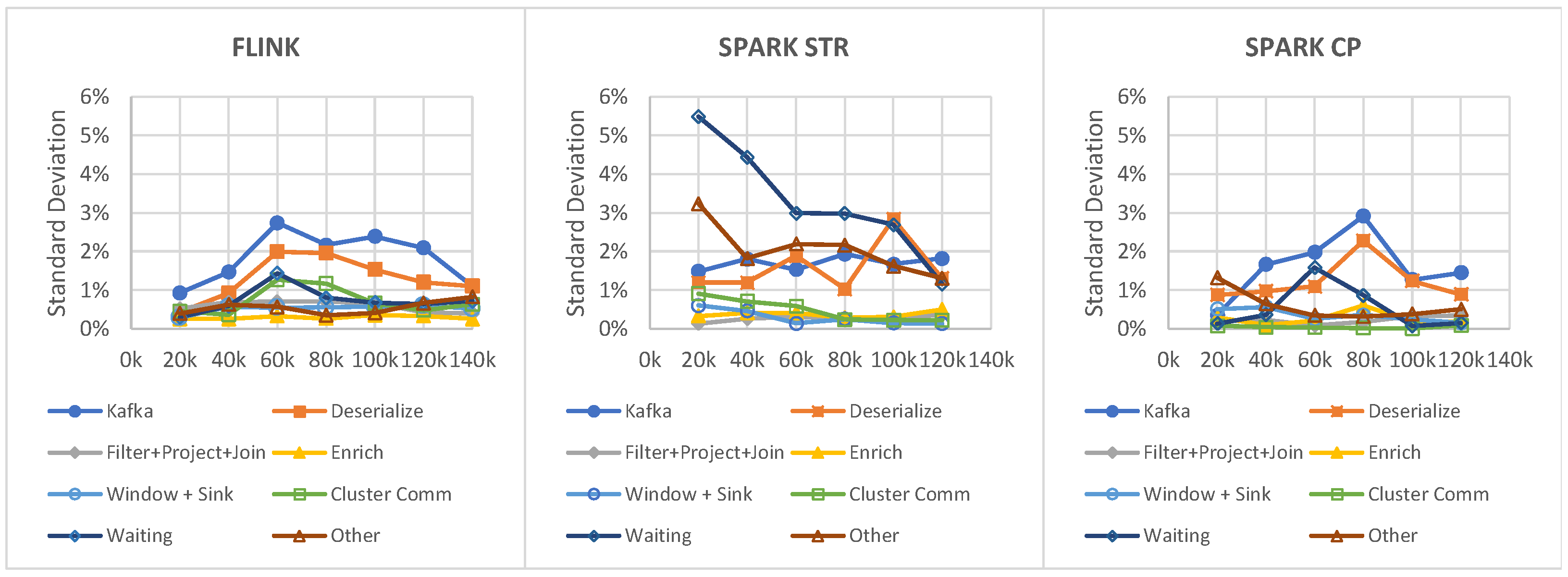
5.1. Profiling Overheads
5.2. Profiling Consistency
5.3. Advantages over Micro-Benchmarking
- First, our approach is not limited to testing a single isolated task but can be applied to complete application pipelines, providing a more comprehensive picture of system performance. This is particularly important in the context of distributed stream processing, where interactions between different tasks and components can have a significant impact on overall performance;
- Second, our approach is designed to be applied to already existing, potentially productive applications. This means that it can be used for monitoring and analysis purposes without the need for a dedicated performance testing environment;
- Third, the approach enables a more holistic picture of system performance by incorporating other context metrics. These include metrics such as IPC value or cache misses, which can provide valuable insights for root cause analysis. The approach manages to embed the measured performance in an overall context to better understand the performance of the streaming application;
- Fourth, our approach requires less effort than micro-benchmarking, as only a single run is required to analyze all tasks of the application. In contrast, micro-benchmarking requires individual measurement runs and customized application pipelines for each operation;
- Finally, our approach allows wide customization via the application profile. This way, developers can start at a higher level of abstraction and gradually refine the scope to gain more granular performance insights.
6. Evaluating Task-Level CPU Efficiency
- Load level: Configured as e/s and per node (10k steps; 10k–150k);
- SPEs: Flink, Spark STR, and Spark CP;
- Nodes: Number of worker nodes (1, 2, 4, 6, 12);
- CPUs: Number of cores per node (1, 2, 4, 6, 12);
- State: Number range of campaign_id (100, 1k, 2k, 4k, 8k, 16k).
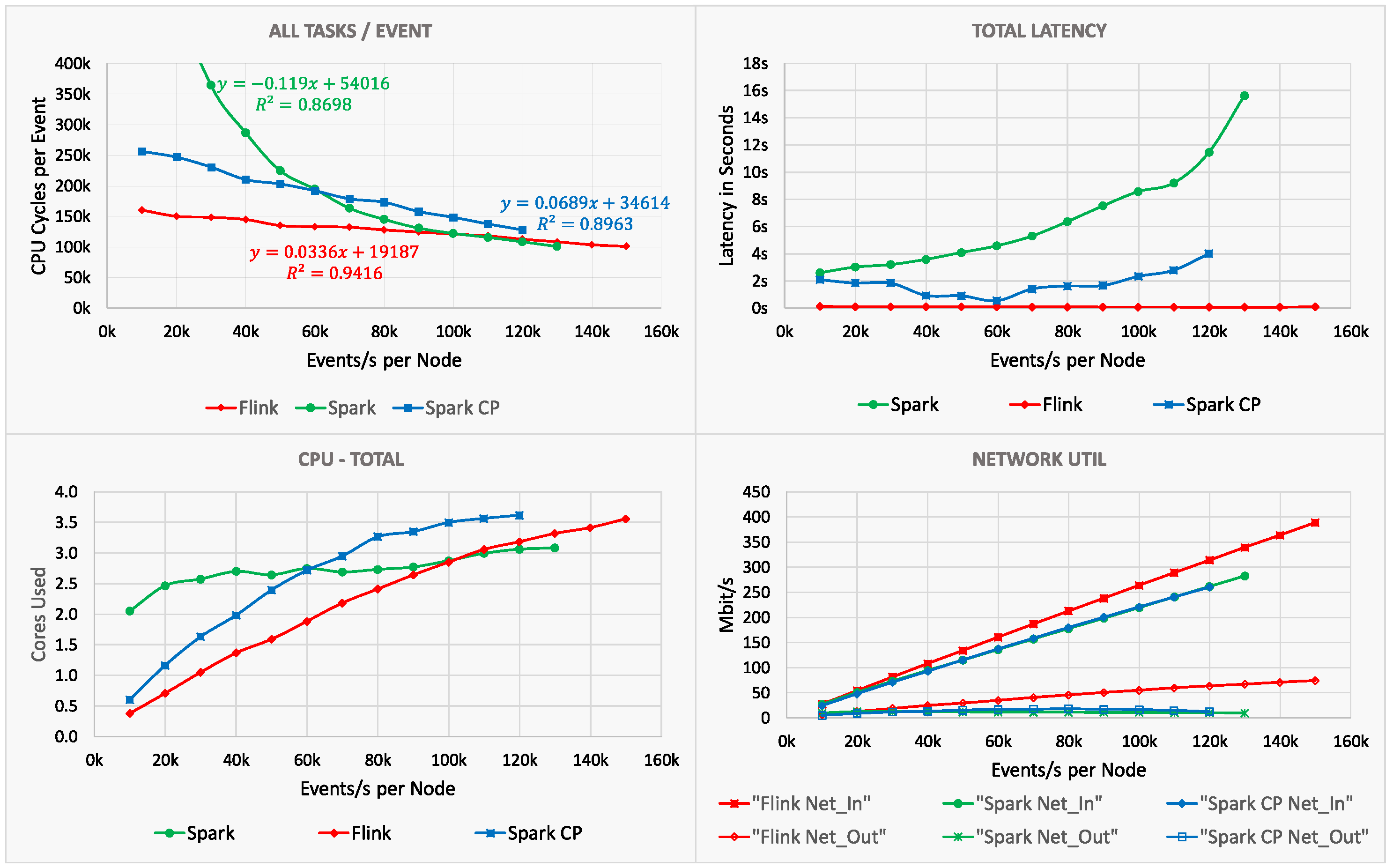
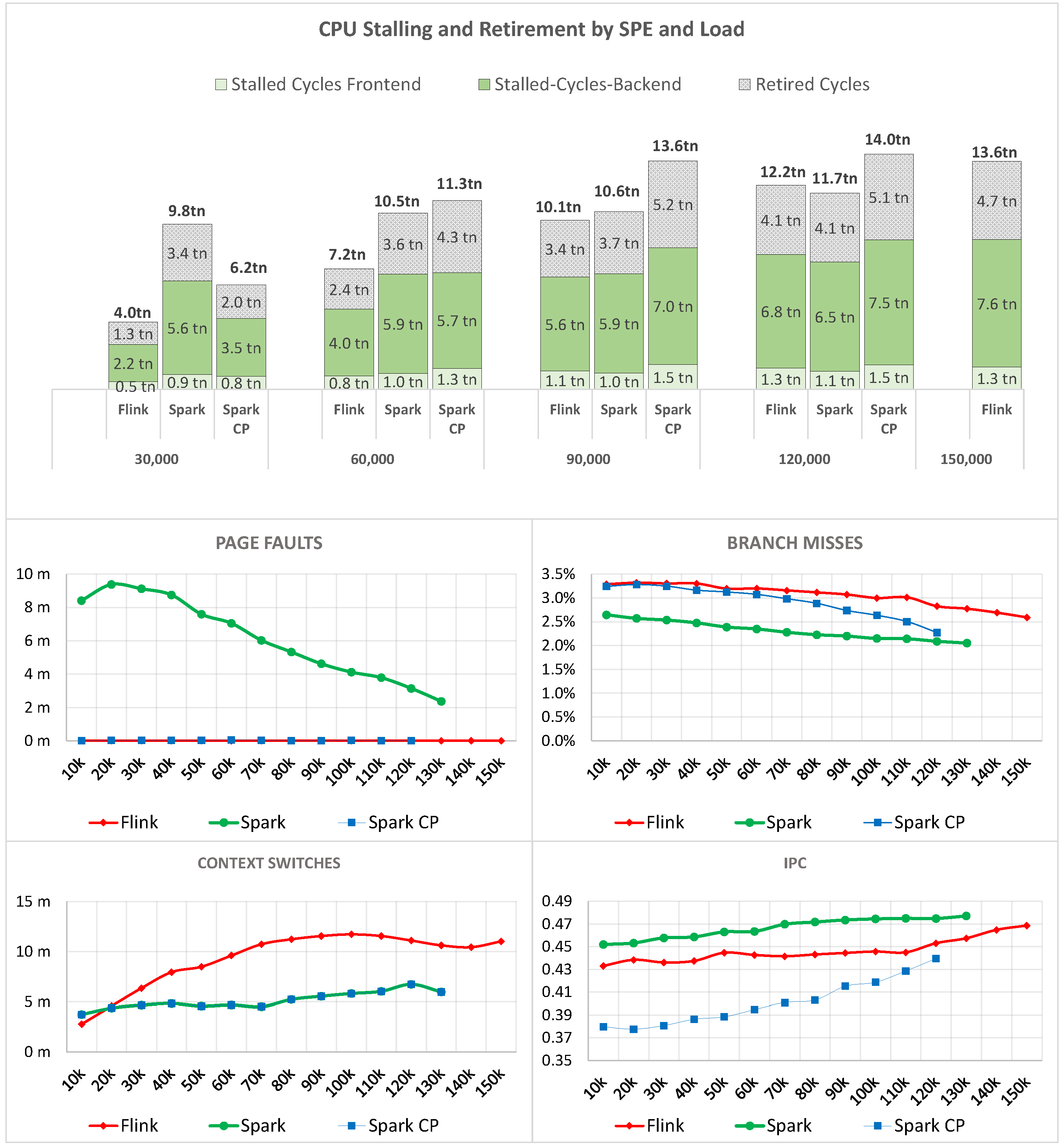
6.1. Load Scalability
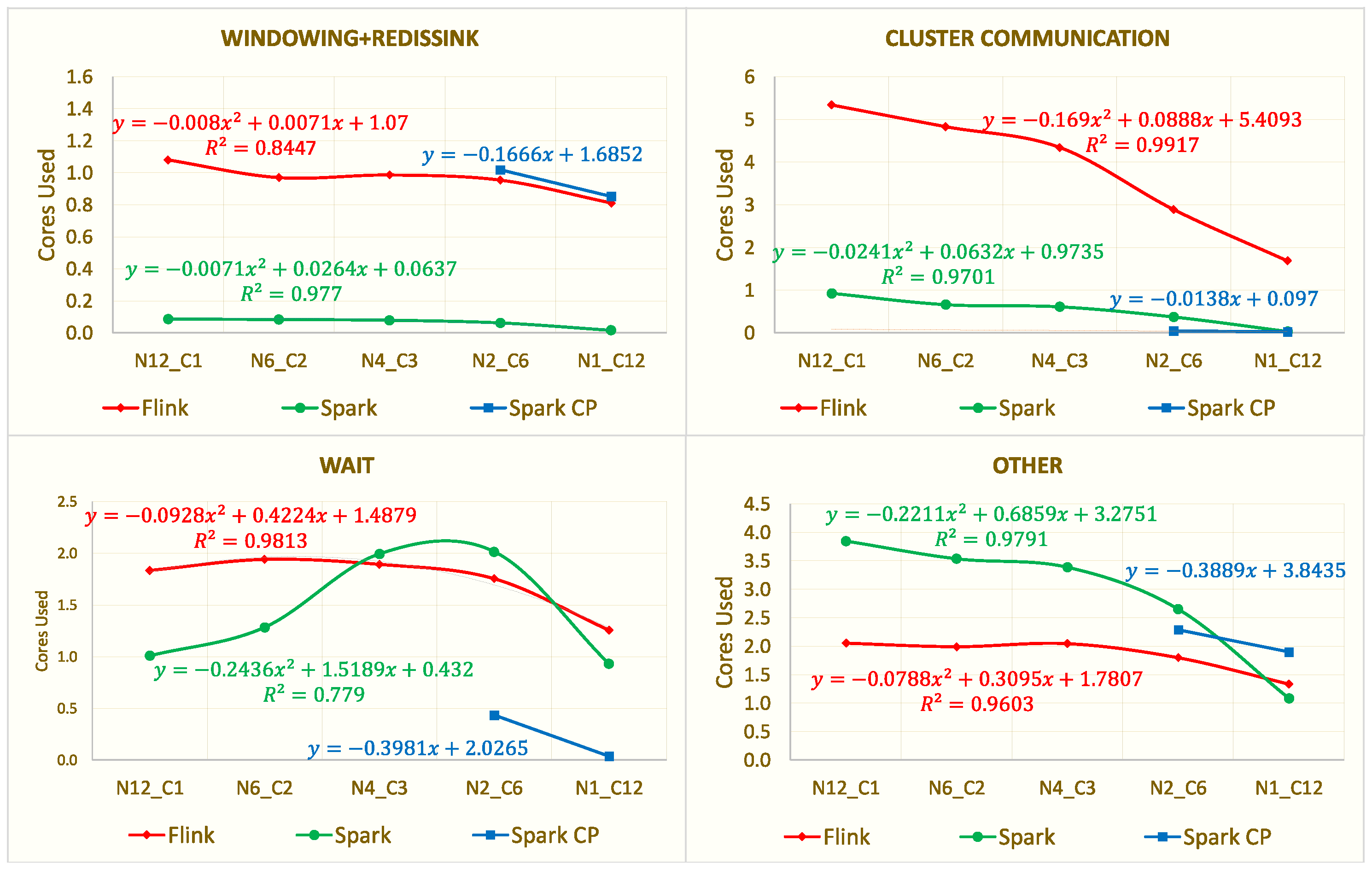
- Windowing: For Flink, the CPU costs remain constant, while, for Spark STR, it decreases. We explain this as follows. Despite the increased load, the number of windows is only affected by the range of campaign_ids (default: 100), which remains the same throughout the different load levels. Nevertheless, Flink has to process every event individually and hence does not benefit from any efficiency gains. Spark STR, on the other hand, increases its efficiency through its use of micro-batches, which leads to fewer window calculations (full evaluation function);
- Sink: The costs for both SPEs, Flink, and Spark STR decrease. This is again due to the number of windows that remain constant (1× window for each campaign_id every 10 s). These windows are in turn directly transformed into write operations. Hence, the actual number of events received by the Sink task is not determined by the load, but by the windows, which is always 10 e/s. In summary, the selectivity of the Windowing task also increases with increasing load levels [27], resulting in higher CPU efficiency for both frameworks.
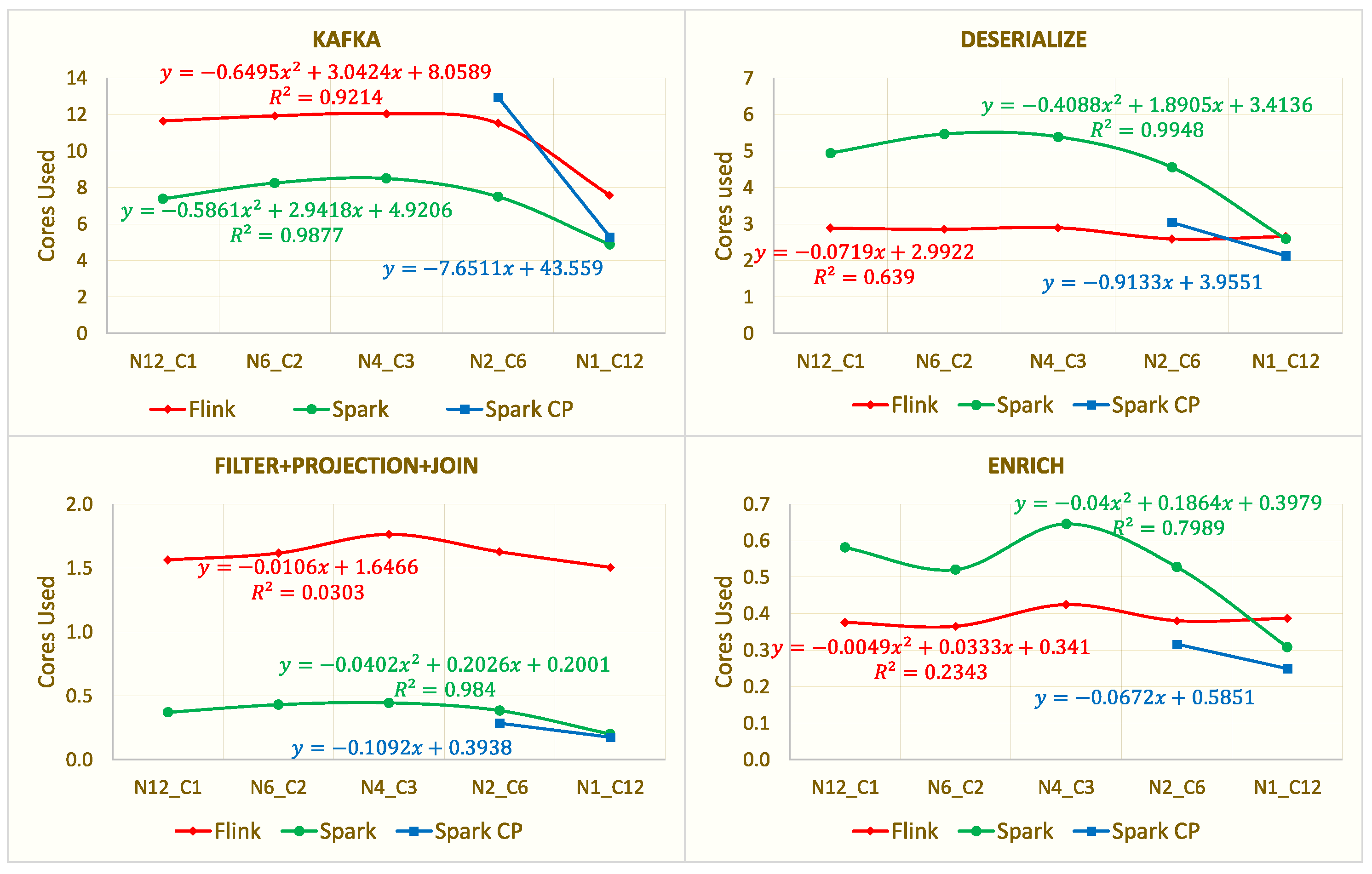
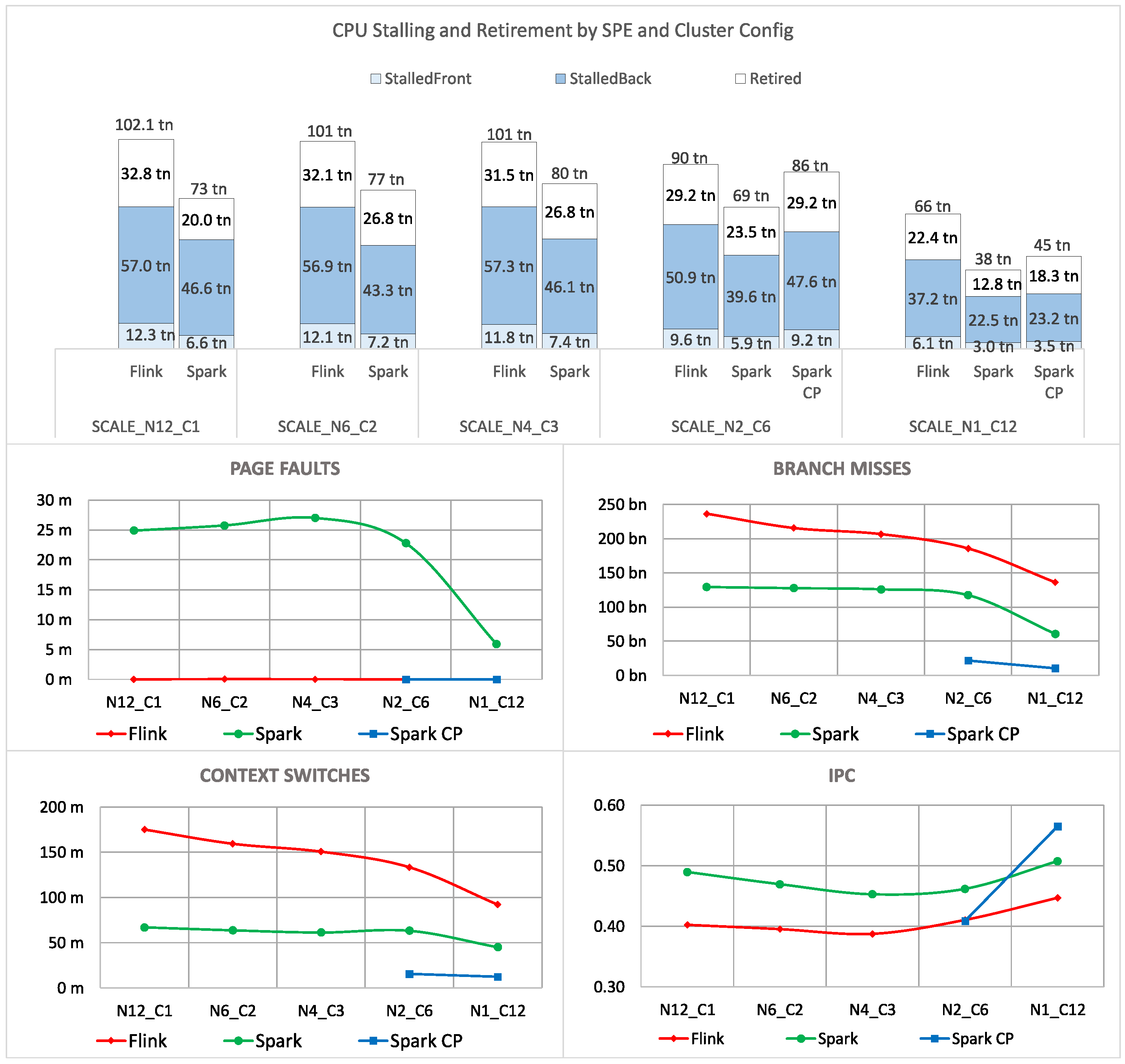
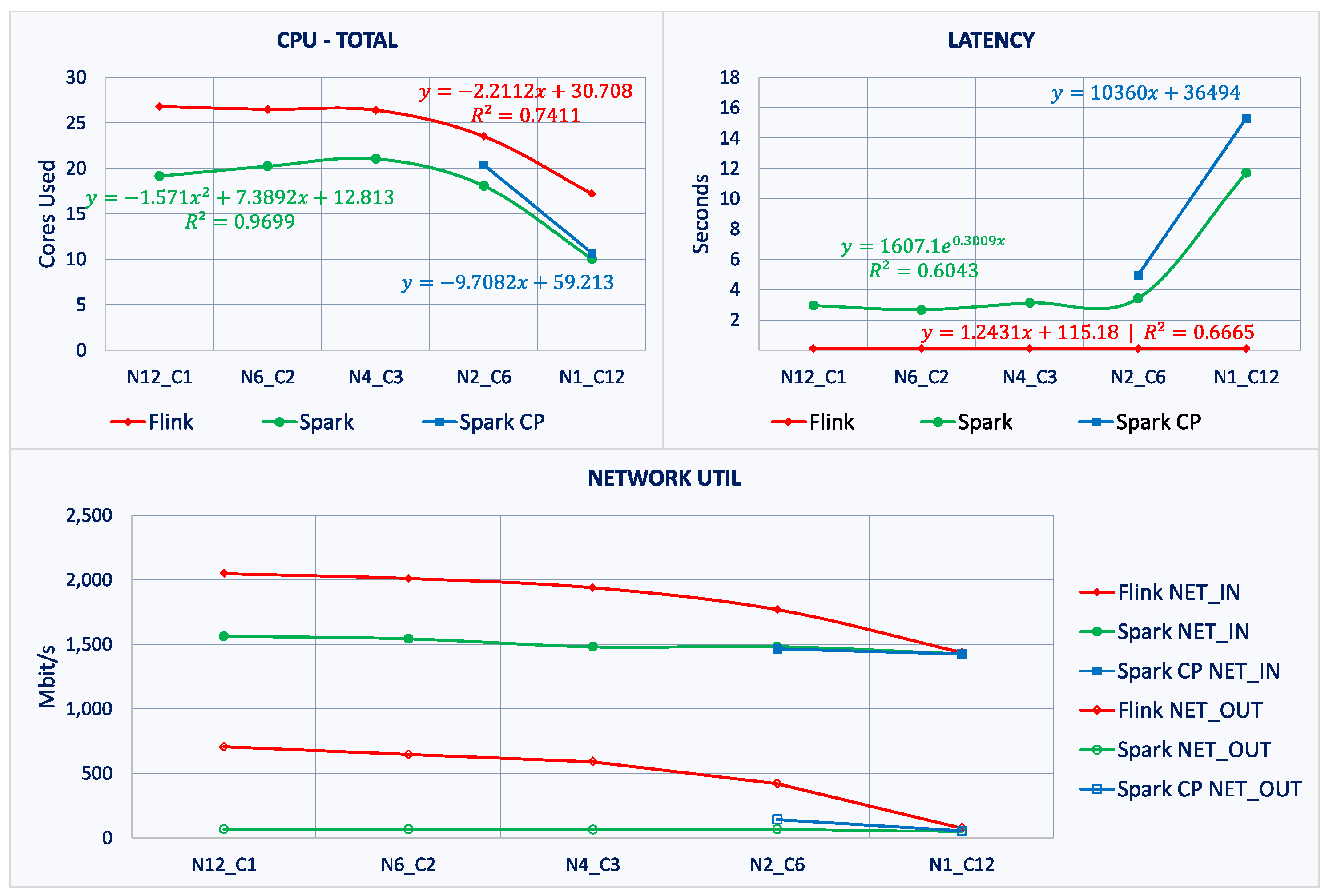
6.2. Scale-Up vs. Scale-Out
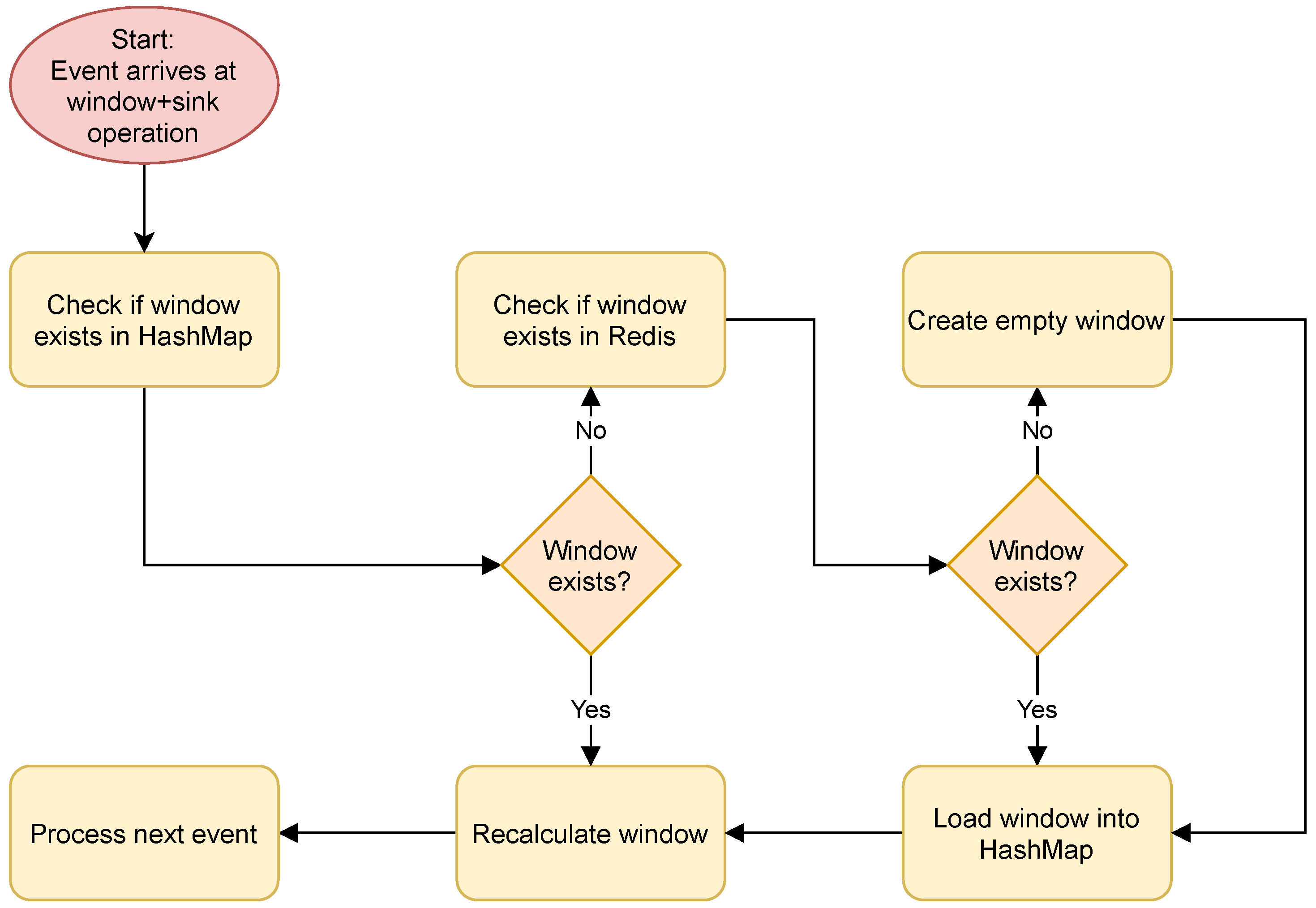
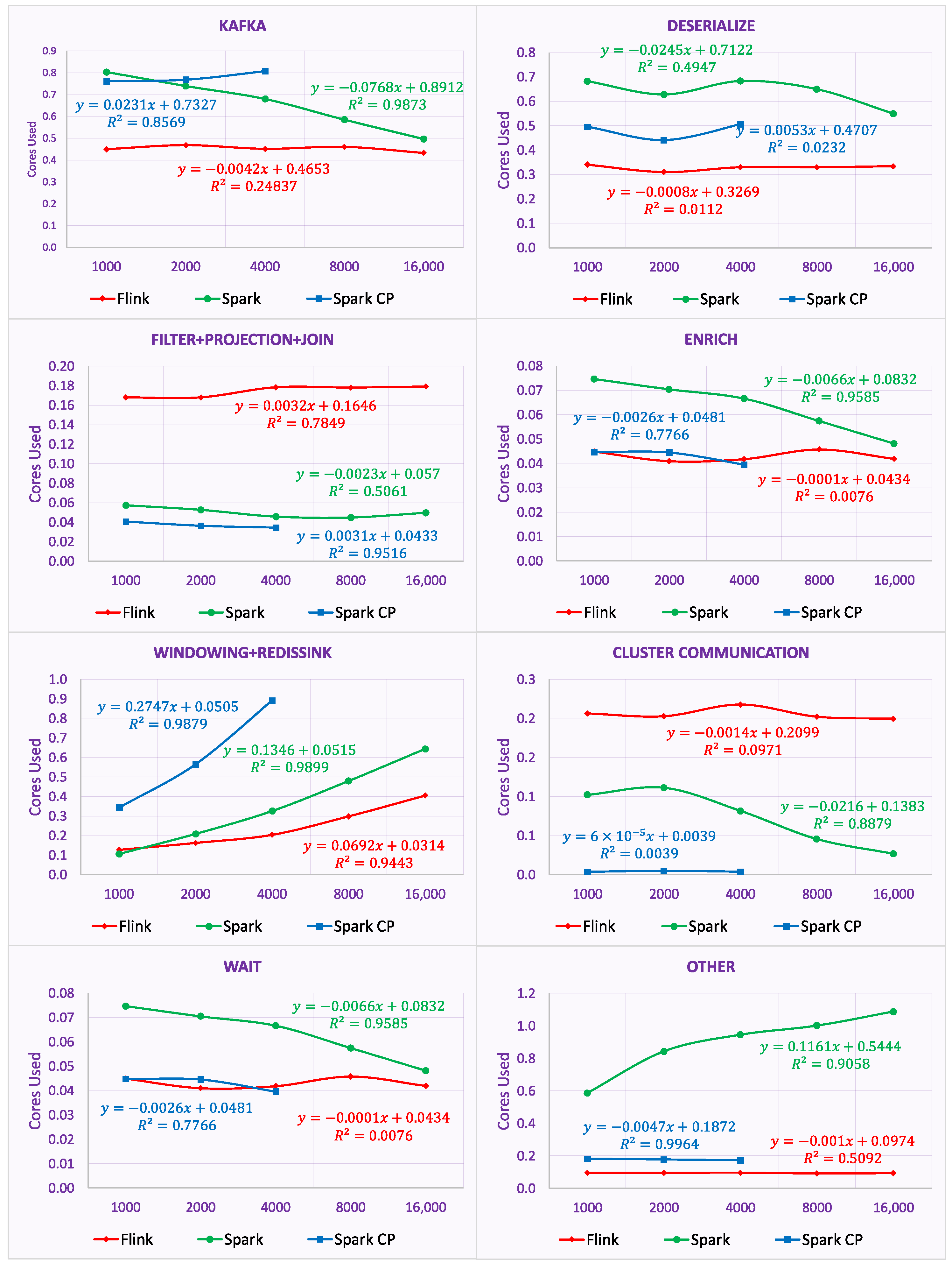
6.3. State Scalability
7. Conclusions
8. Limitations and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| DSPS | Distributed Stream Processing System |
| eBPF | Extended Berkley Package Filter |
| IoT | Internet of Things |
| LUW | Logical Unit of Work |
| PID | Process ID |
| PMC | Performance Monitoring Counters |
| YSB | Yahoo Streaming Benchmark |
| SLO | Service Level Objective |
| Spark CP | Spark Continuous Processing |
| Spark STR | Spark Structured Streaming |
| SPE | Stream Processing Engine |
References
- Jung, J.J. Special Issue Editorial: Big Data for Mobile Services. Mob. Netw. Appl. 2018, 23, 1080–1081. [Google Scholar] [CrossRef] [Green Version]
- Tan, L.; Wang, N.M. Future internet: The Internet of Things. In Proceedings of the 2010 3rd International Conference on Advanced Computer Theory and Engineering (ICACTE), Chengdu, China, 20–22 August 2010; Volume 5, pp. V5–376–V5–380. [Google Scholar]
- Apiletti, D.; Barberis, C.; Cerquitelli, T.; Macii, A.; Macii, E.; Poncino, M.; Ventura, F. iSTEP, an integrated Self-Tuning Engine for Predictive maintenance in Industry 4.0. In Proceedings of the 2018 IEEE International Conference on Big Data and Cloud Computing, Yonago, Japan, 12–13 July 2018; pp. 924–931. [Google Scholar]
- Umadevi, K.; Gaonka, A.; Kulkarni, R.; Kannan, R.J. Analysis of Stock Market using Streaming data Framework. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018; pp. 1388–1390. [Google Scholar] [CrossRef]
- Akram, S.; Bilas, A. A Sleep-based Communication Mechanism to Save Processor Utilization in Distributed Streaming Systems. In Proceedings of the Second Workshop on Computer Architecture and Operating SYSTEM Co-Design, Heraklion, Greece, 24–26 May 2011. [Google Scholar]
- Brunnert, A.; Vögele, C.; Danciu, A.; Pfaff, M.; Mayer, M.; Krcmar, H. Performance management work. Wirtschaftsinformatik 2014, 56, 197–199. [Google Scholar] [CrossRef]
- Kim, T.; Yoo, S.; Kim, Y. Edge/Fog Computing Technologies for IoT Infrastructure. Sensors 2021, 21, 3001. [Google Scholar] [CrossRef] [PubMed]
- Xhafa, F.; Kilic, B.; Krause, P. Evaluation of IoT stream processing at edge computing layer for semantic data enrichment. Future Gener. Comput. Syst. 2020, 105, 730–736. [Google Scholar] [CrossRef]
- Dhakal, A.; Kulkarni, S.G.; Ramakrishnan, K.K. Machine Learning at the Edge: Efficient Utilization of Limited CPU/GPU Resources by Multiplexing. In Proceedings of the 2020 IEEE 28th International Conference on Network Protocols (ICNP), Madrid, Spain, 13–16 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Abdallah, H.B.; Sanni, A.A.; Thummar, K.; Halabi, T. Online Energy-efficient Resource Allocation in Cloud Computing Data Centers. In Proceedings of the 2021 24th Conference on Innovation in Clouds, Internet and Networks and Workshops (ICIN), Paris, France, 1 March 2021; pp. 92–99. [Google Scholar]
- Chintapalli, S.; Dagit, D.; Evans, B.; Farivar, R.; Graves, T.; Holderbaugh, M.; Liu, Z.; Nusbaum, K.; Patil, K.; Peng, B.J.; et al. Benchmarking Streaming Computation Engines: Storm, Flink and Spark Streaming. In Proceedings of the 2016 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Chicago, IL, USA, 23–27 May 2016; pp. 1789–1792. [Google Scholar] [CrossRef]
- Grier, J. Extending the Yahoo! Streaming Benchmark. Available online: https://www.ververica.com/blog/extending-the-yahoo-streaming-benchmark (accessed on 8 December 2022).
- Karakaya, Z.; Yazici, A.; Alayyoub, M. A Comparison of Stream Processing Frameworks. In Proceedings of the 2017 International Conference on Computer and Applications (ICCA), Doha, United Arab Emirates, 6–7 September 2017; pp. 1–12. [Google Scholar] [CrossRef]
- Shahverdi, E.; Awad, A.; Sakr, S. Big Stream Processing Systems: An Experimental Evaluation. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering Workshops (ICDEW), Macao, Macao, 8–12 April 2019; pp. 53–60. [Google Scholar] [CrossRef]
- Karimov, J.; Rabl, T.; Katsifodimos, A.; Samarev, R.; Heiskanen, H.; Markl, V. Benchmarking Distributed Stream Data Processing Systems. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 1507–1518. [Google Scholar] [CrossRef] [Green Version]
- van Dongen, G.; Steurtewagen, B.; Van den Poel, D. Latency Measurement of Fine-Grained Operations in Benchmarking Distributed Stream Processing Frameworks. In Proceedings of the 2018 IEEE International Congress on Big Data (BigData Congress), San Francisco, CA, USA, 2–7 July 2018; pp. 247–250. [Google Scholar] [CrossRef]
- Van Dongen, G.; Van den Poel, D.E. Evaluation of Stream Processing Frameworks. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1845–1858. [Google Scholar] [CrossRef]
- Van Dongen, G.; Van Den Poel, D. Influencing Factors in the Scalability of Distributed Stream Processing Jobs. IEEE Access 2021, 9, 109413–109431. [Google Scholar] [CrossRef]
- Kroß, J.; Krcmar, H. PerTract: Model Extraction and Specification of Big Data Systems for Performance Prediction by the Example of Apache Spark and Hadoop. Big Data Cogn. Comput. 2019, 3, 47. [Google Scholar] [CrossRef] [Green Version]
- Reussner, R.H.; Becker, S.; Happe, J.; Heinrich, R.; Koziolek, A. Modeling and Simulating Software Architectures: The Palladio Approach; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Rank, J.; Hein, A.; Krcmar, H. A Dynamic Resource Demand Analysis Approach for Stream Processing Systems. In Proceedings of the Symposium on Software Performance, Leipzig, Germany, 5–6 November 2020. [Google Scholar]
- Gregg, B. BPF Performance Tools; Addison-Wesley Professional: Boston, MA, USA, 2019. [Google Scholar]
- Souza, P.R.R.D.; Matteussi, K.J.; Veith, A.D.S.; Zanchetta, B.F.; Leithardt, V.R.Q.; Murciego, A.L.; Freitas, E.P.D.; Anjos, J.C.S.D.; Geyer, C.F.R. Boosting Big Data Streaming Applications in Clouds With BurstFlow. IEEE Access 2020, 8, 219124–219136. [Google Scholar] [CrossRef]
- EJ-Technologies. Java Profiler-JProfiler. Available online: https://www.ej-technologies.com/products/jprofiler/overview.html (accessed on 30 December 2022).
- Jain, R. The Art of Computer Systems Performance Analysis: Techniques for Experimental Design, Measurement, Simulation, and Modeling; Wiley Professional Computing; Wiley: Hoboken, NJ, USA, 1991. [Google Scholar]
- Nabi, Z.; Bouillet, E.; Bainbridge, A.; Thomas, C. of Streams and Storms a Direct Comparison of IBM InfoSphere Streams and Apache Storm in a Real World Use Case. IBM White Paper 2014. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=c82f170fbc837291d94dc0a18f0223d182144339 (accessed on 6 December 2022).
- Shukla, A.; Chaturvedi, S.; Simmhan, Y. Riotbench: An iot benchmark for distributed stream processing systems. Concurr. Comput. Pract. Exp. 2017, 29, e4257. [Google Scholar] [CrossRef] [Green Version]
- Hesse, G.; Matthies, C.; Perscheid, M.; Uflacker, M.; Plattner, H. ESPBench: The Enterprise Stream Processing Benchmark. In Proceedings of the ACM/SPEC International Conference on Performance Engineering, Virtual, 19–23 April 2021; pp. 201–212. [Google Scholar] [CrossRef]
- Abadi, D.J.; Carney, D.; Çetintemel, U.; Cherniack, M.; Convey, C.; Lee, S.; Stonebraker, M.; Tatbul, N.; Zdonik, S. Aurora: A new model and architecture for data stream management. VLDB J. 2003, 12, 120–139. [Google Scholar] [CrossRef]
- Abadi, D.J.; Ahmad, Y.; Balazinska, M.; Cetintemel, U.; Cherniack, M.; Hwang, J.H.; Lindner, W.; Maskey, A.; Rasin, A.; Ryvkina, E.; et al. The design of the borealis stream processing engine. In Proceedings of the Cidr, Asilomar, CA, USA, 4–7 January 2005; Volume 5, pp. 277–289. [Google Scholar]
- Kruber, N. A Deep-Dive into Flink’s Network Stack. Available online: https://flink.apache.org/2019/06/05/flink-network-stack.html (accessed on 7 September 2022).
- Chatzopoulos, G.; Dragojević, A.; Guerraoui, R. ESTIMA: Extrapolating Scalability of in-Memory Applications. In Proceedings of the 21st ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP), Barcelona, Spain, 12–16 March 2016. [Google Scholar] [CrossRef] [Green Version]
- Hill, M.D. What is Scalability? SIGARCH Comput. Archit. News 1990, 18, 18–21. [Google Scholar] [CrossRef] [Green Version]
- Hwang, K.; Shi, Y.; Bai, X. Scale-Out vs. Scale-Up Techniques for Cloud Performance and Productivity. In Proceedings of the 2014 IEEE 6th International Conference on Cloud Computing Technology and Science, Singapore, 15–18 December 2014; pp. 763–768. [Google Scholar] [CrossRef]
- Awan, A.J.; Brorsson, M.; Vlassov, V.; Ayguade, E. How Data Volume Affects Spark Based Data Analytics on a Scale-up Server. In Proceedings of the Big Data Benchmarks, Performance Optimization, and Emerging Hardware; Zhan, J., Han, R., Zicari, R.V., Eds.; Springer International Publishing: Basel, Swizterland, 2016; pp. 81–92. [Google Scholar]
- McSherry, F.; Isard, M.; Murray, D.G. Scalability! However, at what COST? In Proceedings of the 15th Workshop on Hot Topics in Operating Systems (HotOS XV), Kartause Ittingen, Switzerland, 18–20 May 2015; USENIX Association: Kartause Ittingen, Switzerland, 2015. [Google Scholar]
- De Matteis, T.; Mencagli, G. Parallel patterns for window-based stateful operators on data streams: An algorithmic skeleton approach. Int. J. Parallel Program. 2017, 45, 382–401. [Google Scholar] [CrossRef] [Green Version]
- To, Q.C.; Soto, J.; Markl, V. A survey of state management in big data processing systems. VLDB J. 2018, 27, 847–872. [Google Scholar] [CrossRef] [Green Version]
- Del Monte, B.; Zeuch, S.; Rabl, T.; Markl, V. Rhino: Efficient Management of Very Large Distributed State for Stream Processing Engines. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 4–19 June 2020; SIGMOD ’20. Association for Computing Machinery: New York, NY, USA, 2020; pp. 2471–2486. [Google Scholar] [CrossRef]
- Kroß, J.; Krcmar, H. Modeling and simulating Apache Spark streaming applications. Softw.-Trends 2016, 36, 1–3. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AVG_LAT | AVG_PRE_WNDW | Processed Events | CPU-Util | ||
|---|---|---|---|---|---|
| Flink | No Profiling | 80.1 | 1.2 | 134,892,334 | 89.0% |
| BPF Profiling | 83.3 | 1.0 | 134,896,023 | 90.8% | |
| Diff-BPF | 3.1 | −0.2 | 3690 | 1.8% | |
| JPROFILER | 75,978.8 | 75,276.7 | 102,057,612 | 76.9% | |
| Diff-JPROF | 75,898.7 | 75,275.5 | −32,834,722 | −0.1 | |
| Spark STR | No Profiling | 9661.8 | 6100.7 | 107,898,950 | 80.4% |
| BPF Profiling | 11,472.6 | 7497.4 | 107,941,936 | 77.8% | |
| Diff-BPF | 1810.8 | 1396.7 | 42,986 | −2.6% | |
| JPROFILER | 15,364.9 | 9935.9 | 108,028,000 | 75.3% | |
| Diff-JPROF | 5703.1 | 3835.2 | 129,050 | −5.1% | |
| Spark CP | No Profiling | 2784.1 | 5.5 | 107,908,636 | 91.8% |
| BPF Profiling | 2852.7 | 8.3 | 107,791,544 | 92.0% | |
| Diff-BPF | 68.6 | 2.9 | −117,092 | 0.2% | |
| JPROFILER | 106,657.0 | 97,112.4 | 80,136,000 | 92.0% | |
| Diff-JPROF | 103,872.9 | 97,106.9 | −27,772,636 | 0.2% | |
| FLINK | SPARK_STR | SPARK_CP | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LOAD | LAT | WNDW | EVENTS | CPU | LAT | WNDW | EVENTS | CPU | LAT | WNDW | EVENTS | CPU |
| 20,000 | 20.4 | 0.5 | 1399 | 0.1% | 176.8 | 10.8 | 1673 | 0.3% | 908.6 | 0.1 | 1089 | 0.1% |
| 40,000 | 7.8 | 0.0 | 3744 | 0.8% | 69.9 | 34.8 | 5021 | 0.1% | 777.4 | 1.2 | 2887 | 0.8% |
| 60,000 | 9.9 | 0.0 | 9773 | 3.0% | 119.7 | 30.8 | 5170 | 0.2% | 454.9 | 2.3 | 410 | 3.0% |
| 80,000 | 4.5 | 0.7 | 8106 | 3.5% | 238.3 | 56.4 | 15,485 | 0.1% | 124.3 | 0.1 | 8485 | 3.5% |
| 100,000 | 2.8 | 0.1 | 11,150 | 3.2% | 496.4 | 128.0 | 6583 | 0.2% | 237.1 | 4.5 | 13,165 | 3.2% |
| 120,000 | 6.6 | 0.6 | 21,167 | 4.2% | 404.4 | 212.0 | 13,161 | 0.2% | 539.0 | 48.3 | 5111 | 4.2% |
| 140,000 | 3.4 | 0.8 | 14,594 | 4.5% | - | - | - | - | - | - | - | - |
| Experiment | Analysis | FLINK | SPARK STR | SPARK CP |
|---|---|---|---|---|
| Total | - CPU efficiency: Highest → low+mid High → high - Latency: Lowest → all - Network util.: Highest → all | - CPU efficiency: Poor → low+mid Highest → high - Latency: High → all - Network util.: Low → all | - CPU efficiency: Poor → high load High → low+mid - Latency: Low → all - Network util.: Low → all | |
| Load Scalability (low→ high) | Task- Level | - Highest CPU efficiency: Deserialize, Enrich, Sink, Framework | - Highest CPU efficiency: ClusterComm., Windowing | - Highest CPU efficiency: Filter+Projection+Join - Kafka: High CPU demand → improvement required |
| Total | - CPU efficiency: Highest → single-node - Latency: Not affected | - CPU efficiency: Lowest → single node - Latency: Poor → single-node → scale-out recommended | - CPU efficiency: Highest → single-node - Latency: Poor → single node → scale-out recommended | |
| Scale-up vs. Scale-out (single→ 12) | Task- Level | - ClusterComm.: Significant CPU efficiency decrease - Kafka: Highest efficiency for single-node; Stable for multi-node - Remaining tasks: Stable | - ClusterComm.: Minor linear efficiency increase - Windowing+Sink: Stable - Remaining tasks: Highest efficiency for single-node; Increasing efficiency for large cluster | - All tasks: Highest efficiency for single-node |
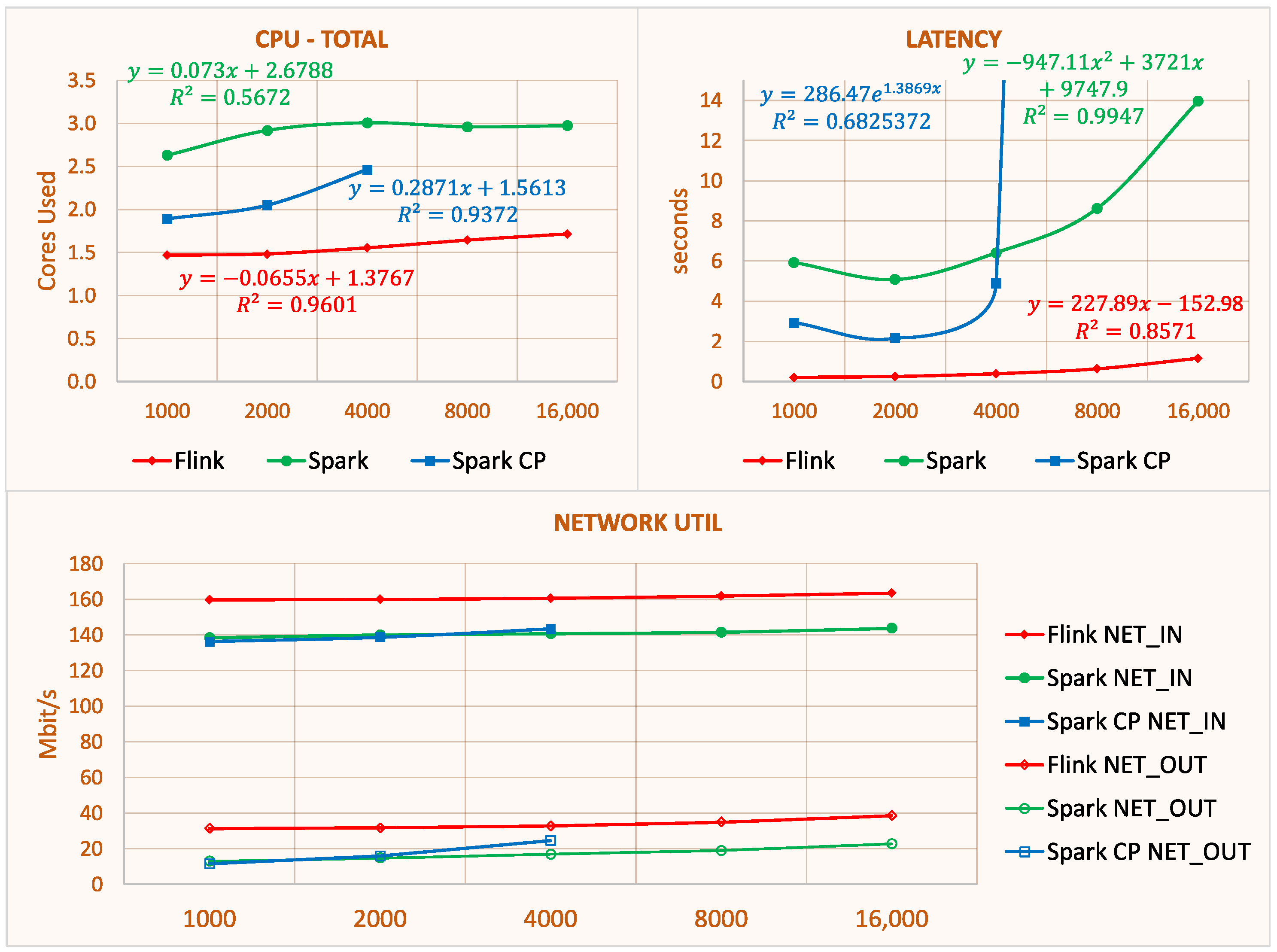
| Total | - CPU efficiency: Slightly decreases - Latency: Slightly increases - Network util.: Slightly increases | - CPU efficiency: Slightly decreses until 4k; Afterwards constant at cost of higher latency - Latency: Rapidly increases after 4k - Network util.: Slightly increases | - CPU efficiency: Decreases - Latency: Slightly increases until 4k; Unsustainable afterwards -Network util.: Slightly increases | |
| State Scalability (1k → 16k) | Task- Level | - Windowing+Sink: CPU efficiency decreases - Remaining tasks: Stable | - Windowing+Sink: CPU efficiency decreases | - Windowing+Sink: CPU efficiency decreases |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rank, J.; Herget, J.; Hein, A.; Krcmar, H. Evaluating Task-Level CPU Efficiency for Distributed Stream Processing Systems. Big Data Cogn. Comput. 2023, 7, 49. https://doi.org/10.3390/bdcc7010049
Rank J, Herget J, Hein A, Krcmar H. Evaluating Task-Level CPU Efficiency for Distributed Stream Processing Systems. Big Data and Cognitive Computing. 2023; 7(1):49. https://doi.org/10.3390/bdcc7010049
Chicago/Turabian StyleRank, Johannes, Jonas Herget, Andreas Hein, and Helmut Krcmar. 2023. "Evaluating Task-Level CPU Efficiency for Distributed Stream Processing Systems" Big Data and Cognitive Computing 7, no. 1: 49. https://doi.org/10.3390/bdcc7010049
APA StyleRank, J., Herget, J., Hein, A., & Krcmar, H. (2023). Evaluating Task-Level CPU Efficiency for Distributed Stream Processing Systems. Big Data and Cognitive Computing, 7(1), 49. https://doi.org/10.3390/bdcc7010049