

DSpamOnto: An Ontology Modelling for Domain-Specific Social Spammers in Microblogging



Abstract
:1. Introduction
2. Related Works
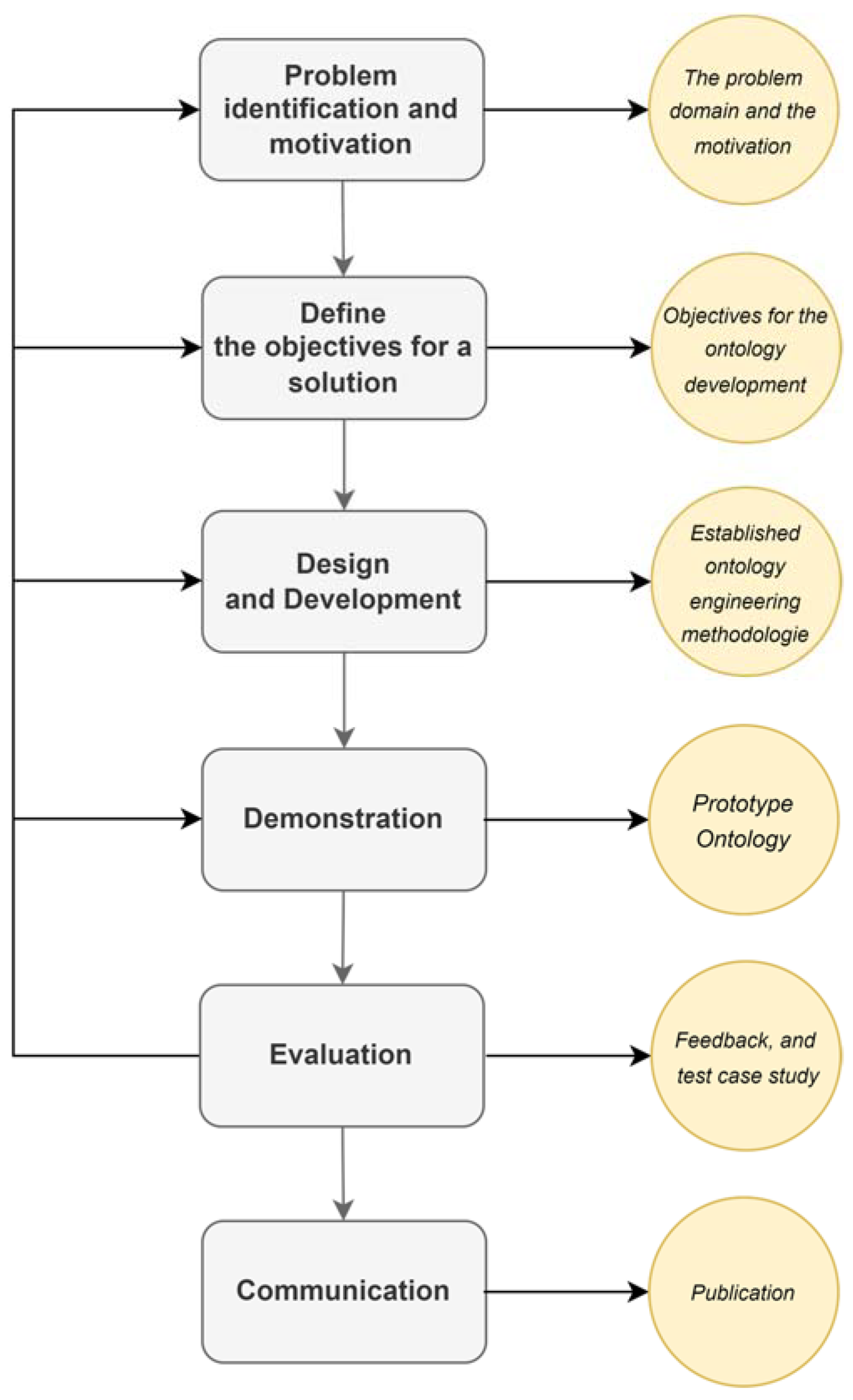
3. Research Methodology
- 1.
- Problem identification and motivation: This involves identifying and defining the problem that the research aims to solve. This activity is critical because it sets the stage for the entire research process, including the subsequent activities involved in designing and developing a solution to the problem. Relevant activities include:
- An analysis of the literature is conducted to find ontologies that are relevant to domain-specific social spam.
- The literature exposes a deficiency of ontologies that conceptualise domain-based social spam. The current social spam ontologies are only able to conceptualise generic-based social spammers.
- 2.
- Define the objectives for a solution: This involves formulating a clear and concise set of objectives for the proposed solution. The objectives are derived from the problem identification and motivation activity and aim to guide the design and development of the artifact. Relevant activities include:
- This study aims to develop a proof-of-concept domain-specific social spam ontology that integrates the key entities and concepts that capture social spammers and their domain-specific behaviour.
- Identify the key concepts and relationships relevant to domain-specific social spam, such as the types of spam messages and the strategies used by spammers to target specific domains.
- 3.
- Design and Development: This entails creating an artifact or solution to address the problem identified in the earlier activities. This activity requires the researcher to use existing theories, frameworks, and best practices to design and develop the artifact that meets the objectives set in the previous activity. Relevant activities include:
- Design and develop the ontology using established ontology engineering methodologies, such as the NeOn methodology or the Methodology framework, and by following established best practices and design patterns.
- This phase will create an artifact in the form of an ontology (DSpamOnto).
- The ontology’s elements, such as its concepts (classes), attributes (properties), restrictions (facets), and instances (individuals), will be identified by examining academic and technical sources.
- The software Protégé is utilized to create the ontological depiction of the elements of the ontology.
- 4.
- Demonstration: This includes showcasing and evaluating the developed artifact to stakeholders and experts to demonstrate its effectiveness and utility in solving the identified problem. Relevant activities include:
- To demonstrate the proposed methodology, a prototype ontology is developed as a proof-of-concept. The ontology’s ability to provide a better comprehension of the social spammer’s behaviours.
- To demonstrate the effectiveness of the ontology by applying it to real-world use cases and scenarios, such as analysing social media data for domain-specific spam or evaluating the effectiveness of different spam detection algorithms.
- 5.
- Evaluation: The goal of this activity is to determine whether the developed artifact meets the objectives set in the earlier activities and provides a satisfactory solution to the identified problem. The evaluation process can take different forms, such as a user study, a controlled experiment, or a case study. Relevant activities include:
- Evaluate the effectiveness of the ontology and its impact on the domain of interest by conducting empirical studies, surveys, or other types of evaluation and feedback mechanisms.
- Various evaluation metrics are integrated to evaluate ontology.
- 6.
- Communication: It involves disseminating the research findings, knowledge, and insights gained from the design and development of the artifact to the wider community of stakeholders, including academics, practitioners, and researchers. Relevant activities include:
- This manuscript discusses information regarding the need for, the design approach of, and usefulness of the developed artifact, facilitating the exchange of information.
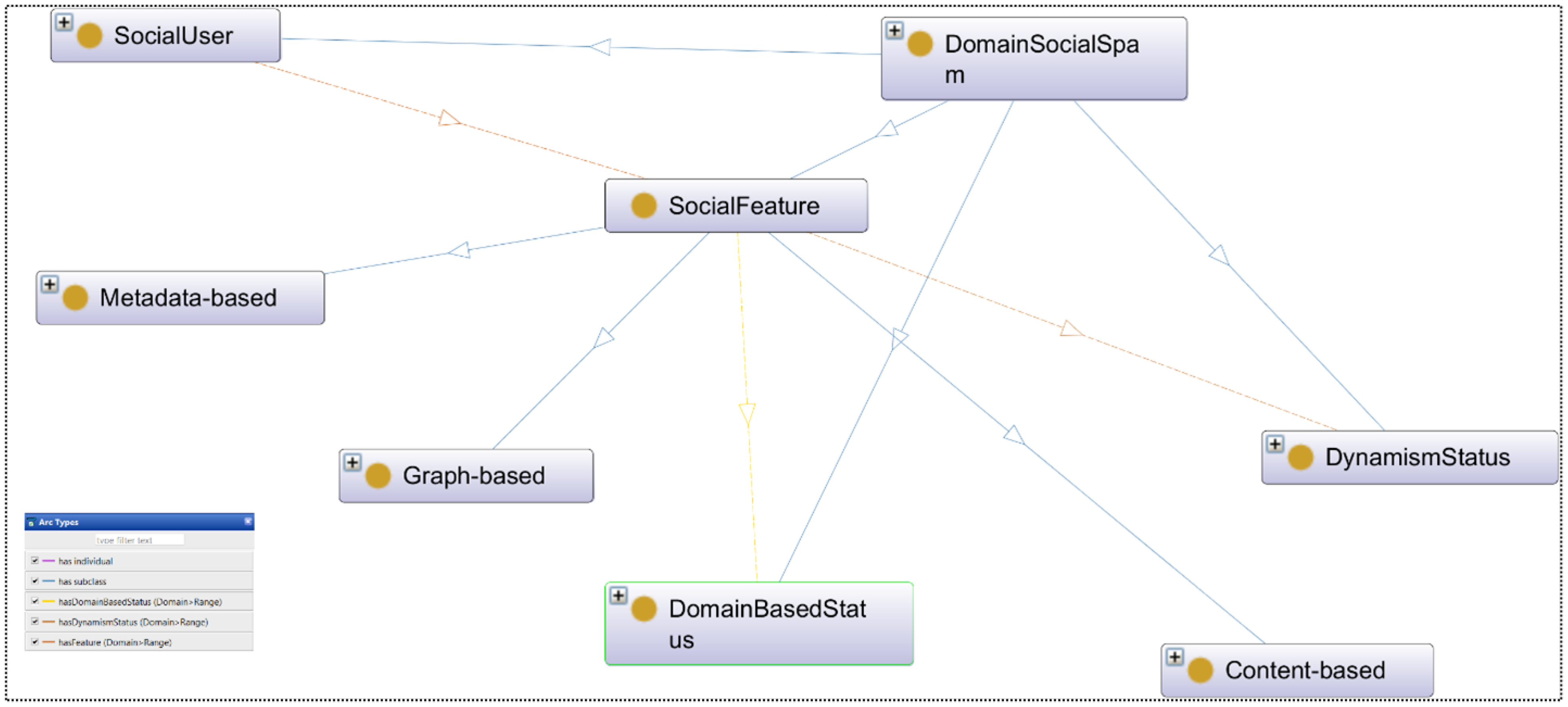
4. DSpamOnto: An Ontology Design for Social Spam
4.1. Identifying the Domain and Extent of the Ontology
4.2. Ontology Reuse
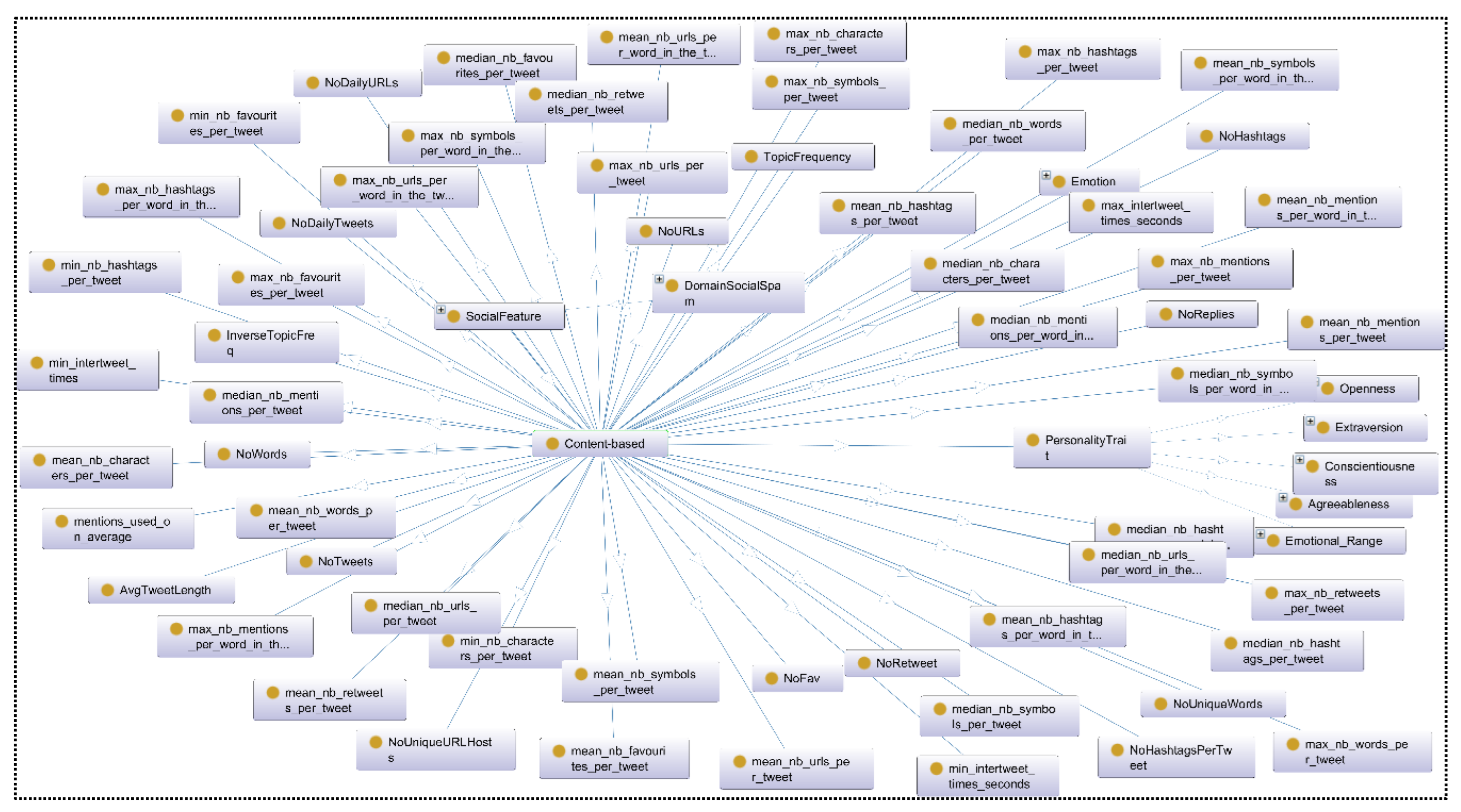
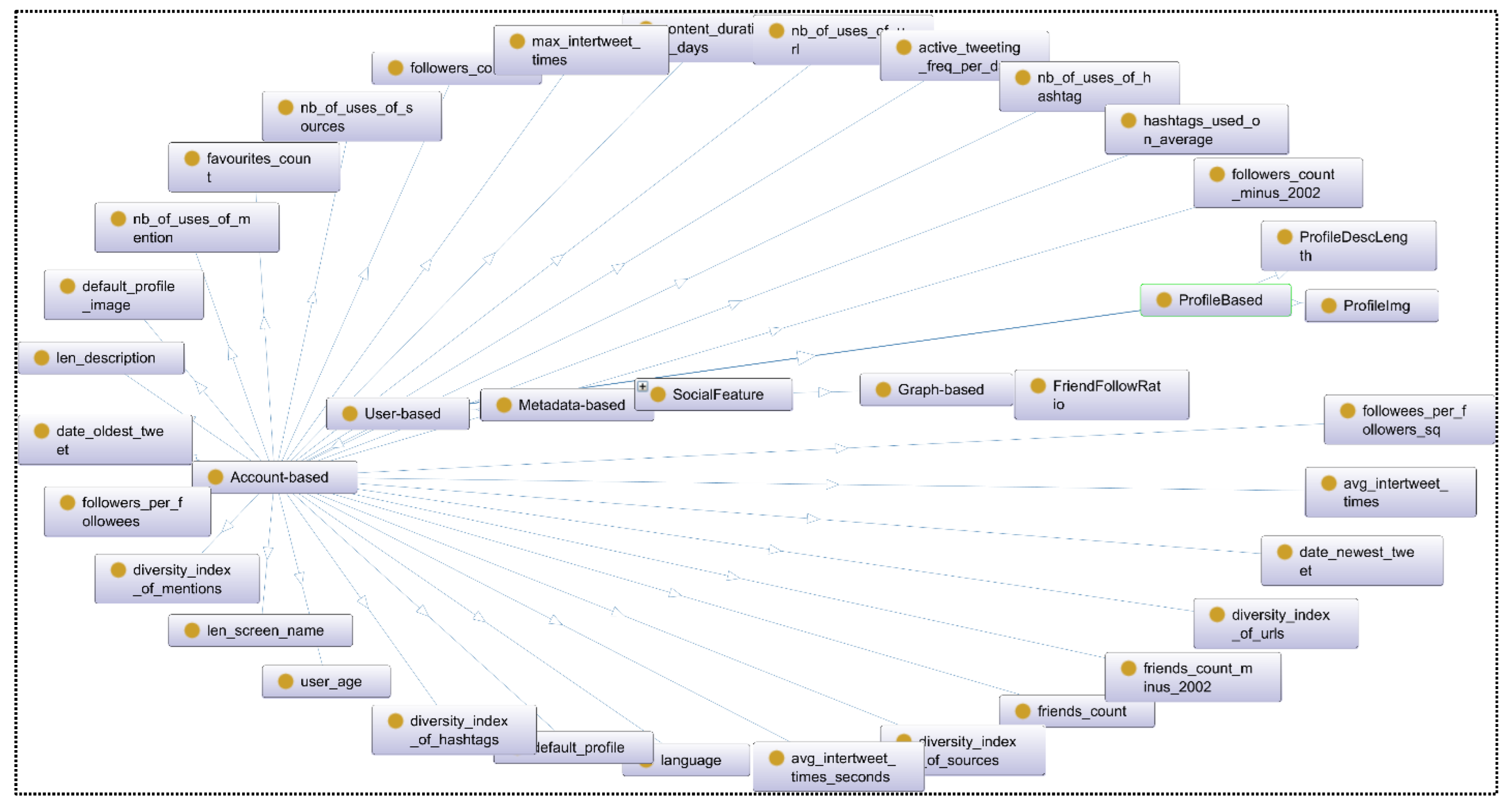
4.3. Development of a Conceptual Model
- Enumerate key terms in the ontology: Identifying and listing out the critical terms or concepts that are relevant to the domain being modelled. These terms should represent the main concepts, attributes, and relationships within the domain, and they form the basis of the ontology’s vocabulary. Enumerating key terms is an important step in ontology engineering, as it provides a foundation for creating a structured and standardized representation of the knowledge within a specific domain.
- Define classes and their hierarchy: Defining classes and class hierarchy involves identifying the key concepts and entities that are relevant to the domain and organizing them into a hierarchical structure. The class hierarchy in the ontology could be organized in a top-down or bottom-up approach, depending on the ontology engineer’s preference and the nature of the domain being modelled. For example, a top-down approach might begin with a general class such as “domain-based social spam” and then create subclasses for different types of social spam, such as “phishing,” “clickbait,” and “fake news”. A bottom-up approach might begin with specific classes such as “spam message” and “spam campaign” and then group them under a more general class such as “social spam”. The class hierarchy should aim to create a structured and organized representation of the knowledge within the social spam domain, allowing for more effective spam detection and prevention systems to be developed.
- Define class properties—slots: After defining the classes and class hierarchy in an ontology, the next step is to define class properties or slots. These slots represent the attributes of the classes and the relationships between them. Class properties can be categorized into two main types: object properties and datatype properties. Object properties connect two classes or entities in the ontology. Datatype properties describe the characteristics of a class or entity.
- Define the facets of slots: Each class property or slot has facets that define its type and value. The physical type defines the kind of data that can be assigned to the slot. For example, a “message_content” property in a social media ontology could have a physical type of “string” because the content is made up of text. A “user_followers” property could have a physical type of “integer” because the number of followers is a whole number. Defining class properties and their facets is a critical step in ontology engineering because it helps to create a precise and detailed representation of the relationships and attributes within the domain.
- Create instances: Populating the ontology with individual values for each class is the last step in ontology design. These instances represent real-world entities that are relevant to the ontology domain. The instances can be created manually or through automated processes such as data extraction or machine learning algorithms. Once the instances are created, they can be used for various tasks such as data analysis, decision-making, and knowledge discovery.
5. Ontology Design Evaluation
5.1. Five Criteria Evaluation Metric
- Consistency: This refers to the absence of contradictions or conflicting information within an ontology. A consistent ontology ensures that any logical inferences made using the ontology are reliable and accurate. In order to check consistency, automated reasoning tools can be used to check that the axioms (statements) in the ontology do not lead to any logical contradictions. If a reasoner can find a contradiction in the ontology, it indicates that the ontology is inconsistent. Consistency checking is particularly important for large and complex ontologies, where it can be difficult to manually detect contradictions. Ensuring consistency can also help identify errors or gaps in the ontology’s design and implementation, allowing for refinement and improvement. To guarantee that DSpamOnto is logically coherent, it has been reasoned using the FaCT++, HermiT, Pellet, Pellet (Incremental), RacerPro, and TrOWL reasoners. The reasoners looked at the class, object, and data property structures, class/object property claims, and the presence of the same entities in the ontology. The DSpamOnto contains no contradictory truths.
- Completeness: This refers to whether or not the ontology covers all the concepts and relationships relevant to its intended domain. In other words, completeness assesses whether the ontology includes all the necessary knowledge required to support the intended tasks. To assess completeness, the proposed ontology is compared against a set of requirements or a benchmark. The benchmark is created based on the domain experts’ knowledge and includes all the concepts and relationships that the ontology is expected to cover. If an ontology satisfies the completeness criterion, it means that it includes all the necessary concepts and relationships required for its intended use. However, if the ontology is incomplete, it indicates that some aspects of the domain are not captured, which can lead to incorrect or incomplete inferences. Despite the importance of the current efforts, there has been no attempt to develop an ontology for domain-specific social spam dedicated to standardising and formalising the specified domain knowledge to the best of our knowledge. Nevertheless, this study benefits from other seminal works to develop a fine-grained ontology that conceptualises domain-specific social spam. It is essential to note that completeness is relative to the intended use of the proposed ontology, and it is not possible to achieve absolute completeness. Ontologies can always be improved and extended as new knowledge is acquired, and new use cases emerge.
- Conciseness: An ontology is considered concise if it contains the minimum number of concepts and relationships necessary to represent the domain it is intended to model. A concise ontology is easier to understand and use, and it has no redundancy. If an ontology is not concise, it will be difficult for users to find the information they need and to understand how the ontology works. To avoid redundancy and ensure conciseness, the developed ontology was crafted with the goal of providing concise information about the domain-based social spammers.
- Expandability: Expandability is the ability of an ontology to be easily modified to add new concepts and relationships. An ontology needs to be expandable because the domain it is intended to model is often dynamic and ever-changing. DSpamOnto is designed to be extensible and interoperable. It can be easily modified by adding, removing, or altering axioms. DSpamOnto also aligns with the four extensibility principles: ontology term reuse, ontology semantic alignment, ontology design patterns (ODP) usage for new term generation and existing term editing, and community extensibility [36].
- Sensitiveness: An ontology is considered sensitive if any change to the ontology could affect the core of the ontology. DSpamOnto is flexible and open to amendments, which means that it can accommodate changes and updates as illustrated in the Expandability evaluation metric.
5.2. Ontology-Level Evaluation
- The size of vocabulary (SOV): is a metric used to measure the size or extent of an ontology’s vocabulary. It is defined as the total number of definitions in the ontology, including classes, individuals, and properties. The SOV can be formulated as follows:
- Edge node ratio (ENR): ENR is a metric used in ontology evaluation to measure the connectivity and complexity of an ontology’s structure. The ENR measures the ratio of edges to nodes in the ontology. In other words, it measures how many relationships (edges) exist for each concept (node) in the ontology:
- Tree impurity (TIP): TIP is a metric used in ontology evaluation to measure the degree of ambiguity or uncertainty in the ontology’s structure. The TIP metric is typically used for tree-structured ontologies, where each concept has only one parent and one or more children. TIP measures the degree to which concepts in the ontology are “impure” or ambiguous, in the sense that they have multiple child concepts that are not related. The TIP metric is based on the Gini impurity measure used in decision tree algorithms and can be calculated as follows:
- The entropy of ontology graph (EOG):EOG measures the information content and complexity of the ontology’s graph structure. The EOG metric is based on the concept of information entropy, which is a measure of the uncertainty or randomness of a set of data. EOG measures the amount of uncertainty or randomness in the ontology’s graph structure, taking into account both the number of nodes and edges in the graph and the distribution of connections between them. The EOG metric can be calculated using the following formula:
5.3. Class-Level Evaluation
- The number of classes (NOC): NOC metric measures the total number of classes defined in the ontology, which can give an indication of the ontology’s breadth and depth in terms of the concepts it covers. The total number of classes in DSpamOnto is 147, indicating a reasonably satisfactory ontology. However, this number is anticipated to be extended considering that this is a new ontology; thus, DSpamOnto will be further expanded and populated.
- The number of properties (NOP): NOP measures the richness and complexity of the ontology’s relationships and attributes. The number of properties in DspamOnto is approximately 170, which shows solid reasoning.
- The number of root classes (NORC): NORC is a metric used in ontology evaluation to measure the total number of classes in the ontology that have no superclasses. These classes are considered to be at the top of the ontology hierarchy and are referred to as root classes. DspamOnto’s NORC is around 60, where the root classes represent distinct but related concepts.
- Relationship richness (RR): RR takes into account both the number and types of relationships defined between classes. A rich ontology relationship structure typically indicates a more comprehensive and well-structured representation of the domain being modelled. The relationships defined between classes can include various types of relationships such as subclass, part-of, instance-of, and many others. RR of DspamOnto is around 0.7, indicating richness in terms of facts rooted in DspamOnto conceptual representation.
5.4. SWRL Rules
| Listing 1: An example of a SWRL rule to detect a social spammer. |
| DomainSocialSpammer(?x) ∧ hasPostingFrequency(?x, ?freq) ∧ hasUserType(?x, ?type) ∧ hasSentimentScore(?x, ?sentiment) ∧ hasEmotion(?x, ?emotion) ∧ hasContentSimilarity(?x, ?similarity) ∧ hasUserBehavior(?x, ?behavior) → SocialSpamDetectionResult(?x, "spammer") ^ (swrlb:greaterThan(?freq, 100) ^ swrlb:equal(?type, "bot") ^ swrlb:lessThan(?sentiment, -0.5) ^ swrlb:equal(?emotion, "anger") ^ swrlb:greaterThan(?similarity, 0.8) ^ swrlb:equal(?behavior, "malicious")) |
| Listing 2: An example of a SWRL rule to detect a social spammer. |
|
DomainSocialSpammer(?s) ∧ CreatedAt(?t, ?d) ∧ DateTime(?d, ?y, ?m, ?day, ?h, ?min, ?sec, ?zone) ∧ Subtract(2023, ?y, ?y_diff) ∧ Subtract(3, ?m, ?m_diff) ∧ GreaterThan(?y_diff, 0) ∧ Or(GreaterThan(?m_diff, 0), And(Equal(?m_diff, 0), GreaterThan(14, ?day))) ∧ Count(?s, ?c) ∧ GreaterThan(?c, 20) ∧ NotExists(?p, Comment(?p, ?s, ?c2) ∧ CreatedAt(?p, ?d2) ∧ DateTime(?d2, ?y2, ?m2, ?day2, ?h2, ?min2, ?sec2, ?zone2) ∧ Subtract(?y_diff, ?y2_diff, ?y_diff_diff) ∧ Subtract(?m_diff, ?m2_diff, ?m_diff_diff) ∧ Or(GreaterThan(?y_diff_diff, 0), And(Equal(?y_diff_diff, 0), GreaterThan(14, ?day_diff)))) → DomainSocialSpammer (?s) |
| Listing 3: An example of a SWRL rule to detect a social spammer. |
|
SocialUserType(?p) ∧ InverseTopicFreq(?p, "1") ∧ (hasExcessiveLinks(?p, true) ∨ hasExcessiveHashtags (?p, true)) → DomainSocialSpammer (?p) |
| Listing 4: An example of a SWRL Rule to detect a social spammer. |
|
SocialUserType (?p) ∧ FriendsWith(?p, ?f) ∧ UserHasManyFollowers(?f) ∧ HighFrequencyOfSpamKeywordsInTweet(?t, ?k) ∧ TweetHasNegativeSentiment(?t) ∧ EmotionDetectedInTweet(?t, ?e) ∧ (?e != "joy" ^ ?e != "love") ∧ TweetContainsManyHashtags(?t) ∧ TweetContainsManyMentions(?t) ∧ TweetContainsManyLinks(?t) ∧ ?nlinks + ?nmentions + ?nhashtags >= 5) → DomainSocialSpammer(?p, ?t) |
6. Experimental Results
6.1. Dataset Selection and Preprocessing
6.2. A Comparison with ML Classifiers
6.3. Results
7. Conclusions
- Incorporating DSpamOnto with machine learning techniques: The proposed domain-specific ontology, DSpamOnto, can be integrated with machine learning algorithms to improve the accuracy of social spam detection in microblogging platforms. By combining the explicit domain knowledge represented by the ontology with the pattern recognition capabilities of machine learning algorithms, more effective and efficient spam detection models can be developed.
- Developing a large labelled dataset for DSpamOnto: In order to train accurate machine learning models using DSpamOnto, a large labelled dataset of domain-specific spam and non-spam content is required. This can be a challenging task as it requires manual labelling of a large amount of data. However, developing such a dataset is crucial for the development and evaluation of machine learning models for detecting domain-specific social spam.
- Testing DSpamOnto on different microblogging platforms: The proposed ontology should be tested on different microblogging platforms to evaluate its effectiveness and applicability in different contexts. This will help to identify any platform-specific issues that may arise when using DSpamOnto and to develop solutions to address them.
- Developing strategies to combat evasive social spammers: As noted in the literature, spammers can use various techniques to evade detection, such as using natural language variations and changing account information frequently. Therefore, it is important to develop strategies to detect and combat these evasive social spammers. This may involve using more sophisticated machine learning algorithms or incorporating additional features into DSpamOnto to identify these tactics.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abu-Salih, B.; Qudah, D.A.; Al-Hassan, M.; Ghafari, S.M.; Issa, T.; Aljarah, I.; Alqahtani, S. An intelligent system for multi-topic social spam detection in microblogging. J. Inf. Sci. 2022. [Google Scholar] [CrossRef]
- Zantal-Wiener, A. 47% of Social Media Users Report Seeing More Spam in Their Feeds, Even as Networks Fight to Stop It. 2019. Available online: https://blog.hubspot.com/marketing/social-media-users-seeing-more-spam (accessed on 3 August 2020).
- Barati, R. Security Threats and Dealing with Social Networks. SN Comput. Sci. 2022, 4, 9. [Google Scholar] [CrossRef]
- Rodrigues, A.P.; Fernandes, R.; Shetty, A.; Lakshmanna, K.; Shafi, R.M. Real-time twitter spam detection and sentiment analysis using machine learning and deep learning techniques. Comput. Intell. Neurosci. 2022, 2022, 5211949. [Google Scholar] [CrossRef] [PubMed]
- Shen, H.; Liu, X.; Zhang, X. Boosting Social Spam Detection via Attention Mechanisms on Twitter. Electronics 2022, 11, 1129. [Google Scholar] [CrossRef]
- Rao, S.; Verma, A.K.; Bhatia, T. Hybrid ensemble framework with self-attention mechanism for social spam detection on imbalanced data. Expert Syst. Appl. 2023, 217, 119594. [Google Scholar] [CrossRef]
- Ghanem, R.; Erbay, H. Spam detection on social networks using deep contextualized word representation. Multimed. Tools Appl. 2023, 82, 3697–3712. [Google Scholar] [CrossRef]
- Shams, R.; Mercer, R.E. Supervised classification of spam emails with natural language stylometry. Neural Comput. Appl. 2016, 27, 2315–2331. [Google Scholar] [CrossRef]
- Çıtlak, O.; Dörterler, M.; Doğru, İ.A. A survey on detecting spam accounts on Twitter network. Soc. Netw. Anal. Min. 2019, 9, 35. [Google Scholar] [CrossRef]
- Concone, F.; Re, G.L.; Morana, M.; Das, S.K. SpADe: Multi-Stage Spam Account Detection for Online Social Networks. IEEE Trans. Dependable Secur. Comput. 2022, 1–16. [Google Scholar] [CrossRef]
- Fernández-López, M.; Gómez-Pérez, A.; Juristo, N. Methontology: From ontological art towards ontological engineering. In Proceedings of the 1997 AAAI Spring Symposium, Palo Alto, CA, USA, 24–26 March 1997. [Google Scholar]
- Lenat, D.; Guha, R. Building large knowledge-based systems: Representation and inference in the CYC project. Artif. Intell. 1993, 61, 4152. [Google Scholar]
- Herath, T.B.G.; Khanna, P.; Ahmed, M. Cybersecurity Practices for Social Media Users: A Systematic Literature Review. J. Cybersecur. Priv. 2022, 2, 1–18. [Google Scholar] [CrossRef]
- Networks, B. Spear Phishing: Top Threats and Trends. 2020. Available online: https://www.barracudamsp.com/resources/reports/spear-phishing-threats-and-trends/#:~:text=Spear%20phishing%20is%20a%20threat,business%20email%20compromise%2C%20and%20blackmail (accessed on 15 March 2023).
- Agrawal, D.; Deepak, G. OntoSpammer: A Two-Source Ontology-Based Spam Detection Using Bagging. In Innovations in Electrical and Electronic Engineering: Proceedings of ICEEE 2022—2022 9th International Conference on Electrical and Electronics Engineering (ICEEE), Alanya, Turkey, 29–31 March 2022; Springer: Berlin/Heidelberg, Germany, 2022; Volume 2, pp. 145–153. [Google Scholar]
- Vidanagama, D.; Silva, A.; Karunananda, A. Ontology based sentiment analysis for fake review detection. Expert Syst. Appl. 2022, 206, 117869. [Google Scholar] [CrossRef]
- Jabardi, M.H.; Hadi, A.S. Ontology Meter for Twitter Fake Accounts Detection. Int. J. Intell. Eng. Syst. 2021, 14, 410–419. [Google Scholar] [CrossRef]
- Halawi, B.; Mourad, A.; Otrok, H.; Damiani, E. Few are as Good as Many: An Ontology-Based Tweet Spam Detection Approach. IEEE Access 2018, 6, 63890–63904. [Google Scholar] [CrossRef]
- Hussain, M.; Ahmed, M.; Khattak, H.A.; Imran, M.; Khan, A.; Din, S.; Ahmad, A.; Jeon, G.; Reddy, A.G. Towards ontology-based multilingual URL filtering: A big data problem. J. Supercomput. 2018, 74, 5003–5021. [Google Scholar] [CrossRef]
- Abu-Salih, B.; Wongthongtham, P.; Kit, C.Y. Twitter mining for ontology-based domain discovery incorporating machine learning. J. Knowl. Manag. 2018, 22, 949–981. [Google Scholar] [CrossRef]
- Wongthongtham, P.; Salih, B.A. Ontology-based approach for identifying the credibility domain in social Big Data. J. Organ. Comput. Electron. Commer. 2018, 28, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Jain, G.; Sharma, M.; Agarwal, B. Spam detection in social media using convolutional and long short term memory neural network. Ann. Math. Artif. Intell. 2019, 85, 21–44. [Google Scholar] [CrossRef]
- Alan, R.H.; Salvatore, T.M.; Jinsoo, P.; Sudha, R. Design science in information systems research. MIS Q. 2004, 28, 75–105. [Google Scholar]
- Jones, D.; Gregor, S. The anatomy of a design theory. J. Assoc. Inf. Syst. 2007, 8. [Google Scholar] [CrossRef] [Green Version]
- Venable, J. Rethinking Design Theory in Information Systems. In Design Science at the Intersection of Physical and Virtual Design; vom Brocke, J., Ed.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 136–149. [Google Scholar]
- Peffers, K.; Tuunanen, T.; Rothenberger, M.A.; Chatterjee, S. A Design Science Research Methodology for Information Systems Research. J. Manag. Inf. Syst. 2007, 24, 45–77. [Google Scholar] [CrossRef]
- Borse, D.; Borse, S. State of the art on Twitter spam detection. In Applied Computational Technologies: Proceedings of ICCET; Springer Nature: Berlin/Heidelberg, Germany, 2022; pp. 486–496. [Google Scholar]
- Sun, N.; Lin, G.; Qiu, J.; Rimba, P. Near real-time twitter spam detection with machine learning techniques. Int. J. Comput. Appl. 2020, 44, 338–348. [Google Scholar] [CrossRef]
- Vives, L.; Tuteja, G.S.; Manideep, A.S.; Jindal, S.; Sidhu, N.; Jindal, R.; Bhatt, A. A novel hybrid approach of gravitational search algorithm and decision tree for twitter spammer detection. Int. J. Mod. Phys. C 2021, 33, 2250060. [Google Scholar] [CrossRef]
- Deng, L.; Wu, C.; Lian, D.; Wu, Y.; Chen, E. Markov-Driven Graph Convolutional Networksfor Social Spammer Detection. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Yu, J.; Thom, J.A.; Tam, A. Requirements-oriented methodology for evaluating ontologies. Inf. Syst. 2009, 34, 766–791. [Google Scholar] [CrossRef] [Green Version]
- Alani, H.; Brewster, C. Metrics for Ranking Ontologies. 2006. Available online: https://eprints.soton.ac.uk/262603/1/Alani-EON06.pdf (accessed on 15 March 2023).
- D’Aquin, M.; Schlicht, A.; Stuckenschmidt, H.; Sabou, M. Criteria and evaluation for ontology modularization techniques. In Modular Ontologies; Springer: Berlin/Heidelberg, Germany, 2009; pp. 67–89. [Google Scholar]
- Dellschaft, K.; Staab, S. Strategies for the Evaluation of Ontology Learning. Ontol. Learn. Popul. 2008, 167, 253–272. [Google Scholar]
- Zavitsanos, E.; Paliouras, G.; Vouros, G.A. Gold Standard Evaluation of Ontology Learning Methods through Ontology Transformation and Alignment. IEEE Trans. Knowl. Data Eng. 2010, 23, 1635–1648. [Google Scholar] [CrossRef]
- Yongqun, H.; Zuoshuang, X.; Jie, Z.; Yu, L.; James, A.O.; Edison, O. The eXtensible ontology development (XOD) principles and tool implementation to support ontology interoperability. J. Biomed. Semant. 2018, 9, 3. [Google Scholar]
- Srinivasulu, S.; Sakthivel, P.; Balamurugan, E. Measuring the ontology level and class level complexity metrics in the semantic web. Int. J. Adv. Comput. Eng. Netw. 2014, 2, 68–74. [Google Scholar]
- Ajami, H.; Mcheick, H. Ontology-Based Model to Support Ubiquitous Healthcare Systems for COPD Patients. Electronics 2018, 7, 371. [Google Scholar] [CrossRef] [Green Version]
- Brewster, C.; Alani, H.; Dasmahapatra, S.; Wilks, Y. Data Driven Ontology Evaluation. 2004. Available online: https://www.researchgate.net/publication/37537072_Data_Driven_Ontology_Evaluation (accessed on 15 March 2023).
- Hassanpour, S.; O’Connor, M.J.; Das, A.K. Exploration of SWRL rule bases through visualization, paraphrasing, and categorization of rules. In Rule Interchange and Applications: International Symposium; Springer: Las Vegas, NV, USA, 2009. [Google Scholar]
- Horrocks, I.; Peter, F.; Harold, B.; Said, T.T.; Benjamin, G.; Mike, D. SWRL: A semantic web rule language combining OWL and RuleML. W3C Memb. Submiss. 2004, 21, 1–31. [Google Scholar]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. Fame for sale: Efficient detection of fake Twitter followers. Decis. Support Syst. 2015, 80, 56–71. [Google Scholar] [CrossRef] [Green Version]
- Zulkarnain, N.Z.; Meziane, F. Ultrasound reports standardisation using rhetorical structure theory and domain ontology. J. Biomed. Informatics 2019, 100, 100003. [Google Scholar] [CrossRef] [PubMed]
- Elhenawy, M.; El-Shawarby, I.; Rakha, H. Modeling the Perception Reaction Time and Deceleration Level for Different Surface Conditions Using Machine Learning Techniques; Springer: Berlin/Heidelberg, Germany, 2016; pp. 131–142. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Year | Social Platform | Method | Evaluation Metric(s) | Limitation(s) |
|---|---|---|---|---|---|
| [15] | 2022 | Ontology, and bagging-based approach | accuracy, precision, recall, and F1 score. | -The paper is only evaluated on a dataset of real spam emails. This means that the approach may not be able to detect spam emails that are written in a different style than the emails in the dataset. -The paper does not address the problem of false positives. | |
| [1] | 2022 | NLP, ML models | accuracy, precision, recall, and F1 score. | -As social spam becomes more sophisticated, the system may need to be updated to maintain its accuracy. | |
| [16] | 2022 | online reviews for e-commerce platforms. | Linguistic, POS tagging, and SWRL rules | accuracy, precision, recall, and F1 score. | -The classification results may be sensitive to the choice of ontology and SWRL rules. -The SWRL rules may not be able to capture all of the relevant relationships between the concepts in the ontology. |
| [17] | 2020 | SWRL | precision, recall, and F1-score, | -It only focuses on detecting fake accounts on Twitter and may not be applicable to other social media platforms. -The ontology used in the study may not capture all possible characteristics of fake accounts, and the study may not have captured all instances of fake accounts on Twitter. | |
| [18] | 2018 | Ontology and clustering techniques | precision, recall, and F1-score | The approach is not robust to changes in the fake Twitter account landscape. | |
| [19] | 2018 | Spam URL | Ontology and ML classifiers | accuracy, precision, recall, and F1 score. | -The study may not have captured all instances of spam URLs in different languages. -The study also does not provide information on the scale of the dataset used in the evaluation. |
| [20] | 2018 | Ontology and ML classifiers | Precision, recall, and F1-score | -The present ML methods presume that uncertainty and incompleteness do not affect Twitter classification accuracy. These aspects might exist. | |
| [20] | 2018 | Ontology and SWRL | Case study, Precision, recall, and F1-score | -The developed ontology is limited in terms of the number of classes and relationships. | |
| [22] | 2019 | Social Media | Ontology and LSTM | Accuracy, precision, recall, F1-score | -The study did not compare the proposed approach with other state-of-the-art methods for spam detection. |
| Query | Response |
|---|---|
| What is the domain that the ontology will conceptualise? | In this paper, we aim to conceptualise domain-specific social spam in microblogging by means of designing a domain ontology, namely DSpamOnto. |
| What is the objective and intent of this ontology? | The purpose of DSpamOnto is to furnish a better understanding of a special category of social spammers, which usually targets a certain domain |
| Who will benefit from this ontology? | Academic scholars and corporate practitioners interested in developing a conceptualised model for social spammers can benefit from this ontology. Based on the advancements in this environment, the suggested ontology can be repurposed and expanded in the future with additional ideas, properties, and examples. |
| What are the important issues that integrated knowledge in ontology can answer? |
|
| Group Name | #Accounts | #Tweets | Year |
|---|---|---|---|
| social spambots | 3457 | 428,542 | 2014 |
| traditional spambots | 433 | 5,794,931 | 2013 |
| fake followers | 3351 | 196,027 | 2012 |
| Model | Accuracy | Prec. | Recall | F1 |
|---|---|---|---|---|
| LR | 0.6999 | 0.6072 | 0.5801 | 0.5925 |
| NB | 0.7268 | 0.597 | 0.8903 | 0.7049 |
| KNN | 0.7378 | 0.6542 | 0.6558 | 0.6535 |
| SVM | 0.7607 | 0.6946 | 0.685 | 0.677 |
| DT | 0.7943 | 0.7189 | 0.7506 | 0.7338 |
| RF | 0.7972 | 0.7055 | 0.799 | 0.7486 |
| Proposed method | 0.8029 | 0.7088 | 0.816 | 0.7579 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Hassan, M.; Abu-Salih, B.; Al Hwaitat, A. DSpamOnto: An Ontology Modelling for Domain-Specific Social Spammers in Microblogging. Big Data Cogn. Comput. 2023, 7, 109. https://doi.org/10.3390/bdcc7020109
Al-Hassan M, Abu-Salih B, Al Hwaitat A. DSpamOnto: An Ontology Modelling for Domain-Specific Social Spammers in Microblogging. Big Data and Cognitive Computing. 2023; 7(2):109. https://doi.org/10.3390/bdcc7020109
Chicago/Turabian StyleAl-Hassan, Malak, Bilal Abu-Salih, and Ahmad Al Hwaitat. 2023. "DSpamOnto: An Ontology Modelling for Domain-Specific Social Spammers in Microblogging" Big Data and Cognitive Computing 7, no. 2: 109. https://doi.org/10.3390/bdcc7020109
APA StyleAl-Hassan, M., Abu-Salih, B., & Al Hwaitat, A. (2023). DSpamOnto: An Ontology Modelling for Domain-Specific Social Spammers in Microblogging. Big Data and Cognitive Computing, 7(2), 109. https://doi.org/10.3390/bdcc7020109